第3章-1流水线技术
计算机系统结构第3章流水线技术

流水线调度
根据指令的依赖关系和资源可用性,动态调 度指令到不同的流水线阶段。
GPU设计中的流水线技术
线程级并行
通过划分线程块和线程束,实现线程级并行执行。
数据级并行
将数据划分为多个块,每个块在GPU的多个处理单元上并行处理。
指令级并行
通过指令调度和分支预测,实现指令级并行执行。
硬件资源共享
01
硬件资源共享是指流水线中的多个操作共享相同的硬件资源, 如寄存器、缓冲区等。
02
硬件资源共享能够提高资源利用率,减少硬件开销,降低成本。
需要注意的是,硬件资源。
流水线的性能指标
01
吞吐量
流水线每单位时间内完成的操作数 或任务数。
流水线调度
根据子任务的依赖关系和资源需求,动态调 度子任务到不同的计算节点。
THANKS
感谢观看
将执行结果写回寄 存器或内存。
02
流水线的工作原理
数据流驱动
1
数据流驱动是指流水线中的操作按照数据流动的 方向依次执行,每个操作在完成前需要等待前一 个操作的结果。
2
数据流驱动的优点是能够充分利用数据依赖关系, 减少等待时间,提高流水线的吞吐量。
3
需要注意的是,数据流驱动需要精确控制数据流 动的顺序,以避免出现数据相关和冒险问题。
调试和维护困难
由于流水线中各个阶段是并行处 理的,调试和维护可能会比串行 系统更加困难。
05
流水线技术的应用
CPU设计中的流水线技术
指令划分
将指令划分为多个阶段,每个阶段对应一个 功能单元,从而并行执行多个指令。
数据路径设计
第3章 先进的生产组织形式《企业生产管理》PPT课件

(1)编码法 (2)生产过程分析法 (3)目测法
3.5 成组技术
3.5 成组技术
3)零件分类编码系统
目前世界上已有十几种零 件分类系统,按分类所依 据的主要特征划分,有以 下三大分类系统: (1)按零件结构特征分 类——布里奇分类系统 (2)按工艺特征分类— —米特洛法诺夫分类系统
3.5 成组技术
3.5.1成组技术的概念和发展 1)成组技术的概念 2)成组技术的发展
3.5 成组技术
3.5.2零件的分类编码 1)零件分类编码、分组的可能性
(1)各种类型零件在整个产品结构的组成中都各有一定的出现率。 (2)在机械制造产品中,零件的结构形状和尺寸分布等具有相对的稳 定性。
3.5 成组技术
3.3 定制生产
3.3.2定制生产方式的运行 1)产品设计
产品模块设计的好处如下: (1)可以把各种产品都用上的标准化部件的数目最大化。 (2)把产品的模块分立,可以使企业在同一时间内制造各个模块。 (3)模块分立化,可以更容易地诊断生产中的质量等问题。
3.3 定制生产
2)制造流程的设计
流程模块的设计应遵循以下原则: (1)使流程的前期阶段生产各个产品品种中公用的部分,须按要求定 制生产的部分放在尽可能后的流程阶段。 (2)企业可对子流程重新排序,以实现定制生产。
现举例说明平准化的含义: (1)生产两种产品且产量相同。 (2)生产两种以上的产品,且产量相同。 (3)多品种生产且产量不同。
3.1 流水生产
3.1.6混流生产投产顺序安排的方法 1)生产比倒数法 2)逻辑运算法
3.1.7瑞典式流水线
3.2 柔性制造系统
3.2.1柔性制造系统的概念
柔性制造系统,指由计算机控制的以数控机床(NC)和加工中心(MC) 为基础适应多品种、中小批量生产的自动化制造系统。
第3章.食品工厂工艺设计

3.4.3 用水量计算
用水量的计算方法有两种,即按单位产品耗水 量定额估算或计算 。 按单位产品耗水量定额估算 根据目前我国相应视频工厂的生产用水量经验 数值来估算生产用水量。
按实际生产用水量计算 (1)首先弄清题意和计算的目的及要求 (2)绘出用水量计算流程示意图 (3) 收集设计基础数据 (4)确定工艺指标及消耗定额等 (5)选定计算基准 (6)由已知数据根据质量守恒定律进行用水量计 算 (7)列出计算表
3.
食品工厂工艺设计
食品工厂工艺设计是整个设计的主体和中心, 决定全厂生产和技术的合理性,并对建厂的费用和 生产的产品质量、产品成本、劳动强度有着重要的 影响,同时又是非工艺设计的依据。因此,食品工 厂工艺设计具有重要的地位和作用。
3.1 工艺设计的内容和步骤
3.1.1工艺设计的依据和内容 设计的主要依据为: 项目建议书和可行性研究报告。 环境影响预评价报告。 厂址选择报告。 项目负责人下达的设计工作提纲和技术决定。 若采用新工艺、新技术和新设备时,必须在 技术上有切实把握并且依据了正式的。试验 研究报告和技术鉴定书,经有关方面核准后 方可作为设计依据。
生产工艺设计的内容 初步设计阶段 1)设计依据和范围。 2)全厂生产车间组成(如空罐车间、实罐 车间、杀菌车间等)。 3)全厂生产工艺流程比较、选择和阐述。 4)各生产车间综合叙述。
5)存在的问题及建议。 6)附件
施工图设计阶段 (1)设计文件目录、列表。 (2)生产工艺设计说明。 (3)工艺安装说明。 (4)详细的设备一览表和各种材料汇总表, 满足订货需要。 (5)带控制点的工艺流程图。 (6)工艺设备布置图。 (7)工艺管道布置图。 (8)非标准设备制造图。
绘制工艺流程草图(定量图); 绘制正式工艺流程图
《技术与设计1》第3章第2节 设计的一般原则

月饼的包装
过度包装,一次性快餐饭盒、筷子,电池, 超市包装袋,汽车燃料等。 思考:设计中如何体现可持续发展原则? ① 尽可能选用可再生的资源和可重复使用的材料; ② 尽量减少原料和自然资源的使用(减少过渡包装); ③ 尽量降低产品在生产中的损耗; ④ 尽可能降低产品使用的能源消耗和材料消耗; ⑤ 有时还要考虑使用和回收问题。 设计的一般原则间的相互关系:相互关联、相互渗透、相互制 约、相互促进。 道德原则是最重要的;实用原则是最基本的;创新原则是最核 心的;美观原则是最诱人的;经济原则是最关心的;有技术规范才 有市场;遵循可持续发展原则才有未来„„ 除了上述的原则外,设计还需遵循哪些原则? 作业:P067 的练习1、2 安全原则、科学原则„„
能,完成下边的连线题。 产品外形 功能分析
水烧开时报警 美观、形象 塞壶嘴,防污染 稳定性好 受热面积大,热效率高 防烫手
功能类别
物理功能 心理功能 物理功能
物理功能 物理功能
生理功能 心理功能 物理功能 物理功能
手感舒适
便于倾倒 便于清洗
浙江省兰溪市第三中学 陈永新
想一想:现在在超市看到的卷纸有什么形状的,哪种 设计好呢?为什么?
产品的实用性需要考虑哪些因素? 物理功能:产品的性能、构造、效率精度、可靠性等; 生理功能:产品使用的方便性、安全性、宜人性等; 心理功能:产品的造型、色彩、机理、装饰诸要素给人 以愉悦感等; 社会功能:产品象征或显示个人的价值、兴趣、爱好、 社会地位等;……。
浙江省兰溪市第三中学 陈永新
格雷夫斯水壶:从实用性出发分析其功
浙江省兰溪市第三中学 陈永新
4 美观原则
爱美之心,人皆有之。好的产品能让人们从产品的外观和造 型上得到美的体验,享受精神上的愉悦。 产品美观是指让人从产品的外观上得到美的体验,享受精神上 的愉悦。
《生产管理》第三章

包括机器设备生产效率(即设备 能力)和生产面积的生产效率。 设备生产效率是用单位机器设备 的产量定额或单位产品的台时定 额表示 生产面积的生产效率是指单位产 品占用生产面积的大小以及时间 的长短
生产能力的计量单位
具体产品
代表产品
品种单一的大量生 产企业中,生产能 力可以用该具体产 品的产量表示
在多品种生产的企业中, 可以在构成相似的产品 中选出代表产品,以生 产代表产品的时间定额 和产量定额作为固定资 产的生产率定额来计算 生产能力
t=250×7.5×2×(1﹣10%)×10/0.5=67500(件)
想一想
代表产品的判别
结合公司实际,谈谈代表产品 的判别标准?
3.4 核定设备组生产结构和工 艺不相似产品的生产能力
项目三 产能平衡
1
产能核定概述
主要内容 2
CONTENTS
假定产品法
3
练习与思考
01
产能核定概述
产能核定概述
是用于编制计划的特殊形
日75历%
式的日历,它是由普通日
历除去每周双休日、假日、
停工和其它不生产的日子,
并将日期表示为顺序形式
而形成的
作业
1计00划%
由MRP输出的零部件 作业计划
能力需求计划的 计算逻辑
CRP的运算过程就是把MRP定单换算成能力需求数量,生成能力需求报表
03
生产能力的影响
因素及计量单位
提升生产能力的策略
结合公司实际,谈谈如何利用 技术组织方法提升生产能力?
3.3 设备组生产结构和工 艺相似产品生产能力的核
定与平衡
项目三 产能平衡
目录
CONTENTS
1
按代表产品作为计量 单位计算生产能力步骤
嵌入式原理思考题及答案

第1章复习要点1.1.1节嵌入式系统的概念1.1.3节嵌入式系统的特点1.3节嵌入式处理器1.4节嵌入式系统的组成第2章复习要点2.1节计算机体系结构分类2.3.1节 ARM和Thumb状态2.3.2节 RISC技术2.3.3节流水线技术2.4.3节 ARM存储系统第3章复习要点3.1节ARM编程模式3.2节ARM指令格式及其寻址方式3.3节ARM指令集(课上所讲的指令)第4章复习要点4.1节汇编语言源程序格式4.2节汇编语言的上机过程第5章复习要点5.1节键盘接口5.2节 LED显示器接口5.5.1节 UART异步串行接口作业题答案:1.什么是嵌入式系统?∙第一种,根据IEEE(国际电气和电子工程师协会)的定义:嵌入式系统是“用于控制、监视或者辅助操作机器和设备的装置”(原文为devices used to control, monitor, or assist the operation of equipment, machinery or plants)。
∙第二种,嵌入式系统是以应用为中心、以计算机技术为基础、软件硬件可裁剪、功能、可靠性、成本、体积、功耗严格要求的专用计算机系统。
2.与通用型计算机相比,嵌入式系统有哪些特点?⏹通常是面向特定应用的;⏹空间和各种资源相对不足,必须高效率地设计,量体裁衣、去除冗余;⏹产品升级换代和具体产品同步,具有较长的生命周期;⏹软件一般都固化在存储器芯片或单片机本身;⏹不具备自举开发能力,必须有一套开发工具和环境才能进行开发3.举例介绍嵌入式微处理器有哪几类?一、嵌入式微处理器(Embedded Microprocessor Unit, EMPU)嵌入式处理器目前主要有Aml86/88、386EX、SC-400、PowerPC、68000、MIPS、ARM系列等。
二、嵌入式微控制器(Microcontroller Unit, MCU)嵌入式微控制器目前的品种和数量最多,比较有代表性的通用系列包括8051、P51XA、MCS-251、MCS-96/196/296、C166/167、MC68HC05/11/12/16、68300等。
《大学计算机基础》第五版 第1-4章课后习题答案

第一章1.计算机的发展经历了那几个阶段?各阶段的主要特征是什么?a)四个阶段:电子管计算机阶段;晶体管电路电子计算机阶段;集成电路计算机阶段;大规模集成电路电子计算机阶段。
b)主要特征:电子管计算机阶段:采用电子管作为计算机的逻辑元件;数据表示主要是定点数;用机器语言或汇编语言编写程序。
晶体管电路电子计算机阶段:采用晶体管作为计算机的逻辑元件,内存大都使用铁金氧磁性材料制成的磁芯存储器。
集成电路计算机阶段:逻辑元件采用小规模集成电路和中规模集成电路.大规模集成电路电子计算机阶段:逻辑元件采用大规模集成电路和超大规模集成电路。
2.按综合性能指标分类,计算机一般分为哪几类?请列出各计算机的代表机型。
高性能计算机(曙光),微型机(台式机算机),工作站(DN—100),服务器(Web服务器)。
3.信息与数据的区别是什么?信息:对各种事物的变化和特征的反映,又是事物之间相互作用和联系表征。
数据:是信息的载体。
4.什么是信息技术?一般是指一系列与计算机等相关的技术。
5.为什么说微电子技术是整个信息技术的基础?晶体管是集成电路技术发展的基础,而微电子技术就是建立在以集成电路为核心的各种半导体器件基础上的高新电子技术。
6.信息处理技术具体包括哪些内容?3C含义是什么?a)对获取的信息进行识别、转换、加工,使信息安全地存储、传送,并能方便的检索、再生、利用,或便于人们从中提炼知识、发现规律的工作手段。
b)信息技术、计算机技术和控制技术的总称7.试述当代计算机的主要应用。
应用于科学计算、数据处理、电子商务、过程控制、计算机辅助设计、计算机辅助制造、计算机集成制造系统、多媒体技术和人工智能等。
第二章1.简述计算机系统的组成。
由硬件系统和软件系统组成2.计算机硬件包括那几个部分?分别说明各部分的作用。
a)主机和外设b)主机包括中央处理器和内存作用分别是指挥计算机的各部件按照指令的功能要求协调工作和存放预执行的程序和数据。
计算机系统结构(张晨曦)基本概念

在同一时刻或是同一时间间隔内完成两种或两种以上性质相同或不相同的工作。 只要时间上 互相重叠,就存在并行性。 同时性 两个或多个事件在同一时刻发生的并行性。 并发性 两个或多个事件在同一时间间隔内发生的并行性。 字串位串 每次只对一个字的一位进行处理。这是最基本的串行处理方式。 字串位并 同时对一个字的全部位进行处理,不同字之间是串行的。 字并位串 同时对许多字的同一位(称为位片)进行处理。 全并行 同时对许多字的全部位或部分位进行处理。 指令内部并行 单条指令中各微操作之间的并行。 指令级并行 并行执行两条或两条以上的指令。 线程级并行 并行执行两个或两个以上的线程,通常是以一个进程内派生的多个线程为调度单位。 任务级或过程级并行 并行执行两个或两个以上的过程或任务(程序段) ,以子程序或进程为调度单元。 作业或程序级并行 并行执行两个或两个以上的作业或程序。 时间重叠 多个处理过程在时间上相互错开, 轮流使用同一套硬件设备的各个部分, 以加快硬件周转而 赢得速度。 资源重复 通过重复设置资源,尤其是硬件资源,大幅度提高计算机系统的性能。 资源共享 是一种软件方法,它使多个任务按一定时间顺序轮流使用同一套硬件设备。 同构型(对称型)多处理机 由多个同类型, 至少担负同等功能的处理机组成, 同时处理同一作业中能并行执行的多个任 务。 异构型(非对称型)多处理机 由多个不同类型,至少担负不同功能的处理机组成,按照作业要求的顺序,利用时间重叠原 理,依次对它们的多个任务进行加工,各自完成规定的功能动作。 分布处理系统 把若干台具有独立功能的处理机(或计算机)相互连接起来,在操作系统的全盘控制下,统 一协调地工作,而最少依赖集中的程序、数据或硬件。 耦合度 反映多机系统各机器之间物理连接的紧密程度和交互作用能力的强弱。 松散耦合 通过通道或通信线路实现计算机间互连, 共享某些外围设备, 机间的相互作用是在文件或数
DSP原理及应用-(修订版)--课后习题答案

第一章:1、数字信号处理的实现方法一般有哪几种?答:数字信号处理的实现是用硬件软件或软硬结合的方法来实现各种算法。
(1) 在通用的计算机上用软件实现;(2) 在通用计算机系统中加上专用的加速处理机实现;(3) 用通用的单片机实现,这种方法可用于一些不太复杂的数字信号处理,如数字控制;(4)用通用的可编程 DSP 芯片实现。
与单片机相比,DSP 芯片具有更加适合于数字信号处理的软件和硬件资源,可用于复杂的数字信号处理算法;(5) 用专用的 DSP 芯片实现。
在一些特殊的场合,要求的信号处理速度极高,用通用 DSP 芯片很难实现( 6)用基于通用 dsp 核的asic 芯片实现。
2、简单的叙述一下 dsp 芯片的发展概况?答:第一阶段, DSP 的雏形阶段( 1980 年前后)。
代表产品: S2811。
主要用途:军事或航空航天部门。
第二阶段, DSP 的成熟阶段( 1990 年前后)。
代表产品: TI 公司的 TMS320C20主要用途:通信、计算机领域。
第三阶段, DSP 的完善阶段( 2000 年以后)。
代表产品:TI 公司的 TMS320C54 主要用途:各个行业领域。
3、可编程 dsp 芯片有哪些特点?答: 1、采用哈佛结构( 1)冯。
诺依曼结构,( 2)哈佛结构( 3)改进型哈佛结构2、采用多总线结构 3.采用流水线技术4、配有专用的硬件乘法-累加器5、具有特殊的 dsp 指令6、快速的指令周期7、硬件配置强8、支持多处理器结构9、省电管理和低功耗4、什么是哈佛结构和冯。
诺依曼结构?它们有什么区别?答:哈佛结构:该结构采用双存储空间,程序存储器和数据存储器分开,有各自独立的程序总线和数据总线,可独立编址和独立访问,可对程序和数据进行独立传输,使取指令操作、指令执行操作、数据吞吐并行完成,大大地提高了数据处理能力和指令的执行速度,非常适合于实时的数字信号处理。
冯。
诺依曼结构:该结构采用单存储空间,即程序指令和数据共用一个存储空间,使用单一的地址和数据总线,取指令和取操作数都是通过一条总线分时进行。
计算机体系结构第三章-3(非线性流水线)

非线性流水线的竞争与调度
2、最优调度
为了避免冲突,就要对指令送入流水线的时间进行控制, 这就是流水线的无冲突调度。(4个步骤)
1)根据预约表写出禁止向量
禁止向量F是一个流水线中所有禁止启动距离构成的集合。 为了找出所有的禁止启动距离,必须考察各段的复用情况。
1
S1 …
2
3
4
5
6
7
8
9
√
√
方法:S1在1,9两个时段中使用,从第1时段到第9时段的距 离差值为8Δt(9Δt – 1Δt = 8Δt),显然这是一个禁止启动 距离。
T1
s1 s2 √ √ √
T2
T3
T4
T5
T6
T7
√
s3
s4
√
√
√
(1) 写出禁止向量,初始冲突向量,画出流水线调度的状态转移图。 (2) 求出流水线最优调度策略和最大吞吐率。
(3) 求出按最优调度策略连续输10个任务,流水线的实际吞吐率、 加速比、效率?
3.5 流水线的实现
3.5 流水线的实现
同样,若选择间隔7拍输入第2条指令,则新冲突向量为:
C4 SHR(7) (C0 ) C0 (00000001 ) (10110001 ) (10110001 ) C0
例子中,C1,C2,C3 继续后续指令的冲突向量计算。反复上述步骤,直 到不再产生新的冲突向量为止。
非线性流水线的竞争与调度
1
2 √
3 √
4
5
6
7
8 √
9
S1
S2 S3
√
√
√
S4
S5
嵌入式系统设计教程(第2版)简答题答案.pdf

第一章嵌入式系统概论1.嵌入式系统的定义是什么?答:以应用为中心,以计算机技术为基础,硬件、软件可裁剪,功能、可靠性、成本、体积、功耗严格要求的专用计算机系统。
2.简述嵌入式系统的主要特点。
答:(1)功耗低、体积小、具有专用性(2)实时性强、系统内核小(3)创新性和高可靠性(4)高效率的设计(5)需要开发环境和调试工具3. 嵌入式系统一般可以应用到那些领域?答:嵌入式系统可以应用在工业控制、交通管理、信息家电、家庭智能管理系统、网络及电子商务、环境监测和机器人等方面。
4. 简述嵌入式系统的发展趋势答:(1)嵌入式应用的开发需要强大的开发工具和操作系统的支持(2)连网成为必然趋势(3)精简系统内核、算法,设备实现小尺寸、微功耗和低成本(4)提供精巧的多媒体人机界面(5)嵌入式软件开发走向标准化5.嵌入式系统基本架构主要包括那几部分?答:嵌入式系统的组织架构是由嵌入式处理器、存储器等硬件、嵌入式系统软件和嵌入式应用软件组成。
嵌入式系统一般由硬件系统和软件系统两大部分组成,其中,硬件系统包括嵌入式处理器、存储器、I/O系统和配置必要的外围接口部件;软件系统包括操作系统和应用软件。
6.嵌入式操作系统按实时性分为几种类型,各自特点是什么?答:(1)具有强实时特点的嵌入式操作系统。
(2)具有弱实时特点的嵌入式操作系统。
(3)没有实时特点的嵌入式操作系统。
第二章嵌入式系统的基础知识1.嵌入式系统体系结构有哪两种基本形式?各自特点是什么?答:冯诺依曼体系和哈佛体系。
冯诺依曼体系结构的特点之一是系统内部的数据与指令都存储在同一存储器中,其二是典型指令的执行周期包含取指令TF,指令译码TD,执行指令TE,存储TS四部分,目前应用的低端嵌入式处理器。
哈佛体系结构的特点是程序存储器与数据存储器分开,提供了较大的数据存储器带宽,适用于数据信号处理及高速数据处理的计算机。
2.在嵌入式系统中采用了哪些先进技术?答:(1)流水线技术(2)超标量执行(3)总线和总线桥3.简述基于ARM架构的总线形式答:ARM架构总线具有支持32位数据传输和32位寻址的能力,通过先进微控制器总线架构AMBA支持将CPU、存储器和外围都制作在同一个系统板中。
第二版信息系统管理工程师课程知识点(汇总)
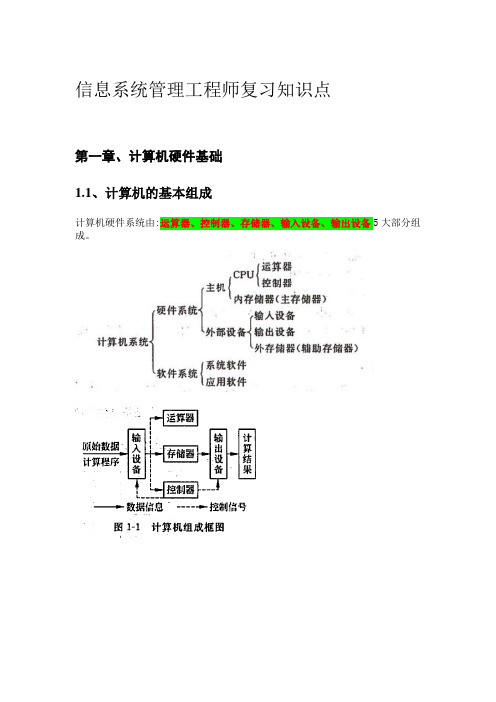
信息系统管理工程师复习知识点第一章、计算机硬件基础1.1、计算机的基本组成计算机硬件系统由:运算器、控制器、存储器、输入设备、输出设备5大部分组成。
1.2、中央处理器(运算器+控制器)1、运算器(算术运算和逻辑运算)运算器通常由算术逻辑运算部件(ALU)和一些寄存器(通用寄存器、特殊寄存器)组成。
2、控制器控制器工作的实质是解释、执行指令。
它的组成包括:a、程序计数器(存放正在执行的指令地址或下一个要执行的地址)b、指令寄存器(存放现行指令)c、指令译码器d、脉冲源及启停控制线路e、时序信号产生部件f、操作控制信号形成部件g、中断机构h、总线控制逻辑3、CPU的功能1.3、存储器a、高速缓冲存储器(高速小容量存储器,用来临时存放指令和数据。
)b、主存储器(存放计算机运行时的大量程序和数据,主要为半导体读写存储器,简称RWM,习惯上称为RAM。
组成为:存储体、读写电路、地址译码和控制电路等。
)c、辅助存储器高速缓存的地址映像方法直接映像、全相连映像、组相连映像1.4、计算机的系统结构1、并行处理的概念所为并行性,是指计算机系统具有可以同时进行运算或操作的特性,它包括同时性与并发性两种含义。
提高并行性的措施主要有3个途径:时间重叠、资源重复、资源共享。
2、计算机的体系结构计算机执行的指令序列称为“指令流”,指令流调用的数据序列称为“数据流”。
计算机同时处理的指令或数据的个数称为“多重性”。
(1)单指令流单数据流:单处理机(2)单指令流多数据流:并行处理机(3)多指令流单数据流:很少见了(4)多指令流多数据流:多处理机3、流水线处理机系统将指令的执行过程分成多个阶段若干个子过程。
流水线技术是一种时间并行技术。
采用重叠执行方式有两个优点:一是程序的执行时间大大缩短;二是功能部件的利用率明显提高。
4、并行处理机系统采用资源重复的措施开发并行性,以SIMD方式工作的。
5、多处理机系统流水线处理器通过若干级流水的时间并行技术来获得高性能。
第3章流水线技术

第2章流水线技术流水线是计算机体系结构设计中普遍应用的技术。
本章介绍流水线的基本概念、表示方法、和分类,讨论流水线实现的基本结构、线性流水线的性能与非线性流水线的调度策略,分析流水线的相关及其处理方法。
2.1 流水线的基本概念2.1.1 多条指令的执行方式一条指令的执行过程可以分为多个阶段,通常分为三个阶段,执行过程如图2-1所示。
第一阶段是取指令,按照程序计数器的内容访问主存储器,取出是一条指令送到指令寄存器。
第二阶段是分析指令,对指令寄存器中的指令进行译码分析,即对指令操作码进行译码,分析指令的功能,依据给定的寻址方式和地址码字段的内容形成操作数地址,并读取操作数(立即数寻址除外);同时,程序计数器自动产生一个增量,指到下一条指令。
第三阶段是执行指令,根据操作码的要求,对操作数进行运算和处理,完成指令规定的功能,并把运算结果送到指定的地址中。
指令执行过程中的第一阶段,一定要访问主存(指令一定在主存中),而在后两个阶段,也可能要访问主存(当操作数在主存中时)。
当有多条指令要在一个处理机中完成时,可以有多种执行方式。
现假设3个阶段所需要的时间均为△t 。
2.1.1.1 顺序执行方式顺序执行方式是指在任何时刻,处理机中只有一条指令在执行,指令之间是顺序串行执行的,即第k条指令执行完成后,再执行完成第k+1条指令,依次类推。
多条指令执行过程如图2-2(a)所示,执行n条指令所需要的时间为T = 3n△t。
顺序执行方式的优点是控制简单,节省设备。
主要缺点有两个,一是处理机执行指令的速度慢。
只有当上一条指令执行完毕后,下一条指令才能开始执行。
二是功能部件的利用率低。
如取指令时主存是忙碌的,而指令执行部件是空闲的。
2.1.1.2 一次重叠执行方式一次重叠执行方式是指在任何时刻,处理机中至多只有两条指令在同时执行,即使第k 条指令的执行阶段与第k+1条指令的取指令同时进行。
多条指令执行过程如图2-2(b)所示,执行n条指令所需要的时间为T = (2n+1)△t。
DSP原理及应用邹彦主编课后答案

《D S P原理及应用(修订版)》邹彦主编课后答案(个人终极修订版)(总10页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--第一章1、数字信号处理实现方法一般有几种答:课本P2(2.数字信号处理实现)2、简要地叙述DSP芯片的发展概况。
答:课本P2( DSP芯片的发展概况)3、可编程DSP芯片有哪些特点答:课本P3( DSP芯片的特点)4、什么是哈佛结构和冯诺依曼结构他们有什么区别答:课本P3-P4(1.采用哈佛结构)5、什么是流水线技术答:课本P5(3.采用流水线技术)6、什么是定点DSP芯片和浮点DSP芯片它们各有什么优缺点答:定点DSP芯片按照定点的数据格式进行工作,其数据长度通常为16位、24位、32位。
定点DSP的特点:体积小、成本低、功耗小、对存储器的要求不高;但数值表示范围较窄,必须使用定点定标的方法,并要防止结果的溢出。
浮点DSP芯片按照浮点的数据格式进行工作,其数据长度通常为32位、40位。
由于浮点数的数据表示动态范围宽,运算中不必顾及小数点的位置,因此开发较容易。
但它的硬件结构相对复杂、功耗较大,且比定点DSP芯片的价格高。
通常,浮点DSP芯片使用在对数据动态范围和精度要求较高的系统中。
7、DSP技术发展趋势主要体现在哪些方面答:课本P9(发展技术趋势)8、简述DSP系统的构成和工作过程。
答:课本P10(系统的构成)9、简述DSP系统的设计步骤。
答:课本P12(系统的设计过程)10、DSP系统有哪些特点答:课本P11(系统的特点)11、在进行DSP系统设计时,应如何选择合理的DSP芯片答:课本P13(芯片的选择)12、TMS320VC5416-160的指令周期是多少毫秒它的运算速度是多少MIPS 解:f=160MHz,所以T=1/160M==;运算速度=160MIPS第二章1、TMS320C54x芯片的基本结构都包括哪些部分答:课本P17(各个部分功能如下)2、TMS320C54x芯片的CPU主要由几部分组成答:课本P18(3、处理器工作方式状态寄存器PMST中的MP/MC、OVLY和DROM3个状态位对’C54x的存储空间结构有何影响答:课本P34(PMST寄存器各状态位的功能表)4、TMS320C54x芯片的内外设主要包括哪些电路答:课本P40(’C54x的片内外设电路)5、TMS320C54x芯片的流水线操作共有多少个操作阶段每个操作阶段执行什么任务完成一条指令都需要哪些操作周期答:课本P45(1.流水线操作的概念)6、TMS320C54x芯片的流水线冲突是怎样产生的有哪些方法可以避免流水线冲突答:由于CPU的资源有限,当多于一个流水线上的指令同时访问同一资源时,可能产生时序冲突。
第三章流水线技术.ppt

ExtOp
MemtoReg
ALUSelB
chapter3.3
3.1 流水线的基本概念
• 洗衣为例 • Ann, Brian, Cathy, Dave 每人进行洗衣的动作: wash, dry, and fold • washer需要 30 minutes • Dryer 需要 40 minutes • “Folder” 需要 20 minutes A B C D
– 45 ns/cycle x 1 CPI x 100 inst = 4500 ns
• 多周期机器
– 10 ns/cycle x 4.6 CPI (due to inst mix) x 100 inst = 4600 ns
• 理想流水线机器
– 10 ns/cycle x (1 CPI x 100 inst + 4 cycle drain) = 1040 ns
32
WrAdr 32 Din Dout
Ideal Memory
Rt 0 Rd
Reg File
busA A
32
2019/3/18
Mux
32
4 B
32
Mem Data Reg
0
1 Mux 0
Mux
1
32
1
2 3
32 32
<< 2
ALU Control
Imm 16
Extend
32
ALUOp
中国科学技术大学
• Step 2 step
ID - instruction decode and register fetch
– A <-- Regs[IR6..10] – B <-- Regs[IR11..16]
管理信息系统习题第3章

第三章管理信息系统的技术基础3.1 单项选择题3.1.1 数据流的具体定义是()。
A、数据处理流程图的内容B、数据字典的内容C、新系统边界分析的内容D、数据动态性分析的内容3.1.2 判断表由以下几方面内容组成()。
A、条件、决策规则和应采取的行动B、决策问题、决策规则、判断方法C、环境描述、判断方法、判断规则D、方案序号、判断规则、计算方法3.1.3 邮政编码是一种()。
A、缩写码B、助忆码C、顺序码D、区间码3.1.4 下面的系统中,哪一个是实时系统()。
A、办公室自动化系统B、航空订票系统C、计算机辅助设计系统D、计算机激光排版系统3.1.5 输入设备将程序和数据送去处理的设备为()。
A、主机B、显示器C、控制器D、磁盘3.1.6 局域网络事实上是()。
A、一种同机种网络B、线路交换方式网络C、面向终端的计算机网络D、一种计算机通信系统3.1.7 在下列设备中,不能作为微计算机的输入设备的是()。
A、激光打印机B、鼠标C、键盘D、硬盘3.1.8 根源性收集数据需要()。
A、人工参与B、由人与计算机结合收集C、由人工收集D、不由人工参与3.1.9 通常唯一识别一个记录的一个或若干个数据项称为()。
A、主键B、副键C、鉴别键D、索引项3.1.10 在索引表中,被索引文件每个记录的关键字相对的是()。
A、文件名B、记录项C、数据项D、相应的存储地址3.1.11 某数据库文件共有6条记录执行了.GO 3.SKIP—5后RECNO()和BOF()的值是()A、-2,.T.B、0,.T.C、1,.T.D、1,.T.3.1.12 在FOXBASE中物理删除一个数据库文件的全部记录的命令是()。
A、DELDTEB、DELETE ALLC、PACKD、ZAP3.1.13 数据查询语言是一种()。
A、程序设计语言B、面向过程语言C、面向问题语言D、描述数据模型语言3.1.14 在计算机的各种存储器中,访问速度最快的是()。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
19 例:add r1, r2, r3; r2 + r3 - > r1
例:Load r1, 10 ( r4 )
多周期实现
例:store 20(r2),r3
20
多周期实现
21 NPC) + 24 - > PC 例:BEQ r1, 24 ;if r1= r0, (
ID
EX
MEM
WB
ID
EX
MEM
(非流水线单周期指令系统实现不介绍)
15
多周期实现
Multi-cycle implementation
例:Load r1, 10 ( r4 )
• 5个周期
– IF: Instruction fetch cycle
• 按照 PC 内容访问指令存储器,取出指令 • PC+4→NPC,以获取下一条指令地址
目标
不仅是实现CPU: 12级流水线用于几何变换的GPU中。
4
例:假定一条指令的执行分为三个阶段:取指令、分析、执行。 下图表示了三种执行方式相邻指令间的时序关系。
90ns
并行 机器周期 30ns
流水段(级): 完成一条指令 的一部分操作
5
二次重叠执行方式的指令流水线:
指令流入 取指 令 部件 分析
部件
流水线锁存器
执行
指令流出 部件
• 类似于工厂的自动装配线:
由工人、机器、装配件构成,
通过工人不断对产品进行装
配直至完成。
1913年福特密歇根工厂移动装配线 (84 个步骤) 6
二次重叠执行方式的指令流水线:
指令流入 取指 令 部件 分析
部件
流水线寄存器 (锁存器)
执行
指令流出 部件
机器周期(流水线周期):指令沿流水线移动一个
– 流水线减少CPI.
30
单周期实现比较流水线
Single Cycle Implementation:
Cycle 1
CPI=1, long clock cycle
Cycle 2
Clk Load Store Waste
Pipeline Implementation:
CPI=1, clock cycle long clock cycle/5
• Branch: 做“=0?”测试,如果条件满足计算目标地址送PC
– MEM: Memory access
• Load: 送有效地址到数据存储器,取数据 • Store: 写ID读出数据到有效地址单元中
– WB: Write-back cycle
• Load or ALU: 写结果到寄存器堆
18
多周期实现
(每个时钟周期执行的指令数)
• 太多的段数:
– 非常复杂 – 处理正在执行指令之间 的冒险(相关) – 控制逻辑很大
13
二、RISC指令系统特点
RISC系统结构有以下几个关键特点:
– 所有参加运算的数据来自寄存器,结果也写入 寄存器。寄存器为32/64位。
– 访存只有load和store指令
– 指令的数量较少,所有指令长度相同。 这种结构可以有效地简化流水线的实现。 MIPS系统是默认的 RISC系统结构。
– ID: Instruction decode/ register fetch cycle
• 指令译码 • 读寄存器
• 如果需要,符号扩展指令中的位移量
17
– EX: Execution/ effective address cycle
• Load/Store: 计算数据存储器有效地址
• R-R/ R-I ALU: 执行运算操作
27
四、经典5段流水线RISC处理器
• 5个段构成了一个指令流水线,一条指令经过每个段。
• CPI 减少到1,因为平均每个时钟周期发射或完成一条指令。
• 在任意时钟周期,在每个流水段正执行一条指令的部分。
• Ideally, performance is increased five fold !
Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Cycle 8 Cycle 9 Cycle 10 Clk Load IF ID Store IF R-type EX ID IF MEM EX ID WB MEM EX
31
WB MEM WB
• 使用分开的指令cache和数据cache
Time (clock cycles)
ALU
I n s t r. O r d e r
Ld/St Instr 1 Instr 2 Instr 3
IM
Reg IM
DM ALU
Reg DM ALU Reg DM ALU Reg DM Reg
Reg IM
Reg IM
• 流水段之间采用同步时钟控制
• 一条指令或操作从流水线一端进入,经过各段,从另一端
流出
• 流水线是开发串行指令流中并行性的一种实现技术
10
为什么采用流水线:结论
• 制造快速CPU的关键技术:减少 CPUtime.
• 改进吞吐量 • 改进资源利用率
11
为什么不开发 50段流水线?
• 有些操作不能分为更细的逻辑实现
5 stages OK
50 stages NO. Sorry!
• 流水线锁存器不是免费的,要占据面积,且有延迟。
机器周期> 锁存器延迟+ 时钟偏移
12
流水线段数实例
• E.g., Intel
– – – – Pentium III, Pentium 4: 20+ stages 正在执行的指令超过20 条 时钟频率(>1GHz) 高 IPC
32
WB MEM WB
流水线真如此简单吗?
store
pipeline registers or latches
load
Why need to add this line?
33
引入流水线后出现的问题
注意:在同一时钟周期不同操作不能使用同一数据通
路资源。(结构冒险structure hazard) • 有访问存储器冲突!
非流水线机器平均指令执行时间 流水线机器段数
非流水线机器平均指令执行时间 流水线机器平均指令执行时间
理想情况:流水线的加速比等于流水线机器的段数。
流水线减少了指令执行的平均时间(减少了CPI或时钟周期) 流水线技术(硬件实现)对编程者透明
9
流水线特点
• 一个流水线类似自动装配线 • 一个流水线有多个段(级),段间有流水线寄存器 • 每个流水段执行指令或操作的不同部分
38
流水线模型
ห้องสมุดไป่ตู้
store
pipeline registers or latches
load
Why need to add this line?
39
流水线寄存器必须引入吗?
A.4
A.5
异常事件处理
扩展流水线到多周期操作
2
A.1 流水线的基本概念
一、什么是流水线?
二、RISC指令系统特点
三、非流水线方式下RISC指令系统的实现
四、经典5段流水线RISC处理器 五、流水线的基本性能
3
一、什么是流水线?
流水线是利用执行指令操作之间的并行性, 实现多条指令重叠执行的技术。 “在前一条指令执行完毕之前开始执行本条指令。” 当今,流水线是实现更快CPU的基本和关键 技术。
28
5-段流水线 MIPS 数据通路
store
pipeline registers or latches
29
load
流水线怎样减少执行时间?
对比不同串行实现的机器:
• 每条指令执行用一个时钟周期的机器(单周期实现)
– 流水线减少时钟周期的长度(时间)
• 每条指令执行用多个时钟周期的机器(多周期实现)
流水段的时间。长度取决于最慢的流水段,一般是一个
时钟周期(有时是两个时钟周期)。
每个流水线周期从指令流水线流出一条指令。
吞吐量:单位时间从流水线流出的指令数。
7
90ns
并行 机器周期 30ns
流水段(级):
完成一条指令
的一部分操作
8
8
流水线设计者:平衡每个流水段的时间,使之等长。 因此,每条指令在流水线的平均时间在理想情况下为:
• branch 指令占2 cycles, store 和 ALU 指令占 4
cycles, 只有load 指令占 5 cycles.
• CPI 降到4.07 ,假定ALU指令操作频率47%
2×12% +4×(10%+47%)+ 31%×5=4.07
25
优化的多周期实现
IF ID EX MEM WB
Single-cycle implementation(参考)
seldom used !
Single Cycle Implementation:
Cycle 1 Clk Load
CPI=1, long clock cycle
Cycle 2
22
Store
Waste
多周期实现
多周期实现的特点
• 数据路径中的暂存器易于实现流水线 • 注意:branch和Store指令花费 4 clock cycles.
37
当更新PC时产生冲突
• 每个时钟周期必须增量PC并存储到PC • 遇到转移指令怎么办?
– 转移可能会改变PC的值—— 但是条件要等到ID段才能得到! – 如果转移发生,在IF段取到的转移指令其后的指令是无效的!