数据挖掘导论Iris KDD分析(DOC)
数据挖掘基本概念解说

效的、新颖的、潜在有用的,以及最终可理解的模式的非平凡过程。
知识发现就是从数据源中抽取感兴趣的数据,并把这些数据组织成符合挖掘
的组织形式,然后利用相应的算法、模型生成想要的知识模式,最后对生成
的知识模式进行评估,并把有价值的知识集成到应用系统当中。
常用KDD过程模型 (KDD process model)
式为直接电邮,考虑到多数用户可能不会对理财产品感兴趣,所以 销售目标为用户群中对产品兴趣度最高的前20%
数据表
有效字段
客户表
姓名、职业、性别、生日、收入
日期对照表
日期的各种转化形式
账号信息表
账号类型,月费、透支额度等
交易信息表
交易类型、交易日期、交易金额
1
19
三、数据挖掘案例
流程
数据评
价
数据预处
理
1995年底美国计算机年会。 开始把数据挖掘认为是KDD过
程中对数据真正应用算法抽取 知识的一个基本步骤。
1995年第一届知识发现和 数据挖掘国际学术会议。首次 提出数据挖掘的概念。
如今各种各样的 数据挖掘软件和算法。
1
6
一、数据挖掘的基本概念
4.数据挖掘基本流程
Data
跨 行 业
Business Understanding
度为C=3/5=0.6,假如设计支持度最小为0.5,置信度为0.6,那么网球
拍和网球的关联关系就是有意义的一对关联关系。
1
16
二、数据挖掘方法分类
5.关联规则(Affinity grouping or association rules)
1
17
三、数据挖掘案例
1
18
《数据挖掘导论》目录

《数据挖掘导论》⽬录⽬录什么是数据挖掘常见的相似度计算⽅法介绍决策树介绍基于规则的分类贝叶斯分类器⼈⼯神经⽹络介绍关联分析异常检测数据挖掘数据挖掘(英语:Data mining),⼜译为资料探勘、数据采矿。
它是数据库知识发现(英语:Knowledge-Discovery in Databases,简称:KDD)中的⼀个步骤。
数据挖掘⼀般是指从⼤量的数据中通过算法搜索隐藏于其中信息的过程。
数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多⽅法来实现上述⽬标。
常见的数据相似度计算汉密尔顿距离(r = 1)欧式距离(r = 2)上确界距离(r = max)⼆元数据相似性简单匹配系数(Simple Matching Coefficient,SMC):Jaccard 系数:余弦相似度:⼴义Jaccard系数:⽪尔逊相关系数(Pearson’s correlation):决策树(decision tree)(TODO)决策树是⼀个树结构(可以是⼆叉树或⾮⼆叉树)。
其每个⾮叶节点表⽰⼀个特征属性上的测试,每个分⽀代表这个特征属性在某个值域上的输出,⽽每个叶节点存放⼀个类别。
使⽤决策树进⾏决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分⽀,直到到达叶⼦节点,将叶⼦节点存放的类别作为决策结果。
构造决策树的关键步骤是分裂属性。
所谓分裂属性就是在某个节点处按照某⼀特征属性的不同划分构造不同的分⽀,其⽬标是让各个分裂⼦集尽可能地“纯”。
尽可能“纯”就是尽量让⼀个分裂⼦集中待分类项属于同⼀类别。
构造决策树的关键性内容是进⾏属性选择度量,属性选择度量是⼀种选择分裂准则,是将给定的类标记的训练集合的数据划分D“最好”地分成个体类的启发式⽅法,它决定了拓扑结构及分裂点split_point的选择。
属性选择度量算法有很多,⼀般使⽤⾃顶向下递归分治法,并采⽤不回溯的贪⼼策略。
kdd数据集详解数据挖掘

根据您提供的信息,我为您整理了一份团餐合同协议书的大致模板,具体内容可能需要根据实际情况进行调整:甲方:(单位名称)乙方:(团餐供应商名称)鉴于甲方需要团餐服务,乙方愿意提供团餐服务,经双方友好协商,特订立本合同,以便共同遵守。
一、团餐服务内容1.1 乙方根据甲方的要求,为甲方提供午餐和/或晚餐的团餐服务。
1.2 团餐标准:每餐人民币____元,包含主食、副食、汤品等。
二、服务时间2.1 乙方应在甲方规定的时间内向甲方提供团餐服务,具体时间为:早餐:____点至____点午餐:____点至____点晚餐:____点至____点三、服务质量3.1 乙方应保证团餐的食品安全与服务质量,确保食品符合国家食品安全标准。
3.2 乙方应建立完善的供应链管理体系,保证食品的可追溯性。
3.3 乙方应定期进行食品安全检测,并对加工过程进行严格监控。
四、费用及支付4.1 甲方应按照本合同约定的服务内容和服务时间,向乙方支付团餐费用。
4.2 甲方支付给乙方的团餐费用,按照每餐每人人民币____元计算。
4.3 甲方应在每月的第一个工作日支付上一个月的团餐费用。
五、违约责任5.1 乙方未按照约定时间提供团餐服务的,甲方有权要求乙方支付违约金。
5.2 乙方提供的团餐不符合约定的质量标准的,甲方有权要求乙方支付违约金,并有权解除本合同。
六、其他6.1 本合同自双方签字盖章之日起生效,有效期为____年。
6.2 本合同一式两份,甲乙双方各执一份。
甲方(盖章):______________乙方(盖章):______________甲方代表(签名):______________乙方代表(签名):______________签订日期:______________。
数据挖掘-数据挖掘导论

2
数据
数据库 管理
数据仓库
数据挖掘
数据智能 分析
解决方案
图-- 数据到知识的演化过程示意描述
随着计算机硬件和软件的飞速发展,尤其是数据库技术与应用的日益普及,人 们面临着快速扩张的数据海洋,如何有效利用这一丰富数据海洋的宝藏为人类服务, 业已成为广大信息技术工作者的所重点关注的焦点之一。与日趋成熟的数据管理技 术与软件工具相比,人们所依赖的数据分析工具功能,却无法有效地为决策者提供 其决策支持所需要的相关知识,从而形成了一种独特的现象“丰富的数据,贫乏的 知识”。为有效解决这一问题,自二十世纪 9 年代开始,数据挖掘技术逐步发展起 来,数据挖掘技术的迅速发展,得益于目前全世界所拥有的巨大数据资源以及对将 这些数据资源转换为信息和知识资源的巨大需求,对信息和知识的需求来自各行各 业,从商业管理、生产控制、市场分析到工程设计、科学探索等。数据挖掘可以视 为是数据管理与分析技术的自然进化产物,如图-- 所示。
)。事实上, 一部人类文明发展史,就是在各种活动中,知识的创造、交流,再创造不断积累的 螺旋式上升的历史。
客观世界 客观世界
收集
数据 数据
分析
信息 信息
深入分析
知识 知识
决策与行动
图-- 人类活动所涉及数据与知识之间的关系描述
计算机与信息技术的发展,加速了人类知识创造与交流的这种进程,据德国《世 界报》的资料分析,如果说 ( 世纪时科学定律(包括新的化学分子式,新的物理关 系和新的医学认识)的认识数量一百年增长一倍,到本世纪 / 年代中期以后,每五 年就增加一倍。这其中知识起着关键的作用。当数据量极度增长时,如果没有有效 的方法,由计算机及信息技术来帮助从中提取有用的信息和知识,人类显然就会感 到像大海捞针一样束手无策。据估计,目前一个大型企业数据库中数据,约只有百 分之七得到很好应用。因此目前人类陷入了一个尴尬的境地,即“丰富的数据”( *)而“贫乏的知识0('
(完整word版)Iris数据判别分析
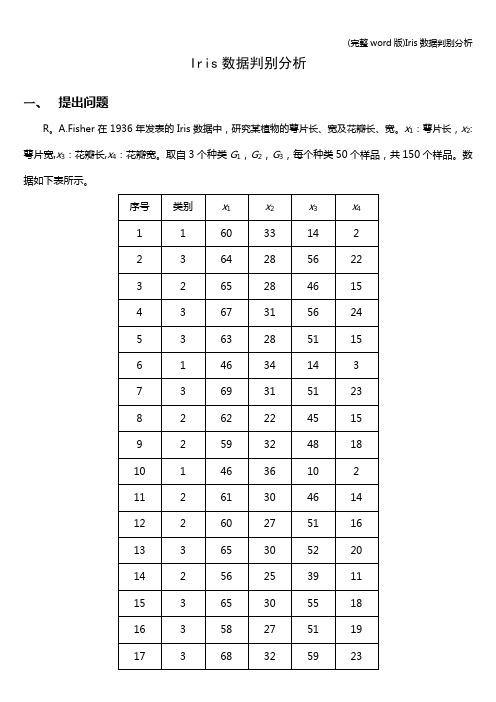
Iris数据判别分析一、提出问题R。
A.Fisher在1936年发表的Iris数据中,研究某植物的萼片长、宽及花瓣长、宽。
x1:萼片长,x2:萼片宽,x3:花瓣长,x4:花瓣宽。
取自3个种类G1,G2,G3,每个种类50个样品,共150个样品。
数据如下表所示。
134255254013135********136********137********138357255020139********14015138153141255234013142266304414143268284814144154341721451513715414615235152147358285124148267305017149363336025150********(1)进行Bayes判别,并用回代法与交叉确认法判别结果;(2)计算每个样品属于每一类的后验概率;(3)进行逐步判别,并用回代法与交叉确认法验证判别结果。
二、判别分析距离形成的矩阵,其中线性判别函数是2.1 Bayes判别先验概率按比例分配,即求得的线性判别函数中关于变量的系数以及常数项均与上面结果相同。
广义平方距离函数,后验概率以下是SPSS软件判别分析结果。
分析觀察值處理摘要未加權的觀察值N百分比有效150100。
0已排除遺漏或超出範圍群組代碼0。
0至少一個遺漏區別變數0.0遺漏或超出範圍群組代碼0。
0及至少一個遺漏區別變數總計150100.0群組平均值的等式檢定Wilks'Lambda (λ)F df1df2顯著性x1.393113.3142147。
000 x2.63841.6762147。
000 x3。
0591180.1612147.000 x4.075902。
5042147。
000聯合組內矩陣ax1x2x3x4共變異x127。
1599。
78316。
7094。
225 x29。
78313.5145。
6103。
464x316。
7095。
61018。
数据挖掘导论

本书的亮点之一在于对可视化分析的独到见解。作者指出,可视化是解决复杂 数据挖掘问题的有效手段,可以帮助我们直观地理解数据和发现隐藏在其中的 规律。书中详细讨论了可视化技术的种类、优缺点以及在数据挖掘过程中的作 用。还通过大量实例,让读者切实感受到可视化分析在数据挖掘中的强大威力。
除了可视化分析,本书还对关联规则挖掘、聚类分析等众多经典算法进行了深 入阐述。例如,在关联规则挖掘部分,作者首先介绍了Apriori算法的基本原 理和实现过程,然后提出了一系列改进措施,如基于哈希表的剪枝、基于密度 的剪枝等,有效提高了算法的效率和准确率。在聚类分析部分,不仅详细讨论 了K-Means、层次聚类等经典算法,还对如何评价聚类效果进行了深入探讨。
第4章:关联规则挖掘。讲解了关联规则的定义、算法和实际应用。
第5章:聚类分析。讨论了聚类算法的类型、原理和应用。
第6章:分类。介绍了分类算法的原理、应用及评估方法。
第7章:回归分析。讲解了回归分析的原理、方法和实际应用。
第8章:时间序列分析。探讨了时间序列的基本概念、模型和预测方法。
第9章:社交网络分析。讲解了社交网络的基本概念、测量指标和挖掘方法。
《数据挖掘导论》是一本非常优秀的书籍,全面介绍了数据挖掘领域的基本概 念、技术和应用。通过阅读这本书,我不仅对数据挖掘有了更深入的了解,还 从中获得了不少启示和收获。书中关键点和引人入胜的内容也让我进行了深入 思考。从个人角度来说,这本书给我带来了很多情感体验和思考。结合本书内 容简单探讨了数据挖掘在生活中的应用前景。
在阅读这本书的过程中,我最大的收获是关于数据挖掘技术的理解。书中详细 介绍了各种数据挖掘技术的原理、优缺点以及适用场景。尤其是关联规则挖掘、 聚类分析和分类算法等部分,让我对这些技术有了更深入的认识。通过这些技 术的学习,我明白了如何从大量数据中提取有用的信息和知识。
数据挖掘导论Iris KDD分析教材

| petal width > 1.7: Iris-virginica (46.0/1.0)
Number of Leaves :5
Size of the tree :9
Time taken to build model: 0.01 seconds
+/-0.4336 +/-0.2934 +/-0.381 +/-0.2799
petal length 3.7587 4.3967 1.464 5.7026
+/-1.7644 +/-0.5269 +/-0.1735 +/-0.5194
petal width 1.1987 1.418 0.244 2.0795
=== Run information ===
Scheme: weka.clusterers.SimpleKMeans -init 0 -max-candidates 100 -periodic-pruning 10000 -min-density 2.0 -t1 -1.25 -t2 -1.0 -V -N 3 -A "weka.core.EuclideanDistance -R first-last" -I 5009 -num-slots 1 -S 10
kMeans
======
Number of iterations: 6
Within cluster sum of squared errors: 1.7050986081225123
Initial starting points (random):
数据挖掘_精品文档

第二章 introduction分类策略:预测型 描述型数据挖掘的具体实际应用:银行,风险,诈骗,关联分析,市场分析……KDD (knowledge )概念, KDD 和数据挖掘的关系:数据挖掘时 KDD 的一个重要组成部份.KDD:选择和处理数据的过程,从而获得新颖的,准确的和游泳的知识,并为问题建立模型。
(数据挖掘是 kdd 的一个重要过程) .KDD 的过程: (数据挖掘是知识发现的核心过程)知识合并(创建数据集),选择和预处理(数据清理: 60%工 作量),数据挖掘,解释评估。
Garbage in garbage out 50-70%花在头两步。
KDD 的良性循环:由KDD 过程得到知识,应用知识得到结果,评价结果得到策略,确定问题共KDD 过程改进。
31数据合并:决定属性,存储到数据库,处理缺值,去掉例外点数据选择和预处理: 生成数据集,减少属性维度, 减少属性值范围,数据转换(归一化…) OLAP(联机分析过程) 和虚拟化工具数据挖掘:自动发现(探索) (如聚类分析,贝叶斯聚类),分类预测(例如回归,遗传算法),解释描述(例 如决策树 关联规则)……n 多方法数据挖掘的所有结果都实用么? 53评估与解释:评估(交叉验证,专家)解释(归纳书和规则模型可直接阅读,聚类结果可视化、表格化。
发现模式的表达(presentation of discovered patterns): 不同用途、背景需要不同的表达。
概念层次很重要,对知 识的高度抽象有时不容易理解。
不同的知识需要不同的表达(关联规则,分类,聚类 等等)数据挖掘的主要问题:挖掘方法(从不同的数据类型中挖掘不同知识,性能(效率,开消,规模),评估,背 景知识的不同,噪声和不完整数据,并行、分布、增量式挖掘方法,知识融合)。
用户交互。
应用和社会影响。
数据挖掘概念:从大量数据中发现实用的知识。
KDD 过程:数据整合,数据选择与预处理,数据挖掘,解释与评估。
数据挖掘导论--第1章绪论

数据挖掘导论--第1章绪论数据挖掘导论-第⼀章-绪论为什么会出现数据挖掘?1. 因为随着社会不断快速发展,信息量在不断增加,由于**信息量太⼤** ,⽽⽆法使⽤传统的数据分析⼯具和技术处理它们;2. 即使数据集相对较⼩,但由于数据本⾝有⼀些**⾮传统特点**,也不能使⽤传统的⽅法进⾏处理。
什么是数据挖掘?数据挖掘是⼀种技术,它将传统的数据分析⽅法与处理⼤量数据的复杂算法相结合。
数据挖掘是在⼤型数据存储库中,⾃动地发现有⽤信息的过程。
数据挖掘是数据库中知识发现(knowledge discovery in database,KDD)不可缺少的⼀部分。
数据挖掘要解决的问题可伸缩⾼维性异种数据和复杂数据数据的所有权与分布⾮传统的分析数据挖掘任务通常,数据挖掘任务分为下⾯两⼤类预测任务:这些任务的⽬标是根据其他属性的值,预测特定属性的值。
被预测的属性⼀般称为⽬标变量或因变量⽤来做预测的属性称说明变量或⾃变量描述任务:其⽬标是导出概括数据中潜在联系的模式(相关、趋势、聚类、轨迹和异常)。
本质上,描述性数据挖掘任务通常是探查性的,并且常常需要后处理技术验证和解释结果下图展⽰了其余部分讲述的四种主要数据挖掘任务预测建模:以说明变量函数的⽅式为⽬标变量建⽴模型。
有两类预测建模任务:分类(classification):⽤于预测离散的⽬标变量回归(regression):⽤于预测连续的⽬标变量关联分析:⽤来发现描述数据中强关联特征的模式。
所发现的模式通常⽤蕴涵规则或特征⼦集的形式表⽰聚类分析:旨在发现紧密相关的观测值组群,使得与属于不同簇的观测值相⽐,属于同⼀簇的观测值相互之间尽可能类似异常检测:任务是识别其特征显著不同于其他数据的观测值。
这样的观测值称为异常点或离群点## 参考⽂献: 1. 数据挖掘导论(完整版)。
数据挖掘导论

数据挖掘导论数据挖掘是一种从大量数据中提取实用信息的过程,通过应用统计学、机器学习和数据库技术等方法,从数据中发现隐藏的模式、关联和趋势。
数据挖掘在各个领域中都有广泛的应用,包括市场营销、金融、医疗保健和社交媒体等。
一、数据挖掘的定义和目标数据挖掘是指从大规模数据集中自动发现实用的信息和模式的过程。
其目标是通过分析数据,提取出有价值的知识,以支持决策和预测。
数据挖掘的任务包括分类、聚类、关联规则挖掘、异常检测和预测等。
二、数据挖掘的流程数据挖掘的流程包括问题定义、数据采集、数据预处理、特征选择、模型构建、模型评估和模型应用等步骤。
1. 问题定义:明确需要解决的问题,并确定数据挖掘的目标和约束条件。
2. 数据采集:采集与问题相关的数据,可以是结构化数据(如数据库)或者非结构化数据(如文本、图象等)。
3. 数据预处理:对采集到的数据进行清洗、集成、转换和加载等操作,以确保数据的质量和一致性。
4. 特征选择:从数据集中选择最相关的特征,以提高模型的性能和效果。
5. 模型构建:选择适当的数据挖掘算法,构建模型来解决问题。
常用的算法包括决策树、神经网络、支持向量机等。
6. 模型评估:通过交叉验证、准确率、召回率等指标评估模型的性能和泛化能力。
7. 模型应用:将训练好的模型应用于实际问题中,进行预测、分类、聚类等操作。
三、数据挖掘的常用技术和方法数据挖掘涉及多种技术和方法,以下是其中一些常用的技术和方法:1. 分类:将数据分为不同的类别或者标签,常用算法有决策树、朴素贝叶斯和支持向量机等。
2. 聚类:将数据分为相似的组别,常用算法有K均值聚类、层次聚类和DBSCAN等。
3. 关联规则挖掘:发现数据中的关联关系,常用算法有Apriori和FP-growth等。
4. 异常检测:检测数据中的异常值或者离群点,常用算法有LOF和孤立森林等。
5. 预测:基于历史数据进行未来事件的预测,常用算法有线性回归、时间序列分析和神经网络等。
数据挖掘导论

数据挖掘导论数据挖掘导论是一门研究如何从大规模数据集中提取有价值信息的学科。
它结合了统计学、机器学习、数据库技术和可视化技术等多个领域的知识和方法,旨在帮助人们发现隐藏在数据中的模式、关联和趋势,以支持决策和预测。
数据挖掘导论的研究对象是大规模、复杂、异构的数据集。
这些数据集可能包含结构化数据(如数据库、数据仓库)和非结构化数据(如文本、图像、音频等)。
数据挖掘导论的目标是通过应用各种数据挖掘技术,从这些数据中提取出有用的信息,并将其转化为知识,以支持决策和预测。
数据挖掘导论的研究内容包括数据预处理、特征选择、特征提取、模型构建、模型评估和模型应用等方面。
数据预处理是指对原始数据进行清洗、集成、转换和规范化等操作,以消除数据中的噪声、冗余和错误。
特征选择是指从大量的特征中选择出最具有代表性和相关性的特征,以提高模型的准确性和效率。
特征提取是指通过对原始数据进行变换和抽象,提取出更加有意义和可解释的特征。
模型构建是指选择合适的算法和模型结构,通过训练数据来学习模型的参数和权重。
模型评估是指使用测试数据对构建的模型进行性能评估和优化。
模型应用是指将构建好的模型应用于新的数据集,进行预测、分类、聚类、关联规则挖掘等任务。
数据挖掘导论的应用领域非常广泛。
在商业领域,数据挖掘导论可以用于市场营销、客户关系管理、风险评估、欺诈检测等任务。
在医疗领域,数据挖掘导论可以用于疾病预测、诊断支持、药物研发等任务。
在社交网络领域,数据挖掘导论可以用于社交推荐、舆情分析、用户行为分析等任务。
在安全领域,数据挖掘导论可以用于威胁检测、入侵检测、网络安全等任务。
在科学研究领域,数据挖掘导论可以用于数据分析、模式识别、科学发现等任务。
数据挖掘导论的研究方法包括统计方法、机器学习方法、人工智能方法等。
统计方法是数据挖掘导论的基础,通过统计学原理和方法来分析数据中的模式和关联。
机器学习方法是数据挖掘导论的核心,通过构建和训练模型来发现数据中的模式和关联。
第二章数据挖掘资料

第二章数据挖掘理论概述2.1数据挖掘的定义和分类目前,对数据挖掘(data mining)有广义的和狭义的两种理解。
广义的理解认为数据挖掘即数据库中的知识发现(Knowledge Discovery in Database,KDD)。
即从大规模的数据库中抽取非平凡的、隐含的、未知的、有潜在使用价值的信息的过程。
狭义的理解认为数据挖掘是KDD的一个步骤。
KDD为从数据中识别正确的、新颖的、有潜在使用价值的、最终可理解的模式的非平凡的过程。
它包括数据选取、数据预处理和数据清洗、数据挖掘、知识评估等多个步骤。
数据挖掘是其中对经过预处理的数据进行处理,抽取知识的过程。
数据挖掘不一定需要建立在数据仓库的基础上,但是如果将数据挖掘和数据仓库协同工作,则可以简化数据挖掘过程的某些步骤,从而大大提高数据挖掘的工作效率。
由于数据仓库的数据来源于整个企业,保证了数据挖掘中数据来源的广泛性和完整性。
数据挖掘技术是数据仓库应用中比较重要且相对独立的部分。
目前,数据挖掘技术正处在发展当中。
数据挖掘涉及到数理统计、模糊理论、神经网络和人工智能等多种技术,技术含量比较高,实现难度较大。
此外,数据挖掘技术还会同可视化技术、地理信息系统、统计分析系统相结合,丰富数据挖掘技术及工具的功能与性能。
Jiawei Han在《Data Mining: Concept & Techniques》[21]中将目前的数据挖掘技术主要分为以下几类:概念描述、关联分析、分类和预测、聚类分析、例外分析、趋势分析。
●概念描述(特性描述和区分)数据可以由一定的概念和类来抽象表示人们对其关心的那部分的性质。
简单明了地描述这些概念和类显然是非常有用的。
关于这些概念的描述称为概念描述(concept description),它包括了特性描述和区分。
●关联分析关联分析(association analysis)是在一个给定的数据集中发现经常同时发生的多个属性值条件(一般称为关联规则)的过程,常用于市场销售和事物数据分析。
数据挖掘导论第一章

2020/9/29
数据挖掘导论
3
2020/9/29
数据挖掘导论
4
2020/9/29
数据挖掘导论
5
Jiawei Han
在数据挖掘领域做出杰出贡献的郑州大学校友——韩家炜
2020/9/29
数据挖掘导论
6
第1章 绪论
?
No
S in g le 4 0 K
?
No
M a rrie d 8 0 K
?
10
Training Set
Learn Classifier
Test Set
Model
2020/9/29
数据挖掘导论
23
分类:应用1
Direct Marketing Goal: Reduce cost of mailing by targeting a set of consumers likely to buy a new cell-phone product. Approach: Use the data for a similar product introduced before. We know which customers decided to buy and which decided otherwise. This {buy, don’t buy} decision forms the class attribute. Collect various demographic, lifestyle, and company-interaction related information about all such customers. Type of business, where they stay, how much they earn, etc. Use this information as input attributes to learn a classifier model.
数据挖掘导论-第3章 数据库中的知识发现

27
第3章 数据库中的知识发现
2)属性和实例选择
数据归约:在保持数据的完整性的前提下,把需要分析的 数据量大幅减小,从而加快算法运行速度,但能够产生
几乎同样质量的分析结果。
通常情况下可以采用以下方法: (1)淘汰属性 (2)构造属性 (3)实例选择 抽样
28
属性筛选
第3章 数据库中的知识发现
(1)淘汰属性
名称 DBMiner
Quest
研究机构或公司 Simon Fraser
IBM Almaden
主要特点 以OLAM引擎为核心的联机挖掘原型系统; 包含多特征/序列/关联等多模式
面向大数据集的多模式(关联规则/分类等) 挖掘工具 包含多种技术(神经网络/统计分析/聚类等) 的辅助挖掘工具集 基于神经网络的辅助挖掘工具 基于实例推理和归纳逻辑的辅助挖掘工具
• 删除明显无价值的属性,例如缺失值比例很高的属性,以 及常数属性,还有取值太泛的类别型属性(例如邮政编码 )。 • 结合业务经验进行筛选。这是最关键、最重要的筛选属性 的方法。很多时候,业务专家一针见血的商业敏感性可以 有效缩小属性的考察范围。 • 多个属性之间线性相关性很强,一个属性可能能由另一个 或一组属性导出,只需要保留一个。
第3章 数据库中的知识发现
第3章 数据库中的知识发现
3.1 知识发现的基本过程 3.2 KDD过程模型的应用
3.3 实验:KDD案例
1
第3章 数据库中的知识发现
本章目标
了解知识发现的基本过程
掌握KDD过程模型的应用 学习KDD实验案例
2
第3章 数据库中的知识发现
3.1 知识发现的基本过程
数据库中的知识发现
相结合,因此,数据挖掘技术专门为了解决某些特定的问 题被使用,成为企业应用系统中一部分。 许多厂商或研究机构可以提供纵向数据挖掘的解决方案。因 此,数据挖掘技术在最近几年开始在一些领域得到应用。 例如,证券系统的趋势预测、银行和电信行业的欺诈行为检 测、在CRM中的应用、在基因分析系统中用于DNA识别等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
`题目 iris数据集的KDD实验学院名称信息科学与技术学院专业名称计算机科学与技术学生姓名何东升学生学号201413030119 指导教师实习地点成都理工大学实习成绩二〇一六年 9月iris数据集的KDD实验第1章、实验目的及内容1.1 实习目的知识发现(KDD:Knowledge Discovery in Database)是从数据集中识别出有效的、新颖的、潜在有用的,以及最终可理解的模式的非平凡过程。
知识发现将信息变为知识,从数据矿山中找到蕴藏的知识金块,将为知识创新和知识经济的发展作出贡献。
该术语于1989年出现,Fayyad定义为"KDD"是从数据集中识别出有效的、新颖的、潜在有用的,以及最终可理解的模式的非平凡过程”。
KDD的目的是利用所发现的模式解决实际问题,“可被人理解”的模式帮助人们理解模式中包含的信息,从而更好的评估和利用。
1.2 算法的核心思想作为一个KDD的工程而言,KDD通常包含一系列复杂的挖掘步骤.Fayyad,Piatetsky-Shapiro 和Smyth 在1996年合作发布的论文<From Data Mining to knowledge discovery>中总结出了KDD包含的5个最基本步骤(如图).1: selection: 在第一个步骤中我们往往要先知道什么样的数据可以应用于我们的KDD工程中.2: pre-processing: 当采集到数据后,下一步必须要做的事情是对数据进行预处理,尽量消除数据中存在的错误以及缺失信息.3: transformation: 转换数据为数据挖掘工具所需的格式.这一步可以使得结果更加理想化.4: data mining: 应用数据挖掘工具.5:interpretation/ evaluation: 了解以及评估数据挖掘结果.1.3实验软件:Weka3-9.数据集来源:/ml/datasets/Iris第2章、实验过程2.1数据准备1.从uci的数据集官网下载iris的数据源2.抽取数据,清洗数据,变换数据3.iris的数据集如图Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。
通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
2.2 实验过程2.2.1.建模(1)C4.5数据挖掘算法使用weka进行有指导的学习训练,选择C4.5数据挖掘算法,在Weka中名为J48,将test options 设置为 Percentage split ,使用默认百分比66%。
选择class作为输出属性。
如图所示:2.设置完成后点击start开始执行(2)Simple KMeans算法1加载数据到Weka,切换到Cluster选项卡,选择Simple KMeans算法、2.设置算法参数,显示标准差,迭代次数设为5000次,其他默认。
簇数选择3,因为花的种类为3。
如下图所示3.在Cluster Mode 面板选择评估数据为Use trainin set,并单击Ignore attribu,忽略class属性。
4.点击start按钮,执行程序第三章实验结果及分析3.1 C4.5结果分析1.运行结果=== Run information ===Scheme: weka.classifiers.trees.J48 -C 0.25 -M 2Relation: irisInstances: 150Attributes: 5sepal lengthsepal widthpetal lengthpetal widthclassTest mode: split 66.0% train, remainder test=== Classifier model (full training set) ===J48 pruned tree------------------petal width <= 0.6: Iris-setosa (50.0)petal width > 0.6| petal width <= 1.7| | petal length <= 4.9: Iris-versicolor (48.0/1.0)| | petal length > 4.9| | | petal width <= 1.5: Iris-virginica (3.0)| | | petal width > 1.5: Iris-versicolor (3.0/1.0)| petal width > 1.7: Iris-virginica (46.0/1.0)Number of Leaves : 5Size of the tree : 9Time taken to build model: 0.01 seconds=== Evaluation on test split ===Time taken to test model on training split: 0 seconds=== Summary ===Correctly Classified Instances 49 96.0784 %Incorrectly Classified Instances 2 3.9216 %Kappa statistic 0.9408Mean absolute error 0.0396Root mean squared error 0.1579Relative absolute error 8.8979 %Root relative squared error 33.4091 %Total Number of Instances 51=== Detailed Accuracy By Class ===TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa1.000 0.063 0.905 1.000 0.950 0.921 0.969 0.905 Iris-versicolor0.882 0.000 1.000 0.882 0.938 0.913 0.967 0.938 Iris-virginicaWeighted Avg. 0.961 0.023 0.965 0.961 0.961 0.942 0.977 0.944=== Confusion Matrix ===a b c <-- classified as15 0 0 | a = Iris-setosa0 19 0 | b = Iris-versicolor0 2 15 | c = Iris-virginica从上述结果可以看出正确率为96.0784 %所以petal width和petal length 可以很好的判断花的类别。
3.1 Simple KMeans 算法结果=== Run information ===Scheme: weka.clusterers.SimpleKMeans -init 0 -max-candidates 100 -periodic-pruning 10000 -min-density 2.0 -t1 -1.25 -t2 -1.0 -V -N 3 -A "weka.core.EuclideanDistance -R first-last" -I 500 -num-slots 1 -S 10Relation: irisInstances: 150Attributes: 5sepal lengthsepal widthpetal lengthpetal widthIgnored:classTest mode: evaluate on training data=== Clustering model (full training set) ===kMeans======Number of iterations: 6Within cluster sum of squared errors: 6.998114004826762Initial starting points (random):Cluster 0: 6.1,2.9,4.7,1.4Cluster 1: 6.2,2.9,4.3,1.3Cluster 2: 6.9,3.1,5.1,2.3Missing values globally replaced with mean/modeFinal cluster centroids:Cluster#Attribute Full Data 0 1 2(150.0) (61.0) (50.0) (39.0)=========================================================== sepal length 5.8433 5.8885 5.006 6.8462+/-0.8281 +/-0.4487 +/-0.3525 +/-0.5025sepal width 3.054 2.7377 3.418 3.0821+/-0.4336 +/-0.2934 +/-0.381 +/-0.2799petal length 3.7587 4.3967 1.464 5.7026+/-1.7644 +/-0.5269 +/-0.1735 +/-0.5194petal width 1.1987 1.418 0.244 2.0795+/-0.7632 +/-0.2723 +/-0.1072 +/-0.2811Time taken to build model (full training data) : 0 seconds=== Model and evaluation on training set ===Clustered Instances0 61 ( 41%)1 50 ( 33%)2 39 ( 26%)从实验结果可以看出分出的类为3个且比例与元数据的class的比例1:1:1的比例不是很相近。
从C4.5的结果来看pental width和pental length 更加符合,重新选择属性,仅选择pental width和pental length 结果如下=== Run information ===Scheme: weka.clusterers.SimpleKMeans -init 0 -max-candidates 100 -periodic-pruning 10000 -min-density 2.0 -t1 -1.25 -t2 -1.0 -V -N 3 -A "weka.core.EuclideanDistance -R first-last" -I 5009 -num-slots 1 -S 10Relation: irisInstances: 150Attributes: 5petal lengthpetal widthIgnored:sepal lengthsepal widthclassTest mode: evaluate on training data=== Clustering model (full training set) ===kMeans======Number of iterations: 6Within cluster sum of squared errors: 1.7050986081225123Initial starting points (random):Cluster 0: 4.7,1.4Cluster 1: 4.3,1.3Cluster 2: 5.1,2.3Missing values globally replaced with mean/modeFinal cluster centroids:Cluster#Attribute Full Data 0 1 2(150.0) (52.0) (50.0) (48.0)=========================================================== petal length 3.7587 4.2962 1.464 5.5667+/-1.7644 +/-0.5053 +/-0.1735 +/-0.549petal width 1.1987 1.325 0.244 2.0562+/-0.7632 +/-0.1856 +/-0.1072 +/-0.2422Time taken to build model (full training data) : 0.02 seconds=== Model and evaluation on training set ===Clustered Instances0 52 ( 35%)1 50 ( 33%)2 48 ( 32%)从结果可以看出pental width和pental length 能够很好的作为分类的属性值第四章心得体会从这次的作业中学习了KDD以及KDD模型过程的建立。