编译原理第7章-中间代码生成
编译原理课件-第7章中间代码生成

● example
例2 suppose the function f has been defined in C as in the previous example. Then, the call
f ( 2+3, 4) 请写出the call三地址码。
解: translates to the three-address code begin_args t1 = 2 + 3 arg t1 arg 4 call f
2023/6/1
● If Statements if ( E ) S1 else S2
Three-Address Code :
If语句前的代码 If测试的代码
<code to evaluate E to t1>
条件
if_false t1 goto L1
<code for S1> goto L2
True情况下的代码
(sub, x, 1, t3 ) (asn, t3, x, _ ) (eq, x, 0, t4 ) (if_f, t4, L2, _) (wri, fact, _, _ ) (lab, L1, _ , _ ) halt, _, _, _ )
2023/6/1
例2 请写出TINY program三地址码的三元式表示。
7.4 Code Generation of Procedure and Function Calls 过程 和函数调用的代码生成
2023/6/1
7.1 Intermediate Code and Data Structures for Code Generation 中间代码和用于代码生成的数据结构
{ AddrKind kind; Union
编译原理语义分析与中间代码生成

编译原理语义分析与中间代码生成在编译原理中,语义分析是编译器的重要组成部分之一,它负责验证和处理源代码中的语义信息,为后续的中间代码生成做准备。
本文将介绍语义分析的基本概念和流程,并探讨中间代码生成的相关技术。
一、语义分析的基本概念和流程语义分析是指对源代码进行语义检查和语义信息提取的过程。
其主要目标是确保源代码在语义上是正确的,并从中提取出各种语义信息,以便后续阶段使用。
语义分析的基本流程如下:1. 词法分析和语法分析:在进行语义分析之前,需要先对源代码进行词法分析和语法分析,以便将代码转化为具有结构的中间表示形式(如抽象语法树)。
2. 符号表的构建:符号表是语义分析的重要数据结构,用于存储程序中出现的各种标识符及其相关信息,如类型、作用域等。
在语义分析阶段,需要构建符号表并实时更新。
3. 类型检查:类型检查是语义分析的核心任务之一。
它通过对表达式、赋值语句、函数调用等进行类型推导和匹配,来验证程序是否存在类型错误。
4. 语义规则检查:除了类型检查外,语义分析还需要检查程序是否符合语言规范中的其他语义规则,如变量是否已声明、函数调用是否正确等。
5. 语义信息提取:语义分析还负责提取源代码中的各种语义信息,如函数调用关系、变量的定义和引用关系、控制流信息等。
这些信息将为后续的代码优化和代码生成提供依据。
二、中间代码生成的相关技术中间代码是指某种形式的中间表示形式,通常与源代码和目标代码之间存在一定的映射关系。
它在编译过程中起到连接前后两个阶段的桥梁作用,并且可以进行一些优化。
常见的中间代码形式之一是三地址码。
三地址码是一种低级的代码表示形式,每条指令最多包含三个操作数。
它具有简洁明了的特点,适合进行后续的优化工作。
在进行中间代码生成时,需要考虑以下几个方面的技术:1. 表达式的翻译:在将源代码转化为中间代码时,需要将源代码中的表达式进行翻译。
这包括对表达式的计算顺序、运算符优先级等方面的处理。
2. 控制流的处理:在编译过程中,需要将源代码中的控制流转化为中间代码中的条件分支和循环结构。
编译原理第三版课后习题答案

编译原理第三版课后习题答案编译原理是计算机科学中的一门重要课程,它研究的是如何将高级程序语言转换为机器语言的过程。
而《编译原理》第三版是目前被广泛采用的教材之一。
在学习过程中,课后习题是巩固知识、提高能力的重要环节。
本文将为读者提供《编译原理》第三版课后习题的答案,希望能够帮助读者更好地理解和掌握这门课程。
第一章:引论习题1.1:编译器和解释器有什么区别?答案:编译器将整个源程序转换为目标代码,然后一次性执行目标代码;而解释器则逐行解释源程序,并即时执行。
习题1.2:编译器的主要任务是什么?答案:编译器的主要任务是将高级程序语言转换为目标代码,包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等过程。
第二章:词法分析习题2.1:什么是词法分析?答案:词法分析是将源程序中的字符序列划分为有意义的词素(token)序列的过程。
习题2.2:请给出识别下列词素的正则表达式:(1)整数:[0-9]+(2)浮点数:[0-9]+\.[0-9]+(3)标识符:[a-zA-Z_][a-zA-Z_0-9]*第三章:语法分析习题3.1:什么是语法分析?答案:语法分析是将词法分析得到的词素序列转换为语法树的过程。
习题3.2:请给出下列文法的FIRST集和FOLLOW集:S -> aAbA -> cA | ε答案:FIRST(S) = {a}FIRST(A) = {c, ε}FOLLOW(S) = {$}FOLLOW(A) = {b}第四章:语义分析习题4.1:什么是语义分析?答案:语义分析是对源程序进行静态和动态语义检查的过程。
习题4.2:请给出下列文法的语义动作:S -> if E then S1 else S2答案:1. 计算E的值2. 如果E的值为真,则执行S1;否则执行S2。
第五章:中间代码生成习题5.1:什么是中间代码?答案:中间代码是一种介于源代码和目标代码之间的表示形式,它将源代码转换为一种更容易进行优化和转换的形式。
编译原理第七章中间代码生成汇编
*
b
*
b
uminus
c
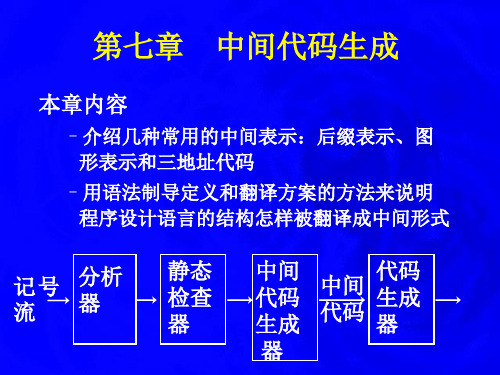
a= b*-c + b*-c
c abc uminus * bc numinus *+ assign
抽象语法树
• 构造赋值语句语法树的语法制导定义: 产生式
S→id = E E→E1 + E2 E→E1 * E2 E→- E1 E→(E1)
• param x1 • param x2 • …… • param x2 • call p, n n表示实参个数。return y中y为过程返回的一个值
– 形如x = y[i]及x[i] = y的索引赋值。
– 形如x = &y, x = *y和*x = y的地址和指针赋值。象形式。 • 这些语句可以以带有操作符和操作数域的记录 来实现。四元式、三元式及间接三元式是三种 这样的表示。
x = y op z
其中,x、y和z是名字,常量或编译器生成的临时变量 op代表任何操作符(定点运算符、浮点运算符、逻辑运算 符等)
• 像x+y*z这样的表达式要翻译为:
T1 = y * z
T2 = x + T1 其中T1 ,T2为编译时产生的临时变量。
三地址语句的类型
• 三地址语句类似于汇编语言代码。语句可以有 符号标号,而且存在各种控制流语句。
– 临时变量也要填入符号表中。
三元式
• 为了避免把临时变量填入符号表,可以通过计 算临时值语句的位置来引用该临时变量。 • 这样三地址代码的记录只需要三个域op, arg1 和arg。
• 对于单目运算符op, arg1和arg2只需用其一。
编译原理中间代码生成

编译原理中间代码生成在编译原理中,中间代码生成是编译器的重要阶段之一、在这个阶段,编译器将源代码转换成一种中间表示形式,这种中间表示形式通常比源代码抽象得多,同时又比目标代码具体得多。
中间代码既能够方便地进行优化,又能够方便地转换成目标代码。
为什么需要中间代码呢?其一,中间代码可以方便地进行编译器优化。
编译器优化是编译器的一个核心功能,它能够对中间代码进行优化,以产生更高效的目标代码。
在中间代码生成阶段,编译器可以根据源代码特性进行一些优化,例如常量折叠、公共子表达式消除、循环不变式移动等。
其二,中间代码可以方便地进行目标代码生成。
中间代码通常比较高级,比目标代码更具有表达力。
通过中间代码,编译器可以将源代码转换成与目标机器无关的形式,然后再根据目标机器的特性进行进一步的优化和转换,最终生成目标代码。
中间代码生成的过程通常可以分为以下几步:1.词法分析和语法分析:首先需要将源代码转换成抽象语法树。
这个过程涉及到词法分析和语法分析两个步骤。
词法分析将源代码划分成一个个的词法单元,例如标识符、关键字、运算符等等。
语法分析将词法单元组成树状结构,形成抽象语法树。
2.语义分析:在语义分析阶段,编译器会对抽象语法树进行静态语义检查,以确保源代码符合语言的语义规定。
同时,还会进行类型检查和类型推导等操作。
3.中间代码生成:在中间代码生成阶段,编译器会将抽象语法树转换成一种中间表示形式,例如三地址码、四元式、特定的中间代码形式等。
这种中间表示形式通常比较高级,能够方便进行编译器的优化和转换。
4.中间代码优化:中间代码生成的结果通常不是最优的,因为生成中间代码时考虑的主要是功能的正确性,并没有考虑性能的问题。
在中间代码生成之后,编译器会对中间代码进行各种优化,以产生更高效的代码。
例如常量折叠、循环优化、死代码删除等等。
5.中间代码转换:在完成了中间代码的优化之后,编译器还可以对中间代码进行进一步的转换。
这个转换的目的是将中间代码转换成更具体、更低级的形式,例如目标机器的汇编代码。
编译原理与中间代码生成技术

编译原理与中间代码生成技术编译原理是计算机科学中的重要理论基础,它研究的是将高级语言翻译成机器语言的转换过程。
而中间代码生成技术则是编译原理中的一个关键环节,它负责将源代码转换为中间表示形式,为后续的优化和目标代码生成做准备。
本文将介绍编译原理的基本概念和中间代码生成技术的原理与应用。
一、编译原理基础编译原理是计算机科学中的一个重要分支,它研究的是高级语言程序如何转换为机器语言的过程。
编译原理包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等多个阶段。
其中,中间代码生成是编译原理的一个关键环节,它将源代码转换为中间表示形式,以便后续的优化和目标代码生成。
二、中间代码生成技术的原理中间代码是源代码与目标代码之间的一种中间表示形式。
它既比源代码更容易理解,又比目标代码更容易生成和优化。
中间代码生成技术的目的是将源代码转换为中间代码,为后续的优化和目标代码生成做准备。
中间代码生成技术的原理可以用以下步骤来描述:1. 词法分析:将源代码分割成一个个语法单元,比如标识符、关键字、操作符等。
词法分析器会根据事先定义好的词法规则,将源代码转换为词法单元序列。
2. 语法分析:将词法单元序列转换为抽象语法树(AST)。
语法分析器会根据事先定义好的语法规则,分析词法单元序列所组成的语法结构,并构建出相应的抽象语法树。
3. 语义分析:对抽象语法树进行语义检查和类型推断。
语义分析器会检查语法结构中是否存在语义错误,并为表达式推导出对应的类型信息。
4. 中间代码生成:将语法树转换为中间代码表示形式。
中间代码生成器会根据语义信息和事先定义好的转换规则,将语法树转换为中间代码表示形式。
三、中间代码生成技术的应用中间代码生成技术广泛应用于编译器、解释器和虚拟机等领域。
以下是中间代码生成技术在这些领域的具体应用场景:1. 编译器:编译器是将高级语言程序转换为机器语言的工具。
中间代码生成技术在编译器中起到了至关重要的作用,它能够将源代码转换为中间代码表示形式,为后续的代码优化和目标代码生成做准备。
编译原理中的中间代码生成

编译原理中的中间代码生成编译原理是计算机科学的一门重要课程。
在编译器的构造过程中,中间代码生成是其核心部分之一。
它是将源代码翻译为目标代码的重要中间阶段。
中间代码生成的过程涉及到链表、树,生成三元式、四元式等多种中间形式。
本文将介绍中间代码生成的过程和其在编译中的作用。
一、中间代码的概念中间代码是指在源程序和目标程序之间所生成的一系列指令的集合。
目标代码是指机器可执行的二进制代码,而中间代码则是一种可传递、可处理和可修改的编译代码形式。
中间代码属于一种中间状态,它不是源代码也不是目标代码,但可以被转换成目标代码。
中间代码可以基于语法树、语法分析栈、语法分析表进行生成,生成的中间代码需要满足语言语法结构和语义规则。
二、中间代码生成的流程在编译过程中,中间代码生成是指将源代码转换成中间代码的过程。
它是在词法分析、语法分析和语义分析阶段之后完成的。
下面介绍一下中间代码生成的流程。
1.源代码转换为语法树编译器通过词法分析和语法分析将源代码转换成语法树。
语法树是一种树形结构,它记录了源代码中各个语句的组成情况。
2.语法树进行语义分析在语法分析之后,编译器进行语义分析,检查语法树的合法性,然后根据语言的语义规则对语法树进行标注。
标注的内容包括符号表信息、数据类型等。
3.中间代码的生成在语义分析后,编译器进入中间代码的生成阶段,生成语句的中间代码。
中间代码通常采用三元式或四元式等形式。
三元式包含操作符、操作数以及结果的地址,四元式中还包括了类型信息。
4.中间代码优化在中间代码生成的过程中,编译器会尽可能地优化中间代码。
可以对中间代码进行多种优化,如常量合并、变量替换、公共子表达式消除等。
5.中间代码转换为目标代码在中间代码生成后,编译器将中间代码转换为目标代码。
目标代码可以是汇编代码或机器代码等不同形式的二进制代码。
三、中间代码生成优化的意义编译器中间代码优化的目标是提高程序的执行效率和降低其资源消耗。
执行效率的提高可以通过以下方式实现:1.减少内存使用编译器可以通过删除冗余代码、去除死代码和不必要的变量等方式来减少中间代码的内存使用。
编译原理中的中间代码生成

编译原理中的中间代码生成编译原理是计算机科学中非常重要的一门课程,它研究的是将高级语言程序转化为低级语言程序,实现计算机能够理解和运行的目的。
但是高级语言相较于机器语言更为抽象和复杂,所以需要经过多个步骤的处理,其中中间代码生成就是其中的一个重要环节。
中间代码是指一种介于高级语言和机器语言之间的表示方式,它的作用是将高级语言程序转化为更容易被计算机处理的形式,同时它也提供了一种通用的平台,可以将同一份高级语言程序转化为多种低级语言程序,如汇编语言、机器语言等。
如今,多数编译器都采用中间代码进行转化和优化,它不仅可以提高代码执行效率,还可以提高程序的可移植性和可维护性。
那么,中间代码的生成是如何进行的呢?和编译器的其它部分一样,中间代码生成也是经过多个步骤的处理,其中最主要的步骤包括词法分析、语法分析、语义分析和中间代码生成。
词法分析的作用是将源程序的字符序列转换为单词序列。
它依靠的是正则表达式的特性,对源程序进行识别和划分,得到一系列单词。
这些单词包括关键字、标识符、常数、字符等,在很大程度上决定了接下来的语法分析和语义分析。
语法分析是将单词序列转化为抽象语法树的过程,它将程序以树的形式进行表示,更为直观和容易理解。
通过对抽象语法树的遍历,可以得到程序的各种信息,如变量名、函数名、常量、运算符和控制语句等。
对于每个节点,编译器会根据其语义和上下文信息,进行类型检查、错误检测和决策生成等操作,最终得到一个可运行的程序。
语义分析是识别程序中不符合语言规范或逻辑错误的部分,它是整个编译过程中最为复杂的一个环节。
在这个过程中,编译器需要根据程序的上下文信息,判断其意义和合理性,并进行正确的处理。
例如,当编译器遇到一个未定义的变量或函数时,它将会报错并停止编译。
语义分析可以避免很多程序运行时的错误,同时也是编译器优化的重要基础。
当编译器通过词法分析、语法分析和语义分析,得到一个完整、正确的程序后,就可以进行中间代码生成了。
编译原理习题及答案(整理后)

第一章1、将编译程序分成若干个“遍”是为了。
b.使程序的结构更加清晰2、构造编译程序应掌握。
a.源程序b.目标语言c.编译方法3、变量应当。
c.既持有左值又持有右值4、编译程序绝大多数时间花在上。
d.管理表格5、不可能是目标代码。
d.中间代码6、使用可以定义一个程序的意义。
a.语义规则7、词法分析器的输入是。
b.源程序8、中间代码生成时所遵循的是- 。
c.语义规则9、编译程序是对。
d.高级语言的翻译10、语法分析应遵循。
c.构词规则二、多项选择题1、编译程序各阶段的工作都涉及到。
b.表格管理c.出错处理2、编译程序工作时,通常有阶段。
a.词法分析b.语法分析c.中间代码生成e.目标代码生成三、填空题1、解释程序和编译程序的区别在于是否生成目标程序。
2、编译过程通常可分为5个阶段,分别是词法分析、语法分析中间代码生成、代码优化和目标代码生成。
3、编译程序工作过程中,第一段输入是源程序,最后阶段的输出为标代码生成程序。
4、编译程序是指将源程序程序翻译成目标语言程序的程序。
一、单项选择题1、文法G:S→xSx|y所识别的语言是。
a. xyxb. (xyx)*c.x n yx n(n≥0) d. x*yx*2、文法G描述的语言L(G)是指。
a. L(G)={α|S+⇒α , α∈V T*}b. L(G)={α|S*⇒α, α∈V T*}c. L(G)={α|S*⇒α,α∈(V T∪V N*)} d. L(G)={α|S+⇒α, α∈(V T∪V N*)}3、有限状态自动机能识别。
a. 上下文无关文法b. 上下文有关文法c.正规文法d. 短语文法4、设G为算符优先文法,G 的任意终结符对a、b有以下关系成立。
a. 若f(a)>g(b),则a>bb.若f(a)<g(b),则a<bc. a~b都不一定成立d. a~b一定成立5、如果文法G是无二义的,则它的任何句子α。
a. 最左推导和最右推导对应的语法树必定相同b. 最左推导和最右推导对应的语法树可能不同c. 最左推导和最右推导必定相同d. 可能存在两个不同的最左推导,但它们对应的语法树相同6、由文法的开始符经0步或多步推导产生的文法符号序列是。
编译原理作业集-第七章(精选.)

编译原理作业集-第七章(精选.)第七章语义分析和中间代码产⽣本章要点1. 中间语⾔,各种常见中间语⾔形式;2. 说明语句、赋值语句、布尔表达式、控制语句等的翻译;3. 过程调⽤的处理;4. 类型检查;本章⽬标掌握和理解中间语⾔,各种常见中间语⾔形式;各种语句到中间语⾔的翻译;以及类型检查等内容。
本章重点1.中间代码的⼏种形式,它们之间的相互转换:四元式、三元式、逆波兰表⽰;3.赋值语句、算术表达式、布尔表达式的翻译及其中间代码格式;4.各种控制流语句的翻译及其中间代码格式;5.过程调⽤的中间代码格式;6.类型检查;本章难点1. 各种语句的翻译;2. 类型系统和类型检查;作业题⼀、单项选择题:1. 布尔表达式计算时可以采⽤某种优化措施,⽐如A and B⽤if-then-else可解释为_______。
a. if A then true else B;b. if A then B else false;c. if A then false else true;d. if A then true else false;2. 为了便于优化处理,三地址代码可以表⽰成________。
a. 三元式b. 四元式c. 后缀式d. 间接三元式3. 使⽤三元式是为了________:a. 便于代码优化处理b. 避免把临时变量填⼊符号表c. 节省存储代码的空间d. 提⾼访问代码的速度4. 表达式-a+b*(-c+d)的逆波兰式是________。
a. ab+-cd+-*;b. a-b+c-d+*;c. a-b+c-d+*;d. a-bc-d+*+;5. 赋值语句x:=-(a+b)/(c-d)-(a+b*c)的逆波兰式表⽰是_______。
a. xab+cd-/-bc*a+-:=;a. xab+/cd-bc*a+--:=;a. xab+-cd-/abc*+-:=;a. xab+cd-/abc*+--:=;6. 在⼀棵语法树中结点的继承属性和综合属性之间的相互依赖关系可以由________来描述。
编译原理第七章中间代码生成

3
循环语句的中间代码生成
循环结构的代码生成方式有多种,并根据循环类型和常量优化代码。
中间代码生成的优化技术
常量合并
把具有相同值的常量合并 为一个。
• 可以节省空间。 • 会改变代码原有结
构,需要小心。
表达式优化
采用数学方法对表达式求 解结果,优化表达式产生 的中间代码。
• 用于优化表达式的 运算过程,提高效
高效的编写代码方法
既要运用科学原理,又要具 备实践经验。而编译原理的 学习可以为我们提供更好的 编写代码方法。
追求突破与创新的开发 者
不断优化自己的编码方式可 以让您编写出更高质量的程 序,使你更好的成为一个有 追求的开发者!
编译原理第七章中间代码 生成
学习了编译原理基础后,我们来进一步了解关于中间代码生成的章节。
课程背景
1 编译器
2 中间代码
将高级语言代码转换成低级语言代码的 程序。
与源代码和目标代码位于中间的代码, 更容易优化和转换。
中间代码生成的定义和作用
定义
中间代码是一种抽象的机器语言,用于编 译过程中的代码转换。化
按照代码的实际运转过程, 进行代码生成顺序的优化。
• 可避免一些冗余工 作,加快程序的执
• 行需要速一度些。优化算法, 不易实现。
总结 and 结论
精通编译原理,写出高 效代码!
各种方法都是在实际生产环 境中总结出来的经验,并根 据实际需要进行选择和判断。
作用
可以用于优化和改变代码结构,同时还可 以提高生成目标代码的速度。
中间代码生成的方法
语法制导的方法
通过语法规则来约束产生 的中间代码,便于生成和 优化代码。
• 可用于处理语法规 则固定的语句。
编译原理chapter7 语义分析及中间代码生成

编译原理
chapter7
语义分三元式 三元式顾名思义就是带有三个域的记录结构。 三元式顾名思义就是带有三个域的记录结构。 一般形式为: (i)( ,arg1,arg2) 一般形式为: )(op, )( , ) 其中,( )为三元式的编号, 其中,(i)为三元式的编号,也代表了该式的运算 ,( 结果, , 的含义与四元式类似, 结果,op,arg1,arg2的含义与四元式类似,区别在 , 的含义与四元式类似 于arg可以是某三元式的序号,表示用该三元式的结果 可以是某三元式的序号, 可以是某三元式的序号 作为运算对象。 作为运算对象。
编译原理
chapter7
语义分析和中间代码生成
对于文法G[E]: E →E+T | T 例:对于文法 T→ digit 产生式 ) E→ E(1)+T E→ T T→ digit 语 法 分 析 栈 T + E … # 语义子程序 ) {E.Val=E(1).Val+T.Val} {E.Val=T.Val} {T.Val=digit} T.Val 语 义 ‘+’ ) E(1).Val 分 析 … 栈 #
编译原理
chapter7
语义分析和中间代码生成
三地址代码可以看成是抽象语法树一种线性表示。 三地址代码可以看成是抽象语法树一种线性表示。 线性表示 例: a=b*-c+b*-c = a + T1=-c T2=b*T1 T3=-c
*
b
* - b
c
c
T4=b*T3 T5=T2+T4 a=T5
编译原理
语义分析和中间代码生成
图表示法—抽象语法树 图表示法 抽象语法树 在语法树中去掉一些对翻译不必要的信息后 在语法树中去掉一些对翻译不必要的信息后,获得 去掉一些对翻译不必要的信息 的更有效的源程序的中间表示, 的更有效的源程序的中间表示,这种经过变换后的语法 树称为抽象语法树。 树称为抽象语法树。 内部结点代表操作符,它的孩子代表对应的操作数。 内部结点代表操作符,它的孩子代表对应的操作数。 例:a+a*(b-c)+(b-c)*d ( ) ( ) + + a a b
编译原理第七章中间代码生成
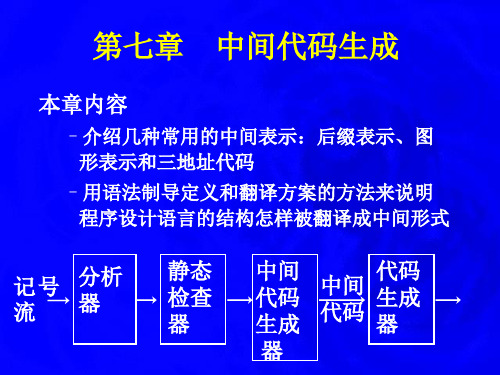
7.2 声 明 语 句
7.2.2 作用域信息的保存
• 所讨论语言的文法
PDS D D ; D | id : T | proc id ; Dktable(previous) enter(table, name, type, offset) addwidth(table, width) enterproc(table, name, newtable)
四元式
• 一个四元式是带有四个域的记录结构,这四个 域分别称为op, arg1, arg2及result。
– 域op包含一个代表运算符的内部码
– 三地址语句x=y op z通过将y放入arg1,z放入arg2 ,并且将x放入result,=为算符。
– 像x=y或x=-y这样的一元操作符语句不使用arg2 – 像param这样的运算符仅使用arg1域。 – 条件和无条件语句将目标标号存入result域。
7.2 声 明 语 句
7.2.1 过程中的声明
计算被声明名字的类型和相对地址 P {offset = 0} D S DD;D D id : T {enter ( , T.type, offset); offset = offset + T.width } T integer {T.type = integer; T.width = 4 } T real {T.type = real; T.width = 8 } T array [ num ] of T1 {T.type = array (num.val, T1.type); T.width = num.val T1.width} T T1 {T.type = pointer (T1.type); T.width = 4 }
uminus
编译原理中的语法分析与中间代码生成

编译原理中的语法分析与中间代码生成编译原理是计算机科学中一门非常重要的学科,主要研究将高级语言翻译成机器语言的方法和技术。
其中,语法分析和中间代码生成是编译器实现的两个重要步骤。
一、语法分析语法分析是编译器将源代码转换成抽象语法树的过程。
在这个阶段,编译器会检查源代码的语法是否符合语言规范,并将代码转化为一系列的语法结构。
一个好的语法分析器能够快速准确地识别代码中的语言结构,同时能够在出现语法错误的时候给出有意义的错误报告。
常见的语法分析方法包括LL(1)分析、LR分析等。
LL(1)分析器通过构造预测分析表来实现分析,而LR分析器则采用自底向上的分析方法,通过状态迁移来实现分析。
在语法分析的过程中,编译器还需要处理语法的优先级,如算术运算符的优先级,逻辑运算符的优先级等。
对于不同的语言规范,将有不同的算法来处理语法。
例如,C语言中的运算符优先级和结合性与其他语言不同,因此需要特殊的处理方式。
二、中间代码生成中间代码生成是语法分析后的下一步,它的作用是将抽象语法树转化为中间表示,通常是三地址码或四地址码。
中间代码可以看作是目标代码的前一步,它是一种更加抽象的代码形式,方便后续的优化和翻译。
中间代码的生成方法有很多种,最常用的是遍历抽象语法树并根据语法结构生成中间代码。
不同的语言规范会对中间代码的生成方式有不同的要求。
例如,Java语言规范对着重于类型检查和异常处理的中间代码生成,而C语言的中间代码生成则着重于指针和数组的处理等。
在生成中间代码的过程中,编译器还需要考虑优化问题。
编译器能够在生成中间代码的时候进行一些基本的优化,例如删除冗余代码、常量合并等等,这样可以减少目标代码的大小和程序的运行时间。
总之,语法分析和中间代码生成是编译器实现的两个关键步骤。
它们需要一个好的算法和优秀的实现方式,以便在编译过程中产生高效、可靠的目标代码。
07-第7章-中间代码生成-编译原理PDF精讲课件-中国科技大学(共13讲)

7.2 声 明 语 句
sort readarray exchange quicksort partition readarray 表头 i 空 sort 表头 指向readarray 指向exchange quicksort 表头 k v partition partition a x readarray exchange quicksort exchange 表头
7.2 声 明 语 句
7.2.2 作用域信息的保存 • 所讨论语言的文法
P D; S D D ; D | id : T | proc id ; D ; S sort var a:…; x:…; readarray var i:…; exchange quicksort var k, v:…; partition var i, j:…; 图6.14的程序 参数被略去
E E1 E2 E.nptr = mkNode( ‘’, E1.nptr, E2.nptr) E.nptr = mkUNode( ‘uminus’, E1.nptr) E E1 E (E1) F id E.nptr = E1.nptr E.nptr = mkLeaf (id, id.entry)
7.2 声 明 语 句
本节介绍 • 为局部名字建立符号表条目 • 为它分配存储单元 • 符号表中包含名字的类型和分配给它的存储 单元的相对地址等信息
7.2 声 明 语 句
7.2.1 过程中的声明
7.2 声 明 语 句
计算被声明名字的类型和相对地址 P {offset = 0} D; S DD;D D id : T {enter ( id.lexeme, T.type, offset); offset = offset + T.width } T integer {T.type = integer; T.width = 4 } T real {T.type = real; T.width = 8 } T array [ num ] of T1 {T.type = array (num.val, T1.type); T.width = num.val T1.width} T T1 {T.type = pointer (T1.type); T.width = 4 }
编译原理-语义分析和中间代码生成

编译器是一种将高级语言翻译成低级语言的程序。语义分析和中间代码生成 是编译器中非常重要的两个步骤。在本次演讲中,我们将深入探讨它们的内 容和作用。
定义和目的
1 语义分析
对代码的意义和上下文进行全面的分析。
2 目的
识别出语法正确但不符合语言规范的代码,以及提取中间代码。
检查和错误
1
步骤
类型检查、控制流检查、错误信息收集。
2
类型
变量未声明、数组维数不符、类型不匹配、函数参数个,中断代码生成流程。
中间代码生成
概述
表示形式
将源代码翻译为一种可读性和 可执行性都比较好的中间代码。
三元式、四元式、静态单赋值 形式。
算法
递归下降法、语法制导翻译、 继承型翻译。
实例和案例分析
实例
对表达式 "a = b + c * d" 进行语义分析和中 间代码生成。
案例
使用LLVM对C语言代码生成中间代码。
总结
语义分析
中间代码生成
全面分析代码以及上下文,发现不符合语言规 范的代码。
将源代码翻译为可读性和可执行性都比较好的 中间代码。
“Your code isn't wrong, it's just not right yet.” "If you can't run with the big dogs, stay on the porch."
编译原理教程第五版课后答案

编译原理教程第五版课后答案第一章:引言问题1答:编译器是一种将高级编程语言源代码转换为目标机器代码的软件工具。
它由多个阶段组成,包括词法分析、语法分析、语义分析、中间代码生成、代码优化和代码生成等。
问题2答:编译器的主要任务包括以下几个方面: - 词法分析:将源代码划分为词法单元,如标识符、关键字、操作符等。
- 语法分析:根据语法规则,将词法单元组成语法树。
- 语义分析:对语法树进行语义检查,如类型匹配、变量声明等。
- 中间代码生成:将语法树转换为中间代码表示形式。
- 代码优化:对中间代码进行优化,以提高程序的效率。
- 代码生成:将优化后的中间代码转换为目标机器代码。
第二章:词法分析问题1答:词法单元是编译器在词法分析阶段识别的最小的语法单位,它由一个或多个字符组成。
常见的词法单元包括关键字、标识符、常量和运算符等。
问题2答:识别词法单元的方法包括以下几种: - 正则表达式:通过正则表达式匹配字符串,识别出各类词法单元。
- 有限自动机:构建有限状态自动机,根据输入字符的不同状态转移,最终确定词法单元。
- 递归下降法:使用递归下降的方式,根据语法规则划分出词法单元。
第三章:语法分析问题1答:语法分析是编译器的一个重要阶段,它的主要任务是根据给定的语法规则,将词法单元序列转换为语法树。
语法分析有两个主要的方法:自顶向下的分析和自底向上的分析。
问题2答:自顶向下的分析是从文法的起始符号开始,根据语法规则逐步向下展开,直到生成最终的语法树。
常见的自顶向下的分析方法包括LL(1)分析和递归下降分析。
问题3答:自底向上的分析是从输入串开始,逐步合并词法单元,最终生成语法树。
常见的自底向上的分析方法包括LR分析和LALR分析。
第四章:语义分析问题1答:语义分析的主要任务是对语法树进行语义检查和类型推断。
语义分析阶段会检查变量的声明和使用是否合法,以及类型是否匹配等。
问题2答:常见的语义错误包括变量未声明、类型不匹配、函数调用参数不匹配等。
编译原理第7章 语法制导翻译和中间代码生成

• 检查静态语义 • 生成中间代码/目标代码
语义处理
语义处理的环境:符号表 • 为语义分析提供类型、作用域等信息。 • 为代码生成提供类型、作用域、存储类别、
存储(相对)位置等信息。
语义处理
PL/0编译程序的语义处理(一)call语句的处理
if sym = callsym
then
源语言程序
词法分析
前
语法分析
端
处理Biblioteka 语义分析语 义 处 理
后 端
代码生成
处
理
汇编代码
语义处理
语义处理的任务: • 静态语义检查
• 静态语义:语法规则的良形式条件 • 静态语义检查:审查静态语义
• 动态语义处理
• 动态语义:程序单元执行的操作 • 动态语义处理:生成(中间/目标)代码
语义处理
语义处理的实现: • 属性文法:描述语义规则。 • 语法制导翻译:在语法分析的同时,执行
类型的基本概念
声明和定义,使用: • 声明:
• 程序通过声明语句把标识符的名称、类型和 作用域等信息传递给编译器。
• 声明语句本身传递名字和类型信息,声明语 句的位置传递作用域信息。
• 定义:
• 变量、类的声明就是定义。 • 函数可以先声明一个原型,在定义中再给出
实现的代码。
类型的基本概念
强类型语言和弱类型语言: • 强类型语言
第七章语法制导翻译和中间代码生成
7.1语义处理概述 7.2属性文法和语法制导翻译 7.3 中间代码生成(一些语句的翻译) 7.4符号表
7.1 语义处理(语义分析和中间代码生成)
在编译中的逻辑阶段
源语言程序
词法分析
编译原理第七章 中间代码生成(1)

带括号表达式的后缀式例子
中缀式: (a + (d + b) * c ) + e #
后缀式: a d b + c * +e +
Operator stack 运算符栈 S1
Operand stack
运算分量栈 S2
7.1 常见的中间表示
抽象语法树-AST 无环有向图-DAG(共享的AST)
+ +
ad*bc*+e+
先根遍历生成前缀式:
c
++*ad*bce
抽象语法树
由Token序列生成后缀式(1)
(1)初始化: S1和S2为空; (2) 读token: tk=ReadOne(); (3) Switch tk of (i) #: if (S1为空) exit; else while (S1不为空) /*产生剩余操作符的后缀表示*/ {op = pop(S1); (str1, str2)=pop(2); push(S2, str2 + str1+ “op”);} (ii)运算分量: push(tk, S2); goto (2); (iii)运算符: if (S1为空 || tk优先级大于Top(S1)) { push (tk, S1); goto(2);} else { while(tk小于等于Top(S1) && S1不为空)) { op = pop(S1); (str1, str2)=pop(2); push(S2, str2+str1 + “op”); } push(tk, S1); goto (2); }
---
把id1的值赋值给id2(长度为n)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
-16-
表达式代码生成的例子
College of Computer Science & Technology
class[5].age + *ptr.age
typedef struct { char name[30]; int age; float height; }person;
int x[10]; person class[10]; person *ptr;
(cSlaUsBs[I5,]5, 0,t4t5) (MULTI, t5, 33, t6) cla(sAsA[5D].aDg,eclasst,1t6, t4) (AADD , t4, 30, t1) *p(t*Arp.astsgrieg,ptt7tr2, _, t7) (AADD , t7, 30, t2)
-7-
四元式
• 表达式运算符 College of Computer Science & Technology
– ADDI, ADDF, SUBI, SUBF, MULTI, MULTF,
– DIVI, DIVF, MOD,
– AND, OR, EQ, NE, GT, GE, LT, LE
• I/O 操作
Compiler Construction Principles & Implementation Techniques
-12-
7.2 表达式的四元式代码
College of Computer Science & Technology
• 表达式的运算分量可以很复杂:
– 多维数组下标变量:A[i][j][k] – 结构体域名变量:st.address.city – 函数调用:f(x,y) – 指针引用:*(p+1) – ……
College of Computer Science & Technology
• 操作分量
操作分量的抽象地址
– 常量: 整数或者实数
– 标号: 标号名
– 变量: 需要更多信息用于形成其目标地址
– 函数/过程:需要更多信息用于得到其代码的目标地址
• 操作分量的ARG结构 --- 抽象地址结构
– 常量: (valKind, C)
(ADDI, t1, t2, t3)
t1,t2,t4和t7的mode是indir;
Compiler Construction Principles & Implementation Techniques
标号
– (LABEL, _, _, label) --- 定义label为标号,并且定位于 当前位置
跳转
– (JUMP, _, _, label)
--- 无条件转向标号label
– (JUMP0, id, _, label) --- 如果id为假则转向标号label
– (JUMP1, id, _, label) --- 如果id为真则转向标号label
• 循环语句 – (WHILE, _, _, _) – (DO, t, _, _) – (ENDWHILE, _, _, _)
Compiler Construction Principles & Implementation Techniques
7.2 表达式的四元式代码
College of Computer Science & Technology
College of Computer Science & Technology
第7章 中间代码生成
7.1 中间代码生成概述 7.2 表达式的四元式代码 7.3 原子语句的四元式代码 7.4 结构语句的四元式代码 7.5 声明的四元式代码 7.6 一些相关问题
Compiler Construction Principles & Implementation Techniques
– (RETURN, -,-, -)
– (RETURN, -,-, t)
– (ENDFUNC,-,-,-)
--- 函数出口
• 传递参数
– (VARACT, id, offset, size )
--- 传地址
– (VALACT, id, offset, size )
--- 传值
– (FUNACT, id, offset, size)
--- 传函数
– (PROACT, id, offset, size )
--- 传过程
Compiler Construction Principles & Implementation Techniques
四元式
College of Computer Science & Technology
• 分支语句 – (THEN, t, _, _) – (ELSE, _, _, _) – (ENDIF, _, _, _)
– (READI, _, _, id)
--- 输入整数到id
– (READF, _, _, id)
--- 输入实数到id
– (WRITE, _, _ 类型转换
– (FLOAT, id1, _, id2) --- 把整数id1转换成实数赋值给id2
• 赋值
– (ASSIG, id1, n, id2) --- 把id1的值赋值给id2(长度为n)
(2) (*, b, c)
(*, b, c, t2)
(3) (+, (1), (2))
(+, t1, t2, t3)
(4) (+, (3), e)
(+, t3, e, t4)
Compiler Construction Principles & Implementation Techniques
-5-
-6-
College of Computer Science & Technology
操作分量的抽象地址
• 变量的ARG结构
– 一般变量: (varkind, L, off, dir)
– 形参变量
• 引值: (varKind, L, off, dir) • 引址: (varKind, L, off, indir)
struct student{ char name[10]; int age;} st[100];
st[5].age +10
(MULTI, 5, 11,t1) (AADD, st,t1,t2) (AADD,t2,10,t3) (ADDI, t3, 10,t4)
Compiler Construction Principles & Implementation Techniques
+
• 中缀式:a*b • 前缀式:*ab • 后缀式:ab*
• 抽象语法树AST
+
e
*
*
• 无环有向图DAG
a
da
d
• 共享的AST
• 三地址中间代码:
• 三元式
+
+
e
• 四元式
*
ad
Compiler Construction Principles & Implementation Techniques
中
M1
源程序的抽象语法树
间 代 中间代码
…
码
生
成
Mn
器
Compiler Construction Principles & Implementation Techniques
-3-
几种常见的中间代码表示
College of Computer Science & Technology
• 后缀式(逆波兰式)
-1-
College of Computer Science & Technology
7.1 中间代码生成概述
• 中间代码生成是否必须? • 几种常见的中间代码表示
Compiler Construction Principles & Implementation Techniques
-2-
7.1 中间代码生成概述
• 表达式的中间代码生成就是依据原表达式的语 义产生出正确计算表达式值的四元式中间代码
• 例如:表达式:a * ( 3.5 + i * b ),假设 a、b 为 实型变量,i 为整型变量,则生成的四元式中间 代码如下:
( FLOAT , i , ─ , t1 ) ( MULTF , t1 , b , t2 ) ( ADDF , 3.5 , t2 , t3 ) ( MULTF , a , t3 , t4 )
-4-
三地址中间代码
College of Computer Science & Technology
• 每个运算涉及三个地址:操作分量(2)、结果(1) • 三元式:用三元式的编号代表结果地址 • 四元式:引入临时变量表示结果地址
a*d + b*c + e
三元式
四元式
(1) (*, a, d)
(*, a, d, t1)
College of Computer Science & Technology
• 中间代码生成是将源程序翻译成某种中间表示
的过程.
• 中间代码生成不是编译程序的必经阶段
• 便于优化:在中间代码级别上,可以进行源程序和目标代码上不 能进行的优化
• 便于移植:生成中间代码后,修改编译程序的后端,就可以生成不 同目标机上的目标代码.
– 临时变量:
• 直接 (varKind, -1, off, dir) • 间接(varKind, -1, off, indir)
• 为了简便起见, 在课件和书中有时用对应的变量名 , 函数名或者标号, 值等代替相应的ARG结构;