T1-1初识结构
市政工程识图

2、资料部分
(1)地质状况 为设计和施工提供依据。 (2)坡度/坡长
3.0 600
表示路线为上坡,坡度3.0%,坡 长600m 表示路线为下坡,坡度1.0%,坡 长380m 其中分格线“ ”表示两坡边坡点 位置,与图形部分变坡点里程一致
1.0 380
3.0 600
1.0 380
纵坡定义及计算 纵坡:路线的纵线坡度,为高差与水平距 的比值,用i表示。 i=(H2-H1)/L*100%
二、识读要求 (一)、道路工程识图 1、看目录表,了解图纸组成 2、看设计说明,了解道路施工图的主要文字 部分 3、识读平面图,了解平面图新建工程的位置、 平面形状。能进行坐标计算、桩号推算、 平曲面计算。
4、识读纵断面图,了解构筑物的外观,纵横 坐标的关系,识读构筑物的标高。 5、识读横断面图,能进行土方的计算。 6、识读沥青路面结构图,了解结构的组合、 组成的材料,能进行工程量的计算。 7、识读水泥路面的结构图,了解水泥混凝土 路面接缝分类名称、对接缝的基本要求, 常用钢筋级别与作用,能进行工程量的计 算。
2.设计高程计算 已知变坡点桩号为K5+030 ,高程H1=427.68 竖曲线起点桩号QD=BPD-T=(K5+030)-90=K4+940 竖曲线起点高程HQD=427.68-90×0.05=423.18m K5+000与起点横距x1=K5+000-K4+940=60m 竖距y1=x12/2R=602/2×2000=0.9m 切线高程=423.18+60×0.05=426.18m 设计高程426.18-0.9=425.28m K5+100与起点横距x2=K5+100-K4+940=160m 竖距y2=x22/2R=1602/2×2000=6.4m 切线高程=423.18+160×0.05=431.18m 设计高程431.18-6.4=424.78m
白介素-1结构式

白介素-1结构式全文共四篇示例,供读者参考第一篇示例:白介素-1(Interleukin-1)是一种由免疫系统产生的细胞因子,它在免疫反应中扮演着重要的角色。
白介素-1分为两种亚型,分别是白介素-1α(IL-1α)和白介素-1β(IL-1β),它们都属于促炎性细胞因子家族。
白介素-1在机体中的产生和作用机制十分复杂。
当机体受到外界侵袭或受损时,免疫细胞会释放白介素-1以启动炎症反应,并吸引其他免疫细胞前来清除病原体。
白介素-1也能促进伤口愈合和组织修复,加速受损细胞的再生。
白介素-1的受体是IL-1R1,当白介素-1结合到其受体上时,会激活多条信号通路,包括NF-κB和MAPK信号通路,进而促进炎症反应的发生。
炎症反应是机体对抗外界侵袭的一种重要防御机制,但如果炎症反应持续时间过长或程度过重,就会导致疾病的发生。
白介素-1也与多种疾病的发生和发展密切相关。
炎症性疾病如类风湿关节炎和炎症性肠病等,白介素-1的过度激活与疾病的发生有着直接的关系。
针对白介素-1信号通路的调控成为治疗这些疾病的重要方式之一。
白介素-1的抗体疗法已经被广泛应用于临床,例如使用IL-1拮抗剂可降低白介素-1的活性,减轻炎症反应,从而治疗炎症性疾病。
还有研究表明,通过调控肠道菌群可以影响白介素-1的产生,从而对炎症性肠病等疾病产生治疗作用。
白介素-1是机体免疫系统中一个非常重要的细胞因子,它在炎症反应的发生和调控中发挥着关键作用。
随着对白介素-1的研究不断深入,我们相信将能够更好地了解其在疾病发生和发展过程中的作用机理,为炎症性疾病的治疗提供更为有效的方法。
【2000字】第二篇示例:白介素-1,也称为IL-1α,是一种细胞因子,属于白细胞介素家族。
它在免疫应答中扮演着关键的角色,能够调节炎症反应、细胞增殖和分化等生理过程。
IL-1α的结构式如下所示:IL-1α是由一个单链多肽组成,其分子量约为17kDa。
在人类中,IL-1α基因位于染色体2的q13-21区域,含有7个外显子和6个内含子。
IL-1α和IL-1β的区别

IL-1α和IL-1β的区别
IL-1α和IL-1β的区别
白介素IL-1早期被描述为引起发烧的蛋白质,称为人白细胞致热原,主要由IL-1α和IL-1β两种蛋白质组成。
IL-1α和IL-1β序列同源性并不高,但他们结合相同的受体复合物,具有相似的生物学活性。
在具体的生物学功能上, IL-1α和IL-1β还是存在一些差别的。
第一, IL-1α通常与其所产生的细胞质膜关系较大,因此只能局部起作用,而IL-1β可以全身分泌并循环作用;第二, IL-1α表达比较普遍,主要在上皮细胞、角化细胞和内皮细胞中表达,也可以在骨髓细胞表达, IL-1β主要由单核细胞和巨噬细胞产生;第三, IL-1α在不同部位被各种蛋白酶(包括钙蛋白酶,颗粒酶B和炎性蛋白酶)加工以达到全部活性,相比之下, IL-1β主要由先天性免疫细胞在炎性损伤中表达。
IL-1β前体的细胞内加工依赖于半胱天冬酶-1。
第四,两个基因在发育过程中和对环境的反应是有差别调控,这在免疫反应中导致了这些细胞因子的不同功能。
第五, IL-1α的前域具有核定位序列,有固有的转录反式激活活性,其通过与组蛋白乙酰转移酶的相互作用而增强,并可影响基因表达模式和细胞存活。
酶分子的一级结构

5-1-1-1 酶分子的一级结构构成酶蛋白的20种基本氨基酸的种类、数目和排列顺序,是酶蛋白的一级结构。
组成酶蛋白的氨基酸的数目和种类与其催化的反应性质及酶的来源有关。
例如,猪胃蛋白酶,在酸性很强的胃液中起催化作用,其分子中酸性氨基酸的数目远大于碱性氨基酸(43:4),这是与其催化的环境相适应的。
来源不同的同一酶或功能相似的酶,氨基酸组成相近。
但并不相同。
存在生物种间的差异,甚至存在个体、器官、组织间的差异。
例如,植物溶菌酶与动物溶菌酶相比,其分子中脯氨酸、酪氨酸和苯丙氨酸含量非常高。
狒狒乳汁溶菌酶与人溶菌酶的一级结构之间,有几个氨基酸残基不同,狒狒溶菌酶含精氨酸少,且不含蛋氨酸。
同是鸭卵溶菌酶,Ⅱ型和Ⅲ型酶中,赖氨酸、酪氨酸、甘氨酸数目,也分别相差1~2个。
在一级结构中,有些酶的-SH参与酶的活性中心,是活性中心最重要基因之一,有些酶的二硫键对维持酶的活性很重要,或通过-S-S-与-SH互变表现酶的活性。
5-1-1-2 酶分子的空间结构酶分子的空间结构即是维持酶活性中心所必需的构象。
酶和其他蛋白质一样,二级结构单元主要是 -螺旋, -折叠、 -转角和无规卷曲四种。
酶分子的肽链以 -折叠结构为主,折且结构间以 -螺旋及折叠肽链段相连。
-折叠为酶分子提供了坚固的结构基础,以保持酶分子呈球状或椭圆状。
在酶的二级结构中,结构单元在结合底物过程中,常发生位移或转变。
从酶活性中心的柔性特征来看,有人提出 -折叠结构可能对肽链的构象相对位移有利,这种结构可以把一些空间位置上邻近的肽段固定在一起,以维持稳定的活性构象。
酶分子(或亚基)的三级结构是球状外观。
在三级结构构建过程中, -折叠总是沿主肽链方向于右手扭曲,构成圆筒形或马鞍形的结构骨架, -螺旋围绕着 -折叠骨架结构的周围或两侧,形成紧密曲折折叠的球状三级结构。
由于非极性氨基酸,如苯丙氨酸、亮氨酸、丙氨酸等在 -折叠中出现的几率很大,因此在分子内部形成疏水核心,而表面则多为 -螺旋酸性氨基酸残基的亲水侧链所占据。
R语言学习总结

R语言学习总结经过接近一个学期的学习,从对R语言的完全陌生,到现在对其有了一些粗浅的认识,其中经历了遇到困难苦思冥想的艰辛,也有解决问题以后豁然开朗的畅快。
在学习的过程中,以前掌握的数理基础给我带来了不少便利,而认真地态度和踏实的性格也使我获益匪浅。
在这个学期中,我学会了R语言的基本操作和语法,以及针对具体的统计学问题相应的解决方法.并按时完成老师布置的课后作业,以达到学以致用的目的,也加强了对R语言操作的熟练度。
一、初识R软件R软件是一套完整的数据处理、计算和制图软件系统。
其功能包括:据存储和处理,数组运算,完整连贯的统计分析工具,优秀的统计制图功能已及简便而强大编程语言。
接触R语言以后,我的第一感觉就是方便和强大。
R语言中有非常多的函数和包,我们几乎不用自己去编一些复杂的算法,而往往只需要短短几行代码就能解决很复杂的问题,这给我们的使用带来了极大地方便;于此同时,它又可操纵数据的输入输出,实习分支、循环,使用者可以自定义功能,这就意味着当找不到合适的函数或包来解决所遇的问题时,我们又可以自己编程去实现各种具体功能,这也正是R语言的强大之处。
二、学习心得在学习该书的过程中,我不仅加深了对统计学方法的理解,同时也掌握了R 软件的编程方法和基本技巧,了解了各种函数的意义和用法,并能把两者结合起来,解决实际中的统计问题。
1、R语言的基本语法及技巧R语言不仅可以进行基础的数字、字符以及向量的运算,内置了许多与向量运算有关的函数。
而且还提供了十分灵活的访问向量元素和子集的功能。
R语言中经常出现数组,它可以看作是定义了维数(dim属性)的向量.因此数组同样可以进行各种运算,以及访问数组元素和子集.二维数组(矩阵)是比较重要和特殊的一类数组,R可以对矩阵进行内积、外积、乘法、求解、奇异值分解及最小二乘拟合等运算,以及进行矩阵的合并、拉直等。
apply()函数可以在对矩阵的一维或若干维进行某种计算,例如apply(A,1,mean)表示对A按行求和.R语言允许将不同类型的元素放在一个集合中,这个集合叫做一个列表,列表元素总可以用“列表名[[下标]]”的格式引用。
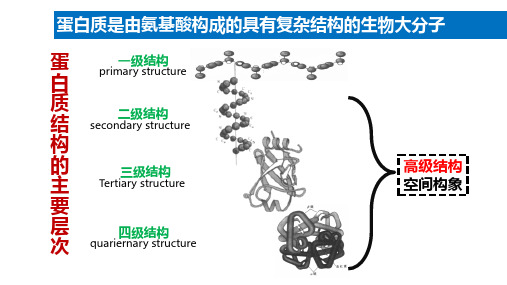
蛋白质一二三四级结构的概念和特点

蛋白质一二三四级结构的概念和特点结构的基本概念:1、一级结构:氨基酸排列顺序;2、二级结构:指蛋白质多肽链本身的折叠和盘绕的方式。
二级结构主要有α-螺旋、β-折叠、β-转角.常见的二级结构有α-螺旋和β-折叠。
二级结构是通过骨架上的羰基和酰胺基团之间形成的氢键维持的,氢键是稳定二级结构的主要作用力。
3、三级结构:蛋白质分子处于它的天然折叠状态的三维构象。
三级结构是在二级结构的基础上进一步盘绕,折叠形成的,指一条多肽链在二级结构的基础上,进一步盘绕,折叠,从而产生特定的空间结构。
三级结构主要是靠氨基酸侧链之间的疏水相互作用,氢键,范德华力和静电作用维持的.4、四级结构:在体内有许多蛋白质含有2条或2条以上多肽链,才能全面地执行功能.没一条多肽链都有其完完整的三级结构,称为亚基(subunit)。
亚基与亚基之间呈特定的三维空间分布,并以非共价键相链接,这种蛋白质分子中各亚基的空间排布及亚基接触部位的布局和相互作用,称为蛋白质的四级结构。
蛋白质的氨基酸序列是由对应基因所编码。
除了遗传密码所编码的20种基本氨基酸,在蛋白质中,某些氨基酸残基还可以被翻译后修饰而发生化学结构的变化,从而对蛋白质进行激活或调控。
多个蛋白质可以一起,往往是通过结合在一起形成稳定的蛋白质复合物,折叠或螺旋构成一定的空间结构,从而发挥某一特定功能。
合成多肽的细胞器是细胞质中糙面型内质网上的核糖体。
蛋白质的不同在于其氨基酸的种类、数目、排列顺序和肽链空间结构的不同。
食入的蛋白质在体内经过消化被水解成氨基酸被吸收后,合成人体所需蛋白质,同时新的蛋白质又在不断代谢与分解,时刻处于动态平衡中。
因此,食物蛋白质的质和量、各种氨基酸的比例,关系到人体蛋白质合成的量,尤其是青少年的生长发育、孕产妇的优生优育、老年人的健康长寿,都与膳食中蛋白质的量有着密切的关系。
蛋白质又分为完全蛋白质和不完全蛋白质。
富含必需氨基酸,品质优良的蛋白质统称完全蛋白质,如奶、蛋、鱼、肉类等属于完全蛋白质,植物中的大豆亦含有完全蛋白质。
教科版教材与人教版教材比较3-3

教科版教材与人教版教材比较 3-3模块第一章 分子动理论 (人教版 第七章)一、两种教材的“交集”1.分子的大小,扫描隧道显微镜,阿伏加德罗常数,实验:油膜法估测油酸分子的大小。
2011年(选修模块3-3)(3)某同学在进行“用油膜法估测分子的大小”的实验前,查阅数据手册得知:油酸的摩尔质量M=0.283kg·mol -1,密度ρ=0.895×103kg·m -3.若100滴油酸的体积为1ml ,则1滴油酸所能形成的单分子油膜的面积约是多少?(取N A =6.02×1023mol -1.球的体积V 与直径D 的关系为316V D π=,结果保留一位有效数字) 2.扩散现象,扩散在半导体生产中的应用,布朗运动及解释,热运动。
3.分子间存在相互作用力,分子间作用力与距离的关系,F-r 图象。
二、教科版的特点【教材处理】1.教科版在第一节中安排了“分子之间存在间隙”的内容,并设计了实验探究。
(P4) 2.把数量级估算作为一种重要的科学方法专门介绍,显示出对新课程标准中的“过程与方法”维度的教学目标的重视。
(P5)3.教科版把油膜法估测油酸分子的大小单独列成一节,有完整的实验目的、实验原理、实验器材和实验步骤。
并要求学生体会运用宏观方法测定微小量的实验思想与方法(P6-7) 4.安排演示实验:气球橡皮膜中分子之间的距离变大时,出现阻止距离变大分子之间的引力。
把微观结构中分子间距离变化、分子力的变化通过宏观的形式反应出来。
(P12) 5.在F-r 图象中标出了对外表现的分子力随距离变化的规律。
(P13) 6.把人教版中的第4、5节(温度和温标、内能)移至第二章气体部分。
【新情景】1.水分子的直径约水分子的直径约 4.0×10-10m ,氢分子的直径约水分子的直径约2.3×10-10m 。
(P2)2.对人体呼吸气体分子数的估算(趣味运算:你吸入了多少个爱因斯坦曾经呼出的气体分子?)。
蛋白质一级结构名词解释

蛋白质一级结构名词解释
蛋白质一级结构是指氨基酸序列的线性顺序。
蛋白质是由氨基酸构成的,而氨基酸的排列顺序决定了蛋白质的功能和结构。
在蛋白质一级结构中,丰富多样的氨基酸序列可以编码出数以百种的蛋白质。
蛋白质一级结构的解释需要理解以下几个概念:
1. 氨基酸
氨基酸是蛋白质的基本单位。
它是由一个氨基(NH2)和一个羧基(COOH)组成,以及一个侧链(R),侧链的种类决定了氨基酸的不同特性。
2. 多肽链
多个氨基酸通过肽键的连接形成多肽链。
肽键是由一个氨基酸的羧基与下一个氨基酸的氨基之间的共价键。
多肽链可以是短的多肽,也可以是长的多肽或蛋白质。
3. 氨基酸序列
氨基酸序列是指蛋白质中氨基酸的线性排列顺序。
氨基酸序列的不同决定了不同蛋白质之间的差异。
4. 多肽链的方向
多肽链有一个氨基端和一个羧基端,这决定了多肽链的方向。
一般来说,氨基端被称为N-端,而羧基端被称为C-端。
5. 氨基酸的属性
氨基酸的侧链决定了其属性,包括电荷、亲水性、疏水性、大小和形状等。
不同氨基酸的组合可以影响蛋白质的形状和功能。
通过对蛋白质一级结构的研究,科学家可以揭示蛋白质的功能和结构。
了解一级结构有助于解释蛋白质的折叠和稳定性,从而有助于设计和开发新的药物、酶和生物材料等。
白介素1β结构

白介素1β结构白介素1β(Interleukin-1β,IL-1β)是一种重要的细胞因子,参与调节免疫和炎症反应。
它由多种细胞产生,如巨噬细胞、淋巴细胞和上皮细胞等。
IL-1β在免疫应答中发挥着重要的作用,既可以促进炎症反应,又可以调节细胞增殖和分化。
IL-1β的结构具有独特的特点,它是一种由成熟的IL-1β前体通过蛋白酶切割而成的活性细胞因子。
IL-1β前体由一个信号肽、一个生物活性的成熟IL-1β分子和一个终止肽组成。
成熟IL-1β分子具有典型的二级结构,包括一个α螺旋和一个β折叠片段。
这种结构使得IL-1β能够与其受体结合,并触发下游信号转导通路。
IL-1β通过与其受体IL-1R结合,引发一系列的信号转导事件。
这些信号转导通路包括NF-κB和MAPK等,进而调节免疫和炎症反应。
IL-1β的作用范围广泛,不仅在免疫和炎症反应中起着重要作用,还参与了一些疾病的发生和发展。
IL-1β在免疫和炎症反应中发挥着重要的作用。
它可以增强免疫细胞的活力,促进炎症反应的发生。
同时,IL-1β还可以诱导细胞凋亡和坏死,对细胞的生存和死亡起着调节作用。
在炎症反应中,IL-1β还可以诱导其他炎症因子和趋化因子的产生,进一步加剧炎症反应。
IL-1β的异常表达与多种疾病的发生和发展密切相关。
例如,IL-1β过度表达与炎症性疾病如类风湿性关节炎和炎症性肠病等有关。
同时,IL-1β在肿瘤的发生和转移过程中也起着重要的作用。
研究表明,抑制IL-1β的活性可以有效抑制肿瘤的生长和转移。
IL-1β作为一种重要的细胞因子,在免疫和炎症反应中发挥着重要的作用。
它的结构独特,通过与其受体结合,调节免疫和炎症反应。
IL-1β的异常表达与多种疾病的发生和发展密切相关。
深入研究IL-1β的结构和功能,对于揭示免疫和炎症反应的机制,以及疾病的防治具有重要意义。
白介素1β结构

白介素1β结构
白介素1β(Interleukin-1 beta,IL-1β)是一种蛋白质,属于白介素家族的一员。
它在免疫系统中发挥着重要的调节作用。
本文将从结构的角度来描述白介素1β,并探讨其在免疫调节中的作用。
白介素1β是由一个单链多肽组成,具有153个氨基酸残基。
它的分子量约为17.5 kDa。
在细胞内,白介素1β以非活性的前体形式存在,需要通过一系列的酶切作用才能激活为活性形式。
激活后的白介素1β能够与其受体结合,进而触发一系列的信号传导通路,从而参与免疫调节过程。
白介素1β在免疫调节中发挥着重要的作用。
它能够诱导炎症反应,并参与免疫细胞的活化和增殖。
此外,白介素1β还能够促进炎症细胞的迁移和粘附,增强炎症反应的持续性。
与此同时,白介素1β还能够调节其他免疫因子的产生,如肿瘤坏死因子-α(TNF-α)和白介素6(IL-6),从而进一步加强炎症反应。
尽管白介素1β在免疫调节中发挥着重要的作用,但过度的白介素1β产生也会对机体产生不利影响。
过度的炎症反应会导致组织损伤和疾病的发生。
因此,调控白介素1β的产生和活性对维持免疫平衡至关重要。
总结起来,白介素1β是一种重要的免疫调节因子,它通过参与炎症反应和调节其他免疫因子的产生来发挥作用。
然而,过度的白介
素1β产生会导致炎症反应的过度,从而对机体产生不利影响。
因此,对白介素1β的调控十分重要,可以为炎症性疾病的治疗提供新的思路。
希望通过对白介素1β结构和功能的深入研究,能够为免疫调节的研究和炎症性疾病的治疗提供更多的启示。
trans 1-t1基因型

trans 1-t1基因型
trans 1-t1基因型是一种与核仁蛋白质相关的基因型。
核仁是细胞核内一个复杂且高度动态变化的无膜亚结构,是细胞核内核糖体RNA(ribosomal RNA, rRNA)的加工厂,它在调节rRNA的转录、加工以及核糖体亚基组装中发挥着重要作用。
研究人员通过实验发现,PDFC关键蛋白质URB1调控pre-rRNA 3’末端ETS区域(External Transcriptions spacer,ETS)折叠和加工,对于维持PDFC的结构和功能至关重要。
URB1缺失会导致3’ETS的加工异常,进而激活RNA稳态监控系统(RNA Exosome)在核仁发挥活性,引发异常pre-rRNA的降解,导致成熟的28S rRNA减少,无法维持细胞内核糖体的稳态和蛋白质合成,造成斑马鱼和小鼠的早期发育缺陷,甚至死亡。
这项研究利用多种研究手段,全面揭示了核仁精细结构与pre-rRNA的加工相互协同,共同维持核仁内微环境稳定,为认识核仁功能提供了全新的见解,同时也为深入理解三维pre-rRNA加工机制、核仁组装形成和功能提供了新的思路。
1.3.1 蛋白质一级结构、二级结构
蛋白质是由氨基酸构成的具有复杂结构的生物大分子蛋白质结构的主要层次一级结构primary structure四级结构quariernary structure高级结构空间构象二级结构secondary structure三级结构Tertiary structure蛋白质一级结构 及二级结构The primary & secondary Structure of Protein蛋白质一级结构(一)蛋白质的一级结构(1)肽键:是由一个氨基酸的α-羧基与另一个氨基酸的α-氨基脱水缩合而形成的化学键,生成的化合物称为肽: (peptide bond) 肽键 氨基酸的连接方式1蛋白质是由多个氨基酸通过肽键有序连接形成的多肽(2)肽:两分子氨基酸缩合形成二肽,三分子氨基酸缩合则形成三肽,……,寡肽,多肽丝氨酰.甘氨酰 .苯丙氨酰.丙氨酰. 亮氨酸六肽蛋白质一级结构主要指蛋白质多肽链中的氨基酸排列顺序。
众多蛋白质一级结构已被测定,并建立了数据库共使用。
N 末端:多肽链中有自由α-氨基的一端C 末端:多肽链中有自由α-羧基的一端(3)多肽链两端(1)主链:由肽键部分规则地重复排列构成的骨干结构 ,包括 肽键﹑ α碳原子﹑氨基末端﹑羧基末端 氨基酸残基(residue): 多肽链中的氨基酸参与肽键形成而基团不全,被称为氨基酸残基(2)侧链:R 基团多肽链(Polypeptide chain)结构2:从N 末端到C 末端书写方式 氨基酸的顺序是从N-端的氨基酸残基开始,以C-端氨基酸残基为终点的排列顺序如下述五肽可表示为H 2N-Ser-Val-Tyr-Asp-Gln -COOH1 H-丝-缬-酪-天冬-谷氨酰胺-OH2 SVYDQ3 多肽链的方向性3蛋白质一级结构一级结构是蛋白质理化特性、空间构象和生物学功能的基础一级结构异常,理化特性、空间构象和生物学功能均受影响!可导致疾病发生,如镰刀型贫血症一级结构的重要性4蛋白质化学(二)蛋白质的二级结构蛋白质的二级结构指的是指多肽链的主链某一段在空间上形成的有规律的折叠或盘绕,是肽段主链骨架原子在空间上的排列分布和相对位置,不涉及侧链的构象形成和稳定蛋白质二级结构的化学键是氢键(1)肽平面: 参与肽键的6个原子C α1、C 、O 、N 、H 、C α2位于同一个刚性平面内,C α1和C α2在平面上所处的位置为反式(trans)构型,此同一平面称为肽平面。
RT-Thread用户手册

6.7
线程相关接口 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3 5 5 5 6 9 9 14 18 20 21 22 27 28 29 29 29 29 31 31 34 43 43 43 44 46 47 47 i
5 内核对象模型 5.1 C语言的对象化模型 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.2 内核对象模型 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 线程调度与管理 6.1 实时系统的需求 6.2 线程调度器 . . . 6.3 线程控制块 . . . 6.4 线程状态 . . . . 6.5 空闲线程 . . . . 6.6 调度器相关接口 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
蛋白质的一级结构的主要作用力

蛋白质的一级结构的主要作用力1.一级结构(primary structure):氨基酸残基在蛋白质肽链中的排列顺序称为蛋白质的一级结构,每种蛋白质都有唯一而确切的氨基酸序列。
2.二级结构(secondary structure):蛋白质分子中肽链并非直链状,而是按一定的规律卷曲(如α-螺旋结构)或折叠(如β-折叠结构)形成特定的空间结构,这是蛋白质的二级结构。
蛋白质的二级结构主要依靠肽链中氨基酸残基亚氨基(—NH—)上的氢原子和羰基上的氧原子之间形成的氢键而实现的。
3.三级结构(tertiary structure):在二级结构的基础上,肽链还按照一定的空间结构进一步形成更复杂的三级结构。
肌红蛋白,血红蛋白等正是通过这种结构使其表面的空穴恰好容纳一个血红素分子。
4.四级结构(quaternary structure):具有三级结构的多肽链按一定空间排列方式结合在一起形成的聚集体结构称为蛋白质的四级结构。
如血红蛋白由4个具有三级结构的多肽链构成,其中两个是α-链,另两个是β-链,其四级结构近似椭球形状。
维持作用力:用约20种氨基酸作原料,在细胞质中的核糖体上,将氨基酸分子互相连接成肽链。
一个氨基酸分子的氨基和另一个氨基酸分子的羧基,脱去一分子水而连接起来,这种结合方式叫做脱水缩合。
通过缩合反应,在羧基和氨基之间形成的连接两个氨基酸分子的那个键叫做肽键。
由肽键连接形成的化合物称为肽。
扩展资料:蛋白质是组成人体一切细胞、组织的重要成分。
机体所有重要的组成部分都需要有蛋白质的参与。
一般说,蛋白质约占人体全部质量的18%,最重要的还是其与生命现象有关。
蛋白质(protein)是生命的物质基础,是有机大分子,是构成细胞的基本有机物,是生命活动的主要承担者。
没有蛋白质就没有生命。
氨基酸是蛋白质的基本组成单位。
它是与生命及与各种形式的生命活动紧密联系在一起的物质。
机体中的每一个细胞和所有重要组成部分都有蛋白质参与。
蛋白质一二三四结构概念

蛋白质一二三四结构概念一、蛋白质一级结构1. 定义- 蛋白质的一级结构是指蛋白质多肽链中氨基酸的排列顺序。
它由基因上遗传密码的排列顺序所决定。
例如,胰岛素是一种蛋白质,其一级结构就是由特定的氨基酸按照一定顺序连接而成的一条多肽链。
2. 化学键- 主要靠肽键(由一个氨基酸的α - 羧基与另一个氨基酸的α - 氨基脱水缩合形成)连接氨基酸残基,在蛋白质分子中,还可能存在二硫键(由两个半胱氨酸残基的巯基( - SH)氧化形成的 - S - S - 键),它对维持蛋白质的一级结构稳定性也有重要作用。
3. 意义- 蛋白质的一级结构是其空间结构和生物学功能的基础。
一级结构的不同会导致蛋白质具有完全不同的性质和功能。
例如,正常的血红蛋白(HbA)和镰刀型细胞贫血症患者的血红蛋白(HbS),二者在一级结构上仅有一个氨基酸的差异(HbA中的谷氨酸被HbS中的缬氨酸取代),却导致红细胞形态和功能的巨大改变,HbS在低氧分压下容易聚集,使红细胞扭曲成镰刀状,影响氧气运输并引发一系列健康问题。
二、蛋白质二级结构1. 定义- 蛋白质的二级结构是指多肽链主链骨架原子的相对空间位置,并不涉及氨基酸残基侧链的构象。
它主要是靠氢键维持稳定。
2. 常见类型- α - 螺旋- 多肽链主链围绕中心轴呈有规律的螺旋式上升,每3.6个氨基酸残基螺旋上升一圈,螺距为0.54nm。
氨基酸残基的侧链伸向螺旋外侧。
α - 螺旋结构中的每个肽键的N - H和第四个肽键的C = O形成氢键,氢键的方向与螺旋长轴基本平行。
例如,毛发中的α - 角蛋白就含有大量的α - 螺旋结构。
- β - 折叠- 是由两条或多条几乎完全伸展的多肽链(或同一肽链的不同肽段)侧向聚集在一起,通过相邻肽链主链上的N - H和C = O之间形成氢键而稳定。
这些肽链可以是平行的(相邻肽链的N端在同一方向),也可以是反平行的(相邻肽链的N端方向相反)。
β - 折叠结构使多肽链形成片层状,如蚕丝中的丝心蛋白就富含β - 折叠结构。
关联规则(初识)

关联规则(初识)关联规则关联规则分析是数据挖掘中最活跃的⽅法之⼀,⽬的是在⼀个数据集中找出各项之间的关联关系,⽽这种关系并没有在数据中直接表⽰出来算法名称算法描述Apriori关联规则最常⽤也是经典的挖掘频繁项集的算法,其核⼼思想是通过连接产⽣候选项及其⽀持度然后通过剪枝⽣成频繁项集FP-Tree针对Apriori算法固有的多次扫描事物数据集的缺陷,提出的不产⽣候选项频繁项集的⽅法.Apriori和FP-Tree都是寻找频繁项集的算法Eclat算法Eclat算法是⼀种深度优先级算法,采⽤垂直数据表⽰形式,在概念格理论的基础上利⽤基于前缀的等价关系将搜索空间划分为较⼩的⼦空间灰⾊关联法分析和确定各因素之间的影响程度或是若⼲个⼦因素(⼦序列)对主因素(母序列)的贡献度⽽进⾏的⼀种分析⽅法.Apriori算法Apriori算法是最经典的挖掘频繁项集的算法,第⼀次实现了在⼤数据集上可⾏的关联规则提取,其核⼼思想是通过连接产⽣候选项与其⽀持度,然后通过剪枝⽣成频繁项集关联规则和频繁项集关联规则的⼀般形式项集A, B同时发⽣的概率称为关联规则的⽀持度(也称相对⽀持度)support(A==>B) = P(A υ B)项集A发⽣,则项集B发⽣的概率为关联规则的置信度Confidence(A==>B) = P(A υ B)最⼩⽀持度和最⼩置信度最⼩⽀持度是⽤户或专家定义的衡量⽀持度的⼀个阈值,表⽰项⽬集在统计意义上的最低重要性最⼩置信度是⽤户或专家定义的衡量置信度的⼀个阈值,表⽰关联规则的最低可靠性.同时满⾜最⼩⽀持度阈值和最⼩置信度阈值的规则称作强规则项集项集是项的集合.包含K个项集称为k项集,如集合(⽜奶, 麦⽚, 糖 B )是⼀个3项集.项集的出现频率是所有包含项集的事务计数,⾛称做绝对⽀持度或⽀持度计数.如果项集I的相对⽀持度满⾜预定义的最⼩⽀持度阈值,则I是频繁项集.频繁项集K项集通常记作K.⽀持度计数项集A的⽀持度是事务数据集中包含项集A的事务的个数,简称为项集的频率或计数已知项集的⽀持度计数,则规则A ==> B的⽀持度和置信度很容易从所有的事务计数,项集A和项集A U B的⽀持度计数推出Support(A ==> B) = A,B同时发⽣的事务的个数 / 所有事务个数 = Support_count(A Ω B) / Total_count(A)Confidence( A == > B) = P( A | B) = Support_count(A Ω B) / Support_count(A)也就是说,⼀旦得到所有事务个数,A,B和AΩB的⽀持度计数,就可以导出对应的关联规则A == > B和B == > A,并可以检查该规则是否是强规则# -*- coding:utf-8 -*-import sysreload(sys)sys.setdefaultencoding("utf-8")"""使⽤Apriori算法挖掘菜品订单关联规则"""from__future__import print_functionfrom apriori import find_common_typeimport pandas as pddata = pd.read_csv("sales.csv", header=None, sep=",")print(u'\n转换原始数据⾄0-1矩阵...')ct = lambda x: pd.Series(1, index=x[pd.notnull(x)]) # 转换矩阵0-1矩阵的过度函数b = map(ct, data.as_matrix()) # ⽤map⽅式执⾏data = pd.DataFrame(list(b)).fillna(0) # 实现矩阵转换,空值⽤0填充print(u'\转换完毕.')del bsupport = 0.2 # 最⼩⽀持度confidence = 0.5 # 最⼩置信度ms = '--'# 连接符,默认'--',⽤来区分不同元素, 如 A--B. 需要保证原始表格中不含有该字符find_common_type(data, support, confidence, ms).to_csv("sales_1.csv")其中,e–a表⽰e能发⽣能够推出a发⽣,置信度为100%,⽀持度为30%; b - c - a表⽰b,c能同时能够推出a发⽣,置信度为60%,⽀持度为30%,搜索出来的关联规则不⼀定具有实际意义,需要根据问题背景筛选出适当的有意义的规则,并赋予合理的解释Apriori算法使⽤候选产⽣频繁项集Apriori算法的主要思想是找出在于事务数据集中最⼤的频繁项集,在利⽤得到的最⼤的频繁项集与预先设定的最⼩置信度阈值⽣成强关联规则Apriori的性质, 频繁项集的所有⾮空⼦集也必须是频繁项集.根据该性质可疑得出,向不是频繁项集I的项集中添加事务A,新的项集I U A⼀定也不是频繁项集Apriori算法实现的两个过程如下:找出所有的频繁项集(⽀持度必须⼤于等于给定的最⼩⽀持度阈值),在这个过程中,连接步和剪枝步相互融合,最终得到最⼤频繁项集Lk.链接步:链接步的⽬的是找到K项集,对于给定的最⼩⽀持度阈值,分别对I项集选集C1,剔除⼩于该与阈值的项集得到1项频繁集L1;下⼀步有L1⾃⾝链接产⽣2项候选集C2,保留C2中满⾜约束条件的项集得到2想频繁项集,记为L2,再下⼀步由L2项候选集C2,保留C2中满⾜约束条件的2项频繁集,极为L2;再下⼀步由L2与L3链接产⽣3项候选集C3,保留C2中满⾜约束条件的项集得到3项频繁集,极为L3,...这样循环下去,得到最⼤的频繁项集 Lk剪枝步:枝步紧接着连接步,再产⽣选项Ck的过程中起到减⼩搜索空间的⽬的由于Ck是Lk-1与L1连接产⽣的,根据Apriori的性质频繁项集,所以不满⾜该性质的项集不会存在Ck中,该过程就是剪枝时序模式常⽤按时间顺序排列的⼀组随机变量X1,X2,X3...,Xt来表⽰⼀个随机事件的时间序列,简记为{Xt};⽤x1,x2,x3,...,xn或{Xt,t=1,2,3...,n}表⽰该随机序列的n个有序观察值,称之为序列长度为n的观察序列.时间序列算法(常⽤的模型)模型名称描述ARCH模型ARCH模型能准确地模拟时间序列变量的波动性的变化,适⽤与序列具有异⽅差性并且异⽅差函数短期⾃相关ARIMA模型许多⾮平稳序列差分后会显⽰出平稳序列的性质,称这个⾮平稳序列为差分平稳序列,对于差分平稳序列可以使⽤ARIMA模型进⾏拟合ARMA模型xt = Φ0 + Φ1xt-1 + Φ2xt-2 + ...+ Φpxt-p + εt - θ1εt-1 - θ2εt-2 - ... - θqεt-q 随机变量Xt的取值xt不仅与前p期的序列值有关,还与前前q期的然东值有关AR模型xt = Φ0 + Φ1xi-1 + Φ2xi-2 + ... + Φpxt-p + εt 以前p期的序列值xt-1,xt-2, ..., +xt-p为⾃变量,随机变量xt的取值,xt为因变量建⽴线性回归模型GARCH模型及其衍⽣模型GARCH模型称为⼴义ARCH模型,是ARCH模型的拓展.相⽐与ARCH模型,GARCH模型机器衍⽣模型更能反映实际序列中的长期记忆性,信息的⾮对称性等.MA模型xt = µ+εt - θ1εt-1 - θ2εt-2-...-θpxt-q 随机变量Xt的取值xt与以前各期的序列值⽆关,建⽴xt与前q期的素鸡扰动εt-1,εt-2,...,εt-q的线性回归模型平滑法平滑法常⽤于趋势分析和预测,利⽤修均技术,削弱短期随机波动对序列的影响,使序列平滑化数据所⽤平滑技术的不同,可具体分为移动平均法和指数平滑发组合模型时间序列的变化主要受到长期趋势(T),季节变动(S).周期变动(C)和不规则变动(ε)这4个因素的影响根据序列的特点,可疑构建加法模型和乘法模型加法模型: xt = Tt + St + Ct + εt 乘法模型: xt = Tt * St * Ct * εt趋势拟合法趋势拟合法把时间作为⾃变量,相应的序列观察值作为因变量,建⽴回归模型,根据序列的特征,可具体分为线性拟合和曲线拟合时间序列的预处理拿到⼀个观察值序列后,⾸先要对它的纯随机性和平稳性进⾏检验,这两个重要的处理称为序列的预处理,根据检验结果可以将序列分为不同的类型,对于不同的类型,对于不同类型的序列会才去不同的分析⽅法对于纯随机序列,⼜称为⽩噪声序列,序列的各项之间没有任何相关关系,序列在⾦鑫完全⽆序的随机波动,可以终⽌对该序列的分析,⽩噪声序列是没有信息可提取的平稳序列对于平稳⾮⽩噪声序列,它的均值和⽅差是常数,现已有⼀套⾮常成熟的平稳序列的建模⽅法.通常是建⽴⼀个线性模型来拟合该序列的发展,借此提取该序列的有⽤信息.ARMA模型是最常⽤的平稳序列拟合模型对于⾮平稳序列,由于它的均值和⽅差不稳定,处理⽅法⼀般是将其转变为平稳序列,这样就可以应⽤有关平稳时间序列的分析⽅法,如建⽴ARMA模型来进⾏相关的研究.如果⼀个时间序列经差分运算后具有平稳性,则该序列为差分平稳序列,可以使⽤ARMA模型进⾏分析平稳性检验平稳时间序列的定义:对于随机变量X,可以计算其均值(数学期望), µ, ⽅差σ2;对于两个随机变量X和Y,可以计算X,Y的协⽅差cov(X,Y) = E[(X-µy)(Y-µy)]和相关系数ρ(X,Y) = cov(X,Y) / σxσy,他们度量了两个不同事件之间的相互影响, 对于时间序列{Xt, t€T},任意时刻的序列值Xt都是⼀个随机变量,每⼀个随机变量都会有有均值和⽅差,记Xt的均值为µt,⽅差为σt;任取t,s€T, 定义序列(Xt)的⾃协⽅差函数γ(t,s) = E[(Xt-µt)(Xs-µs)]和⾃相关系数ρ(t,s) = cov(Xt, Xs) / σtσs(特别的,γ(t,s)γ(0) = 1,ρ0 = 1),之所以称它们为⾃协⽅差和相关系数,是因为他们衡量的是同⼀个事件在两个不同时期(时刻t/s)之间的相关程度,形象地讲就是度量⾃⼰过去的⾏为对⾃⼰现在的影响如果时间序列{Xt, t€T}在某⼀常数附近波动且波动范围有限,即有常数均值和常数⽅差,并且延迟k期的序列变量的⾃协⽅差和相关系数,是因为他们衡量的是同⼀个事件在两个不同时期(时刻t和s)之间的相关程度,形象地讲就是度量⾃⼰过去的⾏为对⾃⼰现在的影响.如果时间序列{Xt,t€T},在某⼀种常数附近波动且波动范围有限,即有常数均值和常数⽅差,并且延迟k期的序列变量的⾃协⽅差和⾃相关系数是相等的或者说延迟k期的序列变量之间的影响程度是⼀样的,则称{Xt,t€T}为平稳序列平稳性的检验.对序列的平稳性的检验有两种检验⽅法,⼀种是根据时序图和⾃相关图的特征做出判断的图检验,该⽅法操作简单,应⽤⼴泛,缺点是带有主观性;另⼀种是构造检验统计量进⾏检验的⽅法,⽬前常⽤⽅法是单位根检验时序图检验.根据平稳时间序列的均值和⽅差都为常数的性质,平稳序列的时序图显⽰该序列值始终在⼀个常数附近随机波动,⽽且波动的范围有界;如果有明显的趋势性或者周期性,那它通常不是平稳序列⾃相关系数.平稳序列具有短期相关性,这个性质表明对平稳序列⽽⾔通常只有近期的序列值对现时值的影响⽐较明显,间隔越远的过去值对现时值的影响越⼩,随延迟期数K的增加,平稳序列的⾃相关系数ρk(延迟k期)会⽐较快的衰减趋势趋于零,并在零附近随机波动,⽽⾮平稳序列的⾃相关系数衰减速度⽐较慢,这就是利⽤⾃相关图进⾏平稳性检验的标准单位根检验,单位根检验是指检验序列中是否存在单位根,如果存在单位根就是⾮平稳序列了纯随机性检验如果⼀个序列时纯随机序列,那么它的序列值之间应该没有任何关系,即满⾜γ(k)=0,k≠0,这是⼀种理论上才会出现的理想状态,实际上纯随机序列的样本⾃相关系数不会绝对为零,但是很接近零,并在零附近随机波动.纯随机性检验也称⽩噪声检验,⼀般是构造检验统计量来检验序列的纯随机性,常⽤的检验统计量有Q统计量,LB统计量,由样本个延迟期数的⾃相关系数可以计算得到检验统计量,让你后,计算出对应的p值,如果p值显著⼤于⽔平α,则表⽰该序列不能拒绝纯随机的原假设,可以停⽌对给序列的分析.平稳时间序列分析ARMA模型的全称时⾃回归移动平均模型,它是⽬前最常⽤的拟合平稳序列的模型.它有可分为AR模型,MA模型和ARMA模型三⼤类.都可以看作多元线性回归模型.AR模型:具有如下结构模型称为ρ阶⾃回归模型,简记AR(ρ).xt = Φ0 + Φ1xt-1 + Φ2xt-2 + ... + Φpxt-p + εt即在t时刻的随机变量Xt的取值时前p期xt-1,xt-2, .., xt-p的多元线性回归,认为xt主要时受过去ρ期的序列值的影响,误差项是当期的随机⼲扰εt,为零均值⽩噪声序列统计量性质统计量性质均值常数均值⾃相关系数(ACF)拖尾⽅差常数⽅差偏⾃相关系数(PACF)ρ阶截尾均值对满⾜平稳性条件的AR(ρ)m模型的⽅程,两边取期望,得:E(xt) = E(Φ0 + Φ1xt-1 + Φ2xt-2 + ... + Φpxt-p + εt)已知E(xt) = µ, E(εt) = 0, 所以µ = Φ0 + Φ1xt-1 + Φ2xt-2 + ... + Φρµ,推出: µ = Φ0 / 1 - Φ1 - Φ2 - ... - Φp⽅差:平稳AR(ρ)模型的⽅差有界,等于常数.⾃相关系数(ACF)平稳AR(ρ)模型的⾃相关系数pk = p(t,t-k) = cov(Xt,Xt-k) / σtσt-k呈指数的速度衰减,始终有⾮零取值,不会在k⼤于某个常数之后就恒等于零,这个性质就是平稳AR(ρ)模型⾃相关系数ρk具有拖尾性.偏⾃相关系数(PACF)对于⼀个平稳AR(ρ)模型,求出延迟k期⾃相关系数ρk时,实际上得到的并不是Xt与Xt-k之间单纯的相关关系,因为Xt同时还会受到中间k-1个随机变量Xt-1,Xt-2,...Xt-k的影响,所以⾃相关系数Pk⾥实际上掺杂了其他变量对Xt与Xt-k的相关影响,为了单纯地测试度Xt-k对Xt的影响,引进偏⾃相关系数的概念.可以证明平稳AR(ρ)模型的偏⾃相关系数具有ρ阶截尾性.这个性质连同前⾯的⾃相关系数的拖尾性AR(ρ)模型重要的识别依据MA模型具有如下结构的模型称为q阶⾃回归模型,简记MA(q)xt = µ + εt - θ1ε1-1 - θ2εt-2 - ... - θqεt-q即在t时刻的随机变量Xt的取值xt时前q期的随机扰动εt-1, εt-2, .. , εt-q的多元线性函数,误差项时当期的随机⼲扰εt,为零均值⽩噪声序列,µ是序列{Xt}的均值,认为xt主要是受获取q期的误差项的影响.统计量性质统计量性质均值常数均值⾃相关系数q阶截尾⽅差常数⽅差偏⾃相关系数拖尾ARMA模型具有如下结构的模型称为⾃回归移动平均模型,简记ARMA(p,q)xt = Φ0 + Φ1xt-1 + ...+ Φpxt-p + εt - Φ0 - Φ1xt-1 - ...- Φpxt-p即在t时刻的随机变量Xt的取值Xt是前p期xt-1,xt-2, ... ,xt-p和前q期εt-1, εt-2, ..., εt-q的多元线性函数,误差项是当期的随机⼲扰εt,为零均值⽩噪声序列,认为xt主要是受过p期的序列值和过去q期的误差项的共同影响.特别的,当q = 0 时,是AR(p)模型;当p = 0 时,是MA(q)模型平稳ARMA模型(p,q)的性质如下:统计量性质统计量性质⽅差常数⽅差偏⾃相关系数(PACF)拖尾均值常数均值⾃相关系数(ACF)拖尾平稳时间序列建模某个时间序列精⼯预处理,被判定为平稳⾮⽩噪声序列,就可以利⽤ARMA模型进⾏建模.计算出平稳⾮⽩噪声序列{Xt}的⾃相关系数和偏⾃相关系数,再由AP(p)模型,MA(q)模型和ARMA(p,q)模型的⾃相关似乎和偏⾃相关系数的性质,选择合适的模型.平稳时间序列建模步骤如下:计算⾮平稳⽩噪声序列的⾃相关系数(ACF)和偏⾃相关系数(PACF).ARMA模型识别,也称为模型定阶,由AR(P)阶模型,MA(q)和ARMA(p,q)的⾃相关系数和偏⾃相关系数的性质.选择合适的模型,识别的原则表如下:模型⾃相关系数(ACF)偏⾃相关系数(PACF)AR(p)拖尾p阶截尾ARMA(p,q)p阶拖尾q阶拖尾MA(q)q阶截尾拖尾估计模型中未知参数的值进⾏参数进⾏检验.模型检验模型优化模型应⽤:进⾏短期预测.⾮平稳时间序列分析前⾯介绍了对平稳时间序列进⾏分析的⽅法.实际上,在⾃然界中绝⼤部分序列都是⾮平稳的.因⽽对⾮平稳序列的分析更普遍,更重要,创造出来的分析⽅法也更多.对于⾮平稳时间序列的分析⽅法可以分为确定性因素分解的时序分析和随机时序分析两⼤类确定性因素分解的⽅法把所有序列的变化够归结为4个因素(长期趋势,季节变动,循环变动和随机波动)的综合影响,其中长期趋势和季节变动的规律性信息通常⽐较容易提取,⽽由随机因素导致的波动则⾮常难确定和分析,对随机信息浪费严重,会导致模型拟合精度不够理想.随机时序分析的发展就是为了弥补确定性因素分解⽅法的不⾜,根据时间序列的不同特点,随机时序分析可以建⽴的模型有ARIMA模型,残差⾃回归模型,季节模型,异⽅差模型等.差分运算相距⼀期的两个序列值之间的剪发运算称为1阶差分运算k步差分相距k期的两个序列值之间的减法运算称为k步差分运算ARIMA模型差分运算具有强⼤的确定性信息提取能⼒,许多⾮平稳序列差分后会显⽰出平稳序列的性质,这时称这个⾮平稳序列为差分平稳序列.对差分平稳序列可以使⽤ARMA模型进⾏拟合.ARIMA模型的实质就是差分运算与ARMA模型的结合,掌握了ARMA模型的建模⽅法和步骤后,对序列建⽴ARIMA模型是⽐较简单的.差分序列平稳时间序列建模步骤如下图:# -*- coding:utf-8 -*-import sysreload(sys)sys.setdefaultencoding("utf-8")"""arima时序模型"""columns = []import pandas as pdforecastnum = 5data = pd.read_csv("sales.csv",header=None,sep=",",names=columns)# 时序图import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['Simhei'] # ⽤来正常显⽰中⽂标签plt.rcParams['axes.unicode_minus'] = False # ⽤来正常显⽰负号data.plot()plt.show()# ⾃相关图from statsmodels.graphics.tsaplots import plot_acfplot_acf(data).show()# 平稳性检测from statsmodels.tsa.stattools import adfuller as ADFprint(u'原始序列的ADF检验结果为:', ADF(data[u'销量']))# 返回值⼀次为adf,pvalue,usedlag,nobs,critical,values, icbest, regresults, resstore# 差分后的结果D_data = data.diff().dropna() # 去掉空值D_data.columns = [u'销量差分']D_data.plot() # 时序图plt.show()plot_acf(D_data).show() # ⾃相关from statsmodels.graphics.tsaplots import plot_pacfplot_pacf(D_data).show() # 偏⾃相关图print(u'差分序列的ADF检验结果为:', ADF(D_data[u'销量差分'])) # 平稳性检测# ⽩噪声检测from statsmodels.stats.diagnostic import acorr_ljungboxprint(u'差分序列的⽩噪声检验结果为:', acorr_ljungbox(D_data, lags=1)) # 返回统计量和p值from statsmodels.tsa.arima_model import ARIMA# 定阶pamx = int(len(D_data) / 10) # ⼀般阶数不超过length / 10qmax = int(len(D_data) / 10) # ⼀般阶数不超过length / 10bic_matrix = [] # bic矩阵for p in range(pamx + 1):tmp = []for q in range(qmax + 1):try: # 存在部分报错,所以⽤try来跳过报错tmp.append(ARIMA(data, (p,1,q)).fit().bic)except:tmp.append(None)bic_matrix.append(tmp)bic_matrix = pd.DataFrame(bic_matrix) # 从中可以找到最⼩值p,q = bic_matrix.stack().idxmin() # 先⽤stack展平,然后⽤idxmin找出最⼩值的位置print(u'BIC最⼩值的p值和q值为: %s,%s' % (p,q))model = ARIMA(data, (p,1,q)).fit() # 建⽴ARIMA(0,1,1)模型并训练model.summary2() # 给出⼀份模型报告model.forecast(5) # 作为5天的预期,返回预测结果,标准误差,置信区间python主要时序模式算法Python实现时序模式的主要库是StatsModels(当然,如果pandas能做的,就可以利⽤Pandas先做),算法主要是ARIMA模型,在使⽤该模型进⾏建模的时候,需要进⾏⼀系列判别操作,主要包含平稳性检验,⽩噪声检验,是否差分,AIC和BIC指标值,模型定阶,最后再做预测.函数名函数功能所属⼯具箱acf()计算机相关函数statsmodels.tsa.stattoolsacorr_ljungbox()Ljung-Box检验,检验是否为⽩噪声statsmodels.stats.diagnosticadfuller()对观测值序列进⾏单位根检验statsmodels.tsa.stattoolsaic/bic/hqic计算ARIMA模型的AIC/BIC/HQIC指标值ARIMA模型对象⾃带的变量ARIMA()创建⼀个ARIMA时序模型ststamodels.tsa.arima_modelduff()对观测值序列进⾏差分计算Pandas对象⾃带的⽅法forecast()应⽤构建的时序模型进⾏预测ARIMA模型对象⾃带的变量pacf()计算偏相关系数statsmodels.tsa.stattoolsplot_acf()画⾃相关系数图statsmodels.graphics.tsaplotsplot_pacf()画偏相关系数图statsmodels.graphics.tsaplotssummary()或summary2给出⼀份ARIMA模型的报告ARIMA模型对象⾃带的⽅法acf()功能:计算⾃相关系数使⽤格式:autocorr = acf(data,unbiased=False, nlags=40, qstat=False, fft=False, alpha=None)输⼊参数data为观测值序列(即为时间序列,可以是DataFrame或Series),返回参数autocorr为观测值序列⼦相关函数.其余为可选参数,如qstat=True时同时返回Q统计量和对应p值.plot_acf()功能:画⾃相关系数图使⽤格式:p = plot_acf(data)返回⼀个Matplotlib对象,可以⽤.show()⽅法显⽰图像acf() / plot_acf()功能:计算偏⾃相关系数/画偏相关系数图使⽤格式:使⽤跟acf() / plot_acf()类似,adfuller()功能:对观测值序列进⾏差分计算使⽤格式:D.diff() D为Pandas的DataFrame或Seriesarima功能:设置时序模式的建模参数,创建ARIMA模型使⽤格式:arima = ARIMA(data, (p,1,q)).fit()data参数为输⼊的时间序列,p,q为对应的阶,d为差分次数summary() / summary2()功能:⽣成已有模型的报告使⽤格式:arima.summaty() / summary2()其中,arima为已经建好的ARIMA模型,返回⼀份格式化的模型报告,包含模型的系数,标准差,p值,AIC和BIC等详细指标aic/bic/hqic功能: 计算ARIMA模型的AIC,BIC,HQIC使⽤格式:arima.aic/arima.bic/arima.hqic其中,arima为已经建⽴好的ARIMA模型,返回值是Model时序模型得到的AIC,BIC和HQIC指标值forecast()功能:⽤得到的时序模型进⾏预测使⽤格式:a,b,c = arima.forecast(num)输⼊参数num为要预测的天数,arima为已经建⽴好的ARIMA模型,a为返回的预测值,b为预测的误差,c为预测置信区间acroo_ljungbox()功能:检测是否为⽩噪声序列使⽤格式:acroo_ljungbox(data, lags=1)输⼊参数为时间序列数据,lags为滞后数,返回统计量和p值。
气体动力学讲义(07)

激波图画
二、激波结构 超声速气流 被压缩 激波
很短的距离 完成压缩
激波的厚度2.5X10-5cm,相当于气体分子自由程。
什么是激波?
激波定义:有限振幅的力学波动、物理参数从一种 状态、经历若干个分子平均自由程的距离后,跳跃 到另外一种状态,宏观上可以看成间断,在静止气 体中以超音速传播。
自然现象. Earnshaw(1851)发现雷电的超音速传播现 象,即雷的响声传播速度快于音速.雷电实际上导致 了激波的产生。
(8)
二、朗金—雨贡纽关系式
(8)式可以变为:
p 2
p 1
V2 1 1n
1
1
2
V12n
p2
2
p1
1
2 1
(9)
p 2
p 1
V2 2 2n
1
2
1
V22n
p2
2
p1
1
12(10)
(9,10)式联立(8)式
可得:
k
k
1
p2
2
p1
1
1 2
V12n V22n
朗金—雨贡纽关系式
p p 1; 1;V c
2
1
2
1
s
c Vs
激波是以超声速在气体中传播的
从激波形成的例子可以看出,对于封闭空间,活 塞作加速运动在管中就可以产生激波,无论活塞 的速度VB是超声,还是亚声,只要恒定,激波强 度不变,并且稳定。
物体在大空间运动时,只有以超音速运动时才可 能形成稳定的激波。
水平来流经过斜激波后气流转折 角,沿楔形体表面流动。
一、激波的基本方程
Comparison between the wave angle and the Mach angle • When generating object is larger than a “point”, shock wave is stronger than mach wave …. Oblique shock wave
简述蛋白质的一级结构

简述蛋白质的一级结构蛋白质是生物体内重要的有机物质,在组成细胞的结构中扮演着至关重要的作用,它也是各种生命活动所必需的材料。
蛋白质主要以氨基酸(肽)链的形式存在,而这种肽链作为一种多聚结构,其尺寸一般为几个厘米,因而聚合物可以分解为更小的单位,从而为我们提供更多的结构细节。
蛋白质的一级结构(也称为本能结构)是指由氨基酸肽链组成的原子和分子结构,这种结构又可以分为三种主要类型:线性结构、叶状结构和环形结构。
线性结构是指一种普遍存在的单一氨基酸链形式,它可以用极坐标表示。
线性结构的氨基酸链可以分为三种:α-螺旋、3.6/3.7/3.8螺旋和β-折叠。
α-螺旋是由α -螺旋结构(α -螺旋)构成的氨基酸链,结构由一连串以四碳酸作为桥梁连接的氨基酸肽链组成,通过构成氨基酸的不同组合形成居中或居左/居右的结构,可以在空间中旋转形成螺旋形或管状形。
第二种类型的结构是3.6/3.7/3.8螺旋结构,这种结构是由三种不同的α-螺旋组成,分别是每一折叠的α-螺旋,即3.6螺旋,每隔三项组成3.7螺旋,每隔四项组成3.8螺旋。
最后一种类型结构是β-折叠,它是由多边形氨基酸环连接以及两个不同链段之间的空间折叠构成的结构,在结构上它有独特的卷曲和折叠,其中空间折叠可以调整蛋白质形成不同的结构。
叶折叠,即β折叠的变形,是指由多边形氨基酸环连接的多聚体,其结构不像α-螺旋或β-折叠那样有明显的线性特征,而是由氨基酸链段组成的折叠结构,呈平面折叠的形态。
类似的叶状结构也可以分为三种:单折叠、双折叠和三折叠。
单折叠是由一个有折叠和叠角的氨基酸链组成;双折叠是由两个氨基酸链组成,一个氨基酸链为折叠,另一个氨基酸链为叠角;三折叠结构是由三个氨基酸链组成,其中两个为折叠,一个为叠角。
最后一类结构是环形结构,也称为环状螺旋结构,它是由氨基酸肽链在空间中构成的螺旋结构,结构由多个氨基酸链组成的一个完整的环状,氨基酸链在空间中沿着螺旋形状旋转,两端再回到环状的起始位置接合,形成完整的环形结构。
t-rna一级结构

t-rna一级结构t-rna(transfer RNA)是一种在蛋白质合成中起着关键作用的核酸分子。
它具有特殊的结构和功能,能够将氨基酸从细胞质中的氨基酸库运输到核糖体上,参与蛋白质的合成过程。
t-rna的一级结构是指该分子的碱基序列,这个序列决定了t-rna的二级和三级结构。
t-rna分子由四个区域组成:双臂(double arm)、TΨC环(TΨC loop)、二级结构中心(anticodon loop)和D环(D loop)。
这四个区域在t-rna的一级结构中分别对应特定的碱基序列。
双臂是t-rna分子的两个突出的区域,其碱基序列通常为CCA。
CC 序列在t-rna的合成过程中起着重要的作用,它可以通过酶的作用与氨基酸结合,形成氨酰-t-rna复合物(aminoacyl-tRNA),从而将氨基酸运输到核糖体上。
TΨC环是t-rna分子上的一个稳定结构,其中的碱基序列包括TΨC,这个序列的存在可以保持t-rna分子的稳定性,并且参与到t-rna 的识别和结合过程中。
二级结构中心是t-rna分子上的一个重要区域,其中包含了t-rna 的反密码子序列(anticodon sequence)。
这个序列可以与mRNA上的密码子序列(codon sequence)互补配对,从而实现t-rna与mRNA的识别和配对。
D环是t-rna分子上的另一个稳定结构,其中的碱基序列通常为D。
D环的存在可以增加t-rna分子的稳定性,并且参与到t-rna的结合和识别过程中。
t-rna的一级结构对于其二级和三级结构的形成和功能的发挥起着至关重要的作用。
t-rna的一级结构是由基因组中的特定DNA序列经过转录和剪接产生的。
这个过程中,RNA聚合酶将DNA模板上的信息转录成RNA链,然后经过剪接和修饰形成成熟的t-rna分子。
在t-rna的一级结构中,碱基的顺序对于t-rna的折叠和稳定性起着重要的作用。
不同的碱基序列会导致t-rna分子折叠成不同的结构,从而影响其功能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第一节 初识结构
内容提要及基本要求:
1、认识身边无所不在的结构。 2、能从力学的角度理解结构的涵义和本质。 3、会对日常常见结构进行归类。
1 无处不在的结构
结构(Structure)
世界上任何事物都存在着结构, 结构多种多样且决定着事物存在 的性质。
1、单杠受力和变形分析
• 看一段视频
受力特点:外力作用在结构体 的表面上,如建筑,汽车外壳, 贝壳。
台灯
材料阅读:
一件建筑和高级工程学的杰作
蛋壳对于压力的承受力是惊人的。人人皆知的是,在中国杂技 佳作中,不仅有人踩鸡蛋的节目,更有提起两桶水踩蛋的精彩 表演。这是巧妙地利用蛋壳承受压力能力的一个极好的例子。 蛋不仅是整个生物界最大的单体细胞,以现代技术和工程知识 系统的眼光来看,它还是一个集工程学、建筑学、防卫战略、 保存能量和使空间利用达到最佳化与将其最完美结合于一身的 大自然的绝妙之作。
我们的观察首先从鸡蛋,特别是从蛋壳开始。蛋壳是由94%的碳酸钙 (以方解石晶体的形式)、1%的碳酸镁、1%的磷酸钙和4%的蛋白 质构成的。方解石晶体基本上是随意排列的,因此在晶体之间形成了 许许多多的小孔,这些蛋孔可以让空气和湿气能通过,而空气和湿度 对于雏鸡,当然还有细菌(比如沙门氏菌)的生存来说是必不可少的。
五种基本的受力方式
拉 作用于物体 ,使它产 力 生弯曲的力
两个距离很近 ,大小 压 相等,方向相反,且作 力 用于同一物体上的
平行力
剪 切 挤压物体的力 力
扭 物体所承受的拉拽 转力 力
弯 反方向向物体两端 曲 均匀施力 ,使物体发 力 生扭转形变的力
马上行动
建筑物的窗户
指出下列结构可以抵抗来自外界 哪些方面的作用力。
鹰眼 与导弹跟踪系统
• 如果在人类的视网膜上象鹰 一样有两个凹槽,世界将会 如何变化?
• 将来运用技术手段在人的视 网膜造出两个凹槽,有这种可 能吗?
马上行动
在生产生活中那些产品的结构是受到自然物 体的结构的启发而产生的?
此款鼠标垫的内部结构为仿 蜂巢设计,这一设计大大降 低了鼠标垫的重量,却不影 响鼠标垫的韧性。蜂巢结构 设计保障了鼠标垫的结构稳 定,使用再久也不会发生变 形。
餐桌
硬纸包装箱
参考答案:
建筑物的窗户: 抵抗来自建筑物墙的正向和侧向
的压力、风的作用力,及其自身 的重力等
餐 桌:
承受来自桌面物体的压力和它自 身的重力等
硬纸包装箱:
承受箱内物体的重力、箱内物体 向外的挤压力以及自身的重力等
3 结构的类型
结构指物体的各组成部分之间的搭配和排列,确定的 搭配和排列决定了物体的性质和形态。 物体的结构是多种多样的,其分类也是多种多样的。
应县木塔
球形空间桁架结构
北京国家大剧院 出这样一座大酒店
松江大酒店
上海松江有个100米深石场,还有一个小湖。 Atkins设计公司就在这里设计了一个22世纪风格的 五星级的松江大酒店。建筑宏伟壮观,有一组瀑布 状的玻璃幕墙,非常漂亮。这还是一座极为环保的 建筑,整个酒店的屋顶种满绿草,石场为酒店提供 了良好的温度控制。酒店总共能住1000位客人,他 们可以享受酒店里的餐厅、咖啡厅、健身房、宴会 厅、水下水族馆、会议厅、泳池、攀岩......
实心结构
常见的结构 框架结构
的类型:
壳体结构
1 实心结构
• 实心结构: 结构体本身是实心的
受力特点:外力承受在 物体的外表,如大坝、 实心墙
• 框架结构:结构体由细长的构件组成的结构 2 框架结构• 受力特点:支撑空间而不充满空间。如铁架塔
建筑用脚手架,厂房的框架。
桁架结构
3 壳体结构
国家大剧院
小试验: 试验不同纸板的承受压力
2 结构与力
从力学的角度来说,结构是指可承受 一定力的架构形态
结构是为了承受力和抵抗变形,这便 是结构的本质。
每个物体都有它特定的架构形态这种架构 形态体现着它的结构,一个复杂的结构由 许多不同的部分组成,这些组成部分通常 称构件。
自行车轮的结构
F
σ=
S
F是内力,S是受力面 积, σ 是应力,应力是 结构的单位横截面上产 生的内力,当内力达到 某一极限时,结构就会 遭到破坏。
方解石晶体的排列赋予了蛋壳与其作用相称的一个完美的结构,也就是它 能够抗较大的压力,但对于拉力来说相对较弱。这样,如果通过两介凸出 的顶端,对蛋壳施加力,那么鸡蛋抗压力就显得很强,这也是由它们的拱 状结构的力学特性决定的,拱形结构使圆屋顶和拱形物能够承受巨大的重 量。在这种状态下,压力沿拱状结构(也就是沿蛋壁)分布,而不会使结 构断裂。而蛋壳又必须是易碎的,这样雏鸡只用微弱的力就能破壳而出。 雏鸡用嘴向外用力,从蛋壳内部看呈凹形的顶部很容易碎裂,因为它的抗 拉力很弱。
使用者将产品对准歹徒,扣动板机,击发弹点击后,形成巨大的 推动力,将产品前置的捕捉网发射出去,在10米的范围内将歹徒 罩住,使歹徒无法奔跑,且越动网罩越紧。在10米左右的范围内, 对准歹徒发射,张开的巨大网罩能准确地罩住歹徒,成功率高达 98%以上。网为高强度尼龙丝编织而成,具有重量轻、韧性强、 不易损坏等特点,能牢牢地罩住歹徒。
输 型电看塔,覆这冰些垮输塌电,塔给属灾于区(人B民)带来了严重的后果。从结构的类
A.实体结构 B.框架结构 C.壳体结构 D.柱形结构
4.在举办运动会的时候,运动员在单杠上做大回环姿势时,
会使杠体产生( A.拉伸
BB.)弯变曲形。
C.压缩
D.断裂
问答题: 晾衣架通常由曲臂、撑杆和挂钩组成,如图所示。当衣物对 称挂在衣架曲臂上时,请问: (1)晾衣架的挂钩、曲臂、撑杆的受力形式分别是什么?
杠体受力弯曲变形、方向
• 构件:事物的各个组成部分 • 架构:事物的主体框架与构造形式
古老的板凳
椅子
蜂 巢
蜘 蛛 网
恐龙骨骼
人体骨骼
树
应县佛宫寺释迦塔位于山西省朔州市应 县城内西北佛宫寺内,俗称应县木塔。建 于辽清宁二年(公元1056年),金明昌 六年(公元1195年)增修完毕。是我国现 存最高最古的一座木构塔式建筑,也是唯 一一座木结构楼阁式塔,为全国重点文物 保护单位。
结构(Structure)
是指事物的各个组成部分之间的 有序搭配和排列。
本质:是为了承受力和抵抗变形
苍耳子 与尼龙搭扣
植物形态 一年生草本,三角状卵形,边 缘有缺刻或3~5浅裂,有不规则粗锯齿,两 面有粗毛;它的表面布满了许多小刺,每根 刺上都有细细的倒钩,碰到纤维类的衣物, 便粘在上面。花期7~10月,果期8~11月。 生于荒地、山坡等干燥向阳处。分布于全国 各地。
利用矿泉水瓶,你能做出什么东西?
矿泉水瓶小制作
当堂训练当堂达标:
1.下列哪种结构是受自然界事物结构启发而产生的?( B)
A.钢笔
B.潜艇 C.课桌 D.黑板 C
2.分析下列物体的结构类型,属于实体结构的是( )
A.电灯泡 B.乒乓球 C.橡皮擦 D.篮球架
3.2008年1月我国南方遭遇了50年一遇的雪灾,很多灾区的
The Question是reebok为艾弗森设计的第一 双鞋。 整双鞋采用reebok的[Hexalite](
蜂巢)技术,利用独特的六角形几何连接 结构,将受力均匀分散,进行很有效的缓 震。后掌采用一整片蜂巢缓震材料,将鞋 底和侧面完全包裹,增加了稳定性。
“德耳塔7运动”(Delta 7 Sports) 公司在他们推出的Arantix山地自行车 上,典型的质密圆柱管形材料被可通风、可看穿的网格结构所取代。这 种网状结构由碳纤维合成物编织而成,并用凯夫拉尔绳(纤维B)进行捆绑。 虽然这张“蜘蛛网”看起来可能很脆弱,但这种名为“IsoTruss”的碳 纤维合成物强度上却要胜过钢、铝和钛,甚至比质密的的碳合成物还要 坚固——当前的超轻型自行车车架一般都使用这种材料。
木塔位于寺南北中轴线上的山门与大 殿之间,属于“前塔后殿”的布局。塔建 造在四米高的台基上,塔高67.31米,底 层直径30.27米,呈平面八角形。第一层 立面重檐,以上各层均为单檐,共五层六 檐,各层间夹设暗层,实为九层。因底层 为重檐并有回廊,故塔的外观为六层屋檐。 各层均用内、外两圈木柱支撑,每层外有 24根柱子,内有八根,木柱之间使用了许 多斜撑、梁、枋和短柱,组成不同方向的 复梁式木架,整个建筑没用一颗钉子。有 人计算,整个木塔共用红松木料3000立 方,约2600多吨重,整体比例适当,建 筑宏伟,艺术精巧,外形稳重庄严。
案例1
应用
用于不闻香臭、时流浊涕,鼻渊头痛, 外感风寒,恶寒无汗,风寒头痛。本品温 和疏达,味辛散风,苦燥湿浊,通窍止痛, 常配伍辛夷、白芷、薄荷同用,即苍耳子 散。
案例2
人类飞翔的梦想源于展翅高飞的鸟, 鸟因为有它自由流畅的体形和翅膀 结构,飞机原型源于飞鸟形体结构 的仿生。
中国的大飞机在研制中
杠体
立 柱
拉杆
(1)杠体的受力与变形
• 运动员在杠体上做各种动作,如大回环等, 通过握杠体的手,对杠体施加了外力
• 包括人体质量、回转运动产生的离心力
杠体受到的力的方向
• 任意时刻,人对杠体的作用力,其方向,都是从杠 体指向人重心所处的瞬间位置。
• 单摆实验
小球对固定点的作用力,其方向,从固定点指向小 球球心所处的瞬间位置。
(2)现有塑料绳、细电线、细竹竿和木条,哪些材料适合 做晾衣架的撑杆?请从撑杆受力角度简要说明理由。
答: (1) 挂钩的直杆受拉力、曲臂受弯曲力、撑 杆受压力 (2) 因为撑杆受压力,所以细竹杆和木条适 合(能够支撑曲臂的两端)。
鹰眼与导弹跟踪系统
• 鹰可以在几千米的高空准确无误地辨别地面上的 动物,这是因为它的眼部结构比较特殊。人类每 只眼睛的视网膜上都有一个凹槽,叫做中央凹。 而老鹰眼中的中央凹却有两个,这两个中央凹的 作用不同,其中一个专门用于接收来自鹰头侧面 物体的像,另一个用于接收来自鹰头前方物体的 像。这样,老鹰的视觉范围就宽多了,能兼顾前 方和侧面。根据鹰眼的结构,人们正在研制“鹰 眼”导弹系统。这种导弹系统能自动寻找、识别 目标并跟踪攻击