人工智能导论_实验指导
人工智能导论实验报告

人工智能导论实验报告
一、实验要求
实验要求是使用Python实现一个简单的人工智能(AI)程序,包括
使用数据挖掘,机器学习,自然语言处理,语音识别,计算机视觉等技术,通过提供用户输入的信息,实现基于信息的自动响应和推理。
二、实验步骤
1. 数据采集:编写爬虫程序或者使用预先定义的数据集(如movielens)从互联网收集数据;
2. 数据预处理:使用numpy对数据进行标准化处理,以便机器学习
程序能够有效地解析数据;
3. 模型构建:使用scikit-learn或者tensorflow等工具,构建机
器学习模型,从已经采集到的数据中学习规律;
4.模型训练:使用构建完成的模型,开始训练,通过反复调整参数,
使得模型在训练集上的效果达到最优;
5.模型评估:使用构建完成的模型,对测试集进行预测,并与实际结
果进行比较,从而评估模型的效果;
6. 部署:使用flask或者django等web框架,将模型部署为网络应用,从而实现模型的实时响应;
三、实验结果
实验结果表明,使用数据挖掘,机器学习,自然语言处理,语音识别,计算机视觉等技术,可以得到很高的模型预测精度,模型的准确性可以明
显提高。
人工智能导论实验指导书

实验一基本的搜索技术【实验目的】通过运行演示程序,理解深度优先、广度优先、A*算法的原理和运行过程。
【实验内容】1.分别以深度优先、广度优先、A*算法为例演示搜索过程2.观察运行过程记录搜索顺序3.设置不同属性,观察和记录搜索过程的变化4.分析不同算法的特点【实验原理】在知识不完全时,一般不存在成熟的求解算法可以利用,只有利用已有的知识摸索前进,从许多可能的解中寻找真正的解这就是搜索。
即使对于结构性能较好,理论上有算法可依的问题,由于问题本身的复杂性以及计算机在时间、空间上的局限性,往往也需要通过搜索来进行求解。
总的来说搜索策略分为两大类:盲目搜索和启发式搜索一、无信息的搜索策略——盲目搜索在不具有对特定问题的任何有关信息的条件下,按固定的步骤(依次或随即调用操作算子)进行的搜索,它能快速地运用一个操作算子。
盲目搜索中,由于没有可参考的信息,因此只要能匹配的操作算子都须运用,这会搜索更多的状态。
最重要的宽度优先和深度优先是最重要的盲目搜索方法。
1. 宽度优先搜索:从根结点出发,按从低到高的层次顺序搜索,同一层的结点按固定的顺序(例如从左到右、从右到左)搜索。
宽度优先总是先搜索到距离最近的目标结点。
宽度优先搜索不适合用于分支较多的情况。
2. 深度优先搜索:用回溯的思想搜索图。
深度优先搜索适用于分支较多而层次较浅的情况。
二、利用知识引导搜索——启发式搜索盲目搜索复杂度很大,为了提高算法效率,应该具体问题具体分析,利用与问题有关的信息,从中得到启发而来引导搜索,以达到减少搜索量的目的,这就是启发式搜索。
启发信息:(1) 陈述性启发信息:一般被用于更准确、更精炼地描述状态,使问题的状态空间缩小,如待求问题的特定状况等属于此类信息(2) 过程性启发信息:一般被用于构造操作算子,使操作算子少而精如一些规律性知识等属于此类信息(3) 控制性启发信息:如何选择操作算子控制性启发信息往往被反映在估价函数之中。
估价函数的任务就是估计待搜索结点的“有希望”程度(或者说估计操作算子的“性能”),并依此给它们排定次序。
哈工大人工智能导论实验报告

人工智能导论实验报告学院:计算机科学与技术学院专业:计算机科学与技术2016.12.20目录人工智能导论实验报告 (1)一、简介(对该实验背景,方法以及目的的理解) (3)1. 实验背景 (3)2. 实验方法 (3)3. 实验目的 (3)二、方法(对每个问题的分析及解决问题的方法) (4)Q1: Depth First Search (4)Q2: Breadth First Search (4)Q3: Uniform Cost Search (5)Q4: A* Search (6)Q5: Corners Problem: Representation (6)Q6: Corners Problem: Heuristic (6)Q7: Eating All The Dots: Heuristic (7)Q8: Suboptimal Search (7)三、实验结果(解决每个问题的结果) (7)Q1: Depth First Search (7)Q2: Breadth First Search (9)Q3: Uniform Cost Search (10)Q4: A* Search (12)Q5: Corners Problem: Representation (13)Q6: Corners Problem: Heuristic (14)Q7: Eating All The Dots: Heuristic (14)Q8: Suboptimal Search (15)自动评分 (15)四、总结及讨论(对该实验的总结以及任何该实验的启发) (15)一、简介(对该实验背景,方法以及目的的理解)1.实验背景1) 自人工智能概念被提出,人工智能的发展就受到了很大的关注,取得了长足的发展,成为一门广泛的交叉和前沿科学。
到目前,弱人工智能取得了长足的发展,而强人工智能则暂时处于瓶颈。
2)吃豆人Pacman 居住在亮蓝色的世界里,在这个世界有弯曲的走廊和美味佳肴。
人工智能导论实验报告模板

《人工智能导论》上机实验八数码问题求解专业班级:姓名:学号:指导教师:基于人工智能的状态空间搜索策略研究——八数码问题求解一、实验软件VC6.0编程语言或其它编程语言二、实验目的1. 熟悉人工智能系统中的问题求解过程;2. 熟悉状态空间的盲目搜索和启发式搜索算法的应用;3. 熟悉对八数码问题的建模、求解及编程语言的应用。
三、需要的预备知识1. 熟悉VC6.0 编程语言;2. 熟悉状态空间的宽度优先搜索、深度优先搜索和启发式搜索算法;3. 熟悉计算机语言对常用数据结构如链表、队列等的描述应用;4. 熟悉计算机常用人机接口设计。
四、实验数据及步骤1. 实验内容八数码问题:在3×3的方格棋盘上,摆放着1到8这八个数码,有1个方格是空的,其初始状态如图1所示,要求对空格执行空格左移、空格右移、空格上移和空格下移这四个操作使得棋盘从初始状态到目标状态。
例如:2 5 4 1 2 33 7 8 41 8 6 7 6 5(a) 初始状态 (b) 目标状态图1 八数码问题示意图请任选一种盲目搜索算法(深度优先搜索或宽度优先搜索)或任选一种启发式搜索方法(A 算法或A* 算法)编程求解八数码问题(初始状态任选),并对实验结果进行分析,得出合理的结论。
2. 实验步骤(1)分析算法基本原理和基本流程;(2)确定对问题描述的基本数据结构,如Open表和Closed表等;(3)编写算符运算、目标比较等函数;(4)编写输入、输出接口;(5)全部模块联调;(6)撰写实验报告。
五、实验报告要求所撰写的实验报告必须包含以下内容:1. 算法基本原理和流程框图;2. 基本数据结构分析和实现;3. 编写程序的各个子模块,按模块编写文档,含每个模块的建立时间、功能、输入输出参数意义和与其它模块联系等;4. 程序运行结果,含使用的搜索算法及搜索路径等;5. 实验结果分析;6. 结论;7. 提供全部源程序及软件的可执行程序。
六、操作实现该设计采用启发式搜索方法编写程序。
人工智能导论_实验指导

《人工智能导论》实验指导实验一Prolog平台使用实验二状态空间搜索:传教士与野人问题求解实验三启发式搜索算法:斑马属谁问题求解实验四小型专家系统设计与实现实验报告的基本内容和书写格式——————————————————————————————————一、实验目的二、实验内容三、实验步骤四、实验结果1. 系统名称〈所做系统的名称〉2. 系统概述(包括所做系统的背景和主要功能等。
)3.系统运行演示过程(1) 输入的初始事实或数据:(2) 系统运行时产生的推理树(网):(3) 输出的结果:——————————————————————————————————《人工智能导论》实验一Prolog平台使用实验目的:熟悉Prolog(包括SWI-Prolog平台、Turbo-Prolog平台),包括编辑器、编译器及其执行模式;熟悉Prolog语法、数据结构和推理机制;熟悉SWI-Prolog平台与Visual C++结合开发应用程序。
实验环境(硬/软件要求):硬件:计算机一台软件:SWI-Prolog、Turbo Prolog、SWI-Prolog-Editor、Visual C++、Eclipse实验内容:1.Prolog平台界面和基本操作;2.熟悉Prolog语法和数据结构;3.熟悉Eclipse PDT插件安装、使用;4.编写简单Prolog程序并测试(输入动物叫声、输出该动物名称);5.熟悉Prolog平台与Visual C++结合开发应用程序;实验主要步骤:1.打开SWI-Prolog平台,熟悉SWIPrologEditor,熟悉操作界面;2.实现Prolog基本语句;3.编写简单Prolog程序并测试(输入动物叫声、输出该动物名称);示例程序(Turbo Prolog)逻辑电路模拟程序。
该程序以逻辑运算“与”、“或”、“非”的定义为基本事实,然后在此基础上定义了“异或”运算。
那么,利用这些运算就可以对“与”、“或”、“非”和“异或”等逻辑电路进行模拟。
《人工智能》实 验 指 导

《人工智能导论》课程实验大纲实验学时:8 课程总学时:46适用专业:计算机科学与技术、软件工程实验项目数:1开课教研室(系):计算机工程大纲执笔人:廉师友一、课程实验的基本理论和目的《人工智能导论》课程主要讲述搜索与问题求解、知识表示与推理、机器学习与知识发现、专家系统、Agent系统、智能化网络和智能程序设计等。
其中专家系统及其设计与实现,涉及该课程的大部分内容,如知识表示与推理、搜索与问题求解、专家系统和智能程序设计等,而且实践性和应用性都很强。
因此,该课程将专家系统设计与实现作为一个上机实验项目,以加深学生对课程内容的理解和掌握,并培养学生综合运用所学知识开发智能系统的初步能力和独立分析问题、解决问题的能力。
二、课程实验的基本要求1.实验前,要认真阅读实验指导书,明确实验目的、内容、方法、步骤和目标;2.自选具体的应用领域,白拟具体的系统名称,但内容绝对不能雷同;3.所实现的专家系统必须上机运行演示;4.提交实验报告。
三、实验项目的设置、内容和学时分配实验项目:1个实验题目:小型专家系统设计与实现(具体应用领域由学生自选,具体系统名称由学生自定。
)实验内容:知识获取与表示、知识库组建、推理机选择/编制、系统调试与测试。
实验学时:8学时四、实验课的考核方法与评分办法采用实验过程考查、实验结果验收和实验报告评阅相结合的考核方法,综合评定实验成绩。
其具体评分标准如下:1.实验准备(所需数据、程序、图形等)20分;2.实验过程(态度、操作、处理问题能力等)20分;3.实验结果(正确性、可用性、创新性等)40分;4.实验报告(格式、内容(翔实、无误)、叙述等)20分;满分共计100分。
审定人: 批准人:。
人工智能导论实验报告

人工智能导论实验报告人工智能导论实验报告一、实验目的本实验旨在通过实际操作,加深对人工智能导论中基本概念和算法的理解,培养我们的实践能力和解决问题的能力。
二、实验原理在人工智能导论中,我们学习了机器学习、深度学习、自然语言处理等重要概念和算法。
本实验将通过应用这些算法,实现对特定数据集的分类、预测和生成等任务。
三、实验步骤1.数据准备:选择合适的数据集,进行预处理和特征工程。
在本实验中,我们选择了经典的MNIST手写数字数据集。
2.模型训练:根据所选择的算法和数据集,构建并训练模型。
本实验中,我们采用了深度学习中的卷积神经网络(CNN)算法进行图像分类。
3.模型评估:使用测试集对模型进行评估,计算准确率、精度等指标。
4.模型优化:根据评估结果,对模型进行优化调整,提高性能。
5.应用扩展:将优化后的模型应用于实际场景中,实现分类、预测等功能。
四、实验结果与分析1.实验结果经过训练和优化,我们在MNIST数据集上达到了95%的准确率,取得了较好的分类效果。
2.结果分析通过对比不同模型结构和参数的实验结果,我们发现以下几点对模型性能影响较大:(1)数据预处理:合适的预处理方法能够提高模型的分类性能。
例如,对手写数字图像进行灰度化和归一化处理后,模型的分类准确率得到了显著提升。
(2)模型结构:在本实验中,我们采用了卷积神经网络(CNN)算法。
通过调整CNN的层数、卷积核大小和池化参数等,可以显著影响模型的分类性能。
(3)优化算法:选择合适的优化算法能够提高模型的训练效果。
我们采用了梯度下降法进行优化,并比较了不同的学习率和优化策略对模型性能的影响。
(4)特征工程:虽然MNIST数据集较为简单,但适当的特征工程仍然可以提高模型的性能。
例如,我们尝试了不同的图像尺寸和归一化方法,发现它们对模型的分类性能具有一定影响。
五、结论与展望通过本次实验,我们深入了解了人工智能导论中的基本概念和算法,并成功应用到了MNIST手写数字分类任务中。
人工智能导论实验报告

院系:计算机科学学院
专业:计算机科学与技术
年级: 2012级
课程名称:人工智能
学号: ********** *名:***
****:**
2014年 6月 24 日
实验结果分析及心得体会实验截图1、A算法:
2、A*算法:
实验截图
实
验
结
果
分
析
及
心
得
体
会
心得体会
本实验利用广度优先搜索找出所有可能解,进一步加深了我对该算法的理解。
成
绩
评
教师签名:
定
2014年月日
实验截图
实
验
结
果
分
析
及
心
得
体
会
心得体会
在遗传算法中,种群内进行交配、变异、选择,从而产生最优解。
该实验加深了我对遗传算法的理解和体会,进一步了解了它的用途和好处。
成
绩
评
教师签名:
定
2014年月日。
《人工智能导论》实验指导书(新)

目录实验一 PROLOG语言编程练习 (2)实验二图搜索问题求解 (4)实验三小型专家系统(原型)设计 (7)实验一 PROLOG语言编程练习一、实验目的加深学生对逻辑程序运行机理的理解,使学生掌握PROLOG语言的特点、熟悉其编程环境,同时为后面的人工智能程序设计做好准备。
1、熟悉PROLOG语言编程环境的使用;2、了解PROLOG语言中常量、变量的表示方法;3、了解利用PROLOG进行事实库、规则库的编写方法;二、实验环境计算机,Turbo PROLOG教学软件。
三、预习要求实验前应阅读实验指导书,了解实验目的、预习PROLOG语言的相关知识。
四、实验内容1、学习使用Turbo PROLOG,包括进入PROLOG主程序、编辑源程序、修改环境目录、退出等基本操作。
2、在Turbo prolog集成环境下调试运行简单的Turbo PROLOG程序,如描述亲属关系的PROLOG程序或其他小型演绎数据库程序等。
五、实验方法和步骤1、启动Windows XP操作环境。
2、打开文件目录,执行prolog应用程序,启动Turbo prolog,并按空格键(SPACE)进入集成开发环境。
3、选择Setup项,打开下拉菜单,选择Directories项,进行工作目录修改,按Esc键退出,选择Save Configuration项,保存修改。
4、选择Files项,打开下拉菜单,选择New file项,进入源程序输入和编辑,或选择Load项,选择要打开的示例程序,再选择Edit项,可以进行编辑源程序。
5、编辑之后,可以选择Run项,执行程序,可以在Dialog窗口进行询问,即外部目标的执行,查看程序运行结果,分析程序之功能。
6、仿前例,可以选择其他程序并运行,分析程序功能。
7、退出,选择Quit项,可以退出Turbo Prolog程序,返回到Windows XP环境。
六、示例程序逻辑电路模拟程序。
该程序以逻辑运算“与”、“或”、“非”的定义为基本事实,然后在此基础上定义了“异或”运算。
人工智能导论实验指导书

实验一 感知器的MATLAB 仿真感知器(Pereceptron)是一种特殊的神经网络模型,是由美国心理学家F.Rosenblatt 于1958年提出的,一层为输入层,另一层具有计算单元,感知器特别适合于简单的模式分类问题,也可用于基于模式分类的学习控制和多模态控制中。
一、感知器神经元模型感知器神经元通过对权值的训练,可以使感知器神经元的输出能代表对输入模式进行的分类,图1.1为感知器神经元模型。
图1.1 感知器神经元模型感知器神经元的每一个输入都对应于一个合适的权值,所有的输入与其对应权值的加权和作为阀值函数的输入。
由于阀值函数的引入,从而使得感知器可以将输入向量分为两个区域,通常阀函数采用双极阶跃函数,如:⎩⎨⎧<≥=0,00,1)(x x x f (1.1) 而感知器神经元模型的实际输出为⎪⎭⎫⎝⎛-=∑-=R i i i b x w f o 1 (1.2)其中b 为阀值二、感知器的网络结构图1.2所描述的是一个简单的感知器网络结构,输入层有R 个输入,Q 个输出,通过权值w ij 与s 个感知器神经元连接组成的感知器神经网络。
根据网络结构,可以写出感知器处理单元对其输入的加权和操作,即:∑==Rj j ij i p w n 1(1.3)而其输出a i 为a i =f (n i +b i ) (1.4)由式2.1易知⎩⎨⎧<+≥+=0001i i i i i b n b n a (1.5) 则当输入n i +b i 大于等于0,即有n i ≥-b i 时,感知器的输出为1;否则输出为0。
上面所述的单层感知器神经网络是不可能解决线性不可分的输入向量分类问题,也不能推广到一般的前向网络中去。
为解决这一问题,我们可以设计多层感知器神经网络以实现任意形状的划分。
图1.3描述了一个双层感知器神经网络。
其工作方式与单层感知器网络一样,只不过是增加了一层而已,具体的内容这里不做讨论。
三、感知器神经网络的学习规则感知器的学习规则主要是通过调整网络层的权值和阀值以便能够地网络的输入向量进行正确的分类。
人工智能实验指导书+作业展示

《人工智能技术导论》实验指导书西北工业大学计算机学院目录一实验纲要 (1)二上机要求 (2)三实验内容 (3)实验一图搜索与问题求解 (3)实验1.1 启发式搜索 (3)实验1.2 A*算法搜索 (9)实验1.3 其他应用问题 (12)实验二产生式系统推理 (14)实验三TSP问题的遗传算法实现 (20)四实验报告模板 (27)人工智能实验一实验报告 (27)人工智能实验二实验报告 (28)人工智能实验三实验报告 (29)附件1 TSP问题的遗传算法程序模板 (30)附件2 学生作业作品展示 (35)一实验纲要一实验教学的目的、任务与要求将人工智能基础理论应用于实际问题的解决当中,加深学生对所学知识的理解,提高学生的实际动手能力。
二实验项目内容1图搜索策略实验用启发式搜索方法/A*算法求解重排九宫问题/八数码问题。
2产生式系统的推理以动物识别系统为例,实现基于产生式规则的推理系统。
3 TSP问题的遗传算法实现以N个结点的TSP问题为例,用遗传算法加以求解。
三参考教材人工智能技术导论-第3版,廉师友编著,西安电子科技大学出版社,2007。
四使用主要仪器设备说明在Windows2000/XP上,选用Java/C/C++/Matlab等语言进行实现。
五实验考核实验为12学时,分4次课完成。
每个实验题目在课堂上分别按百分制给出。
其中包括课堂纪律、程序运行结果、课堂回答问题及实验报告成绩等。
实验课总成绩为3个实验题目的平均成绩。
实验课要求学生提前预习,上课时需向辅导老师提交预习报告,报告格式和内容不作过多要求,只需简要说明自己本次实验的大体思想。
预习报告形式不限,电子版或手写版均可。
1 考核方法由各班辅导老师当堂检查源程序和运行结果,并提问相关问题,课堂上给出成绩并记录。
每个题目完成后把源代码和实验报告提交,由辅导老师检查实验报告并给出报告成绩。
2 评分标准每个实验题目根据以下标准进行考核:1)考勤分20分。
922252-人工智能导论第4版试验参考程序-2模糊推理系统实验要求

实验二 模糊推理系统实验一、实验目的:理解模糊逻辑推理的原理及特点,熟练应用模糊推理,了解可能性理论。
二、实验原理模糊推理所处理的事物自身是模糊的,概念本身没有明确的外延,一个对象是否符合这个概念难以明确地确定模糊推理是对这种不确定性,即模糊性的表示与处理。
模糊逻辑推理是基于模糊性知识(模糊规则)的一种近似推理,一般采用Zadeh 提出的语言变量、语言值、模糊集和模糊关系合成的方法进行推理。
三、实验条件:Matlab 7.0 的Fuzzy Logic Tool 。
四、实验内容:1.设计洗衣机洗涤时间的模糊控制。
已知人的操作经验为:“污泥越多,油脂越多,洗涤时间越长”;“污泥适中,油脂适中,洗涤时间适中”;“污泥越少,油脂越少,洗涤时间越短”。
要求:(1)设计相应的模糊控制器,给出输入、输出语言变量的隶属函数图,模糊控制规则表和推论结果立体图。
(2)假定当前传感器测得的信息为00(60,70x y ==污泥)(油脂),采用面积重心法反模糊化,给出模糊推理结果,并观察模糊控制的动态仿真环境,给出模糊控制器的动态仿真环境图。
提示:模糊控制规则如图4-1。
其中SD (污泥少)、MD (污泥中)、LD (污泥多)、NG (油脂少)、MG (油脂中)、LG (油脂多)、VS (洗涤时间很短)、S (洗涤时间短)、M (洗涤时间中等)、L (洗涤时间长)、VL (洗涤时间很长)。
2.假设两汽车均为理想状态,即2Y()4U()20.724s s s s =+⨯⨯+,Y 为速度,U 为油门控制输入。
(1)设计模糊控制器控制汽车由静止启动,追赶200m 外时速90km 的汽车并与其保持30m 的距离。
(2)在25时刻前车速度改为时速110km 时,仍与其保持30m 距离。
(3)在35时刻前车速度改为时速70km 时,仍与其保持30m 距离。
要求:(1)设计两输入一输出的模糊控制器,给出输入、输出语言变量的隶属函数图,模糊控制规则表,推论结果立体图。
人工智能导论实验

人工智能导论实验报告姓名:蔡鹏学号:1130310726实验一一、实验内容有如下序列,试把所有黑色格移到所有白色格的右边,黄色格代表空格,黑色格和白色格可以和距离不超过三的空格交换。
二、实验代码#include <iostream>#include <stdlib.h>#include <stdio.h>#define N 10#define inf 9999int g=999;void tree_gener(struct node *fn,struct node *root);struct node{char seq[7];int f,g,n;struct node *sn[N];};struct stack{int num;struct node *n[50];};void Enstack(struct node *sn,struct stack *S){S->n[S->num]=sn;S->num++;}struct node *Destack(struct stack *S){S->num--;return S->n[S->num];}void find_min_f(struct node *root){int i;struct node *n,*min;struct stack S;S.num=0;min=root;Enstack(root,&S);while(S.num!=0){n=Destack(&S);if(n->f < min->f){min=n;}for(i=0;i<n->n;i++){Enstack(n->sn[i],&S);}}tree_gener(min,root);if(g>min->g){printf("seq:%c %c %c %c %c %c %c | g:%d \n",min->seq[0],min->seq[1],min->seq[2],min->seq[3],min->seq[4],min->seq[5],min->seq[6],min->g);}g=min->g;}void swap(struct node *sn,struct node *fn,int n,int m){int i;for(i=0;i<7;i++){sn->seq[i]=fn->seq[i];}sn->seq[n]=fn->seq[m];sn->seq[m]=fn->seq[n];}int calcu_h(char seq[]){int m=0,n=0,i;for(i=0;i<7;i++){if(seq[i]=='B'){m++;}if(seq[i]=='W'){n=n+m;}}return n;}void tree_gener(struct node *fn,struct node *root){if (calcu_h(fn->seq)!=0){int i;int j=0,k;for (i=0;i<7;i++){if(fn->seq[i]=='#'){for(k=1;k<=3;k++){if(i+k<7){fn->sn[j]=(struct node *)malloc(sizeof(struct node));swap(fn->sn[j],fn,i,i+k);fn->sn[j]->g = fn->g+k;fn->sn[j]->f = fn->sn[j]->g + 3*calcu_h(fn->sn[j]->seq);fn->sn[j]->n=0;j++;}if(i-k>=0){fn->sn[j]=(struct node *)malloc(sizeof(struct node));swap(fn->sn[j],fn,i,i-k);fn->sn[j]->g = fn->g+k;fn->sn[j]->f = fn->sn[j]->g + 3*calcu_h(fn->sn[j]->seq);fn->sn[j]->n=0;j++;}}}}fn->n=j;fn->f=inf;find_min_f(root);}}int main() {struct node *root;printf("seq:每一次选择的f最小的序列\ng:当前节点已花费的代价\nf:预计花费和已花费的代价的和。
人工智能导论综合设计实验
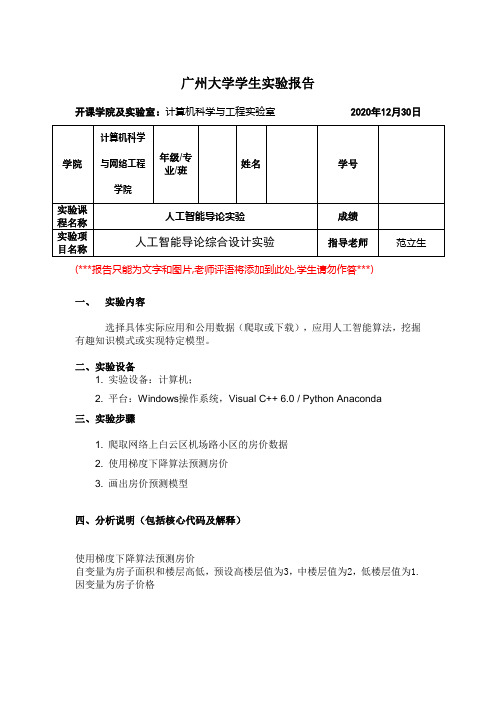
广州大学学生实验报告开课学院及实验室:计算机科学与工程实验室 2020年12月30日(***报告只能为文字和图片,老师评语将添加到此处,学生请勿作答***)一、实验内容选择具体实际应用和公用数据(爬取或下载),应用人工智能算法,挖掘有趣知识模式或实现特定模型。
二、实验设备1. 实验设备:计算机;2. 平台:Windows操作系统,Visual C++ 6.0 / Python Anaconda三、实验步骤1. 爬取网络上白云区机场路小区的房价数据2. 使用梯度下降算法预测房价3. 画出房价预测模型四、分析说明(包括核心代码及解释)使用梯度下降算法预测房价自变量为房子面积和楼层高低,预设高楼层值为3,中楼层值为2,低楼层值为1. 因变量为房子价格将爬取的数据进行数据清洗后可得第一行数据为房子面积第二行数据为楼层高低,第三行为房子价格源代码:##多特征线性回归的房价预测import numpy as npfrom matplotlib import pyplot as pltnp.set_printoptions(suppress=True) # 禁止科学计数法plt.rcParams['font.sans-serif'] = ['SimHei'] # 允许画图中中文出现plt.rcParams['axes.unicode_minus'] = False # 解决画图中出现负数刻度显示异常的情况itersNum = 1000 # 迭代次数learnRate = 0.01 # 学习率# 1、首先读取文件中的数据def loadFile(path):return np.loadtxt(path, dtype=np.float64, delimiter=',')# 2、定义一个线性回归函数def linerRegression():data = loadFile('baiyun_jichanglu_clean.csv') # 读取文件数据x_data = np.array(data[:, 0:-1])y_data = np.array(data[:, -1]).reshape(-1, 1)x_data = meanNormalization(x_data)plotMeanNormalization(x_data)x_data = np.hstack((np.ones((len(y_data), 1)), x_data)) # 插入一列为1的数组colNmus = x_data.shape[1] # 计算出行数,以便确定所求参数个数theta = np.zeros((colNmus, 1)) # 构建一个参数向量theta, costAll = gradientDescent(x_data, y_data, theta)plotCostCurve(costAll)plotLinearRegression(x_data, theta, y_data)return theta# 3、均值归一化函数def meanNormalization(x_data):columnsMean = np.mean(x_data, 0) # 求出每一列的均值,0表示求列的均值,1表示求行的均值columnsStd = np.std(x_data, 0) # 求出每一类的标准差,0表示求列的标准差,1表示求行的标准差for i in range(x_data.shape[1]): # 归一化每一列的中的值减去均值,然后除去标准差shape[0]输出行数,shape[1]输出列数x_data[:, i] = (x_data[:, i] - columnsMean[i]) / columnsStd[i] return x_data# 4、显示均值归一化的效果,也就是散点图def plotMeanNormalization(x_data):plt.scatter(x_data[:, 0], x_data[:, 1])plt.title('数据均值归一化效果')plt.savefig('均值归一化效果.png') # 保存拟合图片plt.show()# 5、核心算法,开始进行迭代,进行梯度下降def gradientDescent(x_data, y_data, theta):theta_num = len(theta)theta_temp = np.matrix(np.zeros((theta_num, itersNum))) # 为了同步更新权重用,保存每一次迭代的结果costAll = np.zeros((itersNum, 1)) # 保存代价for i in range(itersNum):hypothesis = np.dot(x_data, theta)theta_temp[:, i] = theta - (learnRate / len(y_data)) *(np.dot(np.transpose(x_data), hypothesis - y_data))theta = theta_temp[:, i]costAll[i] = costFunction(x_data, y_data, theta)return theta, costAll# 6、计算代价函数def costFunction(x_data, y_data, theta):return np.sum(np.power(np.dot(x_data, theta) - y_data, 2)) / (2 *len(y_data))# 7、为了检验算法能否正确执行,现在将代价以图像的形式展现出来def plotCostCurve(costAll):x = np.arange(0, itersNum)plt.plot(x, costAll)plt.xlabel('迭代次数')plt.ylabel('代价值')plt.title('代价随迭代次数变化曲线')plt.savefig('CostCurve.png')plt.show()# 8、将拟合的过程以3D立体图像形式展现出来def plotLinearRegression(x_data, theta, y_data):plt.figure(figsize=(8, 10))x = x_data[:, 1]y = x_data[:, 2]theta = theta.flatten()z = theta[0, 0] + (theta[0, 1] * x) + (theta[0, 2] * y)ax = plt.subplot(211, projection='3d')ax.plot_trisurf(x, y, z)ax.scatter(x_data[:, 1], x_data[:, 2], y_data, label='实际数据') ax.set_xlabel('房屋大小')ax.set_ylabel('楼层')ax.set_zlabel('价格')plt.savefig('3d拟合theta值.png')plt.show()print(linerRegression()) # 执行算法.模型图:五、总结心得通过这次实验,我学会了如何使用梯度下降算法来预测房价,以及爬取数据和数据清洗。
人工智能实验指导书-1

人工智能导论实验指导一、实验整体要求(包括进度、实验预习和报告要求、结果形式、考核等)共分两个实验,12学时内完成,每次3学时,共4次上机。
每个实验相当于一个大作业,锻炼学生运用知识解决实际问题的能力,对所学知识有更深刻的理解。
要求提交源代码,运行结果和相关文档(包括核心算法)。
由实验老师逐一检查考核,占考试成绩的20%。
二、(有关说明:软/硬环境、实验基本方法、调试和测试工具的使用等)在Windows2000/XP环境下,语言可以采用C/C++/JAVA/Matlab等。
实验室提供相关软件可由学生根据需要安装。
三、实验内容实验_图搜索策略1.实验目的(说明本次实验应对那些知识达到何种认知程度,如了解/掌握)(1)加深对各种图搜索策略概念的理解;(2)进一步了解启发式搜索;(3)比较并分析各种图搜索策略的异同°2.实验预习内容(1)了解重排九宫问题、一字棋游戏、八皇后问题;(2)各种图搜索算法及剪枝技术等。
3.实验内容和步骤结合第二章内容,以一字棋游戏,八皇后问题,重排九宫问题等为例,分组编程演示其搜索策略.题目:b 以重排九宫问题为例演示各种搜索策略的搜索过程,要求程序具有一定的普适性,重点是要把算法描述清楚。
6学时2,对博弈感兴趣的同学可选做一字棋游戏的实现。
4.实验总结及思考总结出各种搜索策略的特点和区别。
实验二产生式系统的推理1.实验目的(说明本次实验应对那些知识达到何种认知程度,如了解、掌握等)理解并掌握基于规则系统的表示与推理。
2.实验预习内容第五章产生式系统3.实验内容和步骤1.内容:结合第五章内容,以动物识别系统(或货物袋装系统)为例,实现基于规则的系统构造实验.6学时。
2.要求:1)根据输入的规则,正确地识别所能识别的动物。
2)能完成正向和/或反向推理我们假设计算机的视觉系统可以识别毛发、羽毛、奶、犬齿、爪、蹄、颜色等等基本的事实。
一个动物识别专家系统的产生式如下:R1:若某动物有奶,则它是哺乳动物。
人工智能 实验指导

《人工智能》课程实验指导书课程代码:H0404X课程编号:09120042适用对象:计算机科学与技术专业指导教师:肖晓明魏世勇实验内容实验一产生式系统实验实验二移动机器人的路径规划与行为决策实验实验三梵塔问题实验实验四 A*算法实验实验五化为子句集的九步法实验实验六子句消解实验实验七模糊假言推理器实验实验八 BP网络实验实验九贝叶斯网络实验实验一产生式系统实验(必修,2学时)一、实验目的:熟悉和掌握产生式系统的运行机制,掌握基于规则推理的基本方法。
二、实验原理产生式系统用来描述若干个不同的以一个基本概念为基础的系统,这个基本概念就是产生式规则或产生式条件和操作对。
在产生式系统中,论域的知识分为两部分:用事实表示静态知识;用产生式规则表示推理过程和行为。
三、实验条件:1.产生式系统实验程序。
2.IE5.0以上,可以上Internet。
四、实验内容:1.对已有的产生式系统(默认的例子)进行演示,同时可以更改其规则库或(和)事实库,进行正反向推理,了解其推理过程和机制。
2.自己建造产生式系统(包括规则库和事实库),然后进行推理,即可以自己输入任何的规则和事实,并基于这种规则和事实进行推理。
这为学生亲手建造产生式系统并进行推理提供了一种有效的实验环境。
五、实验步骤:1.定义变量,包括变量名和变量的值。
2.建立规则库,其方法是,(a) 输入规则的条件:每条规则至少有一个条件和一个结论,选择变量名,输入条件(符号);选择变量值,按确定按钮就完成了一条条件的输入。
重复操作,可输入多条条件;(b) 输入规则的结论:输入完规则的条件后,就可以输入规则的结论了,每条规则必须也只能有一个结论。
选择变量名,输入条件(符号),选择变量值,按确定按钮就完成了一个结论的输入。
重复以上两步,完成整个规则库的建立。
3.建立事实库(总数据库):建立过程同步骤2。
重复操作,可输入多条事实。
4.然后按“开始”或“单步”按钮即可。
此外,利用实例演示,可以运行系统默认的产生式系统,并且可以进行正反向推理。
哈工大人工智能导论实验报告

)(人工智能导论实验报告学院:计算机科学与技术学院专业:计算机科学与技术*!目录人工智能导论实验报告 (1)一、简介(对该实验背景,方法以及目的的理解) (3)1. 实验背景 (3)2. 实验方法 (3)3. 实验目的 (3)二、方法(对每个问题的分析及解决问题的方法) (4).Q1: Depth First Search (4)Q2: Breadth First Search (4)Q3: Uniform Cost Search (5)Q4: A* Search (6)Q5: Corners Problem: Representation (6)Q6: Corners Problem: Heuristic (6)Q7: Eating All The Dots: Heuristic (7)Q8: Suboptimal Search (7)/三、实验结果(解决每个问题的结果) (7)Q1: Depth First Search (7)Q2: Breadth First Search (9)Q3: Uniform Cost Search (10)Q4: A* Search (12)Q5: Corners Problem: Representation (13)Q6: Corners Problem: Heuristic (14)Q7: Eating All The Dots: Heuristic (14)《Q8: Suboptimal Search (15)自动评分 (15)四、总结及讨论(对该实验的总结以及任何该实验的启发) (15)一、简介(对该实验背景,方法以及目的的理解)1.实验背景1)自人工智能概念被提出,人工智能的发展就受到了很大的关注,取得了长足的发展,成为一门广泛的交叉和前沿科学。
到目前,弱人工智能取得了长足的发展,而强人工智能则暂时处于瓶颈。
2)吃豆人Pacman 居住在亮蓝色的世界里,在这个世界有弯曲的走廊和美味佳肴。