编译原理-词法分析
编译原理词法分析与语法分析的核心算法

编译原理词法分析与语法分析的核心算法编译原理是计算机科学与技术领域中的一门重要课程。
在编程中,我们常常需要将高级语言编写的程序翻译成机器语言,使计算机能够理解并执行我们编写的程序。
而编译原理中的词法分析和语法分析是编译器的两个核心算法。
一、词法分析词法分析是编译器的第一个阶段,它负责将输入的字符序列(源代码)划分为一个个的有意义的词素(Token),并生成相应的词法单元(Lexeme)。
词法分析的核心算法主要包括以下两个步骤:1. 正则表达式到有限自动机的转换:正则表达式是一种描述字符串匹配模式的表达式,它可以用来描述词法分析中各种词素的规则。
而有限自动机则是一种用来识别或匹配正则表达式所描述的模式的计算模型。
将正则表达式转换为有限自动机是词法分析的关键步骤之一。
2. 词法分析器的生成:在将正则表达式转换为有限自动机后,我们可以使用生成器工具(如Lex、Flex等)来生成词法分析器。
词法分析器可以按照预定的规则扫描源代码,并将识别出的词素转换成相应的词法单元,供后续的语法分析使用。
二、语法分析语法分析是编译器的第二个阶段,它负责分析和处理词法分析阶段生成的词法单元序列,并根据预定的语法规则确定语法正确的序列。
语法分析的核心算法主要包括以下两个步骤:1. 上下文无关文法的定义:上下文无关文法(Context-Free Grammar,简称CFG)是一种用于描述形式语言的文法。
它由一组产生式和终结符号组成,可以用于描述语法分析中的语法规则。
在语法分析中,我们需要根据具体编程语言的语法规则,编写相应的上下文无关文法。
2. 语法分析器的生成:通过使用生成器工具(如Yacc、Bison等),我们可以根据上下文无关文法生成语法分析器。
语法分析器可以根据预先定义的文法规则,对词法单元序列进行分析,并构建出语法树(Parse Tree)供后续的语义分析和代码生成使用。
综上所述,词法分析与语法分析是编译原理中的两个重要阶段,也是实现编译器的核心算法。
编译原理中的词法分析与语法分析原理解析

编译原理中的词法分析与语法分析原理解析编译原理中的词法分析和语法分析是编译器中两个基本阶段的解析过程。
词法分析(Lexical Analysis)是将源代码按照语法规则拆解成一个个的词法单元(Token)的过程。
词法单元是代码中的最小语义单位,如标识符、关键字、运算符、常数等。
词法分析器会从源代码中读取字符流,将字符流转换为具有词法单元类型和属性值的Token序列输出。
词法分析过程中可能会遇到不合法的字符序列,此时会产生词法错误。
语法分析(Syntax Analysis)是对词法单元序列进行语法分析的过程。
语法分析器会根据语法规则,将词法单元序列转换为对应的抽象语法树(Abstract Syntax Tree,AST)。
语法规则用于描述代码的结构和组织方式,如变量声明、函数定义、控制流结构等。
语法分析的过程中,语法分析器会检查代码中的语法错误,例如语法不匹配、缺失分号等。
词法分析和语法分析是编译器的前端部分,也是编译器的基础。
词法分析和语法分析的正确性对于后续的优化和代码生成阶段至关重要。
拓展部分:除了词法分析和语法分析,编译原理中还有其他重要的解析过程,例如语义分析、语法制导翻译、中间代码生成等。
语义分析(Semantic Analysis)是对代码进行语义检查的过程。
语义分析器会根据语言的语义规则检查代码中的语义错误,例如类型不匹配、变量声明未使用等。
语义分析还会进行符号表的构建,维护变量和函数的属性信息。
语法制导翻译(Syntax-Directed Translation)是在语法分析的过程中进行语义处理的一种技术。
通过在语法规则中嵌入语义动作(Semantic Action),语法制导翻译可在语法分析的同时进行语义处理,例如求解表达式的值、生成目标代码等。
中间代码生成(Intermediate Code Generation)是将高级语言源代码转换为中间表示形式的过程。
中间代码是一种抽象的表示形式,可以是三地址码、四元式等形式。
编译原理实验一词法分析

编译原理实验⼀词法分析实验⼀词法分析【实验⽬的】 (1)熟悉词法分析器的基本功能和设计⽅法; (2)掌握状态转换图及其实现; (3)掌握编写简单的词法分析器⽅法。
【实验内容】 对⼀个简单语⾔的⼦集编制⼀个⼀遍扫描的词法分析程序。
【实验要求】 (1)待分析的简单语⾔的词法 1) 关键字 begin if then while do end 2) 运算符和界符 := + - * / < <= <> > >= = ; ( ) # 3) 其他单词是标识符(ID)和整形常数(NUM),通过以下正规式定义: ID=letter(letter|digit)* NUM=digitdigit* 4) 空格由空⽩、制表符和换⾏符组成。
空格⼀般⽤来分隔 ID、NUM、运算符、界符和关键字,词法分析阶段通常被忽略。
(2)各种单词符号对应的种别编码 (3)词法分析程序的功能 输⼊:所给⽂法的源程序字符串 输出:⼆元组(syn,token 或 sum)构成的序列。
syn 为单词种别码; token 为存放的单词⾃⾝字符串; sum 为整形常数。
【实验代码】1 #include<iostream>2 #include<string.h>3 #include<conio.h>4 #include<ctype.h>5using namespace std;6int sum,syn,p,m,n;7char ch,chs[8],s[100];8char *tab[6]={"begin","if","then","while","do","end"};910int scanner(){11for(n=0;n<8;n++) chs[n]='\0';12 m=0;13 n=0;14 ch=s[p++];15while(ch=='') ch=s[p++];16if(isalpha(ch)){17while(isalpha(ch)||isdigit(ch)){18//isalpha(ch)函数:判断字符ch是否为英⽂字母,⼩写字母为2,⼤写字母为1,若不是字母019//isdigit(ch)函数:判断字符ch是否为数字,是返回1,不是返回020 chs[m++]=ch;21 ch=s[p++];22 }23 syn=10;24for(n=0;n<6;n++)25if(strcmp(chs,tab[n])==0) syn=n+1;26 p--;27 }else if(isdigit(ch)){28 sum=0;29while(isdigit(ch)){30 sum=sum*10+(ch-'0');31 ch=s[p++];32 }33 syn=11;34 p--;35 }else if(ch==':'){36 syn=17;37 chs[m++]=ch;38 ch=s[p++];39if(ch=='='){ syn=18;chs[m]=ch;p++;}40 p--;41 }else if(ch=='<'){42 syn=20;43 chs[m++]=ch;44 ch=s[p++];45if(ch=='>') { syn=21;chs[m]=ch;p++;}46if(ch=='=') { syn=22;chs[m]=ch;p++;}47 p--;48 }else if(ch=='>'){49 syn=23;50 chs[m++]=ch;51 ch=s[p++];52if(ch=='=') { syn=24;chs[m]=ch;p++;}53 p--;54 }else switch(ch){55case'+':syn=13;chs[m]=ch;break;56case'-':syn=14;chs[m]=ch;break;57case'*':syn=15;chs[m]=ch;break;58case'/':syn=16;chs[m]=ch;break;59case'=':syn=25;chs[m]=ch;break;60case';':syn=26;chs[m]=ch;break;61case'(':syn=27;chs[m]=ch;break;62case')':syn=28;chs[m]=ch;break;63case'#':syn=0;chs[m]=ch;break;64default:syn=-1;65 }66return0;67 }68int main(){69 p=0;70 cout<<"Please input code and end with character '#':"<<endl;71do{72//cin>>ch;不识别空格73 ch=getchar();74 s[p++]=ch;75 }while(ch!='#');76 p=0;77do{78 scanner();79switch(syn){80case11:cout<<'('<<syn<<','<<sum<<')'<<endl;break;81case -1:cout<<'('<<syn<<','<<"error"<<')'<<endl;break;82default:cout<<'('<<syn<<','<<chs<<')'<<endl;83 }84 }while(syn!=0);85//getch():是⼀个不回显函数,当⽤户按下某个字符时,函数⾃动读取,⽆需按回车,所在头⽂件是conio.h。
编译原理----词法分析程序----C语言版

编译原理----词法分析程序----C语⾔版#include<stdio.h>#include<string.h>#include<stdlib.h>char KeyWord[20][100]={"begin","end","if","while","var","procedure","else","for","do","int","read","write"};char yunsuanfu[]="+-*/<>%=";char fenjiefu[]=",;(){}:";int main(){char test[]="var a=10;\nvar b,c;\nprocedure p; \n\tbegin\n\t\tc=a+b\n\tend\n";int len_yunsuanfu=strlen(yunsuanfu);int len_fenjiefu=strlen(fenjiefu);puts(test);int length=strlen(test),i,j,k;for(i=0;i<length;i++){if(test[i]==' '||test[i]=='\n'||test[i]=='\t')continue;int tag=0;for(j=0;j<len_fenjiefu;j++){if(fenjiefu [j]==test[i]){printf("分界符\t%c\n",test[i]);tag=1;break;}}if(tag==1)continue;tag=0;for(j=0;j<len_yunsuanfu;j++){if(yunsuanfu[j]==test[i]){printf("运算符\t%c\n",test[i]);tag=1;break;}}if(tag==1)continue;if(test[i]>='0'&&test[i]<='9'){printf("数字\t");while(test[i]>='0'&&test[i]<='9'){printf("%c",test[i]);i++;}printf("\n");continue;}char temp[100];j=0;while(test[i]>='0'&&test[i]<='9'||test[i]>='a'&&test[i]<='z'||test[i]>='A'&&test[i]<='Z'||test[i]=='_') {temp[j++]=test[i];i++;}i--;temp[j++]='\0';tag=0;for(j=0;j<20;j++){if(strcmp(temp,KeyWord[j])==0){tag=1;printf("关键字\t%s\n",temp);break;}}if(tag==0)printf("标识符\t%s\n",temp);}}。
编译原理词法分析

❖ =、<、>、!:读下一个字符,判断是否为双字 符分界符,若是,组成双字符分界符,输出类码; 若不是,输出单分界符记号;
编译原理
❖ 非=、<、>、/等与双分界符首字符不同的单分界 字符:输出相应单词记号及单分界符。
1.S是一个有穷集,它的每个元素称为一个状态;
2.Σ是一个有穷字母表,它的每个元素称为一个输入 符号,所以也称Σ为输入符号表;
3.δ是在S×Σ→S上的单值映射,即,如δ (s,a)=s’, (s∈S,s’∈S)就意味着,当前状态为s,输入符为 a时,将转换为下一个状态s’,我们把s’称作s的一 个后继状态;
编译原理 在 入 准初带备整•••始的读输读有个时开入始入头穷模,始,状带:控型读位状态:可制由头置态存以器如状的所三处,处放在:果态符识部于表于输输控读正号别分输示初入入制头好组组符带状移是成成号上态动终的:向发到结字后生最状能移变后态被头每有动化一,该转向读穷个则有移后入控符输限到移一 制号入自下动个器后带动一一符控面上机个个号制,状位,状态置读态,
编译原理
词法分析 读字符
结束 Y
结束
N Y 空字
N 字母 N 数字
Y 组合标识符 Y 组合整数
查保留字Βιβλιοθήκη N 纯单分符Y 输出单分符
N
>,<,!,= Y 读字符
=
N
N
/ Y 读字符
*
N
Y
错误处理
输出保留字
Y 保留字
N 输出标识符
组合整数
读字符
Y 输出双分符
输出单分符 N 输出单分符/
注释处理
读字符
编译原理中的词法分析与语法分析原理解析

编译原理中的词法分析与语法分析原理解析编译原理是计算机科学中的重要课程,它研究的是如何将源程序翻译成目标程序的过程。
而词法分析和语法分析则是编译过程中的两个重要阶段,它们负责将源程序转换成抽象语法树,为接下来的语义分析和代码生成阶段做准备。
本文将从词法分析和语法分析的原理、方法和实现技术角度进行详细解析,以期对读者有所帮助。
一、词法分析的原理1.词法分析的定义词法分析(Lexical Analysis)是编译过程中的第一个阶段,它负责将源程序中的字符流转换成标记流的过程。
源程序中的字符流是没有结构的,而编程语言是有一定结构的,因此需要通过词法分析将源程序中的字符流转换成有意义的标记流,以便之后的语法分析和语义分析的进行。
在词法分析的过程中,会将源程序中的字符划分成一系列的标记(Token),每个标记都包含了一定的语义信息,比如关键字、标识符、常量等等。
2.词法分析的原理词法分析的原理主要是通过有限状态自动机(Finite State Automaton,FSA)来实现的。
有限状态自动机是一个数学模型,它描述了一个自动机可以处于的所有可能的状态以及状态之间的转移关系。
在词法分析过程中,会将源程序中的字符逐个读取,并根据当前的状态和字符的输入来确定下一个状态。
最终,当字符读取完毕时,自动机会处于某一状态,这个状态就代表了当前的标记。
3.词法分析的实现技术词法分析的实现技术主要有两种,一种是手工实现,另一种是使用词法分析器生成工具。
手工实现词法分析器的过程通常需要编写一系列的正则表达式来描述不同类型的标记,并通过有限状态自动机来实现这些正则表达式的匹配过程。
这个过程需要大量的人力和时间,而且容易出错。
而使用词法分析器生成工具则可以自动生成词法分析器的代码,开发者只需要定义好源程序中的各种标记,然后通过这些工具自动生成对应的词法分析器。
常见的词法分析器生成工具有Lex和Flex等。
二、语法分析的原理1.语法分析的定义语法分析(Syntax Analysis)是编译过程中的第二个阶段,它负责将词法分析得到的标记流转换成抽象语法树的过程。
编译原理词法分析与语法分析的过程与方法

编译原理词法分析与语法分析的过程与方法编译原理是计算机科学领域中的重要内容之一,它研究如何将高级语言程序转化为机器语言的过程。
其中,词法分析和语法分析是编译原理中的两个重要阶段。
本文将详细介绍词法分析与语法分析的过程与方法。
一、词法分析的过程与方法词法分析是编译器的第一个阶段,其主要任务是将源程序的字符序列划分成有意义的语言单元,也就是词法单元。
以下是词法分析的过程与方法:1. 扫描:词法分析器从源程序中读取字符序列,并按照事先定义的规则进行扫描。
2. 划分词法单元:根据事先定义的规则,词法分析器将字符序列划分为不同的词法单元,如关键字、标识符、常量、运算符等。
3. 生成词法单元流:将划分好的词法单元按照顺序生成词法单元流,方便后续的语法分析阶段使用。
4. 错误处理:在词法分析过程中,如果发现了不符合规则的字符序列,词法分析器会进行错误处理,并向用户报告错误信息。
二、语法分析的过程与方法语法分析是编译器的第二个阶段,其主要任务是分析词法单元流,并判断是否符合语法规则。
以下是语法分析的过程与方法:1. 构建语法树:语法分析器根据语法规则构建抽象语法树(AST),用于表示源程序的语法结构。
2. 自顶向下分析:自顶向下分析是一种常用的语法分析方法,它从根节点开始,按照语法规则向下递归分析,直到生成叶子节点对应的词法单元。
3. 底部向上分析:底部向上分析是另一种常用的语法分析方法,它从词法单元开始,逐步合并为更高级的语法结构,直到生成抽象语法树的根节点。
4. 错误处理:在语法分析过程中,如果发现了不符合语法规则的词法单元流,语法分析器会进行错误处理,并向用户报告错误信息。
三、词法分析与语法分析的关系与区别词法分析和语法分析在编译原理中起着不同的作用:1. 关系:词法分析是语法分析的前置阶段,它为语法分析提供了有意义的词法单元流。
语法分析基于词法单元流构建语法树,判断源程序是否满足语法规则。
2. 区别:词法分析主要关注词法单元的划分和分类,它是基于字符序列的处理;而语法分析主要关注词法单元之间的组合和语法结构的判断,它是基于语法规则的处理。
编译原理实验一 词法分析

实验一词法分析一、实验目的:通过本实验理解词法分析的整个过程,处理对象和处理的结果,了解词法分析在整个编译过程中的作用。
二、实验学时:2学时。
三、实验内容根据给出的简单语言的词法构成规则和单词集合,编制词法分析程序,要求能用给定的简单语言书写的源程序进行词法分析,同时建立相应的符号表文件存放正确的单词。
输出分析结果于文件中,包括:(1)正确的单词符号及其单词种类的序对二元组。
具体输出形式为:二元组:(单词种类,单词内码值)单词种类见五。
四、实验方法构造识别单词集的自动机,编写程序实现。
五、实验的处理单词集(注:单词种类统一分类如下:)七、实验报告要求给出单词识别的状态转换图;带有注释(简单说明)的源程序。
程序运行截图,要求运行结果内有输出自己的名字和学号.状态转换图源程序#include<iostream>#include<string>using namespace std;//单词结构定义struct WordType{int code;string pro;};//关键字表和对应的编码string codestring[6]={"main","int","if","then","else","return"};int codebook[6]={26,21,22,23,24,25};//全局变量char ch;int flag=0;//函数声明WordType get_w();void getch();void getBC();bool isLetter();bool isDigit();void retract();int Reserve(string str);string concat(string str);//主函数int main(){WordType word;cout<<"请输入源程序列:";word=get_w();while(word.pro!="#")//为自己设置的结束标志{cout<<word.code<<'\t'<<word.pro<<endl;word=get_w();};return 0;}WordType get_w(){string str="";int code;WordType wordtmp;getch();//读一个字符getBC();//去掉空白符if(isLetter()){//以字母开头while(isLetter()||isDigit()){str=concat(str);getch();}retract();code=Reserve(str);if(code==-1){wordtmp.code=0;wordtmp.pro=str;}//不是关键字else{ wordtmp.code=code;wordtmp.pro=str;}//是关键字}else if(isDigit()){//以数字开头while(isDigit()){str=concat(str);getch();}retract();wordtmp.code=30;wordtmp.pro=str;}else if(ch=='('){ wordtmp.code=1; wordtmp.pro="(";}else if(ch==')'){ wordtmp.code=2; wordtmp.pro=")";}else if(ch=='{'){ wordtmp.code=3; wordtmp.pro="{";}else if(ch=='}'){ wordtmp.code=4; wordtmp.pro="}";}else if(ch==';'){ wordtmp.code=5; wordtmp.pro=";";}else if(ch=='='){ wordtmp.code=6; wordtmp.pro="=";}else if(ch=='+'){ wordtmp.code=7; wordtmp.pro="+";}else if(ch=='*'){ wordtmp.code=8; wordtmp.pro="*";}else if(ch=='>'){ wordtmp.code=9; wordtmp.pro=">";}else if(ch=='<'){ wordtmp.code=10; wordtmp.pro="<";}else if(ch==','){ wordtmp.code=11; wordtmp.pro=",";}else if(ch=='\''){ wordtmp.code=12; wordtmp.pro="\'";}else {wordtmp.code=100;wordtmp.pro=ch;}return wordtmp;}void getch(){if(flag==0)//没有回退的字符ch=getchar();else//有回退字符,用回退字符,并重置标志flag=0;}void getBC(){while( ch==' '||ch=='\t'||ch=='\n')ch=getchar();}bool isLetter(){if(ch>='a'&&ch<='z'||(ch>='A'&&ch<='Z'))return true;elsereturn false;}bool isDigit(){if(ch>='0'&&ch<='9')return true;elsereturn false;}string concat(string str){return str+ch;}void retract(){flag=1;}int Reserve(string str){int i;for(i=0;i<=5;i++){if(codestring[i]==str)//是某个关键字,返回对应的编码return codebook[i];}if(i==6)//不是关键字return -1;}截图实验心得此次实验让我了解了如何设计、编制并调试词法分析程序,并加深了我对词法分析器原理的理解;熟悉了直接构造词法分析器的方法和相关原理。
编译原理-词法分析
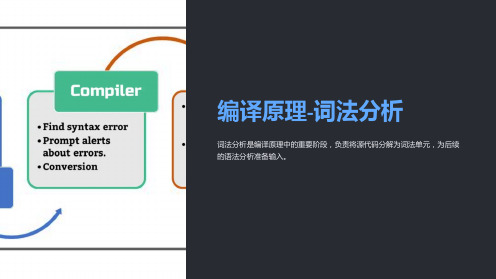
词法分析是编译原理中的重要阶段,负责将源代码分解为词法单元,为后续 的语法分析准备输入。
词法分析的定义和作用
词法分析是编译器的第一阶段,其主要目的是将源代码转换为有意义的词法 单元,如标识符、关键字、操作符等,以便后续的语法分析和语义分析使用。
词法分析的流程
1
扫描
将源代码分割为符号序列。
2
识别
将符号序列映射到相应的词法单元。
归类
将词法单元分为不同的类别,如标识符、关键字、操作符等。
常见的词法分析技术
正则表达式
用于描述词法单元的模式。
有限自动机
用于识别符号序列并生成词法 单元。
词法分析器生成器
自动生成词法分析器的工具。
词法分析的应用场景
词法分析广泛应用于编译器、解释器和语言处理工具等领域,确保源代码的正确解析和语义分析。
词法分析的挑战和解决方案
错误处理
如何处理错误输入和不合法的词法 单元。
性能优化
如何提高词法分析的速度和效率。
跨平台兼容
如何处理不同编程语言和操作系统 的词法规则。
结论和总结
词法分析是编译原理中不可或缺的一部分,对于编译器的正确性和性能有着 重要影响。了解词法分析的流程和技术,可帮助开发者构建更高效的编译器 和语言处理工具。
编译原理 实验一 词法分析

《编译系统设计实践》实验项目一:词法分析指导老师:陈晖组长:许堃组员:一、实验目的词法分析的目的是将输入的源程序进行划分,给出基本符号(token)的序列,并掠过注解和空格等分隔符号。
基本符号是与输入的语言定义的词法所规定的终结符。
二、实验内容本实验要求学生编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。
并依次输出各个单词的内部编码及单词符号自身值。
(遇到错误时可显示“Error”,然后跳过错误部分继续进行)三、程序设计与实现程序功能描述:程序从文本读入一段程序代码,对每一个字符进行分析,识别出各个具有独立意义的单词,并依次输出各个单词的内部编码及单词符号自身值。
过程描述:过程描述:先从文本中读入字符,定义两个指针begin和forward,begin指向每一个词素的首个字符,forward一直向前扫描,直到发现某个单词被匹配为止,一旦确定了下一个单词,forward指针将指向该词素结尾的字符,确定词素后,根据内部编号输出其编号和自身值。
数据结构:数组程序流程图:正则表达式:标识符 id->letter_(letter_|digit)*无符号数 number->digit optitionalfraction optionalexponent 空白符 ws->(blank|tab|newline)+ 关系运算符 relop-> <|>|<=|>=|=|<> 运算符 operator->+|-|*|/DFA 图:=|<>|<|>|<=|>=|+|-|*|/ a —z A--Z0--9;| ( | ) | ,| [ | ] | .开始(每个词素首个字符)符号转化 符号转化符号转化符号转化关键字?标识符?结束startdelim22other24 23*19 12141316151817 startotherdigit. digit E+ | -digitdigit digitdigit Edigit *startletter9other 11 10letter/dig*start<other= 67 8return(relop, LE) 54>= 123other>=* * return(relop, NE)return(relop, LT)return(relop, EQ)return(relop, GE)return(relop, GT)10四、程序测试第一组测试:输入:输出:第二组测试:输入:输出:第三组测试:输入:输出:五、小组成员分工与实验小结由于有一段时间没有编程序,而且实验本身也有些难度,所以在实验初期遇到了很大阻碍,不知道该从何下手。
编译原理词法分析报告

实验一:词法分析一、实验目的:1、通过设计编制调试一个具体的词法分析程序,加深对词法分析原理的理解。
并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。
2、编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本关键字、标识符、常数、运算符、分隔符五大类。
并依次输出各个单词的内部编码及单词符号自身值。
(遇到错误时可显示“Error”,然后跳过错误部分继续显示)二、实验预习提示1、词法分析器的功能和输出格式词法分析器的功能是输入源程序,输出单词符号。
词法分析器的单词符号常常表示成以下的二元式(单词种别码,单词符号的属性值)。
本实验中,采用的是一类符号一种别码的方式。
2、单词的BNF表示<标识符>-> <字母><字母数字串><字母数字串>-><字母><字母数字串>|<数字><字母数字串>|<下划线><字母数字串>|ε<无符号整数>-> <数字><数字串><数字串>-> <数字><数字串> |ε<加法运算符>-> +<减法运算符>->-<大于关系运算符>->><大于等于关系运算符>-> >=3、“超前搜索”方法词法分析时,常常会用到超前搜索方法。
如当前待分析字符串为“a>+”,当前字符为’>’,此时,分析器到底是将其分析为大于关系运算符还是大于等于关系运算符呢?显然,只有知道下一个字符是什么才能下结论。
于是分析器读入下一个字符’+’,这时可知应将’>’解释为大于运算符。
但此时,超前读了一个字符’+’,所以要回退一个字符,词法分析器才能正常运行。
在分析标识符,无符号整数等时也有类似情况。
编译原理词法分析

编译原理词法分析
编译原理的词法分析是编译器中的一个重要过程,它负责将源代码分
割成一个个的词法单元(Token)。
词法单元是程序中的最小语法单位,
如标识符、关键字、运算符、常数等。
词法分析的主要任务是从左到右扫描源代码字符流,逐个字符进行解析,并根据预先定义的词法规则识别出各种词法单元。
为了实现词法分析,通常会采用有限自动机(DFA)或正则表达式来描述词法规则。
具体的词法分析过程包括以下几个步骤:
1.建立输入缓冲区:将源代码存储在缓冲区中,方便逐个字符进行读
取和处理。
2.扫描字符流:从缓冲区中逐个字符读取并处理,跳过空白字符(空格、制表符、换行符等)。
3.根据词法规则识别词法单元:根据预先定义的词法规则,将字符序
列转换为词法单元,并记录其类型和属性信息。
4.错误处理:如果遇到无法识别的字符序列或不符合词法规则的情况,进行相应的错误处理并报告错误。
5.输出词法单元流:将识别出的词法单元按照顺序输出,作为下一步
的输入。
词法分析是编译器的前端处理阶段,它为语法分析提供了基础数据,
将源代码转化为一个个的词法单元,为后续的语法分析、语义分析和代码
生成等阶段提供支持。
编译原理的词法分析与语法分析

编译原理的词法分析与语法分析编译原理是计算机科学中的一门重要课程,它研究如何将源代码转换为可执行的机器代码。
在编译过程中,词法分析和语法分析是其中两个基本的阶段。
本文将分别介绍词法分析和语法分析的基本概念、原理以及实现方法。
1. 词法分析词法分析是编译过程中的第一个阶段,主要任务是将输入的源代码分解成一个个的词法单元。
词法单元是指具有独立意义的最小语法单位,比如变量名、关键字、操作符等。
词法分析器通常使用有限自动机(finite automaton)来实现。
在词法分析的过程中,需要定义词法规则,即描述每个词法单元的模式。
常见的词法规则有正则表达式和有限自动机。
词法分析器会根据这些规则匹配输入的字符序列,并生成相应的词法单元。
2. 语法分析语法分析是编译过程中的第二个阶段,它的任务是将词法分析器生成的词法单元序列转换为语法树(syntax tree)或抽象语法树(abstract syntax tree)。
语法树是源代码的一种抽象表示方式,它反映了源代码中语法结构和运算优先级的关系。
语法分析器通常使用上下文无关文法(context-free grammar)来描述源代码的语法结构。
常见的语法分析算法有递归下降分析法、LR分析法和LL分析法等。
递归下降分析法是一种自顶向下的分析方法,它从源代码的起始符号开始,递归地展开产生式,直到匹配到输入的词法单元。
递归下降分析法的实现比较直观,但对于左递归的文法处理不方便。
LR分析法是一种自底向上的分析方法,它使用一个自动机来分析输入的词法单元,并根据文法规则进行规约操作,最终生成语法树。
常见的LR分析法有LR(0)、SLR、LR(1)和LALR等。
LL分析法是一种自顶向下的分析方法,它从源代码的起始符号开始,预测下一个要匹配的词法单元,并进行相应的推导规则。
LL分析法常用于编程语言中,如Java和Python。
3. 词法分析和语法分析的关系词法分析是语法分析的一个子阶段,它为语法分析器提供了一个符号序列,并根据语法规则进行分析和匹配。
编译原理 第五章 词法分析

三、LEX编译程序的工作过程:
1.根据每条识别规则Pi {ACTION i}构造相应的非确 定有限自动机NFA,分别画出它们的状态转换图; 2.将所有的状态转换图连接成一个完整的状态转换图; 3.由状态转换图构造状态转换矩阵; 4.将状态转换矩阵确定化; 5.根据DFA,构造词法分析器;
预处理 子程序 扫描器 单词符号
输入 列表 输入缓冲区
扫描缓冲区
词法分析器的结构
三、设置缓冲器的必要性
之所以要设置缓冲器,是因为对于许多源程序而言,有 时词法分析器为了得到某个单词符号的确切性质,只从该符 号本身所含有的字符不能作出判定,还需要超前扫描若干字 符之后,才能作出确切的分析。 例如:有合法的Fortran语句: DO99K=1,10 和 DO99K=1.10 前者是循环语句,后者是赋值语句,两者的区别在于等 号后的第一个界符不同,前者是逗号,后者是句号,因此为 了识别前者中的关键字‘“DO”,必须超前扫描若干字符之 后,才能作出确切的判定。
3、词法分析器和语法分析器作为协同程序 如果两个或两个以上的程序,他们之间交叉执行,这些程序称为协同程 序。词法分析器和语法分析器也可协工作的方式安排在同一遍中,以生产 者和消费者的关系同步运行。
1.词法分析单独作为一遍
S.P.(字符串)
第一 遍 词法分析 单词 串 S.P.(符号串) 第二 遍 语法分析
例如:
%{ int wordCount = 0; int noCount = 0; %} chars [A-za-z] numbers ([0-9])+ words {chars}+ 注意:凡是对已经定义的正则表达式的名字的引用,都必须用花括 号将它们括起来。在LEX源程序中,起标识作用的符号%%,%{以及%}都 必须处在所在行的最左字符位置。
编译原理词法分析与语法分析

编译原理词法分析与语法分析在计算机科学领域,编译器是一个非常重要的工具,它将高级程序语言转换为能够被计算机处理的低级机器语言。
编译器的设计与开发离不开以下两个主要部分:词法分析和语法分析。
本文将着重介绍编译原理中的词法分析和语法分析的定义、原理、方法以及它们之间的关系。
一、词法分析词法分析是编译器的第一个阶段,负责将源代码转化为一个个“词法单元”,也称为“记号”。
词法单元是计算机程序中的最小语义单位,例如变量名、关键字、操作符等。
词法分析器会从源代码中连续读取字符,并将其组成具有独立意义的词法单元。
词法分析的主要任务是识别代码中的词法单元,并将其分类。
它采用正则表达式来定义词法单元的模式,并通过有限状态自动机(FSM)进行匹配。
以下是词法分析的一般步骤:1. 输入源代码,逐字符读取。
2. 将字符组合成词法单元。
3. 跳过空格、换行符等不相关的字符。
4. 使用正则表达式判断词法单元的类型。
5. 将识别出的词法单元传递给语法分析阶段。
二、语法分析语法分析是编译器的第二个阶段,它将从词法分析器获得的词法单元串转换为语法树。
语法树是一种树状结构,用于表示程序的语法结构。
它通过分析词法单元之间的关系来检查程序是否符合语法规则。
在语法分析过程中,会根据源代码中的语法规则使用上下文无关文法(Context-Free Grammar)进行分析。
常用的语法分析算法有自顶向下分析(Top-Down Parsing)和自底向上分析(Bottom-Up Parsing)。
自顶向下分析是从语法的起始符号开始,逐步展开已识别的符号,直到生成源代码。
这种分析方法常用的算法有LL(k)和递归下降(Recursive Descent)。
自顶向下分析器按照语法规则从上到下预测并展开符号。
自底向上分析是从词法单元串的底部开始,逐步归约已识别的符号,直到生成源代码。
这种分析方法常用的算法有LR(k)和LALR(k)。
自底向上分析器按照语法规则从下往上扫描,并进行归约操作。
编译原理实验-词法分析器

编译原理实验-词法分析器⼀、实验⽬的设计、编制、调试⼀个词法分析程序,对单词进⾏识别和编码,加深对词法分析原理的理解。
⼆、实验内容1.选定语⾔,编辑任意的源程序保存在⽂件中;2.对⽂件中的代码预处理,删除制表符、回车符、换⾏符、注释、多余的空格并将预处理后的代码保存在⽂件中;3.扫描处理后的源程序,分离各个单词符号,显⽰分离的单词类型。
三、实验思路对于实验内容1,选择编写c语⾔的源程序存放在code.txt中,设计⼀个c语⾔的词法分析器,主要包含三部分,⼀部分是预处理函数,第⼆部分是扫描判断单词类型的函数,第三部分是主函数,调⽤其它函数;对于实验内容2,主要实现在预处理函数processor()中,使⽤⽂档操作函数打开源程序⽂件(code.txt),去除两种类型(“//”,“/*…*/”)的注释、多余的空格合并为⼀个、换⾏符、回车符等,然后将处理后的保存在另⼀个新的⽂件(afterdel.txt)中,最后关闭⽂档。
对于实验内容3,打开处理后的⽂件,然后调⽤扫描函数,从⽂件⾥读取⼀个单词调⽤判断单词类型的函数与之前建⽴的符号表进⾏对⽐判断,最后格式化输出。
四、编码设计代码参考了两篇博主的,做了部分改动,添加了预处理函数等1 #include<iostream>2 #include<fstream>3 #include<cstdio>4 #include<cstring>5 #include<string>6 #include<cstdlib>78using namespace std;910int aa;// fseek的时候⽤来接着的11string word="";12string reserved_word[20];//保留13char buffer;//每次读进来的⼀个字符14int num=0;//每个单词中当前字符的位置15int line=1; //⾏数16int row=1; //列数,就是每⾏的第⼏个17bool flag; //⽂件是否结束了18int flag2;//单词的类型192021//预处理函数22int processor(){//预处理函数23 FILE *p;24int falg = 0,len,i=0,j=0;25char str[1000],str1[1000],c;26if((p=fopen("code.txt","rt"))==NULL){27 printf("⽆法打开要编译的源程序");28return0;29 }30else{31//fgets(str,1000,p);32while((c=getc(p))!=EOF){33 str[i++] = c;34 }35 fclose(p);36 str[i] = '\0';37for(i=0;i<strlen(str);i++){38if(str[i]=='/'&&str[i+1]=='/'){39while(str[i++]!='\n'){}40 }//单⾏注释41else if(str[i]=='/'&&str[i+1]=='*'){42while(!(str[i]=='*'&&str[i+1]=='/')){i++;}43 i+=2;44 }//多⾏注释45else if(str[i]==''&&str[i+1]==''){46while(str[i]==''){i++;}47 i--;48if(str1[j-1]!='')49 str1[j++]='';50 }//多个空格,去除空格51else if(str[i]=='\n') {52if(str1[j-1]!='')53 str1[j++]='';54 }//换⾏处理,55else if(str[i]==9){56while(str[i]==9){57 i++;58 }59if(str1[j-1]!='')60 str1[j++]='';61 i--;62 }//tab键处理63else str1[j++] = str[i];//其他字符处理64 }65 str1[j] = '\0';66if((p = fopen("afterdel.txt","w"))==NULL){ 67 printf("can not find it!");68return0;69 }70else{71if(fputs(str1,p)!=0){72 printf("预处理失败!");73 }74else printf("预处理成功!");75 }76 fclose(p);77 }78return0;79 }8081//设置保留字82void set_reserve()83 {84 reserved_word[1]="return";85 reserved_word[2]="def";86 reserved_word[3]="if";87 reserved_word[4]="else";88 reserved_word[5]="while";89 reserved_word[6]="return";90 reserved_word[7]="char";91 reserved_word[8]="for";92 reserved_word[9]="and";93 reserved_word[10]="or";94 reserved_word[11]="int";95 reserved_word[12]="bool";96 }9798//看这个字是不是字母99bool judge_word(char x)100 {101if(x>='a' && x<='z' || x>='A' && x<='Z' ){ 102return true;103 }104else return false;105 }106107//看这个字是不是数字108bool judge_number(char x)109 {110if(x>='0' && x<='9'){111return true;112 }113else return false;114 }115116//看这个字符是不是界符117bool judge_jiefu(char x)118 {119if(x=='('||x==')'||x==','||x==';'||x=='{'||x=='}'){ 120return true;121 }122else return false;123 }124125126//加减乘127bool judge_yunsuanfu1(char x)128 {129if(x=='+'||x=='-'||x=='*')130 {131return true;132 }133else return false;134 }135136//等于赋值,⼤于⼩于⼤于等于,⼩于等于,⼤于⼩于137bool judge_yunsuannfu2(char x)138 {139if(x=='='|| x=='>'||x=='<'||x=='&'||x=='||'){140return true;141 }142else return false;143 }144145146//这个最⼤的函数的总体作⽤是从⽂件⾥读⼀个单词147int scan(FILE *fp)148 {149 buffer=fgetc(fp);//读取⼀个字符150if(feof(fp)){//检测结束符151 flag=0;return0;152 }153else if(buffer=='')154 {155 row++;156return0;157 }158else if(buffer=='\n')159 {160 row=1;161return0;162 }163//如果是字母开头或'_' 看关键字还是普通单词164else if(judge_word(buffer) || buffer=='_')165 {166 word+=buffer;167 row++;168while((buffer=fgetc(fp)) && (judge_word(buffer) || judge_number(buffer) || buffer=='_'))169 {170 word+=buffer;171 row++;172 }173if(feof(fp)){174 flag=0;175return1;176 }177for(int i=1;i<=12;i++){178if(word==reserved_word[i]){179 aa=fseek(fp,-1,SEEK_CUR);//如果执⾏成功,stream将指向以fromwhere为基准,偏移offset(指针偏移量)个字节的位置,函数返回0。
编译原理实验报告 词法分析

编译原理实验一·词法分析一、实验目的通过动手实践,使学生对构造编译系统的基本理论、编译程序的基本结构有更为深入的理解和掌握;使学生掌握编译程序设计的基本方法和步骤;能够设计实现编译系统的重要环节。
同时增强编写和调试程序的能力。
二、实验内容及要求对某特定语言A ,构造其词法规则。
该语言的单词符号包括:保留字(见左下表)、标识符(字母大小写不敏感)、整型常数、界符及运算符(见右下表) 。
功能要求如下所示:·按单词符号出现的顺序,返回二元组序列,并输出。
·出现的标识符存放在标识符表,整型常数存放在常数表,并输出这两个表格。
·如果出现词法错误,报出:错误类型,位置(行,列)。
·处理段注释(/* */),行注释(//)。
·有段注释时仍可以正确指出词法错误位置(行,列)。
三、实验过程1、词法形式化描述使用正则文法进行描述,则可以得到如下的正规式:其中ID表示标识符,NUM表示整型常量,RES表示保留字,DEL表示界符,OPR表示运算符。
A→(ID | NUM | RES | DEL | OPR) *ID→letter(letter | didit)*NUM→digit digit*letter→a | …| z | A | …| Zdigit→0 | …| 9RES→program | begin | end | var | int | and | or | not | if | then | else | while | doDEL→( | ) | . | ; | ,OPR→+ | * | := | > | < | = | >= | <= | <>如果关键字、标识符和常数之间没有确定的算符或界符作间隔,则至少用一个空格作间隔。
空格由空白、制表符和换行符组成。
2、单词种别定义;3、状态转换图;语言A的词法分析的状态转换图如下所示:空格符,制表符或回车符字母或数字4、运行环境介绍;本次实验采用win-tc进行代码的编写和编译及运行程序的运行环境为windows5、关键算法的流程图及文字解释;程序中用到的函数列表:变量ch储存当前最新读进的字符的地址strToken存放当前字符串voidmain() //主函数struct binary *lexicalAnalyze(); //词法分析的主函数,返回一个二元组的指针void GetBC(); //检查ch指向的字符是否为空格、制表或回车符,如果是则调用GetChar()直至不是上述字符void GetChar(); //ch前移一个地址单元int ConCat(); //将ch指向的字符连接到strToken之后int isLetter(); //判断ch指向的字符是否字母int isDigit(); //判断ch指向的字符是否数字int insertId(); //向标识符表中插入当前strToken的字符串int insertConst(); //将strToken的常数插入常数表中int Reserved(); //检测当前strToken中的字符串是否保留字,若是,则返回编码,否则返回0int isId(); //检测当前strToken中的字符串是否在标识符表中已存在,若是,则返回其编号,否则返回0int isConst(); //检测当前strToken中的字符串是否在常数表中已存在,若是,则返回其编号,否则返回0void errProc(int errType); //出错处理过程,errType是错误类型,将错误信息加入错误表中main()函数的流程图如下:lexicalAnalyze()函数的流程图如下所示:Reserved()、isId()和isConst()函数均采用了对链表的遍历算法,errProc()函数通过识别不同的错误编号,向错误链表中添加相应的错误信息。
编译原理_实验一_词法分析
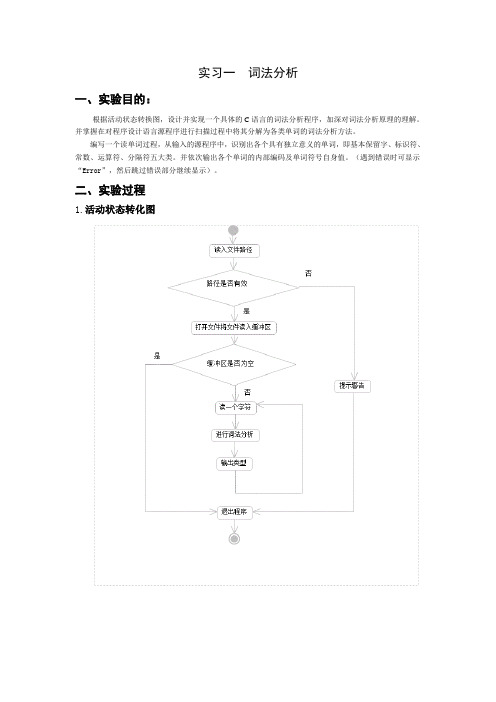
实习一词法分析一、实验目的:根据活动状态转换图,设计并实现一个具体的C语言的词法分析程序,加深对词法分析原理的理解。
并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。
编写一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。
并依次输出各个单词的内部编码及单词符号自身值。
(遇到错误时可显示“Error”,然后跳过错误部分继续显示)。
二、实验过程1.活动状态转化图2.设计思路本C语言词法分析器使用JAVA语言编写。
(1)C语言词法分析●关键字将C语言32关键字"auto", "double", "int", "struct", "break","else","long", "switch", "case", "enum", "register", "typedef","char", " extern", "return", "union", "const", "float", "short"," unsigned", "continue", "for", "signed", "void","default", "goto","sizeof", "volatile", "do", "if", "while", "static"存储在keyword[]字符串数组中;●专用符号= + -* / <=>>= == != ;:, { } [ ] ( )将读入的字符与ASCLL表进行比较判断;对于像“==”,“<=”等字符进行超前搜索;●空格和空白、制表符和换行符。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
学生实验报告实验项目名称:词法分析实验学时:同组学生姓名:实验地点:实验日期:实验成绩:批改教师:批改时间:一、实验目的和要求通过编写并上机调试一个词法分析程序,掌握在对程序设计语言的源程序进行扫描的过程中,将其分解后各类单词的词法分析方法。
二、实验仪器和设备硬件:PC机软件:Visual Studio 2005工具三、实验过程输入:从具有代表性的高级程序设计语言中,选取一个适当大小的子集,例如可以选取一类典型单词,也可以尽可能使各种类型的单词都能兼顾到。
输出:单词串的输出形式,所输出的每一单词均按形如(字符类型单词和其它字符<行,列>)的三元式编码。
字符类型包括关键字、标识符、浮点数、指数形式、常数、引入文件、分隔符。
<行,列>标识单词及各个字符在文本框中出现的位置。
词法规则∙关键字: 本程序识别的关键字为int real if then else while ,仅当单独出现以上标识符时识别为关键字,对于inta,ifb等识别为标识符。
∙标识符: 一个标识符必须以字母开头,后面接上字母和数字,否则产生报错信息,程序停止词法分析,输出相关错误信息如: 正确:abc, abc123, 等,错误:123abc∙操作符: 本程序识别的操作符为: + - / * = == < <= > >= != & ^ | && || ? &= |= ^= ++ -- += -= /= *= <<= << >>= >> % %= 当!后跟其它字符时产生出错信息。
∙分隔符: 本程序识别的分隔符为: ( ) { } ; : , [ ] “∙数字: 识别的数字遵循以下文法规则:digit ←0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9intnumber ← digit+exponent ←(E|e) ( + | - | ε ) digit+fraction ← . digit+realnumber ← digit+ exponent | digit+ fraction ( exponent | ε )例如:正确: 123, 123E2, 123.3123.3E4错误: 123A,123E, 123.A . 123.3A, 123.3E∙注释符: 本程序对// /**/三者的注释符均识别.∙引入文件为#include<**>形式,其他做出错处理设计思路本程序采用字符流形式读入文件,识别其中的关键字,标识符,分隔符,注释符,引入文件声明等.设计了一个灵活的读取字符的自动机为如下图所显示词法分析部分的Lexical类如下:using System;using System.IO;using System.Collections;namespace Lexical_Analyzer{public class Lexical{private int rnum;//行号private int rpos;//列号private static ArrayList symbolTable;private StreamReader br;private char c;private char bC;private int state;private String str;private int a = 0;private static string[] str1={"bool","break","case","char","do","double","else","main","false","float","for","if","int", "long","main","new","null","private","protected","public","static","true","try","typeof","un it","void","while","return","short","sizeof","switch","console","write","string","length"};public Lexical(StreamReader br){symbolTable = new ArrayList();this.br = br;c = ' ';bC = ' ';state = 0;rnum = 1;rpos = 0;str = "";}public ArrayList getSymbolTable(){c = nextChar();state = 0;analyzer();return symbolTable;}private void analyzer(){bool isRunning = true;while (isRunning){switch (state){case 0:if (c == ' ' || (int)c == 13) //空格{}else if (c == '\t') //tab{rpos += 3;}else if ((int)c == 10) //回车{rnum++;}else if (c == '~') //结束符{return;}else if (c == '"'){install("分隔符", c.ToString(), rpos, rnum); }else if (c.ToString() == "'"){install("分隔符", c.ToString(), rpos, rnum); }else if (c == '+') //操作符+{state = 15;//install("操作符","+",rpos,rnum);}else if (c == '-') //操作符-{state = 14;//install("操作符","-",rpos,rnum);}else if (c == '/') //操作符/{state = 1;}else if (c == '*') //操作符*{state = 16;//install("操作符","*",rpos,rnum);}else if (c == '=') //操作符={state = 2;}else if (c == '<') //操作符<{state = 3;}else if (c == '>') //操作符>{}else if (c == '!') //操作符!{state = 5;}else if (c == '?')//操作符?{state = 19;}else if (c == '%'){state = 17;}else if (c == '&'){state = 18;}else if (c == '|'){state = 20;}else if (c == '^'){state = 21;}else if (c == '{' || c == '}' || c == '[' || c == ']' || c == '(' || c == ')' || c == ':' || c == ';' || c == ',') //分隔符{install("分隔符", c.ToString (), rpos, rnum);}else if ((int)c == 65535){isRunning = false;}else if (isLetter(c)) //读到了字符{bC = c;state = 6;}else if (isDigit(c)) //读到了数字符{bC = c;str = "";}else if (c == '#'){state = 13;}else{state = 0;isRunning = false;fail(0);}c = nextChar();break;case 1:if (c == '='){state = 0;install("操作符", "/=", rpos - 1, rnum);c = nextChar();}else if (c == '/') //表示注释后面的东西,不读它 {while ((int)c != 10)//回车{c = nextChar();}rpos = 0; //从下一行开始rnum++;c = nextChar();state = 0;}else if (c == '*'){char b = ' ';while (c != '/')//回车{b = c;c = nextChar();}if (b == '*'){c = nextChar();state = 0;}}else{state = 0; // 下一个不是/, 后退一步到state=0 install("操作符", "/", rpos - 1, rnum);}break;case 2:if (c == '=') //表示操作符=={state = 0;install("操作符", "==", rpos - 1, rnum);c = nextChar();}else{state = 0;install("操作符", "=", rpos - 1, rnum);}break;case 3:if (c == '<') //表示操作符<<{state = 0;install("操作符", "<<", rpos - 1, rnum);c = nextChar();if (c == '='){state = 0;install("操作符", "<<=", rpos - 1, rnum);c = nextChar();}}else if (c == '=') //表示操作符<={state = 0;install("操作符", "<=", rpos - 1, rnum);c = nextChar();}else{state = 0;install("操作符", "<", rpos - 1, rnum);}break;case 4:if (c == '>') //表示操作符>>{state = 0;install("操作符", ">>", rpos - 1, rnum);c = nextChar();if (c == '='){state = 0;install("操作符", ">>=", rpos - 1, rnum);c = nextChar();}}else if (c == '=') //表示操作符>={state = 0;install("操作符", ">=", rpos - 1, rnum);c = nextChar();}else{state = 0;install("操作符", ">", rpos - 1, rnum);}break;case 5:if (c == '=') // 表示操作符!={state = 0;install("操作符", "!=", rpos - 1, rnum);c = nextChar();}else{state = 0;isRunning = false;fail(1);}break;//***********************************//读入标识符,后面是数字符和字母才是对的//***********************************case 6:String id = "" + bC;if (c != '[' && c != ']'){while ((isLetter(c) || isDigit(c)) && c != '[' && c != ']') {id += c;c = nextChar();}if (isKey(id))install("关键字", id, rpos - id.Length, rnum);elseinstall("标识符", id, rpos - id.Length, rnum);if (c == '.'){install("分隔符", c.ToString(), rpos - id.Length, rnum);c = nextChar();}state = 0;}else{install("标识符", id, rpos - id.Length, rnum);state = 0;}break;//*********************************************//读入数字符,后面是数字符(循环); .(转状态);E(转状态)//**********************************************case 7:str += bC;if (c != ']'){while (isDigit(c) && c != ']'){str += c;c = nextChar();}if (c == ']'){install("数字符", str, rpos - str.Length, rnum); }else if (c == '.'){state = 8;c = nextChar();}else if (c == 'E' || c == 'e'){if (c == 'e')a = 1;state = 10;c = nextChar();}//需要判断是否是 11w等else if (isLetter(c)){state = 0;isRunning = false;fail(4);}else{state = 0;install("数字符", str, rpos - str.Length, rnum); }}else{state = 0;install("数字符", str, rpos - str.Length, rnum);}break;//***********************************// " ." 后面跟的字符,除了数字符其它都出错//***********************************case 8:str += '.';if (isDigit(c)){state = 9;str += c;}else{state = 0;isRunning = false;fail(2);}break;//***********************************************************************************// ".数字符" 后面字符,可以是数字符或者是E(需要加错误提示,当不是空格而是其他字母时候)//************************************************************************************case 9:while (isDigit(c)){str += c;c = nextChar();}if (c == 'E' || c == 'e'){if (c == 'e')a = 1;state = 10;c = nextChar();}//需要判断是否是 11w 等else if (isLetter(c)){state = 0;isRunning = false;fail(2);}else{state = 0;install("浮点数", str, rpos - str.Length, rnum);}break;//*********************************************// "E" 后面字符, "+";"-";"数字符" 都是对的,其他都是错的//********************************************case 10:if (a == 1)str += 'e';elsestr += 'E';if (c == '+' || c == '-'){state = 11;str += c;c = nextChar();}else if (isDigit(c)){state = 12;str += c;c = nextChar();}else{state = 0;isRunning = false;fail(2);}break;//*****************************************// "+" "-" 后面字符, 数字符是对的.其他都是错的//*****************************************case 11:if (isDigit(c)){state = 12;str += c;c = nextChar();}else{state = 0;isRunning = false;fail(2);}break;//***********************************// "E数字符" 后面字符,只有数字符是对的//*********************************case 12:while (isDigit(c)){str += c;c = nextChar();}if (isLetter(c)){state = 0;isRunning = false;fail(2);}install("指数形式", str, rpos - str.Length, rnum);state = 0;break;case 13: //声明部分id = "#";while (isLetter(c)){id += c;c = nextChar();}if (id == "#include" && c == '<'){id += c;c = nextChar();while (isLetter(c) || this.isDigit(c)||c=='.'){id += c;c = nextChar();}if (c == '>'){id += c;install("文件引入", id, rpos - id.Length, rnum);c = nextChar();}elsefail(3);}elsestate = 0;break;case 14: // 表示操作符-=或--或-if (c == '='){state = 0;install("操作符", "-=", rpos - 1, rnum);c = nextChar();}else if (c == '-'){state = 0;install("操作符", "--", rpos - 1, rnum);c = nextChar();}else{state = 0;install("操作符", "-", rpos - 1, rnum); }break;case 15: // 表示操作符+=或++或+if (c == '='){state = 0;install("操作符", "+=", rpos - 1, rnum);c = nextChar();}else if (c == '+'){state = 0;install("操作符", "++", rpos - 1, rnum);c = nextChar();}else{state = 0;install("操作符", "+", rpos - 1, rnum); }break;case 16: // 表示操作符*=if (c == '='){install("操作符", "*=", rpos - 1, rnum);c = nextChar();}else{state = 0;install("操作符", "*", rpos - 1, rnum);c = nextChar();}break;case 17:if (c == '=')//表示操作符%={state = 0;install("操作符", "%=", rpos - 1, rnum);c = nextChar();}else{state = 0;install("操作符", "%", rpos - 1, rnum);c = nextChar();}break;case 18:if (c == '='){state = 0;install("操作符", "&=", rpos - 1, rnum);c = nextChar();}else if (c == '&'){state = 0;install("操作符", "&&", rpos - 1, rnum);c = nextChar();}else{state = 0;install("操作符", "&", rpos - 1, rnum);c = nextChar();}break;case 19:if (c == ':') // 表示操作符?:{state = 0;install("操作符", "?:", rpos - 1, rnum);c = nextChar();}else{state = 0;isRunning = false;fail(1);}break;case 20:if (c == '='){state = 0;install("操作符", "|=", rpos - 1, rnum);c = nextChar();}else if (c == '|'){state = 0;install("操作符", "||", rpos - 1, rnum);c = nextChar();}else{state = 0;install("操作符", "|", rpos - 1, rnum);c = nextChar();}break;case 21:if (c == '='){state = 0;install("操作符", "^=", rpos - 1, rnum);c = nextChar();}else{state = 0;install("操作符", "^", rpos - 1, rnum);c = nextChar();}break;}}}private void fail(int i){string typeerror = ""; ;switch (i){case 0:typeerror = "输入非法字符错误";break;case 1:typeerror = "操作符错误";break;case 2:typeerror = "数字符错误";break;case 3:typeerror = "声明错误";break;case 4:typeerror = "标识符错误";break;}Console.Write(typeerror + ",位置<" + rnum + "," + rpos + ">");}private char nextChar(){char t;rpos++;//列if (br.Peek() == -1){br.Close();return'~';}t = (char)br.Read();return t;}private void install(String tType, String aValue, int rpos, int rnum){ArrayList tokenArray = new ArrayList();tokenArray.Add(tType);tokenArray.Add(aValue);tokenArray.Add("<" + rnum.ToString() + "," + rpos.ToString() + ">");symbolTable.Add(tokenArray);ArrayList tempArray = tokenArray;for (int j = 0; j < tempArray.Count; j++){Console.Write(tempArray[j].ToString() + " ");}Console.WriteLine();str = "";}private bool isLetter(char checkChar){int checkInt = (int)checkChar;if ((checkInt <= 122 && checkInt >= 97) || (checkInt >= 65 && checkInt <= 97)) {return true;}return false;}private bool isDigit(char checkChar){int checkInt = (int)checkChar;if (checkInt <= 57 && checkInt >= 48){return true;}return false;}private bool isKey(String checkKey){for (int i = 0; i < str1.Length; i++){if (checkKey.Equals(str1[i])){return true;}}return false;}}}四、实验结果与分析1、对程序的基本词法分析main(){a=1;if(a==1)then a=2.3;else a=3;}图12、变量命名标准识别标识符以字母开头,以下程序将产生错误main(){int 12a=123;if(a==1)then a=2.3;else a=3;}图23、数字识别main(){int a=123;float a=3.1514;if(a==1)then a=2.3;else a=3a;}由词法规则可得”3a”为错误的数字表示形式,可识别浮点数,输入信息如下:图34、头文件的识别#include<stdio.h>main(){int a=123;if(a!1)then a=2.3;else a=3;}图45、注释的识别对//、/*/两种注释的识别main(){int a=123;/ghfhgh/if(a!1)then a=2.3;else a=3;/*jkhjkhjh*/ }图56、数组的识别main(){string a[]={"a"}}这块程序代码实现了数组的表示识别图6五、实验心得。