[VIP专享]一个简单的去除重复字段的SQL查询语句
sql查询去掉重复数据的方法

sql查询去掉重复数据的方法
在SQL中,你可以使用`DISTINCT`关键字来查询并去掉重复的数据。
以下是一个简单的例子:
```sql
SELECT DISTINCT column_name
FROM table_name;
```
在这个例子中,`column_name`是你想要查询的列的名称,`table_name`是你想要查询的表的名称。
`DISTINCT`关键字将返回所有不重复的行。
如果你想要根据多个列来去除重复数据,你可以在`DISTINCT`后面列出多个列名,用逗号隔开:
```sql
SELECT DISTINCT column_name1, column_name2
FROM table_name;
```
这个查询将返回在`column_name1`和`column_name2`组合上都不重复的所有行。
请注意,使用`DISTINCT`可能会影响查询的性能,特别是在大数据集上。
如果你经常需要去除重复数据,可能需要考虑使用其他方法,如使用视图或索引,或者在插入数据时进行适当的规范化,以减少重复数据的可能性。
SQL优化技巧之DISTINCT去重

SQL优化技巧之DISTINCT去重DISTINCT是SQL语言中常用的关键词之一,用于去除查询结果中的重复记录。
当查询结果包含重复数据时,使用DISTINCT可以去重,返回唯一的结果。
虽然DISTINCT可以方便地去重,但在处理大数据集时,性能可能会受到影响。
在实际应用中,我们经常遇到需要使用DISTINCT去重的场景,如统计不同城市的用户数量、商品销售记录、订阅用户的订阅频道等。
下面我们将重点介绍几种优化DISTINCT查询的技巧。
1.使用索引在进行DISTINCT查询时,使用适当的索引可以提高查询性能。
创建一个包含DISTINCT字段的索引,可以加快数据库对该字段的速度,从而提高查询效率。
2.使用LIMIT如果查询结果只需要返回少量记录,可以在查询中使用LIMIT限制返回的结果数量。
这样,数据库只需要找到足够数量的唯一记录,而不需要继续和排序,提高了查询性能。
3.使用UNION在一些情况下,使用UNION操作可以代替DISTINCT查询。
UNION操作可以将多个查询结果合并,并去除重复记录。
相比于使用DISTINCT,UNION有时可以更快速地达到去重的效果。
4.使用GROUPBY在一些复杂查询中,使用GROUPBY可以达到去重的目的。
通过将查询结果按照其中一列进行分组,然后使用聚合函数进行统计,即可得到唯一的结果。
5.使用临时表在有大量重复数据的情况下,可以使用临时表进行去重。
将查询结果插入到一个临时表中,然后在临时表上进行DISTINCT操作,最后将去重后的结果返回。
6.考虑业务需求在使用DISTINCT去重前,应该仔细考虑业务需求是否真的需要去重。
有时候,重复数据是由于业务上的不同维度导致的,不一定需要去除。
在确保数据准确性的前提下,根据具体需求决定是否使用DISTINCT。
此外,还有一些SQL引擎或数据库的特定优化,例如MySQL的优化技巧。
可以通过调整数据库配置、使用合适的索引和分区表等方式,进一步提高DISTINCT查询的性能。
一个简单的去除重复字段的SQL查询语句

一个简单的去除重复字段的SQL查询语句2009-11-16 17:12一个简单的去除重复字段的SQL查询语句[2008-11-04 16:01:15 by rainoxu] | 分类:我的知识库今天公司里让.Net程序修改一个程序,需要去掉输出中的重复楼盘名称,一开始想到的是Distinct,但死路不通,只能改道,最终偶在网上找到了一个思路,修改了一下就有了。
先看所有记录(这是我在测试的数据库里做的):OK,我们这样来消除重复项:1.select * from table1 as awhere not exists(select 1 from table1 where logID=a.LogID and ID>a.ID)2.最近做一个数据库的数据导入功能,发现联合主键约束导致不能导入,原因是源表中有重复数据,但是源表中又没有主键,很是麻烦。
经过努力终于解决了,现在就来和大家分享一下,有更好的办法的可以相互交流。
有重复数据主要有一下几种情况:1.存在两条完全相同的纪录这是最简单的一种情况,用关键字distinct就可以去掉example:select distinct * from table(表名) where (条件)2.存在部分字段相同的纪录(有主键id即唯一键)如果是这种情况的话用distinct是过滤不了的,这就要用到主键id的唯一性特点及group by分组example:select * from table where id in (select max(id) from table group by [去除重复的字段名列表,....])3.没有唯一键ID这种情况我觉得最复杂,目前我只会一种方法,有那位知道其他方法的可以留言,交流一下:example:select identity(int1,1) as id,* into newtable(临时表) from table select * from newtable where id in (select max(id) from newtable group by [去除重复的字段名列表,....])drop table newtable关于一个去除重复记录的sql语句2009-8-24 16:33提问者:lichuanbao1234|悬赏分:30 |浏览次数:1075次我要查询一个表中content字段相同的记录的详细信息。
SQL查询去掉重复数据
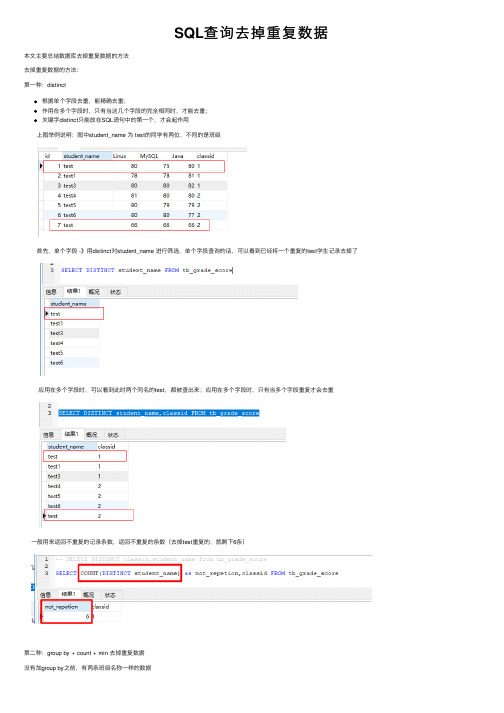
SQL查询去掉重复数据本⽂主要总结数据库去掉重复数据的⽅法去掉重复数据的⽅法:第⼀种:distinct根据单个字段去重,能精确去重;作⽤在多个字段时,只有当这⼏个字段的完全相同时,才能去重;关键字distinct只能放在SQL语句中的第⼀个,才会起作⽤上图举例说明:图中student_name 为 test的同学有两位,不同的是班级⾸先,单个字段 -》⽤distinct对student_name 进⾏筛选,单个字段查询的话,可以看到已经将⼀个重复的test学⽣记录去掉了应⽤在多个字段时,可以看到此时两个同名的test,都被查出来;应⽤在多个字段时,只有当多个字段重复才会去重⼀般⽤来返回不重复的记录条数,返回不重复的条数(去掉test重复的,就剩下6条)第⼆种:group by + count + min 去掉重复数据没有加group by之前,有两条班级名称⼀样的数据加上group by 后,会将重复的数据去掉了count + group +min:去掉重复数据⾸先根据查出重复的数据然后再加上id不在查询结果⾥⾯的,去掉重复数据SELECT * from tb_class where classname in (SELECT classname from tb_class GROUP BY classname HAVING COUNT(classname)>1) and id NOT in (SELECT min(id) from tb_class GROUP BY classname HAVING count(classname)>1)第三种:min、max(这种⽅法在第⼆种中已经⽤到了)参考:https:///download/liangfei207/10325028https:///firstdream/p/7985584.html (较复杂)。
SQL去重的三种方法汇总

SQL去重的三种⽅法汇总
SQL去重的三种⽅法汇总
这⾥的去重是指:查询的时候, 不显⽰重复,并不是删除表中的重复项
1.distinct去重
注意的点:distinct
只能⼀列去重,当distinct后跟⼤于1个参数时,他们之间的关系是&&(逻辑与)关系,只有全部条件相同才会去重
弊端:当查询的字段⽐较多时,distinct会作⽤多个字段,导致去重条件增多
select distinct UserResult from Table1
2.group by去重
去重原理:将重复的⾏进⾏分组,相同的数据只显⽰第⼀⾏
弊端:使⽤group by后,所有查询字段都需要使⽤聚合函数,⽐较繁琐
select min(UserName)UserName,min(UserSex)UserSex,min(UserSubject)UserSubject,min(UserResult)UserResult from Table1 group by UserResult
3.row_number() over (parttion by 分组列 order by 排序列)
弊端:⼩孟还不知道
去重原理:现根据重复列进⾏分组,分组后再进⾏排序,不同的组序号为1,相同的组序号为2,排除为2的就达到了去重效果select *from
(
--查询出重复⾏
select *,row_number() over (partition by UserResult order by UserResult desc)num from Table1
)A
where A.num=1
这⾥安利第三个,row_number(),稳⼀些!。
使用SQL语句去掉重复的记录【两种方法】

使⽤SQL语句去掉重复的记录【两种⽅法】海量数据(百万以上),其中有些全部字段都相同,有些部分字段相同,怎样⾼效去除重复?如果要删除⼿机(mobilePhone),电话(officePhone),邮件(email)同时都相同的数据,以前⼀直使⽤这条语句进⾏去重:delete from 表 where id not in(select max(id) from 表 group by mobilePhone,officePhone,email )ordelete from 表 where id not in(select min(id) from 表 group by mobilePhone,officePhone,email )delete from 表 where id not in(select max(id) from 表 group by mobilePhone,officePhone,email )ordelete from 表 where id not in(select min(id) from 表 group by mobilePhone,officePhone,email )其中下⾯这条会稍快些。
上⾯这条数据对于100万以内的数据效率还可以,重复数1/5的情况下⼏分钟到⼏⼗分钟不等,但是如果数据量达到300万以上,效率骤降,如果重复数据再多点的话,常常会⼏⼗⼩时跑不完,有时候会锁表跑⼀夜都跑不完。
⽆奈只得重新寻找新的可⾏⽅法,今天终于有所收获://查询出唯⼀数据的ID,并把他们导⼊临时表tmp中select min(id) as mid into tmp from 表 group by mobilePhone,officePhone,email//查询出去重后的数据并插⼊finally表中insert into finally select (除ID以外的字段) from customers_1 where id in (select mid from tmp)//查询出唯⼀数据的ID,并把他们导⼊临时表tmp中select min(id) as mid into tmp from 表 group by mobilePhone,officePhone,email//查询出去重后的数据并插⼊finally表中insert into finally select (除ID以外的字段) from customers_1 where id in (select mid from tmp)效率对⽐:⽤delete⽅法对500万数据去重(1/2重复)约4⼩时。
如何在MySQL中进行数据去重和重复数据处理

如何在MySQL中进行数据去重和重复数据处理在MySQL中进行数据去重和重复数据处理概述:在处理大量数据的过程中,经常会遇到数据重复的情况,这不仅会浪费存储空间,还会对数据分析和处理带来困难。
因此,在MySQL数据库中进行数据去重和重复数据处理是一项重要的工作。
本文将介绍一些常用的方法和技巧来帮助你在MySQL中有效地进行数据去重和重复数据处理。
第一部分:数据去重数据去重是指从一个数据集合中删除重复的数据,以保留唯一的数据记录。
方法一:使用DISTINCT关键字在SQL查询中,可以使用DISTINCT关键字来去除重复的数据。
例如,以下查询将返回去除了重复数据的结果集:SELECT DISTINCT column1, column2, ...FROM table_name;请注意,DISTINCT关键字将根据指定的列来判断数据是否重复,因此需要根据实际的需求来选择相应的列。
方法二:使用GROUP BY子句GROUP BY子句用于根据指定的列对数据进行分组,并可用于数据去重。
例如,以下查询将返回根据column1列分组后的结果集,从而去除了重复数据:SELECT column1, column2, ...FROM table_nameGROUP BY column1;需要注意的是,使用GROUP BY子句进行数据去重时,只能选择需要去重的列,而其他列的取值可能是不确定的。
因此,在实际应用中需要注意这一点。
第二部分:重复数据处理重复数据处理是指对数据进行进一步的操作,以处理重复的数据。
方法一:使用DELETE语句在MySQL中,可以使用DELETE语句来删除重复的数据。
例如,以下语句将删除table_name表中column1、column2列有重复值的数据:DELETE FROM table_nameWHERE (column1, column2) IN (SELECT column1, column2FROM table_nameGROUP BY column1, column2HAVING COUNT(*) > 1);需要注意的是,使用DELETE语句会直接删除数据,因此在执行前一定要确保操作正确。
sql语句去除重复记录(多表连接的查询)

sql语句去除重复记录(多表连接的查询)--处理表重复记录(查询和删除)/******************************************************************************************************************************************************1、Num、Name相同的重复值记录,没有⼤⼩关系只保留⼀条2、Name相同,ID有⼤⼩关系时,保留⼤或⼩其中⼀个记录******************************************************************************************************************************************************/--1、⽤于查询重复处理记录(如果列没有⼤⼩关系时2000⽤⽣成⾃增列和临时表处理,SQL2005⽤row_number函数处理)--> --> ⽣成測試數據if not object_id('Tempdb..#T') is nulldrop table#TGoCreate table#T([ID] int,[Name] nvarchar(1),[Memo] nvarchar(2))Insert#Tselect1,N'A',N'A1'union allselect2,N'A',N'A2'union allselect3,N'A',N'A3'union allselect4,N'B',N'B1'union allselect5,N'B',N'B2'Go--I、Name相同ID最⼩的记录(推荐⽤1,2,3),⽅法3在SQl05时,效率⾼于1、2⽅法1:Select* from#T a where not exists(select1 from#T where Name= and ID<a.ID)⽅法2:select a.* from#T a join(select min(ID)ID,Name from#T group by Name) b on = and a.ID=b.ID⽅法3:select* from#T a where ID=(select min(ID) from#T where Name=)⽅法4:select a.* from#T a join#T b on = and a.ID>=b.ID group by a.ID,,a.Memo having count(1)=1⽅法5:select* from#T a group by ID,Name,Memo having ID=(select min(ID)from#T where Name=)⽅法6:select* from#T a where(select count(1) from#T where Name= and ID<a.ID)=0⽅法7:select* from#T a where ID=(select top1 ID from#T where Name= order by ID)⽅法8:select* from#T a where ID!>all(select ID from#T where Name=)⽅法9(注:ID为唯⼀时可⽤):select* from#T a where ID in(select min(ID) from#T group by Name)--SQL2005:⽅法10:select ID,Name,Memo from(select*,min(ID)over(partition by Name) as MinID from#T a)T where ID=MinID⽅法11:select ID,Name,Memo from(select*,row_number()over(partition by Name order by ID) as MinID from#T a)T where MinID=1⽣成结果:/*ID Name Memo----------- ---- ----1 A A14 B B1(2 ⾏受影响)*/--II、Name相同ID最⼤的记录,与min相反:⽅法1:Select* from#T a where not exists(select1 from#T where Name= and ID>a.ID)⽅法2:select a.* from#T a join(select max(ID)ID,Name from#T group by Name) b on = and a.ID=b.ID order by ID⽅法3:select* from#T a where ID=(select max(ID) from#T where Name=) order by ID⽅法4:select a.* from#T a join#T b on = and a.ID<=b.ID group by a.ID,,a.Memo having count(1)=1⽅法5:select* from#T a group by ID,Name,Memo having ID=(select max(ID)from#T where Name=)⽅法6:select* from#T a where(select count(1) from#T where Name= and ID>a.ID)=0⽅法7:select* from#T a where ID=(select top1 ID from#T where Name= order by ID desc)⽅法8:select* from#T a where ID!<all(select ID from#T where Name=)⽅法9(注:ID为唯⼀时可⽤):select* from#T a where ID in(select max(ID) from#T group by Name)--SQL2005:⽅法10:select ID,Name,Memo from(select*,max(ID)over(partition by Name) as MinID from#T a)T where ID=MinID⽅法11:select ID,Name,Memo from(select*,row_number()over(partition by Name order by ID desc) as MinID from#T a)T where MinID=1⽣成结果2:/*ID Name Memo----------- ---- ----3 A A35 B B2(2 ⾏受影响)*/--2、删除重复记录有⼤⼩关系时,保留⼤或⼩其中⼀个记录--> --> ⽣成測試數據if not object_id('Tempdb..#T') is nulldrop table#TGoCreate table#T([ID] int,[Name] nvarchar(1),[Memo] nvarchar(2))Insert#Tselect1,N'A',N'A1'union allselect2,N'A',N'A2'union allselect3,N'A',N'A3'union allselect4,N'B',N'B1'union allselect5,N'B',N'B2'Go--I、Name相同ID最⼩的记录(推荐⽤1,2,3),保留最⼩⼀条⽅法1:delete a from#T a where exists(select1 from#T where Name= and ID<a.ID)⽅法2:delete a from#T a left join(select min(ID)ID,Name from#T group by Name) b on = and a.ID=b.ID where b.Id is null⽅法3:delete a from#T a where ID not in(select min(ID) from#T where Name=)⽅法4(注:ID为唯⼀时可⽤):delete a from#T a where ID not in(select min(ID)from#T group by Name)⽅法5:delete a from#T a where(select count(1) from#T where Name= and ID<a.ID)>0⽅法6:delete a from#T a where ID<>(select top1 ID from#T where Name= order by ID)⽅法7:delete a from#T a where ID>any(select ID from#T where Name=)select* from#T⽣成结果:/*ID Name Memo----------- ---- ----1 A A14 B B1(2 ⾏受影响)*/--II、Name相同ID保留最⼤的⼀条记录:⽅法1:delete a from#T a where exists(select1 from#T where Name= and ID>a.ID)⽅法2:delete a from#T a left join(select max(ID)ID,Name from#T group by Name) b on = and a.ID=b.ID where b.Id is null⽅法3:delete a from#T a where ID not in(select max(ID) from#T where Name=)⽅法4(注:ID为唯⼀时可⽤):delete a from#T a where ID not in(select max(ID)from#T group by Name)⽅法5:delete a from#T a where(select count(1) from#T where Name= and ID>a.ID)>0⽅法6:delete a from#T a where ID<>(select top1 ID from#T where Name= order by ID desc)⽅法7:delete a from#T a where ID<any(select ID from#T where Name=)select* from#T/*ID Name Memo----------- ---- ----3 A A35 B B2(2 ⾏受影响)*/--3、删除重复记录没有⼤⼩关系时,处理重复值--> --> ⽣成測試數據if not object_id('Tempdb..#T') is nulldrop table#TGoCreate table#T([Num] int,[Name] nvarchar(1))Insert#Tselect1,N'A'union allselect1,N'A'union allselect1,N'A'union allselect2,N'B'union allselect2,N'B'Go⽅法1:if object_id('Tempdb..#') is not nulldrop table#Select distinct* into# from#T--排除重复记录结果集⽣成临时表#truncate table#T--清空表insert#T select* from# --把临时表#插⼊到表#T中--查看结果select* from#T/*Num Name----------- ----1 A2 B(2 ⾏受影响)*/--重新执⾏测试数据后⽤⽅法2⽅法2:alter table#T add ID int identity--新增标识列godelete a from#T a where exists(select1 from#T where Num=a.Num and Name= and ID>a.ID)--只保留⼀条记录goalter table#T drop column ID--删除标识列--查看结果select* from#T/*Num Name----------- ----1 A2 B(2 ⾏受影响)*/--重新执⾏测试数据后⽤⽅法3⽅法3:declare Roy_Cursor cursor local forselect count(1)-1,Num,Name from#T group by Num,Name having count(1)>1declare@con int,@Num int,@Name nvarchar(1)open Roy_Cursorfetch next from Roy_Cursor into@con,@Num,@Namewhile @@Fetch_status=0beginset rowcount @con;delete#T where Num=@Num and Name=@Nameset rowcount 0;fetch next from Roy_Cursor into@con,@Num,@Nameendclose Roy_Cursordeallocate Roy_Cursor--查看结果select* from#T /*Num Name ----------- ----1 A2 B(2 ⾏受影响)*/。
sql针对某一字段去重,并且保留其他字段

sql针对某⼀字段去重,并且保留其他字段今天客户提了⼀个⼩需求,希望我能提供⼀条sql语句,帮助他对数据中 _field 这个字段的值去重,并且保留其他字段的数据。
第⼀反应是select distinct,但这种语句在对某个字段去重时,⽆法保留其他字段,所以select distinct不成⽴。
因为⽤户对去重没有要求,字段值重复时保留任意⼀⾏就⾏,所以我想到当字段值重复时,选出对应主键最⼤的那条数据作为保留数据,这样可以实现⽤户的去重需求。
但是⽤户的表中⼜没有主键,没办法,我们只好先使⽤窗⼝函数创建主键了。
因为平时喜欢⽤hive on spark写sql,所以sql语句使⽤中间表的形式来写,_field为去重字段,other_fields为原表table中_field外的其他字段1.创建主键(存在主键则⽆需创建,窗⼝函数需要遍历所有⾏数据,数据量⼤时会很慢)TEMP table1 = select row_number() over (order by _field) as id, _field, other_fields from table2.选出每个_field对应的最⼤主键TEMP table2 = select max(id) as max_id from table1 group by _field3.找出选中的主键对应的原表数据TEMP table3 = select _field, other_fields from table2 left join table on table2.max_id = table1.idOUTPUT table3中间表写法看起来可能有些乱,对于mysql这种⽀持嵌套查询的数据库来说,写起来更好理解id为主键,_field为去重字段,other_fields为原表table中_field外的其他字段select * from table where id in (select max(id) from table group by _field);。
SQL语句去除重复项

SQL语句去除重复项SQL语句去除重复字段项直接上代码--测试数据库Create table Test(Id int primary key identity(1,1) not null,name varchar(100) null,age varchar(100) null)GO--测试数据insert into Test values('aa',18)insert into Test values('aa',19)insert into Test values('aa',20)insert into Test values('bb',25)insert into Test values('bb',20)insert into Test values('cc',22)--解析--分组SELECT name FROM TestGROUP BY name--出现次数SELECT name,COUNT(name) AS出现次数FROM TestGROUP BY name--有重复的数据SELECT NAME,COUNT(NAME) AS重复数量FROM TESTGROUP BY nameHAVING COUNT(name)>1--找出重复项中ID 最⼤的⼀个SELECT NAME,COUNT(NAME) AS重复数量,MAX(ID)AS最⼤的ID FROM TESTGROUP BY nameHAVING COUNT(name)>1--找出重复项中ID 最⼩的⼀个SELECT NAME,COUNT(NAME) AS重复数量,MIN(ID)AS最⼩的ID FROM TESTGROUP BY nameHAVING COUNT(name)>1--找出整个表中的重复数据;SELECT*FROM TESTWHERE name IN(SELECT name FROM TESTGROUP BY nameHAVING COUNT(name)>1)--删除所有重复出现过的项DELETE FROM TESTWHERE ID IN(SELECT ID FROM TEST WHERE name IN(SELECT name FROM TESTGROUP BY nameHAVING COUNT(name)>1))--删除重复项,保留重复项中的⼀个(通常⽤的是这个)--第⼀步:找出重复项--第⼆步:找出重复项中的最⼤id--第三步:删除重复项中ID NOT IN (第⼆步)DELETE FROM TESTWHERE ID IN(SELECT ID FROM TEST WHERE name IN(SELECT name FROM TEST GROUP BY name HAVING COUNT(name)>1) ANDID NOT IN(SELECT MAX(ID) FROM TEST GROUP BY name HAVING COUNT(name)>1))完美。
sqlserver查询去掉重复数据的实现

sqlserver查询去掉重复数据的实现说明:只要数据表“列名”数据相同,则说明是两条重复的数据(ID为数据表的主键⾃动增长)。
推荐使⽤⽅法⼀-- ⽅法⼀select * from 表名 A where not exists(select 1 from 表名 where 列名=A.列名 and ID<A.ID)-- ⽅法⼆select A.* from 表名 A inner join (select min(ID) ID,列名 from 表名 group by 列名) B on A.列名=B.列名 and A.ID=B.ID-- ⽅法三select * from 表名 A where ID=(select min(ID) from 表名 where 列名=A.列名)补充:SQL SERVER 查询去重 PARTITION BYrownumber() over(partition by col1 order by col2)去重的⽅法,很不错,在此记录下:row_number() OVER ( PARTITION BY COL1 ORDER BY COL2)表⽰根据COL1分组,在分组内部根据 COL2排序,⽽此函数计算的值就表⽰每组内部排序后的顺序编号(组内连续的唯⼀的).直接查询,中间很多相同的,但我只想取createdate时间最⼤的⼀条select fromid,subunstall,kouchu,creatdate,syncdate,relate_key from BoxCount_Froms_Open使⽤PARTITION BY fromid ORDER BY creatdate DESC根据中的 fromid分组,根据creatdate组内排序WHERE RN= 1;取第⼀条数据SELECT * FROM (SELECT fromid,subunstall,kouchu,creatdate,syncdate,relate_key,ROW_NUMBER() OVER( PARTITION BY fromid ORDER BY creatdate DESC)RN FROM BoxCount_Froms_Open ) T WHERE RN= 1;以上为个⼈经验,希望能给⼤家⼀个参考,也希望⼤家多多⽀持。
使用MySQL进行数据去重和重复项查找的高效方法

使用MySQL进行数据去重和重复项查找的高效方法概述:数据去重和重复项查找是在数据处理过程中常见的需求,MySQL提供了一些高效的方法来实现这些操作。
本文将介绍如何使用MySQL进行数据去重和重复项查找,并提供一些优化技巧以提高操作效率。
1. 去重方法数据去重是将重复的数据记录合并为一条记录的过程。
MySQL提供了多种方法来实现数据去重,下面列举了几种常见的方法:1.1 使用DISTINCT关键字在SELECT语句中使用DISTINCT关键字可以去除查询结果中的重复记录。
例如,可以使用以下语句查询去重后的数据:```sqlSELECT DISTINCT column1, column2 FROM table;```1.2 使用GROUP BY关键字GROUP BY关键字可以将相同的数据记录按照指定的列进行分组,并可以使用聚合函数对每个分组进行处理。
通过将数据分组,可以实现数据去重的效果。
例如,可以使用以下语句查询去重后的数据:```sqlSELECT column1, column2 FROM table GROUP BY column1, column2;```1.3 使用临时表可以创建一个临时表,将需要去重的数据插入到临时表中后再查询临时表,这样可以方便地实现数据去重。
以下是一个示例代码:```sqlCREATE TABLE temp_table AS SELECT DISTINCT column1, column2 FROM table;```2. 重复项查找方法重复项查找是寻找数据中重复的记录的过程。
MySQL提供了多种方法来实现重复项查找,下面列举了几种常见的方法:2.1 使用GROUP BY关键字和HAVING子句GROUP BY关键字和HAVING子句可以将相同的数据记录按照指定的列进行分组,并筛选出满足条件的分组。
通过将数据分组和筛选,可以实现重复项查找的效果。
例如,可以使用以下语句查询重复项:```sqlSELECT column1, column2 FROM table GROUP BY column1, column2 HAVING COUNT(*) > 1;```2.2 使用自连接可以通过自连接将相同的数据记录连接在一起,通过比较连接后的结果,可以找出重复的记录。
SQL中删除重复记录

SQL中删除重复记录在SQL中删除重复记录是一个常见的操作任务。
重复记录可以在数据表中出现多次,这可能是由于错误的数据导入、重复的插入操作或其他数据更新问题导致的。
删除重复记录可以提高数据的准确性和一致性,从而保证数据的完整性。
下面是一些常见的方法,用于在SQL中删除重复记录。
1.使用DISTINCT关键字:DISTINCT关键字可以用于SELECT语句,以消除查询结果中的重复记录。
通过使用SELECTDISTINCT语句,我们可以获取没有重复记录的结果集。
然后,我们可以将这个结果集插入到新的表中,并删除原始表中的重复记录。
```--创建新表CREATE TABLE new_employeesSELECT DISTINCT name, phoneFROM employees;--删除原始表DROP TABLE employees;--重命名新表ALTER TABLE new_employeesRENAME TO employees;```2.使用ROW_NUMBER(函数和临时表:ROW_NUMBER(函数可以分配唯一的行号给查询结果集中的每一行。
我们可以将这个函数与临时表结合使用,以生成只包含非重复记录的结果集。
然后,我们可以使用新结果集创建一个新表,并删除原始表中的重复记录。
以下示例演示了如何使用ROW_NUMBER(函数和临时表删除重复记录:```--创建临时表CREATE TABLE tmp_employees ASSELECT *, ROW_NUMBER( OVER (PARTITION BY phone ORDER BY name) AS rnFROM employees;--创建新表CREATE TABLE new_employeesSELECT name, phoneFROM tmp_employeesWHERE rn = 1;--删除原始表DROP TABLE employees;--重命名新表ALTER TABLE new_employeesRENAME TO employees;--删除临时表DROP TABLE tmp_employees;```3.使用GROUPBY和HAVING子句:GROUPBY子句用于将查询结果按照指定的列进行分组。
使用SQL语句对重复记录查询、统计重复次数、删除重复数据

使用SQL语句对重复记录查询、统计重复次数、删除重复数据
上周工作中数据库中出现了N多重复记录的情况,导致联合查询时数据异常。
由于数据是客户提供的,当时并没有提供唯一标识列,而且也没预料到会出现重复数据。
哎,大意了。
后来对表中的数据进行了一次重复查询。
1、查找表中重复记录,重复记录是根据单个字段来判断,并统计重复次数
select [字段],count(0) AS 重复次数 from[表名] group by [字段] having count([字段]) > 1
2、删除表中多余的重复记录,重复记录是根据单个字段来判断,只留有rowid最小的记录
delete from [表名] where [字段] in ( select [字段] from [表名] group by [字段] having count([字段]) > 1 )
and rowid not in ( select min(rowid) from [表名] group by [字段] having count([字段]) > 1 )
3、查询无重复记录,根据单个字段查询
select distinct [字段] from [表名] order by [字段] desc
PS:血淋淋的教训,不管别人提供的数据里面否真的都是唯一的,一定要唯一主键或标识列(就算有重复的数据也不怕)。
操作的时候都已唯一主键或标识列来联合,要合理的使用本表主键和对方提供的唯一主键进行操作。
MySQL数据查重、去重的实现语句

MySQL数据查重、去重的实现语句有⼀个表user,字段分别有id、nick_name、password、email、phone。
⼀、单字段(nick_name)查出所有有重复记录的所有记录select * from user where nick_name in (select nick_name from user group by nick_name having count(nick_name)>1);查出有重复记录的各个记录组中id最⼤的记录select * from user where id in (select max(id) from user group by nick_name having count(nick_name)>1);查出多余的记录,不查出id最⼩的记录select * from user where nick_name in (select nick_name from user group by nick_name having count(nick_name)>1) and id not in (select min(id) from user group by nick_name having count(nick_name)>1);删除多余的重复记录,只保留id最⼩的记录delete from user where nick_name in (select nick_name from (select nick_name from user group by nick_name having count(nick_name)>1) as tmp1) and id not in (select id from (select min(id) from user group by nick_name having count(nick_name)>1) as tmp ⼆、多字段(nick_name,password)查出所有有重复记录的记录select * from user where (nick_name,password) in (select nick_name,password from user group by nick_name,password where having count(nick_name)>1);查出有重复记录的各个记录组中id最⼤的记录select * from user where id in (select max(id) from user group by nick_name,password where having count(nick_name)>1);查出各个重复记录组中多余的记录数据,不查出id最⼩的⼀条select * from user where (nick_name,password) in (select nick_name,password from user group by nick_name,password having count(nick_name)>1) and id not in (select min(id) from user group by nick_name,password having count(nick_name)>1);删除多余的重复记录,只保留id最⼩的记录delete from user where (nick_name,password) in (select nick_name,password from (select nick_name,password from user group by nick_name,password having count(nick_name)>1) as tmp1) and id not in (select id from (select min(id) id from user group by nic 以上就是MySQL 数据查重、去重的实现语句的详细内容,更多关于MySQL 数据查重、去重的资料请关注其它相关⽂章!。
sql语句去重

sql语句去重1. distinct表userinfo 数据如下:id name age height10xiaogang2318111xiaoli3117612xiaohei2215213xiaogang2617214xiaoming31176现在需要当前用户表不重复的用户名select distinct name from userinfo如结果(1):name xiaogangxiaoheixiaolixiaoming可是我现在又想得到Id的值,改动如下select distinct name,id from userinfo如结果(2)xiaogang 10xiaoli 11xiaohei 12xiaogang 13xiaoming 14此时distinct同时作用了两个字段,即必须得id与name都相同的才会被排除2. group byselect namefrom userinfogroub by name运行上面3行sql的结果如上面distinct中的结果(1)select name,idfrom userinfogroub by name ,id运行上面3行sql的结果如上面distinct的结果(2)3. row_number() overSQL Server 通过Row_Number 函数给数据库表的记录进行标号,在使用的时候后面会跟over 子句,而over 子句主要用来对表中的记录进行分组和排序的。
语法如下:ROW_NUMBER() OVER(PARTITION BY COLUMN1 ORDER BY COLUMN2)1:Partition BY 用来分组2:Order by 用来排序接下来用 row_number() over 进行去重。
首先用name 进行分组,id进行排序。
具体SQL 语句如下SELECT * FROM (select *,ROW_NUMBER() over(partition by name order by id desc) AS rn from userinfo ) AS u WHERE u.rn=1结果如下id name age height rn13 xiaogang 26 172 112 xiaohei 22 152 111 xiaoli 31 176 114 xiaoming 31 176 1通过使用 row_number over 子句就能将所有的列展示出来,同时进行去重。
一次SQL如何查重及去重的实战记录
⼀次SQL如何查重及去重的实战记录⽬录前⾔1.distinct2.groupby3.row_number窗⼝函数4.删除重复数据第⼀步:找出重复的数据第⼆步:删除重复的数据总结前⾔在使⽤SQL提数的时候,常会遇到表内有重复值的时候,就需要做去重,本⽂归类了常⽤⽅法。
1.distinct题⽬:现在运营需要查看⽤户来⾃于哪些学校,请从⽤户信息表中取出学校的去重数据⽰例:user_profilemysql>SELECT DISTINCT university FROM user_profile;根据⽰例,查询返回以下结果⼩贴⼠:SQL中关键词distinct去重:英语中distinct 代表独⼀⽆⼆的意思,他在SQL表⽰去重的意思:⽐如本题中university这⼀列出现了两次北京⼤学,使⽤distinct进⾏去重查询后,则北京⼤学只出现⼀次。
distinct 通常效率较低distinct 使⽤中,放在 select 后边,对后⾯所有的字段的值统⼀进⾏去重拓展:题⽬:现在运营需要查看⽤户的总数select count(distinct university) from user_profile;2.group by举个栗⼦,现有这样⼀张表 task备注:task_id: 任务id;order_id: 订单id;start_time: 开始时间注意:⼀个任务对应多条订单题⽬:列出任务总数根据⽰例,查询⽅法如下:第1步:列出 task_id 的所有唯⼀值(去重后的记录,null也是值)select task_idfrom Taskgroup by task_id;第⼆步:任务总数select count(task_id) task_numfrom (select task_idfrom Taskgroup by task_id) tmp;3.row_number 窗⼝函数举个栗⼦,现有这样⼀张表 task备注:task_id: 任务id;order_id: 订单id;start_time: 开始时间注意:⼀个任务对应多条订单题⽬:查询整个表重复的数据根据⽰例,查询⽅法如下:– 在⽀持窗⼝函数的 sql 中使⽤select count(case when rn=1 then task_id else null end) task_numfrom (select task_id, row_number() over (partition by task_id order by start_time) rnfrom Task) tmp;⼩贴⼠:MySQL8.0 中可以利⽤ ROW_NUMBER(),DENSE_RANK(),RANK() 三个窗⼝函数来实现排序需要注意的⼀点是 as 后的别名,千万不要与前⾯的函数名重名,否则会报错下⾯给出这三种函数实现排名的案例:–三条语句对于上⾯三种排名select xuehao,score, ROW_NUMBER() OVER(order by score desc) as row_r from scores_tb;select xuehao,score, DENSE_RANK() OVER(order by score desc) as dense_r from scores_tb;select xuehao,score, RANK() over(order by score desc) as r from scores_tb;– ⼀条语句也可以查询出不同排名SELECT xuehao,score,ROW_NUMBER() OVER w AS ‘row_r',DENSE_RANK() OVER w AS ‘dense_r',RANK() OVER w AS ‘r'FROM scores_tbWINDOW w AS (ORDER BY score desc);4.删除重复数据创建测试数据我们创建⼀个⼈员信息表并在⾥⾯插⼊⼀些重复的数据CREATE TABLE Person(id int auto_increment primary key comment ‘主键',Name VARCHAR(20) NULL,Age INT NULL,Address VARCHAR(20) NULL,Sex CHAR(2) NULL);INSERT INTO Person(ID,Name,Age,Address,Sex)VALUES( 1, ‘张三', 18, ‘北京路18号', ‘男' ),( 2, ‘李四', 19, ‘北京路29号', ‘男' ),( 3, ‘王五', 19, ‘南京路11号', ‘⼥' ),( 4, ‘张三', 18, ‘北京路18号', ‘男' ),( 5, ‘李四', 19, ‘北京路29号', ‘男' ),( 6, ‘张三', 18, ‘北京路18号', ‘男' ),( 7, ‘王五', 19, ‘南京路11号', ‘⼥' ),( 8, ‘马六', 18, ‘南京路19号', ‘⼥' );题⽬:数据库中存在重复记录,删除保留其中⼀条我们发现除了⾃增长ID不同以为,有⼏条其他字段都重复的数据出现第⼀步:找出重复的数据mysql>SELECT MAX(ID) ID,Name,Age,Address,SexFROM PersonGROUP BY Name,Age,Address,SexHAVING COUNT(1)>1⼩贴⼠:HAVING将分组后统计出来的数量⼤于1的数据⾏,就是我们要找的重复数据上⾯⽤Max函数或者Min函数均可,只是为了保证取出来的数据的唯⼀性。
SQL中常见的三种去重方法
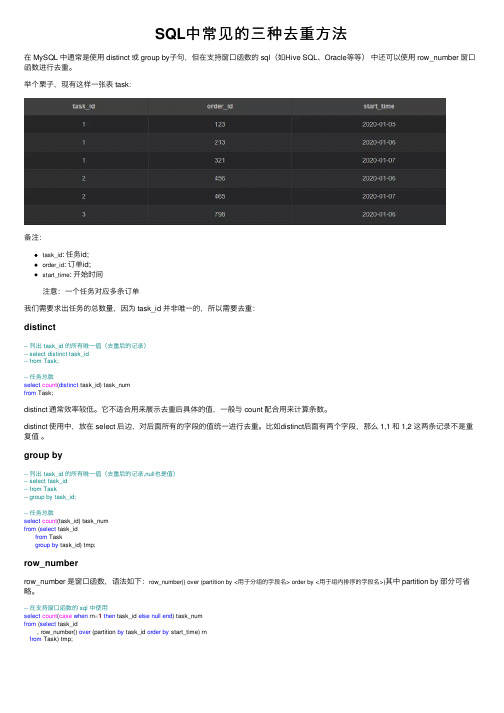
SQL中常见的三种去重⽅法在 MySQL 中通常是使⽤ distinct 或 group by⼦句,但在⽀持窗⼝函数的 sql(如Hive SQL、Oracle等等)中还可以使⽤ row_number 窗⼝函数进⾏去重。
举个栗⼦,现有这样⼀张表 task:备注:task_id: 任务id;order_id: 订单id;start_time: 开始时间注意:⼀个任务对应多条订单我们需要求出任务的总数量,因为 task_id 并⾮唯⼀的,所以需要去重:distinct-- 列出 task_id 的所有唯⼀值(去重后的记录)-- select distinct task_id-- from Task;-- 任务总数select count(distinct task_id) task_numfrom Task;distinct 通常效率较低。
它不适合⽤来展⽰去重后具体的值,⼀般与 count 配合⽤来计算条数。
distinct 使⽤中,放在 select 后边,对后⾯所有的字段的值统⼀进⾏去重。
⽐如distinct后⾯有两个字段,那么 1,1 和 1,2 这两条记录不是重复值。
group by-- 列出 task_id 的所有唯⼀值(去重后的记录,null也是值)-- select task_id-- from Task-- group by task_id;-- 任务总数select count(task_id) task_numfrom (select task_idfrom Taskgroup by task_id) tmp;row_numberrow_number 是窗⼝函数,语法如下:row_number() over (partition by <⽤于分组的字段名> order by <⽤于组内排序的字段名>)其中 partition by 部分可省略。
-- 在⽀持窗⼝函数的 sql 中使⽤select count(case when rn=1then task_id else null end) task_numfrom (select task_id, row_number() over (partition by task_id order by start_time) rnfrom Task) tmp;。
sql查询去除重复值语句

sql查询去除重复值语句sql 单表/多表查询去除重复记录单表distinct多表group bygroup by 必须放在 order by 和 limit之前,不然会报错************************************************************************************1、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断select * from peoplewhere peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最⼩的记录delete from peoplewhere peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)3、查找表中多余的重复记录(多个字段)select * from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)4、删除表中多余的重复记录(多个字段),只留有rowid最⼩的记录delete from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)5、查找表中多余的重复记录(多个字段),不包含rowid最⼩的记录select * from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)(⼆)⽐⽅说在A表中存在⼀个字段“name”,⽽且不同记录之间的“name”值有可能会相同,现在就是需要查询出在该表中的各记录之间,“name”值存在重复的项;Select Name,Count(*) From A Group By Name Having Count(*) > 1如果还查性别也相同⼤则如下:Select Name,sex,Count(*) From A Group By Name,sex Having Count(*) > 1(三)⽅法⼀declare @max integer,@id integerdeclare cur_rows cursor local for select 主字段,count(*) from 表名 group by 主字段 having count(*) >; 1open cur_rowsfetch cur_rows into @id,@maxwhile @@fetch_status=0beginselect @max = @max -1set rowcount @maxdelete from 表名 where 主字段 = @idfetch cur_rows into @id,@maxendclose cur_rowsset rowcount 0⽅法⼆"重复记录"有两个意义上的重复记录,⼀是完全重复的记录,也即所有字段均重复的记录,⼆是部分关键字段重复的记录,⽐如Name字段重复,⽽其他字段不⼀定重复或都重复可以忽略。
SQL去重distinct方法解析

SQL去重distinct⽅法解析⼀ distinct含义:distinct⽤来查询不重复记录的条数,即distinct来返回不重复字段的条数(count(distinct id)),其原因是distinct只能返回他的⽬标字段,⽽⽆法返回其他字段⽤法注意:1.distinct 【查询字段】,必须放在要查询字段的开头,即放在第⼀个参数;2.只能在SELECT 语句中使⽤,不能在 INSERT, DELETE, UPDATE 中使⽤;3.DISTINCT 表⽰对后⾯的所有参数的拼接取不重复的记录,即查出的参数拼接每⾏记录都是唯⼀的4.不能与all同时使⽤,默认情况下,查询时返回的就是所有的结果。
1.1只对⼀个字段查重对⼀个字段查重,表⽰选取该字段⼀列不重复的数据。
⽰例表: psur_listPLAN_NUMBER字段去重,语句:SELECT DISTINCT PLAN_NUMBER FROM psur_list;结果如下:1.2多个字段去重对多个字段去重,表⽰选取多个字段拼接的⼀条记录,不重复的所有记录⽰例表: psur_listPLAN_NUMBER和PRODUCT_NAME字段去重,语句:SELECT DISTINCT PLAN_NUMBER,PRODUCT_NAME FROM psur_list;结果如下:期望结果:只对第⼀个参数PLAN_NUMBER取唯⼀值解决办法⼀:使⽤ group_concat 函数语句:SELECT GROUP_CONCAT(DISTINCT PLAN_NUMBER) AS PLAN_NUMBER,PRODUCT_NAME FROM psur_list GROUP BY PLAN_NUMBER解决办法⼆:使⽤group by语句:SELECT PLAN_NUMBER,PRODUCT_NAME FROM psur_list GROUP BY PLAN_NUMBER结果如下:1.3针对null处理distinct不会过滤掉null值,返回结果包含null值表psur_list如下:对COUNTRY字段去重,语句:SELECT DISTINCT COUNTRY FROM psur_list结果如下:1.4与distinctrow同义语句:SELECT DISTINCTROW COUNTRY FROM psur_list结果如下:⼆聚合函数中使⽤distinct在聚合函数中DISTINCT ⼀般跟 COUNT 结合使⽤。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一个简单的去除重复字段的SQL查询语句2009-11-16 17:12一个简单的去除重复字段的SQL查询语句[2008-11-04 16:01:15 by rainoxu] | 分类:我的知识库今天公司里让.Net程序修改一个程序,需要去掉输出中的重复楼盘名称,一开始想到的是Distinct,但死路不通,只能改道,最终偶在网上找到了一个思路,修改了一下就有了。
先看所有记录(这是我在测试的数据库里做的):OK,我们这样来消除重复项:1.select * from table1 as awhere not exists(select 1 from table1 where logID=a.LogID and ID>a.ID)2.最近做一个数据库的数据导入功能,发现联合主键约束导致不能导入,原因是源表中有重复数据,但是源表中又没有主键,很是麻烦。
经过努力终于解决了,现在就来和大家分享一下,有更好的办法的可以相互交流。
有重复数据主要有一下几种情况:1.存在两条完全相同的纪录这是最简单的一种情况,用关键字distinct就可以去掉example:select distinct * from table(表名) where (条件)2.存在部分字段相同的纪录(有主键id即唯一键)如果是这种情况的话用distinct是过滤不了的,这就要用到主键id 的唯一性特点及group by分组example:select * from table where id in (select max(id) from table group by [去除重复的字段名列表,....])3.没有唯一键ID这种情况我觉得最复杂,目前我只会一种方法,有那位知道其他方法的可以留言,交流一下:example:select identity(int1,1) as id,* into newtable(临时表) from table select * from newtable where id in (select max(id) from newtable group by [去除重复的字段名列表,....])drop table newtable关于一个去除重复记录的sql语句2009-8-24 16:33提问者:lichuanbao1234|悬赏分:30 |浏览次数:1075次我要查询一个表中content字段相同的记录的详细信息。
其中每条记录都有一个标识符state,0表示未发送,1表示已发送。
我要统计所有content相同的记录的信息,包括其中已发送(state=1)的记录。
请问大家看看我这样写有什么问题?select distinct content,name,push_date,total,e.total_sended fromtbl_jingwei_push a,(select count(*) as total_sended from tbl_jingwei_push where state=1 and content=a.content) e这样查出的其他字段都是符合要求的,唯独e.total_sended的结果出问题,它显示的是表中所有state=1的记录,请问大家我要怎么改呢?问题补充:这个sql语句是不对的。
表a是错误的。
请大家指点迷津,我要统计content 相同并且state为1的记录数目。
谢谢各位。
我就是想去掉重复记录并统计一下,只不过如果state=1的话,我要统计一下state=1的记录数。
前提是这些记录的content是相同的。
二楼回答的不对,这和我写的是一样的,a表是不能在e表中用的。
2009-8-24 16:57最佳答案select distinct content,name,push_date,total,sum(case state when 1 then 1 when 0 then 0 end) as total_sended from tbl_jingwei_push以上,希望对你有所帮助!select distinct content,name,push_date,total,e.total_sended fromtbl_jingwei_push a,(select count(*) as total_sended from tbl_jingwei_push where state=1 and e.content=a.content) e|评论2009-8-24 16:54 hrhero|五级select distinct content,name,push_date,total,e.total_sended fromtbl_jingwei_push a,(select count(*) as total_sended from tbl_jingwei_push where state=1 and content=a.content group by content ) e试试这样SQLServer:Distinct和Group by去除重复字段记录2010-10-14 11:31:27| 分类:默认分类 | 标签:|字号大中小订阅重复记录有两个意义,一是完全重复的记录,也即所有字段均重复的记录二是部分关键字段重复的记录,比如Name字段重复,而其他字段不一定重复或都重复可以忽略。
1、对于第一种重复,比较容易解决,使用 select distinct * from tableName 就可以得到无重复记录的结果集。
如果该表需要删除重复的记录(重复记录保留1条),可以按以下方法删除 select distinct * into #Tmp from tableName drop table tableName select * into tableName from #Tmp drop table #Tmp 发生这种重复的原因是表设计不周产生的,增加唯一索引列即可解决。
2、这类重复问题通常要求保留重复记录中的第一条记录,操作方法如下 假设有重复的字段为Name,Address,要求得到这两个字段唯一的结果集 select identity(int,1,1) as autoID, * into #Tmp from tableName select min(autoID) as autoID into #Tmp2 from #Tmp group by Name select * from #Tmp where autoID in(select autoID from #tmp2) 最后一个select即得到了Name,Address不重复的结果集(但多了一个autoID字段,实际写时可以写在select子句中省去此列)其它的数据库可以使用序列,如:create sequence seq1;select seq1.nextval as autoID, * into #Tmp from tableName============zuolo: 我根据上面实例得到所需要的语句为SELECT MAX(id) AS ID,Prodou_id,FinalDye FROM anwell..tblDBDdata GROUP BY Prodou_id,FinalDye ORDER BY id,之前一直想用Distinct来得到指定字段不重复的记录是个误区。
如何写一个SQL语句,能检索出所有某个字段内容有重复的记录A :比如:Name Adress Tele1 Yao China 1102 Zhang Moon 1103 Wang China 1104 Wang China 1105 Yao China 110根据姓名字段检索以后,能筛选出的记录有:1,3,4,5select b.id from table as b,(select count(field),field from table where count(field)>2 group by field) as a where a.field=b.fieldSELECT id from tb where dcount("id","tb","name='"&name&"'")>1附:DCount FunctionSee Also SpecificsYou can use the DCount function to determine the number of records that are in a specified set of records (a domain). Use the DCount function in Visual Basic, a macro, a query expression, or a calculated control.For example, you could use the DCount function in a module to return the number of records in an Orders table that correspond to orders placed on a particular date.DCount(expr, domain, [criteria])The DCount function has the following arguments.Argument Descriptionexpr An expression that identifies the field for which you want to count records. It can be a string expression identifying a field in a table or query, or it can be an expression that performs a calculation on data in that field. In expr, you can include the name of a field in a table, a control on a form, a constant, or a function. If expr includes a function, it can be either built-in or user-defined, but not another domain aggregate or SQL aggregate function.domain A string expression identifying the set of records that constitutes the domain. It can be a table name or a query name for a query that does not require a parameter.criteria An optional string expression used to restrict the range of data on which the DCount function is performed. For example, criteria is often equivalent to the WHERE clause in an SQL expression, without the word WHERE. If criteria is omitted, the DCount function evaluates expr against the entire domain. Any field that is included in criteria must also be a field in domain; otherwise the DCount function returns a Null.RemarksUse the DCount function to count the number of records in a domain when you don't need to know their particular values. Although the expr argument can perform a calculation on a field, the DCount function simply tallies the number of records. The value of any calculation performed by expr is unavailable.Use the DCount function in a calculated control when you need to specify criteria to restrict the range of data on which the function is performed. For example, to display the number of orders to be shipped to California, set the ControlSource property of a text box to the following expression:=DCount("[OrderID]", "Orders", "[ShipRegion] = 'CA'")If you simply want to count all records in domain without specifying any restrictions, use the Count function.Tip The Count function has been optimized to speed counting of records in queries. Use the Count function in a query expression instead of the DCount function, and set optional criteria to enforce any restrictions on the results. Use the DCount function when you must count records in a domain from within a code module or macro, or in a calculated control.You can use the DCount function to count the number of records containing a particular field that isn't in the record source on which your form or report is based. For example, you could display the number of orders in the Orders table in a calculated control on a form based on the Products table.The DCount function doesn't count records that contain Null values in the field referenced by expr unless expr is the asterisk (*) wildcard character. If you use an asterisk, the DCount function calculates the total number of records, including those that contain Null fields. The following example calculates the number of records in an Orders table.intX = DCount("*", "Orders")If domain is a table with a primary key, you can also count the total number of records by setting expr to the primary key field, since there will never be a Null in the primary key field.If expr identifies multiple fields, separate the field names with a concatenation operator, either an ampersand (&) or the addition operator (+). If you use an ampersand to separate the fields, the DCount function returns the number of records containing data in any of the listed fields. If you use the addition operator, the DCount function returns only the number of records containing data in all of the listed fields. The following example demonstrates the effects of each operator when used with a field that contains data in all records (ShipName) and a field that contains no data (ShipRegion).intW = DCount("[ShipName]", "Orders")intX = DCount("[ShipRegion]", "Orders")intY = DCount("[ShipName] + [ShipRegion]", "Orders")intZ = DCount("[ShipName] & [ShipRegion]", "Orders")Note The ampersand is the preferred operator for performing string concatenation. You should avoid using the addition operator for anything other than numeric addition, unless you specifically wish to propagate Nulls through an expression.Unsaved changes to records in domain aren't included when you use this function. If you want the DCount function to be based on the changed values, you must first save the changes by clicking Save Record on the Records menu, moving the focus to another record, or by using the Update method.ExampleThe following function returns the number of orders shipped to a specified country after a specified ship date. The domain is an Orders table.Public Function OrdersCount(ByVal strCountry As String, _ByVal dteShipDate As Date) As IntegerOrdersCount = DCount("[ShippedDate]", "Orders", _"[ShipCountry] = '" & strCountry & _"' AND [ShippedDate] > #" & dteShipDate & "#")End FunctionTo call the function, use the following line of code in the Immediate window::OrdersCount "UK", #1/1/96#我现在正在DAO里面,头都大了就用简单的吧CString strSQL;帮我把上面那一句怎么放入CString 里面?谢谢啊,已经搞定,留给后来人吧:)strSQL.Format("SELECT * from WeakTab where dcount(%c*%c,%cWeakTab%c,%cname='%c&name&%c'%c)>1",34,34,34,34,34,34,34,34);比较麻烦的sql语句,分页的同时要去除某个字段的重复值作者: sql语句来源: sql数据库学习网时间: 2011-05-24 阅读: 次在线投稿回应楼主:或你划定只保留熬头个siteid,后面这个字段反复的记载不要。