5编译原理,陈意云 ,课后答案5
编译原理陈意云课后答案.ppt

5
3.2
• 考虑文法 S -> aSbS|bSaS|ε (a) 为句子abab构造两个不同的最左推导, 以说明此文法二义 (b) 为abab构造对应的最右推导 (c) 为abab构造对应的分析树 (d) 这个文法产生的语言是什么
2019/3/22
luanj@
6
3.2 (续)
luanj@ 9
2019/3/22
3.4 (续)
• 该文法没有体现运算符 |、*、() 、并置的优 先级,因而是二义的。
R=>R|R=> a|R =>a|R*=>a|b* R=>R*=>R|R*=>a|R*=>a|b*
• E -> E’|’T | T T -> TF | F F -> F* | (E) | a | b
• (1) S=>aSbS=>abS=>abaSbS=>ababS=>abab (2) S=>aSbS=>abSaSbS=>abaSbS=>ababS=>abab • S=>aSbS=>aSb=>abSaSb=> abSab =>abab (2)
S a S ε b a S ε (1) 描述的语言是a,b数目相等的串 S b S ε S
S
( L S a L , ( L S a
2019/3/22 luanj@ 3
) S L , ) S a
3.1 (续) - (a,((a,a),(a,a)))
S =>(L) =>(L,S) =>(S,S) =>(a,S) =>(a,(L)) =>(a,(L,S)) =>(a,(S,S)) =>(a,((L),S)) =>(a,((L,S),S)) =>(a,((S,S),S)) =>(a,((a,S),S)) =>(a,((a,a),S)) =>(a,((a,a),(L))) =>(a,((a,a),(L,S))) =>(a,((a,a),(S,S))) =>(a,((a,a),(a,S))) =>(a,((a,a),(a,a))) S =>(L) =>(L,S) =>(L,(L)) =>(L,(L,S)) =>(L,(L,(L))) =>(L,(L,(L,S))) =>(L,(L,(L,a))) =>(L,(L,(S,a))) =>(L,(L,(a,a))) =>(L,(S,(a,a))) =>(L,((L),(a,a))) =>(L,((L,S),(a,a))) =>(L,((L,a),(a,a))) =>(L,((S,a),(a,a))) =>(L,((a,a),(a,a))) =>(S,((a,a),(a,a))) =>(a,((a,a),(a,a)))
编译原理课后答案-第二版
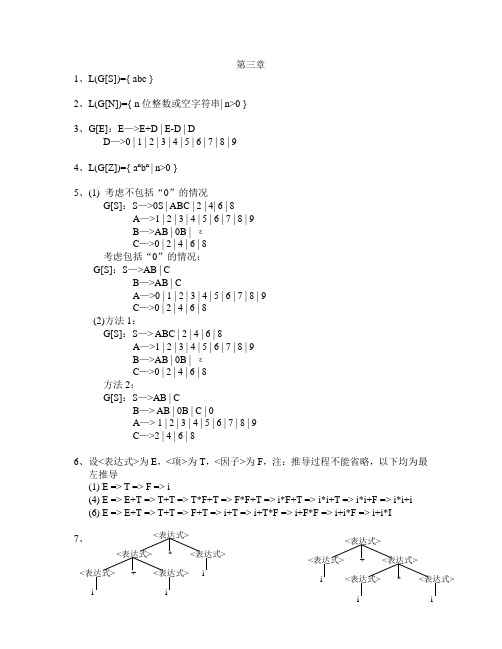
第三章1、L(G[S])={ abc }2、L(G[N])={ n位整数或空字符串| n>0 }3、G[E]:E—>E+D | E-D | DD—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 94、L(G[Z])={ a n b n | n>0 }5、(1) 考虑不包括“0”的情况G[S]:S—>0S | ABC | 2 | 4| 6 | 8A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9B—>AB | 0B | εC—>0 | 2 | 4 | 6 | 8考虑包括“0”的情况:G[S]:S—>AB | CB—>AB | CA—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9C—>0 | 2 | 4 | 6 | 8(2)方法1:G[S]:S—> ABC | 2 | 4 | 6 | 8A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9B—>AB | 0B | εC—>0 | 2 | 4 | 6 | 8方法2:G[S]:S—>AB | CB—> AB | 0B | C | 0A—> 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9C—>2 | 4 | 6 | 86、设<表达式>为E,<项>为T,<因子>为F,注:推导过程不能省略,以下均为最左推导(1) E => T => F => i(4) E => E+T => T+T => T*F+T => F*F+T => i*F+T => i*i+T => i*i+F => i*i+i(6) E => E+T => T+T => F+T => i+T => i+T*F => i+F*F => i+i*F => i+i*I7、<表达式><表达式>*<表达式><表达式>+<表达式>i i i<表达式><表达式>+<表达式>i <表达式>*<表达式>i i8、是有二义性的,因为句子abc 有两棵语法树(或称有两个最左推导或有两个最右推导)最左推导1:S => Ac => abc 最左推导2:S => aB => abc 9、(1)(2) 该文法描述了变量a 和运算符+、*组成的逆波兰表达式10、(1) 该文法描述了各种成对圆括号的语法结构(2) 是有二义性的,因为该文法的句子()()存在两种不同的最左推导: 最左推导1:S => S(S)S => (S)S => ()S => ()S(S)S => ()(S)S => ()()S => ()()最左推导2:S => S(S)S => S(S)S(S)S => (S)S(S)S=> ()S(S)S => ()(S)S => ()()S => ()()11、(1) 因为从文法的开始符E 出发可推导出E+T*F ,推导过程如下:E => E+T =>E+T*F ,所以E+T*F 是句型。
编译原理陈意云版答案

编译原理陈意云版答案一. 引言编译原理是计算机科学中的一门重要课程,它研究的是将高级语言源代码转换为机器能够理解和执行的目标代码的方法和技术。
编译原理的学习对于理解计算机系统的运行原理和提高程序开发效率具有重要意义。
本文将以陈意云版的答案作为参考,向大家介绍编译原理的相关知识。
二. 词法分析词法分析是编译的第一个阶段,它将源代码分解成一个个单词(Token)。
在陈意云版中,常用的词法分析方法有正则表达式和有限自动机。
正则表达式可以方便地描述语言的词法规则,而有限自动机可以用于实现对输入的扫描和匹配。
词法分析器还可以将未识别的字符输入报告为错误。
三. 语法分析语法分析是编译的第二个阶段,它将词法分析器产生的Token序列转化为语法树。
在陈意云版中,常用的语法分析方法是上下文无关文法和递归下降分析。
上下文无关文法用于描述语言的语法规则,而递归下降分析是一种自顶向下的语法分析方法。
语法分析器还可以检查语法错误,并生成错误报告。
四. 语义分析语义分析是编译的第三个阶段,它对语法树进行语义检查和语义处理。
在陈意云版中,常用的语义分析方法有类型检查和符号表管理。
类型检查用于检查表达式和语句中的类型错误,而符号表管理用于管理变量和函数的定义和引用。
语义分析器还可以生成中间代码。
五. 中间代码生成中间代码生成是编译的第四个阶段,它将源代码转化为一种中间形式的代码。
在陈意云版中,常用的中间代码形式有三地址码和虚拟机代码。
中间代码是一种介于源代码和目标代码之间的形式,它可以方便地进行优化和生成目标代码。
六. 代码优化代码优化是编译的第五个阶段,它对中间代码进行优化,以提高程序的执行效率和减少代码的大小。
在陈意云版中,常用的代码优化技术有常量传播、公共子表达式消除和循环优化等。
代码优化器可以根据优化规则对中间代码进行优化,并生成优化后的中间代码。
七. 目标代码生成目标代码生成是编译的最后一个阶段,它将中间代码转化为目标代码。
《编译原理》课后习题答案第5章

《编译原理》课后习题答案第5章《编译原理》课后习题答案第5章.pdf《编译原理》课后习题答案第5章.pdf第5章自顶向下语法分析方法第1题对文法G[S] S→a|∧|(T) T→T,S|S(1) 给出(a,(a,a))和(((a,a),∧,(a)),a)的最左推导。
(2) 对文法G,进行改写,然后对每个非终结符写出不带回溯的递归子程序。
(3) 经改写后的文法是否是LL(1)的?给出它的预测分析表。
(4) 给出输入串(a,a)#的分析过程,并说明该串是否为G的句子。
答案:(1) 对(a,(a,a)的最左推导为:S(T) (T,S) (S,S) (a,S) (a,(T)) (a,(T,S)) (a,(S,S)) (a,(a,S)) (a,(a,a))对(((a,a),∧,(a)),a) 的最左推导为:S(T) (T,S) (S,S) ((T),S) ((T,S),S) ((T,S,S),S) ((S,S,S),S) (((T),S,S),S) (((T,S),S,S),S) (((S,S),S,S),S) (((a,S),S,S),S) (((a,a),S,S),S) (((a,a),∧,S),S) (((a,a),∧,(T)),S)(((a,a),∧,(S)),S)《编译原理》课后习题答案第5章.pdf《编译原理》课后习题答案第5章.pdf(((a,a),∧,(a)),S) (((a,a),∧,(a)),a)(2) 改写文法为:0) S→a 1) S→∧ 2) S→( T ) 3) T→S N 4) N→, S N 5) N→ε非终结符FIRST集FOLLOW集S {a,∧,(} {#,,,)} T {a,∧,(} {)} N {,,ε} {)}对左部为N的产生式可知:FIRST (→, S N)={,} FIRST (→ε)={ε} FOLLOW (N)={)}由于SELECT(N →, S N)∩SELECT(N →ε) ={,}∩ { )}= 所以文法是LL(1)的。
编译原理课后答案 (5)
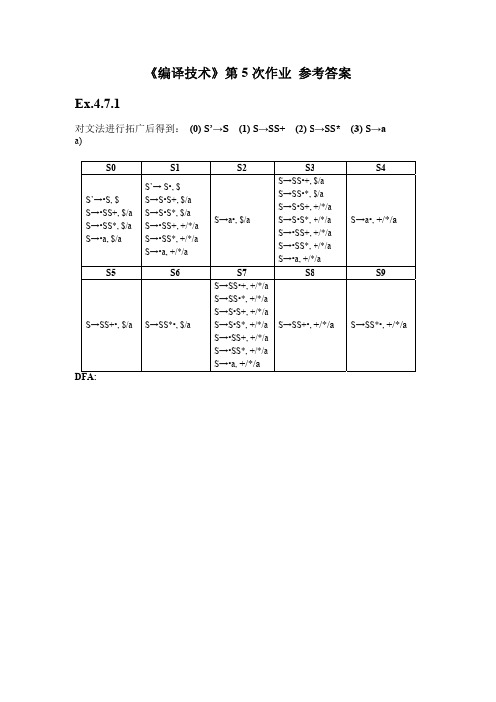
拓广文法的LR(1)项目集规范族及Go函数如下:
I1 I0 S’ S, $ S Aa, $ S bAc, $ S Bc, $ S bBa, $ A d, a B d, c B S A b d S’ S , $ I2 S A a, $ S b Ac, $ S b Ba, $ A d, c B d, a A d , a I10 B d , c I11 S B c, $
S→SS+•,+/*/a/$ $
S→SS*•,+/*/a/$
DFA A:
x. 4.7.4 Ex
说明 明下面文法是 是LALR(1),但 但不是SLR文法 法。 S → Aa | bAc b | dc | bd a A → d 解:拓广文法: (0) S’ → →S (1) S → → Aa (2) S → bAc (3 3) S → dc (4) S → → bda (5) A → d
《编译 译技术》第 5 次作 作业 参考 考答案 Ex x.4.7.1
对文 文法进行拓 拓广后得到: (0) S’→S (1) S→SS+
a) S0 S1 1
S’→ S•, $ S→S•S+, $/a S→S•S*, $/a S→•SS+, +/*/a S→•SS*, +/*/a S→•a, +/* */a
广文法的LR(1)项目集规范 范族及Go函数 数如下: 拓广
I0 S’ S, $ S Aa, $ S bAc, $ S dc, $ S bda, $ A d, a
S A b d
I1 S’ S , $ S A a, $ S b Ac, $ I4 A S b da, $ A d, c d S d c, $ A d , a I9 c I2 I3 S Aa , $ I5 S bA c, $ S bd a, $ A d , c S dc , $ I10 c I6 S bAc , $ a I8 S bda , $
5编译原理,陈意云 ,课后答案5

2019/2/12
luanj@
8
7.4 (续)
• D -> ID_LIST:T ID_LIST -> ID_LIST,ID_LIST|id • D -> { Init(idtable) } ID_LIST:T { for each name in idtable do enter(name, T.type, offset); offset := offset + T.width; end; } ID_LIST -> { Init(idtable1); Init(idtable2) } ID_LIST1,ID_LIST2 { merge(idtable1, idtable2, idtable) } ID_LIST -> id { add(idtable, ); }
编译原理习题课(5)
栾 俊 luanj@ 2019/2/12
7.1
• 把算术表达式 –(a+b)*(c+d)+(a+b-c) 翻译成: (a) 语法树 (b) 有向无环图 (c) 后缀表示 (d) 三地址代码
2019/2/12
luanj@
{ enter(, T.type, offset); offset += T.width; } { T.type = integer; T.width = 4; } { T.type = real; T.width = 8; } { T.type = array(num.val, T1.type); T.width = num.val * T1.width; } { T.type = pointer(T1.type); T.width = 4; }
2019/2/12 luanj@ 11
编译原理-第五章习题答案

上一页
下一页
11
例:5.3 文法:SaAcBe A bAb B d 句子:abbcde
步骤 (1) (2) (3) (4) (5) (6)
栈
# #a #ab #aA #aAb #aA #aAc #aAcd #aAcB #aAcBe #S
输入 abbcde# bbcde# bcde# bcde# cde# cde#
上一页
下一页
20
5)构造算符优先文法G的优先表的算法
思路:对文法中的每一个产生式的候选式检查,判断句型中相邻符号之间 的关系 来构造优先表; 具体算法: FOR 每条产生式P→X1X2…Xn FOR i=1 TO n-1 IF Xi,Xi+1∈VT,THEN Xi=Xi+1; IF i ≤n-2且Xi,Xi+2∈VT,Xi+1∈VN THEN Xi=Xi+2; IF Xi∈VT,Xi+1∈VN THEN FOR FIRSTVT(Xi+1)中的每个a Xi <. a; NEXT IF Xi∈VN,Xi+1∈VT THEN FOR LASTVT(Xi)中的每个a DO a .> Xi+1; NEXT NEXT NEXT
上一页
下一页
8
例:5.1 P85 文法: E→T|E+T T→F|T*F F→i|(E) 句型:i1*i2+i3其中:短语有i1、i2、i3、i1*i2、 i1*i2+i3 直接短语:i1、i2、i3;句柄:i1 例:5.2 P85 文法如上 E 句型:E+T*F+i 短语:E+T*F+i,E+T*F,T*F,i 直接短语:T*F和i E + 句柄:T*F
编译原理(第2版)陈意云张昱编著课后答案

8
(b) 对于句子abab构造两个相应的最右推导.
S aSbS aSb abSaSb abSab abab
rm
rm
rm
rm
rm
S aSbS aSbaSbS aSbaSb aSbab abab
rm
rm
rm
rm
rm
(c)对于句子abab构造两个相应的分析树.
S
S
aSbS
(b) 句子a|aa的两种最左推导. 句子aa*的两种最左推导.
R
R
R
R
R
*
(c)消除二义性
R R ‘|’ S | S S ST | T T U* | U U (R) | a | b
aR
*
R
R
a
a
a
28
4.5 dangling-else文法: stmt if expr then stmt | matched-stmt
tcodenumlexval冶膝嘉篮瞄畅耽找捕案赶骂恭凶魏承弹特选虽丰仁宇汀刺蚁疵夷铁蟹暑牡编译原理第2版陈意云张昱编著课后答案编译原理第2版陈意云张昱编著课后答案stcetcetcttcetcttcnumnumttcnumnum俗铸涣甩呕灿樱涨巾陆蕾胯涣吁飞猜放渭溢惕想诊祭冕捌责境楔烦贴玛耀编译原理第2版陈意云张昱编著课后答案编译原理第2版陈意云张昱编著课后答案55s
( bexpr ) bexpr or bterm bterm bfactor bfactor false
11
true
(c) 试说明此文法产生的语言是全体布尔表达式.
12
练习: 长度为n的字符串, 分别有多少个 前缀, 后缀, 子串, 真前缀, 子序列 ? 前缀: n+1 后缀: n+1 子串: 1+ n+(n-1)+...+1 = 1+n(n+1)/2 真前缀: n 子序列: 1+Cn1+Cn2+Cn3+...+Cnn = 2n
编译原理陈意云课后答案

22.07.2020
luanj@
9
3.16 (续)
• Goto(I4, )) =
I6 S -> (L ) ∙
• Goto(I4, ,)=
I7 L -> L , ∙ S S -> ∙(L) S -> ∙a22.07.20来自0luanj@23
谢谢!!
22.07.2020
luanj@
19
3.26 (续)
I0 L’ -> ∙L, $ L -> ∙MLb, $ L -> ∙a, $ M -> ∙ , a
L I1 L’ -> L ∙, $
I2
M
L -> M ∙Lb, $ L -> ∙MLb, b
L -> ∙a, b
M -> ∙, a
• 只有直接左递归 S -> (L)|a L -> SL’ L’-> ,SL’|ε
22.07.2020
luanj@
3
3.8(b) (续)
• S -> (L)|a L -> SL’ L’-> ,SL’|ε
• FIRST(S) = {(, a} FIRST(L) = FIRST(S) = {(, a} FIRST(L’) = {,, ε}
➢S->aAc A->bAb|b
22.07.2020
luanj@
22
3.30 (续)
• 第二个不是LR(1)文法 第二个文法在句子的正中心按A->b规约, 而只向后看一位是无法判断是否到达句子 的中心位置的
• 存在冲突的项目集:
S -> a∙Ac, $ A -> ∙bAb, c A -> ∙b, c
编译原理(第2版)陈意云张昱编著课后答案

Use as a study resource to enhance comprehension and retention of the material.
编译原理概述
1 Definition
Study of translating source code into machine-readable format.
A tool that performs lexical analysis by scanning and tokenizing the source code.
结论和要点
Key Takeaways
1. Understanding compilation principles is essential for software development.
3 Group Study
Collaborate with classmates to compare and discuss solutions.
第一章:引论
1
Introduction to Compilation
Overview of the compilation process and its importance.
2 Importance
Essential for understanding software development and building compilers.
3 Topics Covered
Lexical analysis, syntax analysis, semantic analysis, code generation, and optimization.
课后答案的使用方法
1 Reference Guide
编译原理(第3版)课本习题答案

第二章 高级语言及其语法描述6.(1)L (G 6)={0,1,2,......,9}+(2)最左推导:N=>ND=>NDD=>NDDD=>DDDD=>0DDD=>01DD=>012D=>0127 N=>ND=>DD=>3D=>34N=>ND=>NDD=>DDD=>5DD=>56D=>568 最右推导:N=>ND =>N7=>ND7=>N27=>ND27=>N127=>D127=>0127 N=>ND=>N4=>D4=>34N=>ND=>N8=>ND8=>N68=>D68=>5687.【答案】G:S →ABC | AC | CA →1|2|3|4|5|6|7|8|9B →BB|0|1|2|3|4|5|6|7|8|9C →1|3|5|7|98.(1)最左推导:E=>E+T=>T+T=>F+T=>i+T=>i+T*F=>i+F*F=>i+i*F=>i+i*iE=>T=>T*F=>F*F=>i*F=>i*(E)=>i*(E+T)=>i*(T+T)=>i*(F+T)=>i*(i+T)=>i*(i+F)=>i*(i+i) 最右推导:E=>E+T=>E+T*F=>E+T*i=>E+F*i=>E+i*i=>T+i*i=>F+i*i=>i+i*iE=>T=>T*F=>T*(E)=>T*(E+T)=>T*(E+F)=>T*(E+i)=>T*(T+i)=>T*(F+i)=>T*(i+i)=>F*(i+i)=>i*(i+i) (2)9.证明:该文法存在一个句子iiiei 有两棵不同语法分析树,如下所示,因此该文法是二义的。
编译原理教程第五版课后答案

编译原理教程第五版课后答案第一章:引言问题1答:编译器是一种将高级编程语言源代码转换为目标机器代码的软件工具。
它由多个阶段组成,包括词法分析、语法分析、语义分析、中间代码生成、代码优化和代码生成等。
问题2答:编译器的主要任务包括以下几个方面: - 词法分析:将源代码划分为词法单元,如标识符、关键字、操作符等。
- 语法分析:根据语法规则,将词法单元组成语法树。
- 语义分析:对语法树进行语义检查,如类型匹配、变量声明等。
- 中间代码生成:将语法树转换为中间代码表示形式。
- 代码优化:对中间代码进行优化,以提高程序的效率。
- 代码生成:将优化后的中间代码转换为目标机器代码。
第二章:词法分析问题1答:词法单元是编译器在词法分析阶段识别的最小的语法单位,它由一个或多个字符组成。
常见的词法单元包括关键字、标识符、常量和运算符等。
问题2答:识别词法单元的方法包括以下几种: - 正则表达式:通过正则表达式匹配字符串,识别出各类词法单元。
- 有限自动机:构建有限状态自动机,根据输入字符的不同状态转移,最终确定词法单元。
- 递归下降法:使用递归下降的方式,根据语法规则划分出词法单元。
第三章:语法分析问题1答:语法分析是编译器的一个重要阶段,它的主要任务是根据给定的语法规则,将词法单元序列转换为语法树。
语法分析有两个主要的方法:自顶向下的分析和自底向上的分析。
问题2答:自顶向下的分析是从文法的起始符号开始,根据语法规则逐步向下展开,直到生成最终的语法树。
常见的自顶向下的分析方法包括LL(1)分析和递归下降分析。
问题3答:自底向上的分析是从输入串开始,逐步合并词法单元,最终生成语法树。
常见的自底向上的分析方法包括LR分析和LALR分析。
第四章:语义分析问题1答:语义分析的主要任务是对语法树进行语义检查和类型推断。
语义分析阶段会检查变量的声明和使用是否合法,以及类型是否匹配等。
问题2答:常见的语义错误包括变量未声明、类型不匹配、函数调用参数不匹配等。
编译原理陈意云版答案

编译原理陈意云版答案: 深入理解编译原理的关键概念和技术介绍编译原理是计算机科学中的重要领域之一,它研究的是将高级程序设计语言转换为计算机能够执行的机器语言的过程。
编译原理涉及到词法分析、语法分析、语义分析、中间代码生成、优化和代码生成等多个方面的知识和技术。
本文将从陈意云的角度出发,对编译原理的关键概念和技术进行深入的解析和讲述。
词法分析词法分析是编译过程的第一个阶段,它的目标是将源程序分解成一个个的记号(token)。
记号可以是关键字、标识符、常量、运算符等。
词法分析器通常采用有限自动机(DFA)来实现。
陈意云在词法分析中着重讲解了正则表达式和有限自动机的理论基础,并提供了一些实例来帮助读者更好地理解和掌握相关概念。
语法分析语法分析是编译过程的第二个阶段,它的目标是根据所给的语法规则,将词法分析产生的记号序列转换为语法树。
语法分析器通常采用上下文无关文法和分析算法来实现。
陈意云在语法分析中详细介绍了上下文无关文法和相关的推导、归约和语法树的构建等概念,并通过实例演示了文法定义和分析过程。
语义分析语义分析是编译过程的第三个阶段,它的目标是检查源程序的语义是否合法,并进行类型检查和作用域分析等。
陈意云在语义分析中提到了常见的语义错误类型和处理方法,并介绍了类型推导、符号表和作用域的概念和实现方式。
语义分析是编译过程中非常重要的阶段,它为后续的中间代码生成和代码优化提供了基础。
中间代码生成中间代码是在编译过程中产生的一种抽象的机器无关的代码表示形式。
中间代码生成是编译过程的第四个阶段,它的目标是将源程序转换为中间表示形式,以便后续的优化和代码生成。
陈意云在中间代码生成中详细介绍了常见的中间表示形式和符号表的设计与实现,并通过实例演示了如何将源程序转换为中间代码。
优化和代码生成优化和代码生成是编译过程的最后两个阶段,它们的目标是提高程序的执行效率和优化代码的质量。
陈意云在优化和代码生成中介绍了常见的优化技术和代码生成策略,并通过实例讲解了如何进行代码优化和生成。
(完整版)编译原理课后习题答案

(完整版)编译原理课后习题答案第一章1.典型的编译程序在逻辑功能上由哪几部分组成?答:编译程序主要由以下几个部分组成:词法分析、语法分析、语义分析、中间代码生成、中间代码优化、目标代码生成、错误处理、表格管理。
2. 实现编译程序的主要方法有哪些?答:主要有:转换法、移植法、自展法、自动生成法。
3. 将用户使用高级语言编写的程序翻译为可直接执行的机器语言程序有哪几种主要的方式?答:编译法、解释法。
4. 编译方式和解释方式的根本区别是什么?答:编译方式:是将源程序经编译得到可执行文件后,就可脱离源程序和编译程序单独执行,所以编译方式的效率高,执行速度快;解释方式:在执行时,必须源程序和解释程序同时参与才能运行,其不产生可执行程序文件,效率低,执行速度慢。
第二章1.乔姆斯基文法体系中将文法分为哪几类?文法的分类同程序设计语言的设计与实现关系如何?答:1)0型文法、1型文法、2型文法、3型文法。
2)2. 写一个文法,使其语言是偶整数的集合,每个偶整数不以0为前导。
答:Z→SME | BS→1|2|3|4|5|6|7|8|9M→ε | D | MDD→0|SB→2|4|6|8E→0|B3. 设文法G为:N→ D|NDD→ 0|1|2|3|4|5|6|7|8|9请给出句子123、301和75431的最右推导和最左推导。
答:N?ND?N3?ND3?N23?D23?123N?ND?NDD?DDD?1DD?12D?123N?ND?N1?ND1?N01?D01?301N?ND?NDD?DDD?3DD?30D?301N?ND?N1?ND1?N31?ND31?N431?ND431?N5431?D5431?7 5431N?ND?NDD?NDDD?NDDDD?DDDDD?7DDDD?75DDD?754 DD?7543D?75431 4. 证明文法S→iSeS|iS| i是二义性文法。
答:对于句型iiSeS存在两个不同的最左推导:S?iSeS?iiSesS?iS?iiSeS所以该文法是二义性文法。
编译原理答案++陈意云+高等教育出版社

《编译原理》习题参考答案(一)Bug report: zpli@Or find: 电一楼二楼全球计算实验室李兆鹏第二章2.3 叙述由下列正规式描述的语言a) 0(0|1)*0b) ((ε|0)1*)*c) (0|1)*0(0|1)(0|1)d) 0*10*10*10*e) (00|11)*((01|10)(00|11)*(01|10)(00|11)*)*Answer:a)以0开始和结尾,而且长度大于等于2的0、1串b)所有0,1串(含空串)c)倒数第三位是0的0、1串d) 仅含3个1的0、1串e) 偶数个0和偶数个1的0、1串(含空串)2.4 为下列语言写出正规定义:f) 由偶数个0和偶数个1构成的所有0和1的串g) 由偶数个0和奇数个1构成的所有0和1的串Answer:标准答案见《编译原理习题精选》P1-P2 1.1&1.2题2.7 用算法2.4为下列正规式构造非确定的有限自动机,给出它们处理输入串ababbab的转换序列。
c)((ε|a)b*)*d)(a|b)*abb(a|b)*Answer:c)NFA:输入串ababbab 的转换序列:0 1456789 145678 789 1456789 10Or 0 1456789 1456789 1236789 1456789 10d) NFA:输入串ababbab 的转换序列:0 1236 1456 789 10 11 12 13 16 11 14 15 16 172.8 用算法2.2把习题2.7的NFA 变换成DFA 。
给出它们处理输入串ababbab 的状态转换序列。
Answer: //针对2.7 (c)3个不同的状态集合:A = {0, 1, 2, 3, 4, 6, 7, 9, 10}B = {1, 2, 3, 4, 5, 6, 7, 9, 10}C = {1, 2, 3, 4, 6, 7, 8, 9, 10} NFA 的转换表:输入符号状态a bA B C B B C C BC子集构造法应用于2.7(c)得DFA:2.11 我们可以从正规式的最简DFA同构来证明两个正规式等价。
编译原理附标准答案五
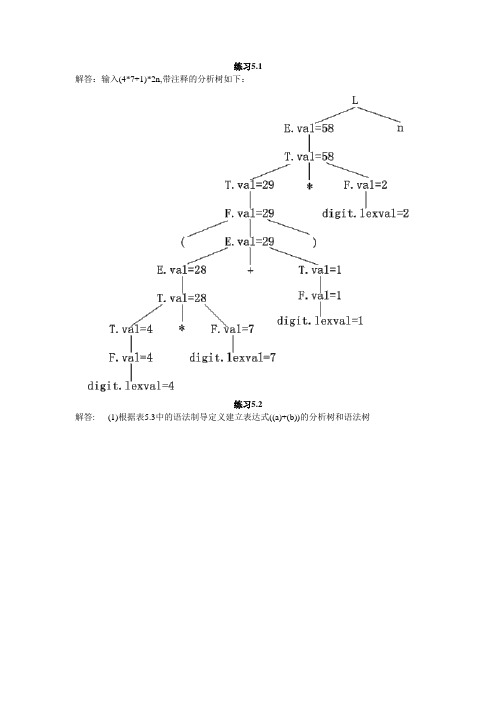
练习5.1解答:输入(4*7+1)*2n,带注释的分析树如下:练习5.2解答: (1)根据表5.3中的语法制导定义建立表达式((a)+(b))的分析树和语法树(2)根据图5.17的翻译模式构造((a)+(b))的分析树和语法树练习5.3解答:设置下面的函数和属性:expr1||expr2:把表达式expr2拼写在表达式expr1后面。
deletep(expr):去掉表达式expr左端的‘(’和右端的‘)’。
E.expr,T.expr,F.expr:属性变量,分别表示E,T,F的表达式。
E.add,T.add,F.add,属性变量,若为true,则表示其表达式中外层有‘+’号,否则无‘+’号。
E.pmark,T.pmark,F.pmark,属性变量,若为true,表示E,T,F的表达式中左端为‘(’,右端是‘)’。
语法制导定义如下:产生式语义规则E -> E1 +T if(T.pmark==true)THEN E.expr=E1.expr||'+'||deletep(T.expr) ELSE E.expr:=E1.expr||'+'||T.expr;E.add:=true;E.pmark:=false;E -> T if(T.pmark==true)THEN E.expr:=deletep(T.expr)ELSE E.expr:=T.expr;E.add:=T.add;E.pmark:=false;T -> T1*F T.expr:=T1.expr||'*'||F.expr; T.add:=false;T.pmark:=false;T -> F T.expr:=F.expr; T.add:=F.add;T.pmark:=F.pmark;F -> (E) if(E.add==false)THEN BEGINF.expr:=E.expr;F.add:=false;F.pmark:=false;ENDELSE BEGINF.expr:='('||E.expr||')';F.add:=true;F.pmark:=true;END;F -> id F.expr:=id.lexval;F.add:=false;F.pmark:=false;练习5.4解答: (1)语法制导定义如下:产生式语义规则E -> E1+T if(E1.type==int) AND (T.type==int) THEN E.type:=intELSE E.type:=real;E -> T E.type:=T.type;T -> num T.type:=int;T -> num.num T.type:=real;(2)设E.pf和T.pf分别是E和T的前缀形式,||是两个字符串的连接,语法制导定义如下:产生式语义规则E -> E1+T if(E1.type==int) AND (T.type==int)THEN E.type:=intELSE BEGINE.type:=real;if(E1.type==int) AND (T.type==real)THEN E1.pf:='inttoreal'||E1.pfELSE if(E1.type==real)AND(T.type==int)THEN T.pf:='inttoreal'||T.pfEND;E.pf:='+'||E1.pf||T.pf;E -> T E.type:=T.type; E.pf:=T.pf;T -> num T.type:=int; T.pf:=int.lexval;T ->num.numT.type:=real; T.pf:=real.lexval;练习5.5解答: (1)用综合属性决定s.val的语法制导定义:产生式语义规则S -> L S.val:=L.val;S ->L1.L2S.val:=L1.val+L2.val*L2.p;L -> B L.val:=B.val; L.p:=2-1;L -> L1B L.val:=L1.val*2+B.val; L.p:=L.p*2-1;B -> 0 B.val:=0;B -> 1 B.val:=1;注:L.p表示恢复L.val的因子。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
10
7.5 (续) (续
• (a) *a-+bc • (c) 表达式翻成前缀形式的语法制导定义
E -> E+T | T T -> T*F | F F -> -F | (E) | id L -> En { printf(E.string); } E -> E1 + T { E.string = “+” + E1.string + T.string; } E -> T { E.string = T.string; } T -> T1*F { T.string = “*” + T1.string + F.string; } T -> F { T.string = F.string; } F -> -F1 { F.string = “-” + F1.string; } F -> (E) { F.string = E.string; } F -> id { F.string = id.value; }
2011-3-28
luanj@
8
7.4 (续) (续
• D -> ID_LIST:T ID_LIST -> ID_LIST,ID_LIST|id • D -> { Init(idtable) } ID_LIST:T { for each name in idtable do enter(name, T.type, offset); offset := offset + T.width; end; } ID_LIST -> { Init(idtable1); Init(idtable2) } ID_LIST1,ID_LIST2 { merge(idtable1, idtable2, idtable) } ID_LIST -> id { add(idtable, ); }
2011-3-28 luanj@ 11
7.7
• 修改图7.11的语法制导定义,为栈机器产生代码。
E → E1 or E2 E → not E1 E → ( E1 ) E → id1 relop id2 E → E1 and E2 { E.place := newtemp; emit (E.place, ‘:=’, E1.place, ‘or’, E2.place) } { E.place := newtemp; emit (E.place, ‘:=’, E1.place, ‘and’, E2.place) } { E.place := E1.place } { E.place := newtemp; emit (E.place, ‘:=’, ‘not’, E1.place) } { E.place := newtemp; emit (‘if’, id1.place, relop.op, id2.place,‘goto’, nextstat+3 ); emit (E.place, ‘:=’, ‘0’ ); emit (‘goto’, nextstat + 2 ); emit (E.place, ‘:=’, ‘1’ ) } { E.place := newtemp; emit (E.place, ‘:=’, ‘1’ ) } { E.place := newtemp; emit (E.place, ‘:=’, ‘0’ ) }
编译原理习题课(5) 编译原理习题课(5)
栾 俊 luanj@ 3/28/2011
7.1
• 把算术表达式 –(a+b)*(c+d)+(a+b-c) 翻译成: (a) 语法树 (b) 有向无环图 (c) 后缀表示 (d) 三地址代码
2011-3-28
luanj@
E → true E → false • 指令解释 指令解释: or: 将栈顶和次栈顶值取出 进行或操作 将结果压栈 将栈顶和次栈顶值取出, 进行或操作,将结果压栈 and: 将栈顶和次栈顶值取出 进行与操作 将结果压栈 将栈顶和次栈顶值取出, 进行与操作,将结果压栈 not: 将栈顶值取出 进行非操作 将结果压栈 将栈顶值取出, 进行非操作,将结果压栈 push name: 将name的值压栈 的值压栈 relop op:将栈顶和次栈顶值取出 判断他们的 关系 将结果压栈 将栈顶和次栈顶值取出, 关系,将结果压栈 将栈顶和次栈顶值取出 判断他们的op关系
2011-3-28 luanj@ 4
7.2
• 把C程序 main(){ int i; int a[10]; while(i <= 10) a[i] = 0; } 的可执行语句翻译成: (a) 语法树 (b) 后缀表示 (c) 三地址代码
2011-3-28 luanj@ 5
2011-3-28 luanj@ 13
7.8
• 表7.4的语法制导定义把E-> id1< id2翻译成 一对语句 if id1<id2 goto ... goto ... 可以用一个语句 if id1>=id2 goto... 来代替,当E是真时执行后继代码。修改表 7.4的语法制导定义,使之产生这种性质的 代码。
2011-3-28
luanj@
9
7.5
• 算符θ作用于表达式e1,e2,...,ek的前缀形式 是θp1p2...pk,其中pi是ei的前缀形式。 (a) 写出a*-(b+c)的前缀形式。 (c) 给出把表达式翻成前缀形式的语法制导 定义。
2011-3-28
luanj@
E → id1 relop id2
E → true E → false
2011-3-28
luanj@
16
7.9
• 下面的C语言程序 main(){ int i, j; while((i || j) && (j > 5)){ i = j; } } 在x86/Linux机器上编译生成的汇编代码如下: 在该汇编代码中有关的指令后加注释,将源程序中的操作 和生成的汇编代码对应起来,以判断确实是用短路计算来 完成布尔表达式计算的。
2011-3-28
luanj@
17
7.9 (续) 题目 (续
… .text .align 4 .gloபைடு நூலகம்l main .type main,@function main: pushl %ebp movl %esp, %ebp subl $8, %esp nop .p2align 4,,7 .L2: cmpl $0, -4(%ebp) jne .L6 cmpl $0, -8(%ebp) jne .L6 jmp .L5 .p2align 4,,7
luanj@ 15
E → E1 and E2
2011-3-28
7.6 (续) 续表 (续
E → not E1 E1.true := E.false; E1.false := E.true; E.code := E1.code E1.true := E.true; E1.false := E.false; E.code := E1.code E.code := gen(‘if’, id1.place, relop.op, id2.place, ‘goto’, E.true) || gen(‘goto’, E.false) [修改为 E.code := gen('if', id1.place, not(relop.op) , 修改为: 修改为 id2.place, 'goto', E.false))] E.code := gen(‘goto’, E.true) E.code := gen(‘goto’, E.false) E → (E1 )
2
7.1 (续) (续
• (a) 语法树
+ + + -
• (b) 有向无环图
+ +
* + + a
c b +
*
+
a
b c
d
a
b
c
d
3
2011-3-28
luanj@
7.1 (续) (续
• (c) 后缀表示 ab+cd+*-ab+c++ • (d) 三地址代码 t1 := a + b t2 := c + d t3 := t1 * t2 t4 := -t3 t5 := t1 + c t6 := t4 + t5
E → true E → false
2011-3-28
luanj@
12
7.7 (续) (续
• E → E1 or E2 E → E1 and E2 E → not E1 E → ( E1 ) E → id1 relop id2 { emit (‘or’) } { emit (‘and’) } { emit (‘not’) } {} { emit(‘push ‘ || ); emit(‘push ’ || ); emit (‘relop ’ || relop.op) } { emit ( ‘1’ ) } { emit ( ‘0’ ) }
7.2 (续) (续
• (a) • (b) 语法树 后缀表示
<= while
= 10 array a i
i 10 <= a i array 0 = while
i 0
2011-3-28
luanj@
6
7.2 (续) (续
• (c) 三地址代码 1: if i <= 10 goto 3 2: goto 5 3: a[i] := 0; 4: goto 1 5: return 0
2011-3-28 luanj@ 14
7.6
• 假转方式 产生式
E → E1 or E2