SPSS学习系列07.-计算与计数
spss第二章变量计算及转换
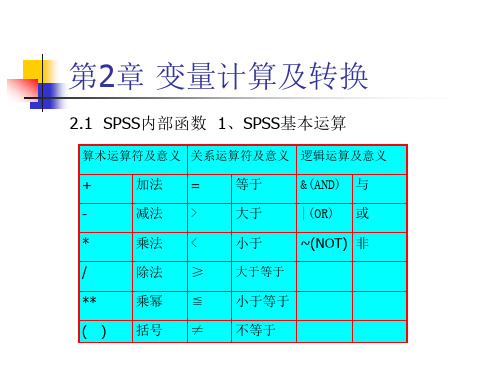
2.1 SPSS内部函数 1、SPSS基本运算
算术运算符及意义 关系运算符及意义 逻辑运算及意义
+
加法 =
等于
&(AND) 与
-
减法 >
大于
|(OR) 或
*
乘法 <
小于
~(NOT) 非
/
除法 ≥ 大于等于
**
乘幂 ≦ 小于等于
( ) 括号 ≠ 不等于
第2章 变量计算及转换
2. SPSS表达式 (1) 算术表达式 A+B (2) 关系表达式 A>B (3) 逻辑表达式 A>b&C=6 逻辑运算中优先级的顺序为:最高级为not, 其次为and,最后为or。
6.排秩的类型,单击Rank Type
2.7 观测量求秩
(1)Rank:
普通秩
(2)Savage score: 基于指数分布规律计算出的一种秩
(3)Fractional rank: 分数形式的秩
(4)Fractional rank as %: 百分比形式的秩
(5)Sum of weights: 加权观测量的总和
3. SPSS内部函数(180个) (1) 算术函数 (2) 统计函数 (3) 概率函数
2.2 变量计算及其运用
Compute 命令 (1)打开数据文件,执行Transform—Compute命令
2.2 变量计算及其运用
(2)输入计算表达式。 (3)定义新变量以及类型。在Target(目标)框中定义目
(6)若选Convert numeric string to numbers 中选项, 则可将字符型转换为数值型
(7)可以同时对多个变量值进行编码
SPSS操作步骤全

两组患者生存时间(月)
无淋巴细胞转移
有淋巴细胞转移
时间 秩次
时间 秩次
12
4.5
5
1
25
10
8
2
27
11
12
4.5
29 12.5
12
4.5
38
17
12
4.5
42
19
17
7
46 20.5
21
8
46 20.5
24
9
56
23
29 12.5
60
24
30
14
34
15
36
16
40
18
48
22
n1=10 T1=162
9 ok
10 统计结果
11 结果解释
卡方检验SPSS操作
二 配对四格表的卡方检验 (配对设计)
1 输入数据
指定频数变量
2 选择Analyze菜单
3 描述统计过程
4 crosstabs过程
5 选行变量 列变量
6 statistics按钮
甲法 乙法
7 选择mcnemar
10 统计结果
抗体滴度 气雾组(亿/ml) 皮下注 合 平均
80
100
射组 计 秩次 80
1:10
2
4
2
8 4.5
9
1:20
15
7
1 31 20 300
1:40
10
12
13 66 49 490
1:80
5
7
9 87 77 385
1:160
1
2
5 95 91.5 91.5
卫生统计学习题软件分析教程例题SPSS07
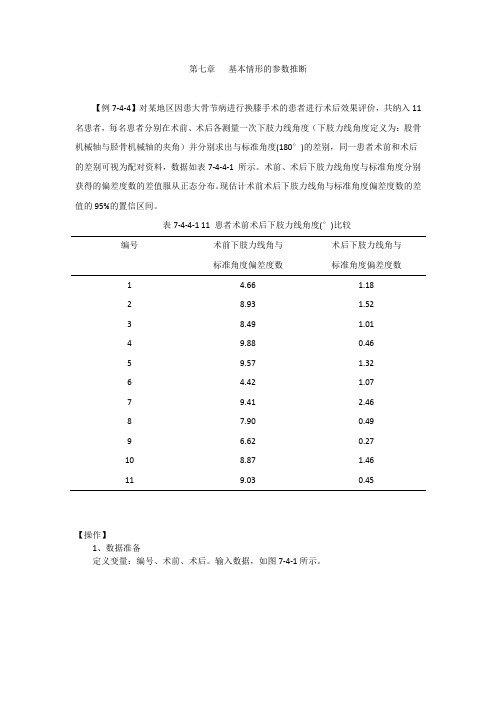
第七章基本情形的参数推断【例7-4-4】对某地区因患大骨节病进行换膝手术的患者进行术后效果评价,共纳入11 名患者,每名患者分别在术前、术后各测量一次下肢力线角度(下肢力线角度定义为:股骨机械轴与胫骨机械轴的夹角)并分别求出与标准角度(180°)的差别,同一患者术前和术后的差别可视为配对资料,数据如表7-4-4-1 所示。
术前、术后下肢力线角度与标准角度分别获得的偏差度数的差值服从正态分布。
现估计术前术后下肢力线角与标准角度偏差度数的差值的95%的置信区间。
表7-4-4-1 11 患者术前术后下肢力线角度(°)比较编号术前下肢力线角与标准角度偏差度数术后下肢力线角与标准角度偏差度数1 4.66 1.182 8.93 1.523 8.49 1.014 9.88 0.465 9.57 1.326 4.42 1.077 9.41 2.468 7.90 0.499 6.62 0.2710 8.87 1.4611 9.03 0.45【操作】1、数据准备定义变量:编号、术前、术后。
输入数据,如图7-4-1所示。
图7-4-1 SPSS的Date View窗口2、统计分析(1)点击Analyze菜单下的Compare Means子菜单,选择Paired-Samples T Test选项,如图7-4-2所示,系统弹出Paired-Samples T Test主对话框,选中变量“术前”、“术后”将其成对送入Paired Variables框内,如图7-4-3所示。
单击OK,输出结果。
图7-4-2 Analyze→Compare Means→Paired-Samples T Test图7-4-3 Paired-Samples T Test主对话框3、输出结果图7-4-4 配对t检验输出结果【例7-6】略。
请根据书上内容自行计算。
【例7-8】将19 只雌性大白鼠随机分为2 组,分别喂以高蛋白和低蛋白饲料8周,各鼠体重的增加克数如下。
spss基础操作及应用PPT课件

4、提供独有的菜单命令向程序文件的转换 功能。几乎每一个对话框都有“Paste”(粘 贴)按钮。可将菜单操作命令直接转换为 程序命令。用户可将命令文件保存或编辑, 也可直接执行该程序文件。因此,编写程 序文件时也不需记忆大量的命令,为高级 用户对数据实现自动分析提供了强有力的 帮助。
8
5、详细的在线帮助(Help)信息。根据不同 层次的用户提供不同的帮助,在使用过程中 用户可以方便地获得相关的帮助信息,也可 直接连接到SPSS Internet主页,查询有关该软 件的最新信息。
可在编辑编辑editedit菜单的选项菜单的选项optionsoptions命令中打开货币命令中打开货币currencycurrency选项卡进行设置其中全部数值选项卡进行设置其中全部数值allallvaluesvalues用于设置首前缀用于设置首前缀prefixprefix尾后缀尾后缀suffixsuffix字符负数字符负数negativevaluenegativevalue栏用于设置负数的首栏用于设置负数的首prefixprefix尾尾suffixsuffix字符系统默认负数的首字符是字符系统默认负数的首字符是小数点分隔符小数点分隔符decimalseparatordecimalseparator栏用于设置小数点的符栏用于设置小数点的符号默认为圆点号默认为圆点periodperiod也可定义为逗号也可定义为逗号commacomma
11
1.2.3 SPSS for Windows的启动
单击“开始”按钮,打开“开始”菜单, 指向“程序”项,选择(单击)“SPSS for Windows\/SPSS for Windows”;或桌面的快 捷方式上双击SPSS for Windows的图标,即 可启动SPSS,SPSS启动成功后出现SPSS的 主画面,进入预备工作状态。
07用SPSS进行卡方检验

③单击
,打开图6-5所示对话框,选中“卡方”,
单击
,返回图6-4所示对话框,再单击
,输出
表6-2和表6-3所示结果。
图6-4 行×列分析对话框
图6-5选择统计方法(卡方检验) 对话框
表6-2 灭螨剂A和灭螨剂B杀灭大蜂螨效果
表6-3 2 检验结果表
3.结果说明
表6-2 灭螨剂A和灭螨剂B杀灭大蜂螨效果
图6-2 例6.1数据输入格式
2. 统计分析 (1)简明分析步骤
数据 → 加权个案 加权个案 频率变量:计数 确定
分析→描述统计→交叉表 行:组别 列:效果 统计量: √ 卡方 继续 确定
频率变量为计数
行变量 列变量 要求进行卡方检验
(2)分析过程说明 ①单击“数据 → 加权个案 ”,打开图6-3对话框,选中
总和
34
46
80
◆ 具体步骤: 1.数据输入 (1)点击数据编辑窗口底部的“变量视图”标签,进入 “变量视图”窗口,分别命名3个变量:“组别”、“效果” 和“计数”。“组别”和“效果”两变量的类型选择为 “字符串”,变量“计数”小数位数定义为0,如图6-1。
图6-1 例6.1资料的变量命名
(2)点击数据编辑窗口底部的“数据视图”标签,进入“数据 视窗”界面,按图6-2格式输入数据资料。
五、用SPSS进行卡方检验
内容
一、2×2列联表的独立性检验 二、R×K列联表的独立性检验 三、适合性检验
一、教学目的、要求: 1. 掌握SPSS中进行X2检验分析的基本命令与操作; 2. 理解用SPSS进行X2检验分析所得结果的含义; 3. 了解X2检验的基本原理。
二、本节重点、难点: 1. SPSS中进行X2检验分析的基本命令与操作; 2. SPSS进行X2检验分析所得结果的含义。
SPSS学习系列07. 计算与计数

07. 计算与计数(一)计算对数据变量做四则运算,并将计算结果存为新变量。
有数据文件:用【计算】功能,求“数学”、“英文”两科的平均成绩。
1. 【转换】——【计算变量】,打开“计算变量”窗口;2. 【目标变量】框输入“平均成绩”作为存放计算结果的新变量,【类型和标签】可选填,3.【数字表达式】框,输入计算表达式:“(数学+英文) / 2”,也可以选用【函数组】中的函数——统计量:“MEAN(数学,英文)”注:使用“自定义表达式”和“函数”的计算结果可能不同,因为二者处理缺失值的方式不同。
例如,自定义加和时,有一个缺失值则和为缺失值;而SUM函数只有全是缺失值时和才为缺失值。
另外,变量可从左侧框中选入。
注:“**”表示次幂;若需要只选择满足某条件的个案进行计算,可以点【如果】,打开“计算变量:If个案”子窗口,设置筛选条件,例如只计算1班学生的平均成绩:4.点【确定】,得到(二)计数统计指定变量“取某个值”或“落入某区间”的出现次数。
例如,统计不及格的学生人数。
有数据文件:一、标记“语文”不及格的学生1.【转换】——【对个案内的值计数】,打开“计算个案内值的出现次数窗口;2.【目标变量】框输入新变量名“语文不及格”,【目标标签】可选填,将左侧变量“语文”选入右侧变量框,3.点【定义值】,打开“要统计的值”子窗口,勾选【范围,从最低到值】,填入59,点【添加】右侧窗口出现“Lowest thru 59”,表示语文成绩最低分到59分的观察值,新变量计数为1,否则计数为0;注:【如果】可选择只满足某条件的个案进行上述计数操作。
4. 点【继续】回到原窗口,点【确定】,得到二、统计每个学生五科中有几科不及格还是数据文件:1.【转换】——【对个案内的值计数】,打开“计算个案内值的出现次数窗口;2.【目标变量】框输入新变量名“不及格科目数”,【目标标签】可选填,把左侧变量“语文”“英语”“数学”“物理”“化学”都选入右侧变量框3.点【定义值】,打开“要统计的值”子窗口,勾选【范围,从最低到值】,填入59,点【添加】右侧窗口出现“Lowest thru 59”,表示五个科目成绩有多少是“最低分到59分”,新变量计数为该值;4. 点【继续】回到原窗口,点【确定】,得到注:若要统计“变量=某值”的个数,第3步“要统计的值”窗口勾选【值】,输入“某值”,点【添加】即可。
SPSSPPT07

对试验结果的分析通常是进行平均数的比较。对于两个平 均数的比较,可以采用均数差异显著性的 t检验。但对两个 以上的平均数进行比较时,若采用逐对均数差异的显著性检 验,则检验的整体可靠性将大大下降。因此,需要考虑采用 其他的方法。
例如:取α =0.05时,3个平均数的差异分析需要进行3次 两两比较,置信水平为0.953=0.86;4个平均数的差异分析 需要进行6次两两比较,置信水平为0.956=0.74;5个平均 数的差异分析需要进行10次两两比较,置信水平为 0.9510=0.60。比较的平均数越多,置信水平就越低。
原假设H0:μ1=μ2=…=μk; 备择假设H1:μ1,μ2,…,μk不全相等。
方差分析的总自由度为数据总个数减1,即:
n
' T
N
1
组间自由度为组数减1,即:
n
' A
k
1
组内自由度为总自由度减组间自由度的差,即:n
' E
n
' T
n
' A
组间方差为:
MSA
SSA
n
' A
SSA k 1
总变差:综合反映数据之间差异的指标叫做总变差。通常 用总离差平方和来表示总变差:
k nj
SST
(Xi j X )2
j 1 i1
组间差异:各试验组相互之间数据的差异叫作组间差异。 由于不同组的试验条件不同,故组间差异主要反映条件误差。 我们用组间离差平方和来表示组间差异:
k
如果“组内差异”占较大的比例,则总变差主要是由试验 误差引起的,此时没有理由认为各组数据之间存在显著差异。
如果“组间差异”占较大的比例,则总变差主要是由条件 误差引起的,此时就有充分的理由认为对不同组施加的不同 试验条件(水平)造成了各组数据之间的显著差异。
SPSS课件-07相关分析

SPSS SPSS 的 操 作 步 骤
第1步:在数据编辑窗口点击分析 / 相关 / 偏相关 在数据编辑窗口点击分析
SPSS SPSS 的 操 作 步 骤
第2步:将身高和肺活量选入变量窗口,将体重选入 将身高和肺活量选入变量窗口, 变量窗口 控制窗口 如果不清楚数据的分布,选择双侧检验。 窗口。 控制窗口。如果不清楚数据的分布,选择双侧检验。
SPSS中相关系数的计算包括: SPSS中相关系数的计算包括: 中相关系数的计算包括
Pearson简单相关系数(最常用)——定距 Pearson简单相关系数(最常用)——定距 简单相关系数 变量
Spearman等级相关系数——定序变量 Spearman等级相关系数——定序变量 等级相关系数—— 相关系数——定序变量( ——定序变量 Kendall τ相关系数——定序变量(非参数 方法) 方法)
描述性统计量
SPSS SPSS 的 输 出 结 果
偏
相关和偏相关系数矩阵
7.3 距离分析
距离分析是衡量变量 间、个案间不相似关 系的指标 例:分析右图两变量y 分析右图两变量y 与x间的不相似性
衡量距离的方法有多种, 衡量距离的方法有多种,其中最常用的是欧氏 距离 欧氏距离: 欧氏距离:是对观测量之间或变量之间相似或 不相似程度的一种测度,以便用于其他分析, 不相似程度的一种测度,以便用于其他分析, 例如聚类分析等。采用以下公式: 例如聚类分析等。采用以下公式:
第7章 相关分析
授课教师:董梅 授课教师: dongmeixz@
第7章 学习内容
7.1 两变量相关分析 7.2 偏相关分析 7.3 距离分析
7.1 两变量相关分析
相关分析可描述几种 变量间的密切程度和 相关方向。 相关方向。常用 Pearson简单相关系数 Pearson简单相关系数 例:右图为15名被调 右图为15 15名被调 查学生的各科成绩, 查学生的各科成绩, 分析各科成绩之间是 否存在相关性。 否存在相关性。
SPSS操作步骤汇总

SPSS操作步骤汇总SPSS学习第⼀章数据⽂件的建⽴数据编码Type:Numeric:数值型 string:字符串型Missing:Measure:scale定量变量 nominal定性变量根据已有的变量建⽴新变量1、对于数据进⾏重新编码Transform—recode into different variables—选择input variable output variable –定义新变量的名称—change—开始定义新旧变量—continue2、通过SPSS函数建⽴新变量Transform—compute variable –从function group中选择公式范围下⾯选择具体的公式—if中设置要改变—continue—OK(可以对变量进⾏各种计算)第⼆章清除数据与基本统计分析1、对不合理的数据检查并清理检查:analysis-description statistic-frequencies—选⼊要检查的数据—OK结果:频数统计表—看是否有错误—missing system清理:1.对系统缺失值的清理Data—select case—if condition is satisfied—if—function group(missing)--下⾯选(missing)--continue—output(delete unselected cases)--OK—对num为哪⼀位的进⾏修改2.对sex=3的清理(直接就清除了)Data—select case—if condition is satisfied—if—sex调⼊再输⼊=3—continue-- output(delete unselected cases)--OK—对num为哪⼀位的进⾏修改2. 对相关变量间逻辑性检查和清理Data—select case—if condition is satisfied—if—输⼊表达式(前后逻辑不相符合的表达式)-- continue-- output(delete unselected cases)--OK—对num为哪⼀位的进⾏修改3.统计描述正态分布统计描述1、正态性检验:Analysis—nonparametric tests—legacy dialogs—1-sample K-S—one-sample Kolomogorov Smirnov test –normal—ok/2、统计描述:Analysis—descriptives--time选⼊—options—ok3、按照男⼥统计描述:data—split file –compare group –sex 调⼊—okAnalysis-descriptive statistic –descriptive—time 调⼊—options选择—OK⾮正态分布资料统计描述1、正态性检验nonparametric2、Analysis—descriptive statistics—frequencies 选⼊--statistics选择—OK第三章T检验1、单样本t检验正态性检验—analyze—compare means—one-sample t test—test value选择要对⽐的数值—OK2、配对样本t检验建⽴数据⽂档—两列(前和后)--正态性检验—analysis- compare means—paired sample t test –调⼊—ok3、两独⽴样本t检验(正态性检验的时候采⽤分开组,其他都要合并在⼀起)建⽴数据库—第⼀列(group)第⼆列(数值)-- data—split file –compare group—调⼊group—ok-正态性检验—OK-- data—split file—选择analysis all—analyze—compare means—independent sample t test—选⼊,分组—OK结果分⽅差齐与否第四章⽅差分析(前提正态)1、单因素⽅差分析(就是平常的三个组⽐较)建⽴数据库—第⼀列(group)第⼆列(数值)- data—split file –compare group—调⼊group—ok-正态性检验—OK-- data—splitfile—选择analysis all--analyze—compare means—one-way-anova—数据调⼊dependent list—分组调⼊factor------options—descriptive基本统计描述—homogeneity of variance做⽅差齐性分析—OK2、⽅差分析两两⽐较analyze—compare means—one-way-anova---数据调⼊dependent list—分组调⼊factor—点post hoc—选择SNK LSD3、随机区组设计⽅差分析建⽴数据库—第⼀列(group)第⼆列(block)第三列(数值)--按照group split开,进⾏正态性检验—OK—general liner model—univairate—数值调⼊dependent variable—group和block 调⼊fixed factor—model—custom—build terms(main effects)再把group和block调⼊model下的矩形框---continue—OK如果区组间⽆差别,组间进⾏两两⽐较。
SPSS操作实验手册

SPSS试验操作指导手册(2023版)2.SPSS数据整顿2.1 SPSS数据文献旳建立SPSS数据文献旳建立可以运用【File(文献)】菜单中旳命令来实现。
详细来说, SPSS提供了四种创立数据文献旳措施:●新建数据文献【File(文献)】→【New(新建)】→【Data(数据)】命令;●直接打开已经有数据文献【File(文献)】→【Open (打开)】→【Data(数据)】命令;●使用数据库查询;【File(文献)】→【Open Database(打开数据库)】→【New Query(新建查询)】命令, 弹出【Database Wizard(数据库向导)】对话框●从文本向导导入数据文献。
【File(文献)】→【Read Text Data(打开文本数据)】命令, 弹出【Open Data(打开数据)】对话框实例分析: 股票指数旳导入文献2-1.xls是上证指数从2023年1月4日至2023年10月16 日旳数据资料, 包括了开盘价、当日最高价、当日最低价和收盘价等选项, 请将该数据导入至SPSS中。
2.2 SPSS数据文献旳属性一种完整旳SPSS文献构造包括变量名称、变量类型、变量名标签、变量值标签等内容。
注意: SPSS数据文献中旳一列数据称为一种变量, 每个变量都应有一种变量名。
SPSS数据文献中旳一行数据称为一条个案或观测量(Case)2.2.1 实例分析: 员工满意度调查表旳数据属性设计1.实例内容为了提高员工旳工作积极性, 完善企业各方面管理制度, 并到达有旳放矢旳目旳, 某企业决定对我司员工进行不记名调查, 但愿理解员工对企业旳满意状况。
请根据该企业设计旳员工满意度调查题目(行政人事管理部分)旳特点, 设计该调查表数据在SPSS旳数据属性。
2.实例操作详细环节如下文献(2-2.sav.)Step01: 打开SPSS中旳Data View窗口, 录入或导入原始调查数据。
Step02:选择菜单栏中旳【File(文献)】→【Save (保留)】命令, 保留数据文献, 以免丢失。
《spss统计学》第七章态度调查及社会测量

第七章态度调查及社会测量第一节态度调查的一般概述一、什么是态度调查态度是个体对某一对象所持的评价和行为倾向。
如果不是不可能的话,至少也是很难对态度进行直接测量。
一般研究者依据个体对其信念和情感的表达即意见来推测或估计他的态度。
这些意见可以通过个体对问题的反应获得。
依据个体表达出来的意见推测其态度有很大的局限性。
首先,人们可以掩饰和隐藏其真实态度,而表达出社会可接受的意见。
其次,人们可能并不一定真正知道他们对一个社会问题的感受,或对这类问题从未考虑过。
第三,人们可能对一个抽象的情景感受不深,除非其面对真实情景,否则无法预测其反应或行为。
即使是个体的行为本身,也不总能标志其态度。
当西方政治家们吻幼儿时,他们的行为不一定真实表示他们喜欢幼儿。
社会风俗或为博得社会赞同的愿望使得许多公开的行为表露仅仅为了形式,很少与人们的内心情感有关。
尽管如此,在许多情况下,意见的描述和测量还是可能与人们的真实态度密切关联的。
二、态度测量的方法H.C.林格伦认为,态度测量主要是测量态度的方向和强度。
态度的方向反映个体对对象的好恶及肯定或否定;态度的强度反映个体对对象感受的力量或深度。
当今测量态度的方法主要有:自我评定法、自由反应法、行为观察法及生理反应法等。
自我评定法是要求被测者对一定项目进行自我评定,测定时主要测定态度的情感成分,一般用数字表示其结果。
自我评定的手段有总和等级评定法和社会距离量表法。
自由反应法主要测定态度的认知成分,测定时要求被测者做出自由反应。
主要包括问卷法、投射法、语句完成法等。
这些方法已有专门叙述,在此不再赘述。
行为观察法主要是观察被测量者的行为表现,根据其行为表现估计其对对象的态度。
它的优点是可以不使被测量者觉察从而获得的资料比较可靠。
其不足在于行为和态度并不是一一对应的简单关系。
因此一般不宜单独以观察行为的结果来确定一个人的态度,而是与其它态度测量方法结合使用。
生理反应法是测量被测者的生理反应以确定其态度的方法,主要测定人们态度的情感因素的强度。
SPSS_17中文教程23414

SPSS 17中文版统计分析典型实例精粹目录第一篇 SPSS 17基础知识第1章 SPSS 17入门 (3)1.1 SPSS 软件的特点 (3)1.2 SPSS的组成与安装 (4)1.2.1 SPSS for Windows 17.0的模块介绍 (4)1.2.2 SPSS for Windows 17.0的安装步骤 (5)1.3 SPSS的运行方式 (10)1.4 SPSS的主要界面 (10)1.4.1 SPSS的启动 (10)1.4.2 SPSS的数据编辑窗口. 111.4.3 SPSS的结果输出窗口 151.5 本章小结 (18)第2章数据的基本操作 (19)2.1 建立数据文件 (19)2.1.1 输入数据建立数据文件 (19)2.1.2 直接打开其他格式的数据文件 (20)2.1.3 使用数据库查询建立数据文件 (21)2.1.4 导入文本文件建立数据文件 (22)2.2 编辑数据文件 (23)2.2.1 输入数据 (23)2.2.2 定义数据的属性 (24)2.2.3 插入或删除数据 (33)2.2.4 数据的排序 (34)2.2.5 选择个案 (35)2.2.6 转置数据 (38)2.2.7 合并数据文件 (38)2.2.8 数据的分类汇总 (44)2.2.9 数据菜单的其他功能.. 462.3 数据加工 (47)2.3.1 数据转换 (47)2.3.2 数据的手动分组(编码) (50)2.3.3 数据的自动分组(编码) (54)2.3.4 产生计数变量 (55)2.3.5 数据秩(序)的确定.. 572.3.6 替换缺失值 (59)2.4 数据文件的保存或导出 (61)2.4.1 保存数据文件 (61)2.4.2 导出数据文件 (62)2.5 本章小结 (62)第3章 SPSS基础统计描述 (63)3.1 数理统计量概述 (63)3.1.1 均值(Mean)和均值标准误差(S.E. Mea n) (63)3.1.2 中位数(Median) (64)3.1.3 众数(Mode) (64)3.1.4 全距(Range) (65)3.1.5 方差(Variance)和标准差(Standard Deviatio n) (65)3.1.6 峰度(Kurtosis)和偏度(Skewness).. 663.1.7 四分位数(Quartiles)、十分位数(Deciles)和百分位数(Percentiles) (66)3.2 数据描述 (67)3.3 频数分析 (69)3.4 探索分析 (73)3.5 交叉列联表分析 (78)3.6 比率分析 (84)3.7 P-P图和Q-Q图 (86)3.8 图表绘制 (89)3.8.1 条形图 (89)3.8.2 线图 (94)3.8.3 面积图 (96)3.8.4 饼形图 (98)3.8.5 高低图 (99)3.8.6 箱图 (101)3.8.7 直方图 (103)3.9 本章小结 (104)第4章 SPSS基础模块分析 (105)4.1 均值分析 (105)4.1.1 均值的计算公式 (105)4.1.2 均值分析菜单 (106)4.2 方差分析 (108)4.2.1 单因素方差分析 (109)4.2.2 其他方差分析 (113)4.3 参数检验 (116)4.3.1 单样本T检验 (117)4.3.2 其他参数检验 (119)4.4 非参数检验 (120)4.4.1 卡方检验 (121)4.4.2 其他非参数检验 (124)4.5 回归分析 (131)4.5.1 线性回归 (131)4.5.2 其他回归分析 (138)4.6 聚类分析 (146)4.6.1 两步聚类分析 (146)4.6.2 其他聚类分析 (152)4.7 判别分析 (154)4.7.1 判别的函数公式 (155)4.7.2 判别分析的菜单 (155)4.8 因子分析与主成分分析 (161)4.8.1 因子分析 (161)4.8.2 主成分分析 (166)4.9 时间序列分析 (167)4.9.1 定义日期变量 (168)4.9.2 创建时间序列 (169)4.9.3 填补缺失数据 (171)4.9.4 时间序列分析 (171)4.10 生存分析 (172)4.10.1 寿命表分析 (173)4.10.2 其他生存分析 (174)4.11 相关分析 (176)4.11.1 简单相关分析 (176)4.11.2 散点图 (181)4.11.3 偏相关分析 (184)4.12 信度分析 (186)4.12.1 信度分析概述 (187)4.12.2 SPSS信度分析 (189)4.12.3 信度分析的其他问题 (192)4.13 本章小结 (197)第二篇 SPSS 17统计分析应用实例第一部分调查统计第5章调查统计入门实例 (203)5.1 硬币均匀性判断 (203)5.1.1 实例内容说明 (203)5.1.2 实现方法分析 (204)5.1.3 具体操作步骤 (204)5.2 使用回归分析判断住房与收入的关系 (207)5.2.1 实例内容说明 (207)5.2.2 实现方法分析 (208)5.2.3 具体操作步骤 (208)5.3 不同性别同学成绩的均值和方差分析 (216)5.3.1 实例内容说明 (216)5.3.2 实现方法分析 (216)5.3.3 具体操作步骤 (216)5.4 本章小结 (220)第6章调查统计提高实例 (221)6.1 学生身高的探索性分析 (221)6.1.1 实例内容说明 (221)6.1.2 实现方法分析 (222)6.1.3 具体操作步骤 (222)6.2 使用对数线性模型分析骨折资料 (229)6.2.1 实例内容说明 (229)6.2.2 实现方法分析 (229)6.2.3 具体操作步骤 (230)6.3 培训班学习成绩的显著性分析 (237)6.3.1 实例内容说明 (237)6.3.2 实现方法分析 (238)6.3.3 具体操作步骤 (238)6.4 本章小结 (241)第7章调查统计经典实例 (243)7.1 学习成绩的聚类分析 (243)7.1.1 实例内容说明 (243)7.1.2 实现方法分析 (243)7.1.3 具体操作步骤 (244)7.2 身体生长发育指标的地区显著性差异判断 (251)7.2.1 实例内容说明 (251)7.2.2 实现方法分析 (252)7.2.3 具体操作步骤 (252)7.3 复习时间和考试成绩的关系判断 (262)7.3.1 实例内容说明 (262)7.3.2 实现方法分析 (263)7.3.3 具体操作步骤 (263)7.4 本章小结 (266)第二部分市场研究第8章市场研究入门实例 (269)8.1 机电产品销售额的影响因素分析 (269)8.1.1 实例内容说明 (269)8.1.2 实现方法分析 (270)8.1.3 具体操作步骤 (270)8.2 消费支出与可支配收入的线性回归分析 (276)8.2.1 实例内容说明 (276)8.2.2 实现方法分析 (277)8.2.3 具体操作步骤 (277)8.3 商品的季节性分析 (289)8.3.1 实例内容说明 (289)8.3.2 实现方法分析 (290)8.3.3 具体操作步骤 (290)8.4 本章小结 (300)第9章市场研究提高实例 (301)9.1 保险公司革新速度与规模及其类型间的关系分析 (301)9.1.1 实例内容说明 (301)9.1.2 实现方法分析 (302)9.1.3 具体操作步骤 (302)9.2 不同厂家同种产品的质量分析 (313)9.2.1 实例内容说明 (313)9.2.2 实现方法分析 (314)9.2.3 具体操作步骤 (314)9.3 合成纤维的强度与拉伸倍数的关系分析 (318)9.3.1 实例内容说明 (318)9.3.2 实现方法分析 (319)9.3.3 具体操作步骤 (319)9.4 本章小结 (325)第10章市场研究经典实例 (327)10.1 灯丝不同的灯泡的使用寿命分析 (327)10.1.1 实例内容说明 (327)10.1.2 实现方法分析 (327)10.1.3 具体操作步骤 (328)10.2 不同商品的消费者满意度分析 (336)10.2.1 实例内容说明 (336)10.2.2 实现方法分析 (337)10.2.3 具体操作步骤 (337)10.3 顾客对不同款式衬衣喜爱程度的分析 (344)10.3.2 实现方法分析 (344)10.3.3 具体操作步骤 (344)10.4 本章小结 (348)第三部分企业/政府数据分析第11章企业/政府数据分析入门实例 (351)11.1 儿童身高数据频数分析 (351)11.1.1 实例内容说明 (351)11.1.2 实现方法分析 (352)11.1.3 具体操作步骤 (352)11.2 百姓对奥运会评价的方差分析 (360)11.2.1 实例内容说明 (360)11.2.2 实现方法分析 (361)11.2.3 具体操作步骤 (361)11.3 居民交通工具使用情况的回归分析 (369)11.3.1 实例内容说明 (369)11.3.2 实现方法分析 (370)11.3.3 具体操作步骤 (370)11.4 本章小结 (377)第12章企业/政府数据分析提高实例 (379)12.1 卫生部门对居民寿命情况的分析 (379)12.1.1 实例内容说明 (379)12.1.2 实现方法分析 (379)12.1.3 具体操作步骤 (380)12.2 农作物产量与降水量和平均温度的相关性分析 (386)12.2.1 实例内容说明 (386)12.2.3 具体操作步骤 (387)12.3 加强体育锻炼与增强身体素质的关系分析.. 39012.3.1 实例内容说明 (390)12.3.2 实现方法分析 (390)12.3.3 具体操作步骤 (391)12.4 本章小结 (394)第13章企业/政府数据分析经典实例 (395)13.1 当代大学生价值观的因子分析 (395)13.1.1 实例内容说明 (395)13.1.2 实现方法分析 (396)13.1.3 具体操作步骤 (397)13.2 职业女性家庭特征资料的信度评价 (404)13.2.1 实例内容说明 (404)13.2.2 实现方法分析 (405)13.2.3 具体操作步骤 (405)13.3 对国内生产总值和零售总额之间的关系分析 (412)13.3.1 实例内容说明 (412)13.3.2 实现方法分析 (413)13.3.3 具体操作步骤 (414)13.4 本章小结 (420)第四部分医学统计分析第14章医学统计分析入门实例 (423)14.1 血红蛋白值描述性统计分析 (423)14.1.1 实例内容说明 (423)14.1.2 实现方法分析 (424)14.1.3 具体操作步骤 (424)14.2 环氯胍的半数致死剂量计算 (428)14.2.1 实例内容说明 (428)14.2.2 实现方法分析 (429)14.2.3 具体操作步骤 (429)14.3 发硒与血硒的相关分析 (435)14.3.1 实例内容说明 (435)14.3.2 实现方法分析 (436)14.3.3 具体操作步骤 (436)14.4 本章小结 (439)第15章医学统计分析提高实例 (441)15.1 用统计图描述血压状态与冠心病的关系 (441)15.1.1 实例内容说明 (441)15.1.2 实现方法分析 (441)15.1.3 具体操作步骤 (442)15.2 判断红细胞计数的频数是否呈正态分布 (448)15.2.1 实例内容说明 (448)15.2.2 实现方法分析 (448)15.2.3 具体操作步骤 (449)15.3 胃癌患者发生术后院内感染的影响因素分析 (452)15.3.1 实例内容说明 (452)15.3.2 实现方法分析 (453)15.3.3 具体操作步骤 (453)15.4 本章小结 (462)第16章医学统计分析经典实例 (463)16.1 不同治疗方案的生存率分析 (463)16.1.1 实例内容说明 (463)16.1.2 实现方法分析 (464)16.1.3 具体操作步骤 (465)16.2 不同制剂的药效分析 (473)16.2.1 实例内容说明 (473)16.2.2 实现方法分析 (473)16.2.3 具体操作步骤 (474)16.3 同种药物在不同治疗阶段的药效分析 (481)16.3.1 实例内容说明 (481)16.3.2 实现方法分析 (481)16.3.3 具体操作步骤 (483)16.4 本章小结 (487)《SPSS 17中文版统计分析典型实例精粹》:以经典统计学软件SPSS 17中文版为写作平台,提供软件命令的中英对照基础篇学习软件基本操作和统计描述知识,实例篇详解案例应用原理、流程和操作技巧36个实例典型、丰富,涉及调查统计、市场研究、企业/政府数据分析和医学统计领域循序渐进、由浅入深,围绕SPSS应用的原理、流程和操作技巧娓娓阐述插图:1.3 SPSS的运行方式SPSS提供了三种基本的运行方式:完全窗口菜单运行方式、程序运行方式和批处理方式。
SPSS使用教程

数据转换
算术表达式
SPSS算术表达式是由常量、变量、算术运算 符、圆括号、函数等组成的句子 算术运算符主要包括:+(加)、-(减)、 *(乘)、/(除)、 **(乘方) 操作对象的数据类型为数值型
例如:根据员工的基本工资、失业保险、奖 金等数据项,计算实际月收入 例如:例如进行标准化处理
对数据的原有分布形态进行转换
数据转换是对所有个案或部分个案进行操作,每个个案有自己 的计算结果,数据转换结果应保存到一个指定变量中,该变量的数据 类型应与计算结果的数据类型一致相
运算顺序:乘方优先,乘、除其次,加、减最后
数据转换——算术表达式
操作演示
运用算术表达式计算“学生成绩一.sav”中 poli、chi和math三门成绩的平均成绩
数据分组——课堂练习2
打开“住房状况调查.sav”,请按照以下 要求,重新记录变量“文化程度”的数据 1:高中(中专)、初中及以下 2:大学(本、专科)、研究生及以上 请同学上讲台演示练习结果
要点小结
掌握和熟悉以下操作
排序 计算(转化) 计数 分类汇总 分组
7
数据排序是对整行数据排序,而不是只对某列变量排序
数据排序
数据排序类型
数据排序
操作演示
单值排序 多重排序
首先按主排序变量值的大小依次排序 然后对那些具有相同主排序变量值的数据,再按 照第二排序变量值的大小次序依次排序下去
住房状况调查.sav 请对住房状况调查.sav中的数据做多重排序 ,要求如下
6
2013-3-19
数据分组
数据分组的目的
spss-07--2-2011

例 数 合 激光组 冷紫组 计
秩号 范围
平均 秩号
例数少组 秩 和
0 6 8 7 21(m)
2 2 25 31 1 9 0 7 28(n)
1~ 2 1. 5 1. 5×0=0 3 ~ 33 18. 0 18. 0×6=108 34 ~ 42 38. 0 38. 0×8=304 43 ~ 49 46. 0 46. 0×7=322 734 (H)
即对四种不同细菌的抑菌效果不都相同。
(Transpose 数据旋转)
2 溶液
6 . 078 , p 0 . 193 0 . 05
即五种不同溶液的抑菌效果差别无显著意义。
Байду номын сангаас
五、 等级计数资料的秩和检验
1、两组等级计数资料的(Wilcoxon)秩和检验 例7. 15 两种方法治疗过敏性鼻炎的疗效结果如下表。试 检验不同疗法间疗效有无差异。
67
假设H0:4组总体分布相同。 统一编秩号,不同组的相同数据编平均秩号。 分组求秩号合计Hi。 求H值 H={12 / [N(N+1)]}∑(Hi2 / ni ) - 3 (N+1) (N=∑ni为总例数) 小样本且组数不超过 3 时,查专用统计表得界值Hα 若H < H0. 05 , P > 0. 05, 不能拒绝H0; 若H ≥Hα(α≤0. 05), P ≤α≤0. 05, 拒绝H0。
计算 Z 值,
本例
Z=
[ | 21×(49+1) / 2-734 | -0. 5 ] [21×28(49+1) / 12][1-(23-2+313-31+93-9+73-7) / (493-49)] 因 Z > 2. 58,P =0.000< 0. 01,结论:两组总体疗效不同,且由
SPSS软件的基本操作教程

选择所有数据
随机选取数据
用过滤器变量 选取数据
数据的选择
根据逻辑关系表 达式选择数据
数据文件的编辑
在给定范围(日期、时间 或个案号等)内选择数据
删除个案
剔除个案(斜杠)
数据文件的编辑
数据的选择(逻辑关系表达式举例)
选择男性并且年龄大于等于35 岁且小于等于74岁的个案
数据的加权
数据文件的编辑
加权是一种通过人为方法来调节样本或数据大小的方法, 在样本分析和科学评价中经常用到。所谓加权,就是给被加权 对象乘上一个系数。
撤消等,以及系统参数设置 View:选择显示状态条、工具栏、网格线、变量标签、变量
视图及字体设置等 Data: 实现文件级别的数据管理,如记录排序、记录拆分、
记录筛选、合并文件等 Transform:实现变量级别的数据管理,如计算新变量、变
量值的分组合并、连续变量的可视化分段等
SPSS菜单栏
Analyze:SPSS的重点菜单项,涵盖各种主要统计分析功能 Graphs:绘制各种普通统计图及交互式统计图,如直方图、
变量的相关操作
• 变量名(Name)的定名规则 • 变量类型(Type) • 变量宽度(Width)和小数位数(Decimal) • 变量标签(Label) • 变量赋值(Value) • 变量缺失值的定义(Missing) • 列宽(Column)和位置(Align) • 度量类型(Measure)
数据的合并
数据文件的编辑
对于存在某种联系的两个数据文件,可以用SPSS的合并功能 将它们按照一定的方式进行合并。
SPSS提供了两种方式来合并数据文件的数据:个案合并(Add Cases)和变量合并(Add Variables)。
数据统计分析SPSS教程完整版

安装完成后,双击桌面快捷方式或从 开始菜单启动SPSS。关闭时,点击右 上角的关闭按钮。
数据输入与保存
数据输入
在SPSS中,可以通过直接输入数据或 导入数据(如Excel、CSV等格式)进 行数据输入。
数据保存
数据输入完成后,点击文件菜单选择 保存,选择保存位置和文件名,保存 为SPSS格式(.sav)。
数据统计分析SPSS教程完 整版
contents
目录
• SPSS基础操作 • 描述性统计分析 • 均值比较与T检验 • 方差分析 • 回归分析 • 聚类分析与判别分析 • 主成分分析与因子分析 • SPSS在社会科学中的应用
01
SPSS基础操作
安装与启动
下载和安装
首先需要从SPSS官网或其他可信来 源下载SPSS软件的安装包,按照提 示进行安装。
1. 基本概念:判别分析试图基于 已知分类的训练数据来创建一个 模型,该模型可以将新的未知分 类的数据点正确分类。
3. 注意事项:选择适当的判别函 数和确保训练数据具有代表性是 关键。
07
主成分分析与因子分析
主成分分析
01
主成分分析是一种降维技术,通过线性变换将多个相关变量转化为少 数几个不相关的变量,这些新变量称为主成分。
详细描述
通过频数分析,可以了解数据集中每个变量的分布情况,例如某个分类变量的各个类别的频数、缺失值的频数等 。在SPSS中,可以通过“频率”命令来执行频数分析。
描述性统计量
总结词
描述性统计量用于描述数据集的集中趋势、离散程度和分布形态。
详细描述
描述性统计量包括均值、中位数、众数、标准差、方差等,用于反映数据集的中心趋势和离散程度。 在SPSS中,可以通过“描述统计”命令来计算描述性统计量。
SPSS统计分析方法及应用(第三版)

– 指定计数区间。
分类汇总
• 分类汇总是按照某分类分别进行计算
数据分组
• 数据分组是对定距型数据进行整理和粗略 把握数据分布的重要工具,因而在实际数据 分
• 析中经常使用。数据分组就是根据统计研 究的需要,将数据按照某种标准重新划分为 不的组别。在数据分组的基础上进行的频 数分析,更能够概括和体现数据的分布特征 。另外,分组还能够实现数据的离散化处理 等
– spv文件格式是SPSS独有的,一般无法通过其他 软件如Word、Excel等打开
SPSS软件的三种基本使用方式
• 窗口菜单方式
– 窗口菜单方式是指在使用SPSS过程中所有的 分析操作都可通过菜单、按钮、输入对话框等 方式来完成
SPSS软件的三种基本使用方式
• 程序运行方式
– 程序运行方式是指:在使用SPSS过程中,统计分 析人员首先根据自己的分析需要,将数据分析的 步骤手工编写成SPSS命令程序,然后将编写好 的程序一次性提交给计算机执行。
计算基本描述统计量
• 计算基本描述统计量的基本操作 • 计算基本描述统计量的应用举例
交叉分组下的频数分析
• 交叉分组下的频数分析又称列联表分析,它 包括两大基本任务:第一,根据收集到的样本
SPSS数据的基本组织方式
• 频数数据的组织方式
– 如果待分析的数据不是原始的调查问卷数据,而 是经过分组汇总后的汇总数据,那么这些数据就 应以频数数据的组织方式组织
SPSS数据的结构和定义方法
• SPSS数据的结构是对SPSS每列变量及其 相关属性的描述。包括:变量名、类型、宽 度、列宽度、变量名标签、变量值标签、 缺失值、计量标准等信息。其中有些内容 是必须定义的,有些是可以省略的
计数数据统计分析的SPSS操作

第七节计数数据统计分析的SPSS操作对于计数数据的统计分析,SPSS提供了不同的分析和检验方法,从总体上来说,大致可以分为:用于比率差异的非参数二项检验,用于离散型变量配合度检验的卡方检验、用于连续型变量配合度检验的单样本K-S检验和正态图检验法和用于独立性检验的列联表分析等,这一节我们简单介绍如何通过SPSS操作解决这些常见的计数数据分析的统计问题。
一、二项分布的非参数检验方法我们常常需要检验一个事件在特定条件下发生的概率是否与已知结论相同,如某地区出生婴儿的性别比例是否与通常男女各半的结论相符,或在一次抽样中,男女两性所占的比例是否与原先设计好的比例相符。
此时即可用二项分布(Binomial)方法进行检验。
下面结合具体数据说明Binomial方法在检验比率差异时的应用。
1.数据所用数据文件为SPSS目录下之GSS93 subset.sav。
这里我们将该数据文件另寸为“8-6-1.sav”。
该文件中有一变量SEX,是回答者的性别,我们想检验这些回答者的性别是否各占一半。
2.理论分析从上面数据来看,我们的目的是检验数据中男生和女生所占的比例是否相等,这等价于检验男生所占的比例是否等于0.5,可以用比例检验的方法进行检验。
在SPSS中对应于二项分布的检验(Binomial Test)过程。
3.二项分布检验过程(1)打开该数据文件后点击菜单Analyze,在下拉菜单中选择Nonparametrics Tests子菜单中的Binomial…,单击可进入二项检验(Binomial Test)的主菜单。
把SEX变量选入到检验变量表列中,其他选项请保持默认(图8-1)。
图8-1:二项分布检验主对话框(2)请单击Options…按钮,打开对话框如图8-2所示。
在此我们想同时在结果中输出一些描述统计量及百分位数,可设置如图所示。
设置完成单击Continue按钮回到主对话框。
图8-2:二项分布Options窗口(3)在主对话框中点击OK得到程序运行结果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
07. 计算与计数
(一)计算
对数据变量做四则运算,并将计算结果存为新变量。
有数据文件:
用【计算】功能,求“数学”、“英文”两科的平均成绩。
1. 【转换】——【计算变量】,打开“计算变量”窗口;
2. 【目标变量】框输入“平均成绩”作为存放计算结果的新变量,【类型和标签】可选填,
3.【数字表达式】框,输入计算表达式:“(数学+英文) / 2”,也可以选用【函数组】中的函数——统计量:“MEAN(数学,英文)”
注:使用“自定义表达式”和“函数”的计算结果可能不同,因为二者处理缺失值的方式不同。
例如,自定义加和时,有一个缺失值则和为缺失值;而SUM函数只有全是缺失值时和才为缺失值。
另外,变量可从左侧框中选入。
注:“**”表示次幂;
若需要只选择满足某条件的个案进行计算,可以点【如果】,打开“计算变量:If个案”子窗口,设置筛选条件,例如只计算1班学生的平均成绩:
4.点【确定】,得到
(二)计数
统计指定变量“取某个值”或“落入某区间”的出现次数。
例如,统计不及格的学生人数。
有数据文件:
一、标记“语文”不及格的学生
1.【转换】——【对个案的值计数】,打开“计算个案值的出现次数窗口;
2.【目标变量】框输入新变量名“语文不及格”,【目标标签】可选填,将左侧变量“语文”选入右侧变量框,
3.点【定义值】,打开“要统计的值”子窗口,勾选【围,从最低到值】,填入59,点【添加】
右侧窗口出现“Lowest thru 59”,表示语文成绩最低分到59分的观察值,新变量计数为1,否则计数为0;
注:【如果】可选择只满足某条件的个案进行上述计数操作。
4. 点【继续】回到原窗口,点【确定】,得到
二、统计每个学生五科中有几科不及格
还是数据文件:
1.【转换】——【对个案的值计数】,打开“计算个案值的出现次数窗口;
2.【目标变量】框输入新变量名“不及格科目数”,【目标标签】可选填,把左侧变量“语文”“英语”“数学”“物理”“化学”都选入右侧变量框
3.点【定义值】,打开“要统计的值”子窗口,勾选【围,从最低到值】,填入59,点【添加】
右侧窗口出现“Lowest thru 59”,表示五个科目成绩有多少是“最低分到59分”,新变量计数为该值;
4. 点【继续】回到原窗口,点【确定】,得到
注:若要统计“变量=某值”的个数,第3步“要统计的值”窗口勾选【值】,输入“某值”,点【添加】即可。