建立分布式文件系统(DFS)时,出现错误的解决办法
分布式文件系统的研究与优化

分布式文件系统的研究与优化分布式文件系统(Distributed File System,简称DFS)是一种基于分布式计算机网络的文件系统,可以支持跨多个节点对文件进行存储和访问。
在大规模分布式系统中,DFS可以提供可靠性、可扩展性和灵活性等优势。
DFS的研究与优化主要围绕以下几个方面展开:1.数据一致性:DFS中的多个节点可能同时对同一个文件进行写入或修改操作,因此数据一致性是一个重要的问题。
研究者们提出了许多解决方案,如锁机制、乐观并发控制等。
优化的目标是在保证数据一致性的前提下,尽量减少对性能的影响。
2.数据分布和负载均衡:DFS中需要将文件划分成多个存储片段,并将这些片段分布到不同的节点上实现负载均衡。
研究者们通过动态调整文件片段的划分策略和节点的选择,以提高系统的整体性能。
3.容错和可靠性:由于DFS的节点数目较多,节点故障是不可避免的。
为了保证DFS的可靠性,研究者们提出了多种容错机制,如数据备份、局部修复等。
优化的目标是在保证可靠性的前提下,提高系统的容错性能。
4.性能优化:DFS的性能优化主要包括数据读取和写入的加速、网络带宽的利用、并行处理等。
研究者们通过改进算法、优化通信协议和提高硬件配置等方式,不断提高DFS的性能。
5.安全性和隐私保护:DFS可能存储着用户的敏感数据,保护用户数据的安全和隐私是一个重要的问题。
研究者们提出了许多安全和隐私保护的方法,如数据加密、访问控制等。
近年来,随着大数据的发展,DFS也面临着新的挑战和优化方向。
例如,如何处理海量数据的并发访问、如何提高系统的可扩展性和容量等。
为了应对这些挑战,研究者们提出了一些新的优化策略和算法,如分布式存储系统的分段管理和数据流水线等。
总之,分布式文件系统的研究与优化是一个复杂而且广泛的领域。
我们需要综合考虑数据一致性、性能、扩展性和安全性等因素,并通过优化算法、网络协议和硬件配置等手段来提高DFS的整体性能和可靠性。
分布式文件系统(DFS)的原理

分布式文件系统(DFS)的原理
应用场景
随着BITC2H公司的网络中共享资源的增多, 有用户提出访问共享资源时,不容易记住其网络路 径,难于查找,资料重复等问题。
你作为公司的网络运维工程师,如何解决上述 问题呢?
学习目标
掌握DFS的基本功能 理解DFS命名空间及类型
共享文件系统当时面临现状
• 创建DFS链接, 每一个链接可以 指向网络中的一 个共享文件夹
采用DFS分布式文件系统的优点
• 使用DFS分布式文件系统,构建统一文件共享平台,改善 用户体验;
• 使用分布式存储,对其用DFS集中管理,来改善磁盘空间 不足的现状;
• 针对不同的共享文件夹配置文件夹配额,空间达到预警后 邮件通知管理员。
• 共享的文件增多,服务器磁盘空间不足; • 文件共享平台数量过多,用户体验差; • 共享平台过多,数据重复存储,造成资源浪费。
什么是分布式文件系统
• 分布式文件系统(Distributed File System,DFS):指系统管理员可以 将网络中分布在各处的共享文件夹,通过分布式文件系统链接组织到 一个目录的逻辑树中,从而使用户,在访问所有共享的时候,只要访问 DFS服务器就可以同时看到所有共享的一种方法.
• 服务器负载均衡,并提高可用性。
DFS常用术语
• 命名空间服务器:用 来承载DFS命名空间。 可以是成员服务器或 者域控制器。
• 命名空间:是共享文 件夹的虚拟视图,这 些共享文件夹可以位 于网络中的不同位置, 但展示给用户的仅仅 是目录树。
• 设置命名空ቤተ መጻሕፍቲ ባይዱ的 名称
DFS常用术语
• 命名空间根路径:是命名空间的起点。 • 文件夹:没有文件夹目标的文件夹将结构和层次结构添加
notleaderforpartitionerror

Notleaderforpartitionerror
"notleaderforpartitionerror" 是一个英文错误信息,通常出现在分布式系统中。
这个错误表示当前节点不是指定分区的领导者,因此无法执行该操作。
在分布式系统中,数据被分成多个分区,每个分区都有一个领导者负责处理与该分区相关的所有操作。
当一个节点想要对某个分区执行操作时,它需要成为该分区的领导者。
如果当前节点不是指定分区的领导者,就会出现 "notleaderforpartitionerror" 错误。
为了解决这个问题,可以尝试以下方法:
1. 确保当前节点是指定分区的领导者。
可以通过检查节点的状态或使用相关命令来确认。
2. 如果当前节点不是领导者,尝试重新配置系统,使当前节点成为指定分区的领导者。
这可能涉及到重新分配分区或更换领导者。
3. 如果问题仍然存在,可能是由于网络故障或其他原因导致当前节点无法连接到指定的分区。
在这种情况下,需要解决网络问题或等待网络恢复后重试操作。
建立分布式文件系统(DFS)时,出现错误的解决办法

建立分布式文件系统(DFS)时,出现错误的解决办法
我的2003AD(R2)主域服务器上建立分布式文件系统(DFS)时,到最后提示以下错误
-----------------------------------------------------------------------------------
在服务器上创建DFS根时出现下列错误:
无法连接指定服务器上的分布式文件系统服务.可能性的原因包括服务未启动、服务器脱机、网络问题阻止访问服务器、或者防火增阻止服务器上的端口445
-------------------------------------------------------------------------------------
(1)主要是让防火墙开启445端口还有139端口,分布式文件系统服务主要就是利用共享来完成的。
(2)启动DFS服务(Distributed File System)这个服务
如果发现没有这个服务,只要手工添加DFS服务就行了,
方法:运行,输入CMD,然后输入sc create DistributedFileSystem binpath= c:\windows\system32\dfssvc.exe 就可以在系统服务里加载了,然后到系统服务找到DistributedFileSystem服务设为自动,重启OK。
Hadoop使用常见问题以及解决方法

Hadoop使用常见问题以及解决方法1:Shuffle Error: Exceeded MAX_FAILED_UNIQUE_FETCHES; bailing-out Answer:程序里面需要打开多个文件,进行分析,系统一般默认数量是1024,(用ulimit -a可以看到)对于正常使用是够了,但是对于程序来讲,就太少了。
修改办法:修改2个文件。
/etc/security/limits.confvi /etc/security/limits.conf加上:* soft nofile 102400* hard nofile 409600$cd /etc/pam.d/$sudo vi login添加 session required /lib/security/pam_limits.so针对第一个问题我纠正下答案:这是reduce 预处理阶段shuffle时获取已完成的map的输出失败次数超过上限造成的,上限默认为5。
引起此问题的方式可能会有很多种,比如网络连接不正常,连接超时,带宽较差以及端口阻塞等。
通常框架内网络情况较好是不会出现此错误的。
2:Too many fetch-failuresAnswer:出现这个问题主要是结点间的连通不够全面。
1) 检查、/etc/hosts要求本机ip对应服务器名要求要包含所有的服务器ip + 服务器名2) 检查 .ssh/authorized_keys要求包含所有服务器(包括其自身)的public key3:处理速度特别的慢出现map很快但是reduce很慢而且反复出现reduce=0% Answer:结合第二点,然后修改conf/hadoop-env.sh 中的export HADOOP_HEAPSIZE=40004:能够启动 datanode ,但无法访问,也无法结束的错误在重新格式化一个新的分布式文件时,需要将你NameNode上所配置的.dir 这一namenode用来存放NameNode持久存储名字空间及事务日志的本地文件系统路径删除,同时将各DataNode上的dfs.data .dir的路径DataNode存放块数据的本地文件系统路径的目录也删除。
分布式文件系统DFS使用方法总结(超详细)

DFS使用方法总结(超详细)使用分布式文件系统 (DFS),系统管理员可以使用户方便地访问和管理物理上分布在网络各处的文件。
通过DFS,可以使分布在多个服务器上的文件如同位于网络上的一个位置一样显示在用户面前。
您可采用两种方式实施分布式文件系统:一种是独立的根目录分布式文件系统,另一种是域分布式文件系统。
独立的DFS根目录:不使用 Active Directory。
至多只能有一个根目录级别的目标。
使用文件复制服务不能支持自动文件复制。
通过服务器群集支持容错。
域DFS根目录:必须宿主在域成员服务器上。
使它的DFS名称空间自动发布到 Active Directory 中。
可以有多个根目录级别的目标。
通过 FRS 支持自动文件复制。
通过 FRS 支持容错。
分布式文件系统 (DFS) 映射由一个DFS根目录、一个或多个DFS链接以及指向一个或多个目标的引用组成。
DFS根目录所驻留的域服务器称为主服务器。
通过在域中的其他服务器上创建根目标,可以复制DFS根目录。
这将确保在主服务器不可用时,文件仍可使用。
因为域分布式文件系统的主服务器是域中的成员服务器,所以默认情况下,DFS映射将自动发布到 Active Directory 中,从而提供了跨越主服务器的DFS拓扑同步。
这反过来又对DFS根目录提供了容错性,并支持目标的可选复制。
通过向DFS根目录中添加DFS链接,您可扩展DFS映射。
Windows Server 2003 家族对DFS映射中分层结构的层数的唯一限制是对任何文件路径最多使用 260 个字符。
新DFS链接可以引用具有或没有子文件夹的目标,或引用整个Windows Server 2003 家族卷。
创建DFS根目录使用DFS管理工具,您可以指定某个目标,指派它为DFS根目录。
除了访问该目标外,用户还可以访问该目标的任何子文件夹。
使用 Windows Server 2003 Enterprise Edition 或Windows Server 2003 Datacenter Edition 时,您可在单独计算机上作为多个DFS根目录的宿主。
sspuliunx 信息安全师操作题参考答案2-1

信息安全师三级复习鉴定模式理论答题时间90分钟判断题:40道占40%选择题:40道占40%多选题:10道占20%操作考分为5个项目,每个项目的答题时间为20分钟操作练习题1. 操作系统(Windows 2000鉴定虚拟机)安全策略关闭端口注册表关闭默认共享分布式文件系统1.1配置帐户策略内容:设置账户密码最长存留期为60天,最短存留期为10天,帐户锁定阀值为5次登录无效,帐户锁定时间为60分钟,复位帐户锁定计数器为50分钟。
步骤:1.依次进入“开始”-“控制面板”-“管理工具”-“本地安全策略”2.展开“帐户策略”-找到“密码最长存留期”-将其修改为“60天”-找到“密码最短存留期”-将其修改为“10天”3.展开“帐户锁定策略”-找到“帐户锁定阀值”-将其值设为“5次”-按“确定”-修改“帐户锁定时间”的值为“60分钟”-修改“复位帐户锁定计数器”的值为“50分钟”1.2配置审核策略及日志内容:设置审核系统登录事件为❽成功,失败❾,设置审核策略为❽成功,失败❾。
同时,设置安全日志的事件来源为❽LSA”,类别为策略改动。
步骤:1.依次进入“开始”-“控制面板”-“管理工具”-“本地安全策略”2.展开“本地策略”-“审核策略”-找到“审核登录事件”-将其值改为“成功,失败”-找到“审核策略更改”-将其值改为“成功,失败”3.依次进入“开始”-“控制面板”-“管理工具”-“事件查看器”-右击“安全日志”-选择“属性”-选择“筛选器”-将“事件来源”改为“LSA”-将“类别”改为“策略改动”(不要关闭窗口)1.3关闭端口内容:禁止除SMTP、POP3、80之外的任何其他端口的TCP通信步骤:1.右击“网络邻居”-“属性”-“本地连接”-“属性”-选择“Internet协议(Tcp/ip)”-点击“属性”-选择“高级”-“选项”-“TCP/IP筛选”-“属性”2.在“TCP端口”一栏中选择“只允许”项-点击“添加”-依次添加“25”、“110”、“80”端口-点击“确定”备注:http:80 ftp:21/20 smtp:25 pop3:110 telnet:231.4修改注册表内容:1.通过修改注册表不显示上次登录名2.通过修改注册表使得注册表无法打开3.修改注册表禁止空连接步骤:1.不显示上次登录用户名:HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\policies\sys tem\dontdisplaylastusername,把REG_DWORD值改为1(或者使用组策略配置:GPEDIT.MSC->在“计算机配置”->“Windows设置”->“安全设置”->“本地策略”->“安全选项”->“不显示上次的用户名”改为已启用。
大数据--Hadoop集群环境搭建

⼤数据--Hadoop集群环境搭建⾸先我们来认识⼀下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式⽂件系统。
它其实是将⼀个⼤⽂件分成若⼲块保存在不同服务器的多个节点中。
通过联⽹让⽤户感觉像是在本地⼀样查看⽂件,为了降低⽂件丢失造成的错误,它会为每个⼩⽂件复制多个副本(默认为三个),以此来实现多机器上的多⽤户分享⽂件和存储空间。
Hadoop主要包含三个模块:HDFS模块:HDFS负责⼤数据的存储,通过将⼤⽂件分块后进⾏分布式存储⽅式,突破了服务器硬盘⼤⼩的限制,解决了单台机器⽆法存储⼤⽂件的问题,HDFS是个相对独⽴的模块,可以为YARN提供服务,也可以为HBase等其他模块提供服务。
YARN模块:YARN是⼀个通⽤的资源协同和任务调度框架,是为了解决Hadoop中MapReduce⾥NameNode负载太⼤和其他问题⽽创建的⼀个框架。
YARN是个通⽤框架,不⽌可以运⾏MapReduce,还可以运⾏Spark、Storm等其他计算框架。
MapReduce模块:MapReduce是⼀个计算框架,它给出了⼀种数据处理的⽅式,即通过Map阶段、Reduce阶段来分布式地流式处理数据。
它只适⽤于⼤数据的离线处理,对实时性要求很⾼的应⽤不适⽤。
多相关信息可以参考博客:。
本节将会介绍Hadoop集群的配置,⽬标主机我们可以选择虚拟机中的多台主机或者多台阿⾥云服务器。
注意:以下所有操作都是在root⽤户下执⾏的,因此基本不会出现权限错误问题。
⼀、Vmware安装VMware虚拟机有三种⽹络模式,分别是Bridged(桥接模式)、NAT(⽹络地址转换模式)、Host-only(主机模式):桥接:选择桥接模式的话虚拟机和宿主机在⽹络上就是平级的关系,相当于连接在同⼀交换机上;NAT:NAT模式就是虚拟机要联⽹得先通过宿主机才能和外⾯进⾏通信;仅主机:虚拟机与宿主机直接连起来。
Win2003登录时卡在正在应用计算机设置

登录时卡在“正在应用计算机设臵”最近公司有台电脑在输入用户名密码之后,总卡在正在应用计算机设臵处。
大概3~4分钟后才能有反应,出现桌面。
这个问题很很奇怪。
网上搜索了无数,也没有个定论。
说的最多的就是重装个系统算了最后一遍一遍的查ou,查组策略,查体日志。
发现并非如网上所说的域的d ns问题。
而是因为1:虚拟机软件在登录的时候在初始化它的两个虚拟网卡,所以这里要比普通电脑多费点时间。
在这之后。
2:有一个服务因为不能启动,系统一直等到它超时才接下去启动别的服务。
于是就遇到了在登录时碰到的这个问题。
在禁用掉启动不起来的服务之后(本来就是个可有可无的服务),登录系统所花的时间已经可以接受(大约1分钟的样子),如果把虚拟机给卸载掉的话,启动起来就可以用飞速来形容了在这里记一笔,希望对碰到同样问题的人有帮助。
最新添加2009-10-27注册表键值:HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control在Control字段下边添加一个新的字段“ServicesPipeTimeout”,类型是DWORD。
它的值设臵为60000,即60秒(DEC十进制)这个值如果不添加,服务启动的超时默认是30秒这里可以自己定义一下服务的超时时间。
是长是短就看自己了最后在转一下一篇kb:使用Windows XP 计算机登录到域或连接到网络资源时遇到延迟/kb/832161/zh-cn概要症状原因解决方案方法1:安装最新的Windows XP Service Pack方法2:配臵Internet Explorer 以绕开代理服务器方法3:更改网络提供程序的顺序方法4:安装相关修复程序方法5:调整Internet Explorer 的安装替代方法状态更多信息Windows XP WebDAV 重定向程序Windows XPMicrosoft Office注意URLScan 禁止WebDAV 请求超时的注册表设臵参考概要本文介绍登录到域和打开网络共享时出现长时间延迟的问题。
fastdfs一些实际应用场景的问题

>>1.除了在storage.conf里的tracker_server增加tracker的ip和端口,其他地方要注意什么?
恩,tracker server ip和端口,肯定是要正确设置的。支持多tracker server,每行设置一个tracker。
另外,base_path也要正确设置。
像你这样的应用场合,再加一层好了,实现文件名到文件ID的转换。比如可以基于数据库来做,或者通过分布式kv系统,如TT、FastDHT等等来做。
>>这些Track Server的内容是对等的,还是分组,每个Track Server负责一部分Storage Server?
对等的。
>>Client是绑定一个Track Server,还是可以绑定多个或全部?
A1: 在storage server上配置它要连接的tracker server,可以配置1个或多个。
组名在storage server上配置的。由storage server主动向tracker server报告其组名和存储空间等信息。
Q2、一些实际的问题:由于fastDFS的存贮特点,它组内的Store server 存贮的数据是一样的。那么如果我同组内的Store server 贮放的地方不一样,比如一台放在上海、一台放在广州、一台在深圳。我在存贮跟数据的时候它必须是要同步的,然后我存贮很大的数据或者并发有很多用户同时上传数据,那么各地方的数据同步肯定也就很大量了,如果机房是共享网络的时候,管理员看到你数据传输量那么大,把它的带宽都吃完了,那么肯定对我的服务器做限制或者什么的。我想问一下,如果是这种情况下,楼主有没有一些好的建议呢?或者能不能做得到每个Store server之间的同步能不能我设定一个时间来做呢?比如是深夜之类的?
Docker中搭建FastDFS文件系统(多图教程)
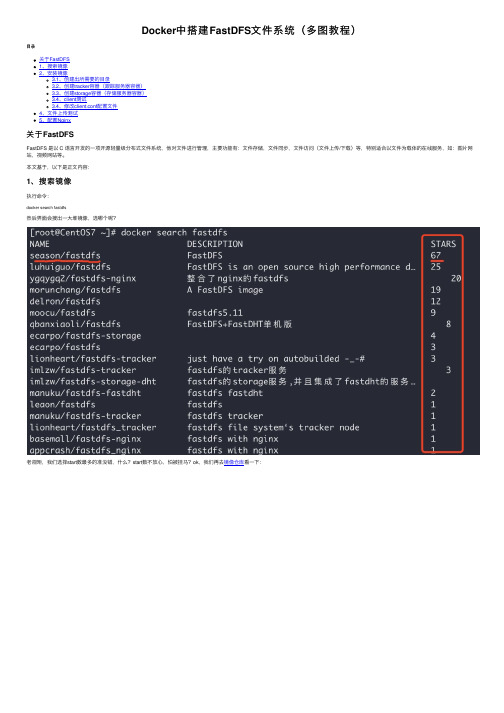
Docker中搭建FastDFS⽂件系统(多图教程)⽬录关于FastDFS1、搜索镜像2、安装镜像3.1、创建出所需要的⽬录3.2、创建tracker容器(跟踪服务器容器)3.3、创建storage容器(存储服务器容器)3.4、client测试3.4、修改client.conf配置⽂件4、⽂件上传测试5、配置Nginx关于FastDFSFastDFS 是以 C 语⾔开发的⼀项开源轻量级分布式⽂件系统,他对⽂件进⾏管理,主要功能有:⽂件存储,⽂件同步,⽂件访问(⽂件上传/下载)等,特别适合以⽂件为载体的在线服务,如:图⽚⽹站,视频⽹站等。
本⽂基于,以下是正⽂内容:1、搜索镜像执⾏命令:docker search fastdfs然后界⾯会搜出⼀⼤堆镜像,选哪个呢?⽼规矩,我们选择start数最多的准没错,什么?start数不放⼼,怕被挂马?ok,我们再去镜像仓库看⼀下:补充:其实看这些镜像的描述也能看出⼀些区别来的,⽐如 ygqygq2/fastdfs-nginx,该镜像是整合了 Nginx 的 fastdfs,那么新的问题来了,为什么要整合 Nginx?因为对于 fastdfs 来说,安装后只能在本机访问… 我上传⽂件肯定是为了能够访问的呀,所以为了提供 web 访问,那么就需要集成 Nginx 了,但是⽐如就是想⾃⼰单独搞 Nginx… 那么肯定就不会选了嘛,season/fastdfs 镜像相对纯净些,本⽂就是基于 season/fastdfs 镜像的,后⾯也附带配置 Nginx…2、安装镜像执⾏命令:docker pull season/fastdfs:1.2之所以选择 1.2 版本,防⽌再次更新后本⽂不适合 latest 版本,执⾏截图如下:3、创建容器并挂载⽬录在创建容器之前我们先简单说⼀下 FastDFS,FastDFS 系统有三个⾓⾊:跟踪服务器(Tracker Server):跟踪服务器,主要做调度⼯作,起到均衡的作⽤;负责管理所有的 storage server和 group,每个 storage 在启动后会连接 Tracker,告知⾃⼰所属 group 等信息,并保持周期性⼼跳。
网络共享之DFS(分布式文件系统)

在我们的络,会有很多的资料或者⽂件等等需要和其他⼈共享,我们可以通过很多⽅式来访问共享的⽂件夹,⽐如上邻居、UNC路径、映射络驱动器等等,但是当我们络中的共享资源⾮常多时,对我们的⽤户来说,记忆很多的路径或者做太多的驱动器映射,都不太合适,有没有⼀种更好的解决⽅法呢,下⾯给⼤家来介绍⼀下—DFS(分布式⽂件系统): 什么是分布式⽂件系统呢?先简单介绍⼀下其特点:通过分布式⽂件系统(Distributed Files System),管理员可以将⽂件分散地存储到络上的多台计算机内,但对⽤户来说,这些⽂件是仅存储在⼀个地点,因此⽤户只要从⼀个地⽅访问这个⽂件。
也就是这些⽂件重复地被存储于多台计算机中,⽤户通过(DFS)读取时,DFS会⾃动地、给⽤户从其中⼀台计算机读取⽂件,考试.⼤提⽰⽤户并不需要知道这些⽂件真正地存储地点。
简单地说,就是把其他服务器上的共享资源映射到该服务器,⽽这对客户端透明,客户端只需要知道⼀个路径就可以访问到所有的共享资源。
分布式⽂件系统的类型:域的DFS和独⽴的DFS。
在域中,两种都可以建⽴,⽽在⼯作组环境中只能建⽴独⽴的DFS。
这⾥主要介绍域DFS的构建(独⽴DFS雷同),因为域的DFS与独⽴DFS相⽐有以下优势: 1、DFS映射关系的同步功能 2、DFS根⽬录的容错功能 3、通过⽂件复制服务⾃动复制DFS根⽬录与⽂件 我们在构建DFS时,有两个东西是必须构建的:第⼀,根⽬录;第⼆,链接。
域DFS的构建步骤: 1、开始—管理⼯具—分布式⽂件系统,右键选择新建DFS根⽬录,选择类型为域DFS,然后选择所在域名,选择根⽬录所在服务器(现在假设根⽬录在ServerA上,名字为dfsroot,并被共享出来了) 2、创建DFS链接(指向其他服务器上的共享⽂件夹) 前⾯提过,我们可以实现容错的功能,所以就需要建⽴多个⽬标,⽽且多个⽬标的名字应该相同,⽐如我可以建⽴多个根⽬录⽬标,⽐如说A服务器上有个根⽬录dfsroot,B服务器上我们也建⽴dfsroot,然后在A服务器上的DFS中新建根⽬录⽬标指向B服务器的dfsroot⽬录,这样对客户来说,就算有⼀台服务器当机了,对他们也没有太⼤影响。
计算机操作系统习题

项目1 网络操作系统导论一.填空题(1)操作系统是用户与计算机之间的接口,网络操作系统可以理解为网络用户与计算机网络之间的接口。
(2)网络通信是网络最基本的功能,其任务是在源主机和目标主机之间实现无差错的数据传输。
(3)1964年,巴兰(Baran)在美国兰德(Rand)公司的“论分布式通信”的研究报告中首次提出了分组的概念。
(4)Web服务、大型数据库服务等都是典型的客户/服务器模式,是近年来流行的应用模式。
项目2 网络操作系统的安装一.填空题(1)Windows Server 2008只能安装在 NTFS 文件系统的分区中,否则安装过程中会出现错误提示而无法正常安装。
(2)Windows Server 2008要管理员口令要求必须符合以下条件:①至少6个字符;②不包含用户账户名称超过两个以上连续字符;③包含大写字母大写字母(A~Z)、小写字母(a~z)、数字(0~9)、特殊字符 4组字符中的3组。
(3)Windows Server 2008中的角色和功能,相当于Windows Server 2003中的Windows组件。
(4)Windows Server 2008安装完成后,为了保证能够长期正常使用,必须和其他版本的Windows操作系统一样进行激活,否则只能够试用 60天。
二、选择题(1)在Windows Server 2008系统中,如果要输入DOS命令,则在“运行”对话框中输入( A )。
A、CMDB、MMCC、AUTOEXED、TTY(2)Windows Server 2008系统安装时生成的Documents and Settings、Windows以及Windows\System32文件夹是不能随意更改的,因为它们是( D )。
A、Windows的桌面B、Windows正常运行时所必需的应用软件文件夹C、Windows正常运行时所必需的用户文件夹D、Windows正常运行时所必需的系统文件夹(3)有一台服务器的操作系统是Windows Server 2003,文件系统是NTFS,无任何分区,现要求对该服务进行Windows Server 2008的安装,保留原数据,但不保留操作系统,应使用下列( B )种方法进行安装才能满足需求。
hadoop一些常见报错的解决方式

hadoop⼀些常见报错的解决⽅式Failed to set setXIncludeAware(true) for parser遇到此问题通常是jar包冲突的问题。
⼀种情况是我们向java的lib⽂件夹加⼊我们⾃⼰的jar包导致hadoop引⽤jar包的冲突。
解决⽅式就是删除我们⾃⼰向系统加⼊的jar包,⼜⼀次配置。
将⾃⼰的jar包或者外部jar放⼊系统⽂件夹会在编译程序时带来⽅便,可是这不是⼀种好习惯,我们应该通过改动CLASSPATH的⽅式指定jar包路径。
Cannot lock storage /tmp/hadoop-root/dfs/name. The directory isalready locked这个错误通常是我们在某次配置失败后。
hadoop创建该⽂件夹,锁定之后失败退出造成的。
解决⽅式就是删除tmp⽂件夹下hadoop创建的相关⽂件夹。
然后⼜⼀次配置。
localhost Name or service not known在配置hadoop单节点环境时。
须要利⽤ssh登录localhost。
假设依照⽹上的⽅式配置之后还是不能正确登录localhost,并报上述错误,能够检查/etc/sysconfig/network和 /etc/hosts下的localhost名字是否⼀致。
有时在某个⽂件⾥localhost是凝视掉的。
ls: Cannot access .: No such file or directory.当在hadoop中执⾏ls命令时常会出现这个错误,这个错误是指hdfs⽂件系统中当前⽂件夹为空,并⾮指本地⽂件系统中当前⽂件夹为空。
当我们使⽤hdfs⽂件系统时,会默认进⼊/user/username下,这个⽂件夹不存在于本地⽂件系统,⽽是由hdfs内部管理的⼀个⽂件夹。
当我们第⼀次使⽤ls命令时,/user/username下是空的。
所以会提⽰上述错误。
当我们加⼊新的⽂件之后就不再报该错。
hdfs dfs 正则

hdfs dfs 正则HDFS(Hadoop 分布式文件系统)是 Hadoop 生态系统中的一部分,是一个专为大型数据集设计的分布式文件系统。
正则表达式是一种多用途的字符串匹配工具,可以在搜索、文本编辑器和其他应用程序中使用。
本文将探讨如何在 HDFS 中使用正则表达式。
第一步:连接 HDFS在进行任何 HDFS 操作之前,需要连接到 HDFS。
可以使用以下命令连接到 HDFS:hdfs dfs -ls /此命令用于连接到 HDFS,然后列出根目录中的内容。
第二步:使用正则表达式在 HDFS 中查找文件使用正则表达式查找特定文件在 HDFS 中非常方便。
在 HDFS 中,可以使用“*”和“?”等特殊符号来代替字符。
例如,要查找名为“file1”的文件,可以使用以下命令:hdfs dfs -ls /path/to/files/file?这将列出任何名为“file1”的文件。
第三步:使用正则表达式在 HDFS 中复制文件要将 HDFS 中的一个或多个文件复制到本地文件系统,请使用以下命令:hdfs dfs -get /path/to/files/*.txt/local/path/to/save/files此命令将复制所有在指定路径下以“.txt”结尾的文件。
第四步:使用正则表达式在 HDFS 中删除文件使用正则表达式删除 HDFS 中的文件与查找文件相似。
以下命令用于删除名为“file1”的文件:hdfs dfs -rm /path/to/files/file?此命令将删除任何名为“file1”的文件。
在 HDFS 中使用正则表达式可以非常方便地找到、复制和删除文件。
但是,需要小心使用正则表达式,以避免错误删除或覆盖文件。
因此,建议在使用正则表达式之前备份数据,并始终检查命令行所执行的操作。
hdfs数据块修复方法

hdfs数据块修复方法HDFS数据块修复方法Hadoop Distributed File System (HDFS) 是 Apache Hadoop 生态系统中的一个核心组件。
它提供了一个分布式的文件系统,用于存储和处理大规模数据,具有高可靠性和高可扩展性。
HDFS 由一个或多个 NameNode 和若干个DataNode 组成。
NameNode 用于管理文件系统的命名空间和元数据,DataNode 负责存储文件块和处理数据读写请求。
在 Hadoop 集群中,如果某个 DataNode 发生故障或网络中断导致数据块丢失,需要尽快修复数据块以避免数据丢失。
本文将详细介绍 HDFS 数据块修复的方法。
一、数据块复制在 HDFS 中,数据块通过多次拷贝来实现高可靠性。
默认情况下,一个数据块会复制三份(即副本因子replication factor 为 3),分别存储在三个不同的DataNode 上。
当一份数据块被认为是“丢失”时,HDFS会使用另外两份数据块作为备份进行修复。
如果只有一份数据块,则无法进行修复,此时数据就会永久丢失。
二、故障检测当某个 DataNode 发生故障或者与 HDFS 集群失去联系时,NameNode 会将这个 DataNode 上的所有数据块标记为“丢失”。
此时,NameNode 会启动一系列任务,以检测数据块的完整性并开始修复。
三、数据块修复数据块修复分为两种情况:一个是已经有存在的正确副本可以被复制到丢失副本;另一个是没有已经存在的正确副本。
对于第一种情况,NameNode 会将其他两份副本作为源数据,在一个新的 DataNode 上创建副本来替换丢失的数据块(即进行复制)。
如果数据块损坏,NameNode 将无法保证数据块的内容与源数据一致,因此需要进行一些检查以确保数据块的正确性。
检查的方法是将数据块划分为若干个内存块,从源 DataNode 读取这些块并复制到新的DataNode 中,最后将两个文件进行比较以验证正确性。
Hadoop“Namenodeisinsafemode”错误解决方法

Hadoop“Namenodeisinsafemode”错误解决⽅法
Hadoop 解除 "Name node is in safe mode"
运⾏hadoop程序时,有时候会报以下错误:
org.apache.hadoop.dfs.SafeModeException: Cannot delete /user/hadoop/input. Name node is in safe mode
这个错误应该还满常见的吧(⾄少我运⾏的时候是这样的)
那我们来分析下这个错误,从字⾯上来理解:
Name node is in safe mode
说明Hadoop的NameNode处在安全模式下。
那什么是Hadoop的安全模式呢?
在分布式⽂件系统启动的时候,开始的时候会有安全模式,当分布式⽂件系统处于安全模式的情况下,⽂件系统中的内容不允许修改也不允许删除,直到安全模式结束。
安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。
运⾏期通过命令也可以进⼊安全模式。
在实践过程中,系统启动的时候去修改和删除⽂件也会有安全模式不允许修改的出错提⽰,只需要等待⼀会⼉即可。
现在就清楚了,那现在要解决这个问题,我想让Hadoop不处在safe mode 模式下,能不能不⽤等,直接解决呢?
答案是可以的,只要在Hadoop的⽬录下输⼊:
bin/hadoop dfsadmin -safemode leave
也就是关闭Hadoop的安全模式,这样问题就解决了。
2022年职业考证-软考-信息系统运行管理员考试全真模拟易错、难点剖析B卷(带答案)第52期

2022年职业考证-软考-信息系统运行管理员考试全真模拟易错、难点剖析B卷(带答案)一.综合题(共15题)1.单选题关于机房防水、防潮、防静电、防雷击安全措施的描述,不正确的是()。
问题1选项A.安装对水敏感的检测仪表对机房进行防水检测,发现水害及时报警B.为计算机系统配置合理的防静电接地与屏蔽系统C.控制机房温/湿度保持在不易产生静电的范围内D.机房地板从表面到接地系统的阻值,不需考虑静电因素【答案】D【解析】本题考核的是设施安全,静电是我们计算机硬件中不可忽视的一个影响因素,经常会因为静电产生事故,所以,机房地板不需要考虑静电因素,这是错误的。
2.单选题()是一种分布式缓存数据库。
问题1选项A.LinuxB.MySQLC.TomcatD.Redis 【答案】D【解析】本题考查分布式缓存。
Linux是操作系统。
MySQL是关系型数据库。
Tomcat是Web应用服务器。
常用的分布式缓存是Memcached和Redis。
3.单选题()和服务网是智能工厂的信息技术基础。
问题1选项A.物联网B.GPSC.云计算D.大数据【答案】A【解析】物联网和服务网是智能工厂的信息技术基础。
GPS是定位技术,云计算和大数据都不属于智能工厂使用的技术。
4.单选题某运维项目业务处理服务器CPU更换后,应启动()流程更新该服务器CPU的信息。
问题1选项A.问题管理B.配置管理C.事件管理D.资源管理【答案】B【解析】本题考查信息系统运维管理流程中的配置管理。
问题管理流程的目标是通过消除引起事故的深层次根源以预防问题和事故的再次放生,并将未能解决的事故影响降到最低。
配置管理的目标是对业务和客户的控制目标及需求提供支持:提供正确的而配置信息,帮助相关人员在正确的时间做出决策,从而维持高效的服务管理流程;减少由不适合的服务或资产配置导致的质量和适应性问题;实现服务资产、IT配置、IT能力和IT资源的最优化。
事件管理的目标是尽快恢复信息系统正常服务并减少对信息系统的不利影响,尽可能保证最好的质量和可用性,同时记录事件并为其他流程提供支持。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
建立分布式文件系统(DFS)时,出现错误的解决办法
我的2003AD(R2)主域服务器上建立分布式文件系统(DFS)时,到最后提示以下错误
-----------------------------------------------------------------------------------
在服务器上创建DFS根时出现下列错误:
无法连接指定服务器上的分布式文件系统服务.可能性的原因包括服务未启动、服务器脱机、网络问题阻止访问服务器、或者防火增阻止服务器上的端口445
-------------------------------------------------------------------------------------(1)主要是让防火墙开启445端口还有139端口,分布式文件系统服务主要就是利用共享来完成的。
(2)启动DFS服务(Distributed File System)这个服务如果发现没有这个服务,只要手工添加DFS服务就行了,
方法:运行,输入CMD,然后输入sc create DistributedFileSystem binpath=
c:\windows\system32\dfssvc.exe
就可以在系统服务里加载了,然后到系统服务找到DistributedFileSystem服务设为自动,重启OK。