数据库结构标准
数据库表结构设计优化原则

数据库表结构设计优化原则在数据库设计过程中,表结构的设计起着至关重要的作用。
一个优化的数据库表结构可以提高数据库的性能和可维护性,提升系统的稳定性和效率。
本文将介绍一些数据库表结构设计的优化原则,以帮助开发人员在设计数据库时做出最佳决策。
1. 规范化设计原则规范化是数据库设计的重要原则,它有助于消除冗余数据并提高数据的一致性。
在规范化过程中,我们将表拆分为更小的关系,减小数据冗余。
这样可以节省存储空间,提高查询性能,并提高系统的可维护性。
2. 合理选择数据类型选择合适的数据类型有助于节省存储空间并提高查询性能。
例如,对于存储范围有限的数据,可以选择较小的整数类型,而不是较大的整数类型。
此外,对于文本类型的字段,应根据实际需求选择合适的字符集和长度。
3. 添加索引索引是提高查询性能的有效方式。
在设计表结构时,应该根据查询的频率和性质来选择合适的字段作为索引。
索引可以加快查询速度,但也会增加写操作的开销,因此需要权衡利弊。
4. 避免过多的关联表在设计表结构时,应尽量避免使用过多的关联表。
虽然关联表可以保持数据的一致性,但在复杂查询时可能会导致性能下降。
可以通过合理使用冗余数据来简化查询,提高系统性能。
5. 使用合适的主键主键对于表的性能和数据完整性非常重要。
在选择主键时,应选择唯一且稳定的字段作为主键,以确保数据的完整性。
此外,主键的数据类型也应选择较小的整数类型,以节省存储空间和提高查询性能。
6. 优化查询语句查询语句的效率直接影响系统的性能。
在设计表结构时,应考虑经常使用的查询需求,并根据实际情况优化查询语句。
可以通过添加合适的索引、减少关联表的使用、使用表连接和子查询等方式来优化查询性能。
7. 分区管理对于大规模数据库,可以考虑使用分区管理来提高系统性能和可维护性。
通过将数据分散存储在不同的分区中,可以提高查询性能,并降低备份和恢复的时间成本。
8. 定期维护和优化数据库表结构的优化不是一次性的任务,应该是一个持续的过程。
数据库标准规范(两篇)2024

数据库标准规范(二)引言:数据库是当代信息系统中关键的存储和管理数据的工具,数据库标准规范的制定对于确保数据的一致性、完整性和可靠性至关重要。
本文将详细阐述数据库标准规范的五个大点,包括数据库设计、数据模型、数据操作、数据存储和数据安全。
概述:在数据库标准规范中,数据库设计是基础,决定了整个数据库系统的架构和功能。
数据模型定义了数据的结构和属性,数据操作确定了对数据库的增删改查操作,数据存储指定了数据的物理存储方式,数据安全保证了数据库的安全性和可用性。
正文内容:一、数据库设计1. 定义数据库设计的目标和要求,包括数据的一致性、可扩展性和易用性。
2. 建立数据库的概念模型,包括实体关系模型、关系模型和层次模型。
3. 制定数据库设计的规范和准则,确保数据库结构的一致性和易维护性。
4. 设计数据库的表结构,包括表的字段、属性和约束等。
5. 定义数据库的索引和视图,提高数据库的查询和操作效率。
二、数据模型1. 介绍常用的数据模型,包括层次模型、网络模型、关系模型和面向对象模型。
2. 选择合适的数据模型,根据数据库的特点和应用需求进行权衡。
3. 设计数据模型的实体和属性,确保数据的准确性和完整性。
4. 定义数据模型之间的关系,包括一对一、一对多和多对多关系。
5. 使用标准的建模工具和方法,对数据模型进行建模和验证。
三、数据操作1. 定义数据操作的目标和要求,包括数据的增加、删除、修改和查询。
2. 设计数据操作的接口和功能,提供简单易用的操作方式。
3. 制定数据操作的规范和约束,确保数据的一致性和安全性。
4. 优化数据操作的性能,提高查询和更新的效率。
5. 实现数据操作的事务管理和并发控制,确保数据的一致和可靠。
四、数据存储2. 设计数据的物理存储结构,包括数据文件、表空间和数据块等。
3. 制定数据存储的规范和准则,确保数据的安全和可靠。
4. 实施数据存储的备份和恢复策略,保护数据的完整性和可用性。
5. 优化数据存储的性能,提高数据访问的效率和响应速度。
数据库三级模式

数据库三级模式人们为数据库设计了一个严谨的体系结构,数据库领域公认的标准结构是三级模式结构,它包括外模式、模式和内模式,有效地组织、管理数据,提高了数据库的逻辑独立性和物理独立性。
用户级对应外模式,概念级对应模式,物理级对应内模式,使不同级别的用户对数据库形成不同的视图。
所谓视图,就是指观察、认识和理解数据的范围、角度和方法,是数据库在用户“眼中"的反映,很显然,不同层次(级别)用户所“看到”的数据库是不相同的。
1、模式模式又称概念模式或逻辑模式,对应于概念级。
它是由数据库设计者综合所有用户的数据,按照统一的观点构造的全局逻辑结构,是对数据库中全部数据的逻辑结构和特征的总体描述,是所有用户的公共数据视图(全局视图)。
它是由数据库管理系统提供的数据模式描述语言(Data Description Language,DDL)来描述、定义的,体现、反映了数据库系统的整体观。
2、外模式外模式又称子模式或用户模式,对应于用户级。
它是某个或某几个用户所看到的数据库的数据视图,是与某一应用有关的数据的逻辑表示。
外模式是从模式导出的一个子集,包含模式中允许特定用户使用的那部分数据。
用户可以通过外模式描述语言来描述、定义对应于用户的数据记录(外模式),也可以利用数据操纵语言(DataManipulation Language,DML)对这些数据记录进行。
外模式反映了数据库的用户观。
3、内模式内模式又称存储模式,对应于物理级,它是数据库中全体数据的内部表示或底层描述,是数据库最低一级的逻辑描述,它描述了数据在存储介质上的存储方式和物理结构,对应着实际存储在外存储介质上的数据库。
内模式由内模式描述语言来描述、定义,它是数据库的存储观。
在一个数据库系统中,只有唯一的数据库,因而作为定义、描述数据库存储结构的内模式和定义、描述数据库逻辑结构的模式,也是唯一的,但建立在数据库系统之上的应用则是非常广泛、多样的,所以对应的外模式不是唯一的,也不可能是唯一的。
数据库的分类标准

数据库的分类标准
数据库的分类标准可以根据不同的维度进行划分。
根据数据的结构化程度,数据库可以分为结构化数据库、半结构化数据库和非结构化数据库。
结构化数据库指的是数据按照预定义的模式进行组织,具有固定的结构形式,如关系型数据库。
半结构化数据库指的是数据具有一定程度的结构,但并不完全遵循预定义的模式,如XML数据库。
非结构化数据库指的是数据没有固定的结构形式,可以以任意方式进行组织,如文本数据库、图像数据库等。
此外,根据数据的组织方式,数据库可以分为层次型数据库、网状型数据库和关系型数据库。
层次型数据库的数据按照树状结构进行组织,具有明显的层次关系。
网状型数据库的数据则是由一系列节点和连接这些节点的边组成的网络结构。
关系型数据库的数据则是由一系列表格组成的,表格之间的关系通过外键进行关联。
总之,数据库的分类标准可以根据不同的维度进行划分,每种类型的数据库都有其独特的特点和适用场景。
数据库系统的体系结构

物理上分布,逻辑上集中
应用1 用户接口 词法及语法分析 查询分解和优化 分布式事务管理 并发控制 恢复 局 部 DBMS 节点 k 数据目录 应用n
通信管理
计算机网络 节点 I 节点 j
4)并行式DBS(Parallel DBS)
现在数据库的数据量急剧提高,巨型数据库的容量已达到 “太拉”级(1太拉为1012,记作T),此时要求事务处理速度极 快,每秒达数千个事务才能胜任系统运行。集中式和C/S式 DBS都不能应付这种环境。并行计算机系统能解决这个问题。 并行系统使用多个CPU和多个磁盘进行并行操作,提高数据 处理和I/O速度。 并行处理时,许多操作同时进行,而不是采用分时的方法。 在大规模并行系统中,CPU不是几个,而是数千个。即使在 商用并行系统中,CPU也可达数百个。
3.3 数据库管理系统(DBMS) 数据库管理系统( )
3.3.1 DBMS的工作模式
数据请求 应用程序 数据(处理结果) 数据(处理结果) DBMS 数据(查询结果) 数据(查询结果) 低层指令 DB
DBMS的工作模式如下: (1)接受应用程序的数据请求和处理请求。 (2)将用户的数据请求转换成复杂的机器代码。 (3)实现对数据库的操作。 (4)从对数据库的操作中接受查询结果。 (5)对查询结果进行处理(格式转换)。 (6)将处理结果返回给用户。
3)逻辑数据库
以外部模式为框架的数据库称为逻辑数据库。 它是数据库结构的最外一层,是用户所看到和使用的数据库, 因而也称为用户数据库或用户视图。
3.1.4 数据模式与数据模型的关系
数据模式与数据模型有着密切联系,通常概念模式和子模式 是建立在一定的逻辑数据模型(如层次模型、网状模型、关 系模型等)上。 另一方面数据模式与数据模型在概念上是有区别的,数据模 式是一个数据库的基于特定数据模型的结构定义,它是数据 模型中有关数据结构及其相互关系的描述,所以仅是数据模 型的一部分。 由于数据模式在数据库设计中的重要性,因此将它作为一个 专门术语提出。
数据库的结构

数据库的结构胡经国本文作者的话本文是根据有关文献和资料编写的《漫话云计算》系列文稿之一。
以此作为云计算学习笔录,供云计算业外读者进一步学习和研究参考。
希望能够得到大家的指教和喜欢!下面是正文一、数据库结构概述数据库(DataBase,DB)是指在计算机的存储设备上合理存放的相关联的有结构的数据集合。
一个数据库含有多种成分,包括:数据表、视图、存储过程、记录、字段、索引等。
1、数据表在Visual Basic中使用的数据库,是关系型数据库(Relational Database)。
一个数据库由一个或一组数据表组成。
每个数据库都以文件的形式存放在磁盘上,即对应于一个物理文件。
不同的数据库,与物理文件对应的方式也不一样。
对于dBASE,FoxPro和Paradox格式的数据库来说,一个数据表就是一个单独的数据库文件;而对于Microsoft Access,Btrieve格式的数据库来说,一个数据库文件可以含有多个数据表。
数据表(Data Table),简称表,由一组数据记录组成。
数据库中的数据是以表为单位进行组织的。
一个表是一组相关的按行排列的数据;每个表中都含有相同类型的信息。
表实际上是一个二维表格。
例如,一个班所有学生的考试成绩,可以存放在一个表中,表中的每一行对应一个学生,这一行包括学生的学号,姓名及各门课程成绩。
⑴、记录表中的每一行称为一个记录。
它由若干个字段组成。
⑵、字段字段,也称为域。
表中的每一列称为一个字段。
每个字段都有相应的描述信息,如数据类型、数据宽度等。
2、索引为了提高访问数据库的效率,可以对数据库使用索引。
当数据库较大时,在查找指定的记录时,使用索引和不使用索引的查找效率有很大差别。
索引实际上是一种特殊类型的表,其中含有关键字段的值(由用户定义)和指向实际记录位置的指针。
这些值和指针按照特定的顺序(也由用户定义)存储,从而可以以较快的速度查找到所需要的数据记录。
3、查询一条SQL(Structured Query Language,结构化查询语言)命令,用来从一个或多个表中获取一组指定的记录,或者对某个表执行指定的操作。
数据库的体系结构

数据库的体系结构1。
三级模式结构数据库的体系结构分为三级:外部级、概念级和内部级(图5。
1),这个结构称为数据库的体系结构,有时亦称为三级模式结构或数据抽象的三个级别。
虽然现在DBMS的产品多种多样,在不同的操作系统下工作,但大多数系统在总的体系结构上都具有三级结构的特征。
从某个角度看到的数据特性,称为数据视图(Data View)。
外部级最接近用户,是单个用户所能看到的数据特性,单个用户使用的数据视图的描述称为外模式。
概念级涉及到所有用户的数据定义,也就是全局性的数据视图,全局数据视图的描述称概念模式.内部级最接近于物理存储设备,涉及到物理数据存储的结构,物理存储数据视图的描述称为内模式。
图5。
1 三级模式结构数据库的三级模式结构是对数据的三个抽象级别。
它把数据的具体组织留给DBMS去做,用户只要抽象地处理数据,而不必关心数据在计算机中的表示和存储,这样就减轻了用户使用系统的负担.三级结构之间往往差别很大,为了实现这三个抽象级别的联系和转换,DBMS在三级结构之间提供两个层次的映象(Mapping):外模式/模式映象,模式/内模式映象.这里的模式是概念模式的简称。
数据库的三级模式结构,即数据库系统的体系结构如图5。
2所示.图5.2 数据库系统的体系结构2.三级结构和两级映象(1)概念模式概念模式是数据库中全部数据的整体逻辑结构的描述。
它由若干个概念记录类型组成,还包含记录间联系、数据的完整性安全性等要求。
数据按外模式的描述提供给用户,按内模式的描述存储在磁盘中,而概念模式提供了连接这两级的相对稳定的中间点,并使得两级中任何一级的改变都不受另一级的牵制。
概念模式必须不涉及到存储结构、访问技术等细节,只有这样,概念模式才能达到物理数据独立性.概念模式简称为模式。
(2)外模式外模式是用户与数据库系统的接口,是用户用到的那部分数据的描述。
外模式由若干个外部记录类型组成。
用户使用数据操纵语言(DML)语句对数据库进行操作,实际上是对外模式的外部记录进行操作.有了外模式后,程序员不必关心概念模式,只与外模式发生联系,按照外模式的结构存储和操纵数据.(3)内模式内模式是数据库在物理存储方面的描述,定义所有内部记录类型、索引和文件的组织方式,以及数据控制方面的细节.(4)模式/内模式映象模式/内模式映象存在于概念级和内部级之间,用于定义概念模式和内模式之间的对应性。
数据库逻辑结构

数据库逻辑结构
数据库逻辑结构是计算机科学中的一门基本分支,它主要负责构建数据库系统的数据模型,使数据库管理系统能够实现完整的数据存储、系统控制和数据处理功能。
数据库逻辑结构的基本思路是从现实世界出发,研究从实体、属性、类型到数据库表结构之间的关系,以及数据库表结构与数据处理功能之间的关系,建立出的一个复杂的数据存储和处理总体架构。
典型的数据库逻辑结构包括:元模型、对象模型、数据字典模型、逻辑数据模型等。
它们之间有关系,彼此想象。
元模型是一个用于构建复杂数据库模型的连接框架,是数据库逻辑结构的最高组织形式。
数据字典模型主要是一些特定表单中数据的描述。
而逻辑数据模型是数据库表结构,它定义了数据表字段、索引字段、关系表等的视图结构,可以五面分别的模型。
数据库逻辑结构的主要作用是实现数据存储和处理功能。
它把各种数据存储和处理结构以及索引结构的表示形式聚集到一起,以保证数据的安全与完整,同时也方便数据库系统的维护。
此外,数据库逻辑结构有利于理解和学习,可以让我们清晰地了解数据库管理系统内部的存储和处理组织结构,也方便随时进行修改。
总之,数据库逻辑结构具有广泛的应用,可以帮助我们更科学的控制和管理数据库系统,让我们可以更好的满足使用者的实际需要。
大数据的结构

大数据的结构随着信息技术的迅速发展和不断进步,大数据已经成为当今社会中不可或缺的一部分。
与传统数据不同,大数据具有三个方面的特点:数据量巨大、数据来源多样、数据处理复杂。
为了更好地应对这些挑战,大数据需要一个合适的结构来进行组织和管理。
本文将讨论大数据的结构以及如何优化其效率。
一、大数据的结构概述大数据的结构可以简单地理解为数据的组织方式和存储方式。
常见的大数据结构包括:关系型数据库结构、非关系型数据库结构、数据仓库结构和分布式文件系统结构。
这些结构都有各自的特点和适用场景。
1. 关系型数据库结构关系型数据库结构是目前应用最广泛的一种结构。
它采用二维表的方式将数据进行存储和组织,通过定义表之间的关系来实现数据的查询和管理。
关系型数据库结构适用于逻辑结构清晰、数据之间有明确关联的场景。
2. 非关系型数据库结构非关系型数据库结构也被称为NoSQL数据库结构,它摒弃了二维表的形式,采用更加灵活的方式来存储和组织数据。
非关系型数据库结构适用于数据结构较为复杂、数据量巨大、读写频率较高的场景。
3. 数据仓库结构数据仓库结构是一种专门用于存储和管理大量历史数据的结构。
它采用星型或雪花型的数据模型,通过ETL(抽取、转换和加载)过程将数据从不同的源导入到数据仓库中。
数据仓库结构适用于数据分析和决策支持等应用场景。
4. 分布式文件系统结构分布式文件系统结构通过将大数据划分为多个小文件,并将这些文件存储在多个节点上来实现数据的存储和管理。
分布式文件系统结构适用于数据分散、持续不断地增长以及需要高可靠性和高可扩展性的场景。
二、优化大数据结构的方法为了提高大数据的效率和性能,有几种方法可以用来优化大数据的结构。
1. 数据分区数据分区是将数据划分为若干部分,并将这些部分分散到不同的存储介质上。
通过数据分区,可以提高数据的读写效率,减少数据冗余和冗杂性。
2. 数据冗余数据冗余是指将数据备份到多个位置,以提高数据的可靠性和可用性。
金蝶标准版数据库结构说明

金蝶标准版数据库结构说明金蝶标准版数据库结构说明1、引言本文档旨在详细描述金蝶标准版数据库的结构,为开发人员、管理员和用户提供清晰的指导和理解。
数据库结构是数据库系统的基础组成,了解数据库结构对于正确使用和维护数据库至关重要。
2、数据库概述2.1 数据库定义2.2 数据库类型2.3 数据库架构3、表结构说明3.1 表1名称3.1.1 字段1字段1说明3.1.2 字段2字段2说明:::3.1:n 字段n字段n说明 3.1:n+1 约束约束说明:::3.1:n+m 索引索引说明3.2 表2名称3.2.1 字段1字段1说明 3.2.2 字段2字段2说明:::3.2:n 字段n字段n说明 3.2:n+1 约束约束说明:::3.2:n+m 索引索引说明:::3:n 表n名称3:n.1 字段1字段1说明 3:n.2 字段2字段2说明:::3:n:n 字段n字段n说明 3:n:n+1 约束约束说明:::3:n:n+m 索引索引说明4、视图结构说明4.1 视图1名称视图1说明:::4.2 视图2名称视图2说明:::4:n 视图n名称视图n说明:::5、存储过程结构说明5.1 存储过程1名称存储过程1说明:::5.2 存储过程2名称存储过程2说明:::5:n 存储过程n名称存储过程n说明:::6、函数结构说明6.1 函数1名称函数1说明:::6.2 函数2名称函数2说明:::6:n 函数n名称函数n说明:::7、附件本文档涉及的附件详见附录。
8、法律名词及注释8.1 法律名词1注释说明:::8.2 法律名词2注释说明:::8:n 法律名词n注释说明:::9、结束语本文档详细描述了金蝶标准版数据库的结构,包括表结构、视图结构、存储过程结构和函数结构的说明。
希望本文档能为开发人员、管理员和用户提供准确的参考和理解。
基础水文数据库表结构及标识符标准sl324

主题:基础水文数据库表结构及标识符标准SL3241. 概述基础水文数据库是对水文数据进行统一管理和储存的重要工具,它的设计和构建需要遵循一定的标准和规范。
而标识符的统一和规范化对于数据库的操作和数据查询至关重要。
本文将对基础水文数据库表结构及标识符标准SL324进行深入探讨。
2. 基础水文数据库表结构基础水文数据库包括多个表,每个表都有其特定的结构和字段。
在设计数据库表结构时,应该考虑到数据的存储和查询效率,同时也要符合一定的规范和标准。
2.1 数据表基础水文数据库包括多个数据表,其中包括水文站点表、水文测项表、水文数据表等。
每个数据表都有其特定的字段和数据类型,用于存储相应的数据。
2.2 字段设计在设计数据表时,需要合理选择和设计字段,包括字段名、数据类型、长度和约束等。
对于水文数据库来说,常见的字段包括站点编号、测项编号、时间、数据值等。
2.3 索引设计为了提高数据查询的效率,需要合理设计表的索引。
索引的设计应该考虑到频繁查询的字段和条件,避免对查询性能造成影响。
3. 标识符标准SL324标识符是数据库中用于唯一标识记录的字段或字段组合,其规范化和统一对于数据的管理和操作至关重要。
3.1 标识符的选择在设计数据库表结构时,需要选择合适的字段作为标识符。
通常情况下,可以选择站点编号和时间作为组合标识符,确保数据的唯一性和完整性。
3.2 标识符的格式标识符的格式应该符合一定的标准和规范,一般采用数字或者字符的组合形式。
站点编号采用4位数字表示,时间采用标准的日期格式表示。
3.3 标识符的管理数据库设计需要考虑到标识符的管理和维护,包括标识符的唯一性、自动生成和自增长等。
合理的标识符管理对于数据库的操作和维护都具有重要意义。
4. 结论基础水文数据库表结构及标识符标准SL324对于水文数据的管理和分析具有重要意义。
合理的数据库设计和标识符规范化可以提高数据操作的效率和准确性,也为水文数据的应用和研究提供了基础支持。
数据库表结构设计

第一范式(1NF) 确保每列保持原子性,即每列不 可再分。
第二范式(2NF) 在第一范式的基础上,消除部分 函数依赖,将数据表分解为更小 的表,并建立适当的关联。
反规范化设计
反规范化设计的定义
反规范化设计是通过引入冗余数据来改进查询 性能和简化数据操作的设计方法。
反规范化设计的好处
提高查询性能、减少JOIN操作、降低数据不一 致的风险。
反规范化设计的注意事项
避免过度冗余、维护数据一致性和完整性、定期更新冗余数据。
第三范式与多范式设计
第三范式与多范式设计的定义
01
第三范式是满足第三范式的数据库表结构,而多范式设计是指
同时满足多个范式的数据库表结构。
第三范式与多范式设计的优势
数据模型设计
概念设计
根据需求文档,设计出满足业务需求的 概念模型,如实体关系图(ER图)。
VS
逻辑设计
将概念模型转换为逻辑模型,如关系模型 ,确定每个数据表的字段和数据类型。
表结构设计
表结构设计
根据逻辑模型,设计出具体的数据库表结构,包括字段名、数据类型、长度、约束等。
索引优化
根据查询需求,合理设计索引,提高数据查询效率。
数据库表结构设计
目录
• 数据库表结构设计概述 • 数据库表的要素 • 数据库表结构设计方法 • 数据库表结构设计实践 • 数据库表结构优化 • 数据库表结构设计案例分析
01
数据库表结构设计概述
数据库表的概念
数据库表是数据库中存储数据的结构 化组织,由行和列组成,类似于电子 表格。
每列定义了数据的属性或字段,如姓 名、地址等,而每行则包含具体的数 据记录。
数据库设计参考标准

数据库设计参考标准数据库设计参考标准文档控制文档属性文档修订历史[1]数据库设计参考标准一、概述为明确公司项目中数据库逻辑设计及物理设计的内容和流程,特制定本规范,供数据库设计、开发及维护人员参考。
数据库设计方法目前可分为四类:直观设计法、规范设计法、计算机辅助设计法和自动化设计法。
新奥尔良法是目前公认的比较完整和权威的一种规范设计法。
新奥尔良法将数据库设计分成需求分析(分析用户需求)、概念设计(信息分析和定义)、逻辑设计(设计实现)和物理设计(物理数据库设计)。
目前,常用的规范设计方法大多起源于新奥尔良法,并在设计的每一阶段采用一些辅助方法来具体实现.以下是两种常用的规范设计方法:1. 基于E—R模型的数据库设计方法。
该方法是由P.P。
S。
chen于1976年提出的数据库设计方法,其基本思想是在需求分析的基础上,用E-R(实体—联系)图构造一个反映现实世界实体之间联系的企业模式,然后再将此企业模式转换成基于某一特定的DBMS的概念模式。
2. 基于3NF的数据库设计方法。
该方法是由S·Atre提出的结构化设计方法,其基本思想是在需求分析的基础上,确定数据库模式中的全部属性和属性间的依赖关系,将它们组织在一个单一的关系模式中,然后再分析模式中不符合3NF的约束条件,将其进行投影分解,规范成若干个3NF关系模式的集合。
其具体设计步骤分为五个阶段:(1)设计企业模式,利用规范化得到的3NF关系模式画出企业模式;(2)设计数据库的概念模式,把企业模式转换成DBMS所能接受的概念模式,并根据概念模式导出各个应用的外模式;(3)设计数据库的物理模式(存储模式);(4)对物理模式进行评价;(5)实现数据库。
备注:数据库设计规范、数据编程规范、数据库物理设计规范中以Oracle 数据库为例,其它结构的数据库类似.二、数据库设计流程[2]数据库设计参考标准以规范性设计为例,把数据库设计流程分为以下几个阶段.(一) 需求分析阶段1. 需求收集和分析,得到数据字典描述的数据需求和数据流图描述的处理需求。
数据库标准表

数据库标准表
数据库标准表是一种在数据库中定义数据结构和关系的方式,它是根据某个标准(例如SQL 或其他相关标准)来创建的。
这些标准通常是为了确保数据的一致性和可移植性,并使不同数据库系统之间的数据交换变得更容易。
常见的数据库标准表有以下几种:
1.关系数据库:如SQL Server、Oracle、MySQL、PostgreSQL 等中的表。
这些表通常包含行和列,并使用特定的数据类型来定义列。
它们可以定
义主键、外键等关系,以及触发器、存储过程等数据库对象。
2.层次数据库:如IBM 的IMS(Information Management System)。
在这
种类型的数据库中,数据存储在一个层次结构中,每个节点都有一个父
节点和多个子节点。
3.键-值存储:如Redis。
在这种类型的数据库中,数据存储在键-值对中,
其中每个键都映射到一个值。
4.文档存储:如MongoDB。
在这种类型的数据库中,数据存储在类似文
档的结构中,每个文档都是一个独立的实体,包含一系列键-值对。
5.列存储:如Apache Cassandra。
在这种类型的数据库中,数据按列存储,
而不是按行存储。
这使得查询和聚合操作更加高效。
6.图形数据库:如Neo4j。
在这种类型的数据库中,数据以图形形式表示,
其中每个节点代表一个实体,每个边代表一个关系。
这些只是数据库的几种类型,实际上还有更多种类的数据库和数据存储系统。
每种系统都有其自己的表和数据结构定义方式。
数据库设计中的表结构规范与设计原则

数据库设计中的表结构规范与设计原则数据库是计算机系统中最重要的组成部分之一,它用于存储、管理和访问数据。
在数据库设计中,表结构是其中一个关键方面,它决定了数据的组织方式、存储形式和操作方式。
本文将介绍数据库设计中的表结构规范与设计原则。
一、表结构规范1. 表名规范:表名应具有描述性,能够准确反映表所存储数据的含义。
表名应使用单数形式,并使用下划线或者驼峰命名法来分隔单词。
2. 字段命名规范:字段名应简洁明了,避免使用过于复杂或过长的命名。
字段命名应使用小写字母,并使用下划线或者驼峰命名法来分隔单词。
3. 主键规范:每个表都应该有一个主键,用于唯一标识表中的每一行数据。
主键字段应该是简洁、唯一且不可更改的。
4. 外键规范:在设计数据库时,需要考虑数据之间的关联性。
外键用于建立表之间的关联关系,应使用与被引用表的主键类型和长度一致的字段。
5. 数据类型规范:选择合适的数据类型来存储数据是非常重要的。
常见的数据类型包括整型、浮点型、字符型、日期型等。
在选择数据类型时,应根据实际需求合理选择,避免浪费存储空间。
6. 索引规范:索引是提高查询速度的重要手段。
在设计表结构时,应考虑哪些字段需要建立索引以及何时建立索引。
需要注意的是,索引也会占用存储空间,并且在插入、更新和删除数据时会增加额外的开销,因此需要权衡利弊。
二、表结构设计原则1. 单一职责原则:每个表应该只包含与其职责相关的字段。
表的职责应尽量单一,避免冗余和重复存储。
2. 数据唯一性原则:在设计表结构时,需要保证数据的唯一性。
可以通过设定主键、唯一约束或者联合约束来实现。
3. 数据完整性原则:保证数据的完整性是数据库设计的基本原则之一。
可以通过外键约束、默认值约束、验证规则等手段实现。
4. 规范化原则:规范化是设计数据库表结构时必须考虑的一项原则。
规范化的目的是消除数据冗余、提高数据存储效率和维护效率。
常用的规范化范式有第一范式、第二范式、第三范式等。
普通高等学校毕业生就业数据库结构及代码标准
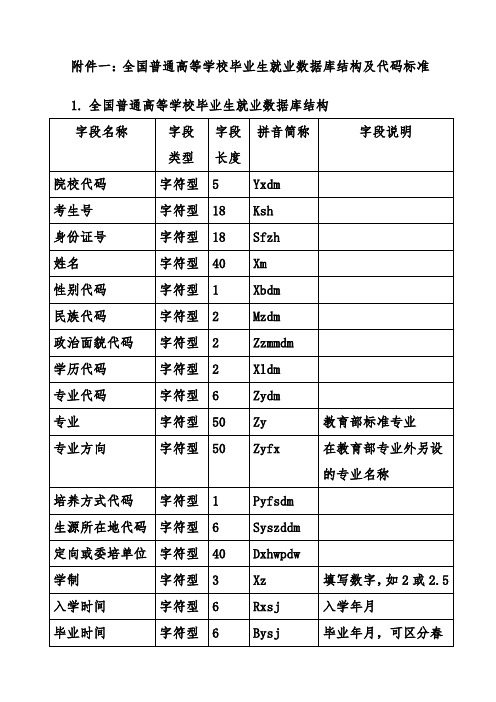
附件一:全国普通高等学校毕业生就业数据库结构及代码标准1.全国普通高等学校毕业生就业数据库结构2.院校代码表(教育部标准)院校代码表将以电子版下发。
3.性别代码表(国家标准)字段顺序:代码、名称1 男2 女4.民族代码表(国家标准)字段顺序:代码、名称01 汉族 02 蒙古族 03 回族04 藏族 05 维吾尔族 06 苗族07 彝族 08 壮族 09 布依族10 朝鲜族 11 满族 12 侗族13 瑶族 14 白族 15 土家族16 哈尼族 17 哈萨克族 18 傣族19 黎族 20 傈僳族 21 佤族22 畲族 23 高山族 24 拉祜族25 水族 26 东乡族 27 纳西族28 景颇族 29 柯尔克孜族 30 土族31 达斡尔族 32 仫佬族 33 羌族34 布朗族 35 撒拉族 36 毛南族37 仡佬族 38 锡伯族 39 阿昌族40 普米族 41 塔吉克族 42 怒族43 乌孜别克族 44 俄罗斯族 45 鄂温克族46 德昂族 47 保安族 48 裕固族49 京族 50 塔塔尔族 51 独龙族52 鄂伦春族 53 赫哲族 54 门巴族55 珞巴族 56 基诺族 97 其它98外国血统中国籍人士5.政治面貌代码表(国家标准)字段顺序:代码、名称01 中共党员 02 中共预备党员03 共青团员 04 民革会员05 民盟盟员 06 民建会员07 民进会员 08 农工党党员09 致公党党员 10 九三学社社员11 台盟盟员 12 无党派民主人士13 群众6.学历代码表(在原就业数据标准基础上修订)字段顺序:代码、名称01 博士生毕业03 博士生结业11 硕士生毕业13 硕士生结业25 二学位毕业26 二学位结业31 本科生毕业33 本科生结业41 专科生毕业43 专科生结业7.专业代码表(教育部标准)专业代码表将以电子版下发。
8.培养方式代码表(教育部标准)字段顺序:代码、名称1 非定向2 定向3 在职4 委培5自筹注:“3在职 4委培 5自筹”仅限研究生使用。
数据库设计说明书-国家标准格式

数据库设计说明书-国家标准格式数据库设计说明书-国家标准格式1、引言1.1 文档目的1.2 文档范围1.3 读者对象1.4 参考资料2、数据库设计总览2.1 数据库系统概述2.2 数据库架构2.3 数据库结构图2.4 数据库功能需求2.5 数据库性能需求2.6 数据库安全需求3、数据库逻辑设计3.1 概念模型设计3.1.1 实体关系图3.1.2 属性定义3.1.3 实体关系模型3.2 数据字典3.3 数据约束3.3.1 实体完整性约束3.3.2 参照完整性约束3.3.3 域完整性约束3.3.4 用户定义完整性约束 3.4 数据库操作规范3.5 数据库视图设计4、数据库物理设计4.1 存储结构设计4.2 索引设计4.3 数据分区设计4.4 安全性设计4.5 性能优化设计4.6 备份与恢复设计5、数据库实施计划5.1 数据库安装与配置5.2 数据迁移计划5.3 数据库测试与验证5.4 数据库启动与运行监控6、数据库维护与管理说明6.1 数据库监控与性能调优 6.2 数据库安全管理6.3 数据库备份与恢复6.4 数据库升级与迁移6.5 数据库故障处理与恢复7、附录7.2 数据库系统配置信息 7.3 数据库表结构详细信息 7.4 数据库脚本本文档涉及附件:附件1:数据库结构图附件2:实体关系图附件3:数据字典附件4:数据库操作规范附件5:数据库视图设计法律名词及注释:- 数据库:根据国家《信息安全法》,数据库是指存储、加工、管理和使用的大量数据集合。
- 实体关系模型:实体关系模型是一种描述数据库中数据结构的概念模型,例如,实体(Entity)、属性(Attribute)和关系(Relationship)。
- 数据约束:数据约束是限制数据库中数据的一组规则,例如,实体完整性约束、参照完整性约束、域完整性约束和用户定义完整性约束。
数据库表结构设计参考

变长字符串(50)
操作时间
Datetime
补充说明
该表暂不用。
表名
信件地区邮编映射表(LetterAreaPostcode)
列名
数据类型(精度范围)
空/非空
约束条件
ID
变长字符串(50)
N
地区名称
变长字符串(50)
N
邮编
变长字符串(10)
N
补充说明
该表为基础码表,小表
表名
报刊常量表(Constant_Mgz)
约束条件
ID
变长字符串(50)
N
名称
变长字符串(50)
N
外键
投递号
变长字符串(255)
N
补充说明
该表记录数固定
表名
急件电话语音记录表(TelCall)
列名
数据类型(精度范围)
空/非空
约束条件
ID
变长字符串(50)
N
发送部门
变长字符串(50)
N
接收部门
变长字符串(50)
N
拨打电话号码
变长字符串(50)
创建者所属部门
变长字符串(50)
创建者
变长字符串(50)
创建时间
Datetime
修改者所属部门
变长字符串(50)
修改者
变长字符串(50)
修改时间
Datetime
数据库表结构设计参考
表名
外部单位表(DeptOut)
列名
数据类型(精度范围)
空/非空
约束条件
外部单位ID
变长字符串(50)
N
主键
类型
变长字符串(50)
N
文艺资源数据库标准

文艺资源数据库标准文艺资源数据库是指收集、整理和管理文艺领域相关信息的数据库。
它涵盖了文艺作品、艺术家、场馆、演出活动等各种资源的信息,并提供给用户进行查询和利用。
为了使不同的文艺资源数据库能够互通有无、共享信息,我们需要制定一套标准,即文艺资源数据库标准。
1. 数据结构标准文艺资源数据库的数据结构应该包括以下基本要素:作品名称、作者/艺术家、创作时间、作品类型、地理位置、关键词等。
这些要素应该是规范的、统一的,并且能够满足各种类型的文艺资源的描述和查询需求。
2. 数据元素标准在文艺资源数据库中,每个数据元素都应该有明确的定义和规范。
例如,作者/艺术家的数据元素应该包括姓名、国籍、生平简介等。
作品类型的数据元素应该包括音乐、舞蹈、戏剧等。
这样的标准可以确保数据库中的数据是清晰、准确、可比较的。
3. 数据编码标准数据编码标准是用于表示文艺资源数据库中数据的一种编码体系。
例如,对于地理位置,可以采用国家、省份、城市的编码。
对于作品类型,可以采用数字编码,如1代表音乐,2代表舞蹈,3代表戏剧等。
这样的编码标准可以提高数据的存储效率、查询效率和分析效果。
4. 数据格式标准数据格式标准是指文艺资源数据库中数据的表现形式。
可以采用常见的数据格式,如XML、JSON等,但需要规范字段名称、字段类型、字段长度等,以保证数据的完整性和一致性。
此外,也可以采用开放的数据格式,以便与其他数据库进行数据交换和共享。
5. 数据交换标准文艺资源数据库应该能够与其他数据库进行数据交换和共享。
为了实现这一目标,可以采用行业通用的数据交换标准,如XML、JSON、CSV等。
此外,还可以在数据交换接口中定义规范的数据格式和数据协议,以确保安全、可靠的数据传输。
6. 数据更新标准文艺资源数据库需要定期更新,以保持数据的时效性和准确性。
为了实现有效的数据更新,可以制定数据更新标准。
例如,规定每个数据元素的更新周期、更新方式和负责人等。