数据结构实验3
数据结构实验报告三

数据结构实验报告三数据结构实验报告三引言:数据结构是计算机科学中的重要内容之一,它研究的是如何组织和存储数据以便高效地访问和操作。
本实验报告将介绍我在数据结构实验三中的实验过程和结果。
实验目的:本次实验的主要目的是熟悉并掌握树这种数据结构的基本概念和操作方法,包括二叉树、二叉搜索树和平衡二叉树等。
实验内容:1. 实现二叉树的创建和遍历在本次实验中,我首先实现了二叉树的创建和遍历。
通过递归的方式,我能够方便地创建一个二叉树,并且可以使用前序、中序和后序遍历方法对二叉树进行遍历。
这些遍历方法的实现过程相对简单,但能够帮助我们更好地理解树这种数据结构的特点。
2. 实现二叉搜索树的插入和查找接下来,我实现了二叉搜索树的插入和查找操作。
二叉搜索树是一种特殊的二叉树,它的左子树上的节点的值都小于根节点的值,右子树上的节点的值都大于根节点的值。
通过这种特性,我们可以很方便地进行插入和查找操作。
在实现过程中,我使用了递归的方法,通过比较节点的值来确定插入的位置或者进行查找操作。
3. 实现平衡二叉树的插入和查找平衡二叉树是为了解决二叉搜索树在某些情况下可能会退化成链表的问题而提出的。
它通过在插入节点的过程中对树进行旋转操作来保持树的平衡。
在本次实验中,我实现了平衡二叉树的插入和查找操作。
通过对树进行左旋、右旋等操作,我能够保持树的平衡,并且能够在O(log n)的时间复杂度内进行插入和查找操作。
实验结果:通过本次实验,我成功地实现了二叉树、二叉搜索树和平衡二叉树的相关操作。
我编写了测试代码,并对代码进行了测试,结果表明我的实现是正确的。
我能够正确地创建二叉树,并且能够使用前序、中序和后序遍历方法进行遍历。
对于二叉搜索树和平衡二叉树,我能够正确地进行插入和查找操作,并且能够保持树的平衡。
实验总结:通过本次实验,我深入了解了树这种数据结构的特点和操作方法。
二叉树、二叉搜索树和平衡二叉树是树的重要应用,它们在实际开发中有着广泛的应用。
数据结构实验三栈和队列的应用

数据结构实验三栈和队列的应用数据结构实验三:栈和队列的应用在计算机科学领域中,数据结构是组织和存储数据的重要方式,而栈和队列作为两种常见的数据结构,具有广泛的应用场景。
本次实验旨在深入探讨栈和队列在实际问题中的应用,加深对它们特性和操作的理解。
一、栈的应用栈是一种“后进先出”(Last In First Out,LIFO)的数据结构。
这意味着最后进入栈的元素将首先被取出。
1、表达式求值在算术表达式的求值过程中,栈发挥着重要作用。
例如,对于表达式“2 + 3 4”,我们可以通过将操作数压入栈,操作符按照优先级进行处理,实现表达式的正确求值。
当遇到数字时,将其压入操作数栈;遇到操作符时,从操作数栈中弹出相应数量的操作数进行计算,将结果压回操作数栈。
最终,操作数栈中的唯一值就是表达式的结果。
2、括号匹配在程序代码中,检查括号是否匹配是常见的任务。
可以使用栈来实现。
遍历输入的字符串,当遇到左括号时,将其压入栈;当遇到右括号时,弹出栈顶元素,如果弹出的左括号与当前右括号类型匹配,则继续,否则表示括号不匹配。
3、函数调用和递归在程序执行过程中,函数的调用和递归都依赖于栈。
当调用一个函数时,当前的执行环境(包括局部变量、返回地址等)被压入栈中。
当函数返回时,从栈中弹出之前保存的环境,继续之前的执行。
递归函数的执行也是通过栈来实现的,每次递归调用都会在栈中保存当前的状态,直到递归结束,依次从栈中恢复状态。
二、队列的应用队列是一种“先进先出”(First In First Out,FIFO)的数据结构。
1、排队系统在现实生活中的各种排队场景,如银行排队、餐厅叫号等,可以用队列来模拟。
新到达的顾客加入队列尾部,服务完成的顾客从队列头部离开。
通过这种方式,保证了先来的顾客先得到服务,体现了公平性。
2、广度优先搜索在图的遍历算法中,广度优先搜索(BreadthFirst Search,BFS)常使用队列。
从起始节点开始,将其放入队列。
数据结构实验三实验报告

数据结构实验三实验报告数据结构实验三实验报告一、实验目的本次实验的目的是通过实践掌握树的基本操作和应用。
具体来说,我们需要实现一个树的数据结构,并对其进行插入、删除、查找等操作,同时还需要实现树的遍历算法,包括先序、中序和后序遍历。
二、实验原理树是一种非线性的数据结构,由结点和边组成。
树的每个结点都可以有多个子结点,但是每个结点只有一个父结点,除了根结点外。
树的基本操作包括插入、删除和查找。
在本次实验中,我们采用二叉树作为实现树的数据结构。
二叉树是一种特殊的树,每个结点最多只有两个子结点。
根据二叉树的特点,我们可以使用递归的方式实现树的插入、删除和查找操作。
三、实验过程1. 实现树的数据结构首先,我们需要定义树的结点类,包括结点值、左子结点和右子结点。
然后,我们可以定义树的类,包括根结点和相应的操作方法,如插入、删除和查找。
2. 实现插入操作插入操作是将一个新的结点添加到树中的过程。
我们可以通过递归的方式实现插入操作。
具体来说,如果要插入的值小于当前结点的值,则将其插入到左子树中;如果要插入的值大于当前结点的值,则将其插入到右子树中。
如果当前结点为空,则将新的结点作为当前结点。
3. 实现删除操作删除操作是将指定的结点从树中移除的过程。
我们同样可以通过递归的方式实现删除操作。
具体来说,如果要删除的值小于当前结点的值,则在左子树中继续查找;如果要删除的值大于当前结点的值,则在右子树中继续查找。
如果要删除的值等于当前结点的值,则有三种情况:- 当前结点没有子结点:直接将当前结点置为空。
- 当前结点只有一个子结点:将当前结点的子结点替代当前结点。
- 当前结点有两个子结点:找到当前结点右子树中的最小值,将其替代当前结点,并在右子树中删除该最小值。
4. 实现查找操作查找操作是在树中寻找指定值的过程。
同样可以通过递归的方式实现查找操作。
具体来说,如果要查找的值小于当前结点的值,则在左子树中继续查找;如果要查找的值大于当前结点的值,则在右子树中继续查找。
数据结构实验报告三

L->r[j+1]=L->r[0];
}
}
main()
{
SortList *L;
int i;
L->r[0].key=0;
L->r[1].key=49;
L->r[2].key=38;
L->r[3].key=65;
L->r[4].key=97;
L->r[5].key=76;
}SortList;
void InsertSort(SortList *L)
{
int i,j;
for(i=2;i<=L->length;i++)
if(L->r[i].key<L->r[i-1].key){
L->r[0]=L->r[i];
for(j=i-1;L->r[0].key<L->r[j].key;j--)
L->r[6].key=13;
L->r[7].key=27;
L->r[8].key=52;
L->length=8;
SelectSort(L);
printf("\n\n");
for(i=1;i<=L->length;i++)
printf("%d\n",L->r[i].key);
}
附2:原程序
#define SORT_LIST_MAXSIZE 20
typedef int KeyType;
typedef int InfoType;
typedef struct{
国家开放大学《数据结构》课程实验报告(实验3 ——栈、队列、递归设计)参考答案

x=Pop(s); /*出栈*/
printf("%d ",x);
InQueue(sq,x); /*入队*/
}
printf("\n");
printf("(10)栈为%s,",(StackEmpty(s)?"空":"非空"));
printf("队列为%s\n",(QueueEmpty(sq)?"空":"非空"));
ElemType Pop(SeqStack *s); /*出栈*/
ElemType GetTop(SeqStack *s); /*取栈顶元素*/
void DispStack(SeqStack *s); /*依次输出从栈顶到栈底的元素*/
void DispBottom(SeqStack *s); /*输出栈底元素*/
} SeqQueue; /*定义顺序队列*/
void InitStack(SeqStack *s); /*初始化栈*/
int StackEmpty(SeqStack *s); /*判栈空*/
int StackFull(SeqStack *s); /*判栈满*/
void Push(SeqStack *s,ElemType x); /*进栈*/
sq=(SeqQueue *)malloc(sizeof(SeqQueue));
InitQueue(sq);
printf("(8)队列为%s\n",(QueueEmpty(sq)?"空":"非空"));
printf("(9)出栈/入队的元素依次为:");
数据结构实验报告3

数据结构实验报告3数据结构实验报告3引言:数据结构是计算机科学中的一个重要概念,它涉及到数据的组织、存储和管理。
在本次实验中,我们将探索一些常见的数据结构,并通过实验来验证它们的性能和效果。
一、线性表线性表是最基本的数据结构之一,它是一种由一组数据元素组成的有序序列。
在本次实验中,我们使用了顺序表和链表来实现线性表。
顺序表是一种连续存储的数据结构,它可以通过下标来访问元素。
我们通过实验比较了顺序表的插入和删除操作的时间复杂度,发现在插入和删除元素较多的情况下,顺序表的性能较差。
链表是一种非连续存储的数据结构,它通过指针来连接各个元素。
我们通过实验比较了链表的插入和删除操作的时间复杂度,发现链表在插入和删除元素时具有较好的性能。
二、栈栈是一种特殊的线性表,它只允许在表的一端进行插入和删除操作。
在本次实验中,我们实现了栈的顺序存储和链式存储两种方式。
顺序存储的栈使用数组来存储元素,我们通过实验比较了顺序存储栈和链式存储栈的性能差异。
结果表明,在元素数量较少的情况下,顺序存储栈具有较好的性能,而在元素数量较多时,链式存储栈更具优势。
三、队列队列是一种特殊的线性表,它只允许在表的一端进行插入操作,在另一端进行删除操作。
在本次实验中,我们实现了队列的顺序存储和链式存储两种方式。
顺序存储的队列使用数组来存储元素,我们通过实验比较了顺序存储队列和链式存储队列的性能差异。
结果表明,顺序存储队列在插入和删除元素时具有较好的性能,而链式存储队列在元素数量较多时更具优势。
四、树树是一种非线性的数据结构,它由一组称为节点的元素组成,通过节点之间的连接来表示数据之间的层次关系。
在本次实验中,我们实现了二叉树和二叉搜索树。
二叉树是一种每个节点最多有两个子节点的树结构,我们通过实验验证了二叉树的遍历算法的正确性。
二叉搜索树是一种特殊的二叉树,它的左子树的所有节点都小于根节点,右子树的所有节点都大于根节点。
我们通过实验比较了二叉搜索树的插入和查找操作的时间复杂度,发现二叉搜索树在查找元素时具有较好的性能。
北京理工大学数据结构实验报告3

《数据结构与算法统计》实验报告——实验三学院:班级:学号:姓名:一、实验目的1 熟悉VC环境,学会使用C++解决关于二叉树的问题。
2 在上机、调试的过程中,加强对二叉树的理解和运用。
3 锻炼动手编程和独立思考的能力。
二、实验内容遍历二叉树。
请输入一棵二叉树的扩展的前序序列,经过处理后生成一棵二叉树,然后对于该二叉树输出前序、中序和后序遍历序列。
三、程序设计1、概要设计为实现上述程序功能,首先需要二叉树的抽象数据结构。
⑴二叉树的抽象数据类型定义为:ADT BinaryTree {数据对象D:D是具有相同特性的数据元素的集合。
数据关系R:若D=Φ,则R=Φ,称BinaryTree为空二叉树;若D≠Φ,则R={H},H是如下二元关系;(1)在D中存在惟一的称为根的数据元素root,它在关系H下无前驱;(2)若D-{root}≠Φ,则存在D-{root}={D1,Dr},且D1∩Dr =Φ;(3)若D1≠Φ,则D1中存在惟一的元素x1,<root,x1>∈H,且存在D1上的关系H1 ⊆H;若Dr≠Φ,则Dr中存在惟一的元素xr,<root,xr>∈H,且存在上的关系Hr ⊆H;H={<root,x1>,<root,xr>,H1,Hr};(4)(D1,{H1})是一棵符合本定义的二叉树,称为根的左子树;(Dr,{Hr})是一棵符合本定义的二叉树,称为根的右子树。
基本操作:CreatBiTree(BiTree &T)操作结果:按先序次序建立二叉链表表示的二叉树TPreOrderTraverse(BiTree T,int (*visit)(char e))初始条件:二叉树T已经存在,visit是对结点操作的应用函数操作结果:先序遍历二叉树T ,对每个结点调用visit函数仅一次;一旦visit()失败,则操作失败。
InOrderTraverse(BiTree T,int (*visit)(char e))初始条件:二叉树T已经存在,visit是对结点操作的应用函数操作结果:中序遍历二叉树T ,对每个结点调用visit函数仅一次;一旦visit()失败,则操作失败。
数据结构_实验三_报告

实验报告实验三二叉树的基本操作实现及其应用一、实验目的1.熟悉二叉树结点的结构和对二叉树的基本操作。
2.掌握对二叉树每一种操作的具体实现。
3.学会利用递归方法编写对二叉树这种递归数据结构进行处理的算法。
4.会用二叉树解决简单的实际问题。
二、实验内容题目一设计程序实现二叉树结点的类型定义和对二叉树的基本操作。
该程序包括二叉树结构类型以及每一种操作的具体的函数定义和主函数。
1 按先序次序建立一个二叉树,2按(A:先序 B:中序 C:后序 D:层序)遍历输出二叉树的所有结点3求二叉树中所有结点数4求二叉树的深度5 判断二叉树是否为空**************************************************************** 三、实验步骤㈠、数据结构与核心算法的设计描述/* 定义DataType为char类型 */typedef char DataType;/* 二叉树的结点类型 */typedef struct BitNode{DataType data;struct BitNode *lchild,*rchild;}*BiTree;相关函数声明:1、/* 初始化二叉树,即把树根指针置空 */void BinTreeInit(BiTree &BT)2、/* 按先序次序建立一个二叉树*/void BinTreeCreat(BiTree &BT)3、/* 检查二叉树是否为空 */int BinTreeEmpty(BiTree &BT)4、/*按任一种遍历次序(包括按先序、中序、后序、按层次)输出二叉树中的所有结点 */void PreOrderBinTraverse(BiTree &T)//先序void InOrderBinTraverse(BiTree &T)//中序void PostOrderBinTraverse(BiTree &T)//后序void LevelOrderTraverse(BiTree &T)//层序5、/* 求二叉树的深度 */int BinTreeDepth(BiTree BT)6、/* 求二叉树中所有结点数 */void BinTreeCount(BiTree T,int &count)㈢程序调试及运行结果分析在调试过程中,开始时按先序次序建立二叉树时,其中一句if(ch=='')T=NULL;调试中发现此句无法是函数结束,经分析知道输入的空格不会被读入,导致函数无法结束,最终将起改为:if(ch=='@')T=NULL;运行正确。
《数据结构》实验3链表

三、源代码以及实验结果为
四、源代码以及实验结果为
五、源代码以及实验结果为
六、源代码以及实验结果为
七、附加题以及实验体会:
{
NODE *s; /*定义指向结点类型的指针*/
s=(NODE *)malloc(sizeof(NODE));
/*生成新结点*/
3
4
5
return 1;
}
/*删除P所指向的结点的后继结点*/
void DelLinkList(NODE *p)
{ NODE *q;
if(p->next!=0)
{ q=p->next; /* q指向p的后继结点*/
ch=getchar();
while(ch!='$')
{ p=(NODE *)malloc(sizeof(NODE));
p->data=ch;
1
2
ch=getchar();
}
return (head);
}
/*在链表的P指定结点之后插入值为x的结点*/
int InsLinkList(NODE *p, char x)
四、设有两个单链表A、B,其中元素递增有序,编写算法将A、B归并成一个按元素值递减(允许有相同值)有序的链表C,要求用A、B中的原结点形成,不能重新申请结点。
五、已知单链表表示的线性表中含有两类的数据元素(字母字符,数字字符)。试设计算法,按结点的值将单链表拆分成两个循环链表,分别只含有数字或字母。要求:利用原表中的结点空间作为这两个表的结点空间,头结点可另开辟空间。
附加题:如果换成循环单链表该如何实现?
即题目变成:已知单循环链表表示的线性表中含有两类的数据元素(字母字符,数字字符)。试设计算法,按结点的值将单链表拆分成两个循环链表,分别只含有数字或字母。
《数据结构》实验报告三:几种查找算法的实现和比较

第三次实验报告:几种查找算法的实现和比较//2019-12-4//1.随机生成5万个整数,存入一个文件;//2.算法实现:(1)顺序查找:读入文件中的数据,查找一个key,统计时间;// (2)二分查找:读入文件,排序,二分查找key,统计时间;// (3)分块查找:读入文件,分100块,每块300+数字,查找key,统计时间// (4)二分查找树:读入文件,形成BST,查找key,统计时间//二叉排序树:建立,查找#include "stdio.h"#include "time.h"#include "stdlib.h"struct JD{//定义分块查找的链表结点结构int data;JD *next;};struct INDEX_T{//定义分块查找中,索引表结构int max;//这一块中最大的数字,<maxJD *block;//每一块都是一个单向链表,这是指向块的头指针};INDEX_T myBlock[100];//这是索引表的100项struct NODE{//定义的二分查找树结点结构int data;NODE *left;NODE *right;};const int COUNT=50000;//结点个数int key=666;//待查找的关键字int m=1;//int *array2;void createData(char strFileName[]){//产生随机整数,存入文件srand((unsigned int)time(0));FILE *fp=fopen(strFileName,"w");for(int i=1;i<=COUNT;i++)fprintf(fp,"%d,",rand());fclose(fp);}void createBST(NODE* &bst){//产生5万个随机整数,创建二叉排序树FILE *fp=fopen("data.txt","r");for(int i=1;i<=COUNT;i++){int num;fscanf(fp,"%d,",&num);//从文件中读取一个随机整数//若bst是空子树,第一个结点就是根结点//若bst不是空子树,从根结点开始左小右大,查找这个数字,找到了直接返回,//找不到,就插入到正确位置//创建一个结点NODE* p=new NODE;p->data=num;p->left=0;p->right=0;if(0==bst)//空子树{bst=p;continue;}//非空子树,//在bst中,查找给结点,NODE *q=bst;//总是从根结点开始查找while(1){if(p->data == q->data)//找到了,直接退出break;if(p->data < q->data && q->left==0){//小,往左找,且左边为空,直接挂在q之左q->left=p;break;}if(p->data < q->data && q->left!=0){//小,往左找,且左边非空,继续往左边找q=q->left;continue;}if(p->data > q->data && q->right==0){//大,往右找,且右边为空,直接挂在q之右q->right=p;break;}if(p->data > q->data && q->right!=0){//大,往右找,且右边非空,继续往右边找q=q->right;continue;}}}}int BST_Search(NODE *bst,int key){//在bst中找key,if(0==bst)return -1;//非空子树,//在bst中,查找给结点,NODE *q=bst;//总是从根结点开始查找while(1){if(key == q->data)//找到了,直接退出return 1;if(key < q->data && q->left==0)//小,往左找,且左边为空,找不到return -1;if(key < q->data && q->left!=0)//小,往左找,且左边非空,继续往左边找{q=q->left;continue;}if(key > q->data && q->right==0)//大,往右找,且右边为空,找不到return -1;if(key > q->data && q->right!=0){//大,往右找,且右边非空,继续往右边找q=q->right;continue;}}}void inOrder(NODE *bst){if(bst!=0){inOrder(bst->left);array2[m]=bst->data;//反写回array数组,使数组有序// printf("%7d",array2[m]);m++;inOrder(bst->right);}}int getBSTHeight(NODE *bst){if(bst==0)return 0;else{int hl=getBSTHeight(bst->left);int hr=getBSTHeight(bst->right);int h=hl>hr?hl:hr;return h+1;}}void makeArray(int array[],char strFileName[]) {//生成5万个随机整数FILE *fp=fopen(strFileName,"r");int i=1;while(!feof(fp)){fscanf(fp,"%d,",&array[i]);// printf("%6d",array[i]);i++;}}int Seq_Search(int array[],int key){//在无序顺序数组中,找data是否存在,-1=不存在,存在返回位置下标//监视哨:把要找的那个数放到首部array[0]=key;//for(int i=COUNT;array[i]!=key;i--);if(i>0)//找到了,返回下标return i;return -1;//查找不成功,返回-1}int Bin_Search(int array[],int key){//在有序存储的数组中查找key,找到返回位置,找不到返回-1 int low=1,high=COUNT,mid;while(1){if(low>high)//找不到return -1;mid=(low+high)/2;if(key == array[mid])return mid;else if(key<array[mid])high=mid-1;elselow=mid+1;}}void makeBlock(INDEX_T myBlock[],char strFileName[]) {//从文件中读取整数,分配到块中去//1.初始化块索引表,分100块,400,800,1200,for(int i=0;i<=99;i++){myBlock[i].max=400+400*i;//400,800,1200, (40000)myBlock[i].block=0;}//2.打开文件,读取整数,把每一个整数分配到相应的块中去FILE *fp=fopen(strFileName,"r");while(!feof(fp)){int num=0;fscanf(fp,"%d,",&num);//把num分配到num/400块中,挂到该块链表第一个int blockID=num/400;//求出应该挂在的块号//生成一个新节点,把num放进去,挂上JD *p=new JD;p->data=num;p->next=myBlock[blockID].block;myBlock[blockID].block=p;}fclose(fp);}int Block_Search(INDEX_T myBlock[],int key){int blockID=key/400;//找到块号JD* p=myBlock[blockID].block;while(p!=0){if(p->data==key)return blockID;//能找到p=p->next;}return -1;//找不到}void main(){clock_t begin,end;int pos=-1;//1.生成文件,存入5万个随机整数createData("data.txt");//2.顺序查找int *array=new int[COUNT+1];makeArray(array,"data.txt");//从文件中读取数据begin=clock();for(int k=1;k<=10000;k++)pos=Seq_Search(array,key);end=clock();printf("顺序查找:%d所在的位置=%d.时间=%d毫秒\n",key,pos,end-begin);//3.二分查找树NODE *bst=0;createBST(bst);//产生5万个随机数字,建立一个二叉排序树begin=clock();for(k=1;k<=10000;k++)pos=BST_Search(bst,key);//在bst中找key,找到返回1,找不到返回-1end=clock();printf("二叉排序树查找:%d所在的位置=%d.时间=%d毫秒\n",key,pos,end-begin);array2=new int[COUNT+1];inOrder(bst);//中序输出bst// int height=getBSTHeight(bst);//求出bst的高度// printf("BST高度=%d.\n\n",height);//4.二分查找,利用前面二叉排序树产生的array2,查找key begin=clock();for(k=1;k<=10000;k++)pos=Bin_Search(array2,key);end=clock();printf("二分查找:%d所在的位置=%d.时间=%d毫秒\n",key,pos,end-begin);//5.分块查找,关键字范围[0,32767],分配到100块中去,每一块中存400个数字makeBlock(myBlock,"data.txt");//从文件中读取数据,产生块begin=clock();for(k=1;k<=10000;k++)pos=Block_Search(myBlock,key);//在block中查找key,找到返回块号,找不到返回-1end=clock();printf("分块查找:%d所在的块=%d.时间=%d毫秒\n",key,pos,end-begin);/*for(k=0;k<=99;k++){printf("\n\n\n第%d块<%d:\n",k,myBlock[k].max);JD *q=myBlock[k].block;//让q指向第k块的第一个结点while(q!=0){//输出第k块中所有数字printf("%7d ",q->data);q=q->next;}}*/}。
数据结构课程实验报告

数据结构课程实验报告数据结构课程实验报告引言:数据结构是计算机科学中非常重要的一门课程,它研究了数据的组织、存储和管理方法。
在数据结构课程中,我们学习了各种数据结构的原理和应用,并通过实验来加深对这些概念的理解。
本文将对我在数据结构课程中的实验进行总结和分析。
实验一:线性表的实现与应用在这个实验中,我们学习了线性表这种基本的数据结构,并实现了线性表的顺序存储和链式存储两种方式。
通过实验,我深刻理解了线性表的插入、删除和查找等操作的实现原理,并掌握了如何根据具体应用场景选择合适的存储方式。
实验二:栈和队列的实现与应用栈和队列是两种常见的数据结构,它们分别具有后进先出和先进先出的特点。
在这个实验中,我们通过实现栈和队列的操作,加深了对它们的理解。
同时,我们还学习了如何利用栈和队列解决实际问题,比如迷宫求解和中缀表达式转后缀表达式等。
实验三:树的实现与应用树是一种重要的非线性数据结构,它具有层次结构和递归定义的特点。
在这个实验中,我们学习了二叉树和二叉搜索树的实现和应用。
通过实验,我掌握了二叉树的遍历方法,了解了二叉搜索树的特性,并学会了如何利用二叉搜索树实现排序算法。
实验四:图的实现与应用图是一种复杂的非线性数据结构,它由节点和边组成,用于表示事物之间的关系。
在这个实验中,我们学习了图的邻接矩阵和邻接表两种存储方式,并实现了图的深度优先搜索和广度优先搜索算法。
通过实验,我深入理解了图的遍历方法和最短路径算法,并学会了如何利用图解决实际问题,比如社交网络分析和地图导航等。
实验五:排序算法的实现与比较排序算法是数据结构中非常重要的一部分,它用于将一组无序的数据按照某种规则进行排列。
在这个实验中,我们实现了常见的排序算法,比如冒泡排序、插入排序、选择排序和快速排序等,并通过实验比较了它们的性能差异。
通过实验,我深入理解了排序算法的原理和实现细节,并了解了如何根据具体情况选择合适的排序算法。
结论:通过这些实验,我对数据结构的原理和应用有了更深入的理解。
大连东软信息学院数据结构III实验报告

实验报告(一)实验过程任务一:下面5个操作任选1个完成,写出代码。
1 修改顺序表insert方法中的for循环语句,初始化j=curLen-1实现插入功能并测试选1package三级项目Text;public class Demo {public Object[] listElem;public int curLen;public Demo(){listElem=new Object[50];}public void insert(int i,Object x)throws Exception{if(curLen==listElem.length)throw new Exception("顺序表已满");if(i<0||i>curLen)throw new Exception("插入位置不合法");for(int j=curLen;j>i;j--)listElem[j]=listElem[j-1];listElem[i]=x;curLen++;}public int indexOf(Object x){int j;for(j=0;j<curLen&&!listElem[j].equals(x);j++);if(j<curLen)return j;elsereturn -1;}}package三级项目Text;public class TestDemo {public static void main(String[]args)throws Exception{Demo L=new Demo();L.insert(0, "系");L.insert(1, "专业");L.insert(2, "Text");L.insert(3, "123123");L.insert(4, "学号");int order=L.indexOf("学号");if(order!=-1)System.out.println("顺序表中出现的值为’学号‘的数据元素的位置为:"+order);elseSystem.out.println("此顺序表中不包含值为'学号'的数据元素");}}2 将顺序表查找方法indexOf(Object x)中的while循环修改为for循环并测试3 实现顺序表的输出方法display(),并测试4 定义indexOf(int i,Object x)方法,实现从顺序表第i个位置开始查找x对象第一次出现的位置,并测试5 定义indexOf2(Object x)方法,实现从顺序表逆序查找x对象第一次出现的位置,并测试任务二:下面3个操作任选1个完成,写出代码。
数据结构实验报告(实验)

数据结构实验报告(实验)数据结构实验报告(实验)1. 实验目的1.1 理解数据结构的基本概念和操作1.2 学会使用数据结构解决实际问题1.3 掌握常用数据结构的实现和应用2. 实验环境2.1 操作系统:Windows 102.2 编程语言:C++2.3 开发工具:Visual Studio3. 实验内容3.1 实验一:线性表的实现和应用3.1.1 设计并实现线性表的基本操作函数3.1.2 实现线性表的插入、删除、查找等功能 3.1.3 实现线性表的排序算法3.1.4 应用线性表解决实际问题3.2 实验二:栈和队列的实现和应用3.2.1 设计并实现栈的基本操作函数3.2.2 设计并实现队列的基本操作函数3.2.3 实现栈和队列的应用场景3.2.4 比较栈和队列的优缺点3.3 实验三:树的实现和应用3.3.1 设计并实现二叉树的基本操作函数3.3.2 实现二叉树的创建、遍历和查找等功能3.3.3 实现树的遍历算法(前序、中序、后序遍历)3.3.4 应用树解决实际问题4. 数据结构实验结果4.1 实验一的结果4.1.1 线性表的基本操作函数实现情况4.1.2 线性表的插入、删除、查找功能测试结果4.1.3 线性表的排序算法测试结果4.1.4 线性表解决实际问题的应用效果4.2 实验二的结果4.2.1 栈的基本操作函数实现情况4.2.2 队列的基本操作函数实现情况4.2.3 栈和队列的应用场景测试结果4.2.4 栈和队列优缺点的比较结果4.3 实验三的结果4.3.1 二叉树的基本操作函数实现情况4.3.2 二叉树的创建、遍历和查找功能测试结果 4.3.3 树的遍历算法测试结果4.3.4 树解决实际问题的应用效果5. 实验分析与总结5.1 实验问题与解决方案5.2 实验结果分析5.3 实验总结与心得体会6. 附件附件一:实验源代码附件二:实验数据7. 法律名词及注释7.1 版权:著作权法规定的对原创作品享有的权利7.2 专利:国家授予的在一定时间内对新型发明享有独占权利的证书7.3 商标:作为标识企业商品和服务来源的标志的名称、符号、图案等7.4 许可协议:指允许他人在一定条件下使用自己的知识产权的协议。
数据结构-实验3

《数据结构》实验报告年级_2012级__ 学号_ 姓名 _ 成绩______专业_计算机科学与技术实验地点__指导教师_实验项目:实验三队列实验性质设计性实验日期:一、实验目的:1、掌握队列及其基本操作的实现。
2、进一步掌握实现数据结构的编程方法。
二、实验内容与要求:1、实验题目一:队列的定义及其相关操作算法的实现要求:编程实现队列的类型定义及其初始化操作、入队操作、出队操作、取队头操作、输出操作等,并对其进行验证。
2、实验题目二:病人看病模拟要求:利用题目一所定义的队列(顺序队或链队)实现病人看病模拟程序,并进行验证给出结果。
三、实验问题描述编写一个程序,反映病人到医院看病,排队看医生的情况。
在病人排队过程中,主要重复两件事:(1)病人到达诊室,将病历本交给护士,拍到等待队列中候诊。
(2)护士从等待队列中取出下一位病人的兵力,该病人进入诊室就诊。
要求模拟病人等待就诊这一过程,程序采用菜单方式,其选项及功能说明如下:(1)排队————输入排队病人的病历号,加入到病人排队队列中。
(2)就诊————病人排队队列中最前面的病人就诊,并将其从队列中删除。
(3)查看排队————从队首到队尾列出所有的排队病人的病历号。
(4)不再排队,余下依次就诊————从队首到队尾列出所有的排队病人的病历号,并退出运行。
(5)下班————退出运行。
四、实验步骤1.实验问题分析此程序采用队列数据结构,存储结构为单链表,采用此种结构一方面可以减少数据复杂程度,增加系统稳定性也利用动态分配内存的方法,便于内存管理,充分利用内存空间2.功能(函数)设计void SeeDoctor(){ int sel,flag=1,find,no;QuType *qu;QNode *p;qu=(QuType *)malloc(sizeof(QuType));qu->front=qu->rear=NULL;}五、实验结果(程序)及分析#include<stdio.h>#include<malloc.h>typedef struct qnode{int data;struct qnode *next;}QNode;typedef struct {QNode *front,*rear;}QuType;void SeeDoctor(){int sel,flag=1,find,no;QuType *qu;QNode *p;qu=(QuType *)malloc(sizeof(QuType));qu->front=qu->rear=NULL;while(flag==1){printf("1:排队 2:就诊 3:查看排队 4:不再排队,余下依次就诊 5:下班请选择:");scanf("%d",&sel);switch(sel){case 1:printf(" >>输入病历号:");do{scanf("%d",&no);find=0;p=qu->front;while(p!=NULL && !find)if(p->data==no)find=1;elsep=p->next;if(find)printf(" >> 输入的病历号重复,重新输入:");}while(find==1);p=(QNode *)malloc(sizeof(QNode));p->data=no;p->next=NULL;if(qu->rear==NULL)qu->front=qu->rear=p;else{qu->rear->next=p;qu->rear=p;}break;case 2:if(qu->front==NULL)printf(" >>没有排队的病人!\n");else{p=qu->front;printf(" >>病人%d就诊\n",p->data);if(qu->rear==p)qu->front=qu->rear=NULL;elsequ->front=p->next;free(p);}break;case 3:if(qu->front == NULL)printf(" >>没有排队的病人!\n");else{p=qu->front;printf(" >>排队病人:");while(p!=NULL){printf("%d",p->data);p=p->next;}printf("\n");}break;case 4:if(qu->front==NULL)printf(" >>没有排队的病人!\n");else{p=qu->front;printf(" >>病人按以下顺序就诊:");while(p!=NULL){printf("%d",p->data);p=p->next;}printf("\n");}flag=0;break;case 5:if(qu->front!=NULL)printf(" >>请排队的病人明天就医!\n"); flag=0;break;}}}int main(){SeeDoctor();return 0;}六、结论与分析在本次试验中进一步理解队列的基本运算的实现,掌握队列的定义及其基本操作,掌握队列的存储结构及基本运算的实现和掌握队列的操作和应用,差不多也提高使用理论知识指导解决实际问题的能力。
数据结构实验三
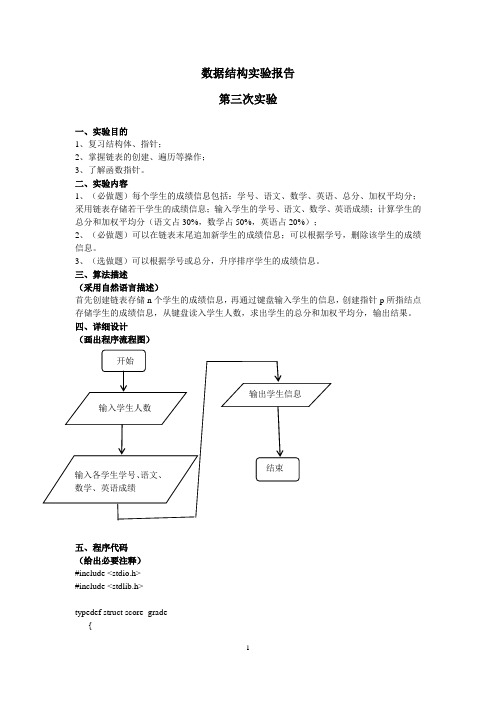
数据结构实验报告第三次实验一、实验目的1、复习结构体、指针;2、掌握链表的创建、遍历等操作;3、了解函数指针。
二、实验内容1、(必做题)每个学生的成绩信息包括:学号、语文、数学、英语、总分、加权平均分;采用链表存储若干学生的成绩信息;输入学生的学号、语文、数学、英语成绩;计算学生的总分和加权平均分(语文占30%,数学占50%,英语占20%);2、(必做题)可以在链表末尾追加新学生的成绩信息;可以根据学号,删除该学生的成绩信息。
3、(选做题)可以根据学号或总分,升序排序学生的成绩信息。
三、算法描述(采用自然语言描述)首先创建链表存储n个学生的成绩信息,再通过键盘输入学生的信息,创建指针p所指结点存储学生的成绩信息,从键盘读入学生人数,求出学生的总分和加权平均分,输出结果。
四、详细设计(画出程序流程图)五、程序代码(给出必要注释)#include <stdio.h>#include <stdlib.h>typedef struct score_grade{long number;int Chinese;int Math;int English;int sum;double average;struct score_grade *next;}student;student* Input_Score(int n){int i;student *stu,*p,*q;p=(student*)malloc(sizeof(student));stu=p;q=p;printf("请输入第1个考生的信息\n");scanf("%ld",&p->number);scanf("%d",&p->Chinese);scanf("%d",&p->Math);scanf("%d",&p->English);p->sum=(p->Chinese)+(p->Math)+(p->English);p->average=(p->Chinese)*0.3+(p->Math)*0.5+(p->English)*0.2;for(i=2;i<=n;i++){p=(student*)malloc(sizeof(student));p->next=NULL;printf("请输入第%d个考生的信息\n",i);scanf("%ld",&p->number);scanf("%d",&p->Chinese);scanf("%d",&p->Math);scanf("%d",&p->English);p->sum=(p->Chinese)+(p->Math)+(p->English);p->average=(p->Chinese)*0.3+(p->Math)*0.5+(p->English)*0.2;q->next=p;q=p;}return stu;}void Output(student *stu,int n){int i;student *p;printf("学生考试信息\n");while(p->next!=NULL){printf("学生学号:%ld\n",p->number);printf("语文成绩:%d\n",p->Chinese);printf("数学成绩:%d\n",p->Math);printf("英语成绩:%d\n",p->English);printf("总分:%d\n",p->sum);printf("平均分:%.1f\n",p->average);printf("\n");p=p->next;}printf("学生学号:%ld\n",p->number);printf("语文成绩:%d\n",p->Chinese);printf("数学成绩:%d\n",p->Math);printf("英语成绩:%d\n",p->English);printf("总分:%d\n",p->sum);printf("平均分:%.1f\n",p->average);printf("\n");}void Delete(student *stu){long number;printf("请输入需要删除的考生学号\n");scanf("%ld",&number);student *a,*b;a=stu;b=stu->next;while(b){if((b->number)==number){a->next=b->next;free(b);break;}a=a->next;b=b->next;}}{int n,a,i;printf("请输入考生人数:\n");scanf("%d",&n);student *stu;stu=Input_Score(n);Output(stu,n);Delete(stu);Output(stu,n);}六、测试和结果(给出测试用例以及测试结果)七、用户手册(告诉用户如何使用程序)输入考生人数和考生信息便可以运行程序。
国家开放大学《数据结构》课程实验报告(实验3 ——栈、队列、递归设计)参考答案
/*判队空*/
int QueueEmpty(SeqQueue *sq)
{
if(sq->rear==sq->front)
return 1;
else
return 0;
}
/*循环队列入队*/
void InQueue(SeqQueue *sq,ElemType x)
{
if ((sq->rear+1)%MaxSize==sq->front) /*队满*/
InitStack(s);
printf("(2)栈为%s\n",(StackEmpty(s)?"空":"非空"));
printf("(3)输入要进栈的数据个数:");
scanf("%d",&n);
printf("依次输入进栈的%d个整数:",n);
/*数据依次进栈*/
for(i=0; i<n; i++)
{
printf("循环队列已空,不能进行出队操作!\n");
exit(1);
}
else{
x=sq->data[sq->front];
sq->front=(sq->front+1)%MaxSize;
return x;
}
}
/*取队头元素*/
ElemType GetQueue(SeqQueue *sq)
{
void InitQueue(SeqQueue *sq); /*初始化队列*/
int QueueEmpty(SeqQueue *sq); /*判队空*/
数据结构实验报告三

<1>初始化一个队列。
循环队列:
链队列:
<2>判断是否队空。
循环队列:
链队列:
<3>判断是否队满。
循环队列:
第一组数据:入队n个元素,判断队满
第二组数据:用循环方式将1到99,99个元素入队,判队满
入队
第一组数据:4,7,8,12,20,50
第二组数据:a,b,c,d,f,g
出队
取队头元素
3.数据结构设计
循环队列
4.算法设计
(除书上给出的基本运算(这部分不必给出设计思想),其它实验内容要给出算法设计思想)
求当前队列中的元素个数:书写函数配合出队函数和判对空函数,定义一个整型变量i计数,在一个循环中每出对一次,计数器加一,直到对空,返回i即为队列元素个数。
第二题:首先判断队列是否队满,如果队满打印队满,结束程序,如果队列不满则进行下一步操作,定义一个变量x,从键盘输入其值,判断如果x的值为0,结束程序,如果不为0进入循环,如果x的模运算不等于0,将x入队,反之出队,直到x的模运算等于0,最后通过循环输出队列。
实现:从列不空,删除Q的队头元素用e返回其值,并返回OK,则返回ERROR
Status EnQueue (LinkQueue *Q, QE1emType e) {
QueuePtr p
if (Q->front==Q- >rear)
三、循环队列与链队列性能分析
1.循环队列与链队列基本操作时间复杂度均为0(1);
2.队列的抽象数据队列Data同线性表。元素具有相同的类型,相邻元素具有前驱和后继关系。Operation InitQueue(*Q):初始化操作,建立一个空队列Q. DestoryQueue(*Q):若队列Q存在,则销毁它。ClearQueue(*Q):将队列Q清空 GetHead(Q,*e):若队列Q存在且非空,用e返回队列Q的队头元素。EnQueue(*Q,e):若队列Q存在且非空, 插入新元素e到队列Q中并称为队元素。DeQueue(*Q,*e):删除队列Q中队头元素,并用e返回其值QueueL ength(Q)。
北京理工大学数据结构实验三报告

} top++; stack[top]=ch; } else if(ch=='^'||ch=='%') { while(stack[top]=='^'||stack[top]=='%') { exp[t]=stack[top]; top--; t++; } top++; stack[top]=ch; } else if(ch=='*'||ch=='/') { while(stack[top]=='*'||stack[top]=='/') { exp[t]=stack[top]; top--; t++; } top++; stack[top]=ch; } else { // printf("第%d 个数开始出错!\n",i+1); judge=1; flag=0; break; } i++; ch=str[i]; } if(k!=l) { printf("括号不匹配!\n"); judge=1; flag=0; } else if (str[zs-1]=='+'||str[zs-1]=='-'||str[zs-1]=='*'||str[zs-1]== '/')
二叉树中不存在度大于 2 的结点) ,并且,二叉树的子树有左右之分, 其次序不能任意颠倒。 4. 二叉树的性质 (1)在二叉树的第 i 层上至多有 个结点(i≥1) 。
(2)深度为 k 的二ቤተ መጻሕፍቲ ባይዱ树至多有
个结点(k≥1) 。
数据结构实验三——二叉树基本操作及运算实验报告

《数据结构与数据库》实验报告实验题目二叉树的基本操作及运算一、需要分析问题描述:实现二叉树(包括二叉排序树)的建立,并实现先序、中序、后序和按层次遍历,计算叶子结点数、树的深度、树的宽度,求树的非空子孙结点个数、度为2的结点数目、度为2的结点数目,以及二叉树常用运算。
问题分析:二叉树树型结构是一类重要的非线性数据结构,对它的熟练掌握是学习数据结构的基本要求。
由于二叉树的定义本身就是一种递归定义,所以二叉树的一些基本操作也可采用递归调用的方法。
处理本问题,我觉得应该:1、建立二叉树;2、通过递归方法来遍历(先序、中序和后序)二叉树;3、通过队列应用来实现对二叉树的层次遍历;4、借用递归方法对二叉树进行一些基本操作,如:求叶子数、树的深度宽度等;5、运用广义表对二叉树进行广义表形式的打印。
算法规定:输入形式:为了方便操作,规定二叉树的元素类型都为字符型,允许各种字符类型的输入,没有元素的结点以空格输入表示,并且本实验是以先序顺序输入的。
输出形式:通过先序、中序和后序遍历的方法对树的各字符型元素进行遍历打印,再以广义表形式进行打印。
对二叉树的一些运算结果以整型输出。
程序功能:实现对二叉树的先序、中序和后序遍历,层次遍历。
计算叶子结点数、树的深度、树的宽度,求树的非空子孙结点个数、度为2的结点数目、度为2的结点数目。
对二叉树的某个元素进行查找,对二叉树的某个结点进行删除。
测试数据:输入一:ABC□□DE□G□□F□□□(以□表示空格),查找5,删除E预测结果:先序遍历ABCDEGF中序遍历CBEGDFA后序遍历CGEFDBA层次遍历ABCDEFG广义表打印A(B(C,D(E(,G),F)))叶子数3 深度5 宽度2 非空子孙数6 度为2的数目2 度为1的数目2查找5,成功,查找的元素为E删除E后,以广义表形式打印A(B(C,D(,F)))输入二:ABD□□EH□□□CF□G□□□(以□表示空格),查找10,删除B预测结果:先序遍历ABDEHCFG中序遍历DBHEAGFC后序遍历DHEBGFCA层次遍历ABCDEFHG广义表打印A(B(D,E(H)),C(F(,G)))叶子数3 深度4 宽度3 非空子孙数7 度为2的数目2 度为1的数目3查找10,失败。
数据结构实验报告三

数据结构实验报告三数据结构实验报告三引言:数据结构作为计算机科学的重要基础,对于计算机程序的设计和性能优化起着至关重要的作用。
在本次实验中,我们将深入研究和实践数据结构的应用,通过实验来验证和巩固我们在课堂上所学到的知识。
一、实验目的本次实验的主要目的是通过实践操作,进一步掌握和理解数据结构的基本概念和操作。
具体来说,我们将学习并实现以下几个数据结构:栈、队列、链表和二叉树。
通过对这些数据结构的实现和应用,我们将更好地理解它们的特点和优势,并能够灵活运用于实际问题的解决中。
二、实验内容1. 栈的实现与应用栈是一种后进先出(LIFO)的数据结构,我们将学习如何使用数组和链表两种方式来实现栈,并通过实例来演示栈的应用场景,如括号匹配、表达式求值等。
2. 队列的实现与应用队列是一种先进先出(FIFO)的数据结构,我们将学习如何使用数组和链表两种方式来实现队列,并通过实例来演示队列的应用场景,如任务调度、消息传递等。
3. 链表的实现与应用链表是一种动态数据结构,相比数组具有更好的灵活性和扩展性。
我们将学习如何使用指针来实现链表,并通过实例来演示链表的应用场景,如链表的插入、删除、反转等操作。
4. 二叉树的实现与应用二叉树是一种常见的树形结构,我们将学习如何使用指针来实现二叉树,并通过实例来演示二叉树的应用场景,如二叉树的遍历、搜索等操作。
三、实验过程1. 栈的实现与应用我们首先使用数组来实现栈,并编写相关的入栈、出栈、判空、获取栈顶元素等操作。
然后,我们通过括号匹配和表达式求值两个实例来验证栈的正确性和应用性。
2. 队列的实现与应用我们使用数组来实现队列,并编写相关的入队、出队、判空、获取队头元素等操作。
然后,我们通过任务调度和消息传递两个实例来验证队列的正确性和应用性。
3. 链表的实现与应用我们使用指针来实现链表,并编写相关的插入、删除、反转等操作。
然后,我们通过链表的插入和删除操作来验证链表的正确性和应用性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《数据结构》实验报告实验序号:3 实验项目名称:链式表的操作1、#include<stdio.h> #include<string.h> #include<stdlib.h> #include<ctype.h>typedef struct LISTNODE//定义结点{char cData[10]; //结点的数据域为字符串struct LISTNODE *pstNext; //结点的指针域}tagListNode_T;typedef tagListNode_T *LinkList; // 自定义LinkList单链表类型LinkList CreatList(); //函数,用尾插入法建立带头结点的单链表tagListNode_T *LocateNode(LinkList pstHead, char *cpKey); //函数,按值查找结点void DeleteList(LinkList pstHead, char *cpKey); //函数,删除指定值的结点void PrintList(LinkList pstHead); //函数,打印链表中的所有值void DeleteAll(LinkList pstHead); //函数,删除所有结点,释放内存//==========主函数==============void main(){char *cpCharData = NULL;char *cpN_Y = NULL;cpN_Y = new char;cpCharData = new char[10];LinkList pstHead;pstHead = CreatList(); //用尾插入法建立单链表,返回头指针PrintList(pstHead); //遍历链表输出其值printf("Delete node (y/n): "); //输入"y"或"n"去选择是否删除结点scanf("%s", cpN_Y);if (strcmp(cpN_Y, "y") == 0 || strcmp(cpN_Y, "Y") == 0){printf("Please input Delete_data: ");scanf("%s", cpCharData); //输入要删除的字符串DeleteList(pstHead, cpCharData);PrintList(pstHead);}DeleteAll(pstHead); //删除所有结点,释放内存}//==========用尾插入法建立带头结点的单链表===========LinkList CreatList(){char *cpCharData = NULL;cpCharData = new char[10];LinkList pstHead = (LinkList)malloc(sizeof(tagListNode_T)); //生成头结点tagListNode_T *pstTemp;tagListNode_T *pstListNode;pstListNode = pstHead;pstListNode ->pstNext = NULL;printf("Input # to end \n"); //输入"#"代表输入结束printf("Please input Node_data:");//scanf("%s",ch); //输入各结点的字符串while ((scanf("%s", cpCharData) == 1) && (strcmp(cpCharData, "#") != 0)) {pstTemp = (tagListNode_T *)malloc(sizeof(tagListNode_T));strcpy(pstTemp->cData, cpCharData);pstListNode ->pstNext = pstTemp;pstListNode = pstTemp;pstListNode ->pstNext = NULL;}return pstHead; //返回头指针}//==========按值查找结点,找到则返回该结点的位置,否则返回NULL========== tagListNode_T *LocateNode(LinkList pstHead, char *cpKey){tagListNode_T *pstTemp = pstHead ->pstNext; //从开始结点比较while (strcmp(pstTemp->cData, cpKey) != 0 && pstTemp)pstTemp = pstTemp ->pstNext; //扫描下一个结点return pstTemp;}//==========删除带头结点的单链表中的指定结点=======void DeleteList(LinkList pstHead, char *cpKey){tagListNode_T *pstDelteNode;tagListNode_T *pstTemp;tagListNode_T *pstFistNode = pstHead;pstDelteNode = LocateNode(pstHead, cpKey); //按key值查找结点的if (pstDelteNode == NULL){ //若没有找到结点,退出printf("position error");exit(0);}while (pstFistNode->pstNext != pstDelteNode)pstFistNode = pstFistNode->pstNext;pstTemp = pstFistNode->pstNext;pstFistNode->pstNext = pstTemp->pstNext;free(pstTemp); //释放结点}//===========打印链表=======void PrintList(LinkList pstHead){tagListNode_T *pstFistNode = pstHead ->pstNext; //从开始结点打印while (pstFistNode){printf("%s, ", pstFistNode ->cData);pstFistNode = pstFistNode ->pstNext;}printf("\n");}//==========删除所有结点,释放空间===========void DeleteAll(LinkList pstHead){tagListNode_T *pstFistNode = pstHead;tagListNode_T *pstNextNode;while (pstFistNode ->pstNext){pstNextNode = pstFistNode->pstNext;free(pstFistNode);pstFistNode = pstNextNode;}free(pstFistNode);}2、1).int Delte_Key_PioneerNode(LinkList pstHead, char *cpKey){tagListNode_T *pstFistNode = pstHead;tagListNode_T *pstCurrentNode = pstHead ->pstNext;tagListNode_T *pstPioneerNode = NULL;tagListNode_T *pstTemp = NULL;while (pstCurrentNode && strcmp(pstCurrentNode->cData, cpKey) != 0) //找到指定的节点{pstPioneerNode = pstCurrentNode; // 记录当前节点的前驱节点,该节点为要删除的节点pstCurrentNode = pstCurrentNode ->pstNext; //若没找到,接着往下查找}while (pstFistNode ->pstNext != pstPioneerNode) //找到要删除的pstPioneerNode节点的前驱节点{pstFistNode = pstFistNode->pstNext;}pstTemp = pstFistNode ->pstNext; //pstTemp为要删除的节点pstFistNode ->pstNext = pstTemp ->pstNext;free(pstTemp); //释放结点return 0;}2).int Reversed_Order_Print_OneWay_CirculationList(LinkList pstListNode){tagListNode_T *pstCourrenNode = pstListNode;tagListNode_T *pstTemp = NULL;do{printf("%s ", pstCourrenNode ->cData);pstTemp = pstCourrenNode;while (pstTemp->pstNext != pstCourrenNode) //找到刚才打印出来的那个节点的前驱节点{pstTemp = pstTemp ->pstNext;}pstCourrenNode = pstTemp; //把刚才打印出来的那个节点的前驱节点再赋值给pstcourrentNode打印出来。
} while (pstCourrenNode != pstListNode ->pstNext); //结束标志printf("\n");return 0;}3).LinkList CreatList(){char *cpCharData = NULL;cpCharData = new char[10];LinkList pstHead = (LinkList)malloc(sizeof(tagListNode_T)); //生成头结点tagListNode_T *pstTemp = NULL;tagListNode_T *pstListNode = NULL;pstListNode = pstHead;pstListNode ->pstNext = NULL;printf("Input # to end \n"); //输入"#"代表输入结束printf("Please input Node_data:");while ((scanf("%s", cpCharData) == 1) && (strcmp(cpCharData, "#") != 0)) //输入各结点的字符串{pstTemp = (tagListNode_T *)malloc(sizeof(tagListNode_T));strcpy(pstTemp->cData, cpCharData);pstListNode ->pstNext = pstTemp;pstListNode = pstTemp;pstListNode ->pstNext = NULL;}char *cpTempString = NULL;cpTempString = new char; //中间变量tagListNode_T *pstFirstNode = NULL;tagListNode_T *pstLaterNode = NULL;pstFirstNode = pstHead->pstNext; //第一个节点while (pstFirstNode) //类似于冒泡法排序{pstLaterNode = pstFirstNode->pstNext; //每次指向相对于pstFirstNode的后面那个节点while (pstLaterNode){if (strcmp(pstLaterNode->cData, pstFirstNode->cData) < 0){strcpy(cpTempString, pstFirstNode ->cData);strcpy(pstFirstNode ->cData, pstLaterNode ->cData);strcpy(pstLaterNode->cData, cpTempString);}pstLaterNode = pstLaterNode->pstNext;}pstFirstNode = pstFirstNode ->pstNext;}// fflush(stdin);//清楚缓冲// pstListNode ->pstNext = pstHead; //单循环链表,尾指针指向头指针//return pstListNode; //返回尾指针return pstHead; //返回头指针}4).int DelteListTheSame(LinkList pstHead){tagListNode_T*pstCurrentNode=pstHead->pstNext;//当前节点tagListNode_T*pstLaterNode=NULL;//相对于pstCurrentNode的后驱节点tagListNode_T*pstPioneerNode=NULL;//相对于pstLaterNode的前驱节点while(pstCurrentNode){pstPioneerNode=pstCurrentNode;pstLaterNode=pstCurrentNode->pstNext;while(pstLaterNode){if(strcmp(pstCurrentNode->cData,pstLaterNode->cData)==0)//判断是否有相同元素{pstPioneerNode->pstNext=pstLaterNode->pstNext;//把pstLaterNode的后驱节点给pstPioneerNode来记录free(pstLaterNode);//清空pstLaterNode=pstPioneerNode->pstNext;//再把pstPioneerNode记录的后驱给pstLaterNode}else//不存在相同元素{pstPioneerNode=pstLaterNode;//把pstLaterNode记录的节点给pstPioneerNodepstLaterNode=pstLaterNode->pstNext;//指向下一节点}}pstCurrentNode=pstCurrentNode->pstNext;}return0;}完整代码:#include <stdio.h>#include <string.h>#include <stdlib.h>#include <ctype.h>typedef struct LISTNODE //定义结点{char cData[10]; //结点的数据域为字符串struct LISTNODE *pstNext; //结点的指针域}tagListNode_T;typedef tagListNode_T *LinkList; // 自定义LinkList单链表类型LinkList CreatList(); //函数,用尾插入法建立带头结点的单链表tagListNode_T *LocateNode(LinkList pstHead, char *cpKey); //函数,按值查找结点void DeleteList(LinkList pstHead, char *cpKey); //函数,删除指定值的结点void PrintList(LinkList pstHead); //函数,打印链表中的所有值void DeleteAll(LinkList pstHead); //函数,删除所有结点,释放内存int Delte_Key_PioneerNode(LinkList pstHead, char *cpKey); //函数,删除指定节点的前驱节点int Reversed_Order_Print_OneWay_CirculationList(LinkList pstListNode); //函数,逆序输出单循环链表中的值int DelteListTheSame(LinkList pstHead);/*生成的非递减有序的单链表中,编写一个算法,删除单链表中值相同的多余结点。