abap基本语法汇总情况
odata abap 语法

odata abap 语法OData(Open Data Protocol)是一种数据协议,用于构建和使用RESTful API。
它定义了一种规范,允许应用程序通过HTTP协议以查询和操作数据的方式进行互操作。
ABAP(Advanced Business Application Programming)是一种用于SAP系统的编程语言。
在ABAP中,可以使用OData语法来构建RESTful API。
以下是OData在ABAP中的一些常见语法:1. URL路径:使用URL路径来指定要访问的资源。
例如,`/sap/opu/odata/sap/ZMY_ORDER_SERVICE`表示访问名为ZMY_ORDER_SERVICE的OData服务。
2. $select:使用$select选项来筛选要返回的属性。
例如,`?$select=OrderID,CustomerName`将只返回OrderID和CustomerName属性。
3. $filter:使用$filter选项来过滤数据。
例如,`?$filter=OrderID eq'A001'`将返回OrderID为'A001'的订单。
4. $expand:使用$expand选项来扩展相关实体。
例如,`?$expand=Customer`将返回订单及其关联的客户信息。
5. $orderby:使用$orderby选项对结果进行排序。
例如,`?$orderby=OrderDate desc`将按OrderDate降序排列订单。
6. $top和$skip:使用$top选项返回前n条结果,使用$skip选项跳过第n条结果。
例如,`?$top=5&$skip=10`将返回第11至15条结果。
这些是OData在ABAP中的一些常见语法,你可以根据具体的需求和OData规范来构建更复杂的查询和操作。
SAP ABAP基本语法介绍

19
内表类型 ➢标准表
系统内建维护了表的行号(即索引),索引和键访问都是允许的。 当经常用索引访问表的时候就选择标准表。
➢排序表
数据记录在表内自动以升序进行排列,索引是系统自动维护的,索 引和键访问都可以用。如果经常使用键来访 问数据,或者希望数据 能够自动排序时,就用排序表。
往内表的最后追加一条记录,只能用于标准表
➢INSERT
向内表插入一条记录
➢READ
把表的指定行拷贝到结构中
➢LOOP
遍历内表
➢MODIFY
使用结构的内容重写表的指定行
➢DELETE
删除表的指定行
➢COLLECT
把结构中的内容累加到内表具有相同键的行上,只有非键字段才执 行累加,并且只有非键字段 都是数值的时候才能执行这个语句
➢CLEAR 语句根据类型清除数据对象,恢复成默认值。
15
基本ABAP语句:运算
➢ABAP 程序中,数学表达式可以进行任意多层嵌套
( 20 + 10) * 10 + 10 / 2
➢二元操作符包括:
+ :加法 - :减法 * :乘法 / :除法 ** :乘方 DIV :整除忽略余数 MOD(%) :取模
包含了接口。类和接口池 (程序类型为 J) 接口都在类制作器中管理,事务码 SE24。
➢类池 (程序类型为 K)
包含了类。类和接口都在类制作器中管理,事务码 SE24
7
数据类型和数据对象
➢形式上的变量描述叫做数据类型,由数据类型具体定义 的变量叫做数据对象 ➢数据类型
标准数据类型(预定义数据类型)、本地数据类型、全 局数据类型
ABAP语法

ABAP语法一、格式。
作用:设置或更改有效的输出格式。
注意:由Format设置的格式会影响到清淡的下一个输出操作,下一个输出命令或下一个新行。
附加ON对于转换贴切的输出格式变得更随意。
你也能设置静态的附加ON,OFF和n(对于颜色)。
1、颜色。
Format Color n [ON] or Format Color n[OFF]作用:行背景颜色。
N能有如下的价值。
OFF or COL_BACKGROUND Background (GUI-specific)1 or COL_HEADING Headers (grayish blue)2 or COL_NORMAL List body (bright gray)3 or COL_TOTAL Totals (yellow)4 or COL_KEY Key columns (bluish green)5 or COL_POSITIVE Positive threshold value (green)6 or COL_NEGATIVE Negative threshold value (red)7 or COL_GROUP Control levels (violet)清单颜色注意:每次一个新的事件(START-OF-SELECTION, TOP-OF-PAGE, ...)开始,这个系统的设置回复到COLOR 0。
附加.. INTENSIFIED和... INVERSE影响颜色的显示属性...COLOR对于线不起作用。
WRITE --- OUTPUT AS lineInclude<Line>(或更多广泛的Include<List>)对于行包含关系识别作为永恒,例如:LINE_TOP_LEFT_CORNER, LINE_BOTTOM_MIDDLE_CORNER。
Line不能有其他的显示属性。
如果像颜色(COLOR),背面VIDEO(INVERSE)或变强(INTENSIFIED)被设置,这些忽略输出。
abap switch 语法

abap switch 语法摘要:一、ABAP Switch 语法简介二、ABAP Switch 语法详解1.基本语法结构2.变量和表达式3.条件分支4.默认分支5.跳出循环正文:【ABAP Switch 语法简介】ABAP(Advanced Business Application Programming)是一种高级企业应用程序编程语言,主要用于SAP ERP 系统的开发。
Switch 语句是ABAP 中的一种选择结构控制语句,可以根据不同的条件执行不同的代码块。
本文将详细介绍ABAP Switch 语法的相关知识。
【ABAP Switch 语法详解】1.基本语法结构ABAP Switch 语句的基本语法结构如下:```SWITCH (<条件表达式>)WHEN (<条件1>) THEN<代码块1>WHEN (<条件2>) THEN<代码块2>...WHEN (<条件n>) THEN<代码块n>ELSE<默认代码块>END-SWITCH```其中,`<条件表达式>` 是用于判断的条件,`<条件1>`、`<条件2>` 等是具体的条件,`<代码块1>`、`<代码块2>` 等是针对不同条件执行的代码块,`<默认代码块>` 是在所有条件都不满足时执行的代码块。
2.变量和表达式在ABAP Switch 语句中,可以使用变量和表达式作为条件。
需要注意的是,Switch 语句中的条件表达式不能包含函数调用。
3.条件分支在Switch 语句中,可以使用WHEN 子句定义多个条件分支。
当条件表达式的值为某个条件时,将执行对应的代码块。
多个WHEN 子句之间可以有任意数量的空行,但它们必须处于同一缩进级别。
4.默认分支如果Switch 语句中没有满足的条件,将执行ELSE 子句中的代码块。
abap基本语法汇总

一数据类型和对象在ABAP中,可以使用与标准数据声明相似的语法处理数据类型,而与数据对象无关。
在程序中必须声明要使用的全部数据对象。
声明过程中,必须给数据对象分配属性,其中最重要的属性就是数据类型。
对算术运算的非整型结果(如分数)进行四舍五入,而不是截断。
类型 P 数据允许在小数点后有数字。
有效大小可以是从 1 到 16 字节的任何值。
将两个十进制数字压缩到一个字节,而最后一个字节包含一个数字和符号。
在小数点后最多允许 14 个数字。
1.3 确定数据对象的属性如果要查明数据对象的数据类型,或者要在程序的运行期间使用其属性,可使用DESCRI BE 语句。
语法如下:DESCRI BE FIELD<f> [LENGTH <l>] [TYPE <t> [COMPON ENTS<n>]][OUTPUT-LENGTH <o>] [DECIMA LS <d>][EDIT MASK <m>].将由语句的参数指定的数据对象<f>的属性写入参数后的变量。
DESCRI1.3.1 确定字段长度要确定数据对象的长度,利用DESCRIBEFIELD语句使用 LENGTH参数,如下所示:DESCRI BE FIELD<f> LENGTH <l>.系统读取字段<f>的长度,并将值写入字段<l>。
1.3.2确定数据类型要确定字段的数据类型,利用DESCRIBEFIELD语句使用 TYPE 参数,如下所示:DESCRI BE FIELD<f> TYPE <t> [COMPON ENTS<n>].系统读取字段<f>的数据类型,然后将值写入字段<t>。
SAPABAP基本语法介绍

SAPABAP基本语法介绍ABAP(Advanced Business Application Programming)是SAP (System, Applications, and Products in Data Processing)系统最常用的编程语言之一,主要用于SAP软件开发和定制。
ABAP具有强大的功能和灵活性,可用于创建和维护企业应用程序,包括各种业务流程和数据处理。
在本文中,我将介绍ABAP的基本语法和一些常见的编程概念。
1.ABAP程序结构ABAP程序由多个模块组成,每个模块都是独立的功能单元。
一个ABAP程序通常由一个开始模块和若干子模块组成。
开始模块包含程序的整体逻辑,而子模块用于实现程序的具体功能。
2.声明变量在ABAP中,变量需要先声明后才能使用。
变量可以是内部表、字段符号、工作区、宏定义等。
声明变量时需要指定数据类型和名称。
例如:DATA: lv_name TYPE string.3.控制语句ABAP支持多种控制语句,用于实现条件判断、循环和跳转等功能。
常见的控制语句包括IF语句、CASE语句、DO循环和WHILE循环等。
例如:WRITE: 'Number is 1'.WRITE: 'Number is 2'.ELSE.WRITE: 'Number is neither 1 nor 2'.ENDIF.4.数据操作ABAP提供了丰富的数据操作函数,可用于对数据进行处理和转换。
例如,可以使用CONCATENATE函数将多个字符串连接在一起,使用SUBSTRING函数获取字符串的子串,使用REPLACE函数替换字符串中的内容等。
5.内部表ABAP中的内部表类似于其他编程语言中的数组或列表,用于存储和处理数据。
内部表可以是标准表、排序表、哈希表等类型。
可以使用内部表来读取、修改和删除数据。
例如:SELECT * FROM kna1 INTO TABLE lt_customers WHERE land1 ='US'.6.函数模块和方法ABAP中的函数模块类似于其他编程语言中的函数或方法。
ABAP基本语法

ABAP基本语法目录1.表声明12.定义变量13.常用算术操作符:14.常用比较操作:15.赋值语句26.IF语句27.CASE语句28.DO语句29.WHILE语句210.从数据库中取数据集211.取出单行记录212.WRITE语句213.ULINE语句314.SKIP语句315.定义常量316.定义结构317.TYPES语句418.LIKE语句419.输入参数520.分块语句521.定义内表522.往内表中添加记录623.用LOOP读取内表数据624.用READ读取内表数据625.把数据库的记录读入内表626.CLEAR清空表头和表记录627.DELETE删除内表记录628.REFRESH删除内表记录629.FREE删除内表记录730.在内表中插入记录731.修改内表记录732.对内表进行排序733.内表的控制语句734.循环跳转语句735.常用系统变量836.子程序的定义837.子程序的调用838.子程序的参数传递839.常用事件840.跳出事件的方法9ABAP/4:Advanced Business Application Programming1.表声明Tables: 表名[,表名]. 声明多个表时可用逗号分隔当你声明了一个数据表的同时,系统也同时自动生成了一个和数据表同名的结构,结构的变量集等于数据表里面的字段。
2.定义变量Data: v1[(l)] [type t] [decimals d] [value 'xxx'].v1 是变量名。
(l) 是变量的长度。
t 是数据类型。
d 是小数位。
'xxx'是缺省值。
如:data num(10) type p decimals 3 value '1.12'.3.常用算术操作符:5.赋值语句total = 10.mess = 'this is a test!'.如果字符串中包括 ' 号,用 '' 进行付值,如:mess = 'this is a ''test''! '.6.IF语句if i = 2.write 'i 等于 2'.[else.write 'i 不等于 2'.]endif.7.CASE语句case i. 类似于VFP中的DO CASE语句when 1. write 'i = 1'.when 2. write 'i = 2'.[when others. write 'i <> 1 and i <> 2'.]endcase.8.DO语句do [n] times. 类似于VFP中的FOR语句[执行代码]enddo.9.WHILE语句while [条件]. 类似于VFP中的DO WHILE语句[执行语句]endwhile.10.从数据库中取数据集select * from 数据表 [where 条件].[操作语句]endselect.如:select * from t000 [where mandt < 200].write: / t000-mandt,t000-mtext.endselect.11.取出单行记录select single * from 数据表 [where 条件]. 注:仅取出符合条件的第一行记录select single 字段 from 数据表 into 变量 [where 条件].12.WRITE语句write: [/][定位][数据1][,[定位] [数据2]]……[/] 为插入一行空行,注意单独write一个[/]和在其它数据之前加 [/] 的效果是不一样的,单独的write[/]在插入空行后光标定位在空行的下面,在其它数据前加[/]在插入空行后光标定位于所插的空行。
abap 常用函数用法 -回复

abap 常用函数用法-回复标题:ABAP常用函数用法详解ABAP(Advanced Business Application Programming)是SAP公司开发的一种高级编程语言,广泛应用于企业资源规划(ERP)系统中。
在ABAP编程中,函数的使用是不可或缺的一部分。
本文将详细介绍一些ABAP常用函数的用法。
1. CONCATENATE函数CONCATENATE函数用于连接两个或更多的字符字段或变量。
其基本语法如下:CONCATENATE expression1 [ INTO target ] [ SEPARATED BY separator ].例如,我们想要连接两个字符串"Hello"和"World":DATA(str1) = 'Hello'.DATA(str2) = 'World'.DATA(result) = CONCATENATE str1 ' ' str2.在上述代码中,'result'的值将会是"Hello World"。
2. SUBSTRING函数SUBSTRING函数用于从字符串中提取一部分子字符串。
其基本语法如下:SUBSTRING string [ OFFSET offset ] [ LENGTH length ].例如,我们想要从字符串"Hello World"中提取"World":DATA(full_str) = 'Hello World'.DATA(sub_str) = SUBSTRING full_str OFFSET 6.在上述代码中,'sub_str'的值将会是"World"。
3. REPLACE函数REPLACE函数用于在字符串中替换某个子字符串。
ABAP基本语法和SQL语句(ABAP内表)

Abap内表什么是内表:内表是内存中建立的一个临时表,你可以在程序运行时对表中的数据进行,插入,修改,删除等操作,程序跑完了,就会被释放。
--内表定义1内表有三种类型:标准表,哈希表,排序表(主要用标准表)。
2预定义的基本数据类型有:C(文本型数据)、N(数字型)、T(时间型)、X(十六进制)、D(日期型)、F(浮点型)、I(整数型)、P(压缩号)。
注意:在abap中要用data定义数据对象,也就是定义变量(内表也是一种变量)。
后面再用type或like来定义变量的类型,这里要要注意type和like的用法,一般能用like的地方都能用type。
当用type的不一定能用like。
因为type一般定义的预定义和自定义的类型,而like用于定义词典对象和已经存在的对象。
其中types直接定义的数据类型与结构,是没有分配内存空间的。
3内表定义三个步骤:1)定义类型2)参考类型定义结构、工作区域、变量3)参考类型定义内表定义类型:通过types开头定义TYPES: BEGIN OF line,field1 TYPE i,field2 TYPE i,END OF line.参考类型定义结构、工作区域、变量:定义结构通过data开头定义DA TA: WA _ITAB TYPE(LIKE) line. “ 声明一个内表工作区参考类型定义内表:定义内表通过data开头定义DA TA: ITAB TYPE(LIKE) line OCCURS 0. “ 声明一个无工作区的内表DA TA: ITAB TY PE(LIKE) STANDARD TABLE OF line INITIAL SIZE 0. “ 声明一个有工作区的内表DA TA: ITAB TYPE(LIKE) line OCCURS 0 WITH HEADER LINE.DA TA: ITAB TYPE(LIKE) STANDARD TABLE OF line INITIAL SIZE 0 WITH HEADER LINE.直接定义内表,这个内表是有工作区的DA TA: BEGIN OF ITAB OCCURS 0 ,CARR1 LIKE SPFLI-CARRID,CONN1 LIKE SPFLI-CONNID,END OF ITAB.[* DATA: ITAB1 TYPE ITAB.(错误的,定义出来的什么都不是)。
ABAP_4语法集锦大全(中文版)

§. ABAP/4 DATA ELEMENT一.Data Type (数据类型)C: 字符(串), 长度为1, 最大有65535 BYTES, 初始值为: space,例: ‘M’;D: 日期, 格式为YYYYMMDD, 最大是’9999/12/31’ ,例:’1999/12/03’.F: 浮点数, 长度为8, 例如: 4.285714285714286E-01I: 整数范围 :-2^31 ~ 2^31-1N: 数值组成的字符串: 011, ‘302’.P: packed 数,用于小数点数值,例如: 12.00542;T: 时间, 格式为HHMMSS,例如: ’14:03:00’, ’21:30:39’.X: 16进制数, 例如‘1A03’.二.变量宣告变量宣告包含name, length, type, structure等,语法如下:DATA <F> [<length>] <type> [<value>] [<decimals>]其中: <f> :变量名称,最长30个字符,不可含有 + , . , : ( ) 等字符;<length><type>:变量类型及长度;<value>:初值<decimals>:小数位数Example 1:DATA: COUNTER TYPE P DECIMALS 3,NAME (10) TYPE C VALUE ‘Delta’,S_DATE TYPE D VALUE ‘19991203’.Example 2:DATA: BEGIN OF PERSON,NAME(10) TYPE C,AGE TYPE I,WEIGHT TYPE P DECIMALS 2,END OF PERSON.另外,有关DATA宣告的指令还有: CONSTANTS(宣告常数)、STATICS(临时变量宣告).三.系统专用变量说明系统内部专门创建了SYST这个STRUCTURE,里面的字段存放系统变量,常用的系统变量有:SY-SUBRC : 系统执行某指令后,表示执行成功与否的变量,’0’表示成功SY-UNAME: 当前使用者登入SAP的USERNAME;SY-DATUM: 当前系统日期;SY-UZEIT: 当前系统时间;SY-TCODE: 当前执行程序的Transaction codeSY-INDEX : 当前LOOP循环过的次数SY-TABIX: 当前处理的是internal table 的第几笔SY-TMAXL: Internal table的总笔数SY-SROWS: 屏幕总行数;SY-SCOLS: 屏幕总列数;SY-MANDT: CLIENT NUMBERSY-VLINE: 画竖线SY-ULINE: 画横线附注:1.SAP的全称是: System Application Products in Data Processing;2.ABAP/4的全称是:Advanced Business Application Programming;3.ABAP/4的路径为:Tools → ABAP/4 WorkBench→ABPA/4 Editor ;4.ABAP/4每条语句以句号结束;5.ABAP/4中象= ,>, <,+,-,*,/等符号左右都需要有至少一个空格;6.整行注释用’*’号, 注释本行后面部分用’”’号;§OUTPUTTING DATA TO SCREEN一. WRITE 语句ABAP/4用来在屏幕上输出数据的指令是WRITE指令,例如:WRITE: ‘USER NAME IS:’, SY-UNAME.二. 指定屏幕输出位置指定输出位置的语句格式为:WRITE: [AT] [ / ] [<pos>] [(<len>)] 资料项 [<par>]其中: / : 在下一行输出<pos>: 指定输出的行号;(<len>):指定输出位数(长度)<par>: 指定显示格式参数,参数有:LEFT-JUSTIFIED 资料靠左对齐CENTERED 数据靠中间对齐RIGHT-JUSTIFIED 资料靠右对齐UNDER <g> 正对在数据项<g>的下面显示NO-GAP 紧接着显示,不留空格USING EDIT MASK <m>: 使用内嵌子元显示, 如 12:03:20 USING NO EDIT MASK: 不使用内嵌子元NO-ZERO: 数字前面 0 的部分不显示NO-SIGN: 不显示正负号DECIMALS <d>: 显示 <d> 位小数EXPOENT <e>: F(浮点数)指数的值ROUND <r>: 四舍五入至小数点后<r>位CURRENCY <c>: 币别显示DD/MM/YY : 日期显示格式MM/DD/YY:YY/MM/DD:YY/DD/MMMM/DD/YYYY:DD/MM/YYYYYYYY/MM/DD:YYYY/DD/MM:例如1: WRITE: /10(6) ‘ABCDEFGHIJK’.输出结果为: ABCDEF例如2: DATA: X TYPE I VALUE ’11:20:30’,A(5) TYPE C VALUE ‘AB CDE’.WRITE: / X USING EDIT MASK ‘__:__:__’.WRITE: / X USING EDIT MASK ‘$___,___’.WRITE: / Y NO-GAP.输出结果为:11:20:30$112,030ABCDEF四.显示图标:语法: WRITE: <symbol-name> AS SYMBOL.WRITE: <icon-name> AS ICON.例如: INCLUDE <SYMBOL>.INCLUDE <ICON>.WRITE: / ‘Phone symbol:’, SYM_PHONE AS SYMBOL.WRITE: / ‘Alarm Icon:’, ICON_VOICE_OUTPUT AS ICON.要查看系统所提供有那些符号及图标,可选择’EDIT’下的’Insert Statement’,选择’Write’,接下来选择要查看的群组,如SYMBOL 或ICON, 接下来按’Display’即可.§INTERNAL TABLE一. Internal Table 的宣告ABAP/4中的Internal Table是一种Data Structure,类似于其它语言中的STRUTURE,它可以由几个不同类型的字段(field)组成,用来表示具有不同属性的某一事物,单独一笔资料表示某个事物,多笔数据表示具有相同属性的多个事物.例如:为了存取或记录某班的同学数据,我们创建如下的internal table:DATA: BEGIN OF STUDENT OCCURS 20,STD_ID TYPE N,NAME(10) TYPE C,AGE TYPE I,BIRTH TYPE D,SCORE TYPE P DECIMALS 2,END OF STUDENT.此时我们已经创建了名叫STUDENT的internal table,并且为它预先申请了能够存放20笔数据的Buffer(当然,如果存取数据不止20笔,程序执行时,会自动申请系统Buffer)Internal table 的定义有以下几种格式:格式一. DATA: BEGIN OF <internal table> OCCURS <n>,<field 1> TYPE <type1>,[<field 2> TYPE <type 2>,<field 3> TYPE <type 3>,… ]END OF <internal table>.格式二. TYPES: BEGIN OF <work area>,<field 1> TYPE <type1>,[<field 2> TYPE <type 2>,<field 3> TYPE <type 3>,… ]END OF <work area>.TYPES <internal table> TYPE <work area> OCCURS <n>.格式三. DATA: BEGIN OF <work area>.INCLUDE STRUCTURE <table name>.DATA: END OF <work area>.DATA: <internal table> LIKE <work area> OCCURS <n>.二. APPEND LINE格式: APPEND [<work area> TO ] <internal table>.举例一. (使用work area)DATA: BEGIN OF LINE,COL1 TYPE I,COL2 TYPE I,END OF LINE.DATA ITAB LIKE LINE OCCURS 10.DO 2 TIMES.LINE-COL1 = SY-INDEX.LINE-COL2 = SY-INDEX ** 2.APPEND LINE TO ITAB.ENDDO.LOOP AT ITAB INTO LINE.WRITE: / LINE-COL1, LINE-COL2.ENDLOOP.执行结果为:1 12 4举例二. (不使用work area)DATA: BEGIN OF ITAB OCCURS 10,COL1 TYPE I,COL2 TYPE I,END OF ITAB.DO 2 TIMES.ITAB-COL1 = SY-INDEX.ITAB-COL2 = SY-INDEX ** 2.APPEND ITAB.ENDDO.LOOP AT ITAB.WRITE: / ITAB-COL1, ITAB-COL2.ENDLOOP.执行结果与举例一相同.举例三. (加入另一个Internal table的元素)格式: APPEND LINES OF <itab1> [FROM <n1> ] [TO <n2>] TO <itab2>.将<itab1>的元素加入至<itab2>中,可选取自<n1>至<n2>的范围.APPEND LINES OF ITAB TO JTAB.三. COLLECT LINECOLLECT 指令也是将元素加入Internal table中,与APPEND 的区别是: COLLECT指令在非数值字段相同的情况下,将数值字段汇总.格式: COLLECT [<work area> INTO ] <itab>DATA: BEGIN OF ITAB OCCURS 3,COL1(3) TYPE C,COL2 TYPE I,END OF ITAB.ITAB-COL1 = ‘ABC’. ITAB-COL2 = 10.COLLECT ITAB.ITAB-COL1 = ‘XYZ’. ITAB-COL2 = 20.COLLECT ITAB.ITAB-COL1 = ‘ABC’. ITAB-COL2 = 80.COLLECT ITAB.此时, internal table中放的是2笔数据, 分别为:ITAB-COL1 ITAB-COL2‘ABC’ 90‘XYZ’ 20四. INSERT LINE将元素插入在指定的internal table位置之前.格式: INSERT [<wa> INTO] [INITIAL LINE INTO ] <itab> [INDEX <idx>] 或者: INSERT LINES OF <itab1> [FROM <n1> TO <n2>] INTO <itab2> INDEX <idx>其中: <wa>即work area,工作区中的元素.[INITIAL LINE INTO] :插入一笔初始化的记录.<itab>: internal table[INDEX <idx>]: internal table 的记录号.(新加入的元素放在此记录前面)五. 读取internal table格式一:LOOP AT <itab> [INTO <wa>][FROM <n1> TO <n2>][WHERE <conditions>]<statement>ENDLOOP.格式二:READ TABLE <itab> [INTO <wa>] [INDEX <idx> / WITH KEY <conditions>]举例. (格式二)DATA: BEGIN OF ITAB OCCURS 10,COL1 TYPE I,COL2 TYPE I,END OF ITAB.DO 10 TIMES.ITAB-COL1 = SY-INDEX.ITAB-COL2 = SY-INDEX * 2.APPEND ITAB.ENDDO.READ TABLE ITAB INDEX 3.(或者: READ TABLE ITAB WITH KEY COL1 = 3.)WRITE: / ‘ITAB-COL1 = ‘, ITAB-COL1, ‘ITAB-COL2 = ‘, ITAB-COL2.执行结果同样是:ITAB-COL1 = 3ITAB-COL2 = 6.六. 修改internal table 中的值格式: MODIFY <itab> [FROM <wa>][INDEX <idx>][TRANSPORTING <f1><f2>…][WHERE <conditions>]举例一. READ TABLE ITAB INDEX 3.LINE-COL1 = 29.MODIFY ITAB FROM LINE TRANSPORTING COL1.将第三笔记录的COL1字段的值修改为29.举例二. T_SALARY – salary = 50.MODIFY T_SALARY TRANSPORTING salary WHERE birthday = ‘1999/12/06’.七. DELETE internal table中的字段格式: DELETE <itab> INDEX <idx>.或: DELETE <itab>[FROM <n1> TO <n2>] [WHERE <conditions>]八. Internal table 排序SORT <itab> [<order way>][BY <f1><f2>…]其中:<order way> 有DESCENDING 和ASCENDING, Default 为ASCENDING.<f1>: 为指定排序的字段.九. 加总SUM.总和计算存放与work area中,但只能在LOOP 中使用.例: LOOP AT ITAB INTO LINE.SUM.ENDLOOP.WRITE: / LINE-COL1, LINE-COL2.十. 初始化internal tableREFRESH <itab>. 清空<itab>中的值.CLEAR <itab>. 清空<itab>的Header Line.FREE <itab>. 释放记忆体空间.§屏幕输入命令在ABAP/4中要从屏幕输入变量, 使用的命令是 PARAMETERS 及SELECTION-OPTIONS:1. PARAMETER: 输入一个变量2. SELECTION-OPTIONS: 使用条件筛选画面来输入数据一. PARAMETERS 指令基本的输入命令, 类似如BASIC的INPUT命令, 但无法使用F格式(浮点数) 语法:PARAMETERS <p> [DEFAULT <f>] [LOWER CASE][OBLIGATORY] [AS CHECKBOX][RADIOBUTTON GROUP <rad>]Example:PARAMETERS: NAME(8),AGE TYPE I,BIRTH TYPE D.执行结果:在日期的输入格式上为 MM/DD/YY , MM/DD/YYYY, MMDDYY或MMDDYYYY , 如输入020165表 1965年02月01日, 与02/01/65的输入是一样的, 日期输入范围为公元1950年至2049年1.DEFAULT设定输入的默认值Example:PARAMETERS: COMPANY(20) DEFAULT ‘DELTA’,BIRTH TYPE D DEFAULT ‘19650201’.2. LOWER CASEABAP/4预设是将字符串输入值自动转换为大写, 加上此参数会将输入的数据转成小写,3. OBLIGATORY强制要求输入, 屏幕上会出现一个 ? , 使用者必须要输入才可.4. AS CHECKBOX输入 CHECKBOX的格式Example:PARAMETERS: TAX AS CHECKBOX DEFAULT ‘X’,NTD AS CHECKBOX.执行结果:5. RADIOBUTTON GROUP <rad>输入 RADIO BUTTON GROUP 的方式Example:PARAMETERS: BOY RADIOBUTTON GROUP SEX DEFAULT ‘X’, GIRL RADIOBUTTON GROUP SEX.执行结果:二. SELECT-OPTIONSSELECTION-OPTIONS所输入的值实际上是放在internal table中的,该Internal table 有四个字段,分别是:SIGN,OPTION,LOW,HIGH.. 条件筛选检查条件输入画面指令, 输入条件后可配合SELECT指令自TABLE读取符合条件的数据, 直接执行或放入 Internal Table中, 条件有四个参数:1. SIGN:I: 表筛选条件符合的资料E: 表筛选条件不符合的资料2. OPTION: 比较的条件符号EQ(等于),NE(不等于),GT(大于),LE(小于),CP(包含),NP(不包含)3. LOW: 最小值4. HIGH: 最大值语法:SELECT-OPTIONS <check-option> FOR <table-field>Example:TABLES SPFLI.SELECT-OPTIONS AIRLINE FOR SPFLI-CONNID.将条件的输入值存放入 AIRLINE, 筛选选择为SPFLI中的CONNID字段执行结果:可直接输入起始范围或按下选择画面, 输入完后按下左上角的执行键三. 条件输入选择画面1.自Table中选取按下输入项的右边往下箭头, 叫出Table中数据项, 选取开始和结束的范围2.Selection Options按下”Selection options”按键, , 输入Option及 Sign参数内容, 屏幕如下:3.Multi-Options输入按下最右边的Multi-Options输入键, 输入条件选取的范围, 画面如下:条件输入完后按下”Copy”按键四. 改变条件输入格式1.DEFAULT <begin> TO <end>设定开始结束范围输入默认值Example:SELECT-OPTIONS AIRLINE FOR SPFLI-CONNIDDEFAULT ‘2042’ TO ‘4555’.2.NO-EXTENSION设定不要Multi-Option输入画面3.NO INTERVALS设定不要区间范围输入画面4.LOWER CASE输入转换成大写5.OBLIGATORY强制要求输入五. 配合 SELECT 命令条件输入完后要将符合条件的数据筛选出来, 可配合使用 SELECT 指令 1.使用WHERE <条件式>Example:SELECT-OPTIONS AIRLINE FOR SPFLI-CONNID.SELECT * FROM SPFLI WHERE CONNID IN AIRLINE.WRITE: / CONNID,FROMCITY,TOCITY.ENDSELECT.2.使用CHECK参数Example:SELECT-OPTIONS AIRLINE FOR SPFLI-CONNID.SELECT * FROM SPFLI.CHECK AIRLINE.WRITE: / CONNID,FROMCITY,TOCITY.ENDSELECT.3.使用 IF … IN 叙述Example:SELECT-OPTIONS AIRLINE FOR SPFLI-CONNID.SELECT * FROM SPFLI.IF SPFLI-CONNID IN AIRLINE.WRITE: / CONNID,FROMCITY,TOCITY.ENDIFENDSELECT.六. SELECTION-SCREEN1.产生空白列语法:SELECTION-SCREEN SKIP [<n>]Example:SELECTION-SCREEN SKIP 2.产生两列空白列2.产生底线语法:SELECTION-SCREEN ULINE / <pos>(length)Example:SELECTION-SCREEN ULINE /10(30).自第10格开始产生长度30的底线3.印出备注说明语法:SELECTION-SCREEN COMMENT / <pos>(length) <name>Example:REMARK = ‘Pls enter your name’.SELECTION-SCREEN COMMENT /10(30) REMARK.4. 同一列中输入数个数据项语法:SELECTION-SCREEN BEGIN OF LINE.……SELECTION-SCREEN END OF LINE.Example:SELECTION-SCREEN BEGIN OF LINE.SELECTION-SCREEN POSITION 20.PARAMETERS NAME(10).SELECTION-SCREEN POSITION 40.PARAMETERS BIRTH TYPE D.SELECTION-SCREEN END OF LINE.在20格输入NAME内容, 40格输入 BIRTH的内容5. 绘出BLOCK PANEL语法:SELECTION-SCREEN BEGIN OF BLOCK <block>[WITH FRAME [TITLE <title>].…….SELECTION-SCREEN END OF BLOCK <block>.Example:SELECTION-SCREEN BEGIN OF BLOCK RADIO WITH FRAME .PARAMETER R1 RADIOBUTTON GROUP GR1.PARAMETER R2 RADIOBUTTON GROUP GR1.PARAMETER R3 RADIOBUTTON GROUP GR1.SELECTION-SCREEN END OF BLOCK RADIO.§SQL语法我们在编写ABAP4程序的时候,经常需要从TABLE中根据某些条件读取数据,.读取数据最常用的方法就是通过SQL语法实现的.ABAP/4中可以利用SQL语法创建或读取TABLE,SQL语法分为DDL(DATA DEFINE LANGUAGE)语言和DML(DATA MULTIPULATION LANGUAGE)语言,DDL语言是指数据定义语言,例如CREATE等, DML语言是数据操作语言,例如SELECT, INSERT等语句. SQL语句有OPEN SQL语句和NATIVE SQL语句. OPEN SQL语句不是标准SQL语句,是ABAP/4语言,利用OPEN SQL语句能在Databases 和 Command 之间产生一个BUFFER,所以它有一个语言转换的过程.而NATIVE SQL语句则是标准的SQL语句, 它直接针对Databases操作.一. OPEN SQLOPEN SQL 语句包含有: SELECT,INSERT,UPDATE,MODIFY,DELETE,OPEN CURSOR, FETCH,CLOSE CURSOR,COMMIT WORK,ROLLBACK WORK等.1. SELECT语句语法格式:SELECT <result> [INTO <target>] [FROM <source>] [WHERE <condition>] [GROUP BY <fields>] [ORDER BY <sort order>]其中: <result>指定要抓取的字段<target>将读取的记录存放在work area中<source>指定从那个TABLE中读取数据<condition>抓取资料的条件<fields>指定按那些字段分组<sort order>排序的字段及方式相关的系统变量:SY-SUBRC = 0 表示读取数据成功<> 0 表示未找到符合条件的记录SY-DBLNT: 被处理过的记录的笔数.相关的命令:EXIT. 退出循环.CHECK <logistic statement>.如果逻辑表达式成立,则继续执行,否则,开始下一次循环.◆.利用循环方式读取所有记录SELECT ….ENDSELECT.是循环方式读取记录的.例如:TABLES MARD.SELECT [DISTINCT] * FROM MARD WHERE MATNR = ‘3520421700’.<Statements>.ENDSELECT.(从MARD中抓取所有料号=3520421700的数据)◆读取一笔数据TABLES MARD.SELECT SINGLE * FROM MARD WHERE MATNR = ‘3520421700’.(从MARA中抓取一笔料号=3520421700的资料)◆将读取的记录放在work area中,并且加入Internal table 中.格式有:... INTO <work area>... INTO CORRESPONDING FIELDS OF <work area>... INTO (f1, ..., fn) 变量组.... INTO TABLE <internal table>... INTO CORRESPONDING FIELDS OF TABLE <internal table>... APPENDING TABLE <internal table>... APPENDING CORRESPONDING FIELDS OF TABLE <internal table> 举例一:TABLES MARD.DATA: BEGIN OF ITAB OCCURS 10,MATNR LIKE MARD-MATNR,WERKS LIKE MARD-WERKS,LGORT LIKE MARD-LGORT,LABST LIKE MARD-LABST,END OF ITAB.SELECT MATNR WERKS LGORT LABSTINTO CORRESPONDING FIELDS OF ITABFROM MARDWHERE MATNR = ‘3520421700’.APPEND ITAB.CLEAR ITAB.ENDSELECT.(将读取的结果放在Internal table ITAB中)举例二.TABLES MARD.SELECT MATNR MTART MAKTX INTO (t_matnr, t_mtart, maktx)FROM MARDWHERE MATNR = ‘3520421700’.<Statements>.ENDSELECT.(从MARD中抓取料号=3520421700的料号、类型和描述,放在变量t_matnr, t_mtart, maktx中)。
abap基本语法汇总
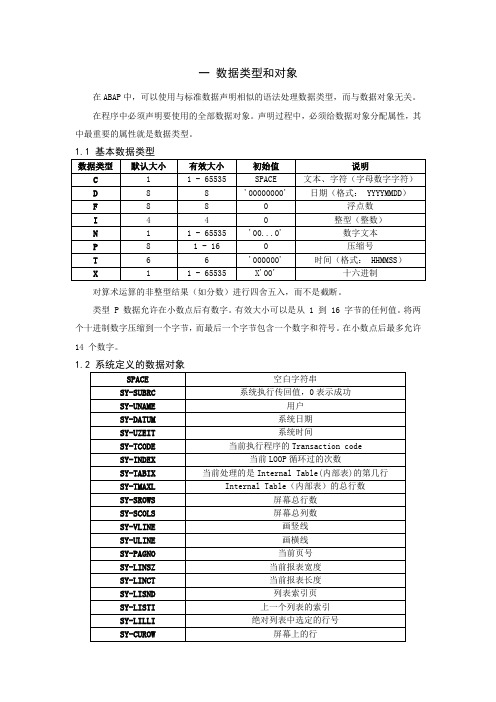
一数据类型和对象在ABAP中,可以使用与标准数据声明相似的语法处理数据类型,而与数据对象无关。
在程序中必须声明要使用的全部数据对象。
声明过程中,必须给数据对象分配属性,其中最重要的属性就是数据类型。
1.1 基本数据类型对算术运算的非整型结果(如分数)进行四舍五入,而不是截断。
类型 P 数据允许在小数点后有数字。
有效大小可以是从 1 到 16 字节的任何值。
将两个十进制数字压缩到一个字节,而最后一个字节包含一个数字和符号。
在小数点后最多允许14 个数字。
1.2 系统定义的数据对象1.3 确定数据对象的属性如果要查明数据对象的数据类型,或者要在程序的运行期间使用其属性,可使用DESCRIBE 语句。
语法如下:DESCRIBE FIELD <f> [LENGTH <l>] [TYPE <t> [COMPONENTS <n>]][OUTPUT-LENGTH <o>] [DECIMALS <d>][EDIT MASK <m>].将由语句的参数指定的数据对象<f>的属性写入参数后的变量。
DESCRIBE FIELDS 语句具有下列参数:1.3.1 确定字段长度要确定数据对象的长度,利用DESCRIBE FIELD 语句使用 LENGTH 参数,如下所示:DESCRIBE FIELD <f> LENGTH <l>.系统读取字段<f>的长度,并将值写入字段<l>。
1.3.2确定数据类型要确定字段的数据类型,利用DESCRIBE FIELD 语句使用 TYPE 参数,如下所示:DESCRIBE FIELD <f> TYPE <t> [COMPONENTS <n>].系统读取字段<f>的数据类型,然后将值写入字段<t>。
SAPABAP_4编程语法汇总

SAPABAP_4编程语法汇总SAP ABAP(Advanced Business Application Programming)是SAP 系统中使用的一种编程语言。
在ABAP_4编程语法中,有一些重要的概念和语法规则需要了解。
下面是SAP ABAP_4编程语法的汇总。
1.ABAP程序的基本结构:ABAP程序由一系列的模块组成,每个模块由一对关键字BEGIN和END 组成。
一个程序通常由多个模块组成,每个模块都以ENDMODULE关键字结束。
模块可以是一个函数,一个子程序或一个方法。
2.数据类型:ABAP支持多种数据类型,包括整型(INT,INT1,INT2,INT4),浮点型(F,D),字符型(CHAR,STRING),日期型(D),时间型(T),结构型(STRUCTURE),表型(TABLE)等。
3.变量声明和赋值:在ABAP中,可以使用DATA语句声明变量,使用WRITE语句输出变量的值。
变量可以通过赋值语句(如"="和"=")来获得新的值。
另外,可以使用CONSTANTS语句定义常量。
4.控制结构:ABAP支持多种控制结构,包括条件语句(如IF,CASE),循环语句(如DO,WHILE,LOOP),跳转语句(如BREAK,CONTINUE,EXIT)等。
5.内部表和工作区:内部表用于存储和操作数据集。
可以使用内部表的语句(如SORT,READTABLE)对内部表进行排序和检索。
内部表可以是标准表,排序表,散列表或索引表。
6.函数和子程序:在ABAP中,可以使用FUNCTION和FORM语句定义函数和子程序。
函数是可重用的代码块,可以被其他程序调用。
子程序是一个独立的代码块,可以在同一个程序中调用。
7.对象和类:ABAP支持面向对象编程,可以使用CLASS语句定义类。
类包含属性和方法,并且可以实例化为对象。
对象可以使用NEW关键字创建,并且可以使用点号(.)来访问对象的属性和方法。
ABAP语法概述

了解ABAP ABAP语法概述 ABAP语言的数据类型 ABAP的语法格式 结构类型和结构体 内表 数据库操作
ABAP
ABAP(Advanced business application program),是一种高级企业 应用编程语言,它支持封装性和继承性, 封装性是面向对象的基础,而继承性是 建立在封装性基础上的重要特性.它适 合生成报表,支持对数据库的操作,如: Sqlserver,Oracle,DB2等主流数据库系统.
Demo:
TYPES: BEGIN OF address, name TYPE string, street(30) TYPE C, city TYPE String, END OF address. DATA my_ add TYPE address. my_ add-name = ' li li' . my_ add-street = ' zhangjiang' . my_ add-city = ' shanghai' . write: my_ add-name , my_ add-street , my_ add-city.
分支结构(IF,CASE)
使用IF的条件分支 IF <条件表达式1>. < statement block > ELSEIF <条件表达式2>. < statement block > ELSEIF <条件表达式3>. < statement block > ..... ELSE. < statement block > ENDIF.
ABAP运算
数值运算(在ABAP中数学表达式可以任意多层嵌套) 算术运算 二元操作符包括: – + :加法 – :减法 – * :乘法 – / :除法 – ** :乘方 – DIV :整除忽略余数 – MOD :取模 需要注意,圆括号和操作符都是关键字,需要跟操作数之 间 至少用一个空格分开. (1+2)*3 应该写成( 1 + 2 ) * 3 注:ABAP中不能使用"&"或"+"做连接(详参见computer语 句的关键字文档 数学函数 时间日期运算
abap基本语法汇总情况

abap基本语法汇总情况⼀数据类型和对象在ABAP中,可以使⽤与标准数据声明相似的语法处理数据类型,⽽与数据对象⽆关。
在程序中必须声明要使⽤的全部数据对象。
声明过程中,必须给数据对象分配属性,其中最重要的属性就是数据类型。
1.1 基本数据类型对算术运算的⾮整型结果(如分数)进⾏四舍五⼊,⽽不是截断。
类型 P 数据允许在⼩数点后有数字。
有效⼤⼩可以是从 1 到 16 字节的任何值。
将两个⼗进制数字压缩到⼀个字节,⽽最后⼀个字节包含⼀个数字和符号。
在⼩数点后最多允许14 个数字。
1.2 系统定义的数据对象1.3 确定数据对象的属性如果要查明数据对象的数据类型,或者要在程序的运⾏期间使⽤其属性,可使⽤DESCRIBE 语句。
语法如下:DESCRIBE FIELD [LENGTH ] [TYPE [COMPONENTS ]][OUTPUT-LENGTH ] [DECIMALS ][EDIT MASK ].将由语句的参数指定的数据对象的属性写⼊参数后的变量。
DESCRIBE FIELDS 语句具有下列参数:1.3.1 确定字段长度要确定数据对象的长度,利⽤DESCRIBE FIELD 语句使⽤ LENGTH 参数,如下所⽰:DESCRIBE FIELD LENGTH .系统读取字段的长度,并将值写⼊字段。
1.3.2确定数据类型要确定字段的数据类型,利⽤DESCRIBE FIELD 语句使⽤ TYPE 参数,如下所⽰:DESCRIBE FIELD TYPE [COMPONENTS ].系统读取字段的数据类型,然后将值写⼊字段。
除返回预定义数据类型 C、D、F、I、N、P、T 和 X 外,该语句还返回XXX s 对于带前导符号的两字节整型XXX b 对于⽆前导符号的⼀字节整型XXX h 对于表XXX C 对于组件中没有嵌套结构的结构XXX C 对于组件中⾄少有⼀个嵌套结构的结构1.3.3确定输出长度要确定字段的输出长度,利⽤ DESCRIBE FIELD 语句使⽤ OUTPUT-LENGTH 参数,如下所⽰:DESCRIBE FIELD OUTPUT-LENGTH .系统读取字段的输出长度,并将值写⼊字段。
ABAP学习(1):基本语法介绍

ABAP学习(1):基本语法介绍ABAP学习ABAP学习基本资料整理。
ABAP基本语法ABAP中不区分⼤⼩写,例如:Type 和type表⽰⼀个意思。
1基本数据类型ABAP基本数据类型:I : 整形数据;C:字符型数据;N:只包含数字的字符串;P:包装数据类型;F:浮点类型;D:⽇期类型;T:时间类型;X:⼗六进制数据。
F和P类型都保存浮点数,P的精度⽐F更⾼,⼀般使⽤P类型。
⽰例:"整型DATA:num1 type I."字符型DATA:num2(3) type C."数字字符型DATA:num3(4) type N."包装类型,decimals指定⼩数位数,只有P类型可⽤DATA:num4(10) type P DECIMALS 4."浮点型DATA:num5 type F."⽇期型DATA:num6 type D."时间型DATA:num7 type T."16进制型DATA:num8(10) type X."字符串DATA:num9 type string."C,N,X,P可以使⽤length定义长度DATA:num10 TYPE C LENGTH 14."赋值操作"move to 语句"MOVE 1333 TO num1.num1 = 1234567890.num2 = 'abc'.num3 = '0010'.num4 = '1.23456789'.num5 = '12.3456789'.num6 = sy-datum.num7 = sy-uzeit.num8 = 1234567890.write :/ 'num1=',num1,'num2=',num2,'num3=',num3,'num4=',num4,'num5=',num5,'num6=',num6,'num7=',num7,'num8=',num8."字符串转I,"不能有汉字,不能是科学计数法"num9 = '1.23300000E+2'.num9 = '12.33334'.num1 = num9.WRITE:/ 'num1',num1."字符串转Cnum9 = '中'.num2 = num9.WRITE:/ 'num2',num2."字符串转N,会将⼩数点去掉num9 = '22.33'.num3 = num9.WRITE:/ 'num3',num3."字符串转P,num9 = '12.3456'.num4 = num9.WRITE:/ 'num4',num4."字符串转F,会变成科学计数法显⽰num9 = '12.34567'.num5 = num9.WRITE:/ 'num5',num5."字符串转D,MMDDYYYY"输出:09302018num9 = '20180930'.num6 = num9.WRITE:/ 'num6',num6."字符串转T,hhmmssnum9 = '014423'.num7 = num9.WRITE:/ 'num7',num7."字符串转X,长度超过20位,截取前20字符num9 = '123456789012345678901234'.num8 = num9.WRITE:/ 'num8',num8."科学计数法转换DATA:str TYPE char25 VALUE '4.3999999999999997E-2'. DATA:m_str LIKE CHA_CLASS_DATA-SOLLWERT. DATA:c_str(16) TYPE C.DATA:c_num(16) TYPE P DECIMALS 3.MOVE str to m_str."科学计数法字符串转换成数字CALL FUNCTION'QSS0_FLTP_TO_CHAR_CONVERSION' EXPORTINGI_NUMBER_OF_DIGITS = 3I_FLTP_VALUE = m_strI_VALUE_NOT_INITIAL_FLAG = 'X'I_SCREEN_FIELDLENGTH = 16 IMPORTINGE_CHAR_FIELD = c_str.IF sy-subrc = 0.WRITE:/ c_str.c_num = c_str.WRITE:/ c_num.ENDIF."不⽤function转换,QSOLLWERTE作为中间数据"将科学计数法字符串转换为其他数据DATA:mid_str TYPE QSOLLWERTE.mid_str = str.c_num = mid_str.View Code2 type定义数据类型语法结构:Types :<类型名> type <数据类型>Types :<类型名> like <数据对象或数据类型>定义结构体Types: begin of <结构名>,<资料名> type <数据类型>,…………end of <结构名>.Data: begin of <结构名>,<资料名> type <数据类型>,…………end of <结构名>."******************************************************************"type定义数据类型"******************************************************************TYPES: length TYPE I.TYPES: str(20) TYPE C.TYPES: BEGIN OF person,Name(10) type C,Age type I,END OF person.3变量声明相关语法:data: <变量名> type <数据类型> [value <值>] 。
ABAP语法概述解析

l l l l l l l 了解ABAP ABAP语法概述 ABAP语言的数据类型 ABAP的语法格式 结构类型和结构体 内表 数据库操作
ABAP
ABAP(Advanced business application program),是一种高级企业 应用编程语言,它支持封装性和继承性, 封装性是面向对象的基础,而继承性是 建立在封装性基础上的重要特性。它适 合生成报表,支持对数据库的操作,如: Sqlserver,Oracle,DB2等主流数据库系统。
ABAP运算
数值运算(在ABAP中数学表达式可以任意多层嵌套) 算术运算 • 二元操作符包括: – + :加法 – :减法 – * :乘法 – / :除法 – ** :乘方 – DIV :整除忽略余数 – MOD :取模 • 需要注意,圆括号和操作符都是关键字,需要跟操作数之 间 至少用一个空格分开。 (1+2)*3 应该写成( 1 + 2 ) * 3 注:ABAP中不能使用”&”或”+”做连接(详参见computer语 句的关键字文档 数学函数 时间日期运算
ABAP不区分大小写,关键字和用户操作数都一样,为了便于 阅读,一般把关键字大写,而操作数小写。 如果连续多行的第一个关键字相同,可以使用链语句方式减少 输入 data: id type I. data: name type c. 可写为: data: id type I , name type c. 注释: 注释行由第一列的星号(*)开头,并且必须写在第一 列,前 面不能有空格。 在行末的注释用双引号(”)作为前导。 data: id type i. “ 定义一个对象num数据类型为I
ABAP的命名规则
ABAP总结

1.引用类型z_ref数据对象myref在程序中的声明方式:DATA myref TYPE z_ref.CREATE DATA myref TYPE z_ref.2.参照数据字典中的表类型生成内表对象或结构体:DATA mytable TYPE z_table,”数据字典表类型,声明内表.myline TYPE LINE OF z_table.”表类型的行结构,声明结构体.3.取系统日期:SY-DATUM,4.取系统时间:SY-UZEIT.05.系统字段定位:SY-FDPOS.字符比较结果为真时,此字段将给出偏移量信息.6.系统字段SY-FDPOS给出字符的位置信息.(P109)7.系统字段SY-INDEX记录循环语句中的循环次数8.操作内表行结束后系统字段SY-TABIX返回该行索引.对于所有行操作,如果操作成功,系统变量SY-SUBRC返回0,否则返回非0值.9.系统用户名:SY-UNAME.10.SY-HOST?屏幕序号:sy-dynnr.11.OK代码:SY-UCOMM或SYST-UCOMM12.屏幕组ID:SY-DYNGR.13.常量声明:CONSTANT const(len) TYPE type|LIKE dobj [DECIMALS dec][V ALUE val].14.确定数据对象属性:DESCRIBE FIELD f [LENGTH l] [TYPE t [CONPONENTSn]] [OUTPUT-LENGTH o] [DECIMALS d] [EDIT MASK m] [HELP-ID h].15.数据赋值:MOVE source TO destination.或destination = source.16.设定初始值:CLEAR F.17.检查字段是否为初始值:f IS INITIAL….18.检查字段是否被分配:fs IS A SSIGNED…..19.检查过程中的参数是否被实参填充:p IS [SUPPLIED|REQUESTED]….20.检查数据对象的值是否属于某范围之间:f1 BETWEEN f2 AND f3…..21.检查数据对象f的内容是否遵从某个选择表的逻辑条件:f in seltab….22.WRITE: /10 g,”在10个空格后输出变量g/(8) time using edit mask ‘__:__:__’.”输出的变量time保持8位的长度.23.将光标移动到下一行:SKIP.24.强制结束循环:EXIT,STOP或REJECT.25.循环的中止:CONTINUE无条件中止当前循环并开始下一轮循环,CHECK条件为真时循环,为假时结束本次循环并开始下一轮循环,EXIT无条件中止并退出整个循环.26.将字符串左移:SHIFT string.27.连接字符串:CONCATENATE s1 s2 …..sn INTO s_dest [SEPARATED BY sep].如果结果出现被截断的情况,将SY-SUBRC返回4,否则返回0.符号&用于在字字符串换行时的连接.28.根据分隔符sep拆分字符串:SPLIT s_source AT sep INT O s1 s2 ……sn.使用内表操作可以避免被截断的情况:SPLIT s_source AT sep INTO TABLE itab.此语句根据子串数目生成n行的内表.29.循环输出内表的每一行数据:LOOP AT itab INTO text.ENDLOOP.30.替换字段内容:REPLACE str1 WITH str2 INTO s_dest [LENGTH len]. 字段SY-SUBRC的返回值为0时表示己成功替换.31.确定字段长度:[COMPUTE] n = STRLEN( str ).32.删除字符串中的多余空格:CONDENSE33.字符转换,如将ABC转换为abc:TRANSLATE34.创建一个可以排序的格式:CONVERT TEXT.35.用一个字符串覆盖另一个字符串:OVERLAY36.WRITE TO赋值时将忽略数据对象的类型,而将其视为字符类型数据.37.字符串比较中的换码字符:#,用于转换比较时使用的通配符:*或+.及进行区分大小写,空格的比较,如#A表示比较大写的A.38.定位操作子串:strName[+0][(1)].39.字段符号,数据引用:动态数据对象.40.子过程定义:FORM subroutine_name USING parameters1parameters2…. ….ENDFORM.41.子程序调用:PERFORM subroutine_name USING actual_parameters1 p2…. (其中USING可换成CHANGING)42.ULINE.输出下划线.43.错误查看:ST2244.程序打包release:SE01:找到对应的程序,点开后点上面小汽车,再选中上面的后再点小汽车.点check.程序修改后需要重新打包.45.制作T-CODE:SE93,TCODE应按顺序编号:ZMF+流水号,我的程序名46.创建table:t-code:se11,attributes:Delivery class:C.开发类别:ZFI,当自定义Fieldtype时,名称需为Z+…..格式.->设置技术属性(Technical Setting):Logicalstorage parameters中Data class:APPL1,Size category:4 创建functiongroup:SE80,创建好后将创建的TABLE挂接到function grouph上去:用se11查出table,点utilites->table maintenance generator:Authorizationgroups:&NC&,Function group中填刚才创建的功能组名称->onestep->overview screen中必须填未使用的number,此处screen number与table 是一一对应的关系,也可让点系统上面的按钮:find screen number来自动搜索适合的scr. Number.->create,成功后,找到对应的function group中的screen number双击即可看到生成的代码.需要修改字段名称可在function group中的element list或layout中.-->se93创建t-code,start object选transaction withparameters(parameter transaction)->default valuesfor->transantion:SM30->Default Values->name of screenfield:viewname\update,value:table name\X.47.field-sign:,field—option:,field-low:表示选择条件中起始值48.在where子句中如果只有一个表的话,可以不用指定表名.49.获取用户IP地址及用户名:call function 'TH_USER_INFO' " Get user IP,hostnameimportinghostaddr = iporg”转化前的IP地址terminal = host”计算机名exceptionsothers = 1."Conv.IP addr to format 'xxx.xxx.xxx.xxx'call function 'ZGJ_IPADR2STRING' "Conv.IP addrexportingipadr = iporg”转化前的IP地址importingstring = ipdec.”转化后的最终需要的IP地址50.删除内表中数据完全相同的行,只保留一行: delete adjacent duplicatesfrom itab1 COMPARING <f1> <f2> / COMPARING ALL FIELDS.51.spro:后台设定52.输出选择框write:/ itab1-flag as checkbox第四章ABAP基础4.1.5 程序运行例:REPORT z_calling_program.START-OF-PROGRAM.WRITE ‘This program calls another program.’.”此内容在输出界面看不到SUBMIT z_simple_program.”上面的输出被此程序覆盖.如果改用SUBMIT AND RETURN来调用则可以输出以上内容.2.结束程序:LEA VE PROGRAM.可在任意点强制结束当前运行的程序.4.1.6 内存管理SAP程序同一个用户和系统可进行最多6个SAPGUI主会话.4.2.1 数据定义TYPES:BEGIN OF t_staff,S_no(3) type n,Name(20),END OF t_staff.DATA staff TYPE t_staff.上例中定义了一个结构类型t_staff,并根据其声明了一个结构体对象staff.数据类型中的扁平结构与纵深结构:扁平类型:运行时长度固定的类型.纵深类型:运行时长度可峦的类型.注意:1.其中C,N,T,D,I,F,P,X为定长类型,即在运行期间长度不能改变.2.类型T,D,I,F的数据存储长度是固定的,不能指定参照其生成的数据对象占用的内存字节数.3.基于类型C,N,P,X生成的数据对象需要在声明时指定其长度.否则取默认值.4.如果在声明一个数据对象时未指明其数据类型,则该数据默认为C类型.5.类型I的数值范围:-231到231-1的整数.如果运算时出现非整型结果则进行四舍五入取值.而不是截断小数.6.类型P用于声明小数字固定的压缩数,其占据内存字节数和数值范围取决于定义时指定的整个数据的大小和小数点后位数,如果不指定小数字,则将其视为I类型数据.有效大小可以是从1~16字节的任意值,小数点后最多允许14个数字. 7,类型F为浮点数,浮点意思是数字在内存中以字节形式表示,数值范围:1*10-307到1*10308,因系统将F类型转换为二进制数,所以可能出现舍入误差,若用户要求较高精度且数值较大时,应使用P类型数据.8.长度可峦的内置类型String, XString是通过引用实际动态的数据对象的固定内存地址来操作.4.2.3 程序内部数据定义参照自定义类型或内置类型生成数据的语法格式:TY PES|DATA …TYPE l_type…参照程序中已经声明的数据对象生成新数据语法:TYPES|DATA …LIKE dobj…3.结构类型和结构体参照结构类型生成的数据对象称为结构体.TYPES|DATA:BEGIN OF structure.k1[TYPE type |LIKE dobj]…,k2[TYPE type |LIKE dobj]…,…k n[TYPE type |LIKE dobj]…,END OF structure.参照生成:参照结构生成:TYPES|DATA structure TYPE str_type |LIKE str_dobj...参照数据库表生成:TYPES|DATA structure TYPE dbtab.4.表类型和内表表类型的对象称为内表.4.2.4 数据字典中的类型●数据元素(Data elements),相当于ABAP中的基本类型和引用类型.●结构(Structures),由数据元素字段构成,对应ABAP中的结构类型.表类型(Table types),对应ABAP中的表类型.数据字典中的数据类型与ABAP中的中数据类型对应关系:4.2.5 程序中的数据对象1.文字对象当字符文字长度超过编辑器的一行时,可以使用”&”进行连接,避免因换行而产生的多余空格,如:long = ‘This is ‘&‘a long sentence’.如果需要输出“’”,则需要在前面多加一个“’”转回愿意.2.有名称的数据对象常量声明:CONSTANT: const(len) TYPE|LIKE dobj [DECIMALS dec] V ALUE val.结构体常量声明(每个组件必须指定初始值):CONSTANT:BEGIN OF structure,str1 TYPE|LIKE dobj [DECIMALS dec] V ALUE val,str2 TYPE|LIKE dobj [DECIMALS dec] V ALUE val,...,strn TYPE|LIKE dobj [DECIMALS dec] V ALUE val,END OF structure.3.系统数据对象(见附表)4.查明数据对象属性DESCRIBE FIELD f LENGTH len.此语句将字段f的长度写入变量len.●LENGTH:确定数据对象长度.●TYPE: 确定数据对象类型.●OUTPUT-LENGTH:确定实际输出长度.●DECIMALS:确定P类型小数位长.●EDIT MASK:确定在数据字典中定义转换例程.●HELP-ID:确定在数据字典中定义的F1帮助信息.4.3 基本数据操作4.3.1数据赋值●MOVE source TO incept.等介于:incept = source.●CLEAR dobj.将数据对象dobj还原为初始值.●结构体间赋值:struct2 = struct1.(组件结构相同).●MOVE-CORRESPONDING struct1 TO struct2.(部分组件结构相同).4.3.2类型转换(见附表).4.3.3数值运算两个结构体的同名字段之间可以整体进行算术运算:ADD-CORRESPONDING struct1 TO struct2.SUBTRACT-CORRESPONDING struct1 FROM struct2.MULTIPLY-CORRESPONDING struct2 BY struct1.DIVIDE-CORRESPONDING struct2 BY struct1.以上将对两个结构体中的同名字段进行相应运算(非数值类型数据会引起错误).2.数学函数任意类型参数的函数列表:注意:函数名与左括号间不能有空格,括号与参数间必须有空格.4.3.4数据输出输出格式化选项:注:用户主记录System->User profile->Own data(SU01).4.3.5逻辑表达式通用逻辑表达式列表:3.IS操作符●...f IS INITIAL...:检查字段f是否为初始值.●...fs IS ASSIGNED...:检查字段符号是否被分配.●...p IS [SUPPLIED|REQUESTED]...:检查过程中的参数是否被实参填充.4.BETWEEN操作符●...f1 BETWEEN f2 AND f3...:检查数据对象的值是否属于特定范围之间.5.IN操作符(P110)●...f IN seltab...:检查一个数据对象的内容是否遵从某个选择表的逻辑条件.6.组合逻辑表达式●AND:与.●OR:或.●NOT:非.注:括号与操作数间至少要有一个空格,如:IF ( c > n ) AND ( c < f ).4.4结构控制程序代码分三种结构:●顺序结构:语句逐行执行.●分支结构:根据不同的条件执行不同语句块.●循环结构:反复执行某个语句.4.4.1分支控制1.IF/ENDIF结构:IF <condition1>.<statement block>ELSEIF <condition2>.<statement block>......ELSE.<statement block>ENDIF.注:可嵌套.2.CASE/ENDCASE结构:CASE f.WHEN f11 [OR f12 OR ...].<statement block>......[WHEN OTHERS.]<statement block>ENDCASE.其中,f为变量,f ij可以是变量或者固定值.4.4.2循环控制1.无条件循环DO [n TIMES].<statement block>ENDDO.说明:n为循环次数,可以是文字或变量,如果没有限定n值,则必须用EXIT,STOP 或REJECT等语句强制结束循环.DO循环可嵌套,SY-INDEX为当前循环次数.2.条件循环WHILE <condition>.<statement block>ENDWHILE.注:可嵌套,其它同上.3.循环中止●CONTINUE:无条件中止当前本轮循环,开始下一轮循环.●CHECK:条件中止当前本轮循环(条件为假时), 开始下一轮循环.●EXIT:无条件完全中止当前循环,继续循环结束语句(ENDDO,ENDWHILE等)后面的代码,如果在嵌套循环中,系统仅退出当前循环.4.5处理字符数据4.5.1字符数据1.连接字符串CONCATENATE s1 s2 ... sn INTO s_dest [SEPARATED BY sep].注:所有字符串操作将忽略s1....sn中的尾部空格(如需保留空格,可使用指定偏移量).如果出现截断情况,将SY-SUBRC设为4,否则返回0.2.拆分字符串SPLIT s_source AT sep INTO s1 s2 ... sn.如果所有子串足够长且不必截断任何部分,则将SY-SUBRC设为0,否则返回4, 如果源字符串能够拆分的子串多过指定的数目,则源子串最后的剩余部分包括其后的分隔符都将写入最后一个子串,要避免这种情况,需要使用内表进行操作: SPLIT s_source AT sep INTO TABLE itab.在该形式中,根据子串数目生成n行的内表.例如:DATA:text type string,itab TYPE TABLE OF string.text = ‘ABAP is a programming language’.SPLIT text AT space INTO TABLE itab.LOOP AT itab INTO text.WRITE / text.ENDLOOP.3.查找子串模式SEARCH c FOR str.在字段c中查找字符串str.如果找到,则将SY-SUBRC返回0,SY-FDPOS返回字段c中该字符串的位置(从左算起的字节偏移量),否则SY-SUBRC返回4,查找模式有以下几种:●str 搜索str并忽略尾部空格.●.str. 搜索str,但不忽略尾部空格.●*str 搜索以str结尾的单词.●str* 搜索以str开始的单词.REPORT z_string_search.DATA string(30) TYPE c VALUE 'This is a testing sentence.'. WRITE: / 'searched','sy-subrc','sy-fdpos'.SEARCH string FOR 'X'.WRITE: / 'X', sy-subrc UNDER 'sy-subrc',sy-fdpos UNDER'sy-fdpos'.SEARCH string FOR 'itt '.WRITE: / 'itt ', sy-subrc UNDER 'sy-subrc',sy-fdpos UNDER'sy-fdpos'.SEARCH string FOR '.e .'.WRITE: / '.e .', sy-subrc UNDER 'sy-subrc',sy-fdpos UNDER'sy-fdpos'.SEARCH string FOR '*e '.WRITE: / '*e ', sy-subrc UNDER 'sy-subrc',sy-fdpos UNDER'sy-fdpos'.SEARCH string FOR 's* '.WRITE: / 's* ', sy-subrc UNDER 'sy-subrc',sy-fdpos UNDER'sy-fdpos'.输出结果如下:searched sy-subrc sy-fdposX 4 0itt 4 0.e . 4 0*e 0 18s* 0 184.替换字段内容.REPLACE str1 WITH str2 INTO s_dest [LENGTH len].搜索s_dest中前len个字符中的子串str1,用str2来替换它,如果成功,SY-SUBRC返回0,否则还回非0值. REPORT z_replace.DATA name TYPE string.name = 'Michael-Cheong'.WHILE sy-subrc = 0.REPLACE '-' WITH ' ' INTO name.ENDWHILE.WRITE / name.输出结果: Michael Cheong5.确定字段长度n = STRLEN( str ).函数将str作为字符数据类型处理,不考虑其实际类型,也不进行转换.计算其首字符到最后一个非空字符的长度,不包括结尾空格.6.其它操作语句●SHIT:将字符串整体或子串进行位移.●CONDENSE:删除字符串中的多余空格.●TRANSLATE:字符转换,如将ABC转换为abc.●CONVERT TEXT:创建一个可以排序的格式.●OVERLAY:用一个字符串覆盖另一个字符串.注:CO,CN,CA,NA比较时区分大小写,且尾部空格也在比较范围之内,CS,NS,CP,NP比较时忽略尾部空格且不区分大小写,比较结束后,如果结果为真,SY-FDPOS将给出s2在s1中的偏移量信息.模式表示可以使用通配符,”*”用于替代任何字符串,”+”用于替代单个字符.换码字符使用:●指定大小写(如#A,#b).●通配符”*”(输入#*),将其转回原义.●通配符”+”(输入#+),将其转回原义.●换码符本身”#”(输入##),将其转回原义.●字符串结尾空格(输入#__),指定比较结尾空格.4.5.3定位操作子串str[+position][(len)].从字符串str中的position位开始取出长度为len的子串.可动态指定偏移量及长度的情况(即position及len可为变量):●用MOVE语句或赋值运算符给字段赋值时.●用WRITE TO语句向字段写入值时.●用ASSIGN将字段分配给字段符号时.●用PERFORM将数据传送给子程序时.off = 6.len = 2.date+off(len) = ‘01’.4.6使用内表types定义的并不是结构体对象,只是结构类型,不能作为工作区,当定义的内表没有表头行(工作区)时,必须为其定义一个结构体作为工作区,否则无法使用此内表.如果没有给内表定义工作区,则在定义内表时必须声明表头行(with header line). DATA:BEGIN OF line, "work area(structure)结构类型且结构体对象num TYPE i,sqr TYPE i,END OF line,"无表头行内表,内表定义都使用data关键词.itab TYPE(LIKE) STANDARD TABLE OF line WITH KEY table_line. DATA DIRTAB LIKE CDIR OCCURS 10 WITH HEADER LINE.定义标准内表DO 5 TIMES.line-num = sy-index.line-sqr = sy-index ** 2.APPEND line TO itab.ENDDO.LOOP AT itab INTO line.WRITE:/ line-num,line-sqr.ENDLOOP.CLEAR itab.注:1.TYPES与DATA区别:TYPES是用来定义某种类(型)的,需(用DATA语句)实例化以后才可以使用,而DATA是用来定义数据对象(实例变量)的,对于用DATA直接定义的结构体对象(不参照其它结构类型),其同时也是一个结构类型.2.TYPE与LIKE区别:TYPE后面跟随的只能是某种类(型),而LIKE后面可以跟随类型或实例对象,参照结构体对象生成内表时只能用LIKE,不能用TYPE,因为结构体对象不是类型,只是一种实例对象,参照结构类型生成内表时可以用LIKE也可以用TYPE.其中通过LIKE定义的内表直接拥有参照结构类型的元素结构,而通过TYPE定义的内表只能间接拥有被参照结构类型的元素结构,结构类型不能作为内表的工作区,只有结构体对象才可以.内表定义语法:1.标准表:可指定或不指定关键词,可重复.逻辑索引,操作数据时数据内存位置不峦,系统只重排数据行的索引值.DATA itab TYPE|LIKE [STANDARD] TABLE OF structure [WITH KEY comp1 ... compn(DEFAULT KEY) WITH HEADER LINE INITIAL SIZE n].2.排序表:可指定唯一或不唯一的关键词,也可不指定,逻辑索引,按关键词升序存储.DATA itab TYPE|LIKE SORTED TABLE OF structure [WITHNON-UNIQUE(UNIQUE) KEY comp1 ... compn(DEFAULT KEY) WITH HEADER LINE INITIAL SIZE n].3.哈希表:必须指定唯一关键词.无索引DATA itab TYPE|LIKE HASHED TABLE OF structure WITH UNIQUE KEY comp1 ... compn(DEFAULT KEY) [WITH HEADER LINE INITIAL SIZE n].注:如果n值为0或不指定的话,程序会为内表对象分配8KB大小内存,所以,如果内表比较小,不要把该值设为0,以避免内存浪费.旧版标准表定义语法:DATA itab TYPE|LIKE [STANDARD] TABLE OF structure OCCURS n.或者DATA:BEGIN OF itab OCCURS n,...,fi...,END OF itab.注:CLEAR itab[].表示操作的是内表对象.而CLEAR itab.当itab有表头行时表示操作表头行,如无表头行时表示操作内表对象.当一个操作语句结束后,SY-TABIX返回该行的索引值,对于所有行操作,如果访问成功,SY-SUBRC返回0,否则返回非0值.4.插入行—INSERT●INSERT structure INTO itab INDEX idx.无表头行索引表,itab的行数应大于或等于idx-1.否则失败●INSERT itab INDEX idx.有表头行索引表.●对于哈希表,系统按关键词将新行插入特定位置.●INSERT structure INTO|INITIAL LINE INTO TABLE itab.此语句对于标准表来说与append效果相同,对于排序表来说,插入的行不可以打乱按照关键词排序的顺序,否则插入不成功,对于哈希表来说,插入过程中系统按照关键词对行进行定位.INITIAL关键词是用于向内表中插入结构中各类型的初始值的.●INSERT LINES OF itab1 [FROM n1] [TO n2] INTO [TABLE] itab2 [INDEXidx].将内表中部分或全部数据行整体插入到另一内表中,指定行数时itab1,itab2必须为索引表,指定TABLE关键词时,itab2可以是任意内表.此方式比其它方式快20倍左右.5.附加行—APPEND(只能操作索引表)APPEND [structure TO|INITIAL LINE TO] itab.APPEND LINES OF itab1 [FORM n1] [TO n2] TO itab2.6.聚集附加—COLLECTCOLLECT line INTO itab.对于需要附加的数据,如果在内表中存在关键词内容与其相同的数据行,则此语句将需要附加的数据累加到内表中的这一行上,而不会另外再添加一行,操作成功后,SY-TABIX返回被处理过的行的索引.注:关键词以外的所有字段必须是数字类型7.读取行—READ(可用于任何类型内表)●READ TABLE itab [INTO wa|ASSIGNING <fs>] INDEX idx.通过索引读取内表中的单行数据. ASSIGNING表表示指派给字段符号.●READ TABLE itab FROM structure [INTO wa|ASSIGNING <fs>].读取与结构相同的工作区中的关键词内容全部相同的内表数据.●READ TABLE itab WITH TABLE KEY field1 = v1 ... field2 = v2 [INTOwa|ASSIGNING <fs>].指定所有关键词值,并读取相等时内表行.●READ TABLE itab WITH KEY field1 = v1 ... field2 = v2 [INTOwa|ASSIGNING <fs>].读取内表中字段fieldn(不一定是表关键词段)与值vn 相同时的内表行.8.修改行—MODIFY●MODIFY itab [FROM wa] [INDEX idx] [TRANSPORTING f1 f2 ...].如果内表包含的行数少于idx,则不更改任何行.●MODIFY TABLE itab FROM wa [TRANSPORTING f1 f2 ...].根据工作区wa中关键词修改内表行, TRANSPORTING表示修改指定字段值.●MODIFY itab FROM wa TRANSPORTING f1 f2 ... WHERE condition.修改符合WHERE子句中条件的内表中的指定字段值.9.删除行—DELETE●DELETE itab INDEX idx.根据索引删除内表行.●DELETE TABLE itab FROM wa.根据工作区关键词删除行.●DELETE TABLE itab WITH TABLE KEY field1 = v1 ... field2 = v2.根据指定关键词值删除行.●DELETE itab [FROM n1] [TO n2] [WHERE <condition>].10.循环处理--LOOPLOOP AT itab [INTO wa] [FROM n1] [TO n2] [WHERE condition].<statement block>.ENDLOOP.4.6.3操作整个内表1.排序SORT itab [ASCENDING|DESCENDING] [AS TEXT] [STABLE][BY f1 [ASCENDING|DESCENDING] [AS TEXT]......f1 [ASCENDING|DESCENDING] [AS TEXT]]说明:●ASCENDING|DESCENDING:升序或降序.默认升序.●AS TEXT:根据当前语言按字母顺序排序字符字段,否则按字符平台相关内部编码进行排序.●STABLE:保持排序前后不需要改变的数据行的相对顺序.2.控制级操作(用于总计,缩进,格式控制等)AT FIRST|LAST|NEW f|END OF f.<statement block>ENDAT.说明:●FIRST:当循环为内表的第一行时,执行语句块中语句.在工作区中,系统用*填充所有关键词内容.●LAST: 当循环为内表的最后一行时,执行语句块中语句. 在工作区中,系统用*填充所有关键词内容.●NEW f:字段f前面(即左边)的全部字段内容之一不同于上一行时, 执行语句块中语句.在工作区中,系统用*填充f后面所有关键词内容.●END OF f:如果下一行行组中的任何字段内容不同于上一行, 执行语句块中语句.在工作区中,系统用*填充f后面所有关键词内容.注:在控制级操作期间,在工作区中,对于非标准关键词段,将全部进行初始化,在执行完控制操作后(即ENDAT语句后)工作区中的数据将全部还原到进入控制级操作语句前(即进入AT前)状态.3.初始化内表●CLEAR itab.:带表头行时只清空表头行,不带表头行时清空整个内表.●CLEAR itab[].:只清空整个内表对象数据.不清空表头行.●REFRESH itab或REFRESH itab[].:只清空整个内表对象数据.不清空表头行.●FREE itab.或FREE itab[].:只清空整个内表对象数据.不清空表头行,同时释放内存.●......itab IS INITIAL....:检查内表是否为空.4.整体复制内表●MOVE itab1 TO itab2.:如果两表都存在表头行,则此语句只复制了表头行.●MOVE itab1[] TO itab2[].:指定表体复制.●MOVE itab1[] TO itab2.:表itab2无表头行时才成立.●itab2 = itab1.同上1●itab2[] = itab1[].同上2●itab2 = itab1[].同上35.比较内表大小... itab1 <operator> itab2...:其中<operator>可以为=,<>,><,>=,<=,>,<等.4.6.4Extract Datasets●FIELD-GROUP fg.行结构分配.●INSERT f1 f2 ... INTO fg.生成字段组fg的具体字段结构.●EXTRACT fg.将字段组填充给EXTRACT.●SORT.排序.●LOOP. <statement block> ENDLOOP.循环输出EXTRACT.4.7动态数据对象4.7.1字段符号●FIELD-SYMBOLS <fs> [TYPE type|LIKE dobj].声明字段符号.●ASSIGN f TO <fs>.静态分配数据对象给字段符号.●ASSIGN f[+i] [(j)] TO <fs>.指定偏移量和长度.●ASSIGN (f) TO <fs>.动态分配,先找到字段f的内容,然后将该内容分配给<fs>.4.7.2数据引用TYPES t_dref TYPE REF TO DATA.DATA dref TYPE REF TO DATA.4.8模块化技术4.8.2子程序1.定义:FORM subr [[USING [V ALUE(p1)]... ] [TYPE t|LIKE f]...] [TYPE ANY][CHANGING [V ALUE(p1)] ... ] [TYPE t|LIKE f]...] [TYPE ANY].<subr codes>ENDFORM.注:●V ALUE参数表未示值传递,此方式在子程序调用后实参的值不会被改变.●无V ALUE参数时表示引用传递,会改变实参的值.●USING与CHANGING无任何区别.●位于两个子程序间的代码不属于任何事件块.●参数传递时不存在类型转换,要求必须兼容.2.调用:PERFORM subr [USING p1 ... pn] [CHANGING pi ... pj].4.8.3功能模块(p153)4.8.5源代码复用1.包含程序包含程序是单纯的代码复用,不是可执行程序,不能单独运行,必须被其它程序调用,包含程序不能调用自身.INCLUDE incl.包含程序调用,此语句必须独占一行.2.宏:(语句块中最多只能包含9个占位符&1...&9).例:DATA:result TYPE i,int1 TYPE i VALUE 1,int2 TYPE i VALUE 2.DEFINE operation.result = &1 &2 &3.output &1 &2 &3 result.END-OF-DEFINITION.DEFINE output.write: / 'The result of &1 &2 &3 is',&4.END-OF-DEFINITION.operation 1 + 2.operation int2 - int1.4.9.1静态错误检查1.语法检查:用Check键.2.扩展语法检查(SLIN):在ABAP初台界面输出程序名后,选择Program->Check->Extended Syntax Check. Standard.4.9.2运行时错误控制1.可捕捉的错误CATCH SYSTEM-EXCEPTIONS exc1 = rc1 ... excn = rcn....ENDCATCH.其中exci表示一个单一可捕捉错误或者一个ERROR类,rci则代表一个数字.如果其中错误之一在CATCH和ENDCATCH语句之间出现,程序就不会中止,而是直接跳至ENDCATCH后,把系统指定的错误代码rci赋给字段SY-SUBRC.此语句可嵌套.例如:DATA:result1 TYPE p DECIMALS 3,number TYPE i VALUE 11.CATCH SYSTEM-EXCEPTIONS arithmetic_errors = 5.DO.number = number - 1.result1 = 1 / number.WRITE: / number,result1.ENDDO.ENDCATCH.IF sy-subrc = 5.WRITE / 'division by zero!'.ENDIF.2.不可捕捉的错误(通过ST22查看,在SAP系统中保存14天,可通过Keep功能保存更长时间).第六章数据库操作6.2.1表字段在数据字典中,每创建一个数据库表后,都将同时生成一个同名的结构化数据类型.6.2.2外部关键词外部关键词内容必须在其对应的约束表(check table)中存在,否则无法插入.6.2.3技术设定1.数据类型(data class):●APPL0(Master data),较少需要被修改的系统数据表,如员工个人信息.●APPL1(Transaction data),需要经常被修改的数据表,如产品库存量表.●APPL2(Organization and customizing),系统定制数据表,在系统安装后很少需要修改,如国家代码等.2.数量级别:0 0 to 6,6001 6,600 to 26,0002 26,000 to 100,0003 100,000 to 420,0004 420,000 to 34,000,0003.缓冲(Buffering)机制如果在缓冲设定中选择了Buffering switched on项,则需要设定其缓冲类型(有Full,Single-record和Generic三种).缓冲机制的意义在于首次查询时将数据表中的数据放入应用服务器缓冲区,以提高后续查询效率,要注意最好不要对经常需要的数据库表设置该机制,对于经常读取但很少更新或者通常只有在60秒后才可能被其它应用服务器程序修改的数据库表,开启缓冲机制可以上百倍地提高效率.4.Log data changes用于设定表中的数据修改时是否在系统日志中记录.6.2.4索引一个数据库表可以包含一个主索引(Primary Index)和多个附属索引(Secondary Indexes).主索引只包含表关键词和指向整个数据条目的指针,由系统自动生成并在添加数据库条目时进行维护.索引中的数据已经排序.6.3.1SELECT语句SELECT <result> FROM <source> INTO <target>[WHERE <condition>] [GROUP BY <fields>][HA VING <cond>] [ORDER BY <fields>].●HA VING子句用于限定ORDER BY子句中数据条目组的选择条件1.选择单行数据:●SELECT SINGLE * FROM tab INTO wa_tab WHERE <condition>.选择单行全部数据.●SELECT SINGLE field1 ... fieldn FROM tab INTO (wa_field1,...,wa_fieldn) WHERE<condition>.选择单行指定字段数据到指定工作区字段.●SELECT SINGLE *|field1 ... fieldn FROM tab INTO CORRESPONDING FIELDS OFwa_tab WHERE <condition>.将选择的值放入工作区中对应的字段中.6.3.3选择多行数据1.循环选择(DISTINCT去掉结果重复的行):SELECT [DISTINCT] ... .<statement block>ENDSELET.系统字段SY-DBCNT给读取的行计数.2.选择至内表:SELECT ... INTO|APPENDING [CORRESPONDING FIELDS OF] TABLE itab.其中INTO选项将复盖itab中的数据,如果不想复盖只想追加则用APPENDING.3.指定选择包大小(一次选择到内表的行数):SELECT * FROM tab INTO|APPENDING TABLE wa_tab PACKAGE SIZE n.<statement block>ENDSELET.6.3.4指定查询条件1.比较运算符:=,<,>,<>,<=,>=.2.范围限定运算符:WHERE ... f [NOT] BETWEEN g1 AND g2 ....3.字符比较运算符:WHERE ... f [NOT] LIKE g [ESCAPE h]...其中g中通配符”_”用于替代单个字符,”%”用于替代任意字符串. ESCAPE选项举例如下: SELECT ... WHERE city LIKE ‘edit#_%’ ESCAPE ‘#’.选择所有以”edit_”开始的城市.4.检查列表值:WHERE ... f [NOT] IN (g1,...gn)...5.检查空值: WHERE ... f IS [NOT] NULL...注:这里的NULL值不等同于初始值INITIAL6.检查选择表.●WHERE ... f [NOT] IN seltab...其中seltab为选择表,如选择屏幕中用户填充数据.●SELECT ... WHERE ( code = ‘01’ OR code = ‘02’ ) AND NOT (country =‘usa’ ).:AND,OR,NOT可以按照任意顺序组合.●SELECT ... WHERE <condition> AND (itab).内表itab仅包含一个类型为C的字段,且最大长度为72.字段中内容不能使用变量.这种方式查询效率很低. 6.3.5多表结合查询1.SELECT语句嵌套DATA:wa_carrid TYPE spfli-carrid,wa_connid TYPE spfli-connid,。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一数据类型和对象在ABAP中,可以使用与标准数据声明相似的语法处理数据类型,而与数据对象无关。
在程序中必须声明要使用的全部数据对象。
声明过程中,必须给数据对象分配属性,其中最重要的属性就是数据类型。
1.1 基本数据类型对算术运算的非整型结果(如分数)进行四舍五入,而不是截断。
类型 P 数据允许在小数点后有数字。
有效大小可以是从 1 到 16 字节的任何值。
将两个十进制数字压缩到一个字节,而最后一个字节包含一个数字和符号。
在小数点后最多允许14 个数字。
1.2 系统定义的数据对象1.3 确定数据对象的属性如果要查明数据对象的数据类型,或者要在程序的运行期间使用其属性,可使用DESCRIBE 语句。
语法如下:DESCRIBE FIELD <f> [LENGTH <l>] [TYPE <t> [COMPONENTS <n>]][OUTPUT-LENGTH <o>] [DECIMALS <d>][EDIT MASK <m>].将由语句的参数指定的数据对象<f>的属性写入参数后的变量。
DESCRIBE FIELDS 语句具有下列参数:1.3.1 确定字段长度要确定数据对象的长度,利用DESCRIBE FIELD 语句使用 LENGTH 参数,如下所示:DESCRIBE FIELD <f> LENGTH <l>.系统读取字段<f>的长度,并将值写入字段<l>。
1.3.2确定数据类型要确定字段的数据类型,利用DESCRIBE FIELD 语句使用 TYPE 参数,如下所示:DESCRIBE FIELD <f> TYPE <t> [COMPONENTS <n>].系统读取字段<f>的数据类型,然后将值写入字段<t>。
除返回预定义数据类型 C、D、F、I、N、P、T 和 X 外,该语句还返回XXX s 对于带前导符号的两字节整型XXX b 对于无前导符号的一字节整型XXX h 对于表XXX C 对于组件中没有嵌套结构的结构XXX C 对于组件中至少有一个嵌套结构的结构1.3.3确定输出长度要确定字段的输出长度,利用 DESCRIBE FIELD 语句使用 OUTPUT-LENGTH 参数,如下所示:DESCRIBE FIELD <f> OUTPUT-LENGTH <o>.系统读取字段<f>的输出长度,并将值写入字段<o>。
1.3.4确定小数位若要确定类型P字段的小数位的个数,利用 DESCRIBE FIELD语句使用 DECIMALS参数,如下所示:DESCRIBE FIELD <f> DECIMALS <d>.系统读取字段<f>的小数个数,并将值写入字段<d>。
1.3.5 确定转换例程要确定 ABAP/4 词典中某字段的转换例程是否存在,如果存在,名称是什么,利用DESCRIBE FIELD 语句使用 EDIT MASK 参数,如下所示:DESCRIBE FIELD <f> EDIT MASK <m>.如果 ABAP/4 词典中字段<f>的转换例程存在,则系统将其写入字段<m>,然后将系统字段 SY-SUBRC 中的返回代码设为 0。
可以像下面所显示的那样,在 WRITE 语句中将字段<m>直接用作格式模板:WRITE <f> USING EDIT MASK <m>.如果字段<f>没有转换例程,则系统将返回代码设为 4。
二数据输出到屏幕2.1 在屏幕上定位Write输出通过制定字段名称前面的格式规,可以在屏幕上定位 WRITE 语句的输出:WRITE AT [/][<pos>][(<len>)] <f>.此处XXX 斜线‘/’表示新的一行XXX <pos>是最长为三位数字的数字或变量,表示在屏幕上的位置XXX <len>是最长为三位数字的数字或变量,表示输出长度如果格式规只包含直接值(即,不是变量),可以忽略关键字 AT。
2.2 格式化选项对 WRITE 语句,可以使用不同的格式化选项。
WRITE ....<f><选项>.(1)所有数据类型的格式化选项:(2)数字字段的格式化选项:(3)日期字段的格式化选项:2.3输出符号和图标使用下列语法,可以在屏幕上输出符号和 R/3 图标:WRITE <symbol-name> AS SYMBOL.WRITE <icon-name> AS ICON.符号和图标的名称(<符号名>和<图标名>)是定义系统的常量,这些常量在包含程序<SYMBOL>和<ICON>(尖括号是名称的一部分)中指定。
这些包含程序也包含符号和图标的简短说明。
输出符号和图标最简单的方法是使用语句结构。
要使符号和图标对程序可用,必须在程序中输入恰当的包含程序或更易理解的包含程序<LIST>。
2.4 输出线和空行(1)水平线用下列语法,可以在输出屏幕上生成水平线:ULINE [AT [/][<pos>][(<len>)]].它等同于WRITE [AT [/][<pos>][(<len>)]] SY-ULINE.AT 后的格式规,与在屏幕上定位 WRITE 输出中为 WRITE 语句说明的格式规完全一样。
如果没有格式规,系统则开始新的一行,并用水平线填充该行。
否则,只按指定输出水平线。
生成水平线的另一种方法,是在 WRITE 语句中键入恰当数量的连字符,如下所示:WRITE [AT [/][<pos>][(<len>)]] '-----...'.(2)垂直线用下列语法,可以在输出屏幕上生成垂直线:WRITE [AT [/][<pos>]] SY-VLINE.或WRITE [AT [/][<pos>]] '|'.(3)空行用下列语法,可以在输出屏幕上生成空行:SKIP [<n>].该语句从当前行开始,在输出屏幕上生成<n>个空行。
如果没有指定<n>的值,就输出一个空行。
(4)要将输出定位在屏幕的指定行上,使用:SKIP TO LINE <n>.该语句允许将输出位置向上或向下移动。
2.5 将字段容作为复选框输出使用下列语法,可以将字段的第一个字符,作为复选框输出到输出屏幕上:WRITE <f> AS CHECKBOX.如果字段<f>的第一个字符是一个“ X”,就显示复选框已填充。
如果字段<f>的第一个字符是 SPACE,就显示复选框为空。
该语句创建的复选框,默认状态是可输入的。
就是说,用户可以通过单击鼠标来填充它们或使其为空。
三赋值在 ABAP/4 中,可以在声明语句和操作语句中给数据对象赋值。
在声明语句中,将初始值赋给声明的数据对象。
为此,可以在 DATA、常量或 STATICS 语句中使用 VALUE 参数。
要在操作语句中给数据对象赋值,可以使用:XXX MOVE 语句和 WRITE TO 语句,对应于赋值运算符(=)3.1用MOVE 赋值3.1.1 基本赋值操作要将值(文字)或源字段的容赋给目标字段,可以使用 MOVE语句或赋值运算符(=)。
MOVE 语句的语法如下所示:MOVE <f1> TO <f2>.MOVE 语句将源字段<f1>的容传送给目标字段<f2>。
<f1>可以是任何数据对象。
<f2>必须是变量,不能是文字或常量。
传送后,<f1>的容保持不变。
赋值运算符(=)的语法如下所示:<f2> = <f1>.MOVE 语句和赋值运算符功能相同。
3.1.2 用指定偏移量赋值可以在每条 ABAP/4 语句中为基本数据类型指定偏移量和长度。
在这种情况下,MOVE 语句语法如下:MOVE <f1>[+<o1>][(<l1>)] TO <f2>[+<o2>][(<l2>)].将字段<f1>从<o1>+1 位置开始且长度为<l1>的段容赋给字段<f2>,覆盖从<o2>+1 位置开始且长度为<l2>的段。
在 MOVE 语句中,所有偏移量和长度指定都可为变量。
3.1.3 在字符串组件之间赋值描述的 MOVE 语句赋值方法适用于基本数据对象和结构化数据对象。
另外,还有一种MOVE 语句变体,允许将源字段串组件容复制到目标字段串组件中。
语法如下:MOVE-CORRESPONDING <string1> TO <string2>.该语句将字段串<string1>组件的容赋给有相同名称的字段串<string2>组件。
对于每对名称,系统都执行 MOVE 语句,如下所示:MOVE STRING1-<component> TO STRING2-<component>.系统分别执行所有必要类型转换。
该处理不同于包括整个字段串的赋值。
在这种情况下,应用不兼容的字段串和基本字段所述的转换规则。
3.2 用WRITE TO 赋值要将值(文字)或源字段容写入目标字段,可以使用 WRITE TO 语句:WRITE <f1> TO <f2> [<option>].WRITE TO 语句将源字段<f1>容写入目标字段<f2>。
<f1>可以是任何数据对象,<f2>必须是变量,不能是文字或常量。
写入后,<f1>容保持不变。
对于<option>,可以使用 WRITE 语句的所有格式化选项(UNDER 和 NO-GAP 除外)。
WRITE TO 语句总是检查用户主记录中的设置。
例如,这些设置指定是将小数点显示为句号(.),还是逗号(,)。
WRITE TO 语句并不遵循类型转换中所述的转换规则。
目标字段解释为类型 C 字段。