源代码结构
openssl代码结构

OpenSSL的源代码目录结构通常是一个典型的C/C++项目结构,包含了各种源文件、头文件、构建脚本和文档等。
其中,`crypto/`目录是OpenSSL的核心加密库代码所在的位置,包含了各种对称加密、非对称加密、哈希算法、消息认证码等的实现。
在`crypto/`目录下,有很多子目录,每个子目录都包含了特定类型或家族的加密算法的实现。
例如:* `asn1/`目录包含了Abstract Syntax Notation One (ASN.1)编码和解码的相关实现,用于处理X.509证书和其他结构化数据的序列化和反序列化。
* `evp/`目录包含了OpenSSL中的高级加密接口(EVP)的实现。
EVP接口提供了一种通用的方式来使用对称加密、非对称加密、哈希等功能,而不需要直接调用底层的具体算法函数。
* `cipher/`目录包含了对称加密算法的实现,如AES(Advanced Encryption Standard)、DES(Data Encryption Standard)、RC4(Rivest Cipher 4)等。
* `rsa/`目录包含了RSA非对称加密算法的实现。
* `dsa/`目录包含了DSA(Digital Signature Algorithm)非对称加密算法的实现。
* `dh/`目录包含了Diffie-Hellman密钥交换算法的实现。
* `digest/`目录包含了哈希函数的实现,如SHA-1(Secure Hash Algorithm 1)、SHA-256(Secure Hash Algorithm 256-bit)、MD5(Message Digest Algorithm 5)等。
* `modes/`目录包含了各种块密码操作模式(如CBC、ECB、GCM等)的实现,用于对大数据块进行加密。
此外,OpenSSL还包含了一些其他的目录,如`apps/`目录包含了OpenSSL的应用程序代码,`include/openssl/`目录包含了OpenSSL的头文件等。
chrome源代码结构

Chrome源代码结构首先,开始接触Chrome得童鞋可能有一个疑惑,Chrome 与Chromium就是同一个东西吗?答案就是,Chrome就是Google官方得浏览器项目名称,Chromium就是Google官方对Chrome开源项目。
说白了就就是Chrome就是Google自己得官方浏览器版本,而Chromium就是开源项目,所有有兴趣得开发者都可以参加,Chromium中出现得新技术如果经过测试就是可靠得,健壮得,那么将可能会出现在未来发布得Chrome官方版本中。
因此,Chrome版本更新速度要远远小于Chromium得更新速度。
在本文中,笔者为了偷懒,直接用项目名称Chrome指代Chromium,废话不多说了,开始为潜入Chrome源代码得海洋作准备了。
源代码目录树Chrome项目就是一个非常庞大得项目工程,包含得工程(Project)数量超过了500个,全部代码加在一起超过4G,全部编译完成将消耗将近30G得磁盘空间,不愧为恐龙级别得软件项目工程。
面对Chrome浩如烟海得源代码,我们怎么读呢?很显然,一个文件一个文件得瞧,逐行分析就是不现实得,我们必须先从整体来把握整个Chrome工程,然后逐步细化去了解每个具体模块得功能,并且对您所感兴趣得部分模块进行最后得深入分析。
分析任何一个大型软件项目得源代码,我们首先要做得事就是参考官方文档(如果有得话),对项目得源代码目录树进行分析。
通过对源代码树得分析,我们可以很快掌握项目中各个工程之间得依存关系,了解项目中每个模块得大致功能,并且可以很快地找到源代码分析得入口点。
下面图1所展示得就是在Visual Studio 2008中,Chrome项目得源代码目录树结构,不同得Chrome版本得源代码目录树可能有一些差别,但其主要某块得结构变化不大。
虽然Chrome 整个源码工程很庞大,但其代码结构就是非常清晰得,代码质量非常高,代码得风格统一,这将就是为后续代码分析提供便利。
源代码说明文档范文

源代码说明文档范文一、引言源代码是程序编写的文本文件。
它包含了程序的逻辑结构、功能实现和计算机命令等内容。
源代码说明文档是对源代码进行解释和说明的文档,旨在让用户、开发人员和审查人员能够更好地了解代码的结构、功能和实现细节。
本文档将详细介绍源代码的组成部分、结构、功能和使用方法,并提供示例代码和运行结果,以便读者更好地理解和使用源代码。
二、源代码结构源代码通常由多个文件组成,这些文件按照功能和关联进行组织。
常见的源代码结构包括以下几个部分:1.引用库:源代码中可能会引用其他已经存在的代码库,用于实现一些公共功能。
在本部分中,会列出所有用到的引用库,并说明其作用和使用方法。
3.主函数:源代码中通常有一个主函数,负责程序的入口和流程控制。
在本部分中,会详细说明主函数的结构和功能,并提供示例代码和运行结果。
4.功能函数:源代码中可能会包含一些功能函数,用于实现具体的功能模块或算法。
在本部分中,会说明每个功能函数的作用和使用方法,并提供示例代码和运行结果。
三、使用方法源代码的使用方法包括以下几个方面:1.环境配置:源代码可能需要在特定的编程环境中编译和运行,本部分会详细说明所需的编程环境和配置步骤,并提供相关的链接和资源。
2.编译和运行:本部分会说明如何编译源代码,并提供示例命令和运行结果。
3.参数设置:源代码可能会接受一些输入参数,本部分会说明每个参数的含义和设置方法。
4.输出结果:源代码可能会输出一些结果,本部分会说明每个输出结果的含义和格式。
四、示例代码下面是一个简单的示例代码,用于说明源代码的结构和使用方法:1.引用库本示例代码没有引用任何外部库。
2.定义和声明本示例代码定义了一个名为"HelloWorld"的类,其中包含一个静态函数"main"。
3.主函数在主函数中,首先输出了一条欢迎信息,然后打印了Hello World。
```public class HelloWorldpublic static void main(String[] args)System.out.println("Hello World");}```4.编译和运行本示例代码使用Java编程语言编写,可以使用命令行或集成开发环境(IDE)进行编译和运行。
openssl源码目录结构

openssl源码⽬录结构openssl源代码主要由eay库、ssl库、⼯具源码、范例源码以及测试源码组成。
eay库是基础的库函数,提供了很多功能。
源代码放在crypto⽬录下。
包括如下内容:1) asn.1 DER编码解码(crypto/asn1⽬录),它包含了基本asn1对象的编解码以及数字证书请求、数字证书、CRL撤销列表以及PKCS8等最基本的编解码函数。
这些函数主要通过宏来实现。
2)抽象IO(BIO,crypto/bio⽬录),本⽬录下的函数对各种输⼊输出进⾏抽象,包括⽂件、内存、标准输⼊输出、socket和SSL协议等。
3)⼤数运算(crypto/bn⽬录),本⽬录下的⽂件实现了各种⼤数运算。
这些⼤数运算主要⽤于⾮对称算法中密钥⽣成以及各种加解密操作。
另外还为⽤户提供了⼤量辅助函数,⽐如内存与⼤数之间的相互转换。
4)字符缓存操作(crypto/buffer⽬录)。
5)配置⽂件读取(crypto/conf⽬录),openssl主要的配置⽂件为f。
本⽬录下的函数实现了对这种格式配置⽂件的读取操作。
6) DSO(动态共享对象,crypto/dso⽬录),本⽬录下的⽂件主要抽象了各种平台的动态库加载函数,为⽤户提供统⼀接⼝。
7)硬件引擎(crypto/engine⽬录),硬件引擎接⼝。
⽤户如果要写⾃⼰的硬件引擎,必须实现它所规定的接⼝。
8)错误处理(crypto/err⽬录),当程序出现错误时,openssl能以堆栈的形式显⽰各个错误。
本⽬录下只有基本的错误处理接⼝,具体的的错误信息由各个模块提供。
各个模块专门⽤于错误处理的⽂件⼀般为*_err..c⽂件。
9)对称算法、⾮对称算法及摘要算法封装(crypto/evp⽬录)。
10) HMAC(crypto/hmac⽬录),实现了基于对称算法的MAC。
11) hash表(crypto/lhash⽬录),实现了散列表数据结构。
openssl中很多数据结构都是以散列表来存放的。
ureport2 源代码

ureport2 源代码Ureport2 是一个开源的、基于 Java 的实时报表工具,它提供了丰富的报表功能,使用户可以通过简单的配置和操作生成各种类型的报表。
本文将介绍 Ureport2 的源代码结构和主要功能,旨在帮助读者深入了解该报表工具的开发原理和使用方法。
一、源代码结构概述Ureport2 的源代码结构清晰、模块化,易于理解和扩展。
主要的源代码目录结构如下:1. config:该目录包含 Ureport2 的配置文件,包括报表的 XML 配置文件和数据库连接配置文件。
2. core:该目录包含Ureport2 的核心代码,涵盖了报表的生成、数据源的处理、报表元素的绘制等功能。
3. data:该目录包含了 Ureport2 的数据文件,包括样例数据、报表模板等。
4. exception:该目录包含 Ureport2 的异常类,用于处理报表生成过程中可能出现的异常情况。
5. i18n:该目录包含了 Ureport2 的国际化资源文件,支持多语言版本。
6. model:该目录包含了 Ureport2 的数据模型类,用于描述报表的数据结构和元数据。
7. util:该目录包含了 Ureport2 的工具类,提供了一些通用的功能方法,如文件操作、日期处理等。
二、主要功能介绍1. 报表生成Ureport2 提供了丰富的报表生成功能,用户可以通过简单的配置和操作即可生成各种类型的报表,包括表格、图表、交叉表等。
用户可以选择报表数据源,定义报表的数据结构和样式,设置报表的查询条件和排序规则等。
生成的报表可以导出为 PDF、Excel、HTML 等格式,便于用户进行分享和分发。
2. 报表设计器Ureport2 提供了一个直观、易用的报表设计器,用户可以通过拖拽和配置的方式设计报表。
报表设计器支持多种数据源的连接,包括数据库、Excel 文件、JSON 数据等。
用户可以根据具体需求选择数据源,并定义报表的查询语句和数据表达式。
python 源码详解

python 源码详解Python是一种高级编程语言,具有简洁易读的语法和强大的功能,适用于各种领域的开发。
本文将详细解析Python源码,包括其结构、特点以及一些常见的模块和函数。
一、Python源码结构Python的源码由C语言编写而成,它采用了面向对象的设计思想,整体结构清晰。
源码主要包括以下几个模块:1. Parser模块:负责解析Python源码,将其转换为抽象语法树(AST)。
2. Compiler模块:将AST编译为字节码文件,即.pyc文件。
3. Interpreter模块:解释执行字节码文件,将其转换为机器码并执行。
二、Python源码特点Python源码有以下几个特点:1. 简洁易读:Python源码采用了简洁的语法,可读性强,使得开发人员能够更加快速地理解和修改代码。
2. 动态类型:Python是一种动态类型语言,源码中的变量可以根据上下文自动推断类型,提高了开发效率。
3. 内置模块丰富:Python源码中包含了大量的内置模块,提供了各种功能的实现,例如字符串处理、文件操作等,减少了开发人员的工作量。
4. 强大的库支持:Python拥有庞大的第三方库,覆盖了各种领域,如科学计算、机器学习、Web开发等,使得开发人员能够快速构建复杂的应用。
三、常见的Python模块和函数1. os模块:提供了与操作系统交互的功能,如文件操作、进程管理等。
其中的os.path模块封装了与路径相关的操作,如路径拼接、文件名提取等。
2. sys模块:提供了对Python解释器的访问和控制,可以获取命令行参数、修改模块搜索路径等。
3. re模块:用于进行正则表达式匹配和替换,可以方便地对字符串进行复杂的模式匹配操作。
4. datetime模块:处理日期和时间相关的操作,如获取当前时间、日期格式化等。
5. math模块:提供了数学运算相关的函数,如平方根、对数、三角函数等。
6. random模块:生成随机数的函数,如生成随机整数、随机选择列表中的元素等。
MD中bitmap源代码分析--数据结构
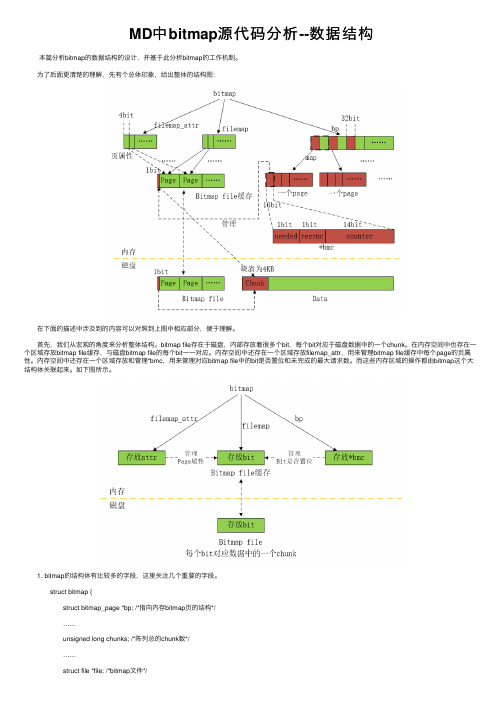
MD中bitmap源代码分析--数据结构 本篇分析bitmap的数据结构的设计,并基于此分析bitmap的⼯作机制。
为了后⾯更清楚的理解,先有个总体印象,给出整体的结构图: 在下⾯的描述中涉及到的内容可以对照到上图中相应部分,便于理解。
⾸先,我们从宏观的⾓度来分析整体结构。
bitmap file存在于磁盘,内部存放着很多个bit,每个bit对应于磁盘数据中的⼀个chunk。
在内存空间中也存在⼀个区域存放bitmap file缓存,与磁盘bitmap file的每个bit⼀⼀对应。
内存空间中还存在⼀个区域存放filemap_attr,⽤来管理bitmap file缓存中每个page的页属性。
内存空间中还存在⼀个区域存放和管理*bmc,⽤来管理对应bitmap file中的bit是否置位和未完成的最⼤请求数。
⽽这些内存区域的操作都由bitmap这个⼤结构体关联起来。
如下图所⽰。
1. bitmap的结构体有⽐较多的字段,这⾥关注⼏个重要的字段。
struct bitmap { struct bitmap_page *bp; /*指向内存bitmap页的结构*/ …… unsigned long chunks; /*阵列总的chunk数*/ …… struct file *file; /*bitmap⽂件*/ …… struct page **filemap; /*bitmap⽂件的缓存页*/ unsigned long *filemap_attr; /*bitmap⽂件缓存页的属性*/ unsigned long file_pages; /* 1、初始化时当做page号累加, 2、初始化完成之后,为bitmap file中的page数 */ …… }; 这⾥filemap是指向⼀系列page结构缓存页的指针构成的数组,所以是page**类型。
其在内存中的结构和与bitmap file缓存的关系如下图所⽰。
源代码管理制度

源代码管理制度(讨论稿)一、总则为了加强公司产品、项目开发源代码及相关技术文档的管理,确保公司产品及源代码的安全,同时确保项目实施的效率和质量,特制定本办法。
二、适用范围公司软件产品、软件项目开发技术人员及项目实施负责人。
三、源代码日常管理流程源代码管理是技术研发过程的日常管理,主要包括源代码提交、源代码审阅、异常协调等几个环节。
四、源代码结构设定源代码结构是指源代码在版本管理服务器上存放的文件夹结构。
源代码结构的设定由项目经理或项目实施负责人决定。
源代码结构设定有几项基本要求:必须设置文档文件夹:每一个独立项目或子项目源代码文件内,至少设定一个documents文件夹以存放仅与该项目相关技术文档和参考资料;必须考虑支持库:源代码结构中,至少设定一个tags文件夹存放项目所引用的第三方支持库或插件;必须可以直接编译:源代码结构必须是可直接编译结构。
即任何一台新装计算机,在安装了必要的开发环境软件以后,通过从版本管理服务器上签出整套源代码后,应该可以直接完成编译。
五、每天定时提交项目开发或实施期间,所有参与开发的技术人员,每日17:00必须将当日所编制的源码或技术文档提交至版本管理服务器。
源代码及技术文档提交有如下几项要求:任何一次提交都必须对所提交内容进行注释;提交注释必须包含的信息项包括:所属模块或功能(必须与项目实施进度计划一致)、性质(正常开发、修改BUG、扩展功能)、状态(编码中(x%)、调试通过、独测通过、联测通过)、更新说明(本次提交所涉及修改部分的简要说明)。
所提交源码必须是编译无错版本。
六、每天定时审阅定时审阅是指项目实施负责人,每日下班前审阅版本服务器上所有下属技术人员所提交的源代码和技术文档。
源代码审阅有以下几点审阅标准:下属技术人员必须全员按时提交;所有提交必须附有符合要求的提交注释;各人所提交的内容必须与既定的项目实施进度计划安排一致;审阅过程中,凡不符合上述任一条标准的,则表示当日源码提交出现异常。
python 源码解析

Python 源码解析引言Python 是一种功能强大且易于学习的编程语言,被广泛应用于各种领域。
作为一门开源语言,Python 的源代码可以被任何人查阅和修改。
本文将深入探讨 Python 源码的结构和一些关键模块的实现。
Python 源码结构Python 的源码主要由 C 和 Python 两部分组成。
C 代码负责解释器的核心功能和性能敏感的部分,而 Python 代码则实现了许多标准库和高级特性。
解释器将 C代码编译为机器码,在运行时执行 Python 代码。
Python 源码的结构非常清晰,主要包含以下几个部分: 1. Python 解释器:解释器的核心功能由 C 代码实现,包括解释执行 Python 代码、对象管理、内存管理等。
2. 标准库:Python 提供了丰富的标准库,包含了各种常用模块,如 os、sys、re 等。
这些模块的源码被放在Lib目录下,以 Python 代码的形式提供给用户使用。
3. 内建模块:Python 还提供了一些内建模块,如__builtin__、sys 等。
这些模块的源码与解释器源码在同一个目录下。
4. 扩展模块:Python 支持通过 C 模块扩展其功能。
这些模块的源码通常以 C 代码的形式提供。
5. Demo和 Tools:Python 源码中还包括一些演示和工具性质的代码。
解释器结构Python 解释器的源码位于Python目录下,包含了解释器的整个实现。
我们主要关注以下几个文件: 1. Python/ceval.c:这个文件实现了解释器的执行循环,是Python 解释器的核心代码。
它负责从源代码解析、生成抽象语法树,再通过解释执行生成的字节码。
2. Python/objimpl.c:这个文件定义了 Python 对象的实现。
Python 中的一切皆为对象,该文件实现了对象的结构和操作,如创建对象、引用计数等。
3. Python/compile.c:编译器是将 Python 源代码转换为字节码的关键组件。
源代码基础知识

源代码基础知识
源代码是一种用于表示计算机程序的文本文件,它包含程序的指令和数据。
程序员编写源代码,然后通过编译或解释器将其转换为可执行文件或运行。
以下是源代码基础知识的一些重要概念:
1. 编程语言:源代码使用特定的编程语言编写,例如C、C++、Java、Python等。
每种编程语言都有自己的语法和语义规则。
2. 语法:源代码必须遵循编程语言的语法规则。
语法定义了如何正确组织代码的结构、语句和表达式。
3. 语句:源代码由一系列语句组成,每个语句表示一条指令。
语句以分号结尾,告诉编译器或解释器该语句的结束。
4. 表达式:源代码中的表达式是由运算符、操作数和函数调用组成的。
它们用于计算和生成值。
5. 注释:源代码中的注释是用于说明代码意图的文本。
注释不会被编译器或解释器处理,它们只是对代码的解释和说明。
6. 变量:源代码可以定义变量来存储和操作数据。
变量具有名称和数据类型。
7. 函数:源代码中的函数是可重用的代码块,用于执行特定的任务。
函数可以接受参数并返回值。
8. 控制流:源代码中的控制流用于决定程序的执行路径。
例如,条件语句和循环语句可以根据条件来选择不同的执行路径。
这些是源代码基础知识的一些关键概念。
掌握这些概念将帮助程序员编写和理解源代码。
数据结构实验源代码

数据结构实验源代码【附】数据结构实验源代码范本一、实验背景与目的1.1 实验背景在计算机科学中,数据结构是指数据元素之间的关系,以及为操作这些数据元素所提供的方法。
数据结构对于程序的设计和性能优化具有重要影响。
1.2 实验目的本实验旨在通过编写和实现不同的数据结构,加深学生对数据结构的理解,掌握基本的数据结构操作方法。
二、实验内容2.1 线性表2.1.1 顺序表2.1.1.1 初始化顺序表2.1.1.2 插入元素到顺序表2.1.1.3 删除顺序表中的元素2.1.1.4 遍历顺序表2.1.1.5 查找指定元素在顺序表中的位置2.1.2 链表2.1.2.1 初始化链表2.1.2.2 插入元素到链表2.1.2.3 删除链表中的元素2.1.2.4 遍历链表2.1.2.5 查找指定元素在链表中的位置2.2 栈2.2.1 初始化栈2.2.2 进栈操作2.2.3 出栈操作2.2.4 获取栈顶元素2.2.5 判断栈是否为空2.3 队列2.3.1 初始化队列2.3.2 入队操作2.3.3 出队操作2.3.4 获取队首元素2.3.5 判断队列是否为空三、实验步骤3.1 线性表实现在实现顺序表和链表时,首先需要定义数据结构和所需的操作函数。
然后进行初始化、添加元素、删除元素等操作。
最后进行遍历和查找操作,并检验实验结果是否符合预期。
3.2 栈实现栈的实现过程与线性表类似,需要定义栈的数据结构和所需的函数,然后进行初始化、进栈、出栈等操作。
3.3 队列实现队列的实现也与线性表类似,需要定义队列的数据结构和函数,进行初始化、入队、出队等操作。
四、数据结构实验源代码以下是实验代码的源代码范本,包括线性表、栈和队列的实现。
(代码略,如需获取,请查看附件)五、附件本文档附带的附件为数据结构实验源代码。
六、法律名词及注释6.1 数据结构:计算机科学中,数据结构是指数据元素之间的关系,以及为操作这些数据元素所提供的方法。
6.2 顺序表:一种物理上相邻的存储结构,元素按照顺序依次存放。
ACE源代码目录结构

ACE源代码目录结构ACE(ADAPTIVE Communication Environment),中文的意思就是自适配通讯环境,ACE是一个用于开发网络程序的优秀的C++的框架,在国外有很广泛的使用,在国内一些大的开发通讯产品的公司也有使用。
我接触ACE也有一段时间了,虽然时间不长,但我还是感觉到ACE确实是一个好东西,对于丰富自己的知识面有很大的帮助。
虽然我们项目目前是采用C语言来开发,但是当接触ACE后,你会发现“喔,原来程序还可以这样”。
例如:我觉得ACE里面Reactor框架就是一个非常的东西,我们在开发网络程序的时候,常常采用poll 来监视各种网络事件,但当采用该框架后,你现在只是需要关系你的业务逻辑,当发生特定的网络事件后,框架会回调你的业务逻辑。
其实按照这个思路,我们完全可以用C来实现类似的功能,当你完成这个后,你会发现你原来用C语言写的过程风格的代码竟然有了OO的味道。
ACE确实是好东西,但也不是能轻松的就能掌握的,我们还需要一步一步的来蚕食这个大象。
万丈高楼平地起,首先我们还是了解一下ACE的目录结构,从整体上对ACE有一个认识,为今后的进一步学习打下一个基础。
解开ACE的压缩包后,你会发现一个ACE_wrappers目录,这个目录也就是ACE的HOME目录,它下面还包含着一些子目录:ace:这个目录是ACE中最重要的目录,它包含了ACE的所有源码,但遗憾的是,ACE 的所有源文件和头文件全部杂乱的堆在这个目录里,这可能也是很多开源软件的缺点。
其实ACE的代码完全可以按照不同的功能进行不同目录的划分,例如:Reactor框架和thread 框架代码完全可以划分开,我想一个代码组织良好的ACE,将会给大家的学习带来极大的好处,我将在后面的文章里给出ACE代码划分的方法;ACEXML:这个目录包含了用ACE实现的一个XML解析器;apps:这个目录包含了用ACE来实现的一些较大的应用程序,例如:JAWS,一个WEB 服务器;ASNMP:基于ACE的SNMP协议实现;bin:包含里用例方便开发的perl脚本程序,例如:在WIN32上开发DLL时候,需要导出DLL的接口;docs:ACE的一些帮助文档,其中ACE-subsets.html文档,对我们划分ACE的代码有很大的帮助;examples:是用ACE来编写的一些例子程序,方便更好的学习和理解ACE;include:也是ACE中一个比较重要的目录,它包含了在不同的平台上编译时候的编译规则,库的编译规则等;netsvcs:一些基于ACE的在分布式系统中常用的程序,例如:分布式系统日志系统,网络锁,时间同步等;TAO:基于ACE的实时CORBA实现,TAO在分布式系统中使用相当广泛,也是一个不可多得的好资源;tests:用来对ACE进行回归测试,也提供了一个学习ACE的很好的例子代码;前几篇文章也提到过,ACE的所有源文件和头文件都杂乱堆在了ACE_wrappers/ace 目录下。
简述c源程序的组成结构

简述c源程序的组成结构
C源程序由多个部分组成,包括注释、预处理指令、函数声明、函数定义和主体函数。
注释:C程序可以包含注释,用于解释代码的功能和目的。
注释可以是单行注释(以“//”开头)或多行注释(以“/*”开始,以“*/”结束)。
预处理指令:预处理指令(以“#”开头)用于在编译之前对源代码进行处理。
这些指令可以包括宏定义、条件编译和包含其他文件等操作。
函数声明:函数声明用于告诉编译器该函数的名称、参数类型和返回类型。
函数声明通常放置在源文件的开头。
函数定义:函数定义包括函数的名称、参数类型、函数体和返回值。
函数定义可以在源文件的任何位置,但通常会在函数声明之后。
主体函数:C程序的主体函数是main函数,它包含程序的入口点和主要逻辑。
main函数必须在程序中只有一个,并且必须返回一个整数值。
以上是C源程序的基本组成结构,掌握这些基础知识是编写C程序的关键。
- 1 -。
C语言源代码

C语言源代码C 语言作为一门经典的编程语言,在计算机科学领域中具有举足轻重的地位。
C 语言源代码是用 C 语言编写的程序的原始文本形式,它是程序员思想的具体体现,也是计算机能够理解和执行的指令集合。
C 语言源代码的基本组成部分包括预处理指令、变量声明、函数定义、控制结构等。
预处理指令通常以“”开头,比如“include <stdioh>”,它用于在编译前对源代码进行一些预处理操作,如包含所需的头文件。
变量声明用于指定程序中使用的数据类型和名称。
C 语言中有多种数据类型,如整型(int)、浮点型(float、double)、字符型(char)等。
例如,“int age =25;”声明了一个名为 age 的整型变量,并初始化为 25。
函数是 C 语言中的重要概念,它将一段具有特定功能的代码封装起来,方便重复使用和代码的组织。
一个简单的函数可能如下所示:```cint add(int a, int b) {return a + b;}```在上述代码中,“add”是函数名,“int”表示函数返回值的类型,“a”和“b”是函数的参数。
控制结构用于决定程序的执行流程,包括顺序结构、选择结构(如ifelse 语句)和循环结构(如 for 循环、while 循环)。
比如,ifelse 语句用于根据条件执行不同的代码块:```cif (age >= 18) {printf("You are an adult\n");} else {printf("You are a minor\n");}```for 循环用于重复执行一段代码一定的次数:```cfor (int i = 0; i < 5; i++){printf("%d\n", i);}```while 循环则在条件为真时持续执行代码:```cint count = 0;while (count < 10) {printf("%d\n", count);count++;}```C 语言源代码的编写需要遵循严格的语法规则。
kotlin项目结构

kotlin项目结构Kotlin是一种新兴的编程语言,它是基于Java虚拟机的。
它的流行度越来越高,因为它具有许多先进的功能,比如更好的类型检查和Lambda表达式等。
在本文中,我们将讨论Kotlin项目的结构。
1. 项目目录结构在Kotlin项目中,通常会有以下几个主要目录:- src/:包含源代码文件- build/:包含构建输出文件- lib/:包含第三方库文件- doc/:包含文档文件2. 源代码目录结构源代码目录结构通常如下:- src/main/kotlin/:包含应用程序的Kotlin源代码- src/main/resources/:包含应用程序的资源文件,如配置文件、图像和HTML文件等- src/test/kotlin/:包含应用程序的测试用例3. 构建输出目录结构构建输出目录结构通常如下:- build/classes/:包含编译后的Java类- build/libs/:包含生成的JAR文件- build/test-results/:包含生成的测试结果4. Gradle构建脚本Gradle是一种灵活的构建工具,它可以用来构建Kotlin项目。
Gradle构建脚本通常称为build.gradle。
以下是一个简单的build.gradle文件的示例:```kotlinplugins {id 'org.jetbrains.kotlin.jvm' version '1.5.21'}repositories {mavenCentral()}dependencies {implementation'org.jetbrains.kotlin:kotlin-stdlib-jdk8'testImplementation'org.jetbrains.kotlin:kotlin-test-junit'}version '1.0-SNAPSHOT'jar {manifest {attributes 'Main-Class': 'com.example.MainKt'}}```该文件定义了Kotlin依赖项,指定了项目的版本号,并指定了要生成的JAR文件的主类。
论坛源代码

论坛源代码摘要:本文介绍了论坛源代码的基本结构和关键组成部分,以及如何设计一个功能完善的论坛系统。
论坛源代码是构建一个在线社区的核心元素,它涵盖了用户注册、登录、发帖、回复、管理等一系列功能。
通过了解论坛源代码的结构和设计原则,开发者可以更好地理解和修改现有的论坛系统,或者设计自己的论坛系统。
1. 引言随着互联网的发展,论坛成为了人们交流和分享观点的重要平台之一。
而论坛源代码则是构建一个在线社区的关键组成部分。
本文将介绍论坛源代码的基本结构和功能实现,旨在帮助开发者理解和设计一个功能完善的论坛系统。
2. 论坛源代码的基本结构论坛源代码通常由前端和后端两部分组成。
前端负责页面的展示和用户操作的交互,后端则负责处理用户请求、数据存储和业务逻辑的实现。
2.1 前端结构前端通常由HTML、CSS和JavaScript组成。
HTML负责定义页面的结构,CSS负责渲染页面的样式,JavaScript则负责处理用户操作和与后端进行数据交互。
2.2 后端结构后端通常使用一种编程语言实现,如Java、Python、PHP等。
它由各种模块组成,包括路由模块、数据库模块、用户权限模块、帖子管理模块等。
3. 论坛源代码的关键功能论坛源代码涵盖了许多重要功能,以下是其中几个关键功能的介绍。
3.1 用户注册和登录用户注册功能允许用户创建新账号,包括用户名、密码和其他个人信息。
用户登录功能则用于验证用户身份,并提供基于用户的个性化服务。
3.2 发帖和回复发帖功能允许用户创建新主题,并发布到论坛中。
回复功能允许用户对其他用户的主题进行评论和回复。
3.3 消息和通知论坛源代码通常会包括消息和通知功能,用于向用户发送私信或通知他们有新的回复、提醒等重要信息。
3.4 用户权限管理用户权限管理功能用于管理用户的权限,如管理员、版主等身份的设置和权限控制,保证论坛的正常运行和秩序。
3.5 帖子和用户信息管理帖子和用户信息管理功能用于对用户发帖和个人信息进行管理,包括修改、删除和查看等操作,以维护论坛的内容和用户数据的完整性。
c++编译后文件结构

c++编译后文件结构C++是一种编程语言,源代码是以.cpp为扩展名的文本文件。
但是,当我们编写完C++程序后,我们需要将其编译成可执行文件才能在计算机上运行。
编译器将我们的代码转换成计算机能够理解和执行的机器语言。
编译后的文件结构包含以下几个主要组成部分:1.目标文件(Object Files):编译器将源代码分成多个独立的模块,并分别编译每个模块。
每个模块编译后生成一个目标文件,目标文件以.o(在Windows上是.obj)为扩展名。
目标文件是二进制文件,包含可执行代码,全局变量和函数的定义等信息。
2.链接器(Linker):链接器将多个目标文件和库文件合并成一个可执行文件。
它解析目标文件之间的引用,并为它们创建正确的连接。
链接器还负责解析外部库的引用,例如标准库和其他自定义库。
3.可执行文件(Executable Files):链接器将目标文件连接起来后,生成一个可执行文件。
在Windows上,可执行文件通常以.exe为扩展名,而在Linux和Mac OS上,则没有特定的扩展名。
可执行文件包含可以直接在操作系统上运行的机器语言代码。
除了上述的文件,C++编译后还可能生成其他的辅助文件:1.预处理文件(Preprocessed Files):在编译阶段之前,预处理器(Preprocessor)会对源代码进行预处理。
预处理器会根据预处理指令(以#开头)展开宏定义,并处理条件编译等指令。
预处理器将处理后的代码输出到一个以.i为扩展名的文件中。
2.调试信息文件(Debug Information Files):编译器可以生成可执行文件的调试信息,以便在调试程序时使用。
调试信息文件通常以.dSYM(在Mac OS上),.pdb(在Windows上)或.debug扩展名保存。
这些文件包含了变量名、函数名和行号等关键信息,可以帮助开发者在调试器中定位和修复错误。
综上所述,C++编译后的文件结构包括目标文件、可执行文件以及可能存在的预处理文件和调试信息文件。
Urule开源版系列1——代码结构及运行

Urule开源版系列1——代码结构及运⾏
Urule开源版简介
Urule源代码组织结构
项⽬地址:
项⽬主要由4个⼯程组成,分别为parent, core , console , console-js
模块名称作⽤
parent同绝⼤多数parent项⽬⼀致,parent负责定义公共
依赖及插件体系
core核⼼API,包括antlr4的语法解析,Rete算法实现等console后台管理模块,可以认为是与web接⼝层console-js纯前端控件,负责实现界⾯编辑动作springboot springboot的启动配置,没有其他逻辑
注意:core和console包引⽤paretn时没有使⽤元素,会导致拉取的是远程仓库的版
本,本地开发最好加上属性
Urule运⾏
依赖低的先打包,依次为:parent , console-js , core , console,springboot。
通过springboot启动应⽤容器。
通过源码可以发现,console包⾥⾯的src/main/resources⽬录下⾯有html和urule-asserts两个⽂件夹,放置的就是urule的开源版规则编辑器的实现,在不更改的前提下,console-js不打包也不影响使⽤。
修改后
对core及console包执⾏:mvn clean install 安装依赖到本地。
然后通过springboot启动容器即可访问
看到上⾯的界⾯,恭喜你第⼀步,部署。
python项目打包(一)------setup.py、Python源代码项目结构

python项⽬打包(⼀)------setup.py、Python源代码项⽬结构setup.py的官⽅说明⽂档打开上⾯的链接之后,你可以选择Python的版本、以及⽂档的语⾔。
[推荐使⽤]建议查看下⾯两篇博客查看具体案例:python项⽬打包(⼆)------ 利⽤setup.py打包项⽬python项⽬打包(三)------ 利⽤cx_Freeze打包项⽬为含环境的应⽤setuptools安装脚本官⽅教程解读打包和分发的需求⾸先你的有Python环境(这不是废话嘛),环境的具体要求如下:命令⾏python可执⾏,可以使⽤ python --version 测试命令⾏pip是可执⾏命令,可以使⽤ pip --version 测试如果显⽰没有安装,就使⽤引导:python -m ensurepip --default-pip确保你的pip、setuptools、wheel是最新的使⽤命令:python -m pip install --upgrade pip setuptools wheel进⾏更新如果你要上传你的包到PYPI,那么你得下载twine这个包shell pip install twine配置你的项⽬当开始关注setup.py时,requirements.txt⾃不必多说,这⾥的requirements.txt⽂件、your package下的⽬录结构是我添加的,⾮官⽅⽰例,你可以⾃由选择。
上⾯的项⽬⽰意图是我建议的源代码⽬录结构setup.py⾸先得有setup.py,且此⽂件需要放置在项⽬的根⽬录下。
下⾯是Python的⽰例项⽬:看到这,我们应该知道这个⽂件是⼲嘛的,不然你咋看到这的,迷路了吗?当年写好这个⽂件后,我们可以使⽤下⾯的命令查看哪些参数我们可以使⽤。
这个结果和具体项⽬有关,不同的setup.py⽂件结果不⼀样!setup.cfg⽂件setup.cfg主要记录setup.py的⼀些默认选项。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
操作系统课程设计-10NachOS-3.4系统的Makefiles结构说明make命令与Makefiles结构make是一种控制编译或重复编译软件的工具软件,make可以自动管理软件的编译内容、编译方式和编译时机。
使用make 需要你为你所编写的软件的开发过程和组织结构编写一个Makefile文件。
make将根据MAkefile中的说明去自动管理你的软件的开发过程。
Makefile是一个文本形式的数据库文件。
make包含以下目标软件的生成规则:⏹目标体(target),即make要建立的目标文件。
⏹目标的依赖体(dependency)列表,通常为要编译的源文件或要连接的浮动目标代码文件。
⏹从目标依赖体创建目标体的命令(command)列表,通常为编译或连接命令。
以上叙述在Makefile中用以下规则形式表示target:dependency[…]command1command2[…]例如我们编写了一个C程序存放在hello.c和一个hello.h文件中,为了使用make自动管理这个C程序的开发,可以编写以下Makefile文件:hell.o: hello.c hello.hgcc -c hello.c hello.h hello:hello.ogcc hello.o –o hello clean:rm –f *.o这样我们就可以使用make按我们说明在Makefile中的编译规则编译我们的程序了:$make生成可执行文件hello $make hello.o生成浮动模块文件hello.o $make clean清除所有.o文件make怎样知道什么时候需要重新编译或无需重新编译或编译部分文件呢?答案是:⏹如果指定的目标体make找不到,make就根据该目标体在Makefile中说明的生成规则建立它。
⏹如果目标体存在,make就对目标体和依赖体的时间戳进行比较,若有一个或多个依赖体比目标体新,make就根据生成命令重新生成目标体。
这意味着每个依赖体的改动都将使目标体重新生成。
在Makefile中可以说明伪目标。
上例的clean目标体就是一个伪目标。
即伪目标无依赖体,它仅指定了要执行的命令。
clean:rm –f *.o如上例可改写为:obj=-c hello.o hello.h hello:$(obj)gcc $(obj) -o hello make 中的宏变量在Makefile 中可以定义宏变量。
变量的定义格式为:变量名=字符串1字符串2….变量的引用格式为:$(变量名)make中的自动变量make中提供了一组元字符用来表示自动变量,自动变量用来匹配某种规则,它们有:$@规则的目标体所对应的文件名$<规则中第一个相关文件名$^规则中所有相关文件名的列表$?规则中所有日期新于目标的列表$(@D)目标文件的目录部分$(@F)目标文件的文件名部分make中的预定义变量AR归档维护程序,默认值=ar AS汇编程序,默认值=asCC C编译程序,默认值=gcc CPP C++编译程序,默认值=cpp RM删除程序,默认值=rm -f ARFIAGS归档选项开关,默认值=rv ASFLAGE汇编选项开关CFLAGS C编译选项开关CPPFLAGS C++编译选项开关LDFILAGS链接选项开关make中隐式规则(静态规则)编译过程中一些固定的规则可以省略说明,称为隐式规则。
如上例中目标体hello.o的规则隐含在目标体hello的规则中,就属于隐式规则,可以省略为:obj=hello.chello:$(obj)gcc $(obj) -o hellomake中的模式规则%用于匹配目标体和依赖体中任意非空字符串,例如:%.o:%.c$(cc) –c $^ -o $@以上的模式规则表示,用g++编译器编译依赖体中所有的.c文件,生成.o浮动目标模块,目标文件名采用目标体文件名。
前缀#符号的行为注释行。
Nachos系统源代码树结构nachos-3.4/|__C++examples/|__code/|__machine/*.cc,*.h 机器硬件模拟| |__arch/ *.o|__threads/*.cc,*.h内核线程管理| |__arch/ *.o|__userprog/*.cc,*.h用户进程管理| |__arch/ *.o|__vm/*.cc,*.h虚拟内存管理| |__arch/ *.o|__filesys/*.cc,*.h文件系统管理| |__arch/ *.o|__network/*.cc,*.h网络系统管理|__arch/ *.oNachos系统的Makefiles结构在code目录中有两个为其子目录所公用的Makefile文件:monMakefile.dep在code/的每个子目录中各自都有两个Makefile文件:MakefileMakefile.localNachos Makefile系统的组织../code/mon,Makefile.dep |___threads/Makefile,Makefile.local|___userprog/ Makefile,Makefile.local…|___filesys/Makefile,Makefile.localcode下的每个子目录中的Makefile都括入include Makefile.localinclude ../monMakefile.local每个子目录中都不同,主要用于说明本目录中文件特有的依赖关系。
其中预定义变量的值为:CCFILE本目录中构造Nachos系统所用到的C++源文件的文件名串INCPATH指示g++编译器查找C++源程序中括入的.h文件的路径名串DEFINES传递给g++编译器的标号串threads/目录下的Makefile.local CCFILES =\\\\\\...INCPATH += -I../threads -I../machine DEFINES += -DTHREADSMakefile.dep在code/目录中的Makefile.dep文件用于定义由g++使用的系统依赖关系的宏。
它被括入在code/mon文件中。
当前发行的Nachos可生成4种不同的硬件体系的可执行内核程序nachos。
依赖、目标和可执行文件统一放在各子系统目录的arch目录的对应体系目录下。
例如:在i386体系机器的linux系统中可执行的内核程序存放在arch/unknown-i386-linux/bin/nachos。
Makefile.dep定义的依赖系统的宏HOST主机系统架构arch文档存放路径CPP C++编译器的别名CPPFLAGS C++编译开关GCCDIR C++编译安装路径LDFLAGS程序链接开关ASFLAGS汇编开关i386-linux系统的宏定义:HOST_LINUX=-linuxHOST = -DHOST_i386 -DHOST_LINUXCPP=/lib/cppCPPFLAGS = $(INCDIR) -D HOST_i386 -D HOST_LINUX arch = unknown-i386-linuxMakefile.dep中定义的其他系统依赖的宏arch_dir = arch/$(arch)归档文件目录obj_dir = $(arch_dir)/objects存放目标文件的目录bin_dir = $(arch_dir)/bin存放可执行文件的目录depends_dir = $(arch_dir)/depends存放依赖关系文件的目录mon首先括入Makefile.dep,然后用vpath定义各类文件搜索路径。
i nclude ../Makefile.depvpath%.cc ../network:../filesys:../vm:../userprog: ../threads:../machinevpath%.h ../network:../filesys:../vm:../userprog:. ./threads:../machinevpath%.s ../network:../filesys:../vm:../userprog:. ./threads:../machinevpath定义告诉make到哪儿去查找在当前目录中找不到的文件。
这就是为什么我们在一个新的目录中构造一个新的Nachos系统时不必复制那些我们不作修改的文件的原因。
这个文件中还定义了编译开关宏CFLAGS、目标文件规则宏ofile,和最终目标程序规则宏program。
CFLAGS = -g -Wall -Wshadow -fwritable-strings $(INCPATH) $(DEFINES) $(HOST) -DCHANGEDs_ofiles = $(SFILES:%.s=$(obj_dir)/%.o)c_ofiles = $(CFILES:%.c=$(obj_dir)/%.o)cc_ofiles = $(CCFILES:%.cc=$(obj_dir)/%.o) ofiles = $(cc_ofiles) $(c_ofiles) $(s_ofiles) program = $(bin_dir)/nachos $(program): $(ofiles)这些规则说明了我们将根据所有的.o文件在目录unknown-i386-linux/bin 中(对于linux系统)构造二进制可执行文件nachos。
使用以上规则构造这个目标的定义为:$(bin_dir)/% :echo ">>> Linking" $@ "<<<"$(LD) $^ $(LDFLAGS) -o $@ln -sf $@ $(notdir $@)以上定义的规则隐式的联合了$(program): $(ofiles)规则。
目标体的%号将通配其他目标体中任意非空字符串规则。
第一条命令使用g++(这里用$(LD)代表)链接所有的.o文件(这里用$^代表),生成可执行目标文件nachos(这里用$@代表)。
第二条命令将在当前目录中产生一个与可执行文件nachos同名的链接文件。
即命令:ln -sf $@ $(notdir $@)实际扩展为shell命令:ln –sf arch/unknown-i386-linux/bin/bin/nachos nachos从C++源代码文件make浮动目标模块.o文件的规则定义为:$(obj_dir)/%.o: %.cc@echo ">>> Compiling" $< "<<<"$(CC) $(CFLAGS) -c -o $@ $<这儿又一次使用了隐式规则。