大数据图形化软件如何新增数据集
arcgis创建镶嵌数据集的方法

arcgis创建镶嵌数据集的方法ArcGIS是一款强大的地理信息系统软件,可以用于管理和分析空间数据。
其中一个重要的功能是创建镶嵌数据集,它可以将多个栅格数据集合并为一个无缝的数据集,方便进行空间分析和可视化呈现。
以下是创建镶嵌数据集的步骤:1. 打开ArcMap,并加载需要创建镶嵌数据集的栅格数据集。
2. 在ArcMap的主菜单中选择“数据管理”>“镶嵌”>“创建镶嵌”。
这将打开“镶嵌数据集创建向导”。
3. 在向导的第一页,“选择输入镶嵌源”,选择需要创建镶嵌数据集的栅格数据集。
可以一次选择多个数据集。
4. 在下一页,“指定坐标系”,选择镶嵌数据集的坐标系。
如果栅格数据集已经具有坐标系,则可以选择“利用源数据栅格坐标系”。
5. 在“缺失值检查”下一页,选择是否对栅格数据集进行缺失值检查。
可以选择自动修复或手动修复。
6. 在下一页,“镶嵌模式和驱动类型”,选择镶嵌数据集的模式。
可以选择互补、融合、尽量大等模式,并选择合适的驱动类型。
7. 定义镶嵌数据集的输出位置和名称。
选择输出位置,并为镶嵌数据集命名。
8. 在最后一页,“创建镶嵌数据集概览”,可以查看创建镶嵌数据集的概览信息,并检查设置是否正确。
9. 单击“完成”按钮,开始创建镶嵌数据集。
创建过程可能需要一些时间,具体取决于数据集的大小和计算机性能。
一旦镶嵌数据集创建完成,您就可以在ArcMap中使用它进行空间分析和可视化呈现。
镶嵌数据集允许您无缝地处理和操作多个栅格数据集,为您的地理信息工作提供更大的灵活性和效率。
总结起来,通过ArcGIS创建镶嵌数据集的步骤包括:加载数据集,打开“镶嵌数据集创建向导”,选择输入镶嵌源数据、指定坐标系、进行缺失值检查、选择镶嵌模式和驱动类型,定义输出位置和命名,查看概览信息并完成创建。
创建完成后,您可以在ArcMap中使用该镶嵌数据集进行空间分析和可视化。
如何拓展训练的数据集

如何拓展训练的数据集
1. 数据增强:通过对原始数据进行随机旋转、翻转、裁剪、缩放等操作,可以增加数据的多样性,从而提高模型的泛化能力。
2. 数据扩充:使用类似的数据来扩充训练数据集,例如使用不同的数据源、不同的传感器或不同的时间段的数据。
3. 数据生成:通过生成新的数据来扩充训练数据集,例如使用生成对抗网络(GAN)来生成新的图像或文本数据。
4. 迁移学习:将在其他任务上训练好的模型应用于新的任务中,可以利用已有的知识和模型结构来提高模型的性能。
5. 多模态数据融合:将不同模态的数据进行融合,例如将图像和文本数据进行融合,可以提供更多的信息和上下文,从而提高模型的性能。
6. 增加数据量:增加更多的训练数据可以提高模型的泛化能力,但需要注意数据的质量和合法性。
总之,拓展训练数据集需要根据具体情况选择合适的方法,并需要进行适当的预处理和清洗,以确保数据的质量和可用性。
同时,需要注意数据的合法性和隐私保护,避免侵犯他人的权益。
大数据建模的基本过程

大数据建模的基本过程大数据建模是指通过对大规模数据集进行分析和处理,从而获取有价值的洞察和知识的过程。
大数据建模通常涉及多种技术和工具,包括数据挖掘、机器学习、统计分析等。
在实际应用中,大数据建模可以帮助企业发现潜在的商业价值、预测未来趋势、优化业务流程等。
大数据建模的基本过程通常包括以下几个主要步骤:数据收集、数据清洗、特征工程、模型训练和模型评估。
这些步骤在整个建模过程中起着至关重要的作用,没有一步是可或缺的。
下面将详细介绍大数据建模的基本过程。
1.数据收集数据收集是大数据建模的第一步,也是最为关键的一步。
在数据收集阶段,需要从各种数据源中采集数据,包括结构化数据(如数据库中的表格数据)、非结构化数据(如文档、图片、视频等)以及半结构化数据(如XML文件、JSON数据等)。
这些数据可以来自于企业内部的系统、外部数据提供商、开放数据源等。
在数据收集阶段,需要考虑的问题包括数据的质量、数据的可靠性、数据的完整性等。
如果数据收集的质量不好,后续的分析和建模结果也会受到影响。
因此,在数据收集阶段需要对数据进行初步的质量评估和清洗。
2.数据清洗数据清洗是指对收集到的数据进行处理,以保证数据的质量和可用性。
在数据清洗阶段,通常会涉及到以下几个方面的工作:(1)数据去重:如果数据中存在重复记录,需要对数据进行去重处理,以确保数据的唯一性。
(2)数据填充:如果数据中存在缺失值,需要对缺失值进行填充,以防止对后续分析造成影响。
(3)数据转换:有些数据可能需要进行转换,以适应建模算法的需求。
比如将文本数据转换为数值型数据,以便于进行后续的分析。
(4)异常值处理:如果数据中存在异常值,需要对异常值进行处理,以避免对建模结果造成干扰。
数据清洗的主要目的是确保数据的准确性和一致性,为后续的分析和建模工作提供可靠的数据基础。
3.特征工程特征工程是指对数据中的特征进行提取、创造和转换,以便于建模算法的需求。
在特征工程阶段,通常会涉及到以下几个工作:(1)特征提取:从原始数据中提取出与建模目标相关的特征,以辅助后续的分析和建模。
数据库系统原理 实验二 以图形界面方式进行数据库和表的创建

实验二以图形界面方式进行数据库和表的创建实验目的:掌握使用图形界面的方式进行库和表的创建,以及数据的插入方法。
实验内容及要求:1、利用图形界面方式创建数据库;2、利用图形界面方式创建一个模式;3、利用图形界面方式在模式中创建表;4、利用图形界面方式在表中插入数据。
实验工具:企业管理器——可以运行在多种操作系统平台上的图形界面总控管理平台。
它允许用户、程序员和管理员进行管理和配置数据库服务器、管理各种数据库对象、管理数据安全、监视数据库服务活动、诊断修改和优化数据库等操作。
企业管理器的总的设计思想是记录下用户通过图形方式进行的操作,并转换成相应的SQL语句。
实验过程及步骤:一、创建TEST数据库创建步骤:打开企业管理器→在企业管理器的【数据库】节点,点击鼠标右键→点击【新建数据库】→弹出【新建数据库窗口】,在该窗口中的“数据库名称”后面输入要创建的数据库名,其他选项默认即可→点击【确定】。
图1 新建数据库二、在TEST数据库中创建SCOT模式实验一中已将TEST数据库创建完成,接下来需要在该数据库中创建SCOT 模式。
模式(Schema)实际上是一个名字空间,它包含命名对象(表,视图,存储过程,函数和序列)。
创建步骤:打开企业管理器→在企业管理器的【模式】节点,点击鼠标右键→点击【新建模式】→弹出【新建模式窗口】,在该窗口中的“模式名”后面输入要创建的模式名,点击【确定】。
图2 新建模式三、创建表在SCOT模式中创建三张表,分别为DEPT部门表、EMP员工表和SALGRADE工资等级表。
其中各表的结构为:DEPT表结构EMP表结构SALGRADE表结构创建步骤:打开企业管理器→在企业管理器的【表】节点,点击鼠标右键→点击【新建表】→弹出【新建表窗口】,在该窗口中的设置列名、数据类型、主键、精度等,点击【保存】,在窗口中输入表名。
图3 创建表四、在表中插入数据DEPT表数据EMP表数据SALGRADE表数据创建步骤:打开企业管理器→在企业管理器的【表】节点中找到插入数据的表名→点击鼠标右键→点击【打开表】下的【返回所有行】→弹出【打开表窗口】,在该窗口中的输入具体数据。
数据集构建流程

数据集构建流程
1.确定数据集目标:首先需要明确数据集的目标,这是决定数据集构建流程的重要一步。
数据集的目标可能是用于机器学习模型训练、数据分析或者其他用途。
2.确定数据来源和采集方式:根据数据集目标,确定数据来源,并选择合适的采集方式。
数据来源可以是公共数据集或者自己采集的数据,采集方式可以是爬虫、传感器、问卷等。
3.数据预处理:采集的原始数据通常存在一些问题,需要进行预处理。
比如去除异常值、处理缺失值、标准化数据等。
4.数据清洗:在数据预处理的基础上,还需要进行数据清洗。
数据清洗包括去除重复数据、纠正错误数据、处理异常数据等。
5.数据标注:数据标注是将数据打上标签或者分类的过程。
对于机器学习来说,数据标注是至关重要的一步。
数据标注可以是手动标注或者自动标注,具体视数据集的特点而定。
6.数据划分和验证:将数据集分为训练集、验证集和测试集。
训练集用于模型训练,验证集用于模型选择,测试集用于模型评估。
数据划分需要遵循一定的比例和随机性原则。
7.数据集发布和维护:数据集构建完成后,需要进行发布和维护。
数据集的发布可以是公开发布或者私有发布,维护包括数据更新、数据质量检查等。
8.数据集应用:数据集构建完成后,可以应用于机器学习模型训练、数据分析等领域,为企业和个人的决策提供支持。
数据集构建流程

数据集构建流程数据集是机器学习和人工智能的基础,它是由大量数据样本组成的集合,用于训练和测试模型。
数据集的质量直接影响到模型的准确性和可靠性。
因此,构建高质量的数据集是非常重要的。
下面是数据集构建的流程。
1. 确定数据集的目的和范围在构建数据集之前,需要明确数据集的目的和范围。
例如,如果是用于图像分类,需要确定分类的类别和数量。
如果是用于自然语言处理,需要确定语言和文本类型等。
2. 收集数据收集数据是构建数据集的第一步。
数据可以从多个渠道获取,例如公共数据集、爬虫、API接口、问卷调查等。
在收集数据时,需要注意数据的来源和质量,确保数据的真实性和可靠性。
3. 数据清洗和预处理收集到的数据可能存在噪声、缺失值、异常值等问题,需要进行数据清洗和预处理。
数据清洗包括去除重复数据、处理缺失值、处理异常值等。
数据预处理包括数据归一化、特征提取、数据转换等。
4. 数据标注数据标注是将数据与标签相对应的过程。
标签可以是分类、回归、聚类等。
数据标注需要专业人员进行,确保标注的准确性和一致性。
5. 数据集划分将数据集划分为训练集、验证集和测试集。
训练集用于训练模型,验证集用于调整模型参数,测试集用于测试模型的准确性和泛化能力。
6. 数据集存储和管理数据集需要进行存储和管理,确保数据的安全性和可用性。
数据集可以存储在本地或云端,可以使用数据库或文件系统进行管理。
总结数据集构建是机器学习和人工智能的基础,它直接影响到模型的准确性和可靠性。
数据集构建的流程包括确定数据集的目的和范围、收集数据、数据清洗和预处理、数据标注、数据集划分和数据集存储和管理。
在构建数据集时,需要注意数据的来源和质量,确保数据的真实性和可靠性。
globaldata使用说明

Globaldata使用说明一、概述G l ob al da ta是一个功能强大的数据分析平台,它提供了海量的数据资源和丰富的分析工具,帮助用户快速、准确地进行数据分析和决策支持。
本文将介绍G lo ba ld a ta的基本使用方法,并提供一些常用操作的示例和技巧。
二、登录和账号管理2.1创建账号首次使用Gl ob al dat a,用户需先创建一个账号。
打开G lob a ld at a官方网站,在首页点击“注册”按钮,填写所需信息,包括用户名、密码等。
完成注册后,即可登录使用。
2.2登录账号访问Gl ob al da ta官方网站,在主页右上角找到“登录”按钮,点击后输入用户名和密码,即可成功登录。
2.3修改密码为了账号安全,建议定期修改密码。
登录G lo ba ld at a后,点击个人信息页面的“修改密码”选项,然后按照提示输入当前密码和新密码,点击确认即可完成密码修改。
三、数据导入和管理3.1导入数据在G lo ba ld at a中,用户可以通过多种方式导入数据,包括上传本地文件、连接数据库、导入UR L等。
具体操作步骤如下:1.上传本地文件:点击“数据导入”页面的“上传文件”按钮,选择需要导入的本地文件,并按照界面指引完成导入操作。
2.连接数据库:在“数据导入”页面选择“连接数据库”,输入相关信息(数据库类型、地址、用户名、密码等),点击确认连接后,根据需要选择要导入的数据库表,并点击导入按钮。
3.导入UR L数据:在“数据导入”页面选择“导入U RL”,输入数据来源的U RL地址,并选择相应的数据格式(如C SV、E xc el等),点击导入按钮。
3.2数据管理导入数据后,用户可以在Gl ob al da ta中进行灵活的数据管理操作,包括创建数据集、添加/删除列、筛选/排序数据等。
以下是一些常用操作示例:1.创建数据集:在数据管理页面点击“新建数据集”,输入数据集名称,并选择数据源,即可创建一个新的数据集。
大数据建模的基本过程

大数据建模的基本过程大数据建模的基本过程可以分为数据收集、数据预处理、特征工程、建模训练、模型评估和部署应用等几个关键步骤。
下面我们将逐一介绍每个步骤的具体内容。
第一步:数据收集数据收集是大数据建模的第一步,通过收集各种各样的数据来满足建模的需求。
数据可以来自于各种不同的来源,包括传感器、移动设备、社交媒体、互联网、企业内部系统等。
这些数据的类型也各不相同,有结构化数据、半结构化数据和非结构化数据等。
因此,在数据收集阶段,需要考虑数据的来源、类型、规模和质量等因素,以确保收集到的数据能够满足建模的需求。
第二步:数据预处理数据预处理是大数据建模的重要环节,通过清洗、转换和集成等方法对收集到的数据进行处理,以使其能够用于建模。
数据预处理包括缺失值处理、异常值处理、重复数据处理、数据转换、数据归一化、数据集成和数据降维等步骤。
在数据预处理过程中,需要借助各种数据预处理工具和技术,以确保数据的质量和完整性,为后续的特征工程和建模训练做好准备。
第三步:特征工程特征工程是大数据建模的关键环节,通过对数据进行特征提取、构建、选择和转换等操作,从而得到能够用于建模的特征数据集。
在特征工程阶段,需要考虑特征的相关性、重要性、多样性和互补性等因素,以确保构建的特征能够有效地描述数据的特性和模式。
特征工程过程中需要结合业务需求和建模目标来选择和构建特征,同时借助各种特征工程工具和技术,以提高特征的质量和效用。
第四步:建模训练建模训练是大数据建模的核心环节,通过选择合适的建模算法和优化方法,对特征数据集进行训练,得到能够用于预测和分类的模型。
在建模训练阶段,需要选择适当的建模算法和优化方法,同时考虑模型的复杂度、泛化能力和运行效率等因素,以确保构建的模型能够满足业务需求和应用场景。
建模训练过程中需要进行参数调优、模型选择和性能评估等操作,以提高模型的质量和效果。
第五步:模型评估模型评估是大数据建模的重要环节,通过评估模型在训练集和测试集上的性能和效果,对模型的质量进行评估和验证。
finereport 数据集基础上新建数据集

在FineReport中,要在已有数据集的基础上新建数据集,可以按照以下步骤操作:
1. 打开FineReport设计器,点击左侧的“数据集”选项卡。
2. 在数据集列表中,找到需要基于的已有数据集,右键点击该数据集,选择“复制”。
3. 在数据集列表的空白区域,右键点击,选择“粘贴”,这样就会在原有数据集的基础上创建一个新的数据集。
4. 双击新创建的数据集,打开数据集编辑界面。
在这里,可以根据需求对数据集进行修改、添加或删除字段等操作。
5. 完成数据集的编辑后,点击“保存”按钮,即可完成基于已有数据集的新数据集创建。
注意:在创建新数据集时,确保原有数据集的数据结构和字段满足新数据集的需求,以免出现数据不一致的问题。
如何在MATLAB中加载和处理大数据集

如何在MATLAB中加载和处理大数据集一、引言在当今信息时代,数据的规模越来越大,处理和分析大数据集已经成为科学研究、商业决策和社会发展的重要课题。
MATLAB作为一种强大的数值计算和数据分析工具,在处理大数据集方面也有着出色的性能。
本文将介绍如何在MATLAB 中加载和处理大数据集,帮助读者更好地应对这一挑战。
二、加载大数据集1. 内存管理:在加载大数据集之前,我们需要评估计算机的内存容量。
如果内存容量较小,不能一次性将整个数据集加载到内存中,可以采取分批加载的方式,利用MATLAB的文件读取函数逐段读取数据。
2. 选择合适的文件格式:当数据集的规模较大时,选择适合的文件格式能够提高加载效率。
常见的文件格式如文本文件、CSV文件、MAT文件等。
文本文件和CSV文件适用于存储结构简单的数据集,而MAT文件则适用于存储结构复杂的数据集。
3. 并行加载:MATLAB提供了并行计算工具箱,可以利用多核处理器同时加载数据集。
通过使用并行加载技术,可以大幅度提高数据集加载的速度。
三、处理大数据集1. 数据预处理:在进行数据分析之前,通常需要对数据集进行预处理。
对于大数据集来说,预处理可能需要消耗大量的计算资源。
MATLAB提供了一系列优化工具和并行计算函数,可以高效地完成数据预处理任务。
2. 数据采样:当数据集较大时,我们可以采用数据采样的方法,从整体数据集中选择一部分样本进行分析。
这种方式可以大大缩小数据集规模,提高计算效率,但需要注意采样方法的科学性和可靠性。
3. 分布式计算:如果数据集的规模超过了单台计算机的处理能力,我们可以采用分布式计算的方法。
MATLAB提供了分布式计算工具箱,可以将任务分发给多台计算机进行并行处理,快速完成对大数据集的分析工作。
四、优化MATLAB代码1. 向量化计算:在MATLAB中,向量化计算是提高代码运行效率的重要技巧。
尽量避免使用循环语句,通过使用向量和矩阵运算,可以大幅度提升代码的运行速度。
数据集扩充方法

数据集扩充方法随着人工智能技术的不断发展,数据集的重要性日益凸显。
一个优秀的数据集可以为模型的训练提供更充分、更准确的数据,从而提高模型的性能和效果。
然而,在实际应用中,往往会遇到数据集不足的情况,这时就需要使用数据集扩充方法来增加数据量,提高模型的性能。
本文将介绍几种常用的数据集扩充方法。
一、传统的数据集扩充方法1. 数据增强数据增强是最常用的数据集扩充方法之一。
它是通过对原始数据进行一系列变换操作,生成新的数据,从而增加数据集的大小。
常见的数据增强方法包括:旋转、平移、缩放、翻转、加噪声等。
这些操作可以使得数据更加丰富多样,有助于提高模型的泛化能力。
但是,数据增强也存在一些问题,比如增强后的数据可能会出现噪声或者失真,这会影响模型的训练效果。
2. 数据合成数据合成是另一种常用的数据集扩充方法。
它是通过将不同的数据组合起来,生成新的数据。
常见的数据合成方法包括:图像叠加、图像融合、图像拼接等。
这些操作可以使得数据更加多样化,有助于提高模型的鲁棒性。
但是,数据合成也存在一些问题,比如可能会出现过拟合的情况,导致模型的泛化能力下降。
二、深度学习中的数据集扩充方法除了传统的数据集扩充方法外,深度学习领域还有一些特别的数据集扩充方法,下面将分别介绍。
1. GANGAN(Generative Adversarial Networks)是一种生成模型,它可以通过训练生成器和判别器两个模型,生成具有高度真实感的图像。
GAN的训练过程是通过让生成器生成的图像与真实图像尽可能相似,同时让判别器尽可能准确地区分生成图像和真实图像,从而使得生成器生成的图像更加逼真。
在数据集扩充中,可以使用GAN生成器生成新的数据,从而扩充数据集的规模。
GAN生成的数据具有高度的真实感,可以使得模型的性能得到提升。
但是,GAN的训练过程比较复杂,需要较长的训练时间和大量的计算资源。
2. VAEVAE(Variational Autoencoder)是一种自编码器,它可以通过学习数据的潜在变量分布,从而生成新的数据。
supermap数据导入方法

supermap数据导入方法
SuperMap是一款专业的地理信息系统(GIS)软件,用于地图
制作、空间数据分析和地理信息系统应用开发。
在SuperMap中,数
据导入是一个非常重要的操作,它涉及到不同数据格式的转换和处理。
以下是一些常见的SuperMap数据导入方法:
1. 矢量数据导入,SuperMap支持导入多种矢量数据格式,如Shapefile、GeoJSON、KML等。
你可以通过SuperMap的数据导入工
具或者API来实现矢量数据的导入。
首先,你需要打开SuperMap软件,然后选择“数据导入”功能,在弹出的对话框中选择要导入的
数据源和数据格式,按照提示完成导入操作即可。
2. 栅格数据导入,SuperMap同样支持导入多种栅格数据格式,如TIFF、JPEG、PNG等。
你可以使用SuperMap的栅格数据导入工具
或者API来进行栅格数据的导入。
同样,首先打开SuperMap软件,
然后选择“数据导入”功能,在对话框中选择要导入的栅格数据源
和数据格式,按照提示完成导入操作。
3. 数据库数据导入,如果你的数据存储在数据库中,SuperMap
也提供了相应的数据库连接和导入功能。
你可以通过SuperMap提供
的数据库连接工具,连接到你的数据库,然后选择要导入的数据表
或者数据集,完成数据的导入操作。
总的来说,SuperMap提供了多种数据导入方法,包括矢量数据、栅格数据和数据库数据的导入,用户可以根据自己的需求和数据格
式选择合适的导入方法进行操作。
希望以上信息能够对你有所帮助。
python扩充数据集方法实例

python扩充数据集方法实例一、数据集介绍本节将介绍数据集的基本信息,包括数据集名称、来源、样本数量、特征和标签等。
二、数据预处理本节将介绍数据预处理的方法,包括数据清洗、缺失值处理、异常值处理、数据标准化等。
三、扩充数据集方法1. 增加样本数量通过增加样本数量来扩充数据集的方法有多种,例如随机生成样本、从其他数据源中提取样本等。
本节将介绍几种常见的增加样本数量的方法,并给出相应的代码实现。
(1) 随机生成样本通过随机生成与已有样本相似的数据来扩充数据集。
可以使用随机生成的特征和标签,或者使用已有的特征和标签,结合一定的规则来生成新的样本。
示例代码:```pythonimport numpy as npfrom sklearn.datasets import make_classification# 生成随机样本X, y = make_classification(n_samples=1000, n_features=10) # 将随机生成的样本添加到原始数据集中X_extended = np.concatenate((X, X[:5]*0.5)) # 添加随机生成的50%相似的样本y_extended = np.concatenate((y, y[:5])) # 将原始标签复制到新样本中# 将扩充后的数据集保存到新的文件中np.savetxt("data_extended.csv", X_extended, delimiter=",") ```(2) 从其他数据源中提取样本通过从其他数据源中提取与已有样本相似的数据来扩充数据集。
可以使用爬虫技术、API调用等方式从互联网上获取数据。
示例代码:```pythonimport requestsfrom sklearn.datasets import fetch_openmlfrom sklearn.model_selection import train_test_splitfrom sklearn.neighbors import KNeighborsClassifier# 从OpenML网站上下载数据集,并按照特征进行划分X, y = fetch_openml("mnist_784", version=1,return_X_y=True)X = X[::2] # 只保留一半特征用于扩充数据集y = y[:len(X)] # 复制标签到新特征上y = np.array([-y[i] for i in range(len(y)) if X[i] < 0]) # 用于区分正负样本的新标签列表,可以作为分类器的输入标签,但注意类别不平衡问题X_extended, y_extended = train_test_split(X, y,test_size=0.2) # 将扩充后的数据集划分为训练集和测试集,进行模型训练和评估```2. 转换特征类型或分布方式来扩充数据集通过转换特征类型或分布方式来扩充数据集的方法包括将连续特征转换为分类特征、将离散特征转换为连续特征等。
Arcmap数据添加基本操作
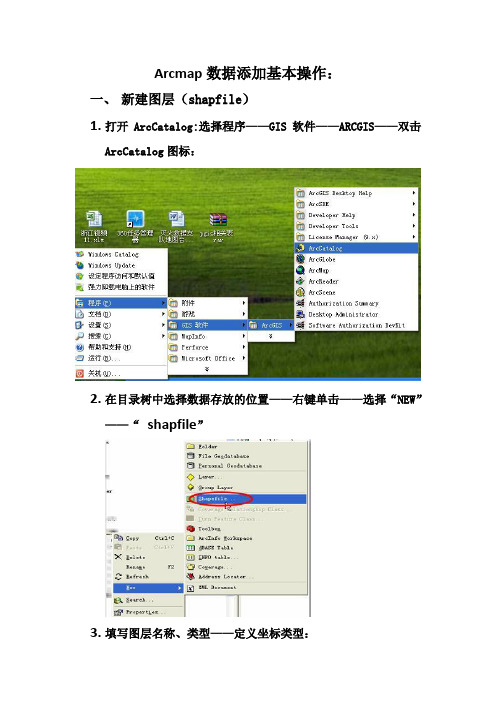
Arcmap数据添加基本操作:一、新建图层(shapfile)1.打开ArcCatalog:选择程序——GIS软件——ARCGIS——双击ArcCatalog图标:2.在目录树中选择数据存放的位置——右键单击——选择“NEW”——“shapfile”3.填写图层名称、类型——定义坐标类型:图层名称图层类型:point(点)、polyline(线)、polygon(面)二、新建图层添加字段:1.选择新建的文件——右击鼠标——点击“属性(propeties)”3、在“属性页面”选择“字段(fields)选项卡:——添加字段:三、在Arcmap打开图层:1在Arcmap中添加数据,可以使用工具栏上的ADD DATA按钮来添加数据:四、图层编辑:1开始编辑:点击工具栏Edit——点击start editing要编辑数据,必须开始一个编辑会话,即开启编辑状态,只有在编辑状态下才可以进行数据编辑。
2、新建要素:点击sketch tool 按钮添加数据3.给新加的要素添加字段内容:点击Attributes按钮,在弹出表里添加字段内容。
4.保存编辑:编辑完成后点击Save edits 按钮,即可保存编辑。
5.结束编辑:点击Stop Editing按钮,即可关闭要素编辑状态,即不能修改数据。
五、通过读取带有经纬度坐标的Excel表导入点数据:1.点击tools——Add XY Date.2、选择带有坐标信息的Excel文件,选取经纬度字段(X:代表经度、Y:代表纬度),点击edit选择坐标系统:一般为(WGS84),点击OK按钮即可生成点。
3把生成的中间文件转成shapfile文件:在生成文件右击鼠标——选DATA——Export Date——选择存放路径——文件格式(shapfile)——保存。
大数据应用中的数据处理和存储技术

大数据应用中的数据处理和存储技术随着人类生产生活的日益数据化,数据量不断增长,如何高效地存储和处理这些数据成为一个巨大的挑战。
大数据技术应运而生,成为处理和存储大型数据的必要技术。
本文将介绍大数据应用中的数据处理和存储技术。
一、数据存储技术数据存储技术是大数据技术的一个重要组成部分,它涉及到如何存储大量的数据。
在大数据应用中,数据存储技术的要求包括高容量、高可靠性、高扩展性、高可用性等。
以下是几种常见的数据存储技术:1. Hadoop存储技术Hadoop是一个开源软件框架,用于存储和处理大规模数据集。
它采用了分布式文件系统(HDFS)和分布式计算框架(MapReduce)来实现数据存储和处理。
Hadoop的主要特点是高可靠性、高扩展性和高容错性。
2. NoSQL存储技术NoSQL(Not Only SQL)是一种非关系型数据库,它旨在通过解决关系型数据库的局限性来支持大规模的分布式数据存储。
NoSQL存储技术根据数据类型和用途的不同,可以分为多种类型,如键值存储、列存储、文档存储、图形数据库等。
3. 分布式存储技术分布式存储技术采用分布式架构来实现数据存储和处理,它将数据分散存储到多台服务器上,从而实现数据的高扩展性和高可用性。
常用的分布式存储技术包括Ceph、GlusterFS、Swift等。
二、数据处理技术数据处理技术是大数据技术的另一个重要组成部分,它涉及到如何高效地处理大量的数据。
在大数据应用中,数据处理技术的要求包括高速度、高效率、高精度等。
以下是几种常见的数据处理技术:1. MapReduce处理技术MapReduce是一种分布式计算模型,它将大规模数据的处理任务分解为多个小任务,并将这些小任务分配给不同的计算节点来执行。
通过分布式计算的方式,MapReduce可以实现对大规模数据的高速处理。
Hadoop是一种基于MapReduce模型的分布式计算框架。
2. 内存计算技术内存计算技术采用内存作为数据存储介质,通过在内存中进行数据处理,可以实现对大规模数据的高速处理。
复制增加样本的方法

复制增加样本的方法
复制增加样本的方法是一种数据增强技术,常用于机器学习和深度学习中。
这种方法通过对现有的数据样本进行复制和变换来增加数据集的大小,从而提高模型的泛化能力。
以下是一些常用的复制增加样本的方法:
1.随机复制:随机选择一些样本并复制它们,然后将复制的样本添加到数据集中。
这种方法
可以简单地增加数据集的大小,但可能不会引入新的信息。
2.镜像翻转:对于图像数据,可以通过沿水平或垂直轴翻转图像来创建新的样本。
这种方法
可以在一定程度上增加数据的多样性。
3.旋转:对于图像数据,可以将图像旋转一定的角度(如90度、180度等)来创建新的样本。
这种方法可以模拟不同的视角和方向,增加数据的多样性。
4.缩放:对于图像数据,可以将图像按照一定的比例进行缩放(放大或缩小)来创建新的样
本。
这种方法可以模拟不同的距离和尺寸,增加数据的多样性。
5.平移:对于图像数据,可以将图像在水平和垂直方向上平移一定的距离来创建新的样本。
这种方法可以模拟不同的偏移和位置,增加数据的多样性。
6.噪声添加:对于图像或文本数据,可以向数据中添加噪声(如高斯噪声、椒盐噪声等)来
创建新的样本。
这种方法可以模拟不同的干扰和噪声,增加数据的鲁棒性。
需要注意的是,复制增加样本的方法虽然可以增加数据集的大小,但也可能引入一些冗余和偏差。
因此,在使用这些方法时需要谨慎选择和应用,以确保数据的质量和模型的性能。
数据宝工具箱操作方法

数据宝工具箱操作方法
数据宝工具箱是一款用于数据分析和可视化的工具,以下是一些常用的操作方法:
1. 导入数据:打开数据宝工具箱,选择“数据源”选项,然后点击“导入数据”按钮。
可以选择从本地计算机导入文件,或者从数据库中导入数据。
2. 数据预处理:一旦数据被导入,可以使用数据宝工具箱进行数据预处理。
例如,可以删除重复的行或列,填充缺失的数据,处理异常值等。
3. 数据转换:数据宝工具箱支持多种数据转换操作,例如合并数据集、拆分数据集、筛选数据等。
这些操作可以通过简单的拖放和设置参数来完成。
4. 数据分析:数据宝工具箱提供了丰富的数据分析功能,包括描述性统计、相关性分析、聚类分析、分类分析等。
可以使用这些功能来发现数据的模式、关系和趋势。
5. 数据可视化:数据宝工具箱支持多种数据可视化方式,包括柱状图、折线图、散点图、饼图等。
可以使用这些图形来呈现数据的分布、变化和比较。
6. 模型建立:数据宝工具箱还提供了机器学习和预测建模的功能。
可以使用这些功能来构建和评估模型,并使用模型进行预测和分类任务。
7. 导出结果:完成数据分析和可视化后,可以将结果导出为各种格式,例如Excel、CSV、PDF等。
完成导出后,可以将结果分享给其他人员或保存供以后使用。
这些只是数据宝工具箱的一些基本操作方法,具体操作还可以根据实际需求进行调整和扩展。
arcCatalog数据添加操作步骤
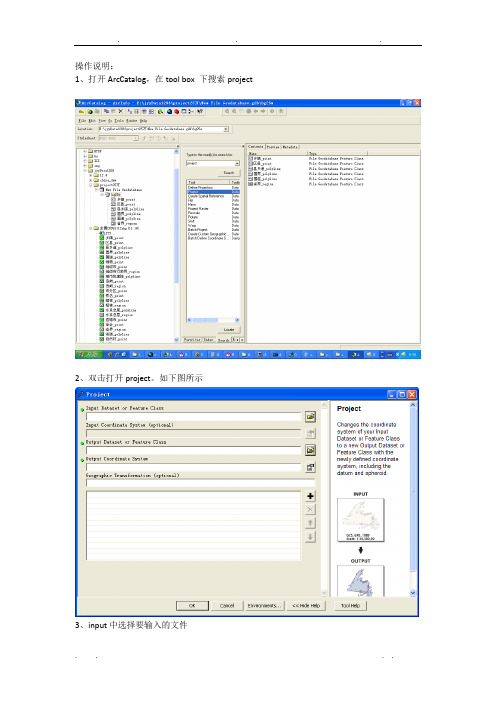
操作说明:
1、打开ArcCatalog,在tool box下搜索project
2、双击打开project。如下图所示
3、input中选择要输入的文件
4、复制输入文件的名称,打开output,选择要输出的路径,将输入文件名粘贴过来,保存
检查输出的路径名是否正确
5、点击output coordinate system,进入窗口如下图
点击import进入如下图所示,选择要输出的系统路径,点击Add
操作结束后显如下图所示
点击确定即可。
操作完毕最终界面如下图所示
6、完成后使用Arcmap检查图层,在layer中添加bg25w查看。
数据可视化流程的实施步骤

数据可视化流程的实施步骤1. 确定可视化目标在开始数据可视化流程之前,第一步是明确你的可视化目标。
你需要思考你想通过数据可视化传达什么信息或达到什么目的。
这可以是任何事情,比如展示数据趋势、识别数据关联性、揭示异常值等。
2. 收集和整理数据在进行数据可视化之前,你需要收集所需的数据。
这可能包括从数据库、Excel 电子表格、API或其他数据源中收集数据。
一旦数据收集完毕,你需要将其整理成适合可视化的格式,例如CSV、JSON等。
3. 数据清洗和处理在可视化之前,你需要对数据进行清洗和处理,以确保数据的准确性和一致性。
这可能包括删除重复数据、填充缺失值、转换数据格式等操作。
4. 选择合适的可视化工具根据你的数据特点和可视化目标,选择合适的可视化工具。
常见的可视化工具包括Tableau、Power BI、Python的matplotlib库、R的ggplot2库等。
根据你的需求,选择一个功能强大且易于使用的工具。
5. 设计和创建可视化图表一旦你选择了合适的可视化工具,就可以开始设计和创建可视化图表了。
根据你的可视化目标和数据特点,选择合适的图表类型,如折线图、柱状图、散点图等。
确保图表的布局清晰、易于理解,并注重细节和美感。
6. 添加交互功能(可选)如果你想进一步提升你的可视化效果,可以添加交互功能。
这将使用户能够自由探索数据并获取更多信息。
例如,通过添加滑块、下拉菜单或点击操作,用户可以根据不同的变量、时间范围或过滤条件查看不同的数据。
7. 调整和优化可视化一旦你创建了可视化图表,你可能需要进行调整和优化。
这包括调整颜色、字体、标签和图形大小等方面,以使图表更加清晰、易读和吸引人。
8. 分析和解读可视化结果可视化图表只是工具,最终目的是为了实现数据的分析和解读。
仔细观察你的可视化结果,并从中提取有关数据的见解和洞察。
这些洞察有助于你做出准确的决策和预测,并推动业务发展。
9. 共享和发布可视化结果一旦你对可视化结果感到满意,你可以将其分享和发布给其他人。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.描述
大数据图形化软件FineBI可以直接通过可视化操作从数据库中添加数据表至业务包中,同时支持SQL语句从数据库中取数和导入外部Excel,下面详细描述。
2.SQL数据集
通过SQL语句写出来的数据表,我们称之为数据集,以大数据图形化软件FineBI的BIdemo为例,点击数据配置>业务包管理,进入BIdemo业务包中进行业务包管理,点击下方的+SQL数据集按钮。
2.1增加SQL语句
在大数据图形化软件FineBI中点击数据连接选择下拉框,选择构建自循环列中建立的mysql数据连接,在SQL语句输入框中输入一个SQL查询语句,如下图:注:数据连接的创建方式请查看大数据图形化软件FineBI的配置数据连接
2.2数据预览
点击预览按钮,即可查看该SQL查询语句的查询结果:
2.3数据表重命名
点击下一步,进入大数据图形化软件FineBI的数据表的配置界面,在表名输入框中输入表名称,比如说公司部门,点击保存,即可在大数据图形化软件FineBI的业务包管理界面看到该业务包中多了一个数据表,如下图:
3.Excel数据集
大数据图形化软件FineBI的Excel数据集就是指以外部Excel中数据为数据源的数据表。
点击+Excel数据集按钮,进入Excel数据集添加界面,如下图:
3.1上传Excel
点击上传数据按钮,选中需要上传的Excel文件,如下图,即可将Excel数据上传至大数据图形化软件FineBI的业务包中:
3.2重命名数据表
点击下一步,回到大数据图形化软件FineBI的表设置界面,在表名后面的文本框中输入上传Excel得到的数据表的名称,比如说省份数据,点击保存,即可在大数据图形化软件FineBI的BIdemo业务包中看到该张数据表,如下图:。