编译原理语法分析实验报告
编译原理语法分析实验报告

编译原理语法分析实验报告编译原理语法分析实验报告引言编译原理是计算机科学中的重要课程,它研究的是如何将高级语言转化为机器语言的过程。
语法分析是编译过程中的一个关键步骤,它负责将输入的源代码转化为抽象语法树,为后续的语义分析和代码生成提供便利。
本实验旨在通过实践,加深对语法分析的理解,并掌握常见的语法分析算法。
实验环境本次实验使用的是Python编程语言,因为Python具有简洁的语法和强大的库支持,非常适合用于编译原理的实验。
实验步骤1. 词法分析在进行语法分析之前,需要先进行词法分析,将源代码划分为一个个的词法单元。
词法分析器的实现可以使用正则表达式或有限自动机等方式。
在本实验中,我们选择使用正则表达式来进行词法分析。
2. 文法定义在进行语法分析之前,需要先定义源代码的文法。
文法是一种形式化的表示,它描述了源代码中各个语法成分之间的关系。
常见的文法表示方法有巴科斯范式(BNF)和扩展巴科斯范式(EBNF)。
在本实验中,我们选择使用BNF来表示文法。
3. 自顶向下语法分析自顶向下语法分析是一种基于产生式的语法分析方法,它从文法的起始符号开始,逐步展开产生式,直到生成目标字符串。
自顶向下语法分析的关键是选择合适的产生式进行展开。
在本实验中,我们选择使用递归下降分析法进行自顶向下语法分析。
4. 自底向上语法分析自底向上语法分析是一种基于移进-归约的语法分析方法,它从输入串的左端开始,逐步将输入符号移入分析栈,并根据产生式进行归约。
自底向上语法分析的关键是选择合适的归约规则。
在本实验中,我们选择使用LR(1)分析法进行自底向上语法分析。
实验结果经过实验,我们成功实现了自顶向下和自底向上两种语法分析算法,并对比了它们的优缺点。
自顶向下语法分析的优点是易于理解和实现,可以直接根据产生式进行展开,但缺点是对左递归和回溯的处理比较困难,而且效率较低。
自底向上语法分析的优点是可以处理任意文法,对左递归和回溯的处理较为方便,而且效率较高,但缺点是实现相对复杂,需要构建分析表和使用分析栈。
编译原理语法分析试验报告

编译原理语法分析试验报告语法分析是编译原理中的重要内容之一,主要用于对源程序进行语法检查,判断其是否符合给定的语法规则。
本次试验通过使用ANTLR工具,对C语言的子集进行了语法分析的实现。
一、实验目的:1.了解语法分析的基本概念和方法;2.使用ANTLR工具生成语法分析器;3.掌握ANTLR工具的基本使用方法;4.实现对C语言子集的语法分析。
二、实验内容:本次试验主要内容是使用ANTLR工具生成C语言子集的语法分析器,并对给定的C语言子集进行语法分析。
三、实验步骤:1.学习ANTLR工具的基本概念和使用方法;2.根据C语言子集的语法规则,编写ANTLR的语法文件(.g文件);3.使用ANTLR工具生成语法分析器;4.编写测试代码,对给定的C语言子集进行语法分析。
四、实验结果:经过以上的步骤,得到了一个完整的C语言子集的语法分析器,并且通过测试代码对给定的C语言子集进行了语法分析。
五、实验总结:通过本次实验,我对语法分析有了更深入的了解,掌握了使用ANTLR工具生成语法分析器的基本方法,同时也巩固了对C语言的基本语法规则的理解。
在实验过程中,遇到了一些问题,例如在编写ANTLR的语法文件时,对一些特殊语法规则的处理上有些困惑,但通过查阅资料和与同学的探讨,最终解决了这些问题。
本次试验对于我的学习有很大的帮助,我了解到了编译原理中的重要内容之一,也更深入地理解了语法分析的基本原理和方法。
通过实验,我发现使用ANTLR工具能够更方便地生成语法分析器,大大提高了开发效率。
总之,本次试验让我对编译原理中的语法分析有了更深入的了解,并且提高了我的编程能力和分析问题的能力。
在今后的学习和工作中,我将继续深入研究编译原理相关的知识,并应用到实际项目中。
编译原理语法分析实验报告

编译原理语法分析实验报告第一篇:编译原理语法分析实验报告实验2:语法分析1.实验题目和要求题目:语法分析程序的设计与实现。
实验内容:编写语法分析程序,实现对算术表达式的语法分析。
要求所分析算术表达式由如下的文法产生。
E→E+T|E-T|TT→T*F|T/F|F F→id|(E)|num实验要求:在对输入表达式进行分析的过程中,输出所采用的产生式。
方法1:编写递归调用程序实现自顶向下的分析。
方法2:编写LL(1)语法分析程序,要求如下。
(1)编程实现算法4.2,为给定文法自动构造预测分析表。
(2)编程实现算法4.1,构造LL(1)预测分析程序。
方法3:编写语法分析程序实现自底向上的分析,要求如下。
(1)构造识别所有活前缀的DFA。
(2)构造LR分析表。
(3)编程实现算法4.3,构造LR分析程序。
方法4:利用YACC自动生成语法分析程序,调用LEX自动生成的词法分析程序。
实现(采用方法1)1.1.步骤:1)对文法消除左递归E→TE'E'→+TE'|-TE'|εT→FT'T'→*FT'|/FT'|εF→id|(E)|num2)画出状态转换图化简得:3)源程序在程序中I表示id N表示num1.2.例子:a)例子1 输入:I+(N*N)输出:b)例子2 输入:I-NN 输出:第二篇:编译原理实验报告编译原理实验报告报告完成日期 2018.5.30一.组内分工与贡献介绍二.系统功能概述;我们使用了自动生成系统来完成我们的实验内容。
我们设计的系统在完成了实验基本要求的前提下,进行了一部分的扩展。
增加了声明变量类型、类型赋值判定和声明的变量被引用时作用域的判断。
从而使得我们的实验结果呈现的更加清晰和易懂。
三.分系统报告;一、词法分析子系统词法的正规式:标识符(|)* 十进制整数0 |(1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)* 八进制整数0(1|2|3|4|5|6|7)(0|1|2|3|4|5|6|7)* 十六进制整数0x(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)* 运算符和分隔符 +| * | / | > | < | = |(|)| <=|>=|==;对于标识符和关键字: A5—〉 B5C5 B5—〉a | b |⋯⋯| y | z C5—〉(a | b |⋯⋯| y | z |0|1|2|3|4|5|6|7|8|9)C5|ε综上正规文法为: S—〉I1|I2|I3|A4|A5 I1—〉0|A1 A1—〉B1C1|ε C1—〉E1D1|ε D1—〉E1C1|εE1—〉0|1|2|3|4|5|6|7|8|9 B1—〉1|2|3|4|5|6|7|8|9 I2—〉0A2 A2—〉0|B2 B2—〉C2D2 D2—〉F2E2|ε E2—〉F2D2|εC2—〉1|2|3|4|5|6|7 F2—〉0|1|2|3|4|5|6|7 I3—〉0xA3 A3—〉B3C3 B3—〉0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f C3—〉(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)|C3|εA4—〉+ |-| * | / | > | < | = |(|)| <=|>=|==; A5—〉 B5C5 B5—〉a | b |⋯⋯| y | z C5—〉(a | b |⋯⋯| y | z |0|1|2|3|4|5|6|7|8|9)C5|ε状态图流程图:词法分析程序的主要数据结构与算法考虑到报告的整洁性和整体观感,此处我们仅展示主要的程序代码和算法,具体的全部代码将在整体的压缩包中一并呈现另外我们考虑到后续实验中,如果在bison语法树生成的时候推不出目标的产生式时,我们设计了报错提示,在这个词的位置出现错误提示,将记录切割出来的词在code.txt中保存,并记录他们的位置。
国开电大 编译原理 实验4:语法分析实验报告

国开电大编译原理实验4:语法分析实
验报告
1. 实验目的
本实验的目的是研究和掌握语法分析的原理和实现方法。
2. 实验内容
本次实验主要包括以下内容:
- 设计并实现自顶向下的LL(1)语法分析器;
- 通过语法分析器对给定的输入串进行分析,并输出相应的分析过程;
- 编写测试用例,验证语法分析器的正确性。
3. 实验步骤
3.1 设计LL(1)文法
首先,根据实验要求和给定的语法规则,设计LL(1)文法。
3.2 构建预测分析表
根据所设计的LL(1)文法,构建预测分析表。
3.3 实现LL(1)语法分析器
根据预测分析表,实现自顶向下的LL(1)语法分析器。
3.4 对输入串进行分析
编写程序,通过LL(1)语法分析器对给定的输入串进行分析,并输出相应的分析过程和结果。
3.5 验证语法分析器的正确性
设计多组测试用例,包括正确的语法串和错误的语法串,验证语法分析器的正确性和容错性。
4. 实验结果
经过实验,我们成功设计并实现了自顶向下的LL(1)语法分析器,并对给定的输入串进行了分析。
实验结果表明该语法分析器具有较好的准确性和容错性。
5. 实验总结
通过本次实验,我们对语法分析的原理和实现方法有了更深入的了解。
同时,我们也学会了如何设计并实现自顶向下的LL(1)语
法分析器,并验证了其正确性和容错性。
这对于进一步研究编译原理和深入理解编程语言的语法结构具有重要意义。
6. 参考资料
- 《编译原理与技术》
- 课程实验文档及代码。
编译原理-语法分析程序报告

编译原理实验实验二语法分析器实验二:语法分析实验一、实验目的根据给出的文法编制LR(1)分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对LR(1)分析法的理解。
二、实验预习提示1、LR(1)分析法的功能LR(1)分析法的功能是利用LR(1)分析表,对输入符号串自下而上的分析过程。
2、LR(1)分析表的构造及分析过程。
三、实验内容对已给语言文法,构造LR(1)分析表,编制语法分析程序,要求将错误信息输出到语法错误文件中,并输出分析句子的过程(显示栈的内容);实验报告必须包括设计的思路,以及测试报告(输入测试例子,输出结果)。
语法分析器一、功能描述:语法分析器,顾名思义是用来分析语法的。
程序对给定源代码先进行词法分析,再根据给定文法,判断正确性。
此次所写程序是以词法分析器为基础编写的,由于代码量的关系,我们只考虑以下输入为合法:数字自定义变量+ * ()$作为句尾结束符。
其它符号都判定为非法。
二、程序结构描述:词法分析器:class wordtree;类,内容为字典树的创建,插入和搜索。
char gettype(char ch):类型处理代入字串首字母ch,分析字串类型后完整读入字串,输出分析结果。
因读取过程会多读入一个字母,所以函数返回该字母进行下一次分析。
bool isnumber(char str[]):判断是否数字代入完整“数字串”str,判断是否合法数字,若为真返回1,否则返回0。
bool isoperator(char str[]):判断是否关键字代入完整“关键字串”str,搜索字典树判断是否存在,若为存在返回1,否则返回0。
语法分析器:int action(int a,char b):代入当前状态和待插入字符,查找转移状态或归约。
node2 go(int a):代入当前状态,返回归约结果和长度。
void printstack():打印栈。
int push(char b):将符号b插入栈中,并进行归约。
编译原理 语法分析实验报告

h=copy[1]-'0';//因为状态从0开始
strcpy(copy1,LR[h]);
while(copy1[0]!=vn[k]) //获取当前k值
k++;
l=strlen(LR[h])-4;
top1=top1-l+1;
top2=top2-l+1;
y=a[top1-1];
p=goto1[y][k];
T->T*F|F
F->(E)|i
2设计及实现能够识别表达式的LR分析程序。
文法如下:
G[E]:E->E+T|T
T->T*F|F
F->(E)|i
③ 设计及实现能够识别表达式的算符优先分析程序。
文法如下:
G[E]:E->E+T|T
T->T*F|F
F->P↑F|P
P->(E)|i
④设计及实现计算表达式的计算器。
{
printf("%c",copy[i])
return 0;
i++;
}
printf("\n");
}
if(copy[0]=='r')
{ /*处理归约*/
i=0;
while(copy[i]!='#')//例 "S3#" 输出ACTION
{
printf("%c",copy[i])
return 0;
i++;
{ /*输出符号栈*/
printf("%c",b[n]);
n=n+1;
编译原理语法分析实验报告

编译原理语法分析实验报告编译原理实验报告-语法分析班级:XXX学号:XXX姓名:XXX年⽉⽇1、摘要:⽤递归⼦程序法实现对pascal的⼦集程序设计语⾔的分析程序2、实验⽬的:通过完成语法分析程序,了解语法分析的过程和作⽤3、任务概述实验要求:对源程序的内码流进⾏分析,如为⽂法定义的句⼦输出”是”否则输出”否”,根据需要处理说明语句填写写相应的符号表供以后代码⽣成时使⽤4、实验依据的原理递归⼦程序法是⼀种⾃顶向下的语法分析⽅法,它要求⽂法是LL(1)⽂法。
通过对⽂法中每个⾮终结符编写⼀个递归过程,每个过程的功能是识别由该⾮终结符推出的串,当某⾮终结符的产⽣式有多个候选式时,程序能够按LL(1)形式唯⼀地确定选择某个候选式进⾏推导,最终识别输⼊串是否与⽂法匹配。
递归⼦程序法的缺点是:对⽂法要求⾼,必须满⾜LL(1)⽂法,当然在某些语⾔中个别产⽣式的推导当不满⾜LL(1)⽽满⾜LL(2)时,也可以采⽤多向前扫描⼀个符号的办法;它的另⼀个缺点是由于递归调⽤多,所以速度慢占⽤空间多,尽管这样,它还是许多⾼级语⾔,例如PASCAL,C等编译系统常常采⽤的语法分析⽅法。
为适合递归⼦程序法,对实验⼀词法分析中的⽂法改写成⽆左递归和⽆左共因⼦的BNF如下:<程序>→<程序⾸部><分程序>。
<程序⾸部>→PROGRAM标识符;<分程序>→<常量说明部分><变量说明部分><过程说明部分> <复合语句><常量说明部分>→CONST<常量定义><常量定义后缀>;|ε<常量定义>→标识符=⽆符号整数<常量定义后缀>→,<常量定义><常量定义后缀> |ε<变量说明部分>→V AR<变量定义><变量定义后缀> |ε<变量定义>→标识符<标识符后缀>:<类型>;<标识符后缀>→,标识符<标识符后缀> |ε<变量定义后缀>→<变量定义><变量定义后缀> |ε<类型>→INTEGER | LONG<过程说明部分>→<过程⾸部><分程序>;<过程说明部分后缀>|ε<过程⾸部>→PROCEDURE标识符<参数部分>;<语句>→<赋值或调⽤语句>|<条件语句>|<当型循环语句>|<读语句>|<写语句>|<复合语句>|ε<赋值或调⽤语句>→标识符<后缀><后缀>→:=<表达式>|(<表达式>)|ε<条件语句>→IF<条件>THEN<语句><当型循环语句>→WHILE<条件>DO <语句><读语句>→READ(标识符<标识符后缀>)<写语句>→WRITE(<表达式><表达式后缀>)<表达式后缀>→,<表过式><表达式后缀>|ε<复合语句>→BEGIN<语句><语句后缀>END<语句后缀>→;<语句><语句后缀>|ε<条件>→<表达式><关系运算符><表达式>|ODD<表达式><表达式>→+<项><项后缀>|-<项><项后缀>|<项><项后缀><项后缀>→<加型运算符><项><项后缀>|ε<项>→<因⼦><因⼦后缀><因⼦后缀>→<乘型运算符><因⼦><因⼦后缀>|e<因⼦>→标识符|⽆符号整数|(<表达式>)<加型运算符>→+|-<乘型运算型>→*|/<关系运算符>→=|<>|<|<=|>|>=5、程序设计思想为每个⾮终结符设计⼀个识别的⼦程序,寻找该⾮终结符也就是调⽤相应的⼦程序。
编译原理语法分析实验报告

//输出转化后
的文法规则串
{
printf("%s\n",text[i]);
}
for(i=0;i<x;i++) /*求每个终结符的推导结果(去掉"->"后的转化文
法,用于最后的规约)*/
{ string[i][0]=text[i][0];
for(j=3,l=1;text[i][j]!='\0';j++,l++)
表1-2 G[S]的算符优先关系矩阵表
#
i
+
*
(
)
#
i
+
*
(
)
二.程序设计
1.总体设计
求FIRSTVT模块 求LASTVT模块 识别终结符模块
读入文法规则 创建文法关系表模块
求下标模块
2.子程序设计
识别终结符模块
读取语法分析串 输入串分析模块 图2-1 总体设计图
求FIRSTVT模块 求LASTVT模块
编译原理语法分析器实验报告

西安邮电大学编译原理实验报告学院名称:计算机学院****:***实验名称:语法分析器的设计与实现班级:计科1405班学号:04141152时间:2017年5月12日一.实验目的1.熟悉语法分析的过程2.理解相关文法分析的步骤3.熟悉First集和Follow集的生成二.实验要求对于给定的文法,试编写调试一个语法分析程序:要求和提示:1)可选择一种你感兴趣的语法分析方法(LL(1)、算符优先、递归下降、SLR(1)等)作为编制语法分析程序的依据。
2)对于所选定的分析方法,如有需要,应选择一种合适的数据结构,以构造所给文法的机内表示。
3)能进行分析过程模拟。
如输入一个句子,能输出与句子对应的语法树,能对语法树生成过程进行模拟;能够输出分析过程每一步符号栈的变化情况。
设计一个由给定文法生成First集和Follow集并进行简化的算法动态模拟三.实验内容1.文法:E->TE’E’->+TE’|εT->FT’T’->*FT’|εF->(E)|i:2.程序描述(LL(1)文法)本程序是基于已构建好的某一个语法的预测分析表来对用户的输入字符串进行分析,判断输入的字符串是否属于该文法的句子。
基本实现思想:接收用户输入的字符串(字符串以“#”表示结束)后,对用做分析栈的一维数组和存放分析表的二维数组进行初始化。
然后取出分析栈的栈顶字符,判断是否为终结符,若为终结符则判断是否为“#”且与当前输入符号一样,若是则语法分析结束,输入的字符串为文法的一个句子,否则出错若不为“#”且与当前输入符号一样则将栈顶符号出栈,当前输入符号从输入字符串中除去,进入下一个字符的分析。
若不为“#”且不与当前输入符号一样,则出错。
3.判断是否LL(1)文法要判断是否为LL(1)文法,需要输入的文法G有如下要求:具有相同左部的规则的SELECT集两两不相交,即:SELECT(A→?)∩SELECT(A→?)= ?如果输入的文法都符合以上的要求,则该文法可以用LL(1)方法分析。
编译原理语法分析试验报告

二、语法分析(一)实验题目编写程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析。
(二)实验内容和要求1.要求程序至少能分析的语言的内容有:1)变量说明语句2)赋值语句3)条件转移语句4)表达式(算术表达式和逻辑表达式)5)循环语句6)过程调用语句2.此外要处理:包括依据文法对句子进行分析;出错处理;输出结果的构造。
3.输入输出的格式:输入:单词文件(词法分析的结果)输出:语法成分列表或语法树(都用文件表示),错误文件(对于不合文法的句子)。
4.实现方法:可以采用递归下降分析法,LL (1)分析法,算符优先法或LR分析法的任何一种,也可以针对不同的句子采用不同的分析方法。
(三)实验分析与设计过程1.待分析的C语言子集的语法:该语法为一个缩减了的C语言文法,估计是整个C语言所有文法的60% (各种关键字的定义都和词法分析中的一样),具体的文法如下:语法:100: program -> declaiationjist101: declarationjist -> declarationjist declaration declaration102: declaiation -> vai_declaiation|fijn_declaration103: vai.declaration -> type_specifier ID;|tvpe_specifier ID [NUM];104: typ Jsp亡cifki -> mt|void|float|chai-|long|double|105: fun_declaration -> type_specifier ID (params)|compound_stmt106: paranis -> params_list|void107: paramjist ->paiam_list.paiam|paiam108: param -> type-spectifier ED|type_specifier LD[]109: compound_stmt -> {locaLdeclaiations statementjist}110: locaLdeclarations -> local_declarations var_declaration|empty111: statementjist -> statementjist statement|emptv112: statement -> epiesion_stmt|conipound_stmtselection.stmt iteration_stmt|retuin_stmt113: expression^stmt -> expression;!;114: selection_stmt -> if{expressionjstatement if(expression)statement elsestatement115: iteration_stmt -> wliile{expression)statement116: return_stmt -> return;|return expression;117: expression -> var = expression|siinple-expression118: var -> ID | ID [expression]119: suuple_expression ->additive_expression relop additive_expression|additive_expression120: relop -> <=|<|>|>=|= =|!=121: additive_expression -> additive_expression addop term | term122: addop -> + | -123: term -> term mulop factor factor124: mulop -> *|/125: factor -> (expression)|var|call|NUM126: call -> ID(aigs)127: args -> aig_list|empty128: arg_list -> arg_list,expression|expression该文法满足了实验的要求,而且多了很多的内容,相当于一个小型的文法说明:把文法标号从100到128是为了程序中便于找到原来的文法。
编译原理语法分析实验报告

编译原理语法分析实验报告《编译原理》实验报告⼀,实验内容设计、编制并调式⼀个语法分析程序,加深对语法分析原理的理解。
⼆,实验⽬的及要求利⽤C++(或C)编制确定的⾃顶向下预测分析语法分析程序,并对简单语⾔进⾏语法分析。
2.1、待分析的简单语⾔的语法若⽂法G[ E]为:(1) E –> TE’(2) E’ –> +TE’(3) E’ –> ε(4) T –> FT’(5) T’ –> *FT’(6) T’ –> ε(7) F –> (E)(8) F –> i2.2、实验要求及说明具体要求如下:1、⽤可视化界⾯分步骤实现,显⽰输出每⼀步的处理结果。
2、⾸先按照判别步骤判断给定⽂法是否LL(1)⽂法。
3、给出⽂法的预测分析表。
4、编写预测分析程序,输出句⼦的分析过程。
5、输⼊源⽂件串,以“#”结束,如果是⽂法正确的句⼦,则输出成功信息,打印“SUCCESS”,否则输出“ERROR”。
例如:输⼊⽂件:i+i*(i+i) #输出success过程:略;输⼊⽂件:i+ii#输出error三,实验环境Dvc++#include#define MAX 50using namespace std;struct T_NT{int code;char str[MAX];};T_NTT[12]={{0,"i"},{1,"+"},{2,"*"},{3,"("},{4,")"},{5,"#"},{6,"!"},{256,"E"},{257,"E'" },{258,"T"},{259,"T'"},{260,"F"}};T_NTR[8]={{0,"->TR"},{1,"->+TR"},{2,"->e"},{3,"->FW"},{4,"->*FW"},{5,"->e"},{6, "->(E)"},{7,"->i"}};stack stak;int Yy_pushab[7][4]={{257,258,6},{257,258,1,6},{6},{259,260,6},{259,260,2,6},{0,6},{4,256,3,6}};int Yy_d[5][6]={{0,-1,-1,0,-1,-1},{-1,1,-1,-1,2,2},{3,-1,-1,3,-1,-1},{-1,2,4,-1,2,2},{5,-1,-1,6,-1,-1}int main(){char c,t[MAX];int s[MAX];cout<<"请输出要输⼊的字符串:";while(c!='#'){cin>>c;t[l]=c;switch(c){case'i':s[l]=0; break;case'+':s[l]=1; break;case'*':s[l]=2; break;case'(':s[l]=3; break;case')':s[l]=4; break;case'#':s[l]=5; break;case'!':s[l]=6; break;}l++;}cout<<"\n LL1⽂法预测分析表如下:\n"<cout<<" ";for(i=0;i<6;i++)//printf("%10c",T[i].str);cout<<" "<cout<for(i=0;i<5;i++){cout<<" -----------------------------------------------------------------"< //printf("%10c",T[i+7].str);cout<<" "<for(j=0;j<6;j++){//printf("%10c");{case 0:cout<case 1:cout<case 2:cout<case 3:cout<case 4:cout<case 5:cout<case 6:cout<case 7:cout<case-1:cout<<" ";break;}}cout<}cout<cout<<"\n 对输⼊句型的分析如下:\n"<cout<<" 步骤栈顶元素剩余输⼊串推到所⽤产⽣式或匹配"<cout<<"-------------------------------------------------------------------------------\n"; stak.push(5);stak.push(256);while(!stak.empty()){cout<<" "<p=stak.top(); //cout<<"p"<for(i=0;i<12;i++) // 输出栈顶元素{if(T[i].code==p){cout<<" "<break;}}cout<<" ";} //输出剩余字符串if(p>=0&&p<6) // 栈顶是终结符{if(p!=s[h]){cout<<" 语法错误!";break;}else if(p==5){cout<<" 接受"<cout<<"-------------------------------------------------------------------------------\n"; cout<<"\n该句型是该⽂法的句⼦\n";stak.pop();}else{cout<<" 与"<w++;h++;stak.pop();}}else{m=p-256;n=s[h];what=Yy_d[m][n]; //预测分析表if(what==-1){cout<<" 没有可⽤的产⽣式"<cout<<"-------------------------------------------------------------------------------\n"; cout<<"\n该句型不是该⽂法的句⼦\n";{cout<<" "<//cout<stak.pop();k=0;while(Yy_pushab[what][k]!=6) //产⽣式{stak.push(Yy_pushab[what][k]);k++;}}}b++;cout<}system("pause");return 0;}五。
编译原理语法分析实验报告
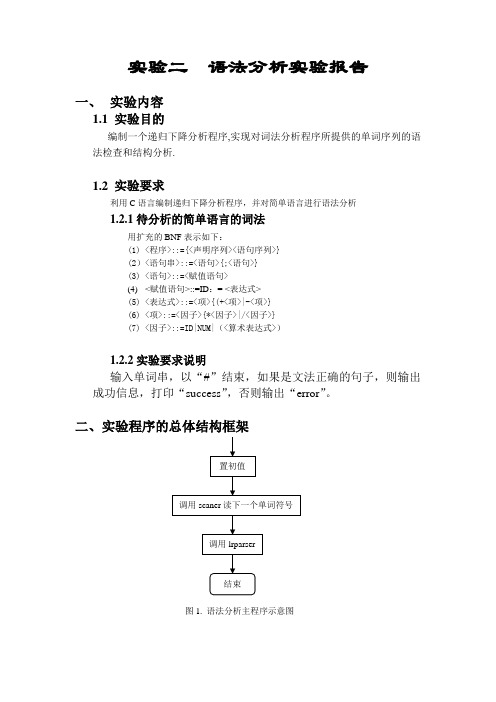
实验二语法分析实验报告一、实验内容1.1 实验目的编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析.1.2 实验要求利用C语言编制递归下降分析程序,并对简单语言进行语法分析1.2.1待分析的简单语言的词法用扩充的BNF表示如下:(1) <程序>::={<声明序列><语句序列>}(2)<语句串>::=<语句>{;<语句>}(3) <语句>::=<赋值语句>(4) <赋值语句>::=ID:= <表达式>(5) <表达式>::=<项>{(+<项>|-<项>}(6) <项>::=<因子>{*<因子>|/<因子>}(7) <因子>::=ID|NUM|(<算术表达式>)1.2.2实验要求说明输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”。
二、实验程序的总体结构框架图1. 语法分析主程序示意图图2.递归下降分析程序示意图图5. expression表达式分析函数示意图图6.term分析函数示意图三、关键技术的实现方法Scanner函数定义已在实验一给出,本实验不再重复给出void Irparser(){kk=0;if(syn==1){scaner();yucu();if(syn==6){scaner();if(syn==0 && (kk==0)) cout<<"success!"<<endl;}else{if(kk!=1)cout<<"缺end!"<<endl;kk=1;}}else {cout<<"缺begin!"<<endl;kk=1;}return;}void yucu(){statement();while(syn==26){scaner();statement();}return;}void statement() {if(syn==10){scaner();if(syn==18){scaner();expression();}else{cout<<"赋值号错误"<<endl;kk=1;}}else{cout<<"语句错误"<<endl;kk=1;}return;}void expression(){term();while((syn==13)||(syn==14)){scaner();term();}return;}void term(){factor();while((syn==15)||(syn==16)){scaner();factor();}return;}void factor(){if((syn==10)||(syn==11))scaner();else if(syn==27){scaner();expression();if(syn==28)scaner();else{cout<<")错误"<<endl;kk=1;}}else{cout<<"表达式错误"<<endl;kk=1;}return;}void main(){p=0;cout<<"Please input string"<<endl;do{cin.get(ch);if(ch!=”\n”)prog[p++]=ch;}while(ch!='#');p=0;scaner();Irparser();}四、实验心得语法分析是编译过程的核心部分,它的主要功能是按照程序语言的语法规则,从由词法分析输出的源程序符号串中识别出各类语法成分,同时进行语法检查,为语义分析和代码生成做准备。
编译原理实验报告-语法分析

编译原理课程实验报告实验2:语法分析
三、系统设计得分
要求:分为系统概要设计和系统详细设计。
(1)系统概要设计:给出必要的系统宏观层面设计图,如系统框架图、数据流图、功能模块结构图等以及相应的文字说明。
1)系统的数据流图:
说明
说明:本语法分析器是基于上一个实验词法分析器的基础上,通过在界面写或者是导入源程序,词法分析器将源程序识别的词法单元传递给语法分析器,语法分析器验证这个词法单元组成的串是否可以由源语言的文法生成,能够输出语法分析的结果,文法的first集、follow 集和预测分析表,当然也可以以易于理解的方式报告语法错误。
2)系统框架图
本系统框架主要是三部分,一部分是词法分析,负责识别源程序的词法单元识别,并将其存
因为预测分析表实在是过于庞大,因此本处分段截取预测分析表,下面的表是接在上面表的右侧。
(3)针对一测试程序输出其句法分析结果;
测试程序:
语法分析结果:
语法分析树:
(4)输出针对此测试程序对应的语法错误报告;
带错误的测试程序:
语法错误报告:
(5)对实验结果进行分析。
总结:
本语法分析器具有强大的语法分析功能
●允许变量的连续声明,比如int a,b,c;
●允许声明的同时赋值,比如string c = “你好”;
●允许对数组的声明和引用,同时进行赋值,比如char[4] a = {‘a’,’b’,’c’,’d’};a[0] = ‘m’;
●支持多种类型的声明和赋值,比如int,short,long,flaot,double,char,string,boolean
的声明和赋值;
●允许声明和使用一个过程函数,比如:。
语法分析实验报告

语法分析实验报告一、实验目的语法分析是编译原理中的重要环节,本次实验的目的在于深入理解和掌握语法分析的基本原理和方法,通过实际操作和实践,提高对编程语言语法结构的分析能力,为进一步学习编译技术和开发相关工具打下坚实的基础。
二、实验环境本次实验使用的编程语言为 Python,使用的开发工具为 PyCharm。
三、实验原理语法分析的任务是在词法分析的基础上,根据给定的语法规则,将输入的单词符号序列分解成各类语法单位,并判断输入字符串是否符合语法规则。
常见的语法分析方法有自顶向下分析法和自底向上分析法。
自顶向下分析法包括递归下降分析法和预测分析法。
递归下降分析法是一种直观、简单的方法,但存在回溯问题,效率较低。
预测分析法通过构建预测分析表,避免了回溯,提高了分析效率,但对于复杂的语法规则,构建预测分析表可能会比较困难。
自底向上分析法主要包括算符优先分析法和 LR 分析法。
算符优先分析法适用于表达式的语法分析,但对于一般的上下文无关文法,其适用范围有限。
LR 分析法是一种功能强大、适用范围广泛的方法,但实现相对复杂。
四、实验内容(一)词法分析首先,对输入的源代码进行词法分析,将其分解为一个个单词符号。
单词符号包括关键字、标识符、常量、运算符、分隔符等。
(二)语法规则定义根据实验要求,定义了相应的语法规则。
例如,对于简单的算术表达式,可以定义如下规则:```Expression > Term | Expression '+' Term | Expression ''TermTerm > Factor | Term '' Factor | Term '/' FactorFactor >'(' Expression ')'| Identifier | Number```(三)语法分析算法实现选择了预测分析法来实现语法分析。
首先,根据语法规则构建预测分析表。
然后,从输入字符串的起始位置开始,按照预测分析表的指导进行分析。
编译原理语法分析实验报告

编译原理语法分析实验报告一、实验目的本实验主要目的是学习和掌握编译原理中的语法分析方法,通过实验了解和实践LR(1)分析器的实现过程,并对比不同的文法对语法分析的影响。
二、实验内容1.实现一个LR(1)的语法分析器2.使用不同的文法进行语法分析3.对比不同文法对语法分析的影响三、实验原理1.背景知识LR(1)分析器是一种自底向上(bottom-up)的语法分析方法。
它使用一个分析栈(stack)和一个输入缓冲区(input buffer)来处理输入文本,并通过移进(shift)和规约(reduce)操作进行语法分析。
2.实验步骤1)构建文法的LR(1)分析表2)读取输入文本3)初始化分析栈和输入缓冲区4)根据分析表进行移进或规约操作,直至分析过程结束四、实验过程与结果1.实验环境本实验使用Python语言进行实现,使用了语法分析库ply来辅助实验。
2.实验步骤1)构建文法的LR(1)分析表通过给定的文法,根据LR(1)分析表的构造算法,构建出分析表。
2)实现LR(1)分析器使用Python语言实现LR(1)分析器,包括读取输入文本、初始化分析栈和输入缓冲区、根据分析表进行移进或规约操作等功能。
3)使用不同的文法进行语法分析选择不同的文法对编写的LR(1)分析器进行测试,观察语法分析的结果。
3.实验结果通过不同的测试案例,实验结果表明编写的LR(1)分析器能够正确地进行语法分析,能够识别出输入文本是否符合给定文法。
五、实验分析与总结1.实验分析本实验通过实现LR(1)分析器,对不同文法进行语法分析,通过实验结果可以观察到不同文法对语法分析的影响。
2.实验总结本实验主要学习和掌握了编译原理中的语法分析方法,了解了LR(1)分析器的实现过程,并通过实验提高了对语法分析的理解。
六、实验心得通过本次实验,我深入学习了编译原理中的语法分析方法,了解了LR(1)分析器的实现过程。
在实验过程中,我遇到了一些问题,但通过查阅资料和请教老师,最终解决了问题,并完成了实验。
编译原理语法分析实验报告

编译原理语法分析实验报告编译原理实验报告二、语法分析(一) 实验题目编写程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析。
(二) 实验内容和要求1. 要求程序至少能分析的语言的内容有:1) 变量说明语句2) 赋值语句3) 条件转移语句4) 表达式(算术表达式和逻辑表达式)5) 循环语句6) 过程调用语句2. 此外要处理:包括依据文法对句子进行分析;出错处理;输出结果的构造。
3. 输入输出的格式:输入:单词文件(词法分析的结果)输出:语法成分列表或语法树(都用文件表示),错误文件(对于不合文法的句子)。
4. 实现方法:可以采用递归下降分析法,LL(1)分析法,算符优先法或LR分析法的任何一种,也可以针对不同的句子采用不同的分析方法。
(三) 实验分析与设计过程1. 待分析的C语言子集的语法:该语法为一个缩减了的C语言文法,估计是整个C语言所有文法的60%(各种关键字的定义都和词法分析中的一样),具体的文法如下:语法:100: program -> declaration_list101: declaration_list -> declaration_list declaration | declaration 102: declaration -> var_declaration|fun_declaration103: var_declaration -> type_specifier ID;|type_specifier ID[NUM]; 104: type_specifier -> int|void|float|char|long|double|105: fun_declaration -> type_specifier ID (params)|compound_stmt 106: params -> params_list|void107: param_list ->param_list,param|param108: param -> type-spectifier ID|type_specifier ID[]109: compound_stmt -> {local_declarations statement_list}110: local_declarations -> local_declarations var_declaration|empty 111: statement_list -> statement_list statement|empty11编译原理实验报告112: statement -> epresion_stmt|compound_stmt|selection_stmt|iteration_stmt|return_stmt113: expression_stmt -> expression;|;114: selection_stmt -> if{expression)statement|if(expression)statement else statement115: iteration_stmt -> while{expression)statement116: return_stmt -> return;|return expression;117: expression -> var = expression|simple-expression118: var -> ID |ID[expression]119: simple_expression ->additive_expression relop additive_expression|additive_expression 120: relop -> <=|<|>|>=|= =|!=121: additive_expression -> additive_expression addop term | term 122: addop -> + | -123: term -> term mulop factor | factor124: mulop -> *|/125: factor -> (expression)|var|call|NUM126: call -> ID(args)127: args -> arg_list|empty128: arg_list -> arg_list,expression|expression该文法满足了实验的要求,而且多了很多的内容,相当于一个小型的文法说明:把文法标号从100到128是为了程序中便于找到原来的文法。
编译原理教程实验报告

一、实验目的本次实验旨在使学生通过编译原理的学习,了解编译程序的设计原理及实现技术,掌握编译程序的各个阶段,并能将所学知识应用于实际编程中。
二、实验内容1. 词法分析2. 语法分析3. 语义分析4. 中间代码生成5. 代码优化6. 目标代码生成三、实验步骤1. 词法分析(1)设计词法分析器,识别输入源代码中的各种词法单元;(2)使用C语言实现词法分析器,并进行测试。
2. 语法分析(1)根据文法规则设计语法分析器,识别输入源代码的语法结构;(2)使用C语言实现语法分析器,并进行测试。
3. 语义分析(1)设计语义分析器,检查语法分析后的语法树,确保语义正确;(2)使用C语言实现语义分析器,并进行测试。
4. 中间代码生成(1)设计中间代码生成器,将语义分析后的语法树转换为中间代码;(2)使用C语言实现中间代码生成器,并进行测试。
5. 代码优化(1)设计代码优化器,对中间代码进行优化,提高程序性能;(2)使用C语言实现代码优化器,并进行测试。
6. 目标代码生成(1)设计目标代码生成器,将优化后的中间代码转换为特定目标机的汇编语言;(2)使用C语言实现目标代码生成器,并进行测试。
四、实验结果与分析1. 词法分析实验结果:成功识别输入源代码中的各种词法单元,包括标识符、关键字、运算符、常量等。
2. 语法分析实验结果:成功识别输入源代码的语法结构,包括表达式、语句、程序等。
3. 语义分析实验结果:成功检查语法分析后的语法树,确保语义正确。
4. 中间代码生成实验结果:成功将语义分析后的语法树转换为中间代码,为后续优化和目标代码生成提供基础。
5. 代码优化实验结果:成功对中间代码进行优化,提高程序性能。
6. 目标代码生成实验结果:成功将优化后的中间代码转换为特定目标机的汇编语言,为程序在目标机上运行做准备。
五、实验心得1. 编译原理是一门理论与实践相结合的课程,通过本次实验,我对编译程序的设计原理及实现技术有了更深入的了解。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
编译原理语法分析实验报告
编译原理实验报告
一、实验目的
本实验的主要目的是熟悉编译原理中的语法分析算法及相关知识,并
通过实际编码实现一个简单的语法分析器。
二、实验内容
1.完成一个简单的编程语言的语法定义,并用BNF范式表示;
2.基于给定的语法定义,实现自顶向下的递归下降语法分析器;
3.实验所用语法应包含终结符、非终结符、产生式及预测分析表等基
本要素;
4.实现语法分析器的过程中,需要考虑文法的二义性和优先级等问题。
三、实验步骤
1.设计一个简单的编程语言的语法,用BNF范式进行表达。
例如,可
以定义表达式文法为:
<exp> ::= <term> { + <term> , - <term> }
<term> ::= <factor> { * <factor> , / <factor> }
<factor> ::= <digit> , (<exp>) , <variable>
<digit> ::= 0,1,2,3,4,5,6,7,8,9
<variable> ::= a,b,c,...,z
2. 根据所设计的语法,构建语法分析器。
首先定义需要用到的终结符、非终结符和产生式。
例如,终结符可以是+、-、*、/、(、)等,非终
结符可以是<exp>、<term>、<factor>等,产生式可以是<exp> ::= <term> + <term> , <term> - <term>等。
3.实现递归下降语法分析器。
根据语法的产生式,编写相应的递归函
数进行递归下降分析。
递归函数的输入参数通常是一个输入字符串和当前
输入位置,输出结果通常是一个语法树或语法分析错误信息。
4.在语法分析的过程中,需要处理语法的二义性和优先级问题。
例如,在表达式文法中,需要考虑加减乘除的优先级。
可以使用优先级表和栈等
数据结构进行处理。
四、实验结果与分析
经过实验,我们成功地实现了一个递归下降的语法分析器。
通过构建BNF范式表达语法,并根据语法定义构建预测分析表,我们可以根据输入
的程序代码进行分析,并生成语法树。
实验结果表明,该语法分析器在正
常情况下可以正确地识别输入的程序代码,并生成对应的语法树。
然而,在实现语法分析器的过程中,我们也面临了一些问题。
首先,
语法的二义性可能导致分析器无法正确识别输入的程序代码。
在设计语法时,我们需要避免二义性,并根据需要添加合适的优先级规则。
其次,语
法的复杂度和规模也会影响语法分析器的性能。
如果语法过于复杂,递归
下降的方法可能会导致栈溢出等问题。
五、实验总结
通过本次实验,我们深入了解了编译原理中的语法分析算法及相关知识。
我们了解了如何根据语法定义构建语法分析器,并掌握了递归下降方
法的原理和实现过程。
同时,我们也意识到语法的二义性和优先级问题的
重要性,需要在语法设计中予以考虑。
在今后的学习和工作中,我们将进一步研究和应用语法分析算法,提
高编译器的性能和效率。
我们还将深入研究其他的语法分析方法,如自底
向上的分析方法,以及更复杂的语法结构,如属性文法和语义分析等内容。
希望通过不断学习和实践,能够提升自己的编译原理技术水平。