基于内存的分布式计算架构
HSF基础知识介绍

HSF基础知识介绍HSF(Hadoop Streaming on Frameworks)是阿里巴巴基于Hadoop Streaming技术,开发的分布式计算框架。
HSF旨在简化开发者在海量数据处理时的工作,提供高性能的计算能力和简单易用的编程模型。
以下是对于HSF基础知识的介绍。
1.HSF架构HSF是一个分布式计算框架,主要由以下几个组件构成:Job Scheduler、Master、Worker、Task和Split。
Job Scheduler负责调度工作和资源管理,Master是Job Scheduler的主节点,Worker是Job Scheduler的工作节点。
Task是计算任务的基本单元,Split是数据的划分单元。
2.编程模型HSF提供了简单易用的编程模型,开发者可以通过编写Map和Reduce 函数来进行数据处理任务。
Map函数对输入的数据进行处理,将其转化为键值对形式的中间结果;Reduce函数之间对Map函数的输出结果进行合并和计算,生成最终的输出结果。
开发者只需关注Map和Reduce函数的实现,而无需考虑分布式计算和数据处理的细节。
3.数据划分和分布式计算HSF将输入数据划分为多个Split,每个Split由一个或多个文件组成。
Job Scheduler将Splits分配给不同的Worker,每个Worker上运行一个或多个Task。
Worker上的Task并行处理各自被分配到的Splits,Map函数负责将输入数据划分为键值对,Reduce函数负责对Map函数的输出结果进行合并和计算。
分布式计算的过程由Job Scheduler进行管理和协调,确保任务的高效执行。
4.高性能计算HSF采用了一系列优化策略来提高计算性能。
首先,HSF利用了数据本地性原理,将计算任务尽量分发到与数据所在位置相近的Worker节点上执行,减少了数据传输所带来的开销。
其次,HSF使用了基于内存的计算模型,将中间结果缓存在内存中,减少了磁盘IO的开销。
FusionInsightHD面试常考基础原理
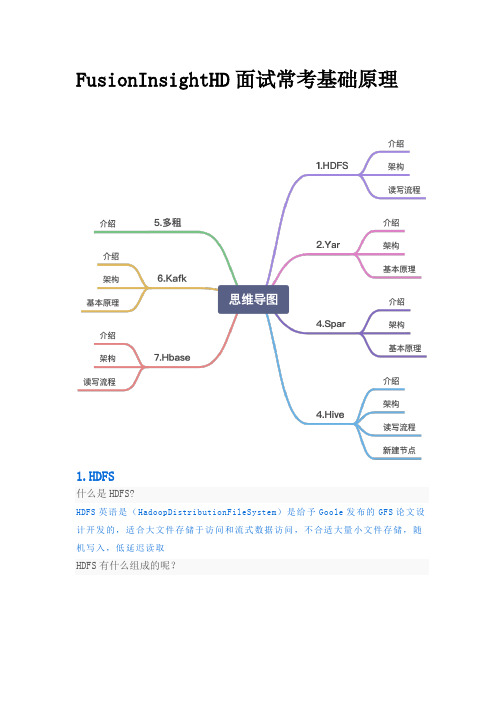
FusionInsightHD面试常考基础原理1.HDFS什么是HDFS?HDFS英语是(HadoopDistributionFileSystem)是给予Goole发布的GFS论文设计开发的,适合大文件存储于访问和流式数据访问,不合适大量小文件存储,随机写入,低延迟读取HDFS有什么组成的呢?HDFS架构包含三个部分:NameNode,DataNode,ClientNanmeNode:用户存储,生成文件系统的元数据。
DataNode:用户存储实际的数据,将自己管理的数据块上报给NameNode。
Client:支持业务访问HDFS,从NameNode,DataNode获取数据返回给业务HDFS读写流程怎样的呢?HDFS数据写入流程如下:1.业务应用调用HDFSClient提供的API,请求写入文件。
2.HDFSClient联系NameNode,NameNode在元数据中创建文件节点。
3.业务应用调用writeAPi写入文件。
4.HDFSClient收到业务数据后,从NameNode获取到数据块编号,位置信息后,联系DataNode,并将需要写入数据的DataNode建立起流水线,完成后,客户端在通过自有协议写入到DataNode1,在有DataNode1复制到DataNode2,DataNode3.5.写完的数据,将返回确定信息给HDFSClient。
6.所有数据确定完成后,将返回确定信息给HDFSClient。
7.业务调用Close,flush后HDFSClient联系NameNode,确认数据写完成后,NameNode持久化元数据。
HDFS数据读取流程如下:1.业务应用调用HDFSClient提供API打开文件。
2.HDFSClient联系NameNode,获取到文件信息(数据块,DataNode位置信息)。
3.业务应用调用readAPI读取文件。
4.HDFSClient根据从NameNode获取到的信息,联系DataNode,获取相应的数据块。
大数据的存储与处理

大数据的存储与处理随着信息技术的发展,大数据已经成为了当前社会和经济中的热门话题。
大数据的存储与处理技术变得愈发重要,因为大数据的有效存储和高效处理对于信息的挖掘和运用至关重要。
本文将重点探讨大数据的存储与处理技术,并分析其应用及发展前景。
一、大数据存储技术大数据的存储技术是指将海量数据保存在可靠、高效的存储系统中的方法和手段。
传统的存储方式已经无法满足大数据存储的需求,因此需要采用特殊的存储技术。
目前,常见的大数据存储技术包括分布式文件系统、列式数据库和NoSQL数据库。
1. 分布式文件系统分布式文件系统是一种将文件分布存储在多台机器上的系统,能够实现数据的高可靠性和高可扩展性。
典型的分布式文件系统有Hadoop 分布式文件系统(HDFS)和谷歌文件系统(GFS)。
这些系统通过将文件切分成多个块并分布存储在不同的节点上,提高了数据的读写速度和容错能力。
2. 列式数据库列式数据库是一种将数据按列存储的数据库系统,相比传统的行式数据库,列式数据库在数据读取和查询方面更加高效。
列式数据库将每一列的数据连续存储,减少了不必要的IO操作,提高了查询性能。
著名的列式数据库包括Google的Bigtable和Apache的HBase。
3. NoSQL数据库NoSQL(Not Only SQL)数据库是一种非关系型数据库,主要应用于大规模分布式数据的存储和处理。
NoSQL数据库放弃了传统关系型数据库的ACID特性,以牺牲一部分数据一致性为代价,实现了更高的性能和可扩展性。
常见的NoSQL数据库有MongoDB、Cassandra和Redis等。
二、大数据处理技术大数据的处理技术是指对大规模数据进行分析和计算的方法和工具。
大数据处理的关键是高效的分布式计算和并行处理能力。
目前,常用的大数据处理技术包括MapReduce、Spark和Storm等。
1. MapReduceMapReduce是一种分布式计算模型,由Google提出并应用于大规模数据处理。
大数据平台建设方案

大数据平台建设方案随着信息技术的不断发展和智能化时代的来临,大数据已经成为企业及各行业决策的重要依据。
为了更好地应对海量数据的处理和分析,企业需要建设一个完备的大数据平台。
本文将从整体架构、硬件设备、软件工具和安全保障等方面,提出一套完善的大数据平台建设方案。
一、整体架构大数据平台的整体架构决定了数据的处理效率和系统的可扩展性。
在构建大数据平台时,应采用分布式、集群化的架构模式,以满足高并发、高容量的需求。
建议采用以下架构:1. 数据采集层:负责从各种数据源收集数据,包括传感器、数据库、日志等。
可使用相关的数据采集工具进行数据的提取和转换,确保数据的准确性和完整性。
2. 数据存储层:用于存储海量的数据,包括结构化数据和非结构化数据。
建议采用分布式文件系统,如HDFS(Hadoop Distributed File System),保证数据的高可靠性和高可扩展性。
3. 数据处理层:负责对存储在数据存储层中的数据进行分析、挖掘和处理。
使用分布式计算框架,如Hadoop、Spark等,实现高效的数据处理和计算。
4. 数据展示层:提供数据可视化和报表功能,便于用户进行数据分析和决策。
可使用开源的数据可视化工具,如Echarts、Tableau等。
二、硬件设备大数据平台的硬件设备对系统性能和处理能力有着重要影响。
根据数据量和业务需求,建议选择高性能的服务器、存储设备和网络设备,以确保系统的稳定和高效运行。
1. 服务器:选择高性能的服务器,可根据实际需求配置多个节点组成集群,提高系统的并发处理能力。
2. 存储设备:采用高容量、高可靠性的存储设备,如分布式文件系统、网络存储等,以满足海量数据存储的需求。
3. 网络设备:建立高速的网络通信环境,提供数据传输和通信的带宽,确保数据的快速传输和实时处理。
三、软件工具在大数据平台建设中,选择适合的软件工具对于系统的性能和数据处理能力至关重要。
下面列举一些常用的大数据软件工具:1. Hadoop:分布式计算框架,提供高效的数据处理和分布式存储功能。
一文看懂分布式存储架构,这篇分析值得收藏

⼀⽂看懂分布式存储架构,这篇分析值得收藏【摘要】本⽂介绍了分布式存储的架构类型、分布式理论、不同的分布式⽂件系统和分布式键值系统等,较为系统详尽,可阅读收藏。
【作者】Rock,⽬前担任某国内著名餐饮连锁企业运维负责⼈,从事过数据库、⼤数据和容器集群的⼯作,对DevOps流程和⼯具⽅⾯有⽐较深刻的理解。
⼀、集中存储结构说到分布式存储,我们先来看⼀下传统的存储是怎么个样⼦。
传统的存储也称为集中式存储,从概念上可以看出来是具有集中性的,也就是整个存储是集中在⼀个系统中的,但集中式存储并不是⼀个单独的设备,是集中在⼀套系统当中的多个设备,⽐如下图中的 EMC 存储就需要⼏个机柜来存放。
在这个存储系统中包含很多组件,除了核⼼的机头(控制器)、磁盘阵列( JBOD )和交换机等设备外,还有管理设备等辅助设备。
结构中包含⼀个机头,这个是存储系统中最为核⼼的部件。
通常在机头中有包含两个控制器,互为备⽤,避免硬件故障导致整个存储系统的不可⽤。
机头中通常包含前端端⼝和后端端⼝,前端端⼝⽤户为服务器提供存储服务,⽽后端端⼝⽤于扩充存储系统的容量。
通过后端端⼝机头可以连接更多的存储设备,从⽽形成⼀个⾮常⼤的存储资源池。
在整个结构中,机头中是整个存储系统的核⼼部件,整个存储系统的⾼级功能都在其中实现。
控制器中的软件实现对磁盘的管理,将磁盘抽象化为存储资源池,然后划分为 LUN 提供给服务器使⽤。
这⾥的 LUN 其实就是在服务器上看到的磁盘。
当然,⼀些集中式存储本⾝也是⽂件服务器,可以提供共享⽂件服务。
⽆论如何,从上⾯我们可以看出集中式存储最⼤的特点是有⼀个统⼀的⼊⼝,所有数据都要经过这个⼊⼝,这个⼊⼝就是存储系统的机头。
这也就是集中式存储区别于分布式存储最显著的特点。
如下图所⽰:⼆、分布式存储分布式存储最早是由⾕歌提出的,其⽬的是通过廉价的服务器来提供使⽤与⼤规模,⾼并发场景下的 Web 访问问题。
它采⽤可扩展的系统结构,利⽤多台存储服务器分担存储负荷,利⽤位置服务器定位存储信息,它不但提⾼了系统的可靠性、可⽤性和存取效率,还易于扩展。
基于共享内存和多进程的分布式数据库架构及其实现方法[发明专利]
![基于共享内存和多进程的分布式数据库架构及其实现方法[发明专利]](https://img.taocdn.com/s3/m/93babee6f12d2af90342e628.png)
专利名称:基于共享内存和多进程的分布式数据库架构及其实现方法
专利类型:发明专利
发明人:王效忠,冀贤亮,何振兴,李英帅
申请号:CN202010772287.5
申请日:20200804
公开号:CN111949687A
公开日:
20201117
专利内容由知识产权出版社提供
摘要:本发明公开了一种基于共享内存和多进程的分布式数据库架构及实现方法,属一种分布式数据库架构,其包括分布式数据库节点,分布式数据库内置系统共享内存单元与系统进程单元;系统共享内存单元包括任务堆栈信息模块与共享缓存模块;任务堆栈信息模块内置多个进程任务;进程任务为系统进程任务信息中的多种用途的系统信息,每个系统信息均对应一个进程任务;通过在分布式数据库节点使用系统共享内存单元,使得在该分布式数据库架构中用户的连接数不与进程或者线程存在对应关系,整个节点的进程或者线程数都不会因为用户连接数的增加而增加,从而有效避免因瞬时用户连接数过多而导致系统响应速度变慢,从而使系统性能不会因此而受到影响。
申请人:贵州易鲸捷信息技术有限公司
地址:550000 贵州省贵阳市贵阳综合保税区都拉营综保路349号海关大楼8楼801
国籍:CN
代理机构:成都中炬新汇知识产权代理有限公司
代理人:罗韬
更多信息请下载全文后查看。
大数据主要所学技术(简介)

大数据主要所学技术(简介)目录大数据主要所学技术简介:一:大数据技术生态体系二:各个技术栈简介一:大数据技术生态体系二:各个技术栈简介Hadoophadoop是一个用java实现的一个开源框架,是一种用于存储和分析大数据的软件平台,专为离线数据而设计的,不适用于提供实时计算。
对海量数据进行分布式计算。
Hadoop=HDFS(文件系统,数据存储相关技术)+ Mapreduce(数据处理)+ Yarn (运算资源调度系统)zookeeper对于大型分布式系统,它是一个可靠的协调系统。
提供功能:[本质是为客户保管数据,为客户提供数据监控服务]1. 统一命名服务:在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。
例如:一个域名下可能有多个服务器,服务器不同,但域名一样。
2. 统一配置管理:把集群统一配置文件交给zookeeper3. 统一集群管理:分布式环境中,实时掌握集群每个节点状态,zookeeper可以实现监控节点状态的变化。
4. 服务器动态上下线:客户端能实时洞察到服务器上下线变化。
5. 软负载均衡:在zookeeper中记录服务器访问数,让访问数最小的服务器去处理最新的客户端请求Hivehive是由facebook开源用于解决海量结构化日志的数据统计,是一个基于hadoop的数据库工具,可以将结构化数据映射成一张数据表,并提供类SQL的查询功能,本质是将SQL语句转化为MapReduce程序。
用hive的目的就是避免去写MapReduce,减少开发人员学习成本。
FlumeFlume是hadoop生态圈中的一个组件,主要应用于实时数据的流处理,是一个高可用,高可靠,分布式的海量日志采集,聚合和传输的系统。
支持多路径流量,多管道接入流量,多管道接出流量。
含有三个组件:•source 【收集】•channel 【聚集,一个通道,类似数据缓冲池】•sink 【输出】基础架构:Kafka分布式的基于发布/订阅模式的消息队列。
spark教学案例

spark教学案例标题:Spark电影评分案例教学一、引言(100字)Spark是一种基于内存的分布式计算框架,广泛用于大规模数据处理和机器学习等领域。
本教学案例将介绍如何使用Spark进行电影评分分析,其中包括数据准备、分析与可视化等环节,旨在帮助学习者快速上手使用Spark。
二、数据准备(200字)1. 数据集选择:本案例使用的是Movielens数据集,包含了用户对电影的评分、电影信息和用户信息等数据。
三、电影评分分析(400字)1. 数据预处理:使用Spark的DataFrame或RDD API对数据进行预处理,如数据清洗、缺失值处理等。
同时,可以对数据进行特征提取和转换,以便后续分析使用。
2. 电影评分统计:使用Spark的分布式计算能力,对电影评分数据进行统计分析,计算每个电影的平均评分、评分人数等指标。
可以使用Spark的聚合操作和排序操作,快速得到需要的结果。
3. 用户评分分析:使用Spark对用户的评分行为进行分析,可以计算每个用户的平均评分、评分次数等指标,并进行可视化展示。
可以使用Spark的DataFrame和Spark SQL进行复杂查询和分析。
4. 电影推荐系统:使用Spark的机器学习库MLlib构建一个简单的电影推荐系统,根据用户的评分数据,预测用户对其他电影的评分,并进行推荐。
可以使用Spark的协同过滤算法或者基于内容的推荐算法进行模型训练和预测。
四、结果可视化(300字)1. Top N电影:使用Spark的数据分析和排序操作,得到评分最高的N部电影,并进行可视化展示。
可以使用matplotlib或者其他可视化库进行数据图表绘制。
2. 用户评分趋势:使用Spark的数据分析和可视化能力,对用户的评分行为进行趋势分析,并将结果进行可视化展示。
可以使用折线图或者柱状图展示用户评分随时间的变化。
3. 电影推荐结果:使用Spark的机器学习库MLlib得到的电影推荐结果,并进行可视化展示。
企业大数据管理与数据基础知识点汇总

企业大数据管理与数据基础●大数据基础●第一章大数据概述●大数据计算模式●批处理计算:针对大规模数据的批量处理●MapReduce●从数据源产生的数据开始经过处理最终流出到稳定的文件系统中如hdfs●spark●采用内存代替hdfs或者本地磁盘来存储中间数据●流计算●流数据:在时间和数量分布上无限的数据的集合,数据的价值随着时间的流逝而减低。
因此计算必须给出实时响应。
●图计算●查询分析计算●大规模数据进行实时或准实时查询的能力。
●内存计算●迭代计算●大数据关键技术●数据采集●数据存储与管理●数据处理与分析●数据隐私与安全●大数据与云计算、物联网的关系●云计算的概念与关键技术●性质:分布式计算●关键技术●虚拟化:基础,将一台计算机虚拟为多台逻辑上的计算机。
每台互不影响,从而提高计算机的工作效率●分布式计算:并行编程模型MapReduce●分布式存储:hbase分布式数据管理系统●多租户:使大量用户共享同一堆栈的软硬件资源●物联网的概念与关键技术●概念:通过局部网和互联网,将c、p、c、c、连接起来从而实现信息化、远程控制●关键技术●识别和感知●网络和通信●数据挖掘与融合●大数据、物联网、云计算相辅相成。
●密不可分、千差万别●区别:侧重点不同●物联网:目标实现物物相连●云计算:整合优化各种IT资源,通过网络以服务的方式廉价的提供给用户●大数据:侧重对海量数据的存储、分析、处理,从海量数据中发现价值、服务与生产和生活。
●联系●整体上相辅相成●物联网的传感器源源不断的产生提供数据,借助云计算、大数据实现分析存储●大数据根植于云计算,云计算提供的对大数据的存储管理,大数据的分析才得以进行●第三章大数据处理架构hadoop●hadoop生态圈●hdfs:分布式文件系统●MapReduce:分布式编程框架●hive:基于hadoop的数据仓库。
●pig:数据流语言和运行环境●大数据存储与管理●第四章分布式文件系统hdfs(数据块、文件块、存储位置、映射关系、)●体系结构●数据结点●数据结点:存储读取数据●数据结点要根据名称结点的指令删除、创建、复制、数据块。
cdh名词解释

cdh名词解释CDH是Cloudera企业级大数据平台的简称,是一种基于Hadoop框架的分布式计算系统,可承载大规模数据存储和处理任务。
该平台提供了包括数据存储、数据处理、数据管理、数据安全等一系列功能,为企业提供了完整的大数据解决方案。
CDH是由Cloudera公司开发和维护的一个大数据平台,其核心是基于Apache Hadoop构建的分布式计算框架。
CDH支持多种数据处理引擎,包括Hadoop、Spark、Impala、HBase等,并且提供了高可靠性、高可扩展性、高安全性等特性。
CDH的设计目标是帮助企业快速构建安全、高效、可靠的大数据处理平台,从而获取更多的商业价值。
CDH平台包含以下组件:1. HDFS(Hadoop Distributed File System):基于Hadoop的分布式文件系统,用于存储大型数据集。
2. YARN(Yet Another Resource Negotiator):负责协调集群中的资源分配和任务调度。
3. MapReduce:基于Hadoop的分布式计算框架,用于处理海量数据。
4. Spark:基于内存的分布式计算框架,支持SQL、图形处理、机器学习等多种应用场景。
5. Impala:基于内存的SQL分析引擎,具有更快的查询速度,并且支持Hadoop存储数据。
6. HBase:分布式的NoSQL数据库,用于存储半结构化数据,并且支持高并发读写。
7. ZooKeeper:用于分布式协调服务,可以有效地管理集群的元数据。
8. Kudu:分布式列存储数据库,用于快速更新、插入和查询数据。
CDH平台的使用可以帮助企业快速处理数据,进行数据挖掘、数据分析、数据可视化等工作,从而迅速获取业务价值,并优化业务流程。
同时,CDH平台提供了完善的安全机制,包括身份验证、数据加密、访问控制等多种措施,确保数据的安全性。
总之,CDH是一个完整的大数据平台,可以支持企业在存储、处理、管理和安全等各方面得到问题。
Spark大数据技术应用于云计算平台的实践探索

Spark大数据技术应用于云计算平台的实践探索云计算平台作为近年来快速发展的技术,为企业和个人提供了各种创新和商业机会。
然而,云计算平台上的大数据处理需求也逐渐增大,要求更高效、更快速的数据处理技术。
在这方面,Spark大数据技术成为了许多云计算平台的首选。
本文将探索Spark大数据技术在云计算平台上的实践应用。
首先,让我们了解一下Spark技术。
Spark是一种基于内存的分布式计算系统,可以处理大规模的数据集并提供高效的数据处理速度。
相比于传统的MapReduce框架,Spark具有更低的延迟和更高的性能。
Spark提供了丰富的API和内置的数据处理模块,比如Spark SQL、Spark Streaming和机器学习库等,使得用户可以方便地进行数据处理、数据分析和机器学习任务。
在云计算平台上,Spark可以发挥其强大的分布式计算能力和高效的内存处理机制。
首先,Spark可以轻松地处理云计算平台上的大规模数据集。
由于云计算平台的规模通常非常大,传统的数据处理技术可能会面临扩展性和性能的挑战。
而Spark的分布式计算模型和优化的内存处理方式能够有效地解决这些问题,提供高效的数据处理能力。
其次,Spark可以与其他云计算平台上的工具和服务集成,发挥协同作用。
例如,Spark可以与Hadoop和其他分布式存储系统进行集成,从而可以直接读取和处理存储在这些系统中的数据。
此外,Spark还可以与云计算平台上的数据仓库、消息队列和流处理引擎等集成,进一步提升数据处理的便利性和效率。
除了数据处理能力,Spark还拥有丰富的数据处理模块和算法库,为云计算平台上的数据分析和机器学习任务提供了强有力的支持。
Spark SQL模块可以方便地进行数据查询和分析,使得用户可以通过类似SQL的语法进行数据探索和分析。
而Spark Streaming模块可以实时处理数据流,满足实时数据分析和处理的需求。
此外,Spark还提供了强大的机器学习库,支持各种常见的机器学习算法和深度学习框架,使得用户可以方便地进行模型训练和预测。
FusionStorage分布式存储系统介绍和架构原理

传统SAN存储
Server1
Server2
Server3
10GE / FC
Server SAN的原理
定义:Server SAN is defined as a combined compute and pooled storage resource comprising more than one storage device directly attached to separate multiple servers (more than one). -- by wikibonServer SAN是由多个独立的服务器自带的存储组成的一个存储资源池,同时融合了计算和存储资源。
EMC VMAX
HDS VSP G1000
Huawei 18000
*数据来源:Gartner 2013Q4报告
存储技术的发展趋势
每次技术发展,存储的性能 容量 可靠性都得到极大的提升
Network
传统存储在扩展性方面挑战仍非常大
Network
Controller
Controller
APP
APP
中低端存储只能垂直扩展
Page
华为云计算存储发展历程
Content
FusionStorage架构
FusionStorage特点
FusionStorage背景
FusionStorage应用场景
FusionStorage架构原理
以数据块为单元进行数据管理I/O在所有磁盘上负载均衡,无热点,磁盘性能最大化利用故障数据重构迅速,整体性能影响小支持精简配置,无需热备盘
据Wikibon评估,传统的企业存储在2013年虽然还占据95%的份额,但接下来的10年将持续下降,下降幅度是16.7%。而企业Server SAN存储将以40.9%的速度野蛮增长,Server SAN存储的收入将超过传统的存储(包括现在的SAN,NAS,DAS)。
大数据存储与计算技术综述

大数据存储与计算技术综述随着信息化时代的到来,大数据的应用越来越广泛,各行各业的数据都在海量增长。
如何高效地存储和处理这些数据就成为了大家关注的话题。
本文将从大数据存储的概念、存储介质、存储架构、计算框架等多个方面来综述大数据存储与计算技术。
一、大数据存储的概念大数据存储可简单理解为存储大规模数据的技术手段。
在数字信息化时代,大数据的产生呈现出爆炸式增长,这使得传统的存储方式无法满足存储和处理的需求。
因此,大数据存储技术应运而生。
二、大数据存储介质1.磁盘存储磁盘存储是最为常见和普及的存储方式。
硬盘是最常见的磁盘存储设备,它通过主板上的SATA数据线来连接CPU,将数字信号转换为磁盘上垂直和水平方向上的磁场变化。
其主要特点是存储器容量大,使用周期长,但读写速度相对较慢。
2.闪存存储和磁盘存储相比,闪存存储的读写速度更快,使用寿命更长,且无噪音,节能环保。
最常用的闪存存储设备是USB闪存盘、固态硬盘等。
3.内存存储内存存储是一种速度非常快的存储方式,其读写速度比磁盘存储和闪存存储高出一个数量级,但存储容量相比之下较小,使用寿命也较短。
三、大数据存储架构1.分布式存储架构分布式存储架构是大数据存储的一种主流方式。
它通过将数据划分为多个部分,分别存储在多台服务器上,从而提升了数据的读写性能和可靠性,具有较好的可扩展性。
目前,分布式存储系统中的代表性技术有HDFS、Ceph等。
2.对象存储架构对象存储架构是一种新兴的存储方式,其可以将数据存储在一组节点上,并且自动分配数据副本,从而保证数据的高可靠性和可用性。
典型的对象存储系统有Amazon S3、Cloudian等。
3.列存储架构列式存储是相对于行式存储而言的一种数据存储方式。
它将数据按照列而非按行进行存储和处理,大大提高了数据的读取速度和压缩率,现在一些大型企业的数据仓库系统都在使用列存储技术来进行存储和处理。
四、大数据计算框架1. Apache HadoopApache Hadoop是大数据处理的一个开源框架,主要由HDFS和MapReduce两个部分组成。
基于 的 系统设计与实现

基于的系统设计与实现基于的系统设计与实现基于是一种分布式计算框架,可以实现大规模数据处理和分析。
它由Google公司开发,是一种开源的分布式计算框架。
基于的系统设计和实现需要考虑以下几个方面:一、系统架构设计基于的系统架构采用了Master/Slave的架构模式,其中Master节点负责任务的调度和资源的管理,Slave节点负责具体的任务执行。
Master和Slave之间通过心跳机制保持通信,Master可以监控Slave的状态,根据负载情况进行任务的调度和资源的分配。
二、数据存储设计基于的数据存储采用了分布式文件系统HDFS,数据被分成多个块存储在不同的节点上,保证了数据的可靠性和高可用性。
同时,基于还提供了一种分布式的内存缓存系统Tachyon,可以提高数据的访问速度。
三、任务调度设计基于的任务调度采用了MapReduce模型,将任务分成Map和Reduce两个阶段。
Map阶段将数据划分成多个小块,分发给不同的Slave节点进行处理;Reduce阶段将Map阶段处理的结果进行合并,生成最终的结果。
基于的任务调度还支持任务的优先级、任务的依赖关系等高级特性。
四、资源管理设计基于的资源管理采用了YARN(Yet Another Resource Negotiator)框架,可以对集群中的资源进行统一管理和分配。
YARN可以根据任务的需求动态调整资源的分配,提高集群的利用率和效率。
五、安全性设计基于的安全性设计包括身份认证、访问控制、数据加密等多个方面。
基于支持多种身份认证方式,包括Kerberos、LDAP等;同时,基于还提供了访问控制机制,可以对不同用户和角色进行权限控制;基于的数据传输和存储都支持加密,保证了数据的安全性。
六、性能优化设计基于的性能优化设计包括多个方面,包括数据压缩、数据本地化、任务并行度等。
基于支持多种数据压缩方式,可以减少数据传输和存储的开销;同时,基于还支持数据本地化,将数据和任务调度到同一节点上进行处理,可以减少网络传输的开销;基于的任务并行度可以根据集群的规模和任务的复杂度进行动态调整,提高任务的执行效率。
大数据架构中的分布式计算与存储

大数据架构中的分布式计算与存储第一章:引言随着互联网和移动互联网的发展和普及,许多行业和领域都开始利用大数据来分析和利用数据,以改善业务流程和创造更多价值。
大数据包括大量的数据,数据类型和数据来源不同。
处理大数据需要高效的计算和存储方式。
随着数据量不断增加,传统的单机计算和存储方式已经不能满足需要了。
大数据处理需要更高效、更可靠、更灵活的分布式计算和存储方式。
本文主要介绍大数据架构中的分布式计算与存储。
首先,本文将介绍分布式计算和存储的基本概念,然后介绍一些流行的分布式计算和存储框架,最后讨论一些大数据架构的设计和部署方法。
第二章:分布式计算分布式计算是指在多台服务器上分配计算任务,以共同完成一个计算任务。
相比较于单机计算,分布式计算处理速度更快、容错性更强,在处理大数据时尤为重要。
分布式计算涉及以下几个方面:任务分配、数据分配、数据传输等。
常见的分布式计算框架有Apache Hadoop、Apache Spark等。
1. Apache HadoopApache Hadoop是一个开源的分布式计算框架,可以高效地处理大规模数据。
其主要特点是可扩展性、可靠性和灵活性。
Hadoop的核心组成部分有:① HDFS(Hadoop分布式文件系统),用于数据存储。
② MapReduce,用于数据分析。
Hadoop的分布式计算过程大致分为以下几个步骤:①任务管理器(JobTracker)将计算任务分配给多台服务器。
②数据管理器(NameNode)将任务和数据分配给不同的服务器。
③每个服务器使用MapReduce进行数据处理。
④处理结果返回给JobTracker,由JobTracker整合结果。
2. Apache SparkApache Spark是一种快速、通用、分布式的计算系统。
它可处理大数据,包括内存计算和磁盘计算。
相比于Hadoop的MapReduce框架,Spark更适用于迭代计算和流式计算。
Spark的分布式计算过程大致分为以下几个步骤:①驱动程序将Spark应用程序发送给Spark集群。
分布式计算框架Spark

分布式计算框架SparkApache Spark是⼀个开源分布式运算框架,最初是由加州⼤学柏克莱分校AMPLab所开发。
Hadoop MapReduce的每⼀步完成必须将数据序列化写到分布式⽂件系统导致效率⼤幅降低。
Spark尽可能地在内存上存储中间结果,极⼤地提⾼了计算速度。
MapReduce是⼀路计算的优秀解决⽅案,但对于多路计算的问题必须将所有作业都转换为MapReduce模式并串⾏执⾏。
Spark扩展了MapReduce模型,允许开发者使⽤有向⽆环图(DAG)开发复杂的多步数据管道。
并且⽀持跨有向⽆环图的内存数据共享,以便不同的作业可以共同处理同⼀个数据Spark不是Hadoop的替代⽅案⽽是其计算框架Hadoop MapReduce的替代⽅案。
Hadoop更多地作为集群管理系统为Spark提供底层⽀持。
Spark可以使⽤本地Spark, Hadoop YARN或Apache Mesos作为集群管理系统。
Spark⽀持HDFS,Cassandra, OpenStack Swift作为分布式存储解决⽅案。
Spark采⽤Scala语⾔开发运⾏于JVM上,并提供了Scala,Python, Java和R语⾔API,可以使⽤其中的Scala和Python进⾏交互式操作。
本⽂测试环境为Spark 2.1.0, Python API.初识Spark弹性分布式数据集(Resilient Distributed Dataset, RDD)是Saprk的基本数据结构,代表可以跨机器进⾏分割的只读对象集合。
RDD可以由Hadoop InputFormats创建(⽐如HDFS上的⽂件)或者由其它RDD转换⽽来, RDD⼀旦创建便不可改变。
RDD操作分为变换和⾏动两种:变换(Transformation): 接受⼀个RDD作为参数,返回⼀个新的RDD,原RDD不变。
包括:map,filter,flatMap,groupByKey,reduceByKey,aggregateByKey,pipe以及coalesce⾏动(Action): 接受⼀个RDD作为参数,进⾏查询并返回⼀个值。
《大数据基础与实务》期末考试题试卷及答案

《大数据基础与实务》期末考试题试卷及答案一、选择题(每题2分,共20分)1. 以下哪个不是大数据的4V特征?A. 体积(Volume)B. 种类(Variety)C. 速度(Velocity)D. 精确度(Veracity)答案:D2. 以下哪个不属于大数据处理技术?A. 分布式存储B. 数据挖掘C. 机器学习D. 量子计算答案:D3. Hadoop的核心组件不包括以下哪个?A. HDFSB. MapReduceC. YARND. Spark答案:D4. 以下哪个数据库系统不属于NoSQL数据库?A. MongoDBB. RedisC. MySQLD. Cassandra答案:C5. 数据仓库的目的是什么?A. 提高数据的实时性B. 提高数据的一致性C. 提高数据的独立性D. 提高数据的可用性答案:B二、填空题(每题2分,共20分)6. 大数据的处理流程包括:数据采集、数据存储、数据清洗、数据分析和数据挖掘。
7. 在Hadoop中,HDFS负责数据的存储,MapReduce负责数据的计算。
8. Spark是一种基于内存的分布式计算框架,具有快速、通用和易于使用等特点。
9. 数据挖掘是从大量数据中挖掘出有价值的信息和知识的过程。
10. 数据可视化是将数据以图形或表格的形式展示出来,以便用户更容易理解和分析数据。
三、判断题(每题2分,共20分)11. 大数据的处理只需要考虑数据的存储和计算,不需要考虑数据的清洗和分析。
()答案:错误12. Hadoop是Google的MapReduce的开源实现。
()答案:正确13. NoSQL数据库主要用于处理结构化数据。
()答案:错误14. 数据仓库主要用于支持决策分析。
()答案:正确15. 数据挖掘是一种数据清洗的方法。
()答案:错误四、简答题(每题5分,共25分)16. 简述大数据处理的挑战。
答案:大数据处理的挑战包括:数据量庞大、数据类型多样、数据增长速度快、数据质量参差不齐、数据安全与隐私保护等。
如何进行并行和分布式计算

如何进行并行和分布式计算随着数据规模和计算复杂度的不断提升,传统的单机计算已经无法满足现代科学研究和工业应用的需求,因此并行和分布式计算成为了一个重要的技术方向。
本文将介绍如何进行并行和分布式计算。
一、并行计算并行计算是指同时使用多个处理器或计算节点来完成一个计算任务,在计算过程中各个处理器之间可以相互通信和协同工作。
并行计算可以大幅度提高计算速度和效率,尤其适合于大规模数据分析和高维计算。
常见的并行计算框架包括OpenMP、MPI、CUDA等。
其中OpenMP是一种基于共享内存的并行计算框架,适合于多核CPU等共享内存的计算平台。
MPI是一种消息传递接口,可以用于分布式计算和集群计算。
CUDA则是一种基于GPU的并行计算框架,可以大幅度提高计算速度和效率。
在进行并行计算时,需要考虑数据划分、任务分配、通信协议等因素。
数据划分是指将数据集划分为多个子集,每个子集由一个处理器或计算节点负责计算。
任务分配是指将计算任务分配给各个处理器或计算节点。
通信协议是指不同处理器或计算节点之间如何协调和通信。
这些因素的不同组合会对并行计算的效率和速度产生不同的影响。
二、分布式计算分布式计算是指将计算任务分布在多个独立的计算节点上进行并行计算。
分布式计算可以提高计算规模和计算速度,尤其适合于数据中心和云计算等需要大规模计算和存储的场景。
常见的分布式计算框架包括Hadoop、Spark、Flink等。
其中Hadoop是一种分布式计算框架,主要用于海量数据的存储和处理。
Spark是一种快速的大数据处理引擎,支持分布式计算和数据流处理。
Flink则是一种分布式流处理引擎,可以高效处理数据流和批处理任务。
在进行分布式计算时,需要考虑数据分布、任务分配、容错机制等因素。
数据分布是指将输入数据划分为多个块,并将其分配到多个计算节点上。
任务分配是指将计算任务分配到多个计算节点上进行并行计算。
容错机制是指在计算过程中出现故障时如何保证计算的正确性和完整性。
基于内存数据库的分布式数据库架构

量 数据 问题 还有 一个重 要特点 ,就是
数 据 结 构 化 及 数 据 之 间 的 关 联 , 淘 宝 如 此 , 里 巴巴也 是 如 此 , 阿 这是 与社 区、
性 能对 比,后者 在插入 和查询上 性能
是 Orce 5 7 。 a l的 — 倍
My QL S 等关系数据库将仍 然扮演重要
角色 。
视频、 博客等互联网站 的显著差异。
No QL是 灵丹 妙 药 吗 ? S
N0 SQ L、 Ke . l e引 擎 如 Y Va u
My QL集 群 S
引入 K yV le l 等 非 关 系数 据 e — au  ̄ 擎 库 无 非 是 要 解 决 海 量 数 据 在 高 并 发 环
Si pl D曩 ^0∞ l m e Mod e
.
储和访 问问题 。 而对于 电子 商务 类网
站 , K yV le N S 并 不 是 解 决 e . au 和 o QL 此 问题 的 灵 丹 妙 药 , 最 多 它们 仅 能 用 于一些数 据模型 较为简单 的应 用 。出
Ds i k o8
图1 传统 磁盘数 据库 的基本 访 问模 式 表 1 a l、Al a e Orce t s 性能 对 比 :插 入5 i b 万条
现这种现象的原因有 以下两个 方面 。
目前 一种 通行 的做 法是My QL S 读
写 分 离 式 集群 , 1 或 少 数 Ma tr , 个 se写
仍 然 比较 耗 时 ( 见 表 1 表 2 , 数 参 和 )
由此可见 :P ( m 内存数据库读写性
能 )远 远 高 于 P ( 盘 数 据 库 读 写 性 d 磁
能)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
技术创新 变革未来
问题
我们团队负责 移动运营平台企业 版 V3.0 及 后 续 版 本 迭代,当时的设计 目标支撑500w日活 , 数 据 库 使 用 MySQL。
500 W
事实证明移动运 营 平 台 企 业 版 V3.0 能 够满足绝大多数企业 客户的需求,能够稳 定地支撑他们的业务。
更新前 Bitmap 1~3MB
我 们 将 bitmap 对 象 作 为blob类型存入MySQL,对 bitmap 索 引 的 某 一 位 更 新 时需要先从DB查询出来, 更 新 之 后 再 update 到 DB 中 。
APP数据处理 程序
1.查询某个维度的bitmap, 比如说今天的活跃用户。
有一天,我们的一个 客 户,他们上线了几个日 活量 较大的APP,系统的整 体日活 达到了2000万,运 维人员反 映MySQL的binlog 增长很快, 快把剩余磁盘空 间占满了。
企业客户APP日活设计目标
2000 W
500 W
问题分析 1
我们使用了bitmap索引 技术保证移动运营各项指标 (如日活、留存、转化漏斗 等) 的 实时 计算, 因 为 bitmap索引高效且能节 省存 储空间,它能很方便 地做指 标的实时排重。
MySQL
磁盘
2.设置某一位为 1
更新后 Bitmap 1~3MB
4.写binlog(磁盘IO) 3.更新到DB(网络IO)
问题分析 3
每个bitmap对
数据分析:
象的大小从数
• 百100wK存B到量数用M户B,不随机60w日活,每个bitmap原始大小 130KB,压缩后126KB
• 等2。000w存量用户,随机200w日活,每个bitmap原始大小 2.6MB,压缩后1.5MB
我们需要考虑如何在分布 式内存中计算以解决此类问题, 解决方案需要满足:
• 第一个,缓存备份 • 第二个,性能高 • 第三个,易于维护
候选解决方案
方 案 一 : 替 换 MySQL , 使 用
druid/rockdb等大数据组件
方案二:在MySQL前面引入redis缓 存层,定时同步到MySQL
方案三:调研使用Apache Ignite组件
(网络IO)
为什么Blade?
Blade能够减少更新MySQL中bitmap索引数据的频率,彻底解决大活跃客户出现的问 题,对比之前提出的三种候选解决方案,它主要有如下优势:
• 基于成熟的组件(Ehcache、redis、zookeeper),易于维护; • 对比单纯使用redis,不需要处理达2到3MB的bitmap索引数据,系统
分布式缓存计算框架简介
代号Blade,意在像锋利的刀锋一样有效解决企业产品的问题
• 它是一个bitmap索引计算的加速框架,专门针对海量bitmap索引计算时频繁更新 DB操作进行优化。
• 它会把bitmap索引缓存在内存中,数据处理程序只需要告诉Blade修改哪个bit即可,
无需把整条bitmap索引从DB拉取到本地更新后再写回DB,Blade会负责内存中的
• 1亿存量用户,随机500w日活,每个bitmap原始大小 11.5MB,压缩后5.2MB
频繁地更新blob二进制数据,导致binlog数据量极大,从而导致存储空间不够用。 这就是前面某客户出现瓶颈的原因所在。
问题域
大块(1M~10M)的二进制 对象(约30w个bitmap对象)频 繁读写,导致网络IO、磁盘IO等 资源耗费巨大,MySQL binlog增 长过快导致存储空间不够与浪费。
bitmap索引与MySQL的同步。
2.设置某一位为1
网络IO
更新前 Bitmap 1~3MB
APP数据处理 1.设置某个维度的
程序
bitmap的某一位为1
Blade
3.定时(如每两小时) 获取该维度的bitmap 。
MySQL
磁盘
4.设置某些位为 1
更新后 Bitmap 1~3MB
6.写binlog(磁盘IO) 5.更新到DB
为什么不选用纯Redis缓存方案
• Redis在高并发下不能支撑对较大bitmap索引的频繁更新,单个bitmap索引平均能 够达到2、3MB,而Redis的value达到1MB时吞吐量不到1000每秒,远远达不到要 求的吞吐量。
• 另外一个重要的原因是Redis的事件机制有问题,expired和eviction事件拿不到缓 存对象的值,这样会导致一旦缓存对象过期或被驱逐,我们无法把缓存对象更新 到数据库。
为什么不选用Druid/RockDB方案
我们在互联网研发线使用了此种方案,但调研下来不适合企业侧产品研发: • 原来我们的系统运维工作很少,整个2000万日活体量的系统,也只需要1个运维人
员;而换了Druid/rockdb,需要有较多的运维工作,等于放弃了我们原有的优势, 增加了对客户运维人员的要求。 • Druid/RockDB 需要大量的服务器资源。
bitmap 第1位 设备1 0
bitmap 1
设备1 0
某APP某天0:0的初始活跃状态
第2位 设备2
0
第3位 设备3
0
… 第N-1位 第N位 设备N-1 设备N
0
0
0
当天8:10,设备3和设备N-1访问了APP
2 设备2
0
3 设备3
1
…
N-1
N
设备N-1 设备N
0
1
0
bitmap
1 设备1
0
当天9:20,设备2和设备N-1访问了APP
• 对大块bitmap索引的频繁更新,导致存储空间耗用巨大,而且大块数据的复制延 迟很严重,Redis变得不稳定。
为什么不选用Apache Ignite方案
• 使用了数据备份功能,因为频繁更新较大的bitmap索引,涉及到数据在不同节点 的备份,导致系统不稳定,经常出现OOM问题。
最终方案
权衡下来,我们决定基于Ehcache、redis和zookeeper实现一套分布式缓存计算框架。
2 设备2
1
3 设备31… NhomakorabeaN-1
N
设备N-1 设备N
0
1
0
问题分析 2
我 们 使 用 MySQL 存 储 bitmap 索 引 , 因 为 MySQL 稳 定 且 易 于 运维。
网络IO
但是, MySQL本 身在业务上是不支 持 bitmap类型的数据 ,不 能够发送指令给 MySQL 让它把bitmap的 某一位 设置为1或0。