语法分析器的设计
语法分析程序的设计与实现

◆词法分析 用户必须提供一个词法分析器来读取输入流并把记号(带有值, 如果需要的话)传达到解析器。词法分析器使叫做 yylex 的整数值的 函数。这个函数返回一个整数的记号编号,它表示读取的记号的种类。 如果这个记号关联着一个值,应当把它赋予外部变量 yylval。 为使通信得以发生,解析器和词法分析器必须在记号编号上达成 一致。编号可以由 Yacc 或用户来选择。在这两种情况下,使用 C 语 言的“# define”机制允许词法分析器使用符号来返回这些编号。例如, 假定在 Yacc 规定文件的声明段中已经定义记号名字 DIGIT。 它的意图是返回一个 DIGIT 记号编号,和等于这个数字的数值 的一个值。倘若词法分析器代码位于规定文件的程序段,标识符 DIGIT 将被定义为与记号 DIGIT 关联的记号编号。 这种机制导致清晰的、易于修改的词法分析器;唯一的缺点是在 文法中需要避免使用任何在 C 语言或解析器中保留的或有意义的记 号名字;例如,使用记号名字 if 或 while 就一定会导致编译词法分 析器时出现严峻的困难。记号名字 error 保留给错误处理,不应该随 便使用。 同上所述,记号编号可以由 Yacc 或用户来选择。在缺省的条件 下,编号由 Yacc 选择。文字字符的缺省记号编号是它在本地字符集 中的字符数值。其他名字赋予从 257 开始的记号编号。 要把一个记号编号赋予一个记号(包括文字),可以在声明段中记 号或文字的第一次出现时直接跟随着一个非负整数。这个整数被接受
第四:YACC 内部名称: ................................................................................................ 7 第五:运行结果(源代码见附录).............................................................................. 8 第六:实验总结 ............................................................................................................... 8 第七:附录 ..................................................................................................................... 10
语法分析器报告

Begin
Repeat
Q:=S[j]
If S[j-1]∈VTthenj:=j-1elsej:=j-2
UntilS[j]<Q
把S[j+1]……S[K]归约为某个N
记录归约产生式序号
K:=j+1
S[K]:=N
End of while
If S[j]<a OR S[j]=a then
j++;
}
strings[m+1]='#';
strings[m+2]='\0';
cout<<"算术表达式"<<id<<"为: "<<oldstrings<<endl;
cout<<"转换为输入串: "<<strings<<endl;
cout<<" 步骤号符号栈优先关系当前分析符剩余输入串动作";
prior_analysis();
cout<<" # < < < < < e3 < ="<<endl;
if((fp=fopen("预处理.txt","r"))==NULL)
{
cout<<"请先将实验文件夹中的预处理.txt文件复制到实验文件夹中!"<<endl;
system("pause");
exit(0);
}
charch=fgetc(fp);
PL0语言语法分析器实验报告

PL0语言语法分析器实验报告一、引言编译器是一种用于把高级语言程序转换成机器可执行代码的软件工具。
编译器由多个组件构成,其中语法分析器是编译器中的重要组成部分,其主要功能是对输入的源代码进行解析,并生成一个语法树。
本实验旨在通过使用BNF(巴科斯范式)描述PL0语言的语法规则,并通过实现PL0语言的语法分析器,来深入理解语法分析的原理和过程。
二、PL0语言的语法规则1.程序结构:<程序>::=[<常量说明部分>][<变量说明部分>][<过程说明部分>]<语句>2.常量说明部分:<常量说明部分> ::= const <常量定义> { , <常量定义> };<常量定义>::=<标识符>=<无符号整数>3.变量说明部分:<变量说明部分> ::= var <标识符> { , <标识符> };4.过程说明部分:<过程说明部分>::=<过程首部><分程序>;<过程首部> ::= procedure <标识符> ;5.语句:<语句> ::= <赋值语句> , <if语句> , <while语句> , <调用语句> , <复合语句> , <读语句> , <写语句> , <空><赋值语句>::=<标识符>:=<表达式><if语句> ::= if <条件> then <语句> else <语句><while语句> ::= while <条件> do <语句><调用语句> ::= call <标识符><复合语句> ::= begin <语句> { ; <语句> } end<读语句> ::= read ( <标识符> )<写语句> ::= write ( <表达式> )6.表达式:<表达式>::=[+,-]<项>{(+,-)<项>}<项>::=<因子>{(*,/)<因子>}<因子>::=<标识符>,<无符号整数>,(<表达式>)7.条件:<条件>::=<表达式><关系运算符><表达式><关系运算符>::==,<>,<,<=,>,>=三、PL0语言的语法分析器设计与实现1.设计思路本次实验中,我们将使用自顶向下的递归下降分析法,来对PL0语言进行语法分析。
Tiny语言语法分析器设计过程

Tiny语言语法分析器设计过程1、创建空工程
运行Microsoft Visual C++ 6.0 File菜单下选择New:
弹出下面对话框:
选择Win32 Console Application,同时在Project Name下输入工程名字:ParserByHand
点击Ok按钮,弹出下面对话框:
不做任何选择,按照默认“An empty project”,直接点击Finish按钮,弹出下面对话框:
直接点击OK按钮,工程创建完毕。
2、添加文件
首先在windows环境下,把设计好的文件GLOBALS.H、MAIN.C、PARSE.C、PARSE.H、SCAN.C、SCAN.H、UTIL.C 和UTIL.H拷贝到ParserByHand工程下:
如图所示,选中Project菜单,选择下面Add To Project子菜单下面的Files子菜单:
点击后弹出对话框:
在左侧的工程文件列表中,可以清楚地看到这些文件:
编译生成可执行文件ParserByHand.exe在本工程的debug目录下:
录下:
4、验证运行结果
Windows环境下点击“开始”,选中其中的“运行(R)”
,弹出下面对话框,输入cmd命令:
直接回车或者点击OK按钮,进入命令行方式(控制台方式):
输入上图所示的类似命令,进入可执行程序所在目录。
在当前目录下输入命令:ParserByHand sample.tny,然后回车,
西安理工大学计算机学院软061班吴松华制作张发存指导则得到相应的运行结果:命令行窗口太小,只显示其中的一部分:
第 11 页共 11 页。
编译原理词法分析器语法分析课程设计范本

《编译原理词法分析器语法分析课程设计-《编译原理》课程设计院系信息科学与技术学院专业软件工程年级级学号 2723姓名林苾湲西南交通大学信息科学与技术学院12月目录课程设计1 词法分析器 (2)设计题目 (2)设计内容 (2)设计目的 (2)设计环境 (2)需求分析 (2)概要设计 (2)详细设计 (4)编程调试 (5)测试 (11)结束语 (13)课程设计2 赋值语句的解释程序设计 (14)设计题目 (14)设计内容 (14)设计目的 (14)设计环境 (14)需求分析 (15)概要设计 (16)详细设计 (16)编程调试 (24)测试 (24)结束语 (25)课程设计一词法分析器设计一、设计题目手工设计c语言的词法分析器(能够是c语言的子集)。
二、设计内容处理c语言源程序,过滤掉无用符号,判断源程序中单词的合法性,并分解出正确的单词,以二元组形式存放在文件中。
三、设计目的了解高级语言单词的分类,了解状态图以及如何表示并识别单词规则,掌握状态图到识别程序的编程。
四、设计环境该课程设计包括的硬件和软件条件如下:.硬件(1)Intel Core Duo CPU P8700(2)内存4G.软件(1)Window 7 32位操作系统(2)Microsoft Visual Studio c#开发平台.编程语言C#语言五、需求分析.源程序的预处理:源程序中,存在许多编辑用的符号,她们对程序逻辑功能无任何影响。
例如:回车,换行,多余空白符,注释行等。
在词法分析之前,首先要先剔除掉这些符号,使得词法分析更为简单。
.单词符号的识别并判断单词的合法性:将每个单词符号进行不同类别的划分。
单词符号能够划分成5中。
(1)标识符:用户自己定义的名字,常量名,变量名和过程名。
(2)常数:各种类型的常数。
(3) 保留字(关键字):如if、else、while、int、float 等。
(4) 运算符:如+、-、*、<、>、=等。
语法分析器的设计

编译原理语法分析器的设计◆根据某一文法编制调试 LL ( 1 )分析程序,以便对任意输入的符号串进行分析。
◆构造预测分析表,并利用分析表和一个栈来实现对上述程序设计语言的分析程序。
◆分析法的功能是利用LL(1)控制程序根据显示栈栈顶内容、向前看符号以及LL(1)分析表,对输入符号串自上而下的分析过程。
实验设计方案1、设计思想(1)、LL(1)文法的定义LL(1)分析法属于确定的自顶向下分析方法。
LL(1)的含义是:第一个L表明自顶向下分析是从左向右扫描输入串,第2个L表明分析过程中将使用最左推导,1表明只需向右看一个符号便可决定如何推导,即选择哪个产生式(规则)进行推导。
LL(1)文法的判别需要依次计算FIRST集、FOLLOW集和SELLECT集,然后判断是否为LL(1)文法,最后再进行句子分析。
需要预测分析器对所给句型进行识别。
即在LL(1)分析法中,每当在符号栈的栈顶出现非终极符时,要预测用哪个产生式的右部去替换该非终极符;当出现终结符时,判断其与剩余输入串的第一个字符是否匹配,如果匹配,则继续分析,否则报错。
LL(1)分析方法要求文法满足如下条件:对于任一非终极符A的两个不同产生式A→α,A→β,都要满足下面条件:SELECT(A→α)∩SELECT(A→β)=∅(2)、预测分析表构造LL(1)分析表的作用是对当前非终极符和输入符号确定应该选择用哪个产生式进行推导。
它的行对应文法的非终极符,列对应终极符,表中的值有两种:一是产生式的右部的字符串,一是null。
若用M表示LL(1)分析表,则M可表示如下:M: VN×VT→P∪{Error}M(A, t) = A→α,当t∈select(A→α) ,否则M(A, t) = Error其中P表示所有产生式的集合。
(3)、语法分析程序构造LL(1)分析中X为符号栈栈顶元素,a为输入流当前字符,E为给定测试数据的开始符号,#为句子括号即输入串的括号。
语法分析器实验报告

词法分析器实验报告实验名称:语法分析器实验内容:利用LL(1)或LR(1)分析语句语法,判断其是否符合可识别语法。
学会根据状态变化、first、follow或归约转移思想构造状态分析表,利用堆栈对当前内容进行有效判断实验设计:1.实现功能可对一段包含加减乘除括号的赋值语句进行语法分析,其必须以$为终结符,语句间以;隔离,判断其是否符合语法规则,依次输出判断过程中所用到的产生式,并输出最终结论,若有错误可以报错并提示错误所在行数及原因2.实验步骤3.算法与数据结构a)LLtable:left记录产生式左端字符;right记录产生式右端字符;ln记录产生式右端字符长度Status:记录token分析情况Token:category,类型;value,具体内容b)根据LL(1)算法,手工构造分析表,并将内容用数组存储,便于查找c)先将当前语句的各token按序存储,当前处理语句最后一个token以#标记,作为输入流与产生式比较,堆栈中初始放入#,x,a为处理输入流中当前读头内容✓若top=a=‘#‘表示识别成功,退出分析程序✓若top=a!=‘#‘表示匹配,弹出栈顶符号,读头前进一个✓若top为i或n,但top!=a,出错,输出当前语句所在行,出错具体字符✓若top不为i或n,查预测分析表,若其中存放关于top产生式,则弹出top,将产生式右部自右向左压入栈内,输出该产生式,若其中没有产生式,出错,输出当前语句所在行,出错具体字符d)以;作为语句终结,每次遇到分号则处理之前语句并清空后预备下语句处理,当遇到$表示该段程序结束,停止继续处理4.分析表构造过程a)x->i=ee->e+t|e-t|tt->t*f|t/f|ff->(e)|i|nnote: i表示变量,n表示数字,!表示空串b)提取左公因子x->i=ee->ea|ta->+t|-tt->tb|fb->*f|/ff->(e)|i|nc)消除左递归x->i=ee->tcc->ac|!a->+t|-tt->fdd->bd|!b->*e|/ff->(e)|i|n5.类class parser{public:LLtable table[100][100]; //LL(1)表void scanner(); //扫描输入流中内容并分析parser(istream& in); //初始化,得到输入文件地址int getLine() const; //得到当前行数private:int match(); //分析语法stack <char> proStack; //分析堆栈void constructTable(); //建立LL(1)表int getRow(char ch); //取字符所在表中行int getCol(char ch); //取字符所在表中列istream* pstream; //输入流void insertToken(token& t); //插入当前tokenstatus getToken(token& t); //找到tokenint getChar(); //得到当前字符int peekChar(); //下一个字符void putBackChar(char ch); //将字符放回void skipChar(); //跳过当前字符void initialization(); //初始化堆栈等int line; //当前行数token tokens[1000]; //字符表int counter; //记录当前字符表使用范围}6.主要代码void parser::constructTable() //建立LL(1)表{for (int i=0;i<8;i++){for (int j=0;j<9;j++){table[i][j].left=' ';for (int k=0;k<3;k++)table[i][j].right[k]=' ';}}table[0][6].left='x';table[0][6].ln=3;table[0][6].right[0]='i';table[0][6].right[1]='=';table[0][6].right[2]='e';table[1][4].left='e';table[1][4].ln=2;table[1][4].right[0]='t';table[1][4].right[1]='c';table[1][6].left='e';table[1][6].ln=2;table[1][6].right[0]='t';table[1][6].right[1]='c';table[1][7].left='e';table[1][7].ln=2;table[1][7].right[0]='t';table[1][7].right[1]='c';table[2][0].left='c';table[2][0].ln=2;table[2][0].right[0]='a';table[2][0].right[1]='c';table[2][1].left='c';table[2][1].ln=2;table[2][1].right[0]='a';table[2][1].right[1]='c';table[2][5].left='c';table[2][5].ln=0;table[2][5].right[0]='!';table[2][8].left='c';table[2][8].ln=0;table[2][8].right[0]='!';table[3][0].left='a';table[3][0].ln=2;table[3][0].right[0]='+'; table[3][0].right[1]='t'; table[3][1].left='a';table[3][1].ln=2;table[3][1].right[0]='-'; table[3][1].right[1]='t'; table[4][4].left='t';table[4][4].ln=2;table[4][4].right[0]='f'; table[4][4].right[1]='d'; table[4][6].left='t';table[4][6].ln=2;table[4][6].right[0]='f'; table[4][6].right[1]='d'; table[4][7].left='t';table[4][7].ln=2;table[4][7].right[0]='f'; table[4][7].right[1]='d'; table[5][0].left='d';table[5][0].ln=0;table[5][0].right[0]='!'; table[5][1].left='d';table[5][1].ln=0;table[5][1].right[0]='!'; table[5][2].left='d';table[5][2].ln=2;table[5][2].right[0]='b'; table[5][2].right[1]='d'; table[5][3].left='d';table[5][3].ln=2;table[5][3].right[0]='b'; table[5][3].right[1]='d'; table[5][5].left='d';table[5][5].ln=0;table[5][5].right[0]='!'; table[5][8].left='d';table[5][8].ln=0;table[5][8].right[0]='!'; table[6][2].left='b';table[6][2].ln=2;table[6][2].right[0]='*'; table[6][2].right[1]='f'; table[6][3].left='b';table[6][3].ln=2;table[6][3].right[0]='/'; table[6][3].right[1]='f'; table[7][4].left='f';table[7][4].ln=3;table[7][4].right[0]='(';table[7][4].right[1]='e';table[7][4].right[2]=')';table[7][6].left='f';table[7][6].ln=1;table[7][6].right[0]='i';table[7][7].left='f';table[7][7].ln=1;table[7][7].right[0]='n';}int parser::match() //分析语法{ofstream ofs("out.txt",ios::app);char a;int i=0;for (int p=0;p<counter;p++){cout<<tokens[p].value;ofs<<tokens[p].value;}cout<<endl;ofs<<endl<<"ANALYSIS:"<<endl;while(1){if(tokens[i].category=='n' || tokens[i].category=='i')a=tokens[i].category;elsea=(tokens[i].value)[0];if(a==proStack.top()){if(a=='#'){cout<<"This is valid!"<<endl<<endl;ofs<<"This is valid!"<<endl<<endl;return 0;}else{proStack.pop();i++;}}else{if(proStack.top() =='n'|| proStack.top() =='i'){if(a!='#'){cout<<"ERROR(LINE "<<getLine()<<" ): "<<a<<" cannot be matched"<<endl;ofs<<"ERROR(LINE "<<getLine()<<" ): "<<a<<" cannot be matched"<<endl;}else{cout<<"ERROR(LINE "<<getLine()<<" ): Unexpected ending"<<endl;ofs<<"ERROR(LINE "<<getLine()<<" ): Unexpected ending"<<endl;}cout<<"This is invalid!"<<endl<<endl;ofs<<"This is invalid!"<<endl<<endl;return 0;}else{if((table[getRow(proStack.top())][getCol(a)]).left!=' '){char pst=proStack.top();int n=table[getRow(pst)][getCol(a)].ln;int k=0;ofs<<table[getRow(pst)][getCol(a)].left<<"->"<<table[getRow(pst)][getCol(a)].right[0]<<table[getRow(pst)][g etCol(a)].right[1]<<table[getRow(pst)][getCol(a)].right[2]<<endl;proStack.pop();while (n>0){//cout<<n<<" "<<table[getRow(pst)][getCol(a)].right[n-1]<<endl;proStack.push(table[getRow(pst)][getCol(a)].right[n-1]);n--;}}else{if(a!='#'){cout<<"ERROR(LINE "<<getLine()<<" ): "<<a<<" cannot be matched"<<endl;ofs<<"ERROR(LINE "<<getLine()<<" ): "<<a<<" cannot be matched"<<endl;}else{cout<<"ERROR(LINE "<<getLine()<<" ): Unexpected ending"<<endl;ofs<<"ERROR(LINE "<<getLine()<<" ): Unexpected ending"<<endl;}cout<<"This is invalid!"<<endl<<endl;ofs<<"This is invalid!"<<endl<<endl;return 0;}}}}}实验结果:●输入(in.txt)●输出1输出2(out.txt)实验总结:原本以为处理四则运算赋值将会很困难,但在使用LL(1)后发现,思路还是挺清晰简单的,但在实验过程中,由于LL(1)不能出现左递归和左公因子,不得不将其消除,原本简单的产生式一下变多了,而在产生式理解上也没有原来直观,不过其状态复杂度没有LR高,故仍选择该方法。
编译原理语法分析器实验报告

编译原理语法分析器实验报告西安邮电大学编译原理实验报告学院名称:计算机学院****:***实验名称:语法分析器的设计与实现班级:计科1405班学号:04141152时间:2017年5月12日把SELECT (i)存放到temp中结果返回1;1.构建好的预测分析表2.语法分析流程图一.实验结果正确运行结果:错误运行结果:二.设计技巧和心得体会这次实验编写了一个语法分析方法的程序,但是在LL(1)分析器的编写中我只达到了最低要求,就是自己手动输入的select集,first集,follow集然后通过程序将预测分析表构造出来,然后自己编写总控程序根据分析表进行分析。
通过本次试验,我能够设计一个简单的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析方法。
还能选择最有代表性的语法分析方法,如LL(1) 语法分析程序、算符优先分析程序和LR分析分析程序。
三.源代码package com.LL1;import java.util.ArrayDeque;import java.util.Deque;/*** LL1文法分析器,已经构建好预测分析表,采用Deque实现* Created by HongWeiPC on 2017/5/12.*/public class LL1_Deque {//预测分析表private String[][] analysisTable = new String[][]{{"TE'", "", "", "TE'", "", ""},{"", "+TE'", "", "", "ε", "ε"},{"FT'", "", "", "FT'", "", ""},{"", "ε", "*FT'", "", "ε", "ε"},{"i", "", "", "(E)", "", ""}};//终结符private String[] VT = new String[]{"i", "+", "*", "(", ")", "#"};//非终结符private String[] VN = new String[]{"E", "E'", "T", "T'", "F"};//输入串strTokenprivate StringBuilder strToken = new StringBuilder("i*i+i");//分析栈stackprivate Deque<String> stack = new ArrayDeque<>();//shuru1保存从输入串中读取的一个输入符号,当前符号private String shuru1 = null;//X中保存stack栈顶符号private String X = null;//flag标志预测分析是否成功private boolean flag = true;//记录输入串中当前字符的位置private int cur = 0;//记录步数private int count = 0;public static void main(String[] args) {LL1_Deque ll1 = new LL1_Deque();ll1.init();ll1.totalControlProgram();ll1.printf();}//初始化private void init() {strToken.append("#");stack.push("#");System.out.printf("%-8s %-18s %-17s %s\n", "步骤", "符号栈", "输入串", "所用产生式");stack.push("E");curCharacter();System.out.printf("%-10d %-20s %-20s\n", count, stack.toString(), strToken.substring(cur, strToken.length()));}//读取当前栈顶符号private void stackPeek() {X = stack.peekFirst();}//返回输入串中当前位置的字母private String curCharacter() {shuru1 = String.valueOf(strToken.charAt(cur));return shuru1;}//判断X是否是终结符private boolean XisVT() {for (int i = 0; i < (VT.length - 1); i++) {if (VT[i].equals(X)) {return true;}}return false;}//查找X在非终结符中分析表中的横坐标private String VNTI() {int Ni = 0, Tj = 0;for (int i = 0; i < VN.length; i++) {if (VN[i].equals(X)) {Ni = i;}}for (int j = 0; j < VT.length; j++) {if (VT[j].equals(shuru1)) {Tj = j;}}return analysisTable[Ni][Tj];}//判断M[A,a]={X->X1X2...Xk}//把X1X2...Xk推进栈//X1X2...Xk=ε,不推什么进栈private boolean productionType() {return VNTI() != "";}//推进stack栈private void pushStack() {stack.pop();String M = VNTI();String ch;//处理TE' FT' *FT'特殊情况switch (M) {case "TE'":stack.push("E'");stack.push("T");break;case "FT'":stack.push("T'");stack.push("F");break;case "*FT'":stack.push("T'");stack.push("F");stack.push("*");break;case "+TE'":stack.push("E'");stack.push("T");stack.push("+");break;default:for (int i = (M.length() - 1); i >= 0; i--) {ch = String.valueOf(M.charAt(i));stack.push(ch);}break;}System.out.printf("%-10d %-20s %-20s %s->%s\n", (++count), stack.toString(), strToken.substring(cur, strToken.length()), X, M);}//总控程序private void totalControlProgram() {while (flag) {stackPeek(); //读取当前栈顶符号令X=栈顶符号if (XisVT()) {if (X.equals(shuru1)) {cur++;shuru1 = curCharacter();stack.pop();System.out.printf("%-10d %-20s %-20s \n", (++count), stack.toString(), strToken.substring(cur, strToken.length()));} else {ERROR();}} else if (X.equals("#")) {if (X.equals(shuru1)) {flag = false;} else {ERROR();}} else if (productionType()) {if (VNTI().equals("")) {ERROR();} else if (VNTI().equals("ε")) {stack.pop();System.out.printf("%-10d %-20s %-20s %s->%s\n", (++count), stack.toString(), strToken.substring(cur, strToken.length()), X, VNTI());} else {pushStack();}} else {ERROR();}}}//出现错误private void ERROR() {System.out.println("输入串出现错误,无法进行分析");System.exit(0);}//打印存储分析表private void printf() {if (!flag) {System.out.println("****分析成功啦!****");} else {System.out.println("****分析失败了****");}}}。
语法分析器实验报告
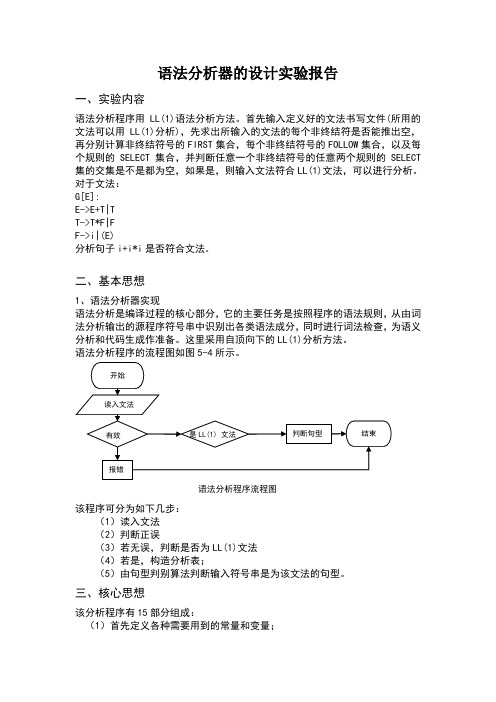
语法分析器的设计实验报告一、实验内容语法分析程序用LL(1)语法分析方法。
首先输入定义好的文法书写文件(所用的文法可以用LL(1)分析),先求出所输入的文法的每个非终结符是否能推出空,再分别计算非终结符号的FIRST集合,每个非终结符号的FOLLOW集合,以及每个规则的SELECT集合,并判断任意一个非终结符号的任意两个规则的SELECT 集的交集是不是都为空,如果是,则输入文法符合LL(1)文法,可以进行分析。
对于文法:G[E]:E->E+T|TT->T*F|FF->i|(E)分析句子i+i*i是否符合文法。
二、基本思想1、语法分析器实现语法分析是编译过程的核心部分,它的主要任务是按照程序的语法规则,从由词法分析输出的源程序符号串中识别出各类语法成分,同时进行词法检查,为语义分析和代码生成作准备。
这里采用自顶向下的LL(1)分析方法。
语法分析程序的流程图如图5-4所示。
语法分析程序流程图该程序可分为如下几步:(1)读入文法(2)判断正误(3)若无误,判断是否为LL(1)文法(4)若是,构造分析表;(5)由句型判别算法判断输入符号串是为该文法的句型。
三、核心思想该分析程序有15部分组成:(1)首先定义各种需要用到的常量和变量;(2)判断一个字符是否在指定字符串中;(3)读入一个文法;(4)将单个符号或符号串并入另一符号串;(5)求所有能直接推出&的符号;(6)求某一符号能否推出‘ & ’;(7)判断读入的文法是否正确;(8)求单个符号的FIRST;(9)求各产生式右部的FIRST;(10)求各产生式左部的FOLLOW;(11)判断读入文法是否为一个LL(1)文法;(12)构造分析表M;(13)句型判别算法;(14)一个用户调用函数;(15)主函数;下面是其中几部分程序段的算法思想:1、求能推出空的非终结符集Ⅰ、实例中求直接推出空的empty集的算法描述如下:void emp(char c){ 参数c为空符号char temp[10];定义临时数组int i;for(i=0;i<=count-1;i++)从文法的第一个产生式开始查找{if 产生式右部第一个符号是空符号并且右部长度为1,then将该条产生式左部符号保存在临时数组temp中将临时数组中的元素合并到记录可推出&符号的数组empty中。
语法分析器的设计

语法分析器的设计1.设计原则在设计语法分析器时,应遵循以下原则:-维护清晰的分析策略:选择合适的文法类别,以便能够使用适当的分析策略,如自上而下分析、自下而上分析或混合分析等。
-使用适当的数据结构:选择合适的数据结构来表示词法单元流和语法树,以提高分析效率和易读性。
-错误处理机制:有效地处理语法错误,提供有用的错误信息以帮助开发人员进行调试和修复。
-可扩展性和可维护性:设计一个灵活的框架,使得分析器能够适应新的语言特性和文法规则,并便于维护和修改。
2.文法规则分析例如,下面是一个简单的四则运算表达式的文法规则:```<expression> ::= <term> '+' <expression><term> '-' <expression<term<term> ::= <factor> '*' <term><factor> '/' <term<factor<factor> ::= '(' <expression> ')'<number<number> ::= [0-9]+```在编写语法分析器时,需要将这些规则翻译为具体的代码逻辑。
3.自上而下分析自上而下分析是一种从文法规则的最上层开始,逐步展开产生式规则,并根据输入的词法单元流进行匹配的分析方法。
以下是一个简单的自上而下分析的伪代码示例:```function parseExpression(:term = parseTermif currentToken.type == '+':match('+')expression = parseExpressionreturn BinaryExpression('+', term, expression)else if currentToken.type == '-':match('-')expression = parseExpressionreturn BinaryExpression('-', term, expression) else:return termfunction parseTerm(:factor = parseFactorif currentToken.type == '*':match('*')term = parseTermreturn BinaryExpression('*', factor, term) else if currentToken.type == '/':match('/')term = parseTermreturn BinaryExpression('/', factor, term) else:return factorfunction parseFactor(:if currentToken.type == '(':match('(')expression = parseExpressionmatch(')')return expressionelse if currentToken.type == 'number':number = currentToken.valuematch('number')return NumberLiteral(number)else:error("Invalid factor")function match(expectedType):if currentToken.type == expectedType:currentToken = getNextTokenelse:error("Unexpected token: " + currentToken.type)```代码示例中的`currentToken`表示当前正在处理的词法单元,`getNextToken(`获取下一个词法单元。
语法分析器设计
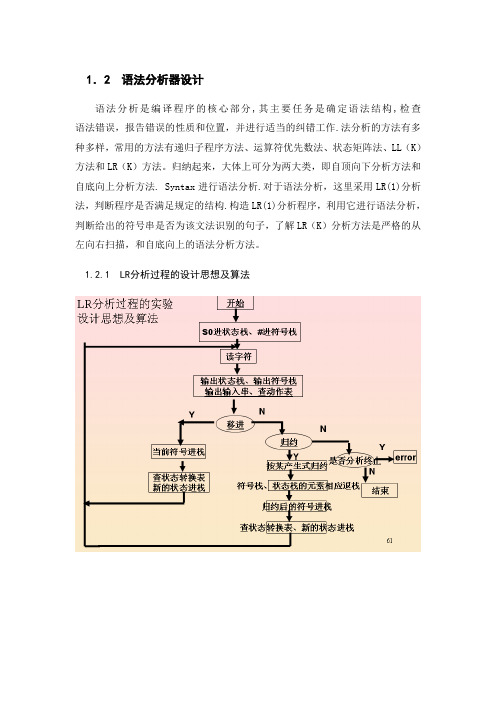
1.2 语法分析器设计语法分析是编译程序的核心部分,其主要任务是确定语法结构,检查语法错误,报告错误的性质和位置,并进行适当的纠错工作.法分析的方法有多种多样,常用的方法有递归子程序方法、运算符优先数法、状态矩阵法、LL(K)方法和LR(K)方法。
归纳起来,大体上可分为两大类,即自顶向下分析方法和自底向上分析方法. Syntax进行语法分析.对于语法分析,这里采用LR(1)分析法,判断程序是否满足规定的结构.构造LR(1)分析程序,利用它进行语法分析,判断给出的符号串是否为该文法识别的句子,了解LR(K)分析方法是严格的从左向右扫描,和自底向上的语法分析方法。
1.2.1LR分析过程的设计思想及算法1:LR-table.txt:存放分析表,其中正数表示移进,负数表示归约,100表示接受状态,0表示不操作。
2:grammar.txt 存放文法开始符号3:lengh.txt 存放产生式右部字符长度4:inpur.txt 输入的程序语法规则定义的文法,如下:(0)Z---→S(1)S---→AB(2)A---->CDE(3)C---→void(4)D---→main(5)E---→()(6)B---→{F}(7)F---→GF(8)F---→G(9)G--->HIJ(10)H--→int(11)I--→KLM(12)K--→character(13)L--→=(14)M--->num(15)J--→;根据上面文法画出的分层有限自动机并根据分层自动机构造的LR(1)分析表:v oi d main(){ intchar= numS A B C D E F G H I J K L M } ; #0 2 1 8 31 Ac2 -33 4 54 -45 6 76 -57 -28 199 -11 0 251113151 1 1 21 2 -61 3 25141315-81 4 -71 5 161721 6 -1 21 7 19181 8 -15-151 9 -9-92 0 21222 1 -1 32 2 23242 32 4 -1 42 5 -1 11.2.2 程序核心代码和注释:public void analyzer(){//***************************//循环读取grammar.txt//***************************/*此处代码略*///***************************//循环读取 lengh.txt//***************************/*此处代码略*///****************************// 读入文件,进行语法分析//****************************string strReadFile;strReadFile="input.txt";myTextRead.myStreamReader=new StreamReader(strReadFile);string strBufferText;int wid =0;Console.WriteLine("分析读入程序(记号ID):\n");do{strBufferText =myTextRead.myStreamReader.ReadLine();if(strBufferText==null)break;foreach (String subString in strBufferText.Split()){if(subString!=""){int ll;if(subString!=null){ll= subString.Length; //每一个长度}else{break;}int a=ll+1;char[] b = new char[a];StringReader sr = new StringReader(subString);sr.Read(b, 0, ll); //把substring 读到char[]数组里int sort=(int)b[0];// word[i] 和 wordNum[i]对应//先识别出一整个串,再根据开头识别是数字还是字母Word[wid]=subString;if(subString.Equals("void")){wordNum[wid]=0;}else{if(subString.Equals("main")){wordNum[wid]=1;}else{if(subString.Equals("()")){wordNum[wid]=2;}else{if(subString.Equals("{")){wordNum[wid]=3;}else{if(subString.Equals("int")){wordNum[wid]=4;}else{if(subString.Equals("=")){wordNum[wid]=6;}else{if(subString.Equals("}")){wordNum[wid]=22;}else{if(subString.Equals(";")){wordNum[wid]=23;}else//识别变量和数字{if(sort>47&sort<58){wordNum[wid]=7;}else{wordNum[wid]=5;}}}}}}}}}Console.Write(subString+"("+wordNum[wid]+")"+" ");wid++;}}Console.WriteLine("\n");}while (strBufferText!=null);wordNum[wid]=24;myTextRead.myStreamReader.Close();//*********************************//读入LR分析表////***********************************/*此处代码略*/int[] state = new int[100];string[] symbol =new string[100];state[0]=0;symbol[0]="#";int p1=0;int p2=0;Console.WriteLine("\n按文法规则归约顺序如下:\n");//***************// 归约算法如下所显示//***************while(true){int j,k;j=state[p2];k=wordNum[p1];t=LR[j,k]; //当出现t为0的时候if(t==0){//错误类型string error;if(k==0)error="void";elseif(k==1)error="main";elseif(k==2)error="()";elseif(k==3)error="{";elseif(k==4)error="int";elseif(k==6)error="=";elseif(k==22)error="}";elseif(k==23)error=";";elseerror="其他错误符号";Console.WriteLine("\n检测结果:");Console.WriteLine("代码中存在语法错误");Console.WriteLine("错误状况:错误状态编号为 "+j+" 读头下符号为"+error);break;}else{if(t==-100) //-100为达到接受状态{Console.WriteLine("\n");Console.WriteLine("\n检测结果:");Console.WriteLine("代码通过语法检测");break;}if(t<0&&t!=-100) //归约{string m=grammar[-t];Console.Write(m+" "); //输出开始符int length=lengh[-t];p2=p2-(length-1);Search mySearch=new Search();int right=mySearch.search(m);if(right==0){Console.WriteLine("\n");Console.WriteLine("代码中有语法错误");break;}int a=state[p2-1];int LRresult= LR[a,right];state[p2]=LRresult;symbol[p2]=m;}if(t>0){p2=p2+1;state[p2]=t;symbol[p2]=Convert.ToString(wordNum[p1]);p1=p1+1;}}}myTextRead.myStreamReader.Close();Console.Read();}示例:1:void main (){int i = 8 ;int aa = 10 ;int j = 9 ;}2:void main (){intq i = 8 ;int aa = 10 ;int j = 9 ;}对于intq i=8 中intq这个错误类型,词法分析通过,而语法分析正确识别出了错误,达到预期目标产生出错信息:运行显示如下:1.3中间代码生成器设计进入编译程序的第三阶段:中间代码产生阶段。
编译原理课程设计-LL(1)语法分析器的构造

LL(1)语法分析器的构造摘要语法分析的主要任务是接收词法分析程序识别出来的单词符由某种号串,判断它们是否语言的文法产生,即判断被识别的符号串是否为某语法部分。
一般语法分析常用自顶向下方法中的LL分析法,采用种方法时,语法分程序将按自左向右的顺序扫描输入的的符号串,并在此过程中产生一个句子的最左推导,即LL是指自左向右扫描,自左向右分析和匹配输入串。
经过分析,我们使用VC++作为前端开发工具,在分析语法成分时比较方便直观,更便于操作。
运行程序的同时不断修正改进程序,直至的到最优源程序。
关键字语法分析文法自顶向下分析 LL(1)分析最左推导AbstractGrammatical analysis of the main tasks was to receive lexical analysis procedure to identify the words from a website, string, and judge whether they have a grammar of the language, that is, judging by the series of symbols to identify whether a grammar part. General syntax analysis commonly used top-down methods of LL analysis, using methods, Grammar hours will be from the procedures of the order left-to-right scanning input string of symbols, and in the process produced one of the most left the sentence is derived, LL is scanned from left to right, From left to right analysis and matching input strings. After analysis, we use VC + + as a front-end development tool for the analysis of syntax ingredients more convenient visual, more easy to operate. Operational procedures at the same time constantly improving procedures, until the source of optimal .Key WordsGrammatical analysis grammar Top-down analysis LL (1) AnalysisMost left Derivation目录摘要 (1)引言 (3)第一章设计目的 (4)第二章设计的内容和要求 (5)2.1 设计内容 (5)2.2 设计要求 (5)2.3 设计实现的功能 (5)第三章设计任务的组织和分工 (6)3.1 小组的任务分工 (6)3.2 本人主要工作 (6)第四章系统设计 (9)4.1 总体设计 (9)4.2 详细设计 (9)第五章运行与测试结果 (22)5.1 一组测试数据 (22)5.2 界面实现情况 (23)第六章结论 (27)课程设计心得 (28)参考文献 (29)致谢 (30)附录(核心代码清单) (31)引言编译器的构造工具是根据用户输入的语言的文法,编译器的构造工具可以生成程序来处理以用户输入的文法书写的文本。
编译原理课程设计_词法语法分析器

编译原理课程设计Course Design of Compiling(课程代码3273526)半期题目:词法和语法分析器实验学期:大三第二学期学生班级:2014级软件四班学生学号:2014112218学生姓名:何华均任课教师:丁光耀信息科学与技术学院2017.6课程设计1-C语言词法分析器1.题目C语言词法分析2.内容选一个能正常运行的c语言程序,以该程序出现的字符作为单词符号集,不用处理c语言的所有单词符号。
将解析到的单词符号对应的二元组输出到文件中保存可以将扫描缓冲区与输入缓冲区合成一个缓冲区,一次性输入源程序后就可以进行预处理了3.设计目的掌握词法分析算法,设计、编制并调试一个词法分析程序,加深对词法分析原理的理解4.设计环境(电脑语言环境)语言环境:C语言CPU:i7HQ6700内存:8G5.概要设计(单词符号表,状态转换图)5.1 词法分析器的结构词法分析程序的功能:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
词法分析程序可以单独为一个程序;也可以作为整个编译程序的一个子程序,当需要一个单词时,就调用此法分析子程序返回一个单词.为便于程序实现,假设每个单词间都有界符或运算符或空格隔开,并引入下面的全局变量及子程序:1) ch 存放最新读进的源程序字符2) strToken 存放构成单词符号的字符串3) Buffer 字符缓冲区4)struct keyType 存放保留字的符号和种别5.3 状态转换图6.详细设计(数据结构,子程序)算法思想:首先设置3个变量:①strToken用来存放构成单词符号的字符串;②ch 用来字符;③struct keyType用来存放单词符号的种别码。
扫描子程序主要部分流程如下图所示。
7.程序清单// ConsoleApplication1.cpp : 定义控制台应用程序的入口点。
//#include"stdafx.h"#include"stdio.h"#include"stdlib.h"#include"conio.h"#include"string.h"#define N 47char ch;char strToken[20];//存放构成单词符号的字符串char buffer[1024]; //字符缓冲区struct keyType {char keyname[256];int value;}Key[N] = { { "$ID",0 },{ "$INT",1 },{ "auto",2 },{ "break",3 },{ "case",4 }, { "char",5 },{ "const",6 },{ "continue",7 },{ "default",8 },{ "do",9 }, { "double",10 },{ "else",11 },{ "enum",12 },{ "extern",13 },{ "float",14 }, { "for",15 },{ "goto",16 },{ "if",17 },{ "int",18 },{ "long",19 },{ "register",20 }, { "return",21 },{ "short",22 },{ "signed",23 },{ "sizeof",24 },{ "static",25 }, { "struct",26 },{ "switch",27 },{ "typedef",28 },{ "union",29 },{ "unsigned",30 }, { "void",31 },{ "volatile",32 },{ "while",33 },{ "=",34 },{ "+",35 },{ "-",36 },{ "*",37 }, { "/",38 },{ "%",39 },{ ",",40 },{ ";",41 },{ "(",42 },{ ")",43 },{ "?",44 },{ "clear", 45 },{ "#",46 } };void GetChar() //读一个字符到ch中{int i;if (strlen(buffer)>0) {ch = buffer[0];for (i = 0; i<256; i++)buffer[i] = buffer[i + 1];}elsech = '\0';}void GetBC()//读一个非空白字符到ch中{int i;while (strlen(buffer)) {i = 0;ch = buffer[i];for (; i<256; i++) buffer[i] = buffer[i + 1];if (ch != ' '&&ch != '\n'&&ch != '\0') break;}}void ConCat()//把ch连接到strToken之后{char temp[2];temp[0] = ch;temp[1] = '\0';strcat(strToken, temp);}bool Letter()//判断ch是否为字母{if (ch >= 'A'&&ch <= 'Z' || ch >= 'a'&&ch <= 'z')return true;elsereturn false;}bool Digit()//判断ch是否为数字{if (ch >= '0'&&ch <= '9')return true;elsereturn false;}int Reserve()//用strToken中的字符查找保留字表,并返回保留字种别码,若返回0,则非保留字{int i;for (i = 0; i<N; i++)if (strcmp(strToken, Key[i].keyname) == 0)return Key[i].value;return 0;}void Retract()//把ch中的字符回送到缓冲区{int i;if (ch != '\0') {buffer[256] = '\0';for (i = 255; i>0; i--)buffer[i] = buffer[i - 1];buffer[0] = ch;}ch = '\0';}keyType ReturnWord(){strcpy(strToken, "\0");int c;keyType tempkey;GetBC();if (ch >= 'A'&&ch <= 'Z' || ch >= 'a'&&ch <= 'z') { ConCat();GetChar();while (Letter() || Digit()) {ConCat();GetChar();}Retract();c = Reserve();strcpy(tempkey.keyname, strToken);if (c == 0)tempkey.value = 0;elsetempkey.value = Key[c].value;}else if (ch >= '0'&&ch <= '9') {ConCat();GetChar();while (Digit()) {ConCat();GetChar();}Retract();strcpy(tempkey.keyname, strToken);tempkey.value = 1;}else {ConCat();strcpy(tempkey.keyname, strToken);tempkey.value = Reserve();}return tempkey;}/*主函数*/int main() {//文件操作FILE *fp;if ((fp = fopen("E:\\作业\\编译原理\\Ccode.txt", "r")) == NULL) { printf("cannot open file/n"); exit(1);}while (!feof(fp)) {if (fgets(buffer, 250, fp) != NULL){printf("E:\\作业\\编译原理\\Ccode.txt\n");}}keyType temp;printf("单词\t种别号\n");while (strlen(buffer)) {temp = ReturnWord();printf("%s\t %d\n\n", temp.keyname, temp.value);}printf("the end!\n");getch();return 0;}8.运行结果E:/作业/编译原理/Code.txt运行结果九、 实验体会通过本次次法分析设计实验,我加深了对词法分析过程的理解。
语法分析器的实现

语法分析器的实现
一.课程设计成员
组长:
成员:
二.实验目的
采用自上而下的语法分析方法,实现对词法分析程序所提供的单词序列的语法检查和结构分析。
三.实验要求
利用C++语言编写自上而下(递归下降)语法分析程序,实现对简单语言进行语法分析。
待分析的简单语言的语法(用扩充的BNF表示)如下:
⑴<程序>-> <语句串>
⑵<语句串>-><语句>{;<语句>}
⑶<语句>-><赋值语句>
⑷<赋值语句>->ID=<表达式>
⑸<表达式>-><项>{+<项> | -<项>}
⑹<项>-><因子>{*<因子> | /<因子>
⑺<因子>->ID | NUM | (<表达式>)
四、实验输入、输出
输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则指出错误位置和错误原因。
例如:
输入y=x+2;#
输出success!
Int a,b,c;
输入x=a+bc; #
输出错误原因和位置
五、语法分析程序的算法思想(流程图)
六、算法实现
参考:(1)教材第4、5章语法分析
(2)教材第10章编译程序实现范例
(3)网络资料。
语法分析器的设计与实现

语法分析器的设计与实现一、设计概述1.定义语法规则:根据所设计的编程语言,确定其语法规则。
可以使用文法或者EBNF(扩展巴科斯-诺尔范式)来定义语法规则。
2. 设计语法分析算法:选择适合的语法分析算法,常见的有自顶向下(Top-Down)和自底向上(Bottom-Up)两种。
自顶向下算法从语法规则的起始符号开始,逐步向下匹配源代码,构建语法树。
自底向上算法则通过逐步将输入的源代码规约为语法规则的右侧,最终得到语法树。
3.实现语法分析器:根据所选择的语法分析算法,实现相应的算法,根据文法定义和源代码进行语法分析。
二、自顶向下语法分析自顶向下语法分析是一种递归的、自上而下构造语法树的方法。
它以文法的起始符号为目标,通过不断向下匹配文法规则,构造出整个语法树。
自顶向下语法分析的步骤如下:1.设计非终结符的产生规则:根据文法的非终结符定义产生规则。
非终结符表示语法规则的左侧。
2.设计终结符的匹配规则:根据文法的终结符定义匹配规则。
终结符表示具体的代码元素,如标识符、关键字等。
3.设计递归下降分析算法:根据文法的产生规则,设计递归下降分析算法。
算法的入口是文法的起始符号,通过递归调用不同的产生规则,不断向下匹配源代码,构造语法树。
三、自底向上语法分析自底向上语法分析是一种逆推的、以产生规则的右侧为目标的方法。
它通过逐步将源代码的串规约为文法规则的右侧,最终得到语法树。
自底向上语法分析的步骤如下:1.设计终结符的匹配规则:根据文法的终结符定义匹配规则。
2.设计产生规则的规约动作:根据文法的产生规则,为每个规则设计规约动作。
规约动作通常是将产生规则的右侧转化为左侧的非终结符。
3.设计移进-规约分析算法:根据终结符的匹配规则和产生规则的规约动作,实现移进-规约分析算法。
算法通过逐步将输入的源代码进行移进和规约操作,直到得到语法树。
四、错误处理在语法分析的过程中,可能会出现各种错误,如语法错误、缺失分号、括号不匹配等。
语法分析器实验报告

语法分析器实验报告实验报告:语法分析器的设计与实现摘要:语法分析器是编译器的一个重要组成部分,主要负责将词法分析器输出的词法单元序列进行分析和解释,并生成语法分析树。
本实验旨在设计与实现一个基于上下文无关文法的语法分析器,并通过实现一个简单的编程语言的解释器来验证其功能。
1.引言在计算机科学中,编译器是将高级程序语言转化为机器语言的一种工具。
编译器通常由词法分析器、语法分析器、语义分析器、中间代码生成器、优化器和目标代码生成器等多个模块组成。
其中,语法分析器负责将词法分析器生成的词法单元序列进行进一步的分析与解释,生成语法分析树,为后续的语义分析和中间代码生成提供基础。
2.设计与实现2.1上下文无关文法上下文无关文法(CFG)是指一类形式化的语法规则,其中所有的产生式规则都具有相同的左部非终结符,且右部由终结符和非终结符组成。
语法分析器的设计与实现需要依据给定的上下文无关文法来进行,在本实验中,我们设计了一个简单的CFG,用于描述一个名为"SimpleLang"的编程语言。
2.2预测分析法预测分析法是一种常用的自顶向下的语法分析方法,它利用一个预测分析表来决定下一步的推导选择。
预测分析表的构造依赖于给定的上下文无关文法,以及文法的FIRST集和FOLLOW集。
在本实验中,我们使用了LL(1)的预测分析法来实现语法分析器。
2.3语法分析器实现在实现语法分析器的过程中,我们首先需要根据给定的CFG构造文法的FIRST集和FOLLOW集,以及预测分析表。
接下来,我们将词法分析器输出的词法单元序列作为输入,通过不断地匹配输入符号与预测分析表中的预测符号,进行语法分析和推导。
最终,根据CFG和推导过程,构建语法分析树。
3.实验结果与分析通过实验发现,自顶向下的预测分析法在对简单的编程语言进行语法分析时具有较高的效率和准确性。
语法分析器能够正确地识别输入程序中的语法错误,并生成相应的错误提示信息。
(完整)编译原理实验报告(词法分析器 语法分析器)

编译原理实验报告实验一一、实验名称:词法分析器的设计二、实验目的:1,词法分析器能够识别简单语言的单词符号2,识别出并输出简单语言的基本字。
标示符。
无符号整数.运算符.和界符。
三、实验要求:给出一个简单语言单词符号的种别编码词法分析器四、实验原理:1、词法分析程序的算法思想算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号.2、程序流程图(1)主程序(2)扫描子程序3、各种单词符号对应的种别码五、实验内容:1、实验分析编写程序时,先定义几个全局变量a[]、token[](均为字符串数组),c,s( char型),i,j,k(int型),a[]用来存放输入的字符串,token[]另一个则用来帮助识别单词符号,s用来表示正在分析的字符.字符串输入之后,逐个分析输入字符,判断其是否‘#’,若是表示字符串输入分析完毕,结束分析程序,若否则通过int digit(char c)、int letter(char c)判断其是数字,字符还是算术符,分别为用以判断数字或字符的情况,算术符的判断可以在switch语句中进行,还要通过函数int lookup(char token[])来判断标识符和保留字。
2 实验词法分析器源程序:#include 〈stdio.h〉#include <math.h>#include <string。
h>int i,j,k;char c,s,a[20],token[20]={’0’};int letter(char s){if((s〉=97)&&(s〈=122)) return(1);else return(0);}int digit(char s){if((s〉=48)&&(s<=57)) return(1);else return(0);}void get(){s=a[i];i=i+1;}void retract(){i=i-1;}int lookup(char token[20]){if(strcmp(token,"while")==0) return(1);else if(strcmp(token,"if")==0) return(2);else if(strcmp(token,"else”)==0) return(3);else if(strcmp(token,"switch”)==0) return(4);else if(strcmp(token,"case")==0) return(5);else return(0);}void main(){printf(”please input string :\n");i=0;do{i=i+1;scanf("%c",&a[i]);}while(a[i]!=’#’);i=1;j=0;get();while(s!=’#'){ memset(token,0,20);switch(s){case 'a':case ’b':case ’c':case ’d':case ’e’:case ’f’:case 'g’:case ’h':case 'i':case ’j':case 'k’:case ’l':case 'm’:case 'n':case ’o':case ’p':case ’q’:case 'r’:case 's’:case 't’:case ’u’:case ’v’:case ’w’:case ’x':case ’y':case ’z’:while(letter(s)||digit(s)){token[j]=s;j=j+1;get();}retract();k=lookup(token);if(k==0)printf("(%d,%s)”,6,token);else printf("(%d,—)",k);break;case ’0':case ’1’:case ’2':case ’3':case '4’:case '5’:case ’6':case ’7’:case ’8’:case '9’:while(digit(s)){token[j]=s;j=j+1;get();}retract();printf(”%d,%s",7,token);break;case '+':printf(”(’+',NULL)”);break;case ’-':printf("(’-',null)");break;case ’*':printf(”('*’,null)");break;case '<':get();if(s=='=’) printf(”(relop,LE)”);else{retract();printf("(relop,LT)");}break;case ’=':get();if(s=='=’)printf("(relop,EQ)");else{retract();printf(”('=',null)”);}break;case ’;':printf(”(;,null)");break;case ' ’:break;default:printf("!\n”);}j=0;get();} }六:实验结果:实验二一、实验名称:语法分析器的设计二、实验目的:用C语言编写对一个算术表达式实现语法分析的语法分析程序,并以四元式的形式输出,以加深对语法语义分析原理的理解,掌握语法分析程序的实现方法和技术.三、实验原理:1、算术表达式语法分析程序的算法思想首先通过关系图法构造出终结符间的左右优先函数f(a),g(a)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
token = getnexttoken( );
编译原理实验指导书
bexp( ); /*括号中仍然是表达式*/ token = getnexttoken( ); if ( token = ")" ) /*括号中的表达式处理完毕,后跟右括号*/
2.4 上机实验
【步骤一 语法分析总控程序的编写】
总控程序的功能就是识别以 program 开头的源程序头部结构,以及整个程序的框架,如 程序头部识别完之后,就是常量说明、变量说明、以及所有可执行语句的分析。具体步骤是:
(1) 利用实验四得到的 token 文件,如果直接调用词法分析,可以不使用文件。 (2) 利用自顶向下、逐个读入单词、判别是否符合程序头部的定义。 (3) 利用实验六的结果,判断各种说明语句和可执行语句是否正确。 (4) 重复(3)步,直到程序结束 例:可以按如下方式来编写总控程序:
编译原理实验指导书
开头),赋值语句(以标识符开头) 。每当读到前导词,表明一个新的语法结构的开始,以此 识别该语法单位是否符合定义。下图是语法分析程序的详细数据流图。
图 2-2 语法分析程序的详细数据流图 在语法分析过程中,各种语句的处理可以采用不同的语法分析方法,实验中希望能够使 用两种语法制导翻译技术:一是对各个语句和布尔表达式采用递归下降翻译法,二是对算术 表达式采用自底向上的算符优先分析方法。 根据采取的语法分析方法不同,就得到不同的详细数据流图。如下图是使用算符优先分 析方法的数据流。
(3) 编写识别算术表达式的函数,利用算符优先分析方法(也可以直接
使用递归下降的方法)。
(4) 实验思考题
1.语法分析程序的功能是什么?使用语法分析程序可以分析语言中的哪些语法成分? 2.语法分析的输入是什么?token 文件的特点是什么?你认为从 token 文件中读取一个 单词应采用什么方法? 3.递归下降分析方法的基本思路是什么?如何用它来编写程序? 4.请叙述对算术表达式的分析过程?
编译原理实验指导书
下面是根据上述处理流程利用递归下降的方法识别布尔表达式的函数描述如下:
bexp(char *token) /* 逻辑表达式的处理*/ {
bt( ); /* 处理布尔量*/ token = getnexttoken(); if ( token = "or" ) { /*首先处理 or*/
2.2 语法分析程序的设计方法
语法分析程序可以根据个人的掌握情况选用常见的几种语法分析方法:递归下降分析方 法、LL(1)预测分析法、算符优先分析、LR 分析等方法中的任何一种来实现,也可以选用不 同的方法来分析不同的语法成分,最后再综合起来。
2.3 语法分析程序的数据流图
词法分析程序把源程序变成 TOKEN 串,存放在 TOKEN 文件中。这个文件是 Sample 语言语法分析程序的输入文件。
实验思考题
1.语法分析总控程序应完成哪些操作? 2.为什么要对语句进行分类? 3.你编写的语法分析程序有哪些不足的地方,还有哪些功能是应该实现而你没有实现 的? 4.语法分析程序能够判别哪些错误?
【步骤二 编写识别算术表达式/逻辑表达式的函数】
(1) 编写从文件中读取一个单词的函数 getnexttoken(),返回该单词。
type = getnexttoken(); /*取出下一个token字,放入type中*/ if (type不是"integer","char","real","bool") error("变量说明错");
/*只能是这几种基本类型,若有其它类型,再加入*/ token= getnexttoken(); /*取出下一个token字*/ if (token不是";") error("缺少 ; ");/*处理完一行变量说明*/ token= getnexttoken(); /*取出下一个token字*/ if (isidentifier(token) ) varst(token);
编译原理实验指导书
《编译原理》综合性实验二:
语法分析器的设计
实验目的:掌握高级语言语法结构的定义,掌握语法分析的常用方法――递归下降的分析方 法。 实验要求:在 6 学时内完成全部内容,要求用 VC++窗口界面实现。 实验内容:分为 3 次实验内容完成。
2.1 语法分析程序的设计要求
语法分析程序要求能实现 Sample 语言中几种最常见的、基本的语法单位的分析:算术 表达式、逻辑表达式、赋值语句、IF 语句、for 语句、while 语句、repeat 语句等,各个语法 单位的定义见第 1 章,要求有完整的程序和说明。
图 2-3 算符优先分析的数据流图
编译原理实验指导书
图 2-4 算符优先分析的详细数据流图
但不管使用哪种语法分析方法,必须根据语法定义,下面详细说明变量说明的处理方法。 变量说明以var开头,格式如下:
<变量说明>::=var <变量定义>|ε <变量定义>::=<标识符表>:<类型>;|<标识符表>:<类型>;<变量定义> <标识符表>::=<标识符>, <标识符表>|<标识符>
处理流程如图:
下面是根据该流程采用递归下降的方法识别变量说明的算法描述。当读入前导词var后, 再读入一个token字,表明它是变量名称,调用下面的varst处理一行变量说明,当处理完一 行(读入;)后,下一行可能仍是变量说明,也可能是begin开始的可执行程序部分,否则就是 出错。
void varst(char *token) /*处理变量说明,读入var后进入该过程*/ {
语法分析是以单词为基本单位,因此,每次应读入一个单词。 语法分析的输入是词法分析的输出,即 token 字文件,在前面的实验中,将每个单词按 一行写入一个 token 文件中,因此首先应该打开文件,函数 getnexttoken()从文件的当前位置 读入一行,在 c 语言中可以使用函数 fgets(token,80,in)读入。
(2) 编制识别布尔表达式的函数
该函数逐个从文本中读取单词,判断所读入的以;结束的多个 token 是否构成了一个正 确的逻辑表达式。可以采用任何一种语法分析方法。布尔表达式的语法定义是:
(a) <逻辑表达式>::=<布尔项> or <布尔表达式> |<布尔项> (b) <布尔项>::=<布尔因子> and <布尔项> |<布尔因子> (c) <布尔因子>::=<布尔量> | not<布尔因子> (d) <布尔量>::=<布尔表达式>|<算术表达式><关系符><算术表达式> (e) <关系符>::=<|>|<>|<=| >=| = 下面是处理布尔表达式的流程:
文件名:parser 函数名:main()/* 从 token 文件中读取单词,根据定义进行分析*/ {
token = getnexttoken(); if (token = "program") { /*处理文件第一语句*/
token = getnexttoken(); isidentifier(token); /*判断是否是标识符*/ } token = getnexttoken(); if (token = ";") {/*程序头的结束*/ token = getnexttoken(); } if (token = "const") { /*表明下面是常量说明语句*/
/* 如果读入是标识符,继续处理变量说明*/ else if (token 是"begin")) return; /* 结束本函数的处理,
转入处理可执行程序部分*/
编译原理实验指导书
else error("语法错误:缺少BEGIN,或变量说明出错"); }
分析各种语法结构(算术表达式、逻辑表达式、说明语句、赋值语句、IF 语句、FOR 语 句、REPEAT 语句、WHILE 语句)的算法描述见语义分析一节。
token = getnexttoken(); bexp( ); /* 递归调用,or 后面应跟随另一个布尔表达式*/ } else 返回; /*布尔表达式分析结束*/ }
bt( ) /*处理 and*/
{
token = getnexttoken();
bf( );
/*处理布尔量*/
token = getnexttoken();
编译原理实验指导书
return 0; /*直接返回分析成功*/ } }
ST_SORT(chart *token) /* 可执行语句分类处理模块主程序*/ {
if (token = "if") ifs(); /*调用 IF 语句分析模块*/ else if (token= "while") whiles();/*调用 while 语句分析模块*/ else if (token= "repeat") repeats();/*调用 repeat 语句分析模块*/ else if (token= "for") fors();/*调用 for 语句分析模块*/ else assign();/*其余情况表示是赋值语句,直接调用赋值语句的分析*/ }