ENVI数据分块
城市微气象模拟工具ENVI-met中文入门

城市微气候仿真软件ENVI-met的应用天津住宅科学研究院有限公司汪磊磊⑴陈丹⑵邮箱:(1)lleiwang@ ;(2)chendan0804@ 城市微气候仿真软件ENVI-met是由德国的Michael Bruse (University of Mainz,Germany)开发的一个多功能系统软件,可以用来模拟住区室外风环境、城市热岛效应、室内自然通风等。
ENVI-met一共由四个模块组成,分别为建模版块ENVI-met Eddi Version、编程模块ENVI-met Configuration Editor、计算版块ENVI-met V3.1 Default Config以及结果显示版块LEONARDO 3.75。
一、建模版块在使用ENVI-met软件的过程中,最重要的一步就是建模,网格尺寸的大小、数量都直接影响到计算结果的准确性。
首先单击,进入建模版块,单击进入参数设置界面,如图1所示。
在此窗口可以设置模型所在地区的经度、纬度,网格尺寸、网格数量。
在实际模拟中,遇到一个问题,需要跟大家交流下,计算区域的高度必须大于等于建筑物最大高度的两倍,软件提供的计算区域最大网格数是250*250*30,因此,我们在编辑网格尺寸的时候要注意这一点,鉴于网格数的限制,可以适当提高网格的尺寸大小,这样既能满足建筑物高度的要求,又能满足计算的要求。
窗口1接下来就可以开始画模型了。
点击窗口2(Edit Building/Vegetation),可以定义建筑物的高度、植物的种类。
在Left Mouse 对应的窗口输入建筑物的高度,然后在网格区域点击鼠标左键画建筑物即可。
点击Left Mouse+Shift对应的下拉键,选择植物的种类,然后点击鼠标左键+Shift按钮在网格区域画植物。
值得注意的一点是,对于屋顶绿化的情况,可以直接在建筑物上单击鼠标左键+Shift键填充植物。
窗口2 窗口3 点击选中窗口3(Edit Soils),在下拉键中选择下垫面的类型,比如loamy road(土壤)、deep water(水面)、Asphalt Road(柏油马路)等,选择合适的下垫面后在网格区域画图。
envi多尺度分割步骤

envi多尺度分割步骤Envi多尺度分割步骤:一、数据预处理在进行多尺度分割之前,首先需要进行数据预处理。
数据预处理的目的是对原始数据进行清洗和转换,使其适用于后续的分割算法。
数据预处理的步骤包括数据获取、数据校正、数据筛选和数据格式转换等。
其中,数据获取是指从各种来源获取原始数据,如卫星遥感数据或地面观测数据等。
数据校正是指对原始数据进行校正,消除由于传感器特性或环境因素引起的噪声和偏差。
数据筛选是指对原始数据进行筛选,选择出具有代表性和可靠性的数据进行分割。
数据格式转换是指将原始数据转换为适用于分割算法的输入格式。
二、多尺度分割算法多尺度分割算法是基于图像的不同尺度特征进行分割的一种方法。
这种方法能够有效地提取出图像中的细节信息,并将图像分割为不同的区域。
多尺度分割算法的步骤包括图像金字塔构建、尺度空间分割和分割结果融合等。
1. 图像金字塔构建图像金字塔是一种用于多尺度图像处理的数据结构。
它通过对原始图像进行不同尺度的平滑和采样,构建了一系列的图像,从而提供了多尺度的图像表示。
图像金字塔的构建可以采用高斯金字塔或拉普拉斯金字塔等方法。
2. 尺度空间分割尺度空间分割是指在不同尺度下对图像进行分割。
在每个尺度上,可以使用不同的分割算法对图像进行分割,得到不同尺度下的分割结果。
常用的尺度空间分割方法包括基于边缘的分割、基于区域的分割和基于混合模型的分割等。
3. 分割结果融合在得到不同尺度下的分割结果后,需要将这些结果进行融合,得到最终的分割结果。
分割结果融合可以采用像素级的融合或基于区域的融合等方法。
像素级的融合是指将不同尺度下的像素进行组合,得到最终的像素分类结果。
基于区域的融合是指将不同尺度下的区域进行组合,得到最终的区域分类结果。
三、结果评估多尺度分割的最终结果需要进行评估,以验证其准确性和可靠性。
结果评估的指标包括精度、召回率和F1值等。
精度是指分割结果中正确分类的像素数占总像素数的比例。
envi混合像元分解步骤

envi混合像元分解步骤
哎呀,envi 混合像元分解呀,这可真是个有意思的事儿呢!咱就一步步来瞧瞧。
首先呢,你得准备好你的数据呀,就像厨师要准备好食材一样。
这些数据就是你的宝贝,要好好对待它们哟!
然后呀,要选择合适的算法,这就好比是选择做菜的方法,不同的算法就像是不同的烹饪技巧,能做出不同风味的成果呢!
接下来,就是开始分解啦!这就好像是把一个大拼图一点点拆开,找出每一块的位置。
在这个过程中呀,你得细心再细心,可不能马虎哟!
分解的时候呢,要注意观察各种特征呀,就像观察菜肴的颜色、形状、味道一样。
每一个细节都可能影响最终的结果呢。
这中间可能会遇到一些小麻烦,就像做菜时不小心盐放多了或者火大了。
但别着急,咱慢慢调整,总能找到最合适的方法。
分解完了之后呢,还得检查检查,看看是不是都分解对了。
这就好比是尝尝菜做的好不好吃,要是味道不对,就得重新调整呀。
你想想看,这 envi 混合像元分解不就像是一场奇妙的冒险嘛!每一步都充满了挑战和惊喜。
咱得有耐心,有毅力,才能把这个任务完成得漂漂亮亮的呀!
在这个过程中,可别嫌麻烦,就跟学骑自行车似的,一开始可能会摔倒,但多练习几次就会啦!而且等你掌握了这个技能,那感觉可太棒啦!就好像你学会了做一道超级美味的菜,能在别人面前好好炫耀一番呢!
总之呀,envi 混合像元分解虽然有点复杂,但只要咱一步一个脚印地去做,就一定能成功的。
加油吧!让我们在这个奇妙的世界里探索出更多的精彩!。
城市微气象模拟工具ENVI-met中文入门
城市微气候仿真软件ENVI-met的应用天津住宅科学研究院有限公司汪磊磊⑴陈丹⑵邮箱:(1)lleiwang@ ;(2)chendan0804@ 城市微气候仿真软件ENVI-met是由德国的Michael Bruse (University of Mainz,Germany)开发的一个多功能系统软件,可以用来模拟住区室外风环境、城市热岛效应、室内自然通风等。
ENVI-met一共由四个模块组成,分别为建模版块ENVI-met Eddi Version、编程模块ENVI-met Configuration Editor、计算版块ENVI-met V3.1 Default Config以及结果显示版块LEONARDO 3.75。
一、建模版块在使用ENVI-met软件的过程中,最重要的一步就是建模,网格尺寸的大小、数量都直接影响到计算结果的准确性。
首先单击,进入建模版块,单击进入参数设置界面,如图1所示。
在此窗口可以设置模型所在地区的经度、纬度,网格尺寸、网格数量。
在实际模拟中,遇到一个问题,需要跟大家交流下,计算区域的高度必须大于等于建筑物最大高度的两倍,软件提供的计算区域最大网格数是250*250*30,因此,我们在编辑网格尺寸的时候要注意这一点,鉴于网格数的限制,可以适当提高网格的尺寸大小,这样既能满足建筑物高度的要求,又能满足计算的要求。
窗口1接下来就可以开始画模型了。
点击窗口2(Edit Building/Vegetation),可以定义建筑物的高度、植物的种类。
在Left Mouse 对应的窗口输入建筑物的高度,然后在网格区域点击鼠标左键画建筑物即可。
点击Left Mouse+Shift对应的下拉键,选择植物的种类,然后点击鼠标左键+Shift按钮在网格区域画植物。
值得注意的一点是,对于屋顶绿化的情况,可以直接在建筑物上单击鼠标左键+Shift键填充植物。
窗口2 窗口3 点击选中窗口3(Edit Soils),在下拉键中选择下垫面的类型,比如loamy road(土壤)、deep water(水面)、Asphalt Road(柏油马路)等,选择合适的下垫面后在网格区域画图。
envi自己总结操作分类后处理

envi自己总结操作分类后处理分类后处理(Post Classification)1. 分类统计:ENVI:Classification>>Post Classification>>Class Statistics:包括每一类的点数、最小值、最大值、平均值以及类的每个波段的标准差等。
其中每一类的最小值、最大值、平均值以及标准差可以以图的方式进行显示。
可以显示出每一类的直方图,并且计算其协方差矩阵、相关矩阵、特征值和特征矢量等。
2. 两个分类结果的比较:ENVI:Classification>>Post Classification>>Confusion Matrix:分类结果的精度,显示在一个混淆矩阵里。
通过用分类结果与地表真实图像(Ground Truth Image)或地表真实感兴趣区(Ground Truth ROIs)相比较来计算混淆矩阵。
分类结果记录了总体精度、准确度、Kappa系数、混淆矩阵、commission 误差(每类中额外像元占的百分比)和冗长误差(类左边的像元占的百分比)等等。
当用地表真实图像计算混淆矩阵时,还可以输出每类图像中没有被正确分类的那些像元。
3. 类别集群:ENVI: Classification>>Post Classification>>Clump Classes细小块的合并,将一些碎块进行合并(平滑处理)。
注:未被选上用于聚块(clumping)的类,在输出图像上无变化。
4. 类别筛选:ENVI: Classification>>Post Classification>> Sieve Classes通过用斑点分组消除这些隔离的被分类的像元。
该功能菜单将删除分类中的孤岛像元,并用黑像元表示,可以用成块分类功能代替黑像元。
注:在“Group Min Threshold” 文本框里,输入一个类组需要包含的最少像元数(4或8)。
ENVI FX4.6操作说明

ENVI FX操作说明ENVI FX的操作可分为两个部分:发现对象(Find Object)和特征提取(Extract features),如图1所示。
图1 FX操作流程示意图(红色字体为可选项)1、准备工作根据数据源和特征提取类型等情况,可以有选择的对数据做一些预处理工作。
●空间分辨率的调整如果您的数据空间分辨率非常高,覆盖范围非常大,而提取的特征地物面积较大(如云、大片林地等)。
可以降低分辨率,提供精度和运算速度。
可利用ENVI主界面->Basic Tool->Resize Data工具实现。
●光谱分辨率的调整如果您处理的是高光谱数据,可以将不用的波段除去。
可利用ENVI主界面->Basic Tool->layer stacking工具实现。
●多源数据组合当您有其他辅助数据时候,可以将这些数据和待处理数据组合成新的多波段数据文件,这些辅助数据可以是DEM, lidar 影像, 和SAR 影像。
当计算对象属性时候,会生成这些辅助数据的属性信息,可以提高信息提取精度。
可利用ENVI主界面->Basic Tool->layer stacking工具实现。
●空间滤波如果您的数据包含一些噪声,可以选择ENVI的滤波功能做一些预处理。
2、发现对象(一)打开数据在ENVI Zoom中打开Processing > Feature Extraction。
如图2所示,Base Image 必须要选择,辅助数据(Ancillary Data)和掩膜文件(Mask File)是可选。
这里选择ENVI 自带数据envidata\feature_extraction \ qb_colorado,它是0.6米的快鸟数据,作为Base Image特征提取数据,不增加辅助数据和掩膜文件。
图2 选择数据(二)影像分割FX根据临近像素亮度、纹理、颜色等对影像进行分割,它使用了一种基于边缘的分割算法,这种算法计算很快,并且只需一个输入参数,就能产生多尺度分割结果。
ENVI分类流程

ENVI分类流程ENVI是一种强大的遥感图像处理和分析软件,用于从航空或卫星遥感数据中提取地物信息和进行环境分析。
ENVI涵盖了广泛的功能,包括遥感图像预处理、分类和监督分类等。
本文将详细介绍ENVI分类流程。
1.数据预处理:在进行分类之前,应该对遥感图像数据进行预处理,以减少数据中的噪声和对比度差异。
ENVI提供了各种图像预处理工具,如辐射校正、大气校正、几何校正和平均滤波等。
这些预处理步骤有助于改善图像质量,并为后续的分类准备工作奠定基础。
2.区域定义:3.光谱统计:在进行分类之前,需要对图像数据中的不同光谱进行统计分析。
ENVI 提供了光谱统计工具,可以从图像中选择感兴趣的区域,并计算选定区域的光谱统计数据,如平均值、方差和标准差等。
这些统计数据对于分类算法的选择和参数设置起着重要的作用。
4.特征选择:根据前一步骤中计算得到的光谱统计数据,可以选择合适的特征用于分类。
ENVI提供了一系列的特征选择工具,可以根据不同的统计指标和算法选择特征。
特征选择的目的是减少特征的维度,提高分类的准确性和效率。
5.分类算法选择:ENVI提供了多种分类算法,如最大似然法、支持向量机、随机森林和人工神经网络等。
在选择分类算法时,需要考虑图像数据的特征和分类的目标。
不同的算法有不同的特点和适用范围。
一些算法适用于特定类型的图像数据,而其他算法则适用于各种类型的数据。
根据需要选择合适的分类算法。
6.分类参数设置:在使用分类算法之前,需要设置一些参数,如类别数、邻域大小和迭代次数等。
这些参数的设置取决于分类的目标和图像数据的特征。
ENVI提供了参数设置界面,可以通过调整参数值来优化分类结果。
7.监督分类:ENVI提供了监督分类工具,可以使用已知的样本数据来训练分类器。
监督分类需要已经标记好的样本数据,其中包含了不同类别的像素。
根据样本数据,分类器可以学习不同类别的特征,并将未知像素分类为相应的类别。
ENVI提供了几种监督分类算法,如最大似然法和支持向量机等。
envi遥感图像处理之分类

ENVI遥感图像处理之计算机分类一、非监督分类1、K—均值分类算法步骤:1)打开待分类的遥感影像数据2)依次打开:ENVI主菜单栏—>Classification—>Unsupervised—>K—Means即进入K均值分类数据文件选择对话框3)选择待分类的数据文件4)选好数据以后,点击OK键,进入K-Means参数设置对话框,进行有关参数的设置,包括分类的类数、分类终止的条件、类均值左右允许误差、最大距离误差以及文件的输出等参数的设置5)建立光谱类和地物类之间的联系:在新窗口中显示分类结果图:然后,打开显示窗口菜单栏Tools菜单—>Color Mapping—>Class Color Mapping…进入分类结果的属性设置对话框,在这里,可以进行类别的名称,显示的颜色等,建立了光谱类和地物类之间的联系。
设置完成以后,点击菜单栏Options—>Save Changes 即完成光谱类与地物类联系的确立6)类的合并问题:如果分出的类中,有一些需要进行合并,可按以下步骤进行:选择ENVI主菜单Classfaction—>Post Classfiction—>Combine Classes,进入待合并分类结果数据的选择对话框点击OK键,进入合并参数设置对话框,在左边选择要合并的类,在右边选择合并后的类,点击Add Combination 键即完成一组合并的设置,如此反复,对其他需合并的类进行此项操作,点击OK,出现输出文件对话框,选择输出方式,即完成了类的合并的操作。
至此,K—均值分类的方法结束。
2、ISODATA算法基本操作与K—均值分类相似。
1)进行分类数据文件的选择(依次打开:ENVI主菜单栏—>Classification—>Unsupervised —>IsoData即进入ISODA TA算法分类数据文件选择对话框,选择待分类的数据文件)2)进行分类的相关参数的设置(点击OK键以后,进入参数设置对话框,可以进行分类的最大最小类数、迭代次数等参数的设置)3)如此,光谱类的划分到此结束。
envi随机森林分类步骤

envi随机森林分类步骤随机森林(Random Forest)是一种常用的集成学习方法,它通过构建大量的决策树并综合它们的结果来进行分类。
下面是随机森林分类的详细步骤,共分为以下几个部分:1.数据准备:-收集并整理需要分类的数据集,包括特征变量(如身高、体重等)和目标变量(如人是否患有其中一种疾病)。
-将收集到的数据集划分为训练集和测试集。
2.随机选取特征:-在随机森林算法中,为了增加每棵树的差异性,每次构建决策树时,从原始特征集中随机选取一部分特征。
-选择的特征数量可以是固定的,也可以是随机的。
3.构建决策树:-从训练集中随机抽样,按照其中一种方法(如ID3、C4.5、CART等)构建一棵决策树。
-决策树的构建过程中,每次在选定的特征集中选择最佳的划分特征,以使得划分后的子集尽可能纯净。
4.重复步骤2和3:-重复步骤2和3多次,构建出多棵不同的决策树。
5.预测分类结果:-使用构建好的随机森林对测试集中的样本进行分类预测。
-对于分类问题,通常采用多数表决的方法,即每棵树根据其分类结果投票,最终分类结果为票数最多的类别。
-对于回归问题,可以采用求平均值的方法,即每棵树返回的预测值取平均。
6.评估分类效果:-根据评估结果判断随机森林的分类效果,并可以根据需要对算法进行调优。
除了以上的基本步骤,还有一些额外的技术和策略可以应用于随机森林的分类过程中,以提升分类效果和泛化能力。
以下是一些常用的技术和策略:-特征重要性评估:-随机森林可以通过计算每个特征在所有决策树中的重要性来评估特征的重要性。
-常用的计算方法有基尼指数、信息增益等。
-调参:-随机森林有一些超参数需要调节以获取最佳的分类效果。
-常见的超参数包括决策树的数量、每棵决策树中选取特征的数量、决策树的最大深度等。
-可以使用交叉验证等方法对超参数进行调优。
-异常值处理:-随机森林对异常值具有一定的鲁棒性,但是严重的异常值可能会影响分类结果。
-可以通过删除异常值、替换异常值等方法进行处理。
envi标准文件格式

envi标准文件格式
ENVI标准文件格式是指一种特定的遥感数据存储格式,主要由头文件(后缀名.hdr)和与之对应的影像文件(通常为.img格式)组成。
这种格式广泛应用于遥感图像处理领域,特别是在ENVI(Environment for Visualization and Interpretation)软件中。
ENVI是一款专业的遥感图像处理和分析软件,它可以读取、显示、编辑和分析各种遥感数据。
ENVI标准文件格式包括以下特点:
1. 数据类型:ENVI标准文件支持多种数据类型,如字节、短整型、整型、浮点型等。
2. 投影坐标信息:头文件中包含数据的投影坐标信息,以便在后续处理中正确显示和分析数据。
3. 文件存储方式:头文件中还包含对应二进制文件的存储方式,如BSQ(行优先)、BIL(列优先)和BIP(页优先)等。
4. 图像行列信息:头文件中包含图像的行列数,以便正确显示和处理图像。
5. 数据分块信息:头文件中可以包含数据分块信息,便于在处理大数据时提高效率。
6. 坐标系统信息:头文件中可以包含图像的坐标系统信息,如地理坐标系(GCJ-02)或投影坐标系(如UTM)等。
总之,ENVI标准文件格式是一种便于遥感数据存储、处理和分析的格式。
在实际应用中,用户可以根据需要将ENVI标准文件转换为其他格式,如TIFF、GeoTIFF等。
envi批量分类方法-概述说明以及解释

envi批量分类方法-概述说明以及解释1.引言1.1 概述概述部分的内容可以按照以下方式进行编写:概述部分旨在介绍本文的主题和目的,为读者提供文章的背景和整体框架。
本篇文章将探讨环境问题分类方法中的envi批量分类方法。
在当今社会中,环境问题日益成为人们关注的焦点。
随着工业化和城市化的快速发展,环境问题愈加突出,对人类健康和整个生态系统造成了极大的威胁。
为了有效地应对和解决这些环境问题,分类方法成为了一项重要的工具。
环境问题分类方法的目的在于将复杂的环境问题进行系统的划分和分类,以便更好地理解和解决这些问题。
其中,envi批量分类方法作为一种先进的分类方法,具备快速、准确、高效的特点,受到了广泛的关注和应用。
通过envi批量分类方法,可以在遥感数据的基础上,利用计算机算法对环境问题进行智能化的分类和识别。
本文将分别介绍环境问题分类方法1和环境问题分类方法2,并对其原理和应用进行详细的讨论。
通过深入探究这两种分类方法,我们可以更全面地了解和掌握envi批量分类方法的核心概念和技术,为环境问题的解决提供有效的支持和指导。
最后,在结论部分,我们将对本文进行总结,并展望envi批量分类方法的未来发展方向。
我们相信,在日益严峻的环境形势下,envi批量分类方法将发挥更大的作用,为环境保护和可持续发展贡献更多的力量。
通过阅读本文,读者将能够了解envi批量分类方法在环境问题分类中的应用和优势,从而更好地认识和应对当前面临的环境挑战。
同时,本文也为相关领域的研究者和从业人员提供了重要的参考和借鉴。
文章结构部分的内容可以写作如下:1.2 文章结构本文主要介绍了envi批量分类方法。
为了使读者更好地理解本篇文章的内容,下面将对文章的结构进行简要概述。
引言部分(第1章)旨在引起读者的兴趣并介绍本文的背景和目的。
第1.1节将对环境问题的概述进行阐述,包括当前全球环境问题的严重性和紧迫性。
第1.2节将详细说明本文的结构,即介绍本文所涵盖的各个部分及其内容。
ENVI中几种监督分类方法精度比较

ENVI中几种监督分类方法精度比较遥感图像的监督分类常用方法目前可以分为:平行六面体法,马氏距离法,最大似然法,神经网络法以及支持向量机法等。
文章将就以上所述的五种常用的监督分类方法在ENVI中分别对汶川县威州镇同一Landsat8 OLI数据进行土地覆盖与利用状况分类.比较各种方法的分类精度,并对之所产生的差异的原因进行浅析,进而对实际的生产以及应用做出借鉴。
标签:监督分类;平行六面体;神经网络;支持向量机;分类精度Abstract:The common methods of supervised classification of remote sensing images can be divided into:parallelepiped classifier method,Mahalanobis distance method,maximum likelihood method,neural network method and support vector machine method. In this paper,the land cover and utilization of the same Landsat8 OLI data in Weizhou Town,Wenchuan County are classified by the five common supervised classification methods mentioned above in ENVI. Comparing the classification accuracy of various methods,we made an analysis of the causes of the differences,and then identify their actual production and application.Keywords:supervised classification;parallelepiped;neural network;support vector machine;classification accuracy1 概述遥感图像的分类主要是利用计算机将遥感图像中的光谱和空间信息进行分析,提出不同地物之间的特征及边界,并利用一定的算法的各个像元划归到互不重叠的各个子空间之中。
ENVI生态分区分类流程

打开envi-file-open image file在下对话框选择RGB Color,4,3,2波段,点击Load RGB在窗口中右键—ROI tool1)点击如上窗口中的ROI_Type—polygon.2)点击上图窗口中的zoom,在zoom窗口中选取样本。
3)选择类型,*为选中状态,每种类型选择样本在40个以上。
(类型相对较少的可适当少选取一些训练样本)4)点击左键,选取样本区域,右键闭合,再右键选中,选中后颜色改变。
注:如若删除选错样本,选择类型后,点击GO to,查看要修改的样本,点击鼠标中键,即可删除。
5)保存ROI文件。
以备后期修改方便点击file——save ROIS…点击select all items ,选择输出路径即可。
加载ROI点击file——restore ROIS…选择之前输出保存的ROI文件点击确定选择Region #1,点击Delete ROI,即可。
出现如下(提交文件一)输出样本文件,操作如下先选择第一类(图中为草地)然后点击file-export ROIS to shapefile裸、林、灌、草等类型提取采用的训练样本文件:文件命名p126_r037_l5_20050612_smp00_**.shp,**代表地类英文名称依次输出每一类的shape文件下图为输出草地的shape文件Classification——supervised——support vector machine分类后,点击classification——post classification ——majority/minority analysis。
选择去噪前的图,然后点击Load Band再选择去噪后的图,选择New display,再点击Load Band出现如下窗口在任意一个image窗口中右键——link displays去噪前后对比修改地类颜色,操作入下选择class color mapping 后出现如下窗口:按下表赋予不同地类RGB值。
ENVI高光谱数据处理流程

ENVI高光谱数据处理流程ENVI(Environment for Visualizing Images)是一款功能强大的遥感数据处理软件,用于高光谱数据的处理和分析。
它提供了许多功能模块,可以进行数据导入、预处理、特征提取、分类和可视化等操作。
下面是ENVI高光谱数据处理流程的详细介绍。
1.数据导入首先,我们需要将高光谱数据导入ENVI软件。
ENVI支持导入多种高光谱数据格式,如Hyperion、AVIRIS等。
可以通过ENVI的文件菜单选择导入数据或者使用ENVI API导入数据。
2.数据预处理在数据导入之后,我们需要对高光谱数据进行预处理,以减少噪声和增强图像的质量。
ENVI提供了多种数据预处理方法,包括大气校正、大气校正和去除噪声。
可以根据数据的需求选择适当的预处理方法。
3.特征提取特征提取是高光谱数据分析的关键步骤。
在这一步骤中,我们可以利用ENVI提供的各种特征提取算法来提取数据中的有用信息。
ENVI提供了许多特征提取算法,包括主成分分析(PCA)、线性判别分析(LDA)、最大似然分类(MLC)等。
4.分类分类是高光谱数据处理的一个重要环节。
ENVI提供了多种分类算法,用于将数据分成不同的类别。
可以使用ENVI的分类工具对特征提取后的数据进行分类,根据分类结果进行应用。
5.可视化可视化是高光谱数据处理的最后一步。
ENVI提供了丰富的可视化工具,可以对数据进行可视化和可视化分析。
可以通过ENVI的图像菜单选择适当的可视化工具,并根据需要生成图像。
以上是ENVI高光谱数据处理的基本流程。
当然,根据具体的应用和需求,还可以根据需要选择其他的处理方法和工具。
此外,ENVI还支持自定义算法和脚本编程,以满足更高级的数据处理需求。
总结起来,ENVI高光谱数据处理流程包括数据导入、数据预处理、特征提取、分类和可视化等步骤。
通过这些步骤,我们可以对高光谱数据进行全面的处理和分析,从而获取有用的信息并进行进一步的应用。
使用影像分块技术

ENVI提供了三种格式的分块:BSQ格式,BIL格式以及 ENVI提供了三种格式的分块:BSQ格式,BIL格式以及 提供了三种格式的分块 格式 BIP格式 格式。 BIP格式。 ENVI还提供了进度条部件来用来显示分块的处理情况。 ENVI还提供了进度条部件来用来显示分块的处理情况 还提供了进度条部件来用来显示分块的处理情况。 ENVI中也提供了未使用分块技术的函数,但是不推荐 ENVI中也提供了未使用分块技术的函数 中也提供了未使用分块技术的函数, 用户使用,因为它仅能用于比较小的文件。 用户使用,因为它仅能用于比较小的文件。 当然未使用分块技术的函数是一种快速访问数据的方 法,因此可用于进行快速程序原型的开发。 因此可用于进行快速程序原型的开发。
分块处理程序原理 ENVI分块处理将输入数据分成同样大小的单元 分块处理将输入数据分成同样大小的单元, ENVI分块处理将输入数据分成同样大小的单元,可以是 空间方式也可以是波谱方式, 空间方式也可以是波谱方式,以确保所有大小的影像都能 被处理。一个空间分块的大小是n 被处理。一个空间分块的大小是n行*所有列 ,而波谱分 块的大小总是Sample*band Sample*band。 块的大小总是Sample*band。
对于内存输出,结果存储在内存中分配的数组中。处 对于内存输出,结果存储在内存中分配的数组中。 理后的数据块将插入合适的存储位置。 理后的数据块将插入合适的存储位置。内存数组的大 小为NS*NL*NB IDL函数BYTARR,INTARR,LONARR, NS*NL*NB, 函数BYTARR 小为NS*NL*NB,IDL函数BYTARR,INTARR,LONARR, FLTARR,DBLARR,以及MAKE_ARRAY MAKE_ARRAY用来创建相对应的 FLTARR,DBLARR,以及MAKE_ARRAY用来创建相对应的 比特类型、整型、长整型、浮点、 比特类型、整型、长整型、浮点、双精度浮点以及任 意类型的内存数组。 意类型的内存数组。 当处理结果完成后,包含处理结果的内存数组可以使 当处理结果完成后, 用ENVI_ENTER_DATA传递给ENVI。在最简单的情况下, ENVI_ENTER_DATA传递给ENVI。在最简单的情况下, 传递给ENVI 仅仅内存数组是必须的。 仅仅内存数组是必须的。同样有一些额外的信息可以 提供, XY的起始位置以及文字描述和波段名称 的起始位置以及文字描述和波段名称。 提供,如XY的起始位置以及文字描述和波段名称。
envi5.6中的分类方法

Envi5.6中的分类方法引言E n vi是一款功能强大的遥感影像处理软件,其分类功能可以高效准确地将遥感影像数据分到不同的类别中。
本文将介绍En vi5.6中的分类方法,包括像元分类、目标分类和像素转标签。
像元分类像元分类是将遥感影像中的每个像元分配到特定的类别中的过程。
在E n vi5.6中,根据像元的光谱信息和统计学特征,可以使用各种算法进行像元分类。
支持向量机(S V M)支持向量机是一种常用的分类算法,它基于特征空间中的超平面来实现分类。
在E nv i5.6中,可以使用支持向量机算法对遥感影像进行像元分类,通过训练样本和测试样本的光谱信息,得到分类结果。
随机森林(R a n d o m F o r e s t)随机森林是一种基于决策树的集成学习方法,它能够充分利用多个决策树的优势进行分类。
在En vi5.6中,可以使用随机森林算法对遥感影像进行像元分类,通过构建多个决策树来得到更准确的分类结果。
目标分类目标分类是将遥感影像中的连通区域(目标)分配到特定的类别中的过程。
在En vi5.6中,可以使用各种算法进行目标分类,例如基于形状和纹理特征的目标分类算法。
形状特征形状特征是指目标在图像上的几何形状信息,例如目标的面积、周长、圆度等。
在E nv i5.6中,可以通过计算目标的形状特征,并结合训练样本和测试样本的光谱信息,对遥感影像进行目标分类。
纹理特征纹理特征是指目标表面上的纹理分布信息,例如目标的纹理熵、对比度、均匀性等。
在En v i5.6中,可以通过提取目标的纹理特征,并结合训练样本和测试样本的光谱信息,对遥感影像进行目标分类。
像素转标签像素转标签是将遥感影像中的每个像素值转换为特定的标签值的过程,用于将连续的遥感影像数据转化为离散的分类结果。
在En vi5.6中,可以使用各种阈值分割方法进行像素转标签。
基于单一阈值的分割基于单一阈值的分割是将遥感影像中的像素根据其灰度值和一个固定的阈值进行分类的方法。
envi多尺度分割步骤

envi多尺度分割步骤环境多尺度分割是地理信息系统(GIS)中的一种技术,用于将地表覆盖类型(如森林、湖泊、道路等)划分为不同的区域。
这个过程涉及将卫星遥感图像分割成许多不同的区域,然后通过对每个区域进行分类来获得地表覆盖类型的信息。
根据地表覆盖类型的详细程度,多尺度分割可以根据需要将图像划分为不同的尺度,以提供更精细或更全面的信息。
在进行多尺度分割时,通常需要遵循以下步骤:1.图像预处理:首先,对卫星遥感图像进行预处理。
这可能包括去除噪声、增强图像质量、校正辐射度等操作,以使图像更加适合进行分割。
2.分割尺度选择:选择适当的分割尺度是非常重要的。
这取决于所需的精度和应用。
有些应用需要更精细的分割,以获得更详细的地表覆盖类型信息,而有些应用则需要更大的尺度,以提供更全面的概览。
3.区域生成:在这一步骤中,通过将像素分组成区域来生成初始的分割结果。
这些区域可以是基于颜色、纹理、形状或其他特征的。
常用的算法包括基于区域的分割算法,如区域增长、标记连接等。
4.区域合并:在这一步骤中,利用区域合并算法对初始的分割结果进行优化。
区域合并算法通过将相似的区域合并在一起,以减少分割错误和提高准确性。
这些算法基于各种相似性度量,如颜色、纹理、形状等。
5.确定地表覆盖类型:在区域合并完成后,需要对每个区域进行地表覆盖类型的分类。
这可以通过训练分类器来实现,训练分类器需要有一定数量的标记样本。
该分类器可以使用各种机器学习算法,如决策树、支持向量机或神经网络等。
6.合并并解决冲突:在分类过程中,可能会出现由于相似区域之间的边界模糊,导致一些区域被分为多个类别的情况。
为了解决这个问题,可以使用一些后处理方法,如逐像元决策、区域增长等。
7. 评估和验证:最后,对分割结果进行评估和验证,以确定其准确性和可行性,并与地面真实数据进行比较。
常用的评估指标包括OA (Overall Accuracy)、Kappa系数等。
总的来说,环境多尺度分割是一个复杂的过程,它涉及到对卫星遥感图像的预处理、分割尺度选择、区域生成、区域合并、地表覆盖类型分类等多个步骤。
ENVI数据分块

分块写HDF示例源码算法原理,该图片是从IDL的jpeg2000help中截取,原理基本类似,依次分块写入程序运行效果如下,将一6000*6000的数据按照tileSize = [1024, 1024]的大小写入一hdf文件中看看最终结果文件(HDF Explorer查看)下载 (142.06 KB)2010/5/9 02:47运行源码;+;+;:Description:PRO CENTERTLB, tlb, x, y, NoCenter=nocenter COMPILE_OPT StrictArrgeom = WIDGET_INFO(tlb, /Geometry)IF N_ELEMENTS(x) EQ 0 THEN xc = 0.5 ELSE xc = FLOAT(x[0])IF N_ELEMENTS(y) EQ 0 THEN yc = 0.5 ELSE yc = 1.0 - FLOAT(y[0])center = 1 - KEYWORD_SET(nocenter);oMonInfo = OBJ_NEW('IDLsysMonitorInfo')rects = oMonInfo -> GetRectangles(Exclude_Taskbar=exclude_Taskbar)pmi = oMonInfo -> GetPrimaryMonitorIndex()OBJ_DESTROY, oMonInfoscreenSize =rects[[2, 3], pmi]; Get_Screen_Size()IF screenSize[0] GT 2000 THEN screenSize[0] = screenSize[0]/2 ; Dual monitors. xCenter = screenSize[0] * xcyCenter = screenSize[1] * ycxHalfSize = geom.Scr_XSize / 2 * centeryHalfSize = geom.Scr_YSize / 2 * centerXOffset = 0 > (xCenter - xHalfSize) < (screenSize[0] - geom.Scr_Xsize)YOffset = 0 > (yCenter - yHalfSize) < (screenSize[1] - geom.Scr_Ysize)WIDGET_CONTROL, tlb, XOffset=XOffset, YOffset=YOffsetEND;; 测试分块写如HDF文件; 读取请参考 C:\Program Files\ITT\IDL71\examples\doc\sdf\hdf_info.pro; Author: DYQ 2010-5-9;;; Blog: /dyqwrp;-PRO WRITEREADHDF;创建隐藏tlb,目的为了显示进度条wtlb = WIDGET_BASE(map = 0)WIDGET_CONTROL,wtlb,/realize;tlb居中显示CENTERTLB,wtlb;创建进度条process = IDLITWDPROGRESSBAR( TIME=0,$GROUP_LEADER=wtlb, $TITLE='测试分块保存HDF... 请等待')IDLITWDPROGRESSBAR_SETVALUE, process, 0;源数据及相关信息image = DIST(6000);求出数据范围myRANGE=[MAX(image,min=min_xray),min_xray]dims = SIZE(image,/dimension);块大小tileSize = [1024, 1024];初始化写入HDF数据filename = 'c:\test.hdf'sd_id=HDF_SD_START(filename,/CREATE);sds_id=HDF_SD_CREATE(sd_id,'largeWrite', $[dims[0],dims[1]],/FLOAT);HDF_SD_SETINFO,sds_id,FILL=0.0,LABEL='data', $UNIT='float',$RANGE=myRANGE;; Write labels to each of the dimensionHDF_SD_DIMSET,HDF_SD_DIMGETID(sds_id,0),NAME='Width',LABEL='Width of data'HDF_SD_DIMSET,HDF_SD_DIMGETID(sds_id,1),NAME='Height',LABEL='Height of data';xn和yn分别是行、列的初始循环次数xn = 0yn = 0;计算循环次数,- 目的为了进度条正确显示IF(dims[1]/tileSize[1] EQ 0 )AND(dims[0]/tileSize[0] EQ 0) THEN BEGINTotalNum = 1ENDIF ELSE IF(dims[1]/tileSize[1] EQ 0 ) THEN BEGINTotalNum = FIX(dims[0]/tileSize[0])+1ENDIF ELSE IF(dims[0]/tileSize[0] EQ 0 ) THEN BEGINTotalNum = FIX(dims[1]/tileSize[1])+1ENDIF ELSE TotalNum = (FIX(dims[1]/tileSize[1])+1)*(FIX(dims[0]/tileSize[0])+1) ; 更新下进度条IDLITWDPROGRESSBAR_SETVALUE, process, 1DoneNum = 0UpRate = 99/TotalNum;分别在水平和竖直方向循环WHILE(yn LT FIX(dims[1]/tileSize[1])) DO BEGINWHILE(xn LT FIX(dims[0]/tileSize[0])) DO BEGIN;计算存储的数据块位置loc = [tileSize[0]*xn,tileSize[1]*yn];提取数据相应位置数据wtImg = image[loc[0]:(loc[0]+tilesize[0]-1),loc[1]:(loc[1]+tilesize[1]-1)] ;写入HDF文件中HDF_SD_ADDDATA, sds_id, wtImg, $START=loc, COUNT=tileSizexn++;更新进度条DoneNum = DoneNum+1IDLITWDPROGRESSBAR_SETVALUE, process, 1+UpRate*DoneNumENDWHILE;IF(dims[0] GT tileSize[0]*xn)THEN BEGIN;计算存储的数据块位置loc = [tileSize[0]*xn,tileSize[1]*yn];提取数据相应位置数据wtImg = image[loc[0]:(dims[0]-1),loc[1]:(loc[1]+tilesize[1]-1)];写入HDF文件中,注意count的变化HDF_SD_ADDDATA, sds_id, wtImg, $START=loc, COUNT=SIZE(wtImg,/dimension)ENDIF;xn = 0yn++;更新进度条DoneNum = DoneNum+1IDLITWDPROGRESSBAR_SETVALUE, process, 1+UpRate*DoneNumENDWHILE; 最后一行不完整的部分IF(dims[1] GT tileSize[1]*yn)THEN BEGINxn = 0WHILE(xn LT FIX(dims[0] /tileSize[0])) DO BEGIN;计算存储的数据块位置loc = [tileSize[0]*xn,tileSize[1]*yn];提取数据相应位置数据wtImg = image[loc[0]:(dims[0]-1),loc[1]:(dims[1]-1)];写入HDF文件中HDF_SD_ADDDATA, sds_id, wtImg, $START=loc, COUNT=SIZE(wtImg,/dimension)xn++;更新进度条DoneNum = DoneNum+1IDLITWDPROGRESSBAR_SETVALUE, process, 1+UpRate*DoneNum ENDWHILEENDIF;关闭HDFHDF_SD_ENDACCESS,sds_idHDF_SD_END,sd_idIDLITWDPROGRESSBAR_SETVALUE, process, 100;销毁没用的WAIT,0.3WIDGET_CONTROL,process,/DestroyWIDGET_CONTROL, wtlb,/DESTROYEND。
ENVI常见问题
【转】FLAASH大气校正常见错误及解决方法本文汇总了ENVI FLAASH大气校正模块中常见的错误,并给出解决方法,分为两部分:运行错误和结果错误。
前面是错误提示及说明,后面是错误解释及解决方法。
FLAASH对输入数据类型有以下几个要求:1、波段范围:卫星图像:400-2500nm,航空图像:860nm-1135nm。
如果要执行水汽反演,光谱分辨率<=15nm,且至少包含以下波段范围中的一个:l1050-1210 nml770-870 nml870-1020 nm2、像元值类型:经过定标后的辐射亮度(辐射率)数据,单位是:(μW)/(cm2*nm*sr)。
3、数据类型:浮点型(Floating Point)、32位无符号整型(Long Integer)、16位无符号和有符号整型(Integer、Unsigned Int),但是最终会在导入数据时通过Scale Factor 转成浮点型的辐射亮度(μW)/(cm2*nm*sr)。
4、文件类型:ENVI标准栅格格式文件,BIP或者BIL储存结构。
5、中心波长:数据头文件中(或者单独的一个文本文件)包含中心波长(wavelenth)值,如果是高光谱还必须有波段宽度(FWHM),这两个参数都可以通过编辑头文件信息输入(Edit Header)。
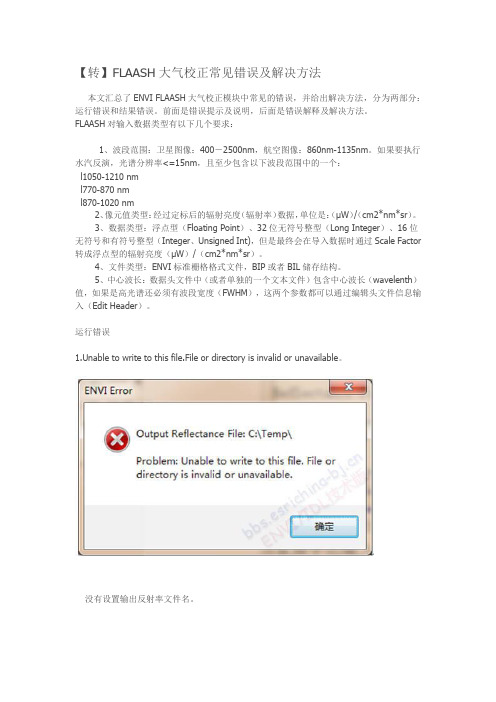
运行错误1.Unable to write to this file.File or directory is invalid or unavailable。
没有设置输出反射率文件名。
解决方法是单击Output Reflectance File按钮,选择反射率数据输出目录及文件名,或者直接手动输入。
2.ACC Error:convert7IDL Error:End of input record encountered on file unit:0.平均海拔高程太大。
注意:填写影像所在区域的平均海拔高程的单位是km:Ground Elevation(Km)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
分块写HDF示例源码
算法原理,该图片是从IDL的jpeg2000help中截取,原理基本类似,依次分块写入
程序运行效果如下,将一6000*6000的数据按照tileSize = [1024, 1024]的大小写入一hdf文件中
看看最终结果文件(HDF Explorer查看)
下载 (142.06 KB)
2010/5/9 02:47
运行源码
;+
;+
;:Description:
PRO CENTERTLB, tlb, x, y, NoCenter=nocenter COMPILE_OPT StrictArr
geom = WIDGET_INFO(tlb, /Geometry)
IF N_ELEMENTS(x) EQ 0 THEN xc = 0.5 ELSE xc = FLOAT(x[0])
IF N_ELEMENTS(y) EQ 0 THEN yc = 0.5 ELSE yc = 1.0 - FLOAT(y[0])
center = 1 - KEYWORD_SET(nocenter)
;
oMonInfo = OBJ_NEW('IDLsysMonitorInfo')
rects = oMonInfo -> GetRectangles(Exclude_Taskbar=exclude_Taskbar)
pmi = oMonInfo -> GetPrimaryMonitorIndex()
OBJ_DESTROY, oMonInfo
screenSize =rects[[2, 3], pmi]
; Get_Screen_Size()
IF screenSize[0] GT 2000 THEN screenSize[0] = screenSize[0]/2 ; Dual monitors. xCenter = screenSize[0] * xc
yCenter = screenSize[1] * yc
xHalfSize = geom.Scr_XSize / 2 * center
yHalfSize = geom.Scr_YSize / 2 * center
XOffset = 0 > (xCenter - xHalfSize) < (screenSize[0] - geom.Scr_Xsize)
YOffset = 0 > (yCenter - yHalfSize) < (screenSize[1] - geom.Scr_Ysize)
WIDGET_CONTROL, tlb, XOffset=XOffset, YOffset=YOffset
END
;
; 测试分块写如HDF文件
; 读取请参考 C:\Program Files\ITT\IDL71\examples\doc\sdf\hdf_info.pro
; Author: DYQ 2010-5-9;
;
; Blog: /dyqwrp
;-
PRO WRITEREADHDF
;创建隐藏tlb,目的为了显示进度条
wtlb = WIDGET_BASE(map = 0)
WIDGET_CONTROL,wtlb,/realize
;tlb居中显示
CENTERTLB,wtlb
;创建进度条
process = IDLITWDPROGRESSBAR( TIME=0,$
GROUP_LEADER=wtlb, $
TITLE='测试分块保存HDF... 请等待')
IDLITWDPROGRESSBAR_SETVALUE, process, 0
;源数据及相关信息
image = DIST(6000)
;求出数据范围
myRANGE=[MAX(image,min=min_xray),min_xray]
dims = SIZE(image,/dimension)
;块大小
tileSize = [1024, 1024]
;初始化写入HDF数据
filename = 'c:\test.hdf'
sd_id=HDF_SD_START(filename,/CREATE)
;
sds_id=HDF_SD_CREATE(sd_id,'largeWrite', $
[dims[0],dims[1]],/FLOAT)
;
HDF_SD_SETINFO,sds_id,FILL=0.0,LABEL='data', $
UNIT='float',$
RANGE=myRANGE
;
; Write labels to each of the dimension
HDF_SD_DIMSET,HDF_SD_DIMGETID(sds_id,0),NAME='Width',LABEL='Width of data'
HDF_SD_DIMSET,HDF_SD_DIMGETID(sds_id,1),NAME='Height',LABEL='Height of data'
;xn和yn分别是行、列的初始循环次数
xn = 0
yn = 0
;计算循环次数,- 目的为了进度条正确显示
IF(dims[1]/tileSize[1] EQ 0 )AND(dims[0]/tileSize[0] EQ 0) THEN BEGIN
TotalNum = 1
ENDIF ELSE IF(dims[1]/tileSize[1] EQ 0 ) THEN BEGIN
TotalNum = FIX(dims[0]/tileSize[0])+1
ENDIF ELSE IF(dims[0]/tileSize[0] EQ 0 ) THEN BEGIN
TotalNum = FIX(dims[1]/tileSize[1])+1
ENDIF ELSE TotalNum = (FIX(dims[1]/tileSize[1])+1)*(FIX(dims[0]/tileSize[0])+1) ; 更新下进度条
IDLITWDPROGRESSBAR_SETVALUE, process, 1
DoneNum = 0
UpRate = 99/TotalNum
;分别在水平和竖直方向循环
WHILE(yn LT FIX(dims[1]/tileSize[1])) DO BEGIN
WHILE(xn LT FIX(dims[0]/tileSize[0])) DO BEGIN
;计算存储的数据块位置
loc = [tileSize[0]*xn,tileSize[1]*yn]
;提取数据相应位置数据
wtImg = image[loc[0]:(loc[0]+tilesize[0]-1),loc[1]:(loc[1]+tilesize[1]-1)] ;写入HDF文件中
HDF_SD_ADDDATA, sds_id, wtImg, $
START=loc, COUNT=tileSize
xn++
;更新进度条
DoneNum = DoneNum+1
IDLITWDPROGRESSBAR_SETVALUE, process, 1+UpRate*DoneNum
ENDWHILE
;
IF(dims[0] GT tileSize[0]*xn)THEN BEGIN
;计算存储的数据块位置
loc = [tileSize[0]*xn,tileSize[1]*yn]
;提取数据相应位置数据
wtImg = image[loc[0]:(dims[0]-1),loc[1]:(loc[1]+tilesize[1]-1)]
;写入HDF文件中,注意count的变化
HDF_SD_ADDDATA, sds_id, wtImg, $
START=loc, COUNT=SIZE(wtImg,/dimension)
ENDIF
;
xn = 0
yn++
;更新进度条
DoneNum = DoneNum+1
IDLITWDPROGRESSBAR_SETVALUE, process, 1+UpRate*DoneNum
ENDWHILE
; 最后一行不完整的部分
IF(dims[1] GT tileSize[1]*yn)THEN BEGIN
xn = 0
WHILE(xn LT FIX(dims[0] /tileSize[0])) DO BEGIN
;计算存储的数据块位置
loc = [tileSize[0]*xn,tileSize[1]*yn]
;提取数据相应位置数据
wtImg = image[loc[0]:(dims[0]-1),loc[1]:(dims[1]-1)]
;写入HDF文件中
HDF_SD_ADDDATA, sds_id, wtImg, $
START=loc, COUNT=SIZE(wtImg,/dimension)
xn++
;更新进度条
DoneNum = DoneNum+1
IDLITWDPROGRESSBAR_SETVALUE, process, 1+UpRate*DoneNum ENDWHILE
ENDIF
;关闭HDF
HDF_SD_ENDACCESS,sds_id
HDF_SD_END,sd_id
IDLITWDPROGRESSBAR_SETVALUE, process, 100
;销毁没用的
WAIT,0.3
WIDGET_CONTROL,process,/Destroy
WIDGET_CONTROL, wtlb,/DESTROY
END。