自然语言理解课程实验报告
自然语言理解课程设计

自然语言理解课程设计报告机器翻译系统的分析一、课题分析机器翻译(machine translation),又称为自动翻译,是利用计算机把一种自然源语言转变为另一种自然目标语言的过程,一般指自然语言之间句子和全文的翻译。
它是自然语言处理(Natural Language Processing)的一个分支,与计算语言学(Computational Linguistics )、自然语言理解(Natural Language Understanding)之间存在着密不可分的关系。
机器翻译的研究是建立在语言学、数学和计算机科学这3门学科的基础之上的。
语言学家提供适合于计算机进行加工的词典和语法规则,数学家把语言学家提供的材料形式化和代码化,计算机科学家给机器翻译提供软件手段和硬件设备,并进行程序设计。
缺少上述任何一方面,机器翻译就不能实现,机器翻译效果的好坏,也完全取决于这3个方面的共同努力。
整个机器翻译的过程可以分为原文分析、原文译文转换和译文生成3个阶段。
在具体的机器翻译系统中,根据不同方案的目的和要求,可以将原文译文转换阶段与原文分析阶段结合在一起,而把译文生成阶段独立起来,建立相关分析独立生成系统。
在这样的系统中,原语分析时要考虑译语的特点,而在译语生成时则不考虑原语的特点。
在搞多种语言对一种语言的翻译时,宜于采用这样的相关分析独立生成系统。
也可以把原文分析阶段独立起来,把原文译文转换阶段同译文生成阶段结合起来,建立独立分析相关生成系统。
在这样的系统中,原语分析时不考虑译语的特点,而在译语生成时要考虑原语的特点,在搞一种语言对多种语言的翻译时,宜于采用这样的独立分析相关生成系统。
还可以把原文分析、原文译文转换与译文生成分别独立开来,建立独立分析独立生成系统。
在这样的系统中,分析原语时不考虑译语的特点,生成译语时也不考虑原语的特点,原语译语的差异通过原文译文转换来解决。
在搞多种语言对多种语言的翻译时,宜于采用这样的独立分析独立生成系统。
自然语言理解课程设计报告

自然语言理解课程设计报告姓名所在学院专业年级报告提交时间联系电话电子信箱1.课题分析课题:分析已有的机器翻译系统(至少6种以上)并比较其优劣。
机器翻译(machine translation),又称为自动翻译,是利用计算机把一种自然源语言转变为另一种自然目标语言的过程,一般指自然语言之间句子和全文的翻译。
它是自然语言处理(Natural Language Processing)的一个分支,与计算语言学(Computational Linguistics )、自然语言理解(Natural Language Understanding)之间存在着密不可分的关系2.国内外研究进展机器翻译,尤其是统计机器翻译方法具有很多优势,如开发速度快、周期短、无需人工干预等,在特定领域训练数据充分的情况下翻译性能基本可以达到实用水平。
因此,统计方法成为众多机器翻译系统开发者的首选。
例如,Google、Microsoft以及国内的百度、有道等互联网公司开发的在线多语言机器翻译系统;Asia Online、SDL Language Weaver等著名公司向企业和政府提供的翻译服务;即时通信工具GoogleTalk、MSN中的即时翻译服务,社交网络Facebook中的翻译服务;以及IBM、Google 推出的实时语音翻译系统等等。
可以看到,在通用领域,机器翻译已经开始进入人们的日常生活。
对于专利翻译而言,由于其领域受限、目标明确,因此,专利翻译一直都是机器翻译的试验场。
机器翻译方法,特别是基于统计的方法和基于翻译记忆(Translation Memory)的方法,在这样的限定领域内已经接近实用化。
很多公司推出了以机器翻译为核心技术的专利翻译服务。
为了推动专利翻译技术的发展,机器翻译峰会(MT Summit)等国际会议举办了多届专利翻译研讨会,日本国家科学咨询系统中心策划的NTCIR项目连续举办了多届专利翻译评测。
尽管机器翻译已经为人们的学习和工作提供了很多便利,但目前的机器翻译技术并不成熟,还存在着很多缺陷,如基于规则的翻译协调依赖于专家制定的规则,规则的维护与更新非常困难,而基于统计的翻译方法则需要大规模的双语平行语料库,并且领域适应能力较差等等。
大自然的语言的研究报告

大自然的语言的研究报告【研究报告】大自然的语言摘要:大自然是地球上丰富多样的生态系统,包括动物、植物和微生物。
这些生物之间通过各种方式进行交流,其中最普遍的方式是语言。
本研究报告调查了大自然中不同生物的语言,包括动物之间的声音通信、植物之间的化学信号以及微生物之间的信号传递。
研究结果表明,大自然中的语言是多样且精确的,起到了促进生物之间的交流和合作的重要作用。
1. 动物的声音通信动物通过声音进行各种形式的交流,包括交配行为、领地宣示和警告声。
不同物种的声音通信具有独特的特征,这些特征可以帮助同种动物互相识别、建立社交群体以及协调行动。
例如,一些鸟类会发出特殊的鸣叫来吸引异性,而一些哺乳动物会通过吼叫来警告入侵者。
2. 植物的化学信号植物通过释放化学物质来传递信息,以吸引传粉媒介、抵御害虫或警示同种植物。
这些化学信号通常以气味或味道形式存在,能够被周围的植物和昆虫感知和解读。
例如,当一棵植物受到害虫的攻击时,它会释放出一种特殊的化学物质,以吸引天敌来消灭害虫。
3. 微生物的信号传递微生物通过分泌化学物质来进行信号传递,以便合作和协调行动。
这些信号可以通过细菌、真菌和原生动物之间的交换来传递。
研究发现,微生物的信号传递在宿主生物的健康和某些疾病的发展中起着重要作用。
例如,某些细菌可以通过释放特定化学物质来调控群体大小和生长速度,以实现资源的最大利用效率。
总结:大自然中的语言是一种复杂而多样的交流方式,各种生物通过声音、化学物质和信号传递来进行交流和合作。
研究大自然语言的深入了解将有助于我们更好地理解生物之间的互动关系,并为环境保护和生物学研究提供新的启示。
关键词:大自然、语言、动物、植物、微生物、声音通信、化学信号、信号传递、交流、合作。
利用自然语言处理技术进行自然语言理解的实验设计

自然语言处理技术(NLP)是一种人工智能技术,它涉及计算机对人类语言进行理解和处理。
自然语言理解(NLU)是NLP的一个重要分支,它主要研究计算机如何理解人类语言。
通过NLU技术,计算机可以理解和处理人类语言,实现语义分析、情感分析、对话系统等应用。
本文将设计一项实验,探讨利用自然语言处理技术进行自然语言理解的实验方法和步骤。
1. 实验背景自然语言处理技术的发展已经取得了很大的进展,但是在自然语言理解方面仍然存在挑战。
例如,语言的歧义性、复杂性以及语境相关性都给自然语言理解带来了困难。
因此,设计一项实验,通过自然语言处理技术进行自然语言理解的研究具有重要意义。
2. 实验目的本实验的目的是验证利用自然语言处理技术进行自然语言理解的可行性,探讨NLP技术在NLU方面的应用能力,并提出相关的实验设计和研究方法。
3. 实验步骤(1)语料收集:首先需要收集大量的语料作为实验数据。
语料可以包括书籍、新闻、论文、对话记录等多种形式,以确保语料的多样性和真实性。
(2)数据预处理:对收集到的语料进行预处理,包括分词、词性标注、句法分析等步骤,以便后续的数据分析和模型训练。
(3)特征提取:通过特征提取技术,将语料转换成计算机可以理解和处理的形式。
常用的特征提取方法包括词袋模型、TF-IDF算法、Word2Vec等。
(4)模型训练:选择合适的自然语言处理模型进行训练,如循环神经网络(RNN)、长短时记忆网络(LSTM)、Transformer模型等。
通过大量的语料训练模型,提高模型对自然语言的理解能力。
(5)实验设计:设计一系列的实验任务,如语义分析、情感分析、命名实体识别等,评估模型在自然语言理解方面的性能。
4. 实验评估在实验设计阶段,需要确定合适的评估指标和评估方法来评价模型的性能。
常用的评估指标包括准确率、召回率、F1值等,评估方法可以采用交叉验证、留出法、自助法等。
通过实验评估,可以全面地了解模型在自然语言理解方面的表现,并对实验结果进行分析和总结。
大班语言游戏教案《大自然的语言》含反思

大班语言游戏教案《大自然的语言》含反思一、教学内容本节课选自大班语言领域教材第四章《大自然的语言》。
详细内容包括:认识大自然中的各种声音,如风声、雨声、雷声等;学习用语言描述大自然的声音和景象;通过语言游戏,培养幼儿对大自然语言的兴趣和热爱。
二、教学目标1. 让幼儿能够识别并模仿大自然中的各种声音,提高幼儿的听觉敏感度。
2. 培养幼儿用语言描述大自然声音和景象的能力,提高幼儿的语言表达能力。
3. 通过游戏活动,激发幼儿对大自然语言的热爱,培养幼儿的环保意识。
三、教学难点与重点教学难点:让幼儿学会用恰当的语言描述大自然的声音和景象。
教学重点:认识大自然中的各种声音,培养幼儿对大自然语言的兴趣。
四、教具与学具准备1. 教具:录音机、磁带、图片、卡片、挂图等。
2. 学具:画笔、彩纸、剪刀、胶水等。
五、教学过程1. 实践情景引入(5分钟)教师播放大自然声音的录音,让幼儿闭上眼睛,认真聆听,并猜一猜这些声音分别来自哪里。
2. 例题讲解(10分钟)教师展示图片,引导幼儿用语言描述图片中的大自然景象和声音。
如:风儿吹过,树叶沙沙作响;雨滴落在地上,发出滴答滴答的声音等。
3. 随堂练习(10分钟)教师发放卡片,让幼儿选择一个大自然声音,用画笔和彩纸制作一幅画,并用自己的语言描述这幅画。
4. 语言游戏(10分钟)教师组织幼儿进行“大自然声音模仿秀”,让幼儿模仿大自然中的声音,其他幼儿猜测是哪种声音。
教师邀请部分幼儿分享自己的作品和描述,对幼儿的表现给予肯定和鼓励。
六、板书设计1. 大自然的语言风声、雨声、雷声等2. 描述方法形容词、动词、拟声词等七、作业设计1. 作业题目:请幼儿回家后,观察大自然中的声音和景象,用画笔记录下来,并尝试用语言描述。
2. 答案:略。
八、课后反思及拓展延伸1. 课后反思本节课通过实践情景引入、例题讲解、随堂练习等多种形式,让幼儿对大自然语言有了更深入的了解,提高了幼儿的语言表达能力。
但在教学过程中,部分幼儿对大自然声音的模仿仍不够准确,需要进一步指导和练习。
自然语言理解-实验报告

分词系统工程报告
课程:自然语言理解
姓名:王佳淼
学号:
班级:信息安全11-1
日期:2013-11-2
实验一宋词字统计
一.研究背景
本实验所涉及的研究背景是利用计算机来“鉴赏”宋词。
主要针对宋词这种特殊的汉语诗歌体裁,开展了有关自动生成算法及其实现方法的探索性研究。
通过对大量语料的学习,来自动生成宋词。
由于宋词自身的特性,能够在经过大量预料学习后,利用在宋词当中出现频率较高的词语或者单字排列组合来生成宋词。
二.实验所采用的开发平台及语言工具
实验在WIN7的环境下利用VC++编程。
三.系统设计
(1)算法基本思想
从文本中字符,判断是否为中文字符(全角字符),若为全角字符则根据需要继续读取,即读取两个或三个字。
利用map容器来存储统计结果。
(2)流程图。
自然语言实验报告

b、 GIZA++-v2 cd GIZA++-v2 #进入目录 #修改 Makefile 文件,删除“-DBINARY_SEARCH_FOR_TTABLE” make #编译 4、 安装 Moses 1> 下载安装 moses 解码器 a、安装所需要的依赖包 sudo apt-get install autoconf automaketexinfo zlib1g zlib1g-dev zlib-bin zlibc b、因为需要从网上直接下载 moses,故先安装 subversion sudo apt-get install subversion c、下载源码包 svn cohttps:///svnroot/mosesdecoder/trunkmosesd ecoder d、moses 的编译相关操作 cd mosesdecoder ./regenerate-makefiles.sh ./configure –with-srilm=/#SRILM #SRILM make -j 4 2> 安装训练脚本 a、建立训练脚本目录: mkdir-p bin/moses-scripts b、修改 makefile:现代汉语切分、标注、注音语料库-1998 年 1 月份样例与规范(北京大学) 1998-01-2003 版-带音(已标注语料库) 语料库规范
三、试验原理
主要是通过下面四个方面: [1] 语料准备 首先需要编程将汉语句子和英语句子分别从1500 句对中抽取出来存在两个文本 文件中,1500 个汉语句子存放在文件chinese 中,1500个英语句子存放在english 中。每个句子一行,并且汉英对应句子的行号一一对应。然后,您需要对chinese 中 的汉语句子进行切分,也就是切成一个个的汉语词。对于english 中的英语句子进 行tokenize。之后english 用做语言模型的训练语料,chinese 和english 用做翻译模
利用自然语言处理技术进行自然语言理解的实验设计(五)

自然语言处理(Natural Language Processing,NLP)技术是一种人工智能领域的重要研究方向,其应用范围涉及文本分析、自动翻译、情感分析等多个领域。
其中,自然语言理解是NLP技术中的重要环节,它旨在让计算机能够理解人类语言的含义和语境。
本文将设计一项实验,探索利用自然语言处理技术进行自然语言理解的方法和过程。
实验背景自然语言理解是NLP技术的核心内容之一,它包括词法分析、句法分析、语义理解等多个层面。
在实际应用中,如何让计算机准确地理解人类语言仍然是一个挑战。
因此,设计一项实验来探索自然语言理解的方法和实现过程具有重要意义。
实验目的本实验旨在通过构建一个自然语言理解的模型,利用自然语言处理技术来实现对人类语言的理解和分析。
具体目的包括:1.了解自然语言理解的基本原理和方法;2.设计并实现一个基于NLP技术的自然语言理解模型;3.评估模型的性能和效果。
实验步骤和设计1. 文本数据收集:首先,我们需要收集一些包括不同领域和主题的文本数据,例如新闻报道、论坛帖子、社交媒体评论等。
这些文本数据将作为我们实验的输入。
2. 文本预处理:在文本数据收集之后,我们需要对文本进行预处理,包括去除停用词、分词、词性标注等操作。
这一步骤旨在准备好清洁、结构化的文本数据,以便后续的分析和建模。
3. 构建语言模型:接下来,我们将利用自然语言处理技术构建一个语言模型,该模型将包括词向量表示、句法分析、语义理解等功能。
这个语言模型将作为我们实验的核心。
4. 自然语言理解实现:基于构建的语言模型,我们将设计并实现一个自然语言理解系统,该系统能够接收输入文本并进行语义理解和分析,最终输出对输入文本的理解结果。
5. 模型评估和优化:最后,我们将对实现的自然语言理解系统进行评估和优化。
评估指标包括模型的准确率、召回率、F1值等,通过不断优化模型参数和算法,提高自然语言理解系统的性能和效果。
实验结果和讨论在进行了上述实验步骤之后,我们将得到一个基于自然语言处理技术的自然语言理解系统。
利用自然语言处理技术进行自然语言理解的实验设计(七)

自然语言处理技术(NLP)是一种利用计算机技术处理和理解自然语言的方法。
随着人工智能技术的迅速发展,NLP技术在各个领域得到了广泛的应用。
其中,自然语言理解(NLU)是NLP技术的一个重要分支,旨在使计算机能够理解和处理人类的自然语言。
本文将设计一个实验,旨在利用自然语言处理技术进行自然语言理解,以期达到更深入的理解和应用。
首先,我们需要收集一些自然语言数据,例如新闻报道、社交媒体信息、学术论文等。
这些数据将被用作实验的输入,以测试NLP技术的自然语言理解能力。
为了保证实验的科学性和客观性,我们需要对收集到的数据进行筛选和清洗,排除一些不必要的信息和噪音,确保数据的质量和准确性。
接下来,我们将选择合适的自然语言处理技术和算法,用于对收集到的数据进行处理和分析。
这些技术和算法包括词法分析、句法分析、语义分析等,旨在从文本中提取关键信息和语义内容,并将其转化为计算机可理解和处理的形式。
例如,我们可以利用词嵌入技术(Word Embedding)将文本转化为向量表示,以便计算机能够对其进行进一步的处理和分析。
在实验设计中,我们还需要考虑如何评估NLP技术在自然语言理解方面的表现。
为此,我们可以设计一些指标和评价标准,例如准确率、召回率、F1值等,用于评估NLP技术在理解和处理自然语言时的性能和效果。
此外,我们还可以利用人工评估的方法,邀请一些专业人士对实验结果进行评价和验证,以确保实验结果的客观性和可靠性。
最后,我们将进行实验验证和分析,以评估NLP技术在自然语言理解方面的实际效果和应用价值。
我们可以将实验数据输入到设计好的NLP模型中,观察模型在处理和理解自然语言时的表现和结果。
通过实验验证,我们可以得出结论,评估NLP技术在自然语言理解方面的优劣势,为今后的研究和应用提供参考和指导。
总之,利用自然语言处理技术进行自然语言理解的实验设计是一项具有挑战性和前沿性的工作。
通过设计和实施这样的实验,我们可以更深入地理解和应用NLP技术,推动其在自然语言理解和处理方面的发展和应用。
自然语言理解课程实验报告

实验一、中文分词一、实验内容用正向最大匹配法对文档进行中文分词,其中:(1)wordlist.txt 词表文件(2)pku_test.txt 未经过分词的文档文件(3)pku_test_gold.txt 经过分词的文档文件二、实验所采用的开发平台及语言工具Visual C++ 6.0三、实验的核心思想和算法描述本实验的核心思想为正向最大匹配法,其算法描述如下假设句子: , 某一词 ,m 为词典中最长词的字数。
(1) 令 i=0,当前指针 pi 指向输入字串的初始位置,执行下面的操作:(2) 计算当前指针 pi 到字串末端的字数(即未被切分字串的长度)n,如果n=1,转(4),结束算法。
否则,令 m=词典中最长单词的字数,如果n<m, 令 m=n;(3) 从当前 pi 起取m 个汉字作为词 wi,判断:(a) 如果 wi 确实是词典中的词,则在wi 后添加一个切分标志,转(c);(b) 如果 wi 不是词典中的词且 wi 的长度大于1,将wi 从右端去掉一个字,转(a)步;否则(wi 的长度等于1),则在wi 后添加一个切分标志,将wi 作为单字词添加到词典中,执行 (c)步;(c) 根据 wi 的长度修改指针 pi 的位置,如果 pi 指向字串末端,转(4),否则, i=i+1,返回 (2);(4) 输出切分结果,结束分词程序。
四、系统主要模块流程、源代码(1) 正向最大匹配算法12n S c c c 12i mw c c c(2) 原代码如下// Dictionary.h#include <iostream>#include <string>#include <fstream>using namespace std;class CDictionary{public:CDictionary(); //将词典文件读入并构造为一个哈希词典 ~CDictionary();int FindWord(string w); //在哈希词典中查找词private:string strtmp; //读取词典的每一行string word; //保存每个词string strword[55400];};//将词典文件读入并CDictionary::CDictionary(){ifstream infile("wordlist.txt"); // 打开词典if (!infile.is_open()) // 打开词典失败则退出程序{cerr << "Unable to open input file: " << "wordlist.txt"<< " -- bailing out!" << endl;exit(-1);}int i=0;while (getline(infile, strtmp)) // 读入词典的每一行并将其添加入哈 希中{strword[i++]=strtmp;}infile.close();}CDictionary::~CDictionary(){}//在哈希词典中查找词,若找到,则返回,否则返回int CDictionary::FindWord(string w){int i=0;while ((strword[i]!=w) && (i<55400))i++;if(i<55400)return 1;elsereturn 0;}// 主程序main.cpp#include "Dictionary.h"#define MaxWordLength 14 // 最大词长为个字节(即个汉字)# define Separator " " // 词界标记CDictionary WordDic; //初始化一个词典//对字符串用最大匹配法(正向)处理string SegmentSentence(string s1){string s2 = ""; //用s2存放分词结果string s3 = s1;int l = (int) s1.length(); // 取输入串长度int m=0;while(!s3.empty()){int len =(int) s3.length(); // 取输入串长度if (len > MaxWordLength) // 如果输入串长度大于最大词长 {len = MaxWordLength; // 只在最大词长范围内进行处理 }string w = s3.substr(0, len); //(正向用)将输入串左边等于最大词长长度串取出作为候选词int n = WordDic.FindWord(w); // 在词典中查找相应的词while(len > 1 && n == 0) // 如果不是词{int j=len-1;while(j>=0 && (unsigned char)w[j]<128){j--;}if(j<1){break;}len -= 1; // 从候选词右边减掉一个英文字符,将剩下的部分作为候选词 w = w.substr(0, len); //正向用n = WordDic.FindWord(w);}s2 += w + Separator; // (正向用)将匹配得到的词连同词界标记加到输出串末尾s3 = s1.substr(m=m+w.length(), s1.length()); //(正向用)从s1-w处开始}return s2;}int main(int argc, char *argv[]){string strtmp; //用于保存从语料库中读入的每一行string line; //用于输出每一行的结果ifstream infile("pku_test.txt"); // 打开输入文件if (!infile.is_open()) // 打开输入文件失败则退出程序{cerr << "Unable to open input file: " << "pku_test.txt"<< " -- bailing out!" << endl;exit(-1);}ofstream outfile1("SegmentResult.txt"); //确定输出文件if (!outfile1.is_open()){cerr << "Unable to open file:SegmentResult.txt"<< "--bailing out!" << endl;exit(-1);}while (getline(infile, strtmp)) //读入语料库中的每一行并用最大匹配法处理{line = strtmp;line = SegmentSentence(line); // 调用分词函数进行分词处理outfile1 << line << endl; // 将分词结果写入目标文件cout<<line<<endl;}infile.close();outfile1.close();return 0;}五、实验结果及分析(1)、实验运行结果(2) 实验结果分析在基于字符串匹配的分词算法中,词典的设计往往对分词算法的效率有很大的影响。
利用自然语言处理技术进行自然语言理解的实验设计(九)

在当今时代,自然语言处理技术正变得越来越重要。
随着人工智能的发展,自然语言处理技术已经在各种领域得到了广泛的应用,比如智能客服、语音识别、机器翻译等。
而自然语言理解作为自然语言处理技术的重要组成部分,也备受关注。
在这篇文章中,我将探讨如何设计一个实验来测试利用自然语言处理技术进行自然语言理解的效果。
首先,我们需要确定实验的目的。
自然语言理解的目标是使计算机能够理解人类的自然语言,包括语句的意思、情感以及意图。
因此,我们的实验目的应该是测试自然语言处理技术在理解自然语言方面的表现。
具体来说,我们可以设计一个实验,通过一系列自然语言处理算法来理解一些给定的语句,并评估其准确性和效率。
接下来,我们需要选择合适的自然语言处理算法。
自然语言处理涉及到词法分析、句法分析、语义分析等多个方面,因此我们可以选择一些常用的自然语言处理算法来进行测试。
比如,词袋模型、词嵌入、循环神经网络等都是比较常用的自然语言处理算法,它们可以帮助我们理解语句的含义、分析语法结构等。
在实验设计中,我们需要考虑到语料的选择。
语料的选择对于实验结果的可靠性至关重要。
我们可以选择一些具有代表性的语料,比如新闻文章、社交媒体评论、电子邮件等,这些语料涵盖了各种语言风格和语境,可以更好地测试自然语言处理算法的泛化能力。
接着,我们需要设计实验的具体流程和指标。
在实验中,我们可以首先对语料进行预处理,包括分词、去停用词、词性标注等,然后利用选择的自然语言处理算法对语料进行处理。
在实验的评估阶段,我们可以使用准确率、召回率、F1值等指标来评估自然语言处理算法的性能,从而确定其在自然语言理解方面的表现。
此外,我们还可以设计一些对照实验,比如使用不同的自然语言处理算法来进行对比,或者使用不同的语料来进行测试。
这样可以更全面地评估自然语言处理算法的性能,并找出其中的优劣势。
最后,我们需要对实验结果进行分析和总结。
在实验结果分析中,我们可以分析自然语言处理算法在不同语料上的表现,找出其优势和不足之处。
自然语言理解实验报告

自然语言理解课程实验报告实验一、中文分词1、实验内容用最大匹配算法设计分词程序实现对文档分词,并计算该程序分词的正确率、召回率及F-测度。
实验数据:(1)wordlist.txt 词表文件(2)pku_test.txt 未经过分词的文档文件(3)pku_test_gold.txt 经过分词的文档文件2、实验所采用的开发平台及语言工具开发平台:Eclipse软件语言工具:Java语言3、实验的核心思想和算法描述核心思想:正向最大匹配算法 (Forward MM, FMM)算法描述:正向最大匹配法算法如下所示:逆向匹配法思想与正向一样,只是从右向左切分,这里举一个例子:输入例句:S1="计算语言学课程有意思" ;定义:最大词长MaxLen = 5;S2= " ";分隔符 = “/”;假设存在词表:…,计算语言学,课程,意思,…;最大逆向匹配分词算法过程如下:(1)S2="";S1不为空,从S1右边取出候选子串W="课程有意思";(2)查词表,W不在词表中,将W最左边一个字去掉,得到W="程有意思";(3)查词表,W不在词表中,将W最左边一个字去掉,得到W="有意思";(4)查词表,W不在词表中,将W最左边一个字去掉,得到W="意思"(5)查词表,“意思”在词表中,将W加入到S2中,S2=" 意思/",并将W 从S1中去掉,此时S1="计算语言学课程有";(6)S1不为空,于是从S1左边取出候选子串W="言学课程有";(7)查词表,W不在词表中,将W最左边一个字去掉,得到W="学课程有";(8)查词表,W不在词表中,将W最左边一个字去掉,得到W="课程有";(9)查词表,W不在词表中,将W最左边一个字去掉,得到W="程有";(10)查词表,W不在词表中,将W最左边一个字去掉,得到W="有",这W 是单字,将W加入到S2中,S2=“ /有 /意思”,并将W从S1中去掉,此时S1="计算语言学课程";(11)S1不为空,于是从S1左边取出候选子串W="语言学课程";(12)查词表,W不在词表中,将W最左边一个字去掉,得到W="言学课程";(13)查词表,W不在词表中,将W最左边一个字去掉,得到W="学课程";(14)查词表,W不在词表中,将W最左边一个字去掉,得到W="课程";(15)查词表,“意思”在词表中,将W加入到S2中,S2=“课程/ 有/ 意思/”,并将W从S1中去掉,此时S1="计算语言学";(16)S1不为空,于是从S1左边取出候选子串W="计算语言学";(17)查词表,“计算语言学”在词表中,将W加入到S2中,S2=“计算语言学/ 课程/ 有/ 意思/”,并将W从S1中去掉,此时S1="";(18)S1为空,输出S2作为分词结果,分词过程结束。
2024年幼儿园大班教案《大自然的话》含反思

2024年幼儿园大班教案《大自然的话》含反思一、教学内容本节课选自幼儿园大班教材《大自然的话》第四章《大自然的语言》,详细内容包括:了解大自然中的各种语言,如动物的叫声、植物的生长变化、自然现象等,让幼儿感受大自然的神奇与美好。
二、教学目标1. 让幼儿了解大自然中的各种语言,提高幼儿对自然的认知。
2. 培养幼儿对大自然的热爱和好奇心,激发幼儿探索自然的兴趣。
3. 培养幼儿的观察能力、表达能力和合作精神。
三、教学难点与重点难点:让幼儿理解大自然中的各种语言及其意义。
重点:培养幼儿对大自然的热爱,提高幼儿观察、表达和合作能力。
四、教具与学具准备1. 教具:大自然的话课件、图片、录音机、磁带、动物叫声卡片。
2. 学具:画纸、彩笔、剪刀、胶水。
五、教学过程1. 实践情景引入(5分钟)(1)带领幼儿观察教室窗外的自然景色,引导幼儿关注大自然。
(2)提问:“你们知道大自然都有哪些语言吗?”让幼儿思考并回答。
2. 例题讲解(10分钟)(1)展示课件,讲解大自然中的各种语言,如动物的叫声、植物的生长变化、自然现象等。
(2)播放录音,让幼儿听辨动物叫声,并说出它们是谁。
3. 随堂练习(10分钟)(1)分组讨论:让幼儿分组讨论自己喜欢的大自然语言,并分享给大家。
(2)画一画:让幼儿用画笔、彩纸等学具,画出自己心中的大自然。
(2)拓展延伸:让幼儿课后与家长一起到大自然中寻找各种语言,并记录下来。
六、板书设计1. 大自然的语言动物的叫声植物的生长变化自然现象2. 我们喜欢的大自然语言七、作业设计1. 作业题目:画出自己喜欢的大自然语言,并写一句话描述。
2. 答案示例:我喜欢小鸟的歌声,因为它让大自然变得更加美好。
八、课后反思及拓展延伸1. 反思:本节课通过讲解、实践、讨论等多种方式,让幼儿了解大自然中的各种语言,达到了教学目标。
2. 拓展延伸:让幼儿在课后与家长一起观察大自然,提高幼儿对自然的认知,增强亲子关系。
同时,鼓励幼儿用自己的方式表达对大自然的热爱,培养幼儿的艺术素养。
自然语言处理实训课程学习总结

自然语言处理实训课程学习总结1. 引言自然语言处理(Natural Language Processing, NLP)是一门研究如何使计算机能够理解和处理人类自然语言的学科。
在这门课程中,我对NLP的基本原理和应用进行了学习和实践。
通过本文,我将总结我在自然语言处理实训课程中的收获和体会。
2. 文本预处理在NLP中,文本预处理是非常重要的一步。
在本课程中,我们学习了文本预处理的一些常用技术,例如词语分割、去除停用词、词性标注等。
我学会了如何使用Python中的NLTK库来进行文本预处理,通过实际操作,我发现文本预处理对后续的分析和建模有着至关重要的影响,能够提高模型的准确性和可靠性。
3. 词向量表示词向量表示是NLP中的重要概念,它将词语映射为固定长度的实数向量,并且能够保留词语之间的语义关系。
在课程中,我们学习了Word2Vec模型和GloVe模型等常用的词向量表示方法。
我通过使用这些模型,学会了如何将词语转换为向量表示,并且可以通过计算向量之间的相似度来衡量词语之间的关系。
4. 文本分类文本分类是NLP中的一个重要任务,它将文本划分到不同的预定义类别中。
在本课程中,我们学习了一些文本分类的方法,例如朴素贝叶斯分类器和卷积神经网络等。
我通过实践,掌握了这些方法的基本原理和使用技巧,并且在一些实验中取得了令人满意的结果。
5. 规则提取与情感分析在NLP中,利用规则提取和情感分析等技术可以从文本中提取出有用的信息。
在课程中,我们学习了如何使用正则表达式和有限状态自动机来进行规则提取,并且了解了情感分析的一些基本概念和方法。
通过实验,我成功地从大量文本数据中提取出了有用的信息,并且分析了文本的情感倾向。
6. 机器翻译机器翻译是NLP的重要应用领域之一,在本课程中,我们学习了统计机器翻译和神经机器翻译等翻译模型的基本原理和实现方法。
我通过实践,掌握了机器翻译的一些基本技巧,并且实现了一个简单的翻译系统。
利用自然语言处理技术进行自然语言理解的实验设计(Ⅲ)

自然语言处理(Natural Language Processing,简称NLP)技术是人工智能领域的一个重要分支,它涉及计算机对人类语言进行处理和理解的能力。
随着NLP 技术的不断发展,人们对于如何更好地利用这一技术进行自然语言理解也提出了更高的要求。
在本文中,我将设计一个实验,利用自然语言处理技术进行自然语言理解的实验设计。
首先,我们需要确定实验的目的。
本实验的目的是通过利用自然语言处理技术,设计一个能够对人类语言进行理解和回答问题的系统。
这将涉及到语义理解、语法分析等方面的技术,旨在验证NLP技术在自然语言理解方面的应用效果。
接下来,我们需要确定实验的方法和步骤。
首先,我们需要收集一定数量的自然语言数据,包括句子、段落甚至是篇章。
这些数据将作为我们实验的输入。
然后,我们需要利用NLP技术进行数据预处理,包括词性标注、句法分析等,以便系统能够更好地理解和处理这些数据。
接着,我们需要设计一个基于NLP技术的自然语言理解系统,该系统应能够对输入的自然语言数据进行分析和理解,并能够回答相关问题。
在设计自然语言理解系统的过程中,我们可以利用一些经典的NLP技术,比如词嵌入、句法分析、语义理解等。
同时,我们也可以结合一些最新的NLP模型,比如Transformer、BERT等,以提高系统的性能和效果。
接着,我们需要进行实验的评估和验证。
这一步骤很关键,因为它能够验证我们设计的自然语言理解系统的效果和性能。
我们可以设计一些测试用例,包括语义理解、问题回答等方面的测试,以验证系统在不同方面的表现。
同时,我们还可以利用一些标准的NLP数据集,比如SQuAD、GLUE等,来对系统进行评估和验证。
最后,我们需要进行实验结果的分析和总结。
通过对实验结果的分析,我们可以得出结论,验证我们设计的自然语言理解系统的效果和性能。
同时,我们还可以对系统存在的问题和不足进行分析,以指导我们下一步的研究和改进。
综上所述,利用自然语言处理技术进行自然语言理解的实验设计,涉及到实验目的的确定、方法和步骤的设计、实验的评估和验证,以及实验结果的分析和总结。
《自然语言处理》教学上机实验报告
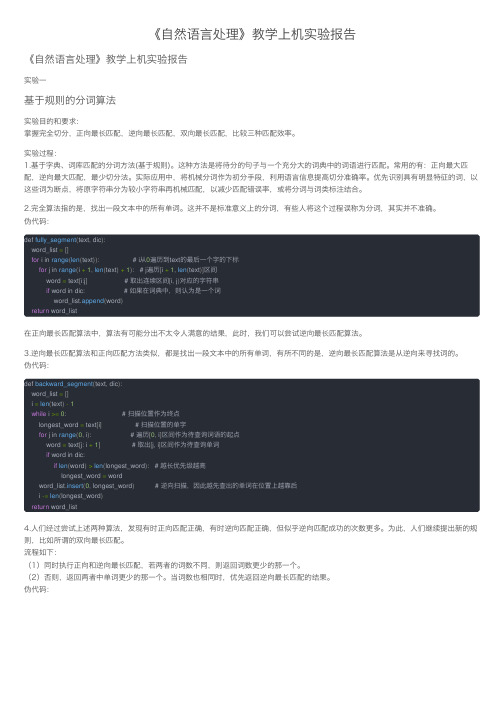
《⾃然语⾔处理》教学上机实验报告《⾃然语⾔处理》教学上机实验报告实验⼀基于规则的分词算法实验⽬的和要求:掌握完全切分,正向最长匹配,逆向最长匹配,双向最长匹配,⽐较三种匹配效率。
实验过程:1.基于字典、词库匹配的分词⽅法(基于规则)。
这种⽅法是将待分的句⼦与⼀个充分⼤的词典中的词语进⾏匹配。
常⽤的有:正向最⼤匹配,逆向最⼤匹配,最少切分法。
实际应⽤中,将机械分词作为初分⼿段,利⽤语⾔信息提⾼切分准确率。
优先识别具有明显特征的词,以这些词为断点,将原字符串分为较⼩字符串再机械匹配,以减少匹配错误率,或将分词与词类标注结合。
2.完全算法指的是,找出⼀段⽂本中的所有单词。
这并不是标准意义上的分词,有些⼈将这个过程误称为分词,其实并不准确。
伪代码:def fully_segment(text, dic):word_list =[]for i in range(len(text)): # i从0遍历到text的最后⼀个字的下标for j in range(i +1,len(text)+1): # j遍历[i +1,len(text)]区间word = text[i:j] # 取出连续区间[i, j)对应的字符串if word in dic: # 如果在词典中,则认为是⼀个词word_list.append(word)return word_list在正向最长匹配算法中,算法有可能分出不太令⼈满意的结果,此时,我们可以尝试逆向最长匹配算法。
3.逆向最长匹配算法和正向匹配⽅法类似,都是找出⼀段⽂本中的所有单词,有所不同的是,逆向最长匹配算法是从逆向来寻找词的。
伪代码:def backward_segment(text, dic):word_list =[]i =len(text)-1while i >=0: # 扫描位置作为终点longest_word = text[i] # 扫描位置的单字for j in range(0, i): # 遍历[0, i]区间作为待查询词语的起点word = text[j: i +1] # 取出[j, i]区间作为待查询单词if word in dic:if len(word)>len(longest_word): # 越长优先级越⾼longest_word = wordword_list.insert(0, longest_word) # 逆向扫描,因此越先查出的单词在位置上越靠后i -=len(longest_word)return word_list4.⼈们经过尝试上述两种算法,发现有时正向匹配正确,有时逆向匹配正确,但似乎逆向匹配成功的次数更多。
自然语言理解实验报告

根据学院要求,专业课都需要有实验。
我们这个课设计了以下几个实验,同学们可以3-5人一组进行实验,最后提交一个报告给我。
实验一汉语分词及词性标注
【实验目的】
1.熟悉基本的汉语分词方法;
2.能综合运用基于规则和概率的方法进行词性标注。
3.理解课堂讲授的基本方法,适当查阅文献资料,在此基础上实现一个分词与词性标
注的系统;
实验二实现一个基于整句转换的拼音汉字转换程序
【实验目的】
1.分析现有拼音输入法的优缺点,采用n元语法的思想,实现一个拼音汉字转换程序。
2.提出自己的一些新思想对原有基于n元语法的方法进行改进。
实验三实现一个(汉语/英语)词义自动消歧系统
【实验目的】
很多词汇具有一词多义的特点,但一个词在特定的上下文语境中其含义却是确定的。
本
项目要求实现系统能够自动根据不同上下文判断某一词的特定含义。
实验四实现一个(汉语/英语)自动摘要系统
【实验目的】
能根据目标对任意给定的一篇文章进行自动摘要生成。
实验五实现一个汉语命名实体自动识别系统
【实验目的】
命名实体一般指如下几类专有名词:中国人名、外国人译名、地名、组织机构名、数字、
日期和货币数量。
大班语言游戏教案《大自然的语言》含反思

大班语言游戏教案《大自然的语言》含反思一、教学内容本节课选自大班语言领域教材第四章《大自然的语言》。
详细内容包括:认识自然界的各种声音,理解大自然的声音所传递的信息,学会用语言描述大自然的声音,以及通过语言游戏,培养幼儿对大自然语言的兴趣。
二、教学目标1. 能够听懂并识别大自然中的各种声音,理解这些声音所传递的信息。
2. 学会用语言描述大自然的声音,提高幼儿的语言表达能力。
3. 培养幼儿热爱大自然,保护环境的情感。
三、教学难点与重点教学难点:用语言描述大自然的声音。
教学重点:认识大自然的声音,理解声音所传递的信息。
四、教具与学具准备教具:录音机、大自然声音的音频、图片、卡片等。
学具:画纸、彩笔、剪刀等。
五、教学过程1. 导入(5分钟):通过播放大自然声音的音频,引导幼儿关注并讨论这些声音是从哪里来的,激发幼儿对大自然声音的兴趣。
2. 讲解(10分钟):结合教材内容,讲解大自然声音的种类,以及这些声音所传递的信息。
3. 实践(10分钟):组织幼儿进行“大自然声音模仿秀”,鼓励幼儿模仿并描述所听到的大自然声音。
4. 例题讲解(10分钟):出示图片,引导幼儿观察并描述图片中的大自然声音。
5. 随堂练习(10分钟):发放卡片,让幼儿用语言描述卡片上的大自然声音。
六、板书设计1. 大自然的语言声音种类:鸟鸣、流水、风吹、动物叫声等声音传递的信息:警告、求偶、寻找食物等2. 描述大自然声音的方法:模仿、画图、语言描述等七、作业设计1. 作业题目:请幼儿回家后,仔细聆听周围的大自然声音,选择一个最喜欢的声音,用语言描述它,并画下来。
2. 答案:根据幼儿的实际完成情况,给予适当评价和指导。
八、课后反思及拓展延伸1. 反思:本节课通过多种形式的活动,让幼儿对大自然语言有了更深入的认识,但在教学过程中,要注意引导幼儿用更丰富的词汇描述声音。
2. 拓展延伸:组织一次户外活动,让幼儿亲自走进大自然,聆听各种声音,感受大自然的魅力,进一步培养幼儿对大自然语言的兴趣。
利用自然语言处理技术进行自然语言理解的实验设计(四)

自然语言处理(Natural Language Processing, NLP)技术是近年来人工智能领域的热点之一,其作用是让计算机能够理解和处理人类语言。
其中,自然语言理解(Natural Language Understanding, NLU)是NLP技术的核心部分,它涉及到计算机对自然语言进行深入的理解和推理。
本文将从实验设计的角度探讨如何利用自然语言处理技术进行自然语言理解。
1. 实验目的和意义自然语言处理技术的发展已经取得了很大的成就,但是自然语言理解仍然是一个具有挑战性的问题。
因此,设计一系列实验来探索自然语言理解的方法和技术,对于推动NLP领域的发展具有重要的意义。
通过这些实验,人们可以更好地了解计算机是如何理解人类语言的,从而为NLP技术的进一步发展提供有益的启示。
2. 实验设计首先,我们需要确定实验的具体内容和目标。
在进行自然语言理解的实验设计时,需要考虑以下几个方面:数据集选择在进行自然语言理解实验时,选择合适的数据集非常重要。
数据集的选择应考虑到数据的规模、多样性和真实性。
一个好的数据集能够有效地反映自然语言的使用场景,从而提高实验的可信度和实用性。
实验方法在确定数据集之后,需要设计合适的实验方法。
这包括选择合适的NLP模型和算法,以及确定实验的具体流程和步骤。
在实验设计中,需要充分考虑到数据预处理、特征提取、模型训练和评估等环节,确保实验能够达到预期的效果。
实验评估实验评估是实验设计中至关重要的一环。
在进行自然语言理解实验时,需要选择合适的评估指标和评估方法,以确保实验结果的客观性和可比性。
常见的评估指标包括准确率、召回率、F1值等,而评估方法则包括交叉验证、留出法等。
3. 实验流程在确定了实验的目标、数据集、方法和评估之后,接下来需要设计具体的实验流程。
实验流程应包括数据预处理、特征提取、模型训练、模型评估等环节。
在每个环节中,需要详细记录实验的过程和结果,以便后续分析和总结。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验一、中文分词一、实验内容用正向最大匹配法对文档进行中文分词,其中:(1)wordlist.txt 词表文件(2)pku_test.txt 未经过分词的文档文件(3)pku_test_gold.txt 经过分词的文档文件二、实验所采用的开发平台及语言工具Visual C++ 6.0三、实验的核心思想和算法描述本实验的核心思想为正向最大匹配法,其算法描述如下假设句子: , 某一词 ,m 为词典中最长词的字数。
(1) 令 i=0,当前指针 pi 指向输入字串的初始位置,执行下面的操作:(2) 计算当前指针 pi 到字串末端的字数(即未被切分字串的长度)n ,如果n=1,转(4),结束算法。
否则,令 m=词典中最长单词的字数,如果n<m, 令 m=n ;(3) 从当前 pi 起取m 个汉字作为词 wi ,判断:(a) 如果 wi 确实是词典中的词,则在wi 后添加一个切分标志,转(c);(b) 如果 wi 不是词典中的词且 wi 的长度大于1,将wi 从右端去掉一个字,转(a)步;否则(wi 的长度等于1),则在wi 后添加一个切分标志,将wi 作为单字词添加到词典中,执行 (c)步;(c) 根据 wi 的长度修改指针 pi 的位置,如果 pi 指向字串末端,转(4),否则, i=i+1,返回 (2);(4) 输出切分结果,结束分词程序。
四、系统主要模块流程、源代码(1) 正向最大匹配算法12n S c c c = 12i m w c c c =(2)原代码如下// Dictionary.h#include <iostream>#include <string>#include <fstream>using namespace std;class CDictionary{public:CDictionary(); //将词典文件读入并构造为一个哈希词典 ~CDictionary();int FindWord(string w); //在哈希词典中查找词private:string strtmp; //读取词典的每一行string word; //保存每个词string strword[55400];};//将词典文件读入并CDictionary::CDictionary(){ifstream infile("wordlist.txt"); // 打开词典if (!infile.is_open()) // 打开词典失败则退出程序{cerr << "Unable to open input file: " << "wordlist.txt"<< " -- bailing out!" << endl;exit(-1);}int i=0;while (getline(infile, strtmp)) // 读入词典的每一行并将其添加入哈希中{strword[i++]=strtmp;}infile.close();}CDictionary::~CDictionary(){}//在哈希词典中查找词,若找到,则返回,否则返回int CDictionary::FindWord(string w){int i=0;while ((strword[i]!=w) && (i<55400))i++;if(i<55400)return 1;elsereturn 0;}// 主程序main.cpp#include "Dictionary.h"#define MaxWordLength 14 // 最大词长为个字节(即个汉字)# define Separator " " // 词界标记CDictionary WordDic; //初始化一个词典//对字符串用最大匹配法(正向)处理string SegmentSentence(string s1){string s2 = ""; //用s2存放分词结果string s3 = s1;int l = (int) s1.length(); // 取输入串长度int m=0;while(!s3.empty()){int len =(int) s3.length(); // 取输入串长度if (len > MaxWordLength) // 如果输入串长度大于最大词长 {len = MaxWordLength; // 只在最大词长范围内进行处理 }string w = s3.substr(0, len); //(正向用)将输入串左边等于最大词长长度串取出作为候选词int n = WordDic.FindWord(w); // 在词典中查找相应的词while(len > 1 && n == 0) // 如果不是词{int j=len-1;while(j>=0 && (unsigned char)w[j]<128){j--;}if(j<1){break;}len -= 1; // 从候选词右边减掉一个英文字符,将剩下的部分作为候选词 w = w.substr(0, len); //正向用n = WordDic.FindWord(w);}s2 += w + Separator; // (正向用)将匹配得到的词连同词界标记加到输出串末尾s3 = s1.substr(m=m+w.length(), s1.length()); //(正向用)从s1-w处开始}return s2;}int main(int argc, char *argv[]){string strtmp; //用于保存从语料库中读入的每一行string line; //用于输出每一行的结果ifstream infile("pku_test.txt"); // 打开输入文件if (!infile.is_open()) // 打开输入文件失败则退出程序{cerr << "Unable to open input file: " << "pku_test.txt"<< " -- bailing out!" << endl;exit(-1);}ofstream outfile1("SegmentResult.txt"); //确定输出文件if (!outfile1.is_open()){cerr << "Unable to open file:SegmentResult.txt"<< "--bailing out!" << endl;exit(-1);}while (getline(infile, strtmp)) //读入语料库中的每一行并用最大匹配法处理{line = strtmp;line = SegmentSentence(line); // 调用分词函数进行分词处理outfile1 << line << endl; // 将分词结果写入目标文件cout<<line<<endl;}infile.close();outfile1.close();return 0;}五、实验结果及分析(1)、实验运行结果(2)实验结果分析在基于字符串匹配的分词算法中,词典的设计往往对分词算法的效率有很大的影响。
正向最大匹配分词算法是最基本的字符串匹配算法之一,它能够保证将词典中存在的最长复合词切分出来。
实验二:ICTCLAS 汉语分词系统说明一、实验内容调用ICTCLAS程序对其中的文档进行分词,并标注词性(实验数据包含1个文件:pku_test.txt 未经过分词的文档文件)二、实验所采用的开发平台及语言工具Visual C++ 6.0ICTCLAS 汉语分词系统/中科院计算所ICTCLAS 5.0接口文档三、实验的核心思想和算法描述分词系统的主要是思想是先通过CHMM(层叠形马尔可夫模型)进行分词,通过分层,既增加了分词的准确性,又保证了分词的效率.共分五层,如下图一所示:基本思路:先进行原子切分,然后在此基础上进行N-最短路径粗切分,找出前N个最符合的切分结果,生成二元分词表,然后生成分词结果,接着进行词性标注ICTCLAS程序软件使用:(1). 在函数里加入对ICTCLAS50.lib的引用#ifndef OS_LINUX#include <Windows.h>#pragma comment(lib, "ICTCLAS50.lib") //ICTCLAS50.lib库加入到工程中#endif(2).ICTCLAS_API bool ICTCLAS_FileProcess函数的调用ICTCLAS_API bool ICTCLAS_FileProcess(const char* pszSrcFileName, //文本文件的读取const char* pszDstFileName, //目标文件的存放eCodeType srcCodeType=CODE_TYPE_UNKNOWN, //类型bool bEnablePOS=false //true表示可以标注词性);(3). ICTCLAS5.0接口文档中的示例四、系统源代码/************(1). 在函数里加入对ICTCLAS50.lib的引用********/#ifndef OS_LINUX#include <Windows.h>#pragma comment(lib, "ICTCLAS50.lib") //ICTCLAS50.lib库加入到工程中#endif#include <stdio.h>#include <stdlib.h>#include <string.h>#include <iostream>#include <string>#include "ICTCLAS50.h"using namespace std;int main(int argc, char* argv[]){if(!ICTCLAS_Init()){printf("Init fails\n");return -1;}ICTCLAS_FileProcess("pku_test.txt","Test_result.txt",CODE_TYPE_GB,true);//分别表示读取所需分次的文件、存放分词结果的文件、类型、标注词性printf("Init ok\n"); //分词结束后输出提示ICTCLAS_Exit();return 0;}五、实验结果及分析(1)分词前分词后:(2)实验结果分析ICTCLAS是中科院计算所研发的中文分词软件,这个软件在第一届国际中文处理研究机构SigHan组织的评测中都获得了多项第一名,是公认的当今最好的中文分词软件。