时间序列分析-sas各种模型-作业神器Word版
时间序列分析(SAS)第3章

结果分析:上图是数据对应的时序图,从图上曲线分析来看,数据并没有周期性或者趋向性规律,因而可以初步判断这是平稳数列。
proc arima data=ex3_1;结果分析:本过程中,我们建立了8阶自回归分析模型,图上依次是变量的描述性统计量、样本自相关图、样本逆相关图和样本偏自相关图。
由于本次实验探究的是平稳序列,因而样本逆相关图先不作分析。
结果分析:从上图可以看出,在众多模型中,MA(4)模型的BIC信息量是最小的,因而我们接下来会采用结果分析:结果分析: 结果分析:结果分析:该图为预测的图像,其中,红色线段表示预测出来的数列,绿色的两条线段分别表示95%的置信下限和95%的置信上限,而黑色的星号标识则是对应的样本数据值。
从图来分析,我们可以看出,黑色的样本数据值跟我们预测出来的线段非常的吻合,因而模型建立得很不错。
再结合上一步骤的参数结果,二、课后习题(老师布置的习题部分)17.data lianxi3_17;input x@@;time=_n_;cards;126.4 82.4 78.1 51.1 90.9 76.2 104.5 87.4110.5 25 69.3 53.5 39.8 63.6 46.7 72.979.6 83.6 80.7 60.3 79 74.4 49.6 54.771.8 49.1 103.9 51.6 82.4 83.6 77.8 79.389.6 85.5 58 120.7 110.5 65.4 39.9 40.188.7 71.4 83 55.9 89.9 84.8 105.2 113.7124.7 114.5 115.6 102.4 101.4 89.8 71.5 70.998.3 55.5 66.1 78.4 120.5 97 110;proc gplot data=lianxi3_17;plot x*time=1;symbol1c=red I=join v=star;run;结果分析:上图是数据对应的时序图,从图上曲线分析来看,数据并没有周期性或者趋向性规律,因而可以初结果分析:本过程中,我们建立了8阶自回归分析模型,图上依次是变量的描述性统计量、样本自相关图、样本逆相关图和样本偏自相关图。
时间序列分析作业

1、某股票连续若干天的收盘价如下表:304 303 307 299 296 293 301 293 301 295 284 286 286 287 284282 278 281 278 277 279 278 270 268 272 273 279 279 280 275271 277 278 279 283 284 282 283 279 280 280 279 278 283 278270 275 273 273 272 275 273 273 272 273 272 273 271 272 271273 277 274 274 272 280 282 292 295 295 294 290 291 288 288290 293 288 289 291 293 293 290 288 287 289 292 288 288 285282 286 286 287 284 283 286 282 287 286 287 292 292 294 291288 289选择适当模型拟合该序列的发展,并估计下一天的收盘价。
解:根据上面的图和SAS软件编辑程序得到时序图,程序如下:data shiyan7_1;input x@@;time=_n_;cards;304 303 307 299 296 293 301 293 301 295 284 286 286 287 284282 278 281 278 277 279 278 270 268 272 273 279 279 280 275271 277 278 279 283 284 282 283 279 280 280 279 278 283 278270 275 273 273 272 275 273 273 272 273 272 273 271 272 271273 277 274 274 272 280 282 292 295 295 294 290 291 288 288290 293 288 289 291 293 293 290288 287 289 292 288 288 285282 286 286 287 284 283 286 282 287 286 287 292 292294 291 288 289;proc print data=shiyan7_1;proc gplot data=shiyan7_1;plot x *time=1;symbol1c=red v=star i=spline;run;通过SAS运行上述程序可得到如下结果:可以看出序列含有长期趋势又含有一定的周期性,故进行差分平稳,又从上述时序图呈现曲线形式,故对原序列作二阶差分,差分程序及时序图如下:data shiyan7_1;input x@@;difx=dif(dif(x));time=_n_;cards;304 303 307 299 296 293 301 293 301 295 284 286 286 287 284282 278 281 278 277 279 278 270 268 272 273 279 279 280 275271 277 278 279 283 284 282 283 279 280 280 279 278 283 278270 275 273 273 272 275 273 273 272 273 272 273 271 272 271273 277 274 274 272 280 282 292 295 295 294 290 291 288 288290 293 288 289 291 293 293 290 288 287 289 292 288 288 285282 286 286 287 284 283 286 282 287 286 287 292 292294 291 288 289;proc print data=shiyan7_1;proc gplot data=shiyan7_1;plot x *time difx*time;symbol1c=red v=star i=join;proc arima;identify var=x(1,1);estimate q=1;forecast lead=5id=time;run;SAS软件运行后可得到差分后的序列时序图,其图形如下:时序图显示差分后序列已无显著趋势或周期,随机波动比较平稳。
SAS学习系列39.时间序列分析Ⅲ—ARIMA模型(可编辑修改word版)

39. 时间序列分析Ⅱ——ARIMA 模型随着对时间序列分析方法的深入研究,人们发现非平稳序列的确定性因素分解方法(如季节模型、趋势模型、移动平均、指数平滑等)只能提取显著的确定性信息,对随机性信息浪费严重,同时也无法对确定性因素之间的关系进行分析。
而非平稳序列随机分析的发展就是为了弥补确定性因素分解方法的不足。
时间序列数据分析的第一步都是要通过有效手段提取序列中所蕴藏的确定性信息。
Box 和Jenkins 使用大量的案例分析证明差分方法是一种非常简便有效的确定性信息的提取方法。
而Gramer 分解定理则在理论上保证了适当阶数的差分一定可以充分提取确定性信息。
(一)ARMA 模型即自回归移动平均移动模型,是最常用的拟合平稳时间序列的模型,分为三类:AR 模型、MA 模型和ARMA 模型。
一、AR(p)模型——p 阶自回归模型1.模型:x t =+1xt-1+pxt-p+t其中,≠ 0 ,随机干扰序列εt为0 均值、2方差的白噪声序列(pE(t s)=0 , t≠s),且当期的干扰与过去的序列值无关,即E(x tεt)=0.11 1 p1 pt t 1p由于是平稳序列,可推得均值=1 - - -. 若0 = 0 ,称为中心化的 AR (p )模型, 对于非中心化的平稳时间序列, 可以令= (1 - - -), x * = x - 转化为中心化。
记 B 为延迟算子, Φ (B ) = I -B - -B p 称为 p 阶自回归多项式,则 AR (p )模型可表示为: Φ p (B )x t = t .2. 格林函数用来描述系统记忆扰动程度的函数,反映了影响效应衰减的快慢程度(回到平衡位置的速度),G j 表示扰动 εt-j 对系统现在行为影响的 权数。
例如,AR(1)模型(一阶非齐次差分方程), G j=j ,j = 0,1, 2,模型解为 x t = ∑G j t - j .j =03. 模型的方差∞22对于 AR(1)模型,Var ( x t ) = ∑G jVar (t - j ) =.4. 模型的自协方差j =01 -2对中心化的平稳模型,可推得自协方差函数的递推公式:用格林函数显示表示:∞ ∞∞(k ) = ∑∑G G E (-- - ) =2∑G + Gij t j t k j j k ji =0 j =0j =0对于 AR(1)模型,∞ p1 111 1i(k)=k (0)=k5.模型的自相关函数递推公式:21 -2对于AR(1)模型,(k ) =k(0) =k.平稳AR(p)模型的自相关函数有两个显著的性质:(1)拖尾性指自相关函数ρ(k)始终有非零取值,不会在k 大于某个常数之后就恒等于零;(2)负指数衰减随着时间的推移,自相关函数ρ(k)会迅速衰减,且以负指数k (其中i为自相关函数差分方程的特征根)的速度在减小。
SAS讲义 第四十课平稳时间序列分析

第四十课 平稳时间序列分析对时间序列数据的分析,首先要对它的平稳性和纯随机性进行检验。
根据检验的结果可以将序列分为不同的类型,对不同类型的序列将会采用不同的分析方法。
如果一个时间序列被识别为平稳非白噪声序列,那就说明该序列是一个蕴涵着相关信息的平稳序列。
在统计上,我们通常是建立一个线性模型来拟合该序列的发展,借此提取该序列中被蕴涵着有用信息。
目前,最常用的拟合平稳序列的模型是ARMA (Auto Regression Moving Average )模型。
一、 平稳性检验1. 严平稳和宽平稳平稳时间序列有两种定义,根据限制条件的严格程度,分为:● 严平稳时间序列(strictly stationary )—指序列所有的统计性质都不会随着时间的推移而发生变化。
● 宽平稳时间序列(week stationary )—指序列的统计性质只要保证序列的二阶矩平稳就能保证序列的主要性质近似稳定。
如果在任取时间t 、s 和k 时,时间序列t X 满足如下三个条件:∞<2t EX(40.1) μ=t EX(40.2) ))(())((t s k t s k k k s s t t X X E X X E -+-+--=--μμμμ(40.3)则称为宽平稳时间序列。
也称为弱平稳或二阶平稳。
对于正态随机序列而言,由于联合概率分布仅由均值向量和协方差阵决定,即只要二阶矩平稳,就等于分布平稳了。
2. 平稳时间序列的统计性质根据平稳时间序列的定义,可以推断出两个重要的统计性质: ● 常数均值。
即式(40.2)的条件。
● 自协方差只依赖于时间的平均长度。
即式(40.3)的条件。
如果定义自协方方差函数(autocovariance function )为:))((),(s s t t X X E s t μμγ--=(40.4)那么它可由二维函数简化为一维函数)(t s -γ,由此引出延迟k 自协方差函数:),()(k t t k +=γγ(40.5)容易推断出平稳时间序列一定具有常数方差:)0(),()(2γγμ==-=t t X E Dx t t t (40.6)如果定义时间序列自相关函数(autocorrelation function ),简记为ACF :st s s t t DX DX X X E s t ⋅--=))((),(μμρ(40.7)由延迟k 自协方差函数的概念可以等价得到延迟k 自相关函数的概念:)0()()0()0()())(()(r k r k DX DX X X E k kt t k t k t t t ==⋅--=+++γγγμμρ (40.8)容易验证自相关函数具有几个基本性质: ● 1)0(=ρ; ●)()(k k ρρ=-;● 自相关阵为对称非负定阵; ● 非惟一性。
时间序列分析word版

第2章 时间序列的预处理拿到一个观察值序列之后,首先要对它的平稳性和纯随机性进行检验,这两个重要的检验称为序列的预处理。
根据检验的结果可以将序列分为不同的类型,对不同类型的序列我们会采用不同的分析方法。
2.1 平稳性检验 2.1.1 特征统计量平稳性是某些时间序列具有的一种统计特征。
要描述清楚这个特征,我们必须借助如下统计工具。
一、概率分布数理统计的基础知识告诉我们分布函数或密度函数能够完整地描述一个随 机变量的统计特征。
同样,一个随机 变量族的统计特性也完全由它们的联 合分布函数或联合密度函数决定。
对于时间序列{t X ,t ∈T },这样来定义它的概率分布:任取正整数m ,任取m t t t ,,,⋯21∈T ,则m 维随机向量(m t t t X X X ,,,⋯21)’的联合概率分布记为),,,(m t t t x x x F m⋯⋯21,,,21,由这些有限维分布函数构成的全体。
{),,,(m t t t x x x F m⋯⋯21,,,21,∀m ∈正整数,∀m t t t ,,,⋯21∈T } 就称为序列{t X }的概率分布族。
概率分布族是极其重要的统计特征描述工具,因为序列的所有统计性质理论上都可以通过 概率分布推测出来,但是概率分布族的重要 性也就停留在这样的理论意义上。
在实际应 用中,要得到序列的联合概率分布几乎是不 可能的,而且联合概率分布通常涉及非常复 杂的数学运算,这些原因使我们很少直接使 用联合概率分布进行时间序列分析。
二、特征统计量 一个更简单、更实用的描述时间序列统计特征的方法是研究该序列的低阶矩,特别是均值、方差、自协方差和自相关系数,它们也被称为特征统计量。
尽管这些特征统计量不能描述随机序列全部的统计性质,但由于它们概率意义明显,易于计算,而且往往能代表随机 序列的主要概率特征,所以我们对时间序列进行分析,主要就是通过分析这些统计量的统计特性,推断出随机序列的性质。
应用时间序列分析sas (2)

应用时间序列分析 SAS什么是时间序列分析?时间序列分析是一种统计学方法,用于处理连续性的数据,这些数据是按照时间顺序收集的。
它的目的是通过分析过去的数据模式和趋势来预测的趋势。
时间序列分析可用于各种领域,如经济学、气象学、股票市场预测等。
时间序列数据通常具有以下特征:•趋势:随着时间的推移,数据的整体趋势可能会上升或下降。
•季节性:数据可能会显示出固定周期的重复模式,如每年的季节性变化。
•周期性:数据可能会显示出非固定周期的重复模式,如商业周期。
•随机性:数据可能会受到许多随机因素的影响,如市场波动或天气变化。
为什么要使用 SAS 进行时间序列分析?SAS(Statistical Analysis System)是一种功能强大的统计分析和数据管理软件。
它提供了丰富的数据分析和建模工具,特别适合应用于时间序列数据分析。
以下是使用 SAS 进行时间序列分析的一些主要优势:1.多种统计模型:SAS 提供了多种用于时间序列分析的统计模型,包括自回归移动平均模型(ARMA)、自回归积分移动平均模型(ARIMA)、季节性自回归移动平均模型(SARIMA)等。
这些模型可以帮助我们更好地理解时间序列数据的模式和趋势。
2.强大的数据处理能力:SAS 提供了丰富的数据处理功能,包括数据清洗、数据转换、变量选择等。
这些功能可以帮助我们对时间序列数据进行预处理,以便更好地应用统计模型进行分析。
3.可视化工具:SAS 提供了各种可视化工具,如图表和图形,可以帮助我们更直观地理解时间序列数据的模式和趋势。
这些可视化工具还可以帮助我们有效地呈现分析结果。
4.自动化分析:SAS 具有自动化分析的能力,可以帮助我们快速而准确地进行时间序列分析。
通过编写脚本和宏,可以自动化执行重复的分析任务,提高工作效率。
使用 SAS 进行时间序列分析的基本步骤以下是使用 SAS 进行时间序列分析的基本步骤:1.导入数据:,需要将时间序列数据导入 SAS 中。
时序第五章SAS作业要点

时序第五章SAS作业要点第五章SAS作业问题1:1867-1938年英国绵⽺数量如下所⽰:2203 2360 2254 2165 2024 2078 2214 2292 2207 2119 2119 21372132 1955 1785 1747 1818 1909 1958 1892 1919 1853 1868 19912111 2119 1991 1859 1856 1924 1892 1916 1968 1928 1898 18501841 1824 1823 1843 1880 1968 2029 1996 1933 1805 1713 17261752 1795 1717 1648 1512 1338 1383 1344 1384 1484 1597 16861707 1640 1611 1632 1775 1850 1809 1653 1648 1665 1627 17911、选择恰当模型,拟合该序列的发展;2、利⽤拟合模型预测1939-1945年英国绵⽺的数量;3、按照书本相应例题的格式完成问题,并附上SAS程序。
答:绘制该序列的时序图如下:时序图显⽰该序列有显著的递减趋势,为⾮平稳序列。
考虑使⽤ARIMA模型拟合。
使⽤⼀阶差分提取序列信息,⼀阶差分后作时序图和ACF图如下:⼀阶差分后的时序图⽆明显趋势和周期性,可认为是平稳序列。
由⾃相关图可知,⾃相关系数衰减到零的速度较快且1阶以后⼤部分都落在两倍标准误以内。
所以可认为⼀阶差分后的序列为平稳序列。
对⼀阶差分后的序列进⾏⽩噪声检验:由SAS结果可知,该序列为⾮⽩噪声序列。
⼀阶差分后序列的PACF图如下:观察ACF图和PACF图后,可认为ACF图拖尾,PACF图3阶截尾。
建⽴AR(3)模型。
SAS输出残差序列及系数检验结果如下:结果显⽰AR(3)模型显著,常数项和φ2未通过检验,先剔除常数项,检验结果如下:φ2仍未通过检验,建⽴疏系数模型ARIMA((1,3),1,0),检验结果如下:由上述结果可知,模型ARIMA((1,3),1,0)显著,系数显著。
时间序列分析试验1-SAS简介

目录
• SAS简介 • 时间序列分析基本概念 • SAS在时间序列分析中的应用 • 时间序列分析试验流程 • SAS在时间序列分析中的优势和不
足 • 时间序列分析试验案例展示
01
SAS简介
SAS的发展历程
1976年,SAS软件创始人创立公司 SAS研究所,推出SAS1.0版本。
了解时间序列分析的基本概念,掌握SAS软件的 基本操作,能够独立完成时间序列数据的处理和 分析。
试验步骤和方法
步骤一:数据准备
2. 数据清洗:对数据进行 预处理,如缺失值填充、 异常值处理等。
1. 数据收集:收集时间序 列数据,确保数据准确、 完整。
试验步骤和方法
步骤二
数据导入和整理
2. 数据整理
试验结果分析和讨论
结果分析
对试验结果进行详细分析,包括模型的拟合效果、预测准确性等。
结果讨论
根据试验结果进行讨论,总结时间序列分析的优缺点和应用场景。
SAS在时间序列分析中的优
05
势和不足
SAS在时间序列分析中的优势
01
强大的数据处理能 力
SAS拥有强大的数据处理能力, 可以高效地处理大规模的时间序 列数据。
自动化和定制化
SAS提供自动化和定制化的功 能,可以根据用户需求定制报 表和数据分析流程。
SAS与其他软件的比较
与Excel相比
SAS在数据管理、统计分析等方面比Excel更加强大和 灵活。
与SPSS相比
SAS在数据处理和分析方面更加全面和灵活,同时提 供了更多的可视化功能。
与Python相比
SAS在数据分析和可视化方面相对较弱,但SAS提供 了更加易用的界面和更加全面的统计分析功能。
SAS-时间序列分析1
1 -0.769468778 0.448845319 -0.334665851 0.229079378 -0.217982096 0.25570847 -0.269632371 0.262451547 0.448845319 0.448845319 0.448845319 0.448845319
xt 1 xt 1 t
87 88 89 90 91 92 93 94 95 96 97 98 99 100
0.078099327 -0.201128107 0.636344859 0.145053721 -1.792626316 1.217088495 -0.414520396 0.537497547 -0.030223842 -2.096745786 2.057030262 -0.732574469 -0.410366351 0.508689501
-2
0.594442829
-3 0.107939746
-4 0.760516205 -5
1.048501639 -0.98318879 0.013741101
0 5 10
33 34 35 36 37 38 39 40
-1.084587106 0.698912998 -0.181458343 0.858879538 -2.411483865 1.860170277
WN (0,1)
30
35
40
45
பைடு நூலகம்
50
55
60
65
70
75
80
85
时间t
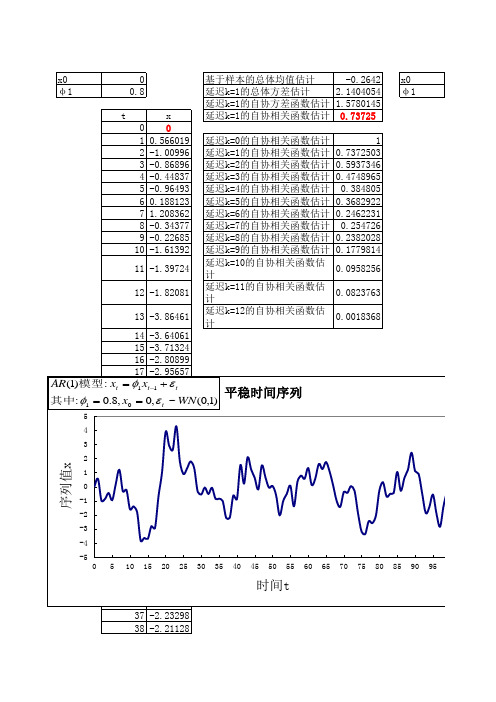
x0 φ1
0 -0.8
t 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
时间序列分析,sas各种模型,作业神器

时间序列分析,sas各种模型,作业神器实验一分析太阳黑子数序列一、实验目的:了解时间序列分析的基本步骤,熟悉SAS/ETS软件使用方法。
二、实验内容:分析太阳黑子数序列。
三、实验要求:了解时间序列分析的基本步骤,注意各种语句的输出结果。
四、实验时间:2小时。
五、实验软件:SAS系统。
六、实验步骤1、开机进入SAS系统。
2、创建名为exp1的SAS数据集,即在窗中输入下列语句:3、保存此步骤中的程序,供以后分析使用(只需按工具条上的保存按钮然后填写完提问后就可以把这段程序保存下来即可)。
4、绘数据与时间的关系图,初步识别序列,输入下列程序:ods html;ods listing close;5、run;提交程序,在graph窗口中观察序列,可以看出此序列是均值平稳序列。
6、识别模型,输入如下程序。
7、提交程序,观察输出结果。
初步识别序列为AR(2)模型。
8、估计和诊断。
输入如下程序:9、提交程序,观察输出结果。
假设通过了白噪声检验,且模型合理,则进行预测。
10、进行预测,输入如下程序:11、提交程序,观察输出结果。
12、退出SAS系统,关闭计算机。
总程序:data exp1;infile "D:\";input a1 @@;year=intnx('year','1jan1742'd,_n_-1);format year year4.;;proc print;run;ods html;ods listing close;proc gplot data=exp1 ;symbol i=spline v=dot h=1 cv=red ci=green w=1;plot a1*year/autovref lvref=2 cframe=yellow cvref=black ;title "太阳黑子数序列";run;proc arima data=exp1;identify var=a1 nlag=24 minic p=(0:5) q=(0:5);estimate p=3;forecast lead=6 interval=year id=year out=out;run;proc print data=out;run;选取拟合模型的规则:1.模型显著有效(残差检验为白噪声)2.模型参数尽可能少3.结合自相关图和偏自相关图以及minic 条件(BIC 信息量最小原则),选取显著有效的参数实验二模拟AR 模型一、实验目的:熟悉各种AR 模型的样本自相关系数和偏相关系数的特点,为理论学习提供直观的印象。
第28章如何用SAS实现时间序列分析

第28章如何⽤SAS实现时间序列分析第28章如何⽤SAS实现时间序列分析所谓时间序列,就是将某⼀指标在不同时间上的不同数值,按照时间先后次序排列⽽成的数列,这种数列由于受到各种偶然因素的影响,往往表现出某种随机性,彼此之间存在统计上的依赖关系。
因此,可以通过对时间序列的研究来认识所研究系统的结构特征(如波动的周期、振幅、趋势的种类),揭⽰其运⾏规律,进⽽⽤以预测、控制未来⾏为,修正和重新设计系统。
时间序列分析是⼀种重要的现代统计学⽅法,主要有确定性时间序列分析和随机时间序列分析⽅法。
另外,在实际问题中会遇到这样的情况,⼀个时间序列⽬前的表现,不仅受过去⾏为的影响,⽽且与另⼀个时间序列相关。
某地区经济增长的情况,不仅与过去有关,还受到投资、政策等因素的影响,进⾏多个因素对结果变量的影响要进⾏多重时间序列分析。
28.1求和⾃回归滑动平均模型(integratedautoregressivemovingaver agemodel,ARIMA)原理概述在SAS软件中,采⽤ARIMA过程进⾏分析和预测等间隔的时间序列。
ARIMA过程提供了⼀个综合的⼯具包来进⾏模型的识别、参数估计及预测。
ARIMA模型通过其⾃⾝的过去值、过去误差、其他时间序列的当前值和过去值的线性组合来预测响应时间序列。
其中,差分具有强⼤的确定性信息提取能⼒,许多⾮平稳序列差分后会显⽰出平稳序列的性质,称该⾮平稳序列为差分平稳序列。
对该种序列常⽤的⽅法就是本章介绍的齐次⾮平稳序列,简记为ARIMA(p,d,q)模型。
ARIMA(p,d,q)模型的结构为:对d阶齐次⾮平稳序列⽽⾔,{}是⼀个平稳序列,设其适合ARIMA(p,q)模型,即或表达为其ARIMA模型的构建由3个阶段组成:(1)模型的识别阶段:在识别阶段,可通过identify语句识别差分数、计算⾃相关、偏⾃相关、逆相关、互相关系数。
还可进⾏平稳性检验和模型阶数的识别。
另外,还可同时写多个identify语句,⽤以寻找模型的适合形式。
SAS 时间序列分析
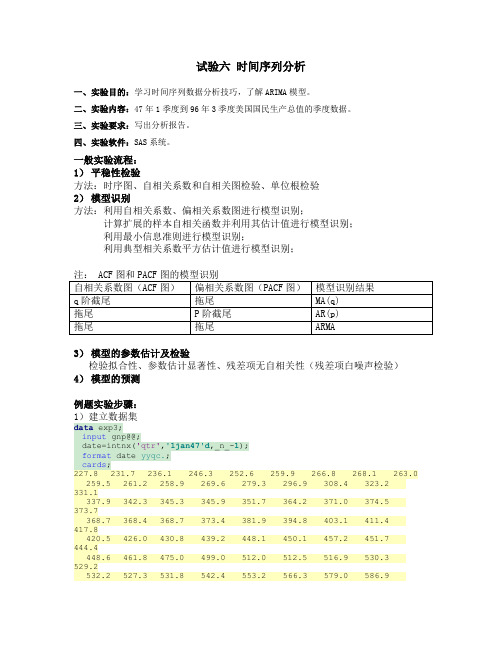
试验六时间序列分析一、实验目的:学习时间序列数据分析技巧,了解ARIMA模型。
二、实验内容:47年1季度到96年3季度美国国民生产总值的季度数据。
三、实验要求:写出分析报告。
四、实验软件:SAS系统。
一般实验流程:1)平稳性检验方法:时序图、自相关系数和自相关图检验、单位根检验2)模型识别方法:利用自相关系数、偏相关系数图进行模型识别;计算扩展的样本自相关函数并利用其估计值进行模型识别;利用最小信息准则进行模型识别;利用典型相关系数平方估计值进行模型识别;3)模型的参数估计及检验检验拟合性、参数估计显著性、残差项无自相关性(残差项白噪声检验)4)模型的预测例题实验步骤:1)建立数据集data exp3;input gnp@@;date=intnx('qtr','1jan47'd,_n_-1);format date yyqc.;cards;227.8 231.7 236.1 246.3 252.6 259.9 266.8 268.1 263.0 259.5 261.2 258.9 269.6 279.3 296.9 308.4 323.2 331.1337.9 342.3 345.3 345.9 351.7 364.2 371.0 374.5 373.7368.7 368.4 368.7 373.4 381.9 394.8 403.1 411.4 417.8420.5 426.0 430.8 439.2 448.1 450.1 457.2 451.7 444.4448.6 461.8 475.0 499.0 512.0 512.5 516.9 530.3 529.2532.2 527.3 531.8 542.4 553.2 566.3 579.0 586.9594.1597.7 606.8 615.3 628.2 637.5 654.5 663.4 674.3 679.9701.2 713.9 730.4 752.6 775.6 785.2 798.6 812.5 822.2828.2 844.7 861.2 886.5 910.8 926.0 943.6 966.3 979.9999.3 1008.0 1020.3 1035.7 1053.8 1058.4 1104.2 1124.9 1144.41158.8 1198.5 1231.8 1256.7 1297.0 1347.9 1379.4 1404.4 1449.71463.9 1496.8 1526.4 1563.2 1571.3 1608.3 1670.6 1725.3 1783.51814.0 1847.9 1899.0 1954.5 2026.4 2088.7 2120.4 2166.8 2293.72356.2 2437.0 2491.4 2552.9 2629.7 2687.5 2761.7 2756.1 2818.82941.5 3076.6 3105.4 3197.7 3222.8 3221.0 3270.3 3287.8 3323.83388.2 3501.0 3596.8 3700.3 3824.4 3911.3 3975.6 4022.7 4100.44158.7 4238.8 4306.2 4376.6 4399.4 4455.8 4508.5 4573.1 4655.54731.4 4845.2 4914.5 5013.7 5105.3 5217.1 5329.2 5423.9 5501.35557.0 5681.4 5767.8 5796.8 5813.6 5849.0 5904.5 5959.4 6016.66138.3 6212.2 6281.1 6390.5 6458.4 6512.3 6584.8 6684.5 6773.66876.3 6977.6 7062.2 7140.5 7202.4 7293.4 7344.3 7426.6 7537.57593.6;run;注:Intnx函数按间隔递增日期,Intnx函数计算某个区间经过若干区间间隔之后的间隔的开始日期或日期时间值,其中开始间隔内的一个日期或日期时间值给出。
时间序列分析模型汇总

时间序列分析模型汇总时间序列分析是一种广泛应用于各个领域的统计分析方法,它用来研究一组随时间而变化的数据。
时间序列数据通常具有趋势、季节性和随机性等特征,时间序列分析的目的是通过建立适当的模型来描述和预测这些特征。
本文将汇总一些常用的时间序列分析模型,包括AR、MA、ARIMA、GARCH和VAR等。
1.AR模型(自回归模型):AR模型是根据过去的观测值来预测未来的观测值。
它假设未来的观测值与过去的一系列观测值有关,且与其他因素无关。
AR模型的一般形式为:Y_t=c+Σ(φ_i*Y_t-i)+ε_t,其中Y_t表示时间t的观测值,c 为常数,φ_i为系数,ε_t为误差项。
2.MA模型(移动平均模型):MA模型是根据过去的误差项来预测未来的观测值。
它假设未来的观测值与过去的一系列误差项有关,且与其他因素无关。
MA模型的一般形式为:Y_t=μ+ε_t+Σ(θ_i*ε_t-i),其中Y_t表示时间t的观测值,μ为平均值,θ_i为系数,ε_t为误差项。
3.ARIMA模型(自回归积分移动平均模型):ARIMA模型是AR和MA模型的组合,它结合了时间序列数据的趋势和随机性特征。
ARIMA模型的一般形式为:Y_t=c+Σ(φ_i*Y_t-i)+Σ(θ_i*ε_t-i)+ε_t,其中Y_t表示时间t的观测值,c为常数,φ_i和θ_i为系数,ε_t为误差项。
4.GARCH模型(广义自回归条件异方差模型):GARCH模型用于建模并预测时间序列数据的波动性。
它假设波动性是由过去观测值的平方误差和波动性的自相关引起的。
GARCH模型的一般形式为:σ_t^2=ω+Σ(α_i*ε^2_t-i)+Σ(β_i*σ^2_t-i),其中σ_t^2为时间t的波动性,ω为常数,α_i和β_i为系数,ε_t为误差项。
5.VAR模型(向量自回归模型):VAR模型用于建模并预测多个时间序列变量之间的相互关系。
它假设多个变量之间存在相互依赖的关系,即一个变量的变动会对其他变量产生影响。
SAS时间序列分析

SAS时间序列分析时间序列分析是一种广泛应用于统计学和经济学领域的方法,用于研究随时间变化的数据。
SAS(统计分析系统)是一种功能强大的统计软件,拥有丰富的时间序列分析工具和函数。
本文将介绍SAS中常用的时间序列分析方法和技术,并探讨其在实际应用中的作用。
首先,时间序列分析的一个重要目标是研究时间序列数据的变化趋势和规律。
在SAS中,可以利用PROCTIMESERIES过程来进行时间序列分析。
该过程能够对时间序列数据进行平滑、分解、预测和模型诊断等操作。
通过该过程,可以将时间序列数据分解成趋势、季节和随机成分,并进行趋势估计和预测。
平滑技术是时间序列分析中常用的一种方法,用于去除时间序列数据的噪声和随机波动。
SAS提供了多种平滑技术,包括移动平均、指数平滑和Hodrick-Prescott滤波器等。
通过对时间序列数据进行平滑处理,可以更好地识别出数据的长期趋势和季节性变化。
时间序列的分解是另一个重要的数据分析方法,在SAS中可以通过PROCTIMESERIES过程中的DECOMPOSE选项实现。
分解将时间序列数据分解为趋势、季节和随机成分,使得数据的特征更明显。
分解后的数据可以用于分析长期趋势、季节性变化和突变点等问题。
预测是时间序列分析中的一个关键任务,它可以帮助我们根据过去的数据来预测未来的发展趋势。
在SAS中,可以使用PROCFORECAST过程进行时间序列数据的预测。
该过程可以基于不同的模型(如移动平均、指数平滑、ARIMA模型等)来进行预测,并提供相应的预测结果和评估指标。
SAS还提供了其他一些常用的时间序列分析方法,比如趋势分析、周期性分析和自回归移动平均模型(ARMA)等。
这些方法可以帮助我们更好地理解和描述时间序列数据的特征和规律。
除了以上介绍的方法和技术,SAS还提供了丰富的时间序列数据处理函数和图形工具,可以用于数据的处理、可视化和报告生成等工作。
通过SAS的时间序列分析工具,我们可以深入挖掘数据背后的规律和趋势,为决策提供科学依据。
SAS学习系列39 时间序列分析Ⅲ—ARIMA模型

39. 时间序列分析Ⅱ——ARIMA 模型随着对时间序列分析方法的深入研究,人们发现非平稳序列的确定性因素分解方法(如季节模型、趋势模型、移动平均、指数平滑等)只能提取显著的确定性信息,对随机性信息浪费严重,同时也无法对确定性因素之间的关系进行分析。
而非平稳序列随机分析的发展就是为了弥补确定性因素分解方法的不足。
时间序列数据分析的第一步都是要通过有效手段提取序列中所蕴藏的确定性信息。
Box 和Jenkins 使用大量的案例分析证明差分方法是一种非常简便有效的确定性信息的提取方法。
而Gramer 分解定理则在理论上保证了适当阶数的差分一定可以充分提取确定性信息。
(一)ARMA 模型即自回归移动平均移动模型,是最常用的拟合平稳时间序列的模型,分为三类:AR 模型、MA 模型和ARMA 模型。
一、AR(p )模型——p 阶自回归模型 1. 模型:011t t p t p t x x x φφφε--=+++其中,0p φ≠,随机干扰序列εt 为0均值、2εσ方差的白噪声序列(()0t s E εε=, t ≠s ),且当期的干扰与过去的序列值无关,即E(x t εt )=0.由于是平稳序列,可推得均值011pφμφφ=---. 若00φ=,称为中心化的AR (p )模型,对于非中心化的平稳时间序列,可以令01(1)p φμφφ=---,*t t x x μ=-转化为中心化。
记B 为延迟算子,1()p p p B I B B φφΦ=---称为p 阶自回归多项式,则AR (p )模型可表示为:()p t t B x εΦ=.2. 格林函数用来描述系统记忆扰动程度的函数,反映了影响效应衰减的快慢程度(回到平衡位置的速度),G j 表示扰动εt -j 对系统现在行为影响的权数。
例如,AR(1)模型(一阶非齐次差分方程),1, 0,1,2,j j G j φ==模型解为0t j t j j x G ε∞-==∑.3. 模型的方差对于AR(1)模型,2221()()1t jt j j Var x G Var εσεφ∞-===-∑. 4. 模型的自协方差对中心化的平稳模型,可推得自协方差函数的递推公式:用格林函数显示表示:200()()i j t j t k j j kj i j j k G G E GG γεεσ∞∞∞---+=====∑∑∑对于AR(1)模型,21121()(0)1k k k εσγφγφφ==- 5. 模型的自相关函数 递推公式:对于AR(1)模型,11()(0)k k k ρφρφ==.平稳AR(p )模型的自相关函数有两个显著的性质: (1)拖尾性指自相关函数ρ(k)始终有非零取值,不会在k 大于某个常数之后就恒等于零;(2)负指数衰减随着时间的推移,自相关函数ρ(k)会迅速衰减,且以负指数k iλ(其中i λ为自相关函数差分方程的特征根)的速度在减小。
时间序列分析(1).doc

第六章时间序列分析6.2自回归模型(AR)自回归模型中最简单的是一阶自回归模型和二阶自回归模型。
为节省篇幅,这里直接给出p 阶自回归模型。
6.2.1功能求出p阶自回归方程的系数,从而得到p阶自回归方程。
6.2.2方法说明6.2.3子程序语句SUBROUTINE ARP(X,N,M,R,FAI)6.2.4哑元说明X——输入参数,一维实型数组,大小为N,存放观测序列值。
N——输入参数,整型变量,为观测序列的长度。
M——输入参数,整型变量,为自回归的阶数。
R——输出参数,一维实型数组,存放自相关系数。
FAI——输出参数,二维实型数组,存放自回归系数。
6.2.5子程序SUBROUTINE ARP(X,N,M,R,FAI)INTEGER::TAO !落后时间REAL(4),DIMENSION(N)::XREAL(4),DIMENSION(M,M)::FAIREAL(4),DIMENSION(M)::RREAL(4),DIMENSION(M)::S !协方差REAL(4)::S2,A1,A2 !S2:方差, A1,A2:中间变量S=0DO TAO=1,MDO I=1,N-TAOS(TAO)=S(TAO)+X(I)*X(I+TAO)END DOS(TAO)=S(TAO)/(N-TAO)END DOS2=0DO I=1,NS2=S2+X(I)*X(I)END DOS2=S2/NDO TAO=1,MR(TAO)=0DO I=1,N-TAOR(TAO)=R(TAO)+X(I)*X(I+TAO)/S2END DOR(TAO)=R(TAO)/(N-TAO)END DOFAI(1,1)=R(1)FAI(2,2)=(R(2)-R(1)*R(1))/(1-R(1)*R(1))FAI(1,2)=FAI(1,1)-FAI(2,2)*FAI(1,1)DO J=3,MA1=0A2=0DO K=1,J-1A1=A1+FAI(K,J-1)*R(J-K)A2=A2+FAI(K,J-1)*R(K)END DOFAI(J,J)=(R(J)-A1)/(1-A2)DO K=1,J-1FAI(K,J)=FAI(K,J-1)-FAI(J,J)*FAI(J-K,J-1)END DOEND DOEND6.2.6例以某海区的22年的逐月气温为例,计算出自回归系数,并给出自回归方程。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验一分析太阳黑子数序列一、实验目的:了解时间序列分析的基本步骤,熟悉SAS/ETS软件使用方法。
二、实验内容:分析太阳黑子数序列。
三、实验要求:了解时间序列分析的基本步骤,注意各种语句的输出结果。
四、实验时间:2小时。
五、实验软件:SAS系统。
六、实验步骤1、开机进入SAS系统。
2、创建名为exp1的SAS数据集,即在窗中输入下列语句:3、保存此步骤中的程序,供以后分析使用(只需按工具条上的保存按钮然后填写完提问后就可以把这段程序保存下来即可)。
4、绘数据与时间的关系图,初步识别序列,输入下列程序:ods html;ods listing close;5、run;提交程序,在graph窗口中观察序列,可以看出此序列是均值平稳序列。
6、识别模型,输入如下程序。
7、提交程序,观察输出结果。
初步识别序列为AR(2)模型。
8、估计和诊断。
输入如下程序:9、提交程序,观察输出结果。
假设通过了白噪声检验,且模型合理,则进行预测。
10、进行预测,输入如下程序:11、提交程序,观察输出结果。
12、退出SAS系统,关闭计算机。
总程序:data exp1;infile "D:\exp1.txt";input a1 @@;year=intnx('year','1jan1742'd,_n_-1);format year year4.;;proc print;run;ods html;ods listing close;proc gplot data=exp1 ;symbol i=spline v=dot h=1 cv=red ci=green w=1;plot a1*year/autovref lvref=2 cframe=yellow cvref=black ;title "太阳黑子数序列";run;proc arima data=exp1;identify var=a1 nlag=24 minic p=(0:5) q=(0:5);estimate p=3;forecast lead=6 interval=year id=year out=out;run;proc print data=out;run;选取拟合模型的规则:1.模型显著有效(残差检验为白噪声)2.模型参数尽可能少3.结合自相关图和偏自相关图以及minic条件(BIC信息量最小原则),选取显著有效的参数实验二 模拟AR 模型一、 实验目的:熟悉各种AR 模型的样本自相关系数和偏相关系数的特点,为理 论学习提供直观的印象。
二、实验内容:随机模拟各种AR 模型。
三、 实验要求:记录各AR 模型的样本自相关系数和偏相关系数,观察各种序列 图形,总结AR 模型的样本自相关系数和偏相关系数的特点四、实验时间:2小时。
五、实验软件:SAS 系统。
六、 实验步骤1、开机进入SAS 系统。
2、模拟实根情况,模拟t t t t a z z z =-+--214.06.0过程。
3、在edit 窗中输入如下程序:4、观察输出的数据,输入如下程序,并提交程序。
观察样本自相关系数和偏相关系数,输入输入如下程序,并提交程序。
作为作业把样本自相关系数和偏相关系数记录下来。
5、 估计模型参数,并与实际模型的系数进行对比,即输入如下程序,并提交。
6、 模拟虚根情况,模拟t t t t a z z z =+---215.0过程。
重复步骤3-7即可(但部分程序需要修改,请读者自己完成)。
7、 模拟AR(3)模型,模拟t t t t t a z z z z =-+----3212.03.04.0过程。
重复步骤3-7即可(但部分程序需要修改,请读者自己完成).10、回到graph窗口观察各种序列图形的异同11、退出SAS系统,关闭计算机.总程序:title;data a;x1=0.5;x2=0.5;do i=-50 to 250;a=rannor(32565);x=a-0.6*x1+0.4*x2; x2=x1;x1=x;output;end;run;proc print data=a;var x;proc gplot data=a;symbol i=spline c=red;plot x*i/haxis=-50 to 255 by 20;run;quit;proc arima data=a;identify var=x nlag=10 minic p=(0:3) q=(0:3) outcov=exp1; estimate p=2 noint;run;proc gplot data=exp1;symbol i=needle width=6;plot corr*lag;run;proc gplot data=exp1;symbol i=needle width=6;plot partcorr*lag;run;实验三 模拟MA 模型和ARMA 模型一、 实验目的:熟悉各种MA 模型和ARMA 模型的样本自相关系数和偏相关系数 的特点,为理论学习提供直观的印象。
二、实验内容:随机模拟各种MA 模型和ARMA 模型。
三、 实验要求:记录各MA 模型和ARMA 模型的样本自相关系数和偏相关系数, 观察各序列的异同,总结MA 模型和ARMA 模型的样本自相关系数和偏相关系数的特点四、实验时间:2小时。
五、实验软件:SAS 系统。
六、 实验步骤1、开机进入SAS 系统。
2、模拟0,021<<θθ情况,模拟t t a B B x )24.065.01(2++=过程。
3 在edit 窗中输入如下程序: 4、观察输出的数据序列,输入如下程序,并提交程序。
5、观察样本自相关系数和偏相关系数,输入输入如下程序,并提交程序。
6、估计模型参数,并与实际模型的系数进行对比,即输入如下程序,并提交。
7、模拟0,021>>θθ情况,模拟t t a B B x )24.065.01(2--=过程。
重复步骤3-7即可(但部分程序需要修改,请读者自己完成)。
8、模拟0,021<>θθ情况,模拟t t a B B x )24.065.01(2+-=过程。
重复步骤3-7即可(但部分程序需要修改,请读者自己完成)。
9、模拟0,021><θθ情况,模拟t t a B B x )24.065.01(2-+=过程。
重复步骤3-7即可(但部分程序需要修改,请读者自己完成)。
10、 模拟ARMA 模型,模拟21214.03.055.075.0------+=++t t t t t t a a a x x x 过程。
重复步骤3-7即可(但部分程序需要修改,请读者自己完成).11、 回到graph 窗口观察各种序列图形的异同。
12、 退出SAS 系统,关闭计算机.总程序:data a;a1=0;a2=0;do n=1to 250;a=rannor(32565);x=a+0.65*a1+0.24*a2;a2=a1;a1=a;output;end;run;proc gplot data=a;symbol i=spline h=1 w=1;plot x*n /haxis=-10 to 260 by 10;run;proc arima data=a;identify var=x nlag=10 minic p=(0:3) q=(0:3) outcov=exp1; estimate q=2 noint;run;proc gplot data=exp1;symbol1 i=needle c=red;plot corr*lag=1;run;proc gplot data=exp1;symbol2 i=needle c=green;plot partcorr*lag=2;run;quit;实验四分析化工生产量数据一、实验目的:进一步熟悉时间序列建模的基本步骤,掌握用SACF及SPACF定模型的阶的方法。
二、实验内容:分析化工生产过程的产量序列。
三、实验要求:掌握ARMA模型建模的基本步骤,初步掌握数据分析技巧。
写出实验报告。
四、实验时间:2小时。
五、实验软件:SAS系统。
六、实验步骤1、开机进入SAS系统。
2、创建名为exp2的SAS数据集,即在窗中输入下列语句:3、保存此步骤中的程序,供以后分析使用(只需按工具条上的保存按钮然后填写完提问后就可以把这段程序保存下来即可)。
4、绘数据与时间的关系图,初步识别序列,输入下列程序:5、提交程序,在graph窗口中观察序列,可以看出此序列是均值平稳序列。
6、识别模型,输入如下程序。
7、提交程序,观察输出结果,发现二阶样本自相关系数和一阶的样本偏相关系数都在2倍的标准差之外,那么我们首先作为一阶AR模型估计,输入如下程序:8、提交程序,观察输出结果,发现残差能通过白噪声检验,但它的二阶的样本偏相关系数比较大,那么我们考虑二阶AR模型。
输入如下程序:9、提交程序,观察输出结果,发现残差样本自相关系数和样本偏相关系数都在2倍的标准差之内。
且能通过白噪声检验。
比较两个模型的AIC和SBC,发现第二个模型的AIC和SBC都比第一个的小,故我们选择第二个模型为我们的结果。
10、记录参数估计值,写出模型方程式。
11、进行预测,输入如下程序:12、提交程序,观察输出结果。
13、退出SAS系统,关闭计算机。
data exp2;infile "D:\exp1.txt";input x @@;n=_n_;proc print;run;proc gplot data=exp2;symbol i=join v=star h=2 ci=green cv=red; plot x*n/vref=30 50 70 cvref=red lvref=2 ; run;proc arima data=exp2;identify var=x nlag=12 minic p=(0:3) q=(0:3); estimate plot p=1;forecast lead=2 out=out;run;quit;实验五 模拟ARIMA 模型和季节ARIMA 模型一、 实验目的:熟悉各种ARIMA 模型的样本自相关系数和偏相关系数的特点, 区别各种ARIMA 模型的图形,为理论学习提供直观的印象。
一、实验内容:随机模拟各种ARIMA 模型。
二、 实验要求:记录各ARIMA 模型的样本自相关系数和偏相关系数观察各序列 图形的异同,总结ARIMA 模型的样本自相关系数和偏相关系数的特点三、实验时间:2小时。
四、实验软件:SAS 系统。
五、 实验步骤1. 开机进入SAS 系统。