jquery字符编码转换
jquery 常见的字符串加解密方法

jquery 常见的字符串加解密方法在jQuery 中,并没有提供专门的字符串加解密方法。
字符串的加解密通常是通过JavaScript 的原生方法或者其他第三方库来实现的。
以下是一些常见的字符串加解密方法:1. Base64 编码解码:Base64 编码不是真正的加密,但它可以用于对字符串进行简单的编码和解码。
编码:```javascriptvar encodedString = btoa("Hello, World!"); // 编码```解码:```javascriptvar decodedString = atob(encodedString); // 解码```2. MD5 加密:MD5 是一种不可逆的哈希算法,用于生成字符串的固定长度散列值。
```javascriptfunction md5(string) {// 通过第三方库或实现MD5算法// 返回MD5散列值}```3. AES 加密解密:AES(Advanced Encryption Standard)是一种对称加密算法,常用于加密和解密数据。
```javascript// 使用第三方库CryptoJS 实现// https://cryptojs.gitbook.io/docs/var encrypted = CryptoJS.AES.encrypt("Hello, World!", "secretKey");var decrypted = CryptoJS.AES.decrypt(encrypted, "secretKey");var decryptedString = decrypted.toString(CryptoJS.enc.Utf8);```4. RSA 加密解密:RSA 是一种非对称加密算法,用于加密和解密数据。
```javascript// 使用第三方库jsencrypt 实现var encrypt = new JSEncrypt();encrypt.setPublicKey("-----BEGIN PUBLIC KEY-----\n ... \n-----END PUBLIC KEY-----");var encrypted = encrypt.encrypt("Hello, World!");var decrypt = new JSEncrypt();decrypt.setPrivateKey("-----BEGIN PRIVATE KEY-----\n ... \n-----END PRIVATE KEY-----");var decrypted = decrypt.decrypt(encrypted);```请注意,这些示例中使用的库(如CryptoJS、jsencrypt)需要在项目中引入并进行适当的配置。
jquery 常见的字符串加解密方法

jquery 常见的字符串加解密方法jQuery常见的字符串加解密方法在前端开发中,数据的安全性至关重要。
为了保护敏感数据,开发人员需要使用加密和解密技术。
jQuery是一款流行的JavaScript库,它提供了一些常见的字符串加解密方法,可以帮助开发人员实现数据的安全传输和存储。
本文将介绍几种常见的字符串加解密方法,帮助读者了解如何使用jQuery保护数据安全。
一、Base64编码解码Base64是一种常见的编码方式,它将二进制数据转换为可打印的ASCII字符。
在前端开发中,Base64常用于加密URL、图片和其他敏感数据。
通过使用jQuery提供的方法,我们可以很方便地进行Base64编码和解码操作。
1.1 Base64编码```javascriptvar encodedString = $.base64.encode("Hello, World!");```1.2 Base64解码```javascriptvar decodedString = $.base64.decode("SGVsbG8sIFdvcmxkIQ==");```二、MD5加密MD5是一种常见的哈希算法,它将任意长度的数据转换为固定长度的字符串。
在前端开发中,MD5常用于对密码等敏感信息进行加密。
虽然MD5是不可逆的,但它可以通过与已知的哈希值进行比对来验证数据的正确性。
```javascriptvar encryptedString = $.md5("Hello, World!");```三、AES加解密AES(Advanced Encryption Standard)是一种对称加密算法,它可以对大块数据进行高效加解密操作。
在前端开发中,AES常用于保护敏感数据的传输和存储。
通过使用一些jQuery插件,我们可以方便地进行AES加解密操作。
3.1 AES加密首先,我们需要引入相关的插件文件,例如CryptoJS。
使用jquery.qrcode生成二维码及常见问题解决方案

使⽤jquery.qrcode⽣成⼆维码及常见问题解决⽅案⼀、jquery.qrcode.js介绍⼆、参数说明1. text : "https:///jeromeetienne/jquery-qrcode" //设置⼆维码内容2. render : "canvas",//设置渲染⽅式(有两种⽅式 table和canvas,默认是canvas)3. width : 256, //设置宽度4. height : 256, //设置⾼度5. typeNumber : -1, //计算模式6. correctLevel : 0,//纠错等级7. background : "#ffffff",//背景颜⾊8. foreground : "#000000" //前景颜⾊三、jquery.qrcode使⽤1. 加载 jQuery 和 jquery.qrcode.js: <script type='text/javascript' src='/jquery/2.1.1/jquery.min.js'></script> <script type="text/javascript" src="/jquery.qrcode/1.0/jquery.qrcode.min.js"></script>2. 创建⼀个⽤于包含 QRcode 图⽚的 DOM 元素,⽐如 div:<div id="qrcode"></div>3.通过下⾯代码⽣成 QRcode: 最简单⽅式:jQuery('#qrcode').qrcode("/mr_smile2014"); ⾃定义⽅式:jQuery('#qrcode').qrcode({render:canvas,width: 64,height: 64,correctLevel:0,text: "/mr_smile2014"});四、常见问题1.在chorme浏览器中⼆维码⽣成成功后⽆法扫描解决⽅法: //改成使⽤table的渲染⽅式,亲测⽀持各种各版本的浏览器 jQuery('#qrcode').qrcode({width: 200,height: 200,correctLevel:0,render: "table",text: "/mr_smile2014"});2.在微信或⼿机浏览器中⽣成的⼆维码⽆法扫描解决⽅法; //改成使⽤默认的渲染⽅式,⽀持微信和QQ内置浏览器及其它⼿机浏览器 jQuery('#qrcode').qrcode({width: 200,height: 200,correctLevel:0,text: "/mr_smile2014"});jquery-qrcode这个库是采⽤ charCodeAt() 这个⽅式进⾏编码转换的,这个⽅法默认会获取它的 Unicode 编码,⼀般的解码器都是采⽤UTF-8, ISO-8859-1等⽅式。
jquery中文乱码

jquery中文乱码escape()除了ASCII 字母、数字和特定的符号外,对传进来的字符串全部进行转义编码,因此如果想对URL编码,最好不要使用此方法。
而encodeURI() 用于编码整个URI,因为URI中的合法字符都不会被编码转换的。
encodeURIComponent方法在编码单个URIComponent(指请求参数)应当是最常用的,它可以讲参数中的中文、特殊字符进行转义,而不会影响整个URL当通过jquery传递中文参数时,页面出现了乱码,这时需要对参数进行处理:javascript中代码:[javascript]view plaincopy1.var subCompanyName = encodeURIComponent(encode URIComponent($("#subCompanyName").val()));2.window.open("../powerStation/doSubAddForward.do?sub CompanyId="+subCompanyId+"&subCompanyName="+subC ompanyName, "添加明细", "width=620,height=360,left=200,location=no");注意对参数subCompanyName进行了两次encodeURIComponent包装。
java代码中:[java]view plaincopy1.String subCompanyName = request.getParameter("subC ompanyName");2.subCompanyName = URLDecoder.decode(subCompanyN ame, "utf-8");[html]view plaincopy.URIDecoder.decode(String s,String enc)方法说明:2.decode3.public static String decode(String s,4.String enc)5.throws UnsupportedEncodingException6.使用指定的编码机制对 application/x-www-form-urlencoded 字符串解码。
JavaScriptjQuery.强制类型转换

JavaScriptjQuery.强制类型转换强制类型转换强制类型转换类型转换有两种:⼀种是显式转换,即需要程序员⼿动写代码转换;另⼀种是隐匿转换,由JavaScript解释器转换。
JavaScript提供以下函数进⾏显式转换:1.转换为数值类型:Number(mix)、parseInt(string,radix)、parseFloat(string)2.转换为字符串类型:toString(radix)、String(mix)3.转换为布尔类型:Boolean(mix)转换为数值类型Number(mix)函数Number(mix)函数,可以将任意类型的参数mix转换为数值类型。
其规则为:1、如果是布尔值,true和false分别被转换为1和02、如果是数字值,返回本⾝。
3、如果是null,返回04、如果是undefined,返回NaN。
5、如果是字符串,遵循以下规则:a.如果字符串中只包含数字,则将其转换为⼗进制(忽略前导0)b.如果字符串中包含有效的浮点格式,将其转换为浮点数值(忽略前导0)c.如果是空字符串,将其转换为0d.如果字符串中包含⾮以上格式,则将其转换为NaN6、如果是对象,则调⽤对象的valueOf()⽅法,然后依据前⾯的规则转换返回的值。
如果转换的结果是NaN,则调⽤对象的toString()⽅法,再次依照前⾯的规则转换返回的字符串值。
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>转换为数值类型Number(mix)函数</title></head><body><script>println(Number(false));println(Number(true));println(Number(123));println(Number(null));println(Number(undefined));println(Number(person));function println(a){document.write(a+'<br>');}var person{};='huangshiren';person.age=59;person.appetite=3;person.eat=function(){document.write('正在吃饭');}</script></body></html>parseInt(string, radix)函数参数说明:string 要被解析的值。
jquery字符编码转换

Ajax遭遇GBK编码(完全解决方案)占个座位先国内互联网普遍都是使用GBK编码。
对于J2EE项目,为了减少编码的干扰通常都是设置一个编码的Filter,强制将Request/Response编码改为GBK。
例如一个Spring的常见配置如下:<filter><filter-name>encodingFilter</filter-name><filter-class>org.springframework.web.filter.CharacterEncodingFil ter</filter-class><init-param><param-name>encoding</param-name><param-value>GBK</param-value></init-param><init-param><param-name>forceEncoding</param-name><param-value>true</param-value></init-param></filter>毫无疑问,这在GBK编码的页面访问、提交数据时是没有乱码问题的。
但是遇到Ajax就不一样了。
Ajax强制将中文内容进行UTF-8编码,这样导致进入后端后使用GBK进行解码时发生乱码。
如果提交数据的时候能够告诉后端传输的编码信息是否就可以避免这种问题?比如Ajax请求告诉后端是UTF-8,其它请求告诉后端是GBK,这样后端分别根据指定的编码进行解码是不是就解决问题了。
问题:1.如何通过Ajax告诉后端的编码?Header过于复杂,Cookie成本太高,使用参数最方便。
2.后端何时进行解码?每一个请求进行解码,过于繁琐;获取参数时解码,此时已经乱码;在Filter里面动态设置编码是最完善的方案。
JQuery字符串的操作

JQuery字符串的操作⼀、String对象属性 1、length属性: length算是字符串中⾮常常⽤的⼀个属性了,它的功能是获取字符串的长度。
当然需要注意的是js中的中⽂每个汉字也只代表⼀个字符,这⾥可能跟其他语⾔有些不⼀样。
var str = 'abc';console.log(str.length); // 3 2、prototype属性: prototype在⾯向对象编程中会经常⽤到,⽤来给对象添加属性或⽅法,并且添加的⽅法或属性在所有的实例上共享。
因此也常⽤来扩展js内置对象,如下⾯的代码给字符串添加了⼀个去除两边空格的⽅法。
String.prototype.trim = function(){return this.replace(/^\s*|\s*$/g, '');}⼆、String对象⽅法 1、获取类⽅法: (1) charAt():stringObject.charAt(index) charAt()⽅法可⽤来获取指定位置的字符串,index为字符串索引值,从0开始到string.leng – 1,若不在这个范围将返回⼀个空字符串。
如:var str = 'abcde';console.log(str.charAt(2)); //返回cconsole.log(str.charAt(8)); //返回空字符串 (2) charCodeAt():stringObject.charCodeAt(index) charCodeAt()⽅法可返回指定位置的字符的Unicode。
charCodeAt()⽅法与charAt()⽅法类似,都需要传⼊⼀个索引值作为参数,区别是前者返回指定位置的字符的编码,⽽后者返回的是字符⼦串。
var str = 'abcde';console.log(str.charCodeAt(0)); //返回97 (3) fromCharCode():String.fromCharCode(numX,numX,…,numX) fromCharCode()可接受⼀个或多个Unicode值,然后返回⼀个字符串。
js中把中文字符转换成Utf8编码

js中把中文字符转换成Utf8编码最近在做个pyhthon应用,有一个逻辑是需要在前台通过JS把一串字符串通过get 方式提交到后台,提交英文和数字都正常,但是提交中文时出现了问题,因为在python的服务器端接收的是utf-8编码,所以需要在前台进行转码,以下是网上找来一段相对还不错的UTF-8 JS转码函数//--------把中文字符转换成Utf8编码------------------------//function EncodeUtf8(s1){var s = escape(s1);var sa = s.split("%");var retV ="";if(sa[0] != ""){retV = sa[0];}ngth; i ++){if(sa[i].substring(0,1) == "u"){retV += Hex2Utf8(Str2Hex(sa[i].substring(1,5)));}else retV += "%" + sa[i];}return retV;}function Str2Hex(s){var c = "";var n;var ss = "0123456789ABCDEF";var digS = "";for(var i = 0; i < s.length; i ++){c = s.charAt(i);n = ss.indexOf(c);digS += Dec2Dig(eval(n));}//return value;return digS;}function Dec2Dig(n1){var s = "";var n2 = 0;for(var i = 0; i < 4; i++){n2 = Math.pow(2,3 - i);if(n1 >= n2){s += '1';n1 = n1 - n2;}elses += '0';}return s;}function Dig2Dec(s){var retV = 0;if(s.length == 4){for(var i = 0; i < 4; i ++){retV += eval(s.charAt(i)) * Math.pow(2, 3 - i);}return retV;}return -1;}function Hex2Utf8(s){var retS = "";var tempS = "";var ss = "";if(s.length == 16){tempS = "1110" + s.substring(0, 4);tempS += "10" + s.substring(4, 10);tempS += "10" + s.substring(10,16);var sss = "0123456789ABCDEF";for(var i = 0; i < 3; i ++){retS += "%";ss = tempS.substring(i * 8, (eval(i)+1)*8);retS += sss.charAt(Dig2Dec(ss.substring(0,4)));retS += sss.charAt(Dig2Dec(ss.substring(4,8)));}return retS;}return "";}。
jq 特殊字符转义方法

jq 特殊字符转义方法在使用 jQuery (jq) 的过程中,有时候我们会遇到需要处理特殊字符转义的情况。
特殊字符包括像引号、斜杠等在字符串中有特殊含义的字符。
本文将介绍几种常用的 jq 特殊字符转义方法。
1. 使用双反斜杠转义在 jq 中,使用双反斜杠 `\\` 可以对特殊字符进行转义。
比如,如果你想在字符串中使用双引号,你可以将双引号转义为 `\"`。
以下是一个示例:```javascriptvar str = "This is a \"quoted\" string.";console.log(str);```输出:```This is a "quoted" string.```2. 使用 \x 转义十六进制字符另一种处理特殊字符的方法是使用 `\x` 加上两个十六进制数字来表示特殊字符的 Unicode 编码。
例如,如果你想在字符串中使用斜杠,你可以将其转义为`\x2F`。
以下是一个示例:```javascriptvar str = "This is a \x2Fslash.";console.log(str);```输出:```This is a /slash.```3. 使用 \u 转义 Unicode 字符如果需要处理非 ASCII 字符,可以使用 `\u` 加上四个十六进制数字来转义Unicode 字符。
例如,如果你想在字符串中使用希腊字母Ω,你可以将其转义为`\u03A9`。
以下是一个示例:```javascriptvar str = "This is a Greek letter: \u03A9.";console.log(str);```输出:```This is a Greek letter: Ω.```以上是几种常用的 jq 特殊字符转义方法。
根据具体的需求,你可以选择适合的方法进行处理。
jqeuryeval将字符串转换json的方法

jqeuryeval将字符串转换json的⽅法前台页⾯复制代码代码如下:$.ajax({type: "post",contentType: "application/json",url: "../WebForm1.aspx/GetRightsStr",dataType: "json",success: function (msg) {alert(msg.d);var data = eval("(" + msg.d + ")");$.each(data.rights, function (index, item) {alert(item.RightsName);});},error: function (e, s, d) {alert(e);alert(s);alert(d);}});后台⽅法:复制代码代码如下:/// <summary>/// DataTable转成Json/// </summary>/// <param name="jsonName">josn名称</param>/// <param name="dt">要转换的数据集</param>/// <returns></returns>public static string DataTableToJson(string jsonName, DataTable dt){StringBuilder Json = new StringBuilder();Json.Append("{\"" + jsonName + "\":[");if (dt.Rows.Count > 0){for (int i = 0; i < dt.Rows.Count; i++){Json.Append("{");for (int j = 0; j < dt.Columns.Count; j++){Json.Append("\"" + dt.Columns[j].ColumnName.ToString() + "\":\"" + dt.Rows[i][j].ToString() + "\""); if (j < dt.Columns.Count - 1){Json.Append(",");}}Json.Append("}");if (i < dt.Rows.Count - 1){Json.Append(",");}}}Json.Append("]}");return Json.ToString();}这个⽅法是⼀个将DataTable转换成字符串的⽅法。
jquery:字符串(string)转json

jquery:字符串(string)转json第⼀种⽅式:使⽤js函数eval();testJson=eval(testJson);是错误的转换⽅式。
正确的转换⽅式需要加(): testJson = eval("(" + testJson + ")");eval()的速度⾮常快,但是他可以编译以及执⾏任何javaScript程序,所以会存在安全问题。
在使⽤eval()。
来源必须是值得信赖的。
需要使⽤更安全的json解析器。
在服务器不严格的编码在json或者如果不严格验证的输⼊,就有可能提供⽆效的json或者载有危险的脚本,在eval()中执⾏脚本,释放恶意代码。
js代码:function ConvertToJsonForJs() {//var testJson = "{ name: '⼩强', age: 16 }";(⽀持)//var testJson = "{ 'name': '⼩强', 'age': 16 }";(⽀持)var testJson = '{ "name": "⼩强", "age": 16 }';//testJson=eval(testJson);//错误的转换⽅式testJson = eval("(" + testJson + ")");alert();}第⼆种⽅式使⽤jquery.parseJSON()⽅法对json的格式要求⽐较⾼,必须符合json格式jquery.parseJSON()js:代码function ConvertToJsonForJq() {var testJson = '{ "name": "⼩强", "age": 16 }';//不知道//'{ name: "⼩强", age: 16 }' (name 没有使⽤双引号包裹)//"{ 'name': "⼩强", 'age': 16 }"(name使⽤单引号)testJson = $.parseJSON(testJson);alert();}。
中文字符编码的相互转换(三)-CSDN博客

中文字符编码的相互转换(三)-CSDN博客终于到讨论编码转换这一步了。
先来看Unicode和UTF-8之间的转换,前面我们说过Unicode 和UTF-8的字符是一一对应的。
他们的对应规则如下:Unicode和UTF-8之间的转换关系表以上表格摘自维基百科,该表格记录了UCS-4 与UTF-8的对应关系。
上面的x表示我们可以编码的位。
这个表记录的内容太多,我们平常使用只需要前三行,也就是UCS-2的表示范围。
这基本可以表示我们国际上通用的所有文字和特殊符号了。
再来解释一下UTF-8编码字节含义:对于UTF-8编码中的任意字节B,如果B的第一位为0,则B为ASCII码,并且B独立的表示一个字符;如果B的第一位为1,第二位为0,则B为一个非ASCII字符(该字符由多个字节表示)中的一个字节,并且不为字符的第一个字节编码;如果B的前两位为1,第三位为0,则B为一个非ASCII字符(该字符由多个字节表示)中的第一个字节,并且该字符由两个字节表示;如果B的前三位为1,第四位为0,则B为一个非ASCII字符(该字符由多个字节表示)中的第一个字节,并且该字符由三个字节表示;有了这层对应关系,Unicode到utf-8的转化代码就不难实现了,以下是我用c实现的,经多年线上验证没有问题。
typedef char T_GB;typedef unsigned short T_UC;typedef unsigned char T_UTF8;/*! * \brief UCS-2编码文本转换为UTF-8编码文本 * \param[in] puc: UCS-2字符串的地址* \param[in] nuclen: UCS-2字符串的长度 * \param[out] putf8: 输出的UTF-8字符串的地址* \param[in] nutf8len: 最大可以允许的UTF-8字符串的长度,如果nutf8len<nuclen*3,可能会出现部分字符被截断* \return int 转换后的字符长度*/int uc2utf8(const T_UC* puc, size_t nuclen, T_UTF8* putf8, size_t nutf8len){ const T_UC* ucbpos = puc; const T_UC* ucepos = puc+nuclen;T_UTF8* utf8bpos = putf8; T_UTF8* utf8epos = putf8+nutf8len; while (ucbpos< ucepos && utf8bpos<utf8epos) { if (*ucbpos < 0x80){ *utf8bpos++ = *ucbpos++; } else if (*ucbpos < 0x800) {if (utf8epos-utf8bpos < 2) {break; }*utf8bpos++ = ((*ucbpos&0x7C0)>>6) | 0xC0;*utf8bpos++ = (*ucbpos++ & 0x3F) | 0x80; } else { if (utf8epos-utf8bpos < 3) { break;} *utf8bpos++ = ((*ucbpos&0xF000)>>12) | 0xE0; *utf8bpos++ = ((*ucbpos&0x0FC0)>>6) | 0x80; *utf8bpos++ = ((*ucbpos++&0x3F)) | 0x80; } } return (utf8bpos-putf8);}/*! * \brief UTF-8编码文本转换为UCS-2编码文本 * \param[in] putf8: UTF-8字符串的地址 * \param[in] nutf8len: UTF-8字符串的长度 * \param[out] puc: 输出的UCS-2字符串的地址* \param[in] nuclen: 最大可以允许的UCS-2字符串的长度,如果nuclen<nutf8len,可能会出现部分字符被截断 * \return int 转换后的字符长度 */int utf8uc2(const T_UTF8* putf8, size_t nutf8len, T_UC* puc, size_t nuclen){ const T_UTF8 * utf8bpos = putf8; const T_UTF8 * utf8epos = putf8 + nutf8len; T_UC * ucbpos = puc;T_UC * ucepos = puc + nuclen;while(utf8bpos<utf8epos && ucbpos< ucepos) {if (*utf8bpos < 0x80) //asc {*ucbpos++ = *utf8bpos++; } else if ( (*utf8bpos&0xE0) == 0xE0 ) //三个字节{if (ucepos - ucbpos < 2) {break; }*ucbpos = (T_UC(*utf8bpos++ & 0x0F)) << 12; *ucbpos |= (T_UC(*utf8bpos++ & 0x3F)) << 6; *ucbpos++ |= (T_UC(*utf8bpos++ & 0x3F));} else if ((*utf8bpos&0xC0) == 0xC0) { if (ucepos - ucbpos < 2) { break;}*ucbpos = (T_UC(*utf8bpos++ & 0x1F)) << 6; *ucbpos++ |= (T_UC(*utf8bpos++ & 0x3F)); } else { utf8bpos++; }} return ucbpos-puc;}那么Unicode和GBK编码之间如何转换呢?因为Unicode和GBK之间没有算法上面的对应关系,只能通过查表来转换。
jquery获取URL中参数解决中文乱码问题的两种方法

jquery获取URL中参数解决中⽂乱码问题的两种⽅法从A页⾯通过url传参到B页⾯时,解析url参数可以⽤下⾯两种⽅法:复制代码代码如下:function getQueryString(name) {var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)", "i");var r = window.location.search.substr(1).match(reg);if (r != null) return unescape(r[2]); return null;}这样调⽤:复制代码代码如下:alert(GetQueryString("参数名1"));alert(GetQueryString("参数名2"));alert(GetQueryString("参数名3"));复制代码代码如下:<span style="font-size: 16px;"><Script language="javascript">function GetRequest() {var url = location.search; //获取url中"?"符后的字串var theRequest = new Object();if (url.indexOf("?") != -1) {var str = url.substr(1);strs = str.split("&");for(var i = 0; i < strs.length; i ++) {theRequest[strs[i].split("=")[0]]=unescape(strs[i].split("=")[1]);}}return theRequest;}</Script></span>复制代码代码如下:<Script language="javascript">var Request = new Object();Request = GetRequest();var 参数1,参数2,参数3,参数N;参数1 = Request['参数1'];参数2 = Request['参数2'];参数3 = Request['参数3'];参数N = Request['参数N'];</Script>如果参数中含有中⽂字符,注意转编码和解码:复制代码代码如下:<span style="font-size:18px;">1.传参页⾯Javascript代码:<script type=”text/javascript”>function send(){var url = "test01.html";var userName = $("#userName").html();window.open(encodeURI(url + "?userName=" + userName)); }</script>2. 接收参数页⾯:test02.html<script>var urlinfo = window.location.href;//获取urlvar userName = urlinfo.split(“?”)[1].split(“=”)[1];//拆分url得到”=”后⾯的参数$(“#userName”).html(decodeURI(userName));</script></span>。
Jquery字符串转数字

Jquery字符串转数字其实在jquery⾥把字符串转换为数字,⽤的还是,因为jquery本⾝就是⽤js封装编写的。
⽐如我们在⽤jquery⾥的ajax来更新⽂章的阅读次数或⼈⽓的时候,就需要⽤到字符串转换为数字的功能了,先来看看JS⾥把字符串转换为数字的函数命令:1:parseInt(string) :这个函数的功能是从string的开头开始解析,返回⼀个整数,说起来⽐较笼统,下⾯来看⼏个实例,⼤家就明⽩了:1.parseInt("1234blue"); //returns 12342.parseInt("123"); //returns 1233.parseInt("22.5"); //returns 224.parseInt("blue"); //returns NaN5.6.//另外parseInt()⽅法还有基模式,就是可以把⼆进制、⼋进制、⼗六进制或其他任何进制的字符串转换成整数。
基是由parseInt()⽅法的第⼆个参数指定的,⽰例如下:7.parseInt("AF", 16); //returns 1758.parseInt("10", 2); //returns 29.parseInt("10", 8); //returns 810.parseInt("10", 10); //returns 1011.12.如果⼗进制数包含前导0,那么最好采⽤基数10,这样才不会意外地得到⼋进制的值。
例如:13.parseInt("010"); //returns 814.parseInt("010", 8); //returns 815.parseInt("010", 10); //returns 102:parseFloat():这个函数与parseInt()⽅法的处理⽅式相似。
JS及JQuery对Html内容编码,Html转义

JS及JQuery对Html内容编码,Html转义话不多说,请看代码:/** JQuery Html Encoding、Decoding* 原理是利⽤JQuery⾃带的html()和text()函数可以转义Html字符* 虚拟⼀个Div通过赋值和取值来得到想要的Html编码或者解码*/<script src="/jquery/1.9.0/jquery.js"></script><script type="text/javascript">//Html编码获取Html转义实体function htmlEncode(value){return $('<div/>').text(value).html();}//Html解码获取Html实体function htmlDecode(value){return $('<div/>').html(value).text();}</script><script type="text/javascript">//获取Html转义字符function htmlEncode( html ) {return document.createElement( 'a' ).appendChild(document.createTextNode( html ) ).parentNode.innerHTML;};//获取Htmlfunction htmlDecode( html ) {var a = document.createElement( 'a' ); a.innerHTML = html;return a.textContent;};</script>//编码function html_encode(str){var s = "";if (str.length == 0) return "";s = str.replace(/&/g, ">");s = s.replace(/</g, "<");s = s.replace(/>/g, ">");s = s.replace(/ /g, " ");s = s.replace(/\'/g, "'");s = s.replace(/\"/g, """);s = s.replace(/\n/g, "<br>");return s;}//解码function html_decode(str){var s = "";if (str.length == 0) return "";s = str.replace(/>/g, "&");s = s.replace(/</g, "<");s = s.replace(/>/g, ">");s = s.replace(/ /g, " ");s = s.replace(/'/g, "\'");s = s.replace(/"/g, "\"");s = s.replace(/<br>/g, "\n");return s;}以上就是本⽂的全部内容,希望本⽂的内容对⼤家的学习或者⼯作能带来⼀定的帮助,同时也希望多多⽀持!。
java字符串的各种编码转换类ChangeCharset

java字符串的各种编码转换类ChangeCharset无论是对程序的本地化还是国际化,都会涉及到字符编码的转换的问题。
尤其在web应用中常常需要处理中文字符,这时就需要进行字符串的编码转换,将字符串编码转换为GBK或者GB2312。
一、关键技术点:1、当前流行的字符编码格式有:US-ASCII、ISO-8859-1、UTF-8、UTF-16BE、UTF-16LE、UTF-16、GBK、GB2312等,其中GBK、GB2312是专门处理中文编码的。
2、String的getBytes方法用于按指定编码获取字符串的字节数组,参数指定了解码格式,如果没有指定解码格式,则按系统默认编码格式。
3、String的“String(bytes[] bs, String charset)”构造方法用于把字节数组按指定的格式组合成一个字符串对象二、实例演示:package book.String;import java.io.UnsupportedEncodingException;/*** 转换字符串的编码* @author joe**/public class ChangeCharset {/** 7位ASCII字符,也叫作ISO646-US、Unicode字符集的基本拉丁块 */public static final String US_ASCII = "US-ASCII";/** ISO拉丁字母表 No.1,也叫做ISO-LATIN-1 */public static final String ISO_8859_1 = "ISO-8859-1";/** 8 位 UCS 转换格式 */public static final String UTF_8 = "UTF-8";/** 16 位 UCS 转换格式,Big Endian(最低地址存放高位字节)字节顺序 */public static final String UTF_16BE = "UTF-16BE";/** 16 位 UCS 转换格式,Litter Endian(最高地址存放地位字节)字节顺序 */public static final String UTF_16LE = "UTF-16LE";/** 16 位UCS 转换格式,字节顺序由可选的字节顺序标记来标识 */public static final String UTF_16 = "UTF-16";/** 中文超大字符集 **/public static final String GBK = "GBK";public static final String GB2312 = "GB2312";/** 将字符编码转换成US-ASCII码 */public String toASCII(String str) throws UnsupportedEncodingException {return this.changeCharset(str, US_ASCII);}/** 将字符编码转换成ISO-8859-1 */public String toISO_8859_1(String str) throws UnsupportedEncodingException {return this.changeCharset(str, ISO_8859_1);}/** 将字符编码转换成UTF-8 */public String toUTF_8(String str) throws UnsupportedEncodingException {return this.changeCharset(str, UTF_8);}/** 将字符编码转换成UTF-16BE */public String toUTF_16BE(String str) throws UnsupportedEncodingException{return this.changeCharset(str, UTF_16BE);}/** 将字符编码转换成UTF-16LE */public String toUTF_16LE(String str) throws UnsupportedEncodingException {return this.changeCharset(str, UTF_16LE);}/** 将字符编码转换成UTF-16 */public String toUTF_16(String str) throws UnsupportedEncodingException {return this.changeCharset(str, UTF_16);}/** 将字符编码转换成GBK */public String toGBK(String str) throws UnsupportedEncodingException {return this.changeCharset(str, GBK);}/** 将字符编码转换成GB2312 */public String toGB2312(String str) throws UnsupportedEncodingException {return this.changeCharset(str,GB2312);}/*** 字符串编码转换的实现方法* @param str 待转换的字符串* @param newCharset 目标编码*/public String changeCharset(String str, String newCharset) throws UnsupportedEncodingException {if(str != null) {//用默认字符编码解码字符串。
JsJquery-Base64和UrlEncode编码解码

JsJquery-Base64和UrlEncode编码解码 最近⼏天遇到⼀些URL参数明⽂显⽰的问题,因为是明⽂显⽰,容易让⼈通过改变参数查看到他没有权限看到内容。
⼀开始我的做法是⾃定义了规则,然后原始的那种URL编码。
可是URL编译后效果不理想,他⽆法编译数字,⽽且编码后的字符串太长。
最后我在⽹上⽤了BASE64这种。
感觉还可以。
摘录下来,做⼀下备忘,以后还会⽤到 C# BASE64 解码和编码string a = "【OK,Let's GO】";byte[] b = System.Text.Encoding.Default.GetBytes(a);//转成 Base64 形式的 System.Stringa = Convert.ToBase64String(b);Console.WriteLine(a);解码://转回到原来的 System.String。
byte[] c = Convert.FromBase64String(a);a = System.Text.Encoding.Default.GetString(c);Console.WriteLine(a); JS BASE64 解码和编码/**** Base64 encode / decode** @author haitao.tu* @date 2010-04-26* @email tuhaitao@**/function Base64() {// private property_keyStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";// public method for encodingthis.encode = function (input) {var output = "";var chr1, chr2, chr3, enc1, enc2, enc3, enc4;var i = 0;input = _utf8_encode(input);while (i < input.length) {chr1 = input.charCodeAt(i++);chr2 = input.charCodeAt(i++);chr3 = input.charCodeAt(i++);enc1 = chr1 >> 2;enc2 = ((chr1 & 3) << 4) | (chr2 >> 4);enc3 = ((chr2 & 15) << 2) | (chr3 >> 6);enc4 = chr3 & 63;if (isNaN(chr2)) {enc3 = enc4 = 64;} else if (isNaN(chr3)) {enc4 = 64;}output = output +_keyStr.charAt(enc1) + _keyStr.charAt(enc2) +_keyStr.charAt(enc3) + _keyStr.charAt(enc4);}return output;}// public method for decodingthis.decode = function (input) {var output = "";var chr1, chr2, chr3;var enc1, enc2, enc3, enc4;var i = 0;input = input.replace(/[^A-Za-z0-9\+\/\=]/g, "");while (i < input.length) {enc1 = _keyStr.indexOf(input.charAt(i++));enc2 = _keyStr.indexOf(input.charAt(i++));enc3 = _keyStr.indexOf(input.charAt(i++));enc4 = _keyStr.indexOf(input.charAt(i++));chr1 = (enc1 << 2) | (enc2 >> 4);chr2 = ((enc2 & 15) << 4) | (enc3 >> 2);chr3 = ((enc3 & 3) << 6) | enc4;output = output + String.fromCharCode(chr1);if (enc3 != 64) {output = output + String.fromCharCode(chr2);}if (enc4 != 64) {output = output + String.fromCharCode(chr3);}}output = _utf8_decode(output);return output;}// private method for UTF-8 encoding_utf8_encode = function (string) {string = string.replace(/\r\n/g,"\n");var utftext = "";for (var n = 0; n < string.length; n++) {var c = string.charCodeAt(n);if (c < 128) {utftext += String.fromCharCode(c);} else if((c > 127) && (c < 2048)) {utftext += String.fromCharCode((c >> 6) | 192);utftext += String.fromCharCode((c & 63) | 128);} else {utftext += String.fromCharCode((c >> 12) | 224);utftext += String.fromCharCode(((c >> 6) & 63) | 128);utftext += String.fromCharCode((c & 63) | 128);}}return utftext;}// private method for UTF-8 decoding_utf8_decode = function (utftext) {var string = "";var i = 0;var c = c1 = c2 = 0;while ( i < utftext.length ) {c = utftext.charCodeAt(i);if (c < 128) {string += String.fromCharCode(c);i++;} else if((c > 191) && (c < 224)) {c2 = utftext.charCodeAt(i+1);string += String.fromCharCode(((c & 31) << 6) | (c2 & 63));i += 2;} else {c2 = utftext.charCodeAt(i+1);c3 = utftext.charCodeAt(i+2);string += String.fromCharCode(((c & 15) << 12) | ((c2 & 63) << 6) | (c3 & 63));i += 3;}}return string;}}JS测试页⾯1.<html>2. <head>3. <script src="lib/base64.js" type="text/javascript"></script>4. <script type="text/javascript">5. var b = new Base64();6. var str = b.encode("admin:admin");7. alert("base64 encode:" + str);8. str = b.decode(str);9. alert("base64 decode:" + str);10. </script>11. </head>12. <body>13. </body>14.</html>顺便把Jquery的UrlEncode也记在这⾥:Jquery字符UrlEncode 编码、解码 --C#UrlEncode C#:Server.UrlEncode(ur)Jquery解码:decodeURIComponent(url); Jquery编码:encodeURIComponent(url);。
实现字符串的编码转换,用以解决字符串乱码问题
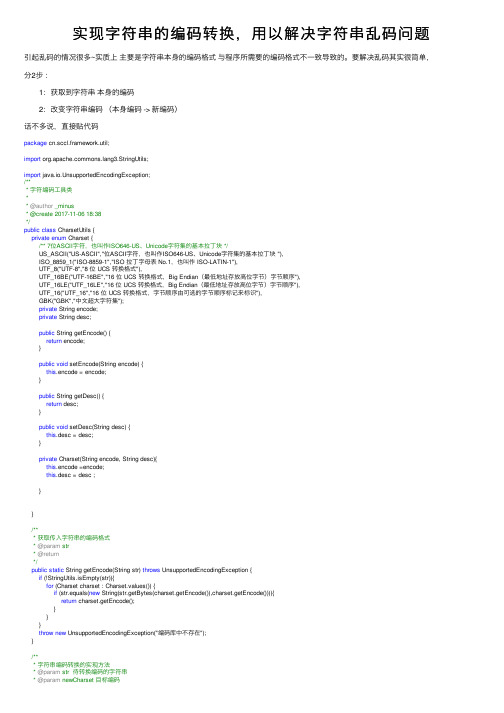
实现字符串的编码转换,⽤以解决字符串乱码问题引起乱码的情况很多~实质上主要是字符串本⾝的编码格式与程序所需要的编码格式不⼀致导致的。
要解决乱码其实很简单,分2步: 1:获取到字符串本⾝的编码 2:改变字符串编码(本⾝编码 -> 新编码)话不多说,直接贴代码package cn.sccl.framework.util;import ng3.StringUtils;import java.io.UnsupportedEncodingException;/*** 字符编码⼯具类** @author _minus* @create 2017-11-06 18:38*/public class CharsetUtils {private enum Charset {/** 7位ASCII字符,也叫作ISO646-US、Unicode字符集的基本拉丁块 */US_ASCII("US-ASCII","位ASCII字符,也叫作ISO646-US、Unicode字符集的基本拉丁块 "),ISO_8859_1("ISO-8859-1","ISO 拉丁字母表 No.1,也叫作 ISO-LATIN-1"),UTF_8("UTF-8","8 位 UCS 转换格式"),UTF_16BE("UTF-16BE","16 位 UCS 转换格式,Big Endian(最低地址存放⾼位字节)字节顺序"),UTF_16LE("UTF_16LE","16 位 UCS 转换格式,Big Endian(最低地址存放⾼位字节)字节顺序"),UTF_16("UTF_16","16 位 UCS 转换格式,字节顺序由可选的字节顺序标记来标识"),GBK("GBK","中⽂超⼤字符集");private String encode;private String desc;public String getEncode() {return encode;}public void setEncode(String encode) {this.encode = encode;}public String getDesc() {return desc;}public void setDesc(String desc) {this.desc = desc;}private Charset(String encode, String desc){this.encode =encode;this.desc = desc ;}}/*** 获取传⼊字符串的编码格式* @param str* @return*/public static String getEncode(String str) throws UnsupportedEncodingException {if (!StringUtils.isEmpty(str)){for (Charset charset : Charset.values()) {if (str.equals(new String(str.getBytes(charset.getEncode()),charset.getEncode()))){return charset.getEncode();}}}throw new UnsupportedEncodingException("编码库中不存在");}/*** 字符串编码转换的实现⽅法* @param str 待转换编码的字符串* @param newCharset ⽬标编码* @return* @throws UnsupportedEncodingException*/public static String changeCharset(String str, String newCharset)throws UnsupportedEncodingException {if (str != null) {//获取到原字符编码String charsetName = getEncode(str);//⽤默认字符编码解码字符串。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Ajax遭遇GBK编码(完全解决方案)占个座位先国内互联网普遍都是使用GBK编码。
对于J2EE项目,为了减少编码的干扰通常都是设置一个编码的Filter,强制将Request/Response编码改为GBK。
例如一个Spring的常见配置如下:<filter><filter-name>encodingFilter</filter-name><filter-class>org.springframework.web.filter.CharacterEncodingFil ter</filter-class><init-param><param-name>encoding</param-name><param-value>GBK</param-value></init-param><init-param><param-name>forceEncoding</param-name><param-value>true</param-value></init-param></filter>毫无疑问,这在GBK编码的页面访问、提交数据时是没有乱码问题的。
但是遇到Ajax就不一样了。
Ajax强制将中文内容进行UTF-8编码,这样导致进入后端后使用GBK进行解码时发生乱码。
如果提交数据的时候能够告诉后端传输的编码信息是否就可以避免这种问题?比如Ajax请求告诉后端是UTF-8,其它请求告诉后端是GBK,这样后端分别根据指定的编码进行解码是不是就解决问题了。
问题:1.如何通过Ajax告诉后端的编码?Header过于复杂,Cookie成本太高,使用参数最方便。
2.后端何时进行解码?每一个请求进行解码,过于繁琐;获取参数时解码,此时已经乱码;在Filter里面动态设置编码是最完善的方案。
3.如何从参数中获取编码?如果是POST的body显然无法获取,因此在获取之前所有参数就已经按照某种编码解码过了,无法还原。
所以通过URL传递编码最有效。
支持GET/POST,同时成本很低。
解决了上述问题,来看具体实现方案。
列一段Java代码:import java.io.IOException;import java.util.regex.Matcher;import java.util.regex.Pattern;import javax.servlet.FilterChain;import javax.servlet.ServletException;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import org.springframework.util.ClassUtils;import org.springframework.web.filter.OncePerRequestFilter;/** 自定义编码过滤器 **/public class MutilCharacterEncodingFilter extends OncePerRequestFilter {static final Pattern inputPattern =pile(".*_input_encode=([\w-]+).*");static final Pattern outputPattern =pile(".*_output_encode=([\w-]+).*");// Determine whether the Servlet 2.4HttpServletResponse.setCharacterEncoding(String)// method is available, for use in the "doFilterInternal" implementation.private final static boolean responseSetCharacterEncodingAvailable = ClassUtils.hasMethod(HttpServletResponse.class,"setCharacterEncoding", new Class[]{String.class});private String encoding;private boolean forceEncoding =false;@Overrideprotected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain)throws ServletException, IOException{String url = request.getQueryString();Matcher m =null;if(url !=null&&(m =inputPattern.matcher(url)).matches()){//输入编码String inputEncoding = m.group(1);request.setCharacterEncoding(inputEncoding);m = outputPattern.matcher(url);if(m.matches()){//输出编码response.setCharacterEncoding(m.group(1));}else{if(this.forceEncoding&& responseSetCharacterEncodingAvailable){response.setCharacterEncoding(this.encoding);}}}else{if(this.encoding!=null&&(this.forceEncoding|| request.getCharacterEncoding()==null)){request.setCharacterEncoding(this.encoding);if(this.forceEncoding&& responseSetCharacterEncodingAvailable){response.setCharacterEncoding(this.encoding);}}}filterChain.doFilter(request, response);}public void setEncoding(String encoding){this.encoding= encoding;}public void setForceEncoding(boolean forceEncoding){this.forceEncoding= forceEncoding;}}解释:1.如果URL的QueryString中包含_input_encode就使用此编码进行设置Request编码,以后参数按照此编码进行解析,例如如果是Ajax就传入UTF-8,如果是普通的GBK请求则无视此参数。
2.如果无视此参数,则按照web.xml中配置的编码规则进行反编码,如果是GBK就按照GBK规则解析。
3.对于输出编码同样使用上述规则。
需要输出编码依赖输入编码,也就是说如果有一个_output_encode的输出编码,则同时需要有一个_input_encode编码来指定输入编码。
当然你可以改造成不依赖输入编码。
4.完全兼容Spring的org.springframework.web.filter.CharacterEncodingFilter编码规则,只需要替换类即可。
5.没有继承org.springframework.web.filter.CharacterEncodingFilter类的原因是,org.springframework.web.filter.CharacterEncodingFilter里面的encoding参数和forceEncoding参数是private,子类无法使用。
在有_input_encode而无_output_encode的时候想依然保持Spring的Response解析规则的话无法做到,所以将里面的代码拷贝过来使用。
(为了展示方便,注释都删掉了)6.正则表达式可以改进成只需要匹配一次,从而可以提高一点点效率。
7.所有后端请求将无视编码的存在,前端Ajax的GET/POST请求也将无视编码的存在,只是在URL地址中加上一个_input_encode=UTF-8的参数。
仅此而已。
8.如果想输出的编码也是UTF-8,比如手机端请求、跨站请求等,则需要URL地址参数_input_encode=UTF-8&_output_encode=UTF-8。
9.对于POST请求,编码参数不能写在body里面,否则无法解析。
10.显然,这种终极解决方案,在任何编码中都可以解决,GBK/UTF-8/ISO8859-1等编码任何组合都可以实现。
11.唯一局限性是,此解决方案限制在J2EE项目中,其它平台不知是否有类似Filter这样的组件能够设置编码的概念。