第7章树和二叉树(2)-数据结构教程(Java语言描述)-李春葆-清华大学出版社
数据结构教程java语言描述李春葆程序

数据结构教程java语言描述李春葆程序摘要:1.数据结构教程概述2.Java语言描述数据结构的优点3.李春葆程序的特点与结构4.教程内容的详细介绍4.1 线性表4.2 栈与队列4.3 树与二叉树4.4 图4.5 排序算法4.6 查找算法5.教程在实际应用中的价值6.对李春葆程序的评价与展望正文:数据结构教程是一门计算机科学与技术专业的基础课程,旨在帮助学生掌握各种常用的数据结构和算法。
近年来,Java语言因其跨平台特性、丰富的类库和简洁的语法,成为了许多开发者编写数据结构教程的首选。
在这样的背景下,李春葆程序以Java语言为基础,为广大学习者提供了一部全面、易懂的数据结构教程。
Java语言描述数据结构的优点在于,它允许开发者直接使用面向对象的特性来表示各种数据结构,使得代码更加直观、易于理解。
此外,Java语言丰富的类库提供了许多现成的方法,方便开发者实现各种操作,从而降低了学习难度。
李春葆程序采用了模块化的设计,将教程划分为线性表、栈与队列、树与二叉树、图、排序算法和查找算法六个部分,每个部分自成体系,方便学习者根据自己的需求进行选择。
教程在讲解每个数据结构时,都从基本概念入手,通过实例和图解,让学习者逐步掌握其原理和应用。
此外,教程还提供了丰富的练习题,帮助学习者巩固所学知识。
在实际应用中,数据结构教程可以帮助开发者更好地理解各种算法和数据结构的原理,从而提高编程效率。
例如,掌握排序算法可以让我们在处理大量数据时更加得心应手;了解树结构可以方便我们实现文件系统、数据库等复杂系统。
总之,数据结构教程是计算机科学与技术专业学生必备的技能。
总的来说,李春葆程序的数据结构教程是一部内容全面、讲解清晰、实例丰富的教材。
当然,教程还可以在某些方面进行改进,例如增加更多的实际应用案例,提供更丰富的编程实践等。
数据结构教程java语言描述李春葆程序

数据结构教程java语言描述李春葆程序李春葆程序是一种经典的数据结构教程,以Java语言描述。
本文将详细介绍李春葆程序的内容和特点,并分析其对学习数据结构的帮助。
李春葆程序是一本由李春葆编写的数据结构教程,以Java语言描述。
该教程主要介绍了常见的数据结构和算法,包括线性表、栈、队列、树、图等。
通过对这些数据结构的介绍和实现,读者可以深入理解数据结构的原理和应用。
李春葆程序的特点之一是注重理论与实践的结合。
在每个章节中,教程首先介绍了数据结构的基本概念和原理,然后通过具体的Java代码实现来展示这些概念的应用。
这种理论与实践相结合的方式,使得读者可以更加直观地理解数据结构的运作方式,并能够通过实际编程来加深对数据结构的理解。
另一个特点是李春葆程序的编程风格简洁明了。
在代码实现中,作者使用了简洁的Java语法和清晰的注释,使得读者可以轻松理解代码的逻辑和功能。
同时,作者还提供了大量的示例代码和练习题,读者可以通过实际编程来巩固所学的知识。
李春葆程序还注重实际应用和问题解决能力的培养。
在每个章节的最后,作者都提供了一些实际应用的案例,读者可以通过这些案例来了解数据结构在实际问题中的应用。
此外,作者还提供了一些问题解决的思路和方法,读者可以通过这些思路和方法来解决实际问题。
通过学习李春葆程序,读者可以获得以下几方面的收益。
首先,读者可以系统地学习和掌握常见的数据结构和算法。
李春葆程序对各种数据结构的原理和实现进行了详细的介绍,读者可以通过学习这些内容来深入理解数据结构的运作方式和应用场景。
其次,读者可以提高编程能力和问题解决能力。
通过实际编程和解决实际问题的练习,读者可以提高自己的编程技巧和问题解决能力。
同时,通过学习数据结构和算法的思想和方法,读者可以培养自己的抽象思维和逻辑思维能力。
最后,读者可以为进一步学习和研究计算机科学领域打下坚实的基础。
数据结构是计算机科学的基础,掌握了数据结构,读者可以更好地理解和应用其他计算机科学领域的知识,如算法、数据库、操作系统等。
第7章树和二叉树(5)-数据结构教程(Java语言描述)-李春葆-清华大学出版社

A
B
C
先序线索二叉树
DE
F
二叉树
A
B
C
DE F
先序序列:ABDCEF
2/38
在原二叉链中增加了ltag和rtag两个标志域。
ltag=
0 表示lchild指向结点的左孩子 1 表示lchild指向结点的前驱结点即为线索
rtag=
0 表示rchild指向结点的左孩子 1 表示rchild指向结点的后继结点即为线索
pre=root;
Thread(b);
pre.rchild=root; pre.rtag=1; root.rchild=pre; } }
//建立以root为头结点的中序线索二叉树 //创建头结点root //头结点域置初值 //b为空树时
//b不为空树时
//pre是p的前驱结点,用于线索化 //中序遍历线索化二叉树 //最后处理,加入指向根结点的线索
ltag=rtag=0; }
public ThNode(char d) { data=d;
lchild=rchild=null; ltag=rtag=0; } }
//线索二叉树结点类型 //存放结点值 //左、右孩子或线索的指针 //左、右标志 //默认构造方法
//重载构造方法
5/38
中序线索化二叉树类ThreadClass
public class ThreadClass
{ ThNode b;
//二叉树的根结点
ThNode root;
//线索二叉树的头结点
ThNode pre;
//用于中序线索化,指向中序前驱结点
String bstr;
public ThreadClass()
第7章图(5)-数据结构教程(Python语言描述)-李春葆-清华大学出版社

B A a2=4 C
D
E
a6=2
F
G a11=4
I
H
14/22
【例7.13】
B
A a2=4 C
E
D
a6=2
F
G a11=4
I
H
先进行拓扑排序,假设拓扑序列为:ABCDEFGHI 计算各事件的ee(v)如下:
ee(A)=0 ee(B)=ee(A)+c(a1)=6 ee(C)=ee(A)+c(a2)=4 ee(D)=ee(A)+c(a3)=5 ee(E)=MAX(ee(B)+c(a4),ee(C)+c(a5)}=MAX{7,5}=7
例如,计算机专业的学生必须完成一系列规定的基础课和专业课才能毕业, 假设这些课程的名称与相应代号有如下关系:
课程代号 C1 C2 C3 C4 C5 C6 C7
课程名称 高等数学 程序设计 离散数学 数据结构 编译原理 操作系统 计算机组成原理
先修课程 无 无 C1 C2,C3 C2,C4 C4,C7 C2
8/22
若用一个带权有向图(DAG)描述工程的预计进度,以顶点表示事件,有 向边表示活动,边e的权c(e)表示完成活动e所需的时间(比如天数), 或者说活动e持续时间 AOE网。 通常AOE网中只有一个入度为0的顶点,称为源点,和一个出度为0的顶点, 称为汇点。 在AOE网中,从源点到汇点的所有路径中,具有最大路径长度的路径称为 关键路径。完成整个工程的最短时间就是网中关键路径的长度。 关键路径上的活动称为关键活动,或者说关键路径是由关键活动构成的。 只要找出AOE网中的全部关键活动,也就找到了全部关键路径了。
有向图 设G=(V,E)是一个具有n个顶点的有向图,V中顶点序列v1、v2、…、vn 称为一个拓扑序列,当且仅当该顶点序列满足下列条件:若<vi,vj>是 图中的有向边或者从顶点vi到顶点vj有一条路径,则在序列中顶点vi必 须排在顶点vj之前。 在一个有向图G中找一个拓扑序列的过程称为拓扑排序。
安装和配置Java-数据结构教程(Java语言描述)-李春葆-清华大学出版社
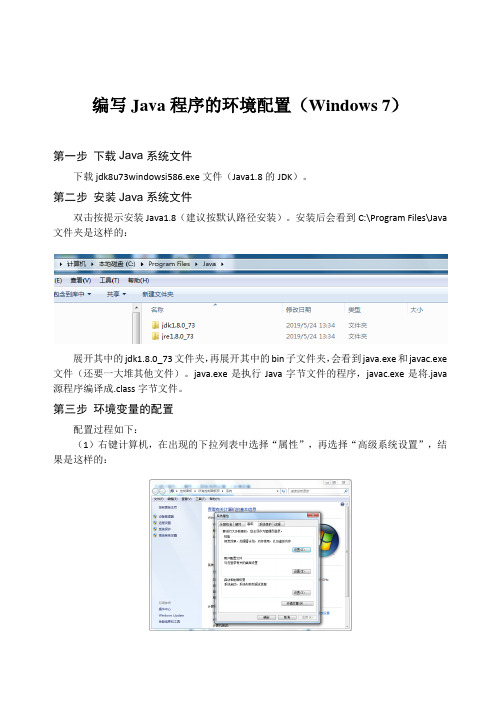
编写Java程序的环境配置(Windows 7)第一步下载Java系统文件下载jdk8u73windowsi586.exe文件(Java1.8的JDK)。
第二步安装Java系统文件双击按提示安装Java1.8(建议按默认路径安装)。
安装后会看到C:\Program Files\Java 文件夹是这样的:展开其中的jdk1.8.0_73文件夹,再展开其中的bin子文件夹,会看到java.exe和javac.exe 文件(还要一大堆其他文件)。
java.exe是执行Java字节文件的程序,javac.exe是将.java 源程序编译成.class字节文件。
第三步环境变量的配置配置过程如下:(1)右键计算机,在出现的下拉列表中选择“属性”,再选择“高级系统设置”,结果是这样的:(2)点击“环境变量”,结果是这样的(其中我已经配置好):(3)单击“用户变量”中的“新建”,变量名中输入“JAVA_HOME”,变量值中输入“C:\Program Files\Java\jdk1.8.0_73”(就是Java的安装文件夹)。
结果是这样的:(4)在“系统变量”列表中查找到“Path”,单击“编辑”,在对应的“变量值”框中末尾添加“;C:\Program Files\Java\jdk1.8.0_73\bin;C:\Program Files\Java\jre1.8.0_73\bin;”。
例如,原来Path值为“C:\ProgramData\Oracle\Java\javapath”,添加后变为“C:\ProgramData\Oracle\Java\javapath;C:\Program Files\Java\jdk1.8.0_73\bin;C:\Program Files\Java\jre1.8.0_73\bin;”。
目的是配置好后能够让我们在系统中的任何地方运行java应用程序。
(5)再在系统变量中新建如下变量:变量名:CLASSPATH变量值:;%JAVA_HOME%lib;%JAVA_HOME%lib\tools.jar;目的是告诉JDK,搜索.class时先查找当前目录的.class文件。
第7章图(4)-数据结构教程(Python语言描述)-李春葆-清华大学出版社

{0,1,2,3,5,4,6} {}
{0, 4, 5, 6, 10, 9, 16} {0, 0, 1, 0, 5, 2, 4}
最小的顶点:2
{0,1,2} {3,4,5,6}
{0, 4, 5, 6, 11, 9, ∞} {0, 0, 1, 0, 1, 2, -1}
13/45
41
0
6
7
1
6
2
6
24
3
5
46
1
6
8
5
S
U
{0,1,2} {3,4,5,6}
{0,1,2,3} {4,5,6}
dist[]
0 123 456
path[]
S
v
i
U=V-S
j
6/45
(2)从U中选取一个顶点u,它是源点v到U中最短路径长度最小的顶点, 然后把顶点u加入S中(此时求出了源点v到顶点u的最短路径长度)。
U=V-S S
u v
i
7/45
(3)以顶点u为新考虑的中间点,修改顶点u的出边邻接点j的最短路 径长度,此时源点v到顶点j的最短路径有两条,即一条经过顶点u,一条 不经过顶点u:
采用广度优先遍历可以求最短路径
1/45
带权图 把一条路径上所经边的权值之和定义为该路径的路径长度或称带权路径 长度。 从源点到终点可能不止一条路径,把带权路径长度最短的那条路径称为 最短路径,其路径长度(权值之和)称为最短路径长度或者最短距离。
采用广度优先遍历可以求最短路径:不适合
2/45
Edsger Wybe Dijkstra 1930年5月11日~2002年8月6日
12/45
示例
41
数据结构教程李春葆课后答案第7章树和二叉树

教材中练习题及参考答案
1. 有一棵树的括号表示为 A(B,C(E,F(G)),D),回答下面的问题: (1)指出树的根结点。 (2)指出棵树的所有叶子结点。 (3)结点 C 的度是多少? (4)这棵树的度为多少? (5)这棵树的高度是多少? (6)结点 C 的孩子结点是哪些? (7)结点 C 的双亲结点是谁? 答:该树对应的树形表示如图 7.2 所示。 (1)这棵树的根结点是 A。 (2)这棵树的叶子结点是 B、E、G、D。 (3)结点 C 的度是 2。 (4)这棵树的度为 3。 (5)这棵树的高度是 4。 (6)结点 C 的孩子结点是 E、F。 (7)结点 C 的双亲结点是 A。
12. 假设二叉树中每个结点值为单个字符,采用二叉链存储结构存储。设计一个算法 计算一棵给定二叉树 b 中的所有单分支结点个数。 解:计算一棵二叉树的所有单分支结点个数的递归模型 f(b)如下:
f(b)=0 若 b=NULL
6 f(b)=f(b->lchild)+f(b->rchild)+1 f(b)=f(b->lchild)+f(b->rchild)
表7.1 二叉树bt的一种存储结构 1 lchild data rchild 0 j 0 2 0 h 0 3 2 f 0 4 3 d 9 5 7 b 4 6 5 a 0 7 8 c 0 8 0 e 0 9 10 g 0 10 1 i 0
答:(1)二叉树bt的树形表示如图7.3所示。
a b c e h j f i d g e h j c f i b d g a
对应的算法如下:
void FindMinNode(BTNode *b,char &min) { if (b->data<min) min=b->data; FindMinNode(b->lchild,min); //在左子树中找最小结点值 FindMinNode(b->rchild,min); //在右子树中找最小结点值 } void MinNode(BTNode *b) //输出最小结点值 { if (b!=NULL) { char min=b->data; FindMinNode(b,min); printf("Min=%c\n",min); } }
第7章图(2)-数据结构教程(Python语言描述)-李春葆-清华大学出版社

4/59
或者
def DFS1(G,v): print(v,end=' ') visited[v]=1 for p in G.adjlist[v]: w=p.adjvex if visited[w]==0: DFS1(G,w)
#邻接表G中从顶点v出发的深度优先遍历 #访问顶点v #置已访问标记 #处理顶点v的所有出边顶点 #取顶点v的一个邻接点w
图采用邻接矩阵为存储结构,其广度优先遍历算法如下:
from collections import deque
MAXV=100
#全局变量,表示最多顶点个数
visited=[0]*MAXV
def BFS(g,v):
#邻接矩阵g中顶点v出发广度优先遍历
qu=deque()
#将双端队列作为普通队列qu
print(v,end=" ")
#访问顶点v
visited[v]=1
#置已访问标记
qu.append(v)
#v进队
while len(qu)>0:
#队不空循环
v=qu.popleft()
#出队顶点v
for w in range(g.n):
if g.edges[v][w]!=0 and g.edges[v][w]!=INF:
#全局变量,表示最多顶点个数
#邻接表G中顶点v出发广度优先遍历 #将双端队列作为普通队列qu #访问顶点v #置已访问标记 #v进队
#队不空循环 #出队顶点v
#处理顶点v的所有出边 #取顶点v的第j个出边邻接点w #若w未访问 #访问顶点w #置已访问标记 #w进队
时间复杂度为O(n+e)。
11/59
第7章图(下)-数据结构简明教程(第2版)-微课版-李春葆-清华大学出版社

成
树
(1)置U的初值等于V(即包含有G中的全部顶点),TE的初
和 最
值为空集(即图T中每一个顶点都构成一个连通分量)。
小
(2)将图G中的边按权值从小到大的顺序依次选取:若选取
生
成
的边未使生成树T形成回路,则加入TE;否则舍弃,直到TE中包
树
含n-1条边为止。
实现克鲁斯卡尔算法的关键是如何判断选取的边是否与生成树 中已保留的边形成回路?
7.4
建立了两个辅助数组closest和lowcost。
所有顶点分为U和V-U两个顶点集。
U中的顶点i:lowcost[i]=0;
生
V-U中的顶点j:lowcost[j]>0。
成
树
和
最
小 生
i
j
成
树
U中i:lowcost[i]=0
V-U中j:lowcost[j]>0
7.4
实现普里姆算法(2/3):
生
通过深度优先遍历产生的生成树称为深度优先生成树。
成
树
通过广度优先遍历产生的生成树称为广度优先生成树。
和
最
小
生
成
树
无向图进行遍历时:
7.4
连通图:仅需要从图中任一顶点出发,进行深度优先遍历或广
度优先遍历便可以访问到图中所有顶点,因此连通图的一次遍
历所经过的边的集合及图中所有顶点的集合就构成了该图的一
7.4
为此设置一个辅助数组vset[0..n-1],它用于判定两个顶点之
生
间是否连通。
成
数组元素vset[i](初值为i)代表编号为i的顶点所属的连通
树
子图的编号。
和
第七章-数据结构教程(Java语言描述)-李春葆-清华大学出版社

第二阶段通常用C语言完成,以便实现更复杂的功能, 也使程序有更好的可读性和可移植性。这个阶段的任 务有: 初始化本阶段要使用到的硬件设备。 检测系统内存映射。 将内核映像和根文件系统映像从Flash读到RAM。 为内核设置启动参数。 调用内核。
ห้องสมุดไป่ตู้
7.1.4常见的BootLoader
(1)Redboot Redboot (Red Hat Embedded Debug and Bootstrap)是Red Hat公司开发的一个独立运行在嵌入式系统上的BootLoader程序, 是目前比较流行的一个功能、可移植性好的BootLoader。 Redboot是一个采用eCos开发环境开发的应用程序,并采用了 eCos的硬件抽象层作为基础,但它完全可以摆脱eCos环境运行, 可以用来引导任何其他的嵌入式操作系统,如Linux、Windows CE等。
BootLoader是嵌入式系统在加电后执行的第一段代码, 在它完成CPU和相关硬件的初始化之后,再将操作系 统映像或固化的嵌入式应用程序装载到内存中然后跳 转到操作系统所在的空间,启动操作系统运行。
对于嵌入式系统而言,BootLoader是基于特定硬件平 台来实现的。因此,几乎不可能为所有的嵌入式系统 建立一个通用的BootLoader,不同的处理器架构都有 不同的BootLoader。
第7章 嵌入式Linux系统移植及调试
目录
7.1 Boot Loader基本概念与典型结构 7.2 U-Boot 7.3 交叉开发环境的建立 7.4 交叉编译工具链 7.5 嵌入式Linux系统移植过程 7.6 Gdb调试器 7.7 远程调试 7.8 内核调试
一个嵌入式linux系统通常由引导程序及参数、 linux内核、文件系统和用户应用程序组成。 由于嵌入式系统与开发主机运行的环境不同, 这就为开发嵌入式系统提出了开发环境特殊化 的要求。交叉开发环境正是在这种背景下应运 而生。
数据结构大纲(60讲课学时)-数据结构教程(Java语言描述)-李春葆-清华大学出版社

《数据结构》课程教学大纲课程代码:********。
课程负责人:********。
课程中文名称: 数据结构。
课程英文名称:Data Structures。
课程类别:专业基础课必修。
课程学分数:5(16学时为1学分)课程学时数:讲课60学时,上机20学时。
授课对象:计算机科学与技术专业。
本课程的前导课程:高级语言程序设计。
本课程的后续课程:操作系统、数据库应用技术等。
一、教学目的《数据结构》是计算机专业一门重要的专业基础课。
通过本课程的学习,使得学生从数据逻辑结构、存储结构和基本运算算法设计三个层面掌握基本的数据组织和数据处理方法,能够从问题出发设计面向数据结构的求解算法,并具有较强的算法时间复杂度和空间复杂度分析能力,为后续课程如操作系统等课程学习打下扎实基础。
二、教学要求通过讲授和上机实验,使学生领会数据结构的基本原理,掌握线性表、栈和队列、串、数组和稀疏矩阵、树和二叉树、图、查找和排序等基本数据结构及其相关算法设计方法,具备数据组织、数据存储和数据处理能力,利用数据结构方法求解实际问题的能力。
与Java语言深度结合,能够熟练地应用Java集合编写解决复杂在线编程问题的程序。
三、授课课时安排(60学时)四、上机课时安排(20课时)上机实验题和在线编程题均来自于教材,教师可以根据学生的情况选择相应的题目。
五、教材及参考用书(1)教材数据结构教程(Java语言描述),李春葆等,北京:清华大学出版社,2020(2)实验指导书数据结构教程学习与上机实验指导,李春葆等,北京:清华大学出版社,2020(3)参考用书[1] Sedgewick R.,Wayne K. 著,谢路云译. 算法(第4版). 人民邮电出版社,2012[2] 李文辉等. 程序设计导引及在线实践(第2版). 清华大学出版社. 2017六、考核(1)期末考试:期末考试形式为笔试,一般以闭卷方式进行。
(2)课程成绩评定方法:期末考试成绩、课后作业、上机实验(含实验报告)和其他。
数据结构教程java语言描述李春葆程序

数据结构教程java语言描述李春葆程序摘要:1.数据结构教程概述2.Java 语言简介3.李春葆及其编程贡献4.程序设计和数据结构的关系正文:1.数据结构教程概述数据结构教程是一本关于计算机科学中数据结构的教材,主要涵盖了数组、链表、栈、队列、树、图等基本数据结构及其操作。
这本教程旨在帮助读者理解数据结构的概念,学会使用Java 语言实现数据结构,并掌握数据结构的算法。
2.Java 语言简介Java 是一种高级编程语言,广泛应用于企业级应用、Web 应用、移动应用等领域。
Java 语言具有跨平台性、安全性、简单性、面向对象等特点,成为当今最流行的编程语言之一。
Java 语言提供了丰富的类库和数据结构,使得程序员可以更加高效地编写代码。
3.李春葆及其编程贡献李春葆是一位著名的计算机科学家和程序员,他致力于计算机教育事业,为学生提供了许多学习资源。
其中,他编写的《数据结构教程》成为许多计算机专业学生的必修教材。
此外,他还开发了许多开源项目,为Java 社区做出了巨大的贡献。
4.程序设计和数据结构的关系程序设计是指用计算机语言编写程序,实现特定的功能和任务。
数据结构是程序设计的基础,它是一种存储和组织数据的方式,能够帮助程序员有效地管理和操作数据。
程序设计和数据结构密切相关,程序员需要使用数据结构来实现程序的特定功能,而数据结构的设计和实现也需要程序员的技术支持。
数据结构教程可以帮助程序员更好地理解和应用数据结构,Java 语言提供了丰富的类库和数据结构,使得程序员可以更加高效地编写代码。
李春葆是一位著名的计算机科学家和程序员,他编写的《数据结构教程》成为许多计算机专业学生的必修教材,他为Java 社区做出了巨大的贡献。
数据结构教程 李春葆 七章习题答案

//在下标为i的前面的数组中寻找两个权值最小的节点,作为孩子节点
for(j = 0; j<i; j++)
{
if(-1==ht[j].parent)
{
if(min1>ht[j].weight)
{
min2 = min1; //至于为什么有这句和下面的一句,,大家依次将权值假设为2 1 3带入里面自己手工模仿运行
设计;狼影
时间:2012.10.5
***************************************/
/******************************************************
若发现错误请 留言本空间,万分感谢!!
/*******************/
-------------------------------------------------------------
权值: 2 3 4 7 8 9 5 9 15 18 33
-------------------------------------------------------------
}
/*************************************************************
输入叶子节点的个数
6
输入6个叶子的权值
2 3 4 7 8 9
哈夫曼树顺序存储如下
-------------------------------------------------------------
{
int i;
printf("\n-------------------------------------------------------------\n");
数据结构(Java语言描述)李春葆习题答案

数据结构(Java语言描述)李春葆习题答案1. 栈和队列1.1 栈的基本操作栈(Stack)是一种后进先出(Last-In-First-Out,LIFO)的线性数据结构,它具有两个基本操作:压栈(Push)和弹栈(Pop)。
使用Java语言描述栈的基本操作。
我们可以使用数组或链表来实现栈的结构。
在这里,我们使用链表来实现栈。
class Node {int value;Node next;Node(int value) {this.value = value;this.next = null;}}class Stack {Node top;public void push(int value) {Node newNode = new Node(value);if (top == null) {top = newNode;} else {newNode.next = top;top = newNode;}}public int pop() {if (top == null) {throw new EmptyStackException();}int value = top.value;top = top.next;return value;}public boolean isEmpty() {return top == null;}}1.2 队列的基本操作队列(Queue)是一种先进先出(First-In-First-Out,FIFO)的线性数据结构,它具有两个基本操作:入队(Enqueue)和出队(Dequeue)。
使用Java语言描述队列的基本操作。
我们可以使用数组或链表来实现队列的结构。
在这里,我们使用链表来实现队列。
class Node {int value;Node next;Node(int value) {this.value = value;this.next = null;}}class Queue {Node front;Node rear;public void enqueue(int value) {Node newNode = new Node(value);if (rear == null) {front = rear = newNode;} else {rear.next = newNode;rear = newNode;}}public int dequeue() {if (front == null) {throw new EmptyQueueException();}int value = front.value;front = front.next;if (front == null) {rear = null;}return value;}public boolean isEmpty() {return front == null;}}2. 链表2.1 单链表的基本操作单链表(Singly Linked List)是一种常见的链表结构,它由一个头节点和一系列的节点构成,每个节点包含一个数据域和一个指向下一个节点的指针。
第7章树和二叉树(4)-数据结构教程(Java语言描述)-李春葆-清华大学出版社

if (p.node.rchild!=null)
//有右孩子时将其进队
qu.offer(new QNode(p.lno+1,p.node.rchild));
}
}
return cnt;
}
7/31
解法2
层次遍历中某层的最右结点last
last
A
B
C
D
EF
G
last的作用确定一层是否遍历完成!
8/31
用cnt变量计第k层结点个数(初始为0)。设计队列仅保存结点引用, 置当前层次curl=1,用last变量指示当前层次的最右结点(根结点)进队。 将根结点进队,队不空循环:
int curl=1;
//当前层次,从1开始
BTNode<Character> last;
//当前层中最右结点
last=bt.b;
//第1层最右结点
qu.offer(bt.b);
//根结点进队
while (!qu.isEmpty())
{ if (curl>k) return cnt; p=qu.poll(); if (curl==k) cnt++; if (p.lchild!=null) { q=p.lchild; qu.offer(q); } if (p.rchild!=null) { q=p.rchild; qu.offer(q); } if (p==last) { last=q; curl++; }
}
Queue<QNode> qu=new LinkedList<QNode>(); //定义一个队列qu
QNode p;
qu.offer(new QNode(1,bt.b)); //根结点(层次为1)进队
第7章图(1)-数据结构教程(Python语言描述)-李春葆-清华大学出版社

CONTENTS
1/42
图G(Graph)由两个集合V(Vertex)和E(Edge)组成,记为G=(V,E)。 V是顶点的有限集合,记为V(G)。 E是连接V中两个不同顶点(顶点对)的边的有限集合,记为E(G)。
2/42
抽象数据类型图的描述
ADT Graph { 数据对象:
D={ai | 0≤i≤n-1,n≥0,ai为int类型} //ai为每个顶点的唯一编号 数据关系:
7/42
【例7.1】一个无向图中有16条边,度为4的顶点有3个,度为3的顶 点有4个,其余顶点的度均小于3,则该图至少有多少个顶点?
解:设该图有n个顶点,图中度为i的顶点数为ni(0≤i≤4)。 n4=3,n3=4。 要使顶点数最少,该图应是连通的,即n0=0。 n=n4+n3+n2+n1+n0=7+n2+n1,即n2+n1=n-7。 度之和=4×3+3×4+2×n2+n1=24+2n2+n1≤24+2(n2+n1)= 24+2×(n-7)=10+2n。 而度之和=2e=32,所以有10+2n≥32,即n≥11。 即这样的无向图至少有11个顶点。
8/42
完全无向图中的每两个顶点之间都存在着一条边。含有n个顶点的 完全无向图有n(n-1)/2条边。
完全有向图中的每两个顶点之间都存在着方向相反的两条边。含 有n个顶点的完全有向图包含有n(n-1)条边。
1
2
0
3 (a)一个完全无向图
1
2
0
3 (b)一个完全有向图
9/42
当一个图接近完全图时,则称为稠密图。 当一个图含有较少的边数(即无向图有e<<n(n-1)/2,有向图有 e<<n(n-1))时,则称为稀疏图。
数据结构新版教案-数据结构教程(Java语言描述)-李春葆-清华大学出版社

武汉大学教案2017 — 2018学年第一学期课程名称数据结构授课教师李春葆教师所在院系计算机学院授课对象 2016级卓越工程师班总学时、学分 72学时、4学分武汉大学第1章-绪论教案一、教学目的(黑体五号)通过本章的学习,学生应达到如下基本要求:1、掌握数据结构的基本概念。
2、掌握数据逻辑结构和存储结构的映射关系。
3、掌握数据类型和数据结构的区别和联系。
4、掌握利用抽象数据类型表述求解问题的方法。
5、掌握算法的特性和采用C/C++语言描述算法的方法。
6、掌握算法设计目标和分析方法,包括时间复杂度和空间复杂度分析。
7、掌握从数据结构的角度设计好算法的过程。
二、教学内容(黑体五号)1、数据结构的概念。
2、数据逻辑结构类型和存储结构类型。
3、数据结构和数据类型的关系。
4、抽象数据类型的作用和描述方法。
5、算法的概念,算法的特性,算法的描述方法。
6、算法的时间复杂度和空间复杂度分析。
7、算法设计的基本过程。
三、教学重点与难点(黑体五号)1、用抽象数据类型描述求解问题。
2、算法特性,理解算法和程序的异同。
3、算法的时间复杂度分析,特别是递归算法的时间复杂度分析。
4、算法的空间复杂度分析,特别是递归算法的空间复杂度分析。
5、设计“好”算法的过程。
四、教学方法(黑体五号)讲授、讨论、提问五、教学时间分配(黑体五号)本章共4学时,安排如下:1、教学内容1~4:2学时。
2、教学内容5~7:2学时。
六、教具准备(黑体五号)教学PPT七、拟向学生提问的问题(黑体五号)1、学习数据结构课程有什么体会?2、如何进行从数据设计到应用程序的设计。
八、复习题(黑体五号)对应第1章的测验题和作业题,见附件(含参考答案),共20题。
九、选用教材(名称、作者、出版社及出版时间)[1] 数据结构教程(第5版),清华大学出版社,李春葆等2017。
[2] 数据结构教程(第5版)学习指导,清华大学出版社,李春葆等2017。
十、参考书目(名称、作者、出版社及出版时间)[1] 数据结构(C语言),清华大学出版社,严蔚敏,2002。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
二叉树也称为二分树,它是有限的结点集合,这个集合或者是空,或者由 一个根结点和两棵互不相交的称为左子树和右子树的二叉树组成。 二叉树中许多概念与树中的概念相同。 在含n个结点的二叉树中,所有结点的度小于等于2,通常用n0表示叶子结 点个数,n1表示单分支结点个数,n2表示双分支结与度为2的树是不同的。
度为2的树至少有3个结点,而二叉树的结点数可以为0。 度为2的树不区分子树的次序,而二叉树中的每个结点最多有 两个孩子结点,且必须要区分左右子树,即使在结点只有一棵 子树的情况下也要明确指出该子树是左子树还是右子树。
2/35
归纳起来,二叉树的5种形态:
Ø
4/35
3. 满二叉树和完全二叉树
在一棵二叉树中,如果所有分支结点都有左孩子结点和右孩子结点,并且 叶子结点都集中在二叉树的最下一层,这样的二叉树称为满二叉树。
可以对满二叉树的结点进行层序编号,约定编号从树根为1开始,按照层 数从小到大、同一层从左到右的次序进行。
满二叉树也可以从结点个数和树高度之间的关系来定义,即一棵高度为h 且有2h-1个结点的二叉树称为满二叉树。
R={r} r={<ai,aj> | ai,aj∈D, 1≤i,j≤n,当n=0时,称为空二叉树;否则其中
有一个根结点,其他结点构成根结点的互不相交的左、右子树,该 左、右两棵子树也是二叉树 } 基本运算: void CreateBTree(string str):根据二叉树的括号表示串建立其存储结构。 String toString():返回由二叉树树转换的括号表示串。 BTNode FindNode(x):在二叉树中查找值为x的结点。 int Height():求二叉树的高度。 … }
5
E
11
K
C3
6
7
F
G
14
12 L 13 M N
15
O
n=15 h=log2(n+1)=4
6/35
若二叉树中最多只有最下面两层的结点的度数可以小于2,并且最下 面一层的叶子结点都依次排列在该层最左边的位置上,则这样的二叉 树称为完全二叉树。
同样可以对完全二叉树中每个结点进行层序编号,编号的方法同满二 叉树相同,图中每个结点外边的数字为对该结点的编号。
14/35
1. 二叉树的顺序存储结构
顺序存储一棵二叉树时,就是用一组连续的存储单元存放二叉树中的结点。 由二叉树的性质4可知,对于完全二叉树(或满二叉树),树中结点层序编 号可以唯一地反映出结点之间的逻辑关系,所以可以用一维数组按从上到 下、从左到右的顺序存储树中所有结点值,通过数组元素的下标关系反映 完全二叉树或满二叉树中结点之间的逻辑关系。
(3)若编号为i的结点有左孩子结点,则左孩子结点的编号为2i;若编号为 i的结点有右孩子结点,则右孩子结点的编号为2i+1。
(4)若编号为i的结点有双亲结点,其双亲结点的编号为i/2。
i/2
i
2i
2i+1
11/35
性质5 具有n个(n>0)结点的完全二叉树的高度为log2(n+1)或 log2n+1。
由完全二叉树的定义和树的性质3可推出。
归纳
一棵完全二叉树中,由结点总数n可以确定其树形。 n1只能是0或1,当n为偶数时,n1=1,当n为奇数时,n1=0。 层序编号为i的结点层次恰好为log2(i+1)或者log2i+1。
12/35
【例7.2】一棵含有882个结点的二叉树中有365个叶子结点,求度为1 的结点个数和度为2的结点个数。
解:这里n=882,n0=365。 由二叉树的性质1可知n2=n0-1=364。 n=n0+n1+n2,即n1=n-n0-n2=882-365-364=153。 所以该二叉树中度为1的结点和度为2的结点个数分别是153和364。
13/35
【例7.4】一棵完全二叉树中有501个叶子结点,则至少有多少个结点。 解:该二叉树中有,n0=501。 由二叉树性质1可知n0=n2+1,所以n2=n0-1=500。 n=n0+n1+n2=1001+n1,由于完全二叉树中n1=0或n1=1,则n1=0时结 点个数最少,此时n=1001,即至少有1001个结点。
10/35
性质4 对完全二叉树中层序编号为i的结点(1≤i≤n,n≥1,n为结点总数)有: (1)若i≤n/2,即2i≤n,则编号为i的结点为分支结点,否则为叶子结点。 (2)若n为奇数,则n1=0,这样每个分支结点都是双分支结点;若n为偶数,
则n1=1,只有一个单分支结点,该单分支结点是编号最大的分支结点(编号为 n/2)。
1
A
2B
4
5
D
E
8H
9 10
11
IJ
K
C3
6
7
F
G
7/35
完全二叉树的特点如下:
叶子结点只可能出现在最下面两层中。 对于最大层次中的叶子结点,都依次排列在该层最左边的位置上。 如果有度为1的结点,只可能有一个,且该结点只有左孩子而无右孩子; 按层序编号后,一旦出现某结点(其编号为i)为叶子结点或只有左孩子, 则编号大于i的结点均为叶子结点。
归纳
在二叉树中计算结点时常用的关系式有:①所有结点的度之和 =n-1 ②所有结点的度之和=n1+2n2 ③n=n0+n1+n2。
9/35
性质2 非空二叉树上第i层上至多有2i-1个结点,这里应有i≥1。 由树的性质2可推出。
性质3 高度为h的二叉树至多有2h-1个结点(h≥1)。 由树的性质3可推出。
(a) 空二 叉树
(b) 只有 一个根结点
的二叉树
(c) 右子树 为空的二叉树
(d) 左子树 为空的二叉树
(e) 左、右子 树非空的二叉树
3/35
2.二叉树抽象数据类型的描述
ADT BTree { 数据对象:
D={ai | 1≤i≤n,n≥0,ai为E类型} //为了简单,除了特别说明外假设E为char 数据关系:
1
A
2B
4
D
10
8H 9 I J
5
E
11
K
C3
6
7
F
G
14
12 L 13 M N
15
O
5/35
满二叉树的特点如下:
叶子结点都在最下一层。 只有度为0和度为2的结点。 含n个结点的满二叉树的高度为log2(n+1),叶子结点个数为n/2+1, 度为2的结点个数为n/2。
1
A
2B
4
D
10
8H 9 I J
1
A
2B
4
5
D
E
8H
9 10
11
IJ
K
C3
6
7
F
G
8/35
性质1 非空二叉树上叶结点数等于双分支结点数加1。即n0=n2+1。
证明: 总结点数n=n0+n1+n2。 一个度为1的结点贡献1个度,一个度为2的结点贡献2个度, 所以总的度数=n1+2n2。 总的度数=总分支数=n-1。 则n1+2n2=n0+n1+n2-1,求出n0=n2+1。