信息论matlab的实验用到的编码
霍夫曼编码的matlab实现(信源编码实验)资料

霍夫曼编码的m a t l a b 实现(信源编码实验)重庆交通大学信息科学与工程学院综合性设计性实验报告专业班级:通信工程2012级1班学号: 631206040118姓名:王松实验所属课程:信息论与编码实验室(中心):软件与通信实验中心指导教师:黄大荣2015年4月霍夫曼编码的matlab实现一、实验目的和要求。
利用哈夫曼编码进行通信可以大大提高信道的利用率,缩短信息传输的时间,降低传输成本。
本实验用Matlab语言编程实现霍夫曼(Huffman)编码。
二、实验原理。
霍夫曼(Huffman)编码算法是满足前缀条件的平均二进制码长最短的编-源输出符号,而将较短的编码码字分配给较大概率的信源输出。
算法是:在信源符号集合中,首先将两个最小概率的信源输出合并为新的输出,其概率是两个相应输出符号概率之和。
这一过程重复下去,直到只剩下一个合并输出为止,这个最后的合并输出符号的概率为1。
这样就得到了一张树图,从树根开始,将编码符号1 和0 分配在同一节点的任意两分支上,这一分配过程重复直到树叶。
从树根到树叶途经支路上的编码最后就构成了一组异前置码,就是霍夫曼编码输出。
离散无记忆信源:例如U u1u2u3u4u5P(U) = 0.4 0.2 0.2 0.1 0.1通过上表的对信源缩减合并过程,从而完成了对信源的霍夫曼编码。
三、实验步骤分为两步,首先是码树形成过程:对信源概率进行合并形成编码码树。
然后是码树回溯过程:在码树上分配编码码字并最终得到霍夫曼编码。
1、码树形成过程:将信源概率按照从小到大顺序排序并建立相应的位置索引。
然后按上述规则进行信源合并,再对信源进行排序并建立新的位置索引,直到合并结束。
在这一过程中每一次都把排序后的信源概率存入矩阵G中,位置索引存入矩阵Index中。
这样,由排序之后的概率矩阵G以及索引矩阵Index就可以恢复原概率矩阵P了,从而保证了回溯过程能够进行下去。
2、码树回溯过程:在码树上分配编码码字并最终得到Huffman 编码。
信息论与编码实习报告

信息论与编码实习报告指导老师:姓名:班级:学号:实验一绘制二进制熵函数曲线一、内容用Matlab软件制作二进制熵函数曲线。
二、要求1.掌握Matlab绘图函数2.掌握、理解熵函数表达式及其性质三.Matlab程序及实验结果1.matlab程序:p=0.00001:0.001:1;h=-p.*log2(p)-(1-p).*log2(1-p);plot(p,h);title('二进制熵函数曲线');ylabel('H(P,1-P)')2.运行结果:结果分析:从图中可已看出当p=0.5即信源等概时熵取得最大值。
实验二一般信道容量迭代算法一、内容编程实现一般信道容量迭代算法。
伪代码见教材。
二、要求1.掌握一般信道容量迭代算法的原理2.掌握MA TLAB开发环境的使用(尤其是程序调试技巧),或者使用C语言完成程序设计三.Matlab程序及运行结果1.matlab程序:clc;clear all;N = input('输入信源符号X的个数N=');M = input('输入信源符号Y的个数M=');p_yx=zeros(N,M); %程序设计需要信道矩阵初始化为零fprintf('输入信道矩阵概率\n')for i=1:Nfor j=1:Mp_yx(i,j)=input('p_yx='); %输入信道矩阵概率if p_yx(i)<0error('不符合概率分布')endendEndfor i=1:N %各行概率累加求和s(i)=0;for j=1:Ms(i)=s(i)+p_yx(i,j);endendfor i=1:N %判断是否符合概率分布if (s(i)<=0.999999||s(i)>=1.000001)error('不符合概率分布')endendb=input('输入迭代精度:'); %输入迭代精度for i=1:Np(i)=1.0/N; %取初始概率为均匀分布endfor j=1:M %计算Q(j)Q(j)=0;for i=1:NQ(j)=Q(j)+p(i)*p_yx(i,j);endendfor i=1:N %计算F(i) f(i)=0;for j=1:Mif(p_yx(i,j)==0)f(i)=f(i)+0;elsef(i)=f(i)+p_yx(i,j)*log(p_yx(i,j)/Q(j));endendF(i)=exp(f(i));endx=0;for i=1:N %计算x x=x+p(i)*F(i);endIL=log2(x); %计算ILIU=log2(max(F)); %计算IUn=1;while((IU-IL)>=b) %迭代计算for i=1:Np(i)=p(i)*F(i)/x; %重新赋值p(i) endfor j=1:M %计算Q(j) Q(j)=0;for i=1:NQ(j)=Q(j)+p(i)*p_yx(i,j);endendfor i=1:N %计算F(i) f(i)=0;for j=1:Mif(p_yx(i,j)==0)f(i)=f(i)+0;elsef(i)=f(i)+p_yx(i,j)*log(p_yx(i,j)/Q(j));endEndF(i)=exp(f(i));endx=0;for i=1:N %计算xx=x+p(i)*F(i);endIL=log2(x); %计算ILIU=log2(max(F)); %计算IUn=n+1;endfprintf('信道矩阵为:\n');disp(p_yx);fprintf('迭代次数n=%d\n',n);fprintf('信道容量C=%f比特/符号',IL);2.运行结果为:若输入信道矩阵为:0.8500 0.15000.7500 0.2500则运行结果为:实验四线性分组码的信道编码和译码一、内容编程实现线性分组码(6,2)重复码的信道编码和译码。
《信息论》实验指导书—-应用MATLAB软件实现

《信息论》实验指导书—-应用M A T L A B软件实现-CAL-FENGHAI.-(YICAI)-Company One1《信息与编码理论》上机实验指导书———————应用MATLAB软件实现UPC通信工程系前言本实验系列是采用MATLAB软件,主要针对《信息论基础》课程中的相关内容进行的实验。
MATLAB是一完整的并可扩展的计算机环境,是一种进行科学和工程计算的交互式程序语言。
它的基本数据单元是不需要制定维数的矩阵,它可直接用于表达数学的算式和技术概念,解决同样的数值计算问题,使用MATLAB要比使用Basic、Fortran和C语言等提高效率许多倍。
MATLAB还是一种有利的教学工具,在大学的线性代数课程以及其它领域的高一级课程的教学中,已称为标准的教学工具。
该指导书共安排了4个实验,现就一些情况作简要说明:各实验要求学生在MATLAB系统上尽量独立完成,弄懂。
实验内容紧扣课程教学内容的各主要基本概念,希望同学们在完成每个实验后,对所学的内容起到巩固和加深理解的作用。
每个实验做完后必须交一份实验报告。
恳请各位实验老师和同学在实验中提出宝贵意见,以利于以后改进提高。
目录实验一离散信源及其信息测度 (3)实验二离散信道及其容量 (6)实验三无失真信源编码 (8)实验四有噪信道编码 (10)附录部分常用MATLAB命令 (12)实验一 离散信源及其信息测度一、[实验目的]离散无记忆信源是一种最简单且最重要的信源,可以用完备的离散型概率空间来描述。
本实验通过计算给定的信源的熵,加深对信源及其扩展信源的熵的概念的理解。
二、[实验环境]windows XP,MATLAB三、[实验原理]信源输出的各消息的自信息量的数学期望为信源的信息熵,表达式如下 1()[()]()log ()qi i i H X E I xi p x p x ===-∑信源熵是信源的统计平均不确定性的描述,是概率函数()p x 的函数。
信息论与编码matlab

信息论实验报告姓名胡小辉班级电子信息工程0902 学号 **********1.实验目的1、掌握哈夫曼编码、费诺编码、汉明码原理;2、熟练掌握哈夫曼树的生成方法;3、学会利用matlab、C语言等实现Huffman编码、费诺编码以及hamming编码。
2.实验原理Huffman编码:哈夫曼树的定义:假设有n个权值,试构造一颗有n个叶子节点的二叉树,每个叶子带权值为wi,其中树带权路径最小的二叉树成为哈夫曼树或者最优二叉树;实现Huffman编码原理的步骤如下:1. 首先将信源符号集中的符号按概率大小从大到小排列。
2. 用0和1表示概率最小的两个符号。
可用0表示概率小的符号,也可用1表示概率小的符号,但整个编码需保持一致。
3. 将这两个概率最小的符号合并成一个符号,合并符号概率为最小概率之和,将合并后的符号与其余符号组成一个N-1的新信源符号集,称之为缩减符号集。
4. 对缩减符号集用步骤1,2操作5. 以此类推,直到只剩两个符号,将0和1分别赋予它们。
6. 根据以上步骤,得到0,1赋值,画出Huffman码树,并从最后一个合并符号回朔得到Huffmaan编码。
费诺编码:费诺编码的实现步骤:1、将信源消息符号按其出现的概率大小依次排列:。
2、将依次排列的信源符号按概率值分为两大组,使两个组的概率之和近似相同,并对各组赋予一个二进制码元“0”和“1”。
3、将每一大组的信源符号再分为两组,使划分后的两个组的概率之和近似相同,并对各组赋予一个二进制符号“0”和“1”。
4、如此重复,直至每个组只剩下一个信源符号为止。
5、信源符号所对应的码字即为费诺码。
hamming编码:若一致监督矩阵H 的列是由不全为0且互不相同的所有二进制m(m≥2的正整数)重组成,则由此H矩阵得到的线性分组码称为[2m-1,2m-1-m,3]汉明码。
我们通过(7,4)汉明码的例子来说明如何具体构造这种码。
设分组码(n,k)中,k = 4,为能纠正一位误码,要求r≥3。
信道编码-MATLAB仿真实验中的应用

⚫ 输入参数2——trellis,卷积码编码器的网格结构;
⚫ 输入参数3——tblen,a positive integer scalar,用于规定回溯深 度。If the code rate is 1/2, a typical value for tblen is about five times the constraint length of the code;
⚫ 输入参数1——msg,未编码的信息符号序列,二进制矢量形式; ⚫ 输入参数2——trellis,卷积码编码器的网格结构; ⚫ 输出参数——code,编码后的卷积码符号序列,二进制矢量形式。
⚫ 卷积码译码的MATLAB函数为:
⚫ vitdec
卷积码的维特比译码(二进制数据)
⚫ 最常用的函数格式为:
⚫ 输入参数5—— dectype,指示译码器的判决类型。其取值不同, 对应的输入参数1——code的数据类型也不同。其取值如下表:
Values of Meaning dectype Input
'unquant' 软判决,code的数据类型为实数(未量化),其中1表示逻 辑‘0’,-1表示逻辑‘1’ 。
decoded = vitdec(code,trellis,tblen,opmode,dectype);
decoded = vitdec(code,trellis,tblen,opmode,'soft',nsdec)
⚫ 输入参数1——code,维特比译码器的输入符号序列,矢量形式。以 前述2/3码率的编码器结构为例,每个符号代表编码器输出的3个bit;
一、信道编码概述 四、卷积码译码
二、卷积码的结构 描述
三、卷积码编码
⚫ 信道编码又称检纠错编码,通过增加一定的 冗余度以提高数字通信系统的可靠性。
MATLAB中的信号编码与解码技巧

MATLAB中的信号编码与解码技巧引言现代通信系统中,信号编码和解码是关键技术,它们在数据传输和存储中扮演着至关重要的角色。
MATLAB作为一种强大的数学计算软件和编程环境,提供了丰富的功能和工具,用于信号处理和通信系统建模。
本文将探讨MATLAB中的一些常见信号编码和解码技巧,以提供读者对这一主题的深入理解。
一、数字信号编码1. PCM编码脉冲编码调制(PCM)是一种常用的数字信号编码技术,在语音和音频传输中广泛应用。
MATLAB提供了丰富的函数,可以帮助我们实现PCM编码。
例如,使用`audioread`函数可以读取音频文件,并使用`pcmenco`函数进行PCM编码。
2. Huffman编码霍夫曼编码是一种无损数据压缩算法,可以根据数据的统计特性进行代码设计。
在MATLAB中,`huffmandict`函数可用于生成霍夫曼编码字典,`huffmanenco`函数用于对数据进行编码,`huffmandeco`函数用于解码。
二、模拟信号编码1. AM编码幅度调制(AM)是一种传统的模拟信号编码技术,常用于广播和无线电通信。
在MATLAB中,我们可以使用`ammod`函数实现AM编码,并使用`amdemod`函数进行解调。
2. FM编码频率调制(FM)是另一种常见的模拟信号编码技术,广泛应用于音频和视频传输。
在MATLAB中,`fmmod`函数可用于FM编码,`fmdemod`函数可用于解调。
三、数字信号解码1. PCM解码PCM编码的逆过程是PCM解码,MATLAB中的`pcmdeco`函数可用于解码PCM信号并恢复原始信号。
2. Huffman解码通过使用霍夫曼编码表,我们可以对霍夫曼编码进行解码。
在MATLAB中,`huffmandeco`函数可用于解码数据,并使用`huffmanenco`函数所生成的编码字典。
四、应用实例:数字音频编码数字音频编码是一个实际应用领域,通过对音频信号进行编码和解码,可以实现音频数据的压缩和传输。
信息论与编码实验报告

实验一:计算离散信源的熵一、实验设备:1、计算机2、软件:Matlab二、实验目的:1、熟悉离散信源的特点;2、学习仿真离散信源的方法3、学习离散信源平均信息量的计算方法4、熟悉 Matlab 编程;三、实验内容:1、写出计算自信息量的Matlab 程序2、写出计算离散信源平均信息量的Matlab 程序。
3、将程序在计算机上仿真实现,验证程序的正确性并完成习题。
四、求解:1、习题:A 地天气预报构成的信源空间为:()⎥⎦⎤⎢⎣⎡=⎥⎦⎤⎢⎣⎡6/14/14/13/1x p X 大雨小雨多云晴 B 地信源空间为:17(),88Y p y ⎡⎤⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦⎣⎦ 小雨晴 求各种天气的自信息量和此两个信源的熵。
2、程序代码:p1=[1/3,1/4,1/4,1/6];p2=[7/8,1/8];H1=0.0;H2=0.0;I=[];J=[];for i=1:4H1=H1+p1(i)*log2(1/p1(i));I(i)=log2(1/p1(i));enddisp('自信息I分别为:');Idisp('信息熵H1为:');H1for j=1:2H2=H2+p2(j)*log2(1/p2(j));J(j)=log2(1/p2(j));enddisp('自信息J分别为');Jdisp('信息熵H2为:');H23、运行结果:自信息量I分别为:I = 1.5850 2.0000 2.0000 2.5850信源熵H1为:H1 = 1.9591自信息量J分别为:J =0.1926 3.0000信源熵H2为:H2 =0.54364、分析:答案是:I =1.5850 2.0000 2.0000 2.5850 J =0.1926 3.0000H1 =1.9591; H2 =0.5436实验2:信道容量一、实验设备:1、计算机2、软件:Matlab二、实验目的:1、熟悉离散信源的特点;2、学习仿真离散信源的方法3、学习离散信源平均信息量的计算方法4、熟悉 Matlab 编程;三、实验内容:1、写出计算自信息量的Matlab 程序2、写出计算离散信源平均信息量的Matlab 程序。
信息论matlab的实验用到的编码

for k=(maxN-1):-1:i
P(:,k+1)=P(:,k);
end
end
end
P(:,i)=MAX;
end
p=P(1,:);
x=P(2,:);
% shannon编码生成器%
%函数说明:%
% [W,L,q]=shannon(p)为shannon编码函数%
% p为信源的概率矢量,W为编码返回的码字%
% Pb:输出概率矩阵,Pab:反向转移概率矩阵%
% C:初始信道容量,r:输入符号数,s:输出符号数%
%**************************************************%
function [CC,Paa]=ChannelCap(P,k)
%提示错误信息
if (length(find(P<0))~=0)
current_index=next_index;
current_P=next_P;
W(i,j)=code_num;
j=j+1;
if (length(current_P)==1)
break;
end
end
l(i)=length(find(abs(W(i,:))~=0)); %得到各码字的长度
end
L=sum(P.*l); %计算平均码字长度
% L为编码返回的平均码字长度,q为编码效率%
%*****************************************%
function [W,L,q]=shannon(p)
%提示错误信息
if (length(find(p<=0))~=0)
实验三-香农编码的MATLAB实现

实验三-⾹农编码的MATLAB 实现信息论编码实验3~9连载,更多看专栏。
⾹农编码仿真实现⼀、⾹农编码的原理⾹农码严格意义上来说不是最佳码,与基于符号概率进⾏映射的哈夫曼编码不同的地⽅在于,⾹农码基于累积概率的⼆进制数进⾏编码。
编码步骤:1. 将概率分布列降序排序;2. 求出每⼀⾏所对应的累加概率 P ;3. 根据累加概率 P 计算该符号对应⾹农码的长度 L ;4. 将累加概率 P 转换成⼆进制数,取其前 L 位,即为该符号的⾹农码。
对于⾹农码的评价:⾹农编码的效率不⾼,实⽤性不⼤,但对其他编码⽅法有很好的理论指导意义。
⼀般情况下,按照⾹农编码⽅法编出来的码,其平均码长不是最短的,即不是紧致码(最佳码)。
只有每⼀个符号的概率都是1/2的整数倍时,编码效率才能达到最⾼。
⼆、⾹农编码实例以后有空再补充吧~三、程序及流程图下⾯是代码:i i i i i%%实验三:⾹农编码仿真实验clear allclc%⽤户输⼊符号概率p =input('请输⼊离散信源概率分布,例如[0.5,0.5]:\n');N =length(p);L =ceil(-log2(p));%获得码长向量,元素表⽰每个符号所对应的码长%获得累加概率P及对应码字[p_SortDescend,reflect]=sort(p,'descend');%将概率从⼤到⼩进⾏排序%注:reflect所表⽰的映射关系很重要P =zeros(1,N);%初始化累加概率CODE =strings(1,N);%初始化对应码字(字符串形式)for i=1:N % i表⽰排序后第⼏个符号code =zeros(1,L(reflect(i)));%初始化对应码字(数组形式)if i==1%定义第⼀个编码为0P(1)=0;CODE(reflect(i))=num2str(code);elseP(i)=sum(p_SortDescend(1,1:i-1));%获得累加概率end%下⾯计算⾹农码(计算累加概率的⼆进制数,并取前Li位)p_count =P(i)*2;% p_count⽤于逐步的计算累加概率的⼆进制数for m=1:L(reflect(i))% m表⽰这个符号⾥第⼏个码字if p_count >=1code(m)=1;p_count = p_count-1;elsecode(m)=0;endp_count = p_count*2;end%将⾹农码赋值给对应的符号CODE(reflect(i))=num2str(code);endH =sum(-p.*log2(p));%计算信源信息熵L_ave =sum(L.*p);%计算平均码长yita = H/L_ave;%计算编码效率%展⽰输出码字、平均码长和编码效率fprintf('\n运⾏结果:\n');disp(['信号符号: ',num2str(1:N)]);disp(['对应概率: ',num2str(p)]);fprintf('对应码字:');disp(CODE);disp(['平均码长:',num2str(L_ave)]);disp(['编码效率:',num2str(yita)]);四、程序运⾏结果下⾯假设输⼊[0.1,0.2,0.3,0.4]五、程序⾃评价怎么说呢,代码原理其实很简单,但是我⼀直对它的命令⾏窗⼝的输出耿耿于怀,这没有达到我理想的输出效果:1. 每⼀列对应元素都对齐;2. “对应码字”的输出不要加引号,并且可以密集排列;3. “对应码字”下⾯不要有换⾏。
基于matlab的信源编码实验系统的设计

标题:深度探讨基于matlab的信源编码实验系统的设计在信息科学与技术领域中,信源编码是指利用编码技术对信号源产生的信号进行编码,以便更有效地传输和存储。
基于matlab的信源编码实验系统的设计,是目前研究热点之一。
本文将从信源编码的基本概念出发,深入探讨基于matlab的信源编码实验系统的设计,让读者在阅读后对该主题有一个全面、深刻的理解。
一、信源编码的基本概念1.1 信源编码的定义和作用在通信领域,信源编码是指利用编码技术对信源产生的信号进行编码,以便更有效地传输和存储。
其作用在于减少数据传输或存储时所需要的比特数,提高传输效率和降低成本。
1.2 信源编码的分类信源编码主要分为无损编码和有损编码两种。
无损编码是指编码解码过程中不会有信息丢失,有损编码则是在编码解码过程中会有信息丢失。
其中,无损编码包括霍夫曼编码、算术编码等;有损编码包括JPEG、MP3等。
二、基于matlab的信源编码实验系统的设计2.1 实验系统的基本组成基于matlab的信源编码实验系统主要包括信源编码器、信道编码器、调制器、信道、调制解调器、信道解码器等组成。
其中,信源编码器用于对信号进行编码,信道编码器用于对数据进行处理以应对信道传输中的噪声,调制器用于将数据转换为模拟信号,信道用于传输信号,调制解调器用于将模拟信号转换为数字信号,信道解码器用于对数据进行解码。
2.2 实验系统的设计原理在实验系统的设计中,需要考虑不同编码方式的选择和实现,以及信道传输中可能出现的噪声和干扰。
还需要考虑编码器和解码器之间的匹配和信道编码器的选择等因素。
三、个人观点和理解在我看来,基于matlab的信源编码实验系统的设计是一个复杂且具有挑战性的任务。
在设计过程中,需要深入理解信源编码的基本原理和各种编码方式的特点,同时还需要考虑到实际应用中可能出现的各种问题和挑战。
只有全面了解和深入思考,才能设计出高效、稳定的实验系统。
总结与回顧本文首先介绍了信源编码的基本概念,包括其定义、作用和分类,然后深入探讨了基于matlab的信源编码实验系统的设计,包括实验系统的基本组成和设计原理。
信息论编码报告---算术编码

基于Matlab的算术编码的研究摘要算术编码属信源编码信源编码又分为离散编码和连续编码,算术编码也属于离散编码。
本文对算术编码的编码理论和译码理论做了详细的分析,并根据理论知识在Matlab中搭建算术编码的系统,实现了对算术编码的整个过程的重现。
算术编码所需参数很少,不像哈弗曼编码那样需要一个很大的码表以及大的存储来存储计算过程的计算值。
但是算术编码的计算复杂性相对较大。
关键词:算术编码、Matlab1、课题研究背景及意义在一个压缩系统中,无论是有损压缩还是无损压缩,编码往往是必须的环节。
算术编码在数据压缩中,提供了一种有效去除冗余度的机制,是一种到目前为止编码效率最高的统计熵编码方法,它比著名的Huffman编码效率提高10%左右,但是由于其编码复杂性和实现技术的限制以及一些专利权的限制,所以并不像Huffman编码那样应用广泛。
国外对算术编码的研究较多,取得了许多重要的应用,但大多都有专利保护,如JPEG,JPEG2000,JBIG中均采用了算术编码;国内的研究相对较少,应用不是很广泛,至今了解的人还不是很多。
其实在Shannon 最早提出信息论后不久,Elias 就提出了基本的算术编码的想法,1987 年Witten 等人在文献中提出了算术编码在数据压缩方面的应用,指出其比Huffman 编码具有更好的压缩效率,它能够在不要求概率分布形式的情况下表现出良好的性质,这使得算术编码在数据压缩方面得到广泛应用及研究。
但是另一方面,包括Huffman 编码在内的早期编码模式都是采用固定的码字来表示每一个需要编码的符号,而从加密的角度来看这些算法都是使用简单的字母替换,即用一个符号或字符串替换另一个符号或字符串,所以都很容易被破解,不能提供真正意义上的数据安全。
相反,算术编码并不是采用固定码字来表示每个符号,它的压缩模式是将一段消息用一个[0,1)的真子集(子区间)来表示,而这个区间被初始化为[0,1),并且每编码一个符号区间就缩小一次。
信息论与编码matlab

信息论实验报告姓名胡小辉班级电子信息工程0902学号 09090911121.实验目的1、掌握哈夫曼编码、费诺编码、汉明码原理;2、熟练掌握哈夫曼树的生成方法;3、学会利用matlab、C语言等实现Huffman编码、费诺编码以及hamming编码。
2.实验原理Huffman编码:哈夫曼树的定义:假设有n个权值,试构造一颗有n个叶子节点的二叉树,每个叶子带权值为wi,其中树带权路径最小的二叉树成为哈夫曼树或者最优二叉树;实现Huffman编码原理的步骤如下:1. 首先将信源符号集中的符号按概率大小从大到小排列。
2. 用0和1表示概率最小的两个符号。
可用0表示概率小的符号,也可用1表示概率小的符号,但整个编码需保持一致。
3. 将这两个概率最小的符号合并成一个符号,合并符号概率为最小概率之和,将合并后的符号与其余符号组成一个N-1的新信源符号集,称之为缩减符号集。
4. 对缩减符号集用步骤1,2操作5. 以此类推,直到只剩两个符号,将0和1分别赋予它们。
6. 根据以上步骤,得到0,1赋值,画出Huffman码树,并从最后一个合并符号回朔得到Huffmaan编码。
费诺编码:费诺编码的实现步骤:1、将信源消息符号按其出现的概率大小依次排列:。
2、将依次排列的信源符号按概率值分为两大组,使两个组的概率之和近似相同,并对各组赋予一个二进制码元“0”和“1”。
3、将每一大组的信源符号再分为两组,使划分后的两个组的概率之和近似相同,并对各组赋予一个二进制符号“0”和“1”。
4、如此重复,直至每个组只剩下一个信源符号为止。
5、信源符号所对应的码字即为费诺码。
hamming编码:若一致监督矩阵H 的列是由不全为0且互不相同的所有二进制m(m≥2的正整数)重组成,则由此H矩阵得到的线性分组码称为[2m-1,2m-1-m,3]汉明码。
我们通过(7,4)汉明码的例子来说明如何具体构造这种码。
设分组码(n,k)中,k = 4,为能纠正一位误码,要求r≥3。
信息论与编码实验报告

信息论与编码实验报告一、实验目的本实验旨在通过实践,使学生们对信息论与编码理论有一个更深入的理解,掌握信息论与编码的基本原理和应用方法。
二、实验环境本次实验使用MATLAB软件来实现相关编码算法。
三、实验内容1.信息熵的计算信息熵是信息理论中的一个重要概念,用来度量一些信息源的不确定性。
在实验中,我们将计算给定的一组消息的信息熵。
首先,我们将给定的消息编码为二进制序列。
然后,我们根据信息熵的定义,使用公式计算信息熵:H(X) = -Σ(p(x) * log2(p(x)))其中,H(X)表示信息熵,p(x)表示消息x发生的概率。
2.香农编码的实现香农编码是一种无失真的编码方法,用于将离散的符号序列编码为二进制码字。
在实验中,我们将实现香农编码算法。
首先,我们需要计算给定符号序列中各个符号的概率。
然后,根据概率大小,将概率最高的符号分配最短的二进制码字,将概率较低的符号分配较长的二进制码字。
实现香农编码算法后,我们将计算编码后的码字的平均码长,并与信息熵进行比较,了解香农编码的效率。
3.赫夫曼编码的实现赫夫曼编码是一种常用的无失真编码方法,也被广泛应用于数据压缩中。
在实验中,我们将实现赫夫曼编码算法。
首先,我们需要计算给定符号序列中各个符号的概率。
然后,根据概率大小,使用最小堆数据结构构建赫夫曼树。
最后,根据赫夫曼树的性质,将每个符号的编码确定下来。
实现赫夫曼编码算法后,我们将计算编码后的码字的平均码长,并与信息熵进行比较,了解赫夫曼编码的效率。
四、实验结果与分析1.实验一结果我们选取了一个包含1000个等概率的二进制消息的序列进行实验。
通过计算,我们得到了该消息序列的信息熵为12.实验二结果我们选取了一个包含1000个符号的序列进行实验。
通过计算,我们得到了编码后的平均码长为2.8、与信息熵的比较发现,香农编码的效率很高。
3.实验三结果我们选取了一个包含1000个符号的序列进行实验。
通过计算,我们得到了编码后的平均码长为2.6、与信息熵的比较发现,赫夫曼编码的效率也很高。
信息论与编码实验报告

实验报告课程名称:信息论与编码姓名:系:专业:年级:学号:指导教师:职称:年月日目录实验一信源熵值的计算 (1)实验二 Huffman信源编码 (5)实验三 Shannon编码 (9)实验四信道容量的迭代算法 (12)实验五率失真函数 (15)实验六差错控制方法 (20)实验七汉明编码 (22)实验一 信源熵值的计算一、 实验目的1 进一步熟悉信源熵值的计算 2熟悉 Matlab 编程二、实验原理熵(平均自信息)的计算公式∑∑=--==qi i i qi i i p p p p x H 1212log 1log )(MATLAB 实现:))(log *.(2x x sum HX -=;或者))((log *)(2i x i x h h -= 流程:第一步:打开一个名为“nan311”的TXT 文档,读入一篇英文文章存入一个数组temp ,为了程序准确性将所读内容转存到另一个数组S ,计算该数组中每个字母与空格的出现次数(遇到小写字母都将其转化为大写字母进行计数),每出现一次该字符的计数器+1;第二步:计算信源总大小计算出每个字母和空格出现的概率;最后,通过统计数据和信息熵公式计算出所求信源熵值(本程序中单位为奈特nat )。
程序流程图:三、实验内容1、写出计算自信息量的Matlab 程序2、已知:信源符号为英文字母(不区分大小写)和空格。
输入:一篇英文的信源文档。
输出:给出该信源文档的中各个字母与空格的概率分布,以及该信源的熵。
四、实验环境Microsoft Windows 7Matlab 6.5五、编码程序#include"stdio.h"#include <math.h>#include <string.h>#define N 1000int main(void){char s[N];int i,n=0;float num[27]={0};double result=0,p[27]={0};FILE *f;char *temp=new char[485];f=fopen("nan311.txt","r");while (!feof(f)) {fread(temp,1, 486, f);}fclose(f);s[0]=*temp;for(i=0;i<strlen(temp);i++){s[i]=temp[i];}for(i=0;i<strlen(s);i++){if(s[i]==' ')num[26]++;else if(s[i]>='a'&&s[i]<='z')num[s[i]-97]++;else if(s[i]>='A'&&s[i]<='Z')num[s[i]-65]++;}printf("文档中各个字母出现的频率:\n");for(i=0;i<26;i++){p[i]=num[i]/strlen(s);printf("%3c:%f\t",i+65,p[i]);n++;if(n==3){printf("\n");n=0;}}p[26]=num[26]/strlen(s);printf("空格:%f\t",p[26]);printf("\n");for(i=0;i<27;i++){if (p[i]!=0)result=result+p[i]*log(p[i]);}result=-result;printf("信息熵为:%f",result);printf("\n");return 0;}六、求解结果其中nan311.txt中的文档如下:There is no hate without fear. Hate is crystallized fear, fear’s dividend, fear objectivized. We hate what we fear and so where hate is, fear is lurking. Thus we hate what threatens our person, our vanity andour dreams and plans for ourselves. If we can isolate this element in what we hate we may be able to cease from hating.七、实验总结通过这次实验,我们懂得了不必运行程序时重新输入文档就可以对文档进行统计,既节省了时间而且也规避了一些输入错误。
信息论实验用matlab实现哈夫曼码编译码

信息论与编码基础课程实验报告实验名称:Huffman码编译码实验姓名:学号:组别:专业:指导教师:班队:完成时间:成绩:Huffman码编译码实验一.实验目的和要求熟悉matlab软件编程环境及工具箱,掌握Huffman码编译码方法的基本步骤,利用matlab实现Huffman码的编译码。
二.试验内容和原理内容:利用matlab编程实现文本的二进制Huffman码的编译码。
任务:构造Huffman树。
原理:在各字符出现概率不均匀的情况下,根据这些概率构造一棵用于编码的Huffman树。
它用最短的二进制位表示出现概率最高的字符,而用较长的为表示出现概率低的字符,从而使平均码长缩短,并且保持编码的唯一可译性。
三.操作方法和实验步骤对一随机英文文本文件进行Huffman编译码仿真,给出各个字母的概率,码字,平均信息量,平均码长,编码效率以及编码序列输出。
(一)编码序列获取使用fopen函数读取.txt文本文件中的数据存储为字符串,使用length获取其长度,使用unique获取字符个数。
(二)获取编码概率矩阵使用strfind函数获取字符个数并计算各个符号的概率,根据哈夫曼编码原理依次获得各步骤中得到的概率,赋值给概率矩阵,使用find查找合并概率在的下标并存储到该列的最后一位,如有两个以上优先存储较大的那个下标。
(三)获取编码矩阵依据哈夫曼编码原理,根据获取的概率矩阵倒序编码。
最后一列直接编码0和1,取出最后一行中记录合并概率下标的数,由于该合并概率在上一列中肯定在最后两行,故优先编码,在字符串尾部加0和1;剩余编码直接平移,使用if 条件控制由于合并概率位置不同带来的平移方法不同。
(四)计算平均码长、自信息等使用公式计算平均码长、自信息、编码效率平均码长自信息编码效率(五)依据编码表编码由于是单符号信源,故使用strrep 字符替换函数直接替换(六)反向译码哈夫曼码是前向译码,遍历编码表,使用strncmpi 比较传输信息前x 个字符,如返回值为真直接译码,传输信息截取已经译码的部分,码字添加到译码信息中。
信息论编码matlab实现

Im=imread('1.png');figure(1);imshow(Im),title('原图');%图像灰度化I=Im(:,:,3);Im=I;figure(2);imshow(Im),title('灰度图');Im=double(Im);[m,n]=size(Im);ImgSize=m*n;ImgLeavel = reshape(Im, 1, prod(size(Im)));i=unique(ImgLeavel);j=ImgLeavel;[Num,Leavel]=hist(j,i); %i是像素点的个数,j是像素值sort(Leavel);Leavel=fliplr(Leavel);for k=1:256p(k) = Num(k)/ImgSize; %求得概率endfigure(3);hist(p,100),title('灰度值统计');for k=1:255 %冒泡法排序得到P从大到小的排列for L=1:256-kif(p(L)<p(L+1))tmp=p(L);p(L)=p(L+1);p(L+1)=tmp;endendendCodeLength=ceil(-log2(p)); %计算码长AddP = zeros(size(p));AddP(1)=0; %计算累加概率for k=2:256AddP(k)=AddP(k-1)+p(k-1);endsheet=cell(5,256);for k=1:256x=dec(AddP(k),CodeLength(k)); %得到码表 sheet(1,k)={[x]};sheet(2,k)={Leavel(k)};sheet(3,k)={AddP(k)};sheet(4,k)={p(k)};sheet(5,k)={Num(k)};endsheet=sheet';global sheet;%编码Img=cell(m,n);for k1=1:mfor k2=1:npixel=Im(k1,k2);Img{k1,k2}=Code(pixel);endend%解码DeImg=zeros(m,n);for k1=1:mfor k2=1:nScode=Img{k1,k2};DeImg(k1,k2)=Decode(Scode);endendfigure(7),imshow(uint8(DeImg)),title('还原后的图像');function pix=Decode(Scode)global sheet;for k=1:256if(isequal(Scode,sheet{k,1}))pix=sheet{k,2};break;endendfunction record=dec(DecNum,length)count=0;tempnum=DecNum;record=zeros(1,length);while(length)count=count+1;%长度小于lengthif(count>length)length=0;endtempnum=tempnum*2;%小数转换为二进制,乘2取整if tempnum>1record(count)=1;tempnum=tempnum-1; elseif(tempnum==1)record(count)=1;length=0;elserecord(count)=0; endendfunction Scode=Code(pix) global sheet;Leavel=zeros(256,1);for k1=1:256Leavel(k1)=sheet{k1,2}; endLocation=find(Leavel==pix); Scode=sheet{Location,1};。
信息论与编码实验程序与结果图(matlab)
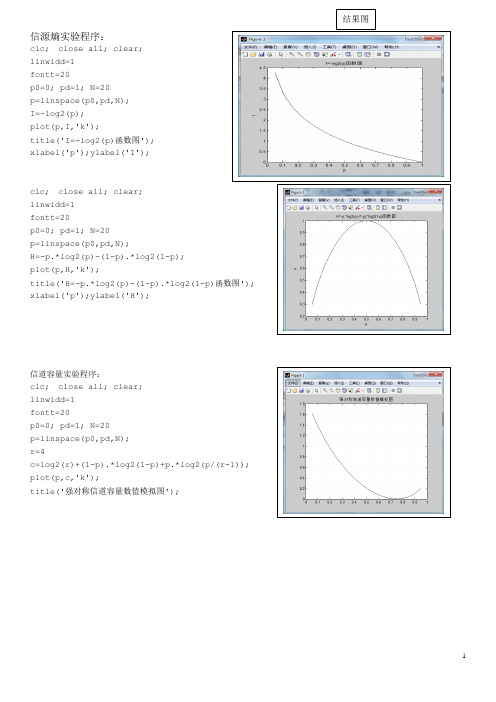
结果图信源熵实验程序:clc; close all; clear;linwidd=1fontt=20p0=0; pd=1; N=20p=linspace(p0,pd,N);I=-log2(p);plot(p,I,'k');title('I=-log2(p)函数图');xlabel('p');ylabel('I');clc; close all; clear;linwidd=1fontt=20p0=0; pd=1; N=20p=linspace(p0,pd,N);H=-p.*log2(p)-(1-p).*log2(1-p);plot(p,H,'k');title('H=-p.*log2(p)-(1-p).*log2(1-p)函数图');xlabel('p');ylabel('H');信道容量实验程序:clc; close all; clear;linwidd=1fontt=20p0=0; pd=1; N=20p=linspace(p0,pd,N);r=4c=log2(r)+(1-p).*log2(1-p)+p.*log2(p/(r-1));plot(p,c,'k');title('强对称信道容量数值模拟图');有噪信道编码--费诺不等式程序:结果图clc;close all;clear;r=3;p0=0.00001;pd=0.99999;N=2000;p=linspace(p0,pd,N);q=1-p;H=-p.*log2(p)-q.*log2(q);hold onHH=H+p.*log2(r-1)title('费诺不等式示意图');box onxlabel('PE');ylabel('H(X/Y)');plot(p,HH,'k:')hold onhold onfill([p,1],[HH,0],[0.6,0.6,0.6])stem((r-1)/r,1.59,'--.r')text(0.66,1.6,'最大值')香农编码程序:clc;clear all;close all;p=[0.2 0.19 0.18 0.17 0.15 0.1 0.01]; if sum(p)<1||sum(p)>1error('输入概率不符合概率分布')end[p index]=sort(p,'descend');n=length(p);pa=zeros(n,1);for ii=2:npa(ii)=pa(ii-1)+p(ii-1);endk=ceil(-log2(p));%码字长度计算c=cell(1,n);%生成元胞数组,用来存不同长度的码字for ii=1:nc{ii}='';tmp=pa(ii);for jj=1:k(ii)tmp=tmp*2;if tmp>=1tmp=tmp-1;%c{ii}{jj}='1';c{ii}=[char(c{ii}),'1']; else%c{ii}{jj}='0';c{ii}=[char(c{ii}),'0']; endendend c(index)=c;%换回原来的顺序codelength=zeros(1,n);%码长初始化for ii=1:nfprintf(['第',num2str(ii),'个消息对应为']);disp(c{ii});%显示码字codelength(ii)=length(c{ii});%endn_average=sum(codelength.*p) %平均码长fprintf('平均码长为');disp(n_average);H=-sum(p.*log2(p));fprintf('信源熵');disp(H);x=H/(n_average.*log2(2))fprintf('编码效率');disp(x);figureh=stem(1:n,codelength);%axis([0 n+1 0 n+1]);set(h,'MarkerFaceColor','blue','linewidth',2)实验结果结果图第1个消息对应为000第2个消息对应为001第3个消息对应为011第4个消息对应为100第5个消息对应为101第6个消息对应为1110第7个消息对应为1111110n_average = 3.1400平均码长为 3.1400信源熵 2.6087x =0.8308编码效率 0.8308费诺编码程序:endfor rr=2:2:needgroupnum*2index2=index_aftergroup(rr,:);for ii=index2(1):index2(2)c{ii}=[char(c{ii}),'1']; endendflag=0;index_p=[];for rr=1:needgroupnum*2indextmp=index_aftergroup(rr,:); if(indextmp(2)-indextmp(1)+1>1) flag=1;index_p=[index_p;indextmp]; endendjj=jj+1;endc(index)=c;codelength=zeros(1,N);for ii=1:Nfprintf(['第',num2str(ii),'个消息对应为']);disp(c{ii});codelength(ii)=length(c{ii}); endn_average=sum(codelength.*p)fprintf('平均码长为');disp(n_average);H=-sum(p.*log2(p));fprintf('信源熵');disp(H);x=H/(n_average.*log2(2))fprintf('编码效率');disp(x); figureh=stem(1:N,codelength);axis([0 N+1 0 N+1]);set(h,'MarkerFaceColor','blue','linewidth',2)endfunction index_aftergroup=func_group(p,index_p)index=index_p(1):index_p(2);n=length(index);p0=p(index);sump0=sum(p0);half_sump0=sump0/2;for ii=1:n-1tmpsum=sum(p0(1:ii));if abs(tmpsum-half_sump0)<=abs(tmpsum-half_sump0+p0(ii+1))index_aftergroup=[index(1) index(ii);index(ii+1) index(n)]; break;endendend实验结果结果图第1个消息对应为00第2个消息对应为010第3个消息对应为011第4个消息对应为10第5个消息对应为110第6个消息对应为1110第7个消息对应为1111n_average = 2.7400平均码长为 2.7400信源熵 2.6087x =0.9521编码效率 0.9521霍夫曼编码程序:clc;clear all;close all; A=[0.4 0.2 0.2 0.1 0.1]; A=sort(A,'descend');T=A;[m,n]=size(A);B=zeros(n,n-1);B(:,1)=T;r=B(n,1)+B(n-1,1);T(n-1)=r; T(n)=0;T=sort(T,'descend');t=n-1;for j=2:n-1B(1:t,j)=T(1:t);K=find(T==r);%B(n,j)=K(end);B(n,j)=K(1);r=(B(t-1,j)+B(t,j));T(t-1)=r;T(t)=0;T=sort(T,'descend');t=t-1;endB;ENDc1=sym('[1,0]');ENDc=ENDc1;t=3;d=1;for j=n-2:-1:1for i=1:t-2if i>1&&B(i,j)==B(i-1,j)d=d+1;elsed=1;endB(B(n,j+1),j+1)=-1;temp=B(:,j+1);x=find(temp==B(i,j));ENDc(i)=ENDc1(x(d));endy=B(n,j+1);ENDc(t-1)=[char(ENDc1(y)),'1']; ENDc(t)=[char(ENDc1(y)),'0'];t=t+1;ENDc1=ENDc;endA%排序后的原概率序列ENDc%编码结果for i=1:n[a,b]=size(char(ENDc(i)));L(i)=b;endavlen=sum(L.*A)%平均码长selen=(L-avlen).^2%?mselen=sum((selen).*A)%码长均方差H=-A*(log2(A'))%?P=H/avlen%?figure;subplot(2,1,1)h=stem(1:n,selen);%axis([0 n+1 0 max(selen)+0.1]);set(h,'MarkerFaceColor','blue','lin ewidth',2)xlabel('信源向上排');ylabel('方差值selen');hold onplot(0:n+1,mselen*ones(1,n+2),'r',' linewidth',2);hold offlegend('每个信源码长与平均码长的方差','码长均方差');A=[0.4 0.2 0.2 0.1 0.1];A=sort(A,'descend');T=A;[m,n]=size(A);B=zeros(n,n-1); B(:,1)=T;r=B(n,1)+B(n-1,1);T(n-1)=r;T(n)=0;T=sort(T,'descend');t=n-1;for j=2:n-1B(1:t,j)=T(1:t);K=find(T==r);B(n,j)=K(end);%B(n,j)=K(1);r=(B(t-1,j)+B(t,j));T(t-1)=r;T(t)=0;T=sort(T,'descend');t=t-1;endB;ENDc1=sym('[1,0]');ENDc=ENDc1;t=3;d=1;for j=n-2:-1:1for i=1:t-2if i>1&&B(i,j)==B(i-1,j)d=d+1;elsed=1;endB(B(n,j+1),j+1)=-1;temp=B(:,j+1);x=find(temp==B(i,j));ENDc(i)=ENDc1(x(d));endy=B(n,j+1);ENDc(t-1)=[char(ENDc1(y)),'1'];ENDc(t)=[char(ENDc1(y)),'0'];t=t+1;ENDc1=ENDc;endA%排序后的原概率序列ENDc%编码结果for i=1:n[a,b]=size(char(ENDc(i)));L(i)=b;endavlen=sum(L.*A)%平均码长selen=(L-avlen).^2%?mselen=sum((selen).*A)%码长均方差H=-A*(log2(A'))%?P=H/avlen%?subplot(2,1,2)h=stem(1:n,selen);%axis([0 n+1 0 max(selen)+0.1]);set(h,'MarkerFaceColor','blue','linewidth',2)xlabel('信源向下排');ylabel('方差值selen');hold onplot(0:n+1,mselen*ones(1,n+2),'r','linewidth',2);hold offlegend('每个码长与平均码长的方差','码长均方差');实验结果A = 0.4000 0.2000 0.20000.1000 0.1000ENDc =[ 11, 1, 0, 101, 100]avlen = 1.8000selen = 0.0400 0.6400 0.64001.4400 1.4400mselen =0.5600H =2.1219P =1.1788A =0.4000 0.2000 0.20000.1000 0.1000ENDc =[ 0, 10, 111, 1101, 1100]avlen =2.2000selen = 1.4400 0.0400 0.64003.2400 3.2400mselen =1.3600H =2.1219P =0.9645结果图。
信息论与编码实验报告

华侨大学工学院实验报告课程名称:信息论与编码实验项目名称:算术编码学院:工学院专业班级:11级信息工程姓名:学号:1195111016指导教师:傅玉青2013年11月25日预习报告一、实验目的(1)进一步熟悉算术编码算法(2)掌握MATLAB语言程序设计和调试过程中数值的进制转换、数值与字符串之间的转换等技术。
二、实验仪器(1)计算机(2)编程软件MATLAB三、实验原理算术编码是图像压缩的主要算法之一。
是一种无损数据压缩方法,也是一种熵编码的方法。
和其它熵编码方法不同的地方在于,其他的熵编码方法通常是把输入的消息分割为符号,然后对每个符号进行编码,而算术编码是直接把整个输入的消息编码为一个数,一个满足(0.0 ≤ n < 1.0)的小数n。
当所有的符号都编码完毕,最终得到的结果区间即唯一的确定了已编码的符号串行。
任何人使用该区间和使用的模型参数即可以解码重建得到该符号串行。
实际上我们并不需要传输最后的结果区间,实际上,我们只需要传输该区间中的一个小数即可。
在实用中,只要传输足够的该小数足够的位数(不论几进制),以保证以这些位数开头的所有小数都位于结果区间就可以了。
预 习 报 告四、实验内容及步骤(1)计算信源符号的个数n(2)将第i (i=1~n )个信源符号变换成二进制数(3)计算i (i=1~n )个信源符号的累加概率Pi 为()11i i k k P p a -==∑(4)预先设定两个存储器,起始时令()()1,0A C φφ==,φ表示空集(5)按以下公式迭代求解C 和A()()()()(),,r rC S r C S A S P A S r A S p =+=对于二进制符号组成的序列,r=0,1。
注意事项:计算C (S ,r )时的加法运用的是二进制加法(6)计算序列S 编码后的码长度L 为()21log L p S ⎡⎤=⎢⎥⎢⎥ (7)如果C 在第L 位后没有尾数,则C 的小数点后L 位即为序列S 的算术编码;如果C 在第L 位后有尾数,则取C 的小数点后L 位,再进位到第L 位,即为序列S 的算术编码。
matlab信源二进制赫夫曼编码

信源二进制赫夫曼编码是一种常见的数据压缩算法,它可以有效地降低数据传输和存储的成本。
在本文中,我将深入探讨matlab中的信源二进制赫夫曼编码的原理、实现和应用,并共享我的个人观点和理解。
让我们来了解一下信源编码的基本概念。
信源编码是一种将离散或连续信号转换为离散符号的过程,其目的是尽量减少信号的冗余度,以便更高效地传输和存储。
在数字通信和数据存储领域,信源编码起着至关重要的作用。
而二进制赫夫曼编码是一种常见的无损数据压缩算法,其核心思想是通过对出现频率较高的符号赋予较短的编码,而对出现频率较低的符号赋予较长的编码,从而实现数据的压缩。
在matlab中,我们可以利用赫夫曼树和编码表来实现信源二进制赫夫曼编码。
接下来,我将详细介绍matlab中的信源二进制赫夫曼编码的实现过程。
在matlab中,我们可以使用`huffmandict`函数来创建赫夫曼编码字典,该函数需要输入符号和它们对应的概率作为参数。
我们可以使用`huffmanenco`函数来对输入的符号序列进行赫夫曼编码,得到压缩后的二进制码字。
我们可以使用`huffmandeco`函数来对压缩后的二进制码字进行解码,得到原始的符号序列。
通过这些函数的组合,我们可以在matlab中轻松实现信源二进制赫夫曼编码。
具体的实现细节和示例代码我将在下文中进行详细讲解。
信源二进制赫夫曼编码的应用非常广泛,特别是在无线通信、图像压缩和音频处理等领域。
通过使用赫夫曼编码,我们可以大大减小数据传输和存储的成本,提高系统的效率和可靠性。
赫夫曼编码也是信息论中的重要概念,它为我们理解信息压缩和编码提供了重要的思路和方法。
从个人观点来看,信源二进制赫夫曼编码作为一种经典的数据压缩算法,具有重要的理论意义和实际应用价值。
在matlab中,我们可以利用现成的函数库来实现赫夫曼编码,同时也可以根据具体的应用场景进行定制化的优化。
通过不断深入研究和实践,我们可以进一步发掘赫夫曼编码的潜力,为数据压缩和信息传输领域带来更多的创新和突破。
香农——费诺编码的matlab的实现

信息论与编码作业香农--费诺编码的matlab实现班级:姓名:学号:摘要:将文字、数字或其他对象编成数码,或将信息、数据转换成规定的电脉冲信号。
编码在电子计算机、电视、遥控和通讯等方面广泛使用。
其中费诺编码有广泛的应用,通过本次设计,了解编码的具体过程,通过编程实现编码,利用matlab实现费诺编码。
关键字:信息论,费诺编码,matlab正文:费诺编码也是一种常见的信源编码方法。
信源符号以概率递减的次序排列进来,将排列好的信源符号划分为两大组,使第组的概率和近于相同,并各赋于一个二元码符号”0”和”1”.然后,将每一大组的信源符号再分成两组,使同一组的两个小组的概率和近于相同,并又分别赋予一个二元码符号.依次下去,直至每一个小组只剩下一个信源符号为止.这样,信源符号所对应的码符号序列则为编得的码字.香农--费诺编码的matlab实现编码如下:clc;clear;A=[0.4,0.3,0.1,0.09,0.07,0.04];A=fliplr(sort(A));%降序排列[m,n]=size(A);for i=1:nB(i,1)=A(i);%生成B的第1列end%生成B第2列的元素a=sum(B(:,1))/2;for k=1:n-1if abs(sum(B(1:k,1))-a)<=abs(sum(B(1:k+1,1))-a)break;endendfor i=1:n%生成B第2列的元素if i<=kB(i,2)=0;elseB(i,2)=1;endend%生成第一次编码的结果END=B(:,2)';END=sym(END);%生成第3列及以后几列的各元素j=3;while (j~=0)p=1;while(p<=n)x=B(p,j-1);for q=p:nif x==-1break;elseif B(q,j-1)==xy=1;continue;elsey=0;break;endendendif y==1q=q+1;endif q==p|q-p==1B(p,j)=-1;elseif q-p==2B(p,j)=0;END(p)=[char(END(p)),'0'];B(q-1,j)=1;END(q-1)=[char(END(q-1)),'1'];elsea=sum(B(p:q-1,1))/2;for k=p:q-2if abs(sum(B(p:k,1))-a)<=abs(sum(B(p:k+1,1))-a);break;endendfor i=p:q-1if i<=kB(i,j)=0;END(i)=[char(END(i)),'0'];elseB(i,j)=1;END(i)=[char(END(i)),'1'];endendendendp=q;endC=B(:,j);D=find(C==-1);[e,f]=size(D);if e==nj=0;elsej=j+1;endendBAENDfor i=1:n[u,v]=size(char(END(i)));L(i)=v;endavlen=sum(L.*A)实验总结:经过本次作业,充分学习了费诺编码理论及其重点内容,掌握了费诺编码原理的同时也锻炼了编程水平,为以后的学习中出现的可能问题做好了准备,锻炼了自己的动手能力和设计能力,掌握了一种科技工具,丰富了自己的学习生活。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
j=1;
current_P=P;
while 1
[next_P,code_num,next_index]=compare(current_P,current_index);
current_index=next_index;
current_P=next_P;
W(i,j)=code_num;
s2='Shannon编码平均码字长度L:';
s3='Shannon编码的编码效率q:';
disp(s0);
disp(s1),disp(B),disp(W);
disp(s2),disp(L);
disp(s3),disp(q);
附录D Fano编码
%函数说明:%
% [next_P,next_index,code_num]=compare(current_P,current_index)%
附录B 离散无记忆信道容量的迭代计算
%信道容量C的迭代算法%
%函数说明:%
% [CC,Paa]=ChannelCap(P,k)为信道容量函数%
%变量说明:%
% P:输入的正向转移概率矩阵,k:迭代计算精度%
% CC:最佳信道容量,Paa:最佳输入概率矩阵%
% Pa:初始输入概率矩阵,Pba:正向转移概率矩阵%
s5='输出符号数s:';
s6='迭代计算精度k:';
for i=1:r
B{i}=i;
end
disp(s0);
disp(s1),disp(B),disp(Paa);
disp(s4),disp(r);
disp(s5),disp(s);
disp(s2),disp(CC);
disp(s6),disp(k);
end
end
% (2)再求Pab
suma=zeros(1,s);
for j=1:s
for i=1:r
Pab(j,i)=Pa(i)*Pba(i,j)/(Pb(j)+eps);
suma(j)=suma(j)+Pa(i)*Pba(i,j)*log2((Pab(j,i)+eps)/(Pa(i)+eps));
end
if (abs(sum(p)-1)>10e-10)
error('Not a ,component do not add up to 1') %判断是否符合概率和为1
end
% 1)排序
n=length(p);
x=1:n;
[p,x]=array(p,x);
% 2)计算代码组长度l
l=ceil(-log2(p));
% L为编码返回的平均码字长度,q为编码效率%
%*****************************************%
function [W,L,q]=shannon(p)
%提示错误信息
if (length(find(p<=0))~=0)
error('Not a ,negative component'); %判断是否符合概率分布条件
end
% 3)求信道容量C
C=sum(suma);
% 4)求下一次Pa,即Paa
L=zeros(1,r);
sumaa=0;
for i=1:r
for j=1:s
L(i)=L(i)+Pba(i,j)*log(Pab(j,i)+eps);
end
a(i)=exp( L(i));
end
sumaa=sum(a);
Pa=(1/(r+eps))*ones(1,r);
sumrow=zeros(1,r);
Pba=P;
% 2)进行迭代计算
n=0;
C=0;
CC=1;
while abs(CC-C)>=k
n=n+1;
% (1)先求Pb
Pb=zeros(1,s);
for j=1:s
for i=1:r
Pb(j)=Pb(j)+Pa(i)*Pba(i,j);
error('Not a ,negative component'); %判断是否符合概率分布条件
end
if (abs(sum(P)-1)>10e-10)
error('Not a ,component do not add up to 1');
end
H=(sum(-P.*log2(P)))/(log2(r)+eps);
error('Not a ,negative component'); %判断是否符合概率分布条件
end
if (abs(sum(P')-1)>10e-10)
error('Not a ,component do not add up to 1') %判断是否符合概率和为1
end
% 1)初始化Pa
[r,s]=size(P);
disp(s3),disp(n);
附录C Shannon编码
%函数说明:%
% [p,x]=array(P,X)为按序排序的函数%
% P为信源的概率矢量,X为概率元素的下标矢量%
% p为排序后返回的信源的概率矢量%
% x为排序后返回的概率元素的下标矢量%
%*******************************************%
% Pb:输出概率矩阵,Pab:反向转移概率矩阵%
% C:初始信道容量,r:输入符号数,s:输出符号数%
%**************************************************%
function [CC,Paa]=ChannelCap(P,k)
%提示错误信息
if (length(find(P<0))~=0)
% L为编码返回的平均码字长度,q为编码效率%
%*****************************************%
function [W,L,q]=fano(P)
%提示错误信息
if (length(find(P<=0))~=0)
error('Not a ,negative component'); %判断是否符合概率分布条件
function [next_P,code_num,next_index]=compare(current_P,current_index);
n=length(current_P);
add(1)=current_P(1);
% 1)求概率的依次累加和
for i=2:n
add(i)=0;
add(i)=add(i-1)+current_P(i);
s2='Fano编码平均码字长度L:';
s3='Fano编码的编码效率q:';
disp(s0);
disp(s1),disp(B),disp(W);
disp(s2),disp(L);
disp(s3),disp(q);
附录E Huffman编码
Huffman编码(1)
% huffman编码生成器%
%函数说明:%
next_P=current_P(1:k);
else
next_index=current_index-k;
code_num=49;
next_P=current_P((k+1):n);
end
% fano编码生成器%
%函数说明:%
% [W,L,q]=fano(P)为fano编码函数%
% P为信源的概率矢量,W为编码返回的码字%
for i=1:n
B{i}=i;
end
[n,m]=size(W);
TEMP=32*ones(n,5);
W=[W,TEMP];
W=W';
[n,m]=size(W);
W=reshape(W,1,n*m);
W=sprintf('%s', W);
s0='很好!输入正确,编码结果如下:';
s1='Fano编码所得码字W:';
j=j+1;
if (length(current_P)==1)
break;
end
end
l(i)=length(find(abs(W(i,:))~=0)); %得到各码字的长度
end
L=sum(P.*l); %计算平均码字长度
H=entropy(P,2); %计算信源熵
q=H/L; %计算编码效率
%打印输出结果
end
if (abs(sum(P)-1)>10e-10)
error('Not a ,component do not add up to 1') %判断是否符合概率和为1
end
% 1)排序
n=length(P);
x=1:n;
[P,x]=array(P,x);
% 2)将信源符号分组并得到对应的码字
for i=1:n
error('Not a ,negative component'); %判断是否符合概率分布条件
end
if (abs(sum(P)-1)>10e-10)
error('Not a ,component do not add up to 1') %判断是否符合概率和为1
if (i<n)
for k=(maxN-1):-1:i