CNN简介
医学影像分析中的卷积神经网络使用教程

医学影像分析中的卷积神经网络使用教程医学影像分析是一项重要且复杂的任务,对医疗诊断和治疗具有重要意义。
随着人工智能的发展,卷积神经网络(Convolutional Neural Networks, CNN)在医学影像分析领域取得了显著的成果。
本篇文章将介绍医学影像分析中的卷积神经网络使用教程,帮助读者理解和应用这一技术。
1. 卷积神经网络简介卷积神经网络是一种深度学习算法,最初被设计用于图像识别任务。
它具有多层神经网络结构,包括卷积层、池化层和全连接层。
卷积层用于从输入图像中提取特征,池化层用于降低特征图的维度,全连接层用于分类或回归预测。
卷积神经网络通过学习权重参数,可以自动从数据中学习特征并进行预测。
2. 医学影像分析中的应用卷积神经网络在医学影像分析中有广泛的应用,例如疾病诊断、影像分割、病灶检测等。
医学影像通常包含复杂的结构和纹理,传统的图像处理方法往往难以准确地提取有用的特征。
而卷积神经网络可以通过学习特征来解决这个问题,有效地抽取和表示医学影像中的信息。
3. 数据准备在使用卷积神经网络进行医学影像分析之前,我们需要准备好训练数据和测试数据。
训练数据是用于训练网络的样本,通常需要标记或注释,以提供预期的输出结果。
测试数据用于评估网络的性能,通常没有标记,需要进行预测并与真实结果进行比较。
4. 构建卷积神经网络模型构建卷积神经网络模型是医学影像分析中的关键步骤。
我们可以选择不同的网络结构和层数,根据具体的任务需求进行调整。
一般来说,常用的卷积神经网络结构有LeNet、AlexNet、VGG、GoogLeNet和ResNet等。
5. 数据预处理在输入数据进入卷积神经网络之前,需要进行预处理以提高网络性能和准确度。
常见的数据预处理方法包括图像增强、去噪、标准化和数据增强等。
图像增强用于增加图像的对比度和清晰度,去噪可以减少噪声对网络的影响,标准化可以将像素值映射到相同的尺度范围,数据增强可以增加样本的多样性和丰富性。
CNN简单介绍及基础知识...

CNN简单介绍及基础知识...文章目录一)卷积神经网络历史沿革二)CNN简单介绍三)CNN相关基础知识前言在过去的几年里,卷积神经网络(CNN)引起了人们的广泛关注,尤其是因为它彻底改变了计算机视觉领域,它是近年来深度学习能在计算机视觉领域取得突破性成果的基石。
它也逐渐在被其他诸如自然语言处理、推荐系统和语音识别等领域广泛使用。
在这里,主要从三个方面介绍CNN,(1)CNN历史发展(2)CNN简单介绍(3)CNN相关基础知识一、卷积神经网络历史沿革卷积神经网络的发展最早可以追溯到上世纪60年代,Hubel等人通过对猫视觉皮层细胞的研究,提出了感受野这个概念,到80年代,Fukushima在感受野概念的基础之上提出了神经认知机的概念,可以看作是卷积神经网络的第一个实现网络。
而后随着计算机软硬件技术的发展,尤其GPU,使得CNN快速发展,在2012年ImageNet大赛中CNN由于其高精确度脱颖而出,于是,深度学习正式进入人们的视野。
而后,R-CNN,FAST-CNN,Faster-cnn等快速发展,在深度学习领域大放异彩。
•1962年 Hubel和Wiesel卷积神经网络的发展,最早可以追溯到1962年,Hubel和Wiesel对猫大脑中的视觉系统的研究。
•1980年福岛邦彦1980年,日本科学家福岛邦彦在论文《Neocognitron: A self-organizing neuralnetwork model for a mechanism of patternrecognition unaffected by shift in position》提出了一个包含卷积层、池化层的神经网络结构。
•1998年 Yann Lecun1998年,在这个基础上,Yann Lecun在论文《Gradient-Based Learning Applied toDocument Recognition》中提出了LeNet-5,将BP算法应用到这个神经网络结构的训练上,就形成了当代卷积神经网络的雏形。
美国有线电视新闻网(CNN)节目编排策略分析

美国有线电视新闻网(CNN)节目编排策略分析闻名全球的美国有线电视新闻网CNN(Cable News Network),其电视网络覆盖212个国家和地区,全球42个分部。
它不仅开创了世界上第一个全天候24小时滚动播送新闻的频道,而且它的运作方式和编排特色对中国新闻频道的建立也提供了有益的经验。
一、CNN概述1980年6月,记者出身的特德·特纳买下亚特兰大一家濒临倒闭的小电视台,创办了CNN,向美洲国家24小时不间断播放电视新闻。
1982年,CNN创办了简明新闻频道(Headline News),经常抢到突发事件的独家新闻,并进行及时、详尽的现场报道。
在刚成立的几年内,由于美国市场已被大电视网垄断,CNN连续亏损。
直到1986年,CNN在报道美国航天飞机挑战者号中脱颖而出,在竞争中站住了阵脚。
此后,在里根遇刺、美军入侵巴拿马、拆除柏林墙、苏联解体、波黑战争等重大新闻事件上,CNN率先做的现场报道都抢尽了风头。
真正值得大书特书的是1991年的海湾战争。
当时,伊拉克把巴格达所有外国记者都驱逐出境,唯独留下CNN的记者报道海湾战争。
战争期间,CNN迅速、及时、详尽地报道了多国部队在伊拉克的“沙漠风暴”行动,成为各国首脑和舆论界了解实际战况的主要渠道,甚至有人称:“海湾战争有3个参战者——布什、萨达姆和CNN。
” 1985年,CNNI国际频道开始面向欧洲24小时播出,迈出了CNN国际化的重要一步。
值得注意的是,这年成为CNN第一个盈利年。
而CNN的国际化步伐,采取的是国际化与本地化两条腿走路的方针。
比如,1987年它建立了北京记者站,随后又设立了马尼拉、汉城、曼谷、香港等记者站,并于1995年在香港设立了亚洲地区制作中心,在CNNI亚洲版当中,关于亚洲的报道日益增加。
本地新闻的增加,吸引了大量的本地观众。
而1988年开办了西班牙语节目,1997年开办了24小时西班牙语频道,也体现了CNN通过吸引特定人群而扩大国际市场和影响的策略。
CNN详解
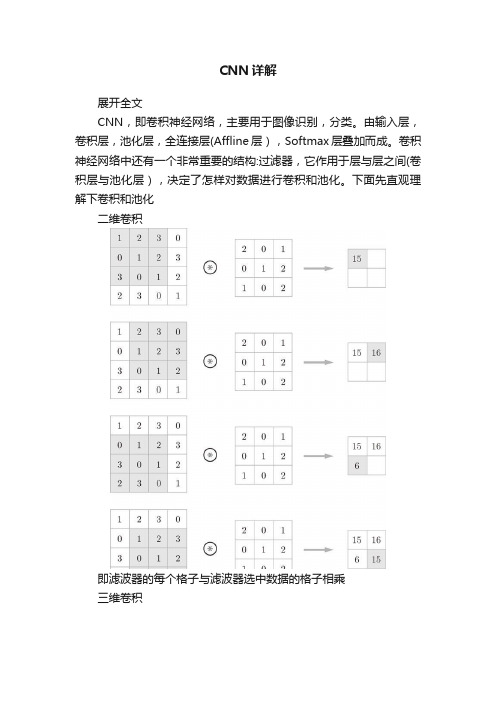
CNN详解展开全文CNN,即卷积神经网络,主要用于图像识别,分类。
由输入层,卷积层,池化层,全连接层(Affline层),Softmax层叠加而成。
卷积神经网络中还有一个非常重要的结构:过滤器,它作用于层与层之间(卷积层与池化层),决定了怎样对数据进行卷积和池化。
下面先直观理解下卷积和池化二维卷积即滤波器的每个格子与滤波器选中数据的格子相乘三维卷积三维数据的话,滤波器的也是三维。
同时对每个维度进行卷积,最后将每个维度的卷积结果相加,输出二维。
池化池化分为最大池化层与平均池化层。
最大池化层对滤波器选中的数据取最大值,平均池化层对滤波器选中的数据求平均值。
一般使用最大池化层。
池化层是单独作用于每个维度,若是三维数据,即对每个维度上进行最大/平均操作,输入结果也是三维。
卷积用于提取高层次特征,池化用于缩小参数。
一般为一层卷积加一层池化反复叠加或多层卷积加一层池化。
全连接层用于卷积池化后,对数据列化然后经过一两层全连接层,得出结果。
softmax用于最后的分类好了,知道卷积池化,下面就来实现最简单的一个卷积网络:灵魂画笔。
(*^__^*) relu为激活函数,FC即全连接层,也即Affine层CNN实现手写数字识别Packageimport sys ,os import numpy as npimport matplotlib.pyplot as pltimport tensorflow as tf #只是用来加载mnist数据集from PIL import Imageimport pandas as pd import math加载MNIST数据集def one_hot_label(y): one_hot_label = np.zeros((y.shape[0],10)) y = y.reshape(y.shape[0]) one_hot_label[range(y.shape[0]),y] = 1 return one_hot_label # #(训练图像,训练标签),(测试图像,测试标签)# # mnist的图像均为28*28尺寸的数据,通道为1(x_train_origin,t_train_origin),(x_test_origin,t_test_origin) = tf.keras.datasets.mnist.load_data()X_train = x_train_origin/255.0X_test = x_test_origin/255.0m,h,w = x_train_origin.shapeX_train = X_train.reshape((m,1,h,w))y_train = one_hot_label(t_train_origin)m,h,w = x_test_origin.shapeX_test = X_test.reshape((m,1,h,w))y_test = one_hot_label(t_test_origin)print('shape of x_train is :'+repr(X_train.shape))print('shape of t_train is :'+repr(y_train.shape))print('shape of x_test is :'+repr(X_test.shape))print('shape of t_test is :'+repr(y_test.shape))shape of x_train is :(60000, 1, 28, 28)shape of t_train is :(60000, 10)shape of x_test is :(10000, 1, 28, 28)shape of t_test is :(10000, 10)显示图像index = 0plt.imshow(X_train[index].reshape((28,28)),cmap = plt.cm.gray)print('y is:'+str(np.argmax(y_train[index]))) y is:5output_7_1.png激活函数def relu(input_X): ''' Arguments: input_X -- a numpy array Return : A: a numpy array. let each elements in array all greater or equal 0 ''' A = np.where(input_X < 0 ,0,input_X) return A def softmax(input_X): ''' Arguments: input_X -- a numpy array Return : A: a numpy array same shape with input_X ''' exp_a = np.exp(input_X) sum_exp_a = np.sum(exp_a,axis=1) sum_exp_a = sum_exp_a.reshape(input_X.shape[0],-1) ret = exp_a/sum_exp_a # print(ret) return ret损失函数def cross_entropy_error(labels,logits): return -np.sum(labels*np.log(logits))卷积层class Convolution: def __init__(self,W,fb,stride = 1,pad = 0): ''' W-- 滤波器权重,shape为(FN,NC,FH,FW),FN 为滤波器的个数 fb -- 滤波器的偏置,shape 为(1,FN) stride -- 步长pad -- 填充个数''' self.W = W self.fb = fb self.stride = stride self.pad = pad self.col_X = None self.X = None self.col_W = None self.dW = None self.db = None self.out_shape = None # self.out = None def forward (self ,input_X): ''' input_X-- shape为(m,nc,height,width) ''' self.X = input_X FN,NC,FH,FW = self.W.shape m,input_nc, input_h,input_w = self.X.shape #先计算输出的height和widt out_h = int((input_h+2*self.pad-FH)/self.stride + 1) out_w = int((input_w+2*self.pad-FW)/self.stride + 1) #将输入数据展开成二维数组,shape为(m*out_h*out_w,FH*FW*C) self.col_X = col_X = im2col2(self.X,FH,FW,self.stride,self.pad) #将滤波器一个个按列展开(FH*FW*C,FN) self.col_W = col_W = self.W.reshape(FN,-1).T out = np.dot(col_X,col_W)+self.fb out = out.T out = out.reshape(m,FN,out_h,out_w) self.out_shape = out.shape return out def backward(self, dz,learning_rate): #print('==== Conv backbward ==== ') assert(dz.shape == self.out_shape) FN,NC,FH,FW = self.W.shape o_FN,o_NC,o_FH,o_FW = self.out_shape col_dz = dz.reshape(o_NC,-1) col_dz = col_dz.T self.dW = np.dot(self.col_X.T,col_dz) #shape is (FH*FW*C,FN) self.db = np.sum(col_dz,axis=0,keepdims=True) self.dW = self.dW.T.reshape(self.W.shape) self.db = self.db.reshape(self.fb.shape) d_col_x = np.dot(col_dz,self.col_W.T) #shape is (m*out_h*out_w,FH,FW*C) dx = col2im2(d_col_x,self.X.shape,FH,FW,stride=1) assert(dx.shape == self.X.shape) #更新W和b self.W = self.W - learning_rate*self.dW self.fb = self.fb -learning_rate*self.db return dx池化层class Pooling: def __init__(self,pool_h,pool_w,stride = 1,pad = 0): self.pool_h = pool_h self.pool_w = pool_w self.stride = stride self.pad = pad self.X = None self.arg_max = None def forward ( self,input_X) : ''' 前向传播 input_X-- shape为(m,nc,height,width) ''' self.X = input_X N , C, H, W = input_X.shape out_h = int(1+(H-self.pool_h)/self.stride) out_w = int(1+(W-self.pool_w)/self.stride) #展开col = im2col2(input_X,self.pool_h,self.pool_w,self.stride,self.pad) col = col.reshape(-1,self.pool_h*self.pool_w) arg_max =np.argmax(col,axis=1) #最大值out = np.max(col,axis=1) out =out.T.reshape(N,C,out_h,out_w) self.arg_max = arg_max return out def backward(self ,dz): ''' 反向传播 Arguments: dz-- out的导数,shape与out 一致 Return: 返回前向传播是的input_X的导数 ''' pool_size = self.pool_h*self.pool_w dmax = np.zeros((dz.size,pool_size))dmax[np.arange(self.arg_max.size),self.arg_max.flatten()] = dz.flatten() dx = col2im2(dmax,out_shape=self.X.shape,fh=self.pool_h,fw=self.po ol_w,stride=self.stride) return dxRelu层class Relu: def __init__(self): self.mask = None def forward(self ,X): self.mask = X <= 0 out = X out[self.mask] = 0 return out def backward(self,dz): dz[self.mask] = 0 dx = dz return dxSoftMax层class SoftMax: def __init__ (self): self.y_hat = None def forward(self,X): self.y_hat = softmax(X) return self.y_hat def backward(self,labels): m = labels.shape[0] dx = (self.y_hat - labels) return dxdef compute_cost(logits,label): return cross_entropy_error(label,logits)Affine FC层class Affine: def __init__(self,W,b): self.W = W # shape is (n_x,n_unit) self.b = b # shape is(1,n_unit) self.X = None self.origin_x_shape = None self.dW = None self.db = None self.out_shape =None def forward(self,X): self.origin_x_shape = X.shape self.X = X.reshape(X.shape[0],-1)#(m,n) out = np.dot(self.X, self.W)+self.b self.out_shape = out.shape return out def backward(self,dz,learning_rate): ''' dz-- 前面的导数''' #print('Affine backward')# print(self.X.shape)# print(dz.shape)# print(self.W.shape) assert(dz.shape == self.out_shape) m = self.X.shape[0] self.dW = np.dot(self.X.T,dz)/m self.db = np.sum(dz,axis=0,keepdims=True)/m assert(self.dW.shape == self.W.shape) assert(self.db.shape == self.b.shape) dx = np.dot(dz,self.W.T) assert(dx.shape == self.X.shape) dx = dx.reshape(self.origin_x_shape) # 保持与之前的x一样的shape #更新W和b self.W = self.W-learning_rate*self.dW self.b = self.b - learning_rate*self.db return dx模型class SimpleConvNet: def __init__(self): self.X = None self.Y= None yers = [] def add_conv_layer(self,n_filter,n_c , f, stride=1, pad=0): ''' 添加一层卷积层 Arguments: n_c -- 输入数据通道数,也即卷积层的通道数 n_filter -- 滤波器的个数 f --滤波器的长/宽Return : Conv -- 卷积层''' # 初始化W,b W = np.random.randn(n_filter, n_c, f, f)*0.01 fb = np.zeros((1, n_filter)) # 卷积层Conv = Convolution(W, fb, stride=stride, pad=pad) return Conv def add_maxpool_layer(self, pool_shape, stride=1, pad=0): ''' 添加一层池化层Arguments: pool_shape -- 滤波器的shape f -- 滤波器大小 Return : Pool -- 初始化的Pool类 ''' pool_h, pool_w = pool_shape pool = Pooling(pool_h, pool_w, stride=stride, pad=pad) return pool def add_affine(self,n_x, n_units): ''' 添加一层全连接层 Arguments: n_x -- 输入个数 n_units -- 神经元个数Return : fc_layer -- Affine层对象''' W= np.random.randn(n_x, n_units)*0.01 b = np.zeros((1, n_units)) fc_layer = Affine(W,b) return fc_layer def add_relu(self): relu_layer = Relu() return relu_layer def add_softmax(self): softmax_layer = SoftMax() return softmax_layer #计算卷积或池化后的H和W def cacl_out_hw(self,HW,f,stride = 1,pad = 0): return (HW+2*pad - f)/stride+1 def init_model(self,train_X,n_classes):''' 初始化一个卷积层网络''' N,C,H,W = train_X.shape #卷积层n_filter = 4 f = 7 conv_layer = self.add_conv_layer(n_filter= n_filter,n_c=C,f=f,stride=1) out_h = self.cacl_out_hw(H,f) out_w = self.cacl_out_hw(W,f) out_ch = n_filter yers.append(conv_layer) #Relu relu_layer = self.add_relu() yers.append(relu_layer) #池化 f = 2 pool_layer = self.add_maxpool_layer(pool_shape=(f,f),stride=2) out_h = self.cacl_out_hw(out_h,f,stride=2) out_w = self.cacl_out_hw(out_w,f,stride=2) #out_ch 不改变yers.append(pool_layer) #Affine层n_x = int(out_h*out_w*out_ch) n_units = 32 fc_layer = self.add_affine(n_x=n_x,n_units=n_units)yers.append(fc_layer) #Relu relu_layer = self.add_relu() yers.append(relu_layer) #Affine fc_layer = self.add_affine(n_x=n_units,n_units=n_classes)yers.append(fc_layer) #SoftMax softmax_layer = self.add_softmax() yers.append(softmax_layer) def forward_progation(self,train_X, print_out = False): ''' 前向传播Arguments: train_X -- 训练数据 f -- 滤波器大小 Return : Z-- 前向传播的结果 loss -- 损失值 ''' N,C,H,W = train_X.shape index = 0 # 卷积层conv_layer = yers[index] X = conv_layer.forward(train_X) index =index+1 if print_out: print('卷积之后:'+str(X.shape)) # Relu relu_layer = yers[index] index =index+1 X = relu_layer.forward(X) if print_out: print('Relu:'+str(X.shape)) # 池化层pool_layer = yers[index] index =index+1 X = pool_layer.forward(X) if print_out: print('池化:'+str(X.shape)) #Affine层fc_layer = yers[index] index =index+1 X = fc_layer.forward(X) if print_out: print('Affline 层的X:'+str(X.shape)) #Relu relu_layer = yers[index] index =index+1 X = relu_layer.forward(X) if print_out: print('Relu 层的X:'+str(X.shape)) #Affine层fc_layer = yers[index] index =index+1 X = fc_layer.forward(X) if print_out: print('Affline 层的X:'+str(X.shape)) #SoftMax层 sofmax_layer = yers[index] index =index+1 A = sofmax_layer.forward(X) if print_out: print('Softmax 层的X:'+str(A.shape)) return A def back_progation(self,train_y,learning_rate): ''' 反向传播 Arguments: ''' index = len(yers)-1 sofmax_layer = yers[index] index -= 1 dz = sofmax_layer.backward(train_y) fc_layer = yers[index] dz = fc_layer.backward(dz,learning_rate=learning_rate) index -= 1 relu_layer = yers[index] dz = relu_layer.backward(dz) index -= 1 fc_layer = yers[index] dz = fc_layer.backward(dz,learning_rate=learning_rate) index -= 1 pool_layer = yers[index] dz = pool_layer.backward(dz) index -= 1 relu_layer = yers[index] dz = relu_layer.backward(dz) index -= 1 conv_layer = yers[index] conv_layer.backward(dz,learning_rate=learning_rate) index -= 1 def get_minibatch(self,batch_data,minibatch_size,num): m_examples = batch_data.shape[0] minibatches = math.ceil( m_examples / minibatch_size) if(num < minibatches): return batch_data[num*minibatch_size:(num+1)*minibatch_size] else: return batch_data[num*minibatch_size:m_examples] def optimize(self,train_X,train_y,minibatch_size,learning_rate=0.05,num_iters=500): ''' 优化方法Arguments: train_X -- 训练数据train_y -- 训练数据的标签learning_rate -- 学习率 num_iters -- 迭代次数 minibatch_size ''' m = train_X.shape[0] num_batches = math.ceil(m / minibatch_size) costs = [] for iteration in range(num_iters): iter_cost = 0 for batch_num in range(num_batches): minibatch_X = self.get_minibatch(train_X,minibatch_size,batch_num)minibatch_y = self.get_minibatch(train_y,minibatch_size,batch_num) # 前向传播A = self.forward_progation(minibatch_X,print_out=False) #损失: cost = compute_cost (A,minibatch_y) #反向传播self.back_progation(minibatch_y,learning_rate) if(iteration%100 == 0): iter_cost += cost/num_batches if(iteration%100 == 0): print('After %d iters ,cost is :%g' %(iteration,iter_cost)) costs.append(iter_cost) #画出损失函数图plt.plot(costs) plt.xlabel('iterations/hundreds') plt.ylabel('costs') plt.show() def predicate(self, train_X): ''' 预测''' logits = self.forward_progation(train_X) one_hot = np.zeros_like(logits) one_hot[range(train_X.shape[0]),np.argmax(logits,axis=1)] = 1 return one_hot def fit(self,train_X, train_y): ''' 训练''' self.X = train_X self.Y = train_y n_y = train_y.shape[1] m = train_X.shape[0] #初始化模型self.init_model(train_X,n_classes=n_y) self.optimize(train_X,train_y,minibatch_size=10,learning_rate=0.05,num_iters=800) logits = self.predicate(train_X) accuracy = np.sum(np.argmax(logits,axis=1) == np.argmax(train_y,axis=1))/m print('训练集的准确率为:%g' %(accuracy))convNet = SimpleConvNet()#拿20张先做实验train_X = X_train[0:10]train_y = y_train[0:10]convNet.fit(train_X,train_y) After 0 iters ,cost is :23.0254After 100 iters ,cost is :14.5255After 200 iters ,cost is :6.01782After 300 iters ,cost is :5.71148After 400 iters ,cost is :5.63212After 500 iters ,cost is :5.45006After 600 iters ,cost is :5.05849After 700 iters ,cost is :4.29723output_32_1.png训练集的准确率为:0.9预测logits = convNet.predicate(X_train[0:10])m = 10accuracy = np.sum(np.argmax(logits,axis=1) == np.argmax(y_train[0:10],axis=1))/mprint('训练的准确率为:%g' %(accuracy))训练的准确率为:0.9index = 0plt.imshow(X_train[index].reshape((28,28)),cmap = plt.cm.gray)print('y is:'+str(np.argmax(y_train[index])))print('your predicate result is :'+str(np.argmax(logits[index])))y is:5your predicate result is :5output_35_1.pnglogits = convNet.predicate(X_test)m = X_test.shape[0]accuracy = np.sum(np.argmax(logits,axis=1) ==np.argmax(y_test,axis=1))/mprint('测试的准确率为:%g' %(accuracy))测试的准确率为:0.1031因为训练的数据只有10个,所以测试的准确率只有0.1。
cnn流程

cnn流程
深度学习中卷积神经网络(Convolutional Neural Network,简
称CNN)是一种流行的深度学习模型,用于图像分类和识别。
CNN被用
来提取和分类图像中的不同特征,并将这些特征连接在一起以产生最
终的识别结果。
CNN的主要工作流程是:第一步是卷积操作,将输入的图像数据
转换为适合其它神经网络处理的抽象特征;其次是用池化(pooling)
去除噪声,减少映射计算量。
这最多包括两层,分别称为Subsampling 和Pooling;第三步则是把这些抽象特征用于全链接卷积神经网络(FCN);最后进入分类器,进行识别操作。
具体地说,CNN由输入层、卷积层、池化层、多层感知机和输出
层构成。
输入层与原输入图像数据一致;卷积层进行卷积并提取特征;池化层则会在保留重要特征的同时减少数据量;多层感知机(MLP)对
抽象特征进行分类;最后,输出层将分类结果反馈给用户。
综上,CNN的主要工作流程是:采用卷积操作提取图像数据的特征,通过池化去除噪声;使用全链接卷积神经网络(FCN)分析抽象特征;将抽象特征输入到多层感知机中进行分类;最后,将分类结果反
馈给用户。
CNN是目前用于图像分类和识别的有效技术,由于其效率高、预测正确率高、能够处理大量的特征,所以被广泛应用于自动驾驶、
医学图像处理和视觉机器人等领域。
一文看懂卷积神经网络-CNN(基本原理独特价值实际应用)

⼀⽂看懂卷积神经⽹络-CNN(基本原理独特价值实际应⽤)卷积神经⽹络 – CNN 最擅长的就是图⽚的处理。
它受到⼈类视觉神经系统的启发。
CNN 有2⼤特点:能够有效的将⼤数据量的图⽚降维成⼩数据量能够有效的保留图⽚特征,符合图⽚处理的原则⽬前 CNN 已经得到了⼴泛的应⽤,⽐如:⼈脸识别、⾃动驾驶、美图秀秀、安防等很多领域。
CNN 解决了什么问题?在 CNN 出现之前,图像对于⼈⼯智能来说是⼀个难题,有2个原因:图像需要处理的数据量太⼤,导致成本很⾼,效率很低图像在数字化的过程中很难保留原有的特征,导致图像处理的准确率不⾼下⾯就详细说明⼀下这2个问题:需要处理的数据量太⼤图像是由像素构成的,每个像素⼜是由颜⾊构成的。
现在随随便便⼀张图⽚都是 1000×1000 像素以上的,每个像素都有RGB 3个参数来表⽰颜⾊信息。
假如我们处理⼀张 1000×1000 像素的图⽚,我们就需要处理3百万个参数!1000×1000×3=3,000,000这么⼤量的数据处理起来是⾮常消耗资源的,⽽且这只是⼀张不算太⼤的图⽚!卷积神经⽹络 – CNN 解决的第⼀个问题就是「将复杂问题简化」,把⼤量参数降维成少量参数,再做处理。
更重要的是:我们在⼤部分场景下,降维并不会影响结果。
⽐如1000像素的图⽚缩⼩成200像素,并不影响⾁眼认出来图⽚中是⼀只猫还是⼀只狗,机器也是如此。
保留图像特征图⽚数字化的传统⽅式我们简化⼀下,就类似下图的过程:图像简单数字化⽆法保留图像特征图像的内容假如有圆形是1,没有圆形是0,那么圆形的位置不同就会产⽣完全不同的数据表达。
但是从视觉的⾓度来看,图像的内容(本质)并没有发⽣变化,只是位置发⽣了变化。
(本质)并没有发⽣变化,只是位置发⽣了变化所以当我们移动图像中的物体,⽤传统的⽅式的得出来的参数会差异很⼤!这是不符合图像处理的要求的。
⽽ CNN 解决了这个问题,他⽤类似视觉的⽅式保留了图像的特征,当图像做翻转,旋转或者变换位置时,它也能有效的识别出来是类似的图像。
卷积神经网络(CNN)介绍

卷积神经网络(CNN)介绍一、基本概念CNN是卷积神经网络(Convolutional Neural Network)的缩写,是目前深度学习中应用广泛的一种神经网络型号,它是一种能够处理序列数据的深度学习模型,如语音识别、自然语言处理等在许多应用中被广泛使用。
CNN是一种前馈神经网络,每个神经元只与与其之前一段距离之内的神经元相连。
它具有强大的特征提取能力和权值共享机制,可以帮助识别出图像、音频和文本中的重要特征。
CNN将输入图像分成若干个子区域,每个子区域被称为卷积核,每个卷积核由若干个神经元组成。
每个卷积核得出一个特征图,这些特征图被拼接起来形成下一层的输入。
CNN在应用中通常包含卷积层、池化层、全连接层和Softmax 层等。
卷积层用于提取图像特征,池化层用于减少特征数量,全连接层用于分类,Softmax层用于输出最终分类结果。
然而,就像其他的技术一样,CNN在实践中也会遇到各种问题。
人工智能工程师在设计和调试CNN时,经常遇到的问题包括过拟合、欠拟合、梯度消失、训练速度慢等。
此外,当CNN 不起作用时,如何快速而准确地诊断相关问题也是一个极其重要的挑战。
二、故障分析与解决方案面对CNN故障,我们可以通过以下几个方面来进行诊断,并尝试找到解决方案。
1. 数据集问题CNN模型需要大量的数据才能训练出准确的模型。
如果训练集不够大,其结果可能会出现不准确的情况。
同时,过拟合也可能出现在训练集数据少,但是特征比较多时。
解决方案:增加训练集,尽可能丰富数据覆盖的范围。
此外,有效的数据预处理方法,如旋转、翻转、缩放等,也能有效地增加训练集的样本。
2. 设计问题CNN模型的设计非常重要,关系到CNN在应用中的准确性。
解决方案:对于CNN的设计,可以采用预训练模型,或选择较好的网络结构和优化算法。
3. 训练问题CNN模型需要进行“拟合”和“调整”,使其能够正确的分类图像。
解决方案:可以尝试增加训练次数或者采用其他的优化方法,如随机梯度下降(SGD)。
一文带你了解CNN(卷积神经网络)

⼀⽂带你了解CNN(卷积神经⽹络)⽬录前⾔⼀、CNN解决了什么问题?⼆、CNN⽹络的结构2.1 卷积层 - 提取特征卷积运算权重共享稀疏连接总结:标准的卷积操作卷积的意义1x1卷积的重⼤意义2.2 激活函数2.3 池化层(下采样) - 数据降维,避免过拟合2.4 全连接层 - 分类,输出结果三、Pytorch实现LeNet⽹络3.1 模型定义3.2 模型训练(使⽤GPU训练)3.3 训练和评估模型前⾔ 在学计算机视觉的这段时间⾥整理了不少的笔记,想着就把这些笔记再重新整理出来,然后写成Blog和⼤家⼀起分享。
⽬前的计划如下(以下⽹络全部使⽤Pytorch搭建):专题⼀:计算机视觉基础介绍CNN⽹络(计算机视觉的基础)浅谈VGG⽹络,介绍ResNet⽹络(⽹络特点是越来越深)介绍GoogLeNet⽹络(⽹络特点是越来越宽)介绍DenseNet⽹络(⼀个看似⼗分NB但是却实际上⽤得不多的⽹络)整理期间还会分享⼀些⾃⼰正在参加的⽐赛的Baseline专题⼆:GAN⽹络搭建普通的GAN⽹络卷积GAN条件GAN模式崩溃的问题及⽹络优化 以上会有相关代码实践,代码是基于Pytorch框架。
话不多说,我们先进⾏专题⼀的第⼀部分介绍,卷积神经⽹络。
⼀、CNN解决了什么问题? 在CNN出现之前,对于图像的处理⼀直都是⼀个很⼤的问题,⼀⽅⾯因为图像处理的数据量太⼤,⽐如⼀张512 x 512的灰度图,它的输⼊参数就已经达到了252144个,更别说1024x1024x3之类的彩⾊图,这也导致了它的处理成本⼗分昂贵且效率极低。
另⼀⽅⾯,图像在数字化的过程中很难保证原有的特征,这也导致了图像处理的准确率不⾼。
⽽CNN⽹络能够很好的解决以上两个问题。
对于第⼀个问题,CNN⽹络它能够很好的将复杂的问题简单化,将⼤量的参数降维成少量的参数再做处理。
也就是说,在⼤部分的场景下,我们使⽤降维不会影响结果。
⽐如在⽇常⽣活中,我们⽤⼀张1024x1024x3表⽰鸟的彩⾊图和⼀张100x100x3表⽰鸟的彩⾊图,我们基本上都能够⽤⾁眼辨别出这是⼀只鸟⽽不是⼀只狗。
卷积神经网络CNN

卷积神经网络CNN一、引言卷积神经网络(Convolutional Neural Network, CNN)是一种常用的深度学习算法,特别适合于处理图像、语音、自然语言等多维度数据。
其重要特点是局部感知和参数共享,这使得它能够快速准确地识别图像特征,并在不同的任务和场景中取得良好的表现。
本文主要介绍卷积神经网络的基本结构、原理和应用。
二、卷积神经网络结构卷积神经网络的基本结构包括输入层、卷积层、池化层、全连接层和输出层等部分。
其中,输入层用来接收原始图像或数据,卷积层和池化层用来提取图像特征,全连接层用来进行分类和回归等任务,输出层则表示最终的输出结果。
下面详细介绍每个部分的作用和特点。
1. 输入层输入层是卷积神经网络的第一层,主要用来接收原始图像或数据。
通常情况下,输入层的数据是二维图像,即图像的宽度、高度和颜色通道。
例如,一张彩色图片的宽度和高度都是像素的数量,而颜色通道就是RGB三个通道。
2. 卷积层卷积层是卷积神经网络的核心层,负责提取图像特征。
它主要通过卷积运算的方式,对输入层的数据进行处理,产生新的特征图。
卷积操作的核心思想是权重共享,即同一个卷积核在不同的位置上进行卷积操作,得到的特征图是一样的,这样能够大大减少网络参数量,防止过拟合现象出现。
卷积操作的数学表达式如下:$$Y = W*X + b$$其中,$W$是卷积核,$X$是输入特征图,$b$是偏置项,$Y$是输出特征图。
在卷积操作中,卷积核的参数是需要学习的参数,它的大小通常为$K*K$($K$是卷积核的大小),步幅通常为$S$。
卷积操作的结果是一个二维数组,它被称为输出特征图。
在实际应用中,卷积核的大小和步幅需要根据不同的数据类型和任务而定。
3. 池化层池化层是卷积神经网络的一个可选层,主要用来减少特征图的大小和数量,从而提高网络性能。
它通常有两种类型:最大池化和平均池化。
最大池化是取一个特征图中的最大值作为输出,而平均池化是取一个特征图中的平均值作为输出。
计算机视觉CNN原理解析

计算机视觉CNN原理解析计算机视觉(Computer Vision)是指计算机通过对图像或视频的处理和分析,模拟人类的视觉系统,从而实现对视觉信息的理解和识别。
近年来,深度学习技术在计算机视觉领域取得了重大突破,其中卷积神经网络(Convolutional Neural Network,CNN)成为了计算机视觉中应用最广泛的深度学习算法之一。
一、CNN的基本结构CNN是一种层级化的网络结构,它由若干层组成,每一层都由多个卷积核组成。
卷积核可以看作是一个滤波器,用于提取输入图像的特征。
每个卷积核通过滑动窗口的方式对输入图像进行卷积运算,并生成一张特征图。
多个卷积核的组合可以提取多种特征,并用于不同的任务,如图像分类、目标检测等。
二、CNN的工作原理CNN的工作原理可以分为两个阶段:前向传播和反向传播。
1. 前向传播在前向传播过程中,CNN从输入层开始逐层进行处理,直到输出层。
每一层都会对输入进行卷积运算,并经过激活函数的处理,将激活后的特征图传递到下一层。
同时,CNN会利用池化操作对特征图进行降采样,以减少参数数量并增强网络的鲁棒性。
2. 反向传播反向传播是指从输出层开始,逆序计算各层的梯度,并利用梯度下降算法来更新网络的参数。
通过不断地反向传播和参数更新,CNN可以逐渐优化网络的权重和偏置,从而提高对输入图像的分类、识别准确率。
三、CNN的优势与应用相比于传统的机器学习算法,CNN在处理图像方面具有明显的优势。
首先,CNN能够自动学习图像特征,无需手工设计特征。
其次,CNN可以处理具有平移、旋转和缩放等不变性的图像,并具有较强的鲁棒性和泛化能力。
此外,基于CNN的深度学习模型还能够进行迁移学习,将已学习的知识应用于新的任务,进一步提升性能。
基于CNN的计算机视觉技术在实际应用中有广泛的应用。
例如,在图像分类中,CNN可以对图像进行正确分类,如将某一图像识别为猫、狗或车辆等。
在目标检测中,CNN可以定位图像中的目标位置,并进行分类。
CNN图像分类简介

由于手动标注数据需要大量时间和人力,有时会出现标注 错误或遗漏的情况,这会影响模型的训练效果和准确性。
模型泛化能力
过拟合与欠拟合
在训练过程中,如果模型过于复杂或训练数据不足,可能会导致过拟合或欠拟合现象。过拟合是指模型在训练数据上 表现很好,但在测试数据上表现较差;欠拟合则是指模型在训练数据和测试数据上的表现都不够理想。
CNN图像分类的重要性
随着大数据时代的到来,图像数据在 各个领域的应用越来越广泛,如医疗 影像分析、安全监控、智能交通等。
CNN图像分类技术能够快速、准确地 处理海量图像数据,提高图像分类的 准确性和效率,对推动人工智能技术 的发展和实际应用具有重要意义。
02
CNN基础知识
CNN基本结构
Convolutional Layer(卷积层):卷积层是CNN的核心部分,用于从输入图像中提取特征。 它通过在输入图像上滑动过滤器并执行卷积运算来工作,每个过滤器都学习检测一种特定的 特征,如边缘、纹理等。
CNN,可以学习到如何将一种风格的特征映射到另一种风格的特征上。
05
CNN图像分类面临的挑战
数据不平衡问题
类别不平衡
在图像分类任务中,各类别的样本数量可能存在显著差异,导致模型在训练时 容易对数量较多的类别产生过拟合,而对数量较少的类别识别能力较弱。
训练与测试数据不平衡
训练数据和测试数据中的类别分布可能不一致,这可能导致模型在测 试时的表现不佳,因为模型没有充分学习到所有类别的特征。
CNN图像分类简介
• 引言 • CNN基础知识 • CNN图像分类原理 • CNN图像分类应用 • CNN图像分类面临的挑战 • CNN图像分类未来展望
01
引言
CNN(卷积神经网络)详解

CNN(卷积神经网络)详解卷积神经网络(Convolutional Neural Network,CNN)是一种前馈神经网络,用于处理具有类似网格结构的数据。
这种网络结构在计算机视觉领域中应用非常广泛,包括图像识别、语音识别等领域。
CNN采用卷积层、池化层和全连接层等多种不同的层来提取特征。
一、卷积层卷积层是CNN的核心,也是最基本的层,它可以检测不同的特征,比如边缘、颜色和纹理等。
通常情况下,卷积层的输入是一个彩色或者灰度的图像,输出则是不同数量的“特征图”。
每个特征图对应一个特定的特征。
卷积层有一个非常重要的参数,叫做卷积核(Kernel),也就是滤波器。
卷积核是一个小的矩阵,它在输入数据的二维平面上滑动,将每个位置的像素值与卷积核的对应位置上的值相乘,然后将结果相加得到卷积层的输出。
通过不同的卷积核可以检测出不同的特征。
二、池化层池化层是CNN中的另一种重要层,它可以对卷积层的输出做降维处理,并且能够保留特征信息。
池化层通常是在卷积层之后加上的,其作用是将附近几个像素点合并成一个像素点。
这样做的好处是可以减小数据量,同时也可以使特征更加鲁棒。
池化层通常有两种类型,分别是最大池化和平均池化。
最大池化是从相邻的像素中寻找最大值,即将一个矩阵划分成多个小矩阵,然后寻找每个小矩阵中的最大值,最后将每个小矩阵中的最大值组成的矩阵作为输出。
平均池化则是简单地取相邻像素的平均值作为输出。
三、全连接层全连接层,也叫做密集连接层,是CNN中的最后一层,它将池化层输出的结果转化成一个一维的向量,并将其送入神经网络中进行分类或者回归预测。
全连接层通常使用softmax或者sigmoid等激活函数来输出分类结果。
四、CNN的应用CNN在计算机视觉领域有着广泛的应用,比如图像分类、物体检测、人脸识别、文字识别等。
其中最常见的应用就是图像分类,即将一张图片分为不同的目标类别。
通过卷积层和池化层不断地提取出图像的特征,然后送进全连接层对不同的类别进行分类。
卷积神经网络(CNN,ConvNet)及其原理详解

卷积神经网络(CNN,ConvNet)及其原理详解卷积神经网络(CNN,有时被称为ConvNet)是很吸引人的。
在短时间内,它们变成了一种颠覆性的技术,打破了从文本、视频到语音等多个领域所有最先进的算法,远远超出了其最初在图像处理的应用范围。
CNN 由许多神经网络层组成。
卷积和池化这两种不同类型的层通常是交替的。
网络中每个滤波器的深度从左到右增加。
最后通常由一个或多个全连接的层组成:图1 卷积神经网络的一个例子Convnets 背后有三个关键动机:局部感受野、共享权重和池化。
让我们一起看一下。
局部感受野如果想保留图像中的空间信息,那么用像素矩阵表示每个图像是很方便的。
然后,编码局部结构的简单方法是将相邻输入神经元的子矩阵连接成属于下一层的单隐藏层神经元。
这个单隐藏层神经元代表一个局部感受野。
请注意,此操作名为“卷积”,此类网络也因此而得名。
当然,可以通过重叠的子矩阵来编码更多的信息。
例如,假设每个子矩阵的大小是5×5,并且将这些子矩阵应用到28×28 像素的MNIST 图像。
然后,就能够在下一隐藏层中生成23×23 的局部感受野。
事实上,在触及图像的边界之前,只需要滑动子矩阵23 个位置。
定义从一层到另一层的特征图。
当然,可以有多个独立从每个隐藏层学习的特征映射。
例如,可以从28×28 输入神经元开始处理MNIST 图像,然后(还是以5×5 的步幅)在下一个隐藏层中得到每个大小为23×23 的神经元的k 个特征图。
共享权重和偏置假设想要从原始像素表示中获得移除与输入图像中位置信息无关的相同特征的能力。
一个简单的直觉就是对隐藏层中的所有神经元使用相同的权重和偏置。
通过这种方式,每层将从图像中学习到独立于位置信息的潜在特征。
理解卷积的一个简单方法是考虑作用于矩阵的滑动窗函数。
在下面的例子中,给定输入矩阵I 和核K,得到卷积输出。
将3×3 核K(有时称为滤波器或特征检测器)与输入矩阵逐元素地相乘以得到输出卷积矩阵中的一个元素。
基于深度学习的手写数字识别系统设计与实现

基于深度学习的手写数字识别系统设计与实现手写数字识别是计算机视觉领域中的一个重要研究方向,它可以应用于自动化识别、数字化转换以及人机交互等领域。
本文将介绍一种基于深度学习的手写数字识别系统的设计与实现。
一、引言在数字化时代,手写数字识别系统扮演着重要角色,为了提高人工误差和效率问题,基于深度学习的手写数字识别系统应运而生。
本文将采用卷积神经网络(Convolutional Neural Network,CNN)作为深度学习模型,并通过系统设计和实现的具体方法,达到提高手写数字识别准确率和效率的目的。
二、深度学习模型1. CNN模型简介CNN是一种深度学习模型,它通过多层卷积和池化层来提取输入数据的特征,并通过全连接层进行最终的分类。
CNN的特点是可以自动学习输入数据的特征,对于图像处理任务具有很好的效果。
2. CNN模型设计手写数字识别任务可以看作是一个图像分类问题,因此我们可以使用经典的CNN模型LeNet-5作为基础模型进行设计。
LeNet-5模型包含了两个卷积层、两个池化层和三个全连接层,能够有效提取手写数字的特征并进行分类。
在设计过程中,我们可以根据实际需求进行调整和优化,例如增加卷积层深度或者全连接层神经元数量等。
三、数据集准备1. 数据集介绍在进行手写数字识别系统设计与实现之前,首先需要准备一个适用于训练和测试的手写数字数据集。
常用的数据集有MNIST、SVHN等。
本文将以MNIST数据集为例进行介绍。
MNIST数据集是一个包含60000个训练样本和10000个测试样本的手写数字数据集,每个样本都是28x28的灰度图像。
2. 数据预处理在使用MNIST数据集进行训练之前,我们需要对数据进行预处理。
预处理步骤包括数据归一化、标签编码等。
归一化可以将原始像素值缩放到0-1的范围内,以便进行更好的训练效果。
标签编码是将原始类别信息进行one-hot编码,方便进行分类模型的训练。
四、系统实现1. 环境搭建在进行系统实现之前,需要搭建相应的开发环境。
CNN评估

CNN评估CNN是一个美国媒体和新闻公司,总部位于亚特兰大。
在全球范围内拥有多个分支机构和办公室,是一家非常著名的新闻机构。
CNN在新闻报道方面扮演着重要角色,以其深度报道和可靠性而闻名。
首先,CNN在新闻报道方面非常专业。
他们拥有一支由经验丰富的记者和编辑组成的团队,这些人员经常在全球各地采访报道重要事件。
无论是国内、国际新闻还是政治、经济、体育等领域,CNN都能提供全面和深入的报道,这使得他们成为人们获取可靠信息的首选。
其次,CNN秉持独立、客观和平衡的原则。
他们对新闻报道进行严格的事实核实,确保报道的准确性和可靠性。
此外,CNN还努力确保他们的报道能够呈现多个观点和声音,以保持平衡。
这种独立和客观的报道态度使得人们对CNN的信任度很高。
此外,CNN在新闻报道中注重深度分析。
他们不仅向观众呈现事件的基本事实,还会对事件的影响和背后的原因进行深入剖析。
这种深度分析能够帮助观众更好地理解事件的背后故事,提供更具价值的信息。
此外,CNN还通过使用多种媒体形式来传播新闻。
除了传统的新闻报道和文章,他们还制作和播放视频、音频、图片等媒体内容,以适应不同受众的需求。
这种多媒体传播方式可以更好地吸引观众的注意力并提供更丰富的新闻内容。
然而,就像所有媒体一样,CNN也存在一些问题和争议。
有些人认为CNN在政治报道中存在倾向性,对某些议题有偏见。
此外,一些观众批评CNN太过重视娱乐新闻和八卦报道,而忽略了一些重要的热点事件。
总的来说,CNN是一个具有广泛影响力的新闻机构,他们在新闻报道方面表现出专业性、独立性和客观性。
他们的深度分析和多媒体传播方式使人们更好地了解和接触新闻。
虽然存在一些问题和争议,但CNN仍然是一个受人尊敬的新闻机构。
走近CNN:美国有线电视新闻网总部所见所闻

除了综合新闻报道外,CNN频道还有众多的新闻专栏。有时事分析类的,被称为News Magazine(新闻杂志),如CNN&Time,这是依托CNN和《时代》周刊的新闻源所作的时事分析、调查、评述;有专题讨论类的,被称为Interview and Debate(谈话、讨论),如Capital Gang,这是由主持人和四位嘉宾在演播室对首都大事所作的讨论。
CNN国际频道是个庞大的系。根据服务地区的不同,它要提供四套、即四个版本的节目:1.欧洲版,按柏林时间编排;2.拉丁美洲版,按布宜诺斯艾利斯时间编排;3.美国版,按亚特兰大、即美国东部时间编排;4.亚太地区版,按十三个国家和地区分别编排,这十三个国家和地区分别是:澳大利亚、香港、印度、印度尼西亚、日本、朝鲜、马来西亚、新西兰、巴基斯坦、菲律宾、新加坡、台湾、泰国。CNN在上述地区普遍设立了分支机构。它的记者或特约通讯员遍布全世界,世界各处发生的任何新闻事件都会迅速及时地得到采访和报道。它租用了地球上空众多通讯卫星或广播卫星上的转发器,采集的任何信息都可以迅速及时、甚至和新闻事件进程同步传向地球各个角落。它使新闻传播完全超越了空间和时间限制。西方报刊说它做到了“让全世界能在同一时间看到同样的新闻”,而CNN则宣称自己是“一家预告时代风云的公司”。目前它在全世界的观众已超过一亿。
卷积神经网络CNN

卷积神经网络(CNN)一、简介卷积神经网络(Convolutional Neural Networks,简称CNN)是近年发展起来,并引起广泛重视的一种高效的识别方法。
1962年,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的局部互连网络结构可以有效地降低反馈神经网络的复杂性,继而提出了卷积神经网络[1](Convolutional Neural Networks-简称CNN)7863。
现在,CNN已经成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了更为广泛的应用。
Fukushima在1980年基于神经元间的局部连通性和图像的层次组织转换,为解决模式识别问题,提出的新识别机(Neocognitron)是卷积神经网络的第一个实现网络[2]。
他指出,当在不同位置应用具有相同参数的神经元作为前一层的patches时,能够实现平移不变性1296。
随着1986年BP算法以及T-C问题[3](即权值共享和池化)9508的提出,LeCun和其合作者遵循这一想法,使用误差梯度(the error gradient)设计和训练卷积神经网络,在一些模式识别任务中获得了最先进的性能[4][5]。
在1998年,他们建立了一个多层人工神经网络,被称为LeNet-5[5],用于手写数字分类,这是第一个正式的卷积神经网络模型3579。
类似于一般的神经网络,LeNet-5有多层,利用BP算法来训练参数。
它可以获得原始图像的有效表示,使得直接从原始像素(几乎不经过预处理)中识别视觉模式成为可能。
然而,由于当时大型训练数据和计算能力的缺乏,使得LeNet-5在面对更复杂的问题时,如大规模图像和视频分类,不能表现出良好的性能。
因此,在接下来近十年的时间里,卷积神经网络的相关研究趋于停滞,原因有两个:一是研究人员意识到多层神经网络在进行BP训练时的计算量极其之大,当时的硬件计算能力完全不可能实现;二是包括SVM在内的浅层机器学习算法也渐渐开始暂露头脚。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
输入: 6*6 超参数: 池化过滤器尺寸:3*3 步长:3 输出: 2*2
0
0
0
10
10
10
重叠池化:有重合
10 10 10 0 0 10 10 10 0 0 10 10 10 0 0 0 0 0 10 10 0 0 0 10 10 0 0 0 10 10
输入: 6*6 超参数: 池化过滤器尺寸:3*3 步长:3 输出: 4*4
Softmax
yc ( z ) c c 1 c
1.多分类 2.正则项
e
c d 1
zc zd
e
Maxout
hi ( x) max zij
j[1, k ]
zij x Wij bij
T
out = max(z z1 = w1x + b1 z 2 = w 2 x + b 2 1 , z 2 , z3 , z 4 , z5 ) z 3 = w 3 x + b3 z 4 = w 4 x + b 4 z 5 = w 5 x + b5
55*55*96 3*3*96 27*27*96 11*11*3 5*5*96 27*27*256 3*3*25613*13*256 步长为2 步长为4 步长为1 步长为2 96个滤波器 96个滤波器 256个滤波器 256个滤波器
CONV3
(22711)/4+1=55
CONV4
16.4%
(55-3)/2+1=27 (27-5+2*2)/1+1=27
均值池化
10 10 10 0 0 10 10 10 0 0 10 10 10 0 0 0 0 0 10 10 0 0 0 10 10 0 0 0 10 10
10
6.67 3.34 0
6.67
5.56 4.44 3.34
3.34
5.56 6.67
0
3.34 6.67 10
0
0
0
10
10
10
0
0
0
10
10
10
空间金字塔池化(SPP)
一般池化和重叠池化在都要 求输入图片尺寸固定情况下 设置参数,一旦输入改变就 需要重新设置超参数 空间金字塔池化,使得任意大小的特征图都能 够转换成固定大小的特征向量 任意图片经过上图的SPP,都会变成21维特征 如果你希望输出n*n个特征 池化的windows size:(w/n,h/n)
卷积神经网络(CNN)
Convolutional Neural Network
1
2
基础知识 Basics
卷积神经网络 Convolutional Neural Network
3
应用和实例 Application and examples
1
基础知识
发展情况
无法解决异或问题
SVM的兴起
硬件性能,大数据
=
6*6*64
池化层设置(无参数)
输入: W1*H1*D1 超参数:卷积核大小F,深度为D1 步长S 池化方式:最大池化,均值池化 固定参数:卷积核个数K=D1 填充P=0 输出:W2=(W1-F)/S+1(下取整) H2=(H1-F)/S+1(下取整) D2=K
提示: 卷积层3*3过滤器 会有9个参数需 要学习,但是池 化层3*3过滤器没 有参数需要学习
224*224*3 224*224*64
POOL1 LAYER2
RELU
112*112*64
7.3%
RELU
14*14*512 7*7*512
112*112*128
3*3*3 3*3*64 224*224*3 步长为1 224*224*64 步长为1 224*224*64 64个滤波器 64个滤波器 (224-3+1+2*1)/1=224 (224-3+1+2*1)/1=224
ReLU
ReLU ( x) max(0, x)
综合速率和效率,学习周期缩短 当学习率设置得太高时,网络中的 大量神经元可能会陷入死亡状态, 从而有效降低模型的容量。
Leaky ReLU
x if x 0 f ( x) 0.01x else
更快更高效 没有梯度消失或者是突变的现象
(27-3)/2+1=13
CONV5
POOL3
SOFTMAX
* =
RELU
* =
RELU
* = RELU * = =
激 全 全 RELU 活 连 连 输 接 接 RELU 出
3*3*256 13*13*384 3*3*384 13*13*384 3*3*384 13*13*256 3*3*256 6*6*256 9216 4096 4096 1000 步长为1 步长为2 步长为1 步长为1 FC1 FC2 256个滤波器 256个滤波器 384个滤波器 384个滤波器 (13-3+2*1)/1+1=13 (13-3+2*1)/1+1=13 (13-3+2*1)/1+1=13 (13-3)/2+1=6
卷积层
0 1 0 0 0 -1 0 1 -1 0 1 -1 0
30 30 30 30
30 30 30 30
0 0 0 0
0 -1 0
10
10
10
10
10
10
0
0
0
0
0
0
输入:5*5 卷积核:3*3 步长:2 输出:2*2
10 1 10 1 10 1 10 1 10 0 10 0 10 1 -1 10 0 10 -1 1 0 0 10 0 10 1 -1 0 0 0 -1 10 1 -1 0 0 0 -1 0 0 0 -1 0 -1
多层感知机
Sigmoid
1 f ( x) x 1 e
当输入非常大或者非常小的时候,这些 神经元的梯度是接近于0。大部分神经元 可能都会处在饱和状态,导致网络学习 率下降。
sigmoid的输出不是零均值的
tanh
e e tanh( x) x x e e
x x
tanh函数的输出是零均值的
池化层
池化方法: 按处理方式: 1.一般池化 2.重叠池化 3.空间金字塔池化(SSP) 按计算方式: 1.均值池化 2.最大池化 3.滑动平均池化 4.L2范数池化
一般池化:不重合
10 10 10 0 0 10 10 10 0 0 10 10 10 0 0 0 0 0 10 10 0 0 0 10 10 0 0 0 10 10
小结
LeNet-5,AlexNet,ZFNet: 超参数很多,卷积核设计复杂 改进: 统一卷积核规范化网络 趋势: 卷积核小型化并且统一设计卷积核和池化
3*3,步长为1,same 最大池化,2*2,步长为2
AGG-16
POOL2 LAYER3 POOL3
RELU
56*56*128
LAYER1
RELU
池化层
常用池化过滤器参数: 1.卷积核大小F=2 步长S=2 2.卷积核大小F=3 步长S=2
全连接层
上一层N-I(m节点) 全连接层N(n节点) 参数:m*n+n个
3
应用和实例
LeNet-5
LAYER1 CONV1 POOL1
LAYER2 POOL2 CONV2
32*32*3
2*2*6 5*5*3 5*5*6 2*2*16 1*1*400 28*28*6 14*14*6 10*10*16 5*5*16 步长为 2 步长为1 步长为1 步长为2 6个滤波器 16个滤波器 6个滤波器 16个滤波器 (32-5)/1+1=28 (28-2)/2+1=14 (14-5)/1+1=10 (10-2)/2+1=5 5*5*16=400
* =
* =
25.8%
* =
* =
=
1*1*400
激 全 全 活 连 连 输 接1*1*120 接 1*1*84 出 1*1*10 FC3 FC4 SOFTMAX
AlexNet
CONV1 POOL1 CONV2 POOL2
* =
227*227*3
RELU
* =
不用 LRN
* =
RELU
* =
不用 LRN
CONV5
POOL3
* =
RELU
* =
RELU
* = RELU * = =
全 全 激 RELU 连 连 活 输 接 接 出 RELU
SOFTMAX
13*13*384 3*3*384 13*13*384 3*3*384 13*13*256 3*3*256 6*6*256 9216 4096 4096 1000 3*3*256 步长为2 步长为1 步长为1 步长为1 FC1 FC2 256个滤波器 384个滤波器 384个滤波器 256个滤波器 (13-3+2*1)/1+1=13 (13-3+2*1)/1+1=13 (13-3+2*1)/1+1=13 (13-3)/2+1=6
2
卷积神经网络
1
2
卷积层
池化层
3
全连接
卷积层参数
输入: W1*H1*D1 超参数:卷积核个数K 卷积核大小F,深度为D1 步长S 填充P 输出:W2=(W1-F+2P)/S+1(下取整) H2=(H1-F+2P)/S+1(下取整) D2=K
输入:6*6 卷积核:3*3 步长:1 输出:4*4
更多激活函数
梯度下降
反向传播-算法改进
随机梯度下降法:需要我们人为的去选择参数 比如学习率、参数初始化 权重衰减系数、Drop out 改进:BN网络(Batch Normalization) 1.白化预处理 2.变换重构 网络可以学习恢复出原始网络所要学习 的特征分布