用python玩转数据-实验2
python实验总结与体会

Python实验总结与体会引言在学习过程中,我们学习了许多关于P yth o n编程语言的知识。
为了更好地巩固所学内容并加深对P yt hon的理解,我们进行了一系列的实验。
通过实验,我们不仅熟悉了P yt ho n的语法和特性,还学会了如何运用P y th on解决实际问题。
本文将对我进行的P yt ho n实验进行总结,并分享我在实验过程中的一些心得和体会。
实验一:Pyth on基础语法实验在第一次实验中,我们主要学习了Py th on的基础语法。
包括变量、数据类型、运算符、条件语句、循环语句等。
1.1变量在P yt ho n中,可以用变量来存储数据。
变量的命名要符合一定的规则,例如变量名不能以数字开头,不能包含空格等。
在实验中,我学会了如何声明变量,并对变量赋值。
1.2数据类型P y th on支持多种数据类型,包括整型、浮点型、字符串、列表、元组、字典等。
在实验中,我学习了如何使用这些数据类型,并了解了它们各自的特点和用途。
1.3运算符P y th on提供了丰富的运算符,包括算术运算符、比较运算符、逻辑运算符等。
在实验中,我学会了如何使用这些运算符来进行各种运算操作。
1.4条件语句条件语句是编程中常用的一种结构,可以根据某个条件的成立与否来执行不同的代码块。
在实验中,我学会了使用if-e ls e语句和i f-e l if-e ls e语句来实现条件判断。
1.5循环语句循环语句可以重复执行某段代码,直到满足特定条件为止。
Py t ho n提供了两种循环结构,即f or循环和w hi le循环。
在实验中,我学会了如何使用这两种循环结构,并能够灵活地应用于不同的场景。
实验二:Pyth on函数实验在第二次实验中,我们学习了Py th on的函数。
函数是一段可重用的代码块,可以接受参数并返回结果。
2.1函数的定义与调用在实验中,我学会了如何定义函数,并通过调用函数来执行其中的代码。
函数的定义需要指定函数名、参数列表和函数体。
使用Python进行大数据分析和处理

使用Python进行大数据分析和处理一、引言随着大数据时代的到来,数据分析和处理技术愈发重要。
Python作为一种简单易学、功能强大的编程语言,被广泛应用于数据科学领域。
本文将介绍如何使用Python进行大数据分析和处理,并分为以下几个部分:数据获取、数据清洗、数据分析、数据可视化和模型建立。
二、数据获取在进行大数据分析和处理之前,我们需要从各种数据源中获取数据。
Python提供了丰富的库和工具,可以轻松地从数据库、API、Web页面以及本地文件中获取数据。
比如,我们可以使用pandas库中的read_sql()函数从数据库中读取数据,使用requests库从API获取数据,使用beautifulsoup库从Web页面获取数据,使用csv库从本地CSV文件中获取数据。
三、数据清洗获取到原始数据之后,通常需要进行数据清洗。
数据清洗是指对数据进行预处理,包括处理缺失值、处理异常值、处理重复值、数据格式转换等。
Python提供了丰富的库和函数来帮助我们进行数据清洗,如pandas库中的dropna()函数用于处理缺失值,使用numpy库中的where()函数用于处理异常值,使用pandas库中的duplicated()函数用于处理重复值。
四、数据分析数据分析是大数据处理的核心环节之一。
Python提供了强大的库和工具来进行数据分析,如pandas库和numpy库。
使用这些库,我们可以进行数据聚合、数据筛选、数据排序、数据计算等。
例如,我们可以使用pandas库中的groupby()函数进行数据聚合,使用pandas库中的query()函数进行数据筛选,使用pandas库中的sort_values()函数进行数据排序,使用numpy库中的mean()函数进行数据计算。
五、数据可视化数据可视化是将数据以图形化的方式展现出来,帮助我们更好地理解数据的分布和趋势。
Python提供了多种库和工具来进行数据可视化,如matplotlib库和seaborn库。
python数字实验报告

python数字实验报告Python数字实验报告引言:Python是一种功能强大的编程语言,它提供了丰富的数字处理功能。
本文将通过一系列实验,探索Python中数字的特性和应用。
我们将介绍数字的基本操作、数值类型转换、数学函数、随机数生成以及数据可视化等方面的内容。
一、数字的基本操作Python中的数字类型包括整数(int)、浮点数(float)和复数(complex)。
我们可以使用基本运算符(如加减乘除)对数字进行操作,并通过变量来存储和使用数字。
Python还提供了丰富的数学函数库,如math模块,可以进行更复杂的数值计算。
二、数值类型转换在实际应用中,我们常常需要将数字从一种类型转换为另一种类型。
Python提供了一些内置函数,如int()、float()和complex(),可以实现不同数值类型之间的转换。
我们可以利用这些函数来处理数据类型不一致的情况,确保数值计算的准确性。
三、数学函数的应用数学函数是Python中的重要工具,它们可以帮助我们解决各种实际问题。
例如,我们可以使用math模块中的函数计算三角函数、指数函数、对数函数等。
这些函数可以在科学计算、数据分析、图像处理等领域发挥重要作用。
四、随机数生成随机数在计算机科学和统计学中有着广泛的应用。
Python中的random模块提供了生成随机数的函数。
我们可以通过random模块生成伪随机数序列,并利用这些随机数进行模拟实验、随机抽样等操作。
同时,我们还可以设置随机数的种子,以确保实验的可重复性。
五、数据可视化数据可视化是数据分析中的重要环节。
Python中的matplotlib库可以帮助我们生成各种图表,如折线图、散点图、柱状图等。
通过可视化手段,我们可以更直观地分析和展示数据,从而得到更深入的洞察。
结论:通过本次实验,我们深入了解了Python中数字的特性和应用。
我们学习了数字的基本操作、数值类型转换、数学函数、随机数生成以及数据可视化等方面的知识。
Python在数据分析中的应用实例

Python在数据分析中的应用实例一、Python在数据分析中的应用概述Python作为一个多功能语言,已成为数据科学领域中最流行的工具之一,因为它既具有高效的数据处理能力,又有可靠的可视化功能。
在这里,我们将探讨Python在数据分析中的应用实例,为读者带来更多有益的知识。
二、数据提取进行数据分析的第一步是获取数据。
Python提供了一些内置库和第三方库,可以帮助我们从各种数据源中提取数据。
1. CSV和Excel文件Python的库pandas可以实现读取和写入CSV和Excel文件的操作。
使用pandas读取这些文件,可以让数据的处理速度更快,也可以让我们更容易地进行数据转换和过滤操作。
2. Web APIsWeb APIs可以用来从各种在线资源获取数据。
Python提供了多个库,可用于访问API,如:Requests,beautifulsoup4以及Python 内置的urllib库。
三、数据清理和处理在收集数据后,需要进行数据清理和处理。
Python能够帮助我们完成许多这样的任务。
1. 数据清理不幸的是,数据通常包含各种缺陷,例如缺少值,错误的格式,重复的值等。
Python的pandas库提供了几种方法来清除这些问题。
使用dropna和fillna可删除或填充缺失值。
使用drop_duplicates可删除重复值。
2. 数据转换使用Python可以更轻松地进行数据转换,包括数据类型转换,重命名列和替换值。
使用pandas库中的方法可轻松处理这些问题。
四、数据分析和可视化完成数据清理和处理后,我们可以开展数据分析和可视化。
Python提供了一些工具,可以让我们对数据进行更深入的探索和可视化。
1. 二维可视化使用Python的matplotlib库,我们可以进行二维可视化。
这意味着我们可以创建各种图表,如直方图,折线图,散点图等来帮助我们更深入地研究我们所收集的数据。
2. 三维可视化对于更复杂的数据,如三维图像,Python的Vispy库是一个很好的选择。
Python玩转股票数据以及简单交易策略

Python 玩转股票数据以及简单交易策略前面的文档《Python获取股票历史数据并分析》详细说明如何获取股票数据,并进行了简单的分布分析。
今天我们将详细讲解如何玩转历史数据,基础数据来源于《Python获取股票历史数据并分析》。
为了取数和查询方便,我把所有的历史交易数据放在了sqlite3数据库文件中,这也是python自带的数据库,操作很方便。
当然你也可以把数据放在其他数据库中。
本文将使用Python来可视化股票数据,比如绘制K线图,并且探究各项指标的含义和关系,最后使用移动平均线方法初探投资策略。
下面开始玩转数据,数据导入为了数据的存储和读取方便,我们预先把历史数据存在路径为'E:\myprog\TestData.db的sqlite文件中。
要分析先从这个数据文件中读取。
我们把股票编码为600866的2017-02-01至2017-06-01的交易数据读取到stdata中。
以上显示了前9行数据,要得到数据的更多信息,可以使用.info()方法。
它告诉我们该数据一共有72行,索引是时间格式,日期从2017-02-01至2017-06-01。
总共有16列,并列出了每一列的名称和数据格式,并且没有缺失值。
除了index,code是object类型外,其他的都是float型。
我们可以将index转化为datetime类型stdata.index= pd.to_datetime(stdata.index) 变化后如下:至此,我们完成了股票数据的导入和清洗工作,接下来将使用可视化的方法来观察这些数据。
数据观察首先,我们观察数据的列名,其含义对应如下:这些指标总体可分为两类:●价格相关指标⏹当日价格:开盘、收盘价,最高、最低价⏹价格变化:价格变动和涨跌幅⏹均价:5、10、20日均价●成交量相关指标⏹成交量⏹换手率:成交量/发行总股数×100%⏹成交量均量:5、10、20日均量由于这些指标都是随时间变化的,所以让我们先来观察它们的时间序列图。
python数据分析案例

python数据分析案例在数据分析领域,Python 凭借其强大的库和简洁的语法,成为了最受欢迎的编程语言之一。
本文将通过一个案例来展示如何使用 Python进行数据分析。
首先,我们需要安装 Python 以及一些数据分析相关的库,如 Pandas、NumPy、Matplotlib 和 Seaborn。
这些库可以帮助我们读取、处理、分析和可视化数据。
接下来,我们以一个实际的数据分析案例来展开。
假设我们有一个包含用户购物数据的 CSV 文件,我们的目标是分析用户的购买行为。
1. 数据加载与初步查看使用 Pandas 库,我们可以轻松地读取 CSV 文件中的数据。
首先,我们导入必要的库并加载数据:```pythonimport pandas as pd# 加载数据data = pd.read_csv('shopping_data.csv')```然后,我们可以使用 `head()` 方法来查看数据的前几行,以确保数据加载正确。
```pythonprint(data.head())```2. 数据清洗在数据分析之前,数据清洗是一个必不可少的步骤。
我们需要处理缺失值、重复数据以及异常值。
例如,我们可以使用以下代码来处理缺失值:```python# 检查缺失值print(data.isnull().sum())# 填充或删除缺失值data.fillna(method='ffill', inplace=True)```3. 数据探索在数据清洗之后,我们进行数据探索,以了解数据的分布和特征。
我们可以使用 Pandas 的描述性统计方法来获取数据的概览:```pythonprint(data.describe())```此外,我们还可以绘制一些图表来可视化数据,例如使用Matplotlib 和 Seaborn 绘制直方图和箱线图:```pythonimport matplotlib.pyplot as pltimport seaborn as sns# 绘制直方图plt.figure(figsize=(10, 6))sns.histplot(data['purchase_amount'], bins=20, kde=True) plt.title('Purchase Amount Distribution')plt.xlabel('Purchase Amount')plt.ylabel('Frequency')plt.show()# 绘制箱线图plt.figure(figsize=(10, 6))sns.boxplot(x='category', y='purchase_amount', data=data) plt.title('Purchase Amount by Category')plt.xlabel('Category')plt.ylabel('Purchase Amount')plt.show()```4. 数据分析在数据探索的基础上,我们可以进行更深入的数据分析。
Python在数据分析中的应用及最佳实践

Python在数据分析中的应用及最佳实践Python是一种简单、易学、高效的编程语言,具有越来越多的应用场景。
特别是在数据分析领域,Python成为了最受欢迎的语言之一。
本文将介绍Python在数据分析中的应用及最佳实践。
一、Python的优势一、Python简单易学。
Python的语法简单易懂,更符合人类思维,使得初学者容易入门。
二、Python强大的生态系统。
Python拥有丰富的开源包和工具,推动了Python在数据科学领域的应用。
三、Python在工业界的应用广泛。
Google、Dropbox、Honda、Ford等多家大型公司都在工业界广泛应用Python。
二、Python在数据分析中的应用Python在数据分析领域应用广泛,可以处理各种类型的数据,并在数据清洗、处理、可视化等方面发挥重要作用。
Python提供了许多网络爬虫框架,如beautifulsoup、scrapy等,可用于数据收集。
使用Python脚本可以轻松地从各种数据源中收集数据,如网页、API、社交网络等。
例如,在收集Twitter数据时,我们可以使用Tweepy进行数据抓取。
2、数据清洗数据清洗是数据分析的重要一步,Python在数据清洗方面表现卓越。
Pandas是最受欢迎的Python库之一,可用于数据清洗和数据处理。
使用Pandas可以轻松处理数据,包括数据去重、数据分组、数据排序等。
3、数据处理一旦数据清洗完成,下一步就是数据处理。
Python的Numpy和Scipy库提供了各种线性代数、统计学、信号处理等数据处理功能。
这些功能使得Python成为处理大型数据集的理想语言。
Python的可视化工具非常丰富。
Matplotlib是Python最受欢迎的绘图库之一,提供了许多绘制二维图表的选项。
除此之外,我们还可以使用Seaborn、Plotly等可视化库进行数据可视化。
5、机器学习Python在机器学习和深度学习领域中也表现出色。
python基本数据类型及运算应用的实验内容和原理

python基本数据类型及运算应用的实验内容和原理文章标题:探索Python基本数据类型及运算应用的实验内容和原理一、引言在计算机编程领域中,Python作为一种高级通用编程语言,其简洁灵活、易学易用的特点备受程序员喜爱。
在Python中,基本数据类型及其相关的运算应用是编程的基础,对初学者来说尤为重要。
本文将带您探索Python基本数据类型及运算应用的实验内容和原理。
二、Python基本数据类型概述1. 整数类型:在Python中,整数类型(int)可以表示正整数、负整数和零。
2. 浮点数类型:浮点数(float)用于表示小数,包括带小数点的数值。
3. 字符串类型:字符串(str)是由字符组成的有序集合,可以用单引号或双引号表示。
4. 列表类型:列表(list)是一种有序的集合,可以容纳任意数量、任意类型的对象。
三、Python基本数据类型的实验内容与应用1. 整数类型实验内容和应用2. 浮点数类型实验内容和应用3. 字符串类型实验内容和应用4. 列表类型实验内容和应用四、Python基本数据类型的运算原理探究1. 整数类型的运算原理2. 浮点数类型的运算原理3. 字符串类型的运算原理4. 列表类型的运算原理五、总结与回顾通过本文的共享,我们深入探讨了Python基本数据类型及运算应用的实验内容和原理。
无论是整数类型、浮点数类型、字符串类型还是列表类型,都有其独特的特点和运算规则。
在编程实践中,我们需要灵活运用这些基本数据类型和运算符号,才能更好地实现自己的编程目标。
六、个人观点与理解在学习和实践Python编程过程中,我深切体会到基本数据类型的重要性。
只有对整数、浮点数、字符串和列表等基本类型有深入的理解,才能在编程时游刃有余,提高编程效率。
对于运算应用的理解和掌握,可以帮助我们更好地处理程序中的逻辑和算法,实现更加复杂、精妙的功能。
七、参考资料1. Python官方文档:2. 《Python编程:从入门到实践》3. 《Python基础教程》在本文中,我们以序号标注的形式,详细探讨了Python基本数据类型及运算应用的实验内容和原理。
关于python的实验报告

关于python的实验报告一、引言Python是一种高级的、解释型、面向对象的脚本语言,具备简单易学、代码可读性强的特点。
本实验旨在通过实践,掌握Python基本语法和常用库函数,提高编程能力。
二、实验内容本次实验分为三个部分:1. Python基础语法学习在这一部分,我们学习了Python的变量和赋值、数据类型、运算符、条件语句、循环语句、列表、字典等基本语法,并通过练习巩固了所学知识。
Python的语法简洁明了,初学者很容易上手。
2. Python库的应用在这一部分,我们学习了Python常用的库函数,如`math`库、`random`库、`datetime`库等,并通过编写程序进行了实践。
这些库函数能够方便地处理数学计算、随机数生成、日期时间操作等常见任务,极大地提高了程序的开发效率。
3. Python图形化界面开发在这一部分,我们学习了Python的图形化界面开发库,如`Tkinter`库、`PyQt`库等,并通过编写程序进行了实践。
图形化界面使得程序更加友好和直观,用户可以通过鼠标进行交互操作,提高了用户体验。
三、实验过程1. Python基础语法学习在学习Python的基础语法时,我首先阅读了相关教材和文档,了解了Python的基本特性和语法规则。
然后,我通过编写一系列的练习题,对所学知识进行了巩固和实践。
通过编写代码,我逐渐掌握了Python的各种基本语法。
2. Python库的应用在学习Python库的应用时,我首先阅读了相关文档和示例代码,了解了库函数的功能和使用方法。
然后,我通过编写一系列的程序,对所学知识进行了实践。
通过编写代码,我逐渐掌握了各种库函数的使用技巧。
3. Python图形化界面开发在学习Python图形化界面开发时,我首先阅读了相关教材和文档,了解了图形化界面的基本原理和开发方法。
然后,我通过编写一系列的程序,对所学知识进行了实践。
通过编写代码,我逐渐掌握了图形化界面开发的基本技巧。
python数据分析实践报告(代码和数据在内)

python数据分析实践报告(代码和数据
在内)
介绍
本报告旨在展示使用Python进行数据分析的实践过程和结果。
报告中包含了使用的代码和相关数据。
数据收集
我们使用了以下数据集进行数据分析:
数据清洗和预处理
在数据分析之前,我们对数据进行了清洗和预处理的步骤,包括:
1. 数据去重
2. 缺失值处理
3. 数据格式转换
4. 异常值处理
数据分析
在进行数据分析时,我们使用了多种Python库和工具,包括:
- Pandas:用于数据读取、处理和转换
- NumPy:用于数值计算和统计分析
- Matplotlib:用于数据可视化
- Scikit-learn:用于机器学习和模型训练
我们对数据进行了以下分析:
1. 描述性统计分析:包括计算均值、中位数、标准差等统计指标
2. 数据可视化:使用折线图、柱状图、散点图等方式展示数据分布和趋势
3. 相关性分析:使用相关系数等方法分析变量之间的相关性
4. 机器学习建模:使用Scikit-learn库中的算法进行模型训练和预测
结果分析和总结
根据我们的数据分析结果,我们得出了以下结论:
1. 结论1
2. 结论2
3. 结论3
附录
本报告的附录包括了使用的Python代码和相关数据。
在此处插入代码
参考资料。
Python程序设计实验二

学院信息工程学院班级软件工程专升本S181 课程名称Python程序设计学号1803120006 姓名郭航日期2018.11.15 实验成绩指导教师刘寒冰实验二Python基本数据类型一、实验目的(1)掌握3种数字类型的使用;(2)掌握字符串类型的使用;(3)能运行Python的标准数学库math进行数值计算。
二、实验内容1、将下列数学表达式用Python程序写出来,并运算结果。
1.1 x=30-3**2+8//3**2*101.2 x=(2.5+1.25j)*4j/21.3 x=(1+32)×(16mod7)/72、利用math库编程实现天天向上的力量的计算。
2.1 以交互方式练习运行天天向上的实例代码3.2,观察运行结果,理解代码含义。
结果:2.2 以文件方式练习运行天天向上的实例代码3.4,观察运行结果,理解代码含义。
结果:2.3 在理解实例代码3.4的基础上解决问题:一年365天,初始水平为1.0,每工作一天水平增加1%,不工作时水平不下降,一周连续工作6天。
编写程序计算,一年后能力值是多少?2.4 天天向上续。
假设能力增长符合如下带有平台期的模型:以7天为周期,连续学习3天能力值不变,从第4天开始至第7天每天能力增长为前一天的1%。
如果7天中有1天间断学习,则周期从头计算。
编写程序计算,如果初始值为1,连续学习365天后能力值是多少?3、以交互方式按要求输出结果。
3.1 将字符串“这是一个很长的字符串”以宽度25位居中,并用“*”号填充输出。
3.2 格式化输出和389的二进制、八进制、十进制、十六进制的表达式,以及对应的Unicode字符。
3.3 格式化输出0.002178对应的科学表示法形式,保留4位有效位的标准浮点形式以及百分形式。
4、编程实现文本进度条。
4.1 以文件方式练习运行带刷新文本进度条的实例代码4.3,观察运行结果,理解代码含义。
4.2 文本进度条续。
仿照实例4.3,打印如下形式的进度条。
Python中的数据分析实战案例

Python中的数据分析实战案例数据分析是一项重要的技能,而Python作为一种流行的编程语言,提供了丰富的工具和库来支持数据分析。
本文将介绍一些Python中的实际数据分析案例,帮助读者更好地理解和运用数据分析的方法和技巧。
一、销售数据分析假设我们是一家电商公司,我们有一份销售数据的表格,包含了产品名称、销售数量、销售额等信息。
我们可以利用Python的数据分析库,如Pandas和NumPy,对销售数据进行统计和分析。
首先,我们可以使用Pandas库加载销售数据表格,并进行数据清洗和预处理。
我们可以去除重复的数据、处理缺失值,并转换数据类型。
然后,我们可以使用Pandas提供的函数和方法对数据进行统计分析,如求和、平均值、最大值、最小值等。
接下来,我们可以使用Matplotlib库创建可视化图表,比如柱状图、折线图、饼图等,以便更直观地展示销售数据的情况。
我们可以通过图表来观察销售额随时间的变化趋势,以及不同产品的销售数量对比情况。
此外,我们还可以使用Python的机器学习库,如Scikit-learn,进行销售趋势预测和销售量预测。
我们可以利用历史销售数据训练模型,然后使用模型对未来的销售情况进行预测,帮助我们做出合理的经营决策。
二、用户行为分析在互联网时代,用户行为数据对于企业的经营和发展非常重要。
Python可以帮助我们分析和挖掘用户行为数据,帮助企业了解用户需求和行为习惯,以便更好地进行市场营销和用户体验优化。
假设我们是一家电商平台,我们有用户的点击记录、购买记录、评论记录等数据。
我们可以使用Python的数据分析库,如Pandas和NumPy,对用户行为数据进行处理和分析。
首先,我们可以使用Pandas库加载用户行为数据,并进行数据清洗和预处理。
我们可以去除异常值、处理缺失值,并转换数据类型。
然后,我们可以使用Pandas提供的函数和方法对数据进行统计分析,如计算用户的平均购买次数、平均评论数量等。
Python玩转数据分析——T检验概念适用条件单样本t检验两独立样本t检验两配对样本t检验

Python玩转数据分析——T检验概念适⽤条件单样本t检验两独⽴样本t检验两配对样本t检验# 概念T检验,也称 student t 检验 ( Student’s t test ) ,⽤来⽐较两个样本的均值差异是否显著,通常⽤于样本含量较⼩ ( n <30 ) 的样本。
分为单样本 t 检验、两独⽴样本 t 检验和两配对样本 t 检验。
# 适⽤条件1. 已知⼀个总体均数;2. 可得到⼀个样本均数及该样本标准差;3. 样本来⾃正态或近似正态总体。
# 单样本 t 检验假设现在有10个男⽣的体重数据(单位:千克),问这些男⽣体重的均值与70千克是否有显著差异(显著性⽔平为0.05)?代码如下:```codeweight=[53,75,69,67,58,64,70,72,65,74]def t_1samp(list_c,u):lst=list_c.copy()n=len(lst)s=np.std(lst)*(n**0.5)/(n-1)**0.5t=(np.mean(lst)-u)/(s/(n)**0.5)sig=2*stats.t.sf(abs(t),n-1)dic_res=[{'t值':t,'⾃由度':n-1,'Sig.':sig,'平均值差值':np.mean(lst)-u}]df_res=pd.DataFrame(dic_res,columns=['t值','⾃由度','Sig.','平均值差值'])return df_rest_1samp(weight,70)```# 两独⽴样本 t 检验假设现在还有另外10个⼥⽣的体重数据,问上⼀组男⽣的体重和这⼀组⼥⽣的体重有⽆明显差异(显著性⽔平为0.05)。
代码如下:```codeweight_f=[42,44,54,62,58,57,63,55,57,48]def t_2samp(list_c1,list_c2):lst1,lst2=list_c1.copy(),list_c2.copy()n1,n2=len(lst1),len(lst2)sig_homovar=stats.levene(lst1,lst2)[1]var1,var2=np.var(lst1)*n1/(n1-1),np.var(lst2)*n2/(n2-1)var12=((n1-1)*var1+(n2-1)*var2)/(n1+n2-2)t_homo=(np.mean(lst1)-np.mean(lst2))/(var12*(1/n1+1/n2))**0.5df_homo=n1+n2-2sig_homo=2*stats.t.sf(abs(t_homo),df_homo)t_nothomo=(np.mean(lst1)-np.mean(lst2))/(var1/n1+var2/n2)**0.5df_nothomo=(var1/n1+var2/n2)**2/((var1/n1)**2/n1+(var2/n2)**2/n2)sig_nothomo=2*stats.t.sf(abs(t_nothomo),df_nothomo)df_res=pd.DataFrame(index=['假定等⽅差','不假定等⽅差'],columns=['显著性','t值','⾃由度','Sig.'])df_res['显著性']=[sig_homovar,'-']df_res['t值']=[t_homo,t_nothomo]df_res['⾃由度']=[df_homo,df_nothomo]df_res['Sig.']=[sig_homo,sig_nothomo]return df_rest_2samp(weight,weight_f)```# 两配对样本 t 检验假设现在这组男⽣开始⽤某种减肥⽅法减肥,⼀个星期后测得各⾃体重,问这种减肥⽅法效果是否显著(显著性⽔平为0.05)。
python实验二

实验二:Python程序设计基础知识的应用(4学时) 一、实验方式:一人一机二、实验目的:1、熟练掌握常用Python内置对象与关键字的用法;2、熟练掌握Python运算符与表达式的用法;3、熟悉常用Python内置函数的用法。
三、实验内容:1、请验证教材中代码,掌握Python内置对象的用法。
2、请验证教材中代码,掌握Python运算符与表达式的用法。
3、请验证教材中代码,掌握常用Python内置函数的用法。
4、输入华氏温度h,求摄氏温度c。
(摄氏温度=5/9*(华氏温度-32))5、输入两个数给变量a和b,交换值后输出。
6、输入一个三位数分别输出各位上的数码。
7、随机生成10个100以内的整数列表,然后将列表内容逆序后显示。
四、实验结果与分析:1、请验证教材中代码,掌握Python内置对象的用法。
1)整数变量一、命令行方式:(1)程序代码(程序运行最终正确代码):>>> x=7>>> type(x)<class 'int'>>>> type(x)==intTrue>>> isinstance(x,int)True>>>(2)程序结果(截图Alt+PrtSc):(3)程序分析(程序运行错误修改或运行结果分析):无2)字符串变量一、命令行方式:(1)程序代码(程序运行最终正确代码):>>> x="青岛科技大学">>> x'青岛科技大学'>>> type(x)<class 'str'>>>> isinstance(x,str)True>>> x=123>>> type(x)<class 'int'>>>> x="青岛科技大学“SyntaxError: EOL while scanning string literal >>> x="青岛科技大学">>> type(x)<class 'str'>>>> x=[1,2,3,4,5,6]>>> type(x)<class 'list'>>>>(2)程序结果(截图Alt+PrtSc):(3)程序分析(程序运行错误修改或运行结果分析):引号使用错误2、请验证教材中代码,掌握Python运算符与表达式的用法。
学习Python实现数据处理与分析

学习Python实现数据处理与分析Python是一种开源的编程语言,具备简洁、高效的特点,并且在数据处理与分析领域有着广泛的应用。
本文将从数据清洗、数据分析和数据可视化三个方面,介绍如何使用Python进行数据处理与分析。
一、数据清洗数据清洗是数据处理的第一步,也是非常重要的一步。
下面介绍几个常用的数据清洗方法。
1. 去除重复值在处理大量数据时,常常会遇到重复的数据。
可以使用Python 的pandas库中的drop_duplicates()函数去除重复值。
例如,我们可以使用以下代码去除data中的重复值:data = data.drop_duplicates()2. 缺失值处理在数据中,经常会遇到缺失值的情况。
可以使用Python的pandas库中的fillna()函数对缺失值进行处理。
例如,我们可以使用以下代码将data中的所有缺失值替换为0:data = data.fillna(0)3. 数据类型转换数据在导入时,可能会出现数据类型不一致的情况,影响后续的数据分析。
可以使用Python的pandas库中的astype()函数将数据类型进行转换。
例如,我们可以使用以下代码将data中的数据转换为整数类型:data = data.astype(int)二、数据分析Python具备强大的数据分析能力,下面介绍几个常用的数据分析方法。
1. 描述性统计描述性统计是对数据进行初步分析的一种方法,可以使用Python的pandas库中的describe()函数来得到数据的基本统计量,如均值、中位数、标准差等。
例如,我们可以使用以下代码计算data的描述性统计量:data.describe()2. 相关性分析相关性分析用来研究两个变量之间的相关关系,可以使用Python的pandas库中的corr()函数来计算变量之间的相关系数。
例如,我们可以使用以下代码计算data中各个变量之间的相关系数:data.corr()3. 数据建模数据建模是数据分析的重要环节,可以使用Python的scikit-learn库进行数据建模。
Python财经数据接口TuShare研究和数据处理分析实例

《用Python玩转数据》之利用免费财经数据接口TuShare获取和分析数据by Dazhuang@NJU1.安装在Anaconda Prompt窗口中输入如下命令安装:> pip install tushare2. 介绍"TuShare是一个免费、开源的python财经数据接口包。
主要实现对股票等金融数据从数据采集、清洗加工到数据存储的过程,能够为金融分析人员提供快速、整洁、和多样的便于分析的数据,为他们在数据获取方面极大地减轻工作量,使他们更加专注于策略和模型的研究与实现上。
考虑到Python pandas包在金融量化分析中体现出的优势,TuShare 返回的绝大部分的数据格式都是pandas DataFrame类型,非常便于用pandas/NumPy/Matplotlib进行数据分析和可视化。
当然,如果您习惯了用Excel或者关系型数据库做分析,您也可以通过TuShare的数据存储功能,将数据全部保存到本地后进行分析。
"这是TuShare官网(/index.html)上对于TuShare的描述,它提供了便捷的各类财经数据和新闻等的接口。
3. 简单示例例如要想获取股票代码是600848的股票在2018年3月1日至3月10日间的基本历史数据,只要使用如下代码即可:>>> import tushare as ts>>> ts.get_hist_data('600848',start='2018-03-01',end='2018-03-08')open high close low volumedate2018-03-08 23.82 24.10 23.99 23.71 34416.472018-03-07 24.06 24.28 23.90 23.89 43007.212018-03-06 24.20 24.28 24.03 23.82 48066.022018-03-05 24.48 24.48 24.13 23.91 37519.752018-03-02 23.90 24.39 24.33 23.63 61194.212018-03-01 23.69 24.48 24.18 23.56 46819.00…get_hist_data()函数可以获取三年内A股历史行情,其他Tushare中功能相似的函数还有get_h_data()和get_k_data()。
python数据科学实践研究报告(包含代码与数据)

python数据科学实践研究报告(包含代码与数据)Python数据科学实践研究报告(包含代码与数据)1. 引言数据科学是一个跨学科领域,涉及使用计算机科学、统计学和领域知识来从数据中提取知识和洞察力。
在本实践报告中,我们将使用Python进行数据科学项目的实施,包括数据处理、分析、可视化和模型构建。
本报告将提供一个详细的概述,包括代码和数据,以展示数据科学的实际应用。
2. 数据预处理数据预处理是数据科学项目中的一个重要步骤,它包括数据清洗、数据转换和数据整合。
在本节中,我们将介绍如何使用Python进行数据预处理。
2.1 数据清洗数据清洗是去除无效或错误的数据的过程。
我们可以使用Python的Pandas库来清洗数据。
以下是一个示例代码:import pandas as pd读取数据data = pd.read_csv('data.csv')删除空值data = data.dropna()删除重复值data = data.drop_duplicates()过滤掉不符合条件的数据data = data[data['column_name'] > 0]2.2 数据转换数据转换是将数据从一种形式转换为另一种形式的过程。
我们可以使用Python的Pandas库来进行数据转换。
以下是一个示例代码:将字符串转换为数值data['column_name'] = pd.to_numeric(data['column_name'],errors='coerce')将日期字符串转换为日期对象data['date_column'] = pd.to_datetime(data['date_column'])2.3 数据整合数据整合是将来自不同来源的数据合并在一起的过程。
我们可以使用Python的Pandas库来进行数据整合。
python实验总结

python实验总结Python实验总结Python是一种高级编程语言,被广泛应用于数据分析、人工智能、网络编程等领域。
在学习Python的过程中,我进行了一些实验,通过这些实验我对Python的理解更加深入,也掌握了一些实用的技巧。
在这篇文章中,我将总结我进行的Python实验,并分享一些心得体会。
实验一:数据分析在这个实验中,我使用Python的pandas库对一份销售数据进行了分析。
我首先使用pandas读取了数据,然后进行了数据清洗和预处理。
接着,我使用pandas的groupby函数对数据进行了分组统计,得出了不同产品的销售情况。
最后,我使用matplotlib库绘制了销售额的折线图和柱状图。
通过这个实验,我学会了如何使用pandas和matplotlib进行数据分析和可视化,对数据分析的流程和方法有了更深入的理解。
实验二:爬虫在这个实验中,我使用Python的requests和BeautifulSoup库编写了一个简单的爬虫程序,用于爬取某个网站的新闻内容。
我首先发送了HTTP请求,然后使用BeautifulSoup解析了网页内容,提取出了新闻标题和链接。
最后,我将提取到的数据保存到了一个文本文件中。
通过这个实验,我学会了如何使用Python编写简单的爬虫程序,对HTTP请求和HTML解析有了更深入的了解。
实验三:机器学习在这个实验中,我使用Python的scikit-learn库对一个数据集进行了机器学习建模。
我首先对数据集进行了特征工程和数据预处理,然后使用了几种不同的机器学习算法进行了模型训练和评估。
最后,我选择了最优的模型,并使用该模型对新的数据进行了预测。
通过这个实验,我学会了如何使用scikit-learn进行机器学习建模,对机器学习算法的原理和应用有了更深入的了解。
总结通过以上三个实验,我对Python的应用有了更深入的理解,也掌握了一些实用的技巧。
我学会了如何使用pandas进行数据分析和可视化,如何使用requests 和BeautifulSoup编写爬虫程序,以及如何使用scikit-learn进行机器学习建模。
python数据分析案例实战

python数据分析案例实战Python数据分析案例实战。
数据分析是当今社会中非常重要的一项技能,而Python作为一种强大的编程语言,被广泛应用于数据分析领域。
本文将通过介绍几个Python数据分析的实战案例,帮助读者更好地了解如何利用Python进行数据分析。
案例一,销售数据分析。
假设我们是一家电商平台,我们收集了一段时间内的销售数据,包括商品名称、销售额、销量等信息。
我们希望利用Python对这些数据进行分析,找出畅销商品、销售额最高的时间段等信息。
首先,我们可以使用pandas库来读取和处理数据,然后利用matplotlib库绘制销售额随时间的变化趋势图,进而找出销售额最高的时间段。
接着,我们可以利用seaborn库绘制商品销量的分布图,找出畅销商品。
通过这些分析,我们可以更好地了解销售情况,为未来的销售策略提供参考。
案例二,股票数据分析。
股票市场是一个充满变化的市场,利用Python进行股票数据分析可以帮助投资者更好地把握市场动向。
我们可以使用pandas库获取股票市场的历史数据,然后利用numpy库计算股票的收益率和波动率。
接着,我们可以利用matplotlib库绘制股票价格随时间的变化趋势图,以及收益率的分布图。
通过这些分析,我们可以更好地了解股票市场的走势,为投资决策提供参考。
案例三,社交媒体数据分析。
社交媒体是人们日常生活中不可或缺的一部分,利用Python进行社交媒体数据分析可以帮助企业更好地了解消费者的喜好和行为习惯。
我们可以使用pandas库获取社交媒体平台的用户行为数据,然后利用nltk库进行文本分析,找出用户的情感倾向和关注点。
接着,我们可以利用wordcloud库生成词云图,直观地展现用户关注的热点话题。
通过这些分析,企业可以更好地了解用户需求,为营销策略提供参考。
总结。
通过以上三个实战案例的介绍,我们可以看到Python在数据分析领域的强大应用。
利用Python进行数据分析不仅可以帮助我们更好地理解数据,还可以为业务决策提供参考。
Python实验报告
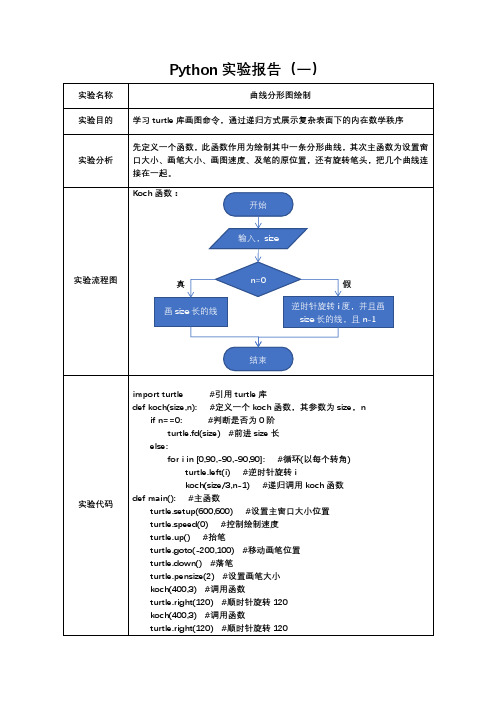
Python实验报告(一)
koch(400,3) #调用函数
turtle.hideturtle()
main()
运行过程
问题分析1、画出图像部分的函数是最为重要的,必须弄清楚它一次性是做了什么工作
2、判断阶的意义在于是对其图像需要进行几次分形的判断
3、Koch函数内的for循环中的循环条件是基于要分形的图形形状
评阅内容填写规范20 过程完整50 实验结果30
得分
Python实验报告(二)
运行过程
问题分析1、光源的俯视角度和方位角度以及深度加权都能可以影响整个图片的效果,depth较小时,画面显示轮廓描绘。
2、光源对xyz轴的影响,即为把角度对应的柱坐标转化为了xyz的立体坐标系‘
3、Clip函数的光源归一化限定范围的最大值应该和前面光源归一化式子用的值相同。
评阅内容填写规范20 过程完整50 实验结果30
得分
Python实验报告(三)
plt.setp(legend.get_texts(), fontsize='small')
#绘制步阶图
plt.grid(True)
plt.show()
运行过程
问题分析1、运行过程出现No module named 'matplotlib',是因为没有安装matplotlib 库,运行命令cmd安装此库就可以了。
2、运行此过程中出现Unknown property frac,解决方法为删除掉frac命令,其结果不会产生影响
评阅内容填写规范20 过程完整50 实验结果30
得分。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验2 选择、循环和异常
注意:
1.作业请提交至ftp://17
2.26.184.2/upload/用Python玩转数据/实验2(2017.
3.23)/中
2.Deadline为
3.28(下周二)18:00
3.请将4个源文件压缩后用“学号姓名.压缩类型”文件名上传
编程题
1.按公式:C= 5/9×(F-32) ,将华氏温度转换成摄氏温度,并产生一张华氏0~300度与对应的摄氏温度之间的对照表(每隔20度输出一次)
2. 找前5个默尼森数。
P是素数且M也是素数,并且满足等式M=2P-1,则称M为默尼森数。
例如,P=5,M=2P-1=31,5和31都是素数,因此31是默尼森数。
3. 编写一个程序,让用户输入苹果个数和单价,然后计算出价格总额。
Enter count: 10
Enter price for each one: 3.5
Pay: 35
运用try-except语句让程序可以处理非数字输入的情况,如果是非数字输入,打印消息并允许用户再次输入,直到输入正确类型值计算出结果后退出。
以下是程序的执行结果:Enter count: 20
Enter price for each one: four
Error, please enter numeric one
Enter count: twenty
Error, please enter numeric one
Enter count: 20
Enter price for each one: 4
The price is 80.
4. 程序随机产生一个0~300间的整数,玩家竞猜,允许玩家自己控制游戏次数,如果猜中系统给出提示并退出程序,如果猜错给出“太大了”或“太小了”的提示,如果不想继续玩可以退出并说再见。