有关JSP和数据库乱码问题的处理方式
JSP中乱码问题

1.中文乱码问题,首先得需要确定的是,数据库的默认编码要
设置正确,一般设为gb2312.
2.JSP中文乱码问题之一:调用JSP页面显示乱码
通过浏览器调用JSP页面,在客户端浏览器中所有的中文内容出现乱码。
解决方案:
首先确认本JSP在编辑器中保存时,使用的是GB2312(或GBK)的编码格式,然后在JSP页面的开始部分添加
<%@ pageEncoding=”GBK”%>就可以解决中文乱码问题。
3.JSP中文乱码问题之二:调用Servlet页面显示乱码
调用Servlet,Servlet在浏览器中显示内容出现乱码
解决方案:
在Servlet使用response在输出内容之前,先执行response.setContentType(”text/html; chatset=GBK”),设定输出内容编码为GBK,注意的是这句话放在方法的第一行。
4.JSP中文乱码问题之三:post表单传递参数乱码
通过JSP页面、HTML页面或者Servlet中的表单元素提交参数给对应的JSP页面或者Servlet而JSP页面或者Servlet接收的中文参数值乱码
解决方案:
在接收post提交的参数之前,使用request.setCharacterEncoding(“GBK”),设定接收参数的内容使
用GBK编码。
JSP+MySQL中文乱码问题post提交乱码解决方案

JSP+MySQL中⽂乱码问题post提交乱码解决⽅案写了两个jsp页⾯index.jsp和mysql_insert.jsp。
数据处理流程为:在浏览器(chrome)上访问index.jsp后在其表单上输⼊数据,提交⾄mysql_insert.jsp,mysql_insert.jsp⾸先将接收到的数据按变量存⼊MySQL的html_db数据库的person_tb中(该表原有部分数据),然后mysql_insert.jsp再拿出该表中所有数据显⽰在mysql_insert.jsp页⾯上。
现在发现,当提交的数据中含有中⽂(⽐如变量姓名的值为中⽂)时,mysql_insert.jsp页⾯上显⽰新增的那条记录中的相应中⽂(姓名的值)乱码,其他数据都显⽰正常,查看数据库,发现也是相应的含有中⽂的变量值(姓名的值)乱码。
乱码情况如下图:index.jsp中第⼀⾏有语句:<%@ page contentType="text/html;charset=gb2312"%> ,在浏览器(chrome)中访问此页⾯时⽆乱码(主要指中⽂乱码,英⽂乱码现象还没遇见过)。
(试过将gb2312换成utf-8,访问后中⽂乱码)mysql_insert.jsp中第⼀⾏有语句:<%@page language="java" pageEncoding="UTF-8"%>,在浏览器中直接访问此页⾯时⽆乱码。
mysql_insert.jsp页⾯的代码如下:复制代码代码如下:<%@page language="java" pageEncoding="UTF-8"%><%@ page import="java.sql.*" %><HTML><HEAD><TITLE>add message into table </TITLE></HEAD><BODY><%String id=request.getParameter("id"); //从表单获得String name=request.getParameter("name"); //从表单获得String sex=request.getParameter("sex"); //从表单获得String age=request.getParameter("age"); //从表单获得try{/** 连接数据库参数 **/String driverName = "com.mysql.jdbc.Driver"; //驱动名称String DBUser = "root"; //mysql⽤户名String DBPasswd = "123456"; //mysql密码String DBName = "html_db"; //数据库名String connUrl = "jdbc:mysql://localhost/" + DBName + "?user=" + DBUser + "&password=" + DBPasswd;Class.forName(driverName).newInstance();Connection conn = DriverManager.getConnection(connUrl);Statement stmt = conn.createStatement();stmt.executeQuery("SET NAMES UTF8");String insert_sql = "insert into person_tb values('" + id + "','" + name + "','" + sex + "','" + age + "')";String query_sql = "select * from person_tb";try {stmt.execute(insert_sql);}catch(Exception e) {e.printStackTrace();}try {ResultSet rs = stmt.executeQuery(query_sql);while(rs.next()) {%>ID:<%=rs.getString("id")%> </br>姓名:<%=rs.getString("name")%> </br>性别:<%=rs.getString("sex")%> </br>年龄:<%=rs.getString("age")%> </br> </br><%}}catch(Exception e) {e.printStackTrace();}//rs.close();stmt.close();conn.close();}catch (Exception e) {e.printStackTrace();}%></body></html>我的数据库设置的是全部使⽤UTF-8编码,如下图:我的虚拟⽬录下的web.xml内容如下:tomcat/conf⽬录下的server.xml⽂件的内容如下:复制代码代码如下:<U><?xml version='1.0' encoding='utf-8'?></U><Server port="8005" shutdown="SHUTDOWN"><Listener className="org.apache.catalina.core.AprLifecycleListener" SSLEngine="on" /> <Listener className="org.apache.catalina.core.JasperListener" /><Listener className="org.apache.catalina.core.JreMemoryLeakPreventionListener" /> <Listener className="org.apache.catalina.mbeans.GlobalResourcesLifecycleListener" /> <Listener className="org.apache.catalina.core.ThreadLocalLeakPreventionListener" /> <GlobalNamingResources><Resource name="UserDatabase" auth="Container"type="erDatabase"description="User database that can be updated and saved"factory="ers.MemoryUserDatabaseFactory"pathname="conf/tomcat-users.xml" /></GlobalNamingResources><Service name="Catalina"><Connector port="8080" protocol="HTTP/1.1"connectionTimeout="20000"redirectPort="8443" /><Connector port="8009" protocol="AJP/1.3" redirectPort="8443" /><Engine name="Catalina" defaultHost="localhost"><Realm className="org.apache.catalina.realm.LockOutRealm"><Realm className="erDatabaseRealm" resourceName="UserDatabase"/></Realm><Host name="localhost" appBase="webapps" unpackWARs="true" autoDeploy="true"> <Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs" prefix="localhost_access_log." suffix=".txt"pattern="%h %l %u %t "%r" %s %b" /></Host></Engine></Service></Server>tomcat/conf⽬录下web.xml⽂件的主要内容如下:复制代码代码如下:<U><?xml version="1.0" encoding="UTF-8"?></U><web-app xmlns="/xml/ns/javaee"xmlns:xsi="/2001/XMLSchema-instance"xsi:schemaLocation="/xml/ns/javaee/xml/ns/javaee/web-app_3_0.xsd"version="3.0"><servlet><servlet-name>default</servlet-name><servlet-class>org.apache.catalina.servlets.DefaultServlet</servlet-class><init-param><param-name>debug</param-name><param-value>0</param-value></init-param><init-param><param-name>listings</param-name><param-value>false</param-value></init-param><load-on-startup>1</load-on-startup></servlet><servlet><servlet-name>jsp</servlet-name><servlet-class>org.apache.jasper.servlet.JspServlet</servlet-class><init-param><param-name>fork</param-name><param-value>false</param-value></init-param><init-param><param-name>xpoweredBy</param-name><param-value>false</param-value></init-param><load-on-startup>3</load-on-startup></servlet><servlet-mapping><servlet-name>default</servlet-name><url-pattern>/</url-pattern></servlet-mapping><!-- The mappings for the JSP servlet --><servlet-mapping><servlet-name>jsp</servlet-name><url-pattern>*.jsp</url-pattern><url-pattern>*.jspx</url-pattern></servlet-mapping><session-config><session-timeout>30</session-timeout></session-config><此处省略了mime-mapping的内容><welcome-file-list><welcome-file>index.html</welcome-file><welcome-file>index.htm</welcome-file><welcome-file>index.jsp</welcome-file></welcome-file-list></web-app>现在我能想到的设置编码的地⽅也就只有这么多了,其他还有哪⾥需要设置编码?恳求指导。
如何处理JSP开发容易出现的中文乱码问题

在java编程中,经常会碰到汉字的处理及显示问题,一不小心就会产生一大堆乱码或问号,这也是让许多初学者手足无措的讨厌问题。
造成这种问题的根本原因是java中默认的编码方式是Unicode,而中国人通常使用的文件和DB都是基于GB2312或者big5等编码,固会出现此问题。
对于中文问题,不同的jdk版本,不同的应用服务器,处理方法都会有一些微小的差异。
在这里,主要针对Tomcat中JSP开发容易出现的中文乱码问题进行讨论,当然,大多数解决方法是通用的。
一般有以下几种情况:1、JSP输出中文的乱码问题所谓在JSP输出中文,即直接在JSP中输出中文,或者给变量赋中文值再输出等,这种情况下的乱码问题往往是因为没有给JSP页面制定显示字符的编码方式,解决方法如下:(1)在JSP页面头部加上语句<% @ page contentType=”text/html;charset=utf-8”%>(在servlet 中使用httpServletResponse.setContentType(“text/html; charset=utf-8”)),最好同时在JSP页面的head部分加上<meta http-equiv=”Content-Type”content=”text/html;charset=utf-8”>。
(2)在每次要输出中文的地方主动转换编码方式,比如要在页面中输入“中文”二字,就可以用以下方法:<%String str = “中文”;Byte[] tmpbyte = str.getBytes(“ISO8859_1”);str = new String(tmpbyte);out.print(str);2、获取表单提交的数据时的中文乱码问题在没有加任何其他处理之前,用request.getParameter(“paramName”)获取表单提交中的数据,且表单数据中含有中文时,返回的字符串会呈现乱码。
JSP+MYSQL中文乱码问题解决方案-UTF8篇

//prepStmt.setString(3,"显示就表明测试正确") ; //prepStmt.executeUpdate() ; //prepStmt.close() ; %> <table border=1 width=400> <tr > <td>id</td> <td>name</td> </tr> <% ResultSet rs = stmt.executeQuery("select * from books") ; while(rs.next()) { String id = rs.getString(1) ; String name = rs.getString(2); %> <tr> <td><%=id%></td> <td><%=name%></td> </tr> <% } %> </table> <% rs.close() ; stmt.close() ; conn.close() ; }catch(Exception e) { out.println("失败"); e.printStackTrace(); } %> </body> </html>
开发工具设置: Dreamweaver 设置: 菜单栏-->编辑-->首选参数-->新建文档-->默认编码-->选择 UTF-8 EditPlus 设置: 菜单栏-->工具-->参数-->文件-->默认编码-->选择 UTF-8 特别重要: 无论使用哪种开发工具,建议不要使用“点右键-->新建-->文本文档-->修改扩展名”的方法, 而该方法是许多教程和书籍普遍介绍的方法,我因为这个走了很多弯路,希望各位引以为戒! 自己提个醒,在这里把原因说出来: 几乎所有的文本编辑工具默认的字符编码为:ANSI 或是 ISO-8859-1;UltraEdit-32默认编码就是 IS0-8859-1;而 EditPlus 则默认为 ANSI 编码!ISO-8859-1编码就不用多说了,我们输入中文然后删除的 话, 可能会出现只删除掉半个字符的情况, 就是因为默认字符编码的问题! ANSI 编码则是多字节字符集, 而 根据你操作系统的内码来决定字符集!我们使用的是 windows 中文系统,所以操作系统内码是 GBK 或是 GB18030编码字符集!因此用 EditPlus 输入中文是没问题的!用来输入 UTF-8字符肯定是有问题的!所以 一定要严格按照上面的步骤操作! JSP 文件的配置指令: JSP 部分:<%@ page contentType="text/html; charset=utf-8" %> 给
jsp中文乱码问题[jsp中文页面乱码与传参乱码]
![jsp中文乱码问题[jsp中文页面乱码与传参乱码]](https://img.taocdn.com/s3/m/ac02d9d677a20029bd64783e0912a21614797fd9.png)
页面乱码这种乱码的原因是应为没有在页面里指定使用的字符集编码,解决方法:只要在页面开始地方用下面代码指定字符集编码即可代码如下数据库乱码这种乱码会使你插入数据库的中文变成乱码,或者读出显示时也是乱码,解决方法如下:在数据库连接字符串中加入编码字符集代码如下 String Url="jdbc:myql://localhot/digitgulfuer=root&paword=root&ueUnicode=true&characterEncoding=GB2312";并在页面中使用如下代码:代码如下 repone.etContentType("te某t/html;charet=gb2312"); requet.etCharacterEncoding("gb2312");URL传值乱码方法一:1. 在b.jp中把pageEncoding="GB2312"改为pageEncoding="ISO8859-1"虽然这样b.jp页面显示的内容还是乱码,但是不是那种“ ”的乱码,而是一些特殊字符2. 然后在浏览器中查看菜单中修改成GB2312的编码,这时乱码就显示中文了。
3. 但是这种方法是不可行的。
方法二:1. 在b.jp中把代码如下 String name=requet.getParameter("name");修改为代码如下 String name=new String(requet.getParameter("name").getByte("ISO-8859-1"),"GB2312");2. 这时再在页面上显示,则就是中文了。
方法三:在请求页面的请求参数需要用encodeURI进行转码,然后在接收请求的页面需要进行字符集转换。
JSP技术中的中文乱码成因与对策探析

JSP技术中的中文乱码成因与对策探析JSP技术是进行动态网页设计过程中的关键技术,然后在进行网页的设计和开发过程中,利用JSP技术会经常出现中文乱码的问题,从而影响了动态网页的正常使用。
因此,本文通过简要介绍JSP技术开发过程出现中文乱码的主要原因,进而针对中文乱码出现的不同原因提出了相应的解决策略。
标签:JSP技术;动态网页技术;中文乱码;显示乱码0 引言中文利用了特殊的字符编码方式,所以在利用JSP技术进行动态网页开发过程中,如果没有注意到这一点,很可能会造成中文乱码问题。
中文乱码问题出现的原因有很多,所以本文主要介绍了中文乱码出现的主要场景,进而针对其出现的原因提出了响应的解决策略,从而为更多的JSP技术开发人员提供参考。
1 字符常见的几种编码格式字符常见的几种编码格式如下:第一,Lain-1编码,这种编码格式仅仅支持英文系列的编码,不支持汉字编码,因此在具有汉字的情况下,一定不能使用这种编码方式;第二,GB2312/GBK编码,这种编码方式是专门用来表示汉字的,而且支持简体字和繁体字两种不同的表示方式;第三,unicode编码,这种编码方式支持中文的编码,同时也支持英文的编码,但是它无法很好地对Latin-1编码格式进行兼容;第四,UTF-8编码,目前很多开发的场景下都是使用该种编码方式进行编码,它不仅支持中英文,而且对其他编码方式都能做的很好的兼容。
2 影响JSP技术中文乱码的外部因素其实在利用JSP技术进行动态网页的开发过程中,会受到很多外在因素的影响,这些因素也是造成中文乱码的重要因素,主要体现在以下几点:2.1 操作系统的字符编码由于操作系统存在很多版本,因此其字符编码也不尽相同,对于很多操作系统来讲,默认的编码方式是Latin-1的编码方式,即很多操作系统默认是不支持中文的。
但是,值得庆幸的是,目前很多操作系统可以通过修改其配置文件,更改它的编码方式,能够满足不同用户对操作系统的需求。
JSP中文乱码问题解决办法

JSP中文乱码问题解决办法当用request对象获取客户提交的汉字字符时,会出现乱码问题,所以对含有汉字字符的信息必须进行特殊处理。
常见的几种字符集编码:⏹ASCII码:不支持中文⏹ISO-8859-1:不支持中文⏹GB2313、GBK:支持中文⏹Unicode:支持中文⏹UTF-8:支持中文在解决JSP中文乱码问题前,弄清以下几点:(1) windows平台采用的默认字符集编码是:GBK(2) IE浏览器默认采用UTF-8字符集编码方式发送Http请求。
(3) Tomcat在处理Get请求时,永远采用ISO-8859-1编码;Tomcat在处理Post请求时,默认采用ISO-8859-1编码;如果进行了如下设置request.setCharacterEncoding(“GBK”),则采用GBK编码。
可以使用如下几种方式解决JSP中文乱码问题。
1、方法一:调用自定义的转换函数<%@page contentType="text/html;charset=GB2312"%><%!public String getStr(String s) {String str = s;try {byte[] b = str.getBytes("ISO-8859-1");str = new String(b);return str;} catch (Exception e) {return str;}}%>使用内置对象request将获取的数据,使用ISO-8859-1进行重新编码,并保存到一个字节数组中,然后调用new String()方法,以GBK方式将这个字节数组构造出一个新的字符串,这个新的字符串就是我们想要的结果。
适用于以下三种情况:(1) 以Get方式提交表单,提交的数据中包含汉字字符。
(2) 以Post方式提交表单,提交的数据中包含汉字字符。
5种JSP页面显示为乱码的解决方法

5种JSP页面显示为乱码的解决方法5种JSP页面显示为乱码的解决方法1. JSP页面显示乱码。
2. Servlet接收Form/Request传递的参数时显示为乱码3. JSP接收Form/Request传递的参数时显示为乱码4. 用<jsp:forward page="catalog2.html"></jsp:forward>时页面显示乱码5. 数据库存取的时候产生乱码。
下面给出全部解决方法:1. JSP页面显示乱码。
第一种为在页面的开头加上:<%@ page language="java" contentType="text/html; charset=GBK" pageEncoding="GBK"%> <!--这里的GBK可以由gb2312代替,此处以GBK为例。
下同 -->注:有时候如果不再页面开头加上这句,则页面中无法保存中文字符,并提示:中文字符在不能被iso-8859-1字符集mapped,这是由于默认情况下,JSP是用iso-8859-1来编码的,可以在Window->Preferences->General->Content Type选项下,在右边的窗口选择Text->Jsp,然后在下面的Default Encoding由默认的iso-8859-1改为GBK,然后点击update即可解决。
然而这种方式会带来一些问题:由于这一句在其他文件include该文件的时候不能被继承,所以include它的文件也需要在文件开头加上这句话,此时如果用的是pageEncoding="gbk"则会出现问题。
类似于org.apache.jasper.JasperException: /top.jsp(1,1) Page directive: illegal to have multiple occurrences of contentType with different values (old: text/html;charset=GBK, new: text/html;charset=gbk).类似地,如果两个文件一个用的是gbk,一个用的是gb2312也会出现问题。
JSP与MySQL交互的中文乱码解决方案及总结

String s2 = new String(s1.getBytes("gb2312"),"ISO-8859-1")进行转码,其中s1为中文字符串.然后再写入到数据库一切显示正常。
为解决这个问题查看了n多资料,现作一个总结:由于字符集和字符编码方式的不同,在OS以及程序之间传递数据(尤其是multiple character sets中的数据)时便会产生乱码以及字符信息的丢失.解决这个问题的关键便是了解数据输出端和接收端使用的字符集和字符编码方式,如果这两种编码方式不同,便需要在数据出口或入口处进行 转码。一般的说,在编写代码,编译,以及运行期间都会字符数据的传递,因此需要特别小心。
IE也可以设置成总是使用UTF-8编码来发送请求.应用程序层,每个配置在服务器下的程序都可以设置自己的编码方式,这个我目前还没有用到,以后再学习。
运行时的转码,运行时期,应用程序很可能需要与外部系统进行交互,例如对数据库进行读写,对外部文件进行读写.在这些情况下,应用程序免不了要和外部系统进行数据交换。那么对于中文字符, 数据出入口的编码方式就显得特别重要了。一般外部系统都有自己的字符编码方式,我的例子中配置的MySQL就是使用的UTF-8编码。JSP页面通过设定"charset=gb2312",
encoding for text file"。如果设置为GBK,那么编写代码并保存这关就过了。
对于JSP程序而言,编写完代码后就交给Container,首先它们会被转成.java文件,然后编译成.class才能提交给服务器执行.这个过程也存在字符编码问题.java编译器(javac)使用操作系统的语言环境作为默认的字符编码方式,JRE(Java Runtime Environment)也是这样。只有当编译和运行环境的字符编码方式与存储源文件的编码方式相同时,中文字符才能正确地显示。否则就需要在运行时进行转码,使它们使用兼容的编码。这里的设置可以分为几个层次:操作系统层支持的语言,这是最重要的,因为它会影响JVM的默认字符编码方式,同时对字符的显示,如字体等有直接影响;J2EE服务器层,大多数服务器都可以对字符编码进行自定义的配置,例如Tomcat就可以通过web.xml中设置javaEncoding参数设置字符编码,默认是UTF-8.
JSP出现中文乱码问题解决方法详解

JSP出现中⽂乱码问题解决⽅法详解在介绍⽅法之前我们⾸先应该清楚具体的问题有哪些,笔者在本博客当中论述的JSP中⽂乱码问题有如下⼏个⽅⾯:页⾯乱码、参数乱码、表单乱码、源⽂件乱码。
下⾯来逐⼀解决其中的乱码问题。
⼀、JSP页⾯中⽂乱码在JSP页⾯中,中⽂显⽰乱码有两种情况:⼀种是HTML中的中⽂乱码,另⼀种是在JSP中动态输出的中⽂乱码。
先看⼀个JSP程序:<%@ page language="java" import="java.util.*" %><html><head><title>中⽂显⽰⽰例</title></head><body>这是⼀个中⽂显⽰⽰例:<%String str = "中⽂";out.print(str);%></body></html>上⾯这个JSP程序看起来好像是在页⾯显⽰⼏句中⽂⽽且标题也是中⽂。
运⾏后在浏览器中显⽰如图所⽰原因在于没有在JSP中指定页⾯显⽰的编码,消除乱码的解决⽅案很简单上⾯代码中page命令修改成如下所⽰即可<%@ page language="java" import="java.util.*" contentType="text/html; charset=GB2312" %><html><head><title>中⽂显⽰⽰例</title></head><body>这是⼀个中⽂显⽰⽰例:<%String str = "中⽂";out.print(str);%></body></html>再次运⾏乱码消失,原理就是向页⾯指定编码为GB2312,那么页⾯就会按照此编码来显⽰,于是乱码消失。
jsp、servlet中文乱码终极解决方法

由此可见在servlet中用doGet()方法或是在JSP中用get方法进行处理要注意。这毕竟涉及到要通过浏览器传递参数信息,很有可能引起常用字符集的冲突或是不匹配。
//这个地方理解为request.setCharacterEncoding("GBK");set的是request中的body,而不是header部分,get请求时把参数放在url后边,不是放在body中,所以这个时候request.setCharacterEncoding("GBK")就没有起到作用,换到post提交就没有问题了,经测试通过,
(二) 当用Request对象获取客户提交的汉字代码的时候,会出现乱码:
解决的办法是:要配置一个filter,也就是一个Servelet的过滤器,代码如下:
public void doFilter(ServletRequest request, ServletResponse response,
String str=request.getParameter(“girl”);
Byte B[]=str.getBytes(“ISO-8859-1”);
Str=new String(B);
通过上述转换的话,提交的任何信息都能正确的显示。
(三) 在Formget请求在服务端用request. getParameter(“name”)时返回的是乱码;按tomcat的做法设置Filter也没有用或者用 request.setCharacterEncoding("GBK");也不管用问题是出在处理参数传递的方法上:如果在servlet中用 doGet(HttpServletRequest request, HttpServletResponse response)方法进行处理的话前面即使是写了:
jsp页面添加中文数据到mysql数据库乱码问题

jsp页面添加中文数据到mysql数据库乱码问题jsp页面中输入中文数据,保存到mysql数据库中是乱码,从数据库中读取数据后在jsp页面显示还是乱码,要解决此问题需从以下几个方面考虑:1、获得mysql的字符集查看mysql字符集的命令是:mysql> show variables like "character_set_%";character_set_system 总是utf-8这5个最好总是保持一致,character_set_clientcharacter_set_connectioncharacter_set_databasecharacter_set_resultscharacter_set_server2、在jsp页面指定编码格式,保证跟mysql的字符集一致:[java]view plaincopy1.<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>3、web.xml添加字符编码过滤器,编码方式也要保证跟mysql的字符集一致:[xhtml]view plaincopy1.<!-- 著名 Character Encoding filter -->2. <filter>3. <filter-name>encodingFilter</filter-name>4. <filter-class>5. org.springframework.web.filter.CharacterEncodingFilter6. </filter-class>7. <init-param>8. <param-name>encoding</param-name>9. <param-value>utf-8</param-value>10. </init-param>11. </filter>12.13. <filter-mapping>14. <filter-name>encodingFilter</filter-name>15. <url-pattern>*.do</url-pattern>16. </filter-mapping>注意:添加数据页面跟显示数据页面的编码格式要保持一致,不然的话就会出现添加到数据库中没乱码,从数据库中显示出现乱码的情况。
JSP中文乱码问题完全解决方案

request.setCharacterEncoding(this.encodingName);
}
chain.doFilter(request, response);
}
public void destroy() {
} else {
this.enable = false;
}
}
public void doFilter(ServletRequest request, ServletResponse response,FilterChain chain) throws IOException, ServletException {
四. 数据库操作中文乱码
在建立数据库的时候,应该选择支持中文的编码格式,最好能和JSP页面的编码格式保持一致,这样就可以尽可能减少数据库操作的中文乱码问题。同时在JDBC连接数据库的时候可以使用类似下面这种形式的URL。jdbc:microsoft:sqlserver://localhost:1433;DatabaseName=pubs;useUnicode=true;characterEncoding=gb2312
import javax.servlet.UnavailableException;
public class SetCharacterEncodingFilter implements Filter {
protected FilterConfig filterConfig;
protected String encodingName;
}
}
在web.xml中添加过滤器的配置如下:
<filter>
中文乱码问题解决方法

在Jsp文件问题时,中文乱码现象经常遇到,现将处理方法总结一下,供大家参考:(在各种编码方案中,UTF-8、GBK、GB2312都是支持中文显示的。
只是GBK比GB2312支持跟多的字符)一、JSP页面显示乱码Jsp文件页面显示乱码,这种情况比较好处理,在页面的Page指令加上如下一项就OK了:<%@ page contentType="text/html; charset=gb2312"%>注:如果是HTML页面显示乱码,则加上:<meta http-equiv="Content-Type" content="text/html; charset=gb2312"> 二、URL传递参数中文乱码当我们把一段中文字符作为参数传递个另一页面时,也会出现乱码情况,解决方法一如下:在参数传递时对参数编码,比如RearshRes.jsp?keywords=" + .URLEncoder.encode(keywords) 然后在接收参数页面使用如下语句接收keywords=newString(request.getParameter("keywords").getBytes("ISO-8859-1"),"UTF-8") ;解决方法二:修改tomcat的server.xml文件中URIEncoding。
<Connectordebug="0"acceptCount="100"connectionTimeout="20000"disableUploadTimeout="true"port="80"redirectPort="8443"enableLookups="false"minSpareThreads="25"maxSpareThreads="75"maxThreads="150"maxPostSize="0"URIEncoding="GBK"></Connector>这个方法主要针对从url中获取字符串的问题。
JSP中文乱码的产生原因及解决方案

JSP中文乱码的产生原因及解决方案在JSP的开发过程中,经常出现中文乱码的问题,可能一直困扰着大家,现在把JSP 开发中遇到的中文乱码的问题及解决办法写出来供大家参考。
首先需要了解一下Java中文问题的由来:Java的内核和class文件是基于unicode的,这使Java程序具有良好的跨平台性,但也带来了一些中文乱码问题的麻烦。
原因主要有两方面,Java和JSP文件本身编译时产生的乱码问题和Java程序于其他媒介交互产生的乱码问题。
首先Java(包括JSP)源文件中很可能包含有中文,而Java和JSP源文件的保存方式是基于字节流的,如果Java和JSP编译成class文件过程中,使用的编码方式与源文件的编码不一致,就会出现乱码。
基于这种乱码,建议在Java文件中尽量不要写中文(注释部分不参与编译,写中文没关系),如果必须写的话,尽量手动带参数-ecoding GBK或-ecoding gb2312或-ecoding UTF-8编译;对于JSP,在文件头加上<%@ page contentType="text/html;charset=GBK"%>或<%@ page contentType="text/html;charset=gb2312"%>基本上就能解决这类乱码问题。
下面是一些常见中文乱码问题的解决方法(下面例子中ecoding采用的是gb2312,也可设为ecoding GBK或ecoding UTF-8):一、JSP页面乱码这种乱码问题比较简单,一般是页面编码不一致导致的乱码,一般新手容易出现这样的问题,具体分以下两种情况:➢未指定使用字符集编码下面的显示页面(display.jsp)就出现乱码:<html><head><title>JSP的中文处理</title><meta http-equiv="Content-Type" content="text/html charset=gb2312"> </head><body><%out.print("JSP的中文处理");%></body>这种乱码的原因是没有在页面里指定使用的字符集编码,JSP页面中出现了中文字符,而默认的ISO-8859-1字符集中无中文字符,解决方法:只要在页面开始地方用下面代码指定字符集编码即可,在JSP页面中指定编码方式(gb2312),和浏览器解码方式设置相同,即在页面的第一行加上:<%@ page contentType="text/html; charset=gb2312"%>,就可以消除乱码了。
乱码解决的四种方法

乱码解决的四种方法下边提供4种不同情况的乱码解决方案,基本上包括了web开发中出现乱码的不同情况。
主要针对java+ mysql 开发环境提出的乱码解决方案,只要作相应修改,可以用于不同语言环境的乱码问题解决。
下边提供4种不同情况的乱码解决方案,基本上包括了web开发中出现乱码的不同情况。
主要针对java+mysql开发环境提出的乱码解决方案,只要作相应修改,可以用于不同语言环境的乱码问题解决。
一、JSP页面显示乱码下面的显示页面(display.jsp)就出现乱码:程序代码<html><head><title>JSP的中文处理</title><meta http-equiv="Content-Type" content="text/html; charset=gb2312"></head><body><%out.print("JSP的中文处理");%></body></html>对不同的WEB服务器和不同的JDK版本,处理结果就不一样。
原因:服务器使用的编码方式不同和浏览器对不同的字符显示结果不同而导致的。
解决办法:在JSP页面中指定编码方式(gb2312),即在页面的第一行加上:<%@ page contentType="text/html; charset=gb2312"%>,就可以消除乱码了。
完整页面如下:<%@ page contentType="text/html; charset=gb2312"%><html><head><title>JSP的中文处理</title><meta http-equiv="Content-Type" content="text/html; charset=gb2312"></head><body><%out.print("JSP的中文处理");%></body></html>二、表单提交中文时出现乱码下面是一个提交页面(submit.jsp),代码如下:程序代码<html><head><title>JSP的中文处理</title><meta http-equiv="Content-Type" content="text/html; charset=gb2312"></head><body><form name="form1" method="post" action="process.jsp"><div align="center"><input type="text" name="name"><input type="submit" name="Submit" value="Submit"></div></form></body></html>下面是处理页面(process.jsp)代码:程序代码<%@ page contentType="text/html; charset=gb2312"%><html><head><title>JSP的中文处理</title><meta http-equiv="Content-Type" content="text/html; charset=gb2312"></head><body><%=request.getParameter("name")%></body></html>如果submit.jsp提交英文字符能正确显示,如果提交中文时就会出现乱码。
jsp读取数据库中文乱码问题

jsp读取数据库中文乱码问题这个问题是从项目中设计数据库和操作数据库的人不同而造成的。
所用的数据库是sybase,设计时把数据类型设计为nvarchar了,如果是中文,读取出来就会得到乱码。
我试了好多方法还是不行,最后无奈,只好将数据类型改为varchar了。
所以在此总结一下中文乱码问题。
一、JSP与页面参数之间的乱码JSP获取页面参数时一般采用系统默认的编码方式,如果页面参数的编码类型和系统默认的编码类型不一致,很可能就会出现乱码。
解决这类乱码问题的基本方法是在页面获取参数之前,强制指定request获取参数的编码方式:request.setCharacterEncoding("GBK")或request.setCharacterEncoding("gb2312")。
如果在JSP将变量输出到页面时出现了乱码,可以通过设置response.setContentType("text/html;charset=GBK")或response.setContentType("text/html;charset=gb2312")解决。
二、Java与数据库之间的乱码大部分数据库都支持以unicode编码方式,所以解决Java与数据库之间的乱码问题比较明智的方式是直接使用unicode编码与数据库交互。
很多数据库驱动自动支持unicode,如Microsoft的SQLServer驱动。
其他大部分数据库驱动,可以在驱动的url参数中指定,如如mm的mysql驱动:jdbc:mysql://localhost/WEBCLDB?useUnicode=true&characterEncoding=GBK。
三、Java与文件/流之间的乱码Java读写文件最常用的类是FileInputStream/FileOutputStream和FileReader/FileWriter。
Jsp乱码解决方法小总结
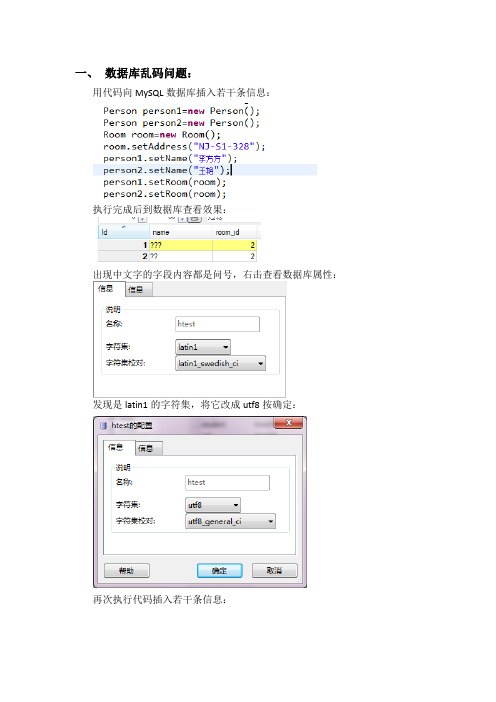
一、数据库乱码问题:用代码向MySQL数据库插入若干条信息:执行完成后到数据库查看效果:出现中文字的字段内容都是问号,右击查看数据库属性:发现是latin1的字符集,将它改成utf8按确定:再次执行代码插入若干条信息:仍然是乱码,不管是改了表的字符集还是数据库的字符集都还是乱码。
当遇到这种情况的时候,需要找到MySQL安装路径,在开始的所有程序中找到:去到相应的路径,找到配置文件并打开,找到配置文件的默认字符集:有两处,发现默认字符集是latin1,将其改为utf8。
保存完成后,重启MySQL服务:再次执行代码二、JSP页面乱码问题:当JSP页面出现乱码时,需要分以下几种情况。
1)在body标签中输入任意中文,若显示出现乱码:则说明JSP页面的字符集编码未正确指定。
将pageEncodeing设置为utf-8,如下:刷新页面查看:2)如果正确指定页面的字符集编码仍然是乱码问题,可能是页面中设置了多个不同的编码字符集:乱码情况如下:将其设置一致以后:如果到这里JSP页面仍然显示乱码,在页面的<hear></head>标签内加入:看到这里,可能同学并不明白以上的设置的具体含义:第一处的编码格式为jsp文件的存储格式,MyEclipse会根据这个编码保存、编译文件。
第二处编码为解码格式,如果不设置默认为ISO-8859-1解码。
第三处编码为控制浏览器的解码方式,一般不需要设置这个。
3)JSP页面之间使用form表单提交时出现乱码:发送name的页面:接收name的页面:出现了乱码,先检查两个JSP页面编码是否统一,如果统一是gb2312或者utf-8,但还是有乱码,可以进行编码转换:再次发送:如果觉得个接收都要进行编码转换十分麻烦,可以使用过滤器:MyFilter.java完成相应的过滤器类之后需要在web.xml中进行配置:4) JSP页面通过URL传递中文参数的乱码问题: 发送的页面可以先进行编码:接收页面进行解码:三、JSP页面到JAVA的乱码问题:一般使用编码转换即可解决:。
JSP+Servlet+mysql中文乱码问题

中文乱码解决方法:(1)在servlet中加上下面两行代码:request.setCharacterEncoding("utf-8");response.setContentType("text/html;charset=utf-8");或者建立专门的过滤文件:普通java文件:package com;import java.io.IOException;import javax.servlet.Filter;import javax.servlet.FilterChain;import javax.servlet.FilterConfig;import javax.servlet.ServletException;import javax.servlet.ServletRequest;import javax.servlet.ServletResponse;public class EncodeFilter implements Filter{public void destroy() {}public void doFilter(ServletRequest request, ServletResponse response,FilterChain chain) throws IOException, ServletException {request.setCharacterEncoding("utf-8");response.setContentType("text/html;charset=utf-8");chain.doFilter(request,response);}public void init(FilterConfig arg0) throws ServletException {}}Web.xml中进行配置:<filter><filter-name>EncodeFilter</filter-name><filter-class>com.EncodeFilter</filter-class></filter><filter-mapping><filter-name>EncodeFilter</filter-name><url-pattern>/*</url-pattern>(此处是对所有类型的文件进行过滤,若为*.jsp只过滤jsp 页面)</filter-mapping>(2)Jsp页面必须加上Method=post(3)数据库连接Contex.xml中要加编码jdbc:mysql://localhost:3306/hwdb?autoReconnect=true&useUnicode=true&character Encoding=UTF-8如果是用hibernate连接的数据库,连接字符串同上(4)数据库编码采用UTF-8,与上面编码保持一致,字符校对集默认即可。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
JSP乱码终极解决方案(2)2008-09-27 01:53 A.M2,具体说来,需要哪些信息才能确定项目中的乱码的根源.a,开发者所用的操作系统b,j2ee容器的名称,版本c,数据库的名称,版本(精确版本)以及jdbc驱动的版本d,出现乱码的source code(比如是system out 出来的,还是jsp页面中的,如果是jsp中的,那么头部声明的情况也很重要)3,如何初步分析乱码出现的原因.有了上述的信息,基本上就可以发帖求助了,相信放到javaworld等论坛上,很快就会有高手给你提出有效的解决方案的.当然不能总靠发帖求助,也要试试自行解决问题.如何下手呢?a,分析一下你的"乱码"到底是什么编码.这个其实不难,比如System.out.println(testString);这一段出现了乱码,那么不妨用穷举法猜测一下它的实际编码格式.System.out.println(new String(testString.getBytes("ISO-8859-1〃),"gb2312〃));System.out.println(new String(testString.getBytes("UTF8〃),"gb2312〃));System.out.println(new String(testString.getBytes("GB2312〃),"gb2312〃));System.out.println(new String(testString.getBytes("GBK"),"gb2312〃));System.out.println(new String(testString.getBytes("BIG5〃),"gb2312〃));等等,上述代码的意思是用制定的编码格式去读取testString这个"乱码",并转换成gb2312(此处仅以中文为例)然后你看哪一个转换出来的结果是ok的,那就……b,如果用上面的步骤能得到正确的中文,说明你的数据肯定是在的,只不过是界面中没有正确显示而已.那么第二步就该纠正你的view部分了,通常需要检查的是jsp中是否选择了正确的页面编码.在此要声明被很多人误解的一点,那就是<%@ page contentType="text/html; charset=GB2312〃%>指令和<META http-equiv=Content-Typecontent="text/html; charset=gb2312〃>两者的不同.通常网上的很多文章在提到中文问题时都是说数据库中选择unicode或者gb2312存储,同时在jsp中用page指令声明编码就可以解决.但是我觉得这种说法很不负责任,害的我费了N多时间为本来并不存在的乱码而郁闷.实际上page的作用是在jsp被编译成为html的过程中提供编码方式让java来"读取"表达式当中的String(有点类似于上面的第三个语句的作用),而meta的作用是众所周知的为IE浏览器提供编码选择,是用来"显示"最后的数据的.但是没有看到有人提醒这一点,我一直把page当成meta在用,导致本来是iso-8859的数据,被page指令读成gb2312,于是乱码,所以又加了编码转化的函数把所有的string数据都从iso8859转到gb2312(为什么这么转,当时也没考虑这么多,因为这么做可以正常显示了,所以就这么改了,呵呵当时实在没有时间慢慢排查问题了).4,数据库选择什么样的编码比较好.目前流行的DB主要有sql server,mysql,oracle,DB2等,其中mysql作为免费DB中的老大,性能和功能是得到公认的,安装配置比较方便,相应的driver也比较完善,性价比是绝对的OK.所以就以mysql为例.我个人建议采用mysql的默认编码来存储,也就是iso-8859-1(在mysql的选项中对应于latin-1).理由主要有这么几个,一是iso-8859-1对中文的支持不错;二是跟java中的默认编码一致,至少在很多地方免除了转换编码的麻烦;三是默认的比较稳定,兼容性也更好,因为多编码的支持是由具体的DB产品提供的,别说跟其它的DB会不兼容,即使自身的不同版本也可能出现兼容性的问题.例如mysql 4.0以前的产品中,很多中文的解决方案是利用connection中的characterEncoding字段来制定编码,比如gb2312什么的,这样是ok的,因为原数据都是ISO8859_1编码,jdbc驱动会采用url里面指定的character set来进行编码,resultSet.getString(*)取出的就是编码后的字符串.这样就直接拿到gb2312的数据了.但是mysql 4.1的推出给很多dbadmin带来了不小的麻烦,因为mysql4.1支持column level 的characterset,每个table,column都可以指定编码,不指定就是ISO8895_1,因此jdbc取出数据后会根据column的character set来进行编码,而不再是用一个全局的参数来取所有的数据了.这从另一个方面也说明了乱码问题的产生实在是很复杂的事情,原因太多了.我也只是针对自己遇////////////////////////////////////////////////////////////////////////////////////////jsp中文问题解决之道[转载]和Java一样,JSP是目前比较热门的一个话题.它是一种在服务器端编译执行的Web设计语言,因为脚本语言采用了Java,所以JSP继承了Java的所有优点.可是在使用JSP程序的过程中,常遇到中文乱码问题,很多人为此头疼不已,初学的时候我就深受其害,而且使用平台不同,中文乱码问题的解决方法也不同,无形中增加了学习JSP的难度.其实,在彻底了解相关原因后,问题还是比较容易解决的.,以下是我总结的解决方法,相信对读者会有一定的借鉴意义. (因为我使用得最多的是Tomcat 环境,所以主要是以Tomcat为例,其它的环境只会提及一下,但解决办法也是差不多的!每个国家(或区域)都规定了计算机信息交换用的字符编码集,如美国的扩展ASCII码、中国的GB2312-80、日本的JIS 等,作为该国家(区域)信息处理的基础,有着统一编码的重要作用.由于各本地字符集代码范围重叠,相互间信息交换困难,软件本地化版本独立维护成本较高.因此有必要将本地化工作中的共性抽取出来,做一致性处理,将特殊的本地化处理内容降低到最少,这就是所谓的国际化(I18N).各种语言信息被规范为本地信息,而底层字符集采用包含了所有字符的Unicode.相信了解JSP代码的读者对ISO8859-1一定不陌生,ISO8859-1是我们平时使用比较多的一个CodePage,它属于西欧语系.GB2312-80 是在国内计算机汉字信息技术发展初始阶段制订的,其中包含了大部分常用的一、二级汉字和9区的符号.该字符集是几乎所有的中文系统和国际化的软件都支持的中文字符集,这也是最基本的中文字符集.GBK 是GB2312-80 的扩展,是向上兼容的.它包含了20902个汉字,其编码范围是0x8140~0xFEFE,剔除高位0x80 的字位,其所有字符都可以一对一映射到Unicode 2.0,也就是说Java实际上提供了对GBK 字符集的支持.>GB18030-2000(GBK2K) 在GBK 的基础上进一步扩展了汉字,增加了藏、蒙等少数民族的文字.GBK2K 从根本上解决了字位不够、字形不足的问题.1.Tomcat 4开发平台这个版本应该是我们经常用到的版本,所以讨论得会比较详细.RWC2008发表于2008-10-11 11:14Windows 98/2000下的Tomcat 4以上版本都会出现中文问题(而在Linux下和Tomcat 3.x中则没有问题),主要表现是页面显示乱码.为解决这个问题,最简单的方法就是在每个JSP的页面开始处加上<%@ page language="Java"contentType="text/html; charset=gb2312"%>.不过,这还不够,虽然这时显示了中文,但是发现从数据库读出的字段变成了乱码.经过分析发现: 在数据库中保存的中文字符是正常的,数据库用ISO8859-1字符集存取数据,而Java程序在处理字符时默认采用统一的ISO8859-1字符集(这也体现了Java国际化思想),所以在数据添加的时候Java和数据库都是以ISO8859-1方式处理,这样不会出错.但是在读取数据的时候就出现问题了,因为数据读出也采用ISO8859-1字符集,而JSP的文件头中有语句<%@ page language="Java" contentType="text/html; charset=gb2312"%>,这说明页面采用GB2312的字符集显示,这样就和读出的数据不一样.这时页面显示从数据库中读出的字符是乱码,解决的方法是对这些字符转码,从ISO8859-1转成GB2312,就可以正常显示了.这个解决办法对很多平台具有通用性,读者可以灵活运用.具体的方法会在以下详细讲解.另外,对于不同的数据库如SQLServer,Oracle,Mysql,Sybase等,字符集的选择很重要.如果考虑多语言版本,数据库的字符集就应该统一采用ISO8859-1,需要输出的时候在不同的字符集之间做转换就可以了.以下是针对不同平台的总结:(1) JSWDK只适合于普通开发,稳定性和其他问题可能不如商业软件. 由于JDK 1.3版性能要好于JDK 1.2.2很多,并且对中文的支持也较好,所以应该尽量采用. 现在jdk已经出到1.4版本了,所以如果允许最好升级到最新的版本,这样对中文的也会较好,而且还可以得到更多的支持.(2) Tomcat仅仅是一个对JSP 1.1、Servlet 2.2标准的实现, 我们不应该要求这个免费软件在细节和性能上都面面俱到, 它主要考虑英文用户, 这也是为什么不做特殊转换,汉字用URL 方法传递就有问题的原因.大部分IE浏览器缺省始终以UTF-8发送, 这似乎是Tomcat的一个不足, 另外Tomcat不管当前的操作系统是什么语言, 都按ISO8859去编译JSP, 似乎也欠妥.2.JSP代码的中文处理(1)如果与数据无关的操作,可以在页面首行加入(2)将Form中的值传送到数据库中再取出来后全变成了"?".Form用POST提交数据,代码中使用了语句:String st=new(request.getParameter("name").getBytes("ISO8859_1")), 而且也声明了charset=gb2312.要处理Form中传递的中文参数,应该在JSP中加入下面的代码,另外定义一个专门解决这个问题的getStr类,然后对接收到的参数进行转换:String keyword1=request.getParameter("keyword1");keyword1=getStr(keyword1);这样就可以解决问题了,代码如下:<%@ page contentType="text/html;charset=gb2312"%><%!public String getStr(String str){try{String temp_p=str;byte[] temp_t=temp_p.getBytes("ISO8859-1");String temp=new String(temp_t);return temp;}catch(Exception e){ }return "NULL";}%><%--[url][/url]测试--%><% String keyword="创联网络技术中心欢迎您的到来";String keyword1=request.getParameter("keyword1");keyword1=getStr(keyword1);out.print(keyword);out.print(keyword1);%>另外,流行的关系数据库系统都支持数据库Encoding,也就是说在创建数据库时可以指定它自己的字符集设置,数据库的数据以指定的编码形式存储.当应用程序访问数据时,在入口和出口处都会有Encoding 转换.对于中文数据,数据库字符编码的设置应当保证数据的完整性. GB2312、GBK、UTF-8 等都是可选的数据库Encoding,也可以选择ISO8859-1 (8-bit), 但会增加了编程的复杂度,ISO8859-1不是推荐的数据库Encoding.在JSP/Servlet编程时,可以先用数据库管理系统提供的管理功能检查其中的中文数据是否正确.(3)JDBC Driver的字符转换目前大多数JDBC Driver采用本地编码格式来传输中文字符,例如中文字符"0x4175"会被转成"0x41"和"0x75"进行传输.因此需要对JDBC Driver返回的字符以及要发给JDBC Driver的字符进行转换.当用JDBC Driver向数据库中插入数据时,需要先将Unicode转成Native code; 当JDBC Driver从数据库中查询数据时,则需要将Native code转换成Unicode.下面给出了这两种转换的实现:String native2Unicode(String s) {if (s == null || s.length() == 0) {return null;}byte[] buffer = new byte[s.length()];for (int i = 0; i s.length(); i++) { if (s.charAt(i)>= 0x100) {c = s.charAt(i);byte []buf = (""+c).getBytes();buffer[j++] = (char)buf[0];buffer[j++] = (char)buf[1];}else {buffer[j++] = s.charAt(i);}}return new String(buffer, 0, j);}要注意的是,有些JDBC Driver如果通过JDBC Driver Manager设置了正确的字符集属性,以上方法就不需要了.具体情况可参考相关JDBC的资料.其实理解了,中文乱码就这么一回事!反复使用就会摸出一定的门道了!我觉得以上的三种方法,只要你真的能弄懂,在遇到中文问题时,在这三种方法多试尝,我保证你不再会使这种中文问题所烦!以上只是自己的一些经验所谈,如果有什么不对,希望能提出,共同学习!//////////////////////////////////////////////////////////////////////////////////////////我的乱码之路--JSP与MySQL交互的中文乱码解决方案及总结首先实现了一个StringConvert bean(GBtoISO()和ISOtoGB()两个方法),解决了与MySQL 数据库交互的时候的部分中文乱码问题:在JSP程序中读取MySQL的中文内容,用这两个方法可以解决乱码问题.但是从JSP写入到MySQL的中文内容都成了乱码,并且再读出来的时候也显示为"??",在这里应该出现了编码转换过程中的字符信息丢失.郁闷的是,我在命令行窗口中登陆到MySQL 后,执行如"INSERT INTO customerVALUES('字符',…)"这样的语句时,写入到数据表中的中文内容又是显示正常的!!!数据库使用的字符集是utf8.碰壁多次,终于发现一条解决问题的路径:查看MySQL手册的时候,看到一条这样的语句:Toallow multiple character sets to be sent from the client, the "UTF-8"encoding should beused, either by configuring "utf8" as the defaultserver character set, or by configuringthe JDBC driver to use "UTF-8"through the characterEncoding property.此外,在查阅《MySQL权威指南》时,发现在查询语句中可以使用这样的语法将字符串转换到一个给定的字符集:_charset str.其中charset必须是服务器支持的某个字符集.在本例中,shopdb数据库使用的默认字符集是utf8,于是开始测试:先输入INSERT INTO publish Values('8',_gb2312 '高等教育出版社') 写入后中文变成"??"再试INSERT INTO publish Values('8',_gbk '高等教育出版社') 结果同上INSERT INTO publish Values('8',_utf8 '高等教育出版社') 这下更干脆,什么都没有!!快疯了!!没办法,用show character set;命令查看MySQL支持的字符集,心想我都试一遍总有一个能成功吧.浏览了一下,发现没有几个熟悉的字符集,就只剩下一个latin1(ISO-8859-1)比较常见了,不会是它吧,一试之下果然便是.INSERT INTO publish Values('8',_latin1 '高等教育出版社') 输入中文能够正确显示.这下总算找到方法了,把Tomcat下配置的数据库连接池的url改为"…characterEncoding=UTF-8",然后把写入数据库的中文内容用String s2 = new String(s1.getBytes("gb2312"),"ISO-8859-1")进行转码,其中s1为中文字符串.然后再写入到数据库一切显示正常.为解决这个问题查看了n多资料,现作一个总结:由于字符集和字符编码方式的不同,在OS以及程序之间传递数据(尤其是multiple character sets中的数据)时便会产生乱码以及字符信息的丢失.解决这个问题的关键便是了解数据输出端和接收端使用的字符集和字符编码方式,如果这两种编码方式不同,便需要在数据出口或入口处进行转码.一般的说,在编写代码,编译,以及运行期间都会字符数据的传递,因此需要特别小心.在编写代码的时候,你可能会使用某种开发工具,例如我正在使用的Eclipse.或许在写的时候一切正常,可是一旦保存后再次打开文档,所有的中文字符都变成了乱码.这是因为在编写的时候,这些字符数据都在内存的某个stream中,ok,这没问题,可是保存的时候这个stream中的数据会被写入到硬盘,使用的就是你的开发工具默认的编码方式,如果很不幸你的开发工具默认编码方式是ISO-8859-1,中文字符信息就不能正确地存储.Eclipse中可以这样查看并修改默认字符编码方式:Project->Properties->info,这里有"defaultencoding for text file".如果设置为GBK,那么编写代码并保存这关就过了.对于JSP程序而言,编写完代码后就交给Container,首先它们会被转成.java文件,然后编译成.class才能提交给服务器执行.这个过程也存在字符编码问题.java编译器(javac)使用操作系统的语言环境作为默认的字符编码方式,JRE(Java Runtime Environment)也是这样.只有当编译和运行环境的字符编码方式与存储源文件的编码方式相同时,中文字符才能正确地显示.否则就需要在运行时进行转码,使它们使用兼容的编码.这里的设置可以分为几个层次:操作系统层支持的语言,这是最重要的,因为它会影响JVM的默认字符编码方式,同时对字符的显示,如字体等有直接影响;J2EE 服务器层,大多数服务器都可以对字符编码进行自定义的配置,例如Tomcat就可以通过web.xml 中设置javaEncoding参数设置字符编码,默认是UTF-8.IE也可以设置成总是使用UTF-8编码来发送请求.应用程序层,每个配置在服务器下的程序都可以设置自己的编码方式,这个我目前还没有用到,以后再学习.运行时的转码,运行时期,应用程序很可能需要与外部系统进行交互,例如对数据库进行读写,对外部文件进行读写.在这些情况下,应用程序免不了要和外部系统进行数据交换.那么对于中文字符, 数据出入口的编码方式就显得特别重要了.一般外部系统都有自己的字符编码方式,我的例子中配置的MySQL就是使用的UTF-8编码.JSP页面通过设定"charset=gb2312",使用gb2312编码,在它与数据库交互的时候就需要进行显式的转码才能正确处理中文字符.RWC2008发表于2008-10-11 11:15解决jsp中文乱码问题2008-08-19 14:16增加filter:UTF/** To change this template, choose Tools | Templates* and open the template in the editor.*/package util;/**** @author MX*/import java.io.IOException;import javax.servlet.Filter;import javax.servlet.FilterChain;import javax.servlet.FilterConfig;import javax.servlet.ServletException;import javax.servlet.ServletRequest;import javax.servlet.ServletResponse;//import javax.servlet.UnavailableException;//import javax.servlet.http.HttpServletRequest;//import javax.servlet.http.HttpServletResponse;public class UTF implements Filter {protected String encoding = null;protected FilterConfig filterConfig = null;protected boolean ignore = true;public void destroy() {this.encoding = null;this.filterConfig = null;}public void doFilter(ServletRequest request, ServletResponse response,FilterChain chain) throws IOException, ServletException {// Conditionally select and set the character encoding to be usedif (ignore || (request.getCharacterEncoding() == null)) {String encoding = selectEncoding(request);if (encoding != null) {request.setCharacterEncoding(encoding);}}// Pass control on to the next filterchain.doFilter(request, response);}public void init(FilterConfig filterConfig) throws ServletException {this.filterConfig = filterConfig;this.encoding = filterConfig.getInitParameter("encoding");String value = filterConfig.getInitParameter("ignore");if (value == null) {this.ignore = true;}else if (value.equalsIgnoreCase("true")) {this.ignore = true;}else if (value.equalsIgnoreCase("yes")) {this.ignore = true;}else {this.ignore = false;}}protected String selectEncoding(ServletRequest request) {return (this.encoding);}}在web.xml中增加配置<filter><filter-name>Set Character Encoding</filter-name><filter-class>util.UTF</filter-class><init-param><param-name>encoding</param-name><param-value>UTF-8</param-value></init-param></filter><filter-mapping><filter-name>Set Character Encoding</filter-name><url-pattern>/*</url-pattern></filter-mapping>RWC2008发表于2008-10-11 11:15过滤器(Filter)解决JSP的Post和Request中文乱码2008-08-23 15:16import javax.servlet.*; import javax.servlet.http.*;public class CharsetFilter implements Filter{public void destroy(){}public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) {try{HttpServletRequest httpRequest = (HttpServletRequest)request;String method = httpRequest.getMethod().toLowerCase();if(method.equals("post")){//如果是post,即表单方法,直接设置charset即可request.setCharacterEncoding("UTF-8");}else if(method.equals("get")){//如果是get方法request.setCharacterEncoding("UTF-8");request = new HttpServletRequestWrapper((HttpServletRequest)request){public String getParameter(String str){try{return new String(super.getParameter(str).getBytes("iso-8859-1"),"GBK");}catch(Exception e){return null;}}};}chain.doFilter(request, response);}catch(Exception e){}}public void init(FilterConfig filterConfig){}}过滤器配置:<filter><filter-name>CharFilter</filter-name><filter-class>CharsetFilter</filter-class></filter><filter-mapping><filter-name>CharFilter</filter-name><url-pattern>/*</url-pattern><dispatcher>REQUEST</dispatcher></filter-mapping>RWC2008发表于2008-10-11 11:16jsp 页面传值中文乱码问题解决2008-09-16 13:43 1、jsp页面中文可以修改pageencoding的值来解决2、Filter可以解决post提交的中文乱码问题3、Tomcat server.xml 里面配置,解决get方式提交的问题第一点比较好办,不用多说。