Oracle数据库工具中文显示乱码问题的解决
ORACLE乱码问题解决

'UNKOWN'),
96,
DECODE(CHARSETFORM, 1, 'CHAR', 2, 'NCHAR', 'UNKOWN'),
一、修改oracle 字符集
由于Oracle 默认安装了SIMPLIFIED CHINESE_CHINA.WE8ISO8859P1字符集,不修改中文会出现乱码现象,输入如下命令:
[oracle@localhost ~]$sqlplus ‘/as sydba’
SQL>shutdown immediate
SQL>Startup restrict
SQL>select userenv('language') from dual;
SIMPLIFIED CHINESE_CHINA.WE8ISO8859P1
SQL>UPDATE sys.PROPS$ SET value$='ZHS16GBK' WHERE NAME='NLS_CHARACTERSET';
5.ALTER SYSTEM SET AQ_TM_PROCESSES=0;
6.ALTER DATABASE OPEN;
9.COL VALUE NEW_VALUE CHARSET
10.SELECT VALUE FROM NLS_DATABASE_PARAMETERS WHERE PARAMETER='NLS_CHARACTERSET';
1,
'VARCHAR2',
2,
'NVARCHAR2',
【IT专家】oracle数据库中文乱码的原因与解决

本文由我司收集整编,推荐下载,如有疑问,请与我司联系oracle数据库中文乱码的原因与解决2008/10/23 54423 资料: 很久以来,字符集一直是困扰着众多Oracle爱好者的问题,在此我们就这个问题做一些分析和探讨。
首先,我们要明确什么是字符集?字符集是一个字节数据的解释的符号集合,有大小之分,有相互的包括关系,如us7ascii就是zhs16gbk的子集,从us7ascii到zhs16gbk不会有数据解释上的问题,不会有数据丢失,Oracle对这种问题也要求从子集到超集的导出受支持,反之不行。
在所有的字符集中utf8应该是最大,因为它基于unicode,双字节保存字符(也因此在存储空间上占用更多)。
其次,一旦数据库创建后,数据库的字符集是不能改变的。
因此,在设计和安装之初考虑使用哪一种字符集是十分重要的。
数据库字符集应该是操作系统本地字符集的一个超集。
存取数据库的客户使用的字符集将决定选择哪一个超集,即数据库字符集应该是所有客户字符集的超集。
在实际应用中,和字符集问题关系最大的恐怕就是exp/imp了。
在做exp/imp时,如果Client 和Server的nls_lang设置是一样的,一般就没有问题的。
但是,要在两个不同字符集的系统之间导数据就经常会有这样或那样的问题,如,导出时数据库的显示正常,是中文,当导入到其他系统时,就成了乱码,这也是一类常见问题。
现在,介绍一些与字符集有关的NLS_LANG参数,NLS_LANG格式:NLS_LANG = language_territory.charset 有三个组成部分(语言、地域和字符集),每个成分控制了NLS子集的特性。
其中:language 指定服务器消息的语言。
territory 指定服务器的日期和数字格式。
charset 指定字符集例如:AMERICAN_7SCII AMERICAN _ AMERICA. ZHS16GBK 还有一些子集可以更明确定义NLS_LANG参数:DICT.BASE 数据字典基本表版本DBTIMEZONE 数据库时区NLS_LANGUAGE 语言NLS_TERRITORY 地域NLS_CURRENCY 本地货币字符NLS_ISO_CURRENCY ISO货币字符NLS_NUMERIC_CHARACTERS 小数字符和组分隔开NLS_CHARACTERSET 字符集NLS_CALENDAR 日历系统NLS_DATE_FORMAT 缺省的日期格式NLS_DATE_LANGUAGE 缺省的日期语。
数据库出现乱码的原因和解决办法

数据库出现乱码的原因和解决办法数据库出现乱码的原因和解决办法“在SQL*Plus中insert进的都是中文的,为什么一存入服务器后,再select出的就是”“有的时候,服务器数据先导出,重装服务器,再导入数据,结果,发生数据查询成”……这些问题,一般,是因为字符集设置不对照成的。
很久以来,字符集一直是困扰着众多Oracle爱好者的问题,笔者从事Oracle数据库管理和应用已经几年了,经常接到客户的类似上面提到的有关数据库字符集的“告急”和“求救”,今天,就这个问题打算做一些分析和探讨。
首先,我们要明确什么是字符集?字符集是一个字节数据的解释的符号集合,有大小之分,有相互的包括关系,如us7ascii就是zhs16gbk 的子集,从us7ascii到zhs16gbk不会有数据解释上的问题,不会有数据丢失,oracle对这种问题也要求从子集到超集的导出受支持,反之不行。
在所有的字符集中utf8应该是最大,因为它基于unicode,双字节保存字符(也因此在存储空间上占用更多)。
其次,一旦数据库创建后,数据库的字符集是不能改变的。
因此,在设计和安装之初考虑使用哪一种字符集是十分重要的。
数据库字符集应该是操作系统本地字符集的一个超集。
存取数据库的客户使用的字符集将决定选择哪一个超集,即数据库字符集应该是所有客户字符集的超集。
在实际的应用中,和字符集问题最相关的恐怕就是exp/imp了。
在做exp/imp是,如果client 和server的nls_lang设置是一样的,一般就没有问题。
但是,要在两个不同字符集的系统之间导数据就经常会有这样那样的问题,如,导出时数据库的显示正常,是中文,当导入到其他系统时,就成了乱码,这也是一类常见问题。
对于这个问题,有一个常用的转换方法,首先用一个二进制编辑器(如,UltraEdit)察看到出文件(DMP文件)的第二和第三字节,这两个字节的内容是服务器端的字符集,比如0001,那么在数据库中查找出它代表的字符集:然后,如果在导入数据时需要修改为ZHS16GBK,我们就需要知道如何修改这两个字节才能让他们和ZHS16GBK对应:因此,可以将这两个字节手工修改为0354(不足4位时前面补0),然后就可以正常导入数据了。
Linux安装Oracle出现乱码怎么解决

Linux安装Oracle出现乱码怎么解决
Linux系统下Oracle经常会出现乱码,不管是安装还是使⽤过程中都会出现中⽂乱码。
这是因为Linux系统中缺少了某些字体,只要安装了这些字体,就能解决这个问题了。
解决办法⼀:
⽅法如下:
把中⽂字体放到Oracle安装包的 jdk/jre/lib/font/fallback下就可以了。
对于使⽤Oracle图形化⼯具时出现的乱码问题:
把中⽂字体复制到 ~/.font下,然后执⾏:
复制代码代码如下:
$ sudo mkfontscale
$ sudo mkfontdir
以上就是Linux安装使⽤Oracle出现乱码怎么办的全部内容了,Oracle中会⽤到jre等字体,如果没有这些字体就会出现中⽂乱码。
解决办法⼆:
exportNLS_LANG=AMERICAN_AMERICA.UTF8
export LC_ALL=C
oracle级别⽤户执⾏即可。
英⽂界⾯显⽰。
[oracle@ora database]$ export LANG=en_US
以后改回来⽐较⿇烦,有个⽐较帅的⽅案,经过测试可⽤使⽤。
解决Linux下Oracle10g数据库em,dbca中文方块乱码问题

解决Linux下Oracle10g数据库em,dbca中文方块乱码问题解决 Linux 下 Oracle 10g 数据库 em,dbca 中文方块乱码问题今天在 linux 下装了 oracle 10g 数据库,装好后将 Linux 系统语言切换为中文后,发现Oracle 的em(Enterprise Manager)、dbca(database configuration assistant)中文界面、按钮全为方块或乱码,十分让人头痛。
通过Google,百度查找原因,经过多次尝试,终于解决看到了em、dbca 界面看到了可爱的中文。
先介绍一下我的系统坏境:操作系统 Oracle 版本 $LANG $ORACLE_HOME Red Hat Enterprise Linux AS 5 10.1.0.3 (10g) zh_CN.UTF-8 /opt/oracle/product/10.1.0/Db_1/linux 系统 oracle 10g 数据库 em,dbca 中文方块乱码问题具体解决方法:一、安装简体中文字体包fonts-chinese-3.02-9.6.el5:我们首先得安装rhel5.0 系统DVD 中自带的中文字体包fonts-chinese-3.02-9.6.el5.noarch.rpm,这是至关重要的。
如果没有安装此字体包,简体中文字体文件/usr/share/fonts/zh_CN/TrueType/zysong.ttf 和/usr/share/fonts/chinese/TrueType/zysong.ttf 就不存在的,中文显示就更无从说起了。
二、设置Linux 系统语言坏境: 1. export LANG=zh_CN.UTF-8三、拷贝替换 font.properties 文件,执行下面两条命令: 1. 2.3. # cd $ORACLE_HOME/jre/1.4.2/lib/ # cp font.properties.zh_CN.Redhat8.0 font.properties //注:也可以用font.properties.zh_CN_UTF8.Redhat,font.properties.zh_CN.* 替换font. properties。
oracle中文乱码解决方法

oracle中文乱码解决方法oracle中文乱码解决方法1. Oracle数据库设置数据库参数NLS_LANG为使Oracle数据库中存储与显示中文时无乱码问题,可以更改Oracle数据库的数据库参数NLS_LANG,更改该参数为中文字符集,如:simplified Chinese_China.ZHS16GBK,此参数设置会对数据库中的所有字符数据有效。
2. Oracle数据库中多个字符集混用的解决方案一般系统及数据库常用的字符集可能存在多样性,例如全角字符、英文字母、空格等,而Oracle数据库支持了多个字符集,用户可以在数据库中多个字符集混合使用。
例如,用UTF8字符集对中文、英文、全角字符编码;用UTF16字符集对Unicode字符编码;用GBK/GB2312字符集对中文字符编码。
3. 注意SQL语句及字符集的指定为了防止运行SQL语句时出现乱码,应当在SQL语句中指定运行的字符集,如:ALTER SESSION SET NLS_LANGUAGE=AMERICAN_AMERICA.AL32UTF84. 客户端应用指定编码格式对于客户端应用,如sqlplus、PL/SQL开发工具,需要在连接之前指定客户端编码格式以确保传输与显示时无乱码问题,这种解决方案比较常用,在客户端应用中设置NLS_LANG参数,让客户端的中文字符使用Unicode,例如: NLS_LANG = SIMPLIFIED CHINESE_CHINA.UTF8 即可成功连接Oracle数据库解决乱码问题。
5. 数据导入导出中文处理从其他数据库导入Oracle数据库时,应从源数据库中查找出字段编码,在导入时将字段编码转换成Oracle数据库中的字符编码,可以增加数据库中文字符的正常显示。
从Oracle数据库导出数据至其他数据库,应将Oracle 数据库中的字符编码转换成目标数据库的编码方式,以保证导出数据无乱码状况。
6. 中文乱码的原因分析中文乱码的常见原因之一是程序的编码格式未正确设置,将GBK/GB2312等字符集与UTF-8 等Unicode字符集混用,也会出现中文乱码的情况。
解决Oracle 中文乱码

解决Oracle 中文乱码一、什么是oracle字符集Oracle字符集是一个字节数据的解释的符号集合,有大小之分,有相互的包容关系。
ORACLE 支持国家语言的体系结构允许你使用本地化语言来存储,处理,检索数据。
它使数据库工具,错误消息,排序次序,日期,时间,货币,数字,和日历自动适应本地化语言和平台。
SELECT * FROM V$NLS_PARAMETERS1 NLS_LANGUAGE SIMPLIFIED CHINESE2 NLS_TERRITORY CHINA3 NLS_CURRENCY RMB4 NLS_ISO_CURRENCY CHINA5 NLS_NUMERIC_CHARACTERS .,6 NLS_CALENDAR GREGORIAN7 NLS_DATE_FORMAT DD-MON-RR8 NLS_DATE_LANGUAGE SIMPLIFIED CHINESE9 NLS_CHARACTERSET AL32UTF810 NLS_SORT BINARY11 NLS_TIME_FORMAT HH.MI.SSXFF AM12 NLS_TIMESTAMP_FORMAT DD-MON-RR HH.MI.SSXFF AM13 NLS_TIME_TZ_FORMAT HH.MI.SSXFF AM TZR14 NLS_TIMESTAMP_TZ_FORMAT DD-MON-RR HH.MI.SSXFF AM TZR15 NLS_DUAL_CURRENCY RMB16 NLS_NCHAR_CHARACTERSET UTF817 NLS_COMP BINARY18 NLS_LENGTH_SEMANTICS BYTE19 NLS_NCHAR_CONV_EXCP FALSE二、如何查询Oracle的字符集ORACLE有三方面的字符集,一是oracel server端的字符集,二是oracle client端的字符集;三是dmp文件的字符集。
解决suse安装oracle中文显示乱码

在Linux上安装过Oracle的时候汉字都是“口口”形乱码最初时间比较紧张只能用英文安装,后来经过反复试验和整理,现在可以完全解决linux下oracle中文乱码的问题,下面是整理后的文档:我想在linux 9 下也应该能够实现吧需要软件j2sdk-1_4_2_04-linux-i586.binjavacn.zip一.安装JDK在/tmp下建立一个临时的文件夹---------------------------------------------------[root@tooth root]# cd /tmp[root@tooth root]# mkdir javacn[root@tooth root]# cd javacn----------------------------------------------------将 j2sdk-1_4_2_02-linux-i586.bin并保存到/tmp/javacn给文件加上可执行的权限----------------------------------------------------[root@tooth root]# chmod 755 j2sdk-1_4_2_02-linux-i586.bin----------------------------------------------------执行文件安装JDK----------------------------------------------------[root@tooth root]# ./j2sdk-1_4_2_02-linux-i586.bin----------------------------------------------------......(一大堆的license的信息)询问是否同意,当然选yes----------------------------------------------------[root@tooth root]# mv j2sdk1.4.2_02 /usr/j2sdk----------------------------------------------------现在JDK还不能算安装完成了,还要设置一下环境变量:----------------------------------------------------[root@tooth root]# vi $HOME/.bash_profile在export PATH前加入下面一段JAVA_HOME=/usr/j2sdkexport JAVA_HOMEJRE=$JAVA_HOME/jreexport JREPATH=$JAVA_HOME/bin:$JRE/bin:$PATH----------------------------------------------------存盘退出,执行[root@tooth root]# source .bash_profile 这样设置的环境变量就生效了二.安装系统字体将附件文件解压到/tmp/javacn中,解压后的结果如下所示:----------------------------------------------------[root@tooth root]# cd /tmp[root@tooth root]# cd javacn[root@tooth javacn]# ls -l-----------------------------------------------------rw-r--r-- 1 root root 8102 1970-01-01 font.propertiesdrwxr-xr-x 9 root root 4096 6月 24 15:36 j2sdk1.4.2_02-rw-r--r-- 1 root root 12642204 1970-01-01 SimSun18030.ttc-rw-r--r-- 1 root root 10500352 1970-01-01 simsun.ttc-rw-r--r-- 1 root root 7764 1970-01-01 sm.sh-rw-r--r-- 1 root root 260472 1970-01-01 tahomabd.ttf-rw-r--r-- 1 root root 265528 1970-01-01 tahoma.ttf下面需要将$JRE/lib中的font.properties文件改名备份,并将/tmp/javacn 中的font.properties文件拷贝到$JRE/lib中----------------------------------------------------[root@tooth root]# cd $JRE[root@tooth jre]# cd lib[root@tooth lib]# mv font.properties font.properties.bak[root@tooth lib]# cp /tmp/javacn/font.properties ./----------------------------------------------------剩下的操作就是执行/tmp/javacn/sm.sh了。
Linux下Oracle_sqlplus中文显示乱码问题的解决

问题:在Windows下sqlplus完全正常,可是到Linux下,sqlplus中文显示就出问题了,总是显示“??”。
解决方法:在/home/oracle/.bash_profile或/etc/profile中设置:export NLS_LANG="SIMPLIFIED CHINESE_CHINA.ZHS16GBK"oracle字符集的查询:A、oracle server 端字符集查询select userenv('language') from dual;select * from V$NLS_PARAMETERS;其中NLS_CHARACTERSET 为server端字符集NLS_LANGUAGE 为server端字符显示形式B、查询oracle client端的字符集echo $NLS_LANG原因分析:对用户反映情况的分析,发现字符集的设置不当是影响ORACLE数据库汉字显示的关键问题。
那么字符集是怎么一会事呢?字符集是ORACLE 为适应不同语言文字显示而设定的。
用于汉字显示的字符集主要有ZHS16CGB231280,US7ASCII,WE8ISO8859P1等。
字符集不仅需在服务器端存在,而且客户端也必须有字符集注册。
服务器端字符集是在安装ORACLE时指定的,字符集登记信息存储在ORACLE数据库字典的V$NLS_PARAMETERS表中;客户端字符集分两种情况,一种情况是sql*net 2.0以下版本,字符集是在windows的系统目录下的oracle.ini文件中登记的;另一种情况是sql*net 2.0以上(即32位)版本,字符集是在windows的系统注册表中登记的。
要在客户端正确显示ORACLE 数据库汉字信息,首先必须使服务器端的字符集与客户端的字符集一致;其次是加载到ORACLE数据库的数据字符集必须与服务器指定字符集一致。
因此,把用户存在的问题归纳分类,产生汉字显示异常的原因大致有以下几种:1.出现问题的原因1.1服务器指定字符集与客户字符集不同,而与加载数据字符集一致这种情况是最常见的,只要把客户端的字符集设置正确即可,解决办法见2.1。
Oracle数据库工具中文显示乱码问题的解决

Oracle数据库工具中文显示乱码问题的解决Oracle客户端查询工具有时会有查处的结果为中文时不能正常显示,要么为乱码,要么为问号,plsql出现这种问题,以为是版本造成的,用了老的和最新的还是一样,换了另外的数据库工具也一样,但注意一点,数据其实是没有问题的,取出来显示是正常的中文,只是在工具里显示的是问号。
其实问题的原理很简单,就是字符集设置不正确造成的,但如此简单的原理在解决的过程中却会遇到很多麻烦,下面结合我遇到和解决的过程,给朋友们一点思路,说不定你们跟我的问题一样,通过这篇文章不用再折腾了,很快搞定,感觉飘飘……首先讲讲字符集的知识,Oracle字符集是一个字节数据的解释的符号集合,有大小之分,有相互的包容关系。
ORACLE 支持国家语言的体系结构允许你使用本地化语言来存储,处理,检索数据。
它使数据库工具,错误消息,排序次序,日期,时间,货币,数字,和日历自动适应本地化语言和平台。
影响oracle数据库字符集最重要的参数是NLS_LANG参数。
它的格式如下:NLS_LANG = language_territory.charset它有三个组成部分(语言、地域和字符集),每个成分控制了NLS子集的特性。
其中: Language 指定服务器消息的语言,territory 指定服务器的日期和数字格式,charset 指定字符集。
如:AMERICAN _ AMERICA. ZHS16GBK。
从NLS_LANG的组成我们可以看出,真正影响数据库字符集的其实是第三部分。
所以两个数据库之间的字符集只要第三部分一样就可以相互导入导出数据,前面影响的只是提示信息是中文还是英文。
如何查询Oracle的字符集,很多人都碰到过因为字符集不同而使数据导入失败的情况。
这涉及三方面的字符集,一是oracel server端的字符集,二是oracle client端的字符集;三是dmp文件的字符集。
在做数据导入的时候,需要这三个字符集都一致才能正确导入。
oracle中文乱码解决方法

oracle中文乱码解决方法
oracle中文乱码解决方法
Oracle中文乱码解决方法
Oracle是一款非常流行的数据库管理系统,但是它有一个比较烦人的问题,就是中文乱码的问题,很多用户反映在使用Oracle时会遇到中文乱码,这让不少用户感到很恼火。
那么,Oracle中文乱码应该如何解决呢?
我们必须确定乱码的原因。
通常,中文乱码的原因有三种:第一种是Oracle数据库编码和程序编码不一致;第二种是Oracle数据库字符集不支持中文;第三种是Oracle数据库表字段设置不正确。
当我们确定了乱码的原因之后,就可以根据具体问题进行解决。
如果是数据库编码和程序编码不一致的问题,我们可以在Oracle数据库中指定编码,这样就可以解决乱码问题;如果是Oracle数据库字符集不支持中文,我们可以在Oracle数据库中添加支持中文的字符集,以解决乱码问题;如果是Oracle数据库表字段设置不正确,我们可以修改表字段的编码,以解决乱码问题。
解决Oracle中文乱码的方法有很多,但是要恰当地识别出乱码的原因,并采取相应的措施,才能有效地解决乱码问题。
因此,当我们遇到Oracle中文乱码问题时,要认真检查,找出乱码的原因,并采取相应措施,解决Oracle中文乱码问题。
Linux上安装Oracle汉字乱码完整解决方案

UAL $CLASSPATHADD oracle.sysman.vtx.vtxOemApp.OemApp $APPLICATION "$2" "$3" "$4"
"$5" "$6" "$7" "$8" "$9"
else
exec $JRE -DADMIN_WRL=$ADMIN_WRL -DORACLE_HOME=$ORACLE_HOME -DORBdisableLoca
tor=true -Djdbc.backward_compatible_to_816=true $JREOPTIONS_STRING -$CLASSPATH_Q
要查看系统上安装了这些程序包的哪些版本,运行以下命令:
-rw-r--r-- 1 root root 10500352 1970-01-01 simsun.ttc
-rw-r--r-- 1 root root 7764 1970-01-01 sm.sh
-rw-r--r-- 1 root root 260472 1970-01-01 tahomabd.ttf
一. 安装JDK
在/tmp下建立一个临时的文件夹
[root@lsjlinux root]# cd /tmp
[root@lsjlinux root]# mkdir javacn
[root@lsjlinux tmp]# cd javacn
从sun网站上下载j2sdk-1_4_2_02-linux-i586.bin并保存到/tmp/javacn
orcale 乱码原因与解决方法

解决方法1、insert之前先设定nls_lang环境变量为中文,然后再插入中文数据export NLS_LANG="SIMPLIFIED CHINESE_CHINA.ZHS16GBK"orexport NLS_LANG="SIMPLIFIED CHINESE_CHINA.ZHS32GB18030"如果这样后,反而插不进去,或者仍然为乱码,表示当初再建库时,没有选择中文字符集(export NLS_LANG=AMERICAN_AMERICA.AL32UTF8)2、dbca一个新库,在字符集处选择中文3、强行修改服务器端ORACLE当前字符集(此方法没有试过,但应该是要在安装db的时候已经安装了此字符集,属猜测)在用cmp命令加载数据前,先在客户端用sql*plus登录system DBA用户,执行下列SQL语句进行当前ORACLE数据库字符集修改:SQL >; create database character set US7ASCII1.* create database character set US7ASCII2.ERROR at line 1:3.ORA-01031: insufficient privileges你会发现语句执行过程中,出现上述错误提示信息,此时不用理会,实际上ORACLE数据库的字符集已被强行修改为US7ASCII,接着用cmp命令装载数据。
等数据装载完成以后,shutdown 数据库,再startup 数据库,用合法用户登录ORACLE数据库,在sql>;命令提示符下,运行select * from V$NLS_PARAMETERS,可以看到ORACLE数据库字符集已复原,这时再查看有汉字字符数据的表时,汉字已能被正确显示。
4、利用数据格式转储,避开字符集限制这种方法主要用于加载外来ORACLE数据库的不同字符集数据。
oracle导入表乱码问题解决方法
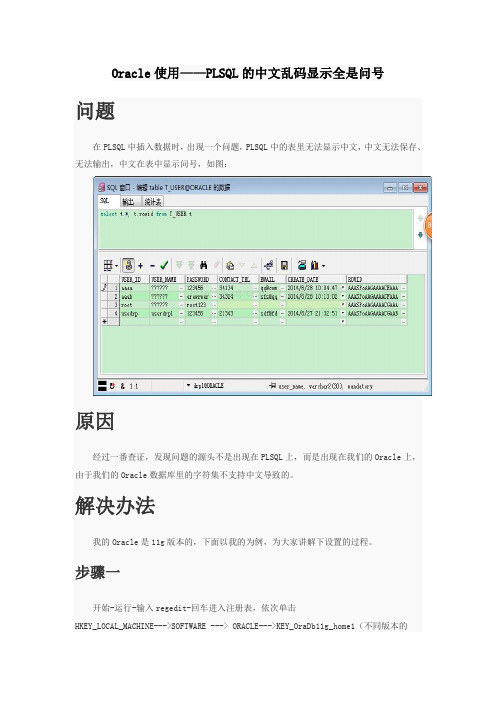
Oracle使用——PLSQL的中文乱码显示全是问号
问题
在PLSQL中插入数据时,出现一个问题,PLSQL中的表里无法显示中文,中文无法保存、无法输出,中文在表中显示问号,如图:
原因
经过一番查证,发现问题的源头不是出现在PLSQL上,而是出现在我们的Oracle上,由于我们的Oracle数据库里的字符集不支持中文导致的。
解决办法
我的Oracle是11g版本的,下面以我的为例,为大家讲解下设置的过程。
步骤一
开始-运行-输入regedit-回车进入注册表,依次单击
HKEY_LOCAL_MACHINE--->SOFTWARE ---> ORACLE--->KEY_OraDb11g_home1(不同版本的
Oracle显示的都不太一样,但都会包含home这个单词),找到“NLS_LANG”,查看数值数据是否为:“SIMPLIFIED CHINESE_CHINA.ZHS16GBK”,如果不是就将它设置为“SIMPLIFIED CHINESE_CHINA.ZHS16GBK。
”
如图
步骤二
设置完注册表后,接下来设置我们的环境变量,计算机(右键) --->属性--->高级系统设置--->高级--->环境变量--->新建,个人建议新建用户变量,变量名输入:“NLS_LANG”,变量值输入:“SIMPLIFIEDCHINESE_CHINA.ZHS16GBK”。
点击确定即可,到此我们就设置完了。
如图
效果
下面就看下我们的效果,关闭PLSQL,重新启动,中文果然出现了,。
orcle导入sql脚本乱码解决

3.orcal数据库乱码解决:
3.1导入脚本的时候,在工具pl/sql 查询数据,中文都显示成???,乱码怎么解决?
乱码:网上大同小异都说是客户端,与数据库的编码格式导致不一致才产生的问题。
3.2查看查看数据库字符集 select userenv('language') from dual;把这个代码运行到sql或者command中,然后把这个字符集复制出来,在环境变量中配置,
NLS_LNAG=复制的编码(网上大部分都是这样解决,网上非常详细)
我也是这样配置但是还是不行,其实是跟导入的数据有关系:
sqlplus里保存的sql脚本的格式都是ANSI的格式.所有导入sql脚本的时候,用记事本打开另存为,格式变成ANSI,就ok了。
这个这个一条弄了我很久时间(我的
就是这种问题)。
oracle显示中文为乱码的解决方法

在Redha t上安装O racle 10g没有设定字符集,采用的是操作系统默认字符集:WE8I SO8859P1,将字符集修改为:ZHS16GBK。
由于过程不可逆,首先需要备份数据库。
1.数据库全备2.查询当前字符集S QL> s elect * fr om nl s_dat abase_para meter s whe repa ramet er='N LS_CH ARACT ERSET';PA RAMET ER V ALUE---------------------------------------- ----------------------------------------NLS_CHAR ACTER SET WE8ISO8859P13.关闭数据库SQL>shutd own i mmedi ateD ataba se cl osed.Data basedismo unted.ORA CLE i nstan ce sh ut do wn.4.启动数据库到mo unt状态SQL> star tup m ountORACL E ins tance star ted.Total Syst em Gl obalArea 205520896 byte sFix ed Si ze 1266608 by tesV ariab le Si ze 100666448bytesData baseBuffe rs 100663296 byt esRe do Bu ffers 2924544 b ytesDatab ase m ounte d.5.限制se ssionSQL> alte r sys tem e nable rest ricte d ses sion;Syst em al tered.6.查询相关参数并修改SQL>showparam eterjob_q ueue_proce sses;NA ME TYPE VAL UE----------------------------------------------- ------------------------------jo b_que ue_pr ocess es integ er 10SQL> show para meter aq_t m_pro cesse s;N AME TYPE VA LUE------------------------------------ ----------- ------------------------------a q_tm_proce sses inte ger 0SQL> alte r sys tem s et jo b_que ue_pr ocess es=0;Syst em al tered.7.打开数据库SQL> alte r dat abase open;Dat abase alte red.8.修改字符集S QL> a lterdatab ase c harac ter s et ZH S16GB K;al ter d ataba se ch aract er se t ZHS16GBK*ER ROR a t lin e 1:ORA-12712: newchara cterset m ust b e a s upers et of oldchara cterset出现错误提示,新字符集必须是老字符集的超集,也就原来字符集是新字符集的子集,可以再Orac le官方文档上查询字符集包含关系。
Oracle数据库中文乱码问题解决

3.设 置 环 境 变 量 计 算 机 ->属 性 ->高 级 系 统 设 置 ->环 境 变 量 ->新 建 设 置 变 量 名 :NLS_LANG,变 量 值 :第 1步 查 到 的 值 , 我 的 是 AMERICAN_AMERICA.ZHS16GBK
4.去 虚 拟 机 修 改 注 册 表 值 , 修 改 NLS_LANG为 服 务 器 端 查 询 到 的 值 。 修 改 以 后 重 新 启 动 一 下 下 图 所 示 的 两 个后台服务
博客园 用户登录 代码改变世界 密码登录 短信登录 忘记登录用户名 忘记密码 记住我 登录 第三方登录/注册 没有账户, 立即注册
Or器 端 编 码 select userenv('language') from dual; 我 实 际 查 到 的 结 果 为 :AMERICAN_AMERICA.ZHS16GBK 2.执 行 语 句 select * from V$NLS_PARAMETERS , 查 看 第 一 行 中 PARAMETER项 中 为 NLS_LANGUAGE 对 应 的 VALUE项 中 是 否 和 第 一 步 得 到 的 值 一 样 。 如果不是,需要设置环境变量。
Oracle汉字乱码问题原因及解决方法

Oracle汉字乱码问题原因及解决方法如果Oracle服务器内部的字符集和NLS_LANG变量里保存的字符集相同,在进行Oracle 查询时,就会将Oracle中的数据直接查出来,返回给查询用户。
进行Oracle的插入操作,就会直接将插入的数据保存进数据库中。
但是如果不同的话,Oracle查询时,会根据这两个字符集的一个映射,将数据库中的数据作一个转换,再返回给查询用户。
进行插入操作时,也会根据映射,将插入的数据作一个转换,再插入数据库。
这也是产生乱码的原因,这一层转换,把数据都给转乱了。
解决办法:将数据库的字符集和NLS_LANG字符集设置的一样,就可以避免乱码的出现了。
修改数据库字符集的步骤如下:1、拥有修改权限(用管理用户登录)。
SQL> conn sys/sys as sysdba;2、关闭数据库。
SQL>shutdown immediate;3、启动数据库到Mount状态下。
SQL> STARTUP MOUNT;ORACLE instance started.Total System Global Area 76619308 bytesFixed Size 454188 bytesVariable Size 58720256 bytesDatabase Buffers 16777216 bytesRedo Buffers 667648 bytesDatabase mounted.SQL> ALTER SESSION SET SQL_TRACE=TRUE;Session altered.SQL> ALTER SYSTEM ENABLE RESTRICTED SESSION;System altered.SQL> ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;System altered.SQL> ALTER SYSTEM SET AQ_TM_PROCESSES=0;System altered.4、启动数据库SQL> Alter database open;5、修改字符集SQL> ALTER DATABASE CHARACTER SET ZHS16GBK;注:1. 如果数据库表中有CLOB类型的列,是不允许修改字符集的,解决方法为,先导出这个表的内容,然后删除这个表,修改完后,再导入这个表的内容就可以了。
oracle乱码问题

ORACLE数据库中文显示乱码问题的解决一.问题描述系统中ORACLE数据库在安装后不能正确显示中文,而是显示为'???'等此类乱码。
二.问题分析经检查发现,是数据库的安装脚本存在问题,为此需要更改smsc0数据库的安装脚本中的CreateDB.sql文件:需要将如下内容:CHARACTER SET WE8ISO8859P1更改为:CHARACTER SET ZHS16GBK三.问题处理和解决对于已经安装的数据库,需要做如下改动:1 登录SQLPLUS(需在操作系统的ORACLE用户下)sqlplus /nologconnect / as sysdba2 查询目前的字符集SQL> select * from props$ where name='NLS_CHARACTERSET';显示如下:NAME V ALUE$ COMMENT$NLS_CHARACTERSET XXXXX Character set其中VALUE$的值应该不是ZHS16GBK或ZHS16CGB231280等标志中文的字符集.3 修改字符集SQL> update props$ set value$='ZHS16GBK' where name='NLS_CHARACTERSET';SQL>commit;4 关掉数据库SQL>shutdown immediate5 重启动数据库SQL>startup6 查询字符集的设置是否生效SQL> select * from props$ where name='NLS_CHARACTERSET';应该有如下结果:NAME V ALUE$ COMMENT$NLS_CHARACTERSET ZHS16GBK Character set四.问题小结和补充如果还没安装客户端,那么在安装客户端时,指定与服务器相吻合的字符集即可;如果已经安装好了客户端,并且客户端为sql*net 2.0 以下版本,进入Windows的系统目录,编辑oracle.ini文件,用US7ASCII替换原字符集,重新启动计算机,设置生效;否则,如果,客户端为sql*net 2.0 以上版本,在Win98 下运行REGEDIT,第一步选HKEY_LOCAL_MACHINE,第二步选择SOFTWARE,第三步选择Oracle,第四步选择NLS_LANG,键入与服务器端相同的字符集(本例为:HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE\NLS_LANG :AMERICAN _ AMERICA. ZHS16GBK)。
PL_SQL汉字乱码和汉字查询不识别问题(已解决)

PL_SQL汉字乱码和汉字查询不识别问题(已解决)
PL/SQL 汉字乱码和汉字查询不识别问题(已解决)
原因分析:本机字符集设置的问题,即PL/SQL所在的终端的字符集设置与Oracle服务器端的字符集设置不统一;
处理方式:
1. 查询Oracle服务器端的字符集设置。
可以通过“SELECT * FROM v$nls_parameters;”获取服务端的字符集设置,如下图:s
2. 设置本地的字符集设置;打开系统”环境变量“设置窗口,查看NLS_LANG变量,若存在则直接参照服务端的设置调整变量值,否则,新建该变量并参照赋值。
特别说明,我将变量值与服务器设置(SIMPLIFIED CHINESE_CHINA.AL32UTF8)统一后问题问题得以解决,而当我把变量值设置为(SIMPLIFIED CHINESE_CHINA.ZHS16GBK)时,问题同样得到了解决。
3. 补充说明,在环境变量配置为AL32UTF8之后,在正常的执行
数据操作(DML)时正常。
但在执行创建表(含汉字备注)脚本的时候,出现“非法字符”的提示,调整为ZHS16GBK后恢复正常。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Oracle数据库工具中文显示乱码问题的解决
Oracle客户端查询工具有时会有查处的结果为中文时不能正常显示,要么为乱码,要么为问号,plsql出现这种问题,以为是版本造成的,用了老的和最新的还是一样,换了另外的数据库工具也一样,但注意一点,数据其实是没有问题的,取出来显示是正常的中文,只是在工具里显示的是问号。
其实问题的原理很简单,就是字符集设置不正确造成的,但如此简单的原理在解决的过程中却会遇到很多麻烦,下面结合我遇到和解决的过程,给朋友们一点思路,说不定你们跟我的问题一样,通过这篇文章不用再折腾了,很快搞定,感觉飘飘……
首先讲讲字符集的知识,Oracle字符集是一个字节数据的解释的符号集合,有大小之分,有相互的包容关系。
ORACLE 支持国家语言的体系结构允许你使用本地化语言来存储,处理,检索数据。
它使数据库工具,错误消息,排序次序,日期,时间,货币,数字,和日历自动适应本地化语言和平台。
影响oracle数据库字符集最重要的参数是NLS_LANG参数。
它的格式如下:
NLS_LANG = language_territory.charset
它有三个组成部分(语言、地域和字符集),每个成分控制了NLS子集的特性。
其中: Language 指定服务器消息的语言,territory 指定服务器的日期和数字格式,charset 指定字符集。
如:AMERICAN _ AMERICA.
ZHS16GBK。
从NLS_LANG的组成我们可以看出,真正影响数据库字符集的其实是第三部分。
所以两个数据库之间的字符集只要第三部分一样就可以相互导入导出数据,前面影响的只是提示信息是中文还是英文。
如何查询Oracle的字符集,很多人都碰到过因为字符集不同而使数据导入失败的情况。
这涉及三方面的字符集,一是oracel server端的字符集,二是oracle client端的字符集;三是dmp文件的字符集。
在做数据导入的时候,需要这三个字符集都一致才能正确导入。
查询oracle server端的字符集,有很多种方法可以查出oracle server 端的字符集,比较直观的查询方法是以下这种:SQL>select userenv(‘language’) from dual;
结果类似如下:AMERICAN _ AMERICA. ZHS16GBK
对于查询工具结果集中的中文乱码,其实有两种情况供参考:
1.安装了服务器及配套工具,这样还出现乱码就去检查注册表中的NLS_LANG项是否设置正确,很有可能是在安装时设置了不正确的字符集造成的;
2.只安装了客户端,没有配套工具(如sqlplus等),以10g为例,注册表中是没有NLS_LANG这项的,那么要改哪?同理,还是要改字符集,不过不是在注册表中设,是要在环境变量中增加或修改,即查看windows系统环境变量是否存在NLS_LANG,若存在则修改,
若不存在新建,将值设为服务器端的字符集,服务器端的字符集可以通过上面的方法查询。
也可以硬性修改服务器端字符集但是不推荐,因为这可能会造成意想不到的问题。
修改server端字符集(不建议使用)。
在oracle 8之前,可以用直接修改数据字典表props$来改变数据库的字符集。
但oracle8之后,至少有三张系统表记录了数据库字符集的信息,只改props$表并不完全,可能引起严重的后果。
正确的修改方法如下:
$sqlplus /nolog
SQL>conn / as sysdba;
若此时数据库服务器已启动,则先执行SHUTDOWN IMMEDIATE命令关闭数据库服务器,然后执行以下命令:
SQL>STARTUP MOUNT;
SQL>ALTER SYSTEM ENABLE RESTRICTED SESSION; SQL>ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0; SQL>ALTER SYSTEM SET AQ_TM_PROCESSES=0;
SQL>ALTER DATABASE OPEN;
SQL>ALTER DATABASE CHARACTER SET ZHS16GBK;
SQL>ALTER DATABASE national CHARACTER SET
ZHS16GBK;
SQL>SHUTDOWN IMMEDIATE;
SQL>STARTUP
对于导入导出的数据文件,也存在字符集匹配的问题,否则不能正常显示。
修改dmp文件字符集
dmp文件的第2第3字节记录了字符集信息,因此直接修改dmp文
件的第2第3字节的内容就可以‘骗’过oracle的检查。
这样做理论上
也仅是从子集到超集可以修改,但很多情况下在没有子集和超集关系的情况下也可以修改,我们常用的一些字符集,如US7ASCII,
WE8ISO8859P1,ZHS16CGB231280,ZHS16GBK基本都可以改。
因为改的只是dmp文件,所以影响不大。
具体的修改方法比较多,最简单的就是直接用UltraEdit修改dmp文
件的第2和第3个字节。
比如想将dmp文件的字符集改为ZHS16GBK,可以用以下SQL查出该种字符集对应的16进制代码:
SQL> select to_char(nls_charset_id('ZHS16GBK'), 'xxxx') from dual;
0354
然后将dmp文件的2、3字节修改为0354即可。
如果dmp文件很大,用ue无法打开,就需要用程序的方法了。
到这里,就算是把乱码的问题基本概述完了,大家可以参考自己的情况来修改,应该会解决的!。