多对多关系 sql语句的实现
connection类执行多条sql的方法_理论说明

connection类执行多条sql的方法理论说明1. 引言1.1 概述在数据库操作中,Connection类是一个非常重要的类。
它作为应用程序与数据库之间的桥梁,负责建立连接、执行SQL语句以及管理事务等功能。
在实际开发中,我们通常会遇到需要同时执行多条SQL语句的情况。
本文将从理论和实践两个方面对Connection类执行多条SQL的方法进行探讨和说明。
1.2 文章结构本文共分为五个部分。
首先引言部分概述了文章的主要内容和目标;其次是Connection类执行多条SQL的方法部分,介绍了Connection类的作用与特点以及多条SQL的执行方式和优缺点;接着是理论说明部分,阐述了数据库事务的概念与原则,ACID特性对多条SQL执行的影响以及并发控制与隔离级别选择;然后是方法实例及使用场景分析部分,给出了几种常见的方法示例,并对它们进行了应用场景分析;最后是结论部分,总结了多条SQL执行方法及其适用性,并展望了未来发展方向。
1.3 目的本文旨在通过对Connection类执行多条SQL的方法进行理论说明和实践案例分析,帮助读者深入了解Connection类在处理多条SQL语句方面的特点和问题,为读者提供指导性的实践经验和思路。
通过本文的阅读,读者将能够更加灵活地应用Connection类,优化多条SQL语句的执行效率,并在实际项目中解决相关的难题。
2. Connection类执行多条SQL的方法2.1 Connection类的作用与特点Connection类是用于建立Java程序与数据库之间的连接的核心类。
它提供了一系列方法来执行SQL语句、获取结果集以及管理事务等操作。
Connection 对象代表着一个实际的数据库会话,具有以下特点:- 可以通过DriverManager类来获取Connection对象。
- 它是线程不安全的,因此在多线程环境下需要进行适当的同步处理。
- 当使用完毕后,必须手动关闭Connection对象释放相关资源。
数据库设计中的多对多关系处理

数据库设计中的多对多关系处理在数据库设计中,多对多关系是一种常见的情况。
它表示两个实体之间存在着多对多的关联,即一个实体可以同时与多个其他实体相关联,而一个实体也可以被多个其他实体所关联。
在本文中,将介绍多对多关系的处理方法和技巧。
一、表结构设计在处理多对多关系时,一种常用的方式是通过引入中间表来处理。
中间表通常包含两个外键字段,分别与两个相关联的实体的主键进行关联。
通过中间表的设计,可以将多对多的关系转化为多个一对多的关系,简化了数据的处理和查询。
例如,我们假设存在两个实体表A和B,这两个实体之间存在多对多的关系。
为了处理这种关系,我们可以创建一个名为AB关系表的中间表,其中包含两个外键字段(例如A_ID和B_ID),分别与A表和B表的主键进行关联。
二、查询处理在数据库中查询多对多关系的数据时,我们通常需要进行关联查询。
通过关联查询,可以同时获取两个相关联实体之间的相关数据。
例如,假设我们想查询用户与角色之间的多对多关系。
我们可以通过以下SQL语句来实现查询:SELECT 用户表.姓名, 角色表.角色名称FROM 用户表INNER JOIN 用户角色关系表 ON 用户表.ID = 用户角色关系表.用户IDINNER JOIN 角色表 ON 用户角色关系表.角色ID = 角色表.ID通过以上查询语句,我们可以获取用户表中的姓名和角色表中的角色名称,实现了多对多关系的查询。
三、数据维护在数据维护方面,处理多对多关系需要特别注意数据的一致性和完整性。
当一个实体关联多个其他实体时,如果其中一个实体被删除或修改,需要相应地更新关联表中的数据,以保持数据的一致性。
例如,当删除一个用户时,需要同时删除用户角色关系表中与该用户相关的记录,以防止关联数据的残余。
同样,当删除一个角色时,也需要删除用户角色关系表中与该角色相关的记录。
四、扩展性考虑在数据库设计中,特别是处理多对多关系时,还需要考虑到系统的扩展性。
当需要增加新的实体或者调整现有实体的关系时,需要对数据库的结构进行相应的调整。
sqlalchemy 一对多和多对多的创建语法

在SQLAlchemy 中,创建一对多(one-to-many)和多对多(many-to-many)关系需要使用不同的语法。
1. 一对多关系:```pythonfrom sqlalchemy import Column, Integer, String, ForeignKeyfrom sqlalchemy.orm import relationshipclass Parent(Base):__tablename__ = 'parent'id = Column(Integer, primary_key=True)name = Column(String)children = relationship('Child', back_populates='parent')class Child(Base):__tablename__ = 'child'id = Column(Integer, primary_key=True)name = Column(String)parent_id = Column(Integer, ForeignKey('parent.id')) ```在上述示例中,`Parent` 类有一个`children` 属性,它表示与该父对象相关联的子对象列表。
`Child` 类有一个`parent_id` 列,它表示父对象的`id`。
通过这种设置,一个父对象可以与多个子对象相关联,而每个子对象只能与一个父对象相关联。
2. 多对多关系:```pythonfrom sqlalchemy import Column, Integer, String, Table, ForeignKey from sqlalchemy.orm import relationship, secondaryassociation_table = Table('association', Base.metadata,Column('left_id', Integer, ForeignKey('left.id')),Column('right_id', Integer, ForeignKey('right.id')))class Left(Base):__tablename__ = 'left'id = Column(Integer, primary_key=True)name = Column(String)related = relationship('Right', secondary=association_table)class Right(Base):__tablename__ = 'right'id = Column(Integer, primary_key=True)name = Column(String)```在上述示例中,`Left` 类有一个`related` 属性,它表示与该左对象相关联的右对象列表。
【Mybatis】Mybatis实战2(一对一、一对多、多对多的设计及实现,高级特性及二级缓存)

【Mybatis】Mybatis实战2(⼀对⼀、⼀对多、多对多的设计及实现,⾼级特性及⼆级缓存)6).多表查询-“⼀对多”(表设计、实体设计、DAO(mapper)设计)(1)关联关系操作(⼀对多)①表设计:以员⼯和部门表为例思想: 1个员⼯对应1个部门,1个部门对应多个员⼯添加数据原则:先添加没有外键的数据(部门信息),再添加存在外键的数据(员⼯信息)注意:将外键添加在n的⼀⽅部门表:create table t_dept(id varchar2(36) primary key,name varchar2(50));员⼯表:create table t_emp(id varchar2(36) primary key,name varchar2(50),age number(3),salary number(10,2),dept_id references t_dept(id));②实体设计a. 在实体中添加关系属性,来表⽰实体之间的关系(对应表数据的关系)b. 在N的⼀⽅添加1的⼀个关系属性。
c. 在1的⼀⽅添加N的⼀个List的关系属性DAO:(MyBatis如何查询两张表信息)需求1:查询员⼯信息(⼯号,名字,年龄,薪资,所属部门的编号和名称)根据员⼯⼯号?DAO接⼝⽅法:public Emp selectById(String id);Mapper⽂件:①SQL:select e.id,,e.age,e.salary,d.id, from t_emp e left join t_dept d on e.dept_id = d.id where e.id = '5';②参数③将查询结果映射成⼀个实体对象特点: 如果关系属性是”1” ,使⽤ <association></association>需求2:根据id查询部门信息,及其内部的所有员⼯信息?DAO接⼝⽅法:public Dept selectById(String id);Mapper⽂件中①SQL:select d.id,,e.id as eid, as ename,e.age as eage,e.salary as salary from t_dept d left join t_emp e on d.id = e.dept_idwhere d.id = ?;②参数绑定③结果映射:ReusultMap映射集合关系属性特点: 关系属性是”n”个的集合 ,使⽤ <collection></ collection >7).多表查询-“⼀对⼀”(表设计、实体设计、DAO(mapper)设计)关联关系操作(⼀对⼀)例如:需求: 学⽣电脑管理系统①库表设计表⽰1对1的关系a. 添加外键(那张表添加都可以)①从业务的⾓度分析,后添加的数据对应的表。
详解sql中的参照完整性(一对一,一对多,多对多)

详解sql中的参照完整性(⼀对⼀,⼀对多,多对多)⼀、参照完整性参照完整性指的就是多表之间的设计,主要使⽤外键约束。
多表设计: ⼀对多、多对多、⼀对⼀设计1.⼀对多关联主要语句:constraint cus_ord_fk foreign key (customer_id) REFERENCES customer(id)创建客户表——订单表⼀个客户可以订多份订单,每份订单只能有⼀个客户。
-- 关联(1对N)create table customer(id int PRIMARY KEY auto_increment,name varchar (20) not null,adress varchar (20) not null);create table orders(order_num varchar(20) PRIMARY KEY,price FLOAT not NULL,customer_id int, -- 进⾏和customer 关联的字段外键constraint cus_ord_fk foreign key (customer_id) REFERENCES customer(id));insert into customer(name,adress) values("zs","北京");insert into customer(name,adress) values("ls","上海");SELECT * from customer;INSERT INTO orders values("010",30.5,1);INSERT INTO orders values("011",60.5,2);INSERT INTO orders values("012",120.5,1);SELECT * from orders;notice: constraint: 约束的意思。
MyBatis的关联映射,resultMap元素之collection子元素,实现多对多关。。。

MyBatis的关联映射,resultMap元素之collection⼦元素,实现多对多关。
MyBatis映射⽂件中的<resultMap>元素中,包含⼀个<collection>⼦元素,MyBatis通过它来处理多对多关联关系。
<collection>⼦元素的⼤部分属性与<association>⼦元素相同,但其还包含⼀个特殊属性——ofType。
ofType属性与javaType属性对应,它⽤于指定实体对象中集合类属性所包含的元素类型。
本⽂是、两篇⽂章的延续,如有配置上的问题,请参考上两篇⽂章。
情景:在实际项⽬开发中,多对多的关联关系是⾮常觉的。
以订单和商品为例,⼀个订单可以包含多种商品,⽽⼀种商品⼜可以属于多个订单,订单和商品就属于多对多的关联关系。
⼀、创建数据结构及插⼊数据(MySQL),注意:请先选择数据库# 创建⼀个名称为tb_product的表CREATE TABLE tb_product(id INT(32) PRIMARY KEY AUTO_INCREMENT,name VARCHAR(32),price DOUBLE);# 插⼊3条数据INSERT INTO tb_product VALUES ('1','Java基础⼊门','44.5');INSERT INTO tb_product VALUES ('2','Java Web程序开发⼊门','38.5');INSERT INTO tb_product VALUES ('3','SSM框架整合实战','50');# 创建⼀个名称为tb_ordersitem 的中间表CREATE TABLE tb_ordersitem(id INT(32) PRIMARY KEY AUTO_INCREMENT,orders_id INT(32),product_id INT(32),FOREIGN KEY(orders_id) REFERENCES tb_orders(id),FOREIGN KEY(product_id) REFERENCES tb_product(id));# 插⼊5条数据INSERT INTO tb_ordersitem VALUES ('1','1','1');INSERT INTO tb_ordersitem VALUES ('2','1','3');INSERT INTO tb_ordersitem VALUES ('3','3','1');INSERT INTO tb_ordersitem VALUES ('4','3','2');INSERT INTO tb_ordersitem VALUES ('5','3','3');⼆、创建实体类Product,并修改Orders实体类package com.itheima.po;import java.util.List;/*** 商品持久化类*/public class Product {private Integer id; //商品idprivate String name; //商品名称private Double price;//商品单价private List<Orders> orders; //与订单的关联属性public Integer getId() {return id;}public void setId(Integer id) {this.id = id;}public String getName() {return name;}public void setName(String name) { = name;}public Double getPrice() {return price;}public void setPrice(Double price) {this.price = price;}public List<Orders> getOrders() {return orders;}public void setOrders(List<Orders> orders) {this.orders = orders;}@Overridepublic String toString() {return "Product [id=" + id + ", name=" + name+ ", price=" + price + "]";}}package com.itheima.po;import java.util.List;/*** 订单持久化类*/public class Orders {private Integer id; //订单idprivate String number;//订单编号//关联商品集合信息private List<Product> productList;public Integer getId() {return id;}public void setId(Integer id) {this.id = id;}public String getNumber() {return number;}public void setNumber(String number) {this.number = number;}public List<Product> getProductList() {return productList;}public void setProductList(List<Product> productList) {this.productList = productList;}@Overridepublic String toString() {return "Orders [id=" + id + ", number=" + number + ", productList=" + productList + "]";}}三、创建映射⽂件ProductMapper.xml、OrdersMapper.xml<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE mapper PUBLIC "-////DTD Mapper 3.0//EN""/dtd/mybatis-3-mapper.dtd"><mapper namespace="com.itheima.mapper.ProductMapper"><select id="findProductById" parameterType="Integer"resultType="Product">SELECT * from tb_product where id IN(SELECT product_id FROM tb_ordersitem WHERE orders_id = #{id})</select></mapper><?xml version="1.0" encoding="UTF-8"?><!DOCTYPE mapper PUBLIC "-////DTD Mapper 3.0//EN""/dtd/mybatis-3-mapper.dtd"><mapper namespace="com.itheima.mapper.OrdersMapper"><!-- 多对多嵌套查询:通过执⾏另外⼀条SQL映射语句来返回预期的特殊类型 --><select id="findOrdersWithPorduct" parameterType="Integer"resultMap="OrdersWithProductResult">select * from tb_orders WHERE id=#{id}</select><resultMap type="Orders" id="OrdersWithProductResult"><id property="id" column="id"/><result property="number" column="number"/><collection property="productList" column="id" ofType="Product"select="com.itheima.mapper.ProductMapper.findProductById"></collection></resultMap><!-- 多对多嵌套结果查询:查询某订单及其关联的商品详情 --><select id="findOrdersWithPorduct2" parameterType="Integer"resultMap="OrdersWithPorductResult2">select o.*,p.id as pid,,p.pricefrom tb_orders o,tb_product p,tb_ordersitem oiWHERE oi.orders_id=o.idand oi.product_id=p.idand o.id=#{id}</select><!-- ⾃定义⼿动映射类型 --><resultMap type="Orders" id="OrdersWithPorductResult2"><id property="id" column="id"/><result property="number" column="number"/><!-- 多对多关联映射:collection --><collection property="productList" ofType="Product"><id property="id" column="pid"/><result property="name" column="name"/><result property="price" column="price"/></collection></resultMap></mapper>四、修改MyBatis配置⽂件(mybatis-config.xml),加⼊如下内容:<mapper resource="com/itheima/mapper/OrdersMapper.xml"/><mapper resource="com/itheima/mapper/ProductMapper.xml"/>五、修改测试程序MybatisAssociatedTest.java,加⼊如下内容:可以将findOrdersWithPorduct修改为findOrdersWithPorduct2,其输出仍然是⼀样的。
数据库题库及答案

数据库1. 在关系数据库系统中,当关系的模式改变时,用户程序也可以不变,这是()[单选题] *A.数据的物理独立性B.数据的逻辑独立性(正确答案)C.数据的位置独立性D.数据的存储独立性2. E-R图用于描述数据库的() [单选题] *A.数据模型B.概念模式(正确答案)C.存储模型D.逻辑模型3. 在建立表时,将年龄字段值限制在18-40之间,这种约束属于() [单选题] * A.实体完整性约束B.用户定义完整性约束(正确答案)C.参照完整性约束D.视图完整性约束4. SQL是一种()语言。
[单选题] *A.高级算法B.人工智能C.关系数据库(正确答案)D.函数型5. SQL语言按其功能可分为4类,包括查询语言、定义语言、操纵语言和控制语言,其中最重要的,使用最频繁的语言为()。
[单选题] *A.定义语言B.查询语言(正确答案)C.操纵语言D.控制语言6. 要保证数据库的数据独立性,需要修改的是()。
[单选题] *A.三层模式之间的两种映射(正确答案)B.模式与内模式C.模式与外模式D.三层模式7. 下列SQL语句中,实现数据记录修改的语句是()。
[单选题] *A. ALTERB. UPDATE(正确答案)C. CREATED.SELECT8. 两个表的记录数为5和4,对两个表执行连接查询,查询结果最多得到()条记录。
[单选题] *A.16B.63C.20(正确答案)D.29. 以下操作不会对数据库安全性产生威胁的是()。
[单选题] *A.非授权用户对数据库的恶意存取和破坏B.数据中重要或敏感的数据被泄露C.安全环境的脆弱D.授权给有资格的用户访问数据库的权限(正确答案)10. 视图是一个“虚表”,视图的构造基于()。
[单选题] *A.基本表B.视图C.基本表或视图(正确答案)D.数据字典11. 一个关系中的候选关键字()。
[单选题] *A.至多一个B.可多个(正确答案)C.必须多个D.至少三个12. 在数据库中,产生数据不一致的根本原因是。
执行多条SQL语句,实现数据库事务。(Oracle数据库)

执⾏多条SQL语句,实现数据库事务。
(Oracle数据库)///<summary>///执⾏多条SQL语句,实现数据库事务。
///</summary>///<param name="SQLStringList">(key为sql语句,value是该语句的OracleParameter[])</param>///<returns></returns>public static bool ExecuteSqlTran(Dictionary<string, object> SQLStringList){using (OracleConnection conn = new OracleConnection(connectionString)){conn.Open();using (OracleTransaction trans = conn.BeginTransaction()){OracleCommand cmd = new OracleCommand();try{//循环foreach (var myDE in SQLStringList){string cmdText=myDE.Key.ToString();OracleParameter[] cmdParms=(OracleParameter[])myDE.Value;PrepareCommand(cmd,conn,trans,cmdText, cmdParms);int val = cmd.ExecuteNonQuery();cmd.Parameters.Clear();}mit();return true;}catch{trans.Rollback();return false;}}}}///<summary>///配置命令对象///</summary>///<param name="cmd">命令对象</param>///<param name="conn">连接对象</param>///<param name="trans">事务对象</param>///<param name="cmdText">sql语句</param>///<param name="cmdParms">参数</param>private static void PrepareCommand(OracleCommand cmd, OracleConnection conn, OracleTransaction trans, string cmdText, OracleParameter[] cmdParms) {if (conn.State != ConnectionState.Open)conn.Open();cmd.Connection = conn;mandText = cmdText;if (trans != null)cmd.Transaction = trans;mandType = CommandType.Text;//cmdType;if (cmdParms != null){foreach (OracleParameter parm in cmdParms)cmd.Parameters.Add(parm);}}。
总结一下mybatis对多对多查询与增删改查的心得

总结一下mybatis对多对多查询与增删改查的心得引言在实际的开发中,多对多关联关系是经常遇到的问题,而m yba t is作为一款高效的持久层框架,为我们提供了便捷的解决方案。
本文将总结一下通过m yb at is对多对多关系进行查询和增删改查的心得。
查询多对多关系在m yb at is中,查询多对多关系可以通过嵌套查询和关联表查询来实现。
嵌套查询嵌套查询是通过在映射文件中定义多个查询语句,并通过r esu l tM ap来关联结果,从而实现多对多关系的查询。
具体步骤如下:1.在映射文件中定义多个s el ec t语句,分别查询两个关联表的数据。
2.使用\<re su lt Map>标签定义一个结果映射,包括两个关联表的字段。
3.在主查询语句中使用\<co ll ec ti on>标签来引用结果映射和关联查询语句。
4.使用联合结果映射来获取最终查询结果。
关联表查询关联表查询是通过多表联查来实现多对多关系的查询。
具体步骤如下:1.在映射文件中编写多表联查的SQ L语句,使用J OI N语句关联两个关联表。
2.在\<s el ec t>标签中使用\<re su lt Ma p>定义结果映射,包括两个关联表的字段。
3.在J av a代码中编写相应的Ma pp er接口和Ma pp er.x ml文件。
4.调用Ma pp er接口中的方法来执行查询操作。
增删改查多对多关系m y ba ti s对多对多关系的增删改查操作也是通过多表关联来实现的。
增加记录要增加多对多关系的记录,需要进行以下操作:1.在映射文件中定义插入操作的SQ L语句,插入关联表的数据。
2.在J av a代码中编写相应的Ma pp er接口和Ma pp er.x ml文件。
3.调用Ma pp er接口中的方法来执行插入操作。
删除记录要删除多对多关系的记录,需要进行以下操作:1.在映射文件中定义删除操作的SQ L语句,删除关联表的数据。
数据库设计中的多对多关系处理技巧

数据库设计中的多对多关系处理技巧在数据库设计中,多对多关系是常见的一种关系类型。
它描述了两个实体集之间的多对多的关联关系,即一个实体可以与多个其他实体相对应,同时一个实体也可以与多个其他实体相对应。
在处理多对多关系时,我们需要采用适当的技巧来设计和实现数据库模式,以满足业务需求并保持数据的一致性。
本文将介绍数据库设计中的多对多关系处理技巧。
一、关系建模在数据库设计阶段,我们首先需要进行关系建模。
对于多对多关系,通常需要引入一个连接表来表示关联关系。
连接表包含两个外键,分别指向参与关联的两个实体,同时还可以添加其他属性来描述关联的细节信息。
这样,通过连接表,我们能够准确地表示多对多关系。
例如,假设我们设计一个在线教育平台的数据库,其中有学生(Student)和课程(Course)两个实体集,一个学生可以选择多门课程,同时一门课程也可以被多个学生选择。
为了表示学生和课程之间的多对多关系,我们可以创建一个名为"Student_Course"的连接表,该表包含学生和课程的外键,在连接表中的每一条记录表示一个学生和一门课程之间的关联。
二、查询处理在处理多对多关系时,我们经常需要进行相关联的查询操作。
下面介绍几种常见的查询处理技巧。
1. 查询某个实体的相关联实体集合:当我们需要查询一个实体所相关联的其他实体集合时,可以通过连接表和JOIN操作来实现。
以学生和课程之间的多对多关系为例,如果我们想查询某个学生所选择的所有课程,可以使用以下SQL语句:```SELECT Course.*FROM StudentJOIN Student_Course ON Student.id = Student_Course.student_idJOIN Course ON Student_Course.course_id = Course.idWHERE Student.id = <学生ID>;```2. 查询关联实体的数量:有时我们需要查询某个实体所关联的实体的数量,可以通过COUNT函数来实现。
oracle表关联方式

oracle表关联方式在Oracle数据库中,表关联是一种将两个或多个表之间建立关系的方法,以便在查询数据时可以更方便地检索和组合数据。
本文将介绍Oracle表关联的常用方式,包括一对一关联、一对多关联和多对多关联,并通过实战案例讲解如何使用关联查询,最后给出关联查询的优化建议。
1.Oracle表关联简介Oracle表关联是基于表之间的主键和外键关系实现的。
通过关联,可以在查询结果中返回多个表的相关数据,从而简化查询语句和提高查询效率。
2.一对一关联一对一关联是指两个表之间存在唯一的关系,其中一个表的主键列与另一个表的外键列相对应。
在这种情况下,可以通过关联查询实现表之间的数据组合和筛选。
例如,设有两个表:用户表(user)和订单表(order)。
用户表中有主键user_id,订单表中有外键order_id。
通过一对一关联,可以查询用户及其对应的订单信息。
3.一对多关联一对多关联是指一个表的主键列与另一个表的外键列相对应,但一个主键值对应多个外键值。
在这种情况下,可以通过关联查询实现对多个相关数据的查询。
例如,设有三个表:产品表(product)、订单表(order)和订单详情表(order_detail)。
产品表中有主键product_id,订单表中有外键order_id,订单详情表中有外键order_detail_id。
通过一对多关联,可以查询某个产品对应的多个订单和订单详情。
4.多对多关联多对多关联是指两个表之间存在多个主键和外键对应关系,即一个主键值对应多个外键值,且多个主键值对应多个外键值。
在这种情况下,可以通过关联查询实现对多个相关数据的查询。
例如,设有两个表:用户表(user)和角色表(role)。
用户表中有主键user_id,角色表中有主键role_id。
用户与角色之间存在多对多关联,可以通过关联查询实现用户及其对应角色的查询。
5.关联查询实战案例以下是一个简单的关联查询实战案例:设有三个表:用户表(user)、订单表(order)和订单详情表(order_detail)。
数据库中表的一对多、多对多、一对一关系等
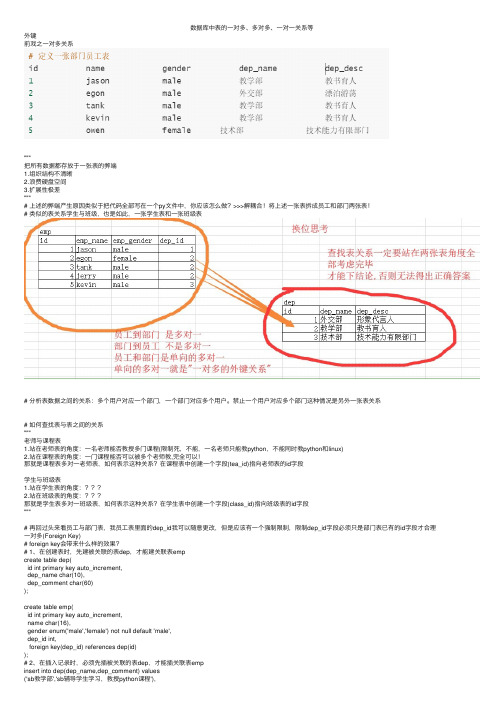
数据库中表的⼀对多、多对多、⼀对⼀关系等外键前戏之⼀对多关系"""把所有数据都存放于⼀张表的弊端1.组织结构不清晰2.浪费硬盘空间3.扩展性极差"""# 上述的弊端产⽣原因类似于把代码全部写在⼀个py⽂件中,你应该怎么做?>>>解耦合!将上述⼀张表拆成员⼯和部门两张表!# 类似的表关系学⽣与班级,也是如此,⼀张学⽣表和⼀张班级表# 分析表数据之间的关系:多个⽤户对应⼀个部门,⼀个部门对应多个⽤户。
禁⽌⼀个⽤户对应多个部门这种情况是另外⼀张表关系# 如何查找表与表之间的关系"""⽼师与课程表1.站在⽼师表的⾓度:⼀名⽼师能否教授多门课程(限制死,不能,⼀名⽼师只能教python,不能同时教python和linux)2.站在课程表的⾓度:⼀门课程能否可以被多个⽼师教,完全可以!那就是课程表多对⼀⽼师表,如何表⽰这种关系?在课程表中创建⼀个字段(tea_id)指向⽼师表的id字段学⽣与班级表1.站在学⽣表的⾓度:2.站在班级表的⾓度:那就是学⽣表多对⼀班级表,如何表⽰这种关系?在学⽣表中创建⼀个字段(class_id)指向班级表的id字段"""# 再回过头来看员⼯与部门表,我员⼯表⾥⾯的dep_id我可以随意更改,但是应该有⼀个强制限制,限制dep_id字段必须只是部门表已有的id字段才合理⼀对多(Foreign Key)# foreign key会带来什么样的效果?# 1、在创建表时,先建被关联的表dep,才能建关联表empcreate table dep(id int primary key auto_increment,dep_name char(10),dep_comment char(60));create table emp(id int primary key auto_increment,name char(16),gender enum('male','female') not null default 'male',dep_id int,foreign key(dep_id) references dep(id));# 2、在插⼊记录时,必须先插被关联的表dep,才能插关联表empinsert into dep(dep_name,dep_comment) values('sb教学部','sb辅导学⽣学习,教授python课程'),('外交部','⽼男孩上海校区驻张江形象⼤使'),('nb技术部','nb技术能⼒有限部门');insert into emp(name,gender,dep_id) values('alex','male',1),('egon','male',2),('lxx','male',1),('wxx','male',1),('wenzhou','female',3);# 当我想修改emp⾥的dep_id或dep⾥⾯的id时返现都⽆法成功# 当我想删除dep表的教学部的时候,也⽆法删除# ⽅式1:先删除教学部对应的所有的员⼯,再删除教学部# ⽅式2:受限于外键约束,导致操作数据变得⾮常复杂,能否有⼀张简单的⽅式,让我不需要考虑在操作⽬标表的时候还需要考虑关联表的情况,⽐如我删除部门,那么这个部门对应的员⼯就应该跟着⽴即清空# 先把之前创建的表删除,先删员⼯表,再删部门表,最后按章下⾯的⽅式重新创建表关系# 3.更新于删除都需要考虑到关联与被关联的关系>>>同步更新与同步删除create table dep(id int primary key auto_increment,dep_name char(10),dep_comment char(60));create table emp(id int primary key auto_increment,name char(16),gender enum('male','female') not null default 'male',dep_id int,foreign key(dep_id) references dep(id)on update cascadeon delete cascade);insert into dep(dep_name,dep_comment) values('sb教学部','sb辅导学⽣学习,教授python课程'),('外交部','⽼男孩上海校区驻张江形象⼤使'),('nb技术部','nb技术能⼒有限部门');insert into emp(name,gender,dep_id) values('alex','male',1),('egon','male',2),('lxx','male',1),('wxx','male',1),('wenzhou','female',3);# 删除部门后,对应的部门⾥⾯的员⼯表数据对应删除# 更新部门后,对应员⼯表中的标⽰部门的字段同步更新多对多# 图书表与作者表之间的关系"""仍然站在两张表的⾓度:1.站在图书表:⼀本书可不可以有多个作者,可以!那就是书多对⼀作者2.站在作者表:⼀个作者可不可以写多本书,可以!那就是作者多对⼀书双⽅都能⼀条数据对应对⽅多条记录,这种关系就是多对多!"""# 先来想如何创建表?图书表需要有⼀个外键关联作者,作者也需要有⼀个外键字段关联图书。
MyBatis使用Collection查询多对多或一对多结果集bug
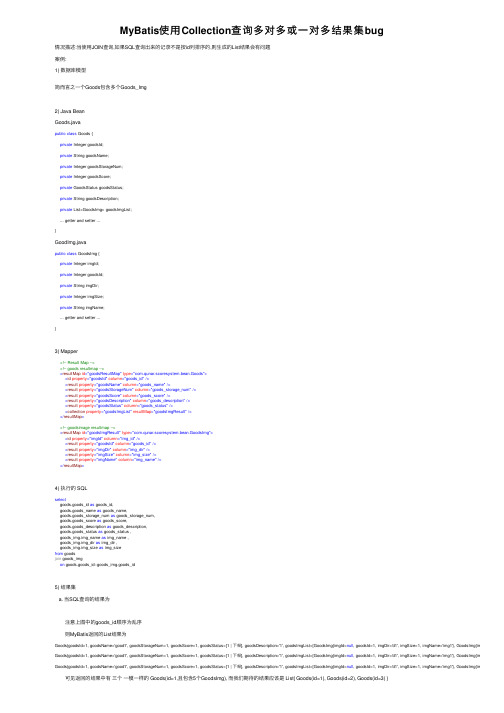
MyBatis使⽤Collection查询多对多或⼀对多结果集bug情况描述:当使⽤JOIN查询,如果SQL查询出来的记录不是按id列排序的,则⽣成的List结果会有问题案例:1) 数据库模型简⽽⾔之⼀个Goods包含多个Goods_Img2) Java BeanGoods.javapublic class Goods {private Integer goodsId;private String goodsName;private Integer goodsStorageNum;private Integer goodsScore;private GoodsStatus goodsStatus;private String goodsDescription;private List<GoodsImg> goodsImgList;... getter and setter ...}GoodImg.javapublic class GoodsImg {private Integer imgId;private Integer goodsId;private String imgDir;private Integer imgSize;private String imgName;... getter and setter ...}3) Mapper<!-- Result Map --><!-- goods resultmap --><resultMap id="goodsResultMap" type="com.qunar.scoresystem.bean.Goods"><id property="goodsId" column="goods_id"/><result property="goodsName" column="goods_name"/><result property="goodsStorageNum" column="goods_storage_num"/><result property="goodsScore" column="goods_score"/><result property="goodsDescription" column="goods_description"/><result property="goodsStatus" column="goods_status"/><collection property="goodsImgList" resultMap="goodsImgResult"/></resultMap><!-- goodsimage resultmap --><resultMap id="goodsImgResult" type="com.qunar.scoresystem.bean.GoodsImg"><id property="imgId" column="img_id"/><result property="goodsId" column="goods_id"/><result property="imgDir" column="img_dir"/><result property="imgSize" column="img_size"/><result property="imgName" column="img_name"/></resultMap>4) 执⾏的 SQLselectgoods.goods_id as goods_id,goods.goods_name as goods_name,goods.goods_storage_num as goods_storage_num,goods.goods_score as goods_score,goods.goods_description as goods_description,goods.goods_status as goods_status ,goods_img.img_name as img_name ,goods_img.img_dir as img_dir ,goods_img.img_size as img_sizefrom goodsjoin goods_imgon goods.goods_id=goods_img.goods_id5) 结果集a. 当SQL查询的结果为 注意上图中的goods_id顺序为乱序 则MyBatis返回的List结果为Goods{goodsId=1, goodsName='good1', goodsStorageNum=1, goodsScore=1, goodsStatus=[1 | 下架], goodsDescription='1', goodsImgList=[GoodsImg{imgId=null, goodsId=1, imgDir='d1', imgSize=1, imgName='img1'}, GoodsImg{imgId= Goods{goodsId=1, goodsName='good1', goodsStorageNum=1, goodsScore=1, goodsStatus=[1 | 下架], goodsDescription='1', goodsImgList=[GoodsImg{imgId=null, goodsId=1, imgDir='d1', imgSize=1, imgName='img1'}, GoodsImg{imgId= Goods{goodsId=1, goodsName='good1', goodsStorageNum=1, goodsScore=1, goodsStatus=[1 | 下架], goodsDescription='1', goodsImgList=[GoodsImg{imgId=null, goodsId=1, imgDir='d1', imgSize=1, imgName='img1'}, GoodsImg{imgId= 可见返回的结果中有三个⼀模⼀样的 Goods(id=1,且包含5个GoodsImg), ⽽我们期待的结果应该是 List{ Goods(id=1), Goods(id=2), Goods(id=3) } b. 当使⽤的SQL查询结果如下 上⾯的查询结果为id有序结果,正则MyBatis返回的Java结果集为:Goods{goodsId=1, goodsName='good1', goodsStorageNum=1, goodsScore=1, goodsStatus=[1 | 下架], goodsDescription='1', goodsImgList=[GoodsImg{imgId=null, goodsId=1, imgDir='d1', imgSize=1, imgName='img1'}, GoodsImg{imgId= Goods{goodsId=2, goodsName='good2', goodsStorageNum=2, goodsScore=2, goodsStatus=[1 | 下架], goodsDescription='2', goodsImgList=[GoodsImg{imgId=null, goodsId=2, imgDir='d5', imgSize=5, imgName='img5'}]}Goods{goodsId=3, goodsName='good3', goodsStorageNum=3, goodsScore=3, goodsStatus=[1 | 下架], goodsDescription='3', goodsImgList=[GoodsImg{imgId=null, goodsId=3, imgDir='d6', imgSize=6, imgName='img6'}]} 观察goodsId,我们取得了期待的结果答案: 根据作者本⼈的解释, MyBatis为了降低内存开销,采⽤ResultHandler逐⾏读取的JDBC ResultSet结果集的,这就会造成MyBatis在结果⾏返回的时候⽆法判断以后的是否还会有这个id的⾏返回,所以它采⽤了⼀个⽅法来判断当前id的结果⾏是否已经读取完成,从⽽将其加⼊结果集List,这个⽅法是: 1. 读取当前⾏记录A,将A加⼊⾃定义Cache类,同时读取下⼀⾏记录B 2. 使⽤下⼀⾏记录B的id列和值为key(这个key由resultMap的<id>标签列定义)去Cache类⾥获取记录 3. 假如使⽤B的key不能够获取到记录,则说明B的id与A不同,那么A将被加⼊到List 4. 假如使⽤B的key可以获取到记录,说明A与B的id相同,则会将A与B合并(相当于将两个goodsImg合并到⼀个List中,⽽goods本⾝并不会增加) 5. 将B定为当前⾏,同时读取下⼀⾏C,重复1-5,直到没有下⼀⾏记录 6. 当没有下⼀⾏记录的时候,将最后⼀个合并的resultMap对应的java对象加⼊到List(最后⼀个被合并goodsImg的Goods)所以a. 当结果⾏是乱序的,例如BBAB这样的顺序,在记录⾏A遇到⼀个id不同的曾经出现过的记录⾏B时, A将不会被加⼊到List⾥(因为Cache⾥已经存在B的id为key的cahce了) b. 当结果是顺序时,则结果集不会有任何问题,因为记录⾏ A 不可能遇到⼀个曾经出现过的记录⾏B, 所以记录⾏A不会被忽略,每次遇到新⾏B时,都不可能使⽤B的key去Cache⾥取到值,所以A必然可以被加⼊到List在MyBatis中,实现这个逻辑的代码如下@Overrideprotected void handleRowValues(ResultSet rs, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultColumnCache resultColumnCache) throws SQLException {final DefaultResultContext resultContext = new DefaultResultContext();skipRows(rs, rowBounds);Object rowValue = null;while (shouldProcessMoreRows(rs, resultContext, rowBounds)) {final ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(rs, resultMap, null);// 下⼀记录⾏的id构成的cache keyfinal CacheKey rowKey = createRowKey(discriminatedResultMap, rs, null, resultColumnCache);Object partialObject = objectCache.get(rowKey);// 判断下⼀记录⾏是否被记录与cache中,如果不在cache中则将该记录⾏的对象插⼊Listif (partialObject == null && rowValue != null) { // issue #542 delay calling ResultHandler until objectif (mappedStatement.isResultOrdered()) objectCache.clear(); // issue #577 clear memory if orderedcallResultHandler(resultHandler, resultContext, rowValue);}// 当前记录⾏的值rowValue = getRowValue(rs, discriminatedResultMap, rowKey, rowKey, null, resultColumnCache, partialObject);}// 插⼊最后⼀记录⾏的对象到Listif (rowValue != null) callResultHandler(resultHandler, resultContext, rowValue);}举例:以 这个结果集为例,MyBatis会逐⾏读取记录⾏,我们将1~6⾏编号为A,B,C,D,E,F1. 读取A⾏(id=1),将A⾏加⼊Cache,查看B⾏(id=1)的id,B⾏在Cache中已存在,不操作2. 读取B⾏(id=1),查看C(id=2)⾏id,C⾏在Cache中不存在,将B⾏对应的Java对象插⼊List3. 读取C(id=2)⾏,查看D(id=1)⾏ID,D⾏在Cache中已存在,不操作(此处漏掉⼀个id=2的Goods)4. 读取D⾏(id=1),查看E⾏(id=3)ID,E⾏在Cache中不存在,将D⾏对应的java对象插⼊List(此处插⼊第⼀个重复的id=1的Goods)5. 读取E⾏(id=3),查看F⾏(id=1)的ID,F⾏在Cache中已存在,不操作(此处漏掉⼀个id=3的Goods) 6. 读取F⾏(id=1),没有下⼀⾏,跳出循环,并插⼊最后⼀个Goods(此处插⼊第⼆个重复id=1的Goods)所以,最后我们得到了3个⼀样的Goods,⾄于有序结果集,⼤家也可以按顺序去推⼀下,得到的结果集就是正确的此外,源码中我们也可以看到作者原先给的注释: issue #542,讨论的就是这个问题,参见如下链接所以,如果我们要⽤这种⽅式去查询⼀对多关系,恐怕只能⼿动排序好结果集才不会出错.另外,我还发现⼀个有趣的现象,就是当MySQL在主表数据量<=3条时,Join的结果集是⽆序的,⽽当结果集的数据量>3条时,Join的结果集就变成有序了a. 主表数据<=3条 主表:Join结果b. 主表数据>3⾏主表Join结果。
java执行多条SQL语句

java执⾏多条SQL语句⼀次执⾏多条SQL的技术要点如下:DatabaseMetaData接⼝是描述有关数据库的整体综合信息,由于DatabaseMetaData是接⼝,所以没有构造⽅法,故不能使⽤new来创建DatabaseMetaData对象,但是可以通过Connection的getMetaData()⽅法创建。
例如:DatabaseMetaDatamd=con.getMetaData()。
DatabaseMetaData类的supportsBatchUpdates⽅法⽤于判断此数据库是否⽀持批量更新。
其返回值类型为boolean,如果此数据库⽀持批量更新,则返回true;否则返回false。
Statement的addBatch(String sql)⽅法将给定的SQL命令添加到此Statement对象的当前命令列表中,此⽅法可多次调⽤。
Statement的executeBatch()⽅法的作⽤是将⼀批命令提交给数据库来执⾏,如果全部命令执⾏成功,则返回更新计数组成的数组。
1.java处理事务的程序在与数据库操作时,如果执⾏多条更新的SQL语句(如:update或insert语句),在执⾏第⼀条后如果出现异常或电脑断电, 则后⾯的SQL语句执⾏不了,这时候设定我们⾃⼰提交SQL语句,不让JDBC⾃动提交,格式为:conn.setAutoCommit(false);stmt.addBatch("insert into people values(078,'ding','duo')");stmt.addBatch("insert into people values(30,'nokia','ddd')");stmt.executeBatch();执⾏多条SQL语句;mit(); //事务提交//恢复⾃动提交模式conn.setAutoCommit(true);....if (con != null) {con.rollback();con.setAutoCommit(true);} //如果发现异常,则采取回滚如果多条语句重复,只是参数不变的话可以这样特殊情况:如果是只是参数不变,如下也是⼀样的PreparedStatement ps=conn.prepareStatement("insert into temp values(?)");ps.setInt(1, 100);ps.addBatch();ps.setInt(1, 200);ps.addBatch();ps.executeBatch();例⼦:package net.xsoftlab.dict;import java.sql.Connection;import java.sql.DatabaseMetaData;import java.sql.DriverManager;import java.sql.ResultSet;import java.sql.SQLException;import java.sql.Statement;public class Batch {/** 判断数据库是否⽀持批处理 */public static boolean supportBatch(Connection con) {try {// 得到数据库的元数据DatabaseMetaData md = con.getMetaData();return md.supportsBatchUpdates();} catch (SQLException e) {e.printStackTrace();}return false;}/** 执⾏⼀批SQL语句 */public static int[] goBatch(Connection con, String[] sqls) throws Exception {if (sqls == null) {return null;}Statement sm = null;try {sm = con.createStatement();for (int i = 0; i < sqls.length; i++) {sm.addBatch(sqls[i]);// 将所有的SQL语句添加到Statement中}// ⼀次执⾏多条SQL语句return sm.executeBatch();} catch (SQLException e) {e.printStackTrace();} finally {sm.close();}return null;}public static void main(String[] args) throws Exception {System.out.println("没有执⾏批处理时的数据为:");query();String[] sqls = new String[3];sqls[0] = "UPDATE staff SET depart='Personnel' where name='mali'";sqls[1] = "INSERT INTO staff (name, age, sex,address, depart, worklen,wage) VALUES ('mali ', 27, 'w', 'china','Technology','2','2300')"; sqls[2] = "DELETE FROM staff where name='marry'";Connection con = null;try {con = getConnection();// 获得数据库连接boolean supportBatch = supportBatch(con); // 判断是否⽀持批处理System.out.println("⽀持批处理? " + supportBatch);if (supportBatch) {int[] results = goBatch(con, sqls);// 执⾏⼀批SQL语句// 分析执⾏的结果for (int i = 0; i < sqls.length; i++) {if (results[i] >= 0) {System.out.println("语句: " + sqls[i] + " 执⾏成功,影响了"+ results[i] + "⾏数据");} else if (results[i] == Statement.SUCCESS_NO_INFO) {System.out.println("语句: " + sqls[i] + " 执⾏成功,影响的⾏数未知");} else if (results[i] == Statement.EXECUTE_FAILED) {System.out.println("语句: " + sqls[i] + " 执⾏失败");}}}} catch (ClassNotFoundException e1) {throw e1;} catch (SQLException e2) {throw e2;} finally {con.close();// 关闭数据库连接}System.out.println("执⾏批处理后的数据为:");query();}public static Connection getConnection() {// 数据库连接Connection con = null;try {Class.forName("com.mysql.jdbc.Driver");// 加载Mysql数据驱动con = DriverManager.getConnection("jdbc:mysql://localhost:3306/myuser", "root", "123456");// 创建数据连接} catch (Exception e) {System.out.println("数据库连接失败");}return con;}public static void query() throws Exception {// 查询所有的数据Connection con = getConnection();Statement st = con.createStatement();ResultSet rs = st.executeQuery("select * from staff");while (rs.next()) {String name = rs.getString("name");int age = rs.getInt("age");String sex = rs.getString("sex");String address = rs.getString("address");String depart = rs.getString("depart");String worklen = rs.getString("worklen");String wage = rs.getString("wage");System.out.println(name + " " + age + " " + sex + " " + address+ " " + depart + " " + worklen + " " + wage);}}}程序解读:1. support_Batch()⽅法判断数据库是否⽀持SQL语句的批处理。
SQL语句多表连接查询语法

SQL语句多表连接查询语法⼀、外连接1.左连接 left join 或 left outer joinSQL语句:select * from student left join score on student.Num=score.Stu_id;2.右连接 right join 或 right outer joinSQL语句:select * from student right join score on student.Num=score.Stu_id;3.完全外连接 full join 或 full outer joinSQL语句:select * from student full join score on student.Num=score.Stu_id;通过上⾯这三种⽅法就可以把不同的表连接到⼀起,变成⼀张⼤表,之后的查询操作就简单⼀些了。
⽽对于select * from student,score;则尽量不使⽤此语句,产⽣的结果过于繁琐。
⼆、内连接join 或 inner joinSQL语句:select * from student inner join score on student.Num=score.Stu_id;此时的语句就相当于:select * from student,score where student.ID=course.ID;三、交叉连接cross join,没有where指定查询条件的⼦句的交叉联接将产⽣两表的笛卡尔积。
SQL语句:select * from student cross join score;四、结构不同的表连接当两表为多对多关系的时候,我们需要建⽴⼀个中间表student_score,中间表⾄少要有两表的主键。
SQL语句:select ,ame from student_score as sc left join student as s on s.Sno=sc.Sno left join score as c on o=o select C_name,grade from student left join score on student.Num=score.Stu_id where name='李五⼀';红⾊部分即中间表,是集合两表所有内容的⼀张总表。
MySQL多表操作(一对一一对多多对多)

MySQL多表操作(⼀对⼀⼀对多多对多) 参考: ⼀,1对1 1⽅建主表(id为主键字段),⼀⽅或多⽅建外键字段(参考主表的主键id,加unique) ⽰例:⼀个⼥⼈(woman)对应⼀个丈夫(man)不能对应多个丈夫,⼀个丈夫也不能对应多个⼥⼈,妻⼦ 创建man表(建表前创建⼀个test库)mysql> create table man(id varchar(32) primary key ,name varchar(30)); 创建woman表mysql> create table woman(id varchar(32) primary key ,name varchar(30),husband varchar(32) unique,constraint wm_fk foreign key(husband) references man(id)); 建表语句解析unique # 设置约束才是1对1否则为1对多constraint wm_fk foreign key(husband) references man(id) #创建外键名为wm_fk 本表字段husband关联表man的id字段 查看建表语句 ⼀⼀对应关系 插⼊数据 ⾸先插⼊3个男⼈mysql> insert into man values('1', '⼩明');Query OK, 1 row affected (0.00 sec)mysql> insert into man values('2', '⼩聪');Query OK, 1 row affected (0.01 sec)mysql> insert into man values('3', '⽼王');Query OK, 1 row affected (0.00 sec) 插⼊⼥⼈并设置对应丈夫关系mysql> insert into woman values('1', '⼩花', 2);Query OK, 1 row affected (0.00 sec)mysql> insert into woman values('2', '⼩静', 1);Query OK, 1 row affected (0.00 sec) 以下插⼊报错 husband可以为空代表为单⾝狗mysql> insert into woman values('3', '⼩红', null); 查看数据 查询夫妻信息mysql> SELECT AS 丈夫, AS 妻⼦ FROM man INNER JOIN woman ON man.id=woman.husband; 当man.id和woman.huaband相同时查询数据即显⽰丈夫和妻⼦对应信息 查询语句解析SELECT AS 丈夫, AS 妻⼦ # 把表man的name字段以丈夫显⽰ woman的name字段以妻⼦显⽰FROM man INNER JOIN woman # 内联查询查询两个表有值相同的字段ON man.id=woman.husband; # 设置查询条件即woman的husband字段和man的id字段相同的则满⾜条件即夫妻的⼀对⼀关系 查询⼩花的丈夫是谁mysql> SELECT AS 丈夫, AS 妻⼦ FROM man INNER JOIN woman ON ='⼩花' and man.id=woman.husband; 注意:需要加and同时满⾜条件man.id=woman.husband 否则会在表man查询出3跳数据 ⼆,1对多 1⽅建主表(id为主键字段),⼀⽅或多⽅建外键字段(参考主表的主键id,不加unique) 创建⼈员表CREATE TABLE `person2` (`id` varchar(32) primary key,`name` varchar(30),`sex` char(1),); 创建对应汽车表,外键为pid连接表person2的主键id 外键未加unique参数代表⼀个car可以对应多个person即多辆汽车可以对应1个⼈即⼀个⼈可以拥有多辆汽车REATE TABLE `car` (`id` varchar(32) PRIMARY KEY,`name` varchar(30),`price` decimal(10,2),`pid` varchar(32) ,CONSTRAINT `car_fk` FOREIGN KEY (`pid`) REFERENCES `person2` (`id`)) 插⼊数据 ⾸先插⼊⼈员数据mysql> insert into person2 values('P01', 'Jack', 1);Query OK, 1 row affected (0.00 sec)mysql> insert into person2 values('P02', 'Tom', 1);Query OK, 1 row affected (0.00 sec)mysql> insert into person2 values('P03', 'Rose', 0);Query OK, 1 row affected (0.01 sec) 插⼊汽车数据# C001 002 003属于⼈P01mysql> insert into car values('C001', 'BMW', 30, 'P01');Query OK, 1 row affected (0.01 sec)mysql> insert into car values('C002', 'BEnZ', 40, 'P01');Query OK, 1 row affected (0.00 sec)mysql> insert into car values('C003', 'Audi', 40, 'P01');Query OK, 1 row affected (0.00 sec)# C004属于⼈员P02mysql> insert into car values('C004', 'QQ', 5.5, 'P02');Query OK, 1 row affected (0.00 sec)# 也可以插⼊两辆汽车不属于任何⼈mysql> insert into car values('C005', 'ABC', 10, null);Query OK, 1 row affected (0.00 sec)mysql> insert into car values('C006', 'BCD', 10, null);Query OK, 1 row affected (0.44 sec) 查询那些⼈有那些车mysql> select , from person2 inner join car on person2.id=car.pid;+------+------+| name | name |+------+------+| Jack | BMW || Jack | BEnZ || Jack | Audi || Tom | QQ |+------+------+4 rows in set (0.00 sec) 查询Jack有哪些车mysql> select , from person2 inner join car on person2.id=car.pid and ='Jack';+------+------+| name | name |+------+------+| Jack | BMW || Jack | BEnZ || Jack | Audi |+------+------+3 rows in set (0.00 sec) 注意:这⾥条件也可以使⽤wheremysql> select , from person2 inner join car on person2.id=car.pid where ='Jack';+------+------+| name | name |+------+------+| Jack | BMW || Jack | BEnZ || Jack | Audi |+------+------+3 rows in set (0.00 sec) 查询谁有两辆及两辆以上的汽车mysql> SELECT , ,car.price FROM car INNER JOIN person2 ON car.pid=person2.id WHERE personn2.id IN( SELECT pid FROM car GROUP BY pid HAVING COUNT(pid)>=2 ); +------+------+-------+| name | NAME | price |+------+------+-------+| Jack | BMW | 30.00 || Jack | BEnZ | 40.00 || Jack | Audi | 40.00 |+------+------+-------+3 rows in set (0.00 sec) 其中语句把两辆汽车以上的pid取到,然后在使⽤person2.id进⾏匹配SELECT pid FROM car GROUP BY pid HAVING COUNT(pid)>=2; 演⽰左关联mysql> select * from person2 left join car on car.pid=person2.id;+-----+------+------+------+------+-------+------+| id | name | sex | id | name | price | pid |+-----+------+------+------+------+-------+------+| P01 | Jack | 1 | C001 | BMW | 30.00 | P01 || P01 | Jack | 1 | C002 | BEnZ | 40.00 | P01 || P01 | Jack | 1 | C003 | Audi | 40.00 | P01 || P02 | Tom | 1 | C004 | QQ | 5.50 | P02 || P03 | Rose | 0 | NULL | NULL | NULL | NULL |+-----+------+------+------+------+-------+------+5 rows in set (0.00 sec) 左关联得到左边表全部数据以及满⾜某⼀条件的右边表数据,如果不存在则填充null 由全表可知只需条件是car.id或NAME或price或pid为空即可查出谁没有车 查询那些⼈没有车mysql> select from person2 left join car on car.pid=person2.id where is null;+------+| name |+------+| Rose |+------+1 row in set (0.00 sec) 其实右关联跟左关联⼀样,只需要把左关联的表调换⼀下位置便成了右关联的结果,所以只要会了左关联,右关联也是⼀样的。
EF里一对一、一对多、多对多关系的配置和级联删除

EF⾥⼀对⼀、⼀对多、多对多关系的配置和级联删除本章节开始了解EF的各种关系。
如果你对EF⾥实体间的各种关系还不是很熟悉,可以看看我的思路,能帮你更快的理解。
I.实体间⼀对⼀的关系添加⼀个PersonPhoto类,表⽰⽤户照⽚类///<summary>///⽤户照⽚类///</summary>public class PersonPhoto{[Key]public int PersonId { get; set; }public byte[] Photo { get; set; }public string Caption { get; set; } //标题public Person PhotoOf { get; set; }}当然,也需要给Person类添加PersonPhoto的导航属性,表⽰和PersonPhoto⼀对⼀的关系:public PersonPhoto Photo { get; set; }直接运⾏程序会报⼀个错:Unable to determine the principal end of an association between the types ‘Model.Per-sonPhoto’ and ‘Model.Person’. The principal end of this association must be explicitly configured using either the relationship fluent API or data annotations.思考:为何第⼀节的Destination和Lodging类直接在类⾥加上导航属性就可以⽣成主外键关系,现在的这个不⾏呢?解答:之前⽂章⾥的Destination和Lodging是⼀对多关系,既然是⼀对多,EF⾃然就知道设置Destination类的DestinationId为主键,同时设置Lodging类⾥的DestinationId为外键;但是现在的这个Person类和PersonPhoto类是⼀对⼀的关系,如果不⼿动指定,那么EF肯定不知道设置哪个为主键哪个为外键了,这个其实不难理解。
Spring中jdbcTemplate实现执行多条sql语句

Spring中jdbcTemplate实现执⾏多条sql语句说⼀下Spring框架中使⽤jdbcTemplate实现多条sql语句的执⾏:很多情况下我们需要处理⼀件事情的时候需要对多个表执⾏多个sql语句,⽐如淘宝下单时,我们确认付款时要对⾃⼰银⾏账户的表⾥减去订单所需的钱数,即需要更新银⾏账户的表,同时需要更新淘宝订单的表将订单状态改为“已付款”,这就需要先后执⾏多个sql(仅仅⽤于表达执⾏多的SQL的举例说明,具体淘宝如何实现并不是很清楚~~~~~); 但如果这中间出现电脑断⽹断电等问题,仅将我们银⾏账户的钱扣掉了,订单状态并没有改,那我们是不是很惨,但实际上我们并没有遇到这种情况对吧,下⾯我就来讲⼀下如何使⽤Spring 中jdbcTemplate 实现执⾏多条sql语句,⽽不出现这种情况1 @Test2public void权限分配(){3//1.客户端复选框传递过来⼀个数组1,2 菜单的ID4 Integer[] menus =new Integer[]{1,2};5//2.声明sql数组6 String [] sql =new String [menus.length+1];7//3.通过Role_id 200 删除表中数据8 sql[0] = "delete from role_link_menu where fk_role_id=200";9//4新数据添加到中间表10for (int i=0;i<menus.length;i++) {11 sql[i+1]="insert into role_link_menu(id,fk_role_id,fk_menu_id) values ('"+UUID.randomUUID().toString()+"',200, "+menus[i]+")";12 }13 jdbcTemplate.batchUpdate(sql);14 }前提我们已经连接好数据库这样我们⼀共执⾏了3条SQL语句1.delete from role_link_menu where fk_role_id=2002.insert into role_link_menu(id,fk_role_id,fk_menu_id) values ('"+UUID.randomUUID().toString()+"',200,1")";3.insert into role_link_menu(id,fk_role_id,fk_menu_id) values ('"+UUID.randomUUID().toString()+"',200,2")";这期间任⼀条SQL语句出现问题都会回滚[**]会所有语句没有执⾏前的最初状态^_^对⽐下⾯⼀组代码,我们就可以发现其中不同1 @Test2public void权限分配单个处理() throws Exception{3//1.通过Role_id 200 删除表中数据4 String sql = "delect from role_link_menu where fk_role_id=200";5 jdbcTemplate.update(sql);6//2.客户端复选框传递过来⼀个数组1,2 菜单的id7 Integer[] menus =new Integer[]{1,2};8//3.新数据添加到中间表9for (int i=0;i<menus.length;i++) {10 String menu_sql="insert into role_link_menu(id,fk_role_id,fk_menu_id) values ('"+UUID.randomUUID().toString()+ "',200,"+menus[i]+")";11if(i==1){12throw new Exception("=====");13 }14 jdbcTemplate.update(menu_sql);15 }16 }这⾥当i=1会出现异常程序终⽌,共执⾏了2条语句1.delect from role_link_menu where fk_role_id=2002.insert into role_link_menu(id,fk_role_id,fk_menu_id) values ('"+UUID.randomUUID().toString()+ "',200,1)";下⾯⼀句不会执⾏,但之前这两条执⾏完毕,就相当于本来我们要买啤酒喝炸鸡,账户钱扣了,结果就只给了你⼀罐啤酒,是不是郁闷捏,啊哈,反正我不会开⼼滴~~~**注: 回滚:事务是⼀组组合成逻辑⼯作单元的操作,虽然系统中可能会出错,但事务将控制和维护事务中每个操作的⼀致性和完整性。
MySQL同时执行多条SQL语句解决办法

经过网上查找,发现有两种解决办法: 1、最简单的办法,在MySQL的连接字符串中设置allowMultiQueries参数置为true。 2、在程序中对SQL语句以分号拆分成多条SQL语句,然后使用Statement的addBatch方法,最后executeBatch就行。 结论:第一种方式最简单。 希望对以后遇到此类问题的朋友有所帮助。
最近做一个数据库初始化工具的时候发现了这个问题就是在一个statement中执行一条sql语句的时候可以正确执行如果同时执行多条就会报sql语法错误伤透了脑筋
MySQL同时执行多条 SQL语句解决办法
最近做一个数据库初始化工具的时候发现了这个问题,就是在一个Statement中执行一条SQL语句的时候可以正确执行,如果同时执行多 条,就会报SQL语法错误,伤透了脑筋。
ER模型到逻辑模型转换考试试卷

ER模型到逻辑模型转换考试试卷(答案见尾页)一、选择题1. 在ER模型中,哪个元素表示实体集?A. 矩阵B. 属性C. 关系D. 键2. 在ER模型中,哪个元素表示属性?A. 实体集B. 属性集C. 关系D. 键3. 在ER模型中,哪个元素表示关系?A. 实体集B. 属性集C. 关系D. 键4. 在ER模型中,哪个元素表示键?A. 实体集B. 属性集C. 关系D. 键5. 在ER模型到逻辑模型的转换过程中,哪个步骤是用来确定实体之间关系的完整性约束的?A. 实体识别B. 关系识别C. 规范化D. 模型验证6. 在ER模型到逻辑模型的转换过程中,哪个步骤是将实体和关系转换为关系表?A. 实体识别B. 关系识别C. 规范化D. 模型验证7. 在ER模型到逻辑模型的转换过程中,哪个步骤是用来消除数据冗余的?A. 实体识别B. 关系识别C. 规范化D. 模型验证8. 在ER模型到逻辑模型的转换过程中,哪个步骤是用来确定实体和关系的主键?A. 实体识别B. 关系识别C. 规范化D. 模型验证9. 在ER模型到逻辑模型的转换过程中,哪个步骤是用来将E-R图转换为关系模型的?A. 实体识别B. 关系识别C. 规范化D. 模型验证10. 在ER模型到逻辑模型的转换过程中,哪个步骤是用来检查模型是否符合完整性约束的?A. 实体识别B. 关系识别C. 规范化D. 模型验证二、问答题1. 什么是ER模型?请简要描述其组成部分。
2. 在ER模型中,如何表示多对多关系?3. 什么是规范化?为什么规范化在数据库设计中很重要?4. 什么是数据字典?它在数据库设计中的作用是什么?5. 请简述数据库中的事务是什么以及它为什么需要ACID特性。
6. 什么是SQL?请列举几种常见的SQL语句。
7. 什么是索引?请简述索引的作用和创建方法。
8. 请简述数据库的三级模式结构,并说明各层级的主要功能。
参考答案选择题:1. C2. B3. C4. D5. C6. B7. C8. B9. B 10. D问答题:1. 什么是ER模型?请简要描述其组成部分。