SAX解析XML(自主判断)
SAXContentHandler解析超大的XML内容

SAXContentHandler解析超大的XML内容Java Sax ContentHandler 解析超大的XML解析超大的XML文件或者文本使用如果用常用的方法,100M的文件可能要1个多小时,甚至于还可能出现内存溢出等问题。
本文介绍ContentHandler解析超大的xml内容,100M的内容1~2秒左右就解析并入库成功1、构造一个ContentHandlerimport java.util.ArrayList;import java.util.List;import org.springframework.util.CollectionUtils;import org.xml.sax.Attributes;import org.xml.sax.SAXException;import org.xml.sax.helpers.DefaultHandler;public class RecipientHandler extends DefaultHandler {private List<Recipient> recipients;private List<NameValue> fields;private Recipient recipient;private NameValue field;private TestService testService;private StringBuilder sb = new StringBuilder();public RecipientHandler(T estService testService) {this.testService = testService;}@Overridepublic void startDocument() throws SAXException {recipients = new ArrayList<>();fields = new ArrayList<>();}@Overridepublic void endDocument() throws SAXException {saveRecipients();}@Overridepublic void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { sb.delete(0, sb.length()); // 清空sbif('recipients'.equals(qName)) {recipient = new Recipient();} else if('fields'.equals(qName)) {field = new NameValue();}}@Overridepublic void endElement(String uri, String localName, String qName) throws SAXException {if ('recipients'.equals(qName)) {// 将fields整理成recipient对象for (NameValue field : fields) {String name = field.getName();if('name'.equals(name)) {recipient.setName(field.getValue());} else if('create_date'.equals(name)) {recipient.setCreateDate(field.getValue());}}recipients.add(recipient);fields.clear();if (recipients.size() >= 1000) {saveRecipients(); // 保存}} else if('fields'.equals(qName)) {fields.add(field);} else if('id'.equals(qName)){recipient.setId(sb.toString());} else if('name'.equals(qName)){field.setName(sb.toString());} else if('value'.equals(qName)){field.setValue(sb.toString());}}private void saveRecipients() {if(CollectionUtils.isEmpty(recipients) || testService == null) { return;}testService.addRecipients(recipients);recipients.clear();}@Overridepublic void characters(char[] ch, int start, int length) throws SAXException {String data = new String(ch, start, length).trim();sb.append(data); // 当文本过大时,可能不能一次取到完整的data值,会分多次获取}}2、使用ContentHandlerXMLReader parser = XMLReaderFactory.createXMLReader();// RecipientHandler 实现了解析数据,并保存到数据库parser.setContentHandler(newRecipientHandler(testService));StringReader stringReader = new StringReader(xmlString);InputSource is = new InputSource(stringReader);is.setEncoding('UTF-8');parser.parse(is);总体代码特别少,SAX一次解析就获取到所有的业务数据。
解析Xml文件的三种方式

解析Xml⽂件的三种⽅式1、Sax解析(simple api for xml) 使⽤流式处理的⽅式,它并不记录所读内容的相关信息。
它是⼀种以事件为驱动的XML API,解析速度快,占⽤内存少。
使⽤回调函数来实现。
1class MyDefaultHander extends DefaultHandler{2private List<Student> list;3private Student student;45 @Override6public void startDocument() throws SAXException {7super.startDocument();8 list=new ArrayList<>();9 }1011 @Override12public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {13super.startElement(uri, localName, qName, attributes);14if(qName.equals("student")){15 student=new Student();1617 }18 preTag=qName;19 }2021 @Override22public void endElement(String uri, String localName, String qName) throws SAXException {23if(qName.equals("student")){24 list.add(student);25 }26 preTag=null;27 }2829 @Override30public void characters(char[] ch, int start, int length) throws SAXException {31if(preTag!=null){32if(preTag.equals("id")){33 student.setId(Integer.parseInt(new String(ch,start,length)));34 }else if(preTag.equals("name")){35 student.setName(new String(ch,start,length));36 }else if(preTag.equals("age")){37 student.setAge(Integer.parseInt(new String(ch,start,length)));38 }39 }40 }41public List<Student> getStudents(){42return list;43 }44 }45public List<Student> sax_parser(){46 List<Student> list=null;47try {48 SAXParser parser= SAXParserFactory.newInstance().newSAXParser();49 InputStream is= getAssets().open("student.xml");50 MyDefaultHander hander=new MyDefaultHander();51 parser.parse(is,hander);52 list= hander.getStudents();53 } catch (ParserConfigurationException e) {54 e.printStackTrace();55 } catch (SAXException e) {56 e.printStackTrace();57 } catch (IOException e) {58 e.printStackTrace();59 }60return list;61 }2、Dom解析 DOM(Document Object Model) 是⼀种⽤于XML⽂档的对象模型,可⽤于直接访问XML⽂档的各个部分。
Android SAX 方式解析XML 字符串

这个是主类:import java.io.StringReader;import javax.xml.parsers.SAXParser;import javax.xml.parsers.SAXParserFactory;import org.xml.sax.InputSource;import org.xml.sax.XMLReader;import android.app.Activity;import android.os.Bundle;import android.util.Log;import android.widget.TextView;public class ParsingXML extends Activity {private final String MY_DEBUG_TAG = "WeatherForcaster";public void onCreate(Bundle icicle) {super.onCreate(icicle);TextView tv = new TextView(this);String xml = "<VCOM version='1.1'><loginlink>aHR0cDovLzE5Mi4xNjguMTA0LjExMy9ldW1zL2NsaWV udC90ZW1 wbGF0ZTIwMDA vbW9iaWxlZW50cnkucGhwP3VzZXJuYW1lPWNlc2hp</loginlink><errmsg ></errmsg></VCOM>";// 创建一个新的字符串StringReader read = new StringReader(xml);// 创建新的输入源SAX 解析器将使用InputSource 对象来确定如何读取XML 输入InputSource source = new InputSource(read);try {SAXParserFactory spf = SAXParserFactory.newInstance();SAXParser sp = spf.newSAXParser();XMLReader xr = sp.getXMLReader();ExampleHandler myExampleHandler = new ExampleHandler();xr.setContentHandler(myExampleHandler);xr.parse(source);ParsedExampleDataSet parsedExampleDataSet = myExampleHandler.getParsedData();String url=Base64Coder.decodeString(parsedExampleDataSet.toString());tv.setText(url);} catch (Exception e) {tv.setText("Error: " + e.getMessage());Log.e(MY_DEBUG_TAG, "WeatherQueryError", e);}this.setContentView(tv);}}下面两个类是以SPX 方式解析XML字符串import org.xml.sax.Attributes;import org.xml.sax.SAXException;import org.xml.sax.helpers.DefaultHandler;public class ExampleHandler extends DefaultHandler{private boolean in_mytag = false;private ParsedExampleDataSet myParsedExampleDataSet = new ParsedExampleDataSet();public ParsedExampleDataSet getParsedData() {return this.myParsedExampleDataSet;}public void startDocument() throws SAXException {this.myParsedExampleDataSet = new ParsedExampleDataSet();}public void endDocument() throws SAXException {}public void startElement(String namespaceURI, String localName,String qName, Attributes atts) throws SAXException {if (localName.equals("loginlink")) {this.in_mytag = true;}}public void endElement(String namespaceURI, String localName, String qName) throws SAXException {if (localName.equals("loginlink")) {this.in_mytag = false;}}public void characters(char ch[], int start, int length) {if(this.in_mytag){myParsedExampleDataSet.setExtractedString(new String(ch, start, length));}}}public class ParsedExampleDataSet {private String extractedString = null;public String getExtractedString() {return extractedString;}public void setExtractedString(String extractedString) { this.extractedString = extractedString;}public String toString(){return "ExtractedString = " + this.extractedString ;}}。
android认证笔试题(一)

Andorid认证笔试题(一)(试卷总分:100分,考试时间:120分钟,答案写在答卷纸上)一、单选题(每题1.5分,共60分)1、下面关于java类描述错误的是____。
A.java文件中一个类引用了其他类,可以用import导入。
B. 一个java文件中可以同时定义多个public属性的类。
C. 在一个类中,可以定义与该类类型一样的成员变量。
D. 类的静态成员变量在进入静态函数main之前已经被赋值。
2. 关于java语言平台描述错误的是____。
A.java中的基本数据类型包括byte、int、char、long、float、double、boolean和short。
B. java中char类型采用Unicode编码,占用2个字节。
可以用来保存一个汉字。
C. java中的基本类型变量存储在栈上,对象的实例存储在堆上。
D.执行String string = new String("string");只产生一个对象。
3. 抽象类和接口的区别,说法错误的是____。
A. 抽象类和接口都能被实例化。
B.抽象类的子类为父类中的所有抽象方法提供实现,否则子类也是抽象类。
C. 接口中的所有方法都是抽象的,接口中只能定义static final成员变量。
D.在抽象类中,不能用接口名作为应用变量的类型。
4. 关于接口和抽象类,描述错误的是____。
A. 接口可以继承接口。
B. 接口可以继承抽象类。
C. 抽象类可以实现接口。
D. 抽象类可以继承实体类,前提是实体类必须有明确的构造函数。
5. 关于多态性,描述错误的是____。
A.多态性是指允许不同的类对象对同一消息有不同的响应。
B. 多态性语言具有灵活,抽象,行为共享,代码共享的优势。
C. 通过解决了应用程序函数同名的问题。
D.多态的实现方式静态绑定。
6. 关于Java异常,说法错误的是____。
A. 一般情况下,用try来执行一段程序,如果出现异常,系统会throws一个异常。
Android考试题库

一、单选题(共33题,共62分)1、(2分) WebView中可以用来处理js中警示,确认等对话框的是(C)A。
WebSettingsB。
WebViewClientC。
WebChromeClientD。
WebViewChrome2、(2分) Android解析xml的方法中,将整个文件加载到内存中进行解析的是?(C)A、SAXB、PULLC、DOM D 、JSON3、(2分)以下属于调用摄像头硬件的权限的是:( A )A。
〈uses—permission android:name="android.permission。
CAMERA"/〉B。
〈uses-permission android:name=”android。
permission。
MOUNT_UNMOUNT_FILESYSTEMS”/〉C。
〈uses-permission android:name="android。
permission.WRITE_EXTERNAL_STORAGE”/> D。
<uses—permission android:name="android。
permission。
INTERNET"/〉4、(1分)使用Android系统进行拍照用到的类有:(D)A。
SurfaceView B。
SurfaceHolder C.Callback D。
Camera5、(2分)LocationManager获取位置信息的途径下列说法不正确的是(B )A, GPS定位更精确,缺点是只能在户外使用B, NETWORK通过基站和Wi— Fi信号来获取位置信息,速度较慢,耗电较少.C,获取用户位置信息,我们可以使用其中一个,也可以同时使用两个。
D, GPS定位耗电严重,并且返回用户位置信息的速度远不能满足用户需求.6、(2分) 在开发AppWidget窗口小部件时, 需要继承(D)类A,AppWidgetReceiverB,AppWidgetConfigureC,AppWidgetManagerD,AppWidgetProvider7、(4分)在AsyncTask中下列哪个方法是负责执行那些很耗时的后台计算工作的(C)A,runB,executeC,doInBackgroundD,onPostExecute8、(2分)如果希望自定义TabHost标题部分的显示内容需要使用下列哪个方法(B)finalTabHosttabHost = getTabHost();A,tabHost。
xml文件解析方法

xml文件解析方法XML文件解析方法引言:XML(可扩展标记语言)是一种用于存储和传输数据的标记语言,它具有良好的可读性和灵活性,被广泛应用于数据交换和配置文件等领域。
在处理XML文件时,解析是必不可少的环节。
本文将介绍几种常用的XML文件解析方法,包括DOM、SAX和StAX。
一、DOM解析方法DOM(文档对象模型)是一种将整个XML文件以树形结构加载到内存中的解析方法。
DOM解析器将XML文件解析为一个树状结构,通过遍历节点来获取和操作XML文件中的数据。
DOM解析方法的优点是易于理解和使用,可以随机访问XML文件中的任意节点,但缺点是占用内存较大,不适用于大型XML文件的解析。
1. 创建DOM解析器对象:使用标准的Java API,可以通过DocumentBuilderFactory类来创建DOM解析器对象。
2. 加载XML文件:通过DOM解析器对象的parse()方法加载XML文件,将其转化为一个树形结构。
3. 遍历节点:使用DOM解析器对象提供的方法,如getElementsByTagName()、getChildNodes()等,可以遍历XML文件中的各个节点,获取节点的名称、属性和文本内容等信息。
4. 获取节点数据:通过节点对象提供的方法,如getNodeName()、getTextContent()等,可以获取节点的名称和文本内容。
二、SAX解析方法SAX(简单API for XML)是一种基于事件驱动的XML解析方法。
在SAX解析过程中,解析器顺序读取XML文件,当遇到节点开始、节点结束或节点文本等事件时,会触发相应的回调方法。
相比于DOM 解析方法,SAX解析方法具有内存占用小、解析速度快的优点,但缺点是无法随机访问XML文件中的节点。
1. 创建SAX解析器对象:使用标准的Java API,可以通过SAXParserFactory类来创建SAX解析器对象。
2. 实现事件处理器:自定义一个事件处理器,实现SAX解析器提供的DefaultHandler类,并重写相应的回调方法,如startElement()、endElement()和characters()等。
SAX解析器解析xml详解

XML的解析器原理及性能比较,SAX详解1 DOMDOM 是用与平台和语言无关的方式表示XML 文档的官方W3C 标准。
DOM 是以层次结构组织的节点或信息片断的集合。
这个层次结构允许开发人员在树中寻找特定信息。
分析该结构通常需要加载整个文档和构造层次结构,然后才能做任何工作。
由于它是基于信息层次的,因而DOM 被认为是基于树或基于对象的。
DOM 以及广义的基于树的处理具有几个优点。
首先,由于树在内存中是持久的,因此可以修改它以便应用程序能对数据和结构作出更改。
它还可以在任何时候在树中上下导航,而不是像SAX 那样是一次性的处理。
DOM 使用起来也要简单得多。
另一方面,对于特别大的文档,解析和加载整个文档可能很慢且很耗资源,因此使用其他手段来处理这样的数据会更好。
这些基于事件的模型,比如SAX。
2 SAX这种处理的优点非常类似于流媒体的优点。
分析能够立即开始,而不是等待所有的数据被处理。
而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。
这对于大型文档来说是个巨大的优点。
事实上,应用程序甚至不必解析整个文档;它可以在某个条件得到满足时停止解析。
一般来说,SAX 还比它的替代者DOM 快许多。
3 选择DOM 还是选择SAX ?对于需要自己编写代码来处理XML 文档的开发人员来说,选择DOM 还是SAX 解析模型是一个非常重要的设计决策。
DOM 采用建立树形结构的方式访问XML 文档,而SAX 采用的事件模型。
DOM 解析器把XML 文档转化为一个包含其内容的树,并可以对树进行遍历。
用DOM 解析模型的优点是编程容易,开发人员只需要调用建树的指令,然后利用navigation APIs访问所需的树节点来完成任务。
可以很容易的添加和修改树中的元素。
然而由于使用DOM 解析器的时候需要处理整个XML 文档,所以对性能和内存的要求比较高,尤其是遇到很大的XML 文件的时候。
由于它的遍历能力,DOM 解析器常用于XML 文档需要频繁的改变的服务中。
xml的四种解析方法及源代码

xml的四种解析方法及源代码(SAX、DOM、JDOM、DOM4J)第二种:DOM解析DOM中的核心概念就是节点。
DOM在分析XML文档时,将将组成XML文档的各个部分(元素、属性、文本、注释、处理指令等)映射为一个对象(节点)。
在内存中,这些节点形成一课文档树。
整棵树是一个节点,树中的每一个节点也是一棵树(子树),可以说,DOM就是对这棵树的一个对象描述,我们通过访问树中的节点来存取XML文档的内容。
PS:属性节点是附属于元素的,不能被看做是元素的子节点,更不能作为一个单独的节点DOMPrinter.javaJava代码import org.w3c.dom.Document;import dNodeMap;import org.w3c.dom.Node;import .apache.xerces.internal.parsers.DOMParser;public class DOMPrinter{public static void main(String[] args){try{/** *//** 获取Document对象 */DOMParser parser = new DOMParser();parser.parse("db.xml");Document document = parser.getDocument();printNode(document);} catch (Exception e){e.printStackTrace();}}public static void printNode(Node node){short nodeType=node.getNodeType();switch(nodeType){case Node.PROCESSING_INSTRUCTION_NODE://预处理指令类型 printNodeInfo(node);break;case Node.ELEMENT_NODE://元素节点类型printNodeInfo(node);printAttribute(node);break;case Node.TEXT_NODE://文本节点类型printNodeInfo(node);break;default:break;}Node child=node.getFirstChild();while(child!=null){printNode(child);child=child.getNextSibling();}}/** *//*** 根据节点类型打印节点* @param node*/public static void printNodeInfo(Node node){if (node.getNodeType() == Node.ELEMENT_NODE){System.out.println("NodeName: " + node.getNodeName()); }else if (node.getNodeType() == Node.TEXT_NODE){String value = node.getNodeValue().trim();if (!value.equals(""))System.out.println("NodeValue: " + value);elseSystem.out.println();}else{System.out.println(node.getNodeName()+" : "+node.getNodeValu e());}}/** *//*** 打印节点属性* @param aNode 节点*/public static void printAttribute(Node aNode){NamedNodeMap attrs = aNode.getAttributes();if(attrs!=null){for (int i = 0; i < attrs.getLength(); i++){Node attNode = attrs.item(i);System.out.println("Attribute: " + attNode.getNodeName() + "=\"" + attNode.getNodeValue()+"\"");}}}DOM生成XML文档:DOMCreateExample.javaJava代码import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import javax.xml.parsers.ParserConfigurationException;import org.w3c.dom.Document;import org.w3c.dom.Element;import .apache.xml.internal.serialize.XMLSerializer;public class DOMCreateExample{public static void main(String[] args) throws ParserConfiguratio nException{//DOMImplementation domImp = DOMImplementationImpl.getDOMImple mentation();DocumentBuilderFactory builderFact = DocumentBuilderFactory.ne wInstance();DocumentBuilder builder = builderFact.newDocumentBuilder();Document doc = builder.newDocument();//Document doc = domImp.createDocument(null, null, null);Element root = doc.createElement("games");Element child1 = doc.createElement("game");child1.appendChild(doc.createTextNode("Final Fantasy VII")); child1.setAttribute("genre", "rpg");root.appendChild(child1);doc.appendChild(root);XMLSerializer serial;try{serial = new XMLSerializer(new FileOutputStream("domcreate.x ml"), null);serial.serialize(doc);} catch (FileNotFoundException e1){e1.printStackTrace();} catch (IOException e){e.printStackTrace();}}}第三种JDOM解析JDOM利用了java语言的优秀特性,极大地简化了对XML文档的处理,相比DOM 简单易用。
南开19春学期(1709、1803、1809、1903)《手机应用软件设计与实现》在线作业[标准答案]
![南开19春学期(1709、1803、1809、1903)《手机应用软件设计与实现》在线作业[标准答案]](https://img.taocdn.com/s3/m/260fb6e6a1c7aa00b52acb9f.png)
(单选题)1: 下列描述有误的选项是A: A、adb?devices这个命令是查看当前连接的设备,?连接到计算机的android设备或者模拟器将会列出显示。
B: B、adb?install?<apk文件路径>这个命令将指定的apk文件安装到设备上。
C: C、adb?shell这个命令将登录设备的shell。
D: D、adb?push?<本地路径>?<远程路径>用pull命令可以把Android目标机上的文件或者文件夹复制到PC。
正确答案:(单选题)2: 事件的名称A: A.都要由用户定义B: B.有的由用户定义,有的有系统定义C: C.是由系统预先定义D: D.是不固定的正确答案:(单选题)3: Android中关于View继承关系的论述错误的是A: A、ViewGroup继承自ViewB: B、AdapterView继承自ViewGroupC: C、TableLayout继承自RelativeLayoutD: D、Menu、Notification和Toast都不是View的子类正确答案:(单选题)4: Matrix 类的作用是?A: A. 可以存储缩小或放大比列B: B. 存储文件中的图片信息C: C. 存储资源中的图片信息D: D. 存储内存中的图片信息正确答案:(单选题)5: 通过使用(??)框架,你能够访问这些传感器,并获取原始的传感器数据A: A.AndroidB: B.?SensorC: C.SensorEventD: D.SensorEventListener正确答案:(单选题)6: 下列哪个可做EditText编辑框的提示信息?A: A. android:inputTypeB: B. android:textC: C. android:digitsD: D. android:hint正确答案:(单选题)7: Android平台支持几种宽泛类别的传感器A: A.1B: B.8C: C.3D: D.12正确答案:(单选题)8: 在Android应用程序中,图片应放在那个目录下A: A、rawB: B、valuesC: C、layoutD: D、drawable正确答案:(单选题)9: 传感器的可用性不但在不同硬件之间有变化,而且不同的Android版本之间也可能有变化,这是因为(????)A: A.原始数据的丢失B: B.系统调用方法的错误C: C.Android传感器的引入需要有几个平台Release的过程D: D.传感器可用性的多变性正确答案:(单选题)10: 关于ImageSwitcher 说法错误的是A: A.ImageSwitcher里可以通过Alpha设定转换时候的透明位B: B.在使用一个ImageSwitcher之前,不一定要调用setFactory方法C: C.setInAnimation是设置资源被读入到这个ImageSwitcher的时候动画效果D: D.setOutAnimation是资源文件从这个ImageSwitcher里消失的时候要实现的动画效果正确答案:(单选题)11: onPause 什么时候调用?A: A. 当界面启动时B: B. 当 onCreate 方法被执行之后C: C. 当界面被隐藏时D: D. 当界面重新显示时正确答案:(单选题)12: 下列选项哪个不是Activity启动的方法?A: A. goToActivityB: B.startActivityC: C.startActivityFromChildD: D.startActivityForResult正确答案:(单选题)13: E/AndroidRuntime(1099): ng.RuntimeException: Unable to instantiate activity ComponentInfo{com.test/com.test.CanvasActivitys}: ng.ClassNotFoundException: com.test.CanvasActivitys in loader dalvik.system.PathClassLoader[/data/app/com.test-1.apA: A程序执行CanvasActivitys的一个代码段时一个View有引用无对象B: B CanvasActivitys类没有在AndroidManifest中正确申明C: C 最小SDK支持版本号比运行这个程序的设备版本号还高D: D CanvasActivitys是一个Activity,但没有重写它的onCreate方法正确答案:(单选题)14: 在开发AppWidget窗口小部件时, 需要继承()类A: A,AppWidgetReceiverB: B,AppWidgetConfigureC: C,AppWidgetManagerD: D,AppWidgetProvider正确答案:(单选题)15: 使用Android系统进行拍照用到的类有:A: A. SurfaceViewB: B. SurfaceHolderC: C.CallbackD: D. Camera正确答案:(单选题)16: 关于res/raw目录说法正确的是?A: A. 这里的文件是原封不动的存储到设备上会转换为二进制的格式B: B. 这里的文件最终以二进制的格式存储到指定的包中C: C. 这里的文件是原封不动的存储到设备上不会转换为二进制的格式D: D. 这里的文件最终不会以二进制的格式存储到指定的包中正确答案:(单选题)17: 下列哪一个选项不属于AdapterView类的子选项A: A.?ListViewB: B.?SpinnerC: C.?GridViewD: D.?ScrollView正确答案:(单选题)18: 给一个TextView设置红色字体,应该使用以下哪种写法A: A、setTextColor(0xffff0000);B: B、setColor("0xffff0000")C: C、setTextColor("0xffff0000")D: D、setColor("red")正确答案:(单选题)19: 在多个应用中读取共享存储数据时,需要用到哪个对象的 query 方法?A: A. ContentResolverB: B. ContentProviderC: C. CursorD: D. SQLiteHelper正确答案:(单选题)20: 当 Activity 被消毁时,如何保存它原来的状态()A: A. 实现 Activity 的 onSaveInstanceState()方法B: B. 实现 Activity 的 onSaveInstance()方法C: C. 实现 Activity 的 onInstanceState()方法D: D. 实现 Activity 的 onSaveState()方法正确答案:(单选题)21: 下列哪一个选项不属于Android中预定义的布局方式?A: A. TabLayoutB: B. RelativeLayoutC: C. FrameLayoutD: D. LinearLayout正确答案:(单选题)22: 关于广播以下陈述正确的是A: A.广播接收器只能在配置文件中注册B: B.广播接收器注册后不能注销C: C.广播接收器只能接收自定义的广播消息D: D.广播接收器可以在Activity中单独注册与注销正确答案:(单选题)23: 创建一个对话框正确的语法是A: A.builder.create()B: B.builder.start()C: C.builder.show()D: D.builder.stop()正确答案:(单选题)24: Android 中下列属于Intent的作用的是?A: A. 处理一个应用程序整体性的工作B: B. 是一段长的生命周期,没有用户界面的程序,可以保持应用在后台运行,而不会因为切换页面而消失C: C. 实现应用程序间的数据共享D: D. 可以实现界面间的切换,可以包含动作和动作数据,连接四大组件的纽带正确答案:(单选题)25: 下列对SharePreferences存、取文件的说法中不正确的是A: A,属于移动存储解决方案B: B,sharePreferences处理的就是key-value对C: C,读取xml文件的路径是/sdcard/shared_prefxD: D,信息的保存格式是xml正确答案:(单选题)26: 以下属于调用摄像头硬件的权限的是A: A.<uses-permission android:name="android.permission.CAMERA"/>B: B.<uses-permission android:name="android.permission.MOUNT_UNMOUNT_FILESYSTEMS" /> C: C.<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/>D: D.<uses-permission android:name="android.permission.INTERNET"/>正确答案:(单选题)27: 下列哪一个不属于Activity的生命周期方法?A: A. onInit( )B: B. onStart( )C: C. onStop( )D: D. onPause( )正确答案:(单选题)28: 下列属于SAX解析xml文件的优点的是?A: A. 将整个文档树存储在内存中,便于操作,支持删除,修改,重新排列等多种功能B: B. 指网页元素的位置,距离右边框和下边框的距离C: C. 整个文档调入内存,浪费时间和空间D: D. 不是长久驻留在内存,数据不是持久的,事件过后,若没有保存数据,数据就会消失正确答案:(单选题)29: Activity生命周期中,第一个需要执行的方法是什么?A: A、onStartB: B、onCreateC: C、onReStartD: D、onResume正确答案:(单选题)30: 上下文菜单与其他菜单不同的是A: A,上下文菜单项上的单击事件可以使用onMenuItemSelected方法来响应B: B,上下文菜单必须注册到指定的view上才能显示C: C,上下文菜单的菜单项可以添加,可以删除D: D,上下文菜单的菜单项可以有子项正确答案:(多选题)31: 下列属于SAX解析XML需要用到的类和接口是A: A,DocumentBuilderB: B,SAXParserC: C,DefaultHandlerD: D,SAXParserFactory正确答案:(多选题)32: 下列属于SOAP优点的是A: A,SOAP 与编程语言无关。
XML解析的三种方法

三种解析XML文件的方法在Android平台上可以使用Simple API for XML(SAX) 、 Document Object Model(DOM)和Android附带的pull解析器解析XML文件。
下面是本例子要解析的XML文件:文件名称:china.xml例子定义了一个javabean用于存放上面解析出来的xml内容,这个javabean为Person,代码:使用SAX读取XML文件SAX是一个解析速度快并且占用内存少的xml解析器,非常适合用于Android等移动设备。
SAX解析XML文件采用的是事件驱动,也就是说,它并不需要解析完整个文档,在按内容顺序解析文档的过程中,SAX会判断当前读到的字符是否合法XML语法中的某部分,如果符合就会触发事件。
所谓事件,其实就是一些回调(callback)方法,这些方法(事件)定义在ContentHandler接口。
下面是一些ContentHandler接口常用的方法:startDocument()当遇到文档的开头的时候,调用这个方法,可以在其中做一些预处理的工作。
endDocument()和上面的方法相对应,当文档结束的时候,调用这个方法,可以在其中做一些善后的工作。
startElement(String namespaceURI, String localName, String qName, Attributes atts) 当读到一个开始标签的时候,会触发这个方法。
namespaceURI就是命名空间,localName 是不带命名空间前缀的标签名,qName是带命名空间前缀的标签名。
通过atts可以得到所有的属性名和相应的值。
要注意的是SAX中一个重要的特点就是它的流式处理,当遇到一个标签的时候,它并不会纪录下以前所碰到的标签,也就是说,在startElement()方法中,所有你所知道的信息,就是标签的名字和属性,至于标签的嵌套结构,上层标签的名字,是否有子元属等等其它与结构相关的信息,都是不得而知的,都需要你的程序来完成。
Android开发基础(习题卷6)

Android开发基础(习题卷6)第1部分:单项选择题,共70题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]对于XML布局文件中的视图控件,layout_width属性的属性值不可以是()A)match_parentB)fill_parentC)wrap_contentD)match_content答案:D解析:2.[单选题]在BaseAdapter的方法中,根据位置得到条目的ID的方法是( )A)getView()B)getItem()C)getItemId()D)getCount()答案:C解析:3.[单选题]为了让一个ImageView控件显示一张图片,可以设置的属性是( )A)android:srcB)android:backgroundC)android: imgD)android:value答案:A解析:4.[单选题]在Java 中, ( )类提供定位本地文件系统,对文件或目录及其属性进行基本操作。
A)FileInputStreamB)FileReaderC)FileWriterD)File答案:D解析:5.[单选题]GestureDetector 中onFling(MotionEvent e1, MotionEvent e2, float velocityX, float velocityY) 方法中的参数e1 代表( ) 。
A)抬起来的那个事件B)按下去和抬起来的事件C)按下去的那个事件D)以上都不对答案:C解析:答案说明: e1: 按下去的那个事件, e2: 抬起来的那个事件velocityX 是X轴的速度, 单位是像素, velocityY 是Y轴的速度, 单位是像素;6.[单选题]下面关于JSON说法错误的是:( )A)json 是一种数据交互格式。
B)json 的数据格式有两种为{ }和[ ]C)json 数据用{ }表示java 中的对象, [ ]表示Java中的List 对象D){“1”:”123”, ”2”:”234”, ”3”:”345”} 不是json 数据答案:D解析:7.[单选题]在播放视频或音频时,如果有电话打入,这时候视频或音频会自动挂起吗?( )A)不会B)会C)有的手机会,有的手机不会D)以上说法都错误答案:A解析:8.[单选题]在Android应用开发中,使用()作为项目唯一标识。
Sax解析器

SAX(Simple API for XML)也是解析XML的一种规范,由一系
列接口组成,但不是W3C推荐的标准,SAX是公开的、开放源代码的。
SAX最初是由David Megginson采用Java语言开发,后来参与开发的程
序员越来越多,组成了互联网上的XML-DEV社区,1998年5月,SAX1.0
版由XML-DEV正式发布。
目前,最新的版本是SAX2.0。
在2.0版本中增加了对名称空间的支
持,而且可以设置解析器是否对文档进行有效性验证,以及怎样来处理
带有名称空间的元素名称等。
SAX2.0中还有一个内置的过滤机制,可以
很轻松地输出一个文档子集或进行简单的文档转换。
SAX2.0版本在多处
不兼容1.0版本,SAX1.0中的接口在SAX2.0中已经不再使用了。
SAX解析器是一种基于事件的解析器,它的核心是事件处理模式。
基于事件的处理模式主要是围绕着事件源以及事件处理器来工作的。
一个可以产生事件的对象被称为事件源,可以针对事件产生响应的对象被称为事件处理器。
事件和事件处理器是通过在事件源中的事件处理器注册的方法连接的。
这样,当事件源产生事件后,调用事件处理器相应的处理方法,一个事件就可以得到处理。
在事件源调用事件处理器中特定方法的时候,还要传递给事件处理器相应事件的状态信息,这样事件处理器才能够根据提供的事件信息来决定自己的行为。
SAX解析XML

SAX解析XMLsax解析特点:1、逐⾏读取2、事件处理-- ⽅法3、解析器调⽤相应的事件 4、只能读取⽂件DefaultHandler 可以触发5个事件*startDocument() 开始⽂档*startElement() 开始元素*characters() ⽂本*endElement() 结束元素*endDocument() 结束⽂档在startElement/*** 如果xml⽂件使⽤了schema约束 <xs:element>* * uri:schema -- targetNameSpace* * localName--element* * qName---xs:element* 如果不使⽤* * uri:null* * localName:null* * qName : element** Attributes:当前元素的所有的属性的集合*/1//获得解析⼯⼚实例2 SAXParserFactory factory=SAXParserFactory.newInstance();3//获得解析器4 SAXParser parser=factory.newSAXParser();5//解析xml6 DefaultHandler dh=new MyDefaultHandler();78 parser.parse("books.xml", dh);Demo1public void SaxDemo() throws Exception2 {3 SAXParser parser= SAXParserFactory.newInstance().newSAXParser();4 parser.parse(Demo.class.getClassLoader().getResourceAsStream("users.xml"), new DefaultHandler(){ 5private boolean nameOrAge=false;6 @Override7public void startElement(String uri, String localName,8 String qName, Attributes attributes) throws SAXException {9if(qName.equals("user"))10 {11 System.err.println(attributes.getValue("id"));12 }13else if(qName.equals("name") || qName.equals("age")){14 nameOrAge=true;15 }16 }1718 @Override19public void endElement(String uri, String localName, String qName)20throws SAXException {21if(qName.equals("name")|| qName.equals("age"))22 {23 nameOrAge=false;24 }25 }2627 @Override28public void characters(char[] ch, int start, int length) 29throws SAXException {30if(nameOrAge)31 {32 String value=new String(ch,start,length);33 System.err.println(value);34 }35 }3637 });38 }。
解析xml格式字符串标签数据的方法

解析xml格式字符串标签数据的方法
XML格式字符串是一种常见的数据格式,它由标签和标签中的数据组成。
解析XML格式字符串中的标签数据可以帮助我们更方便地获取和处理数据。
以下是解析XML格式字符串标签数据的方法:
1. 使用DOM解析器:DOM解析器是一种常用的解析XML格式字符串的方法。
它可以将整个XML文档加载到内存中,然后通过对DOM树进行操作来获取标签数据。
具体步骤是:使用DOM解析器加载XML文件,然后通过对DOM树进行遍历,找到所需的标签并获取其中的数据。
2. 使用SAX解析器:SAX解析器是一种基于事件驱动的解析XML格式字符串的方法。
它可以在解析XML文件的过程中触发一系列事件,程序员可以根据这些事件来获取标签数据。
具体步骤是:使用SAX解析器解析XML文件,然后在遇到标签时触发startElement事件,在标签结束时触发endElement事件,程序员可以在这些事件中获取标签数据。
3. 使用XPath:XPath是一种用于在XML文档中定位节点的语言,它可以帮助我们更方便地获取标签数据。
具体步骤是:使用XPath解析器加载XML文件,然后使用XPath表达式在XML文档中定位所需的标签,最后获取标签中的数据。
以上是解析XML格式字符串标签数据的一些常用方法,程序员可以根据自己的需求选择适合的方法来获取和处理数据。
解析xml格式字符串标签数据的方法

解析xml格式字符串标签数据的方法XML格式字符串是一种常用的数据格式,它可以表示复杂的数据结构。
在处理XML格式字符串时,我们需要解析其中的标签数据,才能获取其中的内容。
下面是几种解析XML格式字符串标签数据的方法: 1. DOM解析:DOM是Document Object Model的缩写,它将XML 数据组织成一个树形结构,可以通过操作节点对象来访问和修改数据。
使用DOM解析XML格式字符串需要加载完整的XML文档到内存中,因此适合处理较小的XML数据,但对于大型XML数据,DOM解析可能会导致性能问题。
2. SAX解析:SAX是Simple API for XML的缩写,它是一种基于事件驱动的解析方式,可以在读取XML数据时逐个处理数据。
SAX解析对内存的要求非常低,适合处理大型XML数据,但由于它是基于事件驱动的,因此需要编写复杂的回调函数来处理数据。
3. XPath解析:XPath是一种查询语言,可以通过路径表达式来访问XML数据中的元素、属性等。
使用XPath解析XML格式字符串时,可以通过XPath表达式来获取特定的元素或属性的值,非常方便。
不过,XPath解析需要加载完整的XML文档到内存中,对于大型XML数据仍然存在性能问题。
4. XML解析器:除了DOM、SAX和XPath解析之外,还有一些XML 解析器可以用来解析XML格式字符串。
例如,Python中的ElementTree 模块提供了一种简单的解析方式,可以快速地访问和修改XML数据。
总之,在解析XML格式字符串时,需要根据实际的需求选择合适的解析方式。
如果对内存要求比较高,可以使用SAX解析;如果需要快速访问和修改XML数据,可以考虑使用XPath解析或XML解析器。
SAX解析
一:SAX 解析:SAX (Simple API for XML )解析二:优缺点:优点:不用实现调入整个文档,占用资源少,尤其在嵌入式环境中,如Android缺点:DOM 解析将文档长期驻留在内存中数据是持久的SAX 解析如果事件过后没有保存数据,数据就会丢失。
特点:不能对文档进行修改,只能读取。
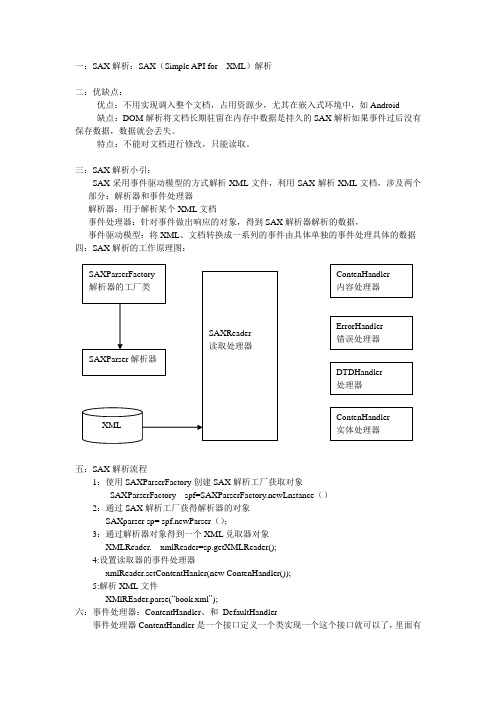
三:SAX 解析小引:SAX 采用事件驱动模型的方式解析XML 文件,利用SAX 解析XML 文档,涉及两个部分:解析器和事件处理器解析器:用于解析某个XML 文档事件处理器:针对事件做出响应的对象,得到SAX 解析器解析的数据,事件驱动模型:将XML 、文档转换成一系列的事件由具体单独的事件处理具体的数据 四:SAX 解析的工作原理图:五:SAX 解析流程1:使用SAXParserFactory 创建SAX 解析工厂获取对象SAXParserFactory spf=SAXParserFactory.newLnstance ()2:通过SAX 解析工厂获得解析器的对象SAXparser sp= spf.newParser ();3:通过解析器对象得到一个XML 兑取器对象XMLReader. xmlReader=sp.getXMLReader();4:设置读取器的事件处理器xmlReader.setContentHanler(new ContenHandler());5:解析XML 文件XMlREader.parse(“book.xml ”);六:事件处理器:ContentHandler 、和 DefaultHandler事件处理器ContentHandler 是一个接口定义一个类实现一个这个接口就可以了,里面有非常多的方法,但是目前能够用到的也就三个分别是startElement():读取到文档开始节点的时候调用例如《书架》参数:url:读取的路径localName:节点的名字qName:也是节点名字区别是前者不带后缀名,后者带后缀名atts:属性characters():读取到节点的内容时调用。
解析XML文档-SAX和DOM

JAXP(Java API for XML Processing)为打包器提供了两种不同的处理XML数据的机制,第一种是XML的简单API(Simple API for XML,即SAX),第二种是文档对象模型(Document Object Model,即DOM)。
SAX解析核心思路:在SAX模型中,XML文档作为一系列的事件提供给应用程序,每个事件表示XML文档的一种转换。
SAX解析优缺点:SAX解析的利用事件进行处理可以处理很大的文档,并且不必立即将整个文档读入内存。
然而使用XML文档的片段可能会变得复杂,因为开发人员必须跟踪给定片段的所有事件。
SAX是个广泛使用的标准,但不受任何行业团体控制。
现在SAX得到开源项目的支持。
SAX事件模型:SAX事件包括:文档事件(通知程序一个XML文档的开始和结束)、元素事件(通知程序每个元素的开始和结束)、字符事件(通知程序在元素之间找到的任何字符数据,包括文本、实体和CDATA段),还有不常见的事件:命名空间、实体和实体声明、可忽略的空白、处理指令。
SAX事件处理器:1.ContentHandlerContentHanler是任何SAX解析器的核心接口。
它定义了在SAX API中最常用的10个回调函数。
2.DefaultHandler具体实现了ContentHandler接口,允许集中于常用的事件。
可以使用自己的子类扩展(extends)DefaultHandler类。
基本的SAX回调函数:1.文档回调public void startDocument() throws SAXException;SAX通过调用该函数来开始每次解析。
public void endDocument() throws SAXException;SAX通过调用该函数来表示解析的结束。
2.元素回调public void startElement(String uri, String localName, String qName, Attributes atts) throwsSAXException;qName是元素的名称;元素的属性可以依据名称简单地进行引用。
sax解析的基础原理

sax解析的基础原理SAX解析的基础原理SAX(Simple API for XML)是一种基于事件驱动的XML解析技术,它适用于处理大型XML文件,可以边读取XML数据边处理,不需要将整个XML文件加载到内存中。
本文将介绍SAX解析的基础原理。
一、SAX解析原理概述SAX解析器将XML文件视为一系列的事件流,当解析器读取到XML 文件的某个部分时,会触发相应的事件,并通知注册的事件处理器进行处理。
这种解析方式相比于DOM(Document Object Model)解析方式更加高效,因为它避免了将整个XML文件加载到内存中的开销。
二、SAX解析器的工作流程SAX解析器的工作流程可以分为以下几个步骤:1. 创建SAX解析器对象:首先需要创建一个SAX解析器对象,该对象用于解析XML文件。
2. 注册事件处理器:在解析XML文件之前,需要注册事件处理器,用于处理解析器触发的不同事件。
3. 解析XML文件:开始解析XML文件之前,需要将XML文件作为输入传递给SAX解析器。
解析器会逐行读取XML文件,并根据文件内容触发相应的事件。
4. 处理事件:当解析器触发某个事件时,会调用注册的事件处理器的相应方法进行处理。
例如,当解析器读取到一个元素的开始标签时,会调用事件处理器的startElement()方法。
5. 返回结果:解析器在解析完整个XML文件后,会返回解析结果给调用者。
解析结果可以是解析器解析到的数据、错误信息等。
三、SAX解析事件及其处理器SAX解析器在解析XML文件时,会触发以下几个事件:1. 文档开始事件(startDocument):当解析器开始解析XML文档时触发。
2. 元素开始事件(startElement):当解析器读取到一个元素的开始标签时触发。
3. 元素内容事件(characters):当解析器读取到元素的内容时触发。
4. 元素结束事件(endElement):当解析器读取到一个元素的结束标签时触发。
Dom4J、JDOM、DOM、SAX和Pull技术解析XML文件

解析XML文件的五种技术1.1SAX技术SAX处理的优点非常类似于流媒体的优点。
分析能够立即开始,而不是等待所有的数据被处理。
而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。
这对于大型文档来说是个巨大的优点。
事实上,应用程序甚至不必解析整个文档;它可以在某个条件得到满足时停止解析。
一般来说,SAX还比它的替代者DOM快许多。
选择DOM还是选择SAX?对于需要自己编写代码来处理XML文档的开发人员来说,选择DOM 还是SAX解析模型是一个非常重要的设计决策。
DOM采用建立树形结构的方式访问XML文档,而SAX采用的事件模型。
DOM解析器把XML文档转化为一个包含其内容的树,并可以对树进行遍历。
用DOM解析模型的优点是编程容易,开发人员只需要调用建树的指令,然后利用navigation APIs访问所需的树节点来完成任务。
可以很容易的添加和修改树中的元素。
然而由于使用DOM解析器的时候需要处理整个XML文档,所以对性能和内存的要求比较高,尤其是遇到很大的XML文件的时候。
由于它的遍历能力,DOM解析器常用于XML文档需要频繁的改变的服务中。
SAX解析器采用了基于事件的模型,它在解析XML文档的时候可以触发一系列的事件,当发现给定的tag的时候,它可以激活一个回调方法,告诉该方法制定的标签已经找到。
SAX对内存的要求通常会比较低,因为它让开发人员自己来决定所要处理的tag.特别是当开发人员只需要处理文档中所包含的部分数据时,SAX这种扩展能力得到了更好的体现。
但用SAX解析器的时候编码工作会比较困难,而且很难同时访问同一个文档中的多处不同数据。
1.1.1 SAX语法简介SAX是一个解析速度快并且占用内存少的xml解析器,非常适合用于Android等移动设备。
SAX 解析XML文件采用的是事件驱动,也就是说,它并不需要解析完整个文档,在按内容顺序解析文档的过程中,SAX会判断当前读到的字符是否合法XML语法中的某部分,如果符合就会触发事件。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SAX解析XML(自主判断)实现方法一:ContentHandler接口:接收文档逻辑内容的通知的处理器接口import org.xml.sax.Attributes;import org.xml.sax.ContentHandler;import org.xml.sax.Locator;import org.xml.sax.SAXException;class MyContentHandler implements ContentHandler{StringBuffer jsonStringBuffer ;int frontBlankCount = 0;public MyContentHandler(){jsonStringBuffer = new StringBuffer();}/** 接收字符数据的通知。
* 在DOM中ch[begin:end] 相当于Text节点的节点值(nodeV alue)*/@Overridepublic void characters(char[] ch, int begin, int length) throws SAXException { StringBuffer buffer = new StringBuffer();for(int i = begin ; i < begin+length ; i++){switch(ch[i]){case '\\':buffer.append("\\\\");break;case '\r':buffer.append("\\r");break;case '\n':buffer.append("\\n");break;case '\t':buffer.append("\\t");break;case '\"':buffer.append("\\\"");break;default : buffer.append(ch[i]);}}System.out.println(this.toBlankString(this.frontBlankCount)+">>> characters("+length+"): "+buffer.toString());}/** 接收文档的结尾的通知。
*/@Overridepublic void endDocument() throws SAXException {System.out.println(this.toBlankString(--this.frontBlankCount)+">>> end document");}/** 接收文档的结尾的通知。
* 参数意义如下:* uri :元素的命名空间* localName :元素的本地名称(不带前缀)* qName :元素的限定名(带前缀)**/@Overridepublic void endElement(String uri,String localName,String qName) throws SAXException {System.out.println(this.toBlankString(--this.frontBlankCount)+ ">>> end element : "+qName+"("+uri+")");}/** 结束前缀URI 范围的映射。
*/@Overridepublic void endPrefixMapping(String prefix) throws SAXException { System.out.println(this.toBlankString(--this.frontBlankCount)+ ">>> end prefix_mapping : "+prefix);}/** 接收元素内容中可忽略的空白的通知。
* 参数意义如下:* ch : 来自XML 文档的字符* start : 数组中的开始位置* length : 从数组中读取的字符的个数*/@Overridepublic void ignorableWhitespace(char[] ch, int begin, int length) throws SAXException {StringBuffer buffer = new StringBuffer();for(int i = begin ; i < begin+length ; i++){switch(ch[i]){case '\\':buffer.append("\\\\");break;case '\r':buffer.append("\\r");break;case '\n':buffer.append("\\n");break;case '\t':buffer.append("\\t");break;case '\"':buffer.append("\\\"");break;default : buffer.append(ch[i]);}}System.out.println(this.toBlankString(this.frontBlankCount)+">>> ignorable whitespace("+length+"): "+buffer.toString());}/** 接收处理指令的通知。
* 参数意义如下:* target : 处理指令目标* data : 处理指令数据,如果未提供,则为null。
*/@Overridepublic void processingInstruction(String target,String data)throws SAXException {System.out.println(this.toBlankString(this.frontBlankCount)+">>> process instruction : (target = \""+target+"\",data = \""+data+"\")");}/** 接收用来查找SAX 文档事件起源的对象。
* 参数意义如下:* locator : 可以返回任何SAX 文档事件位置的对象*/@Overridepublic void setDocumentLocator(Locator locator) {System.out.println(this.toBlankString(this.frontBlankCount)+">>> set document_locator : (lineNumber = "+locator.getLineNumber()+",columnNumber = "+locator.getColumnNumber()+",systemId = "+locator.getSystemId()+",publicId = "+locator.getPublicId()+")");}/** 接收跳过的实体的通知。
* 参数意义如下:* name : 所跳过的实体的名称。
如果它是参数实体,则名称将以'%' 开头,* 如果它是外部DTD 子集,则将是字符串"[dtd]"*/@Overridepublic void skippedEntity(String name) throws SAXException { System.out.println(this.toBlankString(this.frontBlankCount)+">>> skipped_entity : "+name);}/** 接收文档的开始的通知。
*/@Overridepublic void startDocument() throws SAXException {System.out.println(this.toBlankString(this.frontBlankCount++)+">>> start document ");}/** 接收元素开始的通知。
* 参数意义如下:* uri :元素的命名空间* localName :元素的本地名称(不带前缀)* qName :元素的限定名(带前缀)* atts :元素的属性集合*/@Overridepublic void startElement(String uri, String localName, String qName, Attributes atts) throws SAXException {System.out.println(this.toBlankString(this.frontBlankCount++)+">>> start element : "+qName+"("+uri+")");}/** 开始前缀URI 名称空间范围映射。
* 此事件的信息对于常规的命名空间处理并非必需:* 当/sax/features/namespaces 功能为true(默认)时,* SAX XML 读取器将自动替换元素和属性名称的前缀。
* 参数意义如下:* prefix :前缀* uri :命名空间*/@Overridepublic void startPrefixMapping(String prefix,String uri)throws SAXException {System.out.println(this.toBlankString(this.frontBlankCount++)+">>> start prefix_mapping : xmlns:"+prefix+" = "+"\""+uri+"\"");}private String toBlankString(int count){StringBuffer buffer = new StringBuffer();for(int i = 0;i<count;i++)buffer.append(" ");return buffer.toString();}}DTDHandler接口:接收与DTD 相关的事件的通知的处理器接口。