ruby文件操作
Ruby编程入门教程

Ruby编程入门教程Ruby是一种简洁、灵活且具有强大功能的面向对象编程语言。
它在编程界备受瞩目,并且在各种应用程序开发中广泛使用。
本教程将带领你从零开始学习Ruby编程,掌握基本的语法和概念,并逐步引领你进入更深入的内容。
无需担心,即使你是一个完全的编程初学者,也能够轻松入门Ruby编程。
1. 准备工作在开始学习Ruby编程前,你需要确保电脑中已经安装了Ruby 解释器。
你可以从Ruby官方网站(官网网址)上下载并安装适合你操作系统的版本。
安装完成后,你可以在命令行中输入"ruby -v"来验证是否成功安装。
2. Hello, Ruby!让我们从一个经典的例子开始,编写一个简单的Ruby程序,用于输出"Hello, Ruby!"这句话。
打开任意文本编辑器,新建一个以.rb为后缀的文件,比如hello.rb。
然后将下面的代码复制进去:```rubyputs "Hello, Ruby!"```保存文件后,在命令行中执行以下命令:```bashruby hello.rb```你将看到输出了"Hello, Ruby!",恭喜你成功运行了你的第一个Ruby程序!3. 变量和数据类型在Ruby中,我们可以使用变量来存储和操作数据。
Ruby有以下几种常用的数据类型:- 整数(Integer):用于表示整数,例如:1, 2, 3。
- 浮点数(Float):用于表示带有小数点的数值,例如:3.14, 2.718。
- 字符串(String):用于表示文本数据,例如:"Hello, Ruby!"。
- 布尔值(Boolean):用于表示真或假,只有两个取值:true (真)和false(假)。
以下是一些例子,展示了如何声明和使用变量:```rubynum1 = 10num2 = 5.5name = "Ruby"is_learning = true```4. 条件语句和循环结构条件语句和循环结构是编程中非常重要的概念,它们能够帮助我们根据特定的条件执行不同的代码。
ruby安装升级及命令

Successfully installed rails-2.3.2
6 gems installed
Installing ri documentation for activesupport-2.3.2...
Installing ri documentation for activerecord-2.3.2...
if [ -d "/usr/local/ruby-1.9.1/bin" ] ; then
PATH="/usr/local/ruby-1.9.1/binPATH"
fi
然后 注销 再登陆一次.
#如无意外
ruby -v
#ruby 1.9.1p0 (2009-01-30 revision 21907) [i686-linux]
解压下,进行解压目录,执行一下 sudo ruby setup.rb , 再执行一下 gem -v,发现已经升级到了1.3.1版本.
gem update rails 升级就完成了.
gem升级后,gem list为空,要重新安装需要的gem包.
项目升级的一个问题:
自己对ActiveRecord的一个open class增强(opar.rb文件中)
再次执行 gem list,可以看到如下信息:
*** LOCAL GEMS ***
Ruby编程入门学习使用Ruby语言进行Web开发

Ruby编程入门学习使用Ruby语言进行Web开发Ruby编程入门:使用Ruby语言进行Web开发Ruby作为一门灵活且富有表达力的编程语言,已经在Web开发中崭露头角。
它的简洁和强大功能吸引了许多开发者的注意力。
本文将介绍Ruby编程的基础知识,并演示如何利用Ruby语言进行Web开发。
一、Ruby简介Ruby是由松本行弘(Yukihiro Matsumoto)开发的一种面向对象的编程语言。
它的设计目标是让开发者更加快乐地编写代码,所以它的语法简单直观。
Ruby有一个非常活跃的开源社区,提供了大量的库和框架,使得在Web开发中使用它非常方便。
二、安装Ruby在开始学习Ruby编程之前,需要安装Ruby解释器。
Ruby的官方网站提供了各种操作系统的安装程序,用户只需根据自己的操作系统下载并按照说明进行安装。
三、基本语法1. 变量与数据类型Ruby是动态类型语言,它不需要声明变量类型。
只需简单地给一个变量赋值即可创建它。
Ruby支持多种数据类型,包括整数、浮点数、字符串、数组和哈希等。
2. 条件语句与循环Ruby提供了if语句、unless语句和case语句来实现条件判断。
此外,Ruby还提供了多种循环语句,如while循环、until循环和for循环等。
3. 函数与类Ruby是一种面向对象的编程语言,所以函数在Ruby中被称为方法。
我们可以使用def关键字定义方法,然后通过对象来调用它们。
此外,Ruby还支持类的定义和继承。
四、Ruby on Rails框架Ruby on Rails是一个基于Ruby的开发框架,旨在加快Web应用程序的开发速度。
它遵循“约定优于配置”的原则,提供了一套组织代码和处理请求的规范,从而使开发者能够更快地构建出稳健和可扩展的Web应用。
Rails框架提供了一些核心功能,如数据库管理、路由和模板等。
同时,它还有许多强大的插件和 gem 可供使用,大大简化了开发过程。
五、使用Ruby on Rails开发Web应用1. 创建新的Rails应用在命令行中运行以下命令,将在当前目录下创建一个新的Rails应用。
ros vim用法

rosvim用法Vim是一款强大的文本编辑器,广泛应用于软件开发领域。
在ROS(机器人操作系统)环境中,Vim是常用的代码编辑工具之一。
本篇文章将介绍ROS环境下Vim的基本用法,包括安装、基本操作、文件操作、代码编辑等。
一、安装Vim在ROS环境中,可以通过以下命令安装Vim:```shellsudoapt-getinstallvim```安装完成后,Vim即可在ROS环境中使用。
二、基本操作1.打开文件:可以使用以下命令打开文件:```rubyvim文件名```2.保存文件:在Vim中,可以通过以下命令保存文件:```ruby:w```保存完成后,可以通过以下命令退出Vim:```ruby:q```3.进入Insert模式:可以通过以下命令进入Insert模式:```rubyi```4.退出Insert模式:可以通过以下命令退出Insert模式:```rubyEsc```5.移动光标:Vim支持多种移动光标的方式,包括上、下、左、右等方向键,以及Home和End键。
6.撤销操作:可以通过以下命令撤销一次操作:```rubyu```7.重做操作:可以通过以下命令重做一次撤销操作:```rubyCtrl+R```三、文件操作1.新建文件:可以使用以下命令新建一个空文件:```rubyvim+新建文件名打开文件路径/新文件路径/新文件名.txt(其中"新文件名"可以自定义)```2.删除文件:可以使用以下命令删除一个文件:在ROS环境中,删除文件需要注意以下几点:①如果该文件在系统根目录下,需要先通过rosversion-p获取文件属性;②如果要删除的目录中有其他重要文件,请务必确认删除后不会造成其他问题。
四、代码编辑和格式化代码使用方法根据具体需求和代码类型,可以使用Vim中的各种编辑和格式化功能。
常用的编辑和格式化功能包括缩进、注释、删除行等。
具体使用方法可以参考Vim的官方文档或相关教程。
ruby教程

ruby教程
Ruby教程简介
Ruby是一种开源的、简洁而有趣的动态编程语言。
它具有极
强的可读性和表达能力,对于初学者来说非常友好。
Ruby语
言的设计理念是“简单而不失强大”,它允许开发者以一种优雅的方式表达自己的想法。
Ruby的特点之一是它的面向对象编程能力。
在Ruby中,一切都是对象,并且每个对象可以拥有自己的方法和属性。
这种特性使得Ruby能够非常方便地实现庞大的复杂系统,并能够以
模块化的方式组织代码。
Ruby的语法非常灵活,允许开发者使用各种不同的编程风格。
它支持面向对象编程、函数式编程和元编程等多种范式,使得开发者能够选择最适合自己的方式来解决问题。
Ruby还有一个非常强大的特性是它的标准库。
标准库中包含
了大量的模块和类,提供了各种各样的功能,从文件操作到网络编程,从数据库连接到图形界面等等。
这使得开发者不需要从头开始编写所有功能,而是可以直接使用标准库中提供的模块和类来加速开发过程。
此外,Ruby社区非常活跃,并且有很多优秀的第三方库和框
架可供选择。
无论是开发Web应用、科学计算还是游戏开发,都能找到适合自己的解决方案。
本教程将介绍Ruby语言的基础知识和常用的编程技巧,帮助
读者快速入门并掌握Ruby的核心概念和特性。
通过学习本教程,读者将能够编写出简洁而功能强大的Ruby程序,并能够继续深入学习和探索更高级的主题。
让我们开始学习Ruby吧!。
uby操作excel文件

uby操作excel文件使用ruby来操作excel文件首先需要在脚本里包含以下语句require 'win32ole'把win32ole包含进来后,就可以通过和windows下的excel api进行交互来对excel文件进行读写了.打开excel文件,对其中的sheet进行访问:excel = WIN32OLE::new('excel.Application')workbook = excel.Workbooks.Open('c:\examples\spreadsheet.xls') worksheet = workbook.Worksheets(1) #定位到第一个sheetworksheet.Select读取数据:worksheet.Range('a12')['Value'] #读取a12中的数据data = worksheet.Range('a1:c12')['Value'] #将数据读入到一个二维表找到第一处a列的值为空值line = 1while worksheet.Range("a#{line}")['Value']line=line+1end #line的值为第一处空白行的行数将第一列的值读入到一个数组中line = '1'data = []while worksheet.Range("a#{line}")['Value']data << worksheet.Range("a#{line}:d#{line}")['Value']line.succ!end将数据写入到excel表格中worksheet.Range('e2')['Value'] = Time.now.strftime '%d/%m/%Y' #单个值worksheet.Range('a5:c5')['Value'] = ['Test', '25', 'result'] #将一个数组写入调用宏定义excel.Run('SortByNumber')设置背景色worksheet.Range('a3:f5').Interior['ColorIndex'] = 36 #pale yellow# 将背景色恢复成无色worksheet.Range('a3:f5').Interior['ColorIndex'] = -4142 # XlColorIndexNone constant# 使用Excel constant 将背景色恢复成无色worksheet.Range('a3:f5').Interior['ColorIndex'] =ExcelConst::XlColorIndexNone保存workbook.Close(1)# 或workbook.SaveAs 'myfile.xls'# 默认路径是系统定义的"我的文档"结束会话excel.Quit一些相对完整的代码片段创建一个excel文件并保存require 'win32ole'excel = WIN32OLE.new("excel.application")excel.visible = true # in case you want to see what happensworkbook = excel.workbooks.addworkbook.saveas('c:\examples\spreadsheet1.xls')workbook.close操作excel文件的几个重要元素Excel => workbook => worksheet => range(cell)我理解的是excel为类名,workbook为一个具体的(excel文件)实例,创建好实例后,worksheet是实例(workbook,工作簿)中的一个工作表,然后可以对工作表中的每个单元格(range(cell))进行具体的读写------------------按照这样操作肯定没有错,不过下面的这些语句又让我有些疑惑excel.workbooks("Mappe1").worksheets("Tabelle1").range("a1").value #读取名为Mappe1的excel文件中工作表名为Tabelle1的a1单元格中的值excel.worksheets("Tabelle1").range("a1").value #作用同第一条语句excel.activeworkbook.activesheet.range("a1").value #作用同第一条语句excel.activesheet.range("a1").value #作用同第一条语句excel.range("a1").value #作用同第一条语句excel可以直接操作所有的属性,默认为当前活跃的工作簿/工作表对单元格的操作:某个单元格: sheet.range("a1")a1到c3的值: sheet.range("a1", "c3") 或sheet.range("a1:c3")第一列: sheet.range("a:a")第三行: sheet.range("3:3")获得单元格的值:range.text #读取值,返回为字符串格式,如果单元格内为数字,有可能会被截断小数点后的位数sheet.range("a1").textrange.value #读取值,数字不会截断sheet.range("a1").value对单元格设置值sheet.range("a1").value = 1.2345或sheet.range("a1").value = '1.2345'迭代访问:sheet.range("a1:a10").each{|cell|puts cell.value}如果范围是一个矩形,则会按行循环迭代访问sheet.range("a1:b5").each{|cell|puts cell.value}block迭代,并打印出每行的第一个值。
绿宝石金手指代码大全

绿宝石金手指代码大全绿宝石(Ruby)是一种简单易学、高效实用的面向对象的编程语言,它的设计者松本行弘(Matz)在1993年首次发布了它。
作为一种动态语言,它注重程序员的生产力和代码的简洁性。
在Ruby的世界里,代码的可读性和开发效率是至关重要的,因此绿宝石金手指代码的编写就显得尤为重要。
绿宝石金手指代码是指那些简洁、高效、优雅的代码,它们能够让程序员事半功倍,提高开发效率,减少出错概率,提升代码的可维护性。
在本文档中,我们将为您提供一份绿宝石金手指代码大全,希望能够帮助您更好地理解和应用绿宝石编程语言。
1. 高效的字符串处理。
在绿宝石中,字符串处理是一个非常常见的任务。
以下是一个高效的字符串处理示例:```ruby。
str = "hello, world"# 替换字符串中的逗号。
str.sub!(',', '!')。
puts str # 输出 hello! world。
```。
2. 简洁的数组操作。
数组是绿宝石中常用的数据结构之一,以下是一个简洁的数组操作示例:```ruby。
arr = [1, 2, 3, 4, 5]# 使用map方法对数组中的每个元素进行平方操作。
new_arr = arr.map { |x| x2 }。
puts new_arr # 输出 [1, 4, 9, 16, 25]```。
3. 优雅的文件操作。
文件操作是编程中常见的任务之一,以下是一个优雅的文件操作示例:```ruby。
File.open('example.txt', 'w') do |file|。
file.puts "Hello, world!"end。
```。
4. 灵活的异常处理。
异常处理是保证程序稳定性的重要手段,以下是一个灵活的异常处理示例:```ruby。
begin。
# 可能会出现异常的代码。
rescue StandardError => e。
rucky 语法

rucky 语法Rucky语法入门指南Rucky是一种简单易学的编程语言,它结合了Ruby和Lucky两种语言的特点,旨在提供一种简洁、优雅且易于使用的编程语言。
本文将介绍Rucky语法的基本要点,帮助读者快速入门。
1. 变量和数据类型在Rucky中,变量的声明不需要指定数据类型,可以直接使用。
例如:```name = "Rucky"age = 25```Rucky支持多种数据类型,包括字符串、整数、浮点数、布尔值等。
可以根据需要随时进行类型转换。
2. 条件语句Rucky使用if语句进行条件判断。
例如:```if age > 18puts "成年人"elseputs "未成年人"```Rucky中使用end来标记代码块的结束,使代码结构清晰。
3. 循环语句Rucky提供了多种循环语句,包括while循环和for循环。
例如:```while i < 10puts ii += 1endfor i in 1..5puts iend```Rucky中的循环语句使用do和end来标记代码块的开始和结束。
4. 函数和方法在Rucky中,函数使用def关键字定义,方法使用class关键字定义。
例如:```def add(a, b)return a + bclass Persondef initialize(name)@name = nameenddef say_helloputs "Hello, #{@name}!"endend```Rucky中的方法可以通过实例化对象来调用。
5. 异常处理Rucky使用begin和rescue来处理异常。
例如:```begin# 可能发生异常的代码rescue# 异常处理代码end```Rucky中的异常处理可以捕获并处理异常,保证程序的正常运行。
6. 类和模块Rucky支持面向对象编程,可以使用class关键字定义类,使用module关键字定义模块。
Ruby 语言介绍

Ruby语言介绍
目录
Ruby语言介绍 (1)
目录 (1)
1.基本的ruby语法 (2)
1.1变量、常量和类型 (2)
1.2注释 (2)
1.3循环和分支 (2)
1.4正则表达式 (4)
2,常用函数 (7)
2.1Numeric 类 (7)
2.2Float 类 (7)
2.3String 类 (7)
2.4Array 类 (9)
2.5Hash 类 (11)
1.基本的ruby语法
1.1变量、常量和类型
1)定义变量
2)变量内插
在双引号内使用“#(变虽名}"内插变最
1.2注释
1)单行注释:以#开头,如:#注释内容
2)多行注释:在=begin和=end之间定义,如: =begin
注释内容
=end
13循环和分支
1.3.4 类
135模块
方法说明
include,watir' 将模块的功能添加到当前空间中,不加载己加载的文件
1.3.6 case 语句case x
1.4正则表达式
1.4.1普通字符
普通字符由字母、数字、下划线和特殊符号组成。
4/13
如:
表达式/b/在匹配字符“abed”时,匹配的内容是“b” 表达式/b_/在匹配字符"ab_cd”时,匹
配的内容是“b_”
1.4.2转义符
1.4.3匹配多种字符
1.4.4修饰匹配次数的方法
1-4.5匹配模式
2.常用函数2.1 Numeric 类
2. 4 Array 类
2.5 Hash 类。
PHP、Python、Ruby的(数据库、文件)比较(原创)

PHP、Python、Ruby的比较(一)主题:数据库、文件的操作侯惠阳(PHPer.yang)我和大家讨论的是(PHP、Python、Ruby)这三种脚本语言各自的特性。
今后每期主题不同,分别阐述他们的效率以及特点。
这一期讨论的是:数据库、文件的操作。
一:PHP部分:A:读取数据库方面PHP对于数据库操作方面比较简单,可以使用MySQL给PHP写的扩展mysql*、mysqli*,以及PHP官方自己写的Mysqlnd。
这里其实我主要想说的是mysql_connect();这个函数。
注意第三个参数new_link(bool)。
如果用同样的参数第二次调用mysql_connect(),将不会建立新连接,而将返回已经打开的连接标识。
参数new_link 改变此行为并使mysql_connect() 总是打开新的连接,甚至当mysql_connect() 曾在前面被用同样的参数调用过。
普通操作:<?php$conn = mysql_connect(“localhost”,”root”,””,true);mysql_select_db(“test”,$conn);$query = mysql_query(“select * from test”);while($rows = mysql_fetch_array($query)) {…}…带存储过程的操作:Mysqlcreate procedure hhy(in yumail varchar(20),out _s int,out _uid int)beginif exists(select * from user where umail = yumail) thenset _s = 1;select uid into _uid from user where umail = yumail;elseset _s = 0;end if;endPHP中使用:mysql_query(“call hhy('test@',@_s,@_uid);”);mysql_query(“select @_s,@_uid;”);…这部分以后在详细叙述。
编程技巧:提高Ruby编程效率的10个方法

编程技巧:提高Ruby编程效率的10个方法Ruby是一种动态、面向对象的编程语言,它简洁、灵活,以人性化的语法而闻名。
然而,在实际开发过程中,我们可能会遇到一些繁琐的任务或效率低下的问题。
本文将介绍10个提高Ruby编程效率的实用方法。
1. 使用Ruby内置类和方法Ruby提供了许多内置类和方法,可以大大简化我们的编码工作。
例如,使用Array类的map或reduce方法可以避免手动迭代数组元素。
2. 学习并掌握Ruby标准库Ruby标准库中有很多功能强大且广泛应用的库,包括日期处理、正则表达式、文件操作等。
学习并熟练使用这些库可以帮助我们更快地完成任务。
3. 使用代码片段和模板借助代码片段和模板工具,我们可以事先定义好常用代码块,并在需要时直接调用。
这样不仅节省时间,还能保证代码一致性。
4. 遵循良好的命名规范给变量、方法和类起一个明确而有意义的名称可以让代码更易于理解和维护。
遵循约定俗成的命名规范,如驼峰命名法或下划线命名,有助于提高代码的可读性。
5. 利用Ruby的元编程能力Ruby具有强大的元编程能力,可以在运行时动态地修改代码。
这意味着我们可以使用元编程技巧来减少重复代码、实现动态代码生成等,从而提高效率。
6. 使用适当的数据结构和算法通过选择适当的数据结构和算法,我们可以优化程序的时间和空间复杂度。
了解不同数据结构和算法及其适用场景,能够更快地解决问题。
7. 编写单元测试编写单元测试是保证代码质量和正确性的关键步骤。
通过自动化测试,我们可以更快地发现潜在bug,并及早修复。
8. 使用调试工具Ruby提供了丰富的调试工具,如pry、byebug等。
利用这些工具进行调试可以帮助我们快速定位问题并找出解决方案。
9. 阅读开源项目代码阅读开源项目代码是学习他人优秀实践经验的一种方式。
通过研究他人的代码,我们可以学到更多技巧和技术,提高自己的编程水平。
10. 不断学习和实践编程技巧需要不断地学习和实践才能够真正掌握。
草图大师插件安装方法
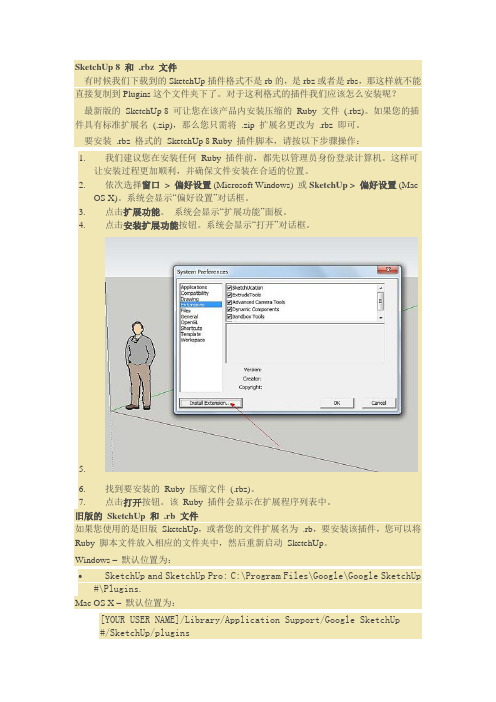
SketchUp 8 和.rbz 文件有时候我们下载到的SketchUp插件格式不是rb的,是rbz或者是rbs,那这样就不能直接复制到Plugins这个文件夹下了。
对于这利格式的插件我们应该怎么安装呢?最新版的SketchUp 8 可让您在该产品内安装压缩的Ruby 文件(.rbz)。
如果您的插件具有标准扩展名(.zip),那么您只需将 .zip 扩展名更改为.rbz 即可。
要安装 .rbz 格式的SketchUp 8 Ruby 插件脚本,请按以下步骤操作:1.我们建议您在安装任何Ruby 插件前,都先以管理员身份登录计算机。
这样可让安装过程更加顺利,并确保文件安装在合适的位置。
2.依次选择窗口> 偏好设置 (Microsoft Windows) 或SketchUp > 偏好设置 (MacOS X)。
系统会显示“偏好设置”对话框。
3.点击扩展功能。
系统会显示“扩展功能”面板。
4.点击安装扩展功能按钮。
系统会显示“打开”对话框。
5.6.找到要安装的Ruby 压缩文件(.rbz)。
7.点击打开按钮。
该Ruby 插件会显示在扩展程序列表中。
旧版的SketchUp 和.rb 文件如果您使用的是旧版SketchUp,或者您的文件扩展名为.rb,要安装该插件,您可以将Ruby 脚本文件放入相应的文件夹中,然后重新启动SketchUp。
Windows –默认位置为:SketchUp and SketchUp Pro: C:\Program Files\Google\Google SketchUp #\Plugins.Mac OS X –默认位置为:[YOUR USER NAME]/Library/Application Support/Google SketchUp#/SketchUp/plugins提示:您可能需要在SketchUp 文件夹中创建您的插件文件夹。
为此,请在Finder 窗口中依次点击文件> 新建文件夹。
利用Docker打包与发布Ruby应用的方法与步骤

利用Docker打包与发布Ruby应用的方法与步骤在当今软件开发的领域,持续集成和交付已经成为一种普遍的实践。
通过集成和交付,开发人员能够更快地将应用程序部署到生产环境中。
而Docker作为一种容器化技术,为应用程序的打包和发布提供了便利。
本文将介绍利用Docker打包和发布Ruby应用程序的方法和步骤。
一、安装Docker在开始之前,我们需要先安装Docker。
Docker提供了不同的安装方式,可以根据操作系统选择合适的方法进行安装。
一般而言,可以通过访问Docker官方网站获取相关安装说明。
二、编写Dockerfile文件在开始Docker化我们的Ruby应用之前,我们需要创建一个名为Dockerfile的文本文件。
Dockerfile是一个用于构建Docker镜像的脚本。
下面是一个简单的Dockerfile示例:```# 指定基础镜像FROM ruby:2.7# 设置工作目录WORKDIR /app# 复制Gemfile和Gemfile.lock到工作目录COPY Gemfile Gemfile.lock ./# 安装依赖RUN bundle install# 复制应用程序代码到工作目录COPY . .# 设置容器启动时执行的命令CMD ["ruby", "app.rb"]```上述Dockerfile文件定义了一个基于ruby:2.7镜像的容器。
首先,我们将工作目录设置为/app,然后将Gemfile和Gemfile.lock复制到工作目录。
接下来,我们运行bundle install命令来安装应用程序的依赖。
然后,将应用程序的所有代码复制到工作目录。
最后,我们设置容器启动时执行的命令为ruby app.rb。
三、构建Docker镜像一旦我们编写好了Dockerfile文件,就可以使用docker build命令构建Docker 镜像。
Docker镜像是一个可执行的软件包,它包含了运行应用程序所需的所有代码、库和依赖。
VSCode调试Ruby脚本详解

VSCode调试Ruby脚本详解现如今,Ruby作为一种强大而灵活的编程语言,越来越受到开发者的喜爱。
为了提高开发效率和代码质量,许多程序员选择使用VSCode作为他们的主要集成开发环境(IDE)。
VSCode不仅提供了丰富的插件和功能,还支持Ruby脚本的调试。
在本文中,我们将详细介绍如何在VSCode中调试Ruby脚本,以帮助读者更好地利用这一特性。
一、安装插件和设置环境要在VSCode中调试Ruby脚本,首先需要安装相应的插件。
打开VSCode,点击扩展按钮,搜索Ruby插件,并安装。
安装完成后,重启VSCode以使插件生效。
接下来,确认你的系统中已经安装了Ruby解释器。
在终端中输入以下命令以检查Ruby是否已经安装:```shellruby -v```如果看到Ruby的版本信息输出,说明Ruby已经安装成功。
如果没有安装,请根据自己的操作系统选择合适的方法进行安装。
二、创建调试配置在VSCode中,每个项目都需要一个针对该项目的调试配置文件。
打开VSCode,点击“调试”选项卡,然后点击左侧的“创建一个launch.json文件”链接。
选择“Ruby”作为启动配置的类型。
```json{"version": "0.2.0","configurations": [{"name": "Debug Ruby Script","type": "Ruby","request": "launch","program": "${workspaceRoot}/your_script.rb","console": "integratedTerminal"}]}```以上是一个简单的Ruby调试配置,你需要将其中的`your_script.rb`替换为你要调试的脚本的路径。
学会使用Ruby编程语言进行开发

学会使用Ruby编程语言进行开发Ruby是一种简洁而强大的编程语言,以其优雅的语法和丰富的功能而受到广泛认可。
本文将介绍学会使用Ruby编程语言进行开发的一些重要方面,以便读者能够更全面地了解和运用Ruby进行软件开发。
一、Ruby简介Ruby是一种面向对象的动态编程语言,由日本程序员松本行弘(Yukihiro Matsumoto)于1993年开发而来。
Ruby的设计理念是简单而强大,注重提高开发效率和代码可读性。
Ruby支持多种编程范式,如面向对象编程、函数式编程和元编程等。
二、Ruby环境配置在学习和使用Ruby之前,首先需要配置Ruby的开发环境。
具体步骤如下:1. 下载和安装Ruby解释器;2. 配置环境变量,使得Ruby解释器可在任意目录下运行;3. 安装Ruby开发工具包,如RubyGems和Bundler等。
三、Ruby语法基础1. 变量和数据类型:Ruby是一种动态类型语言,变量无需事先声明。
Ruby支持多种数据类型,包括整型、浮点型、字符串、布尔型和数组等。
2. 控制流语句:Ruby提供了丰富的控制流语句,如条件语句(if-else语句)、循环语句(while和for循环)和异常处理语句(begin-rescue语句)等。
这些语句可以实现程序的不同逻辑分支和错误处理。
3. 函数和方法:Ruby允许定义函数和方法来组织代码。
函数是一段可重复调用的代码块,而方法则是与对象关联的函数。
学习如何编写并调用函数和方法是Ruby开发的基础。
4. 类和对象:Ruby是一种面向对象的语言,类是其核心概念之一。
通过定义类和创建对象,可以实现代码的封装和复用。
同时,Ruby还支持继承、多态和模块等面向对象的高级特性。
四、Ruby标准库和常用库Ruby标准库是Ruby提供的一组常用功能的集合,包括文件操作、网络通信、数据处理和日期时间等。
同时,Ruby社区也提供了大量的第三方库和框架,以扩展Ruby的功能。
ruby语言基础教程

15
二、Ruby条件判断、循环
16
三、Ruby目录与文件
17
12
一、Ruby基础知识-哈希
Hash和数组一样,也可以作为对象集合的对象,数组用索引来访问元素, 而hash是通过“键”来访问。 Person =Hash.new Person[“name”] =“Kael” Person.store(“age”,”30) Puts Person[“name”] Puts Person.fetch(“name”) Person[“address”] =“XX路” Book ={“name”=>”C#”,”isbn” =>”123344545”} h2 =hash.new(“”) h1 =hash.new puts h1[“not_key”] => nil puts h2[“not_key”] => “”
13
Hash哈希类
以数组方式 取出键 keys 以迭代方式 each_key{|key|…}
取出值
取出“键,值”对
values
To_a
each_key{|value|…}
each_key{|key,value| ..}
14
一、Ruby基础知识-哈希
在建立hash指定默认值 H1 =Hash.new(1) h1[“a”]=5 puts H1[“a”] =>5 puts H1[“b”] =>1 puts H1[“c”] =>1 指定用来产生默认值的区块 h=Hash.new{|hash,key| Hash[key] =key.upcase} h[“a”]=“@” puts h[“x”] =“X”
3
一、Ruby基础知识
Mac命令行快速执行脚本操作

Mac命令行快速执行脚本操作在Mac系统中,命令行是一个强大的工具,可用于执行各种操作和任务。
通过使用命令行,我们可以快速执行脚本操作,提高工作效率。
本文将介绍一些常用的Mac命令行快速执行脚本操作。
一、执行脚本操作的前提条件在进行Mac命令行快速执行脚本操作之前,我们需要确保以下几个前提条件已满足:1. 确保已经具备基本的命令行使用知识,了解常用命令和参数的使用方法。
2. 确保已经安装了所需的软件和依赖,例如Python、Ruby等。
3. 确保脚本文件已经编写好,并保存在本地。
二、执行Python脚本Python是一种广泛使用的高级编程语言,在Mac系统中执行Python脚本可以通过以下步骤进行:1. 打开终端:在“应用程序”文件夹中找到“实用工具”文件夹,然后双击打开终端。
2. 进入脚本文件所在目录:使用cd命令切换到脚本文件所在的目录。
例如,如果脚本文件保存在桌面上的“Scripts”文件夹中,可以使用以下命令进行切换:```shellcd ~/Desktop/Scripts```3. 执行脚本:使用python命令加上脚本文件名称进行执行。
例如,如果脚本文件名为“test.py”,可以使用以下命令进行执行:```shellpython test.py```执行以上步骤后,系统将会执行Python脚本,并输出脚本的结果。
三、执行Ruby脚本Ruby是另一种常用的编程语言,在Mac系统中执行Ruby脚本可以通过以下步骤进行:1. 打开终端:同上述步骤一。
2. 进入脚本文件所在目录:同上述步骤二。
3. 执行脚本:使用ruby命令加上脚本文件名称进行执行。
例如,如果脚本文件名为“test.rb”,可以使用以下命令进行执行:```shellruby test.rb```执行以上步骤后,系统将会执行Ruby脚本,并输出脚本的结果。
四、执行Shell脚本Shell脚本是一种在Unix或类Unix系统中广泛使用的脚本语言,用于执行一系列命令。
学习使用Ruby进行脚本编程

学习使用Ruby进行脚本编程当谈到脚本编程语言时,Ruby通常是一个备受推崇的选择。
Ruby是一种简洁而强大的编程语言,广泛用于Web开发、自动化脚本和数据分析等领域。
本文将深入探讨学习使用Ruby进行脚本编程的过程,从基础知识到高级技巧,帮助初学者快速入门并提供一些进一步学习的路径。
1. Ruby的特点在学习使用Ruby进行脚本编程之前,我们首先了解一下Ruby的一些特点。
Ruby是一种面向对象的语言,具有简单易读的语法和丰富的内置库。
这种可读性使得Ruby成为初学者和专业开发人员喜欢的语言之一。
此外,Ruby还支持代码块和迭代器,使得编程变得更加灵活和高效。
2. 安装Ruby要开始使用Ruby进行脚本编程,首先需要在计算机上安装Ruby环境。
可以从Ruby官方网站上下载适用于不同操作系统的安装包,并按照官方指南进行安装配置。
3. Ruby基础知识在准备好环境之后,我们可以开始学习Ruby的基础知识。
Ruby的语法相对简单且易于学习,下面是一些必备的基础知识点:- 变量和数据类型:学习如何声明变量和使用不同的数据类型,例如字符串、整数、浮点数、数组和哈希等。
- 条件语句和循环:了解如何使用条件语句(if-else)和循环语句(for、while)来控制程序的流程。
- 函数和方法:学习如何定义和调用函数和方法,以及如何传递参数和返回值。
- 文件操作:掌握如何读取和写入文件,处理文件的内容和结构。
- 异常处理:了解如何捕获和处理异常,以及如何使程序更加健壮和容错。
4. Ruby标准库和GemRuby的标准库提供了许多有用的功能和模块,可以帮助我们更高效地编写脚本。
例如,我们可以使用`net/http`模块进行网络请求,使用`csv`模块处理CSV文件,使用`json`模块解析和生成JSON数据等等。
通过阅读官方文档和实践,我们可以逐渐熟悉这些库的使用方法,并在实际开发中充分发挥它们的作用。
此外,Ruby还拥有一个丰富的第三方库生态系统,称为Gem。
文件及文件夹操作

ruby文件操作大全【转】-------------------------------------------------------------目录操作:使用Dir类的静态方法或创建一个Dir类的实例对象。
-------------------------------------------------------------一Dir类的静态方法Dir类提供了一组静态方法用于目录的创建,删除以及遍历,可以指定路径全名称增删查目录,缺省操作对象是当前脚本工作目录。
获取当前脚本工作目录Dir::pwd属性或者Dir.getwd()改变当前脚本工作目录Dir::chdir创建目录Dir::mkdir不指定目录全名称时,缺省为工作目录删除目录Dir::rmdir不指定目录全名称时,缺省为工作目录遍历目录Dir::foreach(arg1){|item1|segment..}如果参数arg1中指定了目录全名称,如"d:/ruby/rubywork/",则遍历该指定目录。
如参数args1中不是目录全名称,如"rubywork",则遍历"当前工作目录/rubywrok/"。
获取当前脚本目录的方法我们知道全局变量$0是当前脚本的全路径,所以,可以依靠File.dirname($0)来获取当前脚本的目录。
(注意:工作目录又称为环境目录,是当前软件运行时的工作目录,当前软件执行的操作都是基于该工作目录的,工作目录一般是脚本所在目录,但工作目录不等于脚本所在目录)二Dir类的实例对象可以使用Dir.new来创建一个Dir类的实例对象,需要有一个参数,该参数指定了一个目录,以后该调用该对象的方法,都将基于这个目录。
Dir#close关闭该对象,释放所占资源Dir#each遍历对象,方法同Dir::foreach,只是没有参数,遍历当前对象的子文件Dir#path返回该实例对象的目录Dir#read返回一个子文件Dir#pos返回当前子文件指针Dir#pos=设置子文件指针Dir#rewind设置子文件指针到起始位置Dir#seek设置子文件指针Dir#tell获取当前指针-------------------------------------------------文件操作:使用File类的静态方法,或者File类的实例对象-------------------------------------------------三File类的静态方法File::atime(filename)返回指定文件的最后访问时间1.创建文件夹Dir.new%%1Dir::mkdir#不指定目录全名称时,缺省为工作目录Dir::chdir()改变当前脚本工作目录FileUtils.mkdir'test'file=File.new("cmd.txt")file.each do|line|puts line if line=~/target/end2.创建文件改变当前根目录Dir.chdir("/home/guy/sandbox/tmp")Dir.chroot("/home/guy/sandbox")Dir.new%%1#Dir::rmdir#不指定目录全名称时,缺省为工作目录3.删除文件改变当前根目录Dir.chdir("/home/guy/sandbox/tmp")Dir.chroot("/home/guy/sandbox")Dir.new%%1#Dir::rmdir#不指定目录全名称时,缺省为工作目录4.删除文件夹#require'fileutils'FileUtils.rm_r(%%1)5.删除一个文件下夹所有的文件夹Dir::chdirDir::pwd属性或者Dir.getwd()#改变当前脚本工作目录6.清空文件夹Dir::chdir%%1改变当前脚本工作目录Dir::rmdir#不指定目录全名称时,缺省为工作目录Dir.new%%1#require'ftools'FileUtils.mkdir'test'file=File.new(%%1)#"cmd.txt"file.each do|line|puts line if line=~/target/end7.读取文件#require'ftools'File.open(%%1).readlines#'文件名'#require'ftools'arr=IO.readlines(%%1)#"myfile"lines=arr.size#puts"myfile has#{lines}lines in it."#longest=arr.collect{|x|x.length}.max#puts"The longest line in it has#{longest}characters."8.写入文件f=open(%%1,"w")f.puts(%%2)9.写入随机文件#require'ftools'file=File.open(%%1,"w")file.seek(5)str=file.gets#"fghi"#require'ftools'File.open('文件名')File.open("cmd.txt","r")do|file|while line=file.getsputs lineendendputsfile=File.new("cmd.txt","r")file.each_line do|line|puts lineendIO.foreach("cmd.txt")do|line|puts line if line=~/target/puts line if line!~/target/end###Dir#pos返回当前子文件指针Dir#pos=设置子文件指针Dir#rewind设置子文件指针到起始位置Dir#seek设置子文件指针Dir#tell获取当前指针10.读取文件属性#文件中是否有内容,(返回false为有内容,返回true为空)File.new('文件名').stat.zero?#文件大小File.size?('文件名')flag1=FileTest::zero?("file1")flag2=FileTest::size?("file2")size1=File.size("file1")size2=File.stat("file2").size###File::atime(filename)返回指定文件的最后访问时间11.写入属性12.枚举一个文件夹中的所有文件夹#require'ftools'puts Dir.glob('**/*').each{|file|file.downcase}#要区分目录和普通文件我们这样使用file1=File.new("/tmp")file2=File.new("/tmp/myfile")test1=file1.directory?#truetest2=file1.file?#falsetest3=file2.directory?#falsetest4=file2.file?#true###遍历目录Dir.foreach(%%1){|entry|puts entry}13.复制文件夹require"fileutils"FileUtils.cp%%1,%%214.复制一个目录下所有的文件夹到另一个文件夹下#require'FileUtils'list=Dir.entries(%%1)list.each_index do|x|FileUtils.cp"#{list[x]}",%%2if!File.directory?(list[x]) end15.移动文件夹#require'FileUtils'FileUtils.mv%%1,%%216.移动一个目录下所有的文件夹到另一个目录下#require'FileUtils'list=Dir.entries(%%1)list.each_index do|x|FileUtils.mv"#{list[x]}",%%2if!File.directory?(list[x])end17.以一个文件夹的框架在另一个目录创建文件夹和空文件#########################//文件是否存在File.exist?('文件名')flag=FileTest::exist?("LochNessMonster")flag=FileTest::exists?("UFO")#########################require'rubygems'require'ruby-debug'require"find"module Cz_dirtoolsdef mkdirs_to(tar,src=Dir.getwd)#debuggerif tar.class==NilClass thenputs"PLZ input target directory name..."returnelsif!FileTest.directory?(tar)#如果tar不是一个目录puts("Creating#{File.expand_path(tar)}")Dir.mkdir("#{File.expand_path(tar)}")#创建tar目录endsrc=if FileTest.directory?(src)thensrc#如果src是一个目录名,则返回自身elseFile.dirname(src)#如果src为一个文件名,则返回该文件所在目录end#Dir.foreach可以复制目标路径第一层目录结构而不复制子目录#~Dir.foreach(src)do|dir|#~if FileTest.directory?(dir)&&dir!=tar&&dir!='..'&&dir!='.'then #忽略自身,忽略上级目录"..",忽略本级目录"."#~#puts dir#~begin#~Dir.mkdir("#{File.expand_path(tar)}/#{dir}")#~rescue#如果该目录已存在则直接跳过否则创建该目录#~end#~end#~end#Find.find可以复制目标路径的完整目录结构,包括子目录dirs=Array.newFind.find(src)do|dir|unless!FileTest.directory?(dir)||File.basename(dir)==tar||File.basename(dir)=='..'||File.basename(dir)=='.'||File.basename(dir)==File.basename(src)#忽略自身,忽略上级目录"..",忽略本级目录"."dirs<<direndend#puts dirsdirs.each do|dir|beginDir.mkdir("#{File.expand_path(tar)}/#{dir.gsub(src,'')}")rescue#如果该目录已存在则直接跳过否则创建该目录endendendendrequire'rubygems'require'ruby-debug'require"find"module Cz_dirtoolsdef mkdirs_to(tar,src=Dir.getwd)#debuggerif tar.class==NilClass thenputs"PLZ input target directory name..."returnelsif!FileTest.directory?(tar)#如果tar不是一个目录puts("Creating#{File.expand_path(tar)}")Dir.mkdir("#{File.expand_path(tar)}")#创建tar目录endsrc=if FileTest.directory?(src)thensrc#如果src是一个目录名,则返回自身elseFile.dirname(src)#如果src为一个文件名,则返回该文件所在目录end#Dir.foreach可以复制目标路径第一层目录结构而不复制子目录#~Dir.foreach(src)do|dir|#~if FileTest.directory?(dir)&&dir!=tar&&dir!='..'&&dir!='.'then #忽略自身,忽略上级目录"..",忽略本级目录"."#~#puts dir#~begin#~Dir.mkdir("#{File.expand_path(tar)}/#{dir}")#~rescue#如果该目录已存在则直接跳过否则创建该目录#~end#~end#~end#Find.find可以复制目标路径的完整目录结构,包括子目录dirs=Array.newFind.find(src)do|dir|unless!FileTest.directory?(dir)||File.basename(dir)==tar||File.basename(dir)=='..'||File.basename(dir)=='.'||File.basename(dir)==File.basename(src)#忽略自身,忽略上级目录"..",忽略本级目录"."dirs<<direndend#puts dirsdirs.each do|dir|beginDir.mkdir("#{File.expand_path(tar)}/#{dir.gsub(src,'')}")rescue#如果该目录已存在则直接跳过否则创建该目录endendendend18.复制文件#require'FileUtils'FileUtils.cp%%1,%%219.复制一个目录下所有的文件到另一个目录#require'FileUtils'list=Dir.entries(%%1)list.each_index do|x|FileUtils.cp"#{list[x]}",%%2if!File.directory?(list[x]) end20.提取扩展名21.提取文件名%%2=File.basename(%%1)22.提取文件路径%%2=File.dirname(%%1)23.替换扩展名24.追加路径25.移动文件26.移动一个文件夹下所有文件到另一个目录#require'FileUtils'list=Dir.entries(%%1)list.each_index do|x|FileUtils.mv"#{list[x]}",%%2if!File.directory?(list[x]) end27.指定目录下搜索文件#require"find"def findfiles(dir,name)list=[]Find.find(dir)do|path|Find.prune if[".",".."].include?pathcase namewhen Stringlist<<path if File.basename(path)==namewhen Regexplist<<path if File.basename(path)=~name elseraise ArgumentErrorendendlistendfindfiles%%1,%%2#"/home/hal","toc.txt"28.打开对话框29.文件分割逐字节对文件进行遍历可以使用each_byte方法,如果你想要转换byte到字符的话使用chr方法:file=File.new("myfile")e_count=0file.each_byte do|byte|e_count+=1if byte==?eend30.文件合并逐字节对文件进行遍历可以使用each_byte方法,如果你想要转换byte到字符的话使用chr方法:file=File.new("myfile")e_count=0file.each_byte do|byte|e_count+=1if byte==?eend31.文件简单加密32.文件简单解密33.读取ini文件属性34.合并一个文件下所有的文件35.写入ini文件属性36.获得当前路径File.dirname($0)37.读取XML数据库38.写入XML数据库39.ZIP压缩文件#require'rubygems'#require'zip/zipfilesystem'Zip::ZipFile.open(%%1,Zip::ZipFile::CREATE)do|zip|#'zipfile.zip'zip.file.open('file1','w'){|f|f<<'This is file1.'}zip.dir.mkdir('sub_dir')zip.file.open('sub_dir/file2','w'){|f|f<<'This is file2.'} end40.ZIP解压缩41.获得应用程序完整路径42.ZIP压缩文件夹#require'rubygems'#require'zip/zipfilesystem'def compressZip::ZipFile.open'zipfile.zip',Zip::ZipFile::CREATE do|zip| add_file_to_zip('dir',zip)endenddef add_file_to_zip(file_path,zip)if File.directory?(file_path)Dir.foreach(file_path)do|sub_file_name|add_file_to_zip("#{file_path}/#{sub_file_name}",zip) unless sub_file_name=='.'or sub_file_name=='..'endelsezip.add(file_path,file_path)endendadd_file_to_zip%%1,%%243.递归删除目录下的文件#require'ftools'file_path=String.newfile_path="D:"if File.directory?file_pathDir.foreach(file_path)do|file|if file!="."and file!=".."puts"File:"+fileendendend44.验证DTD45.Schema验证46.Grep#!/usr/bin/env ruby#Grep with full regexp-functionality via rubyif ARGV.shift=="-p"pattern=Regexp.new(ARGV.shift)elseputs"Please give me a pattern with the'-p'option"exitendARGV.each do|filename|File.open(filename)do|file|file.each do|line|puts"#{filename}#{file.lineno.to_s}:#{line}"if pattern.match(line)endendendUsing it via:rgrep-p'/delete/i'*.php does not match anything,but this#!/usr/bin/env ruby#Grep with full regexp-functionality via rubyif ARGV.shift=="-p"pattern=Regexp.new(ARGV.shift)elseputs"Please give me a pattern with the'-p'option"exitendARGV.each do|filename|File.open(filename)do|file|file.each do|line|puts"#{filename}#{file.lineno.to_s}:#{line}"if/delete /i.match(line)endendend47.直接创建多级目录#require"fileutils"FileUtils.makedirs(%%1)48.批量重命名49.文本查找替换ReplaceText50.文件关联51.操作Excel文件52.设置JDK环境变量53.选择文件夹对话框54.删除空文件夹55.发送数据到剪贴板56.从剪贴板中取数据57.获取文件路径的父路径58.创建快捷方式CreateShortCut59.弹出快捷菜单60.文件夹复制到整合操作61.文件夹移动到整合操作62.目录下所有文件夹复制到整合操作63.目录下所有文件夹移动到整合操作64.目录下所有文件复制到整合操作65.目录下所有文件移动到整合操作66.对目标压缩文件解压缩到指定文件夹67.创建目录副本整合操作68.打开网页69.删除空文件夹整合操作70.获取磁盘所有分区后再把光驱盘符去除(用"\0"代替),把结果放在数组allfenqu[]中,数组中每个元素代表一个分区盘符,不包括:\\这样的路径,allfenqu[]数组开始时存放的是所有盘符。
在Docker容器中运行Ruby应用的技巧

在Docker容器中运行Ruby应用的技巧Docker是一种开源的容器化平台,可以帮助开发人员在不同的环境中轻松部署和运行应用程序。
Ruby是一种强大的动态编程语言,被广泛用于Web开发和其他应用程序开发。
在本文中,我们将探讨在Docker容器中运行Ruby应用的一些技巧。
1. 选择合适的Ruby镜像首先,您需要选择一个适合您的应用程序的Ruby镜像。
Docker Hub提供了许多不同版本和变体的Ruby镜像,您可以根据您的需求选择一个合适的镜像。
2. 使用Dockerfile为了在Docker容器中运行Ruby应用,您需要创建一个Dockerfile。
Dockerfile 是一个文本文件,其中包含一系列的指令,用于构建容器镜像。
以下是一个Dockerfile的示例:```DockerfileFROM ruby:2.7.2WORKDIR /appCOPY Gemfile Gemfile.lock ./RUN bundle installCOPY . .CMD ["ruby", "app.rb"]```在上面的示例中,我们首先选择了ruby:2.7.2作为基础镜像。
然后,我们将工作目录设置为/app,并将Gemfile和Gemfile.lock复制到工作目录中。
接下来,我们运行bundle install安装所有依赖项。
最后,我们将应用程序的源代码复制到工作目录,并通过CMD指令运行应用程序。
3. 理解容器与主机的文件系统隔离Docker容器与主机之间有一个文件系统隔离,这意味着只有在Docker容器内部进行的操作才会影响到容器的文件系统。
这对于运行Ruby应用程序来说是一个重要的方面,因为您的应用程序可能需要读取或写入文件。
为了使您的Ruby应用程序能够读取和写入文件,您可以使用容器内的共享文件夹。
在创建容器时,通过将主机目录映射到容器内的一个目录,您可以让容器和主机之间共享文件。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1ruby文件操作关键字:file ruby转!1检测文件是否存在及其大小FileTest的exist?方法可以检测一个文件是否存在:Ruby代码1.flag=FileTest::exist?("LochNessMonster")2.flag=FileTest::exists?("UFO")3.#exists?is a synonym for exist?Ruby代码1.flag=FileTest::exist?("LochNessMonster")2.flag=FileTest::exists?("UFO")3.#exists?is a synonym for exist?如果我们想要知道文件是否有内容,可以使用File::Stat的zero?方法:Ruby代码1.flag=File.new("somefile").stat.zero?Ruby代码1.flag=File.new("somefile").stat.zero?这个将会返回true,这是因为在ruby中0也是true,nil才是false.所以我们可以使用size?方法:Ruby代码1.if File.new("myfile").stat.size?2.puts"The file has contents."3.else4.puts"The file is empty."5.end1.if File.new("myfile").stat.size?2.puts"The file has contents."3.else4.puts"The file is empty."5.endFileTest模块里面也有zero?和size?方法:Ruby代码1.flag1=FileTest::zero?("file1")2.flag2=FileTest::size?("file2")Ruby代码1.flag1=FileTest::zero?("file1")2.flag2=FileTest::size?("file2")这里还有一个size方法:Ruby代码1.size1=File.size("file1")2.size2=File.stat("file2").sizeRuby代码1.size1=File.size("file1")2.size2=File.stat("file2").size2检测特殊文件属性这边要注意,File类mix了FIleTest模块,并且FileTest模块和File::Stat 模块功能上也有很多重复.unix/linux有面向字符和面向块的设备。
FileTest的方法blockdev?和chardev?可以进行测试:1.flag1=FileTest::chardev?("/dev/hdisk0")#false2.flag2=FileTest::blockdev?("/dev/hdisk0")#trueRuby代码1.flag1=FileTest::chardev?("/dev/hdisk0")#false2.flag2=FileTest::blockdev?("/dev/hdisk0")#true有时我们想要知道一个流是否联系到了终端,这时我们可以使用IO类的tty?方法:Ruby代码1.flag1=STDIN.tty?#true2.flag2=File.new("diskfile").isatty#falseRuby代码1.flag1=STDIN.tty?#true2.flag2=File.new("diskfile").isatty#false一个流可以是一个管道,或者一个socket:Ruby代码1.flag1=FileTest::pipe?(myfile)2.flag2=FileTest::socket?(myfile)Ruby代码1.flag1=FileTest::pipe?(myfile)2.flag2=FileTest::socket?(myfile)要区分目录和普通文件我们这样使用:Ruby代码1.file1=File.new("/tmp")2.file2=File.new("/tmp/myfile")3.test1=file1.directory?#true4.test2=file1.file?#false5.test3=file2.directory?#false6.test4=file2.file?#trueRuby代码1.file1=File.new("/tmp")2.file2=File.new("/tmp/myfile")3.test1=file1.directory?#true4.test2=file1.file?#false5.test3=file2.directory?#false6.test4=file2.file?#trueFile还有一个类方法ftype,他将返回流的类型.他也在File::Stat里面,只不过是实例方法.它的返回值可能是下面的字符串(file、directory、blockSpecial、characterSpecial、fifo、link或socket).Ruby代码1.this_kind=File.ftype("/dev/hdisk0")#"blockSpecial"2.that_kind=File.new("/tmp").stat.ftype#"directory"Ruby代码1.this_kind=File.ftype("/dev/hdisk0")#"blockSpecial"2.that_kind=File.new("/tmp").stat.ftype#"directory"要测试一个文件是否为另一个文件的链接,可以使用FileTest的symlink?方法,要计算链接数量,可以使用nlink方法:Ruby代码1.File.symlink("yourfile","myfile")#Make a link2.is_sym=FileTest::symlink?("myfile")#true3.hard_count=File.new("myfile").stat.nlink#0Ruby代码1.File.symlink("yourfile","myfile")#Make a link2.is_sym=FileTest::symlink?("myfile")#true3.hard_count=File.new("myfile").stat.nlink#03使用管道ruby中使用IO.popen打开管道:Ruby代码1.check=IO.popen("spell","r+")2.check.puts("'T was brillig,and the slithy toves")3.check.puts("Did gyre and gimble in the wabe.")4.check.close_write5.list=check.readlines6.list.collect!{|x|x.chomp}7.#list is now%w[brillig gimble gyre slithy toves wabe]Ruby代码1.check=IO.popen("spell","r+")2.check.puts("'T was brillig,and the slithy toves")3.check.puts("Did gyre and gimble in the wabe.")4.check.close_write5.list=check.readlines6.list.collect!{|x|x.chomp}7.#list is now%w[brillig gimble gyre slithy toves wabe]要注意必须调用close_write,如果没有调用它,读取管道的时候,就不能到达文件的末尾.下面是一个block的形式:Ruby代码1.File.popen("/usr/games/fortune")do|pipe|2.quote=pipe.gets3.puts quote4.#On a clean disk,you can seek forever.-Thomas Steel5.endRuby代码1.File.popen("/usr/games/fortune")do|pipe|2.quote=pipe.gets3.puts quote4.#On a clean disk,you can seek forever.-Thomas Steel5.end如果指定了一个字符串"-",那么一个新的ruby实例将被创建.如果指定了一个block,那么这个block将会作为两个独立的进程运行。
子进程得到nil,父进程得到一个IO对象:Ruby代码1.IO.popen("-")do|mypipe|2.if mypipe3.puts"I'm the parent:pid=#{Process.pid}"4.listen=mypipe.gets5.puts listen6.else7.puts"I'm the child:pid=#{Process.pid}"8.end9.end10.11.#Prints:12.#I'm the parent:pid=1058013.#I'm the child:pid=10582Ruby代码1.IO.popen("-")do|mypipe|2.if mypipe3.puts"I'm the parent:pid=#{Process.pid}"4.listen=mypipe.gets5.puts listen6.else7.puts"I'm the child:pid=#{Process.pid}"8.end9.end10.11.#Prints:12.#I'm the parent:pid=1058013.#I'm the child:pid=10582pipe方法也返回互相连接的一对管道:Ruby代码1.pipe=IO.pipe2.reader=pipe[0]3.writer=pipe[1]4.5.str=nil6.thread1=Thread.new(reader,writer)do|reader,writer|7.#writer.close_write8.str=reader.gets9.reader.close10.end11.12.thread2=Thread.new(reader,writer)do|reader,writer|13.#reader.close_read14.writer.puts("What hath God wrought?")15.writer.close16.end17.18.thread1.join19.thread2.join20.21.puts str#What hath God wrought?Ruby代码1.pipe=IO.pipe2.reader=pipe[0]3.writer=pipe[1]4.5.str=nil6.thread1=Thread.new(reader,writer)do|reader,writer|7.#writer.close_write8.str=reader.gets9.reader.close10.end11.12.thread2=Thread.new(reader,writer)do|reader,writer|13.#reader.close_read14.writer.puts("What hath God wrought?")15.writer.close16.end17.18.thread1.join19.thread2.join20.21.puts str#What hath God wrought?4使用非阻塞IOruby会在后台执行一些操作,使io不会被阻断,因此大部分情况下可以使用ruby 线程来管理IO,当一个线程被Io阻塞之后,另外的线程能够继续执行.由于ruby的线程不是一个native的线程,因此ruby的线程都在同一个进程里面.如果你想关闭一个非阻塞io,你可以这样做:Ruby代码1.require'io/nonblock'2.3.#...4.5.test=mysock.nonblock?#false6.7.mysock.nonblock=true#turn off blocking8.#...9.mysock.nonblock=false#turn on again10.11.mysock.nonblock{some_operation(mysock)}12.#Perform some_operation with nonblocking set to true13.14.mysock.nonblock(false){other_operation(mysock)}15.#Perform other_operation with non-blocking set to falseRuby代码1.require'io/nonblock'2.3.#...4.5.test=mysock.nonblock?#false6.7.mysock.nonblock=true#turn off blocking8.#...9.mysock.nonblock=false#turn on again10.11.mysock.nonblock{some_operation(mysock)}12.#Perform some_operation with nonblocking set to true13.14.mysock.nonblock(false){other_operation(mysock)}15.#Perform other_operation with non-blocking set to false5使用readpartialreadpartial被设计来用于就像socket这样的流.readpartial要求提供最大长度的参数,如果指定了buffer,那么这个buffer 应指向用于存储数据的一个字符串。