数据仓库与数据挖掘复习提纲
数据仓库和数据挖掘复习

数据仓库和数据挖掘复习第一章数据仓库和数据挖掘概述一、概念题1、数据仓库的定义是什么?答:数据仓库是面向主题的、集成的、稳定的、不同时间的数据集合,用于支持经营管理中央决策制定过程。
2、数据仓库的特点是什么?答:数据仓库的特点是:(1)数据仓库是面向主题的;(2)数据仓库是集成的;(3)数据仓库是稳定的;(4)数据仓库是随时间变化的;(5)数据仓库中的数据量大;(6)数据仓库软硬件要求较高。
3、什么是商业智能?答:商业智能以数据库为基准,通过联机分析处理和数据挖掘技术帮助企业领导者针对市场变化的环境,做出快速、准确的决策。
二、简答题1、数据仓库和数据挖掘的区别和联系。
区别:数据仓库是一种存储技术,它的数据存储量是一般数据库的100倍,它包含大量的历史数据、当前的详细数据以及综合数据。
它能适应于不同用户对不同决策需要提供所需的数据和信息。
数据挖掘是从人工智能机器学习中发展起来的。
它研究各种方法和技术,从大量的数据中挖掘出有用的信息和知识。
联系:数据仓库和数据挖掘都是决策支持新技术。
但他们有着完全不同的辅助决策方式。
数据仓库中存储着大量辅助决策的数据,它为不同的用户随时提供各种辅助决策的随机查询、综合信息或趋势分析信息。
数据挖掘是利用一系列算法挖掘数据中隐含的信息和知识,让用户在进行决策中使用。
第二章 数据仓库原理一、概念题1、数据仓库结构图是什么?2、数据集市的定义是什么?答:数据集市是指具有特定应用的数据仓库,主要针对某个具有战略意义的应用或者具体部门级的应用,支持用户利用已有的数据获得重要的竞争优势或者找到进入新市场的具体解决方案,它包括两种,即独立的数据集市,它的数据直接来源于各生产系统;从属数据集市,它的数据直接来自于中央数据仓库。
3、多维数据模型有哪些?答:对于逻辑数据模型,使用的多维数据模型主要有星型模型、雪花模型、星网模型、第三范式等。
4、ETL 过程是什么?答:数据仓库的数据获取需要经过抽取、转换、装载三个过程,即ETL 过程。
数据挖掘复习题纲

一、1.2 数据仓库与数据库有何不同?它们有哪些相似之处?简而言之,数据库是面向事务的设计,数据仓库是面向主题设计的。
数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。
数据库设计是尽量防止冗余,一般采用符合式的规那么来设计,数据仓库在设计是有意引入冗余,采用反式的方式来设计。
数据库是为捕获数据而设计,数据仓库是为分析数据而设计,它的两个根本的元素是维表和事实表。
维是看问题的角度,比方时间,部门,维表放的就是这些东西的定义,事实表里放着要查询的数据,同时有维的ID。
单从概念上讲,有些晦涩。
任何技术都是为应用效劳的,结合应用可以很容易地理解。
以银行业务为例。
数据库是事务系统的数据平台,客户在银行做的每笔交易都会写入数据库,被记录下来,这里,可以简单地理解为用数据库记帐。
数据仓库是分析系统的数据平台,它从事务系统获取数据,并做汇总、加工,为决策者提供决策的依据。
比方,某银行某分行一个月发生多少交易,该分行当前存款余额是多少。
如果存款又多,消费交易又多,那么该地区就有必要设立ATM了。
显然,银行的交易量是巨大的,通常以百万甚至千万次来计算。
事务系统是实时的,这就要求时效性,客户存一笔钱需要几十秒是无法忍受的,这就要求数据库只能存储很短一段时间的数据。
而分析系统是事后的,它要提供关注时间段所有的有效数据。
这些数据是海量的,汇总计算起来也要慢一些,但是,只要能够提供有效的分析数据就到达目的了。
数据仓库,是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的,它决不是所谓的“大型数据库〞。
那么,数据仓库与传统数据库比拟,有哪些不同呢?让我们先看看W.H.Inmon关于数据仓库的定义:面向主题的、集成的、与时间相关且不可修改的数据集合。
“面向主题的〞:传统数据库主要是为应用程序进展数据处理,未必按照同一主题存储数据;数据仓库侧重于数据分析工作,是按照主题存储的。
这一点,类似于传统农贸市场与超市的区别—市场里面,白菜、萝卜、香菜会在一个摊位上,如果它们是一个小贩卖的;而超市里,白菜、萝卜、香菜那么各自一块。
数据仓库复习提纲

数据仓库复习提纲-标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII数据库应用技术(数据仓库与数据挖掘复习提纲)说明:考试形式:闭卷考试题型:填空、选择、判断、名词解释、简答题、综合题。
(由于试题是随机从试题库中抽取,有可能抽取的试题中不会全部包含上述的所有题型)另外:本提纲仅针对试题中的名词解释、简答题和综合题提供复习参考,不包括填空、选择、判断等其它题型的参考。
一、名词解释:1、数据仓库:是面向主题的、综合的、不同时间的、稳定的数据的集合,用以支持经营管理中的决策制定过程;2、数据挖掘:就是从大量数据中获取有效的、新颖的、潜在有用的、最终可以理解的模式的过程;简单的说是从大量数据中提取或挖掘知识,又被称为数据库中的知识发现。
3、操作数据存储:是一种DW的混合形式,它面向主题的、及时的、最近的和集成的信息,用于支持企业的日常的全局应用和决策制定,其中数据可以作为DW的通用数据源。
4、OLAP:是数据库系统主要应用,支持复杂的分析操作,侧重决策支持,且提供直观易懂的结果。
5、商业智能:是数据仓库(DW)、联机分析处理(OLAP)、数据挖掘等技术与资源管理系统ERP结合起来应用于商业活动实际过程中,实现了技术服务于决策的目的。
二、简答题:1、试叙述数据仓库系统与传统数据库系统的区别:(1)、操作型数据库中的数据针对事务处理任务,各个业务系统之间各自分离,而数据仓库中的数据是按照一定的主题域进行组织的;(2)、操作型数据库通常与某些特定的应用相关,数据库之间相互独立,并且往往是并构的,而数据仓库中的数据在对原有分期的数据库数据做抽取、清理的基础上经过系统的加工、汇总和整理得到的;(3)、操作型数据库中的数据通常实时更新,数据根据需要及时发生变化,数据仓库的数据主要用于决策分析,对涉及的数据操作主要是数据查询和定期更细,一旦某个数据加载到数据仓库以后,一般情况下将作为数据档案长期保存;(4)、操作型数据库主要关心当前某一个时间段内的数据,而数据仓库中的数据通常包含较久远的历史单位,因此总是包括一个时间维,以便可以研究趋势和变化。
数据仓库与数据挖掘期末综合复习

数据仓库与数据挖掘期末综合复习第一章1、数据仓库就是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合。
2、元数据是描述数据仓库内数据的结构和建立方法的数据,它为访问数据仓库提供了一个信息目录,根据数据用途的不同可将数据仓库的元数据分为技术元数据和业务元数据两类。
3、数据处理通常分成两大类:联机事务处理和联机分析处理。
4、多维分析是指以维”形式组织起来的数据(多维数据集)采取切片、切块、钻取和旋转等各种分析动作,以求剖析数据,使拥护能从不同角度、不同侧面观察数据仓库中的数据,从而深入理解多维数据集中的信息。
5、ROLAP是基于关系数据库的OLAP实现,而MOLAP是基于多维数据结构组织的OLAP 实现。
OLAP技术的有关概念:OLAP根据其存储数据的方式可分为三类:ROLAP、MOLAP、HOLAP6、数据仓库按照其开发过程,其关键环节包括数据抽取、数据存储与管理和数据表现等。
7、数据仓库系统的体系结构根据应用需求的不同,可以分为以下4种类型:两层架构、独立型数据集合、以来型数据结合和操作型数据存储和逻辑型数据集中和实时数据仓库。
&操作型数据存储实际上是一个集成的、面向主题的、可更新的、当前值的(但是可挥发”的)、企业级的、详细的数据库,也叫运营数据存储。
9、实时数据仓库”以为着源数据系统、决策支持服务和仓库仓库之间以一个接近实时的速度交换数据和业务规则。
10、从应用的角度看,数据仓库的发展演变可以归纳为5个阶段:以报表为主、以分析为主、以预测模型为主、以运营导向为主和以实时数据仓库和自动决策为主。
11、什么是数据仓库?数据仓库的特点主要有哪些?数据仓库通常是指一个数据库环境,而不是支一件产品,它是提供用户用于决策支持的当前和历史数据,这些数据在传统的数据库中通常不方便得到。
数据仓库就是一个面向主题的(Subject Oriented )、集成的(Integrate )、相对稳定的(Non-Volatile )、反映历史变化(Time Variant )的数据集合,通常用于辅助决策支持。
2011121数据仓库与数据挖掘技术复习题纲_显示

数据仓库与数据挖掘技术期末复习纲要2011-2012(1)一、掌握以下基本概念:1.数据挖掘:就是从存放在数据库,数据仓库或其他信息库中的大量的数据中获取有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。
数据挖掘(Data Mining),又称为数据库中的知识发现(Knowledge Discovery in Database, KDD),就是从大量数据中获取有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程,简单的说,数据挖掘就是从大量数据中提取或“挖掘”知识。
2.数据仓库:英文名称:Data W arehouse,可简写为DW或DWH。
定义:数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。
数据仓库是决策支持系统(DSS)和联机分析应用数据源的结构化数据环境。
数据仓库研究和解决从数据库中获取信息的问题。
数据仓库的四大关键特征:面向主题性、数据集成性、数据的时变性和数据的非易失性。
3.商业智能英文名称:Business Intelligence,简写为BI。
定义:商业智能描述了一系列的概念和方法,通过应用基于事实的支持系统来辅助商业决策的制定。
商业智能系统是一个学习型系统,能自动适应商务不断变化的要求。
4.决策支持系统英文名称:decision support system ,简称DSS定义:是辅助决策者通过数据、模型和知识,以人机交互方式进行半结构化或非结构化决策的计算机应用系统。
DSS主要是基于数据仓库,联机数据分析和数据挖掘技术的应用。
5. 主题: (Subject)主题是一个在较高层次上将数据归类的标准,每一个主题基本对应一个宏观的分析领域。
主题域的特征:独立性,完备性6. 数据集市:小型的,面向部门或工作组级别的数据仓库。
7. 数据仓库的元数据:关于数据的数据,用于构造、维持、管理、和使用数据仓库,在数据仓库中尤为重要。
8. ETL (Extraction-Transformation-Loading):数据抽取(Extract),数据转换(Transform),数据装载(Load)。
数据仓库与数据挖掘复习资料

1.数据仓库的概念和特点p11定义:一个面向主题的、集成的、非易失的且随时间变化的数据集合,用来支持管理人员作出决策。
特性:面向主题的、集成的、非易失的、随时间不断变化的。
1、面向主题的:数据仓库以一个奇特或组织机构中固有的业务主题作为处理的主体,是从整体的、全局的角度来衡量这些主题在企业中的作用。
2、集成的:数据仓库必须将不一致的数据进行有效的集成,使之在数据仓库中有一致性的表示形式。
一致性问题只是集成所包含的一部分工作,另外还需要根据主题进行有效的数据组织。
3、非易失性:一旦操作型数据进入数据仓库,只要数据未超过数据仓库的数据存储期限,通常不对数据进行更新操作,而只进行查询操作。
即不进行一般意义上的更新,而且与操作型数据相比,更新频率要低得多,对时间的要求更为宽松。
4、随时间不断变化的(数据因时而变的特点)《与操作型数据比较的,书上14页》:(1)数据仓库中的数据的时间期限要远远长于操作型环境中的数据的时间期限。
操作型环境一般60-90天,数据仓库5-10年。
一个数据仓库的大小一般都是在100GB以上通常,数据仓库系统应该包含下列程序:(1)抽取数据与加载数据(2)整理并转换数据(采用一种数据仓库适用的数据格式)(3)备份与备存数据(4)管理所有查询(即将查询导向适当的数据源)数据仓库中的数据只是一系列某一时刻所生成的数据的复杂快照。
数据仓库的键码结构总是包含某时间元素。
2.数据仓库中的关键概念14外部数据源:就是从系统外部获取的同分析主题相关的数据。
数据抽取:是数据仓库按分析的主题从业务数据库抽取相关数据的过程。
现有的数据仓库产品几乎都提供关系型数据接口,提供抽取引擎以从关系型数据中抽取数据。
数据清洗:从多个业务系统中获取数据时,必须进行必要的数据清洗,从而得到准确的数据。
所谓“清洗”是指在放入数据仓库之前将错误的、不一致的数据予以更正或删除,以免影响DSS决策的正确性。
(15页有例子)数据转换:各种数据库产品所提供的数据类型可能不同,需要将不同格式的数据转换成统一的数据格式,称为数据转换。
数据仓库与数据挖掘复习

2011春《数据仓库与数据挖掘》复习提纲1、商务智能【参考:是一种解决方案,它的目的是把用户积累下来的、大量的数据转化为业务容易理解的信息,进而辅助决策。
】2、对数据仓库的定义【参考:仅仅是构成它的数据集市的联合。
】3、对数据仓库的定义【参考:一个面向主题的、集成的、随时间变化的、非易逝的用于支持管理的决策过程的数据集合。
】4、【参考:数据的提取、转换和装载,预处理数据并装在中。
】5、数据仓库总线矩阵【参考:该矩阵将公司业务过程映射到参与这些过程的实体或对象。
矩阵的每一行对应一个业务过程,每一列描述对象,它们参与了各种业务过程。
】6、事实【参考:对一些事件发生结果的度量。
】7、维度【参考:维度是维度模型的基础,用来描述业务的对象。
】8、粒度【参考:事实表中包含信息的详尽程度。
】9、维度模型【参考:由一个中心事实表(或者多个事实表)和与其相关的维度构成。
事实表位于中心,而所有维度表环绕在其周围,类似于星形结构,因此又把维度模型称为星形模式。
】10、业务过程维度模型【参考:关于一个业务过程所有的维度模型的集合。
】11、多维数据集(又称为数据立方体)由维度和一个或多个度量组构成的多维分析结构,用于12、部署【参考:将多维数据集的定义发布到服务器上的过程。
】13、联机分析处理采用多维数据结构和层次结构作为导航,探查汇总数据,辅助决策。
14、代理键【参考:对于系统,需要在数据仓库数据库中建立一组与事务处理源系统中的键分离开来的全新的键,称这种键为代理键。
】独立于业务键的用于数据仓库中的从中的人工键15、渐变维度【参考:属性值可以改变的维度。
分为值的改变需要跟踪和不需要跟踪两种。
】16、聚合【参考:经过预先计算后形成的汇总表,主要目标是用来改进查询性能。
】17、星型模型【参考:由一个事实表和多个维度表构成的模型。
事实表与维度表是1对多关系。
事实表位于中心,而所有维度表环绕在其周围,类似于星形结构。
】18、雪花模型【参考:雪花模型是将维度表中的字段和查找表相连接而得到的结果。
数据仓库复习资料提纲

数据库应用技术(数据仓库与数据挖掘复习提纲)说明:考试形式:闭卷考试题型:填空、选择、判断、名词解释、简答题、综合题。
(由于试题是随机从试题库中抽取,有可能抽取的试题中不会全部包含上述的所有题型)另外:本提纲仅针对试题中的名词解释、简答题和综合题提供复习参考,不包括填空、选择、判断等其它题型的参考。
一、名词解释:1、数据仓库:是面向主题的、综合的、不同时间的、稳定的数据的集合,用以支持经营管理中的决策制定过程;2、数据挖掘:就是从大量数据中获取有效的、新颖的、潜在有用的、最终可以理解的模式的过程;简单的说是从大量数据中提取或挖掘知识,又被称为数据库中的知识发现。
3、操作数据存储:是一种DW的混合形式,它面向主题的、及时的、最近的和集成的信息,用于支持企业的日常的全局应用和决策制定,其中数据可以作为DW的通用数据源。
4、OLAP:是数据库系统主要应用,支持复杂的分析操作,侧重决策支持,且提供直观易懂的结果。
5、商业智能:是数据仓库(DW)、联机分析处理(OLAP)、数据挖掘等技术与资源管理系统ERP结合起来应用于商业活动实际过程中,实现了技术服务于决策的目的。
二、简答题:1、试叙述数据仓库系统与传统数据库系统的区别:(1)、操作型数据库中的数据针对事务处理任务,各个业务系统之间各自分离,而数据仓库中的数据是按照一定的主题域进行组织的;(2)、操作型数据库通常与某些特定的应用相关,数据库之间相互独立,并且往往是并构的,而数据仓库中的数据在对原有分期的数据库数据做抽取、清理的基础上经过系统的加工、汇总和整理得到的;(3)、操作型数据库中的数据通常实时更新,数据根据需要及时发生变化,数据仓库的数据主要用于决策分析,对涉及的数据操作主要是数据查询和定期更细,一旦某个数据加载到数据仓库以后,一般情况下将作为数据档案长期保存;(4)、操作型数据库主要关心当前某一个时间段内的数据,而数据仓库中的数据通常包含较久远的历史单位,因此总是包括一个时间维,以便可以研究趋势和变化。
数据仓库和数据挖掘技术复习提纲

数据仓库和数据挖掘技术复习提纲一.数据仓库导论1.数据仓库的定义及其基本特征。
2.数据仓库与传统数据库的区别。
.综述建设数据仓库的必要性。
二.数据仓库的体系结构1.数据仓库系统的结构及各部分的主要功能。
2.数据仓库的结构及各部分的主要功能。
3.简述星型模型的结构特征。
.综述元数据的定义及作用。
三.数据仓库设计1.简述数据仓库开发的生命周期。
2.简述数据仓库的技术体系结构及各模块的功能。
3.数据仓库高层建摸与中间层建摸的区别和联系。
4.在数据仓库物理建摸时,如何提高的性能。
5.什么是粒度,进行粒度设计的基本方法是什么。
.综述数据仓库开发的步骤及各步骤之间的联系。
四.数据仓库管理技术1.什么是休眠数据,产生休眠数据的原因是什么。
2.综述邻线存储方案的基本思想及实现方法。
3.简述元数据的管理方法和使用方法。
4.数据仓库增量式更新的主要技术是什么.防止数据仓库中数据急剧增长的主要方法是什么五.联机分析处理1.的定义及主要特征。
2.图示与的关系。
3.举例说明什么是的切片、切块、下钻操作。
4.和的主要区别是什么。
5.和(多维数据库)的区别是什么。
6.分析的基本步骤。
.什么是,它有什么意义。
六.数据挖掘技术1.什么是数据挖掘,它与传统分析方法的主要区别是什么。
2.数据挖掘有那些主要方法。
3.什么是关联规则?举例说明。
4.简述关联规则的支持度,可信度的定义,并举例说明。
5.简述算法的基本思想。
6.设有交易数据库如图所示。
若最小支持度计数阈值为,最小可信度计数阈值为,试按算法求出<> 频繁项集<> 关联规则<> 根据你的理解,说明这些关联规则的意义,并指出使用那一条规则,公司可能赢利。
数据仓库与挖掘复习资料

数据仓库与挖掘复习资料一、第一章1、元数据是描述数据仓库内数据的结构和建立方法的数据,它为访问数据仓库提供了一个信息目录,根据元数据用途的不同可将数据仓库的元数据分为技术元数据和业务元数据两类。
2、数据处理通常分成两大类:联机事务处理和联机分析处理。
3、多维分析是指对以“维”形式组织起来的数据(多维数据集)采取切片、切块、钻取和旋转等各种分析动作,以求剖析数据,使用户能从不同角度、不同侧面观察数据仓库中的数据,从而深入理解多维数据集中的信息。
5.ROLAP是基于关系数据库的OLAP实现,而MOLAP是基于多维数据结构组织的OLAP实现。
12、简述数据仓库4种体系结构的异同点及其适用性。
(1)两层架构。
(2)独立型的数据集市。
采用这种体系结构的优点是其方便性,可快速启动,这个数据仓库架构可通过一系列的小项目来实现。
(3)依赖型数据集市和操作型数据存储。
优势是它们可以处理各个用户群的需求,甚至是探索性数据仓库的需求。
(4)逻辑型数据集市和实时数据仓库。
是建立数据仓库的一种较佳方法,特别是在硬件性能不断提高,成本不断下降的条件下。
14、请列出3种数据仓库产品,并说明其优缺点。
答:1、IBM公司提供了一套基于可视化数据仓库的商业智能BI解决方案。
2、Oracle数据仓库解决方案主要包括Oracle Express和Oracle Discover两个部分。
3、Microsoft 将OLAP功能集成到SQL Server数据库中,其解决方案包括BI平台、BI终端工具、BI门户和BI应用四个部分。
二、什么是数据挖掘?(p4)数据挖掘就是从从大量数据数据中提取或“挖掘”知识,又被称为数据库中的知识发现。
三、数据仓库与传统的数据库有何区别?(1)数据库是面向事务的设计,数据仓库是面向主题设计的。
(2)数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。
(3)数据库设计是尽量避免冗余,一般采用符合范式的规则来设计,数据仓库在设计时有意引入冗余,采用反范式的方式来设计。
数据挖掘 复习题纲

数据仓库与数据挖掘复习题1、什么是数据仓库?数据仓库的特点有哪些?2、简述数据仓库的四种体系结构的异同点及其适用性。
3、什么是数据仓库的三层结构?什么是数据ETL过程?星型模式的定义与特征是什么?4、什么是信息包图法?请画出Adventure Works Cycles公司销售情况的信息包图法。
(1)获取各个业务部门对业务数据的多维特性分析结果,确定影响销售额的维度,包括时间、区域、产品和客户等维度。
(2)对每个维度进行分析,确定维度与类别之间的传递和映射关系,如在Adventure Works业务数据库中,时间维有年度,季度,月和日等级别,而区域分为国家、省州、城市和具体的销售点。
(3)确定用户需要的度量指标体系,这里以销售情况作为事实依据确定的销售相关指标包括实际销售额、计划销售额和计划完成率等。
5、设定,使用Aprori算法完成下表所示的数据集关联规则的挖掘。
交易号TID 商品ItemsT1 A B CT2 A CT3 A DT4 B E F6、对于下表所示的数据集,利用决策树ID3算法构造决策树。
Age Salary Class<=40 High C1<=40 High C1<=40 Low C241~50 High C1<=40 Low C2>50 Low C1>50 Low C1>50 High C241~50 High C17、给定训练集为,其中,每个训练样本是一个二维特征微量;为类标号,即训练集中的数据样本包含两个类别。
现有:+1+1+1-1-1-1-1分别用最近邻分类方法、k—近邻分类方法(k=3)对x8进行分类。
8样本序号描述属性1 描述属性2x1 6 4X2 7 5X3 6 3X4 4 6X5 3 89、计算有酒精味、头疼、X射线检查呈阳性时,患脑瘤的概率,也就是计算P(BT|SA,HA,PX)。
10对象x 属性1 属性2 属性31 1 1 32 1 1 33 2 1 14 3 2 2P(PT) P(BT)True 0.2 0.001False 0.8 0.999P(HO|PT) PT=T PT=FTrue 0.7 0False 0.3 1P(SA|HO) HO=T HO=FTrue 0.8 0.1False 0.2 0.9 P(PX|BT) BT=T BT=FTrue 0.98 0.01False 0.02 0.99P(HA|HO,BT) HO=T HO=FBT=T BT=F BT=T BT=FTrue 0.99 0.7 0.9 0.02False 0.01 0.3 0.1 0.985 3 2 16 2 1 2令,求:(1)由分别形成的等价划分。
数据仓库与挖掘期末考试知识点复习

数据挖掘知识点(考点)复习第6章的知识点 1.哪些学科和数据挖掘有密切联系?(P68数据挖掘关系图)2.数据挖掘的定义(P69)数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的数据中提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
第7章的知识点1.数据挖掘步骤(P74)确定目标、数据准备、数据挖掘、结果分析2.数据选择的内容(包括哪两部分)(P75)属性选择和数据抽样3.数据清理的方法(P75) 了解小规模数据、大数据集的清理方法。
小规模数据:人工清理大数据集:自动清理(测定→识别→ 纠正)4.常见的模式有哪些(P78)尤其是分类、回归、聚类模式之间的分析比较。
① 分类模式(用于离散值)② 回归模式(用于连续值)③ 聚类模式④ 关联模式⑤序列模式即将数据间的关联性事件发生的顺序联系起来。
⑥时间序列模式根据数据随时间变化的趋势预测将来的值。
5.模式的精确度(P79)训练和测试模式需将数据分成哪两部分以及各自用途?模式准确性的测试方法及其比较。
训练和测试模式需将数据分成:一是训练数据,主要用于模式训练;另一个是测试数据,主要用于模式测试。
模式准确性的测试方法:封闭测试:测试集即训练模式的训练数据。
可测试模式的稳定性,但无法验证其推广能力。
开放测试:测试模式的数据是模式先前未见的数据。
可以很好地度量模式的准确度。
6.数据预处理的任务有哪些?(P83-89)数据清理、数据集成和转换7.空缺值的处理方法(P83-84)忽略该条记录(不很有效)、手工填补遗漏值(可行性差)、利用缺省值填补遗漏值(不推荐)数据库理论 数据仓库数据统计 机器学习 人工智能 数据挖掘利用均值填补遗漏、利用同类别均值填补遗漏值、利用最可能的值填补遗漏值(较常用)8.分箱技术(P84-86) 分箱之前要做的工作?P84 分箱之前需要对记录按目标属性值的大小进行排序(1)要求能描述出常见的分箱方法和数据平滑方法(简答)。
数据挖掘期末复习提纲(整理版)
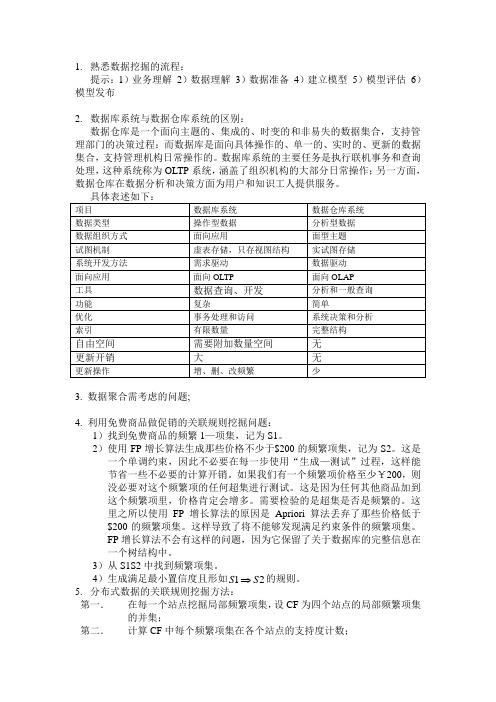
1.熟悉数据挖掘的流程:提示:1)业务理解2)数据理解3)数据准备4)建立模型5)模型评估6)模型发布2.数据库系统与数据仓库系统的区别:数据仓库是一个面向主题的、集成的、时变的和非易失的数据集合,支持管理部门的决策过程:而数据库是面向具体操作的、单一的、实时的、更新的数据集合,支持管理机构日常操作的。
数据库系统的主要任务是执行联机事务和查询处理,这种系统称为OLTP系统,涵盖了组织机构的大部分日常操作;另一方面,数据仓库在数据分析和决策方面为用户和知识工人提供服务。
3. 数据聚合需考虑的问题;4. 利用免费商品做促销的关联规则挖掘问题:1)找到免费商品的频繁1—项集,记为S1。
2)使用FP增长算法生成那些价格不少于$200的频繁项集,记为S2。
这是一个单调约束,因此不必要在每一步使用“生成—测试”过程,这样能节省一些不必要的计算开销。
如果我们有一个频繁项价格至少¥200,则没必要对这个频繁项的任何超集进行测试。
这是因为任何其他商品加到这个频繁项里,价格肯定会增多。
需要检验的是超集是否是频繁的。
这里之所以使用FP增长算法的原因是Apriori算法丢弃了那些价格低于$200的频繁项集。
这样导致了将不能够发现满足约束条件的频繁项集。
FP增长算法不会有这样的问题,因为它保留了关于数据库的完整信息在一个树结构中。
3)从S1S2中找到频繁项集。
4)生成满足最小置信度且形如2S 的规则。
1S5.分布式数据的关联规则挖掘方法:第一.在每一个站点挖掘局部频繁项集,设CF为四个站点的局部频繁项集的并集;第二.计算CF中每个频繁项集在各个站点的支持度计数;第三.计算CF中每个项集的全局支持度计数,可以通过将它在四个站点的局部支持度计数累加起来;那些全局支持度大于支持度阀值的项集为频繁项集;第四.从全局频繁项集里导出强规则。
6.急切分类、惰性分类的优缺点:急切分类比惰性分类在速度上要更快。
因为它在接受新的待测数据之前已经构造了一个概括的模型。
数据仓库与数据挖掘复习资料

概念
• “清洗”就是将错误的、不一致的数据在进 入数据仓库之前予以更正或删除,以免影 响DSS决策的正确性。
• 元数据:是用来描述数据的数据。它描述 和定位数据组件、它们的起源及它们在数 据仓库进程中的活动;关于数据和操作的 相关描述(输入、计算和输出)。元数据可用 文件存在元数据库中。
Data Warehouse
Selection
Data Cleaning Data Integration
Databases
A5
预处理:对数据列的基本处理
– 对于数据挖掘十分重要的一些特例的分布情况:
• 只有一种值的列
– 缺乏任何信息内容,忽略。
– 例如:1. null,no,0
–
2. 如建立一个模型预测新泽西州的汽车客户损失率,关
星型结构和雪花型结构
• 星型结构
–通过将事实表和维表进行连接,我们就可以得 到“星型结构”(Star-Scheme)。
雪花型结构
• 实际应用需求并不像标准星型结构描述的那么简 单,当问题涉及的维度很多时,事实表中的条目 数将迅速增长。
• 假定原来的事实表条目数为m,增加一个具有n个 条目的维表,通常,事实表的条目数将变成mn条, 这样事实表所占用的存储空间将迅速增大。
• Cluster analysis 聚类分析
– Class label类标记 is unknown: Group data to form new classes, e.g., cluster houses to find distribution patterns
数据仓库与数据挖掘,DBMS题库考试大纲和答案.

11.数据仓库的设计方法与操作型环境中系统设计采用的系统生命周期法有什么不同?12.举例说明多维分析操作(切片、切块、旋转)的含义是什么?切片和切块(slice and dice)在多维数组的某一维选定一个维成员的动作称为切片。
在多维数组的某一维上选定某一区间的维成员的动作称为切块旋转是改变一个报告或页面显示的维方向,以用户容易理解的角度来观察数据13.数据挖掘的步骤是什么?确定挖掘对象,准备数据,建立模型,数据挖掘,结果分析,知识应用阶段14.简要说明数据仓库环境中元数据的内容。
元数据(Meta Data)——“关于数据的数据”,是指在数据仓库建设过程中产生的有关数据源定义、目标定义、转换规则等关键数据,是定义数据仓库对象的数据。
如传统数据库中的数据字典就是一种元数据。
15.企业的数据库体系化环境的四个层次是什么?它们之间的关系是什么?数据库的体系化环境,是在一个企业或组织内部,由各面向应用的OLTP数据库及各级面向主题的数据仓库所组成的完整的数据环境四层体系化环境:操作型环境——OLTP,全局级——数据仓库,部门级——局部仓库,个人级——个人仓库,用于启发式的分析16.简要说明数据仓库设计的步骤。
数据仓库的设计可以分为以下几个步骤:◆明确主题◆概念模型设计所要完成的工作:界定系统边界,确定主要的主题域及其内容◆技术准备工作这一阶段的工作包括:技术评估,技术环境准备。
形成技术评估报告、软硬件配置方案、系统(软、硬件)总体设计方案。
◆逻辑模型设计进行的工作主要:分析主题域,确定当前要装载的主题确定粒度层次划分确定数据分割策略关系模式定义◆物理模型设计这一步所做的工作:确定数据的存储结构 ---RAID技术确定索引策略——B树索引位图索引等确定数据存放位置——磁带磁盘等确定存储分配优化◆数据仓库生成通过专用的数据抽取工具或者通过自行编程实现数据抽取、转换和装载。
◆数据仓库运行与维护建立DSS应用,使用数据仓库理解需求,调整和完善系统,维护数据仓库。
数据仓库与数据挖掘复习资料

数据仓库与数据挖掘简答题资料1.数据库与数据仓库的本质差别?《第一章》答:a.数据库是用于事务处理,数据仓库用于决策分析;b.数据库保持事务处理的当前状态,数据仓库既保存过去的数据又保存当前的数据;c.数据仓库的数据是大量数据库的集成;d.对数据库的操作比较明确,操作数据量少。
对数据仓库操作不明确,操作数据量大。
e.数据库是细节的、在存取时准确的、可更新的、一次操作数据量小、面向应用且支持管理;数据仓库是综合或提炼的、代表过去的数据、不更新、一次操作数据量大、面相分析且支持决策。
2.联机分析处理(OLAP)的简单定义是什么?它体现的特征是什么?《第三章》联机分析处理简单定义:即OLAP是共享多维信息的快速分析。
体现了4个特征:a.快速性:用户对OLAP的快速反应能力有很高的要求。
b.可分析性:OLAP系统应能处理与应用有关的任何逻辑分析和统计分析。
c.多维性:多维性是OLAP的特点,系统必须提供对数据分析的多维视图和分析,包括对层次维和多重层次维的完全支持。
d.信息性:不论数据量有多大,也不管数据存储在何处,OLAP系统都应能及时获得信息,并且管理大容量信息。
3.数据仓库两类用户有什么本质的不同?《第五章》数据仓库的用户有两类:信息使用者和探索者。
信息使用者是使用数据仓库的大量用户,信息使用者以一种可预测、重复性的方式使用数据仓库。
探索者完全不同于信息使用者,他们有一个完全不可预测的、非重复性的数据使用模式。
探索者查看海量详细数据,而概括数据则会妨碍探索者的数据分析。
探索者经常查看历史数据,且查看时间比使用者长的多。
探索者的任务是寻找公司数据内隐含的价值并且根据过去的事件努力预测未来决策的结果。
探索者是典型的数据挖掘者。
4.信息论的基本原理是什么?《第七章》一个传递信息的系统是由发送端(信源)和接收端(信宿)以及连接两者的通道(信道)组成的。
信息论把通信过程看做是在随机干扰的环境中传递信息的过程。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据仓库与数据挖掘复习提
纲
-标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
数据库应用技术(数据仓库与数据挖掘复习提纲)
说明:
考试形式:闭卷
考试题型:填空、选择、判断、名词解释、简答题、综合题。
(由于试题是随机从试题库中抽取,有可能抽取的试题中不会全部包含上述的所有题型)另外:本提纲仅针对试题中的名词解释、简答题和综合题提供复习参考,不包括填空、选择、判断等其它题型的参考。
一:名词解释
数据仓库、数据挖掘、OLAP、ODS(操作数据存储)
二.简答题
1.试述数据仓库系统与数据库系统的区别与相似之处。
2.试述数据仓库设计的步骤以及每一步所完成的工作。
3.OLAP与OLTP的区别有哪些?它们适合于运行在同一个服务器上吗为什么4.在数据挖掘前,为什么要对数据进行预处理,数据预处理的有哪些主要的处理方法?
5.在现实世界的数据中,元组在某些属性上缺少值是常有的。
描述处理该问题的各种方法。
6.什么是数据仓库中的元数据,元数据包含哪些内容其重要性体现在哪些方面
7.试述ODS在“DB-ODS-DW”体系结构中的作用。
8.请解释OLAP中维、维层次与维成员的概念,并举例说明。
9. 数据仓库中的数据是数据库中数据的简单堆积吗它有哪些常用的数据组织方式
10.数据仓库和数据集市的区别是什么数据仓库的体系环境具有什么特点有哪些建立数据仓库体系化环境的方法它们各有何优劣
11.数据仓库的设计包括哪些内容?
12.在内容和使用者方面,数据仓库环境中的元数据与操作型环境中的元数据有何异同?
13.为了提高数据仓库的性能,可以在哪些方面作一些努力在各个方面分别采用什么样的技术这些技术易于实现吗
14.OLAP提供哪些基本操作?
15.OLAP服务器有哪些实现方法它们的优劣是什么
16.为什么不能依靠传统的业务处理系统进行决策分析
17.自然演化体系结构中存在的问题?
18.试述建立多维数据库的过程。
19.数据挖掘的主要方法。
20.数据挖掘中的数据分类是个两步的过程,简述每步过程。
21.对于类特征化,基于数据立方体的实现与诸如面向属性归纳的关系实现之间的主要不同是什么?讨论哪种方法最有效,在什么条件下最有效。
22. 一般来说,数据仓库采用什么样的数据模型与OLTP的数据库模型相比,这些模型有什么特点
三.综合题
第一类:给定一个表的结构及数据,计算每个决策属性的信息增益(请同学们掌握该方法,不同的试题中给定的表结构及数据是不同的)
例一:假设有如下的“雇员基本信息”表的结构及数据,其中属性“工资”为类别标识属性,属性“部门”、“职位”、“年龄”作为决策属性集。
第一种出题形式:请计算每个决策属性“部门”、“职位”、“年龄”的信息增益。
第二种出题形式:建立决策树,并产生IF-THEN规则。
第二类:利用Apriori算法寻找事务集中的频繁项集,并由找到的频繁项集产生强关联规则。
(请同学们掌握该方法,不同的试题中给定的事务集是不同的)
例一:假设现有如下表所示的一个事务数据库,数据库中有10个事务,即
|D|=10。
假定最小支持度minsup=20%,最小置信度minsup=65%,利用Apriori 算法寻找D中的频繁项集,并由找到的频繁项集产生强关联规则。
(另外请同
第三类:利用简单贝叶斯分类对数据进行分类(请同学们掌握该方法,不同的试题中给定的表结构及数据是不同的)
例一:假设有如下的“雇员基本信息”表的结构及数据,其中属性“工资”为类别标识属性,类别标识有3个取值(C1、C2、C3),属性“部门”、“职位”、“年龄”作为决策属性集,请利用贝叶斯简单分类方法对未知数据:
X=(部门=‘系统部’,职位=‘高级’年龄=‘21…30’)进行分类。
(另外请。