编译原理教程课后习题答案——第七章
编译原理 第7章习题解答

第七章习题解答7.1 给定文法:S→(A)A→ABBA→BB→bB→c①构造它的基本LR(0)项目集;②构造它的LR(0)项目集规范族;③构造识别该文法活前缀的DFA;④该文法是SLR文法吗?若是,构造它的SLR分析表。
7.2 给定文法:E→EE+E→EE*E→a①构造它的LR(0)项目集规范族;②它是SLR(1)文法吗?若是,构造它的SLR(1)分析表;③它是LR(1)文法吗?若是,构造它的LR(1)分析表;④它是LALR(1)文法吗?若是,构造它的LALR分析表。
7.3 给出一个非LR(0)文法。
7.4 给出一个SLR(1)文法,但它不是LR(0)文法,构造它的SLR分析表。
7.5 给出一个LR(1)文法,但它不是LALR(1)文法,构造它的规范LR(1)分析表。
7.6 给定二义性文法:① E→E+E② E→E*E③ E→(E)④ E→id用所述的无二义性规则和(或)另加一些无二义性规则,例如,给算符*、+施加某种结合规则。
①构造它的LR(0)项目集规范族及识别活前缀的DFA;②构造它的LR分析表。
习题参考答案7.1 解:文法的基本LR(0)项目集为S→.(A) S→(.A) S→(A.) S→(A).A→.ABB A→A.BB A→AB.B A→ABB.A→.B A→B. B→.b B→b.B→.c B→c.构造该文法的识别活前缀的DFSA如下图所示:I文法的识别活前缀的DFSA该文法的LR(0)项目集规范族={I0,I1,I2,I3,I4,I5,I6,I7,I8}因为在构造出来的识别活前缀的DFA中,每一个状态对应的项目集都不含有移进-归约、归约-归约冲突,所以该文法是LR(0)文法,当然也是SLR文法。
因为 FOLLOW(S)={#}FOLLOW(A)=FIRST{)}∪FIRST(BB)={),b,c}FOLLOW(B)=FIRST(B)∪FOLLOW(A)={b,c,)}其对应的SLR(1)分析表如下表所示。
《编译原理》(陈火旺版)课后作业参考答案ch6-10

第6章属性文法和语法制导翻译7. 下列文法由开始符号S产生一个二进制数,令综合属性val给出该数的值:试设计求的属性文法,其中,已知B的综合属性c, 给出由B产生的二进位的结果值。
例如,输入时,=,其中第一个二进位的值是4,最后一个二进位的值是。
【答案】11. 设下列文法生成变量的类型说明:(1)构造一下翻译模式,把每个标识符的类型存入符号表;参考例。
【答案】第7章语义分析和中间代码产生1. 给出下面表达式的逆波兰表示(后缀式):【答案】3. 请将表达式-(a+b)*(c+d)-(a+b+c)分别表示成三元式、间接三元式和四元式序列。
【答案】间接码表:(1)→(2)→(3)→(4)→(1)→(5)→(6)4. 按节所说的办法,写出下面赋值句A:=B*(-C+D) 的自下而上语法制导翻译过程。
给出所产生的三地址代码。
【答案】5. 按照7.3.2节所给的翻译模式,把下列赋值句翻译为三地址代码:A[i, j]:=B[i, j] + C[A [k, l]] + d[ i+j]【答案】6. 按7.4.1和节的翻译办法,分别写出布尔式A or ( B and not (C or D) )的四元式序列。
【答案】用作数值计算时产生的四元式:用作条件控制时产生的四元式:其中:右图中(1)和(8)为真出口,(4)(5)(7)为假出口。
7. 用7.5.1节的办法,把下面的语句翻译成四元式序列: While A<C and B<D do if A=1 then C:=C+1 else while A ≦D do A:=A+2; 【答案】第9章 运行时存储空间组织4. 下面是一个Pascal 程序:当第二次( 递归地) 进入F 后,DISPLAY 的内容是什么当时整个运行栈的内容是什么 【答案】第1次进入F 后,运行栈的内容: 第2次进入F 后,运行栈的内容: 109 87 6 5 4 3 2 1 017 1615 14 13 12 11 10 9 8 7 6 5第2次进入F 后,Display 内容为:5. 对如下的Pascal 程序,画出程序执行到(1)和(2)点时的运行栈。
《编译原理教程》习题解析与上机指导(第四版) 第七章

(1) 试应用DAG进行优化; (2) 假定只有R、H在基本块出口是活跃的,写出优化后 的四元式序列; (3) 假定只有两个寄存器AX、BX,试写出上述优化后 的四元式序列的目标代码。 【解答】 (1) 根据DAG的构造算法构造基本块P的DAG 步骤如图7-1的(a)到(h)所示。
MOV MUL
R1, A R1, R0 该结果
//取一个空闲寄存器 R1 //运算结束后 R1 中为 T2 结果,内存中无
MOV R0, D
ADD R0, ?1? 该结果
/*此时 R0 中结果 T1 已经没有引用点, 且临时单元 T1 是非活跃的,所以,寄存 器 R0 可作为空闲寄存器使用*/ //运算结束后 R0 中为 T3 结果,内存中无
本块时,所有的寄存器被当成空闲的寄 存器使用,从而造成计算结果的丢失。
考虑到寄存器 R0 中的 T5和寄存器 R1 中 的 W,临时单元 T5 是非活跃的,因此 只要将结果 W 存回对应单元即可*/
7.4 对基本块 P:
S0=2 S1=3/S0 S2=T-C S3=T+C R=S0/S3 H=R S4=3/S1 S5=T+C S6=S4/S5 H=S6*S2
我们以四元式T=a+b为例来说明其翻译过程。 汇编语言的加法指令代码形式为
ADD R, X
其中,ADD为加法指令;R为第一操作数,第一操作数必须 为寄存器类型;X为第二操作数,它可以是寄存器类型,也 可以是内存型的变量。ADD R,X指令的含义是:将第一操 作数R与第二操作数相加后,再将累加结果存放到第一操作 数所在的寄存器中。要完整地翻译出四元式T=a+b,则可能 需要下面三条汇编指令:
MOV T2, R1
MOV R1, E SUB R1, F MUL R0, R1
编译原理第三版课后习题答案

编译原理第三版课后习题答案编译原理是计算机科学中的一门重要课程,它研究的是如何将高级程序语言转换为机器语言的过程。
而《编译原理》第三版是目前被广泛采用的教材之一。
在学习过程中,课后习题是巩固知识、提高能力的重要环节。
本文将为读者提供《编译原理》第三版课后习题的答案,希望能够帮助读者更好地理解和掌握这门课程。
第一章:引论习题1.1:编译器和解释器有什么区别?答案:编译器将整个源程序转换为目标代码,然后一次性执行目标代码;而解释器则逐行解释源程序,并即时执行。
习题1.2:编译器的主要任务是什么?答案:编译器的主要任务是将高级程序语言转换为目标代码,包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等过程。
第二章:词法分析习题2.1:什么是词法分析?答案:词法分析是将源程序中的字符序列划分为有意义的词素(token)序列的过程。
习题2.2:请给出识别下列词素的正则表达式:(1)整数:[0-9]+(2)浮点数:[0-9]+\.[0-9]+(3)标识符:[a-zA-Z_][a-zA-Z_0-9]*第三章:语法分析习题3.1:什么是语法分析?答案:语法分析是将词法分析得到的词素序列转换为语法树的过程。
习题3.2:请给出下列文法的FIRST集和FOLLOW集:S -> aAbA -> cA | ε答案:FIRST(S) = {a}FIRST(A) = {c, ε}FOLLOW(S) = {$}FOLLOW(A) = {b}第四章:语义分析习题4.1:什么是语义分析?答案:语义分析是对源程序进行静态和动态语义检查的过程。
习题4.2:请给出下列文法的语义动作:S -> if E then S1 else S2答案:1. 计算E的值2. 如果E的值为真,则执行S1;否则执行S2。
第五章:中间代码生成习题5.1:什么是中间代码?答案:中间代码是一种介于源代码和目标代码之间的表示形式,它将源代码转换为一种更容易进行优化和转换的形式。
编译原理(清华大学-第2版)课后习题答案

编译原理(清华⼤学-第2版)课后习题答案第三章N=>D=> {0,1,2,3,4,5,6,7,8,9}N=>ND=>NDDL={a |a(0|1|3..|9)n且 n>=1}(0|1|3..|9)n且 n>=1{ab,}a nb n n>=1第6题.(1) <表达式> => <项> => <因⼦> => i(2) <表达式> => <项> => <因⼦> => (<表达式>) => (<项>)=> (<因⼦>)=>(i)(3) <表达式> => <项> => <项>*<因⼦> => <因⼦>*<因⼦> =i*i(4) <表达式> => <表达式> + <项> => <项>+<项> => <项>*<因⼦>+<项>=> <因⼦>*<因⼦>+<项> => <因⼦>*<因⼦>+<因⼦> = i*i+i (5) <表达式> => <表达式>+<项>=><项>+<项> => <因⼦>+<项>=i+<项> => i+<因⼦> => i+(<表达式>) => i+(<表达式>+<项>)=> i+(<因⼦>+<因⼦>)=> i+(i+i)(6) <表达式> => <表达式>+<项> => <项>+<项> => <因⼦>+<项> => i+<项> => i+<项>*<因⼦> => i+<因⼦>*<因⼦> = i+i*i第7题第9题语法树ss s* s s+aa a推导: S=>SS*=>SS+S*=>aa+a*11. 推导:E=>E+T=>E+T*F语法树:E+T*短语: T*F E+T*F直接短语: T*F句柄: T*F12.短语:直接短语:句柄:13.(1)最左推导:S => ABS => aBS =>aSBBS => aBBS=> abBS => abbS => abbAa => abbaa 最右推导:S => ABS => ABAa => ABaa => ASBBaa => ASBbaa => ASbbaa => Abbaa => a1b1b2a2a3 (2) ⽂法:S → ABSS → AaS →εA → aB → b(3) 短语:a1 , b1 , b2, a2 , , bb , aa , abbaa,直接短语: a1 , b1 , b2, a2 , ,句柄:a114 (1)S → ABA → aAb | εB → aBb | ε(2)S → 1S0S → AA → 0A1 |ε第四章1. 1. 构造下列正规式相应的DFA (1)1(0|1)*101NFA(2) 1(1010*|1(010)*1)*0NFA(3)NFA(4)NFA2.解:构造DFA 矩阵表⽰b其中0 表⽰初态,*表⽰终态⽤0,1,2,3,4,5分别代替{X} {Z} {X,Z} {Y} {X,Y} {X,Y,Z} 得DFA状态图为:3.解:构造DFA矩阵表⽰构造DFA的矩阵表⽰其中表⽰初态,*表⽰终态替换后的矩阵4.(1)解构造状态转换矩阵:{2,3} {0,1}{2,3}a={0,3}{2},{3},{0,1}{0,1}a={1,1} {0,1}b={2,2}(2)解:⾸先把M的状态分为两组:终态组{0},和⾮终态组{1,2,3,4,5} 此时G=( {0},{1,2,3,4,5} ) {1,2,3,4,5}a={1,3,0,5} {1,2,3,4,5}b={4,3,2,5}由于{4}a={0} {1,2,3,5}a={1,3,5}因此应将{1,2,3,4,5}划分为{4},{1,2,3,5}G=({0}{4}{1,2,3,5}){1,2,3,5}a={1,3,5}{1,2,3,5}b={4,3,2}因为{1,5}b={4} {23}b={2,3}所以应将{1,2,3,5}划分为{1,5}{2,3}G=({0}{1,5}{2,3}{4}){1,5}a={1,5} {1,5}b={4} 所以{1,5} 不⽤再划分{2,3}a={1,3} {2,3}b={3,2}因为 {2}a={1} {3}a={3} 所以{2,3}应划分为{2}{3}所以化简后为G=( {0},{2},{3},{4},{1,5})7.去除多余产⽣式后,构造NFA如下G={(0,1,3,4,6),(2,5)} {0,1,3,4,6}a={1,3}{0,1,3,4,6}b={2,3,4,5,6}所以将{0,1,3,4,6}划分为 {0,4,6}{1,3} G={(0,4,6),(1,3),(2,5)}{0,4,6}b={3,6,4} 所以划分为{0},{4,6} G={(0),(4,6),(1,3),(2,5)}不能再划分,分别⽤ 0,4,1,2代表各状态,构造DFA 状态转换图如下;b8.代⼊得S = 0(1S|1)| 1(0S|0) = 01(S|ε) | 10(S|ε) = (01|10)(S|ε)= (01|10)S | (01|10)= (01|10)*(01|10)构造NFA由NFA可得正规式为(01|10)*(01|10)=(01|10)+9.状态转换函数不是全函数,增加死状态8,G={(1,2,3,4,5,8),(6,7)}(1,2,3,4,5,8)a=(3,4,8) (3,4)应分出(1,2,3,4,5,8)b=(2,6,7,8)(1,2,3,4,5,8)c=(3,8)(1,2,3,4,5,8)d=(3,8)所以应将(1,2,3,4,5,8)分为(1,2,5,8), (3,4)G={(1,2,5,8),(3,4),(6,7)}(1,2,5,8)a=(3,4,8) 8应分出(1,2,5,8)b=(2,8)(1,2,5,8)c=(8)(1,2,5,8)d=(8)G={(1,2,5),(8),(3,4),(6,7)}(1,2,5)a=(3,4,8) 5应分出G={(1,2), (3,4),5, (6,7) ,(8) }去掉死状态8,最终结果为 (1,2) (3,4) 5,(6,7) 以1,3,5,6代替,最简DFA为b正规式:b*a(da|c)*bb*第五章1.S->a | ^ |( T )(a,(a,a))S => ( T ) => ( T , S ) => ( S , S ) => ( a , S) => ( a, ( T )) =>(a , ( T , S ) ) => (a , ( S , S )) => (a , ( a , a ) ) S=>(T) => (T,S) => (S,S) => ( ( T ) , S ) => ( ( T , S ) , S ) => ( ( T , S , S ) , S ) => ( ( S , S , S ) , S )=> ( ( ( T ) , S , S ) , S ) => ( ( ( T , S ) , S , S ) , S ) =>( ( ( S , S ) , S , S ) , S ) => ( ( ( a , S ) , S , S ) , S ) => ( ( ( a , a ) , S , S ) , S ) => ( ( ( a , a ) , ^ , S ) , S ) => ( ( ( a , a ) , ^ , ( T ) ) , S )=> ( ( ( a , a ) , ^ , ( S ) ) , S ) => ( ( ( a , a ) , ^ , ( a ) ) , S ) => ( ( ( a , a ) , ^ , ( a ) ) , a )S->a | ^ |( T )T -> T , ST -> S消除直接左递归:S->a | ^ |( T )T -> S T’T’ -> , S T’ | ξSELECT ( S->a) = {a}SELECT ( S->^) = {^}SELECT ( S->( T ) ) = { ( }SELECT ( T -> S T’) = { a , ^ , ( }SELECT ( T’ -> , S T’ ) = { , }SELECT ( T’ ->ξ) = FOLLOW ( T’ ) = FOLLOW ( T ) = { )}构造预测分析表分析符号串( a , a )#分析栈剩余输⼊串所⽤产⽣式#S ( a , a) # S -> ( T )# ) T ( ( a , a) # ( 匹配# ) T a , a ) # T -> S T’# ) T’ S a , a ) # S -> a# ) T’ a a , a ) # a 匹配# ) T’,a) # T’ -> , S T’# ) T’ S , , a ) # , 匹配# ) T’ S a ) # S->a# ) T’ a a ) # a匹配# ) T’) # T’ ->ξ# ) ) # )匹配# # 接受2.E->TE’E’->+E E’->ξT->FT’T’->T T’->ξF->PF’F’->*F’F’->ξP->(E) P->a P->b P->∧SELECT(E->TE’)=FIRST(TE’)=FIRST(T)= {(,a,b,^)SELECT(E’->+E)={+}SELECT(E’->ε)=FOLLOW(E’)= {#,)}SELECT(T->FT’)=FIRST(F)= {(,a,b,^}SELECT(T’ —>T)=FIRST(T)= {(,a,b,^)SELECT(T’->ε)=FOLLOW(T’)= {+,#,)}SELECT(F ->P F’)=FIRST(F)= {(,a,b,^}SELECT(F’->*F’)={*}SELECT(F’->ε)=FOLLOW(F’)= {(,a,b,^,+,#,)}3. S->MH S->a H->Lso H->ξK->dML K->ξL->eHf M->K M->bLM FIRST ( S ) =FIRST(MH)= FIRST ( M ) ∪FIRST ( H ) ∪{ξ}∪{a}= {a, d , b , e ,ξ} FIRST( H ) = FIRST ( L ) ∪{ξ}= { e , ξ}FIRST( K ) = { d , ξ}FIRST( M ) = FIRST ( K ) ∪{ b } = { d , b ,ξ}FOLLOW ( S ) = { # , o }FOLLOW ( H ) = FOLLOW ( S ) ∪{ f } = { f , # , o }FOLLOW ( K ) = FOLLOW ( M ) = { e , # , o }FOLLOW ( L ) ={ FIRST ( S ) –{ξ} } ∪{o} ∪FOLLOW ( K )∪{ FIRST ( M ) –{ξ} } ∪FOLLOW ( M )= {a, d , b , e , # , o }FOLLOW ( M ) ={ FIRST ( H ) –{ξ} } ∪FOLLOW ( S )∪{ FIRST ( L ) –{ξ} } = { e , # , o }SELECT ( S-> M H) = ( FIRST ( M H) –{ξ} ) ∪FOLLOW ( S )= ( FIRST( M ) ∪FIRST ( H ) –{ξ} ) ∪FOLLOW ( S )= { d , b , e , # , o }SELECT ( S-> a ) = { a }SELECT ( H->L S o ) = FIRST(L S o) = { e }SELECT ( H ->ξ) = FOLLOW ( H ) = { f , # , o }SELECT ( K->ξ) = FOLLOW ( K ) = { e , # , o }SELECT ( L-> e H f ) = { e }SELECT ( M->K ) = ( FIRST( K ) –{ξ} ) ∪FOLLOW ( M ) = {d,e , # , o }SELECT ( M -> b L M )= { b }4 . ⽂法含有左公因式,变为S->C $ { b, a }C-> b A { b }C-> a B { a }A -> b A A { b }A-> a A’ { a }A’-> ξ{ $ , a, b }A’-> C { a , b }B->a B B { a }B -> b B’ { b }B’->ξ{ $ , a , b }B’-> C { a, b }5. <程序> --- S <语句表>――A <语句>――B <⽆条件语句>――C <条件语句>――D <如果语句>――E <如果⼦句> --FS->begin A end S->begin A end { begin }A-> B A-> B A’ { a , if }A-> A ; B A’-> ; B A’ { ; }A’->ξ{ end }B-> C B-> C { a } B-> D B-> D { if }C-> a C-> a { a }D-> E D-> E D’ { if }D-> E else B D’-> else B { else }D’->ξ{; , end } E-> FC E-> FC { if }F-> if b then F-> if b then { if }⾮终结符是否为空S-否A-否A’-是B-否C-否D-否D’-是E-否F-否FIRST(S) = { begin }FIRST(A) = FIRST(B) ∪FIRST(A’) ∪{ξ} = {a , if , ; , ξ} FIRST(A’) ={ ; , ξ}FIRST(B) = FIRST(C) ∪FIRST(D) ={ a , if }FIRST(C) = {a}FIRST(D) = FIRST(E)= { if }FIRSR(D’) = {else , ξ}FIRST(E) = FIRST(F) = { if }FIRST(F) = { if }FOLLOW(S) = {# }FOLLOW(A) = {end}FOLLOW(A’) = { end }FOLLOW(B) = {; , end }FOLLOW (C) = {; , end , else }FOLLOW(D) = {; , end }FOLLOW( D’ ) = { ; , end }FOLLOW(E) = { else , ; end }FOLLOW(F) = { a }S A A’ B C D D’ E F if then else begin end a b ;6. 1.(1) S -> A | B(2) A -> aA|a(3)B -> bB |b提取(2),(3)左公因⼦(1) S -> A | B(2) A -> aA’(3) A’-> A|ξ(4) B -> bB’(5) B’-> B |ξ2.(1) S->AB(2) A->Ba|ξ(3) B->Db|D(4) D-> d|ξ提取(3)左公因⼦(1) S->AB(2) A->Ba|ξ(3) B->DB’(4) B’->b|ξ(5) D-> d|ξ3.(1) S->aAaB | bAbB(2) A-> S| db(3) B->bB|a4(1)S->i|(E)(2)E->E+S|E-S|S提取(2)左公因⼦(1)S->i|(E)(2)E->SE’(3)E’->+SE’|-SE’ |ξ5(1)S->SaA | bB(2)A->aB|c(3)B->Bb|d消除(1)(3)直接左递归(1)S->bBS’(2)S’->aAS’|ξ(3)A->aB | c(4) B -> dB’(5)B’->bB’|ξ6.(1) M->MaH | H(2) H->b(M) | (M) |b消除(1)直接左递归,提取(2)左公因⼦(1)M-> HM’(2)M’-> aHM’ |ξ(3)H->bH’ | ( M )(4)H’->(M) |ξ7. (1)1)A->baB4)B->a将1)、2)式代⼊3)式1)A->baB2)A->ξ3)B->baBbb4)B->bb5)B->a提取3)、4)式左公因⼦1)A->baB2)A->ξ3)B->bB’4)B’->aBbb | b5)B->a(3)1)S->Aa2)S->b3)A->SB4)B->ab将3)式代⼊1)式1)S->SBa2)S->b3)A->SB4)B->ab消除1)式直接左递归1)S->bS’2)S’->BaS’ |ξ3)S->b4)A->SB5)B->ab删除多余产⽣式4)1)S->bS’(5)1)S->Ab2)S->Ba3)A->aA4)A->a5)B->a提取3)4)左公因⼦1)S->Ab4)A’-> A |ξ5)B->a将3)代⼊1)5)代⼊21)S->aA’b2)S->aa3)A->aA’4)A’-> A |ξ5)B->a提取1)2)左公因⼦1)S-> aS’2)S’->A’b | a3)A->aA’4)A’-> A |ξ5)B->a删除多余产⽣式5)1)S-> aS’2)S’->A’b | a3)A->aA’4)A’-> A |ξA A’S’S将3)代⼊4)1)S-> aS’2)S’->A’b | a3)A->aA ’4)A’-> aA’ |ξ3)S’->a4)S’->b5)A->aA ’6)A’-> aA’ |ξ对2)3)提取左公因⼦1)S->aS’2)S’->aS’’3)S’’->A’b|ξ4)S’->b5)A->aA ’6)A’-> aA’ |ξ删除多余产⽣式5)1)S->aS’2)S’->aS’’3)S’’->A’b|ξ4)S’->b第六章1S → a | ∧ | ( T )T → T , S | S解:(1) 增加辅助产⽣式 S’→#S#求 FIRSTVT集FIRSTVT(S’)= {#}FIRSTVT(S)= {a ∧ ( }= { a ∧ ( } FIRSTVT (T) = {,} ∪ FIRSTVT( S ) = { , a ∧ ( }求 LASTVT集LASTVT(S’)= { # }LASTVT(S)= { a ∧ )}LASTVT (T) = { , a ∧ )}(2)因为任意两终结符之间⾄多只有⼀种优先关系成⽴,所以是算符优先⽂法(3)a ∧( ) , #F 1 1 1 1 1 1g 1 1 1 1 1 1f 2 2 1 3 2 1g 2 2 2 1 2 1f 3 3 1 3 3 1g 4 4 4 1 2 1f 3 3 1 3 3 1g 4 4 4 1 2 1(4)栈优先关系当前符号剩余输⼊串移进或规约#<·( a,a)# 移进#( <· a ,a)# 移进#(T <·, a)# 移进#(T,<· a )# 移进#(T,a ·> ) # 规约#(T,T ·> ) # 规约#(T =·) # 移进#(T) ·> #规约#T =·#接受4.扩展后的⽂法S’→#S# S→S;G S→G G→G(T) G→H H→a H→(S)T→T+S T→S(1)FIRSTVT(S)={;}∪FIRSTVT(G) = {; , a , ( }FIRSTVT(G)={ ( }∪FIRSTVT(H) = {a , ( }FIRSTCT(H)={a , ( }FIRSTVT(T) = {+} ∪FIRSTVT(S) = {+ , ; , a , ( }LASTVT(S) = {;} ∪LASTVT(G) = { ; , a , )}LASTVT(G) = { )} ∪LASTVT(H) = { a , )}LASTVT(H) = {a, )}LASTVT(T) = {+ } ∪LASTVT(S) = {+ , ; , a , ) }构造算符优先关系表因为任意两终结符之间⾄多只有⼀种优先关系成⽴,所以是算符优先⽂法(2)句型a(T+S);H;(S)的短语有:a(T+S);H;(S) a(T+S);H a(T+S) a T+S (S) H直接短语有: a T+S H (S)句柄: a素短语:a T+S (S)最左素短语:a(3)(4)不能⽤最右推导推导出上⾯的两个句⼦。
编译原理清华大学出版社第7章习题重点题解答

1S → a | ∧ | ( T )T → T , S | S解:(1) 增加辅助产生式 S’→#S#求 FIRSTVT集FIRSTVT(S’)= {#}FIRSTVT(S)= {a ∧ ( }FIRSTVT (T) = {,} ∪ FIRSTVT( S ) = { , a ∧ ( }求 LASTVT集LASTVT(S’)= { # }LASTVT(S)= { a ∧ )}LASTVT (T) = { , a ∧ )}(2)算符优先关系表a ∧( ) , #a ·> ·> ·> ∧·> ·> ·> ( <·<·<·=·<·) ·> ·> ·>, <·<·<··> ·># <·<·<·=·因为任意两终结符之间至多只有一种优先关系成立,所以是算符优先文法(3)a ∧( ) ,F 1 1 1 11 1g 1 1 1 11 1f 2 2 1 3 2g 2 2 2 1 2f 3 3 1 3 3g 4 4 4 1 2f 3 3 1 3 3g 4 4 4 1 2(4)栈优先关系当前符号剩余输入串移进或规约#<·( a,a)#移进#( <· a,a)# 移进# (a ·> , a)# #(T <·, a)# #(T,<· a )# #(T,a ·> ) # #(T,T ·> ) # #(T =·) # #(T) ·> ##T =·#4.扩展后的文法S’→#S# S→S;G S→G G→G(T)G→H H→a H→(S)T→T+S T→S(1)FIRSTVT(S)={;}∪FIRSTVT(G) = {; , a , ( } FIRSTVT(G)={ ( }∪FIRSTVT(H) = {a , ( } FIRSTCT(H)={a , ( }FIRSTVT(T) = {+} ∪FIRSTVT(S) = {+ , ; , a , ( }LASTVT(S) = {;} ∪LASTVT(G) = { ; , a , )}LASTVT(G) = { )} ∪LASTVT(H) = { a , )}LASTVT(H) = {a, )}LASTVT(T) = {+ } ∪LASTVT(S) = {+ , ; , a , ) }构造算符优先关系表; ( ) a + # ;·> <··> <··> ·> ( <·<·=·<·<·) ·> ·> ·> ·> ·> a ·> ·> ·> ·> ·> + <·<··> <··># <·<·<·=·因为任意两终结符之间至多只有一种优先关系成立,所以是算符优先文法(2)句型a(T+S);H;(S)的短语有:a(T+S);H;(S) a(T+S);H a(T+S) a T+S (S) H直接短语有: a T+S H (S)句柄: a素短语:a T+S (S)最左素短语:a(3)分析a;(a+a)栈优先关系当前符号剩余输入串移进或规约##a #T #T;#T;(<··><·<·<·a;;(a;(a+a)#(a+a)#(a+a)#a+a)#+a)#移进规约移进移进移进#T;(T #T;(T +#T;(T +a#T;(T +T#T;(T #T;(T)#T;T #T <·<··>·>=··>·>=·+a)))###a)#)####移进移进规约规约移进规约规约接受分析a;(a+a)栈优先关系当前符号剩余输入串移进或规约##(#(a #(T #(T+<·<··><·<·(a++aa+a)#+a)#a)#移进移进规约移进移进#(T+T #(T#(T)#T ·>=··>=·))##)####规约移进规约接受(4)不能用最右推导推导出上面的两个句子。
编译原理作业集-第七章(DOC)

第七章语义分析和中间代码产生本章要点1. 中间语言,各种常见中间语言形式;2. 说明语句、赋值语句、布尔表达式、控制语句等的翻译;3. 过程调用的处理;4. 类型检查;本章目标掌握和理解中间语言,各种常见中间语言形式;各种语句到中间语言的翻译;以及类型检查等内容。
本章重点1.中间代码的几种形式,它们之间的相互转换:四元式、三元式、逆波兰表示;3.赋值语句、算术表达式、布尔表达式的翻译及其中间代码格式;4.各种控制流语句的翻译及其中间代码格式;5.过程调用的中间代码格式;6.类型检查;本章难点1. 各种语句的翻译;2. 类型系统和类型检查;作业题一、单项选择题:1. 布尔表达式计算时可以采用某种优化措施,比如A and B用if-then-else可解释为_______。
a. if A then true else B;b. if A then B else false;c. if A then false else true;d. if A then true else false;2. 为了便于优化处理,三地址代码可以表示成________。
a. 三元式b. 四元式c. 后缀式d. 间接三元式3. 使用三元式是为了________:a. 便于代码优化处理b. 避免把临时变量填入符号表c. 节省存储代码的空间d. 提高访问代码的速度4. 表达式-a+b*(-c+d)的逆波兰式是________。
a. ab+-cd+-*;b. a-b+c-d+*;c. a-b+c-d+*;d. a-bc-d+*+;5. 赋值语句x:=-(a+b)/(c-d)-(a+b*c)的逆波兰式表示是_______。
a. xab+cd-/-bc*a+-:=;a. xab+/cd-bc*a+--:=;a. xab+-cd-/abc*+-:=;a. xab+cd-/abc*+--:=;6. 在一棵语法树中结点的继承属性和综合属性之间的相互依赖关系可以由________来描述。
编译原理第7章答案
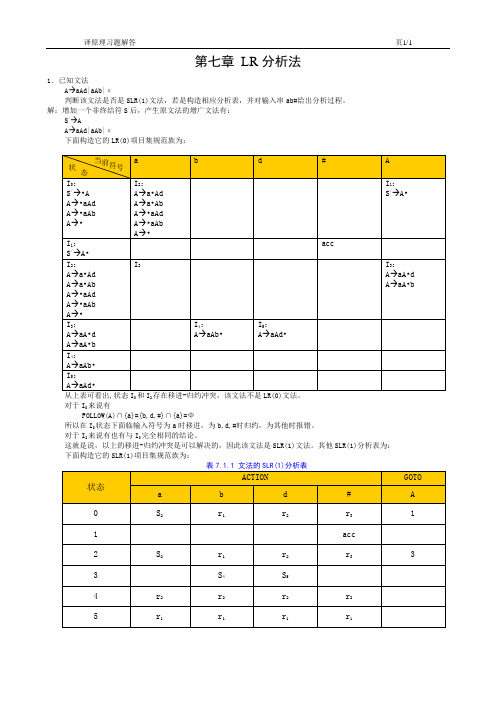
第七章LR分析法1.已知文法A→aAd|aAb|ε判断该文法是否是SLR(1)文法,若是构造相应分析表,并对输入串ab#给出分析过程。
解:增加一个非终结符S/后,产生原文法的增广文法有:S/→AA→aAd|aAb|ε下面构造它的LR(0)项目集规范族为:02对于I0来说有FOLLOW(A)∩{a}={b,d,#}∩{a}=Φ所以在I0状态下面临输入符号为a时移进,为b,d,#时归约,为其他时报错。
对于I2来说有也有与I0完全相同的结论。
这就是说,以上的移进-归约冲突是可以解决的,因此该文法是SLR(1)文法。
其他SLR(1)分析表为:下面构造它的SLR(1)项目集规范族为:15S→a|^|(T)T→T,S|S(1)构造它的LR(0),LALR(1),LR(1)分析表。
(2)给出对输入符号串(a#和(a,a#的分析过程。
(3)说明(1)中三种分析表发现错误的时刻和输入串的出错位置有何区别。
解:(1)加入非终结符S/,方法的增广文法为:S/→SS→aS→^S→(T)T→T,ST→S下面构造它的LR(0)项目集规范族为:表7.15.1 文法的LR(0)分析表17.若包含条件语句的语句文法可缩写为:S→iSeS|iS|S;S|a其中:i代表if,e代表else,a代表某一语句。
若规定:(1)else与其左边最近的if结合(2);服从左结合试给出文法中i,e,; 的优先关系,然后构造出无二义性的LR分析表,并对输入串iiaea#给出分析过程。
解:加入S/→S产生式构造出增广文法如下:[0] S/→S[1] S→iSeS[2] S→iS[3] S→S;S[4] S→a由习惯可知,定义文法中i,e,;,a4个算符的优先关系为:a>e>i>;。
并且i与;的结合方向均为自左至右。
由上述状态项目集可见:a.状态I1存在移进-归约冲突,由于FOLLOW(S/)∩{;}={#}∩{;}=Φ,所以面临#号时应acc,面临;号时应移进。
编译原理-第七章解析资料

中间代码 中间 中间代码 生成器 代码 优化器
静态语义检查和中间代码生成器的位置
2018/10/26
TJNU-COCIE-WJW
5
第七章 语义分析和中间代码产生
中间语言 7.2 说明语句 7.3 赋值语句的翻译 7.4 分情况语句 7.5 回填技术 7.6 类型检查
7.1
2018/10/26 TJNU-COCIE-WJW 6
TJNU-COCIE-WJW 28
2018/10/26
例子:语句a:=b*-c+b*-c 的三元式表示
op arg1 arg2
(0) (1) (2) (3) (4) (5)
uminus * uminus * + Assign
c b c b
(1)
(0) (2) (3) (4)
a
2018/10/26
TJNU-COCIE-WJW
例:x
+ y * z翻译成 t1 := y * z t2 := x + t1
TJNU-COCIE-WJW 16
2018/10/26
1.一般形式(续)
三地址代码是AST或DAG的线性化表示
DAG图对应的三地址代码可能比相应的AST
对应的三地址代码要优化,因为可以复用中 间结果
2018/10/26
29
注意: 有些三地址语句要多个三元式表示 例子: x[i] := y op arg1 arg2 (0) [ ]= x i (1) := (0) y
y := x[i] op arg1 (0) =[ ] x (1) := y arg2 i (0)
2018/10/26
TJNU-COCIE-WJW
编译原理王生原课后习题第七章

编译原理模拟试卷一、选择题(每题1分,共5分)1.在编译过程中,词法分析的主要任务是什么?A.构建语法树B.将源程序分解为单词序列C.语义分析D.代码2.下列哪个不属于编译器的组成部分?A.词法分析器B.语法分析器C.代码器D.数据库管理系统3.在编译器中,中间代码的作用是什么?A.提高编译速度B.方便目标代码C.提高程序的可读性4.下列哪种语言通常被用作编译器的实现语言?A.PythonB.JavaC.C++5.在编译原理中,形式语言的主要作用是什么?A.描述程序设计语言的语法B.描述程序的语义C.描述程序的数据结构D.描述程序的算法二、判断题(每题1分,共5分)1.编译器的主要任务是将源程序转换为目标代码。
(正确/错误)2.语法分析器负责检查源程序中的语法错误。
(正确/错误)3.语义分析是在语法分析之后进行的。
(正确/错误)4.中间代码是一种与机器无关的代码。
(正确/错误)5.代码优化不会影响程序的正确性。
(正确/错误)三、填空题(每题1分,共5分)1.编译器包括____、____、____、____等组成部分。
2.在编译过程中,____负责将源程序分解为单词序列。
3.语法分析器的主要任务是构建____。
4.语义分析器负责检查____。
5.代码器负责____。
四、简答题(每题2分,共10分)1.简述编译器的工作流程。
2.解释什么是词法分析。
3.什么是语法分析?它的主要任务是什么?4.什么是语义分析?它的主要作用是什么?5.简述中间代码的作用。
五、应用题(每题2分,共10分)1.给出一个简单的C语言程序,请描述它通过编译器的过程。
2.什么是编译器的优化?请给出一个例子。
3.解释什么是编译器的错误处理。
4.什么是编译器的调试信息?它的作用是什么?5.请解释编译器的前端和后端。
六、分析题(每题5分,共10分)1.分析并解释编译器中的词法分析、语法分析和语义分析之间的关系。
2.分析并解释编译器中的中间代码和目标代码之间的关系。
编译原理习题答案,1-8章龙书第二版7.8章

第七章
习题7.2.6 :C语言函数f的定义如下:
Int f(int x, *py, **ppz){
**ppz +=1;*py +=2;x +=3; return x+*py+**ppz;
}
变量a是一个指向b的指针;变量b是一个指向c的指针,而c是一个当前值为4的整数变量。
如果我们调用f(c,b,a),返回值是什么?
答:x是传值,而b和c是传地址方式;由函数定义可以得到:b=&c,a=&b, 而**a=**a+1=c+1=5 => c=5; *b=*b+2=c+2=7 =>c=7,**a=7;c=c+3=4+3=7
所以调用f(c,b,a)返回值是7+7+ 7=21
练习7.3.2:假设我们使用显示表来实现下图中的函数。
请给出对fib0(1)的第一次调用即将返回时的显示表。
同时指明那时在栈中的各种活动记录中保存的显示表条目
答:结果如下
第八章
练习8.2.1:假设所有的变量都存放在内存中,为下面的三地址语句生成代码:
5)下面的两个语句序列
X=b*c
Y=a+X
答:生成的代码如下
练习8.5.1:为下面的基本块构造构造DAG
d=b*c
e=a+b
b=b*c
a=e-d
答:DAG如下
练习8.6.1:为下面的每个C语言赋值语句生成三地址代码1)x=a+b*c
答:生成的三地址代码如下。
编译原理第三版答案

编译原理第三版答案编译原理是计算机科学中非常重要的一门课程,它涉及到程序设计语言的语法、语义和编译器的设计与实现等内容。
《编译原理》(Compilers: Principles, Techniques, and Tools)是编译原理领域的经典教材,由Alfred V. Aho、Monica S. Lam、Ravi Sethi和Jeffrey D. Ullman合著,已经出版了三个版本。
本文将针对《编译原理》第三版中的习题和答案进行整理和总结,以帮助学习者更好地理解和掌握编译原理相关知识。
第一章,引论。
1.1 什么是编译器?编译器是一种将源程序翻译成目标程序的程序,它包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等阶段。
1.2 编译器的主要任务是什么?编译器的主要任务是将高级语言程序翻译成等价的目标程序,同时保持程序的功能和性能。
1.3 编译器的结构包括哪些部分?编译器的结构包括前端和后端两部分,前端包括词法分析、语法分析和语义分析,后端包括中间代码生成、代码优化和目标代码生成。
第二章,词法分析。
2.1 什么是词法分析?词法分析是编译器中的第一个阶段,它将源程序中的字符序列转换成单词(Token)序列。
2.2 词法分析的主要任务是什么?词法分析的主要任务是识别源程序中的单词,并将其转换成单词符号表中的标识符。
2.3 词法分析中常见的错误有哪些?词法分析中常见的错误包括非法字符、非法注释、非法标识符等。
第三章,语法分析。
3.1 什么是语法分析?语法分析是编译器中的第二个阶段,它将词法分析得到的单词序列转换成抽象语法树。
3.2 语法分析的主要任务是什么?语法分析的主要任务是识别源程序中的语法结构,并检查语法的正确性。
3.3 语法分析中常见的错误有哪些?语法分析中常见的错误包括语法错误、缺失分号、缺失括号等。
第四章,语义分析。
4.1 什么是语义分析?语义分析是编译器中的第三个阶段,它对源程序的语义进行分析和处理。
编译原理教程第五版课后答案

编译原理教程第五版课后答案第一章:引言问题1答:编译器是一种将高级编程语言源代码转换为目标机器代码的软件工具。
它由多个阶段组成,包括词法分析、语法分析、语义分析、中间代码生成、代码优化和代码生成等。
问题2答:编译器的主要任务包括以下几个方面: - 词法分析:将源代码划分为词法单元,如标识符、关键字、操作符等。
- 语法分析:根据语法规则,将词法单元组成语法树。
- 语义分析:对语法树进行语义检查,如类型匹配、变量声明等。
- 中间代码生成:将语法树转换为中间代码表示形式。
- 代码优化:对中间代码进行优化,以提高程序的效率。
- 代码生成:将优化后的中间代码转换为目标机器代码。
第二章:词法分析问题1答:词法单元是编译器在词法分析阶段识别的最小的语法单位,它由一个或多个字符组成。
常见的词法单元包括关键字、标识符、常量和运算符等。
问题2答:识别词法单元的方法包括以下几种: - 正则表达式:通过正则表达式匹配字符串,识别出各类词法单元。
- 有限自动机:构建有限状态自动机,根据输入字符的不同状态转移,最终确定词法单元。
- 递归下降法:使用递归下降的方式,根据语法规则划分出词法单元。
第三章:语法分析问题1答:语法分析是编译器的一个重要阶段,它的主要任务是根据给定的语法规则,将词法单元序列转换为语法树。
语法分析有两个主要的方法:自顶向下的分析和自底向上的分析。
问题2答:自顶向下的分析是从文法的起始符号开始,根据语法规则逐步向下展开,直到生成最终的语法树。
常见的自顶向下的分析方法包括LL(1)分析和递归下降分析。
问题3答:自底向上的分析是从输入串开始,逐步合并词法单元,最终生成语法树。
常见的自底向上的分析方法包括LR分析和LALR分析。
第四章:语义分析问题1答:语义分析的主要任务是对语法树进行语义检查和类型推断。
语义分析阶段会检查变量的声明和使用是否合法,以及类型是否匹配等。
问题2答:常见的语义错误包括变量未声明、类型不匹配、函数调用参数不匹配等。
编译原理第七章答案

第7 章 LR 分析第1 题已知文法A→aAd|aAb|ε判断该文法是否是SLR(1)文法,若是构造相应分析表,并对输入串ab#给出分析过程。
答案:文法:A→aAd|aAb|ε拓广文法为G′,增加产生式S′→A若产生式排序为:0 S' →A1 A →aAd2 A →aAb3 A →ε由产生式知:First (S' ) = {ε,a}First (A ) = {ε,a}Follow(S' ) = {#}Follow(A ) = {d,b,#}G′的LR(0)项目集族及识别活前缀的DFA 如下图所示:所以在I0、I2 中的移进-归约冲突可以由Follow 集解决,所以G 是SLR(1)文法。
构造的SLR(1)分析表如下:题目1 的SLR(1)分析表分析成功,说明输入串ab 是文法的句子。
第2 题若有定义二进制数的文法如下:S→L·L|LL→LB|BB→0|1(1) 试为该文法构造LR 分析表,并说明属哪类LR 分析表。
(2) 给出输入串101.110 的分析过程。
答案:文法:S→L.L|LL→LB|BB→0|1拓广文法为G′,增加产生式S′→S若产生式排序为:0 S' →S1 S →L.L2 S →L3 L →LB4 L →B5 B →06 B →1由产生式知:First (S' ) = {0,1}First (S ) = {0,1}First (L ) = {0,1}First (B ) = {0,1}Follow(S' ) = {#}Follow(S ) = {#}Follow(L ) = {.,0,1,#}Follow(B ) = {.,0,1,#}G′的LR(0)项目集族及识别活前缀的DFA 如下图所示:在I2 中:B →.0 和 B →.1 为移进项目,S →L.为归约项目,存在移进-归约冲突,因此所给文法不是LR(0)文法。
在I2、I8 中:Follow(s) ∩{0,1}= { #} ∩{0,1}=所以在I2 、I8 中的移进-归约冲突可以由Follow 集解决,所以G 是SLR(1)文法。
编译原理课后习题答案-清华大学-第二版

《编译原理》课后习题答案第二章
第 2 章 PL/0 编译程序的实现
第1题
PL/0 语言允许过程嵌套定义和递归调用,试问它的编译程序如何解决运行时的存储管 理。
答案: PL/0 语言允许过程嵌套定义和递归调用,它的编译程序在运行时采用了栈式动态存储
管理。(数组 CODE 存放的只读目标程序,它在运行时不改变。)运行时的数据区 S 是由 解释程序定义的一维整型数组,解释执行时对数据空间 S 的管理遵循后进先出规则,当每 个过程(包括主程序)被调用时,才分配数据空间,退出过程时,则所分配的数据空间被释放。 应用动态链和静态链的方式分别解决递归调用和非局部变量的引用问题。
(2) 扩充 repeat 语句的语法图为:
EBNF 的语法描述为: 〈 重复语句〉::= repeat〈语句〉{;〈语句〉}until〈条件〉
《编译原理》课后习题答案第三章
第 3 章 文法和语言
第1题
文法 G=({A,B,S},{a,b,c},P,S)其中 P 为: S→Ac|aB A→ab B→bc 写出 L(G[S])的全部元素。
注意:如果问编译程序有哪些主要构成成分,只要回答六部分就可以。如果搞不清楚, 就回答八部分。 第3题
何谓翻译程序、编译程序和解释程序?它们三者之间有何种关系? 答案:
翻译程序是指将用某种语言编写的程序转换成另一种语言形式的程序的程序,如编译程 序和汇编程序等。
编译程序是把用高级语言编写的源程序转换(加工)成与之等价的另一种用低级语言编 写的目标程序的翻译程序。
地址,用以过程执行结束后返回调用过程时的下一条指令继续执行。 在每个过程被调用时在栈顶分配 3 个联系单元,用以存放 SL,DL, RA。
第5题
PL/0 编译程序所产生的目标代码是一种假想栈式计算机的汇编语言,请说明该汇编语 言中下列指令各自的功能和所完成的操作。 (1) INT 0 A (2) OPR 0 0 (3) CAL L A
编译原理第7章 习题与答案

第7章习题7-1 设有如下的三地址码(四元式)序列:read NI:=NJ:=2L1 : if I≤J goto L3L2 : I:=I-Jif I>J goto L2if I=0 goto L4J:=J+1I:=Ngoto L1L3 : Print ′YES′haltL4 : Print ′NO′halt试将它划分为基本块,并作控制流程图。
7-2 考虑如下的基本块:D:=B*CE:=A+BB:= B*CA:=E+D(1) 构造相应的DAG;(2) 对于所得的DAG,重建基本块,以得到更有效的四元式序列。
7-3 对于如下的两个基本块:(1) A:=B*CD:=B/CE:=A+DF:=2*EG:=B*CH:=G*GF:=H*GL:=FM:=L(2) B:=3D:=A+CE:=A*CF:=E+DG:=B*FH:=A+CI:=A*CJ:=H+IK:=B*5L:=K+JM:=L分别构造相应的DAG,并根据所得的DAG,重建经优化后的四元式序列。
在进行优化时,须分别考虑如下两种情况:(ⅰ)变量G、L、M在基本块出口之后被引用;(ⅱ)仅变量L在基本块出口之后被引用。
7-4 对于题图7-4所示的控制流程图:(1) 分别求出它们各个结点的必经结点集;(2) 分别求出它们的各个回边;(3) 找出各流程图的全部循环。
7-5 对于如下的程序:I:=1read J,KL: A:=K*IB:=J*IC:=A*Bwrite CI:=I+1if A<100 goto Lhalt试对其中的循环进行可能的优化。
第8章习题答案7-1 解:划分情况及控制流程如答案图7-1所示:答案图7-1 将四元式序列划分为基本块7-2 解:(1) 相应的DAG如答案图7-2所示。
答案图7-2 DAG(2) 优化后的代码为:D:=B*CE:=A+BB:=DA:=E+D7-3 解:(1) 相应的DAG如答案图7-3-(1)所示。
若只有G、L、M在出口之后被引用,则优化后的代码为:G:=B*CH:=G*GL:=H*GM:=L若只有L在出口之后被引用,则代码为:G:=B*CH:=G*GL:=H*G(2) 相应的DAG如答案图7-3-(2)所示。
《编译原理》西北工业大学第三版课后答案

第一章习题解答1.解:源程序是指以某种程序设计语言所编写的程序。
目标程序是指编译程序(或解释程序)将源程序处理加工而得的另一种语言(目标语言)的程序。
翻译程序是将某种语言翻译成另一种语言的程序的统称。
编译程序与解释程序均为翻译程序,但二者工作方法不同。
解释程序的特点是并不先将高级语言程序全部翻译成机器代码,而是每读入一条高级语言程序语句,就用解释程序将其翻译成一段机器指令并执行之,然后再读入下一条语句继续进行解释、执行,如此反复。
即边解释边执行,翻译所得的指令序列并不保存。
编译程序的特点是先将高级语言程序翻译成机器语言程序,将其保存到指定的空间中,在用户需要时再执行之。
即先翻译、后执行。
2.解:一般说来,编译程序主要由词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、代码优化程序、目标代码生成程序、信息表管理程序、错误检查处理程序组成。
3.解:C语言的关键字有:auto break case char const continuedefault do double else enum extern float for goto if int longregister return short signed sizeof static struct switch typedef union unsigned void volatile while。
上述关键字在C语言中均为保留字。
4.解:C语言中括号有三种:{},[],()。
其中,{}用于语句括号;[]用于数组;()用于函数(定义与调用)及表达式运算(改变运算顺序)。
C语言中无END关键字。
逗号在C语言中被视为分隔符和运算符,作为优先级最低的运算符,运算结果为逗号表达式最右侧子表达式的值(如:(a,b,c,d)的值为d)。
5.略第二章习题解答1.(1)答:26*26=676(2)答:26*10=260(3)答:{a,b,c,...,z,a0,a1,...,a9,aa,...,az,...,zz,a00,a01,...,zzz},共26+26*36+26*36*36=34658个2.构造产生下列语言的文法(1){anbn|n≥0}解:对应文法为G(S) = ({S},{a,b},{ S→ε| aSb },S)(2){anbmcp|n,m,p≥0}解:对应文法为G(S) = ({S,X,Y},{a,b,c},{S→aS|X,X→bX|Y,Y→cY|ε},S)(3){an # bn|n≥0}∪{cn # dn|n≥0}解:对应文法为G(S) = ({S,X,Y},{a,b,c,d,#}, {S→X, S→Y,X→aXb|#,Y→cYd|# },S)(4){w#wr# | w?{0,1}*,wr是w的逆序排列}解:G(S) = ({S,W,R},{0,1,#}, {S→W#, W→0W0|1W1|# },S)(5)任何不是以0打头的所有奇整数所组成的集合解:G(S) = ({S,A,B,I,J},{-,0,1,2,3,4,5,6,7,8,9},{S→J|IBJ,B→0B|IB|e, I→J|2|4|6|8, Jà1|3|5|7|9},S)(6)所有偶数个0和偶数个1所组成的符号串集合解:对应文法为 S→0A|1B|e,A→0S|1C B→0C|1S C→1A|0B3.描述语言特点(1)S→10S0S→aAA→bAA→a解:本文法构成的语言集为:L(G)={(10)nabma0n|n, m≥0}。
编译原理_第三版_课后答案

1 0 a b (b) b 0 3 2 a a a b 5 4 1 a 已经确定化了,进行最小化 最小化: b 0 2 1 a a b b a a b a b b a
P64–14
(1) 1 0 0 1
0 (2):
Y X 2 0 1 Y 1 X 0 确定化: 0 {X,1,Y} {1,Y} {2} φ 给状态编号: 0 1 2 3 0 1 0 {1,Y} {1,Y} {1,Y} φ 0 1 1 1 3 1 {2} {2} φ φ 1 2 2 3 3
P36-10
/************** ***************/
P36-11
/*************** L1: L2: L3: L4: ***************/
第三章习题参考答案 P64–7
(1)
X Y 0 X 1 2 3 4 Y 5 1 1 1 确定化: 0 {X} φ {1,2,3} {2,3} {2,3,4} {2,3,5} {2,3,4,Y} φ φ {2,3} {2,3} {2,3,5} {2,3} {2,3,5} 0 1 3 2 0 1 {1,2,3} φ {2,3,4} {2,3,4} {2,3,4} {2,3,4,Y} {2,3,4,} 1 0
动
进 进 归
进
归
P134–5
(1)
0. 4. 8. (2) 1
1. 5. 9. 6. 10.
2. 11.
3. 7.
S 9 8 7 S a 11 10 0
A
4 3 2 A d 5 6 确定化: S {0,2,5,7,10} {1,2,5,7,8,10} {2,3,5,7,10} {2,5,7,8,10} {1,2,5,7,8,10} {2,5,7,8,10} {2,4,5,7,8,10} {2,5,7,8,10} A {2,3,5,7,10} {2,3,5,7,9,10} {2,3,5,7,10} {2,3,5,7,9,10} a {11} {11} {11} {11} b {6} {6} {6} {6} S
编译原理教程课后习题答案——第七章

第七章目标代码生成7.1 对下列四元式序列生成目标代码:T=A-BS=C+DW=E-FU=W/TV=U*S其中,V是基本块出口的活跃变量,R0和R1是可用寄存器。
【解答】简单代码生成算法依次对四元式进行翻译。
我们以四元式T=a+b为例来说明其翻译过程。
汇编语言的加法指令代码形式为ADD R, X其中,ADD为加法指令;R为第一操作数,第一操作数必须为寄存器类型;X为第二操作数,它可以是寄存器类型,也可以是内存型的变量。
ADD R,X指令的含意是:将第一操作数R与第二操作数相加后,再将累加结果存放到第一操作数所在的寄存器中。
要完整地翻译出四元式T=a+b,则可能需要下面三条汇编指令:MOV R, aADD R, bMOV T, R第一条指令是将第一操作数a由内存取到寄存器R中;第二条指令完成加法运算;第三条指令将累加后的结果送回内存中的变量T。
是否在翻译成目标代码时都必须生成这三条汇编指令呢?从目标代码生成的优化角度考虑,即为了使生成的目标代码更短以及充分利用寄存器,上面的三条指令中,第一条和第三条指令在某些情况下是不必要的。
这是因为,如果下一个四元式紧接着需要引用操作数T,则第三条指令就不急于生成,可以推迟到以后适当的时机再生成。
此外,如果必须使用第一条指令,即第一操作数不在寄存器而是在内存中,且此时所有可用寄存器都已分配完毕,这时就要根据寄存器中所有变量的待用信息(也即引用点)来决定淘汰哪一个寄存器留给当前的四元式使用。
寄存器的淘汰策略如下:(1) 如果某寄存器中的变量已无后续引用点且该变量是非活跃的,则可直接将该寄存器作为空闲寄存器使用。
(2) 如果所有寄存器中的变量在基本块内仍有引用点且都是活跃的,则将引用点最远的变量所占用寄存器中的值存放到内存与该变量对应的单元中,然后再将此寄存器分配给当前的指令使用。
因此,本题所给四元式序列生成的目标代码如下:MOV R0, ASUB R0, C /*R0=T*/MOV R1, CADD R1, D /*R1=S*/MOV S, R1 /*S引用点较T引用点远,故将R1的值送内存单元S*/MOV R1, ESUB R1, F /*R1=W*/SUB R1, R0 /*R1=U*/MUL R1, S /*R1=V*/7.2 假设可用的寄存器为R0和R1,且所有临时单元都是非活跃的,试将以下四元式基本块:T1=B-CT2=A*T1T3=D+1T4=E-FT5=T3*T4W=T2/T5用简单代码生成算法生成其目标代码。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第七章目标代码生成
7.1 对下列四元式序列生成目标代码:
T=A-B
S=C+D
W=E-F
U=W/T
V=U*S
其中,V是基本块出口的活跃变量,R0和R1是可用寄存器。
【解答】简单代码生成算法依次对四元式进行翻译。
我们以四元式T=a+b为例来说明其翻译过程。
汇编语言的加法指令代码形式为
ADD R, X
其中,ADD为加法指令;R为第一操作数,第一操作数必须为寄存器类型;X为第二操作数,它可以是寄存器类型,也可以是内存型的变量。
ADD R,X指令的含意是:将第一操作数R与第二操作数相加后,再将累加结果存放到第一操作数所在的寄存器中。
要完整地翻译出四元式T=a+b,则可能需要下面三条汇编指令:
MOV R, a
ADD R, b
MOV T, R
第一条指令是将第一操作数a由内存取到寄存器R中;第二条指令完成加法运算;第三条指令将累加后的结果送回内存中的变量T。
是否在翻译成目标代码时都必须生成这三条汇编指令呢?从目标代码生成的优化角度考虑,即为了使生成的目标代码更短以及充分利用寄存器,上面的三条指令中,第一条和第三条指令在某些情况下是不必要的。
这是因为,如果下一个四元式紧接着需要引用操作数T,则第三条指令就不急于生成,可以推迟到以后适当的时机再生成。
此外,如果必须使用第一条指令,即第一操作数不在寄存器而是在内存中,且此时所有可用寄存器都已分配完毕,这时就要根据寄存器中所有变量的待用信息(也即引用点)来决定淘汰哪一个寄存器留给当前的四元式使用。
寄存器的淘汰策略如下:
(1) 如果某寄存器中的变量已无后续引用点且该变量是非活跃的,则可直接将该寄存器作为空闲寄存器使用。
(2) 如果所有寄存器中的变量在基本块内仍有引用点且都是活跃的,则将引用点最远的变量所占用寄存器中的值存放到内存与该变量对应的单元中,然后再将此寄存器分配给当前的指令使用。
因此,本题所给四元式序列生成的目标代码如下:
MOV R0, A
SUB R0, C /*R0=T*/
MOV R1, C
ADD R1, D /*R1=S*/
MOV S, R1 /*S引用点较T引用点远,故将R1的值送内存单元S*/
MOV R1, E
SUB R1, F /*R1=W*/
SUB R1, R0 /*R1=U*/
MUL R1, S /*R1=V*/
7.2 假设可用的寄存器为R0和R1,且所有临时单元都是非活跃的,试将以下四元式基本
块:
T1=B-C
T2=A*T1
T3=D+1
T4=E-F
T5=T3*T4
W=T2/T5
用简单代码生成算法生成其目标代码。
【解答】该基本块的目标代码如下(指令后面为相应的注释):
MOV R0, B /*取第一个空闲寄存器R0*/
SUB R0, C /*运算结束后R0中为T1结果,内存中无该结果*/
MOV R1, A /*取一个空闲寄存器R1*/
MUL R1, R0 /*运算结束后R1中为T2结果,内存中无该结果*/
MOV R0, D /*此时R0中结果T1已经没有引用点,且临时单元T1是非活跃的,所以,寄存器R0可作为空闲寄存器使用*/
ADD R0, ″1″/*运算结束后R0中为T3结果,内存中无该结果*/
MOV T2, R1 /*翻译四元式T4=E-F时,所有寄存器已经分配完毕,寄存器R0中存的T3和寄存器R1中存的T2都是有用的。
由于T2的下一个引用点较T3的下一个引用点更远,所以暂时可将寄存器R1中的结果存回到内存的变量T2中,从而将寄存器R1空闲以备使用*/
MOV R1, E
SUB R1, F /*运算结束后R1中为T4结果,内存中无该结果*/
MUL R0, R1 /*运算结束后R0中为T5结果,内存中无该结果。
注意,该指令将寄存器R0中原来的结果T3冲掉了。
可以这么做的原因是,T3在该指令后不再有引用点,且是非活跃变量*/
MOV R1, T2 /*此时R1中结果T4已经没有引用点,且临时单元T4是非活跃的,因此寄存器R1可作为空闲寄存器使用*/
DIV R1, R0 /*运算结束后R1中为W结果,内存中无该结果。
此时所有指令部分已经翻译完毕*/
MOV W, R1 /*指令翻译完毕时,寄存器中存有最新的计算结果,必须将它们存回到内存相应的单元中去,否则,在翻译下一个基本块时,所有的寄存器被当成空闲的寄存器使用,从而造成计算结果的丢失。
考虑到寄存器R0中的T5和寄存器R1中的W,临时单元T5是非活跃的,因此只要将结果W存回对应单元即可*/
7.3 对基本块P:
S0=2
S1=3/S0
S2=T-C
S3=T+C
R=S0/S3
H=R
S4=3/S1
S5=T+C
S6=S4/S5
H=S6*S2
(1) 试应用DAG 进行优化;
(2) 假定只有R 、H 在基本块出口是活跃的,写出优化后的四元式序列;
(3) 假定只有两个寄存器AX 、BX ,试写出上述优化后的四元式序列的目标代码。
【解答】 (1) 根据DAG 的构造算法构造基本块P 的DAG 步骤如图7-1所示的(a)到(h)。
图7-1 基本块P 的DAG
按图7-1(h)和原来构造结点的顺序,优化后的四元式序列为
S0=2
S4=2
S1=1.5
S2=T-C
S3=T+C
S5=S3
R=2/S3
S6=R
H=S6*S2
(2) 假定只有R 、H 在基本块出口是活跃的,则上述优化后的四元式序列可进一步优化为 S 0S 0S 1
S 0S 1
S 0S 1
S 2
S 2S 2S 2
S 2
(a )(b )(c )(d )(e )( f )
(g )(h )
S0=T-C
S3=T+C
R=2/S3
H=R*S2
(3) 假定只有两个寄存器AX、BX,上述优化后的四元式序列的目标代码为
MOV AX, T
SUB AX, C
MOV AX, S2
MOV AX, T
ADD AX, C
MOV BX, 2
DIV BX
MOV AX, S2
MUL BX
MOV BX, H
7.4 参考附录1和附录2(《编译原理教程》一书),将下列汇编程序片段翻译为对应的8086/8088机器语言代码(汇编地址由1000开始):
MOV AX,01
MOV BX,10
CMP AX,BX
JA L1
ADD AX,BX
L1:
【解答】该汇编程序片段翻译如下:
地址机器码
1000 B80100
1003 BB1000
1006 39D8
1008 7702
100A 01D8
100C。