《统计分析与SPSS的应用 第五版 》课后练习答案 第 章
《统计分析与SPSS的应用第五版》课后练习答案第5章.doc
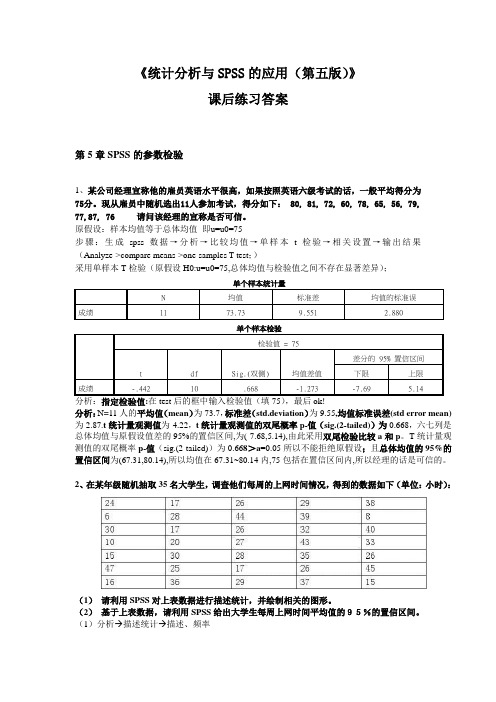
《统计分析与SPSS的应用(第五版)》课后练习答案第5章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下: 80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss数据→分析→比较均值→单样本t检验→相关设置→输出结果(Analyze->compare means->one-samples T test;)采用单样本T检验(原假设H0:u=u0=75,总体均值与检验值之间不存在显著差异);单个样本统计量N 均值标准差均值的标准误成绩11 73.73 9.551 2.880单个样本检验检验值 = 75t df Sig.(双侧) 均值差值差分的 95% 置信区间下限上限成绩-.442 10 .668 -1.273 -7.69 5.14分析:指定检验值:在test后的框中输入检验值(填75),最后ok!分析:N=11人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean)为2.87.t统计量观测值为-4.22,t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。
T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668>a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用SPSS对上表数据进行描述统计,并绘制相关的图形。
《统计分析与SPSS的应用(第五版)》课后练习答案(第1章)

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第1章SPSS统计分析软件概述1、SPSS的中文全名和英文全名是什么SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案)英文全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions)2、SPSS有哪两个主要窗口它们的作用和特点各是什么SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。
数据编辑器窗口的主要功能是定义SPSS数据的结构、录入编辑和管理待分析的数据;结果查看器窗口的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、什么是SPSS的数据集什么是SPSS的活动数据集SPSS的数据集:SPSS运行时可同时打开多个数据编辑器窗口。
每个数据编辑器窗口分别显示不同的数据集合(简称数据集)。
活动数据集:其中只有一个数据集为当前数据集。
SPSS只对某时刻的当前数据集中的数据进行分析。
4、SPSS有哪三种主要使用方式各自的特点是什么SPSS的三种基本运行方式:完全窗口菜单方式、程序运行方式、混合运行方式。
完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简洁和直观。
程序运行方式:是指在使用SPSS的过程中,统计分析人员根据自己的需要,手工编写SPSS命令程序,然后将编写好的程序一次性提交给计算机执行。
该方式适用于大规模的统计分析工作。
混合运行方式:是前两者的综合。
5、.sav、.spo、.sps分别是SPSS哪类文件的扩展名.sav是数据编辑器窗口中的SPSS数据文件的扩展名.spv是结果查看器窗口中的SPSS分析结果文件的扩展名.sps是语法窗口中的SPSS程序6、SPSS的数据加工和管理功能主要集中在哪些菜单中统计绘图和分析功能主要集中在哪些菜单中SPSS的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
《统计分析与SPSS的应用(第五版)》课后练习答案(第5章)
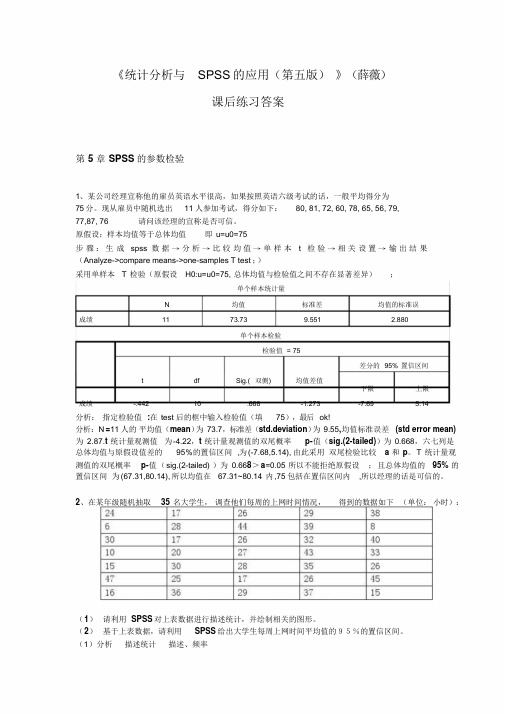
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第5 章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下:80, 81, 72, 60, 78, 65, 56, 79,77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss 数据→分析→比较均值→单样本t 检验→相关设置→输出结果(Analyze->compare means->one-samples T test ;)采用单样本T 检验(原假设H0:u=u0=75, 总体均值与检验值之间不存在显著差异);单个样本统计量N 均值标准差均值的标准误成绩11 73.73 9.551 2.880单个样本检验检验值= 75差分的95% 置信区间t df Sig.( 双侧) 均值差值下限上限成绩-.442 10 .668 -1.273 -7.69 5.14分析:指定检验值:在test 后的框中输入检验值(填75),最后ok!分析:N=11 人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean) 为2.87.t 统计量观测值为-4.22,t 统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14), 由此采用双尾检验比较 a 和p。
T 统计量观测值的双尾概率p-值(sig.(2-tailed) )为0.668>a=0.05 所以不能拒绝原假设;且总体均值的95% 的置信区间为(67.31,80.14), 所以均值在67.31~80.14 内,75 包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35 名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用SPSS 对上表数据进行描述统计,并绘制相关的图形。
《统计分析与SPSS的应用(第五版)》课后练习答案(第5章)

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第5章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下: 80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss数据→分析→比较均值→单样本t检验→相关设置→输出结果(Analyze->compare means->one-samples T test;)采用单样本T检验(原假设H0:u=u0=75,总体均值与检验值之间不存在显著差异);分析:指定检验值:在test后的框中输入检验值(填75),最后ok!分析:N=11人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean)为2.87.t统计量观测值为-4.22,t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。
T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668>a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用SPSS对上表数据进行描述统计,并绘制相关的图形。
(2)基于上表数据,请利用SPSS给出大学生每周上网时间平均值的95%的置信区间。
(1)分析描述统计描述、频率(2)分析比较均值单样本T检验每周上网时间的样本平均值为27.5,标准差为10.7,总体均值95%的置信区间为23.8-31.2.3、经济学家认为决策者是对事实做出反应,不是对提出事实的方式做出反应。
统计分析与SPSS的应用第五版课后练习答案精编版

统计分析与S P S S的应用第五版课后练习答案公司内部编号:(GOOD-TMMT-MMUT-UUPTY-UUYY-DTTI-《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第3章SPSS数据的预处理1、利用第2章第7题数据,采用SPSS数据筛选功能将数据分成两份文件。
其中,第一份数据文件存储常住地是“沿海或中心繁华城市”且本次存款金额在1000至5000之间的调查数据;第二份数据文件是按照简单随机抽样所选取的70%的样本数据。
第一份文件:选取数据数据——选择个案——如果条件满足——存款>=1000&存款<5000&常住地=沿海或中心繁华城市。
第二份文件:选取数据数据——选择个案——随机个案样本——输入70。
2、利用第2章第7题数据,将其按常住地(升序)、收入水平(升序)、存款金额(降序)进行多重排序。
排序数据——排序个案——把常住地、收入水平、存款金额作为排序依据分别设置排列顺序。
3、利用第2章第9题的完整数据,对每个学生计算得优课程数和得良课程数,并按得优课程数的降序排序。
计算转换——对个案内的值计数输入目标变量及目标标签,把所有课程选取到数字变量,定义值——设分数的区间,之后再排序。
4、利用第2章第9题的完整数据,计算每个学生课程的平均分以及标准差。
同时,计算男生和女生各科成绩的平均分。
方法一:利用描述性统计,数据——转置学号放在名称变量,全部课程放在变量框中,确定后,完成转置。
分析——描述统计——描述,将所有学生变量全选到变量框中,点击选项——勾选均值、标准差。
先拆分数据——拆分文件按性别拆分,分析——描述统计——描述,全部课程放在变量框中,选项——均值。
方法二:利用变量计算,转换——计算变量分别输入目标变量名称及标签——均值用函数mean完成平均分的计算,标准差用函数SD完成标准差的计算。
数据——分类汇总——性别作为分组变量、全部课程作为变量摘要、(创建只包含汇总变量的新数据集并命名)——确定5、利用第2章第7题数据,大致浏览存款金额的数据分布状况,并选择恰当的组限和组距进行组距分组。
统计分析与SPSS的应用第五版课后练习答案第章

统计分析与SPSS的应用第五版薛薇课后练习答案第3章SPSS数据的预处理1、利用第2章第7题数据,采用SPSS数据筛选功能将数据分成两份文件;其中,第一份数据文件存储常住地是“沿海或中心繁华城市”且本次存款金额在1000至5000之间的调查数据;第二份数据文件是按照简单随机抽样所选取的70%的样本数据;第一份文件:选取数据数据——选择个案——如果条件满足——存款>=1000&存款<5000&常住地=沿海或中心繁华城市;第二份文件:选取数据数据——选择个案——随机个案样本——输入70;2、利用第2章第7题数据,将其按常住地升序、收入水平升序、存款金额降序进行多重排序;排序数据——排序个案——把常住地、收入水平、存款金额作为排序依据分别设置排列顺序;3、利用第2章第9题的完整数据,对每个学生计算得优课程数和得良课程数,并按得优课程数的降序排序;计算转换——对个案内的值计数输入目标变量及目标标签,把所有课程选取到数字变量,定义值——设分数的区间,之后再排序;4、利用第2章第9题的完整数据,计算每个学生课程的平均分以及标准差;同时,计算男生和女生各科成绩的平均分;方法一:利用描述性统计,数据——转置学号放在名称变量,全部课程放在变量框中,确定后,完成转置;分析——描述统计——描述,将所有学生变量全选到变量框中,点击选项——勾选均值、标准差;先拆分数据——拆分文件按性别拆分,分析——描述统计——描述,全部课程放在变量框中,选项——均值;方法二:利用变量计算,转换——计算变量分别输入目标变量名称及标签——均值用函数mean完成平均分的计算,标准差用函数SD完成标准差的计算;数据——分类汇总——性别作为分组变量、全部课程作为变量摘要、创建只包含汇总变量的新数据集并命名——确定5、利用第2章第7题数据,大致浏览存款金额的数据分布状况,并选择恰当的组限和组距进行组距分组;根据存款金额排序,观察其最大值与最小值,算出组数和组距;转换——重新编码为其他变量——将存款金额作为输出变量——定义输出变量的名称及标签——设定旧值和新值.6、在第2章第7题数据中,如果认为调查中“今年的收入比去年增加”且“预计未来一两年收入仍会增加”的人是对自己收入比较满意和乐观的人,请利用SPSS 的计数和数据筛选功能找到这些人;转换——对个案的值计数——设定目标变量及标签——将“今年的收入比去年增加”和“预计未来一两年收入仍会增加”两个变量选中——定义值;7、对第2章第4题数据,选择恰当的加权变量进行加权处理进而还原为原始数据为后续分析做准备;数据——加权个案——点击加权个案——将人数作为频率变量——确定;8、利用SPSS的变量计算功能,随机生成服从标准正态分布的100个样本数据;⑴在空表中先列100个序号,激活表;⑵转换随机数生成器设置起点勾选“随机”⑶转换计算变量目标变量:随机数数字表达式:0,1 确定结果:9、简述SPSS排序功能与拆分功能的不同点;SPSS排序功能仅实现将观测按用户指定顺序重新排列;拆分功能在按序排列的基础上,能够实现对数据按排序变量进行分组,并分组进行后续的统计分析;。
《统计分析和SPSS的应用(第五版)》课后练习答案解析(第5章)

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第5章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下: 80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss数据→分析→比较均值→单样本t检验→相关设置→输出结果(Analyze->compare means->one-samples T test;)采用单样本T检验(原假设H0:u=u0=75,总体均值与检验值之间不存在显著差异);(单个样本统计量N均值标准差均值的标准误成绩11【单个样本检验检验值 = 75t—df Sig.(双侧)均值差值差分的 95% 置信区间下限上限成绩10.668>分析:指定检验值:在test后的框中输入检验值(填75),最后ok!分析:N=11人的平均值(mean)为,标准差()为,均值标准误差(std error mean)为统计量观测值为,t统计量观测值的双尾概率p-值(sig.(2-tailed))为,六七列是总体均值与原假设值差的95%的置信区间,为,,由此采用双尾检验比较a和p。
T统计量观测值的双尾概率p-值(sig.(2-tailed))为>a=所以不能拒绝原假设;且总体均值的95%的置信区间为,,所以均值在~内,75包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用SPSS 对上表数据进行描述统计,并绘制相关的图形。
;(2)基于上表数据,请利用SPSS给出大学生每周上网时间平均值的95%的置信区间。
(1)分析描述统计描述、频率(2)分析比较均值单样本T检验每周上网时间的样本平均值为,标准差为,总体均值95%的置信区间为、经济学家认为决策者是对事实做出反应,不是对提出事实的方式做出反应。
《统计分析和SPSS的应用(第五版)》课后练习答案解析(第5章)教学教材

《统计分析和S P S S 的应用(第五版)》课后练习答案解析(第5章)《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第5章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下: 80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss数据→分析→比较均值→单样本t检验→相关设置→输出结果(Analyze->compare means->one-samples T test;)采用单样本T检验(原假设H0:u=u0=75,总体均值与检验值之间不存在显著差异);分析:N=11人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean)为2.87.t统计量观测值为-4.22,t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。
T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668>a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用SPSS对上表数据进行描述统计,并绘制相关的图形。
(2)基于上表数据,请利用SPSS给出大学生每周上网时间平均值的95%的置信区间。
(1)分析→描述统计→描述、频率(2)分析→比较均值→单样本T检验每周上网时间的样本平均值为27.5,标准差为10.7,总体均值95%的置信区间为23.8-31.2.3、经济学家认为决策者是对事实做出反应,不是对提出事实的方式做出反应。
《统计分析与SPSS的应用(第五版)》课后练习答案(第5章)
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第5 章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下:80, 81, 72, 60, 78, 65, 56, 79,77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss 数据→分析→比较均值→单样本t 检验→相关设置→输出结果(Analyze->compare means->one-samples T test ;)采用单样本T 检验(原假设H0:u=u0=75, 总体均值与检验值之间不存在显著差异);单个样本统计量N 均值标准差均值的标准误成绩11 73.73 9.551 2.880单个样本检验检验值= 75差分的95% 置信区间t df Sig.( 双侧) 均值差值下限上限成绩-.442 10 .668 -1.273 -7.69 5.14分析:指定检验值:在test 后的框中输入检验值(填75),最后ok!分析:N=11 人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean) 为2.87.t 统计量观测值为-4.22,t 统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14), 由此采用双尾检验比较 a 和p。
T 统计量观测值的双尾概率p-值(sig.(2-tailed) )为0.668>a=0.05 所以不能拒绝原假设;且总体均值的95% 的置信区间为(67.31,80.14), 所以均值在67.31~80.14 内,75 包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35 名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用SPSS 对上表数据进行描述统计,并绘制相关的图形。
统计分析与SPSS课后习题课后习题答案汇总

《统计分析与SPSS的应用(第五版)》课后练习答案第一章练习题答案1、SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案)英文全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions)2、SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。
数据编辑器窗口的主要功能是定义SPSS数据的结构、录入编辑和管理待分析的数据;结果查看器窗口的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、SPSS的数据集:SPSS运行时可同时打开多个数据编辑器窗口。
每个数据编辑器窗口分别显示不同的数据集合(简称数据集)。
活动数据集:其中只有一个数据集为当前数据集。
SPSS只对某时刻的当前数据集中的数据进行分析。
4、SPSS的三种基本运行方式:完全窗口菜单方式、程序运行方式、混合运行方式。
完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简洁和直观。
程序运行方式:是指在使用SPSS的过程中,统计分析人员根据自己的需要,手工编写SPSS命令程序,然后将编写好的程序一次性提交给计算机执行。
该方式适用于大规模的统计分析工作。
混合运行方式:是前两者的综合。
5、.sav是数据编辑器窗口中的SPSS数据文件的扩展名.spv是结果查看器窗口中的SPSS分析结果文件的扩展名.sps是语法窗口中的SPSS程序6、SPSS的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
7、概率抽样(probability sampling):也称随机抽样,是指按一定的概率以随机原则抽取样本,抽取样本时每个单位都有一定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。
《统计分析与spss的应用(第五版)》课后练习答案(第章)

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第2章SPSS数据文件的建立和管理1、SPSS中有哪两种基本的数据组织形式?各自的特点和应用场合是什么?SPSS中两个基本的数据组织方式:原始数据的组织方式和计数数据的组织方式。
●原始数据的组织方式:待分析的数据是一些原始的调查问卷数据,或是一些基本的统计指标。
●计数数据的组织方式:所采集的数据不是原始的调查问卷数据,而是经过分组汇总后的数据。
2、什么是SPSS的个案?什么SPSS的变量?个案:在原始数据的组织方式中,数据编辑器窗口中的一行称为一个个案或观测。
变量:数据编辑器窗口中的一列。
3、在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强SPSS统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明?默认的变量名:VAR------;默认的变量类型:数值型。
变量名标签和变量值标签可增强统计分析结果的可读性。
4、收集到以下关于两种减肥产品试用情况的调查数据,请问在SPSS中应如何组织该份资料?体重变化情况产品类型明显减轻无明显变化第一种产品27 19第二种产品20 33问:在SPSS中应如何组织该数据?数据文件如图所示:5、什么是SPSS的用户缺失值?为什么要对用户缺失值进行定义?如何在SPSS中指定用户缺失值?缺失值分为用户缺失值(User Missing Value)和系统缺失值(System Missing Value)。
用户缺失值指在问卷调查中,将无回答的一些数据以及明显失真的数据当作缺失值来处理。
用户缺失值的编码一般用研究者自己能够识别的数字来表示,如“0”、“9”、“99”等。
系统缺失值主要指计算机默认的缺失方式,如果在输入数据时空缺了某些数据或输入了非法的字符,计算机就把其界定为缺失值,这时的数据标记为一个圆点“•”。
在变量视图中定义。
6、从计量尺度角度看,变量包括哪三种主要类型?请各举出一个相应的实际数据。
《统计分析与SPSS的应用第五版》课后练习答案

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第3章SPSS数据的预处理1、利用第2章第7题数据,采用SPSS数据筛选功能将数据分成两份文件。
其中,第一份数据文件存储常住地是“沿海或中心繁华城市”且本次存款金额在1000至5000之间的调查数据;第二份数据文件是按照简单随机抽样所选取的70%的样本数据。
第一份文件:选取数据数据——选择个案——如果条件满足——存款>=1000&存款<5000&常住地=沿海或中心繁华城市。
第二份文件:选取数据数据——选择个案——随机个案样本——输入70。
2、利用第2章第7题数据,将其按常住地(升序)、收入水平(升序)、存款金额(降序)进行多重排序。
排序数据——排序个案——把常住地、收入水平、存款金额作为排序依据分别设置排列顺序。
3、利用第2章第9题的完整数据,对每个学生计算得优课程数和得良课程数,并按得优课程数的降序排序。
计算转换——对个案内的值计数输入目标变量及目标标签,把所有课程选取到数字变量,定义值——设分数的区间,之后再排序。
4、利用第2章第9题的完整数据,计算每个学生课程的平均分以及标准差。
同时,计算男生和女生各科成绩的平均分。
方法一:利用描述性统计,数据——转置学号放在名称变量,全部课程放在变量框中,确定后,完成转置。
分析——描述统计——描述,将所有学生变量全选到变量框中,点击选项——勾选均值、标准差。
先拆分数据——拆分文件按性别拆分,分析——描述统计——描述,全部课程放在变量框中,选项——均值。
方法二:利用变量计算,转换——计算变量分别输入目标变量名称及标签——均值用函数mean完成平均分的计算,标准差用函数SD完成标准差的计算。
数据——分类汇总——性别作为分组变量、全部课程作为变量摘要、(创建只包含汇总变量的新数据集并命名)——确定5、利用第2章第7题数据,大致浏览存款金额的数据分布状况,并选择恰当的组限和组距进行组距分组。
《统计分析与SPSS的应用(第五版)》课后练习答案(第5章)
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第5 章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下:80, 81, 72, 60, 78, 65, 56, 79,77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss 数据→分析→比较均值→单样本t 检验→相关设置→输出结果(Analyze->compare means->one-samples T test ;)采用单样本T 检验(原假设H0:u=u0=75, 总体均值与检验值之间不存在显著差异);单个样本统计量N 均值标准差均值的标准误成绩11 73.73 9.551 2.880单个样本检验检验值= 75差分的95% 置信区间t df Sig.( 双侧) 均值差值下限上限成绩-.442 10 .668 -1.273 -7.69 5.14分析:指定检验值:在test 后的框中输入检验值(填75),最后ok!分析:N=11 人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean) 为2.87.t 统计量观测值为-4.22,t 统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14), 由此采用双尾检验比较 a 和p。
T 统计量观测值的双尾概率p-值(sig.(2-tailed) )为0.668>a=0.05 所以不能拒绝原假设;且总体均值的95% 的置信区间为(67.31,80.14), 所以均值在67.31~80.14 内,75 包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35 名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用SPSS 对上表数据进行描述统计,并绘制相关的图形。
统计分析与SPSS课后习题课后习题答案汇总(第五版)

《统计分析与SPSS的应用(第五版)》课后练习答案第一章练习题答案1、SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案)英文全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions)2、SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。
●数据编辑器窗口的主要功能是定义SPSS数据的结构、录入编辑和管理待分析的数据;●结果查看器窗口的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、SPSS的数据集:●SPSS运行时可同时打开多个数据编辑器窗口。
每个数据编辑器窗口分别显示不同的数据集合(简称数据集)。
●活动数据集:其中只有一个数据集为当前数据集。
SPSS只对某时刻的当前数据集中的数据进行分析。
4、SPSS的三种基本运行方式:●完全窗口菜单方式、程序运行方式、混合运行方式。
●完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简洁和直观。
●程序运行方式:是指在使用SPSS的过程中,统计分析人员根据自己的需要,手工编写SPSS命令程序,然后将编写好的程序一次性提交给计算机执行。
该方式适用于大规模的统计分析工作。
●混合运行方式:是前两者的综合。
5、.sav是数据编辑器窗口中的SPSS数据文件的扩展名.spv是结果查看器窗口中的SPSS分析结果文件的扩展名.sps是语法窗口中的SPSS程序6、SPSS的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
7、概率抽样(probability sampling):也称随机抽样,是指按一定的概率以随机原则抽取样本,抽取样本时每个单位都有一定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。
《统计分析与SPSS的应用(第五版)》课后练习答案(第3章).doc

《统计分析与SPSS的应用(第五版)》课后练习答案第3章SPSS数据的预处理1、利用第2章第7题数据,采用SPSS数据筛选功能将数据分成两份文件。
其中,第一份数据文件存储常住地是“沿海或中心繁华城市”且本次存款金额在1000至5000之间的调查数据;第二份数据文件是按照简单随机抽样所选取的70%的样本数据。
第一份文件:选取数据数据——选择个案——如果条件满足——存款>=1000&存款<5000&常住地=沿海或中心繁华城市。
第二份文件:选取数据数据——选择个案——随机个案样本——输入70。
2、利用第2章第7题数据,将其按常住地(升序)、收入水平(升序)、存款金额(降序)进行多重排序。
排序数据——排序个案——把常住地、收入水平、存款金额作为排序依据分别设置排列顺序。
3、利用第2章第9题的完整数据,对每个学生计算得优课程数和得良课程数,并按得优课程数的降序排序。
计算转换——对个案内的值计数输入目标变量及目标标签,把所有课程选取到数字变量,定义值——设分数的区间,之后再排序。
4、利用第2章第9题的完整数据,计算每个学生课程的平均分以及标准差。
同时,计算男生和女生各科成绩的平均分。
方法一:利用描述性统计,数据——转置学号放在名称变量,全部课程放在变量框中,确定后,完成转置。
分析——描述统计——描述,将所有学生变量全选到变量框中,点击选项——勾选均值、标准差。
先拆分数据——拆分文件按性别拆分,分析——描述统计——描述,全部课程放在变量框中,选项——均值。
方法二:利用变量计算,转换——计算变量分别输入目标变量名称及标签——均值用函数mean完成平均分的计算,标准差用函数SD完成标准差的计算。
数据——分类汇总——性别作为分组变量、全部课程作为变量摘要、(创建只包含汇总变量的新数据集并命名)——确定5、利用第2章第7题数据,大致浏览存款金额的数据分布状况,并选择恰当的组限和组距进行组距分组。
《统计分析和SPSS的应用(第五版)》课后练习答案与解析(第5章)
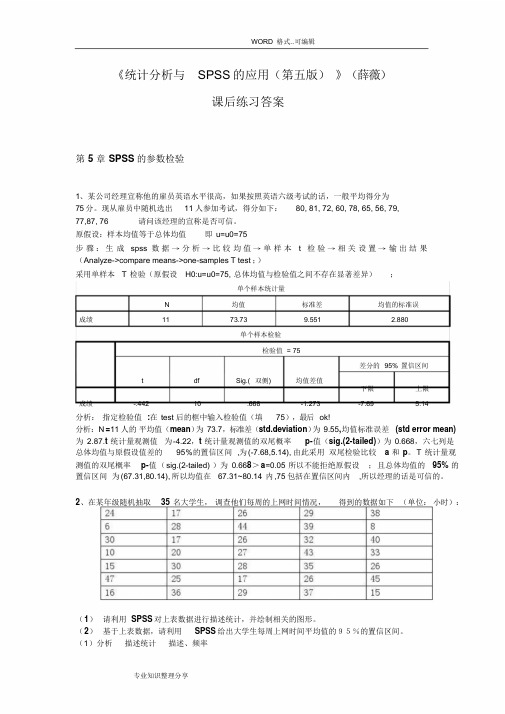
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第5 章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下:80, 81, 72, 60, 78, 65, 56, 79,77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss 数据→分析→比较均值→单样本t 检验→相关设置→输出结果(Analyze->compare means->one-samples T test ;)采用单样本T 检验(原假设H0:u=u0=75, 总体均值与检验值之间不存在显著差异);单个样本统计量N 均值标准差均值的标准误成绩11 73.73 9.551 2.880单个样本检验检验值= 75差分的95% 置信区间t df Sig.( 双侧) 均值差值下限上限成绩-.442 10 .668 -1.273 -7.69 5.14分析:指定检验值:在test 后的框中输入检验值(填75),最后ok!分析:N=11 人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean) 为2.87.t 统计量观测值为-4.22,t 统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14), 由此采用双尾检验比较 a 和p。
T 统计量观测值的双尾概率p-值(sig.(2-tailed) )为0.668>a=0.05 所以不能拒绝原假设;且总体均值的95% 的置信区间为(67.31,80.14), 所以均值在67.31~80.14 内,75 包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35 名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用SPSS 对上表数据进行描述统计,并绘制相关的图形。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《统计分析与SPSS的应用(第五版)》(薛薇)
课后练习答案
第2章SPSS数据文件的建立和管理
1、SPSS中有哪两种基本的数据组织形式?各自的特点和应用场合是什么?SPSS中两个基本的数据组织方式:原始数据的组织方式和计数数据的组织方式。
●原始数据的组织方式:待分析的数据是一些原始的调查问卷数据,或是一
些基本的统计指标。
●计数数据的组织方式:所采集的数据不是原始的调查问卷数据,而是经过
分组汇总后的数据。
2、什么是SPSS的个案?什么SPSS的变量?
个案:在原始数据的组织方式中,数据编辑器窗口中的一行称为一个个案或观测。
变量:数据编辑器窗口中的一列。
3、在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强SPSS 统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明?
默认的变量名:VAR------;默认的变量类型:数值型。
变量名标签和变量值标签可增强统计分析结果的可读性。
4、收集到以下关于两种减肥产品试用情况的调查数据,请问在SPSS中应如何组织该份资料?
问:在SPSS中应如何组织该数据?
数据文件如图所示:
5、什么是SPSS的用户缺失值?为什么要对用户缺失值进行定义?如何在SPSS中指定用户缺失值?
缺失值分为用户缺失值(User Missing Value)和系统缺失值(System Missing Value)。
用户缺失值指在问卷调查中,将无回答的一些数据以及明显失真的数据当作缺失值来处理。
用户缺失值的编码一般用研究者自己能够识别的数字来表示,如“0”、“9”、“99”等。
系统缺失值主要指计算机默认的缺失方式,如果在输入数据时空缺了某些数据或输入了非法的字符,计算机就把其界定为缺失值,这时的数据标记为一个圆点“?”。
在变量视图中定义。
6、从计量尺度角度看,变量包括哪三种主要类型?请各举出一个相应的实际数据。
如何在SPSS中指定变量的计算尺度?
变量类型包括:数值型(身高)、定序型(受教育程度)以及定类型(性别)。
在变量视图中定义。
7、有一份关于居民储蓄调查的模拟数据存储在Excel中,文件名为“居民储蓄调查数据.xls”。
该数据的第一行是变量名,格式如下图所示。
请将该份数据转换成SPSS数据文件,并在SPSS中指定其变量名标签和变量值标签。
(该份数据的具体含义见Excel文件的后半部分)
【文件(F)】→【打开(O)】→【数据(A)】→文件类型选“Excel(*.xls,…)”,文件名选“居民储蓄调查数据.xls”→【打开】→选中“从第一行数据读取变量
名”,在“范围”中输入“A1:Q283”→【确定】→在“变量视图”窗口,调整
A1变量的宽度,输入变量名标签和变量值标签→在主菜单窗口选定【文件(F)】→【保存】→选择保存路径,保存类型为“sav”,?文件名为“居民储蓄调查数据” →【保存】.
8、现有股民投资状况调查的文本数据,文件名为“股民投资数据.txt”。
其中各变量的含义和编码见文件“股民投资数据.xls”。
请将该文本数据读入SPSS,并定义变量名标签和变量值标签。
其中各变量取值为9的均为用户缺失值,请加以定义说明。
(注:本调查问卷中涉及多选项问题,以及多选项问题的编码等,可先忽略。
)
【文件(F)】→【打开文本数据(D)】→【数据(A)】→文件类型选“Text(*.txt,…)”,文件名选“股民投资数据.txt”,【打开】→在“您的文本文件与预定义的格式匹配吗?”中选“否”,【下一步】→在“变量名称是否包括在文件的顶部”中选“是”,【下一步】→在“第一个数据个案从哪个行号开始”中输入“2”,其他默认,【下一步】→【下一步】→在“数据格式”中输入“字符串”,接着在弹出的窗口输入“4”,【下一步】→默认各选项,【完成】→在主菜单窗口选定【文件(F)】→【保存】→选择保存路径,保存类型为“sav”,?文件名为“股民投资数据” →【保存】.
9、现有两个SPSS数据文件,分别名为“学生成绩一.sav”和“学生成绩
二.sav”,存放了关于学生学号、性别和若干门课程成绩的数据。
请将这两份数据文件以学号为关键变量进行横向合并,形成一个完整的数据文件。
(1)打开待合并的两个文件“学生成绩一 .sav”和“学生成绩二 .sav”,并按照下列程序将这两个文件排序:【数据(D)】→【排列个案】→选“xh”入“排序
依据”,“排列顺序”选“升序”,【确定】
(2)选“学生成绩一 .sav”数据编辑器窗口为当前窗口→【数据(D)】→【合并文件】→【添加变量】→选中“打开的数据集(O)”且选中“学生成绩二 .sav”,【继续】→选中“按照文件中的关键变量匹配个案”同时选中“两个文件都提供个案”,然后将“xh”变量选入“关键变量”框中,选中“将个案源表示为变量”,【继续】→【确定】→【确定】→【保存】
.
10、针对当前学校或社会关心的热点问题,以小组形式设计一份调查问卷并进行调查。
试在SPSS中录入所获得的调查数据形成一份SPSS数据文件。
其中,变量的类型应包括字符型和数字型,变量的计量尺度应包括定距型、定类型和定序型。
如果调查资料中存在缺失数据应在SPSS数据文件建立过程中进行必要的定义说明。
(答案略)。