SqlserverSQL性能优化经验
sqlsqerver语句优化方法

sqlsqerver语句优化方法SQL Server是一种关系型数据库管理系统,可以使用SQL语句对数据进行操作和管理。
优化SQL Server语句可以提高查询和操作数据的效率,使得系统更加高效稳定。
下面列举了10个优化SQL Server语句的方法:1. 使用索引:在查询频繁的列上创建索引,可以加快查询速度。
但是要注意不要过度索引,否则会影响插入和更新操作的性能。
2. 避免使用SELECT *:只选择需要的列,避免不必要的数据传输和处理,提高查询效率。
3. 使用JOIN替代子查询:在进行关联查询时,使用JOIN操作比子查询更高效。
尽量避免在WHERE子句中使用子查询。
4. 使用EXISTS替代IN:在查询中使用EXISTS操作比IN操作更高效。
因为EXISTS只需要找到一个匹配的行就停止了,而IN需要对所有的值进行匹配。
5. 使用UNION替代UNION ALL:如果对多个表进行合并查询时,如果不需要去重,则使用UNION ALL操作比UNION操作更高效。
6. 使用TRUNCATE TABLE替代DELETE:如果要删除表中的所有数据,使用TRUNCATE TABLE操作比DELETE操作更高效。
因为TRUNCATE TABLE不会像DELETE一样逐行删除,而是直接删除整个表的数据。
7. 使用分页查询:在需要分页显示查询结果时,使用OFFSET和FETCH NEXT操作代替传统的使用ROW_NUMBER进行分页查询。
这样可以减少查询的数据量,提高效率。
8. 避免使用CURSOR:使用游标(CURSOR)会增加数据库的负载,降低查询效率。
如果可能的话,应该尽量避免使用游标。
9. 使用参数化查询:使用参数化查询可以减少SQL注入的风险,同时也可以提高查询的效率。
因为参数化查询会对SQL语句进行预编译,可以复用执行计划。
10. 定期维护数据库:定期清理过期数据、重建索引、更新统计信息等维护操作可以提高数据库的性能。
SQLServer数据库中的性能优化技巧

SQLServer数据库中的性能优化技巧随着企业信息化程度的不断提高,数据库已成为重要的企业数据存储和管理平台。
然而,随着数据库中数据量的增长和业务需求的不断变更,数据库性能优化愈发成为一个迫切的问题。
本文将通过探讨SQLServer数据库中的性能优化技巧,为读者解决这一问题提供一定参考价值。
一、透彻的SQLServer架构理解要想有效优化SQLServer数据库性能,首先需要充分理解其架构及其特点。
SQLServer 的架构由表、索引、存储过程、视图、触发器、函数、约束以及数据库模式(schema)等构成。
此外,SQLServer还有两个关键组件:SQLServer实例和SQLServer代理。
SQLServer实例是SQLServer运行环境的一部分,它具有独立的内存和处理能力。
而SQLServer代理则是自动执行作业的一种机制。
深入了解SQLServer架构是性能优化的基础。
二、优化查询语句对SQLServer数据库进行性能优化的第二步是优化查询语句。
查询语句是数据库操作的核心,也是导致性能问题的重要原因。
开发人员在编写查询语句时,应遵循以下几个优化点:1.减少Join的使用Join是SQLServer中最慢的一种查询方式,尽量用Where子句代替Join语句。
2.避免在查询中使用SELECT *SELECT *在数据库中是一种非常低效的查询方式,因为它会扫描所有表格,并提取出每一个列。
指定要查询的列格外重要,应尽量将查询中的选择列数目减至最小。
3.尽早的删选出不需要的记录查询语句中应该尽早地删选出不需要的记录,可以通过将这些条件放在Where子句中实现。
4.避免使用 costly functions在计算列(如使用SUM、AVG、COUNT)时应尽量避免使用高花费的函数,如自联接和复杂的计算等。
5.切勿在查询中使用模糊查询查询语句中尽量不要使用LIKE操作符,因为它会扫描所有的符合特定模式的记录。
SQLSERVERSQL性能优化技巧

SQLSERVERSQL性能优化技巧1.选择最有效率的表名顺序(只在基于规则的优化器中有效)SQLSERVER的解析器按照从右到左的顺序处理FROM⼦句中的表名,因此FROM⼦句中写在最后的表(基础表driving table)将被最先处理,在FROM⼦句中包含多个表的情况下,必须选择记录条数最少的表作为基础表,当SQLSERVER处理多个表时,会运⽤排序及合并的⽅式连接它们,⾸先,扫描第⼀个表(FROM⼦句中最后的那个表)并对记录进⾏排序;然后扫描第⼆个表(FROM⼦句中最后第⼆个表);最后将所有从第⼆个表中检索出的记录与第⼀个表中合适记录进⾏合并例如: 表 TAB1 16,384 条记录表 TAB2 5 条记录,选择TAB2作为基础表 (最好的⽅法) select count(*) from tab1,tab2 执⾏时间0.96秒,选择TAB2作为基础表 (不佳的⽅法) select count(*) from tab2,tab1 执⾏时间26.09秒;如果有3个以上的表连接查询,那就需要选择交叉表(intersection table)作为基础表,交叉表是指那个被其他表所引⽤的表例如:EMP表描述了LOCATION表和CATEGORY表的交集SELECT *FROM LOCATION L,CATEGORY C,EMP EWHERE E.EMP_NO BETWEEN 1000 AND 2000AND E.CAT_NO = C.CAT_NOAND E.LOCN = L.LOCN将⽐下列SQL更有效率SELECT *FROM EMP E ,LOCATION L ,CATEGORY CWHERE E.CAT_NO = C.CAT_NOAND E.LOCN = L.LOCNAND E.EMP_NO BETWEEN 1000 AND 20002.WHERE⼦句中的连接顺序SQLSERVER采⽤⾃下⽽上的顺序解析WHERE⼦句,根据这个原理,表之间的连接必须写在其他WHERE条件之前,那些可以过滤掉最⼤数量记录的条件必须写在WHERE⼦句的末尾例如:(低效,执⾏时间156.3秒)SELECT *FROM EMP EWHERE SAL > 50000AND JOB = 'MANAGER'AND 25 < (SELECT COUNT(*) FROM EMP WHERE MGR=E.EMPNO);(⾼效,执⾏时间10.6秒)SELECT *FROM EMP EWHERE 25 < (SELECT COUNT(*) FROM EMP WHERE MGR=E.EMPNO)AND SAL > 50000AND JOB = 'MANAGER';3.SELECT⼦句中避免使⽤'*'。
SQLServer数据库性能调优技巧

SQLServer数据库性能调优技巧第一章:SQLServer数据库性能调优概述SQLServer是一种常用的关系型数据库管理系统,在大型企业和云计算环境中广泛应用。
为了确保数据库的高性能和可靠性,进行数据库性能调优非常重要。
本章将介绍SQLServer数据库性能调优的概念和目标。
1.1 数据库性能调优的概念数据库性能调优是指通过分析和优化数据库的结构、查询、索引、存储和配置等方面的问题,以提高数据库系统的效率和性能。
优化数据库性能可以显著提升数据的访问速度、减少系统响应时间和提高数据库的处理能力。
1.2 数据库性能调优的目标数据库性能调优的主要目标是提高数据库的运行效率和用户的体验,具体目标包括:- 提高数据的访问速度:通过合理的查询优化和索引设计,加快数据的检索速度。
- 减少系统响应时间:通过调整数据库配置、优化SQL 查询和提高硬件性能等措施,缩短系统响应时间。
- 提高数据库的处理能力:通过合理的分区设计、并行处理和负载均衡等措施,提高数据库的并发处理能力。
第二章:SQLServer数据库性能调优基础在进行SQLServer数据库性能调优之前,有几个基础概念需要了解,包括数据库的结构、查询执行计划和索引等。
2.1 数据库的结构SQLServer数据库由多个表组成,每个表由多个行和列组成。
表有一定的关系,通过主键和外键来建立关联。
了解数据库的结构对于进行性能调优非常重要。
2.2 查询执行计划查询执行计划是SQLServer数据库执行查询语句时的执行路径和操作过程的详细描述。
通过分析查询执行计划,可以找到潜在的性能问题,并进行相应的优化。
2.3 索引索引是一种特殊的数据库对象,用于加快查询速度。
常见的索引类型包括聚集索引、非聚集索引和全文索引等。
合理设计索引可以提高查询的性能。
第三章:SQLServer数据库性能调优技巧本章将介绍一些常用的SQLServer数据库性能调优技巧,包括查询优化、索引优化、配置优化和硬件优化等。
SQLServer数据库优化实用技巧

SQLServer数据库优化实用技巧SQL Server数据库优化实用技巧随着互联网的飞速发展,海量数据的存储和处理变得越来越重要。
而SQL Server数据库就是其中之一。
随着数据库的规模增大,数据量也会随之增加,导致查询速度变得很慢。
所以,我们需要对SQL Server数据库进行优化来提高其处理速度和稳定性,本文将从以下几个方面来讲解SQL Server数据库的优化实用技巧。
一、数据库优化前的准备工作在进行SQL Server数据库优化之前,我们需要做好以下准备工作:1.备份数据库:在数据库优化之前需要备份数据库,以防因操作失误导致数据丢失。
2.生成关键字:根据数据库的运行情况,生成关键字来优化查询。
例如,数据倾斜、常用的表连接等。
3.性能监控:使用SQL Server Profiler来监控数据库运行的临时数据、活动情况等。
4.目录重建:重建索引,以提高查询速度。
5.删除不必要的表和视图:删除对整个数据库只起到负面影响的表和视图对象。
二、SQL Server数据库性能优化SQL Server数据库性能优化需要注意以下几点:1.数据类型:选择合适的数据类型可以提高数据库的性能。
数据类型包括大小、数据格式等。
尽量使用较小的数据类型,以减少I/O的负担。
2.索引:索引可以大大提高查询速度,但是索引也会占用大量的存储空间,因此需要根据实际情况来选择和创建索引。
为频繁查询的列或组合列创建索引是比较合适的。
3.使用视图:使用视图可以减少数据访问的复杂度,提高查询速度。
但过多的视图也会影响数据库的性能,因此需要注意选择使用视图的频率。
4.分区表:分区表将一个大表分成多个小表,可以提高查询速度,减少对整个表的访问开销。
5.使用存储过程:存储过程可以提高数据库的效率和稳定性。
通过存储过程,可以将多个SQL语句封装到一起,减少客户端和服务器之间的通信,大大提高数据库的性能。
6.升级硬件:在处理大量数据时,硬件性能的升级也是提高数据库性能的有效方法。
SQLServer数据库性能优化技术

1数据库设计要在良好的SQLServer方案中实现最优的性能,最关键的是要有1个很好的数据库设计方案。
在实际工作中,许多SQLServer方案往往是由于数据库设计得不好导致性能很差。
所以,要实现良好的数据库设计就必须考虑这些问题。
1.1逻辑库规范化问题一般来说,逻辑数据库设计会满足规范化的前3级标准:1.第1规范:没有重复的组或多值的列。
2.第2规范:每个非关键字段必须依赖于主关键字,不能依赖于1个组合式主关键字的某些组成部分。
3.第3规范:1个非关键字段不能依赖于另1个非关键字段。
遵守这些规则的设计会产生较少的列和更多的表,因而也就减少了数据冗余,也减少了用于存储数据的页。
但表关系也许需要通过复杂的合并来处理,这样会降低系统的性能。
某种程度上的非规范化可以改善系统的性能,非规范化过程可以根据性能方面不同的考虑用多种不同的方法进行,但以下方法经实践验证往往能提高性能。
1.如果规范化设计产生了许多4路或更多路合并关系,就可以考虑在数据库实体中加入重复属性。
2.常用的计算字段可以考虑存储到数据库实体中。
比如某一个项目的计划中有计划表,其字段为:项目编号、年初计划、二次计划、调整计划、补列计划…,而计划总数是用户经常需要在查询和报表中用到的,在表的记录量很大时,有必要把计划总数作为1个独立的字段加入到表中。
这里可以采用触发器以在客户端保持数据的一致性。
3.重新定义实体以减少外部属性数据或行数据的开支。
相应的非规范化类型是:把1个实体分割成2个表。
这样就把频繁被访问的数据同较少被访问的数据分开了。
这种方法要求在每个表中复制首要关键字。
这样产生的设计有利于并行处理,并将产生列数较少的表。
把1个实体分割成2个表。
这种方法适用于那些将包含大量数据的实体。
在应用中常要保留历史记录,但是历史记录很少用到。
因此可以把频繁被访问的数据同较少被访问的历史数据分开。
而且如果数据行是作为子集被逻辑工作组访问的,那么这种方法也是很有好处的。
SQLServer数据库性能优化技巧

SQLServer数据库性能优化技巧查询速度慢的原因很多,常见如下⼏种:1、没有索引或者没有⽤到索引;2、I/O吞吐量⼩,形成了瓶颈效应;3、内存不⾜;4、⽹络速度慢;5、查询出的数据量过⼤;6、锁或者死锁;7、返回了不必要的⾏和列;8、查询语句不好,没有优化。
可以通过如下⽅法来优化查询:硬件/⽹络⽅⾯1、升级硬件。
2、提⾼⽹速。
3、扩⼤服务器的内存。
4、增加服务器CPU个数。
5、把数据、⽇志、索引放到不同的I/O设备上。
6、DB Server和APP Server分离。
7、应⽤分布式分区视图。
索引⽅⾯8、根据查询条件建⽴索引,优化索引。
9、索引应该尽量⼩,使⽤字节数⼩的列建索引好。
10、不要对有限的⼏个值的字段建单⼀索引(如性别字段)。
11、对于查询字段的值很长的建全⽂索引。
12、要注意索引的维护,周期性重建索引,重新编译存储过程。
13、如果使⽤了IN或者OR等时发现查询没有⾛索引,使⽤显⽰声明指定索引。
14、不要在WHERE⼦句中的“=”左边进⾏函数、算术运算或其他表达式运算,否则系统将可能⽆法正确使⽤索引。
15、在使⽤索引字段作为条件时,如果该索引是联合索引,那么必须使⽤到该索引中的第⼀个字段作为条件时才能保证系统使⽤该索引,否则该索引将不会被使⽤。
16、如果临时表的数据量较⼤,需要建⽴索引,那么应该将创建临时表和建⽴索引的过程放在单独⼀个⼦存储过程中,这样才能保证系统能够很好的使⽤到该临时表的索引。
17、如果某列存在空值,即使对该列建索引也不会提⾼性能。
SQL语句⽅⾯18、如果是使⽤LIKE进⾏查询的话,简单的使⽤索引是不⾏的,LIKE 'a%' 使⽤索引,LIKE '%a' 不使⽤索引,⽤ LIKE '%a%' 查询时,查询耗时和字段值总长度成正⽐,所以不能⽤CHAR类型,⽽是VARCHAR。
19、查询时不要返回不需要的⾏、列。
20、⼀定要将函数和列名分开。
SQL Server数据库性能优化之SQL语句篇

SQL Server数据库性能优化之SQL语句篇sqlserver数据库性能优化之sql语句篇sqlserver数据库性能优化之sql语句篇(转自重名鸟bolgjava)近期项目须要,搞了一段时间的sqlserver性能优化,碰到了一些问题,也累积了一些经验,现总结一下,与君共享资源。
sqlserver性能优化牵涉至许多方面,例如较好的系统和数据库设计,优质的sql撰写,最合适的数据表索引设计,甚至各种硬件因素:网络性能、服务器的性能、操作系统的性能,甚至网卡、交换机等。
这篇文章主要谈至如何提升sql语句,还将存有另一篇探讨如何提升索引。
如何改善sql语句的一些原则:1.按须要索要字段,跟“select*”说道拜拜字段的提取一定要按照“用多少提多少”的原则,避免使用“select*”这样的操作。
做了这样一个实验,表tbla有1000万数据:selecttop10000c1,c2,c3,c4fromtblaorderbyc1desc--用时:4673毫秒selecttop10000c1,c2,c3fromtblaorderbyc1desc--用时:1376毫秒selecttop10000c1,c2fromtblaorderbyc1desc--用时:80毫秒由此看来,我们每少提取一个字段,数据的提取速度就会有相应的提升。
但提升的速度还要看您舍弃的字段的大小来判断。
另外,关于“select*“的问题,可以参照这篇文章:2.字段名和表名要写规范,注意大小写这一点必须多特别注意,如果大小写弄错的话,虽然sql仍然能够正常继续执行,但数据库系统会花一定的开支和时间先要把您写下的规范成恰当的,然后再继续执行sql。
写下对的话,这个时间就省了。
正常的:selecttop10dtetransaction,txtsystem_idfromtbltransactionsystem不小心的:selecttop10dtetransaction,txtsystem_idfromtbltransactionsystem3.适度采用过渡阶段表中把表的一个子集进行排序并创建临时表,有时能加速查询。
SQLServer数据库sql语句性能优化

SQLServer数据库sql语句性能优化分析⽐较执⾏时间计划读取情况1. 查看执⾏时间和cpuset statistics time onselect * from Bus_DevHistoryDataset statistics time off执⾏后在消息⾥可以看到2. 查看查询对I/O的操作情况set statistics io onselect * from Bus_DevHistoryDataset statistics io off执⾏之后的结果:扫描计数:索引和表执⾏次数逻辑读取:数据缓存中读取的页数物理读取:从磁盘中读取的页数预读:查询过程中,从磁盘放⼊缓存的页数lob逻辑读取:从数据缓存中读取image、text、ntext或⼤型数据的页数lob物理读取:从磁盘中读取image、text、ntext或⼤型数据的页数lob预读:查询过程中,从磁盘放⼊缓存的image、text、ntext或⼤型数据的页数如果物理读取次数和预计次数⽐较多,可以使⽤索引进⾏优化。
上述两种信息的查看如果不想写sql,可以通过设置完成:⼯具->选项3. 查看执⾏计划选中查询语句,点击⼀、数据库设计优化1、不要使⽤游标。
使⽤游标不仅占⽤内存,⽽且还⽤不可思议的⽅式锁定表,它们可以使DBA所能做的⼀切性能优化等于没做。
游标⾥每执⾏⼀次fetch就等于执⾏⼀次select。
2、创建适当的索引每当为⼀个表添加⼀个索引,select会更快,可insert和delete却⼤⼤变慢,因为创建了维护索引需要许多额外的⼯作。
(1)采⽤函数处理的字段不能利⽤索引(2)条件内包括了多个本表的字段运算时不能进⾏索引3、使⽤事务对于⼀些耗时的操作,使⽤事务可以达到很好的优化效果。
4、⼩⼼死锁按照⼀定的次序来访问你的表。
如果你先锁住表A,再锁住表B,那么在所有的存储过程中都要按照这个顺序来锁定它们。
如果某个存储过程先锁定表B,再锁定表A,这可能会导致⼀个死锁。
SQLServer数据库的性能优化

SQLServer数据库的性能优化随着企业数据量不断增长,数据库系统已经成为企业不可或缺的一部分。
随之而来的问题是,在应对海量数据的同时,如何保证数据库系统的高效运行,以满足业务需要。
而数据库性能优化就是为了解决这一问题而存在的。
但是,由于SQLServer数据库系统具有复杂性和高度的可配置性,使得数据库性能优化成为了非常复杂的工作。
如果我们没有足够的知识与技巧,很容易导致不经意间影响数据库系统的正常工作。
本文将介绍SQLServer数据库性能优化的关键点。
1. 容量规划在数据库性能优化的开始阶段,我们需要明确数据库的容量规划,该规划应该包含这些内容:- 确认数据库的大小和增长趋势;- 选择合适的服务器硬件配置;- 选择合适的存储设备和存储配置;- 确认数据库备份和还原方案。
当确认好这些规划后,我们可以愉快地开启数据库系统的优化之旅了。
2. 关注I/O操作I/O操作是数据库性能优化中最重要的因素之一。
在SQLServer 中,我们需要通过以下几点来关注IO操作:- 确认合适的RAID配置;- 选择合适的磁盘类型;- 确认合适的磁盘块大小。
对于I/O操作的优化,我们可以在两个方面进行,一个是硬件方面,另一个则是SQLServer配置。
硬件方面,我们需要考虑到一下几个方面:- 升级服务器硬件设备;- 将磁盘储存设备升级为SSD硬盘;- 增加内存的容量。
对于SQLServer的配置,则可以通过以下几点进行:- 合适的磁盘和RAID配置;- 合适的max degree of parallelism 配置;- 合适的max server memory配;3. 使用合适的索引在SQLServer中,索引的作用是加速数据查询和数据修改,从而提高整个数据库系统的运行效率。
而在使用索引时,我们需要特别注意这些要素:- 创建索引可以减少IO操作;- 索引优化的关键点是选择合适的包含数据条目最多的列;- 在大型多元素表中使用Clustered Index;- 对于包含大量重复元素的列,可以直接采用非聚集索引。
sql server性能的优化

“水可载舟,亦可覆舟”,索引也一样。 索引有助于提高检索性能,但过多或不当 的索引也会导致系统低效。因为用户在表 中每加进一个索引,数据库就要做更多的 工作。过多的索引甚至会导致索引碎片
三.使用数据库分区表
什么是分表区
答:表分区分为水平分区和垂直分区;水平分区将表分为多个表。每个 表包含的列数相同,但是行更少;垂直分区将原始表分成多个只包含 较少列的表;水平分 区是最常用分区方式,后面我们以水平分区来介 绍具体实现方法。
分享内容
利用索引优化查询
使用数据库分区表提高程序检索效率 提高数据库查询效率的实用方法 SQL数据进行排序、分组、统计技巧
SQL Server查询速度慢的原因
1、没有索引或者没有用到索引(这是查询慢最常见的问题) 2、I/O吞吐量小,形成了瓶颈效应。 3、内存不足
4、网络速度慢
5、查询出的数据量过大(可以采用表分区) 6、锁或者死锁(这也是查询慢最常见的问题) 7、返回了不必要的行和列 8、查询语句不好,没有优化 ……
Hale Waihona Puke 二.理解sqlserver索引结构
索引是什么
可以把索引理解为一种特殊的目录。 SQL SERVER提供了两种索引:聚集索 引 (clustered index,也称聚类索引、簇集索引)和非聚集索引(nonclustered index ,也称非聚类索引、非簇集索引)。
举例来说明一下聚集索引和非聚集索引的区别:(汉语字典为例)
2、结合实际,谈索引使用的误区
1、主键就是聚集索引
通常,我们会在每个表中都建立一个ID列,以区分每条数据,并且这个ID列是自动增大的,步长一般1, 把它设为主键,SQL SERVER会将此列默认为聚集索引,这样做有好处,就是可以让您的数据在数据库中 按照ID进行物理排序,但是这样做的意义不大。 从我们前面谈到的聚集索引的定义我们可以看出,使用聚集索引的最大好处就是能够根据查询要求, 迅速缩小查询范围,避免全表扫描。在实际应用中,因为ID号是自动生成的,我们并不知道每条记录的 ID号,所以我们很难在实践中用ID号来进行查询。这就使让ID号这个主键作为聚集索引成为一种资源浪 费。
sql server 常见优化技巧

sql server 常见优化技巧SQL Server 是一种常用的关系型数据库管理系统,用于存储和管理大量结构化数据。
在使用SQL Server 进行开发和维护数据库时,优化技巧是非常重要的,可以提高数据库的性能和效率。
本文将介绍一些常见的SQL Server 优化技巧,帮助开发人员更好地利用和管理数据库。
1. 索引优化索引是提高 SQL 查询性能的重要手段之一。
在 SQL Server 中,可以使用聚集索引和非聚集索引来优化查询。
聚集索引定义了数据的物理排序顺序,而非聚集索引则提供了对聚集索引或表中数据的快速访问。
为频繁查询的列创建适当的索引,可以显著提高查询性能。
2. 查询优化在编写 SQL 查询语句时,可以采用一些技巧来优化查询性能。
例如,避免使用SELECT * 查询所有列,而是只查询需要的列。
此外,可以使用JOIN 语句来优化多表查询,避免使用子查询和临时表等复杂操作。
3. 分区表当数据库中的表数据量非常大时,可以考虑使用分区表来优化查询性能。
通过将表数据分散存储在不同的分区中,可以减少查询的数据量,提高查询速度。
4. 缓存优化SQL Server 会自动缓存查询的执行计划,以便下次查询时可以直接使用缓存中的执行计划。
可以通过监控缓存的命中率来评估缓存的效果,并使用适当的缓存清除策略来优化缓存性能。
5. 锁定优化在多用户并发访问数据库时,锁定机制是确保数据一致性的重要手段。
但是,过多的锁定操作可能导致性能下降。
可以通过使用合适的锁定级别、合理设置事务隔离级别和减少事务的持续时间等方式来优化锁定性能。
6. 存储过程和触发器优化存储过程和触发器是SQL Server 中常用的数据库对象,可以用于封装和执行复杂的业务逻辑。
在使用存储过程和触发器时,可以遵循一些优化原则,如避免使用动态SQL、减少过多的触发器嵌套等,以提高执行效率。
7. 适当使用数据库维护计划SQL Server 提供了一些数据库维护计划,如备份、索引重建、统计信息更新等。
SQLServer性能优化(小总结)SQLServer2000SQLServer2000升华人生

SQLServer性能优化(小总结)SQLServer2000SQLServer2000升华人生1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:select id from t where num is null可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:select id from t where num=03.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
4.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:select id from t where num=10 or num=20可以这样查询:select id from t where num=10union allselect id from t where num=205.in 和 not in 也要慎用,否则会导致全表扫描,如:select id from t where num in(1,2,3)对于连续的数值,能用 between 就不要用 in 了:select id from t where num between 1 and 36.下面的查询也将导致全表扫描:select id from t where name like ‘%abc%‘若要提高效率,可以考虑全文检索。
7.如果在 where 子句中使用参数,也会导致全表扫描。
因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。
然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。
sqlServer优化50种方法

sqlServer优化50种方法查询速度慢的原因很多,常见如下几种:1、没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷)2、I/O吞吐量小,形成了瓶颈效应。
3、没有创建计算列导致查询不优化。
4、内存不足5、网络速度慢6、查询出的数据量过大(可以采用多次查询,其他的方法降低数据量)7、锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷)8、sp_lock,sp_who,活动的用户查看,原因是读写竞争资源。
9、返回了不必要的行和列10、查询语句不好,没有优化可以通过如下方法来优化查询 :1、把数据、日志、索引放到不同的I/O设备上,增加读取速度,以前可以将Tempdb应放在RAID0上,SQL2000不在支持。
数据量(尺寸)越大,提高I/O越重要.2、纵向、横向分割表,减少表的尺寸(sp_spaceuse)3、升级硬件4、根据查询条件,建立索引、优化索引、优化访问方式,限制结果集的数据量。
注意填充因子要适当(最好是使用默认值0)。
索引应该尽量小,使用字节数小的列建索引好(参照索引的创建),不要对有限的几个值的字段建单一索引如性别字段5、提高网速;6、扩大服务器的内存,Windows 2000和SQL server2000能支持4-8G的内存。
配置虚拟内存:虚拟内存大小应基于计算机上并发运行的服务进行配置。
运行 Microsoft SQL Server 2000 时,可考虑将虚拟内存大小设置为计算机中安装的物理内存的1.5 倍。
如果另外安装了全文检索功能,并打算运行Microsoft 搜索服务以便执行全文索引和查询,可考虑:将虚拟内存大小配置为至少是计算机中安装的物理内存的 3 倍。
将 SQL Server max server memory 服务器配置选项配置为物理内存的 1.5 倍(虚拟内存大小设置的一半)。
7、增加服务器CPU个数;但是必须明白并行处理比串行处理更需要资源例如内存。
sqlserver优化思路

sqlserver优化思路SQL Server的优化思路主要涉及以下几个方面:1. 索引优化:通过创建适当的索引,可以显著提高查询性能。
但是,请注意,索引虽然提高了查询速度,但会降低插入、删除和更新操作的速度,因为数据库需要维护索引结构。
因此,索引应谨慎创建,只在必要和常用查询条件的字段上创建索引。
2. 查询优化:优化查询语句是提高SQL Server性能的重要手段。
应尽量避免在查询中使用复杂的函数和计算,这会导致查询优化器无法有效使用索引。
此外,应尽量减少查询中的数据量,只获取必要的字段,而不是使用SELECT 。
3. 数据库设计优化:良好的数据库设计对于性能至关重要。
这包括合理的数据表结构设计、规范化的数据、合适的数据类型和大小、以及合适的数据分区和归档方法。
4. 硬件和配置优化:硬件性能(如CPU、内存和磁盘I/O)对数据库性能有很大影响。
根据工作负载调整SQL Server的配置参数(如最大内存、自动增长设置等)也是必要的。
5. 并发和事务管理:合理地管理并发事务可以避免资源争用和死锁,从而提高系统吞吐量。
这包括使用适当的锁策略、合理地设计事务、以及在必要时使用乐观或悲观锁定。
6. 定期维护:定期进行数据库维护,如更新统计信息、重建索引、清理旧数据等,可以保持数据库的健康状态和最佳性能。
7. 使用适当的工具和技术:SQL Server提供了一些工具和技术,如SQL Server Profiler、Execution Plans、Table Valued Parameters等,可以帮助开发者诊断和优化性能问题。
请注意,优化是一个持续的过程,需要根据工作负载的变化和技术的进步定期进行。
SQLServer的性能优化技巧

SQLServer的性能优化技巧随着IT技术的快速发展,数据库作为系统的核心组成部分,在各行各业的信息化建设中扮演着至关重要的角色。
作为一种重要的关系型数据库管理系统,SQLServer的性能往往直接影响着系统的运行效率和稳定性。
本文将介绍一些SQLServer的性能优化技巧,供读者参考。
一、使用恰当的数据库引擎SQLServer支持多种不同的数据库引擎,如MyISAM、InnoDB 等。
每一种引擎都有自己的特点和适用范围。
在进行数据建模时,要根据应用场景的需要选择最适合的引擎。
一般来说,InnoDB引擎支持事务、外键以及行级锁等特性,适合于对数据完整性要求比较高的系统;而MyISAM引擎则适合于读写比例较低的系统。
选择恰当的数据库引擎可以提高SQLServer的性能。
二、适当调整缓存参数SQLServer有多种缓存,包括查询缓存、表缓存、索引缓存等等。
合理的调整这些缓存参数,可以提高系统的性能。
其中,查询缓存可以减少重复查询的时间,提高响应速度;表缓存可以满足多次使用同样的查询所需的表缓存需求;索引缓存则可以提供快速的查询性能。
在具体的应用中,需要根据场景和需求选择不同的缓存参数,以达到最优的性能表现。
三、使用合适的索引策略索引是SQLServer中非常重要的性能优化策略。
适当的索引可以提高系统的查询速度和效率。
但是,在使用索引时,需要考虑到索引对插入、修改、删除等操作的影响。
如果索引过多,会导致这些操作的性能下降。
因此,必须在保证查询速度和效率的基础上,综合考虑索引对系统整体运行的影响。
四、合理使用分区技术对于大型的数据库系统,分区技术可以将数据划分为多个小段,降低系统的压力和负载,提高系统的处理速度。
在SQLServer中,可以根据表大小或者数据时间等因素进行分区。
通过使用分区技术,可以实现数据存储和查询的快速响应,同时有效地缓解系统的负载压力。
五、使用恰当的查询语句查询语句在SQLServer中起着至关重要的作用。
SQLSERVER的SQL语句优化方式小结

SQLSERVER的SQL语句优化⽅式⼩结1、SQL SERVER 2005的性能⼯具中有SQL Server Profiler和数据库引擎优化顾问,极好的东东,必须熟练使⽤。
2、查询SQL语句时打开“显⽰估计的执⾏计划”,分析每个步骤的情况3、初级做法,在CPU占⽤率⾼的时候,打开SQL Server Profiler运⾏,将跑下来的数据存到⽂件中,然后打开数据库引擎优化顾问调⽤那个⽂件进⾏分析,由SQL SERVER提供索引优化建议。
采纳它的INDEX索引优化部分。
4、但上⾯的做法经常不会跑出你所需要的,在最近的优化过程中CPU占⽤率极⾼,但根本提不出我需要的优化建议,特别是有些语句是在存储过程中并且多表联⽴。
这时就需要⽤中级做法来定位占⽤CPU⾼的语句。
5、还是运⾏SQL Server Profiler,将运⾏结果保存到某个库的新表中(随便起个名字系统会⾃⼰建)。
让它运⾏⼀段时间,然后可以⽤select top 100 * from test where textdata is not null order by duration desc这个可以选出运⾏时间长的语句,在ORDER BY 中可以替换成CPU、READS,来选出CPU占⽤时间长和读数据过多的语句。
定位出问题的语句之后就可以具体分析了。
有些语句在执⾏计划中很明显可以看出问题所在。
常见的有没有建索引或索引建⽴不合理,会出现table scan或index scan,凡是看到SCAN,就意味着会做全表或全索引扫描,这是带来的必然是读次数过多。
我们期望看到的是seek或键查找。
6、怎么看SQL语句执⾏的计划很有讲究,初学者会过于关注⾥⾯显⽰的开销⽐例,⽽实际上这个有时会误导。
我在实际优化过程中就被发现,⼀个index scan的执⾏项开销只占25%,另⼀个键查找的开销占50%,⽽键查找部分根本没有可优化的,SEEK谓词就是ID=XXX这个建⽴在主键上的查找。
sqlserver性能调优常用方法
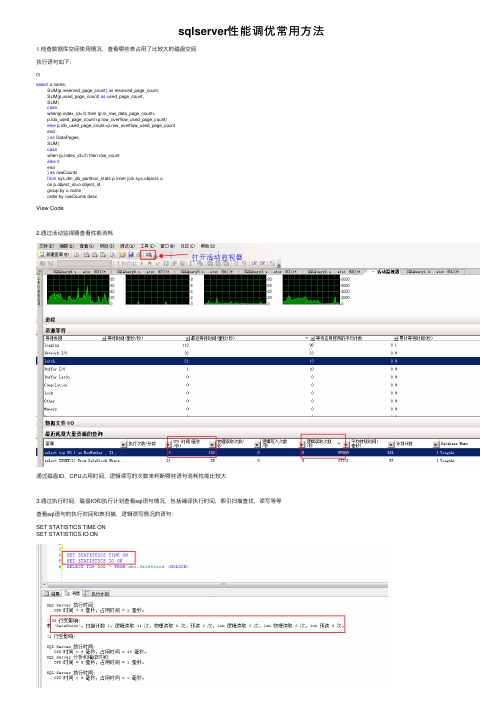
sqlserver性能调优常⽤⽅法1.检查数据库空间使⽤情况,查看哪些表占⽤了⽐较⼤的磁盘空间执⾏语句如下:select ,SUM(p.reserved_page_count) as reserved_page_count,SUM(ed_page_count) as used_page_count,SUM(casewhen(p.index_id<2) then (p.in_row_data_page_count+p.lob_used_page_count+p.row_overflow_used_page_count)else p.lob_used_page_count+p.row_overflow_used_page_countend) as DataPages,SUM(casewhen (p.index_id<2) then row_countelse0end) as rowCountsfrom sys.dm_db_partition_stats p inner join sys.objects oon p.object_id=o.object_idgroup by order by rowCounts descView Code2.通过活动监视器查看性能消耗通过磁盘IO,CPU占⽤时间,逻辑读写的次数来判断哪些语句消耗性能⽐较⼤3.通过执⾏时间,磁盘IO和执⾏计划查看sql语句情况,包括编译执⾏时间,索引扫描查找,读写等等查看sql语句的执⾏时间和表扫描,逻辑读写情况的语句:SET STATISTICS TIME ONSET STATISTICS IO ON预读:在查询计划⽣成的过程中,⽤统计信息去硬盘读取数据到缓存中,读⼀次就是读了⼀页数据物理读:查询计划⽣成好以后,如果缓存缺少所需要的数据,再从硬盘⾥读取缺少的数据到缓存⾥,读⼀次就是读了⼀页数据逻辑读:直接从缓存中读取数据,读⼀次就是读了⼀页数据,可以通过索引减少逻辑读的次数因为物理读需要从硬盘从读取数据,会增加IO读开销,所以尽量减少物理读4.处理内存占⽤过⾼⽅法1.增加服务器内存2.设置sqlserver占⽤服务器内存的⼤⼩3.清空sqlserver占⽤缓存4.查找占⽤内存⽐较⼤的sql语句进⾏优化,这个是主要办法5.重启服务器(清空占有的缓存,关掉线程,但是只能解决⼀时问题)。
SQL Server数据库性能优化

SQL Server数据库性能优化SQL Server 数据库是许多组织和企业中最常用的关系型数据库之一。
它被广泛应用于数据存储和管理,但随着数据库规模和负载的增加,性能问题可能出现。
本文将探讨一些 SQL Server 数据库性能优化的策略,并提供一些建议和实践方法来提高数据库性能。
1. 使用适当的索引:索引是优化查询性能的重要因素之一。
通过为常用的查询添加适当的索引,可以提高查询的速度。
然而,索引的设计需要谨慎考虑。
过多或不必要的索引可能会导致额外的存储和维护开销。
在选择索引列时,经常使用用于过滤、排序和连接的列,并避免在频繁更新的列上创建索引。
2. 慎重使用数据库范围的约束:数据库的完整性约束如主键、外键和唯一约束是必要的,但过多或复杂的约束可能会影响性能。
当插入大量数据时,暂时禁用约束可以提高性能,之后再重新启用。
3. 使用合理的数据类型:选择正确的数据类型对于提高数据库的存储效率和查询性能至关重要。
使用合理的数据类型可以节省存储空间,并减少磁盘 I/O 操作的次数。
4. 对查询语句进行优化:优化查询语句是提高数据库性能的重点。
确保使用正确的查询语法,避免在WHERE 子句中进行非索引列的计算,避免重复计算和不必要的 JOIN 操作。
使用EXPLAIN 等工具来分析和调试查询计划,并根据需要更改查询策略。
5. 定期进行数据库维护:进行定期的数据库维护活动可以帮助提高性能。
这包括索引重建、数据库压缩、统计信息更新和日志清理等操作。
定期的数据库备份和恢复测试也是数据库性能优化的重要组成部分。
6. 有效管理数据库日志文件:SQL Server 使用事务日志(或事务日志文件)来记录数据库中发生的更改。
大型事务日志文件可能导致性能下降。
通过定期备份、压缩和定期清理事务日志文件,可以最大程度地减少数据库维护操作对性能的影响。
7. 并行处理和资源管理:将适当的操作并发处理可以提高查询性能。
有效管理系统资源,如 CPU、内存和磁盘 I/O,可以防止资源竞争和瓶颈。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Sqlserver SQL性能优化经验1.选择最有效率的表名顺序(只在基于规则的优化器中有效)SQLSERVER的解析器按照从右到左的顺序处理FROM子句中的表名,因此FROM子句中写在最后的表(基础表driving table)将被最先处理,在FROM子句中包含多个表的情况下,必须选择记录条数最少的表作为基础表,当SQLSERVER处理多个表时,会运用排序及合并的方式连接它们,首先,扫描第一个表(FROM子句中最后的那个表)并对记录进行排序;然后扫描第二个表(FROM子句中最后第二个表);最后将所有从第二个表中检索出的记录与第一个表中合适记录进行合并例如: 表TAB1 16,384 条记录表TAB2 5 条记录,选择TAB2作为基础表(最好的方法) select count(*) from tab1,tab2 执行时间0.96秒,选择TAB2作为基础表(不佳的方法) select count(*) from tab2,tab1 执行时间26.09秒;如果有3个以上的表连接查询,那就需要选择交叉表(intersection table)作为基础表,交叉表是指那个被其他表所引用的表例如:EMP表描述了LOCATION表和CATEGORY表的交集SELECT *FROM LOCATION L,CATEGORY C,EMP EWHERE E.EMP_NO BETWEEN 1000 AND 2000AND E.CAT_NO = C.CAT_NOAND E.LOCN = L.LOCN将比下列SQL更有效率SELECT *FROM EMP E ,LOCATION L ,CATEGORY CWHERE E.CAT_NO = C.CAT_NOAND E.LOCN = L.LOCNAND E.EMP_NO BETWEEN 1000 AND 20002.WHERE子句中的连接顺序SQLSERVER采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前,那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾例如:(低效,执行时间156.3秒)SELECT *FROM EMP EWHERE SAL > 50000AND JOB = ’MANAGER’AND 25 < (SELECT COUNT(*) FROM EMP WHERE MGR=E.EMPNO);(高效,执行时间10.6秒)SELECT *FROM EMP EWHERE 25 < (SELECT COUNT(*) FROM EMP WHERE MGR=E.EMPNO)AND SAL > 50000AND JOB = ’MANAGER’;3.SELECT子句中避免使用’*’。
当你想在SELECT子句中列出所有的COLUMN时,使用动态SQL列引用’*’是一个方便的方法,不幸的是,这是一个非常低效的方法。
实际上,SQLSERVER在解析的过程中,会将’*’依次转换成所有的列名,这个工作是通过查询数据字典完成的,这意味着将耗费更多的时间4.减少访问数据库的次数。
当执行每条SQL语句时,SQLSERVER在内部执行了许多工作:解析SQL语句,估算索引的利用率,绑定变量,读数据块等等由此可见,减少访问数据库的次数,就能实际上减少SQLSERVER的工作量,例如:以下有三种方法可以检索出雇员号等于0342或0291的职员方法1 (最低效)SELECT EMP_NAME, SALARY, GRADEFROM EMPWHERE EMP_NO = 342;SELECT EMP_NAME, SALARY, GRADEFROM EMPWHERE EMP_NO = 291;方法2 (次低效)DECLARECURSOR C1 (E_NO NUMBER) ISSELECT EMP_NAME,SALARY,GRADEFROM EMPWHERE EMP_NO = E_NO;BEGINOPEN C1(342);FETCH C1 INTO …,…,…;…OPEN C1(291);FETCH C1 INTO …,…,…;…CLOSE C1;END;方法2 (高效)SELECT A.EMP_NAME, A.SALARY, A.GRADE,B.EMP_NAME, B.SALARY, B.GRADEFROM EMP A, EMP BWHERE A.EMP_NO = 342AND B.EMP_NO = 291;5.使用DECODE函数来减少处理时间使用DECODE函数可以避免重复扫描相同记录或重复连接相同的表例如:SELECT COUNT(*), SUM(SAL)FROM EMPWHERE DEPT_NO = ’0020’AND ENAME LIKE ’SMITH%’;SELECT COUNT(*), SUM(SAL)FROM EMPWHERE DEPT_NO = ’0030’AND ENAME LIKE ’SMITH%’;你可以用DECODE函数高效地得到相同结果SELECT COUNT(DECODE(DEPT_NO, ’0020’, ’X’, NULL)) D0020_COUNT,COUNT(DECODE(DEPT_NO, ’0030’, ’X’, NULL)) D0030_COUNT,SUM(DECODE(DEPT_NO, ’0020’, SAL, NULL)) D0020_SAL,SUM(DECODE(DEPT_NO, 0030, SAL, NULL)) D0030_SALFROM EMPWHERE ENAME LIKE ’SMITH%’;’X’表示任何一个字段类似的,DECODE函数也可以运用于GROUP BY和ORDER BY子句中6.用Where子句替换HAVING子句避免使用HAVING子句,HAVING只会在检索出所有记录之后才对结果集进行过滤,这个处理需要排序、统计等操作如果能通过WHERE子句限制记录的数目,那就能减少这方面的开销例如:低效SELECT REGION, AVG(LOG_SIZE)FROM LOCATIONGROUP BY REGIONHAVING REGION REGION != ’SYDNEY’AND REGION != ’PERTH’高效SELECT REGION, AVG(LOG_SIZE)FROM LOCATIONWHERE REGION REGION != ’SYDNEY’AND REGION != ’PERTH’GROUP BY REGION7.减少对表的查询在含有子查询的SQL语句中,要特别注意减少对表的查询例如:低效SELECT TAB_NAMEFROM TABLESWHERE TAB_NAME = (SELECT TAB_NAMEFROM TAB_COLUMNSWHERE VERSION = 604)AND DB_VER = (SELECT DB_VERFROM TAB_COLUMNSWHERE VERSION = 604)高效SELECT TAB_NAMEFROM TABLESWHERE (TAB_NAME, DB_VER) = (SELECT TAB_NAME, DB_VERFROM TAB_COLUMNSWHERE VERSION = 604)Update多个Column例子:低效UPDATE EMPSET EMP_CAT = (SELECT MAX(CATEGORY)FROM EMP_CATEGORIES),SAL_RANGE = (SELECT MAX(SAL_RANGE)FROM EMP_CATEGORIES)WHERE EMP_DEPT = 0020;高效UPDATE EMPSET (EMP_CAT, SAL_RANGE) = (SELECT MAX(CATEGORY), MAX(SAL_RANGE)FROM EMP_CATEGORIES)WHERE EMP_DEPT = 0020;8.使用表的别名(Alias),当在SQL语句中连接多个表时,请使用表的别名并把别名前缀于每个Column上,这样可以减少解析的时间并减少那些由Column歧义引起的语法错误9.用EXISTS替代IN在许多基于基础表的查询中,为了满足一个条件,往往需要对另一个表进行联接在这种情况下,使用EXISTS(或NOT EXISTS)通常将提高查询的效率低效SELECT *FROM EMP (基础表)WHERE EMPNO > 0AND DEPTNO IN (SELECT DEPTNOFROM DEPTWHERE LOC = ’MELB’)高效SELECT *FROM EMP (基础表)WHERE EMPNO > 0AND EXISTS (SELECT ’X’FROM DEPTWHERE DEPT.DEPTNO = EMP.DEPTNOAND LOC = ’MELB’)10.用NOT EXISTS替代NOT IN在子查询中,NOT IN子句将执行一个内部的排序和合并无论在哪种情况下,NOT IN都是最低效的,因为它对子查询中的表执行了一个全表遍历为了避免使用NOT IN,我们可以把它改写成外连接(Outer Joins)或NOT EXISTS例如:SELECT …FROM EMPWHERE DEPT_NO NOT IN (SELECT DEPT_NOFROM DEPTWHERE DEPT_CAT = ’A’);为了提高效率改写为高效SELECT …FROM EMP A, DEPT BWHERE A.DEPT_NO = B.DEPT(+)AND B.DEPT_NO IS NULLAND B.DEPT_CAT(+) = ’A’最高效SELECT …FROM EMP EWHERE NOT EXISTS (SELECT ’X’FROM DEPT DWHERE D.DEPT_NO = E.DEPT_NOAND DEPT_CAT = ’A’);11.用表连接替换EXISTS通常来说,采用表连接的方式比EXISTS更有效率例如:SELECT ENAMEFROM EMP EWHERE EXISTS (SELECT ’X’FROM DEPTWHERE DEPT_NO = E.DEPT_NOAND DEPT_CAT = ’A’);更高效SELECT ENAMEFROM DEPT D, EMP EWHERE E.DEPT_NO = D.DEPT_NOAND DEPT_CAT = ’A’;12.用EXISTS替换DISTINCT当提交一个包含多表信息(比如部门表和雇员表)的查询时,避免在SELECT子句中使用DISTINCT,一般可以考虑用EXIST替换例如:低效SELECT DISTINCT DEPT_NO, DEPT_NAMEFROM DEPT D, EMP EWHERE D.DEPT_NO = E.DEPT_NO高效SELECT DEPT_NO, DEPT_NAMEFROM DEPT DWHERE EXISTS (SELECT ’X’FROM EMP EWHERE E.DEPT_NO = D.DEPT_NO);EXISTS使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立刻返回结果13.用索引提高效率索引是表的一个概念部分,用来提高检索数据的效率。