VC中Unicode字符串的处理
c语言中去掉字符串中的重音符号和变音符号的方法

文章主题:C语言中去掉字符串中的重音符号和变音符号的方法在C语言中,处理文本是一个常见的任务。
而在处理文本的过程中,有时会遇到需要去掉字符串中的重音符号和变音符号的情况。
这些符号通常是为了表示特定的发音或语调,但在某些情况下,我们可能希望将字符串中的这些符号去掉,以便更方便地处理和比较文本。
现在,让我们来探讨一下在C语言中去掉字符串中的重音符号和变音符号的方法。
在这篇文章中,我将向你介绍几种不同的方法,以及它们各自的优缺点。
通过本文的阅读,你将能够全面、深入地理解这个主题,并为在实际项目中处理文本时做出更明智的决策。
1. 使用iconv库函数在C语言中,可以使用iconv库函数来进行字符编码的转换。
这些函数可以将字符串从一种字符编码转换为另一种字符编码,其中就包括了去掉重音符号和变音符号的操作。
通过使用iconv库函数,我们可以很方便地实现对字符串中特定字符的转换或去除。
然而,使用iconv库函数也存在一些缺点。
iconv函数的使用方式相对复杂,需要对字符编码有一定的了解才能够正确操作。
iconv库函数是一个比较底层的操作,需要开发者自行处理一些细节,可能会增加代码的复杂性和出错的可能性。
2. 使用strchr和strcpy函数另一种常见的方法是使用C语言标准库中的strchr和strcpy函数。
通过这两个函数的结合,我们可以在字符串中逐个查找需要去除的字符,并将剩余的部分逐个复制到新的字符串中。
这样一来,就能够去掉字符串中的重音符号和变音符号。
与使用iconv库函数相比,这种方法的优点在于简单易懂,不需要对字符编码有深入的了解。
但这种方法的缺点也是显而易见的,即复制大量字符可能会导致性能上的损失,尤其是对于长字符串的处理。
3. 使用正则表达式正则表达式是一种强大的文本匹配工具,可以用来查找和替换字符串中的特定模式。
在C语言中,我们可以使用POSIX标准库中的regex 函数来进行正则表达式的操作。
VC中Ansi、Unicode、UTF8字符串之间的转换和写入文本

//同上,分配空间要给'\0'留个空间
//UTF8虽然是Unicode的压缩形式,但也是多字节字符串,所以可以以char的形式保存
{
// ansi to unicode
char* szAnsi = "abcd1234你我他";
//预转换,得到所需空间的大小
int wcsLen = ::MultiByteToWideChar(CP_ACP, NULL, szAnsi, strlen(szAnsi), NULL, 0);
::MessageBoxW(GetSafeHwnd(), wszString, wszString, MB_OK);
//写文本同ansi to unicode
}
Ansi转换utf8和utf8转换Ansi就是上面2个的结合,把unicode作为中间量,进行2次转换即可
//最后加上'\0'
szAnsi[ansiLen] = '\0';
//Ansi版的MessageBox API
::MessageBoxA(GetSafeHwnd(), szAnsi, szAnsi, MB_OK);
//接下来写入文本
//写文本文件,ANSI文件没有BOM
VC中Ansi、Unicode、UTF8字符串之间的转换和写入文本
Ansi字符串我们最熟悉,英文占一个字节,汉字2个字节,以一个\0结尾,常用于txt文本文件
VC中实现GB2312、BIG5、Unicode编码转换的方法

VC中实现GB2312、BIG5、Unicode编码转换的⽅法本⽂主要以实例形式讨论了VC编译环境下,实现字符串和⽂件编码⽅式转换的⽅法,在linux下请使⽤Strconv来实现。
具体⽅法如下:⼀、⽂件编码格式转换//GB2312 编码⽂件转换成 Unicode:if((file_handle = fopen(filenam,"rb")) != NULL){//从GB2312源⽂件以⼆进制的⽅式读取buffernumread = fread(str_buf_pool,sizeof(char),POOL_BUFF_SIZE,file_handle);fclose(file_handle);//GB2312⽂件buffer转换成UNICODEnLen =MultiByteToWideChar(CP_ACP,0,str_buf_pool,-1,NULL,0);MultiByteToWideChar(CP_ACP,0,str_buf_pool,-1,(LPWSTR)str_unicode_buf_pool,nLen);//组装UNICODE Little Endian编码⽂件⽂件头标⽰符"0xFF 0xFE"//备注:UNICODE Big Endian编码⽂件⽂件头标⽰符"0xFF 0xFE"//Little Endian与Big Endian编码差异此处不详述unicode_little_file_header[0]=0xFF;unicode_little_file_header[1]=0xFE;//存储⽬标⽂件if((file_handle=fopen(filenewname,"wb+")) != NULL){fwrite(unicode_little_file_header,sizeof(char),2,file_handle);numwrite = fwrite(str_unicode_buf_pool,sizeof(LPWSTR),nLen,file_handle);fclose(file_handle);}}⼆、字符串编码格式转换//GB2312 转换成 Unicode:wchar_t* GB2312ToUnicode(const char* szGBString){UINT nCodePage = 936; //GB2312int nLength=MultiByteToWideChar(nCodePage,0,szGBString,-1,NULL,0);wchar_t* pBuffer = new wchar_t[nLength+1];MultiByteToWideChar(nCodePage,0,szGBString,-1,pBuffer,nLength);pBuffer[nLength]=0;return pBuffer;}//BIG5 转换成 Unicode:wchar_t* BIG5ToUnicode(const char* szBIG5String){UINT nCodePage = 950; //BIG5int nLength=MultiByteToWideChar(nCodePage,0,szBIG5String,-1,NULL,0);wchar_t* pBuffer = new wchar_t[nLength+1];MultiByteToWideChar(nCodePage,0,szBIG5String,-1,pBuffer,nLength);pBuffer[nLength]=0;return pBuffer;}//Unicode 转换成 GB2312:char* UnicodeToGB2312(const wchar_t* szUnicodeString){UINT nCodePage = 936; //GB2312int nLength=WideCharToMultiByte(nCodePage,0,szUnicodeString,-1,NULL,0,NULL,NULL);char* pBuffer=new char[nLength+1];WideCharToMultiByte(nCodePage,0,szUnicodeString,-1,pBuffer,nLength,NULL,NULL);pBuffer[nLength]=0;return pBuffer;}//Unicode 转换成 BIG5:char* UnicodeToBIG5(const wchar_t* szUnicodeString){UINT nCodePage = 950; //BIG5int nLength=WideCharToMultiByte(nCodePage,0,szUnicodeString,-1,NULL,0,NULL,NULL);char* pBuffer=new char[nLength+1];WideCharToMultiByte(nCodePage,0,szUnicodeString,-1,pBuffer,nLength,NULL,NULL);pBuffer[nLength]=0;return pBuffer;}//繁体中⽂BIG5 转换成简体中⽂ GB2312char* BIG5ToGB2312(const char* szBIG5String){LCID lcid = MAKELCID(MAKELANGID(LANG_CHINESE,SUBLANG_CHINESE_SIMPLIFIED),SORT_CHINESE_PRC);wchar_t* szUnicodeBuff = BIG5ToUnicode(szBIG5String);char* szGB2312Buff = UnicodeToGB2312(szUnicodeBuff);int nLength = LCMapString(lcid,LCMAP_SIMPLIFIED_CHINESE, szGB2312Buff,-1,NULL,0);char* pBuffer = new char[nLength + 1];LCMapString(0x0804,LCMAP_SIMPLIFIED_CHINESE,szGB2312Buff,-1,pBuffer,nLength);pBuffer[nLength] = 0;delete[] szUnicodeBuff;delete[] szGB2312Buff;return pBuffer;}//简体中⽂ GB2312 转换成繁体中⽂BIG5char* GB2312ToBIG5(const char* szGBString){LCID lcid = MAKELCID(MAKELANGID(LANG_CHINESE,SUBLANG_CHINESE_SIMPLIFIED),SORT_CHINESE_PRC);int nLength = LCMapString(lcid,LCMAP_TRADITIONAL_CHINESE,szGBString,-1,NULL,0);char* pBuffer=new char[nLength+1];LCMapString(lcid,LCMAP_TRADITIONAL_CHINESE,szGBString,-1,pBuffer,nLength);pBuffer[nLength]=0;wchar_t* pUnicodeBuff = GB2312ToUnicode(pBuffer);char* pBIG5Buff = UnicodeToBIG5(pUnicodeBuff);delete[] pBuffer;delete[] pUnicodeBuff;return pBIG5Buff;}三、API 函数:MultiByteToWideChar参数说明第⼀个参数为代码页, ⽤ GetLocaleInfo 函数获取当前系统的代码页,936: 简体中⽂, 950: 繁体中⽂第⼆个参数为选项,⼀般⽤ 0 就可以了第三个参数为 ANSI 字符串的地址, 这个字符串是第⼀个参数指定的语⾔的 ANSI 字符串 (AnsiString)第四个参数为 ANSI 字符串的长度,如果⽤ -1, 就表⽰是⽤ 0 作为结束符的字符串第五个参数为转化⽣成的 unicode 字符串 (WideString) 的地址, 如果为 NULL, 就是代表计算⽣成的字符串的长度第六个参数为转化⽣成的 unicode 字符串缓存的容量,也就是有多少个UNICODE字符。
VC++中的char wchar_T和TCHAR

大家一起做一个项目,经常发现有的人爱用strcpy等标准ANSI函数,有的人爱用_tXXXX 函数,这个问题曾经搞的很混乱。
为了统一,有必要把来龙去脉搞清楚。
为了搞清这些函数,就必须理请几种字符类型的写法。
char就不用说了,先说一些wchar_t。
wchar_t是Unicode字符的数据类型,它实际定义在<string.h>里:typedef unsigned short wchar_t;不能使用类似strcpy这样的ANSI C字符串函数来处理wchar_t字符串,必须使用wcs前缀的函数,例如wcscpy。
为了让编译器识别Unicode字符串,必须以在前面加一个“L”,例如:wchar_t *szTest=L"This is a Unicode string.";下面在看看TCHAR。
如果你希望同时为ANSI和Unicode编译的源代码,那就要include TChar.h。
TCHAR是定义在其中的一个宏,它视你是否定义了_UNICODE宏而定义成char 或者wchar_t。
如果你使用了TCHAR,那么就不应该使用ANSI的strXXX函数或者Unicode 的wcsXXX函数了,而必须使用TChar.h中定义的_tcsXXX函数。
另外,为了解决刚才提到带“L”的问题,TChar.h中定义了一个宏:“_TEXT”。
以strcpy函数为例子,总结一下:.如果你想使用ANSI字符串,那么请使用这一套写法:char szString[100];strcpy(szString,"test");.如果你想使用Unicode字符串,那么请使用这一套:wchar_t szString[100];wcscpyszString,L"test");.如果你想通过定义_UNICODE宏,而编译ANSI或者Unicode字符串代码:TCHAR szString[100];_tcscpy(szString,_TEXT("test"));2.字符串及处理之三: 使用TCHAR系列方案使用TCHAR系列方案编写程序TCHAR是一种字符串类型,它让你在以MBCS和UNNICODE来build程序时可以使用同样的代码,不需要使用繁琐的宏定义来包含你的代码。
如何处理代码中的 Unicode 编码问题

如何处理代码中的 Unicode 编码问题在编程中,处理Unicode编码问题是一个非常重要的技能。
Unicode编码是一种用来表示世界上所有语言字符的标准编码方式,它可以避免在不同的编程环境中出现乱码问题。
本文将介绍如何处理代码中的Unicode编码问题,包括Unicode编码的基本知识、在不同编程语言中处理Unicode编码的方法,以及常见的Unicode编码问题及解决方法。
一、Unicode编码的基本知识Unicode编码是一种全球通用的字符编码标准,它可以表示世界上所有的语言字符,包括ASCII字符以及各种语言的特殊字符。
Unicode 编码采用多字节编码方式,每个字符对应一个或多个字节,这样就可以表示更多的字符,避免了以前使用的ASCII编码的限制。
在Unicode编码中,不同的字符对应不同的编码值,这些编码值可以直接用来表示字符,而不需要像ASCII编码一样限制在127个字符范围内。
Unicode编码采用16位或32位的编码方式,可以表示2^16或2^32个字符,这样就可以满足不同语言字符的表示需求。
二、在不同编程语言中处理Unicode编码的方法1. Python中处理Unicode编码Python是一种非常流行的编程语言,它天生支持Unicode编码,在Python中处理Unicode编码非常简单。
在Python 2.x版本中,字符串默认使用ASCII编码,需要在字符串前加上u前缀表示Unicode 编码;而在Python 3.x版本中,默认使用Unicode编码,不需要加前缀表示。
在Python中,可以使用encode()和decode()方法来进行Unicode 编码和解码操作,也可以使用unicode和str类型来表示Unicode字符串和字节串。
在处理文件读写时,可以使用codecs模块来设置文件的编码格式,这样就可以避免文件读写时出现的Unicode编码问题。
2. Java中处理Unicode编码Java是一种非常流行的编程语言,它也天生支持Unicode编码。
用VC++编程实现转换文本文件的字符编码

用 记 事 本 打 开 时 将 会 显 示 乱 码 , 将 设 置 改 为 C iee (R ) hn s P C 就可 正 常显 示 。 由于 U i d nc e是 国 际 通 用 的 宽 字 节 字 符 集 , o 所 以用 U i d n o e编 码 的 文 本 文 件 不 受 此 处 设 置 的影 响 , 都 可 c
件 从 一 种 字 符 编 码转 为 由另 一 种 字 符 编 码 来 存 储 .一 般 使 用 查 表 映射 的 方 式 。 在 Wi o s系列 操 作 系 统 中 ,使 用 V + 编 程 n w d C+ 时 ,这 种 字 符 映射 不 需 要 由程 序 员 来 编 写 , 可 以使 用 Widw no s
96 ( B 字符 集 ) 中 国台湾地 区使用代 码 化 大 全 的 程 序界 面
符 集 ) 程 序 启 动 时 . 自动 将 多 字 节 代 码 页设 置 为 操 作 系 统 。 默 认 的 代 码 页 。 运 行 库 中 大 多 数 多 字 节 字 符 函 数 的 行 为 , 与 当前 多 字 节 代 码 页设 置 有 关 。 比如 记 事 本 程 序 (o pdee nt a . ) e x 在 打 开 一 个 A S 编 码 的 文 本 时 ,会 根 据 操 作 系 统 的 中 的 设 NI
节 省 存 储 空 间 、提 高处 理 速 度 ,一 些 国家 和 地 区为 文 字 制 定 了 相 应 的字 符 集 ,有 的 一 种文 字 存 在 多种 字 符 集 。字 符 集 可 以 以 表 格 形 式 描 述 为 字 符 到单 字 节值 或 多 字节 值 的 映射 。 A C I S I码
Unicode和UTF-8之间的转换

Unicode和UTF-8之间的转换⼀、引⾔通过这⼏天的研究,终于明⽩了Unicode和UTF-8之间编码的区别。
Unicode是⼀个字符集,⽽UTF-8是Unicode的其中⼀种,Unicode是定长的都为双字节,⽽UTF-8是可变的,对于汉字来说Unicode占有的字节⽐UTF-8占⽤的字节少1个字节。
Unicode为双字节,⽽UTF-8中汉字占三个字节。
注: Unicode编码⽬前规划的总空间是17个平⾯,0x0000 ⾄ 0x10FFFF。
每个平⾯有 65536 个码点。
因此这个总的长度也有⼀百多万个。
⼆、UTF-8 UTF-8编码字符理论上可以最多到6个字节长,然⽽16位BMP(Basic Multilingual Plane)字符最多只⽤到3字节长。
下⾯看⼀下UTF-8编码表:1 U-00000000 - U-0000007F: 0xxxxxxx23 U-00000080 - U-000007FF: 110xxxxx 10xxxxxx45 U-00000800 - U-0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx67 U-00010000 - U-001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx89 U-00200000 - U-03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx1011 U-04000000 - U-7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx xxx 的位置由字符编码数的⼆进制表⽰的位填⼊,越靠右的 x 具有越少的特殊意义,只⽤最短的那个⾜够表达⼀个字符编码数的多字节串。
注意在多字节串中,第⼀个字节的开头"1"的数⽬就是整个串中字节的数⽬。
VC2010中初学者常见错误、警告和问题

《Visual C++ 2010入门教程》系列四:VC2010中初学者常见错误、警告和问题这一章将帮助大家解释一些常见的错误、警告和问题,帮助大家去理解和解决一些常见问题,并了解它的根本原因。
iostream.h与<iostream>下面的代码为什么在VC2010下面编译不过去?#include <iostream.h>int main(){cout<<"Hello World."<<endl;return 0;}错误信息:fatal error C1083: 无法打开包括文件:“iostream.h”: No such file or directory造成这个错误的原因在于历史原因,在过去C++98标准尚未订立的时候,C++的标准输入输出流确实是定义在这个文件里面的,这是C风格的定义方法,随着C++98标准的确定,iostream.h已经被取消,至少在VC2010下面是这样的,取而代之的是我们要用<iostream>头文件来代替,你甚至可以认为<iostream>是这样定义的:namespace std{#include "iostream.h"}因此我们可以简单的修改我们的Hello World。
#include <iostream>using namespace std;int main(){cout<<"Hello World."<<endl;return 0;}iostream.h是属于C++的头文件,而非C的,因此标准订立的时候被改成了<iostream>。
而C的头文件stdio.h等依然可以继续使用,这是为了兼容C代码。
但是它们依然有对应的C++版本,如<cstdio> <cstdlib>等。
常见的VC获取字符串长度的方法

常见的VC获取字符串长度的方法字符串的长度通常是指字符串中包含字符的数目,但有的时候人们需要的是字符串所占字节的数目。
常见的获取字符串长度的方法包括如下几种。
后面有源码和最终效果图1.使用sizeof获取字符串长度sizeof的含义很明确,它用以获取字符数组的字节数(当然包括结束符0)。
对于ANSI字符串和UNICODE字符串,形式如下:sizeof(cs)/sizeof(char) sizeof(ws)/sizeof(wchar_t) 可以采用类似的方式,获取到其字符的数目。
如果遇到MBCS,如"中文ABC",很显然,这种办法就无法奏效了,因为sizeof()并不知道哪个char是半个字符。
2.使用strlen()获取字符串长度strlen()及wcslen()是标准C++定义的函数,它们分别获取ASCII字符串及宽字符串的长度,如:size_t strlen( const char *string ); size_t wcslen( const wchar_t *string ); strlen()与wcslen()采取0作为字符串的结束符,并返回不包括0在内的字符数目。
3.使用CString::GetLength()获取字符串长度CStringT继承于CSimpleStringT类,该类具有函数:int GetLength( ) const throw( ); GetLength()返回字符而非字节的数目。
比如:CStringW中,"中文ABC"的GetLength()会返回5,而非10。
那么对于MBCS呢?同样,它也只能将一个字节当做一个字符,CStringA表示的"中文ABC"的GetLength()则会返回7。
4.使用std::string::size()获取字符串长度basic_string同样具有获取大小的函数:size_type length( ) const; size_type size( ) const; length()和size()的功能完全一样,它们仅仅返回字符而非字节的个数。
C语言:ASCII编码与Unicode编码

C语言:ASCII编码与Unicode编码C语言:ASCII编码与Unicode编码我们知道编程的语言种类比较多,每一个种类中还会细分框架与知识点,那么,ASCII编码与Unicode编码你了解吗?欢迎大家阅读!更多相关信息请关注相关栏目!计算机是以二进制的形式来存储数据的,它只认识0和1两个数字,我们在屏幕上看到的文字,在存储到内存之前也都被转换成了二进制(0和1序列)。
可想而知,特定的文字必然对应着固定的二进制,否则将无法转换。
那么,怎样将文字与二进制对应呢?这就需要有一套规范,计算机公司和软件开发者都必须遵守。
ASCII码我们知道,一个二进制位(Bit)有0、1两种状态,一个字节(Byte)有8个二进制位,有256种状态,每种状态对应一个符号,就是256个符号,从00000000到11111111。
计算机诞生于美国,早期的计算机使用者大多使用英文,上世纪60年代,美国制定了一套英文字符与二进制位的对应关系,称为ASCII码,沿用至今。
ASCII码规定了128个英文字符与二进制的对应关系,占用一个字节(实际上只占用了一个字节的后面7位,最前面1位统一规定为0)。
例如,字母 a 的的ASCII码为 01100001,那么你暂时可以理解为字母 a 存储到内存之前会被转换为01100001,读取时遇到01100001 也会转换为 a。
Unicode编码随着计算机的流行,使用计算机的人越来越多,不仅限于美国,整个世界都在使用,这个时候ASCII编码的问题就凸现出来了。
ASCII编码只占用1个字节,最多只能表示256个字符,我大中华区10万汉字怎么表示,日语韩语拉丁语怎么表示?所以90年代又制定了一套新的规范,将全世界范围内的字符统一使用一种方式在计算机中表示,这就是Unicode编码(Unique Code),也称统一码、万国码。
Unicode 是一个很大的集合,现在的'规模可以容纳100多万个符号,每个符号的对应的二进制都不一样。
Unicode下CString与char_转换

Unicode下CString与char *转换在Visual C++.NET2005中,默认的字符集形式是Unicode,但在VC6.0等工程中,默认的字符集形式是多字节字符集(MBCS:Multi-Byte Character Set),这样导致在VC6.0中非常简单实用的各类字符操作和函数在VS2005环境下运行时会报各种各样的错误,这里总结了在Visual C++.NET2005环境中Unicode字符集下CString和char *之间相互转换的几种方法,其实也就是Unicode字符集与MBCS字符集转换。
(1)、Unicode下CString转换为char *方法一:使用API:WideCharToMultiByte进行转换CString str = _T("D:\\校内项目\\QQ.bmp");//注意:以下n和len的值大小不同,n是按字符计算的,len是按字节计算的int n = str.GetLength(); // n = 14, len = 18//获取宽字节字符的大小,大小是按字节计算的int len = WideCharToMultiByte(CP_ACP,0,str,str.GetLength(),NULL,0,NULL,NULL);//为多字节字符数组申请空间,数组大小为按字节计算的宽字节字节大小char * pFileName = new char[len+1]; //以字节为单位//宽字节编码转换成多字节编码WideCharToMultiByte(CP_ACP,0,str,str.GetLength(),pFileName,len,NULL,NULL);pFileName[len+1] = '\0'; //多字节字符以'\0'结束方法二:使用函数:T2A、W2ACString str = _T("D:\\校内项目\\QQ.bmp");//声明标识符USES_CONVERSION;//调用函数,T2A和W2A均支持ATL和MFC中的字符转换char * pFileName = T2A(str);//char * pFileName = W2A(str); //也可实现转换注意:有时候可能还需要添加引用#include <afxpriv.h>(2)、Unicode下char *转换为CString方法一:使用API:MultiByteToWideChar进行转换char * pFileName = "D:\\校内项目\\QQ.bmp";//计算char *数组大小,以字节为单位,一个汉字占两个字节int charLen = strlen(pFileName);//计算多字节字符的大小,按字符计算。
VC++中数据类型转换大全

vc数据类型转换大全(转载)int i = 100;long l = 2001;float f=300.2;double d=12345.119;char username[]=”程佩君”;char temp[200];char *buf;CString str;_variant_t v1;_bstr_t v2;一、其它数据类型转换为字符串短整型(int)itoa(i,temp,10);///将i转换为字符串放入temp中,最后一个数字表示十进制itoa(i,temp,2); ///按二进制方式转换长整型(long)ltoa(l,temp,10);浮点数(float,double)用fcvt可以完成转换,这是MSDN中的例子:int decimal, sign;char *buffer;double source = 3.1415926535;buffer = _fcvt( source, 7, &decimal, &sign );运行结果:source: 3.1415926535 buffer: ‘31415927′ decimal: 1 sign: 0decimal表示小数点的位置,sign表示符号:0为正数,1为负数CString变量str = “2008北京奥运”;buf = (LPSTR)(LPCTSTR)str; //这个因为buf是个char*变量先把CString 变量转换为const char*类型的再变为char*类型的上面的CString转换为char*型号的必须经过两次反之的直接赋值就可以BSTR变量BSTR bstrValue = ::SysAllocStri ng(L”程序员”);char * buf = _com_util::ConvertBSTRToString(bstrValue); SysFreeString(bstrValue);一定注意凡是定义的指针变量一定要用delete显示删除AfxMessageBox(buf);delete(buf);CComBSTR变量CComBSTR bstrVar(”test”);char *buf = _com_util::ConvertBSTRToString(bstrVar.m_str); AfxMessageBox(buf);delete(buf);_bstr_t变量_bstr_t类型是对BSTR的封装,因为已经重载了=操作符,所以很容易使用_bstr_t bstrVar(”test”);const char *buf = bstrVar;///不要修改buf中的内容_bstr_t实际上是个字符指针型的AfxMessageBox(buf);通用方法(针对非COM数据类型)用sprintf完成转换char buffer[200];char c = ‘1′;int i = 35;long j = 1000;float f = 1.7320534f;sprintf( buffer, “%c”,c);sprintf( buffer, “%d”,i);sprintf( buffer, “%d”,j);sprintf( buffer, “%f”,f);二、字符串转换为其它数据类型strcpy(temp,”123″);短整型(int)i = atoi(temp);长整型(long)l = atol(temp);浮点(double)d = atof(temp);CString变量CString name = temp;BSTR变量BSTR bstrValue = ::SysAllocString(L”程序员”);…///完成对bstrValue的使用SysFreeString(bstrValue);CComBSTR变量CComBSTR类型变量可以直接赋值CComBSTR bstrVar1(”test”);CComBSTR bstrVar2(temp);_bstr_t变量_bstr_t类型的变量可以直接赋值_bstr_t bstrVar1(”test”);_bstr_t bstrVar2(temp);三、其它数据类型转换到CString使用CString的成员函数Format来转换,例如:整数(int)str.Format(”%d”,i);浮点数(float)str.Format(”%f”,i);字符串指针(char*)等已经被CString构造函数支持的数据类型可以直接赋值str = username;对于Format所不支持的数据类型,可以通过上面所说的关于其它数据类型转化到char*的方法先转到char *,然后赋值给CString变量。
vc6.0unicode+和utf8相互转换

Vc下unicode和UTF8相互转换在vc下使用SQLite数据库时,由于SQL语句使用utf8 编码,而CString 是unicode编码。
一,utf8 转UnicodeCString UTF8ToUnicode(char* UTF8){DWORD dwUnicodeLen; //转换后Unicode的长度TCHAR *pwText; //保存Unicode的指针CString strUnicode; //返回值//获得转换后的长度,并分配内存dwUnicodeLen = MultiByteToWideChar(CP_UTF8,0,UTF8,-1,NULL,0);pwText = new TCHAR[dwUnicodeLen];if (!pwText){return strUnicode;}//转为UnicodeMultiByteToWideChar(CP_UTF8,0,UTF8,-1,pwText,dwUnicodeLen);//转为CStringstrUnicode.Format(_T("%s"),pwText);//清除内存delete []pwText;//返回转换好的Unicode字串return strUnicode;}二,Unicode转utf8size_t CDGQDialog::g_f_wctou8(char * dest_str, const wchar_t src_wchar){int count_bytes = 0;wchar_t byte_one = 0, byte_other = 0x3f; // 用于位与运算以提取位值0x3f--->00111111unsigned char utf_one = 0, utf_other = 0x80; // 用于"位或"置标UTF-8编码0x80--->1000000 wchar_t tmp_wchar =L'0'; // 用于宽字符位置析取和位移(右移位)unsigned char tmp_char =L'0';if (!src_wchar)//return (size_t)-1;for (;;) // 检测字节序列长度{if (src_wchar <= 0x7f){ // <=01111111count_bytes = 1; // ASCII字符: 0xxxxxxx( ~ 01111111)byte_one = 0x7f; // 用于位与运算, 提取有效位值, 下同utf_one = 0x0;break;}if ( (src_wchar > 0x7f) && (src_wchar <= 0x7ff) ){ // <=0111,11111111count_bytes = 2; // 110xxxxx 10xxxxxx[1](最多个位, 简写为*1)byte_one = 0x1f; // 00011111, 下类推(1位的数量递减)utf_one = 0xc0; // 11000000break;}if( (src_wchar> 0x7ff) && (src_wchar<= 0xffff) ){ //0111,11111111<=11111111,11111111 count_bytes = 3; // 1110xxxx 10xxxxxx[2](MaxBits: 16*1)byte_one = 0xf; // 00001111utf_one = 0xe0; // 11100000break;}if ( (src_wchar > 0xffff) && (src_wchar <= 0x1fffff) ){ //对UCS-4的支持..count_bytes = 4; // 11110xxx 10xxxxxx[3](MaxBits: 21*1)byte_one = 0x7; // 00000111utf_one = 0xf0; // 11110000break;}if ( (src_wchar > 0x1fffff) && (src_wchar <= 0x3ffffff) ){count_bytes = 5; // 111110xx 10xxxxxx[4](MaxBits: 26*1)byte_one = 0x3; // 00000011utf_one = 0xf8; // 11111000break;}if ( (src_wchar > 0x3ffffff) && (src_wchar <= 0x7fffffff) ){count_bytes = 6; // 1111110x 10xxxxxx[5](MaxBits: 31*1)byte_one = 0x1; // 00000001utf_one = 0xfc; // 11111100break;}return (size_t)-1; // 以上皆不满足则为非法序列}// 以下几行析取宽字节中的相应位, 并分组为UTF-8编码的各个字节tmp_wchar = src_wchar;for (int i = count_bytes; i > 1; i--){ // 一个宽字符的多字节降序赋值tmp_char = (unsigned char)(tmp_wchar & byte_other);///后位与byte_other 00111111dest_str[i - 1] = (tmp_char | utf_other);/// 在前面加----跟或tmp_wchar >>= 6;//右移位}//这个时候i=1//对UTF-8第一个字节位处理,//第一个字节的开头"1"的数目就是整个串中字节的数目tmp_char = (unsigned char)(tmp_wchar & byte_one);//根据上面附值得来,有效位个数dest_str[0] = (tmp_char | utf_one);//根据上面附值得来1的个数// 位值析取分组__End!return count_bytes;}int CDGQDialog::g_f_wcs_to_pchar(CString& wstr,char * p){wchar_t wc=L'1';char c[10]="1";//申请一个缓存size_t r=0; //size_t unsigned integer Result of sizeof operatorint i=0;int j=0;for(i=0;i<wstr.GetLength();i++){wc=wstr.GetAt(i);//得到一个宽字符r=g_f_wctou8(c,wc);//将一个宽字符按UTF-8格式转换到p地址if(r==-1)//出错判断AfxMessageBox(_T("wcs_to_pchar error"));p[j]=c[0];//第一个值附给pj++;if(r>1){for(size_t x=1;x<r;x++){p[j]=c[x];j++;}}}//p[j]='0';return 1;}三.转换实例void CMytestDlg::OnBnClickedButton2(){// TODO: 在此添加控件通知处理程序代码CString ccId=L"2007071王";CString sql;char mySql[100];memset(mySql,0,sizeof(mySql));sql.Format(L"select cxrq,cxdw,dxrq,dxdw,fxrq,fxdw,cx,flx from j_clxx where trainnum_info_id ='%s'",ccId);//wchar_t sql=L'你';g_f_wcs_to_pchar(sql,mySql);CString sql1 =UTF8ToUnicode(mySql);MessageBox(sql);//g_f_wctou8(mySql,sql);// CString str_temp;// for (int i=90;i<strlen(mySql);i++)// {// str_temp.Format(L"%c",mySql[i]);// MessageBox(str_temp);// }。
UnicodeString基本操作(Ring3)

UnicodeString基本操作(Ring3)// 纯粹做个记录,微软源码1// Unicode_String_Ring3.cpp : 定义控制台应⽤程序的⼊⼝点。
2//34 #include "stdafx.h"5 #include "Unicode_String_Ring3.h"67/*8所有带Ums_前缀的函数都是⾃⼰根据windows2000源码实现的910因为Ring3不能直接定义UnicodeString11所以根据微软的源代码来实现1213*/1415int main()16 {17 Test();18return0;19 }2021void Test()22 {23//初始化24//StringInitTest();2526//拷贝操作27//StringCopyTest();2829//字符串⽐较30//StringCompareTest();3132//字符串变⼤写***33 StringToUpperTest();3435//字符串与整型相互转化36//StringToIntegerTest();373839//ANSI_STRING字符串与UNICODE_STRING字符串相互转换40//StringConverTest();41//最后未释放内存,bug42434445 printf("Input AnyKey To Exit\r\n");46 getchar();47 }4849//初始化50void StringInitTest()51 {52 Sub_1();53//Sub_2();54//Sub_3();55 }5657void Sub_1()58 {59 UNICODE_STRING v1;6061 Ums_RtlInitUnicodeString(&v1, L"HelloWorld");6263 printf("%Z\r\n", &v1);64656667 }68 VOID69 Ums_RtlInitUnicodeString(70 OUT PUNICODE_STRING DestinationString,71 IN PCWSTR SourceString OPTIONAL72 )73 {74 USHORT Length = 0;75 DestinationString->Length = 0;76 DestinationString->Buffer = (PWSTR)SourceString;77if (SourceString != NULL)78 {79while (*SourceString++)80 {81 Length += sizeof(*SourceString);82 }8384 DestinationString->Length = Length;8586 DestinationString->MaximumLength = Length+(USHORT)sizeof(UNICODE_NULL);87 }88else89 {90 DestinationString->MaximumLength = 0;91 }92 }93void Sub_2()94 {95 UNICODE_STRING v1;96 WCHAR BufferData[] = L"HelloWorld";97 v1.Buffer = BufferData;98 v1.Length = wcslen(BufferData) * sizeof(WCHAR);99 v1.MaximumLength = (wcslen(BufferData) + 1) * sizeof(WCHAR);100 printf("%Z\r\n", &v1);101 }102103void Sub_3()104 {105 UNICODE_STRING v1;106 WCHAR BufferData[] = L"HelloWorld";107108 v1.Length = wcslen(BufferData) * sizeof(WCHAR);109 v1.MaximumLength = (wcslen(BufferData) + 1) * sizeof(WCHAR);110 v1.Buffer = (WCHAR*)malloc(v1.MaximumLength);111 RtlZeroMemory(v1.Buffer, v1.MaximumLength);112 RtlCopyMemory(v1.Buffer, BufferData, v1.Length);113114 printf("%Z\r\n", &v1);115if (v1.Buffer != NULL)116 {117free(v1.Buffer);118 v1.Buffer = NULL;119 v1.Length = v1.MaximumLength = 0;120 }121 }122123//拷贝操作124void StringCopyTest()125 {126 UNICODE_STRING SourceString;127 Ums_RtlInitUnicodeString(&SourceString, L"HelloWorld");128129 UNICODE_STRING DestinationString = { 0 };130 DestinationString.Buffer = (PWSTR)malloc(BUFFER_SIZE);131 DestinationString.MaximumLength = BUFFER_SIZE;132133 Ums_RtlCopyUnicodeString(&DestinationString, &SourceString);134135 printf("SourceString:%wZ\r\n", &SourceString);136 printf("DestinationString:%wZ\n", &DestinationString);137138 Ums_RtlFreeUnicodeString(&DestinationString);139 }140141 VOID142 Ums_RtlCopyUnicodeString(143 OUT PUNICODE_STRING DestinationString,144 IN PUNICODE_STRING SourceString OPTIONAL145 )146 {147 UNALIGNED WCHAR *Source, *Dest;148 ULONG n;149150if (SourceString!=NULL)151 {152 Dest = DestinationString->Buffer;153 Source = SourceString->Buffer;154 n = SourceString->Length;155if ((USHORT)n > DestinationString->MaximumLength)156 {157 n = DestinationString->MaximumLength;158 }159160 DestinationString->Length = (USHORT)n;161 RtlCopyMemory(Dest, Source, n);162if (DestinationString->Length < DestinationString->MaximumLength)163 {164 Dest[n / sizeof(WCHAR)] = UNICODE_NULL;165 }166167 }168else169 {170 DestinationString->Length = 0;171 }172173return;174 }175 VOID176 Ums_RtlFreeUnicodeString(177 IN OUT PUNICODE_STRING UnicodeString178 )179 {180if (UnicodeString->Buffer)181 {182//free(UnicodeString->Buffer);183184 memset( UnicodeString, 0, sizeof( *UnicodeString ) );185 }186 }187188189190191//字符串⽐较192void StringCompareTest()193 {194//初始化UnicodeString1195 UNICODE_STRING UnicodeString1;196 Ums_RtlInitUnicodeString(&UnicodeString1,L"HELLOWORLD"); 197198//初始化UnicodeString2199 UNICODE_STRING UnicodeString2;200//Ums_RtlInitUnicodeString(&UnicodeString2, L"Hello");201//Ums_RtlInitUnicodeString(&UnicodeString2, L"HELLOWORLD"); 202 Ums_RtlInitUnicodeString(&UnicodeString2, L"helloworld");203204if (Ums_RtlEqualUnicodeString(205 &UnicodeString1,206 &UnicodeString2,207 TRUE208//If TRUE,209//case should be ignored when doing the comparison.210 )211 )212 {213 printf("UnicodeString1 and UnicodeString2 are equal\n");214 }215else216 {217 printf("UnicodeString1 and UnicodeString2 are NOT equal\n"); 218 }219 }220 BOOLEAN221 Ums_RtlEqualUnicodeString(222 IN const PUNICODE_STRING String1,223 IN const PUNICODE_STRING String2,224 IN BOOLEAN CaseInSensitive225 )226 {227 UNALIGNED WCHAR *s1, *s2;228 USHORT n1, n2;229 WCHAR c1, c2;230231 s1 = String1->Buffer;232 s2 = String2->Buffer;233 n1 = (USHORT )(String1->Length / sizeof(WCHAR));234 n2 = (USHORT )(String2->Length / sizeof(WCHAR));235236if ( n1 != n2 )237 {238return FALSE;239 }240241if (CaseInSensitive)242 {243while ( n1 )244 {245if ( *s1++ != *s2++ )246 {247 c1 = upcase(*(s1-1));248 c2 = upcase(*(s2-1));249if (c1 != c2)250 {251return( FALSE );252 }253 }254 n1--;255 }256 }257else258 {259while ( n1 )260 {261262if (*s1++ != *s2++)263 {264return( FALSE );265 }266267 n1--;268 }269 }270return TRUE;271 }272273274275276277//字符串变⼤写278void StringToUpperTest()279 {280 UNICODE_STRING SourceString;281 Ums_RtlInitUnicodeString(&SourceString, L"Hello World");282283 UNICODE_STRING DestinationString;284 DestinationString.Buffer = (PWSTR)malloc(BUFFER_SIZE);285 DestinationString.MaximumLength = BUFFER_SIZE;286287//变化前288 printf("变化前:%wZ\n", &SourceString);289//变⼤写290 Ums_RtlUpcaseUnicodeString(291 &DestinationString, //DestinationString292 &SourceString, //SourceString293 FALSE//Specifies if RtlUpcaseUnicodeString is to allocate the buffer space for the DestinationString.294//If it does, the buffer must be deallocated by calling RtlFreeUnicodeString.295 );296297//变化后298 printf("变化后:%wZ\n", &DestinationString);299300 Ums_RtlFreeUnicodeString(&DestinationString);301 }302303304305306 BOOL307 Ums_RtlUpcaseUnicodeString(308 OUT PUNICODE_STRING DestinationString,309 IN PCUNICODE_STRING SourceString,310 IN BOOLEAN AllocateDestinationString311 )312 {313 ULONG Index;314 ULONG StopIndex;315316317318if ( AllocateDestinationString )319 {320 DestinationString->MaximumLength = SourceString->Length;321//DestinationString->Buffer = (Ums_RtlAllocateStringRoutine)((ULONG)DestinationString->MaximumLength); 322323 DestinationString->Buffer = (PWSTR)malloc((ULONG)DestinationString->MaximumLength);324325if ( !DestinationString->Buffer )326 {327return FALSE;328 }329 }330else331 {332if ( SourceString->Length > DestinationString->MaximumLength )333 {334return FALSE;335 }336 }337338 StopIndex = ((ULONG)SourceString->Length) / sizeof( WCHAR );339340for (Index = 0; Index < StopIndex; Index++)341 {342 DestinationString->Buffer[Index] = (WCHAR)NLS_UPCASE(SourceString->Buffer[Index]); 343 }344345 DestinationString->Length = SourceString->Length;346347return TRUE;348 }349350351//字符串与整型相互转化352void StringToIntegerTest()353 {354//(1)字符串转换成数字355 UNICODE_STRING UnicodeString1;356 Ums_RtlInitUnicodeString(&UnicodeString1, L"-100");357358 ULONG lNumber;359 NTSTATUS Status =360 Ums_RtlUnicodeStringToInteger(//第⼆个参数Base361 &UnicodeString1,362//10,//-100是10进制 //输出-100363//16,//-100是16进制 //输出-2563648, //-100是8进制 //输出-64365 &lNumber366 );367368if (NT_SUCCESS(Status))369 {370 printf("Conver to integer succussfully!\n");371 printf("Result:%d\n", lNumber);372 }373else374 {375 printf("Conver to integer unsuccessfully!\n");376 }377//(2)数字转换成字符串378 UNICODE_STRING UnicodeString2 = { 0 };379 UnicodeString2.Buffer = (PWSTR)malloc(BUFFER_SIZE);380 UnicodeString2.MaximumLength = BUFFER_SIZE;381382 Status = Ums_RtlIntegerToUnicodeString(//同上第⼆参数是Base383200,384//10, //输出200385//8, //输出31038616, //输出 C8387 &UnicodeString2388 );389390/*391 HEX C8392 DEC 200393 OCT 310394395*/396if (NT_SUCCESS(Status))397 {398 printf("Conver to string succussfully!\n");399 printf("Result:%wZ\n", &UnicodeString2);400 }401else402 {403 printf("Conver to string unsuccessfully!\n");404 }405406//销毁UnicodeString2407//注意!!UnicodeString1不⽤销毁408 Ums_RtlFreeUnicodeString(&UnicodeString2);409410411 }412 BOOL413 Ums_RtlUnicodeStringToInteger(414 IN PUNICODE_STRING String,415 IN ULONG Base OPTIONAL,416 OUT PULONG Value417 )418 {419 PCWSTR s;420 WCHAR c, Sign;421 ULONG nChars, Result, Digit, Shift;422423 s = String->Buffer;424 nChars = String->Length / sizeof(WCHAR); 425while (nChars-- && (Sign = *s++) <= '') { 426if (!nChars) {427 Sign = UNICODE_NULL;428break;429 }430 }431432 c = Sign;433if (c == L'-' || c == L'+') {434if (nChars) {435 nChars--;436 c = *s++;437 }438else {439 c = UNICODE_NULL;440 }441 }442443if (((ULONG_PTR)Base)!=NULL) {444 Base = 10;445 Shift = 0;446if (c == L'0') {447if (nChars) {448 nChars--;449 c = *s++;450if (c == L'x') {451 Base = 16;452 Shift = 4;453 }454else455if (c == L'o') {456 Base = 8;457 Shift = 3;458 }459else460if (c == L'b') {461 Base = 2;462 Shift = 1;463 }464else {465 nChars++;466 s--;467 }468 }469470if (nChars) {471 nChars--;472 c = *s++;473 }474else {475 c = UNICODE_NULL;476 }477 }478 }479else {480switch (Base) {481case16: Shift = 4; break;482case8: Shift = 3; break;483case2: Shift = 1; break;484case10: Shift = 0; break;485default: return(FALSE);486 }487 }488489 Result = 0;490while (c != UNICODE_NULL) {491if (c >= L'0' && c <= L'9') {492 Digit = c - L'0';493 }494else495if (c >= L'A' && c <= L'F') {496 Digit = c - L'A' + 10;497 }498else499if (c >= L'a' && c <= L'f') {500 Digit = c - L'a' + 10;501 }502else {503break;504 }505506if (Digit >= Base) {507break;508 }509510if (Shift == 0) {511 Result = (Base * Result) + Digit;512 }513else {514 Result = (Result << Shift) | Digit;515 }516517if (!nChars) {518break;519 }520 nChars--;521 c = *s++;522 }523524if (Sign == L'-') {525 Result = (ULONG)(-(LONG)Result);526 }527528 __try529 {530 *Value = Result;531 }532 __except(EXCEPTION_EXECUTE_HANDLER) {533return(GetExceptionCode());534 }535536return(TRUE);537 }538539 BOOL540 Ums_RtlIntegerToUnicodeString(541 IN ULONG Value,542 IN ULONG Base OPTIONAL,543 IN OUT PUNICODE_STRING String544 )545 {546 BOOL IsOk;547char ResultBuffer[16];548 ANSI_STRING AnsiString;549550 IsOk = Ums_RtlIntegerToChar(Value, Base, sizeof(ResultBuffer), ResultBuffer); 551if (IsOk)552 {553 AnsiString.Buffer = ResultBuffer;554 AnsiString.MaximumLength = sizeof(ResultBuffer);555 AnsiString.Length = (USHORT)strlen(ResultBuffer);556 IsOk = Ums_RtlAnsiStringToUnicodeString(String, &AnsiString, FALSE);557 }558559return(IsOk);560 }561562 BOOL563 Ums_RtlAnsiStringToUnicodeString(564 OUT PUNICODE_STRING DestinationString,565 IN PANSI_STRING SourceString,566 IN BOOLEAN AllocateDestinationString567 )568 {569 ULONG UnicodeLength;570 ULONG Index;571 NTSTATUS st;572573 UnicodeLength = (SourceString->Length << 1) + sizeof(UNICODE_NULL);574575if (UnicodeLength > MAXUSHORT) {576return FALSE;577 }578579 DestinationString->Length = (USHORT)(UnicodeLength - sizeof(UNICODE_NULL)); 580581/*582 if (AllocateDestinationString) {583 return FALSE;585 else {586 if (DestinationString->Length >= DestinationString->MaximumLength) {587 return FALSE;588 }589 }590*/591//DestinationString->buffer没有申请内存所以我们这⾥仿造上⼀个函数的申请 592 DestinationString->Buffer = (PWCHAR)malloc(UnicodeLength);593594 Index = 0;595while (Index < DestinationString->Length)596 {597 DestinationString->Buffer[Index] = (WCHAR)SourceString->Buffer[Index]; 598 Index++;599 }600 DestinationString->Buffer[Index] = UNICODE_NULL;601602return TRUE;603 }604605606 BOOL607 Ums_RtlIntegerToChar(608 IN ULONG Value,609 IN ULONG Base OPTIONAL,610 IN LONG OutputLength,611 OUT char* String612 )613 {614 CHAR Result[33], *s;615 ULONG Shift, Mask, Digit, Length;616617 Shift = 0;618switch (Base) {619case16: Shift = 4; break;620case8: Shift = 3; break;621case2: Shift = 1; break;622623case0: Base = 10;624case10: Shift = 0; break;625default: return(FALSE);626 }627628if (Shift != 0) {629 Mask = 0xF >> (4 - Shift);630 }631632 s = &Result[32];633 *s = '\0';634do {635if (Shift != 0) {636 Digit = Value & Mask;637 Value >>= Shift;638 }639else {640 Digit = Value % Base;641 Value = Value / Base;642 }643644 *--s = RtlpIntegerChars[Digit];645 } while (Value != 0);646647 Length = (ULONG)(&Result[32] - s);648if (OutputLength < 0) {649 OutputLength = -OutputLength;650while ((LONG)Length < OutputLength) {651 *--s = '0';652 Length++;653 }654 }655656if ((LONG)Length > OutputLength)657 {658return(FALSE);659 }660else {661 __try {662 RtlMoveMemory(String, s, Length);663664if ((LONG)Length < OutputLength) {665 String[Length] = '\0';666 }667 }669 __except(EXCEPTION_EXECUTE_HANDLER)670 {671return(GetExceptionCode());672 }673674return(TRUE);675 }676 }677678679680681682683684685686687//ANSI_STRING字符串与UNICODE_STRING字符串相互688void StringConverTest()689 {690//(1)将UNICODE_STRING字符串转换成ANSI_STRING字符串691//初始化UnicodeString1692 UNICODE_STRING UnicodeString1;693 Ums_RtlInitUnicodeString(&UnicodeString1, L"HelloWorld");694695 ANSI_STRING AnsiString1;696 NTSTATUS Status = Ums_RtlUnicodeStringToAnsiString(697 &AnsiString1,698 &UnicodeString1,699 TRUE700//TRUE if this routine is to allocate the buffer space for the DestinationString.701//If it does, the buffer must be deallocated by calling RtlFreeAnsiString.702 );703704if (NT_SUCCESS(Status))705 {706 printf("Conver succussfully!\n");707//printf("Result:%Z\n", &AnsiString1);708//printf("Result:%Z\n", AnsiString1.Buffer);709 printf("Result:%s\n", AnsiString1.Buffer);710 }711else712 {713 printf("Conver unsuccessfully!\n");714 }715716//销毁AnsiString1717 Ums_RtlFreeAnsiString(&AnsiString1);718719/******************************************/720721//(2)将ANSI_STRING字符串转换成UNICODE_STRING字符串722723 ANSI_STRING AnsiString2;724 Ums_RtlInitString(&AnsiString2, "HelloWorld");725726 UNICODE_STRING UnicodeString2;727 Status = Ums_RtlAnsiStringToUnicodeString(728 &UnicodeString2,729 &AnsiString2,730 TRUE731//Specifies if this routine should allocate the buffer space for the destination string. 732//If it does, the caller must deallocate the buffer by calling RtlFreeUnicodeString. 733734735 );736737if (NT_SUCCESS(Status))738 {739 printf("Conver succussfully!\n");740//printf("Result:%wZ\n", &UnicodeString2);741//printf("Result:%wZ\n", UnicodeString2.Buffer);742 printf("Result:%S\n", UnicodeString2.Buffer);743 }744else745 {746 printf("Conver unsuccessfully!\n");747 }748749//销毁UnicodeString2750 Ums_RtlFreeUnicodeString(&UnicodeString2);751 }752753 VOID754 Ums_RtlFreeAnsiString(755 IN OUT PANSI_STRING AnsiString756 )757 {758if (AnsiString->Buffer) {759free(AnsiString->Buffer);760 memset(AnsiString, 0, sizeof(*AnsiString));761 }762 }763 VOID764 Ums_RtlInitString(765 OUT PSTRING DestinationString,766 IN char* SourceString OPTIONAL767 )768 {769 DestinationString->Length = 0;770 DestinationString->Buffer = (PCHAR)SourceString;771if ( SourceString !=NULL ) {772while (*SourceString++) {773 DestinationString->Length++;774 }775776 DestinationString->MaximumLength = (SHORT)(DestinationString->Length+1); 777 }778else {779 DestinationString->MaximumLength = 0;780 }781 }782783 BOOL784 Ums_RtlUnicodeStringToAnsiString(785 OUT PANSI_STRING DestinationString,786 IN PUNICODE_STRING SourceString,787 IN BOOLEAN AllocateDestinationString788 )789 {790 ULONG AnsiLength;791 ULONG Index;792 NTSTATUS st;793 BOOL ReturnStatus = TRUE;794795796797 AnsiLength = Ums_RtlxUnicodeStringToAnsiSize(SourceString);798if ( AnsiLength > MAXUSHORT ) {799return FALSE;800 }801802 DestinationString->Length = (USHORT)(AnsiLength - 1);803if ( AllocateDestinationString )804 {805 DestinationString->MaximumLength = (USHORT)AnsiLength;806//DestinationString->Buffer = (RtlAllocateStringRoutine)(AnsiLength);807 DestinationString->Buffer = (PCHAR)malloc(AnsiLength);808809810if ( !DestinationString->Buffer ) {811return FALSE;812 }813 }814else {815if ( DestinationString->Length >= DestinationString->MaximumLength ) {816/*817 * Return STATUS_BUFFER_OVERFLOW, but translate as much as818 * will fit into the buffer first. This is the expected819 * behavior for routines such as GetProfileStringA.820 * Set the length of the buffer to one less than the maximum821 * (so that the trail byte of a double byte char is not822 * overwritten by doing DestinationString->Buffer[Index] = '\0').823 * RtlUnicodeToMultiByteN is careful not to truncate a824 * multibyte character.825*/826if (!DestinationString->MaximumLength) {827return FALSE;828 }829 ReturnStatus = FALSE;830 DestinationString->Length = DestinationString->MaximumLength - 1;831 }832 }833834 st = Ums_RtlUnicodeToMultiByteN(835 DestinationString->Buffer,836 DestinationString->Length,837 &Index,838 SourceString->Buffer,839 SourceString->Length840 );841842if (!NT_SUCCESS(st)) {843if ( AllocateDestinationString ) {844free(DestinationString->Buffer);845 DestinationString->Buffer = NULL;846 }847848return st;849 }850851 DestinationString->Buffer[Index] = '\0';852853return ReturnStatus;854 }855856 BOOL857 Ums_RtlUnicodeToMultiByteN(858 OUT PCH MultiByteString,859 IN ULONG MaxBytesInMultiByteString,860 OUT PULONG BytesInMultiByteString OPTIONAL,861 IN PWCH UnicodeString,862 IN ULONG BytesInUnicodeString863 )864 {865 ULONG TmpCount;866 ULONG LoopCount;867 ULONG CharsInUnicodeString;868 UCHAR SbChar;869 WCHAR UnicodeChar;870 ULONG i;871872//873// Convert Unicode byte count to character count. Byte count of874// multibyte string is equivalent to character count.875//876 CharsInUnicodeString = BytesInUnicodeString / sizeof(WCHAR);877878 LoopCount = (CharsInUnicodeString < MaxBytesInMultiByteString) ? 879 CharsInUnicodeString : MaxBytesInMultiByteString;880881if ((BytesInMultiByteString) != NULL)882 *BytesInMultiByteString = LoopCount;883884885for (i = 0; i < LoopCount; i++) {886 MultiByteString[i] = (CHAR)UnicodeString[i];887 }888889return TRUE;890891 }892 ULONG893 Ums_RtlxUnicodeStringToAnsiSize(894 IN PUNICODE_STRING UnicodeString895 )896 {897 ULONG cbMultiByteString;898899900901//902// Get the size of the string - this call handles DBCS.903//904 Ums_RtlUnicodeToMultiByteSize( &cbMultiByteString,905 UnicodeString->Buffer,906 UnicodeString->Length );907908//909// Return the size in bytes.910//911return (cbMultiByteString + 1);912 }913 BOOL914 Ums_RtlUnicodeToMultiByteSize(915 OUT PULONG BytesInMultiByteString,916 IN PWCH UnicodeString,917 IN ULONG BytesInUnicodeString)918 {919 ULONG cbMultiByte = 0;920 ULONG CharsInUnicodeString;921922/*923 * convert from bytes to chars for easier loop handling.924*/925 CharsInUnicodeString = BytesInUnicodeString / sizeof(WCHAR); 926927if (NlsMbCodePageTag) {928 USHORT MbChar;929930while (CharsInUnicodeString--) {931 MbChar = NlsUnicodeToMbAnsiData[ *UnicodeString++ ]; 932if (HIBYTE(MbChar) == 0) {933 cbMultiByte++ ;934 } else {935 cbMultiByte += 2;936 }937 }938 *BytesInMultiByteString = cbMultiByte;939 }940else {941 *BytesInMultiByteString = CharsInUnicodeString;942 }943944return TRUE;945 }946947 ULONG948 Ums_RtlxAnsiStringToUnicodeSize(949 IN PANSI_STRING AnsiString950 )951952953 {954 ULONG cbConverted;955956957//958// Get the size of the string - this call handles DBCS.959//960 Ums_RtlMultiByteToUnicodeSize( &cbConverted ,961 AnsiString->Buffer,962 AnsiString->Length );963964//965// Return the size in bytes.966//967return ( cbConverted + sizeof(UNICODE_NULL) );968 }969 BOOL970 Ums_RtlMultiByteToUnicodeSize(971 OUT PULONG BytesInUnicodeString,972 IN PCH MultiByteString,973 IN ULONG BytesInMultiByteString974 )975 {976 ULONG cbUnicode = 0;977if (NlsMbCodePageTag) {978//979// The ACP is a multibyte code page. Check each character 980// to see if it is a lead byte before doing the translation.981//982while (BytesInMultiByteString--) {983if (NlsLeadByteInfo[*(PUCHAR)MultiByteString++]) {984//985// Lead byte - translate the trail byte using the table986// that corresponds to this lead byte. NOTE: make sure 987// we have a trail byte to convert.988//989if (BytesInMultiByteString == 0) {990//991// RtlMultibyteToUnicodeN() uses the unicode992// default character if the last multibyte993// character is a lead byte.994//995 cbUnicode += sizeof(WCHAR);996break;997 } else {998 BytesInMultiByteString--;999 MultiByteString++;1000 }1001 }1002 cbUnicode += sizeof(WCHAR);1003 }1004 *BytesInUnicodeString = cbUnicode;1005 } else {1006//1007// The ACP is a single byte code page.1008//1009 *BytesInUnicodeString = BytesInMultiByteString * sizeof(WCHAR);1010 }10111012return TRUE;1013 }1#pragma once2 #include <windows.h>3 #include <iostream>45using namespace std;67#define BUFFER_SIZE 0x4008#define DBCS_TABLE_SIZE 2569#define NT_SUCCESS(Status) (((NTSTATUS)(Status)) >= 0)1011//拷贝12#define upcase(C) \13 (WCHAR )(((C) >= 'a' && (C) <= 'z' ? (C) - ('a' - 'A') : (C)))141516//字符串变⼤写17#define LOBYTE(w) ((UCHAR)((w)))18#define HIBYTE(w) ((UCHAR)(((USHORT)((w)) >> 8) & 0xFF))19#define GET8(w) ((ULONG)(((w) >> 8) & 0xff))20#define GETHI4(w) ((ULONG)(((w) >> 4) & 0xf))21#define GETLO4(w) ((ULONG)((w) & 0xf))22#define TRAVERSE844W(pTable, wch) \23 ( (pTable)[(pTable)[(pTable)[GET8((wch))] + GETHI4((wch))] + GETLO4((wch))] )2425 PUSHORT Nls844UnicodeUpcaseTable;26extern PUSHORT Nls844UnicodeUpcaseTable;2728#define NLS_UPCASE(wch) ( \29 ((wch) < 'a' ? \30 (wch) \31 : \32 ((wch) <= 'z' ? \33 (wch) - ('a'-'A') \34 : \35 ((WCHAR)((wch) + TRAVERSE844W(Nls844UnicodeUpcaseTable,(wch)))) \36 ) \37 ) \38 )39#define MAXUSHORT USHRT_MAX4041 typedef char *PSZ;4243 typedef struct _UNICODE_STRING44 {45 USHORT Length;46 USHORT MaximumLength;47 PWCHAR Buffer;48 }UNICODE_STRING, *PUNICODE_STRING;4950 typedef const UNICODE_STRING *PCUNICODE_STRING;5152 typedef struct _STRING {53 USHORT Length;54 USHORT MaximumLength;55 #ifdef MIDL_PASS56 [size_is(MaximumLength), length_is(Length)]57#endif// MIDL_PASS58 _Field_size_bytes_part_opt_(MaximumLength, Length) PCHAR Buffer;59 } STRING;60 typedef STRING *PSTRING;61 typedef STRING ANSI_STRING;62 typedef PSTRING PANSI_STRING;636465 CHAR RtlpIntegerChars[] = { '0', '1', '2', '3', '4', '5', '6', '7',66'8', '9', 'A', 'B', 'C', 'D', 'E', 'F' };676869707172 BOOLEAN NlsMbCodePageTag = FALSE; // TRUE -> Multibyte ACP, FALSE -> Singlebyte ACP73 USHORT NlsLeadByteInfoTable[DBCS_TABLE_SIZE]; // Lead byte info. for ACP74 PUSHORT NlsLeadByteInfo = NlsLeadByteInfoTable;75 PUSHORT NlsUnicodeToMbAnsiData; // Unicode to Multibyte Ansi CP translation table 76777879void Test();8081//初始化82void StringInitTest();8384void Sub_1();85 VOID86 Ums_RtlInitUnicodeString(87 OUT PUNICODE_STRING DestinationString,88 IN PCWSTR SourceString OPTIONAL89 );9091void Sub_2();92void Sub_3();93949596//拷贝操作97void StringCopyTest();98 VOID99 Ums_RtlCopyUnicodeString(100 OUT PUNICODE_STRING DestinationString,101 IN PUNICODE_STRING SourceString OPTIONAL102 );103 VOID104 Ums_RtlFreeUnicodeString(105 IN OUT PUNICODE_STRING UnicodeString106 );107108109110//字符串⽐较111void StringCompareTest();112 BOOLEAN113 Ums_RtlEqualUnicodeString(114 IN const PUNICODE_STRING String1,115 IN const PUNICODE_STRING String2,116 IN BOOLEAN CaseInSensitive117 );118119120121//字符串变⼤写122void StringToUpperTest();123 BOOL124 Ums_RtlUpcaseUnicodeString(125 OUT PUNICODE_STRING DestinationString,126 IN PCUNICODE_STRING SourceString,127 IN BOOLEAN AllocateDestinationString128 );129130131132133//字符串与整型相互转化134void StringToIntegerTest();135136 BOOL137 Ums_RtlUnicodeStringToInteger(138 IN PUNICODE_STRING String,139 IN ULONG Base OPTIONAL,140 OUT PULONG Value141 );142 BOOL143 Ums_RtlIntegerToUnicodeString(144 IN ULONG Value,145 IN ULONG Base OPTIONAL,146 IN OUT PUNICODE_STRING String147 );148 BOOL149 Ums_RtlIntegerToChar(150 IN ULONG Value,151 IN ULONG Base OPTIONAL,152 IN LONG OutputLength,153 OUT PSZ String154 );155 BOOL156 Ums_RtlAnsiStringToUnicodeString(157 OUT PUNICODE_STRING DestinationString,。
VC调试版(DebugVersion)和发行版(ReleaseVersion)

VC调试版(DebugVersion)和发⾏版(ReleaseVersion)调试是纠正或修改代码,使之可以顺利地编译、运⾏的过程。
为此,VC IDE提供了功能强⼤的调试和跟踪⼯具。
1.1.1 调试版(Debug Version)和发⾏版(Release Version)开发环境总是为你的⼯程创建调试版和发⾏版。
在调试版⾥,我们排查各种可能的程序错误,然后制作成发⾏版以获得较好的信息。
这就是调试版与发⾏版的区别:前者包含了较多调试信息,最终执⾏⽂件较⼤,性能较差;后者最终执⾏⽂件较⼩,性能更好。
具体地讲,发⾏版和调试版区别有:1. 调试版下,可以使⽤诊断和跟踪宏,如ASSERT和TRACE,MFC类的DUMP功能也定义在调试版下。
2. 额外的变量初始化。
编译器会⾃动将你未初始化的变量逐每字节赋值为0xCC。
3. 内存分配监视。
在调试版下,在堆上分配的内存都会记录,做额外的初始化(0xCD),在释放时,会将其内容逐字节置0xFD。
怎样配置调试版或发⾏版?调试版和发⾏版都可以从 Build | Configurations中增加,或者当这两个配置已存在的情况下,从Project | Settings命令下进⾏配置。
两者在配置上主要有以下不同:1. 两个版本应该配置成不同的输出⽂件夹。
这在Project | Settings | General中的两个编辑框中设定。
2. 调试版下,程序应该链接Debug版的c运⾏时库、禁⽌代码优化,并在C++属性页中的Preprocessor类别中加上预定义标识符_DEBUG。
在Link属性页中的Debug类别中,选中DebugInfo和Microsoft Format选框。
4. 发⾏版下,程序应该链接Release版的c运⾏时库、设置代码优化,不定义_DEBUG标识符,去掉DebugInfo选框中的选择。
1.1.2 排除编译错误VC6.0的编译器可以报告⼤约1100个左右的错误,这还不包含警告。
Visual C++ 6.0 - 工程设置解读
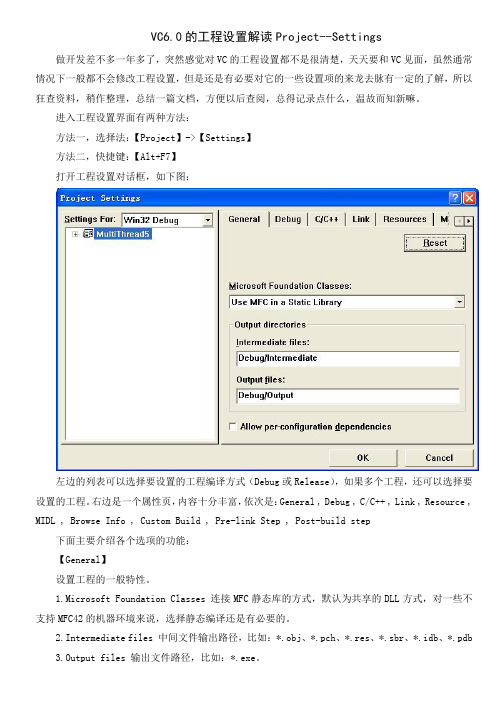
VC6.0的工程设置解读Project--Settings 做开发差不多一年多了,突然感觉对VC的工程设置都不是很清楚,天天要和VC见面,虽然通常情况下一般都不会修改工程设置,但是还是有必要对它的一些设置项的来龙去脉有一定的了解,所以狂查资料,稍作整理,总结一篇文档,方便以后查阅,总得记录点什么,温故而知新嘛。
进入工程设置界面有两种方法:方法一,选择法:【Project】->【Settings】方法二,快捷键:【Alt+F7】打开工程设置对话框,如下图:左边的列表可以选择要设置的工程编译方式(Debug或Release),如果多个工程,还可以选择要设置的工程。
右边是一个属性页,内容十分丰富,依次是:General , Debug , C/C++ , Link , Resource , MIDL , Browse Info , Custom Build , Pre-link Step , Post-build step下面主要介绍各个选项的功能:【General】设置工程的一般特性。
1.Microsoft Foundation Classes 连接MFC静态库的方式,默认为共享的DLL方式,对一些不支持MFC42的机器环境来说,选择静态编译还是有必要的。
2.Intermediate files 中间文件输出路径,比如:*.obj、*.pch、*.res、*.sbr、*.idb、*.pdb3.Output files 输出文件路径,比如:*.exe。
4.Allow per-configuration dependencies 按外部制作文件(exported makefile)方式为每个工程配置导出不同的可建立项目。
【Debug】设置工程调试的选项。
Category 选项种类,先看看General种类选项卡1.Executable for debug session 如果是dll的工程,需要指定启动它的exe文件路径,如果是exe工程,默认当前工程路径。
LPSTR、LPCSTR、LPTSTR和LPCTSTR的意义及区别

LPSTR、LPCSTR、LPTSTR 和 LPCTSTR 的意义及区别
2009-09-28 17:09:58| 分类: 默认分类|字号 订阅
1、ANSI(即 MBCS):为多字节字符集,它是不定长表示世界文字的编码方式。ANSI 表示 英文字母时就和 ASCII 一样,但表示其他文字时就需要用多字节。 2、Unicode:用两个字节表示一个字符的编码方式。比如字符'A'在 ASCII 下面用一个字节 表示,而在 Unicode 下面用两个字节表示,其中高字节用“0”填充;函数'程'在 ASCII 下面用两个字节表 示,而在 Unicode 下面也是用两个字节表示。Unicode 的用处就是定长表示世界文字,据统计,用两 个字节可以编码 现存的所有文字而没有二义。 3、Windows 下的程序设计可以支持 ANSI 和 Unicode 两种编码方法的字符串,具体使用哪 种就要看定义了 MBCS 宏还是 Unicode 宏。MBCS 宏对应的字符串指针为 LPSTR(即 char*),Unicode 对应 的指针为 LPWSTR(即 unsigned char*)。为了写程序的方便,微软定义了类型 LPTSTR,在 MBCS 下 它表示 char*, 在 Unicode 下它表示 unsigned char*,这就可以重定义一个宏进行不同字符集的转换了。 4、关系 LPSTR:指向一个字符串的32位指针,每个字符占1个字节。 LPCSTR:指向一个常量字符串的32位指针,每个字符占1个字节。 LPTSTR:指向一个字符串的32位指针,每个字符可能占1个字节或2个字节。 LPCTSTR:指向一个常量字符串的32位指针,每个字符可能占1个字节或2个字节。 5、Windows 使用两种字符集 ANSI 和 Unicode,前者在处理英文字符时使用单字节方式,在 处理中文字符时 使用双字节方式。后者不管是英文字符还是中文字符都是采用双字节方式表示。Windows NT 的所有与字符 有关的函数都提供了两种方式的版本,而 Windows 9x 只支持 ANSI 方式。_T 一般同字符常 量相关,如_T("你
VC++中的char,wchar_t,TCHAR

1.VC++中的char,wchar_t,TCHAR(转载)总体简介:由于字符编码的不同,在C++中有三种对于字符类型:char, wchar_t , TCHAR。
其实TCHAR不能算作一种类型,他紧紧是一个宏。
我们都知道,宏在预编译的时候会被替换成相应的内容。
TCHAR 在使用多字节编码时被定义成char,在Unicode编码时定义成wchar_t。
1.VC++中的char,wchar_t,TCHAR大家一起做一个项目,经常发现有的人爱用strcpy等标准ANSI函数,有的人爱用_tXXXX 函数,这个问题曾经搞的很混乱。
为了统一,有必要把来龙去脉搞清楚。
为了搞清这些函数,就必须理请几种字符类型的写法。
char就不用说了,先说一些wchar_t。
wchar_t是Unicode字符的数据类型,它实际定义在<string.h>里:typedef unsigned short wchar_t;不能使用类似strcpy这样的ANSI C字符串函数来处理wchar_t字符串,必须使用wcs 前缀的函数,例如wcscpy。
为了让编译器识别Unicode字符串,必须以在前面加一个“L”,例如:wchar_t *szTest=L"This is a Unicode string.";下面在看看TCHAR。
如果你希望同时为ANSI和Unicode编译的源代码,那就要include TChar.h。
TCHAR是定义在其中的一个宏,它视你是否定义了_UNICODE宏而定义成char或者wchar_t。
如果你使用了TCHAR,那么就不应该使用ANSI的strXXX 函数或者Unicode的wcsXXX函数了,而必须使用TChar.h中定义的_tcsXXX函数。
另外,为了解决刚才提到带“L”的问题,TChar.h中定义了一个宏:“_TEXT”。
以strcpy函数为例子,总结一下:.如果你想使用ANSI字符串,那么请使用这一套写法:char szString[100];strcpy(szString,"test");.如果你想使用Unicode字符串,那么请使用这一套:wchar_t szString[100];wcscpyszString,L"test");.如果你想通过定义_UNICODE宏,而编译ANSI或者Unicode字符串代码:TCHAR szString[100];_tcscpy(szString,_TEXT("test"));2.字符串及处理之三: 使用TCHAR系列方案使用TCHAR系列方案编写程序TCHAR是一种字符串类型,它让你在以MBCS和UNNICODE来build程序时可以使用同样的代码,不需要使用繁琐的宏定义来包含你的代码。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
From:/kf/201108/102015.html
Unicode :宽字节字符集
1. 如何取得一个既包含单字节字符又包含双字节字符的字符串的字符个数?
可以调用Microsoft Visual C++的运行期库包含函数_mbslen来操作多字节(既包括单字节也包括双字节)字符串。
调用strlen函数,无法真正了解字符串中究竟有多少字符,它只能告诉你到达结尾的0之前有多少个字节。
2. 如何对DBCS(双字节字符集)字符串进行操作?
函数描述
PTSTR CharNext (LPCTSTR ); 返回字符串中下一个字符的地址
PTSTR CharPrev (LPCTSTR, LPCTSTR );返回字符串中上一个字符的地址
BOOL IsDBCSLeadByte( BYTE );如果该字节是DBCS字符的第一个字节,则返回非0值
3. 为什么要使用Unicode?
(1)可以很容易地在不同语言之间进行数据交换。
(2)使你能够分配支持所有语言的单个二进制.exe文件或DLL文件。
(3)提高应用程序的运行效率。
Windows 2000是使用Unicode从头进行开发的,如果调用任何一个Windows函数并给它传递一个ANSI字符串,那么系统首先要将字符串转换成Unicode,然后将Unicode字符串传递给操作系统。
如果希望函数返回ANSI字符串,系统就会首先将Unicode字符串转换成ANSI字符串,然后将结果返回给你的应用程序。
进行这些字符串的转换需要占用系统的时间和内存。
通过从头开始用Unicode来开发应用程序,就能够使你的应用程序更加有效地运行。
Windows CE 本身就是使用Unicode的一种操作系统,完全不支持ANSI Windows 函数
Windows 98 只支持ANSI,只能为ANSI开发应用程序。
Microsoft公司将COM从16位Windows转换成Win32时,公司决定需要字符串的所有COM接口方法都只能接受Unicode字符串。
4. 如何编写Unicode源代码?
Microsoft公司为Unicode设计了WindowsAPI,这样,可以尽量减少代码的影响。
实际上,可以编写单个源代码文件,以便使用或者不使用Unicode来对它进行编译。
只需要定义两个宏(UNICODE和_UNICODE),就可以修改然后重新编译该源文件。
_UNICODE宏用于C运行期头文件,而UNICODE宏则用于Windows头文件。
当编译源代码模块时,通常必须同时定义这两个宏。
5. Windows定义的Unicode数据类型有哪些?
数据类型说明
WCHAR Unicode字符
PWSTR 指向Unicode字符串的指针
PCWSTR 指向一个恒定的Unicode字符串的指针
对应的ANSI数据类型为CHAR,LPSTR和LPCSTR。
ANSI/Unicode通用数据类型为TCHAR,PTSTR,LPCTSTR。
6. 如何对Unicode进行操作?
字符集特性实例
ANSI 操作函数以str开头strcpy
Unicode 操作函数以wcs开头wcscpy
MBCS 操作函数以_mbs开头_mbscpy
ANSI/Unicode 操作函数以_tcs开头_tcscpy(C运行期库)
ANSI/Unicode 操作函数以lstr开头lstrcpy(Windows函数)
所有新的和未过时的函数在Windows2000中都同时拥有ANSI和Unicode两个版本。
ANSI 版本函数结尾以A表示;Unicode版本函数结尾以W表示。
Windows会如下定义:#ifdef UNICODE
#define CreateWindowEx CreateWindowExW
#else
#define CreateWindowEx CreateWindowExA
#endif // !UNICODE
7. 如何表示Unicode字符串常量?
字符集实例
ANSI “string”
Unicode L“string”
ANSI/Unicode T(“string”)或_TEXT(“string”)if( szError[0] == _TEXT(‘J’) ){ }
8. 为什么应当尽量使用操作系统函数?
这将有助于稍稍提高应用程序的运行性能,因为操作系统字符串函数常常被大型应用程序比如操作系统的外壳进程Explorer.exe所使用。
由于这些函数使用得很多,因此,在应用程序运行时,它们可能已经被装入RAM。
如:StrCat,StrChr,StrCmp和StrCpy等。
9. 如何编写符合ANSI和Unicode的应用程序?
(1)将文本串视为字符数组,而不是chars数组或字节数组。
(2)将通用数据类型(如TCHAR和PTSTR)用于文本字符和字符串。
(3)将显式数据类型(如BYTE和PBYTE)用于字节、字节指针和数据缓存。
(4)将TEXT宏用于原义字符和字符串。
(5)执行全局性替换(例如用PTSTR替换PSTR)。
(6)修改字符串运算问题。
例如函数通常希望在字符中传递一个缓存的大小,而不是字节。
这意味着不应该传递sizeof(szBuffer),而应该传递(sizeof(szBuffer)/sizeof(TCHAR)。
另外,如果需要为字符串分配一个内存块,并且拥有该字符串中的字符数目,那么请记住要按字节来分配内存。
这就是说,应该调用malloc(nCharacters *sizeof(TCHAR)),而不是调用malloc(nCharacters)。
10. 如何对字符串进行有选择的比较?
通过调用CompareString来实现。
标志含义
NORM_IGNORECASE 忽略字母的大小写
NORM_IGNOREKANA TYPE 不区分平假名与片假名字符
NORM_IGNORENONSPACE 忽略无间隔字符
NORM_IGNORESYMBOLS 忽略符号
NORM_IGNOREWIDTH 不区分单字节字符与作为双字节字符的同一个字符
SORT_STRINGSORT 将标点符号作为普通符号来处理
11. 如何判断一个文本文件是ANSI还是Unicode?
判断如果文本文件的开头两个字节是0xFF和0xFE,那么就是Unicode,否则是ANSI。
12. 如何判断一段字符串是ANSI还是Unicode?
用IsTextUnicode进行判断。
IsTextUnicode使用一系列统计方法和定性方法,以便猜测缓存的内容。
由于这不是一种确切的科学方法,因此IsTextUnicode有可能返回不正确的结果。
13. 如何在Unicode与ANSI之间转换字符串?
Windows函数MultiByteToWideChar用于将多字节字符串转换成宽字符串;函数WideCharToMultiByte将宽字符串转换成等价的多字节字符串。
本文出自“踏雪无痕”。