SELECT语句参数详解
mysql select参数

mysql select参数MySQL SELECT参数详解在MySQL中,SELECT语句是最常用的操作之一,用于从数据库表中检索数据。
为了实现更灵活、准确的数据检索,MySQL提供了一系列的SELECT参数,本文将详细介绍这些参数的用法和功能。
1. SELECT语句的基本语法在开始介绍具体的SELECT参数之前,先来回顾一下SELECT语句的基本语法:```SELECT 列名1, 列名2, ... FROM 表名 WHERE 条件;```其中,列名指的是要检索的表中的列,可以是单个列名,也可以是多个列名,多个列名之间用逗号分隔。
表名指的是要检索的表的名称。
WHERE条件用于筛选符合条件的数据行。
2. DISTINCT参数DISTINCT参数用于去除检索结果中重复的数据行。
例如,我们有一个学生表,其中包含了学生的姓名和班级信息,现在需要查询所有班级的名称,可以使用以下语句:```SELECT DISTINCT 班级 FROM 学生表;```这样就会返回不重复的班级名称列表。
3. ORDER BY参数ORDER BY参数用于对检索结果进行排序。
可以根据一个或多个列进行排序,还可以指定升序(ASC)或降序(DESC)。
例如,我们有一个商品表,其中包含了商品的名称和价格信息,现在需要按照价格从高到低的顺序查询商品列表,可以使用以下语句:```SELECT 商品名称, 价格 FROM 商品表 ORDER BY 价格 DESC;```这样就会返回按照价格降序排列的商品列表。
4. LIMIT参数LIMIT参数用于限制检索结果的数量。
可以指定要返回的数据行数的范围。
例如,我们有一个新闻表,其中包含了新闻的标题和发布时间,现在需要查询最新发布的5条新闻,可以使用以下语句:```SELECT 标题, 发布时间 FROM 新闻表 ORDER BY 发布时间 DESC LIMIT 5;```这样就会返回最新发布的5条新闻。
基础select语句详解
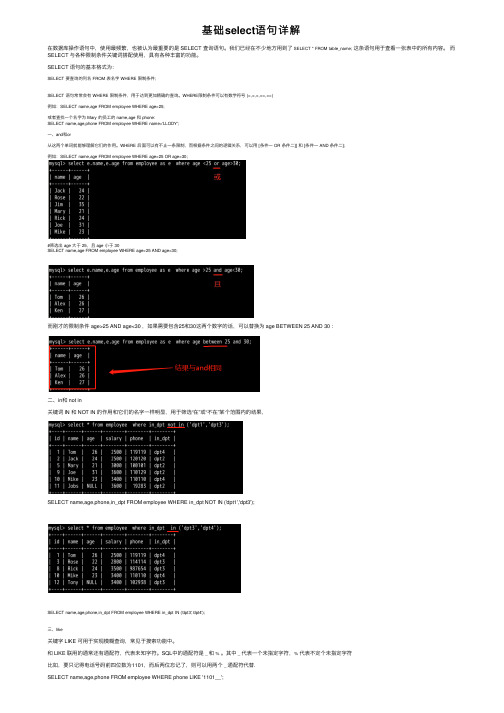
基础select语句详解在数据库操作语句中,使⽤最频繁,也被认为最重要的是 SELECT 查询语句。
我们已经在不少地⽅⽤到了SELECT * FROM table_name;这条语句⽤于查看⼀张表中的所有内容。
⽽SELECT 与各种限制条件关键词搭配使⽤,具有各种丰富的功能。
SELECT 语句的基本格式为:SELECT 要查询的列名 FROM 表名字 WHERE 限制条件;SELECT 语句常常会有 WHERE 限制条件,⽤于达到更加精确的查询。
WHERE限制条件可以有数学符号 (=,<,>,>=,<=)例如:SELECT name,age FROM employee WHERE age>25;或者查找⼀个名字为 Mary 的员⼯的 name,age 和 phone:SELECT name,age,phone FROM employee WHERE name='LLODY';⼀、and和or从这两个单词就能够理解它们的作⽤。
WHERE 后⾯可以有不⽌⼀条限制,⽽根据条件之间的逻辑关系,可以⽤ [条件⼀ OR 条件⼆]] 和 [条件⼀ AND 条件⼆];例如:SELECT name,age FROM employee WHERE age<25 OR age>30;#筛选出 age ⼤于 25,且 age ⼩于 30SELECT name,age FROM employee WHERE age>25 AND age<30;⽽刚才的限制条件 age>25 AND age<30 ,如果需要包含25和30这两个数字的话,可以替换为 age BETWEEN 25 AND 30 :⼆、in和 not in关键词 IN 和 NOT IN 的作⽤和它们的名字⼀样明显,⽤于筛选“在”或“不在”某个范围内的结果,SELECT name,age,phone,in_dpt FROM employee WHERE in_dpt NOT IN ('dpt1','dpt3');SELECT name,age,phone,in_dpt FROM employee WHERE in_dpt IN ('dpt3','dpt4');三、like关键字 LIKE 可⽤于实现模糊查询,常见于搜索功能中。
bootstrapselect2参数详解

bootstrapselect2参数详解1. `liveSearch`:是否启用功能。
默认值为false,表示禁用功能。
设置为true时,下拉框将显示一个框,用于过滤选项。
2. `maxOptions`:设置最大可选项数。
默认值为null,表示不限制最大可选项数。
可以设置一个数字,限制最多可以选择的选项数量。
超过限制的选项将被禁用。
3. `selectedTextFormat`:选择项的展示格式。
可以设置为"values"、"count"或"static"。
默认值为"values",表示展示选中的值。
如果设置为"count",将展示选中的项数量。
如果设置为"static",将展示静态文本,例如"selected items"。
4. `width`:设置下拉框宽度。
可以设置为"auto"、"fit"或一个具体的数值。
默认值为"auto",表示下拉框的宽度将根据内容自动调整。
如果设置为"fit",将根据父容器的宽度来决定下拉框的宽度。
如果设置为一个具体的数值,将按照该数值来设置宽度。
5. `actionsBox`:是否显示操作按钮框。
默认值为false,表示不显示操作按钮框。
设置为true时,将显示一个包含确认和取消按钮的框,用于进行多选操作。
6. `showTick`:是否显示选中的图标。
默认值为false,表示不显示选中的图标。
设置为true时,选中的选项将显示一个小的勾号图标。
7. `multipleSeparator`:多选时选项的分隔符。
默认值为", ",表示使用逗号+空格作为分隔符。
可以设置为任意字符串,用于分隔多选的选项。
8. `noneResultsText`:时无结果时的提示文本。
文管二级Access数据库SQL语句详解
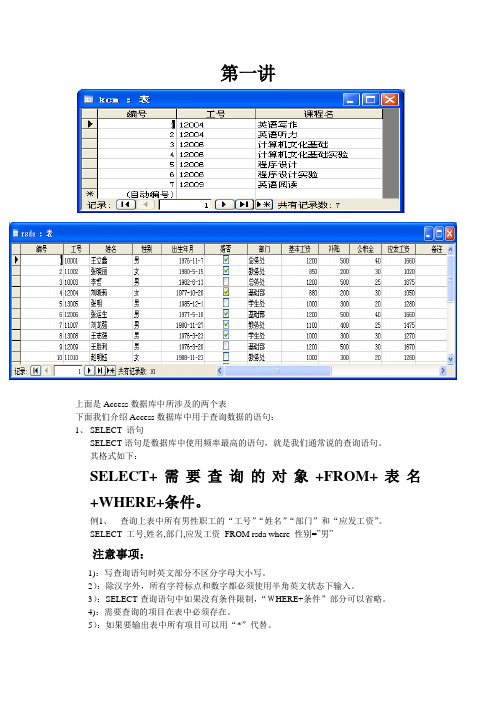
第一讲上面是Access数据库中所涉及的两个表下面我们介绍Access数据库中用于查询数据的语句:1、SELECT 语句SELECT语句是数据库中使用频率最高的语句,就是我们通常说的查询语句。
其格式如下:SELECT+需要查询的对象+FROM+表名+WHERE+条件。
例1、查询上表中所有男性职工的“工号”“姓名”“部门”和“应发工资”。
SELECT 工号,姓名,部门,应发工资FROM rsda where 性别=”男”注意事项:1):写查询语句时英文部分不区分字母大小写。
2):除汉字外,所有字符标点和数字都必须使用半角英文状态下输入。
3):SELECT查询语句中如果没有条件限制,“WHERE+条件”部分可以省略。
4):需要查询的项目在表中必须存在。
5):如果要输出表中所有项目可以用“*”代替。
例如:查询上表中所有人员的姓名,出生年月及部门SELECT 姓名,出生年月,部门FROM rsda;显示表中的所有信息Select * from rsda;显示表中所有女性职工的信息Select * from rsda where 性别=”女”;要求:查询表中所有“未婚”男性职工的信息。
Select * from rsda where (性别=”男”)and(婚否=no);有两个知识点需要掌握:1):运算符:A、算术运算符:加(+)、减(-)、乘(*)、除(/)、和取模(%)。
算术运算符可以完成对两个表达式的数学运算。
B:赋值运算符:等号(=)C:比较运算符:等于(=)、大于(>)、大于或等于(>=)、小于(<)、小于或等于(<=)、不等于(<>或!=)、不小于(!<)、不大于(!>).D:逻辑运算符:与(and)、或(or)和非(not)。
对于AND运算,只有当运算符两端的表达式的值都为真时,结果才返回真,只要有一股表达式的值为假,结果就是假;对于or 运算,只要运算符两端的表达式的值有一个位真,结果就返回真,只有两个表达式的值都是假,结果才为假;NOT运算是对表达式的值取反。
mysql select 参数

mysql select 参数MySQL是一种关系型数据库管理系统,它提供了一种查询语言,称为SQL(Structured Query Language),用于检索和操作数据库中的数据。
SELECT语句是SQL中最常用的语句之一,用于从表中检索数据。
SELECT语句通常由以下几部分组成:1. SELECT子句:指定要检索的列或表达式。
2. FROM子句:指定要从哪个表中检索数据。
3. WHERE子句:指定要检索的数据的条件。
4. ORDER BY子句:指定检索结果的排序方式。
在SELECT语句中,有一些参数可以用来控制查询结果。
以下是一些常用的参数:1. DISTINCT:用于去重。
例如,SELECT DISTINCT 列名 FROM 表名将返回表中不重复的列值。
2. LIMIT:用于限制结果数量。
例如,SELECT * FROM 表名LIMIT 10将返回表中的前10行。
3. ORDER BY:用于指定结果的排序方式。
例如,SELECT * FROM 表名 ORDER BY 列名 ASC将按升序排列结果。
4. WHERE:用于指定检索的条件。
例如,SELECT * FROM 表名WHERE 列名 = '值'将只返回符合条件的行。
5. GROUP BY:用于按照指定列进行分组。
例如,SELECT 列名, COUNT(*) FROM 表名 GROUP BY 列名将返回每个不同列值的数量。
除了上述参数之外,SELECT语句还有许多其他参数,例如JOIN、HAVING、LIKE、IN等等。
这些参数可以帮助我们更精确地指定检索条件,并返回我们所需要的数据。
在使用SELECT语句时,我们需要注意一些常见的错误。
例如,使用SELECT * FROM 表名时可能会返回大量不必要的数据;在指定WHERE条件时,要避免使用过于复杂的表达式,以免影响查询效率。
总之,SELECT语句是MySQL中非常重要的一个功能,我们可以通过合理地使用各种参数来实现我们需要的数据检索。
select2 所有参数列表及常见使用方法

select2 所有参数列表及常见使用方法Select2 所有参数列表及常见使用方法1. 引言Select2 是一个功能强大的下拉选择框插件,通过提供丰富的选项和事件,可以满足各种需求。
本文将详细介绍 Select2 的所有参数以及常见的使用方法,帮助您快速掌握该插件的强大功能。
2. 基本用法初始化 Select2•使用select元素初始化 Select2:$('select').select2();•使用input元素初始化 Select2:$('input').select2();改变 Select2 主题•使用自定义的主题,例如classic:$('select').select2({theme: 'Classic'});3. 参数列表数据源相关参数•data: 设置下拉选项数据源,支持数组或 AJAX 请求的 URL。
•ajax: 用于异步加载下拉选项数据,配置 URL、查询条件等信息。
样式相关参数•placeholder: 设置默认提示文本。
•width: 设置下拉框宽度,支持像素值或百分比。
•minimumInputLength: 设置显示下拉选项的最低输入长度。
•maximumSelectionLength: 设置可选的最大选项数量。
•maximumInputLength: 设置输入框的最大长度。
事件相关参数•select: 当选项被选中时触发的事件。
•open: 当下拉框被展开时触发的事件。
•close: 当下拉框被关闭时触发的事件。
其他参数•disabled: 设置是否禁用下拉选择框。
•allowClear: 设置是否允许清除选中项。
•multiple: 设置是否可多选。
4. 常见使用方法添加默认值可以通过val方法设置默认选中的值:$('select').val('default').trigger('change');动态加载数据使用ajax方法异步加载数据:$('select').select2({ajax: {url: '',dataType: 'json',delay: 250,data: function (params) {return {q: ,page:};},processResults: function (data, params) {= || 1;return {results: ,pagination: {more: ( * 10) < _count}};},cache: true},minimumInputLength: 1});自定义模板可以使用templateResult方法自定义下拉选项的显示方式:function formatState (state) {if (!) {return ;}var $state = $('<span><img src="' + () + '.png" class="img-flag" /> ' + + '</span>');return $state;};$('select').select2({templateResult: formatState});5. 总结本文详细介绍了 Select2 的所有参数以及常见的使用方法。
1Select语句——语法及参数解释

- -或//:表示注释,本内容将不被执行/*………………*/:表示注释,可以将“一段”(很多)内容同时标为注释,而不被执行(但有些内容不可被"注释"掉,比如go)语法SELECT [ ALL | DISTINCT ][ TOP n [ PERCENT ] [ WITH TIES ] ]< select_list > < select_list > ::={ * | { table_name | view_name | table_alias }.* | { column_name | expression | IDENTITYCOL | ROWGUIDCOL } [ [ AS ] column_alias ]| column_alias = expression} [ ,...n ]参数ALL——指定在结果集中可以显示重复行。
ALL 是默认设置。
DISTINCT——指定在结果集中只能显示唯一行。
为了 DISTINCT 关键字的用途,空值被认为相等。
TOP n [PERCENT]——指定只从查询结果集中输出前n行。
n是介于 0 和 4294967295 之间的整数。
如果还指定了 PERCENT,则只从结果集中输出前百分之 n 行。
当指定时带 PERCENT 时,n 必须是介于 0 和 100 之间的整数。
如果查询包含 ORDER BY 子句,将输出由 ORDER BY 子句排序的前n行(或前百分之n行)。
如果查询没有 ORDER BY 子句,行的顺序将任意。
WITH TIES——指定从基本结果集中返回附加的行,这些行包含与出现在 TOP n (PERCENT) 行最后的 ORDER BY 列中的值相同的值。
如果指定了 ORDER BY 子句,则只能指定 TOP ...WITH TIES。
< select_list >——为结果集选择的列。
选择列表是以逗号分隔的一系列表达式。
select 语句简明教程

一、简单查询简单的Transact-SQL查询只包括选择列表、FROM子句和WHERE子句。
它们分别说明所查询列、查询的表或视图、以及搜索条件等。
例如,下面的语句查询testtable表中姓名为"张三"的nickname字段和email字段。
SELECT nickname,email FROM testtable WHERE name= '张三'(一) 选择列表选择列表(select_list)指出所查询列,它可以是一组列名列表、星号、表达式、变量(包括局部变量和全局变量)等构成。
1、选择所有列例如,下面语句显示testtable表中所有列的数据:SELECT * FROMtesttable2、选择部分列并指定它们的显示次序查询结果集合中数据的排列顺序与选择列表中所指定的列名排列顺序相同。
例如:SELECT nickname,email FROM testtable3、更改列标题在选择列表中,可重新指定列标题。
定义格式为:列标题=列名列名列标题如果指定的列标题不是标准的标识符格式时,应使用引号定界符,例如,下列语句使用汉字显示列标题:SELECT 昵称=nickname,电子邮件=email FROM testtable4、删除重复行SELECT语句中使用ALL或DISTINCT选项来显示表中符合条件的所有行或删除其中重复的数据行,默认为ALL。
使用DISTINCT选项时,对于所有重复的数据行在SELECT返回的结果集合中只保留一行。
5、限制返回的行数使用TOP n [PERCENT]选项限制返回的数据行数,TOP n说明返回n行,而TOP n PERCENT时,说明n是表示一百分数,指定返回的行数等于总行数的百分之几。
例如:SELECT TOP 2 * FROMtesttableSELECT TOP 20 PERCENT * FROMtesttable(二) FROM子句FROM子句指定SELECT语句查询及与查询相关的表或视图。
select基本用法 -回复

select基本用法-回复【select基本用法】,以中括号内的内容为主题,写一篇1500-2000字文章,一步一步回答在计算机编程中,select是一种重要的操作,用于多路复用输入/输出。
通过使用select,程序可以同时监听多个文件描述符,从而实现高效的IO 操作。
本文将介绍select的基本用法,包括select函数的使用和原理,以及一些常见的应用场景。
一、select函数的使用select函数是一个系统调用,用于在一组文件描述符上进行监视。
它的声明如下:cint select(int nfds, fd_set *readfds, fd_set *writefds, fd_set*exceptfds, struct timeval *timeout);函数的参数含义如下:- nfds:被监听的最大文件描述符值加一,例如,如果被监听的文件描述符范围是0到fdmax,那么nfds应该为fdmax+1。
- readfds:指向fd_set类型的指针,用来检查可读性,即是否有数据可读。
- writefds:指向fd_set类型的指针,用来检查可写性,即是否可以写入数据。
- exceptfds:指向fd_set类型的指针,用来检查异常情况,例如套接字错误。
- timeout:指向struct timeval类型的指针,用于设定select的超时时间。
在调用select函数之前,需要对fd_set类型的指针进行初始化,并添加要监听的文件描述符。
可以使用FD_ZERO和FD_SET宏来进行初始化和添加操作。
select函数会返回一个整数值,表示满足条件的文件描述符的个数。
如果返回值为0,则表示超时,没有满足条件的文件描述符;如果返回值为-1,则表示出错。
二、select函数的原理select函数的原理是通过轮询各个文件描述符的状态,以确定是否有可读、可写或异常事件发生。
内核会不断扫描每个文件描述符,如果有事件发生,则将其对应的文件描述符添加到相应的fd_set中。
select2 参数

select2 参数摘要:1.select2 简介2.select2 参数概述3.常用select2 参数详解a.data 参数b.placeholder 参数c.multiple 参数d.maximumSelectionLength 参数e.minimumInputLength 参数f.allowClear 参数g.selectOnClose 参数h.closeOnSelect 参数i.dropdownParent 参数j.openOnEnter 参数k.openOnFocus 参数4.select2 参数设置实例5.select2 参数配置总结正文:select2 是一款非常流行的jQuery 插件,用于改进HTML5 中的select 元素。
通过简单的设置,select2 可以实现搜索、多选、清空等功能,极大地提升了用户体验。
本文将详细介绍select2 的参数及其配置方法。
1.select2 简介select2 是一款基于jQuery 的开源插件,用于改进HTML5 中的select 元素。
它为select 元素提供了搜索、多选、清空等功能,并支持动态数据绑定。
select2 默认情况下会自动适配移动设备,因此具有良好的跨平台性能。
2.select2 参数概述select2 提供了丰富的参数选项,以满足不同场景的需求。
主要包括以下几类参数:- data 参数:用于设置select 元素的数据源。
- placeholder 参数:用于设置下拉框中的占位符。
- multiple 参数:用于设置是否支持多选。
- maximumSelectionLength 参数:用于设置用户最多可以选择的项目数。
- minimumInputLength 参数:用于设置用户最少需要输入多少字符才触发搜索功能。
- allowClear 参数:用于设置是否允许清空已选择的项目。
- selectOnClose 参数:用于设置是否在关闭下拉框时自动选择第一个匹配项。
select函数详解及实例分析

select函数详解及实例分析Select函数在Socket编程中还是比较重要的,可是对于初学Socket的人来说都不太爱用Select写程序,他们只是习惯写诸如connect、accept、recv或recvfrom这样的阻塞程序(所谓阻塞方式block,顾名思义,就是进程或是线程执行到这些函数时必须等待某个事件的发生,如果事件没有发生,进程或线程就被阻塞,函数不能立即返回)。
可是使用Select就可以完成非阻塞(所谓非阻塞方式non-block,就是进程或线程执行此函数时不必非要等待事件的发生,一旦执行肯定返回,以返回值的不同来反映函数的执行情况,如果事件发生则与阻塞方式相同,若事件没有发生则返回一个代码来告知事件未发生,而进程或线程继续执行,所以效率较高)方式工作的程序,它能够监视我们需要监视的文件描述符的变化情况——读写或是异常。
下面详细介绍一下!先说明两个结构体:1、select机制中提供了一个数据结构 struct fd_set ,可以理解为一个集合,实际上是一个位图,每一个特定为来标志相应大小文件描述符,这个集合中存放的是文件描述符(file descriptor),即文件句柄(也就是位图上的每一位都能与一个打开的文件句柄(文件描述符)建立联系,这个工作由程序员来完成),这可以是我们所说的普通意义的文件,当然Unix下任何设备、管道、FIFO等都是文件形式,全部包括在内,所以毫无疑问一个socket就是一个文件,socket句柄就是一个文件描述符。
fd_set集合可以通过一些宏由人为来操作,程序员通过操作4类宏,来完成最fd_set的操作:(1)、FD_ZERO(fd_set *) 清空一个文件描述符集合;(2)、FD_SET(int ,fd_set *)将一个文件描述符添加到一个指定的文件描述符集合中;(3)、FD_CLR(int ,fd_set*) 将一个给定的文件描述符从集合中删除;(4)、FD_ISSET(int ,fd_set* )检查集合中指定的文件描述符是否可以读写。
SELECT语句的基本语法

2016-04-05SELECT语句的基本语法格式如下:SELECT<输出列表>[ INTO<新表名>]FROM<数据源列表>[ WHERE <查询条件表达式> ][GROUP BY <分组表达式> [HA VING<过滤条件> ] ][ ORDER BY <排序表达式> [ ASC | DESC ] ]|(竖线)分隔括号或大括号中的语法项。
只能选择其中一项。
[ ](方括号)可选语法项。
不要键入方括号。
< >(小括号)必选语法项。
不要键入小括号。
参数说明如下:SELECT子句用于指定所选择的要查询的特定表中的列,它可以是星号(*)、表达式、列表、变量等。
INTO子句用于指定所要生成的新表的名称。
FROM子句用于指定要查询的表或者视图,最多可以指定个表或者视图,用逗号相互隔开。
WHERE子句用来限定查询的范围和条件。
GROUP BY子句是分组查询子句。
HA VING子句用于指定分组子句的条件。
GROUP BY子句、HA VING子句和集合函数一起可以实现对每个组生成一行和一个汇总值。
ORDER BY子句可以根据一个列或者多个列来排序查询结果。
在SELECT语句中,可以在SELECT子句中选择指定的数据列、改变列标题、执行数据运算、使用ALL关键字、使用DISTINCT关键字等。
-----------------------------------------------------------------------------------------------------------1.查询所有的列。
SELECT语句中使用使用*表示查询所有列。
--【例-1】查询所有学生的信息。
SELECT*FROM students--2.查询指定的列。
选择部分列并指定它们的显示次序,选择的列名必须存在,但列名称之间的顺序既可以与表中定义的列顺序相同,也可以不相同。
SELECT语句参数详解

SELECT语句参数详解
在SQL中,SELECT语句是一种用于从数据库表中检索数据的查询语句。
它允许您指定要返回的列和筛选条件。
FROM表名
WHERE条件;
其中,参数的说明如下:
1.列名:指定要返回的列。
可以是单个列名,多个列名以逗号分隔,也可以使用通配符(*),表示返回所有列。
2.表名:指定要检索数据的表名。
3.WHERE条件:可选参数,用于筛选检索的数据。
条件是一个逻辑表达式,返回TRUE或FALSE。
在SELECT语句中,还可以使用其他参数来对返回的数据进行排序、分组、聚合等操作。
1.ORDERBY:用于按指定列对结果进行排序,可以指定多个列,以逗号分隔。
2.GROUPBY:用于将结果分组。
3.HAVING:在GROUPBY子句后使用,用于筛选分组后的数据。
4.LIMIT:用于限制返回的结果集的数量。
例如
FROM students
WHERE gender = 'Male'
ORDER BY age DESC
LIMIT10;
这个查询将返回名字和年龄列,从名为students的表中选择性别为"Male"的数据,并按年龄降序排列,最多返回10条结果。
总之,SELECT语句参数的目的是允许您指定要返回的列、检索的数据条件以及对结果进行排序、分组和聚合操作。
SELECT语句参数详解

SELECT语句参数详解1.列参数:用于指定查询返回的列。
可以是具体的列名,也可以是通配符"*"表示返回所有列。
例如:SELECT column1, column2 FROM table;2.表参数:用于指定查询的表。
可以是单个表名,也可以是多个表名组合的JOIN表。
例如:SELECT * FROM table1, table2;3.条件参数:用于指定查询的条件。
常用的条件操作符包括等于(=)、不等于(!=)、大于(>)、小于(<)、大于等于(>=)、小于等于(<=)、LIKE、IN等。
例如:SELECT * FROM table WHERE condition;4.排序参数:用于指定查询结果的排序方式。
可以使用ORDERBY子句,并指定一个或多个列名以及排序顺序(升序ASC或降序DESC)。
例如:SELECT * FROM table ORDER BY column DESC;5.分组参数:用于对查询结果进行分组,并进行聚合计算。
可以使用GROUPBY子句,并指定一个或多个列名。
例如:SELECT column, COUNT(*) FROM table GROUP BY column;6.聚合参数:用于对查询结果进行聚合计算,常用的聚合函数包括COUNT、SUM、AVG、MIN、MAX等。
例如:SELECT COUNT(*) FROM table;7.限制参数:用于限制查询结果的返回行数。
可以使用LIMIT子句,并指定返回的行数和起始位置。
例如:SELECT * FROM table LIMIT 10;以上是常用的SELECT语句的参数。
根据具体的需求,还可以使用其他参数和子句来进行高级的查询操作。
mysql select参数

mysql select参数MySQL SELECT参数详解在MySQL数据库中,SELECT语句是最常用的查询语句之一。
通过选择不同的参数,我们可以根据自己的需求来查询数据库中的特定数据。
本文将详细介绍SELECT语句中常用的参数及其用法。
1. SELECT * FROM table_name这是SELECT语句最简单的形式,表示选择表中的所有列。
table_name是要查询的表名。
这个参数可以根据实际情况进行修改,以指定要查询的表。
2. SELECT column_name FROM table_name这个参数表示选择表中的特定列。
column_name是要查询的列名,可以指定多个列名以逗号分隔。
使用该参数可以只选择需要的列,避免不必要的数据冗余。
3. SELECT DISTINCT column_name FROM table_name DISTINCT参数用于去除查询结果中的重复数据。
通过指定DISTINCT column_name,我们可以仅获取列中的不同值。
这在需要统计或筛选唯一值时非常有用。
4. SELECT column_name FROM table_name WHERE condition WHERE参数用于筛选符合条件的数据。
condition是一个逻辑表达式,可以使用比较运算符(如=、<、>)、逻辑运算符(如AND、OR)和通配符(如%、_)进行条件筛选。
其中,%表示任意字符,_表示任意单字符。
5. SELECT column_name FROM table_name ORDER BY column_name ASC/DESCORDER BY参数用于对查询结果进行排序。
ASC表示升序排列,DESC表示降序排列。
通过指定ORDER BY column_name,我们可以按照特定列的值对结果进行排序。
6. SELECT column_name FROM table_name LIMIT offset, countLIMIT参数用于限制结果集的数量。
select语句的定义

select语句的定义Select语句是SQL语言中用于从数据库中检索数据的关键部分。
通过使用不同的条件和参数,可以筛选出满足特定要求的数据集合。
下面将介绍一些常见的select语句及其用法:1. 基本的select语句:```sqlSELECT column1, column2FROM table_name;```这是最基本的select语句,用于选择指定表中的指定列。
可以通过逗号分隔的方式选择多个列。
如果要选择表中的所有列,可以使用星号代替列名。
2. 使用WHERE子句进行条件筛选:```sqlSELECT column1, column2FROM table_nameWHERE condition;```在WHERE子句中可以指定条件,只有满足条件的行会被返回。
条件可以包括比较操作符(如=、>、<)、逻辑操作符(如AND、OR)和通配符(如LIKE)等。
3. 使用DISTINCT关键字去除重复行:```sqlSELECT DISTINCT column1, column2FROM table_name;```DISTINCT关键字用于去除结果集中重复的行,保留每行的唯一性。
可以应用于一个或多个列。
4. 使用ORDER BY关键字对结果排序:```sqlSELECT column1, column2FROM table_nameORDER BY column1 ASC, column2 DESC;```ORDER BY关键字用于对结果进行排序,默认为升序(ASC),也可以指定降序(DESC)。
可以根据一个或多个列进行排序。
5. 使用LIMIT关键字限制返回行数:```sqlSELECT column1, column2FROM table_nameLIMIT 10;```LIMIT关键字用于限制返回的行数,可以指定返回的起始行和数量,也可以仅指定数量。
6. 使用GROUP BY关键字进行分组:```sqlSELECT column1, COUNT(*)FROM table_nameGROUP BY column1;```GROUP BY关键字用于对结果集进行分组,通常与聚合函数一起使用,如COUNT、SUM、AVG等。
VFP select 详解

VFP select 详解从一个或多个表中检索数据。
语法SELECT [ALL | DISTINCT] [TOP nExpr [PERCENT]] [Alias.] Select_Item [ASolumn_Name][, [Alias.] Select_Item [AS Column_Name] ...]FROM [FORCE][DatabaseName!]Table [[AS] Local_Alias][[INNER | LEFT [OUTER] | RIGHT [OUTER] | FULL [OUTER JOINDatabaseName!]Table] Local_Alias][ONoinCondition …][[INTOtination] && into <tabel|cursor|ARRAY><名称> 可选项| [TO FILE FileName [ADDITIVE] | TO PRINTER [PROMPT] | TO SCREEN]][PREFERENCE PreferenceName][NOCONSOLE][PLAIN][NOWAIT][WHERE JoinCondition [AND JoinCondition ...][AND | OR FilterCondition [AND | OR FilterCondition ...]]] [GROUP BY GroupColumn [, GroupColumn ...]][HA VING FilterCondition][UNION [ALL] SELECT命令][ORDER BY Order_Item [ASC | DESC] [, Order_Item [ASC | DESC] ...]]参数SELECT在SELECT 子句中指定在查询结果中包含的字段、常量和表达式。
ALL|*查询结果中包含所有行( 包括重复值)。
select的参数

在计算机编程中,`select` 是一种用于多路复用(multiplexing)I/O 操作的系统调用函数。
它允许程序在多个输入/输出源(如文件描述符、套接字等)上进行非阻塞的监视,并在其中一个或多个源可用时立即进行处理。
`select` 函数可以用于实现高效的并发操作,常见于网络编程和并发服务器中。
`select` 函数的主要参数如下所述:1. `nfds`:这是要监听的所有文件描述符的最大值加1。
它指示`select` 在文件描述符集合中查找的范围。
2. `readfds`、`writefds` 和`exceptfds`:它们是分别用于监听读、写和异常状态的文件描述符集合。
它们是用位掩码实现的整数集合,可以使用一些辅助函数(如`FD_ZERO`、`FD_SET`)进行设置和操作。
3. `timeout`:这是一个时间结构体,用于设置`select` 的超时时间。
它可以指定`select` 在等待I/O 就绪时间的长度。
如果设置为`NULL`,`select` 将一直等待直到有文件描述符就绪。
`select` 的返回值表示就绪文件描述符的数量,如果返回值小于0,表示出现了错误。
在成功调用`select` 后,程序可以通过检查相应的文件描述符集合中的位来确定哪些文件描述符已经准备好读取、写入或出现异常。
`select` 的工作原理是将文件描述符集合传递给操作系统,并阻塞等待,直到集合中的一个或多个文件描述符变为可读、可写或出现异常。
一旦有文件描述符就绪,`select` 将返回,并通过位掩码表示就绪的文件描述符。
需要注意的是,`select` 函数具有一些缺点,如效率低下、最大文件描述符数量的限制等。
在某些情况下,可以考虑使用更高级的I/O 复用机制,如`epoll` 或`kqueue`,以提高性能和可伸缩性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
可选的 WHERE 条件有如下常见的形式:
WHERE boolean_expr
boolean_expr 可以包含任意个得出布尔值的表达式。通常表达式会是
expr cond_op expr
或
log_op expr
这里 cond_op 可以是: =,<,<=, >,>= 或 <>, 或条件操作符象 ALL,ANY,IN,LIKE 等,或者用户定义的操作符,而 log_op 可以为 : AND,OR,NOT. SELECT 将忽略所有 WHERE 条件不为 TRUE 的行.
相反, RIGHT OUTER JOIN 返回所有连接的行, 另外加上所有未匹配右手边行(左手边插入 NULL 扩展为全长). 这个字句只是符号方便,因为你可以调换左右输入而改用 LEFT OUTER JOIN.
FULL OUTER JOIN 返回所有连接行,加上所有未匹配的左手边行 (右边插入 NULL 扩展为全长), 再加上所有未匹配的右手边行(左手边插入 NULL 扩展为全长).
SELECT
Name
SELECT -- 从表或视图中取出若干行.
Synopsis
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ]
* | expression [ AS output_name ] [, ...]
[ FROM from_item [, ...] ]
LEFT OUTER JOIN 返回所有符合条件的迪卡尔积 (也就是说,所有符合它的 ON 条件的组合了的行),另外加上 所有没有右手边行符合 ON 条件的左手边表中的行. 这样的左手边行通过向右手边行插入 NULL 扩展为全长. 请注意,当判断哪些行合格的时候,只考虑 JOIN 自己的 ON 或 USING. 然后才考虑外层的 ON 或 WHERE 条件.
|
( select )
[ AS ] alias [ ( column_alias_list ) ]
|
from_item [ NATURAL ] join_type from_item
[ ON join_condition | USING ( join_column_list ) ]
HAVING 允许只选择那些满足声明条件的行组(参阅 HAVING 子句.)
ORDER BY 导致返回的行按照声明的顺序排列. 如果没有给出 ORDER BY,输出的行的顺序将以系统认为开销最小的顺序产生. (参阅 ORDER BY 子句.)
多个 SELECT 查询可以用 UNION,INTERSECT,和 EXCEPT 操作符 组合起来.必要时请使用圆括弧确定这些操作符的顺序.
UNION 操作符计算是那些参与的查询所返回的行的集合。 如果没有声明 ALL,那么重复行被删除. (参阅 UNION 子句.)
INTERSECT 给出两个查询公共的行。 如果没有声明 ALL,那么重复行被删除. (参阅 INTERSECT 子句.)
EXCEPT 给出存在于第一个查询而不存在于第二个查询的行。 如果没有声明 ALL,那么重复行被删除. (参阅 EXCEPT 子句.)
join_condition
一个条件限制.类似 WHERE 条件,只不过它只应用于在这条 JOIN 子句里 连接的两个 from_item.
join_column_list
一个 USING 字段列表 (a, b, ... ) 是 ON 条件 left_table.a = right_table.a AND left_table.b = right_table.b ... 的缩写.
输入
expression
表的列/字段名或一个表达式.
output_name
使用 AS 子句为一个列/字段或一个表达式声明另一个名称. 这个名称主要用于标记输出列用于显示。 它可以在 ORDER BY 和 GROUP BY 子句里代表列/字段的值. 但是 output_name 不能用于 WHERE 或 HAVING 子句;用表达式代替.
[ WHERE condition ]
[ GROUP BY expression [, ...] ]
[ HAVING condition [, ...] ]
[ { UNION | INTERSECT | EXCEPT } [ ALL ] select ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [, ...] ]
如果 FROM 项是一个简单表名字,它隐含包括来自该表子表(继承子表)的行. ONLY 将消除从该表的子表来的行. 在 PostgreSQL 7.1 以前,这是缺省结果, 而获取子表的行是通过在表名后面附加 * 实现的. 这种老式性质可以通过命令 SET SQL_Inheritance TO OFF; 获取.
GROUP BY 子句
GROUP BY 声明一个分了组的表,该表源于应用使用下面的子句:
GROUP BY expression [, ...]
GROUP BY 将把所有在组合了的列上共享同样的值的行压缩成一行。 如果存在聚集函数,这些聚集函数将计算每个组的所有行,并且为 每个组计算一个独立的值(如果没有 GROUP BY, 聚集函数对选出的所有行计算出一个数值)。存在 GROUP BY 时,除了在聚集函数 里面,SELECT 输出表达式对任何非组合列的引用都是非法的, 因为对一个非组合列会有多于一个可能的返回值。
FROM 项也可以是一个加了圆括弧的子查询 (请注意子查询需要一个别名子句!). 这个特性非常实用,因为这是在一条查询中获得多层分组, 聚集,或者排序的唯一方法.
最后,FROM 项可以是一条 JOIN 子句,它把两个简单的 FROM 项组合 在一起.(必要时使用圆括弧来描述嵌套顺序.)
from_item
一个表引用,子查询,或者 JOIN 子句.详见下文.
condition
一个布尔表达式,给出真或假的结果. 参见下面描述的 WHERE 和 HAVING 子句.
select
一个选择语句,可以有除 ORDER BY,FOR UPDATE,和 LIMIT 子句以外的所有 特性(甚至在加了括弧的情况下那些语句也可以用).
DISTINCT ON 删除匹配所有你声明的表达式的行, 只保留每个重复集的第一行。 DISTINCT ON 表达式是用和 ORDER BY 项一样的规则来解释的,见下文. 注意这里每个重复集的"第一行"是不可预料的,除非我们用 ORDER BY 来保证我们希望的行最先出现。例如,
SELECT DISTINCT ON (location) location, time, report
FROM 项可以包括:
table_name
一个现存的表或视图的名字.如果声明了 ONLY,则只扫描该表. 如果没有声明ONLY,该表和所有其派生表(如果有的话)都被扫描. 可以在表名后面跟一个 * 来表示扫所有其后代表, 但在目前的版本里,这是缺省特性. (在 PostgreSQL 7.1 以前的版本里, ONLY 是缺省特性.)
CROSS JOIN 或 INNER JOIN 是简单的迪卡尔积, 和你在顶层 FROM 里列出这两个项得到的一样. CROSS JOIN 等效于 INNER JOIN ON (TRUE),也就是说, 不会有任何行被条件删除.这些连接类型只是符号上的便利, 因为它们做得一点不比你只利用 FROM 和 WHERE 来的多.
[ FOR UPDATE [ OF tablename [, ...] ] ]
[ LIMIT { count | ALL } ]
[ OFFSET start ]
这里 from_item 可以是:
[ ONLY ] table_name [ * ]
[ [ AS ] alias [ ( column_alias_list ) ] ]
FOR UPDATE 子句允许 SELECT 语句对选出的行执行排他锁。
LIMIT 子句允许给用户返回一个查询生成的结果的子集。(参阅 LIMIT 子句.)
你必须有 SELECT 权限用来从表中读取数值 (参阅 GRANT/REVOKE语句.)
FROM 子句
FROM 子句为 SELECT 声明一个或多个源表. 如果声明了多个源表,则概念上结果是所有源表所有行的迪卡尔积 --- 不过通常会增加限制条件以把返回的行限制为迪卡尔积的一个小子集.
FROM weatherReports
ORDER BY location, time DESC;
检索出每个地区的最近的天气预报。 但是如果我们没有使用 ORDER BY 来强制每个地区按时间值降续排列, 我们得到的将是每个地区的不可预料的时间的报告。
GROUP BY 子句允许用户把表分成匹配一个或多个数值的不同行的组. (参考 GROUP BY 子句.)
除了CROSS JOIN 以外的所有 JOIN 类型,你必须写 ON join_condition, USING ( join_column_list ), 和 NATURAL 中的一个. 大多数情况下会是 ON:你可以写涉及两个连接表的任何条件表达式. USING 字段列表 (a, b, ...) 是 ON 条件 left_table.a = right_table.a AND left_table.b = right_table.b ... 的缩写. 另外,USING 假设两对等式中只有一个包含在 JOIN 输出中,而不是两个. NATURAL 是提及表中所有相似名字字段的 USING 列表的缩写.