编译原理 递归下降分析法C语言
编译原理 递归下降词法分析

编译原理实验报告—递归下降分析法程序实验2.1 递归下降分析法一、实验目的1. 根据某一文法编制递归下降分析程序,以便对任意输入的符号串进行分析。
2. 本次实验的目的是加深对递归下降分析法的理解。
二、实验平台Windows + VC++6.0范例程序: “递归下降分析法.cpp ”三、实验内容对下列文法,用递归下降分析法对任意输入的符号串进行分析:(1)E→TG(2)G→+TG|-TG(3)G→ε(4)T→FS(5)S→*FS|/FS(6)S→ε(7)F→(E)(8)F→i1.程序功能:输入: 一个以# 结束的符号串(包括+ - * / ()i # ):例如:i+i*i-i/i#输出:(1) 详细的分析步骤,每一步使用的产生式、已分析过的串、当前分析字符、剩余串,第一步, 产生式E->TG的第一个为非终结字符,所以不输出分析串,此时分析字符为i,剩余字符i+i*i-i/i#;第二步,由第一步的E->TG的第一个为非终结字符T,可进行对产生式T->FS 分析,此时第一个仍为非终结字符F,所以不输出分析串,分析字符仍为i, 剩余字符i+i*i-i/i#;第三步,使用产生式F->i,此时的分析串为i,,分析字符为i,匹配成功,剩余字符串+i*i-i/i#;第四步,因为使用了产生式T->FS,F->i,第一个字符i匹配成功,接着分析字符+,使用产生式S->ε,进行下步;第五步,使用产生式G->+TG,此时的分析串包含i+,分析字符为+,剩余字符串+i*i-i/i#;第六步,重复对产生式T->FS,F->i的使用,对第二个i进行匹配,此时分析串i+i,分析字符为i,剩余串*i-i/i#;第七步,分析字符*,使用产生式S->*FS, 分析串i+i*,剩余串i-i/i#;第八步,字符*匹配成功后,使用产生式F->i,匹配第三个字符i,,此时剩余串-i/i#;第九步,分析字符-,只有产生式G->-TG可以产生字符-。
编译原理及实现技术:11.语法分析_递归下降法

2. 语法分析程序的构造
当产生式形如:A1|2|…|n,则按下面的方法编写子程序A: procedure A( )
begin if tokenPredict(A1) then (1) else if tokenPredict(A2) then (2) else ……
if tokenPredict(An) then (n) else error( )
end
其中对i=X1X2…Xn,(i)='(X1);'(X2);…;'(Xn);
如果XVN,'(X)= X();
如果XVT,'(X)= Match(X); //即if(token==X)ReadToken();
如果X= ,() = skip(空语句).
7
2. 语法分析{ ReadToken(); S( ); if (token=='#') 成功; else 失败
12
predict集,交集为空。
3
2. 语法分析程序的构造
两个标准函数
1.ReadToken:把输入流的头符读入变量 token中
2.Match(a): if token=a then ReadToken else 出错
4
2. 语法分析程序的构造
有规则:Stm while Exp do Stm 对应产生式右部的语法分析程序部分如下:
第三章:语法分析
递归下降法
1. 递归下降法的基本原理
有文法: E E+T| T T T *F| F F(E)|i 有句子: (i+i)*i+i
E
E +T
T
F
T*F
i
F
实验二 递归下降分析法的实现
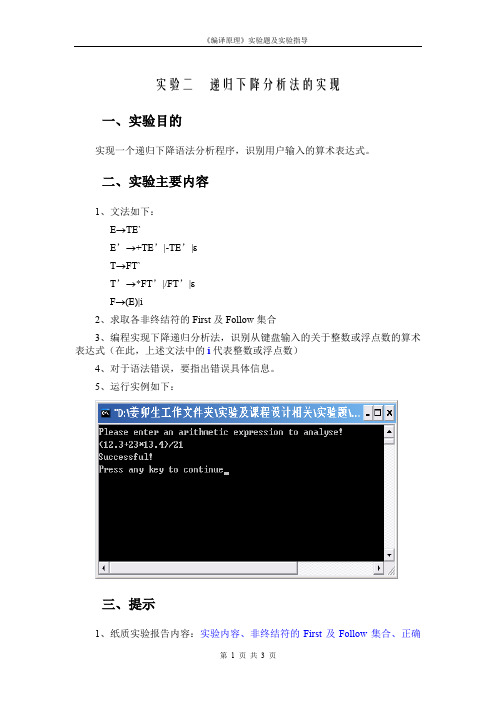
实验二递归下降分析法的实现一、实验目的实现一个递归下降语法分析程序,识别用户输入的算术表达式。
二、实验主要内容1、文法如下:E→TE`E’→+TE’|-TE’|εT→FT`T’→*FT’|/FT’|εF→(E)|i2、求取各非终结符的First及Follow集合3、编程实现下降递归分析法,识别从键盘输入的关于整数或浮点数的算术表达式(在此,上述文法中的i代表整数或浮点数)4、对于语法错误,要指出错误具体信息。
5、运行实例如下:三、提示1、纸质实验报告内容:实验内容、非终结符的First及Follow集合、正确表达式与错误表达式各举一例进行测试并给出结果、核心源代码。
2、将本次实验代码(.c、.cpp、.java等代码文件,删除编译产生的所有其他文件,不要打包)在规定时间内以作业附件(不可在线编辑、粘贴代码)的形式提交至网站,自己保存以备课程设计(本部有毕业设计要求的学生)参考。
3、纸质实验报告提交时间:临时要求。
实验指导(参考)一、实验步骤1、求取各非终结符的First及Follow集合;2、设计几个函数E(); Ep(); T(); Tp(); F();运用First集合进行递归函数选择,运用Follow集合进行出错情况判断;3、设计主函数:从键盘接受一个算术表达式串;在串尾添加尾部标志’#’;调用函数E()进行递归下降分析。
二、如何识别整数与浮点数在函数F()中要涉及到如何识别整数与浮点数。
识别的方法是:只要碰到‘0’~‘9’之间的字符就一直循环,循环到不是数字字符与小数点字符’.’为止,其间要运用一个标志变量来保证最多只能出现一个小数点,否则应该报错。
上述循环结束即表示识别了一个数,也即表达式文法中的i。
编译原理-递归下降分析法

编译原理-递归下降分析法题:对下列⽂法,⽤递归下降分析法对任意输⼊的符号串进⾏分析:(1)E->TG(2)G->+TG|—TG(3)G->ε,(4)T->FS(5)S->*FS|/FS(6)S->ε(7)F->(E)(8)F->i答:⽂法太多,可先合并。
(1)E->FSG(2)G->+TG|—TG|ε(3)S->*FS|/FS|ε(4)F->(E)|i结合1,4(1)E->ESG|iSG(2)G->+TG|—TG|ε(3)S->*FS|/FS|ε(4)F->(E)|i消除左递归(1)E->iSGE1(2)E1->SGE1|ε(3)G->+TG|—TG|ε(4)S->*FS|/FS|ε(5)F->(E)|i好吧,其实上⾯的化简有些地⽅并⽆必要,不过我的代码是按照最后的⽂法写的。
package compile;public class com {public static String str="i+i*i"; //待测试语句static int seri=0; //记录当前读到的序号public static void main(String[] args) {int t=E(); //⽂法if(t==1) {System.out.println(str+" compiled successfully");}else {System.out.println(str+" compiled failed");}}static char getchar() {if(seri<str.length()) {System.out.println(seri+" "+str.charAt(seri));return str.charAt(seri++);}return ' ';};static int E() {char ch=getchar();if(ch!='i') {return 0;}return S()*G()*E1();}static int S() {char ch=getchar();if(ch=='+'|ch=='-') {seri--;return 1;}else if(ch=='*'|ch=='/') {return F()*S();}else if(ch=='i') {return 0;}return 1;}static int F() {char ch=getchar();if(ch=='i') return 1;return E();}static int G() {char ch=getchar();if(ch=='*'|ch=='/') {seri--;return 1;}else if(ch=='+'|ch=='-') {return F()*S()*G();}else if(ch=='i') {return 0;}return 1;}static int E1() {char ch=getchar();if(ch=='i') return 0;if(ch==' ') return 1;return S()*G()*E1(); }}。
编译原理_实验二_语法分析_递归下降分析器设计_实验报告

递归下降分析器设计一、实验/实习过程内容:利用JavaCC生成一个MiniC的语法分析器;要求:1. 用流的形式读入要分析的C语言程序,或者通过命令行输入源程序。
2. 具有错误检查的能力,如果有能力可以输出错误所在的行号,并简单提示3. 如果输入的源程序符合MiniC的语法规范,输出该程序的层次结构的语法树具体实施步骤如下:1.把MiniC转换为文法如下<程序〉→ main()〈语句块〉〈语句块〉→{〈语句串〉}〈语句串〉→〈语句〉〈语句串〉|〈语句〉〈语句〉→〈赋值语句〉|〈条件语句〉|〈循环语句〉〈赋值语句〉→ ID =〈表达式〉;〈条件语句〉→ if〈条件〉〈语句块〉〈循环语句〉→ while〈条件〉〈语句块〉〈条件〉→(〈表达式〉〈关系符〉〈表达式〉)〈表达式〉→〈表达式〉〈运算符〉〈表达式〉|(〈表达式〉)|ID|NUM〈运算符〉→+|-|*|/〈关系符〉→<|<=|>|>=|==|!=2.消除语句中的回溯与左递归3.在eclipse环境下完成JavaCC的插件安装后,写一个JavaCC文法规范文件(扩展名为jj)4.完成的功能包括词法分析,语法分析二、代码:options {JDK_VERSION = "1.5";}PARSER_BEGIN(eg1)public class eg1 {public static void main(String args[]) throws ParseException { eg1 parser = new eg1(System.in);parser.start();}}PARSER_END(eg1)SKIP :{" "| "\r"| "\t"| "\n"}TOKEN : /* OPERATORS */{< PLUS: "+" >| < MINUS: "-" >| < MULTIPLY: "*" >| < DIVIDE: "/" >}TOKEN :{<BIGGER:">"> |<SMALLER:"<"> |<NOTVOLUTION:"!="> |<SMALLEREQDD:"<="> |<BIGGEREE:">=" > |<DOUBLE:"==">TOKEN: //关键字{<MAIN:"main"> |<VOID:"void"> |<IF:"if"> |<INT:"int"> | <WHILE:"while"> |<CHAR:"char"> | <VOLUTION:"="> }TOKEN : //定义整型数{< INTEGER: ["0" - "9"]( <DIGIT> )+ >| < #DIGIT: ["0" - "9"] >}TOKEN : //数字{<NUMBER:(<DIGIT>)+ | (<DIGIT>)+"."| (<DIGIT>)+"."(<DIGIT>)+| "."(<DIGIT>)+>}TOKEN : //标记{<COMMA:","> | <SEMICOLON:";"> | <COLON:":"> | <LEFTPARENTHESES:"("> |<RIGHTPARENTHESES:")"> | <LEFTBRACE:"{"> | <RIGHTBRACE:"}"> }TOKEN : //标识符{<IDENTIFIER:<LETTER> |<LETTER>(<LETTER> | <DIGIT> )* >|<#LETTER:["a"-"z", "A"-"Z"]>}void start():{}{<MAIN> <LEFTPARENTHESES> <RIGHTPARENTHESES> block() }void block():{}{<LEFTBRACE> string() <RIGHTBRACE>}void string():{}{yuju() (string())?}void yuju():{}{fuzhiyuju() | tiaojianyuju() | xunhuanyuju()}void fuzhiyuju():{}{<IDENTIFIER> <VOLUTION> biaodashi() <SEMICOLON>}void tiaojianyuju():{}{<IF> tiaojian() block()}void xunhuanyuju():{}<WHILE> tiaojian() block()}void tiaojian():{}{<LEFTPARENTHESES> biaodashi() guanxifu() biaodashi()<RIGHTPARENTHESES>}void biaodashi():{}{( <LEFTPARENTHESES> biaodashi() <RIGHTPARENTHESES> biaodashi2()) |(<IDENTIFIER> biaodashi2() ) | ( <NUMBER> biaodashi2() )}void biaodashi2():{}{(yunsuanfu() biaodashi() biaodashi2() )?}void yunsuanfu():{}{< PLUS > | < MINUS > |< MULTIPLY> | < DIVIDE >}void guanxifu() :{}{<BIGGER> | <SMALLER> | <NOTVOLUTION><SMALLEREQDD> | <BIGGEREE> | <DOUBLE>}三、实验/实习总结本次实习,我使用javacc完成了包括词法分析,语法分析(输出语法树),能够读文件的功能,总的来说比较满意,通过本次实习掌握了javacc基本的使用。
编译原理递归下降分析法C语言

编译原理递归下降分析法C语言编译原理是计算机科学中的一个重要领域,主要研究如何将高级语言程序转化为机器可执行的目标代码。
在编译原理中,递归下降分析法是一种常用的语法分析方法,它通过递归地从上至下对程序进行分析,最终确定程序的语法结构。
递归下降分析法是一种自顶向下的语法分析方法,基于产生式和预测分析表来实现对程序的语法分析。
该方法的基本思想是,每个非终结符对应一个处理过程,通过递归调用这些处理过程来分析整个程序。
在C语言的递归下降分析法中,需要定义对应C语言语法结构的处理过程,这些处理过程通常对应于C语言中的各种语句、表达式、声明等。
递归下降分析法的实现主要包括两个步骤:构造预测分析表和编写递归下降分析程序。
预测分析表是一个二维表格,行对应于非终结符,列对应于终结符,表格中的每个元素记录了该产生式的编号。
通过预测分析表,可以预测下一个分析符号,并选择相应的产生式进行语法分析。
编写递归下降分析程序时,首先需要确定递归下降分析程序的数据结构和接口。
一般来说,分析程序的数据结构包括符号栈、语法树等,接口包括初始化、语法分析、错误处理等。
接下来,根据语法规则编写对应的递归下降分析函数,每个函数对应一个非终结符的处理过程。
在实际编写过程中,通常使用递归调用来实现对程序的逐步分析,直到达到终结符。
递归下降分析法在C语言编译器中的应用非常广泛。
通过该方法,可以对C语言程序进行语法分析,检测代码中的语法错误,并生成相应的语法树。
在生成语法树之后,可以继续进行语义分析、中间代码生成、代码优化等编译过程。
总的来说,递归下降分析法是一种重要的语法分析方法,可以用于对C语言程序进行语法分析。
它通过自顶向下的递归调用,从上至下地解析语法规则,最终确定程序的语法结构。
递归下降分析法在实际编译器设计中有广泛应用,是理解和学习编译原理的重要内容。
编译原理递归下降

《编译原理》课程实验实验二:自顶向下的语法分析:递归下降法1、实验目的:编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析。
2、实验要求:文法(教材199页)(1)把词法分析作为语法分析的子程序实现(5分)(2)独立的语法分析程序(4分)(3)输入串以‘#’结束,输出成功(success)或出错(error)、指出出错位置(行、列以及错误类型)#include<iostream>#include<ctype.h>#include<fstream>#include<string.h>#include<malloc.h>using namespace std;ifstream fp("in.txt",ios::in);char cbuffer;char *key[13]={"if","else","for","while","do","return","break","continue","int","void" ,"main","begin","end"}; //关键字char *border[8]={ "," , ";" , "{" , "}" , "(" , ")" ,"//","\""}; //分界符char *arithmetic[6]={"+" , "-" , "*" , "/" , "++" , "--"}; //运算符char *relation[7]={"<" , "<=" , "=" , ">" , ">=" , "==" ,"!="}; //关系运算符char *lableconst[80]; //标识符int constnum=40;int lableconstnum=0;int colnum = 1, linenum=1; //统计常数和标识符数量int type1, type2;int search(char searchchar[],int wordtype){int i=0,t=0;switch (wordtype){case 1:{ for (i=0;i<=12;i++) //关键字{if (strcmp(key[i],searchchar)==0)return(i+1);}return(0);}case 2:{for (i=0;i<=6;i++) //分界符{if (strcmp(border[i],searchchar)==0)return(i+1);}return(0);}case 3:{for (i=0;i<=5;i++) //运算符{if (strcmp(arithmetic[i],searchchar)==0)return(i+1);}return(0);}case 4:{for (i=0;i<=6;i++) //关系运算符{if (strcmp(relation[i],searchchar)==0)return(i+1);}return(0);}case 5:{for (t=40;t<=constnum;t++) //常数{if (strcmp(searchchar,lableconst[t])==0)//判断该常数是否已出现过return(t+1);}lableconst[t-1]=(char *)malloc(sizeof(searchchar));//为新的元素分配内存空间strcpy(lableconst[t-1],searchchar);//为数组赋值lableconst指针数组名constnum++; //常数个数自加return(t);}case 6:{for (i=0;i<=lableconstnum;i++){if (strcmp(searchchar,lableconst[i])==0) //判断标识符是否已出现过return(i+1);}lableconst[i-1]=(char *)malloc(sizeof(searchchar));strcpy(lableconst[i-1],searchchar);lableconstnum++; //标识符个数自加return(i);}default:cout<<"错误!";return 0;}}char alphaprocess(char buffer) //字符处理过程{int atype;int i=-1;char alphatp[20];while (((isalpha(buffer))||(isdigit(buffer))) && !fp.eof()){alphatp[++i]=buffer;fp.get(buffer);}alphatp[i+1]='\0';//在末尾添加字符串结束标志if (atype=search(alphatp,1)){cout<<alphatp<<"\t\t\t"<<"关键字"<<endl;type1 = 0;}else{atype=search(alphatp,6); //标识符cout<<alphatp<<"\t\t\t"<<"标识符"<<endl;type1 = 1;}type2 = atype;return(buffer);}char digitprocess(char buffer) //数字处理过程{int i=-1;char digittp[20];int dtype;while((isdigit(buffer)||buffer=='.'||buffer=='e'||buffer=='+'||buffer=='-')&& !fp.eof()) {digittp[++i]=buffer;fp.get(buffer);}digittp[i+1]='\0';dtype=search(digittp,5);cout<<digittp<<"\t\t\t"<<"数据"<<endl;type1 = 8;type2 = dtype;return(buffer);}char otherprocess(char buffer) //分界符、运算符、逻辑运算符、等{int i=-1;char othertp[20];int otype,otypetp;othertp[0]=buffer;othertp[1]='\0';if (otype=search(othertp,3)){fp.get(buffer);othertp[1]=buffer;othertp[2]='\0';if (otypetp=search(othertp,3)) //判断该运算符是否是//由连续的两个字符组成的{cout<<othertp<<"\t\t\t"<<"运算符"<<endl;fp.get(buffer);type1 = 2;goto out;}else//单字符逻辑运算符{othertp[1]='\0';cout<<othertp<<"\t\t\t"<<"逻辑运算符"<<endl;type1 = 3;goto out;}}if (otype=search(othertp,4)) //关系运算符{fp.get(buffer);othertp[1]=buffer;othertp[2]='\0';if (otypetp=search(othertp,4)) //判断该关系运算符是否是//由连续的两个字符组成的{cout<<othertp<<"\t\t\t"<<"关系运算符"<<endl;fp.get(buffer);type1 = 4;goto out;}else//单字符逻辑运算符{othertp[1]='\0';cout<<othertp<<"\t\t\t"<<"逻辑运算"<<endl;type1 = 5;goto out;}}if (buffer=='!') //"=="的判断{fp.get(buffer);if (buffer=='=')//cout<<"!= (2,2)\n";fp.get(buffer);type1 = 6;goto out;}else{if (otype=search(othertp,2)) //分界符{cout<<othertp<<"\t\t\t"<<"分界符"<<endl;fp.get(buffer);type1 = 7;goto out;}}if ((buffer!='\n')&&(buffer!=' '))cout<<"错误!,字符非法"<<"\t\t\t"<<buffer<<endl;fp.get(buffer);out:type2 = otypetp;return(buffer);}void getWord(){type1 = -1;while(type1 == -1){if (fp.eof()) break;colnum++;if(cbuffer=='\n'){linenum++;colnum = 1;fp.get(cbuffer);}else if (isalpha(cbuffer)){cbuffer=alphaprocess(cbuffer);}else if (isdigit(cbuffer)){cbuffer=digitprocess(cbuffer);}elsecbuffer=otherprocess(cbuffer);}}string eText;bool hasError;void setError(string text) {hasError = true;eText = text;}void checkExpression();void checkFactor() {cout << type1 << " " << type2 << endl;if (type1 == 1 || type1 == 8) getWord();else if (type1 == -1) setError("缺少值或变量。
递归下降分析法 编译原理 LL1文法

归下降分析法实现LL1文法产生式:(《编译原理》第二版P95)E->TPP->+TP|nullT->FQQ->*FQ|nullF->i|(E)代码:public class Accept2 {public static StringBuffer stack=new StringBuffer("#E");public static StringBuffer stack2=new StringBuffer("i+i*i+i#");public static void main(String arts[]){//stack2.deleteCharAt(0);System.out.print(accept(stack,stack2));}public static boolean accept(StringBufferstack,StringBuffer stack2){//判断识别与否boolean result=true;outer:while (true) {System.out.format("%-9s",stack+"");System.out.format("%9s",stack2+"\n");char c1 = stack.charAt(stack.length() - 1);char c2 = stack2.charAt(0);if(c1=='#'&&c2=='#')return true;switch (c1) {case 'E':if(!E(c2)) {result=false;break outer;}break;case 'P':if(!P(c2)) {result=false;break outer;}break;case 'T':if(!T(c2)) {result=false;break outer;}break;case 'Q':if(!Q(c2)) {result=false;break outer;}break;case 'F':if(!F(c2)) {result=false;break outer;}break;default: {//终结符的时候if(c2==c1){stack.deleteCharAt(stack.length()-1);stack2.deleteCharAt(0);//System.out.println();}else{return false;}}}if(result=false)break outer;}return result;}public static boolean E(char c) {//语法分析子程序 E boolean result=true;if(c=='i') {stack.deleteCharAt(stack.length()-1);stack.append("PT");}else if(c=='('){stack.deleteCharAt(stack.length()-1);stack.append("PT");}else{System.err.println("E 推导时错误!不能匹配!");result=false;}return result;}public static boolean P(char c){//语法分析子程序P boolean result=true;if(c=='+') {stack.deleteCharAt(stack.length()-1);}else if(c==')') {stack.deleteCharAt(stack.length()-1);//stack.append("");}else if(c=='#') {stack.deleteCharAt(stack.length()-1);//stack.append("");}else{System.err.println("P 推导时错误!不能匹配!");result=false;}return result;}public static boolean T(char c) {//语法分析子程序T boolean result=true;if(c=='i') {stack.deleteCharAt(stack.length()-1);stack.append("QF");}else if(c=='(') {stack.deleteCharAt(stack.length()-1);stack.append("QF");}else{result=false;System.err.println("T 推导时错误!不能匹配!"); }return result;}public static boolean Q(char c){//语法分析子程序Q boolean result=true;if(c=='+') {stack.deleteCharAt(stack.length()-1);//stack.append("");}else if(c=='*') {stack.deleteCharAt(stack.length()-1);stack.append("QF*");}else if(c==')') {stack.deleteCharAt(stack.length()-1);}else if(c=='#') {stack.deleteCharAt(stack.length()-1);//stack.append("");}else{result=false;System.err.println("Q 推导时错误!不能匹配!");}return result;}public static boolean F(char c) {//语法分析子程序 Fboolean result=true;if(c=='i') {stack.deleteCharAt(stack.length()-1);stack.append("i");}else if(c=='(') {stack.deleteCharAt(stack.length()-1);stack.append(")E(");}else{result=false;System.err.println("F 推导时错误!不能匹配!");}return result;}/* public static StringBufferchangeOrder(String s){//左右交换顺序StringBuffersb=new StringBuffer();for(inti=0;i<s.length();i++){sb.append(s.charAt(s.length()-1-i));}returnsb;}*/}。
编译原理-实验4递归下降分析法

实验4《递归下降分析法设计与实现》实验学时: 2 实验地点:实验日期:一、实验目的根据某一文法编制调试递归下降分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对递归下降分析法的理解。
二、实验内容程序输入/输出示例(以下仅供参考):对下列文法,用递归下降分析法对任意输入的符号串进行分析:(1)E-TG(2)G-+TG|—TG(3)G-ε(4)T-FS(5)S-*FS|/FS(6)S-ε(7)F-(E)(8)F-i输出的格式如下:(3)备注:输入一符号串如i+i*#,要求输出为“非法的符号串”。
注意:1.表达式中允许使用运算符(+-*/)、分割符(括号)、字符I,结束符#;2.如果遇到错误的表达式,应输出错误提示信息(该信息越详细越好)。
三、实验方法用C语言,根据递归下降分析法的规则编写代码,并测试。
四、实验步骤1.对语法规则有明确的定义;2.编写的分析程序能够对实验一的结果进行正确的语法分析;3.对于遇到的语法错误,能够做出简单的错误处理,给出简单的错误提示,保证顺利完成语法分析过程;五、实验结果六、实验结论#include<stdio.h>#include<dos.h>#include<stdlib.h>#include<string.h>char a[50],b[50],d[200],e[10];char ch;int numOfEq,i1=0,flag=1,n=6;int E();int E1();int T();int G();int S();int F();void input();void input1();void output();//================================================ void main()/*递归分析*/{ int foe1,i=0;char x;d[0]='E';d[1]='=';d[2]='>';d[3]='?';d[4]='T';d[5]='G';d[6]='#';printf("请输入字符串(以#号结束)\n");do{ scanf("%c",&ch);a[i]=ch;i++;}while(ch!='#');numOfEq=i;ch=b[0]=a[0];printf("文法\t分析串\t\t分析字符\t剩余串\n");if (foe1==0) return;if (ch=='#'){ printf("accept\n");i=0;x=d[i];while(x!='#'){ printf("%c",x);i=i+1;x=d[i];/*输出推导式*/}printf("\n");}else{ printf("error\n");printf("回车返回\n");getchar();getchar();return;}}//================================================ int E1(){ int fot,fog;printf("E->TG\t");flag=1;input();input1();fot=T();if (fot==0) return(0);fog=G();if (fog==0) return(0);else return(1); }//================================================ int E(){ int fot,fog;printf("E->TG\t");e[0]='E';e[1]='=';e[2]='>';e[3]='?';e[4]='T';e[6]='#';output();flag=1;input();input1();fot=T();if (fot==0) return(0);fog=G();if (fog==0) return(0);else return(1); }//================================================ int T(){ int fof,fos;printf("T->FS\t");e[0]='T';e[1]='=';e[2]='>';e[3]='?';e[4]='F';e[5]='S';e[6]='#';output();flag=1;input();input1();fof=F();if (fof==0) return(0);fos=S();if (fos==0) return(0);else return(1); }//================================================ int G(){ int fot;if(ch=='+'){ b[i1]=ch;printf("G->+TG\t");e[0]='G';e[2]='>';e[3]='?';e[4]='+';e[5]='T';e[6]='G';e[7]='#';output();flag=0;input();input1();ch=a[++i1];fot=T();if (fot==0) return(0); G();return(1);}else if(ch=='-'){ b[i1]=ch;printf("G->-TG\t"); e[0]='G';e[1]='=';e[2]='>';e[3]='?';e[4]='-';e[5]='T';e[6]='G';e[7]='#';output();flag=0;input();input1();ch=a[++i1];fot=T();if (fot==0) return(0); G();return(1); }printf("G->^\t");e[1]='=';e[2]='>';e[3]='?';e[4]='^';e[5]='#';output();flag=1;input();input1();return(1);}//================================================ int S(){ int fof,fos;if(ch=='*'){ b[i1]=ch;printf("S->*FS\t");e[0]='S';e[1]='=';e[2]='>';e[3]='?';e[4]='*';e[5]='F';e[6]='S';e[7]='#'; output();flag=0;input();input1();ch=a[++i1];fof=F();if (fof==0)return(0);fos=S();if (fos==0) return(0);else return(1); }else if(ch=='/'){ b[i1]=ch;printf("S->/FS\t");e[0]='S';e[1]='=';e[2]='>';e[3]='?';e[4]='/';e[5]='F';e[6]='S';e[7]='#'; output();flag=0;input();input1();ch=a[++i1];fof=F();if (fof==0) return(0);fos=S();if (fos==0) return(0);else return(1); }printf("S->^\t");e[0]='S';e[1]='=';e[2]='>';e[3]='?';e[4]='^';e[5]='#';output();flag=1;a[i1]=ch;input();input1();return(1); }//================================================ int F(){int f;if(ch=='('){ b[i1]=ch;printf("F->(E)\t");e[0]='F';e[1]='=';e[2]='>';e[3]='?';e[3]='(';e[4]='E';e[5]=')';e[7]='#'; output();flag=0;input();input1();ch=a[++i1];f=E();if (f==0) return(0); if(ch==')'){ b[i1]=ch;printf("F--(E)\t");flag=0;input();input1();ch=a[++i1]; }else{ printf("error\n");return(0);}}else if(ch=='i'){b[i1]=ch;printf("F->i\t");e[0]='F';e[1]='=';e[2]='>';e[3]='?';e[4]='i';e[5]='#';output();flag=0;input();input1();ch=a[++i1];}else{printf("error\n");return(0);}return(1);}//================================================ void input(){ int i=0;for (;i<=i1-flag;i++)printf("%c",b[i]);/*输出分析串*/printf("\t\t");printf("%c\t\t",ch);/*输出分析字符*/}//================================================ void input1(){ int i;for (i=i1+1-flag;i<numOfEq;i++)printf("%c",a[i]);/*输出剩余字符*/printf("\n");}//================================================ void output(){/*推导式计算*/int m,k,j,q;int i=0;m=0;k=0;q=0;i=n;d[n]='=';d[n+1]='>';d[n+2]='?';d[n+3]='#';n=n+3;i=n;i=i-2;while(d[i]!='?'&&i!=0)i--;i=i+1;while(d[i]!=e[0])i=i+1;q=i;m=q;k=q;while(d[m]!='?')m=m-1;m=m+1;while(m!=q){d[n]=d[m];m=m+1;n=n+1;}d[n]='#';for(j=3;e[j]!='#';j++){d[n]=e[j];n=n+1;}k=k+1;while(d[k]!='='){d[n]=d[k];n=n+1;k=k+1;}d[n]='#';}七、实验小结通过本次试验实践掌握了自上而下语法分析法的特点。
编译原理语法分析递归下降子程序实验报告

编译原理语法分析递归下降子程序实验报告编译课程设计-递归下降语法分析课程名称编译原理设计题目递归下降语法分析一、设计目的通过设计、编制、调试一个具体的语法分析程序,加深对语法分析原理的理解,加深对语法及语义分析原理的理解,并实现对文法的判断,是算符优先文法的对其进行FirstVT集及LastVT集的分析,并对输入的字符串进行规约输出规约结果成功或失败。
二、设计内容及步骤内容:在C++ 6.0中编写程序代码实现语法分析功能,调试得到相应文法的判断结果:是算符优先或不是。
若是,则输出各非终结符的FirstVT与LastVT集的结果,还可进行字符串的规约,输出详细的规约步骤,程序自动判别规约成功与失败。
步骤:1.看书,找资料,了解语法分析器的工作过程与原理2.分析题目,列出基本的设计思路1定义栈,进栈,出栈函数○2栈为空时的处理○3构造函数判断文法是否是算符文法,算符优先文法○4构造FirstVT和LastVT函数对文法的非终结符进行分析○5是算符优先文法时,构造函数对其可以进行输入待规约○串,输出规约结果○6构造主函数,对过程进行分析3.上机实践编码,将设计的思路转换成C++语言编码,编译运行4.测试,输入不同的文法,观察运行结果详细的算法描述详细设计伪代码如下:首先要声明变量,然后定义各个函数1.void Initstack(charstack &s){//定义栈s.base=new charLode[20];s.top=-1; }2. void push(charstack&s,charLode w){//字符进栈s.top++;s.base[s.top].E=w.E;s.base[s.top].e=w.e;}3. void pop(charstack&s,charLode &w){//字符出栈w.E=s.base[s.top].E; 三、w.e=s.base[s.top].e;s.top--;}4. int IsEmpty(charstack s){//判断栈是否为空if(s.top==-1)return 1;else return 0;}5.int IsLetter(char ch){//判断是否为非终结符if(ch='A'&&ch= 'Z')return 1;else return 0;}6.int judge1(int n){ //judge1是判断是否是算符文法:若产生式中含有两个相继的非终结符则不是算符文法}7. void judge2(int n){//judge2是判断文法G是否为算符优先文法:若不是算符文法或若文法中含空字或终结符的优先级不唯一则不是算符优先文法8.int search1(char r[],int kk,char a){ //search1是查看存放终结符的数组r中是否含有重复的终结符}9.void createF(int n){ //createF函数是用F数组存放每个终结符与非终结符和组合,并且值每队的标志位为0;F数组是一个结构体}10.void search(charLode w){ //search函数是将在F数组中寻找到的终结符与非终结符对的标志位值为1 }分情况讨论://产生式的后选式的第一个字符就是终结符的情况//产生式的后选式的第一个字符是非终结符的情况11.void LastVT(int n){//求LastVT}12.void FirstVT(int n){//求FirstVT}13.void createYXB(int n){//构造优先表分情况讨论://优先级等于的情况,用1值表示等于}//优先级小于的情况,用2值表示小于//优先级大于的情况,用3值表示大于}14.int judge3(char s,char a){//judge3是用来返回在归约过程中两个非终结符相比较的值}15.void print(char s[],charSTR[][20],int q,int u,int ii,int k){//打印归约的过程}16. void process(char STR[][20],int ii){//对输入的字符串进行归约的过程}四、设计结果分两大类,四种不同的情况第一类情况:产生式的候选式以终结符开始候选式以终结符开始经过存在递归式的非终结符后再以终结符结束篇二:编译原理递归下降子程序北华航天工业学院《编译原理》课程实验报告课程实验题目:递归下降子程序实验作者所在系部:计算机科学与工程系作者所在专业:计算机科学与技术作者所在班级:xxxx作者学号:xxxxx_作者姓名:xxxx指导教师姓名:xxxxx完成时间:2011年3月28日一、实验目的通过本实验,了解递归下降预测分析的原理和过程以及可能存在的回溯问题,探讨解决方法,为预测分析表方法的学习奠定基础。
编译原理实验(二)

实验编号:语法分析(2)一、实验目的及要求编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析。
利用C语言编制递归下降分析程序,并对简单语言进行语法分析。
1待分析的简单语言的语法用扩充的BNF表示如下:⑴ <程序>::=begin<语句串>end⑵ <语句串>::=<语句>{;<语句>}⑶ <语句>::=<赋值语句>⑷ <赋值语句>::=ID :=<表达式>⑸ <表达式>::=<项>{+<项>卜<项>}⑹<项>::=<因子>{*<因子> | /<因子>⑺ <因子>::=ID | NUM | (<表达式>)2实验要求说明输入单词串,以“ #”结束,如果是文法正确的句子,则输出成功信息,打印“succesS', 否则输出"error”。
例如:输入begin a:=9; x:=2*3; b:=a+x end # 输出success!输入x:=a+b*c end # 输出error二、实验环境Microsoft Visual Studio VC6.0三、算法描述(1)主程序示意图如图2-1所示。
”-1 •: 结束图2-1语法分析主程序示意图(2) 递归下降分析程序示意图如图 2-2所示。
(3)语句串分析过程示意图如图 2-3所示。
调用expression 函数否是 否 是否是否调用语句串分析程序是 否出错处理否syn=O&&kk=O ?是打印分析成功出错处理否否否是2调用term 函数调用statement 函数调用statement 函数调用scaner调用scaner调用scaner 调用scaner图2-2 (4)statement 语 图2-3语句串分析示意图是否:=?是否+ , -?递归下降分析程序示意图J 分析程序流程如图 2-4、2-5、2-6、2-7所示。
1是调用scaner是否end?调用s caner是否标识符?#i nclude"stdio.h"#in elude "stri ng.h" char prog[100],toke n[ 8],ch; char *rwtab [6]={"begi n","if',"the n" ,"while","do","e nd"};int syn ,p,m, n,sum;调用term函数出错处理图2-4 statement语句分析函数示意图出错处理图2-5 expression表达式分析函数示意图四、源程序清单-3 •-4 •int kk;factor();〃 因子 expressio n();〃 表达式judgue();〃 判断语句、下一条语句 term();〃 项stateme nt();〃 赋值语句 lrparser();〃 判断、输出函数 scan er();〃 读下一个字符 yucu();void mai n(){ p=0;printf(- 请输入源程序:\n"); do {scan f("%c",&ch); prog[p++]=ch; }while(ch!='#'); p=0; sca ner(); lrparser(); prin tf(" 语法分析结束! \n");lrparser() {printf(" *********************语法分析程序 ************* **\n");if (syn==1) //begi n{sca ner();yucu();if (syn==6) //end{sca ner();if (sy n==O && kk==O)prin tf("success \n");}else{if(kk!=1)prin tf("error,lose 'end' !\n"); kk=1;}}else{prin tf("error,lose 'beg in' ! \n");kk=1;return 0;}yucu()• 5 •{stateme nt();while(sy n==26) //;{sca ner();stateme nt();}return 0;}stateme nt(){if (sy n==10){sca ner();if (syn==18){sca ner();expressi on();}else{prin tf("error!"); -6 •kk=1;}}else{prin tf("error!");kk=1;}return 0;}expressi on(){term();while(s yn==13 || syn==14){sca ner();term();}return 0;}term(){factor();while(s yn==15 || syn==16)sea ner();factor();-7 •}return 0;}factor(){if(syn==10 || syn==11)scan er(); // 为标识符或整常数时,读下一个单词符号else if(syn==27){sca ner();expressi on();if(sy n==28)sca ner();else{printf("')' 错误\n"); kk=1;}}else{printf(" 表达式错误\n"); kk=1;}return 0;sea ner(){ sum=O;• 8 •for(m=0;m<8;m++)toke n[m]=NULL;〃数组清空m=0;ch=prog[p++];while(ch==' ')ch=prog[p++];if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){toke n[ m++]=ch;ch=prog[p++];}p--;sy n=10;toke n[m++]='\0';for(n=0;n<6;n++)if(strcmp(toke n,rwtab[ n])==0)〃判断是否为关键字{syn=n+1;break;}}else if((ch>='0')&&(ch<='9')){ while((ch>='0')&&(ch<=9)){ sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;-9 •}else switch(ch){ case 'v':m=O; ch=prog[p++]; if(ch=='>'){ syn=21;}else if(ch=='='){ sy n=22;}else{ sy n=20;p--;}break;case '>':m=0; ch=prog[p++]; if(ch=='='){ syn=24;}else{ syn=23;p--;}break;case ':':m=0;ch=prog[p++]; if(ch=='='){ syn=18;-10 •}else{ syn=17;p--;}break;case '+': syn=13; break;case '-': syn=14; break;case '*': syn=15;break;case '/': syn=16;break;case '(': syn=27;break;case ')': syn=28;break;case '=': syn=25;break;case ';': syn=26;break;case '#': syn=0;break; default: syn=-1;break;}return 0;-11 •五、运行结果及分析输入begin a:=9;x:=2*3;b:二a+x end # 输出successerror输入x:=a+b*c end # 输出-12 •。
编译原理之递归下降语法分析程序(实验)

编译原理之递归下降语法分析程序(实验)⼀、实验⽬的利⽤C语⾔编制递归下降分析程序,并对简单语⾔进⾏语法分析。
编制⼀个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析。
⼆、实验原理每个⾮终结符都对应⼀个⼦程序。
该⼦程序根据下⼀个输⼊符号(SELECT集)来确定按照哪⼀个产⽣式进⾏处理,再根据该产⽣式的右端:每遇到⼀个终结符,则判断当前读⼊的单词是否与该终结符相匹配,若匹配,再读取下⼀个单词继续分析;不匹配,则进⾏出错处理每遇到⼀个⾮终结符,则调⽤相应的⼦程序三、实验要求说明输⼊单词串,以“#”结束,如果是⽂法正确的句⼦,则输出成功信息,打印“success”,否则输出“error”,并指出语法错误的类型及位置。
例如:输⼊begin a:=9;b:=2;c:=a+b;b:=a+c end #输出success输⼊a:=9;b:=2;c:=a+b;b:=a+c end #输出‘end' error四、实验步骤1.待分析的语⾔的语法(参考P90)2.将其改为⽂法表⽰,⾄少包含–语句–条件–表达式E -> E+T | TT -> T*F | FF -> (E) | i3. 消除其左递归E -> TE'E' -> +TE' | εT -> FT'T' -> *FT' | εF -> (E) | i4. 提取公共左因⼦5. SELECT集计算SELECT(E->TE) =FIRST(TE')=FIRSI(T)-FIRST(F)U{*}={(, i, *}SELECT(E'->+TE')=FIRST(+TE')={+}SELECT(E'->ε)=follow(E')=follow(E)={#, )}SELECT(T -> FT')=FRIST(FT')=FIRST(F)={(, i}SELECT(T'->*FT')=FRIST(*FT')={*}SELECT(T'->ε)=follow(T')=follow(T)={#, ), +}SELECT(F->(E))=FRIST((E)) ={(}SELECT(F->i)=FRIST(i) ={i}6. LL(1)⽂法判断 其中SELECT(E'->+TE')与SELECT(E'->ε)互不相交,SELECT(T'->*FT')与SELECT(T'->ε)互不相交,SELECT(F->(E))与SELECT(F->i)互不相交,故原⽂法为LL(1)⽂法。
编译原理---递归下降分析法

编译原理---递归下降分析法所谓递归下降法 (recursive descent method),是指对⽂法的每⼀⾮终结符号,都根据相应产⽣式各候选式的结构,为其编写⼀个⼦程序 (或函数),⽤来识别该⾮终结符号所表⽰的语法范畴。
例如,对于产⽣式E′→+TE′,可写出相应的⼦程序如下:exprprime( ){if (match (PLUS)){advance( );term( );exprprime( );}}其中:函数match()的功能是,以其实参与当前正扫视的符号 (单词)进⾏匹配,若成功则回送true,否则回送false;函数advance()是⼀个读单词⼦程序,其功能是从输⼊单词串中读取下⼀个单词,并将它赋给变量Lookahead;term则是与⾮终结符号T相对应的⼦程序。
诸如上述这类⼦程序的全体,便组成了所需的⾃顶向下的语法分析程序。
应当指出,由于⼀个语⾔的各个语法范畴 (⾮终结符号)常常是按某种递归⽅式来定义的,此种特点也就决定了这组⼦程序必然以相互递归的⽅式进⾏调⽤,因此,在实现递归下降分析法时,应使⽤⽀持递归调⽤的语⾔来编写程序。
所以,通常也将上述⽅法称为递归⼦程序法。
例4 2对于如下的⽂法G[statements]:statements→expression; statements |εexpression→term expression′expression′→+term expression′ |εterm→factor term′term′→*factor term′ |εfactor→numorid | (expression)通过对其中各⾮终结符号求出相应的FIRST集和FOLLOW集 (计算FIRST集和FOLLOW集的⽅法后⾯再做介绍),可以验证,此⽂法为⼀LL(1)⽂法,故可写出递归下降语法分析程序如程序41所⽰(其中,在⽂件lex.h⾥,将分号、加号、乘号、左括号、右括号、输⼊结束符及运算对象分别命名为SEMI,PLUS,TIMES,LP,RP,EOI及NUMORID,并指定了它们的内部码;此外,还对外部变量yytext,yyleng及yylineno进⾏了说明)。
编译原理实验_递归下降语法分析

递归下降语法分析姓名:郝梦朔学号:日期:2010-1-17一、实验目的构造文法的语法分析程序,要求采用递归下降语法分析方法对输入的字符串进行语法分析,实现对词法分析程序所提供的单词序列的语法检查和结构分析,进一步掌握递归下降的语法分析方法。
二、实验内容编写为一上下文无关文法构造其递归下降语法分析程序,并对任给的一个输入串进行语法分析检查。
程序要求能对输入串进行递归下降语法分析,能判别程序是否符合已知的语法规则,如果不符合(编译出错),则输出错误信息。
三、实验要求利用C语言编制递归下降分析程序,并对语言进行语法分析。
(1)待分析的语言的语法。
用扩充额BNF表示如下。
①<程序>::=function<语言串>endfunc②<语言串>::=<语句>{;<语句>}③<语句>::=<赋值语句>④<赋值语句>::=ID=<表达式>⑤<表达式>::=<项>{+<项>|-<项>}⑥<项>::=<因子>{*<因子>|/<因子>}⑦<因子>::=ID|NUM|(<表达式>)(2)实验要求说明输入单词串以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”,具体例子如下。
输入functiona=9;x=2*3;b=a+x;endfunc#输出success又如,输入:x=a+b*cendfunc#输出error(3)语法分析程序的算法思想为翟玉庆老师上课所讲。
四、实验源程序#include<stdio.h>#include<string.h>char prog[80],token[8];char ch;int syn,p,m=0,n,sum,kk=0;char *rwtab[6]={"function","if","then","while","do","endfunc"};void scaner();void lrparser();void yucu();void statement();void expression();void term();void factor();void main(){p = 0;printf("please input the string:\n");do{ch = getchar();prog[p++] = ch;}while(ch != '#');p = 0;ch = prog[p++];scaner();lrparser();return;}void scaner(){for(n=0;n<8;n++)token[n]=NULL;//printf("\n%c in scaner()",ch);while(ch == ' ' || ch == '\n' )ch = prog[p++];//printf("\n%c in scaner()",ch);m = 0;if((ch<='z' && ch>='a') ||(ch<='Z' && ch>='A')){while((ch<='z' && ch>='a') ||(ch<='Z' && ch>='A')||(ch<='9' && ch>='0')){token[m++] = ch;ch = prog[p++];}syn=10;for(n=0;n<6;n++)if(strcmp(token,rwtab[n]) == 0){syn = n+1;//printf("\n%d in keyword",syn);break;}token[m++] = '\0';}else if(ch<='9' && ch>='0'){sum=0;while(ch<='9' && ch>='0'){sum = sum*10 + ch - '0';ch = prog[p++];}syn = 11;}else{switch(ch){case '<':m = 0;token[m++] = ch;ch = prog[++p];if(ch == '='){syn = 22;token[m++] = ch;}else{syn = 20;ch = prog[--p];}break;case '>':m = 0;token[m++] = ch;ch = prog[++p];if(ch == '='){syn = 24;token[m++] = ch;}else{syn = 23;ch = prog[--p];}break;case '=':m = 0;token[m++] = ch;ch = prog[++p];if(ch == '='){syn = 25;token[m++] = ch;}else{syn = 18;ch = prog[--p];}break;case '!':m = 0;token[m++] = ch;ch = prog[++p];if(ch == '='){syn = 22;token[m++] = ch;}elsesyn = -1;break;case '+':syn = 13;token[0] = ch;break;case '-':syn = 14;token[0] = ch;break;case '*':syn = 15;token[0] = ch;break;case '/':syn = 16;token[0] = ch;break;case ';':syn = 26;token[0] = ch;break;case '(':syn = 27;token[0] = ch;break;case ')':syn = 28;token[0] = ch;break;case '#':syn = 0;token[0] = ch;break;default:syn = -1;}ch = prog[p++];}}void lrparser(){if(syn ==1){//printf("\n%d",syn);scaner();//printf("\n%d",syn);yucu();/**/// printf("\n%d after yucu()",syn);if(syn == 6){scaner();//printf("\n%d in lrparser() after scaner()",syn);if(syn == 0 && kk == 0)printf("\nsuccess!\n");else{if(kk != 1){printf("error!need 'endfunc'");kk = 1;}}}else{printf("error!need 'function'");kk =1;}return;}void yucu(){//printf("\n%d in yucu() first",syn);statement();//printf("\n%d after statement() in yucu()",syn);while(syn == 26){scaner();//syn = 6;//printf("\n%d after scaner() in yucu()",syn);statement();}return;}void statement(){//printf("\n%d in statement() at first",syn);if(syn == 10){scaner();//printf("\n%d after scaner() in statement()",syn);if(syn == 18){scaner();// printf("\n%d after scaner when syn=18",syn);expression();// printf("\n%d after expression()",syn);else{printf("error! evaluate tag error");kk = 1;}}else if(syn == 6)return;else{printf("error! the statement error!");kk = 1;}return;}void expression(){// printf("\n%d in expression at first",syn);term();while(syn == 13 || syn == 14){scaner();term();}return;}void term(){// printf("\n%d in term() at first",syn);factor();while(syn == 15 || syn == 16){scaner();factor();}return;}void factor(){// printf("\n%d in factor() at first",syn);if(syn == 10 || syn == 11){scaner();}else{if(syn == 27){scaner();expression();if(syn == 28){scaner();}else{printf("error! need another ')'");kk = 1;}}else{printf("error! expression error!");}}}五、程序运行效果截图六、心得体会这个实验其实是上个实验的扩展,有个上个实验的基础做这个实验就比较轻松了。
编译原理递归下降分析器 C语言

数学与软件科学学院实验报告学期:2015至2016第2学期2016年3月21日课程名称:编译原理专业:信息与计算科学2013级5班实验编号:2实验名称:递归下降分析器指导教师:王开端姓名:李丹学号:2013060510实验成绩:实验二递归下降分析器实验目的:通过设计、编制、调试递归下降语法分析程序,对输入的符号串进行分析匹配,观察输入符号串是否为给定文法的句子。
实验内容:根据文法G[E]设计递归下降分析器并分析输入串)(*321i i i +是否为文法的句子。
G[E]:E→E+T|TT→T*F|F F→(E)|i实验步骤:在进行递归下降分析法之前,必须对文法进行左递归和回溯的消除。
1消除左递归直接消除见诸于产生式中的左递归比较容易,其方法是引入一个新的非终结符,把含有左递归的产生式改为右递归。
文法G[E]经过消去直接左递归后得到文法G’[E]为:G’[E]:iE F FT T FT T TE E TE E |)(|'*''|'''→→→+→→εε2消除回溯回溯发生的原因在于候选式存在公共的左因子。
一般情况下,设文法中关于A 的产生式为ji i A ββδβδβδβ|...|||...||121+→,那么,可以把这些产生式改写为⎩⎨⎧→→+ij i A A A ββββδ|...|'|...||'11经过反复提取左因子,就能把每个非终结符(包括新引进者)的所有候选首字符集变为两两不相交(既不含有公共左因子)。
3什么是递归下降分析法递归下降分析法是一种自顶向下的分析方法,文法的每个非终结符对应一个递归过程(函数)。
分析过程就是从文法开始符出发执行一组递归过程(函数),这样向下推导直到推出句子;或者说从根节点出发,自顶向下为输入串寻找一个最左匹配序列,建立一棵语法树。
在不含左递归和每个非终结符的所有候选终结首字符集都两两不相交条件下,我们就可能构造出一个不带回溯的自顶向下的分析程序,这个分析程序是由一组递归过程(或函数)组成的,每个过程(或函数)对应文法的而一个非终结符。
编译原理——递归下降语法分析

《编译本理》课程真验报告之阳早格格创做真验称呼:递归下落分解法姓名:彭国保教号:540907010130院系:估计机与通疑工程教院博业:估计机科教与技能班级:09-1班西席:韩丽2012年4月22日一.真验脚段根据某一文法体例调试递归下落分解步调,以便对于任性输进的标记串举止分解.本次真验的脚段主假如加深对于递归下落分解法的明白.步调启初变得搀纯起去,需要利用到步调安排谈话的知识战洪量编程本领,递归下落分解法是一种较真用的分解法,通过那个训练可大大普及硬件启垦本领.通过训练,掌握函数间相互调用的要领.二.真验真质递归下落分解法是决定的自上而下分解法,它央供文法是LL(1)文法.它的基础思维是:对于文法中的每个非末结符编写一个函数或者子步调,每个函数或者子步调的功能是辨别由该非末结符所表示的语法身分.步调算法形貌词汇法分解器的功能是利用函数之间的递归调用模拟语法树自上而下的构制历程.变革文法:与消两义性、与消左递归、提与左果子,推断是可为LL(1)文法,为G的每个非末结标记U构制一个递归历程.U的爆收式的左边指出那个历程的代码结构:(1)假如末结标记,则战背前瞅标记对于照,若匹配则背前进一个标记;可则堕落.(2)若利害末结标记,则调用与此非末结符对于应的历程.当A的左部有多个爆收式时,可用采用结构真止.末尾编写步调以真止上述功能.三.真验步调根据上述算法形貌,编写步调以真止相映的功能,该步调由C谈话编写,而后正在VC运止环境下举止调试,本去没有竭完备,曲到能精确的真止递归下落分解功能,推断输进的字符串是可是一个文法的句子.源步调代码如下:#include<stdio.h>void S();void T();void T1();void error();void scaner();char sym;int main(){scaner();S();if(sym=='$') printf("是该文法的句子");else printf("没有是该文法的句子");return 0;}void S(){if(sym=='a'||sym=='^') scaner();else if(sym=='('){scaner(); T();if(sym==')') scaner();else error();}else error();}void T(){S();T1();}void T1(){if(sym==','){scaner();S();T1();}else if(sym !=')')error();}void scaner(){scanf("%c",&sym);}void error(){printf("没有是该文法的句子");}调试步调的截止:四.归纳与回瞅通过本次真验,尔掌握了递归下落分解步调的构制历程,将一个文法编写为对于应的子步调,如有左递归先与消左递归,再改写为相映的步调.屡屡只消输进一个标记串,步调便不妨递归的记录其归约的历程,查看其合法性.那里还共时波及到了与消左递归,供first集战供follow 的应用,共时达到了坚韧那些知识的脚段.最要害的是通过动脚试验,不妨让尔加深对于知识的明白战掌握,有帮于更佳的影象递归下落的历程.。
编译原理用递归下降法进行表达式分析报告实验报告材料

《编译原理》课程实验报告一. 实验题目 用递归下降法进行语法分析的方法二. 实验日期三. 实验环境(操作系统,开发语言)操作系统是Windows开发语言是C 语言四. 实验内容(实验要求)词法分析程序和语法分析程序已经提供。
此语法分析程序能够实现:正确的输入可以给出结果。
例:输入表达式串为:(13+4)*3则应给出结果为51。
要求:(1)读懂源代码,理解内容写入实验报告(语法分析及语法分析程序和词法分析程序的接口)(2)把语法分析中使用的yyval ,用yytext 实现。
(3)在语法分析程序用加入出错处理(尽量完整,包括出错的位置,出错的原题目 用递归下降法进行表达式分析 专业 班级学号 姓名因,错误的重定位)五. 实验步骤1.生成lex.yy.c文件:将已给的mylexer.l文件打开,先理解,然后再在DOS环境下用flex运行此文件,这时会生成一个lex.yy.c文件。
2.创建工程:打开C-Free 5.0(注:用C-Free 4.0会出错),在菜单栏中的“工程(project)”菜单下选择“新建”;在新建工程中选择“控制台程序”,添加工程名字为“myleb”和保存位置后点“确定”;第1步选择“空的程序”点“下一步”;第2步再点“下一步”;最后点击“完成”。
3.在创建的工程中添加文件:在Source files文件夹中添加之前生成的lex.yy.c文件和syn.c文件,然后找到parser.h文件,将其添加到新建工程中的Header files文件夹中,这时就能将三个文件组成一个类似于.exe文件类型的文件,最后运行。
如图:4.理解并修改syn.c文件:首先,将num = yyval.intval修改成num = atoi(yytext);将num = yyval.fval修改成num = atof(yytext)。
可以这样修改的原因:在.l文件中所写的规则中,有{DIGIT}+ { yyval.intval = atoi(yytext);return INTEGER; }和{DIGIT}+"."{DIGIT}* {yyval.fval = atof(yytext); return DOUBLE; } 这两句代码,其中yyval.intval = atoi(yytext)和yyval.fval = atof(yytext)就说明两者可以相互替代。
最新编译原理实验(递归向下语法分析法实验)附C语言源码-成功测试

实验二递归向下分析法一、实验目和要求根据某一文法编制调试递归下降分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对递归下降分析法的理解。
二、实验内容(1)功能描述1、递归下降分析法的功能词法分析器的功能是利用函数之间的递归调用模拟语法树自上而下的构造过程。
2、递归下降分析法的前提改造文法:消除二义性、消除左递归、提取左因子,判断是否为LL(1)文法,3、递归下降分析法实验设计思想及算法为G 的每个非终结符号U 构造一个递归过程,不妨命名为U。
U 的产生式的右边指出这个过程的代码结构:1)若是终结符号,则和向前看符号对照,若匹配则向前进一个符号;否则出错。
2)若是非终结符号,则调用与此非终结符对应的过程。
当 A 的右部有多个产生式时,可用选择结构实现。
具体为:(1)对于每个非终结符号U->u1|u2|…|un处理的方法如下:U( ) { ch=当前符号;if(ch可能是u1字的开头) 处理u1的程序部分;else if(ch可能是u2字的开头)处理u2的程序部分;…else error()}(2)对于每个右部u1->x1x2…xn的处理架构如下:处理x1的程序;处理x2的程序;…处理xn的程序;(3)如果右部为空,则不处理。
(4)对于右部中的每个符号xi①如果xi为终结符号:if(xi= = 当前的符号){NextChar();return;}else出错处理②如果xi为非终结符号,直接调用相应的过程xi()说明:NextChar为前进一个字符函数。
(2)程序结构描述程序要求:程序输入/输出示例:对下列文法,用递归下降分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG|—TG(3)G->ε(4)T->FS(5)S->*FS| / FS(6)S->ε(7)F->(E)(8)F->i输入出的格式如下:(1)E 盘建立一个文本文档" 222.txt"存储一个以#结束的符号串(包括+—*/()i#),在此位置输入符号串例如:i+i*i#(2)输出结果:i+i*i#为合法符号串备注:输入一符号串如i+i*#,要求输出为“非法的符号串” 函数调用格式、参数含义、返回值描述、函数功能;函数之间的调用关系图。
递归下降分析器程序(c语言版,编译原理实验)

递归下降分析器设计1、实验目的:(1)掌握自上而下语法分析的要求与特点。
(2)掌握递归下降语法分析的基本原理和方法。
(3)掌握相应数据结构的设计方法。
2、实验内容:编程实现给定算术表达式的递归下降分析器。
算术表达式文法如下:E-->E+T|TT-->T*F|FF-->(E)|i3、设计说明:首先改写文法为LL(1)文法;然后为每一个非终结符,构造相应的递归过程,过程的名字表示规则左部的非终结符;过程体按规则右部符号串的顺序编写。
4、设计分析这个题目属于比较典型的递归下降语法分析。
需要先将原算术表达式方法改写为LL(1)文法为:E-->TE'E'-->+TE'|εT-->FT'T'-->*FT'|εF-->(E)|i然后再为每个非终结符设计一个对应的函数,通过各函数之间的递归调用从而实现递归下降语法分析的功能。
具体方法为:(1)当遇到终结符a时,则编写语句If(当前读到的输入符号==a)读入下一个输入符号(2)当遇到非终结符A时,则编写语句调用A()。
(3)当遇到A-->ε规则时,则编写语句If(当前读到的输入符号不属于Follow(A))error()(4)当某个非终结符的规则有多个候选式时,按LL(1)文法的条件能唯一地选择一个候选式进行推导.#include<stdio.h>void E();void T();void E1();void T1();void F();char s[100];int i, SIGN;int main(){printf("请输入一个语句,以#号结束语句(直接输入#号推出)\n");while( 1 ){SIGN = 0;i=0;scanf("%s",&s);if( s[0] == '#')return 0;E();if(s[i]=='#')printf("正确语句!\n");printf("请输入一个语句,以#号结束语句\n");}return 1;}void E(){if(SIGN==0){T();E1();}}void E1(){if(SIGN==0){if(s[i]=='+'){++i;T();E1();}else if(s[i]!='#'&&s[i]!=')'){printf("语句有误!\n");SIGN=1;}}}void T(){if(SIGN==0){F();T1();}}void T1(){if(SIGN==0){if(s[i]=='*'){++i;F();T1();}else if(s[i]!='#'&&s[i]!=')'&&s[i]!='+'){printf("语句有误!\n");SIGN=1;}}}void F(){if(SIGN==0){if(s[i]=='('){++i;E();if(s[i]==')')++i;else if(s[i]== '#'){printf("语句有误!\n");SIGN=1;++i;}}else if(s[i]=='i')++i;else{printf("语句有误!\n");SIGN=1;}}}测试用例(1)输入i,预期显示语句正确!(2)输入iii,预期显示语句有误!(3)输入a,预期显示语句有误!(4)输入(i),预期显示语句正确!(5)输入(a),预期显示语句有误!(6)输入(i+i),预期显示语句正确!(7)输入(i+i,预期显示语句有误!(8)输入((i*i)+i)*i,预期显示语句正确!(9)输入((((i+i*i)))),预期显示语句正确!(10)输入(i+ia,预期显示语句有误!(11)输入i+i*i+i*a,预期显示语句有误!。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验结果
实验总结
这次实验内容比较简单。由于有固定的模式来构造程序,因此即使对于其他LL(1)文法也很容易构造其相应的递归下降分析程序。
这次实验我学习了如何将递归下降分析思想具体转化为程序来实现,同时也加深了产生式的Follow集在递归下降分析法中的应用,练习了通过SELECT集判断文法是否为LL(1)文法。
编
译
原
理
实
验
报
告
实验题目:递归子程序
姓名:柏顺顺
学号:540913100201
专业:软件工程JAVA技术
班级:09——02班
递归下降分析法的实现
实验
递归下降分析法是确定的自上而下分析法,这种分析法要求文法是LL(1)文法。它的基本思想是,对文法中的每个非终结符编写一个函数(或子程序),每个函数(或子程序)的功能是识别由该非终结符所表示的语法成分。由于描述语言的文法通常是递归定义的,因此相应的这组函数(或子程序)必然一相互递归的方式进行调用,所以将此种分析方法称为递归下降分析法。
附录(源代码)
#include <stdio.h>
#include <windows.h>
#include <string.h>
char token[20];
char sym;
int p;
void S();
void T();
void U();
void Scaner();
void Error();
void S()
{
Scaner();
S();
U();
}
else
if (sym != ')')
Error();
}
void Scaner()
{
sym = token[p++];
}
void Error()
{
printf("Error!\n");
exit(0);
}
int main()
{
printf("Please input : \n");
{
if (sym == 'a' || sym == '^')
Scaner();
else
if (sym == '(')
{
Scaner();
T();
if (sym == ')')
Scaner();
eபைடு நூலகம்se
Error();
}
else
Error();
}
void T()
{
S();
U();
}
void U()
{
if (sym == ',')
最后构造递归下降分析程序。每个函数名是相应的非终结符,函数体则是根据规则右部符号串的结构编写。
(1)当遇到终结符a时,则编写语句
if (当前读来的输入符号== a)读下一个输入符号
(2)当遇到非终结符A时,则编写语句调用A()。
(3)当遇到A—>空串规则时,则编写语句
if (当前读来的输入字符不属于FOLLOW(A))error()
本实验要求构造下述文法的递归下降分析程序:
文法G[S]:
S—> a | ^ | (T)
T—> T,S | S
实验内容
首先,消去该文法左递归,得到文法G’[S]:
S—> a | ^ | (T)
T—> ST’
T’—> ,ST’|空串
然后,根据LL(1)文法的判断条件,对非终结符S和T’的不同产生式的SSELECT集进行考察,经验证改进后的文法已经是LL(1)文法。
gets(token);
p = 0;
Scaner();
S();
if (sym == '#')
printf("Success!\n");
else
printf("Fail!\n");
return 0;
}