从-sgd-到-adam--深度学习优化算法概览(一)
sgd和adam 用法

sgd和adam 用法SGD(Stochastic Gradient Descent)和Adam(Adaptive Moment Estimation)是两种常用的优化算法,用于训练神经网络模型。
本文将详细介绍这两种算法的原理和使用方法,并对它们的优缺点进行比较。
一、SGD(Stochastic Gradient Descent)SGD是一个基本的优化算法,它通过计算每个训练样本的梯度来更新模型的参数。
具体来说,SGD的更新规则如下:```θ' = θ - η * ∇J(θ;x)```其中,θ表示模型的参数,η表示学习率,∇J(θ;x)表示损失函数对参数的梯度,x表示训练样本。
从更新规则可以看出,SGD每次只用一个样本来更新参数,因此计算速度较快。
然而,由于每次更新都是基于单个样本的梯度,所以参数的更新方向可能并不是最优的,容易陷入局部最优解。
为了解决SGD的问题,人们引入了一种称为“Mini-batch”的方式,即每次更新不再使用单个样本,而是使用一小批样本的平均梯度。
这样,往往能够更准确地估计真实梯度,并且减少了更新的方差。
具体来说,SGD的Mini-batch更新规则如下:```θ' = θ - η * (1/m) * ∑[∇J(θ;x(i))]```其中,m表示每个Mini-batch中的样本数,∇J(θ;x(i))表示第i 个样本的梯度。
通过使用Mini-batch更新规则,SGD可以在一定程度上兼顾计算速度和参数更新的准确性。
在实际使用SGD时,我们需要设置学习率η的大小。
通常来说,较小的学习率可以使模型更加稳定,但也会导致收敛速度较慢;而较大的学习率可能导致模型无法收敛。
因此,在实践中经常使用学习率衰减的方式,即开始时使用较大的学习率,随着训练的进行逐渐减小学习率的值。
二、Adam算法(Adaptive Moment Estimation)Adam算法是一种自适应学习率的优化算法,它结合了Momentum算法和RMSprop算法的优点。
sgd和adam 用法

随机梯度下降(SGD,Stochastic Gradient Descent)和Adam 优化器是两种在深度学习领域广泛使用的优化算法。
它们用于在训练神经网络时更新权重,以最小化损失函数。
以下是SGD 和Adam 的基本用法:1. 首先,需要安装依赖:```bashpip install tensorflow```2. 导入所需库:```pythonimport tensorflow as tf```3. 初始化变量和损失函数:```python# 初始化变量W = tf.Variable(0., name='weights')b = tf.Variable(0., name='bias')# 定义损失函数loss_fn = tf.square(tf.matmul(X, W) + b - y)```4. 初始化SGD 优化器:```python# 初始化SGD 优化器sgd_op = tf.train.GradientDescentOptimizer(learning_rate=0.01)```5. 更新权重:```python# 训练循环for epoch in range(num_epochs):# 生成批数据batch_x, batch_y = ...# 计算梯度gradients = tf.gradients(loss_fn, [W, b])# 更新权重with tf.control_dependencies(gradients):sgd_op.minimize(gradients)# 更新损失值loss_val = loss_fn.eval(feed_dict={X: batch_x, y: batch_y})print('Epoch: %d, Loss: %f' % (epoch + 1, loss_val))```6. 对于Adam 优化器,首先初始化Adam 优化器:```python# 初始化Adam 优化器adam_op = tf.train.AdamOptimizer(learning_rate=0.01, beta1=0.9, beta2=0.999, epsilon=1e-8)```7. 更新权重:```python# 训练循环for epoch in range(num_epochs):# 生成批数据batch_x, batch_y = ...# 计算梯度gradients = tf.gradients(loss_fn, [W, b])# 更新权重with tf.control_dependencies(gradients):adam_op.minimize(gradients)# 更新损失值loss_val = loss_fn.eval(feed_dict={X: batch_x, y: batch_y})print('Epoch: %d, Loss: %f' % (epoch + 1, loss_val))```在上述示例中,我们使用了TensorFlow 库来实现SGD 和Adam 优化器的的基本用法。
深度学习优化算法总结——从SGD到Adam

深度学习优化算法总结——从SGD 到Adam本⽂参考⾃:上⼀篇博客总结了⼀下随机梯度下降、mini-batch 梯度下降和batch 梯度下降之间的区别,这三种都属于在Loss 这个level 的区分,并且实际应⽤中也是mini-batch 梯度下降应⽤的⽐较多。
为了在实际应⽤中弥补这种朴素的梯度下降的⼀些缺陷,有许多另外的变种算法被提出,其中⼀些由于在许多情况下表现优秀⽽得到⼴泛使⽤,包括Momentum 、Nesterov Accelerated Gradient 、Adagrad 和Adam 等。
梯度下降利⽤梯度下降求解的时候遵循这样⼀个模式,对于当前模型的参数 θ,计算在训练样本上的损失 θ,接下来计算损失函数 θ 关于参数 θ 的梯度 ∇θJ (θ),接下来沿着 ∇θJ (θ) 的反⽅向更新。
再考虑到计算参数更新量的⽅式,可以将其⼀般化为下⾯这⼏个步骤:(1)计算损失函数关于参数 θ 的梯度:g t =∇θJ (θ)(2)根据历史梯度计算⼀阶动量和⼆阶动量:m t =ϕg 1,g 2,⋯,g tV t =ψg 1,g 2,⋯,g t(3)计算参数更新量,其中 η 为学习率,ε防⽌分母为0,通常取1e-8:Δθt=η⋅m tV t +ε(4)进⾏参数更新:θt +1=θt −Δθt 随机梯度下降SGD朴素的SGD 中没有动量的概念,即 m t =g t ,V t =I ,ε=0。
此时参数更新量就是Δθt =η⋅g t ,即θt +1=θt −η⋅g tSGD 在下降过程中会出现震荡(即使通过mini-batch 梯度下降能够缓解),特别是容易陷⼊局部最优点或者是鞍点。
MomentumMomentum 借鉴了物理中动量的概念,能够有效的加速学习速度。
原因在于Momentum 使⽤了历史梯度的指数加权平均来调整参数更新⽅向,使得震荡⽅向的更新减慢,向最优解⽅向的更新加快,最终更快的收敛。
Momentum 使⽤了⼀阶动量来实现这个⽬的:m t =β1m t −1+(1−β1)g t没有使⽤⼆阶动量V t =I ,ε=0。
深度学习中的优化算法了解常用的优化算法

深度学习中的优化算法了解常用的优化算法深度学习已成为人工智能领域最重要的分支之一。
企业、研究机构和个人都在使用深度学习来解决各种问题。
优化算法是深度学习的重要组成部分,因为深度学习任务通常涉及到大量的训练数据和参数。
本文将介绍常用的深度学习优化算法。
一、梯度下降法(Gradient Descent)梯度下降法是深度学习中最常用的优化算法之一。
它是一种基于机器学习模型的损失函数的单调优化方法。
优化过程中,梯度下降法一直追踪损失函数梯度并沿着下降最快的方向来调整模型参数。
该优化算法非常简单,易于实现。
同时,在一些简单的任务中,也可以取得很好的结果。
但是,它也有一些缺点。
例如,当损失函数有多个局部最小值的时候,梯度下降法可能会收敛到局部最小值而不是全局最小值。
此外,梯度下降法有一个超参数学习率,这个参数通常需要根据数据和模型来进行手动调整。
二、随机梯度下降法(Stochastic Gradient Descent,SGD)随机梯度下降法是一种更为高效的优化算法。
在训练集较大时,梯度下降法需要计算所有样本的损失函数,这将非常耗时。
而SGD只需要选取少量随机样本来计算损失函数和梯度,因此更快。
此外,SGD 在每一步更新中方差较大,可能使得部分参数更新的不稳定。
因此,SGD也可能无法收敛于全局最小值。
三、动量法(Momentum)动量法是对梯度下降法进行的改进。
梯度下降法在更新参数时只考虑当前梯度值,这可能导致优化算法无法充分利用之前的梯度信息。
动量法引入了一个动量项,通过累积之前的参数更新方向,加速损失函数收敛。
因此,动量法可以在参数空间的多个方向上进行快速移动。
四、自适应梯度算法(AdaGrad、RMSProp和Adam)AdaGrad是一种适应性学习速率算法。
每个参数都拥有自己的学习率,根据其在之前迭代中的梯度大小进行调整。
每个参数的学习率都减小了它之前的梯度大小,从而使得训练后期的学习率变小。
RMSProp是AdaGrad的一种改进算法,他对学习率的衰减方式进行了优化,这使得它可以更好地应对非平稳目标函数。
机器学习中几种优化算法的比较(SGD、Momentum、RMSProp、Adam)

机器学习中⼏种优化算法的⽐较(SGD、Momentum、RMSProp、Adam)有关各种优化算法的详细算法流程和公式可以参考【】,讲解⽐较清晰,这⾥说⼀下⾃⼰对他们之间关系的理解。
BGD 与 SGD⾸先,最简单的 BGD 以整个训练集的梯度和作为更新⽅向,缺点是速度慢,⼀个 epoch 只能更新⼀次模型参数。
SGD 就是⽤来解决这个问题的,以每个样本的梯度作为更新⽅向,更新次数更频繁。
但有两个缺点:更新⽅向不稳定、波动很⼤。
因为单个样本有很⼤的随机性,单样本的梯度不能指⽰参数优化的⼤⽅向。
所有参数的学习率相同,这并不合理,因为有些参数不需要频繁变化,⽽有些参数则需要频繁学习改进。
第⼀个问题Mini-batch SGD 和 Momentum 算法做出的改进主要是⽤来解决第⼀个问题。
Mini-batch SGD 算法使⽤⼀⼩批样本的梯度和作为更新⽅向,有效地稳定了更新⽅向。
Momentum 算法则设置了动量(momentum)的概念,可以理解为惯性,使当前梯度⼩幅影响优化⽅向,⽽不是完全决定优化⽅向。
也起到了减⼩波动的效果。
第⼆个问题AdaGrad 算法做出的改进⽤来解决第⼆个问题,其记录了每个参数的历史梯度平⽅和(平⽅是 element-wise 的),并以此表征每个参数变化的剧烈程度,继⽽⾃适应地为变化剧烈的参数选择更⼩的学习率。
但 AdaGrad 有⼀个缺点,即随着时间的累积每个参数的历史梯度平⽅和都会变得巨⼤,使得所有参数的学习率都急剧缩⼩。
RMSProp 算法解决了这个问题,其采⽤了⼀种递推递减的形式来记录历史梯度平⽅和,可以观察其表达式:早期的历史梯度平⽅和会逐渐失去影响⼒,系数逐渐衰减。
Adam简单来讲 Adam 算法就是综合了 Momentum 和 RMSProp 的⼀种算法,其既记录了历史梯度均值作为动量,⼜考虑了历史梯度平⽅和实现各个参数的学习率⾃适应调整,解决了 SGD 的上述两个问题。
从SGD到Adam——常见优化算法总结

从SGD到Adam——常见优化算法总结1 概览虽然梯度下降优化算法越来越受欢迎,但通常作为⿊盒优化器使⽤,因此很难对其优点和缺点的进⾏实际的解释。
本⽂旨在让读者对不同的算法有直观的认识,以帮助读者使⽤这些算法。
在本综述中,我们介绍梯度下降的不同变形形式,总结这些算法⾯临的挑战,介绍最常⽤的优化算法,回顾并⾏和分布式架构,以及调研⽤于优化梯度下降的其他的策略。
2 Gradient descent 变体有3种基于梯度下降的⽅法,主要区别是我们在计算⽬标函数( objective function)梯度时所使⽤的的数据量。
2.1 Batch gradient descent 批梯度下降法计算公式如下:其中η表⽰学习率。
该⽅法在⼀次参数更新时,需要计算整个数据集的参数。
优点:可以保证在convex error surfaces 条件下取得全局最⼩值,在non-convex surfaces条件下取得局部极⼩值。
缺点:由于要计算整个数据集的梯度,因此计算⽐较慢,当数据量很⼤时,可能会造成内存不⾜。
另外,该⽅法也⽆法在线(online)更新模型。
计算的伪代码如下:for i in range ( nb_epochs ):params_grad = evaluate_gradient ( loss_function , data , params )params = params - learning_rate * params_grad其中,params和params_grad均是向量(vector)。
2.2 Stochastic gradient descent(SGD)随机梯度下降计算公式如下:随机梯度下降法每次更新参数时,只计算⼀个训练样本(x(i), y(i))的梯度。
优点:计算速度快,可以⽤于在线更新模型。
缺点:由于每次只根据⼀个样本进⾏计算梯度,因此最终⽬标函数收敛时曲线波动可能会⽐较⼤。
由于SGD的波动性,⼀⽅⾯,波动性使得SGD可以跳到新的和潜在更好的局部最优。
深度学习的优化器选择(SGD、Momentum、RMSprop、Adam四种)

深度学习的优化器选择(SGD、Momentum、RMSprop、Adam四种)import torchimport torch.utils.data as Dataimport torch.nn.functional as Fimport matplotlib.pyplot as pltimport torch.nn as nnLR=0.01BATCH_SIZE=32EPOCH=5x=torch.unsqueeze(torch.linspace(-1,1,1000),dim=1)#将⼀维数据转换为⼆维数据y=x.pow(2)+0.1*torch.normal(torch.zeros(*x.size()))torch_dataset=Data.TensorDataset(x,y)loader=Data.DataLoader(dataset=torch_dataset,batch_size=BATCH_SIZE,shuffle=True)#构建⽹络class Net(nn.Module):def__init__(self):super(Net,self).__init__()self.hidden=nn.Linear(1,20)#Sequential是将⽹络的层组合到⼀起self.predict = nn.Linear(20,1)def forward(self,x):x=F.relu(self.hidden(x))#将ReLU层添加到⽹络x = F.relu(self.predict(x))return xnet_SGD=Net()net_Momentum=Net()net_RMSProp=Net()net_Adam=Net()nets=[net_SGD,net_Momentum,net_RMSProp,net_Adam]opt_SGD=torch.optim.SGD(net_SGD.parameters(),lr=LR)opt_Momentum=torch.optim.SGD(net_Momentum.parameters(),lr=LR,momentum=0.9)opt_RMSProp=torch.optim.RMSprop(net_RMSProp.parameters(),lr=LR,alpha=0.9)opt_Adam=torch.optim.Adam(net_Adam.parameters(),lr=LR,betas=(0.9,0.99))optimizers=[opt_SGD,opt_Momentum,opt_RMSProp,opt_Adam]loss_func=torch.nn.MSELoss()loss_his=[[],[],[],[]]for epoch in range(EPOCH):for step,(batch_x,batch_y) in enumerate(loader):for net,opt,l_his in zip(nets,optimizers,loss_his):output=net(batch_x)loss=loss_func(output,batch_y)opt.zero_grad()loss.backward()opt.step()l_his.append(loss.data.numpy())labels=['SGD','Momentum','RMSprop','Adam']print(loss_his)for i,l_his in enumerate(loss_his):plt.plot(l_his,label=labels[i])plt.legend(loc='best')plt.xlabel('Steps')plt.ylabel('Loss')plt.ylim((0,0.4))plt.show()最终得到的训练⽐较图,如下,可以看出各种个优化器的:。
深度学习技术中的优化器选择与调优方法

深度学习技术中的优化器选择与调优方法引言:随着深度学习技术的快速发展,优化器选择与调优方法变得越来越重要。
在深度学习中,优化是指通过调整模型的参数来最小化损失函数。
优化器则是指用于更新模型参数的算法。
本文将介绍深度学习技术中常用的优化器选择与调优方法。
一、优化器选择1. SGD(随机梯度下降法):SGD是最简单、最常用的优化器之一。
它在每一次迭代中随机选取一个样本,并计算该样本的梯度来进行参数更新。
尽管SGD在训练初期可能具有较大的噪声,但它有助于逃离局部最小值,并且可以应用于大型数据集。
然而,SGD的缺点是梯度计算较慢,尤其在具有大量参数的深度学习模型中。
2. Momentum(动量法):动量法通过引入一个动量项来加速SGD的收敛。
它可以理解为一个在梯度方向上积累速度的小球,从而减少了震荡和波动,以获得更平滑的收敛。
动量法不仅可以加快训练速度,还可以帮助跳出局部最小值。
3. Adagrad:Adagrad是一种自适应优化器,它可以在不同参数上自动调整学习率。
它的主要思想是根据参数在过去迭代中的梯度来自动调整逐渐缩小的学习率。
这使得Adagrad适用于稀疏数据集,并且可以自动调整学习率,以便更好地适应参数。
4. RMSprop:RMSprop是对Adagrad的改进,主要是为了解决学习率衰减过快的问题。
RMSprop使用了指数加权平均来计算梯度的移动平均值,并通过除以其平方根来缩小学习率。
这种方法可以使学习率在训练过程中适当地衰减,从而提高收敛速度。
5. Adam:Adam是一种结合了动量法和RMSprop的自适应优化器。
它不仅直接利用了梯度的一阶矩估计(均值),还使用了二阶矩估计(方差),从而更好地适应不同的数据集和任务。
Adam被广泛应用于许多深度学习任务,并取得了显著的优化效果。
二、优化器调优方法1. 学习率调整:学习率是优化器中非常重要的超参数之一。
过大的学习率可能导致模型不稳定和振荡,而过小的学习率可能导致收敛速度过慢。
深度学习模型常用优化算法介绍

深度学习模型常用优化算法介绍深度学习是人工智能领域中一个非常热门的话题,其已经被广泛应用于图像处理、自然语言处理和语音识别等领域,深度学习算法的进步也使得这些领域有了更多的突破性进展。
然而,通过深度学习构建的神经网络通常有着非常复杂的结构,其参数数量十分庞大,因此如何进行高效的优化是深度学习研究的一个关键领域。
本文将从深度学习优化的角度,介绍几种常用的深度学习优化算法。
一、梯度下降法将梯度下降法作为深度学习模型优化的开篇,是因为梯度下降法非常基础而且常用,作为基准方法常常用来比较新算法的性能。
梯度下降法的思路是:通过计算误差函数对模型参数的梯度,然后通过该梯度对参数值进行更新,不断迭代直至误差趋近于最小值。
在优化过程中,需要指定学习率这一超参数,例如,将学习率设置得太小会导致训练收敛到局部最小值,而学习率太大则可能导致误差函数在最小点附近来回振荡,无法稳定收敛。
二、动量法动量法是另一种非常常用的优化算法,其基本思想是在进行梯度下降的同时,利用物理学中的动量,累计之前的梯度以平滑参数更新。
具体而言,动量法引入了一个动量变量 v,它会保留之前的梯度方向,并在当前梯度方向上进行加速。
通过这种方式,能够加快梯度下降的速度,避免在减速时被卡住。
不过需要注意的是,如果超参数设置不恰当,动量法可能会导致优化过程高速偏移。
三、Adam算法Adam算法是梯度下降算法的一种变种,其利用了人工神经网络的特殊结构,并结合动量法和RMSprop的思想得到了非常广泛的应用。
Adam算法除了使用梯度信息之外,还考虑了之前的梯度变化,利用一个动态调整的学习率去更新网络中的参数。
除此之外,Adam算法还考虑了梯度方差和均值的指数加权平均值来调整学习率,因此其有着比较快的收敛速度和一定的鲁棒性。
四、RMSprop算法RMSprop算法和Adam算法类似,也是一种自适应学习率算法。
它改变了Adagrad算法中对学习率逐步变小的方式,引入了对梯度平方的指数加权平均。
关于Adam和SGD等优化方法的讨论

关于Adam和SGD等优化⽅法的讨论第⼀篇是这个:在上⾯⼀篇⽂章已经讲了:接下来是这篇⽂章:《Adam那么棒,为什么还对SGD念念不忘 (2)—— Adam的两宗罪》Adam罪状⼀:可能不收敛Adam罪状⼆:可能错过全局最优解他们提出了⼀个⽤来改进Adam的⽅法:前期⽤Adam,享受Adam快速收敛的优势;后期切换到SGD,慢慢寻找最优解。
第三篇是这个:《Adam那么棒,为什么还对SGD念念不忘 (3)—— 优化算法的选择与使⽤策略》不同优化算法的核⼼差异:下降⽅向从第⼀篇的框架中我们看到,不同优化算法最核⼼的区别,就是第三步所执⾏的下降⽅向:这个式⼦中,前半部分是实际的学习率(也即下降步长),后半部分是实际的下降⽅向。
SGD算法的下降⽅向就是该位置的梯度⽅向的反⽅向,带⼀阶动量的SGD的下降⽅向则是该位置的⼀阶动量⽅向。
⾃适应学习率类优化算法为每个参数设定了不同的学习率,在不同维度上设定不同步长,因此其下降⽅向是缩放过(scaled)的⼀阶动量⽅向。
主流的观点认为:Adam等⾃适应学习率算法对于稀疏数据具有优势,且收敛速度很快;但精调参数的SGD(+Momentum)往往能够取得更好的最终结果。
优化算法的常⽤tricks最后,分享⼀些在优化算法的选择和使⽤⽅⾯的⼀些tricks。
1. ⾸先,各⼤算法孰优孰劣并⽆定论。
如果是刚⼊门,优先考虑SGD+Nesterov Momentum或者Adam.( : The two recommendedupdates to use are either SGD+Nesterov Momentum or Adam)2. 选择你熟悉的算法——这样你可以更加熟练地利⽤你的经验进⾏调参。
3. 充分了解你的数据——如果模型是⾮常稀疏的,那么优先考虑⾃适应学习率的算法。
4. 根据你的需求来选择——在模型设计实验过程中,要快速验证新模型的效果,可以先⽤Adam进⾏快速实验优化;在模型上线或者结果发布前,可以⽤精调的SGD进⾏模型的极致优化。
深度学习必备:随机梯度下降(SGD)优化算法及可视化
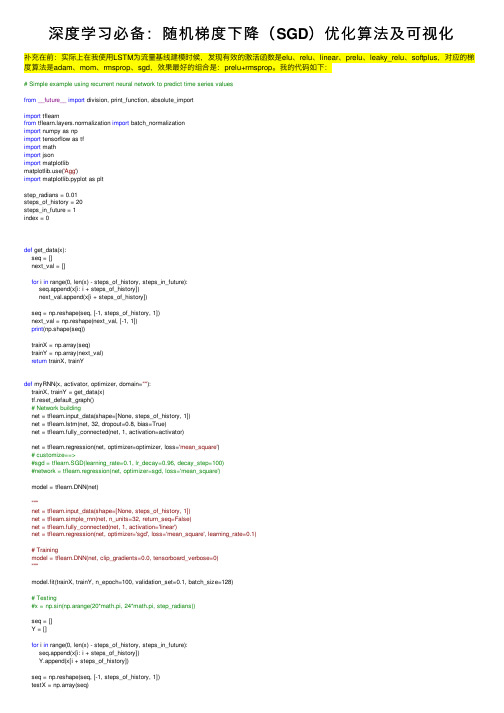
深度学习必备:随机梯度下降(SGD)优化算法及可视化补充在前:实际上在我使⽤LSTM为流量基线建模时候,发现有效的激活函数是elu、relu、linear、prelu、leaky_relu、softplus,对应的梯度算法是adam、mom、rmsprop、sgd,效果最好的组合是:prelu+rmsprop。
我的代码如下:# Simple example using recurrent neural network to predict time series valuesfrom__future__import division, print_function, absolute_importimport tflearnfrom yers.normalization import batch_normalizationimport numpy as npimport tensorflow as tfimport mathimport jsonimport matplotlibe('Agg')import matplotlib.pyplot as pltstep_radians = 0.01steps_of_history = 20steps_in_future = 1index = 0def get_data(x):seq = []next_val = []for i in range(0, len(x) - steps_of_history, steps_in_future):seq.append(x[i: i + steps_of_history])next_val.append(x[i + steps_of_history])seq = np.reshape(seq, [-1, steps_of_history, 1])next_val = np.reshape(next_val, [-1, 1])print(np.shape(seq))trainX = np.array(seq)trainY = np.array(next_val)return trainX, trainYdef myRNN(x, activator, optimizer, domain=""):trainX, trainY = get_data(x)tf.reset_default_graph()# Network buildingnet = tflearn.input_data(shape=[None, steps_of_history, 1])net = tflearn.lstm(net, 32, dropout=0.8, bias=True)net = tflearn.fully_connected(net, 1, activation=activator)net = tflearn.regression(net, optimizer=optimizer, loss='mean_square')# customize==>#sgd = tflearn.SGD(learning_rate=0.1, lr_decay=0.96, decay_step=100)#network = tflearn.regression(net, optimizer=sgd, loss='mean_square')model = tflearn.DNN(net)"""net = tflearn.input_data(shape=[None, steps_of_history, 1])net = tflearn.simple_rnn(net, n_units=32, return_seq=False)net = tflearn.fully_connected(net, 1, activation='linear')net = tflearn.regression(net, optimizer='sgd', loss='mean_square', learning_rate=0.1)# Trainingmodel = tflearn.DNN(net, clip_gradients=0.0, tensorboard_verbose=0)"""model.fit(trainX, trainY, n_epoch=100, validation_set=0.1, batch_size=128)# Testing#x = np.sin(np.arange(20*math.pi, 24*math.pi, step_radians))seq = []Y = []for i in range(0, len(x) - steps_of_history, steps_in_future):seq.append(x[i: i + steps_of_history])Y.append(x[i + steps_of_history])seq = np.reshape(seq, [-1, steps_of_history, 1])testX = np.array(seq)# Predict the future valuespredictY = model.predict(testX)print(predictY)# Plot the resultsplt.figure(figsize=(20,4))plt.suptitle('Prediction')plt.title('History='+str(steps_of_history)+', Future='+str(steps_in_future))plt.plot(Y, 'r-', label='Actual')plt.plot(predictY, 'gx', label='Predicted')plt.legend()if domain:plt.savefig('pku_'+activator+"_"+optimizer+"_"+domain+".png")else:plt.savefig('pku_'+activator+"_"+optimizer+".png")def main():out_data = {}with open("out_data.json") as f:out_data = json.load(f)#x = out_data[""]#myRNN(x, activator="prelu", optimizer="rmsprop", domain="")# I find that prelu and rmsprop is best choicex = out_data[""]activators = ['linear', 'tanh', 'sigmoid', 'softmax', 'softplus', 'softsign', 'relu', 'relu6', 'leaky_relu', 'prelu', 'elu']optimizers = ['sgd', 'rmsprop', 'adam', 'momentum', 'adagrad', 'ftrl', 'adadelta']for activator in activators:for optimizer in optimizers:print ("Running for : "+ activator + " & " + optimizer)myRNN(x, activator, optimizer)main()梯度下降算法是机器学习中使⽤⾮常⼴泛的优化算法,也是众多机器学习算法中最常⽤的优化⽅法。
AI训练中的优化技巧 Adam优化器

AI训练中的优化技巧 Adam优化器AI训练中的优化技巧:Adam优化器在人工智能领域,训练模型是一个至关重要的过程。
为了使模型能够准确地预测并做出正确的决策,我们需要使用适当的优化技巧来提高训练效果。
在这篇文章中,我们将重点介绍一种被广泛应用的优化算法——Adam优化器。
一、Adam优化器的介绍Adam(Adaptive Moment Estimation)优化器是一种基于梯度的优化算法,结合了动量法和自适应学习率方法。
1. 动量法动量法的目的是在训练过程中增加模型的稳定性,避免陷入局部最优解。
它通过在更新权重时引入一个动量项,使得模型在梯度方向上具有一定的“惯性”。
也就是说,当梯度方向相同时,更新步长较大;当梯度方向相反时,更新步长减小。
这样可以加快收敛速度,并提高模型的泛化能力。
2. 自适应学习率方法自适应学习率方法的目的是根据梯度的变化情况调整学习率,使得模型在不同参数处能够拥有合适的学习率。
传统的学习率调整方法往往需要手动设置学习率,然而,这样的设置很难找到全局最优解。
Adam优化器通过计算每个参数的一阶动量和二阶动量的估计,并使用这些估计来调整学习率。
这样就能够自动适应不同参数的变化,从而提高训练效果。
二、Adam优化器的算法原理Adam优化器的算法原理如下:1. 初始化参数首先,需要初始化参数,包括权重和偏置项。
这些参数将被用来计算梯度和更新模型。
2. 计算梯度在每一次训练迭代中,需要计算当前参数下的梯度。
梯度可以通过反向传播算法计算得到。
3. 更新参数使用Adam优化器的公式来更新参数。
公式的具体形式如下:m_t = β_1 * m_(t-1) + (1 - β_1) * g_tv_t = β_2 * v_(t-1) + (1 - β_2) * g_t^2^m_t = m_t / (1 - β_1^t)^v_t = v_t / (1 - β_2^t)θ_t = θ_(t-1) - α * ^m_t / (√^v_t + ε)其中,m_t 和 v_t 是动量的一阶和二阶动量估计值,^m_t 和 ^v_t 是偏差校正后的估计值,θ_t 是更新后的参数,α 是学习率,β_1 和β_2是控制动量和动量平方的两个超参数,ε 是一个很小的常数,用来避免除以零的情况。
神经网络的优化器比较从SGD到Adam

神经网络的优化器比较从SGD到Adam神经网络是一种常用的机器学习模型,用于处理各种复杂的任务,例如图像识别、自然语言处理和预测分析等。
然而,在神经网络的训练过程中,优化器的选择对模型性能的影响至关重要。
本文将从随机梯度下降(Stochastic Gradient Descent,SGD)到自适应矩估计(Adam)这两个优化器进行比较与分析。
1. 随机梯度下降(SGD)随机梯度下降是最简单、最基础的优化器之一,其主要思想是通过计算损失函数对参数的梯度来更新参数。
每次迭代时,SGD随机选择一个小批量的训练样本进行梯度计算和参数更新,因此它的计算效率相对较高。
然而,SGD存在一些缺点。
首先,由于其随机性,SGD在参数更新时可能会陷入局部最优解。
其次,在参数更新时,SGD只考虑当前的梯度信息,可能导致收敛过程较慢。
此外,SGD对学习率的设置较为敏感,较大的学习率可能导致参数更新过快,而较小的学习率则可能导致收敛速度过慢。
2. 自适应矩估计(Adam)自适应矩估计是一种近年来提出的优化算法,其综合考虑了梯度的一阶矩估计和二阶矩估计,通过自适应地调整学习率来优化参数。
相比于传统的优化算法,Adam在参数更新过程中具有更好的适应性和鲁棒性。
具体来说,Adam通过计算梯度的一阶矩估计(即梯度的平均值)和二阶矩估计(即梯度的方差)来更新参数。
通过自适应地调整学习率,Adam能够根据不同参数的特点来控制参数更新的速度,从而更好地平衡快速收敛和避免陷入局部最优解的问题。
此外,Adam还引入了偏差修正机制,解决了初始时期的偏差问题。
通过动量项的引入,Adam能够有效地减少梯度更新的方差,加速参数更新的过程。
与SGD相比,Adam通常能够更快地收敛,并且对学习率的设置不太敏感。
3. 优化器比较与选择在实际应用中,优化器的选择应根据具体问题和数据集的特点来决定。
如果数据集较大,并且模型具有较多的参数,Adam通常能够更好地应对这些挑战。
神经网络中的常用优化算法

神经网络中的常用优化算法神经网络是一种类似于人脑思考模式的信息处理系统,可以用于识别、分类、预测、控制等不同领域的问题。
神经网络模型的训练需要通过大量的数据和优化方法来确定模型中的参数,使其能够更好的拟合训练数据并在未知数据上得到更好的泛化性能。
本文将介绍神经网络中常用的优化算法,并对其优缺点进行比较。
梯度下降算法梯度下降算法是最基本的神经网络优化算法之一。
其基本思想是通过计算损失函数对模型参数的梯度,来更新模型参数以尽可能减小损失函数的值。
梯度下降算法可以使用随机梯度下降(SGD)、批量梯度下降(BGD)、小批量梯度下降(MBGD)等多种变种实现。
SGD是一种在每次迭代中,随机选取一个样本计算梯度和更新模型参数的算法。
由于每次更新只考虑单个样本,使得算法收敛速度较快,但随机选择样本会带来噪声,降低了收敛的稳定性。
BGD是一种在每次迭代中使用所有样本计算梯度和更新模型参数的算法,由于全部数据都参与到更新中,使得收敛速度较慢,但减少了训练的随机性,提高了稳定性。
MBGD是一种随机选取一个小批量的样本计算梯度和更新模型参数的算法。
相比于SGD和BGD,MBGD在训练过程中减少了噪声和计算量,使得算法既具备了收敛速度,又具有了收敛稳定性。
梯度下降算法虽然是一种最基本的优化算法,但其会受损失函数的局部极小点、学习率选择以及问题的复杂度等因素的影响,从而无法达到全局最优。
动量优化算法为了解决梯度下降算法收敛速度慢以及在某些情况下无法跳出局部最优解的问题,动量优化算法被提出。
动量优化算法通过引进动量项,综合考虑当前梯度和历史梯度的信息来更新模型参数。
动量项为模型上下文的历史梯度方向提供了反向动力,加速训练时的学习过程,使得梯度更新更加顺畅和稳定。
动量算法最大的优点是可以快速跳过局部最小值,并更快地达到全局最小值。
但是在一些马鞍点上,动量算法的效果较差,这时候通常使用NAG算法(Nesterov Accelerated Gradient)。
纯Python和PyTorch对比实现SGDMomentumRMSpropAdam梯

纯Python和PyTorch对比实现SGDMomentumRMSpropAdam梯在机器学习训练过程中,梯度下降算法是最常用的优化算法之一、经典的梯度下降算法包括SGD(Stochastic Gradient Descent)、Momentum、RMSprop和Adam等。
下面将逐一对比纯Python和PyTorch的实现。
1.SGD(随机梯度下降):SGD是最基本的优化算法,每次迭代仅使用一个随机样本进行梯度计算和参数更新。
以下是纯Python和PyTorch的SGD实现:```pythondef sgd(params, lr):for param in params:param -= lr * param.grad```PyTorch实现:```pythonimport torch.optim as optimoptimizer = optim.SGD(params, lr)optimizer.step```PyTorch提供了torch.optim模块来实现优化算法,可以直接调用其中的SGD类进行参数更新。
2. Momentum:Momentum算法在SGD的基础上引入了动量项,用于加速收敛过程。
以下是纯Python和PyTorch的Momentum实现:```pythondef momentum(params, velocities, lr, momentum):for param, velocity in zip(params, velocities):velocity = momentum * velocity + lr * param.gradparam -= velocityvelocity *= 0.9 # 0.9为动量因子```PyTorch实现:```pythonimport torch.optim as optimoptimizer = optim.SGD(params, lr, momentum=momentum)optimizer.step```PyTorch的SGD类也支持设置动量因子参数,因此可以直接传入momentum参数来实现。
机器学习中的加速一阶优化算法

机器学习中的加速一阶优化算法一阶优化算法是机器学习中常用的优化算法。
它利用搜索技术,利用最小化函数极小化函数的方向调整优化参数,以达到最优化模型预测结果的目的。
一阶优化算法包括:一、梯度下降法:梯度下降法是一种最常用的优化方法,它主要针对于有多维参数空间的函数,利用“梯度”概念,在沿下降的梯度的反方向搜索,最终找到极值点。
1. 随机梯度下降法(SGD):它是对梯度下降法的改进,应用更加广泛,SGD采用迭代,每次迭代只求解所样本点,利用每次所取样本点所求出的梯度方向更新参数,主要用于优化稀疏数据或者大规模数据,测试计算的时候能节省时间开销。
2. 动量法:动量法也是一种梯度下降算法,它引入了动量变量,在优化参数的同时加入动量变量来控制参数的变化,这样可以在一定程度上避免局部极小值的情况,从而加快收敛速度。
二、陡峭边界方法:陡峭边界方法是另一种有效的一阶优化算法,它将优化问题转换成求解一个小球在多维空间跳动求解原点问题。
在这种方法中,对参数做出移动及修正操作,同时,利用拐点和弥散符合,实时调整参数搜索方向,以达到收敛到最优解的目的。
1. 共轭梯度法:它是最常用的算法,采用最快下降法和陡峭边界方法的结合体,进行统一的参数调整,并且不断的更新搜索方向。
2. LBFGS算法:LBFGS(Limited-memory Broyden-Fletcher-Goldfarb-Shanno)同样使用共轭梯度方法,在这种方法中,减少了随机的计算量,通过评估一定个数的搜索步骤,并维护开销小的内存,以计算出搜索方向。
三、其他一阶优化算法:1. Adagrad算法:Adagrad算法是一种专门为稀疏数据集设计的优化方法,它采用“自适应”学习率原则,通过偏导数以及参数的规模和变化,改变学习率的大小,达到调整收敛状态的目的。
2. RMSProp:RMSProp是一种自适应学习率优化算法,它通过“梯度过去平方和的衰减平均”来更新学习率,它可以赋予参数不同的学习率,如果学习率较小,则对参数估计更加稳定;如果学习率较大,则可以快速搜索到最优解。
Adam优化算法

Adam优化算法深度学习常常需要⼤量的时间和计算机资源进⾏训练,这也是困扰深度学习算法开发的重⼤原因。
虽然我们可以采⽤分布式并⾏训练加速模型的学习,但需要的计算资源并没有丝毫减少。
⽽唯有需要资源更少、令模型收敛更快的最优化算法,才能从根本上加速机器的学习速度和效果,Adam算法正为此⽽⽣!Adam优化算法是随机梯度下降算法的扩展式,进来其⼴泛的应⽤与深度学习的应⽤中,尤其是计算机视觉和⾃然语⾔处理等任务。
本⽂分为两部分,前⼀部分简要介绍了Adam优化算法的特性和其在深度学习中的应⽤,后⼀部分从Adam优化算法的原论⽂出发,详细解释和推导了他的算法过程和更新规则,我们希望读者在苏皖这两部分后能了解掌握以下⼏点:1) Adam算法是什么,他为优化深度学习模型带来了哪些优势2) Adam算法的原理机制是怎样的,它与相关的AdaGrad和RMSProp⽅法有什么区别3) Adam算法应该如何调参,它常⽤的配置参数是怎么样的4) Adam的实现优化的过程和权重更新规则5) Adam的初始化偏差修正的推导6) Adam的扩展形式:AdaMax1、什么是Adam优化算法?Adam是⼀种可以替代传统随机梯度下降过程的⼀阶优化算法,它能基于训练数据迭代的更新神经⽹络权重。
⾸先该算法名【Adam】,其并不是⾸字母缩写,也不是⼈名。
他的名称来源于⾃适应矩估计(adaptive moment estimation)。
在介绍这个算法时,原论⽂列举了将Adam优化算法应⽤在⾮凸优化问题中所获得的优势:1)直截了当的实现2)⾼效的计算3)所需内存少4)梯度对⾓缩放的不变性5)适合解决含⼤规模数据和参数的优化问题6)使⽤于⾮稳态⽬标7)适⽤于解决包含很⾼噪声或稀疏梯度的问题8)超参数可以很直观地解释,并且基本上只需要极少量的调参2、 Adam优化算法的基本机制Adam算法和传统的随机梯度下降不同。
随机梯度下降保持单⼀的学习率(即alpha)更新所有的权重,学习率在训练过程中并不会改变。
adam优化算法公式

adam优化算法公式Adam优化算法是目前比较流行的一种自适应学习率算法。
本篇文章将从Adam的背景、原理、优点等方面进行介绍。
一、Adam背景Adam优化算法源自RMSprop和Momentum算法,以解决神经网络优化过程中的学习率问题。
在深度神经网络训练中,如果采用固定的学习率,可能会出现过拟合或者模型学习不充分的情况,而自适应学习率方法可以根据当前梯度值自适应地更新学习率,提高模型的训练效果。
二、Adam原理Adam算法主要有两个部分:动量部分和自适应学习率部分。
动量部分:Adam算法使用了梯度的一阶(平方梯度)和二阶矩(平均梯度),通过加权平均法计算出动量,并使用动量来加速梯度下降过程。
下面是Adam算法动量更新的公式:v(t)=μv(t-1)+(1-μ)g(t)其中, v(t)是第t次的动量,μ是一个介于0和1之间的超参数,用于控制历史动量的权重,g(t)是梯度值。
自适应学习率部分:Adam算法使用梯度的平方和平均值来进行学习率的自适应。
具体来说,Adam算法同时使用平均梯度和平方梯度的移动平均值来计算自适应学习率,计算公式如下:m(t)=β1m(t-1)+(1-β1)g(t)s(t)=β2s(t-1)+(1-β2)g²(t)其中,m(t)和s(t)分别代表平均梯度和平方梯度的移动平均值,β1和β2分别是控制梯度平均值和梯度平方平均值的超参数,g(t)是当前训练batch的梯度值。
计算完平均梯度和平方梯度的移动平均值后,会根据公式计算出自适应学习率的值α(t):α(t)=η μ^t/(sqrt{s(t)}+ε)其中,η 是初始学习率,μ是动量的超参数,ε是防止除零错误的偏置项,t是迭代次数。
三、Adam优点相对于传统的梯度下降算法,Adam优化算法有以下优点:1. 收敛速度快:Adam算法兼具两者的优点,既能加速训练,又能保证收敛速度。
2. 自适应学习率:Adam算法能够根据目标函数局部的梯度信息,自动地调整学习率,从而避免了手动调节学习率带来的不便。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
从SGD 到Adam ——深度学习优化算法概览(一)
楔子前些日在写计算数学课的期末读书报告,我选择的主题是「分析深度学习中的各个优化算法」。
在此前的工作中,自己通常就是无脑「Adam 大法好」,而对算法本身的内涵不知所以然。
一直希望能抽时间系统的过一遍优化算法的发展历程,直观了解各个算法的长处和短处。
这次正好借着作业的机会,补一补课。
本文主要借鉴了@Juliuszh 的文章[1]思路,使用一个general 的框架来描述各个梯度下降变种算法。
实际上,本文可以视作对[1]的重述,在此基础上,对原文描述不够详尽的部分做了一定补充,并修正了其中许多错误的表述和公式。
另一主要参考文章是Sebastian Ruder 的综述[2]。
该文十分有名,大概是深度学习优化算法综述中质量最好的一篇了。
建议大家可以直接阅读原文。
本文许多结论和插图引自该综述。
对优化算法进行分析和比较的文章已有太多,本文实在只能算得上是重复造轮,旨在个人学习和总结。
希望对优化算法有深入了解的同学可以直接查阅文末的参考文献。
引言最优化问题是计算数学中最为重要的研究方向之一。
而在深度学习领域,优化算法的选择也是一个模型的重中之重。
即使在数据集和模型架构完全相同的情况下,采用不同的优化算法,也很可能导致截然不同的训练效果。
梯度下降是目前神经网络中使用最为广泛的优
化算法之一。
为了弥补朴素梯度下降的种种缺陷,研究者们发明了一系列变种算法,从最初的SGD (随机梯度下降) 逐步演进到NAdam。
然而,许多学术界最为前沿的文章中,都并没有一味使用Adam/NAdam 等公认“好用”的自适应算法,很多甚至还选择了最为初级的SGD 或者SGD with Momentum 等。
本文旨在梳理深度学习优化算法的发展历程,并在一个更加概括的框架之下,对优化算法做出分析和对比。
Gradient Descent梯度下降是指,在给定待优化的模型参数和目标函数后,算法通过沿梯度的相反方向更新来最小化。
学习率决定了每一时刻的更新步长。
对于每一个时刻,我们可以用下述步骤描述梯度下降的流程:(1) 计算目标函数关于参数的梯度(2) 根据历史梯度计算一阶和二阶动量(3) 更新模型参数其中,为平滑项,防止分母为零,通常取1e-8。
Gradient Descent 和其算法变种根据以上框架,我们来分析和比较梯度下降的各变种算法。
Vanilla SGD朴素SGD (Stochastic Gradient Descent) 最为简单,没有动量的概念,即这时,更新步骤就是最简单的SGD 的缺点在于收敛速度慢,可能在鞍点处震荡。
并且,如何合理的选择学习率是SGD 的一大难点。
MomentumSGD 在遇到沟壑时容易陷入震荡。
为此,可以为其引入动量Momentum[3],加速SGD 在正确方向的下降并抑制震荡。
SGD-M 在原步长之上,增加了与上一
时刻步长相关的,通常取0.9 左右。
这意味着参数更新方向不仅由当前的梯度决定,也与此前累积的下降方向有关。
这使得参数中那些梯度方向变化不大的维度可以加速更新,并减少梯度方向变化较大的维度上的更新幅度。
由此产生了加速收敛和减小震荡的效果。
图1(a): SGD图1(b): SGD with momentum从图1 中可以看出,引入动量有效的加速了梯度下降收敛过程。
Nesterov Accelerated Gradient图2: Nesterov update更进一步的,人们希望下降的过程更加智能:算法能够在目标函数有增高趋势之前,减缓更新速率。
NAG 即是为此而设计的,其在SGD-M 的基础上进一步改进了步骤1 中的梯度计算公式:参考图2,SGD-M 的步长计算了当前梯度(短蓝向量)和动量项(长蓝向量)。
然而,既然已经利用了动量项来更新,那不妨先计算出下一时刻的近似位置(棕向量),并根据该未来位置计算梯度(红向量),然后使用和SGD-M 中相同的方式计算步长(绿向量)。
这种计算梯度的方式可以使算法更好的“预测未来”,提前调整更新速率。
AdagradSGD、SGD-M 和NAG 均是以相同的学习率去更新的各个分量。
而深度学习模型中往往涉及大量的参数,不同参数的更新频率往往有所区别。
对于更新不频繁的参数(典型例子:更新word embedding 中的低频词),我们希望单次步长更大,多学习一些知识;对于更新频繁的参数,我们则希望
步长较小,使得学习到的参数更稳定,不至于被单个样本影响太多。
Adagrad[4] 算法即可达到此效果。
其引入了二阶动量:其中,是对角矩阵,其元素为参数第维从初始时刻到时刻的梯度平方和。
此时,可以这样理解:学习率等效为。
对于此前频繁更新过的参数,其二阶动量的对应分量较大,学习率就较小。
这一方法在稀疏数据的场景下表现很好。
RMSprop在Adagrad 中,是单调递增的,使得学习率逐渐递减至0,可能导致训练过程提前结束。
为了改进这一缺点,可以考虑在计算二阶动量时不累积全部历史梯度,而只关注最近某一时间窗口内的下降梯度。
根据此思想有了RMSprop。
记为,有其二阶动量采用指数移动平均公式计算,这样即可避免二阶动量持续累积的问题。
和SGD-M 中的参数类似,通常取0.9 左右。
Adadelta待补充AdamAdam[5] 可以认为是前述方法的集大成者。
和RMSprop 对二阶动量使用指数移动平均类似,Adam 中对一阶动量也是用指数移动平均计算。
此外,对一阶和二阶动量做偏置校正,再进行更新,可以保证迭代较为平稳。
NAdam待补充可视化分析图3: SGD optimization on loss surface contours图4: SGD optimization on saddle point图3 和图4 两张动图直观的展现了不同算法的性能。
(Image credit: Alec Radford)图3 中,我们可以看到不同算法在损失面等高线图中的学
习过程,它们均同同一点出发,但沿着不同路径达到最小值点。
其中Adagrad、Adadelta、RMSprop 从最开始就找到了正确的方向并快速收敛;SGD 找到了正确方向但收敛速度很慢;SGD-M 和NAG 最初都偏离了航道,但也能最终纠正到正确方向,SGD-M 偏离的惯性比NAG 更大。
图4 展现了不同算法在鞍点处的表现。
这里,SGD、SGD-M、NAG 都受到了鞍点的严重影响,尽管后两者最终还是逃离了鞍点;而Adagrad、RMSprop、Adadelta 都很快找到了正确的方向。
关于两图的讨论,也可参考[2]和[6]。
可以看到,几种自适应算法在这些场景下都展现了更好的性能。
讨论、选择策略读书报告中的讨论内容较为杂乱,该部分待整理完毕后再行发布。
References[1] Adam那么棒,为什么还对SGD念念不忘(1) ——一个框架看懂优化算法[2] An overview of gradient descent optimization algorithms[3] On the momentum term in gradient descent learning algorithms[4] Adaptive Subgradient Methods for Online Learning and Stochastic Optimization[5] A Method for Stochastic Optimization[6] CS231n Convolutional Neural Networks for Visual Recognition。