SQLServer插入数据得到上一条数据的自增ID
C#--SqlServer--插入一条数据和插入多条数据的方法

C#--SqlServer--插⼊⼀条数据和插⼊多条数据的⽅法1,SQLHelper帮助类using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Threading.Tasks;using System.Data;using System.Data.SqlClient;using System.Configuration;//引⼊读取配置⽂件的命名空间namespace DAL.Helper{/// <summary>/// 通⽤数据访问类/// </summary>public class SQLHelper{// private static string connString = "Server=aaaa\\sqlexpress;DataBase=StudentManageDB;Uid=sa;Pwd=password01!";//public static readonly string connString = Common.StringSecurity.DESDecrypt(ConfigurationManager.ConnectionStrings["connString"].ToString());static string connString = "Server=.;DataBase=TighteningResultDB;Uid=sa;Pwd=123";/// <summary>/// 执⾏增、删、改⽅法/// </summary>/// <param name="sql"></param>/// <returns></returns>public static int Update(string sql){SqlConnection conn = new SqlConnection(connString);SqlCommand cmd = new SqlCommand(sql, conn);try{conn.Open();return cmd.ExecuteNonQuery();}catch (Exception ex){//将错误信息写⼊⽇志...throw ex;}finally{conn.Close();}}/// <summary>/// 执⾏单⼀结果(select)/// </summary>/// <param name="sql"></param>/// <returns></returns>public static object GetSingleResult(string sql){SqlConnection conn = new SqlConnection(connString);SqlCommand cmd = new SqlCommand(sql, conn);try{conn.Open();return cmd.ExecuteScalar();}catch (Exception ex){//将错误信息写⼊⽇志...throw ex;}finally{conn.Close();}}/// <summary>/// 执⾏结果集查询/// </summary>/// <param name="sql"></param>/// <returns></returns>public static SqlDataReader GetReader(string sql){SqlConnection conn = new SqlConnection(connString);SqlCommand cmd = new SqlCommand(sql, conn);try{conn.Open();return cmd.ExecuteReader(CommandBehavior.CloseConnection);}catch (Exception ex){conn.Close();//将错误信息写⼊⽇志...throw ex;}}/// <summary>/// 执⾏查询返回⼀个DataSet/// </summary>/// <param name="sql"></param>/// <returns></returns>public static DataSet GetDataSet(string sql){SqlConnection conn = new SqlConnection(connString);SqlCommand cmd = new SqlCommand(sql, conn);SqlDataAdapter da = new SqlDataAdapter(cmd);//创建数据适配器对象DataSet ds = new DataSet();//创建⼀个内存数据集try{conn.Open();da.Fill(ds);//使⽤数据适配器填充数据集return ds;}catch (Exception ex){//将错误信息写⼊⽇志...throw ex;}finally{conn.Close();}}}}2,插⼊⼀条数据:public int AddTighteningResult(PMOpenProtocol.TighteningResultData data){//【1】编写SQL语句StringBuilder sqlBuilder = new StringBuilder();//如果字符串⽐较长,可以⽤StringBuildersqlBuilder.Append("insert into TighteningResult(TighteningID,ProductSN,StationCode,StationName,BoltNumber,TighteningStatus,ResultDateTime,FinalTouque,FinalAngle,OperateDateTime,OperateFlat,ErrorInfo)"); sqlBuilder.Append(" values('{0}','{1}','{2}','{3}','{4}','{5}','{6}','{7}','{8}','{9}',{10},'{11}')");//【2】解析对象string sql = string.Format(sqlBuilder.ToString(),"", "", "", data.StationName, data.OrdinalBoltNumber_1, data.t_D_TIGHTENING_STATUS_1, Convert.ToDateTime(data.t_D_REAL_TIME), data.t_D_TORQUE_1, data.t_D_ANGLE_1, "", 0, "");//【3】提交到数据库try{return SQLHelper.Update(sql);}catch (SqlException ex){throw new Exception("数据库操作出现异常!具体信息:" + ex.Message);}catch (Exception ex){throw ex;}}sql语句:insert intoTighteningResult(TighteningID,ProductSN,StationCode,StationName,BoltNumber,TighteningStatus,ResultDateTime,FinalTouque,FinalAngle,OperateDateTime,OperateFlat,ErrorInfo) values('','','','Stn 01','01','NG','2021/8/29 23:05:42','4.1983','0','',0,'') 3,插⼊多条数据:搜索到的⽅法:使⽤UNION ALL来进⾏插⼊操作:代码如下:INSERT INTO MyTable(ID,NAME)SELECT 4,'000'UNION ALLSELECT 5,'001'UNION ALLSELECT 6,'002'实现上⾯的⽅法:public int AddMultiTighteningResult(PMOpenProtocol.TighteningResultData data){//【1】编写SQL语句StringBuilder sqlBuilder = new StringBuilder();//如果字符串⽐较长,可以⽤StringBuildersqlBuilder.Append("insert into TighteningResult(TighteningID,ProductSN,StationCode,StationName,BoltNumber,TighteningStatus,ResultDateTime,FinalTouque,FinalAngle,OperateDateTime,OperateFlat,ErrorInfo)"); sqlBuilder.Append(" select '{0}','{1}','{2}','{3}','{4}','{5}','{6}','{7}','{8}','{9}',{10},'{11}'");//【2】解析对象string sql = string.Format(sqlBuilder.ToString(),"", "", "", data.StationName, data.OrdinalBoltNumber_1, data.t_D_TIGHTENING_STATUS_1, Convert.ToDateTime(data.t_D_REAL_TIME), data.t_D_TORQUE_1, data.t_D_ANGLE_1, "", 0, "");if (data.t_D_Number_of_Bolts >= 2){sqlBuilder=new StringBuilder(sql);sqlBuilder.Append("union all select '{0}','{1}','{2}','{3}','{4}','{5}','{6}','{7}','{8}','{9}',{10},'{11}'");sql = string.Format(sqlBuilder.ToString(),"", "", "", data.StationName, data.OrdinalBoltNumber_2, data.t_D_TIGHTENING_STATUS_2, Convert.ToDateTime(data.t_D_REAL_TIME), data.t_D_TORQUE_2, data.t_D_ANGLE_2, "", 0, "");}if (data.t_D_Number_of_Bolts >= 3){sqlBuilder = new StringBuilder(sql);sqlBuilder.Append("union all select '{0}','{1}','{2}','{3}','{4}','{5}','{6}','{7}','{8}','{9}',{10},'{11}'");sql = string.Format(sqlBuilder.ToString(),"", "", "", data.StationName, data.OrdinalBoltNumber_3, data.t_D_TIGHTENING_STATUS_3, Convert.ToDateTime(data.t_D_REAL_TIME), data.t_D_TORQUE_3, data.t_D_ANGLE_3, "", 0, "");}if (data.t_D_Number_of_Bolts >= 4){sqlBuilder = new StringBuilder(sql);sqlBuilder.Append("union all select '{0}','{1}','{2}','{3}','{4}','{5}','{6}','{7}','{8}','{9}',{10},'{11}'");sql = string.Format(sqlBuilder.ToString(),"", "", "", data.StationName, data.OrdinalBoltNumber_4, data.t_D_TIGHTENING_STATUS_4, Convert.ToDateTime(data.t_D_REAL_TIME), data.t_D_TORQUE_4, data.t_D_ANGLE_4, "", 0, "");}if (data.t_D_Number_of_Bolts >= 5){sqlBuilder = new StringBuilder(sql);sqlBuilder.Append("union all select '{0}','{1}','{2}','{3}','{4}','{5}','{6}','{7}','{8}','{9}',{10},'{11}'");sql = string.Format(sqlBuilder.ToString(),"", "", "", data.StationName, data.OrdinalBoltNumber_5, data.t_D_TIGHTENING_STATUS_5, Convert.ToDateTime(data.t_D_REAL_TIME), data.t_D_TORQUE_5, data.t_D_ANGLE_5, "", 0, "");}if (data.t_D_Number_of_Bolts >= 6){sqlBuilder = new StringBuilder(sql);sqlBuilder.Append("union all select '{0}','{1}','{2}','{3}','{4}','{5}','{6}','{7}','{8}','{9}',{10},'{11}'");sql = string.Format(sqlBuilder.ToString(),"", "", "", data.StationName, data.OrdinalBoltNumber_6, data.t_D_TIGHTENING_STATUS_6, Convert.ToDateTime(data.t_D_REAL_TIME), data.t_D_TORQUE_6, data.t_D_ANGLE_6, "", 0, "");}//【3】提交到数据库try{return SQLHelper.Update(sql);}catch (SqlException ex){throw new Exception("数据库操作出现异常!具体信息:" + ex.Message);}catch (Exception ex){throw ex;}}sql语句:insert intoTighteningResult(TighteningID,ProductSN,StationCode,StationName,BoltNumber,TighteningStatus,ResultDateTime,FinalTouque,FinalAngle,OperateDateTime,OperateFlat,ErrorInfo)select '','','','Stn 01','01','NG','2021/8/29 23:09:20','4.1983','0','',0,''union all select '','','','Stn 01','02','NG','2021/8/29 23:09:20','0','0','',0,''union all select '','','','Stn 01','03','OK','2021/8/29 23:09:20','475.19','360.791','',0,''union all select '','','','Stn 01','04','NG','2021/8/29 23:09:20','4.5254','0','',0,''union all select '','','','Stn 01','05','NG','2021/8/29 23:09:20','4.6731','0','',0,''union all select '','','','Stn 01','06','NG','2021/8/29 23:09:20','3.9974','0','',0,''。
sqlserver生成id的方法

SQL Server是一种流行的关系型数据库管理系统,它提供了许多不同的方法来生成唯一的ID。
在本篇文章中,我将探讨几种在SQL Server 中生成ID的方法,并分析它们各自的优缺点。
1. 自增字段自增字段是SQL Server中最常用的生成唯一ID的方法之一。
这种方法利用了数据库管理系统的自动增长功能,每当插入一条新的记录时,自增字段的值就会自动加1。
这种方法简单、直观,并且保证了唯一性,因此在许多情况下都是非常合适的选择。
但是,自增字段也存在一些局限性。
它只能应用在单表中,并且只能有一个自增字段。
一旦插入的记录被删除,相应的ID就会永久丢失,导致ID的不连续性。
另外,如果需要在插入记录之前就获取新记录的ID,自增字段也无法满足这一需求。
2. GUID全局唯一标识符(GUID)是一种128位的二进制标识符,它能够在全球范围内保证唯一性。
在SQL Server中,可以使用NEWID()函数来生成一个新的GUID。
这种方法的优点是非常适合分布式系统和复制环境,因为它可以保证不同数据库中的记录的唯一性,并且不需要和其他数据库进行通信。
然而,GUID也存在一些缺点。
由于它的长度较长,因此不适合作为主键,并且会占用更多的存储空间。
由于其无序性,在某些情况下会导致性能问题。
另外,GUID对于人类用户来说是不可读的,因此在某些情况下可能不够直观。
3. 序列SQL Server 2012引入了序列(Sequence)对象,它提供了一种可复用的数字范围生成器。
使用序列,可以在每次需要生成新的ID时调用NEXT VALUE FOR语句,来获取一个新的序列值。
序列在保证唯一性的还具有一定的灵活性,比如可以指定增量、起始值和最大值等属性。
然而,序列也存在一些限制。
它只能应用在单表中,且每个表只能有一个序列。
序列并不是完全自动增长的,需要显式地调用NEXT VALUE FOR语句,这使得它不太适合与INSERT语句一起使用。
sqlserver字段自增长函数

sqlserver字段自增长函数在SQL Server中,要创建一个自增长字段,你可以使用IDENTITY属性。
IDENTITY属性允许你在插入新记录时自动生成唯一的、递增的值。
下面我会详细介绍如何在SQL Server中使用IDENTITY属性来实现字段自增长的功能。
首先,让我们假设我们有一个名为"employees"的表,我们想要为"employee_id"字段创建自增长功能。
我们可以使用以下的SQL语句来创建这个表:sql.CREATE TABLE employees.(。
employee_id INT IDENTITY(1,1) PRIMARY KEY,。
first_name VARCHAR(50),。
last_name VARCHAR(50),。
hire_date DATE.);在上面的SQL语句中,我们在"employee_id"字段的定义中使用了"IDENTITY(1,1)"。
第一个参数"1"表示起始值,第二个参数"1"表示每次递增的步长。
这意味着在插入新记录时,"employee_id"字段的值将从1开始,每次递增1。
当你插入一条新记录时,你不需要提供"employee_id"字段的值,数据库会自动为你生成一个唯一的递增值。
例如:sql.INSERT INTO employees (first_name, last_name,hire_date)。
VALUES ('John', 'Doe', '2022-01-01');在这个例子中,数据库会自动为"employee_id"字段赋予一个唯一的递增值,而不需要我们显式地指定它。
总之,使用IDENTITY属性是在SQL Server中实现字段自增长的一种常见方法。
sqlserver建表时设置ID字段自增的简单方法

sqlserver建表时设置ID字段⾃增的简单⽅法1. 打开要设置的数据库表,点击要设置的字段,⽐如id,这时下⽅会出现id的列属性表2. 列属性中,通过设置“标识规范”的属性可以设置字段⾃增,从下图上看,“是标识”的值是否,说明id还不是⾃增字段3. 能够设置ID字段⾃增的字段必须是可⾃增的,⽐如int,bigint类型,⽽varchar类型是不可⾃增的。
⽐如查看name的列属性时,可以看到“是标识”是否且不可更改。
4. 点击“标识规范”,展开后,点击“是标识”会出现下拉列表按钮,可以双击设置也可以从下拉列表选择。
5. 设置“是标识”的值是“是”之后,可以看到下⾯的属性会默认写上值6. 可以设置标识增量和标识种⼦。
标识增量是字段每次⾃动增加的值,⽐如1,则字段每次增加1;标识种⼦是字段的初始值,⽐如1,则第⼀条记录的该字段值是17. 设置完成后,别忘记点击“保存”END注意事项设置⾃增字段时要注意字段的类型,不是所有字段类型都可以设置⾃增的SQLServer 中含⾃增主键的表,通常不能直接指定ID值插⼊,可以采⽤以下⽅法插⼊。
1. SQLServer ⾃增主键创建语法:identity(seed, increment)其中seed 起始值increment 增量⽰例:create table student(id int identity(1,1),name varchar(100))2. 指定⾃增主键列值插⼊数据(SQL Server 2000)先执⾏如下语句SET IDENTITY_INSERT [ database. [ owner. ] ] { table } ON然后再执⾏插⼊语句最后执⾏如下语句SET IDENTITY_INSERT [ database. [ owner. ] ] { table } OFF⽰例:表定义如下create table student(id int identity(1,1),name varchar(100))插⼊数据set IDENTITY_INSERT student ONinsert into student(id,name)values(1,'student1');insert into student(id,name)values(2,'student2');set IDENTITY_INSERT student OFF总结以上所述是⼩编给⼤家介绍的sql server建表时设置ID字段⾃增的简单⽅法,希望对⼤家有所帮助,如果⼤家有任何疑问请给我留⾔,⼩编会及时回复⼤家的。
MySql 主键自动增长

MySql 主键自动增长Mysql,SqlServer,Oracle主键自动增长设置1、把主键定义为自动增长标识符类型MySql在mysql中,如果把表的主键设为auto_increment类型,数据库就会自动为主键赋值。
例如:createtable customers(id int auto_increment primarykey not null, name varchar(15));insertinto customers(name) values("name1"),("name2");select id from customers;以上sql语句先创建了customers表,然后插入两条记录,在插入时仅仅设定了name字段的值。
最后查询表中id字段,查询结果为:由此可见,一旦把id设为auto_increment类型,mysql数据库会自动按递增的方式为主键赋值。
Sql Server在MS SQLServer中,如果把表的主键设为identity类型,数据库就会自动为主键赋值。
例如:createtable customers(id int identity(1,1) primarykey not null, name varchar(15));insertinto customers(name) values('name1'),('name2');select id from customers;注意:在sqlserver中字符串用单引号扩起来,而在mysql中可以使用双引号。
查询结果和mysql的一样。
由此可见,一旦把id设为identity类型,MS SQLServer数据库会自动按递增的方式为主键赋值。
identity包含两个参数,第一个参数表示起始值,第二个参数表示增量。
以前经常会碰到这样的问题,当我们删除了一条自增长列为1的记录以后,再次插入的记录自增长列是2了。
SQL如何在自增列插入指定数据

SQL如何在⾃增列插⼊指定数据
SQL Server 中数据表往往会设置⾃增列,常见的⽐如说⾸列的ID列。
往数据表插⼊新数据的时候,⾃增列是跳过的,⽆需插⼊即会按照设置的⾃增规则进⾏列增长。
那么,如果我们想往⾃增列插⼊我们指定的数据时该怎么做呢?
⼀:建⽴⼀张简单的测试表
CREATE TABLE randy_test (id INT IDENTITY(1,1), num INT)
⼆:如果强⾏插⼊数据时:
INSERT INTO randy_test VALUES (1,11)
消息8101,级别16,状态1,第1⾏
仅当使⽤了列列表并且IDENTITY_INSERT为ON时,才能为表'randy_test'中的标识列指定显式值。
可以看到,数据库提⽰不能给标识列指定显⽰值,除⾮将数据表设置IDENTITY_INSERT为ON
三:设置标识列插⼊开关开启,然后执⾏我们的插⼊操作
SET IDENTITY_INSERT randy_test ON
INSERT INTO randy_test (id,num) VALUES (1,11);
INSERT INTO randy_test (id,num) VALUES (2,22);
set identity_insert randy_test OFF
(1⾏受影响)
(1⾏受影响)
结果如下图:
SELECT*FROM randy_test AS rt
id num
1 11
2 22。
SQLSERVER自增列的方法

SQLSERVER自增列的方法1、定义自增长列可以使用IDENTITY选项来定义自增长列,下面是定义一个名为ID的自增长列的语法:[ID][INT]IDENTITY(1,1)NOTNULL上面定义的自增长列ID默认从1开始,每次增加1,正常情况下不能以其他值开始,也不能以其他值增加,但都是可以在定义时进行修改的。
例如,如果想从1000开始,每次增加100,那么可以这样定义:[ID][INT]IDENTITY(1000,100)NOTNULL另外还可以将自增长列定义为BIGINT,这样可以支持更大范围内的增长:[ID][BIGINT]IDENTITY(1000,100)NOTNULL2、获取当前最大自增ID有时候我们需要在SQL中获取数据表中当前最大的自增ID值,可以使用SELECTIDENT_CURRENT函数来实现:SELECT IDENT_CURRENT('table_name')其中table_name是表名,SELECT之后得到的值就是当前最大的自增ID值。
3、修改自增ID的起步值如果想要修改数据表中自增ID的起步值,可以使用以下语法:DBCC CHECKIDENT ('table_name', RESEED, start_value)其中table_name是表名,start_value是起始值,之后自增ID将以start_value为起始值。
4、修改自增ID的增长值如果要修改自增ID的增长值,可以使用ALTERTABLE语句将自增ID 的IDENTITY选项修改即可:ALTER TABLE table_name ALTER COLUMN column_name IDENTITY (start_value,increment_value)其中table_name是表名,column_name是自增列的列名,start_value是起始值,increment_value是增长值。
SqlServer将数据库中的表数据复制到另一个数据库对应的表
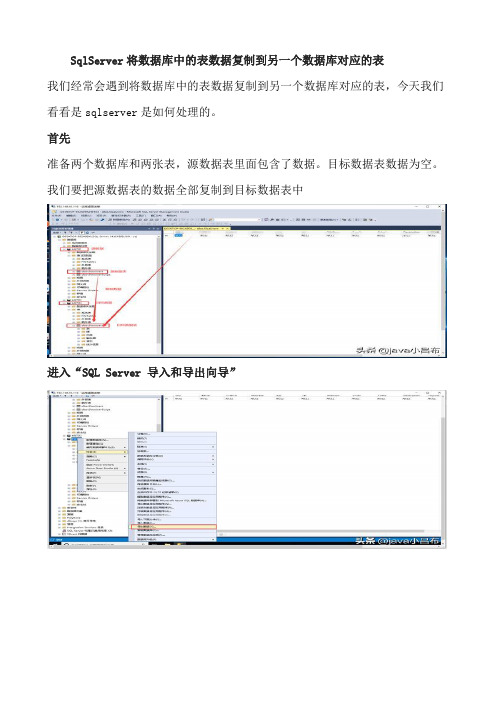
SqlServer将数据库中的表数据复制到另一个数据库对应的表
我们经常会遇到将数据库中的表数据复制到另一个数据库对应的表,今天我们看看是sqlserver是如何处理的。
首先
准备两个数据库和两张表,源数据表里面包含了数据。
目标数据表数据为空。
我们要把源数据表的数据全部复制到目标数据表中
进入“SQL Server 导入和导出向导”
选择数据源
选择目标数据库
指定表复制或查询
选择源表和源视图
编辑映射
勾选启用标识插入,启用标识是自增id对应数据源表的ID,就不会自增了
保存并运行包
后面都是一直点下一步了
数据复制完成。
SQLServer中identity(自增)的用法详解

SQLServer中identity(⾃增)的⽤法详解⼀、identity的基本⽤法1.含义identity表⽰该字段的值会⾃动更新,不需要我们维护,通常情况下我们不可以直接给identity修饰的字符赋值,否则编译时会报错2.语法列名数据类型约束 identity(m,n)m表⽰的是初始值,n表⽰的是每次⾃动增加的值如果m和n的值都没有指定,默认为(1,1)要么同时指定m和n的值,要么m和n都不指定,不能只写其中⼀个值,不然会出错3.实例演⽰不指定m和n的值create table student1(sid int primary key identity,sname nchar(8) not null,ssex nchar(1))insert into student1(sname,ssex) values ('张三','男');insert into student1 values ('李四','⼥');--可以省略列名insert into student1 values ('王五','⼥');指定m和n的值create table student2(sid int primary key identity(20,5),sname nchar(8) not null,ssex nchar(1))insert into student2(sname,ssex) values ('张三','男');insert into student2 values ('李四','⼥');--可以省略列名insert into student2 values ('王五','⼥');4.删除⼀条记录接着插⼊把sid为2的记录删除,继续插⼊,新插⼊的记录的sid不是2,⽽是3create table student3(sid int primary key identity,sname nchar(8) not null,ssex nchar(1))insert into student3(sname,ssex) values ('张三','男');insert into student3 values ('李四','⼥');delete from student3 where sid=2;--把sid为2的记录删除insert into student3 values ('王五','⼥');⼆、重新设置identity的值1.语法dbcc checkident(表名,reseed,n);n+1表⽰的是表中identity字段的初始值(n的值可以为0)也就是说:如果插⼊的是id为2的记录,则n的值是12.实例演⽰create table student4(sid int primary key identity,sname nchar(8) not null,ssex nchar(1))insert into student4(sname,ssex) values ('张三','男');insert into student4 values ('李四','⼥');delete from student4 where sid=2;--把sid为2的记录删除dbcc checkident('student4',reseed,1);--把student4表中identity字段的初始值重新设置为1insert into student4 values ('王五','⼥');三、向identity字段插⼊数据1.语法set identity_insert 表名 on;insert into 表名(列名1,列名2,列名3,列名4) values (数据1,数据2,数据3,数据4);set identity_insert 表名 off;注意:插⼊数据时必须得指定identity修饰的字段的名字2.实例演⽰create table student5(sid int primary key identity(20,5),sname nchar(8) not null,ssex nchar(1))insert into student5(sname,ssex) values ('张三','男');insert into student5 values ('李四','⼥');insert into student5 values ('王五','⼥');set identity_insert student5 on;/*insert into student5 values ('⿊六','男');--errorinsert into student5 values (21,'⿊六','男');--error*/insert into student5(sid,sname,ssex) values (21,'⿊六','男');set identity_insert student5 off;/*insert into student5 values (22,'赵七','⼥');--errorinsert into student5(sid,sname,ssex) values (22,'赵七','⼥');--error*/insert into student5 values ('赵七','⼥');补充知识:SQL Server 添加与删除主键约束PRIMARY KEY 约束唯⼀标识数据库表中的每条记录。
oracle中的last_insert_id使用方法

oracle中的last_insert_id使用方法在Oracle数据库中,LAST_INSERT_ID是一个十分实用的功能,它可以返回最近一次插入操作生成的自增主键值。
以下将详细介绍LAST_INSERT_ID 的使用方法、应用场景及其实用性。
1.Oracle中LAST_INSERT_ID的作用LAST_INSERT_ID主要用于获取最近一次插入操作生成的自增主键值。
在Oracle数据库中,当执行插入操作时,系统会自动为插入的数据生成一个自增主键。
通过LAST_INSERT_ID,我们可以获取到这个自增主键值,以便于后续处理。
ST_INSERT_ID的用法示例在Oracle中,可以使用如下语法调用LAST_INSERT_ID:```SELECT LAST_INSERT_ID();```例如,假设我们有一个名为`test_table`的表,其中有一个自增主键`id`,我们可以通过以下语句插入一条数据并获取插入后的主键值:```sqlINSERT INTO test_table (name, age) VALUES ("张三", 25);SELECT LAST_INSERT_ID();```执行上述语句后,我们可以在后续查询中使用获取到的自增主键值:```sqlSELECT * FROM test_table WHERE id = (SELECT LAST_INSERT_ID());```3.与其他插入语句的区别在Oracle中,LAST_INSERT_ID与普通的插入语句有所不同。
普通的插入语句仅能插入数据,而不能直接获取插入操作生成的自增主键值。
使用LAST_INSERT_ID可以让我们在插入数据的同时,获取到对应的自增主键,提高了操作便利性。
4.应用场景及实用性LAST_INSERT_ID在以下场景中具有较高的实用性:- 当需要对插入的数据进行后续处理时,如插入数据后需要更新其他表或执行其他操作,可以使用LAST_INSERT_ID获取自增主键,便于后续处理。
SQL Server获取插入数据的自增长字段的值

在Sql Server中插入一条数据,想立即获取它标识值,可以用以下
三中方法:
1.SCOPE_IDENTITY - scope_identity()
返回当前会话和当前作用域中的任何表最后生成的标识值。
一个作用域就是一个模块——存储过程、触发器、函数或批处理。
因此,如果两个语句处于同一个存储过程、函数或批处理中,则它们位于相同的作用域中。
2.IDENT_CURRENT - ident_current('表名')
返回任何会话和任何作用域中的指定表最后生成的标识值。
这个函数需要一个以表名为值的变量,也就是说虽然不受会话和作用域的限制,却会受到表的限制。
3.@@IDENTITY - 全局变量
返回为当前会话的所有作用域中的任何表最后生成的标识值。
一直以来都是使用@@identity来获得最后一个插入到表的记录的identity值,最近发现这种方法在某种情况是不可靠的,先来看看
两个概念
作用域:在SQL SERVER作用域就是一个模块-存储过程,触发器,
函数或批处理
会话:一个用户连接产生的所有上下文信息
相同点:都是返回最后插入的标识值
不同点:
@@identity:返回当前会话最后一个标识值,不限于特定的作用域;ident_current('tablename'):返回任何会话,任何作用域中的指定表中生成的最后一个标识值;
scope_identity:返回当前会话当前作用域任何表生成的最后一个标识值。
SqlServer数据库优化之添加主键和自增长

SqlServer数据库优化之添加主键和⾃增长今天需要给有500万条数据的表添加主键和⾃增长列,其中最⼤的难度在于如何UPDATE这500万多条数据,开始吧!1.先给表添加⼀个字段叫ID,并允许空2.查询表,我想到了使⽤其中的时间列排序来创建表的序号来⽣成我们想要的⾃增列ID。
--其中查询出来的字段将作为我UPDATE时的匹配条件SELECT row_number() over(order by InsertTime asc) as num,UserID cUserID,Score cScore,InsertTime cInsertTime,InoutIndex cInoutIndex,ChairID cChairID FROM[RecordDrawScore] ) c序号已经⾃动⽣成了,下⼀步update到我们的表--其中我优化下把查询到的结果放到临时表#Temp3.update这些数据UPDATE[RecordDrawScore]SET ID = c.numFROM #Temp cWHERE UserID=c.cUserID AND InsertTime = c.cInsertTime AND Score = c.cScore AND InoutIndex =c.cInoutIndex AND ChairID=cChairID4.检查我们update的效果如何SELECT id FROM[dbo].[RecordDrawScore]GROUP BY id HAVING COUNT(id)>1我们添加的id没有重复的,就代表成功了!5.将表中的id设置为主键并添加⾃增长6.新增⼀条记录试试如果⼀切操作顺利,那么会有⼀个新的id注意要是在UPDATE表时,要停掉INSERT操作!不然会有新的列没有ID,就⽆法继续设置为⾃增长列!。
SqlServer数据库自增长字段标识列的插入或更新修改操作办法

SqlServer数据库⾃增长字段标识列的插⼊或更新修改操作办法写在前⾯的话:在⽇常的Sql server开发中,经常会⽤到Identity类型的标识列作为⼀个表结构的⾃增长编号。
⽐如⽂章编号、记录编号等等。
⾃增长的标识很⼤程度上⽅便了数据库程序的开发,但有时候这个固执的字段类型也会带来⼀些⿇烦。
1、修改标识列的字段值有时为了实现某些功能,需要修改类型为identity⾃增长类型的字段的值,但由于标识列的类型所限,这种操作默认是不允许的。
⽐如⽬前数据库有5条正常添加的数据,此时删除2条,那么如果再添加数据时,⾃增长的标识列会⾃动赋值为6,可这时如果想在插⼊数据时赋值给3呢,默认是不允许的。
如果你特别想改变这个值,完全由⾃⼰来控制该标识字段值的插⼊,⽅法还是有的。
set INENTITY_INSERT [tableName] [on/off]使⽤上述语句,可以⽅便的控制某个表的某个⾃增长列标识是否⾃动增长,也就是说是否允许你在inset⼀条记录时⼿动指定列标识字段的值,如果指定为on,则可以在insert时指定标识列字段的值,该值不⾃动增长赋值。
当然使⽤完毕,还需要⽤这个语句将开关关闭到原始状态off,否则下次insert数据时该字段还是不会⾃动增长赋值的。
set IDENTITY_INSERT [tableName] oninsert into tableNameset IDENTITY_INSERT [tableName] off2、重置标识列字段值当数据记录被删除⼀部分后,后⾯再添加的新数据记录,标识列数值会有很⼤的空闲间隔,看起来很不爽。
即使你删除表中所有数据,identity标识列还是会⽆休⽌的⾃动增长下去,⽽不是重头开始增长,通过下⾯的语句可以重置⾃增长字段的种⼦值:dbcc CHECKIDENT(table, [reset|noreset], 200)上述语句将把指定的种⼦值强制重设为200。
详解mysql插入数据后返回自增ID的七种方法

详解mysql插⼊数据后返回⾃增ID的七种⽅法引⾔mysql 和 oracle 插⼊的时候有⼀个很⼤的区别是:oracle ⽀持序列做 id;mysql 本⾝有⼀个列可以做⾃增长字段。
mysql 在插⼊⼀条数据后,如何能获得到这个⾃增 id 的值呢?⼀:使⽤ last_insert_id()SELECT LAST_INSERT_ID();1. 每次 mysql 的 query 操作在 mysql 服务器上可以理解为⼀次“原⼦”操作, 写操作常常需要锁表,这⾥的锁表是 mysql 应⽤服务器锁表不是我们的应⽤程序锁表。
2. 因为 LAST_INSERT_ID 是基于 Connection 的,只要每个线程都使⽤独⽴的 Connection 对象,LAST_INSERT_ID 函数将返回该 Connection 对 AUTO_INCREMENT列最新的 insert or update* 作⽣成的第⼀个 record 的ID。
这个值不能被其它客户端(Connection)影响,保证了你能够找回⾃⼰的 ID ⽽不⽤担⼼其它客户端的活动,⽽且不需要加锁。
使⽤单INSERT 语句插⼊多条记录, LAST_INSERT_ID 返回⼀个列表。
3. LAST_INSERT_ID 是与 table ⽆关的,如果向表 a 插⼊数据后,再向表 b 插⼊数据,LAST_INSERT_ID 会改变。
⼆:使⽤ max(id)如果不是频繁的插⼊我们也可以使⽤这种⽅法来获取返回的id值select max(id) from user;这个⽅法的缺点是不适合⾼并发。
如果同时插⼊的时候返回的值可能不准确。
三:创建⼀个存储过程在存储过程中调⽤先插⼊再获取最⼤值的操作。
DELIMITER $$DROP PROCEDURE IF EXISTS `test` $$CREATE DEFINER=`root`@`localhost` PROCEDURE `test`(in name varchar(100),out oid int)BEGINinsert into user(loginname) values(name);select max(id) from user into oid;select oid;END $$DELIMITER ;call test('gg',@id);四:使⽤ @@identityselect @@IDENTITY@@identity 是表⽰的是最近⼀次向具有 identity 属性(即⾃增列)的表插⼊数据时对应的⾃增列的值,是系统定义的全局变量。
SQLSERVER如何向表中插入数据

下面我们再用另外一种传统的插入方法同样添加5行数据,也就是使用带SELECT从句的INSERT SQL语句,脚本如下:insert into MyTest2 select 1 , 'John' , 'Smith' , 150000.00insert into MyTest2 select 2 , 'Hillary' , 'Swank' , 250000.00insert into MyTest2 select 3 , 'Elisa' , 'Smith' , 120000.00insert into MyTest2 select 4 , 'Liz' , 'Carleno' , 151000.00insert into MyTest2 select 5 , 'Tony' , 'Mcnamara' , 150300.00执行结果如下:(1 row(s) affected)(1 row(s) affected)(1 row(s) affected)(1 row(s) affected)(1 row(s) affected)方法三同样的,我们再假设上述的MyTestDB数据库中有表MyTest3,如下:下面我们用第三种传统的插入方法同样添加5行数据,这里使用的是带SELECT从句和UNION从句的INSERT SQL语句,脚本如下:insert into MyTest3select 1 , 'John' , 'Smith' , 150000.00union select 2 , 'Hillary' , 'Swank' , 250000.00union select 3 , 'Elisa' , 'Smith' , 120000.00union select 4 , 'Liz' , 'Carleno' , 151000.00union select 5 , 'Tony' , 'Mcnamara' , 150300.00执行结果如下:现在我们要用到SQL Server 2008中提供的新方法——行值构造器的插入SQL语句为上述表插入5行数据,这种方法可以在一个INSERT语句中一次性插入多行数据,脚本如下:insert into MyTest4 (id ,fname ,lname , salary) values(1 , 'John' , 'Smith' , 150000.00),(2 , 'Hillary' , 'Swank' , 250000.00),(3 , 'Elisa' , 'Smith' , 120000.00),(4 , 'Liz' , 'Carleno' , 151000.00),(5 , 'Tony' , 'Mcnamara' , 150300.00)执行结果如下:(5 row(s) affected)。
SQL Server 返回插入记录的自增编号

最近在开发项目的过程中遇到这么一个问题,就是在插入一条记录的后立即获取其在数据库中自增的ID,以便处理相关联的数据,怎么做?在sql server 2000中可以这样做,有几种方式。
详细请看下面的讲解与对比。
一、要获取此ID,最简单的方法就是:(以下举一简单实用的例子)--创建数据库和表create database MyDataBaseuse MyDataBasecreate table mytable(id int identity(1,1),name varchar(20))--执行这个SQL,就能查出来刚插入记录对应的自增列的值insert into mytable values('李四')select @@identity二、三种方式的比较SQL Server 2000中,有三个比较类似的功能:他们分别是:SCOPE_IDENTITY、IDENT_CURRENT 和@@IDENTITY,它们都返回插入到IDENTITY 列中的值。
IDENT_CURRENT 返回为任何会话和任何作用域中的特定表最后生成的标识值。
IDENT_CURRENT 不受作用域和会话的限制,而受限于指定的表。
IDENT_CURRENT 返回为任何会话和作用域中的特定表所生成的值。
@@IDENTITY 返回为当前会话的所有作用域中的任何表最后生成的标识值。
SCOPE_IDENTITY 返回为当前会话和当前作用域中的任何表最后生成的标识值SCOPE_IDENTITY 和@@IDENTITY 返回在当前会话中的任何表内所生成的最后一个标识值。
但是,SCOPE_IDENTITY 只返回插入到当前作用域中的值;@@IDENTITY 不受限于特定的作用域。
例如,有两个表T1 和T2,在T1 上定义了一个INSERT 触发器。
当将某行插入T1 时,触发器被激发,并在T2 中插入一行。
此例说明了两个作用域:一个是在T1 上的插入,另一个是作为触发器的结果在T2 上的插入。
取得SQLServer自增列(IDENTITY)的id值(转)

取得SQLServer⾃增列(IDENTITY)的id值(转)⽅案⼀语法:insert into tablename (字段1,字段1) output inserted.id values ('hhh','123');inserted.id的id是你表的id,执⾏此语句就可以返回⾃增的id例⼦:insert into applyinfo (a_hospital,a_barcode) output inserted.a_id values ('1','2');⽅案⼆SQLServer⽀持⾃增列作为主键,⾃增列为数据库开发带来很多便利,但同时也带来⼀些⿇烦1、如何在插⼊数据记录后获得⾃增列主键值通过SQLServer帮助可以知道使⽤select scope_identity()是获得刚刚插⼊的⾃增列值的最好⽅法,但select scope_identity()必须在⼀个scope中才能获得,因此jdbc开发中你不可能在第⼆条SQL语句中获得⾃增列值,即使在同⼀个statement中;唯⼀的⽅法就是在插⼊数据的同时获得⾃增列值,这给数据库开发过程带来不便:String sql = "insert into table(a,b) values('a','b') select scope_identity()";statement.execute(sql);statement.getMoreResults();ResultSet rs = statement.getResultSet();rs.next();int no = rs.getInt(1);2 、如何在不希望插⼊数据的时候获得下⼀个⾃增列值在有些情况下,需要获得下⼀个⾃增列值,但⼜不希望插⼊记录到数据库,⽽且获得的⾃增列值,在后续操作中不会被数据库在作为主键产⽣;⾯对这中状况⼏乎唯⼀的办法就是,在⼀个事务,产⽣⼀条任意的合法的数据插⼊数据库,然后获得⾃增列值,再删除该记录;这也给开发过程带来不少的⿇烦,因为要插⼊的数据必须符合数据库约束,必须满⾜业务逻辑,这对数据库SQL语句⾃动⽣成和执⾏带来额外的挑战C#中取⾃增字段的⽅法是: int id = Convert.ToInt32(cmd.ExecuteScalar());。
SQLserver自增ID--序号自动增加的字段操作
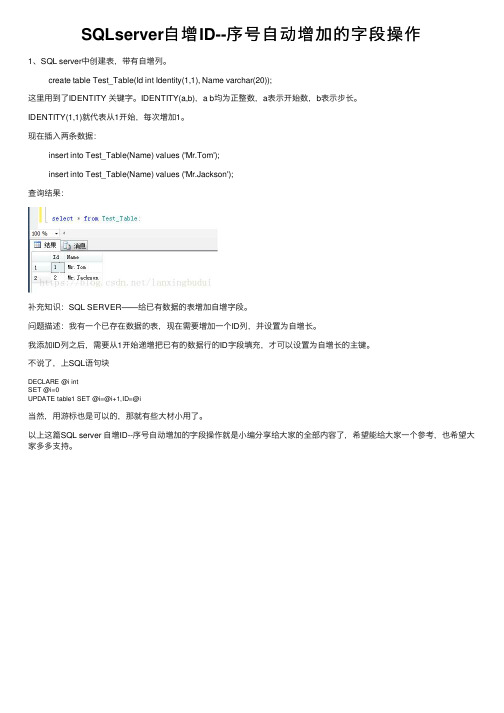
SQLserver⾃增ID--序号⾃动增加的字段操作
1、SQL server中创建表,带有⾃增列。
create table Test_Table(Id int Identity(1,1), Name varchar(20));
这⾥⽤到了IDENTITY 关键字。
IDENTITY(a,b),a b均为正整数,a表⽰开始数,b表⽰步长。
IDENTITY(1,1)就代表从1开始,每次增加1。
现在插⼊两条数据:
insert into Test_Table(Name) values ('Mr.Tom');
insert into Test_Table(Name) values ('Mr.Jackson');
查询结果:
补充知识:SQL SERVER——给已有数据的表增加⾃增字段。
问题描述:我有⼀个已存在数据的表,现在需要增加⼀个ID列,并设置为⾃增长。
我添加ID列之后,需要从1开始递增把已有的数据⾏的ID字段填充,才可以设置为⾃增长的主键。
不说了,上SQL语句块
DECLARE @i int
SET @i=0
UPDATE table1 SET @i=@i+1,ID=@i
当然,⽤游标也是可以的,那就有些⼤材⼩⽤了。
以上这篇SQL server ⾃增ID--序号⾃动增加的字段操作就是⼩编分享给⼤家的全部内容了,希望能给⼤家⼀个参考,也希望⼤家多多⽀持。
sql_获得自增长ID的3种方法比较

sql_获得自增长ID的3种方法比较在SQL中,获得自增长ID的三种常见方法是使用自增长列、使用序列(Sequence)和使用触发器(Trigger)。
1.自增长列:自增长列是最常见和最简单的方法之一、在创建表时,可以将列的数据类型设置为自增长,通常是整数类型(如INT或BIGINT)并设置为自动递增。
在每次插入新记录时,数据库会自动为该列生成唯一的自增长值。
优点:-简单易用:只需在创建表时设置自增长列即可,不需要额外的配置或编程。
-效率高:数据库引擎会自动管理和生成唯一的自增长值。
缺点:-不适用于所有情况:一些情况下可能需要手动控制ID值的生成,此时使用自增长列就不合适。
-缺乏灵活性:自增长列只能生成整数类型的值,无法生成其他类型的标识符。
2. 序列(Sequence):序列是另一种用于生成唯一标识符的方法。
序列是一个独立的数据库对象,可以根据一定规则生成一个递增序列。
在插入数据时,可以使用序列来生成新的ID值。
优点:-灵活性:序列可以生成不同类型的标识符,不仅局限于整数类型。
-可以手动控制:可以根据实际需求手动控制序列的生成规则和起始值。
缺点:-更复杂:相比于自增长列,序列需要更多的配置和编程工作。
-性能开销:生成序列值需要更多的计算和存储开销。
3. 触发器(Trigger):触发器是一段自动执行的代码,可以在数据库中的特定事件发生时被触发执行。
可以通过触发器来生成新的ID值,并将其插入到对应的记录中。
优点:-灵活性:触发器可以根据特定的事件和条件来生成ID值。
-可以自定义:可以使用编程语言和逻辑来自定义生成规则。
缺点:-复杂性高:触发器需要编写和维护复杂的代码。
-性能开销:触发器的执行可能会对数据库的性能造成一定的影响。
总结:自增长列是最简单和常见的方法,适用于大多数情况下。
序列和触发器可以提供更高的灵活性和自定义性,但需要更多的配置和编程工作。
选择使用哪种方法取决于具体的需求和数据库系统的支持程度。
sqlserver表插入数据写法

sqlserver表插入数据写法在使用SQL Server数据库管理系统时,表是存储和组织数据的重要对象。
插入数据是在表中添加新记录的常见操作,而正确的插入语句写法对于数据的准确性和数据库性能至关重要。
本文将深入探讨SQL Server表插入数据的详细写法,包括基本的插入语句、常用插入方法和注意事项。
第一:基本插入语句在SQL Server中,使用INSERT INTO语句可以向表中插入新的记录。
基本插入语句的写法如下:sqlINSERT INTO表名(列1, 列2, 列3, ...)VALUES(值1, 值2, 值3, ...);其中,表名是目标表的名称,列1、列2等是要插入数据的列的名称,而值1、值2等则是对应列的实际值。
举例来说,如果有一个名为Employees的表,包含EmployeeID、FirstName和LastName等列,插入一条新员工记录的语句可以如下:sqlINSERT INTO Employees (EmployeeID, FirstName, LastName)VALUES(1, 'John', 'Doe');第二:使用默认值插入数据在某些情况下,表的某些列可能有默认值,而我们希望插入数据时使用这些默认值。
这时,可以省略插入语句中的列名和对应的值,数据库将使用列的默认值进行插入。
sqlINSERT INTO表名VALUES(值1, 值2, 值3, ...);例如,如果表Products中有一列CreateDate,其默认值为当前日期,可以使用如下语句插入数据:sqlINSERT INTO ProductsVALUES('ProductA', 100, 10.99, GETDATE());第三:插入查询结果有时,我们需要从一个表中选择数据并将其插入到另一个表中。
这时可以使用INSERT INTO的SELECT子句:sqlINSERT INTO目标表(列1, 列2, 列3, ...)SELECT列1, 列2, 列3, ...FROM源表WHERE条件;例如,将Customers表中所有城市为‘New York’的记录插入到NewYorkCustomers表中:sqlINSERT INTO NewYorkCustomers (CustomerID, CustomerName, City)SELECT CustomerID, CustomerName, CityFROM CustomersWHERE City ='New York';第四:批量插入数据在一次性插入大量数据时,使用INSERT INTO的VALUES子句可能效率较低。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
server 2005中有几种方式可以实现。
要获取此ID,最简单的方法就是在查询之后select @@indentity
--SQL语句创建数据库和表
create database dbdemo
go
use dbdemo
go
create table tbldemo
(
id int primary key identity(1,1),
name varchar(20)
)
go
--执行下面SQL语句就能查出来刚插入记录对应的自增列的值
insert into tbldemo values('测试') select @@identity
SQL Server 2000中,有三个比较类似的功能:SCOPE_IDENTITY、IDENT_CURRENT 和@@IDENTITY,它们都返回插入到IDENTITY 列中的值。
1)IDENT_CURRENT 返回为任何会话和任何作用域中的特定表最后生成的标识值,它不受作用域和会话的限制,而受限于所指定的表。
2)@@IDENTITY返回为当前会话的所有作用域中的任何表最后生成的标识值。
3) SCOPE_IDENTITY 返回为当前会话和当前作用域中的任何表最后生成的标识值。
SCOPE_IDENTITY 和@@IDENTITY 返回在当前会话中的任何表内所生成的最后一个标识值。
但是,SCOPE_IDENTITY 只返回插入到当前作用域中的值;@@IDENTITY 不受限于特定的作用域。
例如,有两个表T1 和T2,在T1 上定义了一个INSERT 触发器。
当将某行插入T1 时,触发器被激发,并在T2 中插入一行。
此例说明了两个作用域:一个是在T1 上的插入,另一个是作为触发器的结果在T2 上的插入。
假设T1 和T2 都有IDENTITY 列,@@IDENTITY 和SCOPE_IDENTITY 将在T1 上的INSERT 语句的最后返回不同的值。
@@IDENTITY 返回插入到当前会话中任何作用域内的最后一个IDENTITY 列值,该值是插入T2 中的值。