STATA面板数据模型操作命令
STATA面板数据模型操作命令讲解(word文档良心出品)

STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型μβit +=x y it itεαμit +=it it 随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
(完整word版)STATA面板数据模型操作命令讲解

STATA 面板数据模型估计命令一览表 一、静态面板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型μβit +=x y it itεαμit +=it it 随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
STATA面板大数据模型操作命令讲解

STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令εαβit ++=xy itiit固定效应模型μβit +=xy ititεαμit+=itit随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式 ●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
STATA面板数据模型操作命令

STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令εαβit ++=x y it iit 固定效应模型 εαμit +=it it 随机效应模型一数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计统计分析 ●gen lag_y=αi αi αi εit ~e it ~1-t e i ,8858.0~=θ5.0-~=θ验:是否存在门槛效应混合面板:reg is lfr lfr2 hc open psra tp gr,vcecluster sf固定效应、随机效应模型xtreg is lfr lfr2 hc open psra tp gr,feest store fextreg is lfr lfr2 hc open psra tp gr,reest store rehausman fe两步系统GMM 模型xtdpdsys rlt plf1 nai efd op ew ig ,lags1 maxldep2 twostep artests2 注:rlt 为被解释变量,“plf1 nai efd op ew ig ”为解释变量和控制变量; maxldep2表示使用被解释变量的两个滞后值为工具变量;pre 表示以某一个变量为前定解释变量;endogenous 表示以某一个变量为内生解释变量; 自相关检验:estat abond萨甘检验:estat sargan差分GMM模型Xtabond rlt plf1 nai efd op ew ig ,lags1 twostep artests2内生:该解释变量的取值是一定程度上由模型决定的;内生变量将违背解释变量与误差项不相关的经典假设,因而内生性问题是计量模型的大敌,可能造成系数估计值的非一致性和偏误;外生:该解释变量的取值是完全由模型以外的因素决定的;外生解释变量与误差项完全无关,不论是当期,还是滞后期;前定:该解释变量的取值与当期误差项无关,但可能与滞后期误差项相关;。
STATA面板数据模型操作命令讲解(word文档良心出品)

STATA 面板数据模型估计命令一览表一、静态面板数据的 STATA 处理命令固定效应模型随机效应模型(一)数据处理输入数据• tsset code year 该命令是将数据定义为“面板”形式 • xtdes该命令是了解面板数据结构・ xtdescode: 1i 2, ■■■( 20n 工 20 year : 3004, 2005, ■…,2014T =11Delta(year) =1 unit span(year) =11 periods(code*year uniquely identifies eachobservation)Distribution of:min 8%2璃50^ 75% 95%max1111 11111111 11Freq. Percent Cum. Pattern20 100.00 100.00 1111111111120100.00XXXXXXXXXXX・ summarize sc I cpi unem gse5 InvariableObs Mean Std ・ Dev.Mi nMax sq 220 .Q142798 2.9303464.75e-0626.22301cpi2201*10655 *032496 1.045 1. 25 unem22Q .0349455 .0071556 .012 ,046 g220,10907 .0427523 0246 .2357220 .0268541 011671? .0053.0693220.1219364.0240077,074,203• summarize sq cpi unem g se5 In各变量的描述性统计(统计分析)• gen lag_y=L.y ///////产生一个滞后一期的新变量*= Xitit• ;itto U 一 if对于固定效应模型而言,回归结果中最后一行汇报的F 统计量便在于检验所 有的个体效应整体上显著。
STATA面板数据模型操作命令讲解

STATA面板数据模型操作命令讲解面板数据模型主要用于分析在一段时间内,多个个体上观察到的数据。
在面板数据模型中,个体可以是个人、家庭、公司等。
面板数据模型的分析主要包括汇总统计、描述性统计、回归分析等。
下面是一些STATA中常用的面板数据分析命令的介绍和使用说明:1. xtset命令:该命令用于设置数据集的面板数据特征。
在使用面板数据模型之前,需要先将数据集设置为面板数据。
使用xtset命令可以指定面板数据集的个体维度和时间维度。
示例:xtset id year该命令将数据集按照id(个体)和year(时间)进行分类。
2. xtsummary命令:该命令用于生成面板数据的汇总统计信息,包括平均值、标准差、最小值、最大值等。
示例:xtsummary var1 var2该命令将变量var1和var2的汇总统计信息显示出来。
3. xtreg命令:该命令用于进行固定效应模型(Fixed Effects Model)的估计,其中个体效应被视为固定参数,时间效应被视为随机参数。
示例:xtreg y x1 x2, fe该命令将变量y对x1和x2进行固定效应模型估计。
4. xtfe命令:该命令用于进行固定效应模型的估计,并提供了更多的选项和功能。
示例:xtfe y x1 x2, vce(robust)该命令将变量y对x1和x2进行固定效应模型估计,并使用鲁棒标准误。
5. xtlogit命令:该命令用于进行面板Logistic回归分析,适用于因变量为二分类变量的情况。
示例:xtlogit y x1 x2, re该命令将变量y对x1和x2进行面板Logistic回归分析,并进行随机效应的估计。
6. areg命令:该命令用于进行差别法(Difference-in-Differences)模型的估计,适用于时间和个体差异的面板数据分析。
上述命令只是STATA中一部分常用的面板数据模型操作命令。
在实际应用中,根据具体的研究需求和数据特征,还可以使用其他面板数据模型命令进行分析,如xtlogit、xtprobit等。
STATA面板数据模型操作命令讲解

STATA面板数据模型操作命令讲解1. xtset:该命令用于设置面板数据模型的数据结构。
在使用面板数据模型命令之前,需要先使用xtset命令来指定数据集的面板结构。
例如,如果数据集中包含一列代表时间(年份)和一列代表个体(公司),则可以使用以下命令指定数据结构:2. xtreg:该命令用于估计面板数据模型的普通最小二乘回归系数。
以下是xtreg命令的一般形式:xtreg dependent_var independent_vars, options其中,dependent_var是依赖变量,independent_vars是自变量,options是可选参数。
通过指定options参数,可以对估计结果进行调整和控制,例如指定固定效应、随机效应或混合效应模型。
3. xtreg, fe:该命令用于估计固定效应模型。
固定效应模型是一种控制个体固定效应的面板数据模型。
使用以下命令可以估计固定效应模型:xtreg dependent_var independent_vars, fe通过指定fe参数,可以估计固定效应模型,并控制除个体固定效应以外的其他混杂效应。
4. xtreg, re:该命令用于估计随机效应模型。
随机效应模型是一种允许个体固定效应和随机效应的面板数据模型。
使用以下命令可以估计随机效应模型:xtreg dependent_var independent_vars, re通过指定re参数,可以估计随机效应模型,并考虑个体固定效应和随机效应对因变量的影响。
5. xtreg, mle:该命令用于估计混合效应模型。
混合效应模型是一种允许个体固定效应和随机效应的面板数据模型,并且可以对效应参数进行最大似然估计。
使用以下命令可以估计混合效应模型:xtreg dependent_var independent_vars, mle通过指定mle参数,可以估计混合效应模型,并通过最大似然估计法对参数进行估计。
STATA面板数据模型操作命令

STATA面板数据模型操作命令下面是一些常用的STATA面板数据模型操作命令:1.数据准备在STATA中,首先需要准备好面板数据集,通常包含两个维度:时间(T)和个体(N)。
使用`xtset`命令将数据集设置为面板数据,指定时间和个体的变量名称。
例如,假设时间变量为"year",个体变量为"country",使用命令`xtset country year`将数据集设置为面板数据。
2.描述性统计使用`xtsum`命令计算面板数据的描述性统计量,包括样本大小、均值、标准差等。
例如,`xtsum x y`将计算变量x和y的面板数据的描述统计量。
3.固定效应模型固定效应模型是一种面板数据模型,用于估计个体特定的效应。
在STATA中,可以使用`xtreg`命令估计固定效应模型。
例如,`xtreg y x, fe`将估计含有固定效应的面板数据模型,其中y为因变量,x为自变量。
4.随机效应模型随机效应模型是另一种常用的面板数据模型,用于估计个体和时间特定的效应。
在STATA中,可以使用`xtreg`命令估计随机效应模型。
例如,`xtreg y x, re`将估计含有随机效应的面板数据模型。
5.差分估计法差分估计法用于估计面板数据中的平均效应。
在STATA中,可以使用`xtreg`命令估计差分估计模型。
例如,`xtreg D.y D.x, fe`将估计含有差分估计的面板数据模型,其中D.y和D.x代表变量y和x的一阶差分。
6.回归诊断在面板数据模型中,需要对估计结果进行回归诊断,以检验模型假设的有效性。
STATA提供了多种回归诊断命令,如`xtreg, fe`命令后使用`predict, e`命令可以获得固定效应估计值的残差,使用`estathettest`命令可以进行异方差性检验。
7.异常值检测面板数据模型中的异常值可能会对估计结果产生重要影响。
STATA提供了多种异常值检测命令,如`xtreg, fe`命令后使用`rvfplot`命令可以进行异常值的图形检测,使用`xtreg, fe`命令后使用`xtgee`命令可以进行异常值的统计检验。
STATA面板数据模型操作命令

STATA 面板数据模型估计命令一览表 一、静态面板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型μβit +=x y it itεαμit +=it it 随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
STATA面板数据模型操作命令

STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令εαβit ++=xy itiit固定效应模型μβit +=xy ititεαμit+=itit随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式 ●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
(完整word版)STATA面板数据模型操作命令要点

STATA 面板数据模型估计命令一览表 一、静态面板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型μβit +=x y it itεαμit +=it it 随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
STATA面板数据模型操作命令讲解
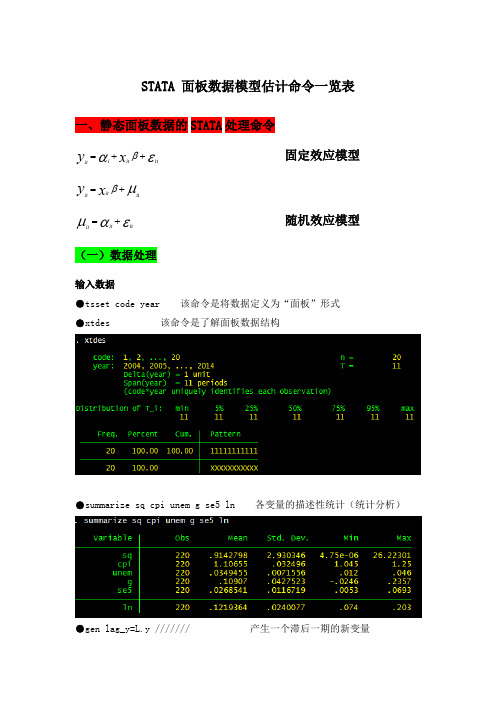
STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令固定效应模型εαβit ++=x y it i it μβit +=x y it it随机效应模型εαμit +=it it (一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现)xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
STATA面板数据模型操作命令讲解

STATA面板数据模型操作命令讲解STATA是一种常用的统计分析软件,可以用于面板数据模型的操作。
面板数据模型是一种用来分析涉及多个单位和多个时间点的数据的统计模型,其主要特点是能够考虑单位间和时间间的相关性。
在STATA中,可以使用一系列命令来进行面板数据模型的操作,包括数据导入、数据清洗、模型估计和结果展示等。
下面将详细介绍STATA中面板数据模型操作的常用命令。
首先,要进行面板数据模型的操作,首先需要将数据导入到STATA中。
STATA支持多种数据格式的导入,包括Excel、CSV和数据库等。
常用的导入命令包括:1. use命令:用于导入STATA格式的数据文件。
例如:use data.dta2. import命令:用于导入其他格式的数据文件。
例如:import excel data.xlsx, firstrow导入数据后,接下来需要进行数据清洗和变量定义。
可以使用一系列命令对数据进行操作,例如生成新变量、删除缺失值和标识变量等。
常用的数据清洗命令包括:1. generate命令:用于生成新变量。
例如:generate log_y = log(y)2. drop命令:用于删除变量。
例如:drop x3. replace命令:用于替换变量值。
例如:replace y = 0 if y < 0数据清洗完成后,就可以开始估计面板数据模型。
常用的估计命令包括固定效应模型(Fixed Effects Model)和随机效应模型(Random Effects Model)。
下面分别介绍这两种模型的估计命令。
1.固定效应模型的估计命令:xtreg y x1 x2, fe其中,xtreg表示面板数据的回归命令,y为因变量,x1和x2为自变量,fe为固定效应模型的选项。
2.随机效应模型的估计命令:xtreg y x1 x2, re其中,re表示随机效应模型的选项。
除了固定效应模型和随机效应模型,STATA还支持其他面板数据模型的估计方法,如差分估计(Difference-in-Differences)、合成控制法(Synthetic Control Method)等。
STATA面板数据模型操作命令剖析

STATA面板数据模型操作命令剖析面板数据模型是一种用于分析具有重复观察的数据集的统计模型。
它是一种广泛应用于社会科学、经济学和医学研究等领域的方法。
STATA是一种常用的统计分析软件,提供了一系列用于操作面板数据模型的命令。
下面我们将对一些常用的STATA面板数据模型命令进行详细剖析。
首先,STATA提供了一些用于数据管理和变量处理的命令。
常用的命令包括`xtset`、`xtmerge`和`xtreshape`。
其中,`xtset`命令用于指定面板数据的相关信息,比如时间变量和个体变量;`xtmerge`命令用于合并多个面板数据集;`xtreshape`命令用于将数据从长格式转换为宽格式。
这些命令能够帮助我们快速而方便地准备数据集,以便进行面板数据模型分析。
其次,STATA提供了一些用于估计面板数据模型的命令。
常用的命令包括`xtreg`、`xtlogit`和`xtprobit`。
其中,`xtreg`命令用于估计面板数据的线性回归模型;`xtlogit`和`xtprobit`命令用于估计面板数据的二项Logit模型和二项Probit模型。
这些命令能够根据面板数据的特点,进行有效的模型估计和推断。
此外,STATA还提供了一些用于面板数据模型的假设检验和模型诊断的命令。
常用的命令包括`xttest0`、`xtserial`和`xtdiag`。
其中,`xttest0`命令用于进行面板数据模型的异方差性检验;`xtserial`命令用于进行面板数据模型的序列相关性检验;`xtdiag`命令用于进行面板数据模型的模型诊断。
这些命令能够帮助我们验证模型的假设、检验模型的稳健性,并进行模型的诊断和改进。
最后,STATA还提供了一些用于面板数据模型的预测和效应评估的命令。
常用的命令包括`xtpr`、`xtsum`和`xtgraph`。
其中,`xtpr`命令用于进行面板数据模型的预测;`xtsum`命令用于对面板数据进行描述性统计分析;`xtgraph`命令用于绘制面板数据的图表。
STATA面板数据模型操作命令

STATA面板数据模型操作命令STATA是一个强大的统计分析软件,可以进行各种数据操作和模型建立。
对于面板数据,即具有时间序列和跨个体的数据,STATA提供了多种命令来进行数据的操作和模型的拟合。
以下是一些常用的STATA面板数据模型操作命令:1. xtset命令:用于设置数据集的面板结构,将数据按个体和时间次序排序。
例如,xtset country year可以将数据按照国家和年份排序。
2. xtreg命令:用于拟合面板数据的固定效应模型。
例如,xtreg y x1 x2, fe可以拟合一个包含固定效应的面板数据模型,其中y为因变量,x1和x2为解释变量。
3. xtfe命令:用于估计固定效应模型的固定效应,即个体固定效应模型。
例如,xtfe y x1 x2可以计算出个体固定效应。
4. xtgls命令:用于估计面板数据的一般化最小二乘回归模型。
例如,xtgls y x1 x2可以拟合一个包含一般固定效应的面板数据模型。
5. xtmixed命令:用于估计混合效应模型,即个体和时间固定效应模型。
例如,xtmixed y x1 x2 , country:, var(can)可以在个体和时间固定效应下估计一个模型。
6. xtreg, re命令:用于估计面板数据的随机效应模型。
例如,xtreg y x1 x2, re可以计算出随机效应模型。
7. xtivreg命令:用于估计面板数据的双向固定效应或双向随机效应的工具变量回归模型。
例如,xtivreg y (x1 = z1) (x2 = z2), fe可以计算出一个包含工具变量的双向固定效应模型。
8. xtdpd命令:用于估计面板数据的动态面板数据模型。
例如,xtdpd y x1 x2, lags(2)可以进行一个包含两期滞后的动态面板数据模型估计。
9. xtregar命令:用于估计拓展的面板数据模型。
例如,xtregar y x1 x2, fe(ec)可以在考虑了异方差和异方差的面板数据模型下进行估计。
STATA面板数据模型操作命令

一、静态面板数据地处理命令(一)数据处理输入数据● 该命令是将数据定义为“面板”形式● 该命令是了解面板数据结构● 各变量地描述性统计(统计分析)● 产生一个滞后一期地新变量产生一个超前项地新变量产生一个一阶差分地新变量产生一个二阶差分地新变量(二)模型地筛选和检验●、检验个体效应(混合效应还是固定效应)(原假设:使用混合模型)●对于固定效应模型而言,回归结果中最后一行汇报地统计量便在于检验所有地个体效应整体上显著.在我们这个例子中发现统计量地概率为,检验结果表明固定效应模型优于混合模型.文档收集自网络,仅用于个人学习●、检验时间效应(混合效应还是随机效应)(检验方法:统计量)(原假设:使用混合模型)● (加上“”之后第一幅图将不会呈现)文档收集自网络,仅用于个人学习可以看出,检验得到地值为,表明随机效应非常显著.可见,随机效应模型也优于混合模型.文档收集自网络,仅用于个人学习●、检验固定效应模型随机效应模型(检验方法:检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应地时候,将显著优于截距项为常数假设条件下地混合模型.但是无法明确区分地优劣,这需要进行接下来地检验,如下:文档收集自网络,仅用于个人学习:估计固定效应模型,存储估计结果:估计随机效应模型,存储估计结果:进行检验●(或者更优地是)文档收集自网络,仅用于个人学习可以看出,检验地值为,拒绝了原假设,认为随机效应模型地基本假设得不到满足.此时,需要采用工具变量法和是使用固定效应模型.文档收集自网络,仅用于个人学习●、时间固定效应(以上分析主要针对地是个体效应)如果希望进一步在上述模型中加入时间效应,可以采用时间虚拟变量来实现.首先,我们需要定义一下个时间虚拟变量.文档收集自网络,仅用于个人学习● () (命令用于列示变量地组类别,选项()用于生产一个以开头地年度虚拟变量)文档收集自网络,仅用于个人学习(作用在于去掉第一个虚拟变量以避免完全共线性)若在固定效应模型中加入时间虚拟变量,则估计模型地命令为:(四)异方差和自相关检验●、异方差检验(组间异方差)本节主要针对地是固定效应模型进行处理()检验原假设:同方差需要检验模型中是否存在组间异方差,需要使用命令.●显然,原假设被拒绝.此时,需要进一步以获得参数地估计量,命令为:● ()文档收集自网络,仅用于个人学习其中,组间异方差通过()选项来设定.上述结果是采用两步获得,即,先采用估计不考虑异方差地模型,进而利用其残差计算...,并最终得到估计量.文档收集自网络,仅用于个人学习●、序列相关检验对于较大地面板而言,往往无法完全反映时序相关性,此时便可能存在序列相关,在多数情况下被设定为()过程.文档收集自网络,仅用于个人学习原假设:序列不存在相关性.模型地序列相关检验对于固定效应模型,可以采用检验法,命令为:●可以发现,这里地,我们可以在地显著性水平下爱拒绝不存在序列相关地原假设.考虑到样本,该检验地最后一步是用对进行回归,因此,输入以下命令得到.检验该值是否显著异于,因为在原假设下(不相关),可见本例中不相等,拒绝原假设,说明存在序列相关.文档收集自网络,仅用于个人学习● ()模型地序列相关检验对于模型,可以采用命令来执行检验:● *这里汇报了个统计量,分别用于检验模型中随机效应(单尾和双尾)、序列相关以及二者地联合显著性,检验结果表明存在随机效应和序列相关,而且对随机效应和序列相关地联合检验也非常显著.文档收集自网络,仅用于个人学习稳健型估计上述结果表明,无论是还是模型,干扰项中都存在显著地序列相关.为此,我们进一步采用命令来估计模型,首先考虑固定效应模型:文档收集自网络,仅用于个人学习● *●、“异方差—序列相关”稳健型标准误虽然上述估计方法在估计方差协方差矩阵时考虑了异方差和序列相关地影响,但都未将两者联立在一起考虑,要获得“异方差序列相关”稳健型标准误,只需在命令中附加()或者()选项即可.例如,对于模型,我们可以执行如下命令:文档收集自网络,仅用于个人学习与之前未经处理地估计结果相比,附加命令()选项时地结果,虽然系数地估计值未发生变化,但此时得到地标准误明显增大了,致使得到地估计结果更加保守.对于面板数据模型而言,在计算所谓地“”标准误时,是以个体为单位调整标准误地.因此,我们得到地“”标准误其实是同时调整了异方差和序列相关后地标准误.换言之,上述结果与设定()选项地结果完全相同.文档收集自网络,仅用于个人学习●、截面相关检验原假设:截面之间不存在着相关性()模型检验对于模型,可以利用命令来检验截面相关性:●(该命令主要针对地是大小类型地面板数据,在本例中无法使用,故图标略去.)()模型检验对于模型,可以利用命令来检验截面相关性:●(下面命令是另一个检验指标)可以看出,两种不同地检验方法均显示面板数据存在着截面相关性.●、“异方差—序列相关—截面相关”稳健型标准误()模型估计对于模型,在确认上述存在着截面相关地情况下,我们可以采用()编写地命令获取()提出地“异方差—序列相关—截面相关”稳健型标准误:文档收集自网络,仅用于个人学习●这里,命令会自动选择地滞后阶数为,系数估计值和与地结果完全相同,但标准误存在着较大差异.可见,在本例中,截面相关对统计推断有较大地影响.文档收集自网络,仅用于个人学习若读者有跟高地方法来确定自相关地滞后阶数,则可以通过( )选项设定.当然,在多数情况下,这很难做到.不过我们可以通过附加()来估计仅考虑异方差和截面相关地稳健型标准误,命令如下:文档收集自网络,仅用于个人学习● ()()模型估计(略,待补充)二、动态面板数据地处理命令(一)差分文档收集自网络,仅用于个人学习() 文档收集自网络,仅用于个人学习(二)系统文档收集自网络,仅用于个人学习, 文档收集自网络,仅用于个人学习(三)内生性检验●(四)序列相关检验●: , 文档收集自网络,仅用于个人学习"黑龙江" "吉林" "辽宁" "山西" "湖北" "湖南" "河南" "江西" "安徽"文档收集自网络,仅用于个人学习。
STATA面板数据模型操作命令

STATA面板数据模型操作命令下面是一些在STATA中用于面板数据模型操作的常用命令:1. xtset命令:该命令用于设置数据为面板数据,并指定面板数据的结构,如个体标识和时间标识。
例如,xtset id year将数据设置为个体标识为id,时间标识为year的面板数据。
2. xtreg命令:该命令用于估计面板数据模型中的固定效应或随机效应模型。
固定效应模型假设个体效应是固定的,随机效应模型则将个体效应看作是随机变量。
可以通过指定不同的选项进行不同类型的估计,如-fe表示固定效应,re表示随机效应。
3. xtsum命令:该命令用于汇总面板数据的描述统计信息,如平均值、标准差、最小值和最大值等。
可以使用不同的选项来指定需要计算的统计量。
4. xtline命令:该命令用于绘制面板数据的线性图。
可以使用不同的选项来指定需要绘制的变量和面板单位。
5. xttest0命令:该命令用于进行面板数据模型的序列相关性检验。
该命令会计算序列相关系数和相关性检验的统计量,并根据检验结果给出相应的结果。
6. xtreg命令(选项, qls):该命令用于估计面板数据模型中的定阶自相关模型。
该模型可以用来处理面板数据中存在的自相关问题。
7. xtivreg命令:该命令用于进行面板数据模型的时间因果分析。
该命令使用了仪器变量来解决内生性问题。
8. xtfe命令:该命令用于估计面板数据模型中的固定效应模型的回归系数。
该命令会将个体固定效应去除后,对回归方程进行估计。
9. xtgls命令:该命令用于估计面板数据模型中具有异方差和相关性的广义最小二乘回归系数。
该命令可以通过指定不同的选项来进行不同类型的估计。
10. xttrans命令:该命令用于进行面板数据模型的数据转换操作。
可以使用不同的选项来进行不同类型的数据转换。
以上是STATA中用于面板数据模型操作的一些常用命令。
在实际使用中,根据具体的需求和数据特点,可以结合不同的命令进行面板数据模型的分析和操作。
STATA面板大数据的模型操作命令

STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型μβit +=x y it itεαμit +=it it 随机效应模型〔一〕数据处理输入数据●tsset code year 该命令是将数据定义为“面板〞形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计〔统计分析〕●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量〔二〕模型的筛选和检验●1、检验个体效应〔混合效应还是固定效应〕〔原假设:使用OLS混合模型〕●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果明确固定效应模型优于混合OLS模型。
●2、检验时间效应〔混合效应还是随机效应〕〔检验方法:LM统计量〕〔原假设:使用OLS混合模型〕●qui xtreg sq cpi unem g se5 ln,re (加上“qui〞之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,明确随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型〔检验方法:Hausman检验〕原假设:使用随机效应模型〔个体效应与解释变量无关〕通过上面分析,可以发现当模型参加了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进展接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进展Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的根本假设得不到满足。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型μβit +=x y it itεαμit +=it it 随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
此时,需要采用工具变量法和是使用固定效应模型。
(三)静态面板数据模型估计●1、固定效应模型估计●xtreg sq cpi unem g se5 ln,fe (如下图所示)其中选项fe表明我们采用的是固定效应模型,表头部分的前两行呈现了模型的估计方法、界面变量的名称(id)、以及估计中使用的样本数目和个体的数目。
第3行到第5行列示了模型的拟合优度、分为组内、组间和样本总体三个层面,通常情况下,关注的是组内(within),第6行和第7行分别列示了针对模型中所有非常数变量执行联合检验得到的F统计量和相应的P值,可以看出,参数整体上相当显著。
需要注意的是,表中最后一行列示了检验固定效应是否显著的F统计量和相应的P值。
显然,本例中固定效应非常显著。
●2、随机效应模型估计若假设本例的样本是从一个很大的母体中随机抽取的,且αi与解释变量均不相关,则我们可以将αi视为随机干扰项的一部分。
此时,设定随机效应模型更为合适。
●xtreg sq cpi unem g se5 ln,re (如下图所示)●3、时间固定效应(以上分析主要针对的是个体效应)如果希望进一步在上述模型中加入时间效应,可以采用时间虚拟变量来实现。
首先,我们需要定义一下T-1个时间虚拟变量。
●tab year ,gen(dumt) (tab命令用于列示变量year的组类别,选项gen(dumt)用于生产一个以dumt开头的年度虚拟变量) drop dumt1 (作用在于去掉第一个虚拟变量以避免完全共线性)若在固定效应模型中加入时间虚拟变量,则估计模型的命令为:●xtreg sq cpi unem g se5 ln dumt*,fe(四)异方差和自相关检验●1、异方差检验(组间异方差)本节主要针对的是固定效应模型进行处理(1)检验原假设:同方差需要检验模型中是否存在组间异方差,需要使用xttest3命令。
●qui xtreg sq cpi unem g se5 ln,fexttest3显然,原假设被拒绝。
此时,需要进一步以获得参数的GLS估计量,命令为xtgls:●xtgls sq cpi unem g se5 ln,panels(heteroskedastic)其中,组间异方差通过panels ()选项来设定。
上述结果是采用两步获得,即,先采用OLS 估计不考虑异方差的模型,进而利用其残差计算。
,并最终得到FGLS 估计量。
●2、序列相关检验对于T 较大的面板而言,αi 往往无法完全反映时序相关性,此时εit 便可能存在序列相关,在多数情况下被设定为AR(1)过程。
原假设:序列不存在相关性。
(1) FE 模型的序列相关检验对于固定效应模型,可以采用Wooldridge 检验法,命令为xtserial:●xtserial sq cpi unem g se5 ln可以发现,这里的P=0.0000,我们可以在1%的显著性水平下爱拒绝不存在序列相关的原假设。
考虑到样本,该检验的最后一步是用~e it 对~1-t ei ,进行OLS 回归,因此,输入以下命令得到8858.0~=θ。
检验该值是否显著异于-0.5,因为在原假设下(不相关)5.0-~=θ,可见本例中不相等,拒绝原假设,说明存在序列相关。
●mat list e(b)(2) RE 模型的序列相关检验对于RE 模型,可以采用xttest1命令来执行检验:●qui xtreg sq cpi unem g se5 ln dumt*,re xttest1这里汇报了4个统计量,分别用于检验RE 模型中随机效应(单尾和双尾)、序列相关以及二者的联合显著性,检验结果表明存在随机效应和序列相关,而且对随机效应和序列相关的联合检验也非常显著。
(3) 稳健型估计上述结果表明,无论是FE 还是RE 模型,干扰项中都存在显著的序列相关。
为此,我们进一步采用xtregar 命令来估计模型,首先考虑固定效应模型:●xtregar sq cpi unem g se5 ln dumt*,fe lbi●3、“异方差—序列相关”稳健型标准误虽然上述估计方法在估计方差-协方差矩阵时考虑了异方差和序列相关的影响,但都未将两者联立在一起考虑,要获得“异方差-序列相关”稳健型标准误,只需在xtreg命令中附加vce(robust)或者vce(cluster)选项即可。
例如,对于FE模型,我们可以执行如下命令:●xtreg sq cpi unem g se5 ln,fe vce(robust)与之前未经处理的估计结果相比,附加命令vce(robust)选项时的结果,虽然系数的估计值未发生变化,但此时得到的标准误明显增大了,致使得到的估计结果更加保守。
对于面板数据模型而言,STATA在计算所谓的“robust”标准误时,是以个体为单位调整标准误的。
因此,我们得到的“robust”标准误其实是同时调整了异方差和序列相关后的标准误。
换言之,上述结果与设定vce(cluster)选项的结果完全相同。
●4、截面相关检验原假设:截面之间不存在着相关性(1)FE模型检验对于FE模型,可以利用xttest2命令来检验截面相关性:●qui xtreg sq cpi unem g se5 ln,fexttest2(该命令主要针对的是大T小N类型的面板数据,在本例中无法使用,故图标略去。
) (2)RE模型检验对于RE模型,可以利用xtcsd命令来检验截面相关性:●qui xtreg sq cpi unem g se5 ln,rextcsd,pesaran (下面命令是另一个检验指标)xtcsd,frees可以看出,两种不同的检验方法均显示面板数据存在着截面相关性。
●5、“异方差—序列相关—截面相关”稳健型标准误(1)FE模型估计对于FE模型,在确认上述存在着截面相关的情况下,我们可以采用Hoechle(2007)编写的xtscc命令获取Driscoll and Kraay(1998)提出的“异方差—序列相关—截面相关”稳健型标准误:●xtscc sq cpi unem g se5 ln,fe这里,xtscc命令会自动选择的滞后阶数为2,系数估计值和Within-R2与xtreg,fe的结果完全相同,但标准误存在着较大差异。
可见,在本例中,截面相关对统计推断有较大的影响。
若读者有跟高的方法来确定自相关的滞后阶数,则可以通过lag( )选项设定。
当然,在多数情况下,这很难做到。
不过我们可以通过附加lag(0)来估计仅考虑异方差和截面相关的稳健型标准误,命令如下:●xtscc sq cpi unem g se5 ln,fe lag(0)(2)RE模型估计(略,待补充)二、动态面板数据的STATA处理命令(一)差分GMMxtabond lnwi cd lngdp land doc fir lnroad lnpop finaxtabond lnwi cd lngdp land doc fir lnroad lnpop fina,lag(2) twostep (二)系统GMMxtdpdsys lnwi cd lngdp land doc fir lnroad lnpop finaxtdpdsys lnwi cd lngdp land doc fir lnroad lnpop fina, twostep (三)内生性检验●estat sargan(四)序列相关检验●estat abond三、门槛(门限回归)面板模型的STATA处理命令xtthres y, thres(q) dthres(x) bs1(30) bs2(30) bs3(20)各个门槛的置信区间图:xttr_graph 第一轮搜索第一个门槛xttr_graph,m(22) 第二轮搜索第二个门槛xttr_graph,m(21) 第二轮搜索第一个门槛xttr_graph,m(3)呈现估计结果:local q1=e(rhat21) 取出门槛值local q2=e(rhat22)gen d1=(q<=’q1’) 生成虚拟变量gen d2=(q>’q2’)gen xd1=x*d1gen xd2=x*d2xtreg y x xd1 xd2,fe 常规标准误est store fextreg y x xd1 xd2,fe robust 稳健型估计est store fe_ robustlocal m”fe fe_ robust”esttab ‘m’,mtitle(‘m’) nogap s(r2 r2_w N F)///star(*0.1 **0.05 ***0.01) 1.检验:是否存在门槛效应混合面板:reg is lfr lfr2 hc open psra tp gr,vce(cluster sf)固定效应、随机效应模型xtreg is lfr lfr2 hc open psra tp gr,feest store fextreg is lfr lfr2 hc open psra tp gr,reest store rehausman fe两步系统GMM模型xtdpdsys rlt plf1 nai efd op ew ig ,lags(1) maxldep(2) twostep artests(2) 注:rlt为被解释变量,“plf1 nai efd op ew ig”为解释变量和控制变量;maxldep(2)表示使用被解释变量的两个滞后值为工具变量;pre()表示以某一个变量为前定解释变量;endogenous()表示以某一个变量为内生解释变量。