DB2存储过程--基础详解
DB2存储过程精简教程

DB2存储过程精简教程DB2存储过程是一种在数据库服务器上执行的可重复使用的代码块,用于完成特定任务。
它可以接受输入参数,并返回结果。
存储过程有助于提高数据库性能和安全性。
在这篇文章中,我们将介绍如何创建和使用DB2存储过程。
一、创建存储过程要创建存储过程,您需要先登录到DB2数据库服务器。
然后,使用CREATEPROCEDURE语句指定存储过程的名称、输入参数和返回结果。
下面是一个示例:CREATE PROCEDURE get_employee(IN employee_id INT, OUT employee_name VARCHAR(255))BEGINSELECT name INTO employee_name FROM employees WHERE id = employee_id;END上面的代码创建了一个名为get_employee的存储过程。
它接受一个输入参数employee_id,并通过输出参数employee_name返回相应的员工姓名。
二、执行存储过程要执行存储过程,您可以使用CALL语句,如下所示:CALL get_employee(1001, ?);上面的代码将调用get_employee存储过程,并将1001作为输入参数传递。
由于我们使用了输出参数,所以使用问号来表示它。
调用语句将返回存储过程中定义的输出参数的值。
三、存储过程中的控制结构存储过程可以包含各种控制结构,如条件语句和循环语句。
下面是一个示例:CREATE PROCEDURE calculate_salary(IN employee_id INT)BEGINDECLARE monthly_salary DECIMAL(10, 2);DECLARE tax DECIMAL(10, 2);SELECT salary / 12 INTO monthly_salary FROM employees WHERE id = employee_id;IF monthly_salary > 5000 THENSET tax = monthly_salary * 0.2;ELSESET tax = monthly_salary * 0.1;ENDIF;SELECT monthly_salary, tax;END上面的代码创建了一个名为calculate_salary的存储过程。
DB2存储过程基本语法

DB2存储过程基本语法存储过程的基本语法如下:1.创建存储过程:```sqlCREATE PROCEDURE procedure_name [ (parameter_name parameter_data_type [, ...]) ]BEGIN-- SQL statementsEND;```存储过程使用`CREATEPROCEDURE`语句来创建,指定存储过程的名称以及可选的参数。
然后使用`BEGIN`和`END`之间的SQL语句来定义过程的操作。
2.存储过程参数:存储过程可以接收参数,并且可以设置参数的初始值。
```sqlCREATE PROCEDURE procedure_name (IN parameter_name parameter_data_type [DEFAULT default_value])BEGIN-- SQL statementsEND;```参数可以设置为输入(IN)参数或者输出(OUT)参数,用于接收过程内部的数据或者返回数据。
3.存储过程返回结果:存储过程可以返回结果集或者只是执行一些操作而不返回结果。
```sqlCREATE PROCEDURE procedure_nameDYNAMIC RESULT SETS integerBEGIN-- SQL statementsEND;```使用`DYNAMICRESULTSETS`关键字来指定结果集的数量。
如果存储过程不返回结果集,可以省略这一行。
4.存储过程操作:存储过程可以包含SQL语句,例如SELECT、INSERT、UPDATE和DELETE等操作。
可以使用条件判断、循环等控制流语句来实现复杂的逻辑。
```sqlCREATE PROCEDURE procedure_nameBEGINDECLARE variable_name data_type [DEFAULT value];-- Variable declarationSET variable_name = value;-- Variable assignment-- SQL statementsIF condition THEN-- StatementsELSEIF condition THEN-- StatementsELSE-- StatementsENDIF;WHILE condition DO-- StatementsENDWHILE;FOR variable_name [AS] data_type [DEFAULT value] TO value DO -- StatementsENDFOR;REPEAT-- StatementsUNTIL condition END REPEAT;-- Other control flow statementsEND;```使用`DECLARE`关键字声明变量,使用`SET`关键字为变量赋值。
DB2 SQLJ 存储过程开发宝典,第 1 部分_216_IT168文库

DB2 SQLJ 存储过程开发宝典,第1 部分简介: SQLJ 存储过程开发宝典将分为 2 个部分。
本文是第 1 部分,在介绍SQLJ 的基础知识的基础上,结合实例,详细介绍如何一步步开发SQLJ 存储过程以及常用的调试方法。
在第2 部分中,我们将集中介绍开发SQLJ 存储过程的常见问题及其解决方法。
SQLJ 的基础知识1. 基本概念SQLJ 是 Java 应用程序与数据库进行数据传递的一种方式,它是将静态 SQL 语句嵌入在 Java 代码中的一种非过程语言。
SQLJ 为标准的 Java 程序提供了一种访问数据库的扩展能力,程序员只需要在 Java 代码中添加以特定符号标记的SQL 语句,Java 程序就可以从数据库获取数据,插入、更新或删除数据库中的数据。
不过,我们把这种嵌入了 SQL 语句的 Java 代码为 SQLJ 源代码。
下面是一段简单的 SQLJ 代码示例,我们可以一睹 SQLJ 代码的“芳容”。
清单1. SQLJ 代码片段示例try{// Retrieve Info from database tableString hostVar = null;#sql[ctx]{SELECT col INTO :hostvar FROM tablename WHERE objID=:objectID};} catch(SQLException e){logf("Error: Cannot execute SQL statement.");e.printStackTrace();}回到 SQLJ 技术本身,它是由 IBM、Oracle 和 Sybase 等数据库厂商于 1997 年提出的技术规范,确定了如何在 Java 变成语言中使用静态 SQL 语句。
同年 12 月,Oracle 提供了 SQL 嵌入于 Java 代码中的参考实现,该参考实现可以运行在任何支持 JDK1.1 的平台。
db2存储过程动态游标及函数返回值总结

db2存储过程动态游标及函数返回值总结DB2存储过程是一种在数据库服务器上执行的事务处理程序,它可以包含SQL语句、控制结构和变量。
在存储过程中,我们经常会使用动态游标和函数返回值来实现一些特定的功能。
下面是关于DB2存储过程中动态游标和函数返回值的总结。
一、动态游标1.动态游标是在存储过程中动态定义的一种游标,它可以根据不同的条件进行查询,并返回满足条件的结果集。
动态游标的定义和使用步骤如下:1.1定义游标:使用DECLARECURSOR语句定义游标,并指定游标的名称和返回结果集的查询语句。
1.2打开游标:使用OPEN语句打开游标,并执行查询语句,将结果集保存在游标中。
1.3获取数据:使用FETCH语句获取游标中的数据,并进行相应的处理。
1.4关闭游标:使用CLOSE语句关闭游标,释放资源。
2.动态游标的优势:2.1灵活性:动态游标可以根据不同的条件查询不同的结果集,满足特定的业务需求。
2.2可读性:通过使用动态游标,可以使存储过程的代码更加清晰和易于理解。
2.3性能优化:动态游标可以根据实际情况进行优化,提高查询性能。
3.动态游标的注意事项:3.1游标的生命周期:动态游标的生命周期是在存储过程执行期间,一旦存储过程结束,游标也会自动关闭。
3.2游标的维护成本:动态游标的使用需要消耗一定的系统资源,所以在使用动态游标时需要注意资源的管理。
二、函数返回值1.函数返回值是存储过程中的一个重要特性,它可以将计算结果返回给调用者。
DB2支持返回多个值的函数,可以通过函数返回表、游标或者多个标量值来实现。
2.函数返回值的定义和使用步骤如下:2.1定义函数返回值:在存储过程中使用RETURNS子句定义函数返回的数据类型。
2.2设置函数返回值:在存储过程中使用SET语句设置函数返回的值。
2.3使用函数返回值:在调用存储过程时,可以使用SELECT语句或者VALUES语句获取函数返回的值。
3.函数返回值的优势:3.1灵活性:函数返回值可以根据实际需求返回不同的结果,满足不同的业务场景。
SQLSERVER和DB2存储过程规范实例

• 带输出存储过程示例
CREATE PROCEDURE titles_sum @@TITLE varchar(40) = \'%\', @@SUM money OUTPUT AS SELECT \'Title Name\' = title FROM titles WHERE title LIKE @@TITLE SELECT @@SUM = SUM(price) FROM titles WHERE title LIKE @@TITLE GO 说明 OUTPUT 变量必须在创建表和使用该变量时都进行定义。 参数名和变量名不一定要匹配,不过数据类型和参数位置必须匹配(除非使用 @@SUM = variable 形式)。
• 什么是SQL语言?
SQL语言是应用程序和SQL Server数据库之间的主要 编程接口。使用SQL语言编写代码时,可用两种方法 存储和执行代码。
① 第一种是在客户端存储代码,并创建向数据库管理系统发送S QL命令(或SQL语句)并处理返回结果给应用程序; ② 第二种是将这些发送的SQL语句存储在数据库管理系统中,这 些存储在数据库管理系统中的SQL语句就是存储过程。
• 使用 WITH ENCRYPTION 选项
WITH ENCRYPTION 子句对用户隐藏存储过程的文本。下例创建加密过程, 使用 sp_helptext 系统存储过程获取关于加密过程的信息,然后尝试直接从 sysco mments 表中获取关于该过程的信息。 GO USE pubs GO CREATE PROCEDURE encrypt_this WITH ENCRYPTION AS SELECT * FROM authors GO EXEC sp_helptext encrypt_this
db2存储过程

USE_CUST_ID NUMBER(12),
ADDRESS_ID NUMBER(12),
COMMON_REGION_ID NUMBER(12),
BASIC_STATE VARCHAR2(10),
EXT_STATE VARCHAR2(3),
VOICE_AOC_TYPE CHAR(3),
DATA_AOC_TYPE CHAR,
ISMP_AOC_TYPE CHAR,
STOP_RENT_DATE DATE,
USE_LATN_ID NUMBER(9),
PAY_LATN_ID NUMBER(9)
)
insert into PROD_INST_919
(
CONTRACT_ID NUMBER(12),
ACCT_ID NUMBER(12),
INSTALL_DATE DATE,
ADDRESS_DESC VARCHAR2(250),
LAST_ORDER_ID NUMBER(12),
PHYSICAL_NBR VARCHAR2(20),
INSTALL_ADDR VARCHAR2(250),
EXT_PROD_INST_ID VARCHAR2(30),
BEGIN_RENT_DATE DATE,
tn_id LATN_ID --本地网标识
from
CIMM.V_USER_INFO_day a
left join det.ofr_prd_inst_main b on a.prd_inst_id=b.prd_inst_id
left join LCUST.SERV_ACCT c on b.serv_id=c.serv_id
DB2_存储过程执行计划的查看及监控方法

一,编写存储过程。
[db2inst1@db2lab ~]$ cat test.sqlcreate procedure sales_status(in quota integer)dynamic result sets 2language sqlbegindeclare SQLSTATE char(5);declare rs cursor with return forselect * from t1;open rs;end@二,建立存储过程[db2inst1@db2lab~]$**************DB20000I The SQL command completed successfully.三,执行存储过程[db2inst1@db2lab ~]$ db2 "call sales_status(1)"Result set 1--------------ID-------1.1 record(s) selected.Return Status = 0四,利用表函数MON_GET_PKG_CACHE_STMT抓取static的信息,获取PACKAGE_NAME及SQL语句[db2inst1@db2lab ~]$ db2 "selectPACKAGE_NAME,SECTION_NUMBER,EXECUTABLE_IDfrom TABLE(MON_GET_PKG_CACHE_STMT ( 'S', NULL, NULL, -1)) as T" PACKAGE_NAMESECTION_NUMBER EXECUTABLE_ID -------------------------------------------------------------------------------------------------------------------------------- -------------------- -------------------------------------------------------------------P04624831x'0100000000000000BE0100000000000001000000010020140415004624839232' 1 record(s) selected.五,利用EXECUTABLE_ID,获取SQL语句[db2inst1@db2lab ~]$ db2 "SELECT STMT_TEXT FROMTABLE(MON_GET_PKG_CACHE_STMT> (null,x'0100000000000000BE0100000000000001000000010020140415004624839232', null, -2))"STMT_TEXT-------------------------------------------------------DECLARE RS cursor with return forselect * from T1 where ID = :HV00008 :HI000081 record(s) selected.六,查看package_name信息,valid列信息需要重点关注,信息中心解释如下:•N = Needs rebinding•V = Validate at run time•X = Package is inoperative because some function instance on which it depends has been dropped; explicit rebind is needed•Y = Valid[db2inst1@db2lab ~]$ db2 list packages for all |grep -i P0462483Bound Total Isolation Package Schema Version by sections Valid Format level Blocking----------- --------- ----------- --------- ------------- ------- -------- --------- --------P0462483 DB2INST1 DB2INST1 1Y 0 CS U七,获取该package_name的执行计划信息[db2inst1@db2lab ~]$ db2expln -d pos -g -c db2inst1 -p P0462483 -s 0 -tDB2 Universal Database Version 9.7, 5622-044 (c) Copyright IBM Corp. 1991, 2008 Licensed Material - Program Property of IBMIBM DB2 Universal Database SQL and XQUERY Explain Tool******************** PACKAGE ***************************************Package Name = "DB2INST1"."P0462483" Version =Prep Date = 2014/04/15Prep Time = 00:46:24Bind Timestamp = 2014-04-15-00.46.24.839232Isolation Level = Cursor StabilityBlocking = Block Unambiguous CursorsQuery Optimization Class = 5Partition Parallel = NoIntra-Partition Parallel = NoSQL Path = "SYSIBM", "SYSFUN", "SYSPROC", "SYSIBMADM","DB2INST1"-------------------- SECTION ---------------------------------------Section = 1Statement:DECLARE RS cursorwith returnforselect *from T1where ID =:HV00008 :HI00008Section Code Page = 1208Estimated Cost = 7.569436Estimated Cardinality = 1.000000Access Table Name = DB2INST1.T1 ID = 2,4| #Columns = 1| Skip Inserted Rows| Evaluate Block/Data Predicates Before Locking Committed Row| May participate in Scan Sharing structures| Scan may start anywhere and wrap, for completion| Fast scan, for purposes of scan sharing management| Scan can be throttled in scan sharing management| Relation Scan| | Prefetch: Eligible| Lock Intents| | Table: Intent Share| | Row : Next Key Share| Sargable Predicate(s)| | #Predicates = 1| | Return Data to Application| | | #Columns = 1Return Data CompletionEnd of sectionOptimizer Plan:RowsOperator(ID)Cost1RETURN( 1)7.56944|1TBSCAN( 2)7.56944|1Table:DB2INST1T1总结:DB2的执行计划变化较多,不经常runstats和rebind的时候,有可能本地执行计划很好,但在实际生产环境上执行计划较差,这需要DBA能抓取实时SQL执行计划,静态sql通过上述方式抓取,动态sql需要借助db2expln的cache选项抓取,来分析sql的消耗情况Dynamic Statement Options:-cache <anchID>,<stmtUID>,<envID>,<varID>= Retrieve the statement identified by the given IDsfrom the dynamic SQL cache. (The IDs can beobtained by running db2pd with the -dynamicoption.。
DB2存储过程学习总结

Db2 存储过程学习总结●在命令窗口执行存储过程,可以方便看出存储过程在哪一行出现错误,方便修改。
●db2 存储过程常用语句格式----定义DECLARE CC VARCHAR(4000);DECLARE SQLSTR VARCHAR(4000);DECLARE st STATEMENT;DECLARE CUR CURSOR WITH RETURN TO CLIENT FOR CC;----执行动态SQL不返回PREPARE st FROM SQLSTR;EXECUTE st;----执行动态SQL返回PREPARE CC FROM SQLSTR;OPEN CUR;----判断是否为空,使用值替代COALESCE(判断对象,替代值)----定义临时表DECLARE GLOBAL TEMPORARY TABLE SESSION.TempResultTable(Organization int,OrganizationName varchar(100),AnimalTypeName varchar(20),ProcessType int,OperatorName varchar(100),OperateCount int)WITH REPLACE -- 如果存在此临时表,则替换NOT LOGGED;DB2 9.x临时表使用总结1). DB2的临时表需要用命令Declare Temporary Table来创建,并且需要创建在用户临时表空间上;2). DB2在数据库创建时,缺省并不创建用户临时表空间,如果需要使用临时表,则需要用户在创建临时表之前创建用户临时表空间;3). 临时表的模式为SESSION,SESSION即基于会话的,且在会话之间是隔离的。
当会话结束时,临时表的数据被删除,临时表被隐式卸下。
对临时表的定义不会在SYSCAT.TABLES中出现 .;4). 缺省情况下,在Commit命令执行时,DB2临时表中的所有记录将被删除; 这可以通过创建临时表时指定不同的参数来控制;5). 运行ROLLBACK命令时,用户临时表将被删除;下面是DB2临时表定义的一个示例:DECLARE GLOBAL TEMPORARY TABLE results(RECID VARCHAR(32) , --idXXLY VARCHAR(100), --信息来源LXDH VARCHAR(32 ), --信息来源联系电话FKRQ DATE --反馈时间) ON COMMIT PRESERVE ROWS WITH REPLACE NOT LOGGED;----字符串函数Substr----隐形游标迭代for 游标名as select....... do使用游标名.字段名内容区块end for;----直接返回值或变量declare rs1 cursor with return to caller for select 0 from sysibm.sysdummy1;----判断表是否存在select count(*) into @exists from syscat.tables where tabschema = current schema and tabname='ZY_PROCESSLOG';----取前面N条记录select * from 表名FETCH FIRST N ROWS ONLY----定义返回值declare rs0 cursor with return to caller for select 0 from sysibm.sysdummy1;declare rs1 cursor with return to caller for select 1 from sysibm.sysdummy1;----得到插入的自增长列最大值VALUES IDENTITY_VAL_LOCAL() INTO 变量Merge into [A] using [B] on 条件when ***通过这个merge你能够在一个SQL语句中对一个表同时执行inserts和updates操作. 当然是update还是insert是依据于你的指定的条件判断的,Merge into可以实现用B表来更新A表数据,如果A表中没有,则把B表的数据插入A表. MERGE命令从一个或多个数据源中选择行来updating或inserting到一个或多个表语法如下MERGE INTO [your table-name] [rename your table here]USING ( [write your query here] )[rename your query-sql and using just like a table]ON ([conditional expression here] AND [...]...)WHEN MATHED THEN [here you can execute some update sql or something else ] WHEN NOT MATHED THEN [execute something else here ! ]我们先看看一个简单的例子,来介绍一个merge into的用法merge into products p using newproducts np on (p.product_id = np.product_id)when matched thenupdate set p.product_name = np.product_namewhen not matched theninsert values(np.product_id, np.product_name, np.category)在这个例子里。
DB2存储过程语法

DB2存储过程语法语法:CREATE PROCEDURE <schema-name>.<procedure-name> (参数) [属性] <语句>--参数:SQL PL 存储过程中有三种类型的参数:IN:输入参数(默认值,也可以不指定)OUT:输出参数INOUT:输入和输出参数--属性1、LANGUAGE SQL指定存储过程使用的语言。
LANGUAGE SQL 是其默认值。
还有其它的语言供选择,比如Java 或者C,可以将这一属性值分别设置为LANGUAGE JAVA 或者LANGUAGE C。
2、DYNAMIC RESULT SETS <n>如果您的存储过程将返回n 个结果集,那么需要填写这一选项。
3、SPECIFIC my_unique_name赋给存储过程一个唯一名称,如果不指定,系统将生成一个惟一的名称。
一个存储过程是可以被重载的,也就是说许多个不同的存储过程可以使用同一个名字,但这些存储过程所包含的参数数量不同。
通过使用SPECIFIC 关键字,您可以给每一个存储过程起一个唯一的名字,这可以使得我们对于存储过程的管理更加容易。
例如,要使用SPECIFIC 关键字来删除一个存储过程,您可以运行这样的命令:DROP SPECIFIC PROCEDURE。
如果没有使用SPECIFIC 这个关键字,您将不得不使用DROP PROCEDURE 命令,并且指明存储过程的名字及其参数,这样DB2 才能知道哪个被重载的存储过程是您想删除的。
4、SQL 访问级别NO SQL:存储过程中不能有SQL 语句CONTAINS SQL:存储过程中不能有可以修改或读数据的SQL 语句READS SQL:存储过程中不能有可以修改数据的SQL 语句MODIFIES SQL:存储过程中的SQL 语句既可以修改数据,也可以读数据默认值是MODIFIES SQL,一个存储过程不能调用具有更高SQL 数据访问级别的其他存储过程。
db2 v9的自动存储管理详细教程

IBM的DB2 V9 引入了自动存储器管理,使用自动存储功能可以帮助您简化表空间的存储管理,新创建的使用自动存储功能的表空间,其容器和空间分配完全由 DB2数据库管理器确定。
本文重点介绍使用DB2® V9 自动存储功能的数据库如何进行非增量重定向还原。
简介数据库可能会因为软件或硬件故障而不可用,可能会遇到存储问题、断电、应用程序故障或误操作等各种需要采取不同恢复措施的故障情况。
本文重点介绍使用了DB2® V9 的自动存储功能,不允许增量备份的数据库如何进行重定向还原。
由于使用自动存储器功能的数据库在还原方面和以往有了很大区别,客户在实际使用的过程中容易出现各种问题,所以本文对自动存储功能会有详细的阐述。
自动存储特性最初是在DB2 V8.2.2中引入的,DB2 V9扩展了这一特性,使用自动存储功能可以帮助您简化表空间的存储管理,新创建的使用自动存储功能的表空间,其容器和空间分配完全由 DB2数据库管理器确定。
自动存储管理自动存储器跨磁盘和文件系统自动增大数据库大小。
因此,在保持数据库管理的存储器性能和灵活性的同时,不再需要管理存储器容器。
在DB2 V9.1中,已对多分区数据库增加了自动存储器支持。
如果您使用的是带DPF(Data Partitioning Feature,数据库分区功能)的企业服务器版,那您可以使用支持自动存储器功能的多分区数据库。
在DB2 V9中创建新数据库的时候,默认启用自动存储功能,主要目的是简化表空间的存储管理,使用自动存储功能的数据库有一个或多个相关联的存储器路径,在创建表空间的时候不用指定存储的路径等特性。
对使用自动存储器功能的数据库,其表空间可以使用自动存储管理,也可以不使用自动存储管理。
对于不使用自动存储器功能的数据库,则其表空间不能使用自动存储管理。
自动存储器简化了存储管理,它使您能够指定用于数据库管理器存放表空间数据以及为各种用途分配空间的存储路径。
DB2存储过程(Merge关键字的使用)

DB2存储过程(Merge关键字的使用)CREATE PROCEDURE COPY_OCJ_LIST_TO_SHIPMENT(IN P_SESSION_ID VARCHAR(40), --当前用户的session ID IN P_IS_REPEAT VARCHAR(20), --如果导入新数据传入值:YES,如果导入全部数据传入值:ALLIN P_IS_SAME VARCHAR(20), --是否保存IN P_ORDER_TYPE VARCHAR(20), --客户发货入库IN P_ORDER_ID VARCHAR(20), --入库编号IN P_ORDER_TIME VARCHAR(30), --入库时间IN P_VENDOR_ID VARCHAR(20), --发货客户IN P_WAREHOUSE_ID VARCHAR(20),--分拨中心IN P_CREATE_BY VARCHAR(20) --创建者)MODIFIES SQL DATA --表示存储过程可以执行任何 SQL 语句LANGUAGE SQL-------------------------------------------------------------------------- SQL 存储过程------------------------------------------------------------------------P1: BEGIN ATOMIC--声明一个变量,用来保存入库计划明细中未失效运单的数量DECLARE D_ODRER_COUNT INTEGER;DECLARE D_ORDER_ID VARCHAR(20);--------------------------- 保存OCJ正式表数据 ---------------------------MERGE INTO OCJ_SHIPMENT OSUSING(--查询OCJ导入的临时表数据SELECTSHIPMENT_ID, --IDSHIPMENT_PLAN_NO, --运单号RECEIVE_DATE, --提货日期VENDOR_ID, --发货客户WAREHOUSE_ID, --原分拨中心IS_CHECK, --是否审核CAR_LICENSE_NO, --车辆牌号DRIVER_NAME, --司机名称STATE, --状态CREATE_BY, --创建者CREATE_DATE, --创建日期LAST_UPDATE_BY, --修改者LAST_UPDATE_DATE, --修改日期SESSION_ID, --用户IDSERIAL_ID, --序列号IS_REPEAT, --是否重复FROM_WAREHOUSE_ID, --来源分拨中心IS_SAME_WAREHOUSE --是否同一分拨中心FROM OCJ_SHIPMENT_TEMPWHERE SESSION_ID = P_SESSION_ID AND IS_REPEAT != P_IS_REPEAT)OSTON(OST.IS_REPEAT != P_IS_REPEAT ANDOS.SHIPMENT_PLAN_NO=OST.SHIPMENT_PLAN_NO ANDOS.VENDOR_ID=OST.VENDOR_ID) --如果临时表中标记为YS_Yes的,则修改WHEN MATCHED THEN--如果指定的条件匹配,则执行修改动作UPDATE SETOS.SHIPMENT_PLAN_NO=OST.SHIPMENT_PLAN_NO, --运单号OS.RECEIVE_DATE=OST.RECEIVE_DATE, --提货日期OS.VENDOR_ID=OST.VENDOR_ID, --发货客户OS.WAREHOUSE_ID =OST.WAREHOUSE_ID, --原分拨中心OS.FROM_WAREHOUSE_ID=OST.FROM_WAREHOUSE_ID, --来源分拨中心OS.IS_CHECK=OST.IS_CHECK, --是否审核OS.CAR_LICENSE_NO=OST.CAR_LICENSE_NO, --车辆编号OS.DRIVER_NAME=OST.DRIVER_NAME, --司机名称OS.STATE=OST.STATE, --状态ST_UPDATE_BY=ST_UPDATE_BY, --修改者ST_UPDATE_DATE=ST_UPDATE_DATE --修改日期WHEN NOT MATCHED THEN--如果指定的条件不匹配,则执行添加动作INSERT(SHIPMENT_ID, --IDSHIPMENT_PLAN_NO, --运单号RECEIVE_DATE, --提货日期VENDOR_ID, --发货客户WAREHOUSE_ID, --原分拨中心 IS_CHECK, --是否审核CAR_LICENSE_NO, --车辆牌号DRIVER_NAME, --司机名称STATE, --状态CREATE_BY, --创建者CREATE_DATE, --创建日期LAST_UPDATE_BY, --修改者LAST_UPDATE_DATE, --修改日期FROM_WAREHOUSE_ID --来源分拨中心 )VALUES(OST.SHIPMENT_ID,OST.SHIPMENT_PLAN_NO,OST.RECEIVE_DATE,OST.VENDOR_ID,OST.WAREHOUSE_ID,OST.IS_CHECK,OST.CAR_LICENSE_NO,OST.DRIVER_NAME,OST.STATE,OST.CREATE_BY,OST.CREATE_DATE,ST_UPDATE_BY,ST_UPDATE_DATE,OST.FROM_WAREHOUSE_ID);-------------------------------- 保存导入数据状态表状态 --------------------------------MERGE INTO SHIPMENT_STATE SSUSING(--查询OCJ导入的临时表数据SELECTSHIPMENT_ID, --IDSHIPMENT_PLAN_NO, --运单号RECEIVE_DATE, --提货日期VENDOR_ID, --发货客户WAREHOUSE_ID, --原分拨中心--IS_CHECK, --是否审核--CAR_LICENSE_NO, --车辆牌号--DRIVER_NAME, --司机名称--STATE, --状态--CREATE_BY, --创建者--CREATE_DATE, --创建日期--LAST_UPDATE_BY, --修改者--LAST_UPDATE_DATE, --修改日期--SESSION_ID, --用户ID--SERIAL_ID, --序列号IS_REPEAT --是否重复--FROM_WAREHOUSE_ID, --来源分拨中心--IS_SAME_WAREHOUSE --是否同一分拨中心FROM OCJ_SHIPMENT_TEMPWHERE SESSION_ID = P_SESSION_ID AND IS_REPEAT != P_IS_REPEAT)OSTON(OST.IS_REPEAT != P_IS_REPEAT ANDSS.SHIPMENT_PLAN_NO=OST.SHIPMENT_PLAN_NO ANDSS.VENDOR_ID=OST.VENDOR_ID) --如果临时表中标记为YS_Yes的,则修改WHEN MATCHED THEN--如果指定的条件匹配,则执行修改动作UPDATE SETSS.RECEIVE_DATE=OST.RECEIVE_DATE --提货日期WHEN NOT MATCHED THEN--如果指定的条件不匹配,则执行添加动作INSERT(SHIPMENT_STATE_ID, --状态表ID(唯一的) SHIPMENT_PLAN_NO, --运单号RECEIVE_DATE, --提货日期VENDOR_ID, --发货客户WAREHOUSE_ID --原分拨中心--CREATE_BY, --创建者--CREATE_DATE --创建日期)VALUES('SS' || OST.SHIPMENT_ID,OST.SHIPMENT_PLAN_NO,OST.RECEIVE_DATE,OST.VENDOR_ID,OST.WAREHOUSE_ID--OST.CREATE_BY, --创建者--OST.CREATE_DATE --创建日期);------------------------------------- 保存导入数据Other状态表状态 -------------------------------------MERGE INTO SHIPMENT_OTHER_STATE SOSUSING(--查询OCJ导入的临时表数据SELECTSHIPMENT_ID, --IDSHIPMENT_PLAN_NO, --运单号RECEIVE_DATE, --提货日期VENDOR_ID, --发货客户--WAREHOUSE_ID, --原分拨中心--IS_CHECK, --是否审核--CAR_LICENSE_NO, --车辆牌号--DRIVER_NAME, --司机名称--STATE, --状态--CREATE_BY, --创建者--CREATE_DATE, --创建日期--LAST_UPDATE_BY, --修改者--LAST_UPDATE_DATE, --修改日期IS_REPEAT, --是否重复FROM_WAREHOUSE_ID, --来源分拨中心IS_SAME_WAREHOUSE --是否同一分拨中心FROM OCJ_SHIPMENT_TEMPWHERE SESSION_ID = P_SESSION_ID AND IS_REPEAT !=P_IS_REPEAT)OSTON(OST.IS_REPEAT != P_IS_REPEAT ANDSOS.SHIPMENT_PLAN_NO=OST.SHIPMENT_PLAN_NO ANDSOS.VENDOR_ID=OST.VENDOR_ID) --如果临时表中标记为YS_Yes的,则修改WHEN MATCHED THEN--如果指定的条件匹配,则执行修改动作UPDATE SETSOS.PLAN_WAREHOUSE_ID=OST.FROM_WAREHOUSE_ID, --来源分拨中心SOS.PLAN_IMPORT='YS_Yes', --可导入SOS.OCJ_IMPORT='YS_Yes', --可导入SOS.OCJ_CHECK='YS_Yes', --可审核SOS.INCOME_ORDER='YS_Yes', --可入库SOS.BOOK_LOC='YS_Yes' --可预排库位ST_UPDATE_BY=ST_UPDATE_BY, --修改者ST_UPDATE_DATE=ST_UPDATE_DATE --修改日期WHEN NOT MATCHED THEN--如果指定的条件不匹配,则执行添加动作INSERT(SHIPMENT_STATE_ID, --状态表ID(唯一的) SHIPMENT_PLAN_NO, --运单号VENDOR_ID, --发货客户PLAN_WAREHOUSE_ID, --来源分拨中心PLAN_IMPORT, --可导入OCJ_IMPORT, --可导入OCJ_CHECK, --可审核INCOME_ORDER, --可入库BOOK_LOC --可预排库位--CREATE_BY, --创建者--CREATE_DATE --创建日期)VALUES('SOS' || OST.SHIPMENT_ID,OST.SHIPMENT_PLAN_NO,OST.VENDOR_ID,OST.FROM_WAREHOUSE_ID,'YS_Yes','YS_Yes','YS_Yes','YS_Yes','YS_Yes'--OST.CREATE_BY, --创建者--OST.CREATE_DATE --创建日期);---------------------------- 保存计划入库头信息 ----------------------------INSERT INTO WMS_INCOMING_ORDER_PLAN (ORDER_ID, --入库计划ID ORDER_NO, --入库计划单号ORDER_TIME, --入库时间ORDER_TYPE, --类型ENTER_TYPE, --自动STATE, --状态CREATE_BY, --创建者CREATE_DATE, --创建时间WAREHOUSE_ID, --分拨中心VENDOR_ID --发货客户)VALUES(P_ORDER_ID,'JHRKD' || P_ORDER_ID,P_ORDER_TIME,P_ORDER_TYPE,'AUTO','State_All_Y',P_CREATE_BY,P_ORDER_TIME,P_WAREHOUSE_ID,P_VENDOR_ID);------------------------------ 修改计划入库明细信息 ------------------------------MERGE INTO WMS_INCOMING_ORDER_ITEM_PLAN WIOIUSING(--查询OCJ导入的临时表数据SELECTSHIPMENT_ID, --IDSHIPMENT_PLAN_NO, --运单号RECEIVE_DATE, --提货日期VENDOR_ID, --发货客户WAREHOUSE_ID, --原分拨中心--IS_CHECK, --是否审核--CAR_LICENSE_NO, --车辆牌号--DRIVER_NAME, --司机名称--STATE, --状态--CREATE_BY, --创建者--CREATE_DATE, --创建日期--LAST_UPDATE_BY, --修改者--LAST_UPDATE_DATE, --修改日期IS_REPEAT, --是否重复FROM_WAREHOUSE_ID, --来源分拨中心IS_SAME_WAREHOUSE --是否同一分拨中心FROM OCJ_SHIPMENT_TEMPWHERE SESSION_ID = P_SESSION_ID AND IS_REPEAT !=P_IS_REPEAT AND IS_SAME_WAREHOUSE='YS_No' --查询当前用户下不同分拨中心的运单信息)OSTON(1=1 AND OST.IS_SAME_WAREHOUSE = 'YS_No' AND WIOI.SHIPMENT_PLAN_NO=OST.SHIPMENT_PLAN_NO ANDWIOI.VENDOR_ID=OST.VENDOR_ID --指定条件)WHEN MATCHED THEN--如果指定的条件匹配,则执行修改动作UPDATE SETSTATE = 'State_All_N';------------------------------ 保存计划入库明细信息 ------------------------------MERGE INTO WMS_INCOMING_ORDER_ITEM_PLAN WIOI USING(--查询OCJ导入的临时表数据SELECTSHIPMENT_ID, --IDSHIPMENT_PLAN_NO, --运单号RECEIVE_DATE, --提货日期VENDOR_ID, --发货客户WAREHOUSE_ID, --原分拨中心--IS_CHECK, --是否审核--CAR_LICENSE_NO, --车辆牌号--DRIVER_NAME, --司机名称--STATE, --状态--CREATE_BY, --创建者--CREATE_DATE, --创建日期--LAST_UPDATE_BY, --修改者--LAST_UPDATE_DATE, --修改日期IS_REPEAT, --是否重复FROM_WAREHOUSE_ID, --来源分拨中心IS_SAME_WAREHOUSE --是否同一分拨中心 FROM OCJ_SHIPMENT_TEMPWHERE SESSION_ID = P_SESSION_ID AND IS_REPEAT != P_IS_REPEAT AND IS_SAME_WAREHOUSE IS NOT NULL)OSTON(1 <> 1 --指定条件)WHEN NOT MATCHED THEN--如果指定的条件不匹配,则执行添加动作INSERT(ORDER_ITEM_ID, --明细IDORDER_ID, --头信息IDSHIPMENT_PLAN_ID, --配送计划IDSHIPMENT_PLAN_NO, --运单号CHECK_STATE, --VENDOR_ID, --发货客户WAREHOUSE_ID, --分拨中心LOC_ID, --库位IDQUANTITY, --数量STATE, --状态CREATE_BY, --创建者CREATE_DATE --创建日期)VALUES('WOIO' || SHIPMENT_ID,P_ORDER_ID,'-',OST.SHIPMENT_PLAN_NO,'YS_No',OST.VENDOR_ID,OST.WAREHOUSE_ID,'-',1,'State_All_Y',P_CREATE_BY,P_ORDER_TIME);------------------------- 修改计划入库信息 ---------------------------如果在入库计划明细中当前ORDER_ID下,不存在状态为State_All_Y,则更新头部信息为State_All_N--查询入库计划表表中有效运单的数据,根据ORDER_ID分组,如果该ORDER_ID下没有有效的入库计划明细,则头部信息失效FOR V ASSELECT count(*) AS count,WIOIP.order_id FROMWMS_INCOMING_ORDER_ITEM_PLAN WIOIPWHERE 1 = 1 AND WIOIP.STATE = 'State_All_Y' --状态为有效的GROUP BY WIOIP.order_id --根据ORDER_ID分组FOR READ ONLYDOSET D_ORDER_ID = V.order_id;SET D_ODRER_COUNT = V.COUNT;--如果有效运单为0,更新头部信息为失效IF D_ODRER_COUNT = 0 THENUPDATE WMS_INCOMING_ORDER_PLAN SET STATE ='State_All_N' WHERE ORDER_ID = D_ORDER_ID;END IF;END FOR;---------------------------------- 添加操作历史初始导入记录 ----------------------------------INSERT INTO ACTION_HISTORY (HISTORY_ID --操作历史ID, REFRENCE_ID --引用ID, REFRENCE_TYPE --操作类型, REFRENCE_OPERATOR --, WAREHOUSE_ID --分拨中心, SUB_WAREHOUSE_ID --, LOC_ID --库位, BEGIN_TIME --开始时间, STATE --状态, COMMENTS --备注, CREATE_BY --创建者, CREATE_DATE --创建时间, LAST_UPDATE_BY --最后修改者, LAST_UPDATE_DATE --最后修改时间, DRIVER_NAME --司机名称, CAR_LICENSE_NO --车辆编号, SHIPMENT_PLAN_ID --配送计划ID , VENDOR_ID --发货客户, SHIPMENT_PLAN_NO --运单号)SELECT 'AHO' || SHIPMENT_ID --操作历史ID, SHIPMENT_ID --引用ID, 'OPERATOR_SHIPMENT_OCJ_IMPORT' --操作类型, 'NEW_OCJ_IMPORT' --, FROM_WAREHOUSE_ID --, '-' --库位, CREATE_DATE --开始时间, 'State_All_Y' --状态, '' --备注, CREATE_BY --创建者, CREATE_DATE --创建时间, CREATE_BY --最后修改者, CREATE_DATE --最后修改时间, DRIVER_NAME --司机名称, CAR_LICENSE_NO --车辆编号, '-' --配送计划ID, VENDOR_ID --发货客户, SHIPMENT_PLAN_NO --运单号FROM OCJ_SHIPMENT_TEMPWHERE SESSION_ID = P_SESSION_ID AND IS_REPEAT = 'YS_No';--初始导入---------------------------------- 添加操作历史覆盖导入记录 ----------------------------------INSERT INTO ACTION_HISTORY(HISTORY_ID --操作历史ID, REFRENCE_ID --引用ID , REFRENCE_TYPE --操作类型, REFRENCE_OPERATOR --, WAREHOUSE_ID --分拨中心, LOC_ID --库位 , BEGIN_TIME --开始时间, STATE --状态 , COMMENTS --备注 , CREATE_BY --创建者 , CREATE_DATE --创建时间, LAST_UPDATE_BY --最后修改者, LAST_UPDATE_DATE --最后修改时间, DRIVER_NAME --司机名称, CAR_LICENSE_NO --车辆编号, SHIPMENT_PLAN_ID --配送计划ID, VENDOR_ID --发货客户, SHIPMENT_PLAN_NO --运单号 )SELECT 'AHO' || SHIPMENT_ID --操作历史ID, SHIPMENT_ID --引用ID, 'OPERATOR_SHIPMENT_OCJ_IMPORT' --操作类型, 'AGAIN_OCJ_IMPORT' --, WAREHOUSE_ID --分拨中心, FROM_WAREHOUSE_ID --, '-' --库位, CREATE_DATE --开始时间, 'State_All_Y' --状态, '' --备注, CREATE_BY --创建者, CREATE_DATE --创建时间, CREATE_BY --最后修改者, CREATE_DATE --最后修改时间, DRIVER_NAME --司机名称, CAR_LICENSE_NO --车辆编号, '-' --配送计划ID, VENDOR_ID --发货客户, SHIPMENT_PLAN_NO --运单号FROM OCJ_SHIPMENT_TEMPWHERE SESSION_ID = P_SESSION_ID AND IS_REPEAT = 'YS_Yes';--覆盖导入END P1本文来自CSDN博客,转载请标明出处:/soft_luo/archive/2009/12/01/4915477.aspx。
db2数据库基础知识

db2数据库基础知识1,db2数据库特点(1)具有很好的并⾏性(DB2把数据库管理扩充到了并⾏的,多节点的环境;数据库分区是数据库的⼀部分,包含⾃⼰的数据,索引,配置⽂件和事务⽇志;数据库分区有时被称为节点)。
(2)获得最⾼认证级别的ISO标准认证。
(3)性能较⾼,适⽤于数据仓库和在线事物处理。
(4)跨平台,多层结构,⽀持ODBC,JDBC等客户。
(5)操作简单,同时提供GUI和命令⾏,在windowsNT和unix下的操作相同。
(6)在巨型企业得到⼴泛的运⽤,向下兼容性好,风险⼩。
(7)能够在所有主流平台上运⾏,最适于海量数据处理。
2,db2数据库的特性(1)完全Web使能的:可以利⽤HTTP来发送询问给服务器。
(2)⾼度可缩放和可靠:⾼负荷时可利⽤多处理器和⼤内存,可以跨服务器地分布数据库和数据负荷;能够以最⼩的数据丢失快速地恢复,提供多种备份策略。
3,实现储存过程存储过程是存储在数据库中的⼀个预编译对象。
这意味着过程是预编译的,可提供给各种应⽤执⾏。
发送查询到服务器、分析和编译过程再不需要花费时间。
(1)特点:存储过程是SQL语句和控制流语句的⼀个集合或批量,它在⼀个名称下存储,按独⽴单元⽅式执⾏。
它能帮助提⾼查询的性能。
(2)好处:提⾼性能(应⽤不必重复地编译此过程)减轻⽹络拥塞(为进⾏处理,应⽤不需要向服务器提交多个SQL语句)⼀致性较好(由于过程作为单⼀控制点,在过程中定义的编码逻辑和SQL语句在所有应⽤中被⼀致地实现)改善安全机制(⽤户可以被授予许可权来执⾏存储过程,尽管他们并不拥有这个过程)(3)执⾏存储过程语句:call proc_name(param,…)(4)RETURN关键字:允许存储过程把整型值返回给调⽤者。
如果没有指定值,那么存储过程返回缺省值0或1,这依赖于存储过程的成功执⾏与否。
RETURN value(5)嵌套过程:可以执⾏或调⽤来⾃另⼀个过程的过程。
4,触发器触发器:⼀个触发器是由SQL语句集组成的代码块,在响应某些动作时激活该语句集。
DB2存储过程快速入门.

1.1 SQL过程的结构命名规则:1、清洗过程名称命名:PROC_业务主题_目标表(PROC_JY_KJYRLJB 交易主题的卡交易日类聚表)2、函数名称命名:PROC_业务主题_函数名(PROC_JY_GETYWZL 交易主题取得卡业务种类函数)3、变量命名:VAR_变量描述(VAR_YWZL 业务种类变量)4、游标命名:CUR_游标描述(CUR_KJYB 对卡交易表进行游标处理)语法:CREATE PROCEDURE 过程名称(参数列表DYNAMIC RESULT SETS 结果集数量是否允许SQLLANGUAGE SQLBEGINSQL 过程体END范例“资产负债.sql ”中第1行:Create Procedure admin.BalanceSheetDayly定义了过程名称参数列表为Out ProcState varchar(100其定义SQL 过程从客户应用获取,或返回客户应用的0个或多个参数,参数列表使用逗号侵害各个参数参数类型有三种:l IN 从客户应用检索值。
其不能够在SQL 过程体中修改l OUT 向客户应用返回值l INOUT 从客户应用检索值,并返回值省略了结果集数量的定义,default 为0。
即表示不返回结果集。
省略了是否允许SQL 的说明。
其值指出了存储过程是否会使用SQL 语句,如果使用,其类型如何:l NO SQL 不能够执行任何SQL 语句l COTAINS SQL 可以执行不会读取SQL 数据,也不会修改SQL 数据的SQL 语句l READS SQL DATA 可以包含不会修改SQL 数据的SQL 语句l MODIFIES SQL DATA 可以执行任何SQL 语句,除了不能够在存储过程中支持的语句以外。
第3~7行,为注释,标明此为SQL 过程,编写、最后修改时间。
注释为“--”开始的行。
第8行和最后一行199共同标识出SQL 过程体过程体存储过程的逻辑内容,包括变量声明、条件控制、流控制语句、以及通过SQL语句处理数据的过程。
DB2学习总结(1)——DB2数据库基础入门

DB2学习总结(1)——DB2数据库基础⼊门DB2的特性完全Web使能的:可以利⽤HTTP来发送询问给服务器。
⾼度可缩放和可靠:⾼负荷时可利⽤多处理器和⼤内存,可以跨服务器地分布数据库和数据负荷;能够以最⼩的数据丢失快速地恢复,提供多种备份策略。
DB2数据库启停启动数据库:db2start停⽌数据库:db2stop检查存在的数据库LIST DATABASE DIRECTORY数据库连接、断开CONNECT TO databasenameCONNECT RESET创建、删除数据库CREATE DB databasename注:如果已经连着⼀个数据库的话,就创建不了数据库,会报“应⽤程序已经与⼀个数据库相连”的错DROP DB databasename第⼆节表数据类型可分为数值型(numeric)、字符串型(character string)、图形字符串(graphic string)、⼆进制字符串型(binary string)或⽇期时间型(datetime)。
还有⼀种叫做DATALINK的特殊数据类型。
DATALINK值包含了对存储在数据库以外的⽂件的逻辑引⽤。
数值型数据类型包括:⼩整型,SMALLINT:两字节整数,精度为5位。
范围从-32,768到32,767。
⼤整型,INTEGER或INT:四字节整数,精度为10位。
范围从-2,147,483,648到2,147,483,647。
巨整型,BIGINT:⼋字节整数,精度为19位。
范围从-9,223,372,036,854,775,808到9,223,372,036,854,775,807。
⼩数型,DECIMAL(p,s)、DEC(p,s)、NUMBERIC(p,s)或NUM(p,s):⼩数型的值是⼀种压缩⼗进制数,它有⼀个隐含的⼩数点。
压缩⼗进制数将以⼆-⼗进制编码(binary-coded decimal,BCD)记数法的变体来存储。
⼩数点的位置取决于数字的精度(p)和⼩数位(s)。
DB2存储过程

--CURSOR---------->
>--FOR--+-select-statement
-+-------------><
.-WITHOUT HOLD-.
|--+--------------+---------------------------------------------|
DB2 支持以下创建数组数据类型的语法:
清单 2. 创建数组数据类型的语法
Sql代码
>>-CREATE TYPE—array-type-name--AS--| data-type |--ARRAY--[---------->
.-2147483647-------.
若要更改默认函数路径,则需要更新专用寄存器 CURRENT PATH。
游标
声明
SQL PL 提供 DECLARE cursor 语句来定义一个游标,并提供其他语句来支持返回其他结果集和游标处理。
下面是游标声明的语法: Leabharlann 清单 7. 游标声明的语法
>>-DECLARE--cursor-name
现在可以在 SQL 过程中使用这个数据类型:
清单 3. 在过程中使用数组数据类型
Sql代码
CREATE PROCEDURE PROC_VARRAY_test (out mynames names)
BEGIN
DECLARE v_pnumb numbers;
'-WITH HOLD----'
.-WITHOUT RETURN-------------.
|--+----------------------------+-------------------------------|
DB2数据库SQL存储过程

DB2数据库SQL存储过程高性能的SQL过程是数据库开发人员所追求的,我将不断把学到的,或在实际开发中用到的一些提高SQL过程性能的技巧整理出来,温故而知新.1,在只使用一条语句即可做到时避免使用多条语句让我们从一个简单的编码技巧开始。
如下所示的单个 INSERT 行序列:INSERT INTO tab_comp VALUES (item1, price1, qty1);INSERT INTO tab_comp VALUES (item2, price2, qty2);INSERT INTO tab_comp VALUES (item3, price3, qty3);可以改写成:INSERT INTO tab_comp VALUES (item1, price1, qty1),(item2, price2, qty2),(item3, price3, qty3);执行这个多行 INSERT 语句所需时间大约是执行原来三条语句的三分之一。
孤立地看,这一改进看起来似乎是微乎其微的,但是,如果这一代码段是重复执行的(例如该代码段位于循环体或触发器体中),那么改进是非常显著的。
类似地,如下所示的 SET 语句序列:SET A = expr1;SET B = expr2;SET C = expr3;可以写成一条 VALUES 语句:VALUES expr1, expr2, expr3 INTO A, B, C;如果任何两条语句之间都没有相关性,那么这一转换保留了原始序列的语义。
为了说明这一点,请考虑:SET A = monthly_avg * 12;SET B = (A / 2) * correction_factor;将上面两条语句转换成:VALUES (monthly_avg * 12, (A / 2) * correction_factor) INTO A, B;不会保留原始的语义,因为是以“并行”方式对 INTO 关键字之前的表达式进行求值的。
DB2存储过程学习笔记资料

创建:db2-td@-vf createSQLproc.db2--end@ (此处的@可替换成其他符号)调用:db2call过程名(参数)1 基础--声明变量:DECLARE<variable-name><data-type><DEFAULT constant>--赋值:SET x=10;SET y=(SELECT SUM(c1)from T1);VALUES10INTO x;SELECT SUM(c1)INTO y from T1;--会话全局变量:CREATE VARIABLE var_name DATATYPE[DEAFULT value];2 、数组2.1定义CREATE TYPE mynames as VARCHAR(30)ARRAY[];--定义数组2.2声明DECLARE nameArr mynames;--声明数组2.3赋值SET TESTARR=ARRAY[1,2,3,4,5,6,7,8,9,10];SET TESTARR=ARRAY[VALU ES(1),(2)];--方法1,使用SET语句SELECT SUM(NUM)INTO TESTARR[1]FROM(VALUES(1),(2))AS TEMP(NU M);--方法2,使用VALUES INTO语句VALUES1INTO TESTARR[1];--方法3,使用SELECT INTO语句SET TESTARR[1]=1;--方法4,使用ARRAY构造函数2.4操作数组的函数ARRAY_DELETE:删除数组元素TRIM_ARRAY:从右开始删除指定数目个元素ARRAY_FIRST:返回数组中第一个元素ARRAY_LAST:返回数组中最后一个元素ARRAY_NEXT:返回数组下一个元素ARRAY_PRIOR:返回数组前一个元素ARRAY_VARIABLE:返回参数指定的元素ARRAY_EXISTS:判断数组是否有元素CARDINALITY:返回数组中元素的个数MAX_CARDINALITY:返回数组中元素的个数UNNEST:将数组转换为表3 复合语句语法:label:BEGIN[ATOMIC|NOT ATOMIC]--ATOMIC关键字封装的复合语句被当作一个处理单元--变量声明、过程逻辑等END label4流程控制--条件判断IFIF<condition>THEN<SQL procedure statement>;ELSEIF<condition>THEN<SQL procedure statement>;ELSE<SQL procedure statement>;END IF;IF FRIEND='张三'THENSET MSG='你好,张三';ELSEIF FRIEND='李四'THENSET MSG='你好,李四';ELSESET MSG='对不起,我不认识你';END IF;--循环WhileWHILE<condition>DO<sql statements>;END WHILE;WHILE I<=10DOSET NUM=NUM+I;SET I=I+1;END WHILE;--循环forFOR<loop_name>AS<sql statements>DO<sql statements>;END FOR;FOR TEST AS SELECT I FROM(VALUES(1),(2),(3))AS TEMP(I)DOSET NUM=NUM+I;END FOR;--循环LOOPLABEL:LOOP<sql statements>;LEAVE LABEL;END LOOP LABEL;TEST_LOOP:LOOPSET NUM=NUM+I;SET I=I+1;IF I>10THENLEAVE TEST_LOOP;END IF;END LOOP TEST_LOOP;--循环RepeatREPEAT<sql statements>;UNTIL<condition>END REPEAT;REPEATSET NUM=NUM+I;SET I=I+1;UNTIL I>10END REPEAT;--其他关键字ITERATE label--。
DB2存储过程——变量赋值DECLARE声明变量
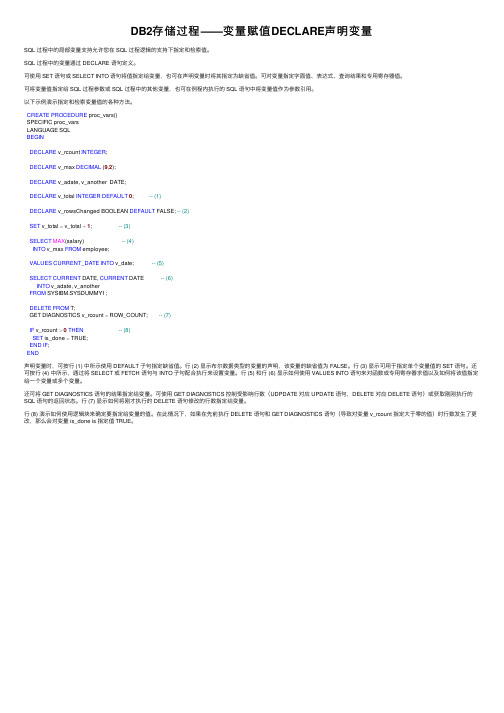
DB2存储过程——变量赋值DECLARE声明变量SQL 过程中的局部变量⽀持允许您在 SQL 过程逻辑的⽀持下指定和检索值。
SQL 过程中的变量通过 DECLARE 语句定义。
可使⽤ SET 语句或 SELECT INTO 语句将值指定给变量,也可在声明变量时将其指定为缺省值。
可对变量指定字⾯值、表达式、查询结果和专⽤寄存器值。
可将变量值指定给 SQL 过程参数或 SQL 过程中的其他变量,也可在例程内执⾏的 SQL 语句中将变量值作为参数引⽤。
以下⽰例演⽰指定和检索变量值的各种⽅法。
CREATE PROCEDURE proc_vars()SPECIFIC proc_varsLANGUAGE SQLBEGINDECLARE v_rcount INTEGER;DECLARE v_max DECIMAL (9,2);DECLARE v_adate, v_another DATE;DECLARE v_total INTEGER DEFAULT0; -- (1)DECLARE v_rowsChanged BOOLEAN DEFAULT FALSE; -- (2)SET v_total = v_total +1; -- (3)SELECT MAX(salary) -- (4)INTO v_max FROM employee;VALUES CURRENT_DATE INTO v_date; -- (5)SELECT CURRENT DATE, CURRENT DATE -- (6)INTO v_adate, v_anotherFROM SYSIBM.SYSDUMMY1;DELETE FROM T;GET DIAGNOSTICS v_rcount = ROW_COUNT; -- (7)IF v_rcount >0THEN-- (8)SET is_done = TRUE;END IF;END声明变量时,可按⾏ (1) 中所⽰使⽤ DEFAULT ⼦句指定缺省值。
db2数据库存储过程

-17-
模块 - 其他语句
删除整个模块
− DROP MODULE myMod;
保留规格说明内容,删除实现
− ALTER MODULE myMod DROP BODY;
删除模块中的存储过程(SP)
− ALTER MODULE myMod DROP PROCEDURE myProc;
将模块的执行权限赋给joe
ITERATE FETCH_LOOP1;
END IF; INSERT INTO department(deptno, deptname, admdept) VALUES(‘NEW’, v_deptname, v_admdept); END LOOP FETCH_LOOP1;
-27-
GOTO语句
GOTO语句用于直接跳转到指定标签处。例如: IF v_DEPT = ‘D11’ GOTO bye; ……
DECLARE my_var INTEGER DEFAULT 6;
条件声明
DECLARE not_found CONDITION FOR SQLSTATE ‘02000’;
游标声明
DECLARE c1 CURSOR FOR select * from staff;
异常处理器声明
DECLARE EXIT HANDLER FOR SQLEXCEPTION …;
(DECLARE关键字,cl游标名称, CURSOR是必须有的,;指通过c1的游标来操作staff里所有的数据)最常用的最普 通的。
2.DECLARE c1 CURSOR WITH HOLD FOR select * form staff; 3.DECLARE c1 CURSOR WITH RETURN TO CALLER FOR select * form staff; 4.DECLARE c1 CURSOR WITH RETURN TO CLIENT FOR select * form staff;
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
DB2存储过程-基础详解2010-12-20 来源:网络简介DB2 SQL Procedural Language(SQL PL)是SQL Persistent Stored Module 语言标准的一个子集。
该标准结合了SQL 访问数据的方便性和编程语言的流控制。
通过SQL PL 当前的语句集合和语言特性,可以用SQL 开发综合的、高级的程序,例如函数、存储过程和触发器。
这样便可以将业务逻辑封装到易于维护的数据库对象中,从而提高数据库应用程序的性能。
SQL PL 支持本地和全局变量,包括声明和赋值,还支持条件语句和迭代语句、控制语句的转移、错误管理语句以及返回结果集的方法。
这些话题将在本教程中讨论。
变量声明SQL 过程允许使用本地变量赋予和获取SQL 值,以支持所有SQL 逻辑。
在SQL 过程中,在代码中使用本地变量之前要先进行声明。
清单 1 中的图演示了变量声明的语法:清单 1. 变量声明的语法.-,-----------------.V ||--DECLARE----SQL-variable-name-+------------------------------->.-DEFAULT NULL------.>--+-data-type--+-------------------+-+-------------------------|| '-DEFAULT--constant-' |SQL-variable-name 定义本地变量的名称。
该名称不能与其他变量或参数名称相同,也不能与列名相同。
图 1 显示了受支持的DB2 数据类型:DEFAULT值– 如果没有指定,在声明时将赋值为NULL。
下面是变量声明的一些例子:•DECLARE v_salary DEC(9,2) DEFAULT 0.0;•DECLARE v_status char(3) DEFAULT ‘YES’;•DECLARE v_descrition VARCHAR(80);•DECLARE v1, v2 INT DEFAULT 0;请注意,从DB2 version 9.5 开始才支持在一个DECLARE 语句中声明多个相同数据类型的变量。
数组数据类型SQL 过程从9.5 版开始支持数组类型的变量和参数。
要定义一个数组类型的变量,需要先在数据库中创建该类型,然后在过程或应用程序中声明它。
数组是临时的值,可以在存储过程和应用程序中操纵它,但是不能将它存储到表中。
DB2 支持以下创建数组数据类型的语法:清单 2. 创建数组数据类型的语法Sql代码1.>>-CREATE TYPE—array-type-name--AS--| data-type |--ARRAY--[---------->2.3. .-2147483647-------.4.>--+------------------+--]-------------------------------------><5. '-integer-constant-'数组类型的名称应该用模式加以限定,并且在当前服务器上应该是惟一的。
LONG VARCHAR、LONG VARGRPAHIC、XML 和用户定义类型不能作为数组元素的数据类型。
下面是数组类型的例子:Sql代码1.CREATE TYPE numbers as INTEGER ARRAY[100];2.CREATE TYPE names as VARCHAR(30) ARRAY[];3.CREATE TYPE MYSCHEMA.totalcomp as DECIMAL(12,2) ARRAY[];请注意,整数“constant” 指定数组的最大基数,它是可选的。
数组元素可以通过ARRAY-VARIABLE(subindex) 来引用,其中subindex 必须介于 1 到数组的基数之间。
现在可以在SQL 过程中使用这个数据类型:清单 3. 在过程中使用数组数据类型Sql代码1.CREATE PROCEDURE PROC_VARRAY_test (out mynames names)2. BEGIN3.DECLARE v_pnumb numbers;4.SET v_pnumb = ARRAY[1,2,3,5,7,11];5.SET mynames(1) =’MARINA’;6.7.…8.ENDDB2 支持一些操作数组的方法。
例如,函数CARDINALITY(myarray) 返回一个数组中元素的个数。
赋值SQL PL 提供了SET 语句来为变量和数组元素赋值。
下面是一个SET 语句的简化的语法:SET variable_name = value/expression/NULL;这个变量名可以是一个本地变量、全局变量或数组元素的名称。
下面是一些例子:如果关闭该游标,则结果集将不能返回给调用者应用程序。
清单10 演示了一个游标的声明,该游标从一个过程中返回一个结果集:清单10. 返回一个结果集的游标的声明CREATE PROCEDURE emp_from_dept()DYNAMIC RESULT SETS 1P1: BEGINDECLARE c_emp_dept CURSOR WITH RETURNFOR SELECT empno, lastname, job, salary, comm.FROM employeeWHERE workdept = ‘E21’;OPEN c_emp_dept;END P1游标处理为了在一个过程中处理一个游标的结果,需要做以下事情:1.在存储过程块的开头部分DECLARE 游标。
2.打开该游标。
3.将游标的结果取出到之前已声明的本地变量中(隐式游标处理除外,在下面的FOR 语句中将对此加以解释)。
4.关闭该游标。
(注意:如果现在不关闭游标,当过程终止时将隐式地关闭游标)。
条件语句SQL PL 中支持两种类型的条件语句— IF 语句和CASE 语句。
IF 语句通过IF 语句可以根据一个条件的状态来实现逻辑的分支。
IF 语句支持使用可选的ELSEIF子句和默认的ELSE子句。
END IF子句是必需的,它用于表明IF 语句的结束。
清单11 展示了一个示例IF 语句。
清单11. IF 语句示例IF years_of_serv > 30 THENSET gl_sal_increase = 15000;ELSEIF years_of_serv > 20 THENSET gl_sal_increase = 12000;ELSESET gl_sal_increase = 10000;END IF;CASE 语句SQL PL 支持两种类型的CASE 语句,以根据一个条件的状态实现逻辑的分支:•simple CASE 语句用于根据一个字面值进入某个逻辑。
•searched CASE 语句用于根据一个表达式的值进入某个逻辑。
清单12 显示了使用searched CASE 语句的一个存储过程的例子。
清单12. 使用searched CASE 语句的存储过程CREATE PROCEDURE sal_increase_lim1 (empid CHAR(6)) BEGINDECLARE years_of_serv INT DEFAULT 0;DECLARE v_incr_rate DEC(9,2) DEFAULT 0.0;SELECT YEAR(CURRENT DATE) - YEAR(hiredate)INTO years_of_servFROM empl1WHERE empno = empid;CASEWHEN years_of_serv > 30 THENSET v_incr_rate = 0.08;WHEN years_of_serv > 20 THENSET v_incr_rate = 0.07;WHEN years_of_serv > 10 THENSET v_incr_rate = 0.05;ELSESET v_incr_rate = 0.04;END CASE;UPDATE empl1SET salary = salary+salary*v_incr_rateWHERE empno = empid;END迭代语句SQL PL 支持一些重复执行某个逻辑的方法,包括简单的LOOP、WHILE 循环、REPEAT 循环和FOR 循环:•LOOP 循环-- 简单的循环o L1: LOOPo SQL statements;o LEAVE L1;o END LOOP L1;•WHILE 循环-- 进入前检查条件o WHILE conditiono DOo SQL statementso END WHILE;•REPEAT 循环-- 退出前检查条件o REPEATo SQL statements;o UNTIL conditiono END REPEAT;•FOR 循环-- 结果集上的隐式循环o FOR loop_name ASo SELECT … FROMo DOo SQL statements;o END FOR;请注意,FOR 语句不同于其他的迭代语句,因为它用于迭代一个定义好的结果集中的行。
为了演示这些循环技巧的使用,我们来编写一个过程,该过程从一个EMPLOYEE 表中获取每个雇员的姓氏、工作年限和年龄,并将其插入到新表REPORT_INFO_DEPT 中,这些信息分别被声明为lname varchar(15)、hiredate date 和birthdate date。
请注意,使用一个简单的SQL 语句也可以做同样的事情,但是在这个例子中我们使用 3 种不同的循环语句。
清单13. 简单的循环例子CREATE PROCEDURE LEAVE_LOOP (DEPTIN char(3), OUT p_counter INTEGER) Ll: BEGINDECLARE v_at_end , v_counter INTEGER DEFAULT 0;DECLARE v_lastname VARCHAR(15);DECLARE v_birthd, v_hired DATE;DECLARE c1 CURSORFOR SELECT lastname, hiredate, birthdate FROM employeeWHERE WORKDEPT = deptin;DECLARE CONTINUE HANDLER FOR NOT FOUND SET v_at_end = 1;OPEN c1;FETCH_LOOP: LOOPFETCH c1 INTO v_lastname, v_hired, v_birthd;IF v_at_end <> 0 THEN -- loop until last row of the cursor LEAVE FETCH_LOOP;END IF;|--DECLARE--+-CONTINUE-+--HANDLER--FOR--------------------------> +-EXIT-----+'-UNDO-----'>--+-specific-condition-value-+--| SQL-procedure-statement |----|'-general-condition-value--'WHERE specific-condition-value.-,----------------------------------------.V .-VALUE-. ||----+-SQLSTATE--+-------+--string-constant-+-+-----------------|'-condition-name-----------------------'下面是演示它如何工作的一些例子。