常用正则表达式(判断)
正则表达式同时匹配中英文及常用正则表达式

正则表达式同时匹配中英⽂及常⽤正则表达式匹配中⽂:[\u4e00-\u9fa5]英⽂字母:[a-zA-Z]数字:[0-9]匹配中⽂,英⽂字母和数字及_:^[\u4e00-\u9fa5_a-zA-Z0-9]+$同时判断输⼊长度:[\u4e00-\u9fa5_a-zA-Z0-9_]{4,10}^[\w\u4E00-\u9FA5\uF900-\uFA2D]*$1、⼀个正则表达式,只含有汉字、数字、字母、下划线不能以下划线开头和结尾:^(?!_)(?!.*?_$)[a-zA-Z0-9_\u4e00-\u9fa5]+$ 其中:^ 与字符串开始的地⽅匹配(?!_) 不能以_开头(?!.*?_$) 不能以_结尾[a-zA-Z0-9_\u4e00-\u9fa5]+ ⾄少⼀个汉字、数字、字母、下划线$ 与字符串结束的地⽅匹配放在程序⾥前⾯加@,否则需要\\进⾏转义 @"^(?!_)(?!.*?_$)[a-zA-Z0-9_\u4e00-\u9fa5]+$"(或者:@"^(?!_)\w*(?<!_)$" 或者 @" ^[\u4E00-\u9FA50-9a-zA-Z_]+$ " )2、只含有汉字、数字、字母、下划线,下划线位置不限:^[a-zA-Z0-9_\u4e00-\u9fa5]+$3、由数字、26个英⽂字母或者下划线组成的字符串^\w+$4、2~4个汉字@"^[\u4E00-\u9FA5]{2,4}$";5、^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$⽤:(Abc)+ 来分析: XYZAbcAbcAbcXYZAbcAbXYZAbcAbcAbcXYZAbcAb6、[^\u4E00-\u9FA50-9a-zA-Z_]34555#5' -->34555#5'[\u4E00-\u9FA50-9a-zA-Z_] eiieng_89_ ---> eiieng_89__';'eiieng_88&*9_ --> _';'eiieng_88&*9__';'eiieng_88_&*9_ --> _';'eiieng_88_&*9_public bool RegexName(string str){bool flag=Regex.IsMatch(str,@"^[a-zA-Z0-9_\u4e00-\u9fa5]+$");return flag;}Regex reg=new Regex("^[a-zA-Z_0-9]+$");if(reg.IsMatch(s)){\\符合规则}else{\\存在⾮法字符}最长不得超过7个汉字,或14个字节(数字,字母和下划线)正则表达式^[\u4e00-\u9fa5]{1,7}$|^[\dA-Za-z_]{1,14}$常⽤正则表达式⼤全!(例如:匹配中⽂、匹配html)匹配中⽂字符的正则表达式: [u4e00-u9fa5] 评注:匹配中⽂还真是个头疼的事,有了这个表达式就好办了 匹配双字节字符(包括汉字在内):[^x00-xff] 评注:可以⽤来计算字符串的长度(⼀个双字节字符长度计2,ASCII字符计1) 匹配空⽩⾏的正则表达式:ns*r 评注:可以⽤来删除空⽩⾏ 匹配HTML标记的正则表达式:<(S*?)[^>]*>.*?|<.*? /> 评注:⽹上流传的版本太糟糕,上⾯这个也仅仅能匹配部分,对于复杂的嵌套标记依旧⽆能为⼒ 匹配⾸尾空⽩字符的正则表达式:^s*|s*$ 评注:可以⽤来删除⾏⾸⾏尾的空⽩字符(包括空格、制表符、换页符等等),⾮常有⽤的表达式 匹配Email地址的正则表达式:w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)* 评注:表单验证时很实⽤ 匹配⽹址URL的正则表达式:[a-zA-z]+://[^s]* 评注:⽹上流传的版本功能很有限,上⾯这个基本可以满⾜需求 匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$ 评注:表单验证时很实⽤ 匹配国内电话号码:d{3}-d{8}|d{4}-d{7} 评注:匹配形式如 0511-******* 或 021-******** 匹配腾讯QQ号:[1-9][0-9]{4,} 评注:腾讯QQ号从10000开始 匹配中国邮政编码:[1-9]d{5}(?!d) 评注:中国邮政编码为6位数字 匹配⾝份证:d{15}|d{18} 评注:中国的⾝份证为15位或18位 匹配ip地址:d+.d+.d+.d+ 评注:提取ip地址时有⽤ 匹配特定数字: ^[1-9]d*$ //匹配正整数 ^-[1-9]d*$ //匹配负整数 ^-?[1-9]d*$ //匹配整数 ^[1-9]d*|0$ //匹配⾮负整数(正整数 + 0) ^-[1-9]d*|0$ //匹配⾮正整数(负整数 + 0) ^[1-9]d*.d*|0.d*[1-9]d*$ //匹配正浮点数 ^-([1-9]d*.d*|0.d*[1-9]d*)$ //匹配负浮点数 ^-?([1-9]d*.d*|0.d*[1-9]d*|0?.0+|0)$ //匹配浮点数 ^[1-9]d*.d*|0.d*[1-9]d*|0?.0+|0$ //匹配⾮负浮点数(正浮点数 + 0) ^(-([1-9]d*.d*|0.d*[1-9]d*))|0?.0+|0$ //匹配⾮正浮点数(负浮点数 + 0) 评注:处理⼤量数据时有⽤,具体应⽤时注意修正 匹配特定字符串: ^[A-Za-z]+$ //匹配由26个英⽂字母组成的字符串 ^[A-Z]+$ //匹配由26个英⽂字母的⼤写组成的字符串 ^[a-z]+$ //匹配由26个英⽂字母的⼩写组成的字符串 ^[A-Za-z0-9]+$ //匹配由数字和26个英⽂字母组成的字符串 ^w+$ //匹配由数字、26个英⽂字母或者下划线组成的字符串 在使⽤RegularExpressionValidator验证控件时的验证功能及其验证表达式介绍如下: 只能输⼊数字:“^[0-9]*$” 只能输⼊n位的数字:“^d{n}$” 只能输⼊⾄少n位数字:“^d{n,}$” 只能输⼊m-n位的数字:“^d{m,n}$” 只能输⼊零和⾮零开头的数字:“^(0|[1-9][0-9]*)$” 只能输⼊有两位⼩数的正实数:“^[0-9]+(.[0-9]{2})?$” 只能输⼊有1-3位⼩数的正实数:“^[0-9]+(.[0-9]{1,3})?$” 只能输⼊⾮零的正整数:“^+?[1-9][0-9]*$” 只能输⼊⾮零的负整数:“^-[1-9][0-9]*$” 只能输⼊长度为3的字符:“^.{3}$” 只能输⼊由26个英⽂字母组成的字符串:“^[A-Za-z]+$” 只能输⼊由26个⼤写英⽂字母组成的字符串:“^[A-Z]+$” 只能输⼊由26个⼩写英⽂字母组成的字符串:“^[a-z]+$” 只能输⼊由数字和26个英⽂字母组成的字符串:“^[A-Za-z0-9]+$” 只能输⼊由数字、26个英⽂字母或者下划线组成的字符串:“^w+$” 验证⽤户密码:“^[a-zA-Z]w{5,17}$”正确格式为:以字母开头,长度在6-18之间, 只能包含字符、数字和下划线。
匹配指定字符串的正则表达式

匹配指定字符串的正则表达式正则表达式是一种强大的文本处理工具,它可以用来匹配指定的字符串。
在实际开发中,我们经常需要使用正则表达式来处理字符串,比如验证邮箱、手机号码等。
本文将介绍如何使用正则表达式来匹配指定的字符串。
一、基本语法正则表达式是由一些特殊字符和普通字符组成的字符串,它可以用来匹配文本中的某些模式。
在正则表达式中,有一些特殊字符具有特殊的含义,比如:1. ^:匹配字符串的开头。
2. $:匹配字符串的结尾。
3. .:匹配任意字符。
4. *:匹配前面的字符零次或多次。
5. +:匹配前面的字符一次或多次。
6. ?:匹配前面的字符零次或一次。
7. []:匹配方括号中的任意一个字符。
8. ():将括号中的内容作为一个整体进行匹配。
例如,正则表达式 ^hello$ 可以匹配字符串 "hello",但不能匹配 "hello world"。
正则表达式 .+ 可以匹配任意长度的字符串,而正则表达式[abc] 可以匹配字符 a、b 或 c。
二、常用正则表达式1. 匹配数字:^\d+$这个正则表达式可以匹配一个或多个数字,其中^ 表示字符串的开头,\d 表示数字,+ 表示匹配前面的字符一次或多次,$ 表示字符串的结尾。
例如,正则表达式^\d+$ 可以匹配字符串"123",但不能匹配"1a2b3c"。
2. 匹配邮箱:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$这个正则表达式可以匹配合法的邮箱地址,其中 \w 表示字母、数字或下划线,+ 表示匹配前面的字符一次或多次,* 表示匹配前面的字符零次或多次,() 表示将括号中的内容作为一个整体进行匹配,[] 表示匹配方括号中的任意一个字符,- 表示匹配一个范围内的字符,. 表示匹配任意字符。
例如,正则表达式 ^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ 可以匹配邮箱地址"***********"。
日期正则表达式(很实用)

日期正则表达式:2009-03-29 19:17一、简单的日期判断(YYYY/MM/DD):^\d{4}(\-|\/|\.)\d{1,2}\1\d{1,2}$二、演化的日期判断(YYYY/MM/DD|YY/MM/DD):^(^(\d{4}|\d{2})(\-|\/|\.)\d{1,2}\3\d{1,2}$)|(^\d{4}年\d{1,2}月\d{1,2}日$)$三、加入闰年的判断的:实例:^((((1[6-9]|[2-9]\d)\d{2})-(0?[13578]|1 [02])-(0?[1-9]|[12]\d|3[01]))|(((1[6-9]|[2-9]\d)\d{2})-(0?[13456789]|1[012])-(0?[1-9]| [12]\d|30))|(((1[6-9]|[2-9]\d)\d{2})-0?2-(0?[1-9]|1\d|2[0-8]))|(((1[6-9]|[2-9]\d)(0[48]| [2468][048]|[13579][26])|((16|[2468][048]| [3579][26])00))-0?2-29-))$分析:1、什么是合法的日期范围?对于不同的应用场景,这个问题有不同的解释。
这里采纳MSDN中的约定:DateTime值类型表示值范围在公元(基督纪元)0001 年 1 月 1 日午夜12:00:00 到公元(C.E.) 9999 年12 月31 日晚上11:59:59 之间的日期和时间。
2、关于闰年的阐释。
关于公历闰年是这样规定的:地球绕太阳公转一周叫做一回归年,一回归年长365日5时48分46秒。
因此,公历规定有平年和闰年,平年一年有365日,比回归年短0.2422日,四年共短0.9688日,故每四年增加一日,这一年有366日,就是闰年。
但四年增加一日比四个回归年又多0.0312日,400年后将多3.12日,故在400年中少设3个闰年,也就是在400年中只设97个闰年,这样公历年的平均长度与回归年就相近似了。
纯数字正则

纯数字正则1. 什么是正则表达式正则表达式是一种强大且灵活的字符串匹配工具,通过定义一种规则来匹配目标字符串。
在计算机编程领域,常常用来处理文本数据和字符串操作。
2. 正则表达式的基本语法正则表达式的基本语法由一系列字符和特殊字符组成,用于构建匹配规则。
其中,纯数字正则主要关注于匹配纯数字的情况。
2.1 匹配单个数字要匹配单个数字,可以使用\d这个元字符。
\d可以匹配任意一个数字字符(0-9)。
示例:正则表达式:\d匹配目标:1匹配结果:匹配成功2.2 匹配多个数字要匹配多个数字,可以使用量词。
常用的量词包括+、*和{n,m}。
•+表示匹配一个或多个前面的元素。
•*表示匹配零个或多个前面的元素。
•{n,m}表示匹配n到m个前面的元素。
示例:正则表达式:\d+匹配目标:123匹配结果:匹配成功正则表达式:\d*匹配目标:0匹配结果:匹配成功正则表达式:\d{2,4}匹配目标:1234匹配结果:匹配成功3. 常用的纯数字正则表达式3.1 匹配整数匹配整数可以使用\d+,表示匹配一个或多个数字字符。
示例:正则表达式:\d+匹配目标:123匹配结果:匹配成功3.2 匹配正整数匹配正整数可以使用[1-9]\d*,表示首位为非零数字,后面可以是任意多个数字。
示例:正则表达式:[1-9]\d*匹配目标:123匹配结果:匹配成功3.3 匹配负整数匹配负整数可以使用-[1-9]\d*,表示首位为负号,后面可以是任意多个数字。
示例:正则表达式:-[1-9]\d*匹配目标:-123匹配结果:匹配成功3.4 匹配小数要匹配小数,可以使用\d+\.?\d*,表示小数点前可以是一个或多个数字,小数点后可以是零个或多个数字。
示例:正则表达式:\d+\.?\d*匹配目标:3.14匹配结果:匹配成功3.5 匹配正小数匹配正小数可以使用[0-9]*\.?[0-9]*[1-9]+[0-9]*,表示首位可以是零个或多个数字,小数点可有可无,小数点后面必须至少有一位非零数字。
判断标点符号的正则表达式

判断标点符号的正则表达式
标点符号在文本中扮演着至关重要的角色,正确使用标点符号可以使文本更加清晰和易于理解。
在计算机编程中,使用正则表达式可以方便地匹配和处理文本中的标点符号。
下面是一些常用的判断标点符号的正则表达式:
1. 匹配所有标点符号:[p{P}]
2. 匹配英文标点符号:[!'#$%&'()*+,-./:;<=>?@[]^_`{|}~]
3. 匹配中文标点符号:
[u3002uff1fuff01uff0cuff1buff1au3001uff08uff09u300au300bu30 0eu300fu201cu201d]
4. 匹配句号:[u3002uff61.]
5. 匹配逗号:[uff0c,]
6. 匹配叹号:[uff01!]
7. 匹配问号:[uff1f?]
8. 匹配分号:[uff1b;]
9. 匹配冒号:[uff1a:]
以上正则表达式可以根据实际需要进行调整和组合。
在编写程序时,可以使用这些正则表达式来匹配和处理文本中的标点符号。
- 1 -。
正则表达式(RegExp)判断文本框中是否包含特殊符号

正则表达式(RegExp)判断⽂本框中是否包含特殊符号前⾔有时,我们希望判断⽂本框中⽤户输⼊的字符是否含有特殊符号(*/#$@),就像⽤户注册时密码框的填写。
demo利⽤ RegExp 对象,能很优雅的实现以上需求:// even(⽂本框内容)function (even) {// 规则对象(flag)var flag = new RegExp("[`~!@#$^&*()=|{}':;',\\[\\].<>《》/?~!@#¥……&*()——|{}【】‘;:”“'。
,、? ]")// 判断 even 是否包含特殊字符if(flag.test(even)){console.log('包含!')}else{console.log('不包含!')}}flag 规则对象中还有很多其他特殊字符,这⾥的demo已经⾜够使⽤,如项⽬另有需求加⼊其他特殊字符即可。
ps:js中⽤正则表达式过滤特殊字符 ,校验所有输⼊域是否含有特殊符号function stripscript(s){var pattern = new RegExp("[`~!@#$^&*()=|{}':;',\\[\\].<>/?~!@#¥……&*()——|{}【】‘;:”“'。
,、?]")var rs = "";for (var i = 0; i < s.length; i++) {rs = rs+s.substr(i, 1).replace(pattern, '');}return rs;}如何只是判断是否存在特殊字符串if(pattern .text(str)){return true}else{return false}总结以上所述是⼩编给⼤家介绍的正则表达式(RegExp)判断⽂本框中是否包含特殊符号,希望对⼤家有所帮助,如果⼤家有任何疑问请给我留⾔,⼩编会及时回复⼤家的。
php判断是否是汉字的方法

php判断是否是汉字的方法PHP判断是否是汉字的方法介绍在开发过程中,我们经常需要判断一个字符是否为汉字。
本文将详细介绍使用PHP进行汉字判断的几种常用方法。
方法一:使用正则表达式1.使用preg_match()函数结合正则表达式进行判断。
2.正则表达式:/^[\x{4e00}-\x{9fa5}]$/u3.代码示例:function isChineseCharacter($char) {return preg_match('/^[\x{4e00}-\x{9fa5}]$/u', $char); }方法二:使用Unicode编码1.判断字符的Unicode编码是否在汉字范围内。
2.代码示例:function isChineseCharacter($char) {$unicode = mb_ord($char);return ($unicode >= 19968 && $unicode <= 40869);}方法三:使用系统函数1.判断字符的字节数是否大于1,来判断是否为汉字。
2.注意:此方法只适用于UTF-8编码。
3.代码示例:function isChineseCharacter($char) {return strlen($char) > 1;}方法四:使用字符集检测函数1.使用mb_detect_encoding()函数判断字符的字符集是否为UTF-8。
2.再判断字符的字节数是否大于1,来判断是否为汉字。
3.代码示例:function isChineseCharacter($char) {return strlen($char) > 1 && mb_detect_encoding($char, 'UTF-8', true);}方法五:使用Unicode范围判断1.判断字符的Unicode范围是否在汉字范围内。
js正则判断是否为数字的方法

js正则判断是否为数字的方法(原创实用版3篇)目录(篇1)1.介绍 JS 正则表达式2.解释如何使用正则表达式判断数字3.提供实例代码正文(篇1)一、JS 正则表达式概述JavaScript(简称 JS)是一种广泛应用于网页开发的脚本语言。
正则表达式(Regular Expression,简称 regex)是 JS 中的一种重要功能,它可以用来处理字符串,进行查找、替换等操作。
正则表达式可以让我们在处理字符串时变得更加简洁和高效。
二、如何使用正则表达式判断数字在 JS 中,我们可以使用正则表达式来判断一个字符串是否为数字。
具体方法是使用正则表达式的测试方法(如:test、match 等)与数字相关的正则表达式。
常用的数字正则表达式有:1.^d+$:匹配整个字符串都是数字的情况。
2.^d+.d+$:匹配整数和小数的情况。
3.^d+(d+)?$:匹配整数和可选的小数部分。
以下是一个简单的示例:```javascriptfunction isNumber(str) {// 使用正则表达式判断字符串是否为数字const regex = /^d+$/;return regex.test(str);}const str1 = "123";const str2 = "123.45";const str3 = "123.456";console.log(isNumber(str1)); // 输出:trueconsole.log(isNumber(str2)); // 输出:trueconsole.log(isNumber(str3)); // 输出:false```三、总结通过使用 JS 正则表达式,我们可以方便地判断一个字符串是否为数字。
目录(篇2)1.介绍 JavaScript 正则表达式2.讲解如何使用正则表达式判断字符串是否为数字3.提供实例代码正文(篇2)一、JavaScript 正则表达式简介正则表达式(Regular Expression,简称 regex)是一种用于处理字符串的强大工具,其广泛应用于文本搜索与替换、数据验证等场景。
英文常用 正则表达式 所有字符串

英文常用正则表达式对所有字符串的判断正则表达式是一种用来匹配字符串的强大工具,它可以帮助我们快速准确地找到特定模式的字符串。
在英文中,我们常常需要对字符串进行判断和筛选,因此掌握英文常用的正则表达式对所有字符串的判断是非常重要的。
在使用正则表达式时,我们经常会碰到一些常见的需求,比如匹配英文单词、判断字符串是否包含特定的字符等。
下面我们就来探讨一些常见的英文正则表达式,以及它们在匹配所有字符串时的应用。
1. 匹配英文单词在英文文章或文本中,我们经常需要对单词进行匹配和筛选。
要匹配英文单词,我们可以使用正则表达式`\b\w+\b`,其中`\b`表示单词的边界,`\w+`表示匹配一个或多个字母或数字。
这个正则表达式可以帮助我们快速准确地匹配英文文章中的单词,并对其进行进一步处理。
2. 判断字符串是否全部由英文字符组成有时候,我们需要判断一个字符串是否全部由英文字符组成。
这时,我们可以使用正则表达式`^[a-zA-Z]+$`,其中`^`表示字符串的开头,`[a-zA-Z]+`表示匹配一个或多个大小写字母,`$`表示字符串的结尾。
这个正则表达式可以帮助我们判断一个字符串是否符合纯英文字符的要求。
3. 匹配特定格式的日期在处理英文文本时,我们经常会碰到日期的格式。
要匹配特定格式的日期,我们可以使用正则表达式`\b\d{1,2}\/\d{1,2}\/\d{4}\b`,其中`\d{1,2}`表示匹配一到两位数字,`\/`表示匹配斜杠字符,`\d{4}`表示匹配四位数字。
这个正则表达式可以帮助我们匹配形如“月/日/年”的日期格式。
4. 判断字符串是否包含特定单词有时候,我们需要判断一个字符串是否包含特定的单词。
这时,我们可以使用正则表达式`\bword\b`,其中`\b`表示单词的边界,`word`表示我们要匹配的特定单词。
这个正则表达式可以帮助我们快速准确地判断一个字符串是否包含我们指定的单词。
总结回顾通过对英文常用的正则表达式进行分析和讨论,我们可以发现正则表达式在处理英文文本时具有很强的适用性和灵活性。
excel if 正则表达式

excel if 正则表达式IF函数是Excel中最常用的函数之一,它的基本语法是:IF(条件, 值1, 值2)。
其中,条件是一个逻辑表达式,值1和值2分别是当条件为真和为假时的返回值。
让我们来看一个简单的例子。
假设我们有一个成绩表,其中包含学生的姓名、科目和成绩。
我们想要根据学生的成绩判断他们是否及格。
在这种情况下,我们可以使用IF函数来判断成绩是否大于等于60分,如果是,则返回“及格”,否则返回“不及格”。
=IF(成绩>=60, "及格", "不及格")这样,我们就可以根据学生的成绩来判断他们是否及格。
除了基本的IF函数外,还有一些高级用法。
比如,我们可以使用IF函数来检查单元格中的文本是否包含特定的关键词。
假设我们有一个产品列表,其中包含产品的名称和描述。
我们想要筛选出所有包含关键词“优惠”的产品。
在这种情况下,我们可以使用正则表达式来进行模糊匹配。
=IF(ISNUMBER(SEARCH("优惠", 描述)), "包含优惠", "不包含优惠")这样,我们就可以根据产品的描述来判断它是否包含关键词“优惠”。
IF函数还可以与其他函数结合使用,以实现更复杂的逻辑判断。
比如,我们可以使用IF函数来计算折扣后的价格。
假设我们有一个产品列表,其中包含产品的原价和折扣率。
我们想要根据折扣率计算折扣后的价格。
在这种情况下,我们可以使用IF函数来判断折扣率是否大于0,如果是,则返回原价乘以折扣率,否则返回原价。
=IF(折扣率>0, 原价*折扣率, 原价)这样,我们就可以根据折扣率来计算折扣后的价格。
总结起来,Excel IF函数是一种非常实用的工具,可以根据特定条件执行不同的操作。
它的用法多种多样,可以根据不同的需求灵活运用。
通过掌握IF函数的使用技巧,我们可以更高效地处理和分析数据,提高工作效率。
正则判断 字符串是否有转义的方法-概述说明以及解释

正则判断字符串是否有转义的方法-概述说明以及解释1.引言1.1 概述字符串是编程中经常使用的数据类型之一,用于存储和操作文本信息。
在处理字符串时,有时需要对其中包含的特殊字符进行转义,以确保其被正确地解析和使用。
而正则表达式则是一种强大的模式匹配和搜索工具,常用于对字符串进行有效的处理和判断。
本文主要介绍如何使用正则表达式来判断字符串中是否包含转义字符的方法。
转义字符是由一个反斜线(\)加上特定字符组成的,用于表示一些特殊的字符或字符序列。
常见的转义字符包括\n(表示换行符)、\t(表示制表符)、\"(表示双引号)等。
在正则表达式中,转义字符同样需要进行转义,通常以反斜线(\)作为转义符。
这就意味着在正则表达式中,要匹配一个反斜线字符,需要使用两个反斜线(\\)进行表示。
通过比对字符串中是否包含反斜线字符,我们可以判断字符串是否包含转义字符。
本文将介绍如何使用正则表达式来实现这一功能,并提供示例代码加深理解。
首先,我们将会对正则表达式进行简要的介绍,以便读者对其有一个基本的了解。
随后,我们会详细解释转义字符的概念及其使用场景。
最后,我们将详细介绍如何使用正则表达式来判断字符串中是否包含转义字符的方法,并给出一些实际应用中的示例。
通过了解本文,读者将能够更好地理解正则表达式的基本概念、转义字符的含义和使用方法,并获得一些实用的技巧,用于在日常开发中判断字符串是否包含转义字符的需求。
接下来,我们将深入探讨正则判断字符串是否有转义的方法。
1.2文章结构1.2 文章结构本文主要讨论正则判断字符串是否有转义的方法。
为了更好地理解这个话题,本文将按照以下结构展开讨论:1. 引言:介绍文章的背景和意义。
2. 正文:包括以下几个方面的内容:- 正则表达式介绍:简要介绍正则表达式的概念和基本语法。
- 字符串转义的概念:解释什么是字符串转义以及为什么会需要对字符串进行转义。
- 正则判断字符串是否有转义的方法:详细介绍如何使用正则表达式来判断给定字符串是否包含转义字符。
判断数字的正则

判断数字的正则
要判断数字的正则,可以使用正则表达式。
以下是一些常见的正则表达式示例,用于匹配不同类型的数字:
1. 非零的正整数:^[19][09]*$
2. 非零的负整数:^[19][09]*$
3. 非负整数(正整数 + 0):^\d+$
4. 非正整数(负整数 + 0):^((\d+)|(0+))$
5. 长度为3的字符:^.{3}$
6. 由26个英文字母组成的字符串:^[AZaz]+$
7. 由26个大写英文字母组成的字符串:^[AZ]+$
8. m~n位的大写字母:^[AZ]{m,n}$
9. 由26个小写英文字母组成的字符串:^[az]+$
10. 由数字和26个英文字母组成的字符串:^[AZaz09]+$
11. 由数字、26个英文字母或者下划线组成的字符串:^\w+$
12. 用户密码:^[azAZ]\w{5,17}$(以字母开头,长度在618之间,只能包含字符、数字和下划线)
这些正则表达式可以用于验证给定的字符串是否符合相应的规则。
java 判断正则表达式方法

java 判断正则表达式方法Java中有多种方法来判断一个字符串是否满足某个正则表达式的模式。
1. 使用String类的matches()方法:matches()方法是String类提供的一个用于正则表达式匹配的方法。
它接受一个正则表达式作为参数,并返回一个boolean值,表示该字符串是否与正则表达式匹配。
示例代码如下:```String regex = "ab+c";String str = "abbc";boolean isMatch = str.matches(regex);System.out.println(isMatch); // 输出:true```2. 使用Pattern类和Matcher类:Pattern类表示正则表达式的编译表示,而Matcher类是匹配器对象,用于对字符串进行匹配操作。
示例代码如下:```String regex = "ab+c";String str = "abbc";Pattern pattern = pile(regex);Matcher matcher = pattern.matcher(str);boolean isMatch = matcher.matches();System.out.println(isMatch); // 输出:true```3. 使用正则表达式库,如Apache Commons Validator:Apache Commons Validator是一个开源库,其中包含了用于验证常见数据的工具类。
它提供了用于验证字符串是否匹配正则表达式的方法。
示例代码如下:```String regex = "ab+c";String str = "abbc";boolean isMatch =mons.validator.routines.RegexValidator.getInstance().isValid(str, regex);System.out.println(isMatch); // 输出:true```请注意,正则表达式在Java中使用时需要使用转义字符"\\"来表示特殊字符。
最全的常用正则表达式大全

最全的常⽤正则表达式⼤全⼀、校验数字的表达式1 数字:^[0-9]*$2 n位的数字:^\d{n}$3 ⾄少n位的数字:^\d{n,}$4 m-n位的数字:^\d{m,n}$5 零和⾮零开头的数字:^(0|[1-9][0-9]*)$6 ⾮零开头的最多带两位⼩数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$7 带1-2位⼩数的正数或负数:^(\-)?\d+(\.\d{1,2})?$8 正数、负数、和⼩数:^(\-|\+)?\d+(\.\d+)?$9 有两位⼩数的正实数:^[0-9]+(.[0-9]{2})?$10 有1~3位⼩数的正实数:^[0-9]+(.[0-9]{1,3})?$11 ⾮零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$12 ⾮零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$13 ⾮负整数:^\d+$ 或 ^[1-9]\d*|0$14 ⾮正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$15 ⾮负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$16 ⾮正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$17 正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$18 负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$19 浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$⼆、校验字符的表达式1 汉字:^[\u4e00-\u9fa5]{0,}$2 英⽂和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$3 长度为3-20的所有字符:^.{3,20}$4 由26个英⽂字母组成的字符串:^[A-Za-z]+$5 由26个⼤写英⽂字母组成的字符串:^[A-Z]+$6 由26个⼩写英⽂字母组成的字符串:^[a-z]+$7 由数字和26个英⽂字母组成的字符串:^[A-Za-z0-9]+$8 由数字、26个英⽂字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$9 中⽂、英⽂、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$10 中⽂、英⽂、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$11 可以输⼊含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+12 禁⽌输⼊含有~的字符:[^~\x22]+三、特殊需求表达式1 Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$2 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?3 InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$4 ⼿机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$5 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$6 国内电话号码(0511-*******、021-********):\d{3}-\d{8}|\d{4}-\d{7}7 ⾝份证号(15位、18位数字):^\d{15}|\d{18}$8 短⾝份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$9 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$10 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$11 强密码(必须包含⼤⼩写字母和数字的组合,不能使⽤特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$12 ⽇期格式:^\d{4}-\d{1,2}-\d{1,2}13 ⼀年的12个⽉(01~09和1~12):^(0?[1-9]|1[0-2])$14 ⼀个⽉的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$15 钱的输⼊格式:16 1.有四种钱的表⽰形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$17 2.这表⽰任意⼀个不以0开头的数字,但是,这也意味着⼀个字符"0"不通过,所以我们采⽤下⾯的形式:^(0|[1-9][0-9]*)$18 3.⼀个0或者⼀个不以0开头的数字.我们还可以允许开头有⼀个负号:^(0|-?[1-9][0-9]*)$19 4.这表⽰⼀个0或者⼀个可能为负的开头不为0的数字.让⽤户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下⾯我们要加的是说明可能的⼩数部分:^[0-9]+(.[0-9]+)?$20 5.必须说明的是,⼩数点后⾯⾄少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$21 6.这样我们规定⼩数点后⾯必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$22 7.这样就允许⽤户只写⼀位⼩数.下⾯我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$23 8.1到3个数字,后⾯跟着任意个逗号+3个数字,逗号成为可选,⽽不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$24 备注:这就是最终结果了,别忘了"+"可以⽤"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在⽤函数时去掉去掉那个反斜杠,⼀般的错误都在这⾥25 xml⽂件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$26 中⽂字符的正则表达式:[\u4e00-\u9fa5]27 双字节字符:[^\x00-\xff] (包括汉字在内,可以⽤来计算字符串的长度(⼀个双字节字符长度计2,ASCII字符计1))28 空⽩⾏的正则表达式:\n\s*\r (可以⽤来删除空⽩⾏)29 HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? /> (⽹上流传的版本太糟糕,上⾯这个也仅仅能部分,对于复杂的嵌套标记依旧⽆能为⼒)30 ⾸尾空⽩字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以⽤来删除⾏⾸⾏尾的空⽩字符(包括空格、制表符、换页符等等),⾮常有⽤的表达式)31 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)32 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字) 33 IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址时有⽤) 34 IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))20个正则表达式必知(能让你少写1,000⾏代码)正则表达式(regular expression)描述了⼀种字符串匹配的模式,可以⽤来检查⼀个串是否含有某种⼦串、将匹配的⼦串做替换或者从某个串中取出符合某个条件的⼦串等。
判断中日韩文的正则表达式

判断中⽇韩⽂的正则表达式PHP中GBK和UTF8编码处理⼀、编码范围1. GBK (GB2312/GB18030)\x00-\xff GBK双字节编码范围\x20-\x7f ASCII\xa1-\xff 中⽂\x80-\xff 中⽂2. UTF-8 (Unicode)\u4e00-\u9fa5 (中⽂)\x3130-\x318F (韩⽂\xAC00-\xD7A3 (韩⽂)\u0800-\u4e00 (⽇⽂)ps: 韩⽂是⼤于[\u9fa5]的字符正则例⼦:preg_replace("/([\x80-\xff])/","",$str);preg_replace("/([u4e00-u9fa5])/","",$str);⼆、代码例⼦//判断内容⾥有没有中⽂-GBK (PHP)function check_is_chinese($s){return preg_match('/[\x80-\xff]./', $s);}//获取字符串长度-GBK (PHP)function gb_strlen($str){$count = 0;for($i=0; $i<strlen($str); $i++){$s = substr($str, $i, 1);if (preg_match("/[\x80-\xff]/", $s)) ++$i;++$count;}return $count;}//截取字符串字串-GBK (PHP)function gb_substr($str, $len){$count = 0;for($i=0; $i<strlen($str); $i++){if($count == $len) break;if(preg_match("/[\x80-\xff]/", substr($str, $i, 1))) ++$i;++$count;}return substr($str, 0, $i);}//统计字符串长度-UTF8 (PHP)function utf8_strlen($str) {$count = 0;for($i = 0; $i < strlen($str); $i++){$value = ord($str[$i]);if($value > 127) {$count++;if($value >= 192 && $value <= 223) $i++;elseif($value >= 224 && $value <= 239) $i = $i + 2;elseif($value >= 240 && $value <= 247) $i = $i + 3;else die('Not a UTF-8 compatible string');}$count++;}return $count;}//截取字符串-UTF8(PHP)function utf8_substr($str,$position,$length){$start_position = strlen($str);$start_byte = 0;$end_position = strlen($str);$count = 0;for($i = 0; $i < strlen($str); $i++){if($count >= $position && $start_position > $i){$start_position = $i;$start_byte = $count;}if(($count-$start_byte)>=$length) {$end_position = $i;break;}$value = ord($str[$i]);if($value > 127){$count++;if($value >= 192 && $value <= 223) $i++;elseif($value >= 224 && $value <= 239) $i = $i + 2;elseif($value >= 240 && $value <= 247) $i = $i + 3;else die('Not a UTF-8 compatible string');}$count++;}return(substr($str,$start_position,$end_position-$start_position));}//字符串长度统计-UTF8 [中⽂3个字节,俄⽂、韩⽂占2个字节,字母占1个字节] (Ruby)def utf8_string_length(str)temp = CGI::unescape(str)i = 0;j = 0;temp.length.times{|t|if temp[t] < 127i += 1elseif temp[t] >= 127 and temp[t] < 224j += 1if 0 == (j % 2)i += 2j = 0endelsej += 1if 0 == (j % 3)i +=2j = 0endend}return i}//判断是否是有韩⽂-UTF-8 (JavaScript)function checkKoreaChar(str) {for(i=0; i<str.length; i++) {if(((str.charCodeAt(i) > 0x3130 && str.charCodeAt(i) < 0x318F) || (str.charCodeAt(i) >= 0xAC00 && str.charCodeAt(i) <= 0xD7A3))) { return true;}}return false;}//判断是否有中⽂字符-GBK (JavaScript)function check_chinese_char(s){return (s.length != s.replace(/[^\x00-\xff]/g,"**").length);三、参考⽂档另:public function csubstr($str, $start=0, $length, $charset="utf-8", $suffix=true){if(function_exists("mb_substr"))return mb_substr($str, $start, $length, $charset);$re['utf-8'] = "/[\x01-\x7f]|[\xc2-\xdf][\x80-\xbf]|[\xe0-\xef][\x80-\xbf]{2}|[\xf0-\xff][\x80-\xbf]{3}/"; $re['gb2312'] = "/[\x01-\x7f]|[\xb0-\xf7][\xa0-\xfe]/";$re['gbk'] = "/[\x01-\x7f]|[\x81-\xfe][\x40-\xfe]/";$re['big5'] = "/[\x01-\x7f]|[\x81-\xfe]([\x40-\x7e]|\xa1-\xfe])/";preg_match_all($re[$charset], $str, $match);$slice = join("",array_slice($match[0], $start, $length));if($suffix) return $slice."…";return $slice;}。
校验时间的正则表达式

校验时间的正则表达式
校验时间的正则表达式是指一种用来判断时间格式是否正确的
表达式。
时间格式通常包括小时、分钟和秒,以及可能的毫秒和时区信息。
常用的时间格式有以下几种:
1. 24小时制:hh:mm:ss(例如:13:45:30)
2. 12小时制:hh:mm:ss am/pm(例如:01:45:30 PM)
3. 带毫秒的24小时制:hh:mm:ss.SSS(例如:13:45:30.123)
4. 带毫秒的12小时制:hh:mm:ss.SSS am/pm(例如:
01:45:30.123 PM)
使用正则表达式来校验时间格式,可以有效地避免用户输入非法的时间格式。
以下是几种常用的校验时间的正则表达式:
1. 24小时制:^(?:[01]d|2[0-3]):[0-5]d:[0-5]d$
2. 12小时制:^(?:0?[1-9]|1[0-2]):[0-5]d:[0-5]d
(AM|PM|am|pm)$
3. 带毫秒的24小时制:
^(?:[01]d|2[0-3]):[0-5]d:[0-5]d.d{1,3}$
4. 带毫秒的12小时制:
^(?:0?[1-9]|1[0-2]):[0-5]d:[0-5]d.d{1,3} (AM|PM|am|pm)$ 以上正则表达式可以用于大多数编程语言中的时间格式校验,例如Java、Python、JavaScript等。
需要注意的是,正则表达式只能校验时间格式是否正确,但并不
能判断时间是否合法,例如不存在的时间点或者非法的时区信息等。
因此,在实际应用中,还需要结合程序逻辑来确保时间的合法性。
正则表达式-用于页面校验
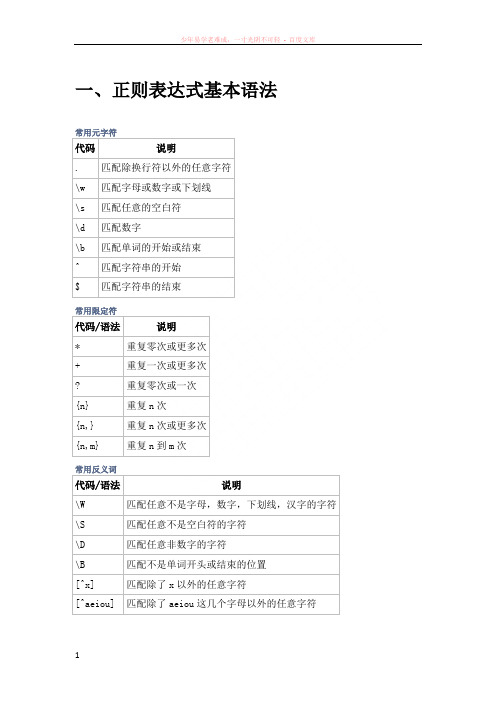
一、正则表达式基本语法常用元字符代码说明. 匹配除换行符以外的任意字符\w 匹配字母或数字或下划线\s 匹配任意的空白符\d 匹配数字\b 匹配单词的开始或结束^ 匹配字符串的开始$ 匹配字符串的结束常用限定符代码/语法说明* 重复零次或更多次+ 重复一次或更多次? 重复零次或一次{n} 重复n次{n,} 重复n次或更多次{n,m} 重复n到m次常用反义词代码/语法说明\W 匹配任意不是字母,数字,下划线,汉字的字符\S 匹配任意不是空白符的字符\D 匹配任意非数字的字符\B 匹配不是单词开头或结束的位置[^x] 匹配除了x以外的任意字符[^aeiou] 匹配除了aeiou这几个字母以外的任意字符二、常见的几种正则表达校验表达式中文字符:[\u4e00-\u9fa5]双字节字符:[^\x00-\xff]空白行:\sEmail地址:\w[-\w.+]*@([A-Za-z0-9][-A-Za-z0-9]+\.)+[A-Za-z]{2,14}网址URL:^((https|http|ftp|rtsp|mms)?:\/\/)[^\s]+手机(国内):0?(13|14|15|18)[0-9]{9}或者/^1[3|4|5|8] \d{9}$/--------------------------------------电话号码(国内):[0-9-()()]{7,18}负浮点数:-([1-9]\d*.\d*|0.\d*[1-9]\d*)匹配整数:-?[1-9]\d*正浮点数:[1-9]\d*.\d*|0.\d*[1-9]\d*腾讯QQ号:[1-9]([0-9]{5,11})邮政编码:\d{6}车牌号: var re=/^[\u4e00-\u9fa5]{1}[A-Z]{1}[A-Z_0-9]{5}$/;//普通车牌@"^[(\u4e00-\u9fa5)|(a-zA-Z)]{1}[a-zA-Z]{1}[a-zA-Z_0-9]{4,6}[a-zA-Z_0-9_\u4e00-\u9fa5] $"//带WJ等特殊车牌^[\u4e00-\u9fa5]{1}代表以汉字开头并且只有一个,这个汉字是车辆所在省的简称[A-Z]{1}代表A-Z的大写英文字母且只有一个,代表该车所在地的地市一级代码[A-Z_0-9]{5}代表后面五个数字是字母和数字的组合。
正则表达式的几种字符判断(包括数字,字母组合等)

正则表达式的⼏种字符判断(包括数字,字母组合等)function isdata(s){var patrn=/^[0-9]{1,20}$/;if (!patrn.exec(s)) return falsereturn true}"^[0-9]*[1-9][0-9]*$" //正整数"^((-\\d+)|(0+))$" //⾮正整数(负整数 + 0)"^-[0-9]*[1-9][0-9]*$" //负整数"^-?\\d+$" //整数"^\\d+(\\.\\d+)?$" //⾮负浮点数(正浮点数 + 0)"^(([0-9]+\\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\\.[0-9]+)|([0-9]*[1-9][0-9]*))$" //正浮点数"^((-\\d+(\\.\\d+)?)|(0+(\\.0+)?))$" //⾮正浮点数(负浮点数 + 0)"^(-(([0-9]+\\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\\.[0-9]+)|([0-9]*[1-9][0-9]*)))$" //负浮点数"^(-?\\d+)(\\.\\d+)?$" //浮点数"^[A-Za-z]+$" //由26个英⽂字母组成的字符串"^[A-Z]+$" //由26个英⽂字母的⼤写组成的字符串"^[a-z]+$" //由26个英⽂字母的⼩写组成的字符串"^[A-Za-z0-9]+$" //由数字和26个英⽂字母组成的字符串"^\\w+$" //由数字、26个英⽂字母或者下划线组成的字符串"^[\\w-]+(\\.[\\w-]+)*@[\\w-]+(\\.[\\w-]+)+$" //email地址"^[a-zA-z]+://(\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S*)?$" //url"^[A-Za-z0-9_]*$"s。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
}
}
}
Phone : /^((\(\d{2,3}\))|(\d{3}\-))?(\(0\d{2,3}\)|0\d{2,3}-)?[1-9]\d{6,7}(\-\d{1,4})?$/
Mobile : /^((\(\d{2,3}\))|(\d{3}\-))?13\d{9}$/
Url : /^http:\/\/[A-Za-z0-9]+\.[A-Za-z0-9]+[\/=\?%\-&_~`@[\]\':+!]*([^<>\"\"])*$/
}
}
//判断日期类型是否为YYYY-MM-DD格式的类型
function IsDate(){
var str = document.getElementById('str').value.trim();
if(str.length!=0){
var reg = /^(\d{1,4})(-|\/)(\d{1,2})\2(\d{1,2})$/;
alert("对不起,您输入的字符串类型格式不正确!");//请将“字符串类型”要换成你要验证的那个属性名称!
}
}
}
//判断是否为字母、数字、中文
function IsString()
{
var str = document.getElementById('str').value.trim();
if(str.length!=0){
if(str.length!=0){
reg=/^[a-zA-Z]+$/;
if(!reg.test(str)){
alert("对不起,您输入的英文字母类型格式不正确!");//请将“英文字母类型”改成你需要验证的属性名称!
}
}
}
//判断输入的字符是否为整数
function IsInteger()
{
var str = document.getElementById('str').value.trim();
if(!reg.test(str)){
alert("对不起,您输入的日期格式不正确!");//请将“日期”改成你需要验证的属性名称!
}
}
}
//判断输入的字符是否为英文字母
function IsLetter()
{
var str = document.getElementById('str').value.trim();
alert("对不起,您输入的字符串类型格式不正确!");//请将“字符串类型”要换成你要验证的那个属性名称!
}
}
}
//判断输入的邮编(只能为六位)是否正确
function IsZIP()
{
var str = document.getElementById('str').value.trim();
if(str.length!=0){
if(str.length!=0){
var reg = /^(\d{1,4})(-|\/)(\d{1,2})\2(\d{1,2}) (\d{1,2}):(\d{1,2}):(\d{1,2})$/;
var r = str.match(reg);
if(r==null)
alert('对不起,您输入的日期格式不正确!'); //请将“日期”改成你需要验证的属性名称!
var r = str.match(reg);
if(r==null)
alert('对不起,您输入的日期格式不正确!'); //请将“日期”改成你需要验证的属性名称!
}
}
//判断日期类型是否为YYYY-MM-DD hh:mm:ss格式的类型
function IsDateTime(){
var str = document.getElementById('str').value.trim();
reg=/^\d{6}$/;
if(!reg.test(str)){
alert("对不起,您输入的字符串类型格式不正确!");//请将“字符串类型”要换成你要验证的那个属性名称!
}
}
}
//判断输入的数字不大于某个特定的数字
function MaxValue()
{
var val = document.getElementById('str').value.trim();
}
}
//判断日期类型是否为hh:mm:ss格式的类型
function IsTime()
{
var str = document.getElementById('str').value.trim();
if(str.length!=0){
reg=/^((20|21|22|23|[0-1]\d)\:[0-5][0-9])(\:[0-5][0-9])?$/
IdCard : /^\d{15}(\d{2}[A-Za-z0-9])?$/
QQ : /^[1-9]\d{4,8}$/
//为上面提供各个JS验证方法提供.trim()属性
String.prototype.trim=function(){
return this.replace(/(^\s*)|(\s*$)/g, "");
}
reg=/^[a-zA-Z0-9_]+$/;
reg1=/^[\u0391-\uFFE5]+$/;
if(!reg.test(str)||!reg1.test(str)){
alert("对不起,您输入的字符串类型格式不正确!");//请将“字符串类型”要换成你要验证的那个属性名称!
}
}
}
//判断输入的EMAIL格式是否正确
function IsEmail()
{
var str = document.getElementById('str').value.trim();
if(str.length!=0){
reg=/^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$/;
if(!reg.test(str)){
正则表达式判断
//判断输入内容是否为空
function IsNull(){
var str = document.getElementById('str').value.trim();
if(str.length==0){
alert('对不起,文本框不能为空或者为空格!');//请将“文本框”改成你需要验证的属性名称!
{
var str = document.getElementById('str').value.trim();
if(str.length!=0){
reg=/^[a-zA-Z0-9_]+$/;
if(!reg.test(str)){
alert("对不起,您输入的字符串类型格式不正确!");//请将“字符串类型”要换成你要验证的那个属性名称!
if(str.length!=0){
reg=/^[-+]?\d*$/;
if(!reg.test(str)){
alert("对不起,您输入的整数类型格式不正确!");//请将“整数类型”要换成你要验证的那个属性名称!
}
}
}
//判断输入的字符是否为双精度
function IsDouble(val)
{
var str = document.getElementById('str').value.trim();
if(str.length!=0){
reg=/^[-+]?\d*$/;
if(!reg.test(str)){//判断是否为数字类型
if(val>parseInt('123')) //“123”为自己设定的最大值
{
alert('对不起,您输入的数字超出范围');//请将“数字”改成你要验证的那个属性名称!
if(str.length!=0){
reg=/^[-\+]?\d+(\.\d+)?$/;
if(!reg.test(str)){
alert("对不起,您输入的双精度类型格式不正确!");//请将“双精度类型”要换成你要验证的那个属性名称!
}
}
}
//判断输入的字符是否为:a-z,A-Z,0-9
function IsString()
}Hale Waihona Puke }}//判断输入的字符是否为中文
function IsChinese()
{
var str = document.getElementById('str').value.trim();
if(str.length!=0){
reg=/^[\u0391-\uFFE5]+$/;
if(!reg.test(str)){