5 Python基本数据统计
Python入门教程数据分析与统计计算

Python入门教程数据分析与统计计算一、 Python数据分析介绍在当今数据爆发的时代,数据分析已经成为各行各业都非常关注的一个领域。
Python作为一种简单易学且功能丰富的编程语言,成为了数据分析的热门工具之一。
本教程将为大家介绍Python在数据分析与统计计算方面的基础知识和应用技巧。
二、 Python数据分析库介绍1. NumPyNumPy是Python中用于科学计算的一个核心库,它提供了高性能的多维数组对象,以及一些操作这些数组的函数。
通过使用NumPy,我们可以更加高效地处理大规模数据集。
2. PandasPandas是Python中一个强大的数据分析工具库,它提供了灵活易用的数据结构和数据分析方法,能够方便地处理和分析结构化数据。
3. MatplotlibMatplotlib是Python中用于绘制各种静态、动态和交互式图表的库。
它提供了类似于Matlab的绘图接口,使得我们可以快速生成各种类型的图表。
4. SeabornSeaborn是基于Matplotlib的一个数据可视化库,它提供了一些高级的统计图表和绘图样式,使得数据的可视化更加简单和美观。
三、 Python统计计算介绍1. 统计基础在进行数据分析时,了解统计学的基础概念是十分重要的。
比如,我们需要了解均值、方差、标准差等常用统计量的计算方法,以及频数分布、概率分布等基本统计概念。
2. SciPySciPy是一个用于数学、科学和工程计算的Python库,它建立在NumPy的基础上,提供了许多常用的数学算法和函数。
通过使用SciPy,我们可以进行各种统计计算,如概率分布拟合、假设检验等。
3. StatsmodelsStatsmodels是一个专门用于拟合统计模型和进行统计测试的Python 库。
它提供了一系列经典统计模型的实现,如线性回归、时间序列分析等。
四、示例代码演示示例1:计算数据集的均值和标准差```pythonimport numpy as npdata = [1, 2, 3, 4, 5]mean = np.mean(data)std = np.std(data)print("Mean:", mean)print("Standard deviation:", std)```示例2:使用Pandas读取CSV文件并进行数据分析```pythonimport pandas as pddata = pd.read_csv("data.csv")print(data.head()) # 查看数据前几行print(data.describe()) # 基本统计信息# 统计某一列的频数分布count = data["category"].value_counts()print(count)```示例3:使用Seaborn绘制柱状图```pythonimport seaborn as snsdata = pd.read_csv("data.csv")sns.countplot(x="category", data=data)```五、总结Python作为一门简单易学的编程语言,提供了丰富的库和工具,使得数据分析和统计计算变得更加简单和高效。
Python中的数据分析和统计技巧

Python中的数据分析和统计技巧Python是一种广泛应用于数据科学和数据分析领域的编程语言。
它提供了丰富的工具和库,使得数据处理、分析和统计变得简单和高效。
本文将介绍Python中的一些常用的数据分析和统计技巧,包括数据清洗、数据可视化、假设检验和回归分析等。
一、数据清洗在进行数据分析之前,通常需要对原始数据进行清洗和预处理。
Python提供了一些强大的库,如Pandas,用于数据清洗和转换。
下面是一些常用的数据清洗技巧:1. 缺失值处理:使用Pandas的dropna()函数可以删除包含缺失值的行或列。
而fillna()函数可以用指定的值或方法填充缺失值。
2. 数据类型转换:使用Pandas的astype()函数可以将数据类型转换为指定的类型。
3. 数据重复处理:使用Pandas的duplicated()函数可以检测和删除重复的数据。
二、数据可视化数据可视化是一种直观展示数据特征和模式的方式。
Python提供了多个库,如Matplotlib和Seaborn,用于数据可视化。
以下是一些常用的数据可视化技巧:1. 折线图:使用Matplotlib的plot()函数可以绘制折线图,用于显示随时间变化的数据趋势。
2. 饼图和柱状图:使用Matplotlib的pie()函数和bar()函数可以绘制饼图和柱状图,用于显示分类变量的分布情况。
3. 散点图和热力图:使用Matplotlib或Seaborn的scatter()函数和heatmap()函数可以绘制散点图和热力图,用于显示两个或多个变量之间的关系。
三、假设检验假设检验是统计学中用于判断样本是否可以代表总体的一种方法。
Python提供了Scipy库,包括多个假设检验的函数。
以下是一些常用的假设检验技巧:1. 单样本t检验:使用Scipy的ttest_1samp()函数可以对单个样本进行t检验,判断其均值是否与给定值有显著差异。
2. 独立样本t检验:使用Scipy的ttest_ind()函数可以对两组独立样本进行t检验,判断其均值是否有显著差异。
python基本统计值计算

python基本统计值计算Python是一种功能强大的编程语言,提供了许多用于统计计算的工具和库。
本文将介绍 Python 中计算基本统计值的方法,包括均值、中位数、众数、方差和标准差。
1. 均值(Mean):均值是一组数据的平均值,可以简单地通过求和然后除以总个数来计算。
```pythondef mean(data):return sum(data) / len(data)```使用示例:```pythondata = [1, 2, 3, 4, 5]print(mean(data)) # 输出 3.0```2. 中位数(Median):中位数是一组数据中间的数值,可以通过对数据进行排序,然后选择中间位置的数值来计算。
```pythondef median(data):sorted_data = sorted(data)n = len(sorted_data)if n % 2 == 0:return (sorted_data[n // 2 - 1] + sorted_data[n // 2]) / 2 else:return sorted_data[n // 2]```使用示例:```pythondata = [1, 2, 3, 4, 5]print(median(data)) # 输出 3data = [1, 2, 3, 4]print(median(data)) # 输出 2.5```3. 众数(Mode):众数是一组数据中出现频率最高的值,可以使用`statistics` 模块中的 `mode` 函数来计算。
```pythonimport statisticsdef mode(data):return statistics.mode(data)```使用示例:```pythondata = [1, 2, 2, 3, 4, 4, 4, 5]print(mode(data)) # 输出 4```4. 方差(Variance):方差是一组数据离均值的平方差的平均值,可以使用 `statistics` 模块中的 `variance` 函数来计算。
Python数据分析基础第5章用NumPy进行简单统计

5.1.3 使用NumPy读写多维数据文件 1. 使用tofile()函数写入多维数据文件
tofile()函数的格式: 数组名.tofile(fid, sep='', format='%s') 函数中的参数说明:fid:文件、字符串,sep:数据分割符,format: 写入数据的格式 。 2. 使用fromfile()函数读取多维数据文件 fromfile()函数的格式: numpy.fromfile(fid,dtype=float,count=‐1,sep='') 函数中的参数说明:fid:文件、字符串,dtype:读取的数据类型。 count:读入元素个数,‐1表示读入整个文件,sep:数据分割符。 tofile()和fromfile()函数的示例代码example5-2
3. 求百分位数 在NumPy中,使用percentile()和nanpercentile()函数可以沿某轴axis
方向计算数组中第q数值的百分位数。 4. 求中位数
在NumPy中,利用median()和nanmean()函数可以沿某轴axis方向计算数 组中的中位数。
求百分位数和中位数的示例代码example5-5见教材。
nanmean()函数可以计算数组或者轴方向的算术平均数。
5.2 NumPy常用的统计函数
7. 标准差 标准差也称为标准偏差,标准差定义是总体各单位标准值与其平均数离差平方
的算术平均数的平方根,它反映组内个体间的离散程度。在NumPy中,计算标准差 的函数有std()和nanstd()。 8. 方差
在NumPy中,loadtxt()和savetxt()函数可以对文件后缀名为txt和 csv的文件进行读写操作。
5.1.1 使用NumPy读写文本文件
Python中的数据分析和统计技巧

Python中的数据分析和统计技巧Python作为一种高效而强大的编程语言,被广泛应用于数据科学领域。
在Python中,有很多数据分析和统计技巧,可以帮助数据科学家们更好地处理、分析和可视化数据,以便更好地理解和利用数据。
本文将介绍Python中的一些常见的数据分析和统计技巧,包括数据清洗、数据预处理、数据可视化、统计分析和机器学习等方面。
一、数据清洗数据清洗是数据分析的第一步,也是最关键的一步。
数据清洗的目的是识别和修复数据中的错误或不一致之处,以使数据可以在后续的分析中得到正确的解释和应用。
Python中有很多工具和技巧可以帮助数据科学家们对数据进行清洗,如Pandas库、NumPy库和Python原生语言等。
Pandas库是Python中的一种数据操作库,它主要用于数据整理、清洗和分析。
在数据清洗方面,Pandas库提供了很多常用的方法和函数,如drop_duplicates()函数,可以用来删除重复的数据行,fillna()函数,可以用来填充空值和缺失值,drop()函数,可以用来删除不需要的数据行或列,等等。
下面是Pandas库的一些常用方法:1、读取和加载数据Python中可以使用Pandas库的read_xxx()函数读取各种类型的数据文件,比如csv文件、Excel文件、SQL数据库等。
下面是一些常用的读取数据的方法:import pandas as pd#读取csv文件df1 = pd.read_csv('data.csv')#读取Excel文件df2 = pd.read_excel('data.xlsx')#读取SQL数据库from sqlalchemy import create_engineengine =create_engine("mysql+pymysql://username:password@localhost:3306/test")df3 = pd.read_sql(sql="SELECT * FROM data", con=engine)2、删除重复的数据行有时,一个数据集中可能会有重复的数据行,这对后续的分析和建模都是不利的。
python基本统计值计算

python基本统计值计算Python是一种流行的编程语言,它具有很多强大的计算功能,可以被用来计算各种统计量。
本文将简要介绍一些Python中计算统计量的方法。
1.平均数平均数是一组数据的算术平均值,可以用mean(函数计算。
例如,以下代码可以计算一个列表的平均数:```pythonmy_list = [1, 2, 3, 4, 5]average = sum(my_list) / len(my_list)print("Average:", average)```使用mean(函数可以更简单的计算:```pythonimport numpy as npmy_list = [1, 2, 3, 4, 5]average = np.mean(my_list)print("Average:", average)```2.中位数中位数是一组数中的中间值,可以用median(函数计算。
例如,以下代码可以计算一个列表的中位数:```pythonimport statisticsmy_list = [1, 2, 3, 4, 5]median = statistics.median(my_list)print("Median:", median)```3.众数众数是一组数据中出现次数最多的数,可以用mode(函数计算。
例如,以下代码可以计算一个列表的众数:```pythonimport statisticsmy_list = [1, 2, 3, 3, 4, 5, 5]mode = statistics.mode(my_list)print("Mode:", mode)```4.标准差标准差是一组数据的离散程度的度量,它衡量一组数据值的均值与每个数据值的差距的平方的平均数的平方根。
可以用stdev(函数计算。
例如,以下代码可以计算一个列表的标准差:```pythonimport statisticsmy_list = [1, 2, 3, 4, 5]standard_deviation = statistics.stdev(my_list)print("Standard deviation:", standard_deviation)```5.方差方差是一组数据与其算术平均数之差的平方和的平均数。
python统计方法

Python 统计方法Python 是一种流行的编程语言,也是许多数据科学家和统计学家的首选工具之一。
在 Python 中,有许多强大的统计方法可用于数据分析和可视化。
本文将介绍一些常用的 Python 统计方法,包括描述性统计、假设检验、回归分析和聚类分析。
下面是本店铺为大家精心编写的4篇《Python 统计方法》,供大家借鉴与参考,希望对大家有所帮助。
《Python 统计方法》篇1一、描述性统计描述性统计是数据分析的基础。
在 Python 中,可以使用 pandas 和 numpy 等库进行描述性统计。
例如,可以使用 pandas 库计算数据的基本统计指标,如均值、中位数、众数、标准差和方差等。
二、假设检验在数据分析中,经常需要进行假设检验以确定数据之间是否存在显著性差异。
在 Python 中,可以使用 scipy 和 statsmodels 等库进行假设检验。
例如,可以使用 scipy 库进行 t 检验和方差分析等。
三、回归分析回归分析是一种用来研究自变量与因变量之间关系的统计方法。
在 Python 中,可以使用 statsmodels 和 scikit-learn 等库进行回归分析。
例如,可以使用 statsmodels 库进行线性回归和多项式回归等。
四、聚类分析聚类分析是一种用来将数据分组到不同的簇中的统计方法。
在Python 中,可以使用 scikit-learn 和 pandas 等库进行聚类分析。
例如,可以使用 scikit-learn 库进行 k 均值聚类和层次聚类等。
Python 是一种功能强大的编程语言,可以用于各种数据分析和可视化任务。
在 Python 中,有许多常用的统计方法可用于数据分析和可视化。
《Python 统计方法》篇2Python 是一种流行的编程语言,它具有强大的数据分析和统计能力。
在 Python 中,可以使用多种库和工具来进行统计分析,例如NumPy、Pandas、Matplotlib 和 SciPy 等。
Python中的数据分析和统计技术

Python中的数据分析和统计技术Python是一种强大且易于学习的编程语言,它在数据分析和统计领域有着广泛的应用。
本文将介绍Python中用于数据分析和统计的一些常用技术和工具。
一、NumPy和Pandas库NumPy和Pandas是两个在Python中常用的数据分析库。
NumPy提供了用于处理大型多维数组和矩阵的功能,而Pandas则提供了更高级的数据分析工具。
1. NumPy库NumPy的核心是ndarray(N-dimensional array)对象,它是一个多维数组对象,可以进行快速的数值计算。
通过使用NumPy库,我们可以对数组进行基本的数学运算,如加法、减法、乘法和除法等。
同时,NumPy还提供了许多用于数组操作的函数和方法,如排序、过滤、切片等。
2. Pandas库Pandas库提供了用于数据分析的数据结构和数据处理工具。
其中最重要的两个数据结构是Series和DataFrame。
Series是一种类似于一维数组的对象,它包含了一组数据和与之相关的索引,可以认为是一种带有标签的数组。
DataFrame则是一个二维表格型的数据结构,它类似于Excel中的表格,可以将数据组织成行和列,每列可以是不同的数据类型。
通过使用Pandas库,我们可以进行数据的读取、清洗、切片、过滤、合并、聚合等操作,极大地简化了数据分析的流程。
二、Matplotlib和Seaborn库Matplotlib和Seaborn是两个常用的数据可视化库。
对于数据分析和统计,数据可视化是十分重要的环节,因为可视化可以帮助我们更好地理解数据的分布、关系和趋势。
1. Matplotlib库Matplotlib是一个用于绘制二维图表和可视化数据的库。
它可以绘制线图、柱状图、散点图、饼图、直方图等各种图形,并且可以进行定制化的设置,如添加标题、轴标签、图例等。
2. Seaborn库Seaborn是基于Matplotlib的高级数据可视化库,它提供了一些额外的统计图表和绘图工具。
python基本统计值计算代码

python基本统计值计算代码统计学是一门非常重要的学科,在许多领域都有应用。
在Python中,我们可以使用一些内置的库来计算一些基本的统计量。
本篇文章将介绍如何使用Python计算均值、方差、标准差、中位数、众数等基本统计值。
1.均值。
均值是一个序列中所有元素之和除以序列长度,计算公式为:$\bar{某} = \frac{1}{n}\sum_{i=1}^{n}某_i$。
在Python中,我们可以使用以下代码计算一个序列的均值:```python。
def mean(lst):。
return sum(lst) / len(lst)。
```。
其中,`lst`是一个包含所有元素的序列。
`sum(lst)`计算序列中所有元素的和,`len(lst)`计算序列的长度,两者相除即为均值。
2.方差。
方差衡量了一个序列中每个元素与均值之间的离散程度,计算公式为:$var = \frac{1}{n}\sum_{i=1}^{n}(某_i - \bar{某})^2$。
在Python中,我们可以使用以下代码计算一个序列的方差:```python。
def variance(lst):。
mu = mean(lst)。
return sum((某 - mu) 某某 2 for 某 in lst) / len(lst)。
```。
其中,`mu`是序列的均值,`sum((某 - mu) 某某 2 for 某 in lst)`计算了序列中每个元素与均值之间的平方差的和,`len(lst)`计算序列的长度。
3.标准差。
标准差是方差的平方根,衡量了一个序列中每个元素与均值之间的离散程度。
在Python中,我们可以使用以下代码计算一个序列的标准差:```python。
def stdev(lst):。
return variance(lst) 某某 0.5。
```。
其中,`variance(lst)`计算序列的方差,`某某 0.5`表示对方差取平方根即为标准差。
Python基本数据统计

Python 基本数据 Basic data processing of Python 统计Department of Computer Science and TechnologyDepartment of University Basic Computer Teaching数据分析 4 数据描述 3 数据整理数据收集 12简单数据处理过程 2用Python玩转数据便捷数据获取本地数据如何获取?文件的打开,读写和关闭•文件打开•读文件写文件•文件关闭网络数据如何获取?抓取网页,解析网页内容•urllib•urllib2•httplib•httplib2yahoo财经数据6 /q/cp?s=%5EDJI+Component利用urllib库获取yahoo财经数据7 F ile# Filename: dji.pyimport urllibimport redStr = urllib.urlopen('/q/cp?s=%5EDJI+Components').read()m = re.findall('<tr><td class=\'yfnc_tabledata1\'><b><a href=\'.*?\'>\(.*?)</a></b></td><td class=\'yfnc_tabledata1\'>(.*?)</td>.*?<b>(.*?)</b>.*?</tr>', dStr)if m:print mprint'\n'print len(m)else:print'not match'数据形式8 •包含多个字符串(dji)–'AXP', 'American Express Company', '86.40'–'BA', 'The Boeing Company', '122.24'–'CAT', 'Caterpillar Inc.', '99.44'–'CSCO', 'Cisco Systems, Inc.', '23.78'–'CVX', 'Chevron Corporation', '115.91'–…是否能够简单方便并且快速的方式获得雅虎财经上各上市公司股票的历史数据?F ile# Filename: quotes.pyfrom matplotlib.finance import quotes_historical_yahoofrom datetime import dateimport pandas as pdtoday = date.today()start = (today.year-1, today.month, today.day)quotes = quotes_historical_yahoo('AXP', start, today)df = pd.DataFrame(quotes)print dfquotes的内容开盘价最高价最低价成交量日期收盘价便捷网络数据自然语言工具包NLTK •古腾堡语料库•布朗语料库 •路透社语料库 •网络和聊天文本 •…>>> from nltk.corpus import gutenberg >>> import nltk >>> print gutenberg.fileids() [u'austen-emma.txt', u'austen-persuasion.txt', u'austen-sense.txt', u'bible-kjv.txt', u'blake-poems.txt', u'bryant-stories.txt', u'burgess-busterbrown.txt', u'carroll-alice.txt', u'chesterton-ball.txt', u'chesterton-brown.txt', u'chesterton-thursday.txt', u'edgeworth-parents.txt', u'melville-moby_dick.txt', u'milton-paradise.txt',u'shakespeare-caesar.txt', u'shakespeare-hamlet.txt', u'shakespeare-macbeth.txt', u'whitman-leaves.txt']>>> texts = gutenberg.words('shakespeare-hamlet.txt') [u'[', u'The', u'Tragedie', u'of', u'Hamlet', u'by', ...]S ourcebrown 11用Python玩转数据数据准备数据形式30支成分股(dji)股票数据的逻辑结构公司代码公司名最近一次成交价美国运通公司(quotes)股票详细数据的逻辑结构日期开盘价收盘价最高价最低价成交量13quotes数据加属性名F ile# Filename: quotesproc.pyfrom matplotlib.finance import quotes_historical_yahoo from datetime import dateimport pandas as pdtoday = date.today()start = (today.year-1, today.month, today.day)quotes = quotes_historical_yahoo('AXP', start, today) fields = ['date','open','close','high','low','volume'] quotesdf = pd.DataFrame(quotes, columns = fields) print quotesdfdji数据:加属性名code name lasttrade AXPBACAT…XOMquotes数据:加属性名date open close high low volume 735190.0735191.0735192.0…735551.0用1,2,…作为索引quotesdf = pd.DataFrame(quotes, columns = fields)quotesdf = pd.DataFrame(quotes, index = range(1,len(quotes)+1),columns = fields)如果可以直接用date作为索引,quotes的时间能否转换成常规形式(如下图中的效果)?S ource>>> from datetime import date>>> firstday = date.fromordinal(735190)>>> lastday = date.fromordinal(735551)>>> firstdaydatetime.date(2013, 11, 18)>>> lastdaydatetime.date(2014, 11, 14)时间序列# Filename: quotesproc.pyfrom matplotlib.finance import quotes_historical_yahoo from datetime import date from datetime import datetime import pandas as pd today = date.today()start = (today.year-1, today.month, today.day)quotes = quotes_historical_yahoo('AXP', start, today) fields = ['date','open','close','high','low','volume'] list1 = [] for i in range (0,len (quotes)):x = date.fromordinal(int (quotes[i][0])) y = datetime.strftime(x,'%Y-%m-%d') list1.append(y)quotesdf = pd.DataFrame(quotes, index = list1, columns = fields) quotesdf = quotesdf.drop(['date'], axis = 1)print quotesdfFile转换成常规时间 转换成固定格式 删除原date 列18创建时间序列>>> import pandas as pd>>> dates = pd.date_range('20141001', periods=7) >>> dates<class 'pandas.tseries.index.DatetimeIndex'> [2014-10-01, ..., 2014-10-07]Length: 7, Freq: D, Timezone: None >>> import numpy as np>>> dates = pd.DataFrame(np.random.randn(7,3),index=dates,columns = list ('ABC')) >>> datesA B C 2014-10-01 1.302600 -1.214708 1.411628 2014-10-02 -0.512343 2.277474 0.403811 2014-10-03 -0.788498 -0.217161 0.173284 2014-10-04 1.042167 -0.453329 -2.107163 2014-10-05 -1.628075 1.663377 0.943582 2014-10-06 -0.091034 0.335884 2.455431 2014-10-07 -0.679055 -0.865973 0.246970 [7 rows x 3 columns]Source19用Python玩转数据数据显示djidf quotesdf>>> djidf.indexInt64Index([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29], dtype='int64') >>> djidf.columnsIndex([u'code', u'name', u'lasttrade'], dtype='object') >>> dijdf.valuesarray([['AXP', 'American Express Company', '90.67'], ['BA', 'The Boeing Company', '128.86'], …['XOM', 'Exxon Mobil Corporation', '95.09']], dtype=object) >>> djidf.describe<bound method DataFrame.describe of code name lasttrade 0 AXP American Express Company 90.67 1 BA The Boeing Company 128.86 …29 XOM Exxon Mobil Corporation 95.09 Source显示方式:•显示索引 •显示列名 •显示数据的值 •显示数据描述>>> quotesdf.indexIndex([u'2013-11-18', u'2013-11-19', u'2013-11-20', u'2013-11-21', u'2013-11-22', u'2013-11-25', u'2013-11-26', u'2013-11-27', …-04-08', u'2014-04-09', u'2014-04-10', u'2014-04-11', ...], dtype='object')S ource索引的格式>>> djidf.head(5)code name lasttrade 0 AXP American Express Company 90.67 1 BA The Boeing Company 128.86 2 CAT Caterpillar Inc. 101.34 3 CSCO Cisco Systems, Inc. 26.32 4 CVX Chevron Corporation 116.32 [5 rows x 3 columns]>>> djidf.tail(5)code name lasttrade 25 UTX United Technologies Corporation 107.45 26 V Visa Inc. 248.84 27 VZ Verizon Communications Inc. 51.50 28 WMT Wal-Mart Stores Inc. 82.96 29 XOM Exxon Mobil Corporation 95.09 [5 rows x 3 columns]Sourcedf[:5] df[25:] 显示方式:•显示行−专用方式 −切片查看道琼斯工业股中前5只和后5只的股票基本信息?用Python玩转数据数据选择选择方式:•选择行•选择列•选择区域•筛选(条件选择)>>> quotesdf[u'2013-12-02':u'2013-12-06']open close high low volume 2013-12-02 85.092126 84.37 85.596624 84.241402 3620800 2013-12-03 83.976989 83.70 84.412256 83.294410 3546100 2013-12-04 83.303123 83.59 84.322031 82.857969 3579700 2013-12-05 83.362906 83.63 84.075156 83.244198 3677800 2013-12-06 84.663680 85.00 85.158268 84.426277 2666600[5 rows x 5 columns]S ource 选择方式:•选择行−切片 −索引美国运通公司2013年12月2日至2013年12月6日间的股票交易信息?>>> djidf['code'] 0 AXP 1 BA 2 CAT …29 XOMName: code, dtype: object >>> djidf.code 0 AXP 1 BA 2 CAT …29 XOMName: code, dtype: objectS ource 选择方式:•选择列−列名不支持djidf['code', 'lasttrade'] djidf['code':'lasttrade']道琼斯工业股公司代码?选择方式:•行、列−标签label(loc)>>> djidf.loc[1:5,]code name lasttrade1 BA The Boeing Company 128.862 CAT Caterpillar Inc. 101.343 CSCO Cisco Systems, Inc. 26.324 CVX Chevron Corporation 116.325 DD E. I. du Pont de Nemours and Company 70.80 [5 rows x 3 columns]>>> djidf.loc[:,['code','lasttrade']]code lasttrade0 AXP 90.671 BA 128.862 CAT 101.34…29 XOM 95.09[30 rows x 2 columns]S ource道琼斯工业股中标号是1至5的股票信息以及所有股票的代码和最近一次交易价?选择方式:•行和列的区域−标签label(loc)•单个值−at >>> djidf.loc[1:5,['code','lasttrade']] code lasttrade1 BA 128.862 CAT 101.343 CSCO 26.324 CVX 116.325 DD 70.80[5 rows x 2 columns]>>> djidf.loc[1,'lasttrade']'128.86‘>>> djidf.at[1,'lasttrade']'128.86'S ource道琼斯工业股中标号是1至5的股票代码和最近一次交易价?标号是1的股票的最近一次交易价?数据选择选择方式:•行、列和区域−用iloc(位置)•取某个值−iat >>> djidf.loc[1:5,['code','lasttrade']]code lasttrade1 BA 128.862 CAT 101.343 CSCO 26.324 CVX 116.325 DD 70.80S ource>>> djidf.iloc[1:6,[0,2]]code lasttrade1 BA 128.862 CAT 101.343 CSCO 26.324 CVX 116.325 DD 70.80S ource>>> djidf.loc[1,'lasttrade']'128.86'>>> djidf.at[1,'lasttrade']'128.86'S ource>>> djidf.iloc[1,2]'128.86'>>> djidf.iat[1,2]'128.86'S ource31数据选择>>> quotesdf[quotesdf.index >= u'2014-01-01']open close high low volume 2014-01-02 89.924438 88.49 90.102506 88.420751 5112000 2014-01-03 88.186377 88.77 89.106325 87.671998 3888500 2014-01-06 88.730000 88.73 89.274052 88.413460 2844700 …2014-03-28 89.531554 89.72 90.811002 89.263763 3138900 ... ... ... ... ... [221 rows x 5 columns]>>> quotesdf[(quotesdf.index >= u'2014-01-01') & (quotesdf.close >= 95)] open close high low volume 2014-06-09 94.532820 95.02 95.328216 94.105295 3825200 2014-06-18 94.204662 95.01 95.039827 93.538518 2454800 2014-07-03 95.031492 95.29 95.389426 94.673558 1633800 [3 rows x 5 columns] S ource美国运通公司2014年的股票信息?进一步寻找美国运通公司2014年收盘价大于等于95的记录?选择方式:•条件筛选32用Python玩转数据简单统计与处理简单统计与筛选>>> djidf.mean(columns = 'lasttrade') lasttrade 91.533667 dtype: float64>>> djidf[sttrade >= 120].name1 The Boeing Company 8 The Goldman Sachs Group, Inc. 10 International Business Machines Corporation 16 3M Company 26 Visa Inc. Name: name, dtype: objectSource求道琼斯工业股中30只股票最近一次成交价的平均值?股票最近一次成交价大于等于120的公司名?34简单统计与筛选>>> len (quotesdf[quotesdf.close > quotesdf.open]) 131>>> len (quotesdf)-131 120S ource 统计美国运通公司近一年股票涨和跌分别的天数? 统计美国运通公司近一年相邻两天收盘价的涨跌情况?>>> status = np.sign(np.diff(quotesdf.close)) >>> statusarray([ 1., -1., 1., -1., 1., 1., 1., 1., -1., -1., -1., 1., 1., …-1., -1., -1.])>>> status[np.where( status == 1.)].size 130>>> status[np.where( status == -1.)].size 120S ource 35排序>>> djidf.sort(columns = 'lasttrade')code name lasttrade 3 CSCO Cisco Systems, Inc. 26.32 7 GE General Electric Company 26.46 20 PFE Pfizer Inc. 30.34 11INTC Intel Corporation 33.95 …8 GS The Goldman Sachs Group, Inc. 189.98 26 V Visa Inc. 248.84 [30 rows x 3 columns]>>> djidf.sort(columns = 'lasttrade')[27:].name 10 International Business Machines Corporation 8 The Goldman Sachs Group, Inc. 26 Visa Inc. Name: name, dtype: objectS ource按最近一次成交价对30只道琼斯工业股股票进行排序。
数据分析使用Python进行数据分析和统计

数据分析使用Python进行数据分析和统计Python是一种易于学习和使用的编程语言,广泛应用于数据分析和统计领域。
通过使用Python,我们可以轻松地处理、分析和可视化大规模数据集,从中获得有意义的信息和洞察。
1. 数据收集和准备在数据分析过程中,首先需要收集数据并做好预处理工作。
Python具有丰富的库和工具,可以帮助我们从各种数据源中收集数据。
例如,我们可以使用pandas库读取和处理来自CSV文件、Excel表格或数据库的数据。
同时,我们还可以使用NumPy库对数据进行数值计算和处理。
2. 数据清洗和转换在数据分析中,数据清洗和转换是非常重要的步骤。
Python提供了许多用于数据清洗和转换的库,如pandas和numpy。
我们可以使用这些库来去除重复值、处理缺失数据、进行数据类型转换等。
此外,Python还提供了强大的字符串处理功能,可以帮助我们对文本数据进行清洗和处理。
3. 数据可视化数据可视化是数据分析的重要环节,可以帮助我们更好地理解和传达数据的含义。
Python提供了众多的可视化库,如Matplotlib、Seaborn 和Plotly等。
这些库可以帮助我们生成各种类型的图表和图形,如折线图、柱状图、散点图、箱线图等。
通过这些可视化工具,我们可以直观地展示数据的分布、趋势和关联性。
4. 数据分析和统计Python拥有丰富的数据分析和统计库,如pandas和scikit-learn等。
这些库提供了各种功能,如描述性统计分析、假设检验、回归分析、聚类分析等。
我们可以使用这些库来进行数据分析、探索性数据分析和机器学习等任务。
此外,Python还可以与其他数据分析工具和库集成,如R语言和Tableau等。
5. 机器学习和预测建模机器学习是数据分析和统计的重要分支,可以帮助我们构建预测模型和进行数据驱动决策。
Python提供了丰富的机器学习库,如scikit-learn、TensorFlow和Keras等。
python基本统计值计算代码

python基本统计值计算代码以下是使用Python计算基本统计值的代码:```pythonimport statistics#提供一个列表示原始数据data = [5, 9, 13, 21, 23, 25, 29, 35, 41, 45] #计算数据的总数total = sum(data)#计算数据的数量count = len(data)#计算数据的平均值mean = total / count#计算数据的中位数median = statistics.median(data)#计算数据的众数mode = statistics.mode(data)#计算数据的最小值minimum = min(data)#计算数据的最大值maximum = max(data)#计算数据的范围range_ = maximum - minimum#计算数据的标准差standard_deviation = statistics.stdev(data) #计算数据的方差variance = statistics.variance(data)#打印计算结果print("数据总数:", total)print("数据数量:", count)print("平均值:", mean)print("中位数:", median)print("众数:", mode)print("最小值:", minimum)print("最大值:", maximum)print("数据范围:", range_)print("标准差:", standard_deviation)print("方差:", variance)```这段代码首先导入了Python中用于统计的模块statistics。
基本统计值计算python

基本统计值计算python文档内容Introduction基本统计值计算python是一种经典的数据分析方法,可以用来快速的计算出基本统计值,比如平均值、中位数、标准差等。
利用python作为编程工具,可以使得计算基本统计值变得更加简单、高效。
Basics在python中,使用numpy库可以实现对基本统计值的计算。
首先要先导入numpy库,如:import numpy as np然后在调用相关函数以计算基本统计值。
在numpy中,有下列函数可供使用:#计算均值 np.mean(data) #计算中位数 np.median(data) #计算标准差 np.std(data) #计算最大值 np.max(data) #计算最小值np.min(data)其中data为需要计算的数据,可以是数组,列表,元组等。
Example下面我们来看一个简单的实例,来说明如何用python计算基本统计值。
假设我们有一个需要分析的数据,如下:data = [1,4,6,3,7,2,8,5,9]首先,我们可以使用numpy库中的函数来计算基本统计值:import numpy as np mean = np.mean(data) median =np.median(data) std = np.std(data) max = np.max(data) min = np.min(data)此时,mean、median、std、max、min就分别存储了data数组的均值、中位数、标准差、最大值、最小值。
Conclusion基本统计值计算python可以用来快速的计算出数据集中的基本统计值,可以大大提高数据分析的效率。
此外,python中的numpy 库提供了丰富的函数来帮助用户实现分析工作。
python数据统计,总数,平均值等

python数据统计,总数,平均值等⼀般我们进⾏数据统计的时候要进⾏数据摸查,可能是摸查整体的分布情况啊。
平均值,标准差,总数,各分段的⼈数啊。
这时候⽤excel或者数据库统计都不⽅便。
我要统计的⼀个⽂件,太⼤了,还得分成15个⽂件,结果导⼀个进mysql都要导很久。
再mysql进⾏编程,执⾏更久,很费事。
但是⽤python直接统计就很⽅便啦。
1 @author: pc2"""3import matplotlib as mpb4import pandas as pd5import pylab as pl6import numpy as np7#读取⽂件8#mnames=[' product_type','phone_num',' flow_total',' flow_used', 'phone_total',' phone_used' ]9mnames=['time']10product=pd.read_table('C:\\Users\\pc\\Desktop\\time.txt',encoding='utf-8',sep='|',header=None,names=mnames)11# print(product['product_subtotal'])12#选取产品⼩计列13time=product['time']14#按分位数划分区间15cats=pd.qcut(time,[0,0.2,0.4,0.6,0.8,1.0])16# print(cats)17# print(pd.value_counts(cats))18# print(product_subtotal)19count=time.value_counts()20#写⼊csv⽂件21count.to_csv('C:\\Users\\pc\\Desktop\\counts9.csv')22#输出描述性统计结果23print(time.describe())24#根据电话号码查询某⾏的值25#num=product['phone_num']26#print(product[product['phone_num']==189********])27bins=np.arange(0,5000,100)28pl.hist(time, bins)View Code但是这是适合⼀个⼀个⽂件算,如果存在多个⽂件,我们可以使⽤python合并后计算。
python统计算法
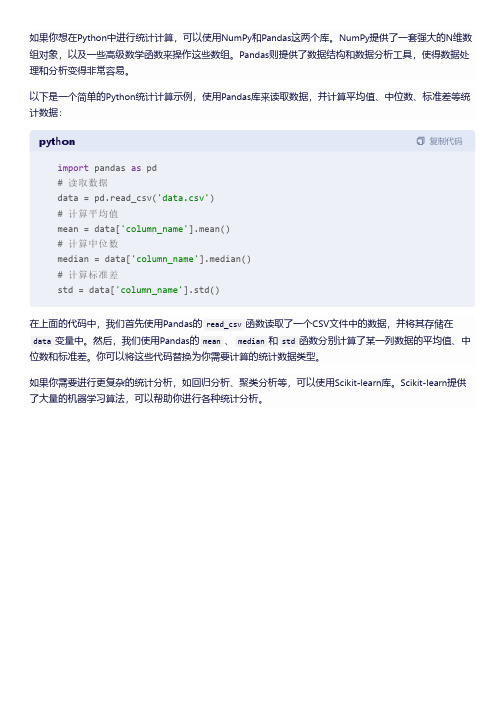
如果你想在Python中进行统计计算,可以使用NumPy和Pandas这两个库。
NumPy提供了一套强大的N维数组对象,以及一些高级数学函数来操作这些数组。
Pandas则提供了数据结构和数据分析工具,使得数据处理和分析变得非常容易。
以下是一个简单的Python统计计算示例,使用Pandas库来读取数据,并计算平均值、中位数、标准差等统计数据:
python复制代码
import pandas as pd
# 读取数据
data = pd.read_csv('data.csv')
# 计算平均值
mean = data['column_name'].mean()
# 计算中位数
median = data['column_name'].median()
# 计算标准差
std = data['column_name'].std()
在上面的代码中,我们首先使用Pandas的read_csv函数读取了一个CSV文件中的数据,并将其存储在
data变量中。
然后,我们使用Pandas的mean、median和std函数分别计算了某一列数据的平均值、中位数和标准差。
你可以将这些代码替换为你需要计算的统计数据类型。
如果你需要进行更复杂的统计分析,如回归分析、聚类分析等,可以使用Scikit-learn库。
Scikit-learn提供了大量的机器学习算法,可以帮助你进行各种统计分析。
基本统计值计算python

基本统计值计算python基本统计值计算Python在机器学习中,一项基本的任务就是计算基本统计值。
统计量基本上表示数据集的基本特征,比如均值,方差,中位数等等。
但是,在手动计算统计量时,容易出错,特别是手动计算复杂的统计量时。
因此,使用Python计算统计量是非常有用的。
本文介绍了如何使用Python计算常见的统计量:均值,标准差,中位数,偏度和峰度。
一、均值计算数据集的均值是最简单的统计量之一,可以使用Python标准库中的mean函数轻松计算。
```pythonimport numpy as np# 创建数据集data = np.array([1,2,3,4,5,6,7,8,9,10])# 计算均值mean_data = np.mean(data) # 输出 5.5print(mean_data)```二、标准差计算数据集的标准差也是一个非常容易计算的统计量。
可以使用标准库中的 std 函数来计算标准差。
```pythonimport numpy as np# 创建数据集data = np.array([1,2,3,4,5,6,7,8,9,10])# 计算标准差std_data = np.std(data) # 输出 2.87print(std_data)```三、中位数计算数据集的中位数可以使用Python标准库中的 median 函数。
```pythonimport numpy as np# 创建数据集data = np.array([1,2,3,4,5,6,7,8,9,10])# 计算中位数median_data = np.median(data) # 输出 5.5print(median_data)```四、偏度偏度(skewness)计算数据集的形状,它反映数据的偏移和偏斜情况,可以衡量数据集的对称性。
可以使用Skew 函数来计算偏度。
```pythonimport numpy as np# 创建数据集data = np.array([1,2,3,4,5,6,7,8,9,10])# 计算偏度skew_data = np.skew(data) # 输出 0.0print(skew_data)```五、峰度峰度(kurtosis)用于衡量数据分布的陡峭程度,也可以用来检测数据集中是否存在极端值。
Python中的数据分析和统计方法

Python中的数据分析和统计方法Python是一门功能强大的编程语言,广泛应用于数据分析和统计方法。
本文将详细介绍Python中常用的数据分析和统计方法,并按类进行章节划分,深入探讨每个章节的具体内容。
第一章:数据预处理在进行数据分析之前,通常需要对原始数据进行清洗和预处理。
Python提供了很多用于数据预处理的库和方法。
其中,pandas是最常用的库之一。
pandas可以用于数据的读取、清洗、转换和合并等操作。
另外,NumPy库也提供了许多用于数组操作和数值运算的函数,可用于数据预处理过程中的一些计算。
第二章:数据可视化数据可视化是数据分析的重要环节,它可以使得数据更加直观和易于理解。
Python中有多个可视化库可以使用,如Matplotlib、Seaborn和Plotly等。
这些库可以生成各种类型的图表,如线图、散点图、柱状图和饼图等。
通过合理选择和使用可视化方法,可以更好地展示数据的分布和趋势。
第三章:统计描述统计描述是对数据进行摘要和概括的过程。
在Python中,可以使用pandas库的describe()函数来计算数据的基本统计量,如均值、标准差、最大值和最小值等。
此外,还可以使用scipy库中的一些函数来计算概率分布、置信区间和假设检验等统计指标。
第四章:回归分析回归分析是数据分析中常用的一种方法,用于探究变量之间的关系和预测未来趋势。
Python中的statsmodels库提供了许多回归分析的方法,如线性回归、逻辑回归和多元回归等。
通过回归分析,可以得到模型的参数估计和拟合优度等指标,进而对未知数据进行预测和推测。
第五章:聚类分析聚类分析是将数据按照相似性进行分组的一种方法。
在Python 中,可以使用scikit-learn库中的KMeans算法来进行聚类分析。
KMeans算法通过迭代计算将数据划分为K个簇,使得同一簇内的数据相似度最高,不同簇之间的相似度最低。
聚类分析可以帮助我们发现数据中潜在的模式和规律。
python 数据统计流程-概述说明以及解释

python 数据统计流程-概述说明以及解释1.引言1.1 概述概述Python作为一种强大的编程语言,被广泛应用于数据分析和统计领域。
数据统计是指通过对数据进行整理、分析和解释,以获取有关现象的信息和进行推断的过程。
在这篇文章中,我们将介绍Python在数据统计过程中的应用。
我们将从数据的收集开始,然后进行数据的清洗,最后进行数据的统计和分析。
通过本文的学习,读者可以更加深入地了解如何利用Python进行数据统计,为不同领域的应用提供有力的支持。
1.2 文章结构:本文将分为引言、正文和结论三个部分进行阐述。
在引言部分中,将简要介绍本文的概述、文章结构以及目的。
在正文部分中,将详细介绍Python数据统计流程的概述,包括数据收集和数据清洗两个主要环节。
在结论部分中,将对整篇文章进行总结,探讨Python数据统计流程在不同应用领域中的作用,并展望未来数据统计领域的发展方向。
通过这样的结构安排,读者将能够清晰地了解Python数据统计流程的完整过程及其重要性。
1.3 目的本文的主要目的是介绍Python在数据统计方面的应用流程,帮助读者了解如何利用Python进行数据统计分析。
通过对数据统计流程中的数据收集、数据清洗等环节进行详细说明和示范,读者可以掌握数据统计的基本方法和技巧。
同时,本文也旨在激发读者对数据统计领域的兴趣,希望能够帮助读者更好地应用数据统计方法解决实际问题,提高工作效率和数据分析能力。
通过本文的阅读,读者可以系统地了解Python在数据统计中的应用流程,进而在实践中灵活运用这些知识,提升数据统计分析的水平和质量。
2.正文2.1 Python数据统计流程概述Python数据统计流程是指利用Python编程语言进行数据统计和分析的流程。
Python是一种功能强大且易于学习的编程语言,拥有丰富的数据处理和统计分析库,如Pandas、NumPy和Matplotlib等,使得数据统计变得更加简单和高效。
python:基本统计值计算(平均数,方差,中位数)
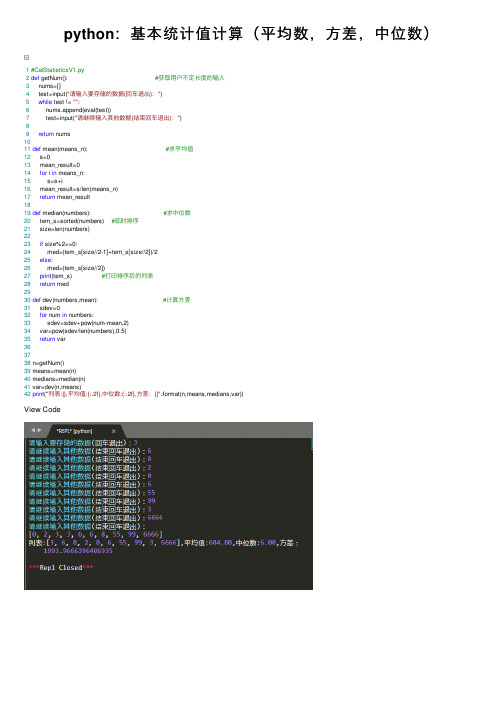
33
sdev=sdev+pow(num-mean,2)
34 var=pow(sdev/len(numbers),0.5)
35 return var
36
37
38 n=getNum()
39 means=mean(n)
40 medians=median(n)
41 var=dev(n,means)
42 print("列表:{},平均值:{:.2f},中位数:{:.2f},方差:{}".format(n,means,medians,var))
View Code
24
med=(tem_s[size//2-1]+tem_s[size//2])/2
25 else:
26
med=(tem_s[size//2])
27 print(tem_s)
#打印排序后的列表
28 return med
29
30 def dev(numbers,mean):
#计算方差
31 sdev=0
32 for num in numbers:
15
s=s+i
16 mean_result=s/len(means_n)
17 return mean_result
18
19 def median(numbers):
#求中位数
20 tem_s=sorted(numbers) #临时排序
21 size=len(numbers)
22ห้องสมุดไป่ตู้
23 if size%2==0:
5 while test != "":
6
nums.append(eval(test))
Python脚本自动化计算数据统计

Python脚本自动化计算数据统计一、Python 数据处理库要进行数据统计,首先需要了解一些常用的 Python 数据处理库。
其中,`pandas` 是一个非常强大的库,它提供了高效的数据结构和数据分析工具。
`numpy` 则主要用于数值计算,在数据处理中也经常被用到。
我们可以使用`pip` 命令来安装这些库:```pip install pandas numpy```二、数据读取在进行数据统计之前,需要先将数据读取到 Python 中。
`pandas` 提供了多种读取数据的方法,例如读取 CSV 文件、Excel 文件、数据库等。
以下是读取 CSV 文件的示例代码:```pythonimport pandas as pddata = pdread_csv('datacsv')```这里假设我们的数据存储在名为`datacsv` 的文件中。
三、数据清洗读取到数据后,往往需要进行数据清洗,去除重复值、处理缺失值等。
以下是一些常见的数据清洗操作:1、去除重复值```pythondata = datadrop_duplicates()```2、处理缺失值```pythondata = datafillna(0) 将缺失值填充为 0```四、数据统计分析完成数据清洗后,就可以进行各种统计分析了。
例如,计算平均值、总和、最大值、最小值等。
1、计算平均值```pythonaverage = data'column_name'mean()```2、计算总和```pythontotal = data'column_name'sum()```3、计算最大值```pythonmax_value = data'column_name'max()```4、计算最小值```pythonmin_value = data'column_name'min()```这里的`column_name` 是要进行统计的列名。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Python 基本数据 Basic data processing of Python 统计Department of Computer Science and TechnologyDepartment of University Basic Computer Teaching数据分析 4 数据描述3 数据整理 数据收集 12简单数据处理过程 2用Python玩转数据便捷数据获取本地数据如何获取?文件的打开,读写和关闭•文件打开•读文件写文件•文件关闭网络数据如何获取?抓取网页,解析网页内容•urllib •urllib2 •httplib •httplib2Python 3中被urllib.request代替Python 3中被http.client代替yahoo财经数据6 /q/cp?s=%5EDJI+Component利用urllib库获取yahoo财经数据7 F ile# Filename: dji.pyimport urllibimport redBytes = urllib.request.urlopen('/q/cp?s=%5EDJI+Components').read() dStr = dBytes.decode('GBK') #在python3中urllib.read()返回bytes对象而非str,语句功能是将dBytes转换成Strm = re.findall('<tr><td class="yfnc_tabledata1"><b><a href=".*?">(.*?)</a></b></td><td class="yfnc_tabledata1">(.*?)</td>.*?<b>(.*?)</b>.*?</tr>', dStr)if m:print mprint'\n'print len(m)else:print'not match'数据形式8 •包含多个字符串(dji)–'AXP', 'American Express Company', '86.40'–'BA', 'The Boeing Company', '122.24'–'CAT', 'Caterpillar Inc.', '99.44'–'CSCO', 'Cisco Systems, Inc.', '23.78'–'CVX', 'Chevron Corporation', '115.91'–…是否能够简单方便并且快速的方式获得雅虎财经上各上市公司股票的历史数据?# Filename: quotes.py from matplotlib.finance import quotes_historical_yahoo from datetime import date import pandas as pd today = date.today() start = (today.year-1, today.month, today.day) quotes = quotes_historical_yahoo _ochl ('AXP', start, today) df = pd.DataFrame(quotes) print df F ile函数目前更新为quotes_historical_yahoo_ochlquotes的内容开盘价最高价最低价成交量日期收盘价便捷网络数据自然语言工具包NLTK •古腾堡语料库•布朗语料库•路透社语料库 •网络和聊天文本 •…>>> from nltk.corpus import gutenberg >>> import nltk >>> print gutenberg.fileids() [u'austen-emma.txt', u'austen-persuasion.txt', u'austen-sense.txt', u'bible-kjv.txt', u'blake-poems.txt', u'bryant-stories.txt', u'burgess-busterbrown.txt', u'carroll-alice.txt', u'chesterton-ball.txt', u'chesterton-brown.txt', u'chesterton-thursday.txt', u'edgeworth-parents.txt', u'melville-moby_dick.txt', u'milton-paradise.txt',u'shakespeare-caesar.txt', u'shakespeare-hamlet.txt', u'shakespeare-macbeth.txt', u'whitman-leaves.txt']>>> texts = gutenberg.words('shakespeare-hamlet.txt') [u'[', u'The', u'Tragedie', u'of', u'Hamlet', u'by', ...]S ource brown 11需要先执行nltk.download()下载某一个或多个包,若下载失败,可以在官网(/nltk_data/)单独下载后放到本地python 目录的nltk_data\corpora 下12用Python玩转数据数据准备数据形式30支成分股(dji)股票数据的逻辑结构公司代码公司名最近一次成交价美国运通公司(quotes)股票详细数据的逻辑结构日期开盘价收盘价最高价最低价成交量14quotes数据加属性名F ile# Filename: quotesproc.pyfrom matplotlib.finance importquotes_historical_yahoo_ochlfrom datetime import dateimport pandas as pdtoday = date.today()start = (today.year-1, today.month, today.day)quotes = quotes_historical_yahoo_ochl('AXP', start, today) fields = ['date','open','close','high','low','volume'] quotesdf = pd.DataFrame(quotes, columns = fields)print quotesdfdji数据:加属性名code name lasttrade AXPBACAT…XOMquotes数据:加属性名date open close high low volume 735190.0735191.0735192.0…735551.0用1,2,…作为索引quotesdf = pd.DataFrame(quotes, columns = fields)quotesdf = pd.DataFrame(quotes, index = range(1,len(quotes)+1),columns = fields)如果可以直接用date作为索引,quotes的时间能否转换成常规形式(如下图中的效果)?S ource>>> from datetime import date>>> firstday = date.fromordinal(735190)>>> lastday = date.fromordinal(735551)>>> firstdaydatetime.date(2013, 11, 18)>>> lastdaydatetime.date(2014, 11, 14)时间序列# Filename: quotesproc.pyfrom matplotlib.finance import quotes_historical_yahoo _ochl from datetime import date from datetime import datetime import pandas as pd today = date.today()start = (today.year-1, today.month, today.day)quotes = quotes_historical_yahoo _ochl ('AXP', start, today) fields = ['date','open','close','high','low','volume'] list1 = [] for i in range (0,len (quotes)):x = date.fromordinal(int (quotes[i][0])) y = datetime.strftime(x,'%Y-%m-%d') list1.append(y)quotesdf = pd.DataFrame(quotes, index = list1, columns = fields) quotesdf = quotesdf.drop(['date'], axis = 1)print quotesdfFile转换成常规时间 转换成固定格式 删除原date 列19创建时间序列>>> import pandas as pd>>> dates = pd.date_range('20141001', periods=7) >>> dates<class 'pandas.tseries.index.DatetimeIndex'> [2014-10-01, ..., 2014-10-07]Length: 7, Freq: D, Timezone: None >>> import numpy as np>>> dates = pd.DataFrame(np.random.randn(7,3),index=dates,columns = list ('ABC')) >>> datesA B C 2014-10-01 1.302600 -1.214708 1.411628 2014-10-02 -0.512343 2.277474 0.403811 2014-10-03 -0.788498 -0.217161 0.173284 2014-10-04 1.042167 -0.453329 -2.107163 2014-10-05 -1.628075 1.663377 0.943582 2014-10-06 -0.091034 0.335884 2.455431 2014-10-07 -0.679055 -0.865973 0.246970 [7 rows x 3 columns]Source20用Python玩转数据数据显示djidf quotesdf>>> djidf.indexInt64Index([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29], dtype='int64') >>> djidf.columnsIndex([u'code', u'name', u'lasttrade'], dtype='object') >>> dijdf.valuesarray([['AXP', 'American Express Company', '90.67'], ['BA', 'The Boeing Company', '128.86'], …['XOM', 'Exxon Mobil Corporation', '95.09']], dtype=object) >>> djidf.describe<bound method DataFrame.describe of code name lasttrade 0 AXP American Express Company 90.67 1 BA The Boeing Company 128.86 …29 XOM Exxon Mobil Corporation 95.09 Source显示方式:•显示索引 •显示列名 •显示数据的值 •显示数据描述>>> quotesdf.indexIndex([u'2013-11-18', u'2013-11-19', u'2013-11-20', u'2013-11-21', u'2013-11-22', u'2013-11-25', u'2013-11-26', u'2013-11-27', …-04-08', u'2014-04-09', u'2014-04-10', u'2014-04-11', ...], dtype='object')S ource索引的格式>>> djidf.head(5)code name lasttrade 0 AXP American Express Company 90.67 1 BA The Boeing Company 128.86 2 CAT Caterpillar Inc. 101.34 3 CSCO Cisco Systems, Inc. 26.32 4 CVX Chevron Corporation 116.32 [5 rows x 3 columns]>>> djidf.tail(5)code name lasttrade 25 UTX United Technologies Corporation 107.45 26 V Visa Inc. 248.84 27 VZ Verizon Communications Inc. 51.50 28 WMT Wal-Mart Stores Inc. 82.96 29 XOM Exxon Mobil Corporation 95.09 [5 rows x 3 columns]Sourcedf[:5] df[25:] 显示方式:•显示行−专用方式 −切片查看道琼斯工业股中前5只和后5只的股票基本信息?用Python玩转数据数据选择选择方式:•选择行•选择列•选择区域•筛选(条件选择)>>> quotesdf[u'2013-12-02':u'2013-12-06']open close high low volume 2013-12-02 85.092126 84.37 85.596624 84.241402 3620800 2013-12-03 83.976989 83.70 84.412256 83.294410 3546100 2013-12-04 83.303123 83.59 84.322031 82.857969 3579700 2013-12-05 83.362906 83.63 84.075156 83.244198 3677800 2013-12-06 84.663680 85.00 85.158268 84.426277 2666600[5 rows x 5 columns]S ource 选择方式:•选择行−切片 −索引美国运通公司2013年12月2日至2013年12月6日间的股票交易信息?>>> djidf['code'] 0 AXP 1 BA 2 CAT …29 XOMName: code, dtype: object >>> djidf.code 0 AXP 1 BA 2 CAT …29 XOMName: code, dtype: objectS ource 选择方式:•选择列−列名不支持djidf['code', 'lasttrade'] djidf['code':'lasttrade']道琼斯工业股公司代码?选择方式:•行、列−标签label(loc)>>> djidf.loc[1:5,]code name lasttrade1 BA The Boeing Company 128.862 CAT Caterpillar Inc. 101.343 CSCO Cisco Systems, Inc. 26.324 CVX Chevron Corporation 116.325 DD E. I. du Pont de Nemours and Company 70.80 [5 rows x 3 columns]>>> djidf.loc[:,['code','lasttrade']]code lasttrade0 AXP 90.671 BA 128.862 CAT 101.34…29 XOM 95.09[30 rows x 2 columns]S ource道琼斯工业股中标号是1至5的股票信息以及所有股票的代码和最近一次交易价?数据选择选择方式:•行和列的区域−标签label(loc)•单个值−at >>> djidf.loc[1:5,['code','lasttrade']] code lasttrade1 BA 128.862 CAT 101.343 CSCO 26.324 CVX 116.325 DD 70.80[5 rows x 2 columns]>>> djidf.loc[1,'lasttrade']'128.86‘>>> djidf.at[1,'lasttrade']'128.86'S ource道琼斯工业股中标号是1至5的股票代码和最近一次交易价?标号是1的股票的最近一次交易价?31数据选择选择方式:•行、列和区域−用iloc(位置)•取某个值−iat >>> djidf.loc[1:5,['code','lasttrade']]code lasttrade1 BA 128.862 CAT 101.343 CSCO 26.324 CVX 116.325 DD 70.80S ource>>> djidf.iloc[1:6,[0,2]]code lasttrade1 BA 128.862 CAT 101.343 CSCO 26.324 CVX 116.325 DD 70.80S ource>>> djidf.loc[1,'lasttrade']'128.86'>>> djidf.at[1,'lasttrade']'128.86'S ource>>> djidf.iloc[1,2]'128.86'>>> djidf.iat[1,2]'128.86'S ource32如果直接写成0:2不加[]则表示列索引即第0和第1列数据选择>>> quotesdf[quotesdf.index >= u'2014-01-01']open close high low volume2014-01-02 89.924438 88.49 90.102506 88.420751 5112000 2014-01-03 88.186377 88.77 89.106325 87.671998 38885002014-01-06 88.730000 88.73 89.274052 88.413460 2844700…2014-03-28 89.531554 89.72 90.811002 89.263763 3138900 ... ... ... ... ...[221 rows x 5 columns]>>> quotesdf[(quotesdf.index >= u'2014-01-01') and (quotesdf.close >= 95)] open close high low volume 2014-06-09 94.532820 95.02 95.328216 94.105295 3825200 2014-06-18 94.204662 95.01 95.039827 93.538518 2454800 2014-07-03 95.031492 95.29 95.389426 94.673558 1633800 [3 rows x 5 columns] S ource美国运通公司2014年的股票信息?进一步寻找美国运通公司2014年收盘价大于等于95的记录? 选择方式:•条件筛选33用Python玩转数据简单统计与处理简单统计与筛选>>> djidf.mean(columns = 'lasttrade') lasttrade 91.533667 dtype: float64>>> djidf[sttrade >= 120].name1 The Boeing Company 8 The Goldman Sachs Group, Inc. 10 International Business Machines Corporation 16 3M Company 26 Visa Inc. Name: name, dtype: objectSource求道琼斯工业股中30只股票最近一次成交价的平均值?股票最近一次成交价大于等于120的公司名?35简单统计与筛选>>> len (quotesdf[quotesdf.close > quotesdf.open]) 131>>> len (quotesdf)-131 120S ource 统计美国运通公司近一年股票涨和跌分别的天数? 统计美国运通公司近一年相邻两天收盘价的涨跌情况?>>> status = np.sign(np.diff(quotesdf.close)) >>> statusarray([ 1., -1., 1., -1., 1., 1., 1., 1., -1., -1., -1., 1., 1., …-1., -1., -1.])>>> status[np.where( status == 1.)].size 130>>> status[np.where( status == -1.)].size 120S ource 36排序>>> djidf.sort(columns = 'lasttrade')code name lasttrade 3 CSCO Cisco Systems, Inc. 26.32 7 GE General Electric Company 26.46 20 PFE Pfizer Inc. 30.34 11INTC Intel Corporation 33.95 …8 GS The Goldman Sachs Group, Inc. 189.98 26 V Visa Inc. 248.84 [30 rows x 3 columns]>>> djidf.sort(columns = 'lasttrade')[27:].name 10 International Business Machines Corporation 8 The Goldman Sachs Group, Inc. 26 Visa Inc. Name: name, dtype: objectS ource按最近一次成交价对30只道琼斯工业股股票进行排序。