sql学习笔记
sql必知必会读书笔记

sql必知必会读书笔记《SQL必知必会》是一本非常实用的SQL学习书籍,以下是我的读书笔记:1. SQL是什么?SQL(Structured Query Language)是一种用于管理关系型数据库的编程语言。
它可以用于创建、修改和删除数据表,以及查询、更新和删除数据。
2. SQL的基本语法SQL语句以分号结尾。
常用的SQL语句包括SELECT、INSERT、UPDATE、DELETE等。
其中,SELECT语句用于查询数据,INSERT语句用于插入数据,UPDATE语句用于更新数据,DELETE语句用于删除数据。
3. SELECT语句的基本结构SELECT语句的基本结构为:SELECT 列名FROM 表名WHERE 条件表达式。
其中,列名表示要查询的数据,表名表示要查询的表,条件表达式表示查询的条件。
4. WHERE子句WHERE子句用于指定查询条件,可以使用比较运算符(如=、<>、>、<、>=、<=)和逻辑运算符(如AND、OR、NOT)进行组合。
例如,查询年龄大于18岁的员工信息:SELECT * FROM employees WHERE age > 18;5. ORDER BY子句ORDER BY子句用于对查询结果进行排序,可以按照一个或多个列进行排序。
默认情况下,排序方式为升序(ASC),也可以使用DESC关键字进行降序排序。
例如,按照员工姓名升序排列:SELECT * FROM employees ORDER BY name ASC;6. GROUP BY子句GROUP BY子句用于将查询结果按照一个或多个列进行分组。
可以使用聚合函数(如COUNT、SUM、AVG、MAX、MIN)对每个分组进行计算。
例如,统计每个部门的平均工资:SELECT department, AVG(salary) FROM employees GROUP BY department;7. HAVING子句HAVING子句用于对分组后的结果进行筛选。
MySql-Mysql技术内幕~SQL编程学习笔记(1)

MySql-Mysql技术内幕~SQL编程学习笔记(1)1、MySQL的历史,⼀些相关概念。
2、MySQL数据类型*通常⼀个页内可以存放尽可能多的⾏,那么数据库的性能就越好,选择⼀个正确的数据类型⾄关重要。
1》UNSIGNED类型:将数字类型⽆符号化。
2》ZEROFILL:可以格式化整形显⽰,⼀旦启⽤该属性,MySQL数据库为列⾃动添加UNSIGNED属性。
0填充。
3》⽇期和时间类型⽇期数据类型占⽤空间的情况类型起始范围结束范围DATETIME1000-01-01 00:00:009999-12-31 23:59:59DATE1000-01-019999-12-31TIMESTAMP1970-01-01 00:00:002038-01-19 03:14:07YEARTIMETIMESTAMP与DATETIME显⽰的格式⼀样,但有些不同的地⽅:1>表⽰的时间范围不同2>TIMESTAMP类型的列可以设置⼀个默认值,⽽DATETIME类型不可以。
3>TIMESTAMP类型在更新表时可以设置⾃动更新为当前时间。
3》和⽇期时间相关的函数1>获取当前系统时间:now()、current_timestamp()、sysdate()1>>now():返回执⾏sql时的时间2>>current_timestamp():返回执⾏sql时的时间3>>sysdate():返回执⾏到当前sql时的时间2>时间加减函数:1>>date_add(date,interval expr unit):date_add(now(),interval 1 day)。
expr可正可负。
unit的值有year、month、day、hour、minute、second、microsecond、week。
2>>date_sub(date,interval expr unit):date_sub(now(),interval 1 day)。
精通 oracle 10g plsql 编程-学习笔记

1.PL/SQL综述本章学习目标,了解如下内容:PL/SQL的功能和作用PL/SQL 的优点和特征;Oracle 10g、Oracle9i 的PL/SQL新特征1.1.SQL简介1.1.1.SQL语言特点SQL语言采用集合操作方式1.1.2.SQL语言分类●数据查询语言(SELECT语句):检索数据库数据。
●数据操纵语言(DML):用于改变数据库数据。
包括insert,update和delete三条语句。
●事务控制语言(TCL):用于维护数据库的一致性,包括commit,rollback和savepoint 三条语句●数据定义语言(DDL):用户建立、修改和删除数据库对象。
●数据控制语言(DDL):用于执行权限授予和收回操作。
包括grant 和revoke两条命令。
1.1.3.SQL 语句编写规则●SQL关键字不区分大小写●对象名和列名不区分大小写●字符值和日期值区分大小写●书写格式随意1.2.PL/SQL简介1.3.Oracle 10G PL/SQL 新特征2.PL/SQL开发工具本章学习目标:学会使用SQL*PLUS学会使用PL/SQL developer;学会使用Procedure Builder。
2.1.SQL*PLUS在命令行运行SQL*PlusSqlplus [username]/[password] [@server]3.PL/SQL 基础学习目标:●了解PL/SQL块的基本结构以及PL/SQL块的分类;●学会在PL/SQL块中定义和使用变量●学会在PL/SQL块中编写可执行语句;●了解编写PL/SQL代码的指导方针;●了解Oracle 10g的新特征——新数据类型BINARY_FLOAT 和BINARY_DOUBLE,以及指定字符串文本的新方法。
3.1.PL/SQL 块简介3.1.1.PL/SQL块结构3.1.2.PL/SQL 块分类匿名块命名块子程序触发器3.2. 定义并使用变量3.2.1.标量变量3.2.2.复合变量3.2.3.参照变量3.2.4.LOB 变量3.2.5.非PL/SQL 变量3.3.编写 PL/SQL 代码3.3.1.PL/SQL 词汇单元分隔符标识符文本(数字文本,字符文本,字符串文本,布尔文本,日期时间文本)注释3.3.2.PL/SQL 代码编码规则标识符命名规则大小写规则代码缩进嵌套块和变量范围PL/SQL中可以使用的SQL函数4.使用SQL语句学习目标:学会使用SELECT语句去完成基本查询功能学会使用INSERT,UPDA TE和DELETE语句去操作数据库数据学会使用COMMIT,ROLLBACK和SA VEPOINT语句去控制事务学会使用SELECT语句去实现各种复杂查询功能(数据分组、连接查询、子查询、层次查询、合并查询等)4.1.使用基本查询处理NULL:函数nvl(expr1,expr2),nvl2(expr1,expr2,expr3)4.2.使用DML语句使用多表插入数据语法:INSERT ALL insert_into_clause [value_clause] subquery;INSERT conditional_insert_clause subquery;示例1:使用ALL 操作符执行多表插入INSERT ALLWHEN deptno=10 THEN INTO dept10WHEN deptno=20 THEN INTO dept20WHEN deptno=30 THEN INTO dept30WHEN job=’CLERK’ THEN INTO clerkELSE INTO otherSelect * from emp;示例2:使用FIRST 操作符执行多表插入INSERT FIRSTWHEN deptno=10 THEN INTO dept10WHEN deptno=20 THEN INTO dept20WHEN deptno=30 THEN INTO dept30WHEN job=’CLERK’ THEN INTO clerkELSE INTO otherSELECT * FROM emp;4.3.使用事务控制语句4.3.1.事务和锁4.3.2.提交事务4.3.3.回退事务设置保存点:savepoint a;或者exec dbms_transaction.savepoint(‘a’)取消部分事务Rollback to a;或者Exec dbms_transaction.rollback_savepoint(‘a’)取消全部事务:Rollback; 或者exec dbms_transaction.rollback() 4.3.4.只读事务4.3.5.顺序事务4.4.数据分组4.4.1.分组函数MaxMinAvgSumCountVarianceStddev使用分组函数注意事项:●当使用分组函数时,除了函数Count(*) 之外,其他分组函数都会忽略NULL行。
SQL学习笔记SQL账户被锁的解锁方法

SQL学习笔记:SQL账户被锁的解锁方法最近的工作当中遇到了一个小问题,就是上海网站建设的SQL账户密码失效了,使用service程序测试了一下,显示了如下的notice:Message: System.Data.SqlClient.SqlException: Login failed for user `dcp_prod`.Reason: The password of the account has expired.显然,这个是因为密码失效了,dcp_prod这个账户使用了密码失效策略,打开数据库查看这个账户的属性,果然,Enforce password policy和Enforce password expiration这两个属性被选中了。
现在只需要重新设置一下密码就可以了。
但是之后又出现了一个错误,提示如下:System.Data.SqlClient.SqlException:Login failed for user `dcp_prod` because the account iscurrently locked out.The system administrator can unlock it.(该帐户当前被锁定。
系统管理员可以解锁。
)上海网站建设该如何解决这个问题呢?locked out是锁住了,然后使用administrator站好去解锁,字面意思是这样的,照着提示区做,再次打开账户属性。
点击Status标签,果然Login is locked out属性被选中,取消选中,点击OK,回到程序中。
奇怪了,还是上面的locked out提示,打开属性查看,这个属性又一次被选中了。
这样连续来回了好几次都是这样,开始纳闷了。
后来在网上查,网上说有其他用户尝试连接数据库,我恍然大悟,是那个service程序在跟我争夺数据库。
这个service程序每3秒钟会连接一次数据库,进行相应的操作,在这中间如果尝试修改密码,账户会被锁定的。
SQL语言学习总结

SQL语言学习总结1. SQL(Structured Query Language)是一种用于管理关系数据库系统的标准语言。
通过SQL语句可以对数据库进行创建、查询、修改和删除等操作。
2. SQL语句主要分为四种类型:数据操作语言(DML),数据定义语言(DDL),数据控制语言(DCL)和事务控制语言(TCL)。
3. 数据操作语言(DML)主要用于对数据库中的数据进行查询和修改操作,常用的DML语句有SELECT、INSERT、UPDATE和DELETE。
4. 数据定义语言(DDL)用于定义数据库结构,包括创建表、修改表和删除表等操作,常用的DDL语句有CREATE、ALTER和DROP。
5. 数据控制语言(DCL)用于设置数据库用户的权限和角色,常用的DCL语句有GRANT和REVOKE。
6. 事务控制语言(TCL)用于管理数据库事务,常用的TCL语句有COMMIT、ROLLBACK和SAVEPOINT。
7. SQL语句可以通过执行顺序分为两种类型:批处理SQL和交互式SQL。
批处理SQL 一次执行多条SQL语句,而交互式SQL是一次执行一条SQL语句。
8. SQL语句可以使用通配符、操作符和函数来进行数据查询和处理。
通配符可以用来匹配模式,操作符用于比较和计算,函数用于处理数据和返回结果。
9. SQL语句可以使用条件语句和连接语句来进行复杂的数据查询和更新操作。
条件语句用于筛选数据,连接语句用于联结多个表进行查询。
10. 使用索引可以提高数据库的查询性能,可以通过创建索引来加快查询速度。
索引可以使用CREATE INDEX语句创建,也可以通过ALTER TABLE语句添加。
总的来说,学习SQL语言需要熟悉常用的语法、理解不同类型的SQL语句的用途和使用场景,并通过实践和练习来加强对SQL语言的理解和应用能力。
SQLServer物化视图学习笔记

SQLServer物化视图学习笔记⼀、基本知识索引视图实际上是⼀种将⼀组唯⼀值“物化”为群集索引形式的视图(⽩话是,给视图中的唯⼀值列加聚集索引,然后数据会存储在硬盘中),提⾼查询速度。
通过使⽤来⾃第⼀个索引的聚集键作为参考点,SQL Server还能在视图上建⽴额外的索引。
其限制如下:1. 如果视图引⽤了任何⽤户⾃定义函数,那么这些函数也必须是模式绑定的;2. 视图不可以引⽤任何其他的视图-只能引⽤表和UDF;3. 在视图中引⽤的所有表和UDF必须采⽤两部分的命名约定(例如:dbo..Customers),并且也必须具有和视图相同的所有者;4. 视图和视图引⽤的所有对象必须在相同的数据库中;5. 在创建视图和所有底层表时,必须打开ANSI_NULLS以及QUOTED_IDENTIFIER选项;6. 视图引⽤的任何函数必须是确定的;7、必须要加上WITH SCHEMABINDING, 就是绑定到架构. 8、创建完视图后, 必须紧跟着创建⼀个CLUSTERED聚集唯⼀索引,⽽且必须在第⼀列(第⼀列是唯⼀值,类似于主键那样). 9、只⽀持两部分命名的表或UDF, 如 dbo.SalesOrder.10. 涉及到多个表连接时, 不⽀持left join 或right join的写法, 只能⽤from...where的⽅式或inner join的⽅式连接. (这⼀点有时很要命只能⽤inner join太蛋疼)11. 不⽀持table.*这种懒省事的⽅式, 得⼀个⼀个把想要的列写清楚.--创建模式绑定视图CREATE VIEW PersonAge_vwWITH SCHEMABINDINGASSELECT Age,COUNT_BIG(*) AS CountAge FROM dbo.PersonTenMillionGROUP BY Age--为视图创建索引CREATE UNIQUE CLUSTERED INDEX ivPersonAgeON PersonAge_vw(Age)SQL Server中的索引视图也具有查询重写的功能, 所谓的查询重写,就是如果符合条件的数据在索引视图上,并且查询列都包含在在索引视图上,此时可以直接通过查询索引视图来替代基于原始表的查询。
sqlserver2012学习笔记

sqlserver2012学习笔记select ProductID, Name as ProductName, --using an alias'The list price for ' + ProductNumber + ' is′+convert(varchar,ListPrice)+′.′,−−usingtheconcatenationtojoincharacterend−to−end.′Thelistpricefor′+ProductNumber+′is ' + convert(varchar,ListPrice) +'.' as [Description] --using brackets to let SQL server conside the strin as a column namefrom Production.Product在where语句中⽤>,=,<等字符eg:select * from [Sales].[SalesOrderHeader]where SalesPersonID=275select * from [Sales].[SalesOrderHeader]where SalesOrderNumber='so43670' //string类型加单引号where语句中使⽤or或andeg:select SalesOrderID,OrderDate,SalesPersonID,TotalDue as TotalSalesfrom [Sales].[SalesOrderHeader]where SalesPersonID=275 and TotalDue>5000 and Orderdate between '2005-08-01' and '1/1/2006'like中使⽤%号 //%表⽰可以有,可以没有select * from [Production].[Product]where name like'Mountain'select * from [Production].[Product]where name like'%Mountain%' --Wildcard % matches any zero or more characters_下划线表⽰前⾯有⼀个不知道的字符select * from [Production].[Product]where name like'_ountain%'Where语句中使⽤in或not inselect * from [Production].[Product]where color in ('red','white','black')select * from [Production].[Product]where class not in ('H') -- same as using: <> 'H'//没有H的is null 与is not null--Topic 10select * from [Production].[Product]where size is nullselect * from [Production].[Product]where size is not nullor与and的理解Processing math: 100%。
Oracle_Plsql个人学习笔记总结

备注:以下是个人学习笔记总结,其实是本人容易忘记,工作中碰到的一些知识点,记录下来整理成笔记了,序号之间并不是按照某种类型划分的,都是随意的标记一下,希望对大家有所帮助。
昵称:阿杜笑傲江湖(其实就是个名字而已,并不江湖…)name:杜立鸿(不要冒充,万一哪天中奖了呢?)sex:爷们---------------------------废话不多说,GO,GO,Go……1.允许修改分区建(有时候分区键更新不了,需要以下这样处理,当然了分区键本来是不允许更新的,都得根据实际情况)alter table t1 enable row movement;2. 获取某一时间最近的时间sqlselect *from t_datetime twhere t.f_time - to_date('2018-09-06 10:10:00','yyyy-mm-ddhh24:mi:ss') =(select min(t.f_time - to_date('2018-09-06 10:10:00','yyyy-mm-ddhh24:mi:ss'))from t_datetime t);3. 1.创建一个object类型的数据库类型对象。
表示学生实体类型。
(注意:此类型必须定义为数据库对象级别的类型,而不能定义成包、函数级别的类型。
否则,函数外部代码是无法识别该类型的)。
CREATE OR REPLACE TYPE student_obj_type AS OBJECT(stu_no NUMBER, --学号stu_name VARCHAR2(255), --姓名stu_sex VARCHAR2(2),--性别score NUMBER--成绩);4.创建一个嵌套表类型的数据库类型对象。
表示学生实体集合类型。
该类型也将用作函数中定义的返回类型。
(注意:此类型必须定义为数据库对象级别的类型,而不能定义成包、函数级别的类型。
Pgsql学习笔记

Pgsql学习笔记RAISE NOTICE '%', a;--输出1、PGSQL自动递增序列的做法首先,在声明该列时用SERIAL类型,然后用setval(‘序列发生器’,递增的初始值)函数设置列的初始值,其中‘序列发生器’可以在表建好后,在系统生成的有关该表的SQL脚本中找到。
其次,在使用时只要调用nextval(‘序列发生器名称’)就可以了。
2、数组构造器,用关键字ARRAY。
行构造器,用关键字row()主要用途可以用在判断某字段是否为空。
3、类型转换的两种方式:CAST ( expression AS type )或expression::type,其expression为需要转换的表达式、type为要转为的类型。
4、可以用以下语句来重命名一个表或者字段重命名一字段:ALTER TABLE 表名 RENAME 字段名 TO 新的字段名重命名表名:ALTER TABLE 表名 RENAME TO 新的表名5、类型 decimal 和 numeric 是等效的。
常用的整型为integer,6、PGSQL实现取第一调记录的方法是在SQL语句后面加上limit 1 。
7、HAVING字句的作用是:当分组后需要加上条件是用HAVING不能用WHERE,而且HAVING子句中可以包含聚合函数。
WHERE 和 HAVING 的基本区别如下: WHERE 在分组和聚集计算之前选取输入行(因此,它控制哪些行进入聚集计算),而 HAVING 在分组和聚集之后选取分组的行。
因此,WHERE 子句不能包含聚集函数;因为试图用聚集函数判断那些行输入给聚集运算是没有意义的。
相反,HAVING 子句总是包含聚集函数。
(严格说来,你可以写不使用聚集的 HAVING 子句,但这样做很少有用。
同样的条件可以更有效地用于 WHERE 阶段。
)8、随机查询一个表中的一条记录的的语句SELECT column FROM table ORDER BY RANDOM() LIMIT 19、PGSQL中几种字符串类型的比较:类型内部名称说明VARCHAR(n) varchar 指定了最大长度,变长字符串,不足定义长度的部分不补齐CHAR(n) bpchar 定长字符串,实际数据不足定义长度时,以空格补齐TEXT text 没有特别的上限限制(仅受行的最大长度限制)BYTEA bytea 变长字节序列(使用NULL也是允许的)"char" char 一个字符由上表可以看出,一般情况下为了避免空格带来的麻烦可以选用VARCHAR(n)这种方式来申明一个字符串10.创建序列号CREATE TABLE person (id SERIAL, --实际上PGSQL是通过SERIAL这种数据类型来实现序列号功能的name TEXT);11、在触发器中有两种对象:NEW和OLD(对于INSERT 和UPDATE 触发器而言,是NEW 行,对于DELETE 触发器而言,是OLD 行)12、触发器实例首先建立一个posts表CREATE TABLE posts(id serial NOT NULL,title character varying(50),body text,created timestamp with time zone DEFAULT now(),modified timestamp with time zone DEFAULT now())WITHOUT OIDS;ALTER TABLE posts OWNER TO postgres;建立触发器函数-- Function: posts_insert()-- DROP FUNCTION posts_insert();CREATE OR REPLACE FUNCTION posts_insert()RETURNS "trigger" AS$BODY$beginif(NEW.title <> 'aaaa')thenNEW.body='ce shi chu fa';end if;return NEW;end$BODY$LANGUAGE 'plpgsql' VOLATILE;ALTER FUNCTION posts_insert() OWNER TO postgres;建立触发器CREATE TRIGGER p_b_insertBEFORE INSERTON postsFOR EACH ROWEXECUTE PROCEDURE posts_insert();13、PGSQL中存在事务的保存点SAVEPOINT,当在事务中设置了保存点,一旦发生错误我们不用回滚到事务的开始,用ROLLBACK TO可以直接回滚到指定的保存点。
SQL语言学习的自我总结

SQL语言学习的自我总结
学习SQL语言的过程中我收获了很多知识和技能,以下是我学习SQL的自我总结:
1. 掌握了SQL语言的基本语法和常用命令,包括SELECT、INSERT、UPDATE、DELETE等,能够使用这些命令来对数据库进行操作。
2. 理解了数据库的基本概念,包括表、字段、主键、外键等,能够设计和管理简单的数据库结构。
3. 学会了使用SQL语句查询数据库中的数据,包括基本的查询、条件查询、多表联合查询等。
4. 掌握了SQL语句的高级用法,包括聚合函数、分组、排序、子查询等,能够处理复杂的数据查询需求。
5. 学会了使用SQL语句进行数据的增删改查操作,能够对数据库中的数据进行灵活的管理。
6. 熟悉了SQL语言的优化技巧,能够提高查询效率和性能。
7. 通过练习和实践,加深了对SQL语言的理解和掌握,能够灵活应用SQL解决实际的数据处理问题。
8. 意识到SQL语言在数据处理和管理中的重要性,为今后的数据工作打下了良好的基础。
SQL必知必会笔记

SQL必知必会笔记第一章了解SQL1. 数据库是一个以某种有组织的方式存储的数据集合保存有组织的数据的容器(通常是一个文件或是一组文件) 2. 数据库软件应成为数据库管理系统DBMS3. 表某种特定类型数据的结构化清单4. 模式(schema)关于数据库和表的布局及特性的信息5. 列(Colomn)表中的一个字段。
所有表都是由一个或是多个列组成的。
6. 数据类型(datatype)所容许的数据的类型。
每个表列都有相应的数据类型,他限制(或容许)该列中存储的数据。
7. 行表中的一个记录8. 主键(primary key)一列或者一组列,其值能够唯一标识表中的每个行唯一标识表中每行的这个列(或这组列)称为主键。
主键用来表示一个特定的行。
没有主键,更新或删除表中特定行很困难,因为没有安全的方法保证只涉及相关的行。
9. 表中任何列都可以作为主键,只要满足(1)任意两行都不具有相同的主键值(2)每个行都必须具有一个主键值(主键列不允许NULL值)(3)主键列中的值不允许修改或更新(4)主键值不能重用,即某列从表中删除,它的主键不能赋给以后的新行。
第三章按多个列排序1( 子句(clause)sql语句由子句构成,有些子句是必须的,而有的是可选的。
一个子句通常由一个加上所提供的数据组成。
2( 子句的例子有SELECT语句的FROM子句3( ORDER BY 子句的位置在指定一条ORDER BY子句时,应保证它是SELECT语句中最后一条子句。
该子句的次序不对将会出现错误消息。
4( 按多个列排序执行多个列排序命令前可以发现同样的工资的人名不是按字典序排列的执行以后~~~撒花~~按列位置排序select FIRST_NAME,salaryfrom employeesorder by salary,FIRST_NAME;等价于select FIRST_NAME,salaryfrom employeesorder by 2,1;5( Order by 默认为升序排序而order by salary DESC 为降序排序DESC关键字只直接应用到位于其前面的列名ORDER BY salary DESC, FIRST_NAME; 6( 在SELECT语句中,数据根据WHERE 子句中指定的搜索条件进行过滤。
韩顺平SQL_Server学习笔记

SQL Server学习资料⏹表的管理---表名和列的命名⏹表的管理---支持的数据类型⏹表的管理----修改数据⏹表的管理---删除数据删除全部数据Delete from 表名;删除指定数据Delete from 表名where 字段名=‘值’and 字段名=‘值’建表:表的基本查询----简单的查询语句使用where子句:或者写成:如何使用like操作符(模糊查询):在where条件中使用in:使用is null的操作符:使用逻辑操作符号:使用order by子句:Select ename,(sal+isnull(comm.,0))*13 as 年薪from emp order by 年薪⏹表的复杂查询数据分组-max,min,avg,sum,count:Group by和having子句:对数据分组的总结:1)分组函数只能出现在选择列表,having,order by,子句中;2)如果在select语句中同时包含group by,having,order by,那么他们的顺序是group by,having,order by;3)在选择列中如果有列,表达式和分组函数,那么这些列和表达式必须有一个出现在group by子句中,否则就会报错;如:select depot,avg(sal),max(sal) from emp group by deptno having avg(sal)<2000;这里deptno就一定要出现在group by中;⏹表的复杂查询----多表查询多表查询是指基于两个或两个以上表或是视图的查询或者:⏹表的复杂查询----子查询1)(子查询)是指嵌入在其它sql语句中的select语句,也叫嵌套查询。
2)(单行子查询)是指只返回一行数据的子查询语句3)(多行子查询)指返回多行数据的子查询⏹在from子句中使用子查询请思考:如何显示高于部门平均工资的员工的姓名,薪水,她部门的平均工资和部门编号分析:1,首先要知道各个部门的平均工资Select avg(sal),dept from emp group by deptno2,把上面的查询结果,当做一个临时表对待这里需要说明的:当在from子句中使用子查询时,该子查询会被作为一个临时表对待,当在from子句中使用子查询时,必须给子查询指定别名。
[SQL学习笔记][用exists代替全称量词]
![[SQL学习笔记][用exists代替全称量词]](https://img.taocdn.com/s3/m/395ad7b964ce0508763231126edb6f1aff007163.png)
[SQL学习笔记][⽤exists代替全称量词]学习sql的必经问题。
学⽣表student (id学号 Sname姓名 Sdept所在系)
课程表Course (crscode课程号 name课程名)
学⽣选课表transcript (studid学号 crscode课程号 Grade成绩)
Question: 对以上表进⾏查寻选修了全部课程的学⽣姓名
--查询选修了所有课程的学⽣
--不存在这样的课程该学⽣没有选修
select*
from student s
where not exists
(
select*
from course c
where not exists
(
select*
from transcript t
where s.id = t.studid and c.crscode = t.crscode
)
)
--拿出⼀个学⽣,对任何⼀个课程,查看该学⽣是否选修了。
如果未选修,返回该课程。
--如果选修了,则查看下⼀个课程。
--最终,如果返回的所有课程为空的话说明该学⽣选修了所有的课程。
此时输出该学⽣的信息。
SQLServer学习笔记sql的范围内查找,sql数据类型,字符串处理函数

SQLServer学习笔记sql的范围内查找,sql数据类型,字符串处理函数sql的范围内查找(1)between.....and⽤法通常情况下我们查找⼀个在某固定区域内的所有记录,可以采⽤>=,<=来写sql语句,例如:查找订单价格在1000到2000之间的所有记录,可以这样写:1 select * from sales.ordervalues2 where val>=1000 and val<=2000查询结果:此处的sales.ordervalues来⾃于定义的视图,关于视图后续会讲到。
如果采⽤between.....and.....则可以同样达到效果。
1 select * from sales.ordervalues2 where val between 1000 and 2000注意⼀点:between....and.....是包含边界的,即此处包含1000和2000这个边界值。
(2)in ⽤法假如要查找1号顾客,2号顾客,9号顾客订单信息,⼀般情况下,我们会这样写:1 select * from sales.ordervalues2 where custid=1 or custid=2 or custid=9结果为:采⽤in,则减少了写法的繁杂,可以这样如下写法也能达到要求。
1 select * from sales.ordervalues2 where custid in(1,2,9)(3)like⽤法,⽤来匹配字符或字符串。
假如要查找雇员表Hr.employees⾥⾯lastname⾥包含a的字符。
可以这样写:1 select * from Hr.employees2 where lastname like '%a%'显⽰结果为:其中%表⽰通配符,即可以为任意字符。
sql数据类型sql包含多种数据类型,满⾜多种开发需求。
常见的数据类型包括:(1)⼆进制数据类型。
teradataSQL学习笔记

teradataSQL学习笔记13.15.23.24.25.26.28.29什么时候要在表名前加数据库的名字,为什么要加不加的时候当前默认数据库为什么是DWMART_BWCMA:这是可以设置的。
FORMAT不好⽤A:这是可以设置的。
TITLE vs ASA:能⽤哪个⽤哪个。
单引号 vs 双引号A:都⽤单引号,保险。
P118.数据存储属性。
包括下⾯各项:1000字节;经过compress之后,可能就变成2字节,或者远远⽐原来所占存储空间更⼩的内存。
但是!compress的过程是消耗系统资源的,也就是会对执⾏效率有⼀定的影响。
所以是否使⽤compress就是效率和空间的⼀个权衡过程。
-Ch 10 内连接-INNER JOIN。
ON 后⾯的条件应该⽤主键连接,为避免连接结果中数据重复。
eg.selb.DIVIDEID,b.REPASSETTYPEID_ON,b.REPASSETTYPEID_ON_DESC ,count(*)from dwmart_bwcm.N_exposures ainner join dwmart_rwa.fc_check_exposure_divide_315bon a.ACCOUNTREFCD=b.ACCOUNTREFCDwhere a.timeid=20130630and a.SOURCEID=9and a.ASSETTYPEID=20and a.ACCOUNTING_SUBJECT in ('3125','3126')and b.timeid=20130630and b.DIVIDEID=9group by1,2,3order by1,2,3;selab.DIVIDEID,ab.REPASSETTYPEID_ON,ab.REPASSETTYPEID_ON_DESC ,count(*)from dwmart_rwa.fc_check_exposure_divide_315abwhere timeid=20130630and ab.ACCOUNTREFCD in(sel A. ACCOUNTREFCDfrom dwmart_bwcm.N_exposures awhere a.timeid=20130630and a.SOURCEID=9and a.ASSETTYPEID=20and a.ACCOUNTING_SUBJECT in ('3125','3126')group by1)and ab.DIVIDEID=9group by1,2,3order by1,2,3;解释:两个查询结果的COUNT(*)不⼀样,因为第⼀个语句块中的内连接字段ACCOUNTREFCD不是表的主键,该字段内存在重复数据,所以内连接的结果有重复数据,导致计数结果不⼀致。
sqlplus学习笔记之编辑缓冲区中的当前行命令
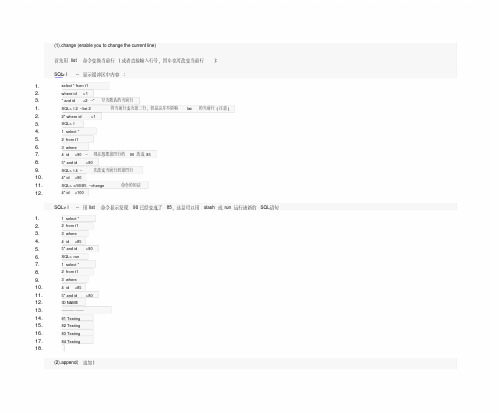
(1).change (enable you to change the current line)首先用list命令变换当前行(或者直接输入行号,回车也可改变当前行):SQL> l --显示缓冲区中内容:1.select * from t12.where id>13.* and id<2 --*号为默认的当前行1.SQL> l 2 --list 2将当前行变为第二行,但是这并不影响list的当前行(注意)2.2* where id>13.SQL> l4. 1 select *5. 2 from t16. 3 where7. 4 id<90 --现在想把第四行的90改成858.5* and id>809.SQL> l 4 --先改变当前行到第四行10.4* id<9011.SQL> c/90/85 --change命令的用法12.4* id<100SQL> l --用list命令显示发现90已经变成了85,这是可以用slash或run运行该新的SQL语句1. 1 select *2. 2 from t13. 3 where4. 4 id<855.5* and id>806.SQL> run7. 1 select *8. 2 from t19. 3 where10. 4 id<8511.5* and id>8012.ID NAME13.---------- ------14.81 Testing15.82 Testing16.83 Testing17.84 Testing18.(2).append(追加)首先用list命令变换当前行(或者直接输入行号,回车也可改变当前行):1. 1 select id,name2. 2 from t13. 3 where4. 4 id<85 --在后面添加and name='Oracle'5.5* and id>806.SQL> 4 --改变当前行7.4* id<858.SQL> a and name='Oracle' --注意这里a和and之间有两个空格,如果只有一个的话9.4* id<85 and name='Oracle' --85和and会挨在一起10.SQL> l --list显示文本已追加11. 1 select id,name12. 2 from t113. 3 where14. 4 id<85 and name='Oracle'15.5* and id>8016.SQL> /17.ID NAME18.---------- --------------------19.83 Oracle20.(3).input命令在当前行后面插入一个新行(to insert a new line after the current line)首先用list命令变换当前行(或者直接输入行号,回车也可改变当前行)定位到你要插入新行,然后i + 要插入的文本:例子:(这个比较特殊)在第一行前面加一段注释/* this is a testing demo! */1.SQL> 0 /* this is a testing demo! */ --就在第一行前面加上了该注释2.SQL> l3. 1 select id,name4. 2 from t15. 3 where6. 4 id<85 --在第四行的下面插入一个新行7.5* and id>808.SQL> 4 --先变换当前行为第四行9.4* id<8510.SQL> i --this is a demo! --input + text(要插入的文本)11.SQL> l12. 1 select id,name13. 2 from t114. 3 where15. 4 id<8516. 5 --this is a demo!17.6* and id>8018.SQL> /19.ID NAME20.---------- --------------------21.81 Testing22.82 Testing23.83 Oracle24.84 Testing25.SQL> 5 --将当前行改为5,在其后加一行,添加新的查询条件and name='Oracle'26.5* --this is a demo!27.SQL> i and name='Oracle' --插入28.SQL> l29. 1 select id,name30. 2 from t131. 3 where32. 4 id<8533. 5 --this is a demo!34. 6 and name='Oracle'35.7* and id>8036.SQL> /37.ID NAME38.---------- --------------------39.83 Oracle(4).del删除行命令a.del n --删除第n行b.del n m --删除从n到m行c.del n * --删除从第n行到当前行d.del n last --删除第n行到最后一行来源:网络编辑:联动北方技术论坛。
SQL学习笔记——创建数据库显示:文件激活错误,物理文件名不存在》解决方案

SQL学习笔记——创建数据库显⽰:⽂件激活错误,物理⽂件名不存在》解决⽅案今天在创建数据库时,跟着⽼师⼀步⼀步的操作创建成功,但出于在厌恶冗长的数据库存储路径,于是,擅⾃更改了数据filename,让他保存在电脑桌⾯新建的⽂件夹,可是⼀执⾏就报错了。
⽼师源码:1create database[DB001]on2 (3 name=DB001_1,4 filename='E:\本地应⽤安装根⽬录\数据库\MSSQL13.MSSQLSERVER\MSSQL\DATA\DB001.ndf',5 size=25MB,6 maxsize=100MB,7 filegrowth=10%8 )910log on11 (12 name=DB001_log,13 filename='E:\本地应⽤安装根⽬录\数据库\MSSQL13.MSSQLSERVER\MSSQL\DATA\DB001_1.ldf',14 size=25MB,15 maxsize=100MB,16 filegrowth=10%17 )⾃⼰改的代码:1create database[DB001]on2 (3 name=DB001_1,4 filename=' C:\Users\wjg\Desktop\DATA\DB001.ndf',5 size=25MB,6 maxsize=100MB,7 filegrowth=10%8 )910log on11 (12 name=DB001_log,13 filename=' C:\Users\wjg\Desktop\DATA\DB001_1.ldf',14 size=25MB,15 maxsize=100MB,16 filegrowth=10%17 )运⾏错误提⽰:消息 5105,级别 16,状态 2,第 1 ⾏出现⽂件激活错误。
物理⽂件名 ’ C:\Users\wjg\Desktop\DATA\DB001.ndf’ 可能不正确。
【学习笔记】使用SQLyog连接MySQL数据库

【学习笔记】使⽤SQLyog连接MySQL数据库⼀、使⽤SQLyog创建数据库⽤来管理学⽣信息1 #创建数据库student2DROP DATABASE IF EXISTS Myschool;3CREATE DATABASE Myschool;45 #在数据库中新建四张数据表6USE Myschool;78 #创建年级表9CREATE TABLE grade(10 gradeID INT(4) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '年级编号',11 gradeName VARCHAR(50) NOT NULL COMMENT '年级名称'12 )COMMENT="年级表";1314 #创建学⽣信息表15CREATE TABLE student(16 studentNo INT(4) NOT NULL PRIMARY KEY COMMENT '学号',17 loginPwd VARCHAR(20) NOT NULL DEFAULT'123' COMMENT '密码',18 studentName VARCHAR(50) NOT NULL COMMENT '姓名',19 sex CHAR(2) NOT NULL DEFAULT'男' COMMENT '性别',20 gradeID INT(4) UNSIGNED COMMENT '年级编号',21 phone VARCHAR(50) COMMENT '电话',22 address VARCHAR(255) DEFAULT'地址不详' COMMENT '地址',23 bornDate DATETIME DEFAULT NOW() COMMENT '出⽣⽇期',24 email VARCHAR(50) DEFAULT'xx@' COMMENT '邮件账号',25 identityCard VARCHAR(18) COMMENT '⾝份证号'26 )COMMENT="学⽣信息表";2728 #创建科⽬表29CREATE TABLE `subject`(30 subjectNo INT(4) NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '课程编号',31 subjectName VARCHAR(50) COMMENT '课程名称',32 classHour INT(4) COMMENT '学时',33 gradeID INT(4) UNSIGNED COMMENT '年级编号'34 )COMMENT="科⽬表";3536 #创建成绩表37CREATE TABLE result(38 studentNo INT(4) NOT NULL COMMENT '学号',39 subjectNo INT(4) NOT NULL COMMENT '课程编号',40 examDate DATETIME DEFAULT NOW() NOT NULL COMMENT '考试⽇期',41 studentResult INT(4) NOT NULL COMMENT '考试成绩'42 )COMMENT="成绩表";4344 #为表添加外键(关系)4546 #在student表中添加gradeID外键47ALTER TABLE student48ADD CONSTRAINT fk_student_grade FOREIGN KEY(gradeID)49REFERENCES grade(gradeID);5051 #在subject表中添加gradeID外键52ALTER TABLE `subject`53ADD CONSTRAINT fk_subject_grade FOREIGN KEY(gradeID)54REFERENCES grade(gradeID);5556 #在result表中添加studentNo,subjectNo外键57ALTER TABLE result58ADD CONSTRAINT fk_result_student FOREIGN KEY(studentNo)59REFERENCES student(studentNo);6061ALTER TABLE result62ADD CONSTRAINT fk_result_subject FOREIGN KEY(subjectNo)63REFERENCES `subject`(subjectNo);6465 #为表添加初始数据6667 #年级表grade的数据68INSERT INTO grade(gradeID,gradeName)69VALUES(1,'⼀年级'),(2,'⼆年级'),(3,'三年级'),(4,'四年级'),(5,'五年级');7071 #科⽬表subject的数据72INSERT INTO `subject`(subjectNo,subjectName,classHour,gradeID)73VALUES(1,'Logic Java',220,1),(2,'HTML',160,1),(3,'Java OOP',230,2);7475 #学⽣信息表student的数据76INSERT INTO student(studentNo,studentName,sex,gradeID,phone,address,bornDate)77VALUES(10000,'郭靖','男',1,136********,'天津市河西区','1990-09-08'),78 (10001,'李⽂才','男',1,136********,'地址不详','1994-04-12'),79 (10002,'李斯⽂','男',1,136********,'河南洛阳','1993-07-23'),80 (10003,'张萍','⼥',1,136********,'地址不详','1995-06-10'),81 (10004,'韩秋洁','⼥',1,138********,'北京市海淀区','1995-07-15'),82 (10005,'张秋丽','⼥',1,135********,'北京市东城区','1994-01-17'),83 (10006,'肖梅','⼥',1,135********,'河北省⽯家庄市','1991-02-17'),84 (10007,'秦洋','男',1,130********,'上海市卢湾区','1992-04-18'),85 (10008,'何睛睛','⼥',1,130********,'⼴州市天河区','1997-07-23'),86 (20000,'王宝宝','男',2,150********,'地址不详','1996-06-05'),87 (20010,'何⼩华','⼥',2,133********,'地址不详','1995-09-10'),88 (30011,'陈志强','⼥',3,136********,'地址不详','1994-09-27'),89 (30012,'李露露','⼥',3,136********,'地址不详','1992-09-27');9091 #成绩表result的数据92INSERT INTO result(studentNo,subjectNo,examDate,studentResult)93VALUES(10000,1,'2016-02-15',71),94 (10000,1,'2016-02-17',60),95 (10001,1,'2016-02-17',46),96 (10002,1,'2016-02-17',83),97 (10003,1,'2016-02-17',65),98 (10004,1,'2016-02-17',70),99 (10005,1,'2016-02-17',95),100 (10006,1,'2016-02-17',93),101 (10007,1,'2016-02-17',23),102 (20000,3,'2016-07-17',68),103 (20010,3,'2016-07-17',90),104 (20000,2,'2016-07-17',88),105 (20010,2,'2016-07-17',78);106107 ##学⽣信息数据库备份##⼆、使⽤SQLyog创建数据库制作图书馆管理系统1 #建⽴⼀个图书馆管理系统的数据库来存放图书馆的相关信息,包括图书的基本信息、图书借阅的信息和读者的信息 23 #创建数据库Library4CREATE DATABASE IF NOT EXISTS Library;5USE Library;6 #创建实体表7 #图书信息表book8CREATE TABLE book(9 bookId VARCHAR(50) PRIMARY KEY NOT NULL COMMENT '图书编号',10 bookName VARCHAR(255) NOT NULL COMMENT '图书名称',11 author VARCHAR(50) COMMENT '作者姓名',12 pubComp VARCHAR(50) COMMENT '出版社',13 pubDate DATE COMMENT '出版⽇期',14 bookCount INT(4) COMMENT '现存数量',15 price DOUBLE COMMENT '单价'16 )COMMENT="图书信息表";1718 #读者信息表reader19CREATE TABLE reader(20 readerId VARCHAR(50) PRIMARY KEY NOT NULL COMMENT '读者编号',21 readerName VARCHAR(50) NOT NULL COMMENT '读者姓名',22 lendNum INT(4) COMMENT '已借书数量',23 readerAddress VARCHAR(255) COMMENT '联系地址'24 )COMMENT="读者信息表";2526 #图书借阅表borrow27CREATE TABLE borrow(28 readerId VARCHAR(50) NOT NULL COMMENT '读者编号',29 bookId VARCHAR(50) NOT NULL COMMENT '图书编号',30 lendDate DATETIME DEFAULT NOW() NOT NULL COMMENT '借阅⽇期',31 willDate DATE COMMENT '应归还⽇期',32 returnDate DATE COMMENT '实际归还⽇期'33 )COMMENT="图书借阅表";3435 #罚款记录表penalty36CREATE TABLE penalty(37 readerId VARCHAR(50) NOT NULL COMMENT '读者编号',38 bookId VARCHAR(50) NOT NULL COMMENT '图书编号',39 pDate DATE NOT NULL COMMENT '罚款⽇期',40 pType INT COMMENT '罚款类型:1-延期,2-损坏,3-丢失',41 amount DOUBLE COMMENT '罚款⾦额'42 )COMMENT="罚款记录表";4344 #删除信息表45USE Library;46DROP TABLE IF EXISTS book;47DROP TABLE IF EXISTS reader;48DROP TABLE IF EXISTS borrow;49DROP TABLE IF EXISTS penalty;5051 #给borrow添加复合主键52ALTER TABLE borrow53ADD CONSTRAINT pk_borrow PRIMARY KEY(readerId,bookId,lendDate); 5455 #给penalty添加复合主键56ALTER TABLE penalty57ADD CONSTRAINT pk_penalty PRIMARY KEY(readerId,bookId,pDate); 5859 ##删除borrow和penalty的主键60ALTER TABLE borrow61DROP PRIMARY KEY;62ALTER TABLE penalty63DROP PRIMARY KEY;64 ##删除borrow和penalty的外键65ALTER TABLE borrow66DROP FOREIGN KEY fk_borrow_book;67ALTER TABLE borrow68DROP FOREIGN KEY fk_borrow_reader;69ALTER TABLE penalty70DROP FOREIGN KEY fk_penalty_book;71ALTER TABLE penalty72DROP FOREIGN KEY fk_penalty_reader;7374 #给borrow添加外键75ALTER TABLE borrow76ADD CONSTRAINT fk_borrow_book FOREIGN KEY(bookId)77REFERENCES book(bookId);78ALTER TABLE borrow79ADD CONSTRAINT fk_borrow_reader FOREIGN KEY(readerId)80REFERENCES reader(readerId);8182 #给penalty添加外键83ALTER TABLE penalty84ADD CONSTRAINT fk_penalty_book FOREIGN KEY(bookId)85REFERENCES book(bookId);86ALTER TABLE penalty87ADD CONSTRAINT fk_penalty_reader FOREIGN KEY(readerId)88REFERENCES reader(readerId);。
pgsql官方文档学习笔记

pgsql官⽅⽂档学习笔记⽬录从头开始安装本次是使⽤docker 拉取的pgsql的镜像来学习pgsql的拉取镜像docker pull postgres查看镜像:docker images启动容器docker run --name pg -e POSTGRES_PASSWORD=123456 -e POSTGRES_USER=postgres -p 5432:5432 -d postgres:latest进⼊容器docker exec -it 5ad99bf0c1d5 /bin/bash连接postgresSql 命令psql -h localhost -p 5432 -U postgres创建⾓⾊赋予权限⼀个数据库⾓⾊可以有⼀系列属性,这些属性定义他的权限,以及与客户认证系统的交互。
登陆权限CREATE ROLE root LOGIN;CREATE USER name; # 默认就有登录权限超级⽤户权限默认的超级⽤户是 postgres ,密码是 123456 ,创建与初始超级⽤户权限⼀样的⾓⾊CREATE ROLE root SUPERUSER;创建数据库的权限⽤户创建数据库也是需要权限的,拥有该权限才能创建数据库(对于超级⽤户是例外,因为他们超越所有权限检查)CREATE ROLE name CREATEDB ;创建⾓⾊权限创建⾓⾊的权限也需要赋予,拥有该权限的⾓⾊,拥有更改和删除其他⾓⾊,以及给其他成员赋予或者撤销成员关系,不过,要创建、更改、删除⼀个超级⽤户⾓⾊的成员关系,需要具有超级⽤户属性;只有CREATEROLE还不够。
CREATE ROLE name CREATEROLE启动复制权限⾓⾊要想启动流复制,必须明确给出权限CREATE ROLE name REPLICATION LOGIN创建删除数据库shell命令创建数据库$ createdb mydb -- 创建数据库删除数据库$ dropdb mydb -- 删除数据库可能的报错报错⼀createdb: command not found原因:那么就是PostgreSQL没有安装好:要么是就根本没装上、要么是搜索路径没有包含它。
mosh的sql笔记

mosh的sql笔记Mosh的SQL笔记主要包含了以下内容:1.选择SQL库:USE sql_store;。
这条命令用于选择要进行操作的数据库。
2.选择全部语句:SELECT * FROM customers;。
这条命令用于从customers表中选择所有列的所有行。
3.选择部分语句:SELECT customer_id FROM customers;。
这条命令用于从customers表中选择customer_id列的所有行。
4.条件筛选:SELECT * FROM customers WHERE customer_id = 1;。
这条命令用于从customers表中选择customer_id等于1的所有行。
5.排序:SELECT * FROM customers WHERE customer_id = 1 ORDER BY first_name;。
这条命令用于从customers表中选择customer_id等于1的所有行,并按first_name列进行排序。
默认是升序排序,如果需要降序排序,需要添加DESC关键字。
6.语句别名:SELECT last_name, first_name, points, (points + 10) * 100 ASdiscount_factor FROM customers;。
这条命令用于从customers表中选择last_name、first_name、points列,并计算(points + 10) * 100的值作为新的列discount_factor。
如果别名中有空格,需要在别名前后添加双引号或单引号。
此外,Mosh的SQL笔记还提到了关于MySQL的安装和数据库创建的内容,以及关于数据表操作的一些基本命令,如创建表的副本、删除表、清空表、更新单行等。
需要注意的是,以上内容仅为Mosh的SQL笔记的一部分,可能并不完整。
同时,由于SQL语言本身非常丰富和复杂,需要不断学习和实践才能掌握。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基础教程
1、SQL SELECT 语句
SELECT 语句用于从表中选取数据。
结果被存储在一个结果表中(称为结果集)。
2、SQL SELECT DISTINCT 语句
关键词DISTINCT 用于返回唯一不同的值。
3、WHERE 子句
如需有条件地从表中选取数据,可将WHERE 子句添加到SELECT 语句。
4、AND 和OR 运算符用于基于一个以上的条件对记录进行过滤。
5、ORDER BY 语句用于对结果集进行排序。
6、INSERT INTO 语句用于向表格中插入新的行。
7、Update 语句用于修改表中的数据。
8、DELETE 语句用于删除表中的行。
高级教程
1、TOP 子句。
TOP 子句用于规定要返回的记录的数目。
对于拥有数千条记录的大型表来说,TOP 子句是非常有用的。
2、LIKE 操作符
LIKE 操作符用于在WHERE 子句中搜索列中的指定模式。
4、IN 操作符。
IN 操作符允许我们在WHERE 子句中规定多个值。
5、BETWEEN 操作符
操作符BETWEEN ... AND 会选取介于两个值之间的数据范围。
这些值可以是数值、文本或者日期。
6、SQL Alias(别名)
假设我们有两个表分别是:"Persons" 和"Product_Orders"。
我们分别为它们指定别名"p" 和"po"。
现在,我们希望列出"John Adams" 的所有定单。
7、SQL join 用于根据两个或多个表中的列之间的关系,从这些表中查询数据。
●JOIN: 如果表中有至少一个匹配,则返回行
●LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行
●RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行
●FULL JOIN: 只要其中一个表中存在匹配,就返回行
8、SQL INNER JOIN 关键字(注释:INNER JOIN 与JOIN 是相同的)
在表中存在至少一个匹配时,INNER JOIN 关键字返回行。
9、SQL LEFT JOIN 关键字(注释:在某些数据库中,LEFT JOIN 称为LEFT OUTER JOIN)LEFT JOIN 关键字会从左表(table_name1) 那里返回所有的行,即使在右表(table_name2) 中没有匹配的行。
10、SQL RIGHT JOIN 关键字(在某些数据库中,RIGHT JOIN 称为RIGHT OUTER JOIN)RIGHT JOIN 关键字会右表(table_name2) 那里返回所有的行,即使在左表(table_name1)
中没有匹配的行。
11、SQL FULL JOIN 关键字(在某些数据库中,FULL JOIN 称为FULL OUTER JOIN)只要其中某个表存在匹配,FULL JOIN 关键字就会返回行。
12、SQL UNION 操作符(默认UNION 操作符选取不同的值。
如果允许重复的值,请使用UNION ALL。
)UNION 操作符用于合并两个或多个SELECT 语句的结果集。
请注意,UNION 内部的SELECT 语句必须拥有相同数量的列。
列也必须拥有相似的数据类
型。
同时,每条SELECT 语句中的列的顺序必须相同。
13、SELECT INTO 语句
SELECT INTO 语句从一个表中选取数据,然后把数据插入另一个表中。
SELECT INTO 语句常用于创建表的备份复件或者用于对记录进行存档。
14、CREATE DATABASE 语句CREATE DATABASE 用于创建数据库。
15、CREATE TABLE 语句CREATE TABLE 语句用于创建数据库中的表。
16、SQL NOT NULL 约束
NOT NULL 约束强制列不接受NULL 值。
17、SQL NOT NULL 约束UNIQUE 约束唯一标识数据库表中的每条记录。
UNIQUE 和PRIMARY KEY 约束均为列或列集合提供了唯一性的保证。
18、SQL PRIMARY KEY 约束PRIMARY KEY 约束唯一标识数据库表中的每条记录。
主键必须包含唯一的值。
主键列不能包含NULL 值。
每个表都应该有一个主键,并且每个表只能有一个主键。
19、SQL FOREIGN KEY 约束一个表中的FOREIGN KEY 指向另一个表中的PRIMARY KEY。
撤销FOREIGN KEY 约束
20、SQL CHECK 约束CHECK 约束用于限制列中的值的范围。
如果对单个列定义CHECK 约束,那么该列只允许特定的值。
如果对一个表定义CHECK 约束,那么此约束会在特定的列中对值进行限制。
21、SQL DEFAULT 约束DEFAULT 约束用于向列中插入默认值。
如果没有规定其他的值,那么会将默认值添加到所有的新记录。
22、CREATE INDEX 语句用于在表中创建索引。
在不读取整个表的情况下,索引使数据库应用程序可以更快地查找数据。
23、SQL DROP INDEX 语句我们可以使用DROP INDEX 命令删除表格中的索引。
24、ALTER TABLE 语句ALTER TABLE 语句用于在已有的表中添加、修改或删除列。
25、AUTO INCREMENT 字段我们通常希望在每次插入新记录时,自动地创建主键字段的值。
我们可以在表中创建一个auto-increment 字段。