服务器双网卡冗余工作的原理与实现
服务器冗余技术

服务器冗余是指重复配置系统的一些部件,当系统发生故障时,冗余配置的部件介入并承担故障部件的工作,由此减少系统的故障时间。
一、在服务器里,冗余系统配件主要有:1、电源:高端服务器产品中普遍采用双电源系统,这两个电源是负载均衡的,即在系统工作时它们都为系统提供电力,当一个电源出现故障时,另一个电源就承担所有的负载。
有些服务器系统实现了DC的冗余,另一些服务器产品如Micron公司的Net FRAME 9000实现了AC、DC的全冗余。
2、存储子系统:存储子系统是整个服务器系统中最容易发生故障的地方。
以下几种方法可以实现该子系统的冗余。
(1)磁盘镜像:将相同的数据分别写入两个磁盘中。
(2)磁盘双联:为镜像磁盘增加了一个I/O(输入/输出)控制器,就形成了磁盘双联,使总线争用情况得到改善。
3、RAID:廉价冗余磁盘阵列(Redundant array of inexpensive disks)的缩写。
顾名思义,它由几个磁盘组成,通过一个控制器协调运动机制使单个数据流依次写入这几个磁盘中。
RAID3系统由5个磁盘构成,其中4个磁盘存储数据,1个磁盘存储校验信息。
如果一个磁盘发生故障,可以在线更换故障盘,并通过另3个磁盘和校验盘重新创建新盘上的数据。
RAID5将校验信息分布在5个磁盘上,这样可更换任意一个磁盘,其余与RAID3相同。
4、 I/O卡:对服务器来说,主要指网卡和硬盘控制卡的冗余。
网卡冗余是在服务器中插上双网卡。
冗余网卡技术原为大型机及中型机上的技术,现在也逐渐被PC服务器所拥有。
PC服务器如Micron公司的NetFRAME9200最多实现4个网卡的冗余,这4个网卡各承担25%的网络流量。
康柏公司的所有ProSignia/Proliant服务器都具有容错冗余双网卡。
5、 PCI总线:代表Micron公司最高技术水平的产品Net FRAME 9200采用三重对等PCI技术,优化PCI总线的带宽,提升硬盘、网卡等高速设备的数据传输速度。
服务器双网卡冗余工作的原理与实现

个 网 卡 的状 态 ,通 过 pn ig命 令 进 行检 测 ,如 果连 续 5 网卡 已经 出现故 障 。缺 省 的故 障检 测 时 间是 1 0秒 , 大 即
( ) 务器 的两 个 网卡 为 h O和 h 1 2服 me me ;
( ) m O的 I 3h e P地 址 为 1 21 88 . 9 .6 .5 1 9,测 试 地 址 为
1 2.6 .5. ; 9 1 88 21
每 个 网 卡 的测 试 I 址 检测 其 自身 的状 态 , 测 的 方 法 P地 检
的地 址 均 发 生 转 移 和 切换 ,所 以测 试 I P地 址 不 能 用 作
他用 。
计 算 机 网络 中关 键 设 备 的 冗 余 工 作 已经 成 为保 障 应 用 业务 稳 定运 行 的关 键 手 段 ,服 务 器 的 网 卡冗 余 工 作
是 在 不增 加 任何 投 入 的基 础 上 ,增 加 服 务器 稳 定 性 的一 种 方 法 , 实 现简 单 , 置 灵 活 , 广 泛地 应 用 到实 践 中 。 它 配 被
1 2 1 88 2 。 9 . 6 .5.2
常被 选 作为 目标 I 址 ,如果 在 链 路 上没 有 路 由器 , P地 那
么 网 卡 状 态 检 测 进 程 会 发 送 多 播 数 据 包 到 所 有 主 机 (2 ...) 2 4001 ,并 随机 选择 其 中一 台主机 的 I 址 作 为被 P地 检 测 的 目标 地址 。
#
i o f hmel a df 1 2 1 88 .2 n t s f ni c g di 9 .6 .52 ema k
双冗余网卡高速切换的实现

为例 ,介 绍在Wno s 作 系统 下 ,通 过在 网 i w操 d
卡 驱动 中读取 寄存 器 ,快速检 测 网卡 故障 ,
从 而实现 双 冗 余 网卡 高速 切换 ,使双 冗 余 网
卡 的切换 时 间缩短 至 7 m ,大 大提 高切换 速 0s
度 ,从 而保 障各 类铁路 通 信设 备应 用的正 确
作系统下 ,若采用在应 用层实现双 网卡冗余 备份技术 ,
驱 动软件 设计分 3 部分 :初 始化 、双冗余 网卡检 测 与切
其 网卡切换 的平 均 时间必然大 于 1 0 。要 实现双冗余 换 、数 据包接收与发送 。初始化 主要 是设 置 网卡 和驱动 2 ms 网卡 的快速切换 ,提高 网络的可靠性 和实时性 ,最理 想 程序 的初始状态 , 包 括初始化变量 、网卡复位及准备发 的办法 是在驱动程序 中实现 。因为操 作系统对 内核模 式 送 和接收 的数据包 等。而数据包 的接 收和发送 主要 是对 的软件 具有 更高的信任度 ,它 工作在r g级 ,可直接 访 网络上 的数据流进行 侦听 ,如果没有 ,则将数据 发送到 i0 n
备 份 网卡能 实时 、 自动地 完成切换 继续工作 。两块 网卡 键 和基础是 网络故障 的检 测 ,可通 过软件检查 、交换 机 使 用 同一个 物理地址 和 同一个 I地址 。从应用 程序角度 及 网络节点 的网卡协同处 理 ,共同完成。 P
CH| NESE RA/ LWAYs 2 2 J (: o J 。 4
的特性 、类 型及驱动允许数据 传输 的方式等信 息 。现 以 网线断 开 、网络接 口松 动及故障等错误 。其原理是 :当
It l 2 4 G 网络控制芯片为例 ,对双冗余 网卡驱动 的 网络链 路链接时 ,网线连接状 态寄存器 中信号为 l 网 ne 5 6 B r8 ,
双网卡绑定实现负载,冗余及内外网设置

Linux配置双网卡绑定,以实现冗余及负载均衡1、首先需要彻底关闭NetworlManger 服务,如果有的话,否则会和bond网卡冲突[root@rhel ~]#service NetworlManger stop[root@rhel ~]#chkconfig NetworlManger off2、新建ifcfg-bond0配置文件[root@rhel ~]#vi /etc/sysconfig/network-scripts/ifcg-bond0DEVICE=bond0BOOTPROTO=noneIPADDR=192.168.1.11NETMASK=255.255.255.0ONBOOT=yesUSERCTL=no #用户控制禁止3、修改ifcfg-eth0配置文件,将IP/GW/NW/ID/HW等注释,保留以下信息[root@rhel ~]#vi /etc/sysconfig/network-scripts/ifcg-eth0DEVICE=eth0BOOTPROTO=noneONBOOT=yesUSERCTL=noMASTER=bond0 #将网卡指向bond0SLAVE=yes #启用双网卡4、修改ifcfg-eth1配置文件[root@rhel ~]#vi /etc/sysconfig/network-scripts/ifcg-eth0DEVICE=eth1BOOTPROTO=noneONBOOT=yesUSERCTL=noMASTER=bond0 #将网卡指向bond0SLAVE=yes #启用双网卡5、修改rc.local文件,添加以下信息[root@rhel ~]#vi /etc/rc.localifenslave bond0 eth0 eth1 #rhel6以上可以不设,但需要重启。
6、修改内核文件,系统不同有差异需要谨慎查看,查看备注。
Rhel6.3以下添加[root@rhel ~]#vi /etc/modprobe.d/dist.confAlias bond0 bondingOptions bond0 mode=1 miimon=50 #可在ifcfg-bond0中添加用BONDING_OPT=””连接。
网络双冗余快速切换的方法与制作流程

本技术涉及一种网络双冗余快速切换的方法,涉及网络通信技术领域。
该方法只在驱动层就可实现网卡切换的动作,不需要更高层的模块协助处理,因此该方法只需要更改网卡的驱动即可实现,而对TCP/IP层的网络协议不做任何的变动,从而可以大大提高网络切换的速度,减少网路切换的时间开销,具体地,切换速度最大可达2倍的任务周期时间,切换时间稳定可调。
该方法在Windows、VxWorks、Linux操作系统中均已实现,满足性能要求。
权利要求书1.一种网络双冗余快速切换的方法,其特征在于,包括以下步骤:步骤S1,系统进行初始化阶段,获取各网卡的硬件资源,并对各网卡做硬件初始化;步骤S2,将第一块网卡注册至系统中;步骤S3,将第一块网卡的注册数据记录到冗余组中的第一个位置;步骤S4,将工作网卡设定为第一块网卡;步骤S5,将第二块网卡注册到系统中;步骤S6,将第二块网卡的IP地址、MAC地址设置为与第一块网卡一致;步骤S7,将第二块网卡加到冗余组中;步骤S8,启动网络监视任务,在此任务中实现网卡连接状态的监视和网卡的切换。
2.如权利要求1所述的方法,其特征在于,步骤S8中在驱动层实现网卡的切换。
3.如权利要求2所述的方法,其特征在于,步骤S8中实现网卡的切换时,在发送时,网络层向驱动层通知从哪个设备指针发送数据,驱动层接到发送命令时,抛弃网络层传递的设备指针,而使用当前工作网卡的设备指针作为物理设备完成数据发送,并返回发送状态;在接收时,网络层向驱动层通知从哪个设备指针接收数据,驱动层接到接收命令时,抛弃网络层传递的设备指针,而使用当前工作网卡的设备指针作为物理设备完成数据接收,并返回发送状态。
4.如权利要求3所述的方法,其特征在于,步骤S8中实现网卡的切换时,在层间的通讯通过返回状态来确认,只要实现网络层接口调用返回值的正确即可实现伪装欺骗。
5.如权利要求4所述的方法,其特征在于,步骤S8中采用定期判断物理状态变化寄存器中网卡的连接状态,实现网卡的切换。
服务器双网卡的冗余备份
服务器双网卡的冗余备份服务器作为企业信息平台的核心,其稳定性和安全性至关重要,连接服务器的网络链路是尤为重要的一环。
增加热备份冗余链路成为保障服务器链路通畅常用的方法之一,此方式可以强化系统网络链路,减少故障率。
如今,许多企业都搭建了各种信息平台,服务器作为信息平台的硬件载体,其稳定性日趋重要。
其中,网络链路又是尤为重要的一环,显然,如何保障服务器网络链路的持续稳定工作已成为摆在网络管理员、系统管理员面前的重要问题了。
增加热备份冗余链路成为保障服务器链路通畅常用的方法之一,此方式可以强化系统网络链路,减少故障率。
这里提到的冗余备份方式可以应用于企业的重要业务访问,实施后,相应业务在多种冗余技术的支持下,将会更加稳固。
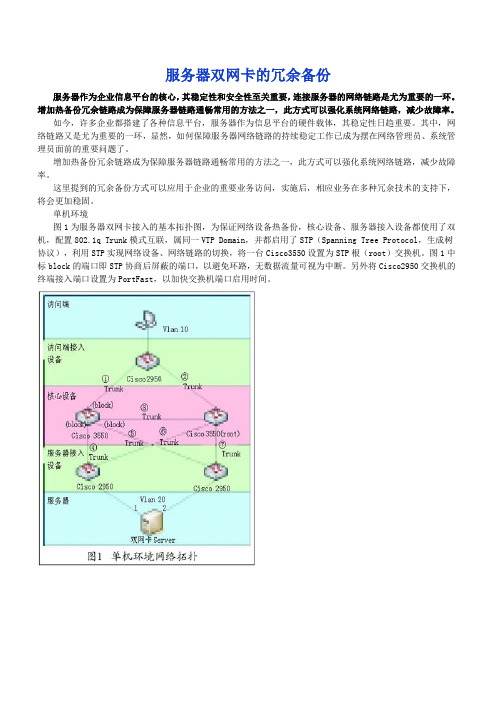
单机环境图1为服务器双网卡接入的基本拓扑图,为保证网络设备热备份,核心设备、服务器接入设备都使用了双机,配置802.1q Trunk模式互联,属同一VTP Domain,并都启用了STP(Spanning Tree Protocol,生成树协议),利用STP实现网络设备、网络链路的切换,将一台Cisco3550设置为STP根(root)交换机。
图1中标block的端口即STP协商后屏蔽的端口,以避免环路,无数据流量可视为中断。
另外将Cisco2950交换机的终端接入端口设置为PortFast,以加快交换机端口启用时间。
1. 软件使用原则服务器接入可以通过使用网卡捆绑软件实现热备冗余,对于服务器双网卡捆绑软件的选择可遵循以下几点原则: 兼容性好,能在不同品牌网卡上使用; 中断恢复快; 能检测深层中断,即能检测到非直连设备的中断。
2. 推荐软件NIC Express 4.0是一款兼容性较好的捆绑软件,它能兼容Broadcom、D-Link等常见网卡,但在Intel网卡上安装会造成大量丢包。
Inter Proset是针对Intel网卡的专用网卡捆绑软件,但Inter Proset只能在Intel网卡上使用,且不支持深层中断的检测。
Linux下通过bonding技术实现网络负载均衡及冗余

Linux Bonding一、什么是bondingLinux bonding 驱动提供了一个把多个网络接口设备捆绑为单个的网络接口设置来使用,用于网络负载均衡及网络冗余二、bonding应用方向1、网络负载均衡对于bonding的网络负载均衡是我们在文件服务器中常用到的,比如把三块网卡,当做一块来用,解决一个IP地址,流量过大,服务器网络压力过大的问题。
对于文件服务器来说,比如NFS或SAMBA文件服务器,没有任何一个管理员会把内部网的文件服务器的IP地址弄很多个来解决网络负载的问题。
如果在内网中,文件服务器为了管理和应用上的方便,大多是用同一个IP地址。
对于一个百M的本地网络来说,文件服务器在多个用户同时使用的情况下,网络压力是极大的,特别是SAMABA和NFS服务器。
为了解决同一个IP地址,突破流量的限制,毕竟网线和网卡对数据的吞吐量是有限制的。
如果在有限的资源的情况下,实现网络负载均衡,最好的办法就是 bonding2、网络冗余对于服务器来说,网络设备的稳定也是比较重要的,特别是网卡。
在生产型的系统中,网卡的可靠性就更为重要了。
在生产型的系统中,大多通过硬件设备的冗余来提供服务器的可靠性和安全性,比如电源。
bonding 也能为网卡提供冗余的支持。
把多块网卡绑定到一个IP地址,当一块网卡发生物理性损坏的情况下,另一块网卡自动启用,并提供正常的服务,即:默认情况下只有一块网卡工作,其它网卡做备份三、bonding实验环境及配置1、实验环境系统为:CentOS,使用4块网卡(eth0、eth1 ==> bond0;eth2、eth3 ==> bond1)来实现bonding技术2、bonding配置第一步:先查看一下内核是否已经支持bonding1)如果内核已经把bonding编译进内核,那么要做的就是加载该模块到当前内核;其次查看ifenslave该工具是否也已经编译modprobe -l bond*或者 modinfo bondingmodprobe bondinglsmod | grep 'bonding'echo 'modprobe bonding &> /dev/null' >> /etc/rc.local(开机自动加载bonding模块到内核)which ifenslave注意:默认内核安装完后就已经支持bonding模块了,无需要自己手动编译2)如果bonding还没有编译进内核,那么要做的就是编译该模块到内核(1)编译bondingtar -jxvf kernel-XXX.tar.gzcd kernel-XXXmake menuconfig选择 " Network device support " -> " Bonding driver support "make bzImagemake modules && make modules_installmake install(2)编译ifenslave工具gcc -Wall -O -I kernel-XXX/include ifenslave.c -o ifenslave第二步:主要有两种可选择(第1种:实现网络负载均衡,第2种:实现网络冗余)例1:实现网络冗余(即:mod=1方式,使用eth0与eth1)(1)编辑虚拟网络接口配置文件(bond0),并指定网卡IPvi /etc/sysconfig/network-scripts/ifcfg-bond0DEVICE=bond0ONBOOT=yesBOOTPROTO=staticIPADDR=192.168.0.254BROADCAST=192.168.0.255NETMASK=255.255.255.0NETWORK=192.168.0.0GATEWAY=192.168.0.1USERCTL=noTYPE=Ethernet注意:建议不要指定MAC地址vi /etc/sysconfig/network-scripts/ifcfg-eth0DEVICE=eth0BOOTPROTO=noneONBOOT=yesUSERCTL=noMASTER=bond0SLAVE=yes注意:建议不要指定MAC地址vi /etc/sysconfig/network-scripts/ifcfg-eth1DEVICE=eth1BOOTPROTO=noneONBOOT=yesUSERCTL=noMASTER=bond0SLAVE=yes注意:建议不要指定MAC地址(2)编辑模块载入配置文件(/etc/modprobe.conf),开机自动加载bonding模块到内核vi /etc/modprobe.confalias bond0 bondingoptions bond0 miimon=100 mode=1alias net-pf-10 off #关闭ipv6支持说明:miimon是用来进行链路监测的。
冗余网络配置实验报告

冗余网络配置实验报告冗余网络配置实验是网络工程中一种重要的设计和实施手段,旨在提高网络的可靠性和稳定性。
本文将从网络冗余的原理、冗余网络的常见形式、实验过程和结果分析等方面进行详细论述。
一、冗余网络的原理冗余网络是通过在网络中增加冗余路径,以提高网络的可靠性和稳定性。
冗余路径即备用路径,当主路径出现故障时,备用路径能够接替主路径的功能,保证网络的连通性。
冗余网络的基本原理是采用备份路径,将网络流量在不同的路径上进行传输,提高了网络的容错能力,减少网络发生故障时网络中断的可能性。
二、冗余网络的常见形式冗余网络可以采用多种形式来实现,常见的几种形式包括:主备式、主主式、冗余链式和冗余环状式。
1. 主备式:主备式是指在网络中设置主路径和备用路径,当主路径发生故障时,备用路径可以接替主路径的功能。
主备式可以简单实现,但是备用路径的利用率较低,效率较低。
2. 主主式:主主式是指设置多个主路径,当其中一个主路径发生故障时,其他主路径可以继续工作。
主主式可以提高网络的可用性,但是配置和管理复杂度较高。
3. 冗余链式:冗余链式是指设置多个路径形成链式结构,当其中一条路径故障时,链式结构中的其他路径可以继续进行数据传输。
冗余链式相对简单,但是链式中的每条路径都是关键路径,一旦出现故障会导致整个链式中断。
4. 冗余环状式:冗余环状式是指设置多个路径形成环状结构,当环状结构中的一条路径故障时,其他路径可以绕过故障路径继续进行数据传输。
冗余环状式相对复杂,但是具有良好的容错能力和高利用率。
三、冗余网络的实验过程本次实验的目的是验证冗余网络对网络可靠性和稳定性的提升效果,实验过程如下:1. 实验准备:准备实验所需要的网络设备和材料,并确保设备的正常运行状态。
2. 实验拓扑设计:根据实验要求,设计适合的网络拓扑结构。
可以选择主备式、主主式、冗余链式或冗余环状式等形式。
3. 网络配置:根据拓扑结构,配置网络设备的相关参数和路径设置。
用Broadcom网卡实现多网卡冗余教程

Broadcom网卡绑定教程组功能用于将任何可用的网络设备组合在一起,以用作一个组。
组是一种创建虚拟局域网(用作单个设备的一组设备)的方法。
此方法的优点是能够实现负载平衡和故障转移。
组通过 Broadcom Advanced Serve r Program 软件来完成。
有关组软件技术和实施注意事项的综合描述,请参见Broadcom NetXtreme 57XX 用户指南中的“Broadcom Gigabit Ethernet 组服务”一节。
注:∙有关组协议的更多信息,请参见Broadcom NetXtreme 57XX 用户指南中的组。
∙在配置组时,如果您未启用 LiveLink™,则建议您在交换机禁用生成树协议 (STP)。
这在故障转移时将由于确定生成树环的停机时间降到了最少。
LiveLink 可以减轻此类问题的严重程度。
∙仅在服务器安装了一个或多个 Broadcom Ethernet 控制器时 BASP 才可用。
∙只有在组中所有成员均支持并且已配置 LSO 和 Checksum Offload 属性的情况下,系统才会自动启用 Large Send Offload (LSO) 和 Checksum Offload 属性。
∙您必须具有管理员权限才能创建或修改组。
∙组环境(组中成员的连接速度各不相同)中的负载平衡算法会优先计算通过 Gigabit Ethernet 链路连接的成员,然后才会计算使用低速链路(100 Mbps 或 10 Mbps)连接的成员,直至达到阈值。
这是很正常的行为。
您可以创建 4 种类型的负载平衡组:智能负载平衡™和故障转移:在这种类型的组中,如果所有负载平衡成员均出现故障,备用成员将处理通信量(故障转移事件)。
必须是在所有负载平衡成员均出现故障之后,备用成员才会接管通信量。
当一个或多个负载平衡成员恢复(回归)时,恢复的组成员重新开始处理通信量。
只有此类型的组才支持 LiveL ink 功能。
手把手教你实现服务器的双网卡冗余

手把手教你实现服务器的双网卡冗余手把手教你实现服务器的双网卡冗余在过去的几篇文章中,我们讨论了一些网卡的理论知识。
接下来,我们就要借助亿时空服务器SX1242平台来实地操作,说明如何实现服务器的双网卡冗余,实现负载均衡。
我们前几天也曾经简单的说到服务器的冗余技术,包括服务器的内存、硬盘、电源、网卡等。
据我所知,服务器里面,除了CPU和主板不能实现冗余外,其余在一定条件下都能做到冗余。
这次我们就一步一步,来实现网卡的冗余功能。
从配置上看,CPU为四核XEON5335,服务器的网卡,也是集成在主板上的,但是不要认为集成的就不好。
网卡好还是不好,主要看采用的芯片,根据亿时空技术人员的说明,亿时空SX1242服务器,采用的是intel 82563EB网络控制器,属于英特尔“Dempsey”平台的组成部分,支持英特尔最新的I/O加速技术,当然,也支持网卡绑定技术了。
详细配置列表其实双网卡冗余技术,并非是高深莫测,只要稍懂一些PC技术就可以搞定,做起来非常容易。
网卡负载均衡,通常就是我们说的网卡冗余,也叫网卡绑定,这一功能即使实现两块或者2块以上(但是有上限的)网卡虚拟成为一块网卡,这个聚合起来的设备看起来是一个单独的以太网接口设备,简单的的说就是这些绑定的网卡具有相同的IP地址而并行链接聚合成一个逻辑链路工作。
这个过程也就像是磁盘阵列的RAID1的形式。
网卡冗余技术是一种在服务器和交换机之间建立冗余连接的技术,亦即在服务器上安装两块网卡,一块为主网卡,另一块作为备用网卡,然后用两根网线将两块网卡都连到交换机上。
网卡冗余技术(AFT)的基本工作过程是,当在服务器上装配两块网卡后,AFT技术就能把这两块网卡当作一个网卡工作组来对待,一块为主网卡,另一块为备用网卡。
当主网卡工作时,软件通过备用网卡对主网卡及连接状态时刻进行监测,即采用一种发送特殊设计的“试探包”的方法来进行的监测。
若连接失效,“试探包”便无法送达主网卡,智能软件发现此情况后,立即将工作(包括MAC网络地址)移交给备用网卡。
在linux下如何做双网卡绑定实现冗余

在linux下如何做雙網卡綁定實現冗餘?一、Linux Channel Bonding目前在各個發行版本的 Linux 中,使用最普遍的內核版本應該就是 2.4.x的版本了,而 Linux Channel Bonding,在 Linux 2.4 的內核中,就提供了 bonding 的驅動,可以支援把多個網路介面卡集合在一起,當作一個網路介面卡來使用。
在 Linux 下,網卡的高可用性是通過 MII 或者 ETHTOOL 的狀態監測來實現的,所以,需要檢查系統中的網路介面卡是否支援 MII 或者 ETHTOOL 的連狀態監測。
可以用命令 "ethtool eth0" 來檢查,如果顯示的 "Link detected:" 資訊與實現的連接狀態一致,就沒有問題。
如果系統中的網路介面卡不支援 MII 或者 ETHTOOL 狀態監測,當連接失效時,系統就不能檢測到,同時,在 bonding 驅動載入時,會記錄一條不支援 MII 和 ETHTOOL 的警告資訊。
下面簡單介紹一下實現的基本方法:首先,我們需要打開內核對 bonding 支援。
設置內核 "make menuconfig/xconfig/config",在"Network device support"區段中選擇"Bonding driver support",建議設置該驅動程式為模組,這樣才能支援給驅動傳遞參數和設置多個bonding設備。
生成並安裝新的內核和模組。
Bonding 的設置我們需要在 /etc/modules.conf 中加入兩行,這樣才可以在設置了 bond 設置後,系統啟動的時候自動載入 bonding 的驅動程式alias bond0 bondingoptions bond0 miimon=100 mode=1當mode=1時為主備模式,mode=0時為負載均衡模式。
双网卡原理

双网卡原理
双网卡是指计算机上同时安装了两块网卡,可以连接两个不同的网络。
双网卡的原理是通过两个网卡分别连接不同的网络,实现对两个网络的同时访问和数据传输。
双网卡的应用范围非常广泛,可以用于网络负载均衡、网络故障转移、网络访问控制等多种场景。
首先,我们来了解一下双网卡的工作原理。
在计算机上安装了两块网卡后,每块网卡都会被分配一个IP地址,分别连接到不同的网络中。
当计算机需要进行网络通信时,根据路由表的设置,可以选择通过哪块网卡进行数据传输。
这样就可以实现对两个网络的同时访问和数据传输。
双网卡的应用场景非常丰富。
首先是网络负载均衡,通过双网卡可以将网络流量分发到不同的网络中,从而避免单一网络的过载,提高网络的整体性能。
其次是网络故障转移,当一块网卡所连接的网络出现故障时,可以通过另一块网卡连接的网络继续进行通信,保证网络的稳定性。
另外,双网卡还可以用于网络访问控制,将不同的网络流量分开处理,提高网络的安全性。
在实际应用中,双网卡需要进行一定的配置才能发挥其作用。
首先需要对每块网卡进行IP地址的配置,确保其能够正常连接到网络中。
然后需要设置路由表,指定通过哪块网卡进行数据传输。
此外,还可以通过网络设备或软件进行进一步的配置,实现更加灵活的网络管理和控制。
总的来说,双网卡是一种非常实用的网络技术,可以帮助我们实现对多个网络的同时访问和数据传输。
通过合理的配置和管理,可以充分发挥双网卡的优势,提高网络的性能和稳定性,满足不同应用场景的需求。
希望本文对大家对双网卡的原理有所了解,也希朗对双网卡的应用有所启发。
实验3windows下服务器多网卡冗余

实验3: Windows下服务器多网卡冗余一、实验目的1.熟悉Windows下多网卡冗余的基本形式,掌握Windows下多网卡绑定的基本步骤。
2. 注意:由于本实验是在虚拟机环境中,所以选用NIC Express软件(根据客户端的不同,自行在网上下载该软件),如果是真实机,应根据所配置网卡的类型,选择相关的绑定驱动。
二、实验内容及步骤拓扑图1. 安装VMware软件。
2.在VMware中新建1台Windows Server 2003并命名,命名例如S1。
3.为Windows Server 2003再添加一块虚拟网卡,选择桥接模式。
4.启动Windows Server 2003,查看网上邻居属性,为两块网卡分别命名进行区分,如net1、net2,分别配置IP地址,网络地址为10.0.0.0。
5、在Windows Server 2003中安装NIC Express软件,进行网卡绑定配置。
6、网上邻居-属性,为新出现的NIC网卡组配置IP地址和子网掩码,如10.0.0.168。
7、在管理工具中打开NIC Express Enterprise Edition,查看Device Stats。
8、在另外一台计算机上命令行中输入:Ping 10.0.0.168 –t 。
查看能否Ping通,并保持Ping的状态不要关闭(注意要事先将这台计算机的IP 地址设置成10的地址,如10.0.0.68,这样才能保证Ping通)9、关闭Windows Server 2003,删除一块网卡,并重新启动。
10、在Windows Server 2003启动时,查看另一台计算机上的Ping界面。
11、根据实验结果对实验各内容进行总结。
三、实验要求1.实验中仔细观察、记录、比较实验结果,如果不一致应找出原因。
2.实验中凡是需要命名的地方,均以自己名字的全拼来命名,可以用不同后缀来区分。
如张三的两台服务器可以命名为:zhangsanS1,zhangsanS2。
双网口冗余模块的设计

双网口冗余,即同一块网卡中有两个网络通道,系统运 行时自动判别两个通道是否正常运行,若一个通道发生故 障,系统便自动切换到另一个通道来保证网络的正常运行。
—162—
连接到双绞线介质或借助工业标准的电绝缘纤维/光纤PMD 收发器直接连接到光纤介质上,而且通过IEEE 802.3u标准的 独立介质接口直接连接到MAC层上,保证在不同设备上不 同情况下产品之间互相协同工作的能力。
3 冗余功能的实现
冗余功能的实现主要靠两个D型触发器,其输出端分别 连接两个MII接口芯片的使能引脚,这些引脚低电平有效。 输入端信号来自21143网络控制器的GPE[1…3]脚。这些引脚 是多用途引脚,可以用软件配置成可执行输出或输入的功 能。选择哪一条通道就是由这3个引脚来确定的。一旦给这 3 个变量赋予一定值,则Q端的输出是可定的且唯一的,由此 决定选用哪一个通道。在两个物理控制器中分别有一个状态 控制寄存器,该状态控制寄存器的4个引脚分别置了不同的 初始值。在系统运行过程中,硬件自动判别默认通道A的状 态控制寄存器是否运行正常,若正常则不改变GPE[1…3] 的 当前值,若不正常则改变GPE[1…3]的当前值,使默认通道 A的MII接口芯片的使能引脚无效,而使连接另一个通道B的 MII接口芯片的使能引脚有效,从而达到切换网络通道的目 的。然后系统读取B通道的状态控制寄存器初始值进行比 较,用前面相同的检测方法来判别、切换通道。系统运行时 的默认通道由触发器的置位端直接确定。冗余部分的硬件连 接如图3所示。
最近由美国扬基集团(Yankee Group)出版的研究报告显 示:中国在2001年拥有的互联网人口达到了4千万,超过亚 洲任何其他国家;到2005年,中国就将超过美国而成为世界 上互联网人口最多的国家。
多网卡原理及作用

多网卡原理及作用.txt今天心情不好。
我只有四句话想说。
包括这句和前面的两句。
我的话说完了对付凶恶的人,就要比他更凶恶;对付卑鄙的人,就要比他更卑鄙没有情人味,哪来人情味拿什么整死你,我的爱人。
收银员说:没零钱了,找你两个塑料袋吧!服务器网卡容错技术----随着计算机网络技术的迅速发展,计算机网络不断推广,人们对计算机网络系统的可靠性要求也越来越高。
今天,网络服务器不仅是用作简单的打字或文件处理,而且往往用在重要的商务处理上,为重要应用提供高可靠性的连接。
----服务器功能越来越强大,服务器在计算机网络中的地位也日益重要。
而服务器至网络的连接性能同样不可忽视,它与服务器的可靠性和整个网络的可靠性同等重要。
在实际应用中,无论是网线断了、丢了、集线器或交换机端口坏了、还是网卡坏了都会造成连接中断。
----关系到计算机网络系统能否正常运行的因素很多,服务器网卡就是其中重要环节之一。
为此,许多网络厂商推出了各自的具有容错功能的服务器网卡。
例如Intel推出了三种容错服务器网卡,它们是:AdapterFaultTolerance(AFT,网卡出错冗余)、AdapterLoadBalancing(ALB,网卡负载平衡)、FastEtherChannel(FEC,快速以太通道)技术,现对这三种技术,逐一进行介绍。
一、网卡出错冗余(AFT)----AFT技术是在服务器和交换机之间建立冗余连接,即在服务器上安装两块网卡,一块为主网卡,另一块作为备用网卡,然后用两根网线将两块网卡都连到交换机上。
在服务器和交换机之间建立主连接和备用连接。
一旦主连接断开,备用连接会在几秒钟内自动顶替主连接的工作,通常网络用户不会觉察到任何变化。
AFT技术工作原理----当Netware或NT服务器装上两块网卡后,AFT技术把这两块网卡作为一个网卡工作组,一块为主网卡,另一块为备用网卡。
当主网卡工作时,智能软件通过备用网卡对主网卡及连接状态进行监测。
双网卡冗余

关于双网卡冗余的问题已解决linux双网卡HA的问题。
原因是我们服务器安装的内核有问题,是带XEN功能(虚拟机)的。
重新安装正确的内核后测试通过。
所有的服务器需要重启一次。
一、修改/etc/modprobe.conf,增加一行alias bond0 bondingoptions bond0 mode=1 miimon=100(2)二、/etc/sysconfig/network-script/下增加文件ifcfg-bond0,红色部分请对应具体的IP等网络设置(1)[root@szbiaap1 network-scripts]# cat ifcfg-bond0DEVICE=bond0BOOTPROTO=noneONBOOT=yesNETWORK=172.25.132.0NETMASK=255.255.255.0IPADDR=172.25.132.17USERCTL=noGATEWAY=172.25.132.1TYPE=EthernetBONDING_OPTS="mode=1 miimon=100"Ex.(2)DEVICE=bond0IPADDR=172.25.1.43NETWORK=172.25.1.0NETMASK=255.255.255.0USERCTL=noBOOTPROTO=noneONBOOT=yes三、双网卡配置如下:[root@szbiaap1 network-scripts]# cat ifcfg-eth0DEVICE=eth0BOOTPROTO=noneONBOOT=yesMASTER=bond0SLAVE=yesUSERCTL=no[root@szbiaap1 network-scripts]# cat ifcfg-eth1DEVICE=eth1BOOTPROTO=noneONBOOT=yesMASTER=bond0SLAVE=yesUSERCTL=no[root@szbiaap1 network-scripts]#四、查看启动文件,可看到启动的kernel为带虚拟机功能。
冗余网卡
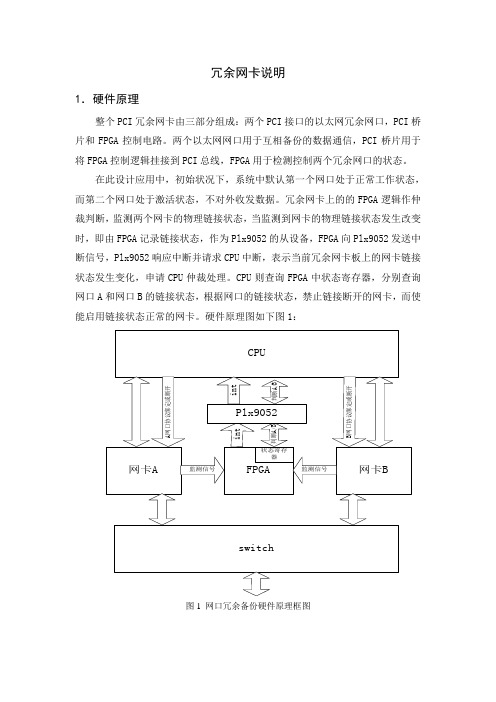
冗余网卡说明1.硬件原理整个PCI冗余网卡由三部分组成:两个PCI接口的以太网冗余网口,PCI桥片和FPGA控制电路。
两个以太网网口用于互相备份的数据通信,PCI桥片用于将FPGA控制逻辑挂接到PCI总线,FPGA用于检测控制两个冗余网口的状态。
在此设计应用中,初始状况下,系统中默认第一个网口处于正常工作状态,而第二个网口处于激活状态,不对外收发数据。
冗余网卡上的的FPGA逻辑作仲裁判断,监测两个网卡的物理链接状态,当监测到网卡的物理链接状态发生改变时,即由FPGA记录链接状态,作为Plx9052的从设备,FPGA向Plx9052发送中断信号,Plx9052响应中断并请求CPU中断,表示当前冗余网卡板上的网卡链接状态发生变化,申请CPU仲裁处理。
CPU则查询FPGA中状态寄存器,分别查询网口A和网口B的链接状态,根据网口的链接状态,禁止链接断开的网卡,而使能启用链接状态正常的网卡。
硬件原理图如下图1:图1 网口冗余备份硬件原理框图2.软件切换原理作为双冗余备份网卡,外界访问到冗余网卡中的任何一个都是透明的,形式上只有一个网卡的存在。
冗余网卡的设计为两个网卡配置同的IP地址和MAC地址。
在使用备份网口之前卸载当前使用网口的IP地址,并解除网卡与协议的绑定,此时,IP协议层与MUX 层断开,将不能受到来自底层设备的数据包。
而备用网口使其IP层和底层驱动绑定,并为其配置同样的IP地址。
备用网口能在极短时间内替代当前网口工作,保证数据最少量的丢失。
3.冗余切换系统执行流程在系统上电启动时,同时初始化两个网口,网口A和网口B,并给其配有相同的MAC地址。
将网口A配置为默认通信网口,而网口B虽然硬件初始化完毕,但不给其分配IP地址,并且不进行其MUX层和协议层的绑定,这样B网口虽然硬件初始化成功,但并不能进行数据收发,处于备用状态。
同时FPGA上电后运行自身逻辑,对网口A,B的链接状态进行监测,准备进行网口切换处理。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一 、双 网 卡 冗 余 工 作 的 原 理 1. 检 测 网 卡 故 障 双网卡冗余工作需要 IP 地址、测试 IP 地址、两个网 卡以及网卡状态检测进程共同完成。实现冗余工作的两 个网卡需要添加到一个工作组内, 并为每个网卡指定一 个 IP 地址和一个测试 IP 地址。网卡状态检测进程使用 每个网卡的测试 IP 地址检测其自身的状态, 检测的方法 是 网卡 状态 检测 进程 使用 每个 网 卡 的 测 试 IP 地 址 向 本 IP 网 段 内 的 某 一 个 计 算 机 的 IP 地 址 发 送 ping 命 令 , 这 个目标计算机的 IP 选择是动态的, 路由器的 IP 地址通 常被选作为目标 IP 地址, 如果在链路上没有路由器, 那 么网卡状态检测进程会发送多播数据包到所有主机 ( 224.0.0.1) , 并随机选择其中一台主机的 IP 地址作为被 检测的目标地址。 网卡状态检测进程分别检测冗余网卡工作组中的每 一个网卡的状态, 通过 ping 命令进行检测, 如果连续 5 个检测数据包没有回应, 那么网卡状态检测进程认为该 网卡已经出现故障。缺省的故障检测时间是 10 秒, 即大 约每 2 秒进行一次检测, 故障检测的时间可以根据实际 网络情况在配置文件中修改。当网卡状态检测进程认为 工作的网卡发生故障后, 该网卡上的所有网络连接全部 转 移 到 工 作 组 中 另 外 一 个 网 卡 接 上 面 。 [1[2] 2. 检 测 网 卡 恢 复 为了检测故障网卡是否恢复, 网卡状态检测进程需 要不断 通过 故障 网卡 的测 试 IP 地 址 发 送 检 测 数 据 包 来 检 测 故 障 网 卡 是 否 恢 复 , 当 连 续 收 到 10 个 检 测 包 回 应 的时候, 认为该故障网卡已经恢复。当故障网卡恢复的
表 1 hme0 故障前
hme0: flags =9000843 <UP, BR OADCAST, R UNNING, MUL - TICAST, IPv4> mtu 1500 index 2
inet 192. 168. 85. 19 netmask ffffff00 broadcast 192. 168. 85. 255 groupname test
# ifconfig hme0 group test # ifconfig hme1 group test 步骤 4: 为物理接口配置测试地址, 命令如下: # ifconfig hme0 addif 192.168.85.21 netmask 255.255.255.0 - failover up # ifconfig hme1 addif 192.168.85.22 netmask 255.255.255.0 - failover up 步骤 5: 阻止其它应用程序使用测试地址, 命令如下: # ifconfig hme0 deprecated # ifconfig hme1 deprecated 步骤 6: 为 了防 止系 统重 新 启 动 配 置 丢 失 , 编 辑/etc/
turn off this option # FAILBACK=yes # # By default only interfaces configured as part of
multipathing groups # are tracked. Turn off this option to track all network
255.255.255.0 + up 编辑/etc/hostname.hme1 文件, 文件内容如下: 192.168.85.20 netmask 255.255.255.0+group test up \ addif 192.168.85.22 deprecated - failover netmask
容如下: # # Time taken by mpathd to detect a NIC failure in ms.
The minimum time # that can be specified is 100 ms. # FAILURE_DETECTION_TIME=10000 # # Failback is enabled by default. To disable failback
255.255.255.0 + up 参数说明: [3] 1) - failover: 带有该参数的地址表明是测试地址。步
骤 4 和 步 骤 6 中 的 192.168.85.21 和 192.168.85.22 是 测 试地址。
2) deprecated: 该参数表示禁止其它应用程序 使用 冗 余 工作 组中 网卡 的测试 IP 地址 , 如果 使 用 , 那 么 应 用 程 序可能无法正常工作。
关键词: 故障 恢复 冗余 容错
中图分类号: TP393.07 文献标识码: A
文章编号: 1673- 8454( 2007) 08- 0020- 03
计算机网络中关键设备的冗余工作已经成为保障 应用业务稳定运行的关键手段, 服务器的网卡冗余工作 是在不增加任何投入的基础上, 增加服务器稳定性的一 种方法, 它实现简单, 配置灵活, 被广泛地应用到实践中。
时候, 网卡状态检测进程根据配置文件决定网络连接 是否重新切换到恢复后的网卡上面。在故障网卡恢复 的时 候, 测 试 IP 地址 是不 发生 转移 和 切 换 的 , 其 余 所 有 的地 址均 发生 转移和 切换 , 所 以 测 试 IP 地 址 不 能 用 作 他用。
二 、双 网 卡 冗 余 工 作 的 实 现 本文以运行 Sun Solaris 9 的 Sun 公司的服务 器为 例 说明双网卡冗余工作是如何实现的, 在 Sun Solaris 中网 卡状态检测进程是 in.mpathd 进程。实现环境如下: ( 1) 网卡冗余工作组的名字为 test; ( 2) 服务器的两个网卡为 hme0 和 hme1; ( 3) hme0 的 IP 地 址 为 192.168.85.19, 测 试 地 址 为 192.168.85.21; ( 4) hme0 的 IP 地 址 为 192.168.85.20, 测 试 地 址 为 192.168.85.22。 实现步骤如下: [3] 步骤 1: 将 服务 器 的 两 个 网 卡 分 别 连 接 到 同 一 个 IP 子网内; 步骤 2: 以超级用户身份登陆系统; 步骤 3: 放置 hme0 和 hme1 到 test 组内, 命令如下:
20 中国 教 育 信 息 化/ 2007.08 (高 教 职 教)
《中国教育信息化》发行部: cyl@moe. edu. cn
网络建设 建 设
hostname. hme0 文件, 文件内容如下: 192.168.85.19 netmask 255f 192.168.85.21 deprecated - failover netmask
表 2 hme0 故障后
hme0: flags = 19000842 < BR OADCAST , R UNNING , MULTICAST , IPv4, NOFAILOVER , FAILED> mtu 0 index 2 inet 0.0.0.0 netmask 0 groupname test hme0: 1: flags = 19040843 < UP, BR OADCAST , R UNNING, MUL - TICAST,DEPR ECATED,IPv4, NOFAILOVER ,FAILED > mtu 1500 index 2 inet 19.16.85.21 netmask ffffff00 broadcast 192.168.85.255 hme1: flags =9000843 <UP, BR OADCAST, R UNNING, MUL - TICAST,IPv4> mtu 1500 index 2 inet 19.16.85.20 netmask ffffff00 broadcast 19.16.85.255 group- name test hme1: 1: flags= 9000843< UP,BR OADCAST , R UNNING, MULTICAST,DEPR ECATED,IPv4, NOFAILOVER > mtu 1500 index 2 inet 19.16.85.22 netmask ffffff00 broadcast 192.168.85.255 hme1: 2: flags=1000843<UP, BR OADCAST, R UNNING, MUL- TICAST,IPv4> mtu 1500 index 6 inet 192.186.85.19 netmask ffffff00 broadcast 192.168.85.255
建 设 网络建设
《中国教育信息化》编辑部: mis@moe. edu. cn
服务器双网卡冗余工作的原理与实现
中国医科大学附属盛京医院计算机中心 全 宇 中国医科大学附属第一医院信息中心 何 苗
摘 要: 本文讨论了服务器双网卡冗余工作的实现原理, 通过一个案例详细介绍了双网卡冗余工作的实
现方法。通过双网卡的冗余工作, 提高了服务器的容错能力, 增强了服务器的可用性和可靠性。
hme1: flags =9000843 <UP, BR OADCAST, R UNNING, MUL - TICAST,IPv4> mtu 1500 index 2
inet 19.16.85.20 netmask ffffff00 broadcast 192.168.85.255 group- name test
hme0: 1: flags=9000843<UP, BR OADCAST, R UNNING, MUL- TICAST,DEPR ECATED,IPv4,