C语言编译器的设计与实现
C语言编译器前端的设计与实现 实训报告

第 1 章 绪论
1.1 C 语言及编译器概述
C 语言是在 70 年代初问世的。一九七八年由美国电话电报公司(AT&T)贝尔实验室正式 发表了 C 语言。同时由 B.W.Kernighan 和 D.M.Ritchit 合著了著名的“THE C PROGRAMMING LANGUAGE”一书。通常简称为《K&R》,也有人称之为《K&R》标准。但是,在《K&R》中并 没有定义一个完整的标准 C 语言,后来由美国国家标准学会在此基础上制定了一个 C 语言 标准,于一九八三年发表。通常称之为 ANSI C。C 语言是一种结构化语言。它层次清晰, 便于按模块化方式组织程序,易于调试和维护。C 语言的表现能力和处理能力极强。它不仅 具有丰富的运算符和数据类型,便于实现各类复杂的数据结构。它还可以直接访问内存的 物理地址,进行位(bit)一级的操作。由于 C 语言实现了对硬件的编程操作,因此 C 语言集 高级语言和低级语言的功能于一体。既可用于系统软件的开发,也适合于应用软件的开发。 此外,C 语言还具有效率高,可移植性强等特点。因此广泛地移植到了各类各型计算机上, 从而形成了多种版本的 C 语言。
2.3.1 自顶向下的语法分析...........................................................................................5 2.3.2 自底向上的语法分析...........................................................................................5 2.4 语义分析.........................................................................................................................6 2.5 符号表.............................................................................................................................6 2.6 类型检查.........................................................................................................................7 第 3 章 系统详细设计..................................................................................................................8 3.1 系统设计基本思路.........................................................................................................8 3.2 词法分析模块设计.........................................................................................................8 3.3 语法分析模块设计.......................................................................................................11 3.4 语义分析模块设计.......................................................................................................14 第 4 章 结束语............................................................................................................................16 参考文献...................................................................................................................................... 16 附录: 附录 1:词法分析核心代码............................................................................................17 附录 2:语法分析核心代码............................................................................................18
编译器设计与实现技术研究

编译器设计与实现技术研究随着计算机软硬件的不断更新,编译器作为一个重要的软件工具,也不断地发展和完善。
编译器是一种将高级语言代码转换成低级代码的程序,它可以将程序员编写的高级语言代码翻译成机器能够识别的汇编代码或者机器语言代码。
编译器的设计和实现技术对于软件开发有着至关重要的作用。
1.编译器的基本工作原理编译器的基本工作原理是将高级语言代码逐步解析成机器能够识别的低级代码。
首先,编译器将高级语言代码进行词法分析,将语句中的标识符、关键字、运算符等转换成对应的记号。
接着,编译器将这些记号进行语法分析,转换成语法树。
语法树表示了给定程序的语法结构,是编译器生成中间代码的重要依据。
编译器根据语法树生成中间代码,并对中间代码进行优化。
最后,编译器将优化后的中间代码转换成机器能够识别的机器码或者汇编代码。
2.编译器的设计与实现技术编译器的设计与实现技术主要包括以下几个方面:2.1.词法分析器词法分析器用于将高级语言代码转换成标记流。
它的主要任务是将输入的文本流转换为一个个逐个扫描的Token 序列,将每个Token 分类为特定的Token 类型,如标识符、关键字、运算符等。
常见的词法分析器生成器有 Flex 和 Lex。
2.2.语法分析器语法分析器用于将标记流转变成一棵语法树。
语法分析器的主要任务是将从词法分析器得到的Token 序列转换成一棵语法树,在语法树上进行语义分析和优化。
常见的语法分析器生成器有 Bison 和 Yacc。
2.3.中间代码生成器中间代码生成器用于将语法树转换成中间代码。
中间代码生成器的主要任务是将语法分析器生成的语法树转换成中间代码。
中间代码表示高级语言代码的语义,是生成目标代码的中间步骤。
常见的中间代码有三地址码、四元式、抽象语法树等。
2.4.中间代码优化器中间代码优化器用于对中间代码进行优化。
中间代码优化器的主要任务是提高目标代码的性能、减小目标代码的大小以及提高编译器的运行效率。
C到VHDL的编译器设计与实现

C到V HDL的编译器设计与实现李 超 方潜生(安徽建筑工业学院计算机与信息工程系,安徽合肥230022)【摘 要】 近年来,微电子技术和超大规模集成电路技术发展迅速,电子系统设计的系统复杂度和异构度都不断加大,软件在系统设计中所占比例也越来越大。
C语言适合对系统进行高层次的描述,V HDL语言适合抽象的硬件描述。
C语言的系统描述经过软硬件划分之后,必须将硬件实现部分转换为适合于综合的V HDL语言。
本文通过比较两种语言的差别,提出并实现适合表达C语言描述内容的V HDL结构形式。
实验表明,本文提出的方案是正确和有效的,并能降低系统设计的复杂度和异构度。
【关键词】 软硬件协同设计;C语言;V HDL;编译器1 引言近年来,随着微电子技术和超大规模集成电路技术的高速发展,进行电子系统设计时的系统复杂度不断加大,系统软件硬件的异构度提高,软件在系统中所占的比例也越来越大。
传统的设计方法在进行电子系统设计时,一般先由系统工程师设计整个系统的架构,画出系统框图(包括各个模块),再用高级编程语言(一般是C/C++/JAVA)实现各个模块的算法,然后进行整个系统的仿真,确定系统的最佳结构、最佳实现算法及其它相关参数。
待系统模型确定以后,进行系统软硬件分割设计,但由于缺乏统一的软硬件协同设计验证平台,大多只能根据经验来定义软件和硬件部分各自应完成的功能。
对于整个系统的功能和行为,在设计最初阶段,描述时尚无硬件的概念,经过软硬件划分之后,将系统规范描述分成软件实现和硬件实现两部分。
虽然VHDL等语言也支持算法级描述,但是大部分硬件描述语言HDL(Hardware Description Language)如VHDL、Verilog等基本上还是面向硬件的描述,面向较低的硬件抽象等级。
同时由于高级编程语言(C/C++/JAVA)不能描述硬件设计中的时间、延迟、信号等物理信息,与后续的硬件设计不兼容,硬件部分需重新用VHDL、Verilog等硬件描述语言来设计,造成大量的设计重复,也增加了系统设计的复杂度。
编译原理课程设计___C语言编译器的实现

扬州大学编译原理课程设计学号:*********姓名:专业:计算机科学与技术课程:编译原理指导教师:***目录一.程序简介与分析---------------------------------------------------------3 二.程序适用范围-----------------------------------------------------------3 三.词法分析---------------------------------------------------------------3 四.语法分析---------------------------------------------------------------4 五.语义分析和中间代码生成------------------------------------------------10 六.代码生成--------------------------------------------------------------12 七.流程图----------------------------------------------------------------13 八.实现------------------------------------------------------------------14 九.程序运行结果----------------------------------------------------------14 十.总结------------------------------------------------------------------18 十一.附录(源程序)--------------------------------------------------------18简单的编译程序设计一.程序简介与分析本程序由四个部分组成:词法分析子程序,语法分析子程序,语义分析子程序,目标代码生成程序。
如何进行编译器设计和解释器开发

如何进行编译器设计和解释器开发编译器和解释器是软件开发中非常重要的工具,它们用于将源代码转换为可以被计算机执行的机器码或者解释执行源代码。
编译器是将源代码一次性地转换为目标代码,而解释器是逐行地解释源代码并执行相应的操作。
本文将介绍编译器的设计和解释器的开发过程,并提供一些实用的技巧和建议。
一、编译器设计编译器设计是一个复杂的任务,需要掌握词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等多个环节。
下面是编译器设计的一般流程:1.词法分析:将源代码分解为一个个token,例如关键词、标识符、数字、操作符等。
可以使用正则表达式或者有限状态自动机来进行词法分析。
2.语法分析:根据语法规则将token组成一个个语法结构,例如函数、表达式、语句等。
可以使用上下文无关文法和语法分析算法(如LL(1)或者LR(1))来进行语法分析。
3.语义分析:对语法结构进行语义检查,例如类型检查、作用域检查、类型转换等。
在这一阶段还可以进行符号表的构建,用于保存变量和函数的信息。
4.中间代码生成:将源代码转换为一种中间表示形式,通常是一个抽象的指令序列,例如三地址码、虚拟机指令、中间表达式等。
中间代码的生成可以使用递归下降、语法制导翻译或者语法制导翻译的变体等方法。
5.代码优化:对中间代码进行优化,以提高代码的执行效率和减小代码的体积。
常见的优化技术包括常量折叠、公共子表达式消除、死代码删除、循环优化等。
6.目标代码生成:将中间代码转换为目标机器的机器码或者汇编代码。
目标代码生成可以分为两个阶段:指令选择(选择适合目标机器的指令)和寄存器分配(将变量分配到寄存器或者内存中)。
7.代码生成完成后,还需要进行链接和装载,将目标代码与库文件进行链接,并将最终的可执行文件加载到内存中执行。
二、解释器开发与编译器不同,解释器是逐行地解释和执行源代码,不需要将源代码先转换为目标代码。
下面是解释器的开发过程:1.词法分析:同编译器设计一样,解释器也需要进行词法分析,将源代码分解为一个个token。
C语言编译原理编译过程和编译器的工作原理

C语言编译原理编译过程和编译器的工作原理C语言是一种广泛使用的计算机编程语言,它具有高效性和可移植性的特点。
在C语言程序的运行之前,需要通过编译器将源代码翻译成机器可以执行的目标代码。
编译器是一种专门用于将高级语言源代码转换为机器语言的程序。
编译过程分为四个主要阶段,包括词法分析、语法分析、语义分析和代码生成。
下面我们逐一介绍这些阶段的工作原理。
1. 词法分析词法分析是编译过程的第一步,它将源代码分解成一系列的词法单元,如标识符、常量、运算符等。
这些词法单元存储在符号表中,以便后续的分析和转换。
2. 语法分析语法分析的目标是将词法单元按照语法规则组织成一个语法树,以便进一步的分析和优化。
语法分析器使用文法规则来判断输入的字符串是否符合语法规范,并根据语法规则生成语法树。
3. 语义分析语义分析阶段对语法树进行分析并在合适的地方插入语义动作。
语义动作是一些与语义相关的处理操作,用于检查和修正代码的语义错误,并生成中间代码或目标代码。
4. 代码生成代码生成是编译过程的最后一个阶段,它将中间代码或语法树翻译为目标代码,使得计算机可以直接执行。
代码生成阶段涉及到指令的选择、寄存器分配、数据位置的确定等一系列的优化操作,以提高程序的性能和效率。
编译器是实现编译过程的工具。
它接收源代码作为输入,并将其转换为目标代码或可执行文件作为输出。
编译器工作原理可以简单概括为:读取源代码、进行词法分析和语法分析、生成中间代码、进行优化、生成目标代码。
编译器在编译过程中还涉及到符号表管理、错误处理、优化算法等方面的工作。
符号表用于管理程序中的标识符、常量、变量等信息;错误处理机制用于检测和纠正程序中的错误;优化算法用于提高程序的性能和效率,例如常量折叠、无用代码删除等。
总结起来,C语言编译过程涉及到词法分析、语法分析、语义分析和代码生成等阶段,每个阶段都有特定的工作原理和任务。
编译器作为实现编译过程的工具,负责将源代码转换为机器可以执行的目标代码。
编译原理c语言编译器的设计与实现
经编译程序运行后得到的输出结果如下:
1〕词法分析得出的相应的名字的号码和他的值2〕列举程序中所有的变量
3〕状态栈的移进-归约过程1.
4〕最后产生的四元式中间代码
一、实验总结:
通过此次实验,让我知道了词法分析的功能是输出把它组织成单个程序,让我理解到如何设计、编制并调试词法分析程序,加深对词法分析原理的理解;对语法规那么有明确的定义;编写的分析程序可以进展正确的语法分析;对于遇到的语法错误,可以做出简单的错误处理,给出简单的错误提示,保证顺利完成语法分析过程;实验报告要求用文法的形式对语法定义做出详细说明,说明语法分析程序的工作过程,说明错误处理的实现。
通过该实验的操作,我理解编译原理课程兼有很强的理论性和理论性,是计算机专业的一门非常重要的专业根底课程,它在系统软件中占有非常重要的地位,是计算机专业学生的一门主修课。
为了让学生可以更好地掌握编译原理的根本理论和编译程序构造的根本方法和技巧,融会贯穿本课程所学专业理论知识,进步他们的软件设计才能,。
单片机c语言编译器及其应用

单片机C语言编译器及其应用一、背景介绍单片机是一种嵌入式系统的核心组成部分,广泛应用于各个领域,例如电子产品、通信设备、汽车电子等。
而单片机的编程语言有多种选择,其中C语言由于其跨平台、易学易用、高效等优势而成为最常用的编程语言之一。
为了能够将C语言程序转换为单片机可以执行的机器语言指令,需要使用单片机C语言编译器进行编译和烧录。
二、单片机C语言编译器的应用过程1. 编写C语言程序首先,需要根据实际需求,编写C语言程序。
C语言是一种高级编程语言,具有结构化、模块化的特点,能够方便地进行程序设计。
在编写程序时,需要考虑单片机的特性和限制,例如内存容量、时钟频率等,以保证程序的正确运行。
2. 选择合适的单片机C语言编译器根据单片机的型号和厂商提供的支持,选择合适的单片机C语言编译器。
市面上有许多编译器可供选择,例如Keil C51、IAR Embedded Workbench、Microchip XC8等。
选择编译器时需要考虑以下几个因素:•兼容性:编译器是否支持目标单片机的型号和指令集。
•性能:编译器是否能够生成高效的机器语言指令,提高程序的执行效率。
•开发环境:编译器是否配套提供友好的集成开发环境(IDE),方便开发和调试。
3. 编译C语言程序打开选择的单片机C语言编译器的IDE,新建一个工程,并将之前编写的C语言程序添加到工程中。
通过编译器的编译功能,将C语言程序转换为单片机可以执行的机器语言指令。
编译过程中,编译器会进行词法分析、语法分析、语义分析等操作,然后生成目标文件(通常是以.hex或.bin格式存储)。
4. 烧录目标文件到单片机完成编译后,需要将生成的目标文件烧录到目标单片机中。
烧录过程可以通过多种方式完成,例如串口下载、并口下载、仿真器等。
烧录后,单片机就可以执行C语言程序了。
三、单片机C语言编译器的应用效果通过单片机C语言编译器,我们可以将高级的C语言程序转换为单片机可以执行的机器语言指令,从而实现对单片机的编程和控制。
分布式并行C语言及其预编译器的设计和实现

编 写 的程序 , 能够有 效地在 分布 式环境 下实现 并行 计 算 , 充分 利 用 系统 中的 多处理 机 资源 , 提
高 系统 效率 。
关键 词 :分 布式 并行计算 ;并行 C语 言 ;预编译 器 ;多线程 ; C 远 程过程 调用) RP ( 中图分类 号 : 3 TP 1 文献标识 码 : A 文章编 号 :1 7 —3 4 2 0 )50 9 —6 6 41 7 ( 0 8 0 —4 60
摘 要 :设计 了可实 现分布 式并行 计算 的并行 编 程语 言—— 并行 C语 言 , 且使 用模 板 机制 并
实现 了将此 并行 C语 言程 序转 换 为标 准 C语 言程 序 的转 换程 序—— 预 编 译 器。 并行 计 算 的 实现采 用 了多线程 和 R C 远程 过程调 用 ) P ( 相结合 的技 术。 实验 结果 表 明, 用此 并行 C语 言 使
V 12 , o 5 o. 9 N . Oc. 0 8 t2 0
分布 式 并 行 C语 言 及 其 预 编 译 器 的设 计 和 实现
邹 晓 辉 邹 跃 鹏 ,
(. i 吉林 师范 大 学 计 算 机 学 院 , 林 四 平 吉 16 0 ;2 吉 林 大 学 计 算 机 科 学 与技 术 学 院 ,吉林 长 春 30 0 . 10 1 ) 3 0 2
p r le o a a l lc mpu i g.The r s ls s o t t pr gr m mi g wih t a a l lC a ua a fe tv l tn e u t h w ha o a n t he p r le lng ge c n e f c i ey
Th e in a d i peme t to ft e ditiu e a al l e d sg n m l n a in o h s rb t d p r l e C a g a e a d i' r c m p l l n u g n t S p e o i er
c语言子集编译器实验报告书

c语言子集编译器实验报告书C语言子集编译器实验报告书一、引言编译器是一种将高级语言代码转换为机器语言代码的工具。
本报告旨在介绍我们设计和实现的C语言子集编译器。
该编译器可以接受符合C语言子集语法规范的源代码,并将其转换为目标机器的可执行文件。
本报告将详细介绍编译器的设计思路、实现过程和测试结果。
二、设计思路我们的编译器主要分为四个阶段:词法分析、语法分析、语义分析和代码生成。
首先,词法分析器将源代码分解为一个个的词法单元,如关键字、标识符、运算符等。
然后,语法分析器将词法单元按照语法规则进行组合,构建出抽象语法树。
接下来,语义分析器对抽象语法树进行语义检查,确保源代码的合法性。
最后,代码生成器将抽象语法树翻译成目标机器的汇编代码,并生成可执行文件。
三、实现过程1.词法分析词法分析器采用有限状态自动机的方式进行实现。
它读取源代码字符流,并根据预定义的正则表达式规则逐个识别出词法单元。
识别出的词法单元被作为输入传递给语法分析器。
2.语法分析语法分析器采用递归下降的方式进行实现。
它根据C语言子集的语法规则,逐步展开抽象语法树的各个节点。
在展开的过程中,语法分析器将词法单元与语法规则进行匹配,确保源代码的语法正确性。
3.语义分析语义分析器在语法分析的基础上,进一步检查源代码的语义错误。
它通过符号表来管理变量和函数的声明和引用,并进行类型检查和作用域检查等。
如果发现语义错误,语义分析器将报告错误信息,并中断编译过程。
4.代码生成代码生成器根据语义分析器生成的抽象语法树,将其翻译成目标机器的汇编代码。
它会为每个变量分配内存空间,并生成相应的加载和存储指令。
最后,代码生成器将生成的汇编代码输出到一个文件中,并调用目标机器的汇编器和链接器生成可执行文件。
四、测试结果为验证编译器的正确性和性能,我们设计了一系列测试用例,涵盖了C语言子集的各种语法和语义规则。
经过测试,编译器能够正确处理各种情况下的源代码,并生成符合预期的可执行文件。
用c语言做毕业设计

用c语言做毕业设计【篇一:c语言编译器实现毕业设计】编译原理课程设计题目 c语言编译器实现计算机科学学院计算机科学与技术专业10 级计本班学号:姓名:指导教师:完成时间: 2013 年 6 月目录c语言编译器实现一、原理1、简介编译程序的工作过程一般可以分为五个阶段:词法分析、语法分析、语义分析与中间代码产生、优化、目标代码生成。
每一个阶段在功能上是相对独立的,它一方面从上一个阶段获取分析的结果来进行分析,另一方面由将结果传递给下一个阶段。
由编译程序的五个阶段就对应了编译系统的结构。
2、单词符号及种别表示3、语法结构定义如下:程序 ::= main()语句块语句块::= ‘{‘语句串’}’ 语句串::=语句{;语句};语句::=赋值语句|条件语句|循环语句赋值语句::=id=表达式条件语句::=if条件语句块循环语句::=do 语句块while 条件条件::=表达式关系运算符表达式表达式 ::= 项{ +项|-项} 项 ::= 因子{*因子|/因子}因子 ::=id|num|(表达式) 关系运算符 ::= |=||=|==|!二、运行环境windows 系统 visual c++ 6.0三、算法设计思想1、词法分析主要算法这部分对源文件进行分析,允许/* */注释。
从源文件依次读取字符,对字符进行分析,组成字符串、数字、关系符等固定含义的token 符,并把它们添加到token链中,如果遇到非法字符报错并退出程序。
2、语法分析主要算法这部分对token链进行分析,利用自底向上的分析方法,构建slr (1)分析表的过程是手工完成的。
语法分析的同时构建语法树,移进时创建叶子,规约时创建节点。
3、语义分析主要算法这部分对语法树从左到右进行遍历,节点记录了规约式的编号,遍历到节点时就进行相应处理。
语义分析主要检查变量、函数是否被定义或重定义,同时产生四元式。
函数一览表void scanner();【篇二:c语言编译器设计与实现毕业论文设计】北京邮电大学毕业设计(论文)任务书第1页第2页第3页c语言编译器设计与实现摘要随着计算机的广泛应用,计算机程序设计语言也从初期的机器语言发展为汇编语言,以及现在的各种高级程序设计语言。
c语言子集编译器实验报告书 -回复

c语言子集编译器实验报告书-回复C语言子集编译器实验报告书为了深入理解编译原理和实践C语言的编译过程,我们小组决定设计和实现一个C语言子集编译器。
本报告将详细介绍我们的实验目标、所采取的实验方法、主要成果和遇到的困难及解决办法等相关内容。
一、实验目标我们的实验目标是设计和实现一个基于C语言子集的编译器。
C语言是一种高级编程语言,对于程序员来说非常重要。
能够编写一个能够正确解析、分析和生成目标代码的编译器对于我们研究和理解底层编程原理具有重要意义。
二、实验方法1. 语法分析器的设计与实现语法分析是编译器的核心部分,用于将源代码转换为可以执行的中间表示。
我们选择使用自上而下的递归下降方法进行语法分析器的设计。
首先,我们仔细研究了C语言的语法规范,并根据其语法规范设计了文法。
然后,我们使用LL(1)文法,并手动实现了对应的递归下降的语法分析器。
2. 词法分析器的设计与实现词法分析器用于将源代码转换为一个个的词法单元(token),即基本的语法单元。
我们使用有限状态自动机(FSM)来设计并实现词法分析器。
首先,我们构建了一个有限状态自动机的状态转移图,然后使用代码实现了相应的状态转移过程。
3. 中间代码生成和代码优化在语法分析的过程中,我们将生成中间表示形式的代码来进一步处理和优化。
我们选择使用三地址码作为中间表示形式,并实现了相应的中间代码生成算法。
此外,我们还进行了局部和全局的代码优化,包括常量合并、无用代码删除等操作。
三、主要成果经过一段时间的实验和努力,我们成功地设计和实现了一个C语言子集编译器。
该编译器能够正确地将C语言子集的源代码转换为目标代码,并生成中间表示形式的代码。
通过该编译器的实验,我们深入理解了编译原理的相关知识,对于C语言的语法、词法和语义有了更加深入的了解。
四、遇到的困难及解决办法在实验的过程中,我们遇到了一些困难,但通过团队合作和不懈的努力,我们最终克服了这些困难。
首先,我们遇到了语法分析器的设计和实现问题。
现代编译原理c语言描述

现代编译原理c语言描述编译原理是计算机科学中的重要分支之一,它主要研究如何将高级语言表示的程序转换成计算机能够执行的机器语言程序。
C语言是一种广泛使用的高级编程语言,其编译器的实现是编译原理的重要应用领域之一。
本文将从编译原理的角度出发,探讨C语言编译器的实现原理和相关技术。
一、编译原理概述编译原理是计算机科学中的一门基础课程,它主要涉及编译程序的设计、实现和优化等方面。
编译程序是一种能够将高级语言表示的程序转换成计算机能够执行的机器语言程序的软件。
编译程序通常由编译器和链接器两部分组成。
编译器负责将源代码转换成中间代码或目标代码,而链接器则负责将多个目标文件合并成一个可执行文件。
编译器的主要工作包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等阶段。
其中,词法分析是将输入的源代码转换成一系列标记或记号的过程,语法分析是将标记序列转换成语法树的过程,语义分析是对语法树进行语义检查的过程,中间代码生成是将语法树转换成中间代码的过程,代码优化是对中间代码进行优化的过程,目标代码生成是将中间代码转换成目标代码的过程。
二、C语言编译器实现原理C语言是一种广泛使用的高级编程语言,其编译器的实现是编译原理的重要应用领域之一。
C语言编译器的实现原理和其他编译器大致相同,但由于C语言的复杂性和灵活性,其编译器实现相对更为复杂。
下面将从C语言编译器的各个阶段入手,介绍其实现原理和相关技术。
1.词法分析词法分析是将输入的源代码转换成一系列标记或记号的过程。
C 语言的词法分析器通常采用有限状态自动机(DFA)或正则表达式来实现。
DFA是一种能够识别正则语言的自动机,它通过状态转移来识别输入的字符串。
正则表达式是一种能够描述正则语言的表达式,它可以用来生成DFA。
C语言的词法分析器通常将输入的源代码分成若干个记号,例如关键字、标识符、常量、运算符和分隔符等。
其中,关键字是C语言中具有特殊含义的词汇,例如if、else、while和for等;标识符是程序员定义的变量名、函数名和类型名等;常量是程序中用到的常量值,例如整数、浮点数和字符常量等;运算符是C语言中用于运算的符号,例如+、-、*和/等;分隔符是用于分隔不同元素的符号,例如逗号和分号等。
c 高级程序设计语言子集的编译系统设计和实现

题目:c 高级程序设计语言子集的编译系统设计和实现正文:一、引言在当今信息技术飞速发展的时代,编程语言的发展也日新月异。
C语言作为一种通用的高级程序设计语言,被广泛应用于软件开发、系统编程等领域。
本文将围绕C语言高级程序设计语言子集的编译系统设计和实现展开深入探讨。
二、C语言高级程序设计语言子集的定义与特点C语言的高级程序设计语言子集是指具有较高级别抽象特性的C语言子集,通常包括对数据类型、控制流、函数等方面的支持,同时不包括如指针运算、内存管理等复杂特性。
高级程序设计语言子集的设计旨在简化语言的复杂性,使其更易学习、易理解和易使用。
三、编译系统的基本原理编译系统是将高级程序设计语言源代码转换为目标机器代码的软件系统。
其基本原理包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等步骤。
在C语言高级程序设计语言子集的编译系统设计和实现中,需要重点考虑如何有效地处理语言子集的特性,保证编译过程的高效性和可靠性。
四、C语言高级程序设计语言子集的编译系统设计1. 词法分析:根据语言子集的语法规则,将源代码分解为词法单元,并构建词法分析器进行词法分析。
2. 语法分析:通过语法分析器对词法单元进行语法分析,构建语法树并进行语法验证。
3. 语义分析:对语法树进行语义分析,包括类型检查、作用域分析等,保证程序的语义正确性。
4. 中间代码生成:根据语法树生成中间代码表示,通常采用三位置区域码形式。
5. 代码优化:对中间代码进行优化,包括常量传播、死代码删除、循环优化等,提高目标代码的执行效率。
6. 目标代码生成:将优化后的中间代码转换为目标机器代码,并进行信息、加载等处理,最终生成可执行文件。
五、C语言高级程序设计语言子集的编译系统实现1. 词法分析器的设计与实现:采用有限自动机等算法设计词法分析器,实现对词法单元的识别和提取。
2. 语法分析器的设计与实现:选择合适的语法分析算法(如LL(1)、LR(1)等)进行语法分析器的设计与实现。
编程语言编译器与解释器的原理与实现

编程语言编译器与解释器的原理与实现编程语言的编译器和解释器是将高级语言代码转换为机器代码的工具,使计算机能够理解和执行代码。
编译器和解释器虽然在实现的方式上有所不同,但它们的共同目标都是将程序员写的高级语言代码转换成计算机可执行的低级机器码。
一、编译器的原理与实现1.编译器的工作原理:编译器在编译过程中会将高级语言代码一次性转换成机器代码,生成可执行文件。
编译器分为多个阶段,包括词法分析、语法分析、语义分析、中间代码生成、优化和目标代码生成等过程。
在编译的最终阶段,生成的目标代码可以在计算机上直接运行。
2.编译器的实现:编译器的实现通常使用编程语言来编写,例如C、C++等。
编译器的设计需要考虑语言的语法规则、语义规则和最终生成的目标代码格式。
通过编写对应的编译器前端来处理源代码的分析和转换,以及编写后端来生成目标代码。
3.相关工具及实践:常见的编译器开发工具有Lex和Yacc等,用于词法和语法分析。
编程语言如C语言的编译器GCC和C++的编译器Clang等都是实际编译器的实现。
开发者可以通过学习编译原理和相关工具,以及阅读编译器源码和实践编写编译器来深入理解编译器的原理和实现。
二、解释器的原理与实现1.解释器的工作原理:解释器是将高级语言代码逐行解释执行的工具,将代码翻译为中间代码或直接在运行时解释执行。
解释器不需要生成目标代码,而是直接在运行时将高级语言代码翻译成机器代码。
2.解释器的实现:解释器的设计需要考虑解释器的结构和执行方式,包括词法分析、语法分析、解释执行等过程。
解释器的实现可以使用解释性语言如Python来编写,并通过解释器环境直接运行高级语言代码。
3.相关工具及实践:常见的解释器有Python解释器、Ruby解释器等。
开发者可以通过学习解释器的实现原理,了解解释器如何逐行解释执行代码,并通过实践编写解释器来深入理解解释器的原理和实现。
三、编译器与解释器的比较1.编译器与解释器在执行效率上的区别:编译器将代码一次性转换成机器代码,生成的可执行文件运行效率高,但在编译期产生目标代码需要一定的时间。
编译器的设计与实现

编译器的设计与实现一、引言编译器是将高级语言代码转换为机器语言的程序,它是计算机科学中的重要组成部分。
编译器的设计和实现涉及到多个方面,包括语法分析、词法分析、代码生成等。
本文将从这些方面介绍编译器的设计和实现。
二、语法分析语法分析是编译器中的一个重要环节,其主要任务是将源代码转换为抽象语法树(AST),以便后续处理。
在进行语法分析时,需要先定义一个文法规则集合,用于描述源代码的结构和语义。
然后使用自顶向下或自底向上的算法来解析源代码,并生成对应的AST。
1. 文法规则集合文法规则集合是描述源代码结构和语义的形式化表示。
常用的文法表示方式有巴克斯-瑙尔范式(BNF)和扩展巴克斯-瑙尔范式(EBNF)。
其中BNF表示方式较为简单,其基本形式如下:<非终结符> ::= <产生式>其中“非终结符”表示一个符号,可以由多个产生式组成;“产生式”则描述了非终结符所能生成的字符串。
2. 自顶向下算法自顶向下算法是一种基于文法规则集合的语法分析算法。
其基本思想是从文法的起始符号开始,递归地展开非终结符,直到生成整个源代码。
自顶向下算法可以用递归下降分析、LL分析等方式实现。
3. 自底向上算法自底向上算法是一种基于输入源代码的语法分析算法。
其基本思想是从输入源代码开始,逐步构建AST,直到生成整个抽象语法树。
自底向上算法可以用LR分析、LALR分析等方式实现。
三、词法分析词法分析是编译器中的另一个重要环节,其主要任务是将源代码转换为单词序列(Token),以便后续处理。
在进行词法分析时,需要先定义一个单词集合,用于描述源代码中可能出现的单词类型和格式。
然后使用有限状态自动机(DFA)或正则表达式来解析源代码,并生成对应的Token序列。
1. 单词集合单词集合是描述源代码中可能出现的单词类型和格式的形式化表示。
常用的单词表示方式有正则表达式和有限状态自动机(DFA)。
2. 有限状态自动机有限状态自动机是一种描述字符串匹配过程的数学模型。
c0编译器设计实现报告
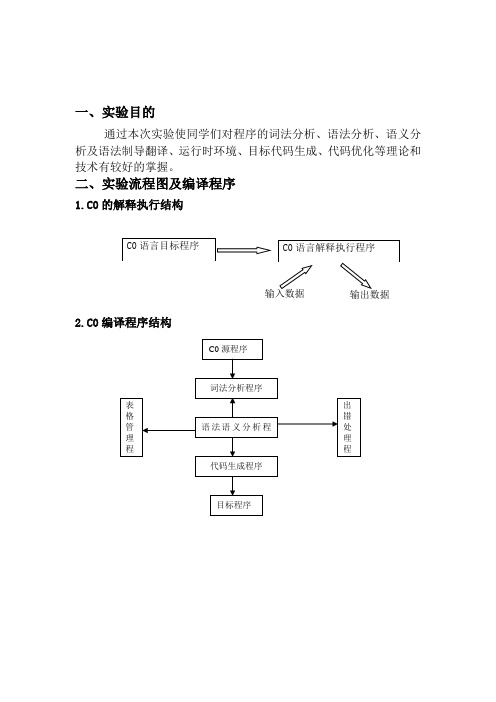
一、实验目的通过本次实验使同学们对程序的词法分析、语法分析、语义分析及语法制导翻译、运行时环境、目标代码生成、代码优化等理论和技术有较好的掌握。
二、实验流程图及编译程序1.C0的解释执行结构2.C0编译程序结构C0语言解释执行程序 C0语言目标程序 输入数据 输出数据词法分析程序语法语义分析程代码生成程序表格管理程序出错处理程序C0源程序目标程序3.执行过程三、名字表设计: Name Kind Lev AdrKind 的类型有:para (全局变量) variable (普通变量) 启动 置初值 调用getsym 取单词 调用block 过程 当前单词是否为源程序结束符‘.’? 源程序中是否有错误? 出错n 打印错误 调用解释过程interpreter 解释执行目标程序 结束voidpro(void函数)ma(main函数)lev:为变量或者函数的层数adr:入口地址四、模块划分1、基础模块(1)写入名字表void enter();(2)查找名字表(想找名字所在的位置,返回在名字表中的位置) int position()返回值为下标i为它在表中位置(3)初始化符号集Void init ()(4)错误处理:n为错误序号,用到的err为错误数Void error(int n)输出n所对应错误2、词法分析模块 int getsym()/*词法分析模块getsym()进行词法分析,里面用到了读取模块getch()用到的变量*有:ssym,word,wsym词法分析结果:输出当前符号或字母的类型放入sym中*/(1)读取模块(获取一行单词)int getch()输出:一个字母,存到ch里(2)生成虚拟机代码int gen(enum f,int l)3、语法语义模块int block()编译程序主体(1)变量声明处理模块int vardefine();(2)语句处理模块int statement();(3)表达式处理模块int expression();(4)项处理模块int term();(5)因子处理模块int factor();(6)If语句处理模块int ifstatement( );(7)语句列处理int statementArray( );(8)while循环处理模块。
C语言程序设计基础与实践

C语言程序设计基础与实践一、基础知识1. C语言编译器C语言编译器是将C语言代码翻译成计算机能够理解的二进制指令的程序。
常见的C语言编译器有Microsoft Visual C++、Borland C++、GCC等。
2. C语言程序开发环境C语言程序开发环境包括编译器、IDE(Integrated Development Environment,集成开发环境)、编辑器和调试器。
常见的开发环境有Visual Studio、CodeBlocks、Dev-C++等。
3. C语言语法C语言的语法非常简单,注重语言结构和思维方式。
C语言的主要特点包括:(1)注释:单行注释以“\/\/”开头,多行注释以“\/*”开头,“*\/”结尾;(2)语句:每条C语言语句以分号“;”结尾;(3)函数:C语言程序中定义一个函数需要定义函数名、函数参数列表、函数返回值类型和函数体;(4)变量:C语言可以定义各种类型的变量,如int、double、char等;(5)运算符:包括算术运算符、关系运算符、逻辑运算符等。
4. C语言程序的编写和编译C语言程序的编写过程分为编辑、编译和运行三个步骤。
编辑器是用于编辑源代码的程序,编译器是将编写好的代码翻译成二进制机器指令的程序,运行器则是将编译后的代码在计算机上运行的程序。
编码过程中,需要注意使用变量和函数命名,以及注释等规范,多使用printf输出调试信息以便查错,编译过程中,需要注意编译器错误和警告信息。
二、实践经验1. C语言内存管理C语言中的指针和动态内存分配是C语言语法中的重要部分。
指针是一种特殊的变量类型,能够直接在内存地址上读写数据。
动态内存分配是在程序运行时分配内存的方法,可以使用malloc和free函数进行动态内存分配和释放。
使用指针和动态内存分配需要注意内存泄漏和段错误等问题。
2. C语言函数函数是C语言中的重要元素,能够让程序更加模块化,更易于维护和重用。
C语言函数的调用过程中需要注意函数调用的参数传递方式(值传递和引用传递)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
C语言编译器的设计与实现01计算机4班18号任春妍2号陈俊我们设计的编译程序涉及到编译五个阶段中的三个,即词法分析器、语法分析器和中间代码生成器。
编译程序的输出结果包括词法分析后的二元式序列、变量名表、状态栈分析过程显示及四元式序列程序,整个编译程序分为三部分:(1) 词法分析部分(2) 语法分析处理及四元式生成部分(3) 输出显示部分一.词法分析器设计由于我们规定的程序语句中涉及单词较少,故在词法分析阶段忽略了单词输入错误的检查,而将编译程序的重点放在中间代码生成阶段。
词法分析器的功能是输入源程序,输出单词符号。
我们规定输出的单词符号格式为如下的二元式:(单词种别,单词自身的值)#define ACC -2#define syl_if 0#define syl_else 1#define syl_while 2#define syl_begin 3#define syl_end 4#define a 5#define semicolon 6#define e 7#define jinghao 8#define s 9#define L 10#define tempsy 11#define EA 12#define EO 13#define plus 14#define times 15#define becomes 16#define op_and 17#define op_or 18#define op_not 19#define rop 20#define lparent 21#define rparent 22#define ident 23#define intconst 241.读取函数readline( )、readch( )词法分析包含从源文件读取字符的操作,但频繁的读文件操作会影响程序执行效率,故实际上是从源程序文件”source.dat ”中读取一行到输入缓冲区,而词法分析过程中每次读取一个字符时则是通过执行readch( )从输入缓冲区获得的;若缓冲区已被读空,则再执行readline( )从source.dat 中读取下一行至输入缓冲区。
2.扫描函数scan( )扫描函数scan( )的功能是滤除多余空格并对主要单词进行分析处理,将分析得到的二元式存入二元式结果缓冲区。
3.变量处理find()变量处理中首先把以字母开头的字母数字串存到spelling[ ]数组中,然后进行识别。
识别过程是先让它与保留关键字表中的所有关键字进行匹配,若获得成功则说明它为保留关键字,即将其内码值写入二元式结果缓冲区;否则说明其为变量,这时让它与变量名表中的变量进行匹配(变量匹配函数find ()),如果成功,则说明该变量已存在并在二元式结果缓冲区中标记为此变量(值填为该变量在变量名表中的位置),否则将该变量登记到变量名表中,再将这个新变量存入二元式缓存数组中。
4.数字识别number( )数字识别将识别出的数字填入二元式结果缓存数组。
5.显示函数显示函数的功能在屏幕上输出词法分析的结果(即二元式序列程序),同时给出二元式个数及源程序行数统计。
二.语法分析器设计语法分析器的核心是三张SLR 分析表以及针对这三张SLR 分析表进行语义加工的语义动作。
编译程序中语法分析处理及四元式生成部分主要是以二元式作为输入,并通过SLR 分析表对语法分析处理过程进行控制,使四元式翻译的工作有条不紊的进行,同时识别语法分析中的语法错误。
在处理if 和while 语句时,需要进行真值或假值的拉链和返填工作,以便转移目标的正确填入。
1. 控制语句的SLR 分析表1 设计过程如下:将扩展文法G’0)S’→ S1)S → if e S else S2)S → while e S3)S → { L }4)S → a;5)L → S6)L → SL用∈_CLOSURE方法构造LR(0)项目规范簇为:I0:S’→·SS →·if e S else SS →·while e SS →·{ L }S →·a ;I2: S → if·e S else SI3: S → while ·e SI4: S → {·L}L →·SL →·SLS →·if e S else SS →·while e SS →·{ L }S →·a ;I5: S → a·;I6: S →if e ·S else SS →·if e S else SS →·while e SS →·{ L }S →·a ;I7: S→ while e ·SS →·if e S else SS →·while e SS →·{ L }S →·a ;I8: S →{ L·}I9: L →S·L → S·LL →·SLL →·SS →·if e S else SS →·while e SS →·{ L }S →·a ;I10: S → a ; ·I11: S → if e S ·else SI12: S → while e S·I13: S → { L }·I14: S → SL ·I15: S → if e S else SS →·if e S else SS →·while e SS →·{ L }S →·a ;I16: S →if e S else S ·构造文法G’中非终结符的FOLLOW集如下:1)FOLLOW(S’) = { # }2)S → if e S else S得FOLLOW(S) = { else }S → { L } 得FOLLOW(L) = { } }3) S’→ S 得FOLLOW(S) = {else , #}L → S 因为FIRST(S) = { { },所以FOLLOW(S) = {else , #, { }在LR(0)项目规范簇中,只有I9有“移进――归约”冲突,L →S·L → S·L因为FOLLOW(L) ∩FIRST(L) = ∮所以可以用SLR方法解决以上冲突,最后我们得到的SLR分析static int action[20][11]=/* 0 */{{ 2, -1, 3, 4, -1, 5, -1, -1, -1, 1, -1},/* 1 */ { -1, -1, -1, -1, -1, -1, -1, -1,ACC, -1, -1},/* 2 */ { -1, -1, -1, -1, -1, -1, -1, 6, -1, -1, -1},/* 3 */ { -1, -1, -1, -1, -1, -1, -1, 7, -1, -1, -1},/* 4 */ { 2, -1, 3, 4, -1, 5, -1, -1, -1, 9, 8},/* 5 */ { -1, -1, -1, -1, -1, -1, 10, -1, -1, -1, -1},/* 6 */ { 2, -1, 3, 4, -1, 5, -1, -1, -1, 11, -1},/* 7 */ { 2, -1, 3, 4, -1, 5, -1, -1, -1, 12, -1},/* 8 */ { -1, -1, -1, -1, 13, -1, -1, -1, -1, -1, -1},/* 9 */ { 2, -1, 3, 4,105, 5, -1, -1, -1, 9, 14},/* 10*/ { -1,104, -1, -1,104, -1, -1, -1,104, -1, -1},/* 11*/ { -1, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1},/* 12*/ { -1,102, -1, -1,102, -1, -1, -1,102, -1, -1},/* 13*/ { -1,103, -1, -1,103, -1, -1, -1,103, -1, -1},/* 14*/ { -1, -1, -1, -1,106, -1, -1, -1, -1, -1, -1},/* 15*/ { 2, -1, 3, 4, -1, 5, -1, -1, -1, 16, -1},/* 16*/ { -1,101, -1, -1,101, -1, -1, -1,101, -1, -1}};其中,前9 列为action 值,后2 列为goto 值;0~16 表示17 个移进状态(即Si);-1表示出错;ACC 表示分析成功;而100~106 对应7 个归约产生式:100S’→ S101S → if e S else S102S → while e S103S → { L }104S → a;105L → S106L → SL2. 算术表达式的LR 分析表2 设计如下:0)S’→ E1) E → E+E2) E → E*E3) E → (E)static int action1[10][7]=/* 0 */ {{ 3, -1, -1, 2, -1, -1, 1},/* 1 */ { -1, 4, 5, -1, -1,ACC, -1},/* 2 */ { 3, -1, -1, 2, -1, -1, 6},/* 3 */ { -1,104,104, -1,104,104, -1},/* 4 */ { 3, -1, -1, 2, -1, -1, 7},/* 5 */ { 3, -1, -1, 2, -1, -1, 8},/* 6 */ { -1, 4, 5, -1, 9, -1, -1},/* 7 */ { -1,101, 5, -1,101,101, -1},/* 8 */ { -1,102,102, -1,102,102, -1},/* 9 */ { -1,103,103, -1,103,103, -1}};3.布尔表达式的SLR 分析表3 设计如下:(过程略)1)S’→ B2) B → i3) B → i rop i4) B → ( B )5) B → ! B6) A → B &&7) B → AB8)O → B ||static int action2[16][11]=/* 0 */ {{ 1, -1, 4, -1, 5, -1, -1, -1, 13, 7, 8}, /* 1 */ { 1, 2, -1,101, -1,101,101,101, -1, -1, -1}, /* 2 */ { 3, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1},/* 3 */ { -1, -1, -1,102, -1,102,102,102, -1, -1, -1},/* 4 */ { 1, -1, 4, -1, 5, -1, -1, -1, 11, 7, 8}, /* 5 */ { 1, -1, 4, -1, 5, -1, -1, -1, 6, 7, 8}, /* 6 */ { -1, -1, -1,104, -1, 9, 10,104, -1, -1, -1},/* 7 */ { 1, -1, 4, -1, 5, -1, -1, -1, 14, 7, 8}, /* 8 */ { 1, -1, 4, -1, 5, -1, -1, -1, 15, 7, 8}, /* 9 */ {105, -1,105, -1,105, -1, -1, -1, -1, -1, -1},/*10 */ {107, -1,107, -1,107, -1, -1, -1, -1, -1, -1},/*11 */ { -1, -1, -1, 12, -1, 9, 10, -1, -1, -1, -1},/*12 */ { -1, -1, -1,103, -1,103,103,103, -1, -1, -1},/*13 */ { -1, -1, -1, -1, -1, 9, 10,ACC, -1, -1, -1},/*14 */ { -1, -1, -1,106, -1, 9, 10,106, -1, -1, -1},/*15 */ { -1, -1, -1,108, -1, 9, 10,108, -1, -1, -1}};LR 分析表控制语义加工的实现:当扫描LR 分析表的当前状态为归约状态时,则在调用与该状态对应的产生式进行归约的同时,调用相应的语义子程序进行有关的翻译工作。