信息论实验信源的二元Huffman编码
第二章 无失真信源编码3Huffman编码

u2 p(u2 )
k
un p(u3 ) p(un ) u3
F (uk ) p(ui )
i 1 k 1
信源符号修正的积累概率为:F (u ) p(u ) 1 p(u ) k i k 2 i 1
码长: l (u k ) lb 1 1 p (u k )
验证n是否满足n=(m-1)Q+m,若不满足,可以人为地增 加一些概率为零的符号,使最后一步有m个信源符号; 取概率最小的m个符号合并成一个新结点,并分别用0, 1,…,(m+1)给各分支赋值,把这些符号的概率相加 作为该新结点的概率; 将新结点和剩下结点重新排队,重复步骤2; 取树根到叶子(信源符号对应结点)的各树枝上的赋值, 得到各符号码字。
1 平均码长: L p(uk )l (uk ) p(uk )( lb 1) k 1 k 1 p(uk )
n n
H (U ) 1 L H (U ) 2
例6:DMS如下,用香农-费诺-埃利斯编码方法编码
u2 u3 u4 U u1 P 0.25 0.5 0.125 0.125
1 ii 1
一、Huffman编码
1.二元Huffman编码 二元Huffman码的特点:
概率大 短码 短码充分利用 概率小 长码
※ ※
每次缩减信源的最后两个码字总是最后一位不同 (前面各位相同)
——惟一可译
一、Huffman编码
2.m元Huffman编码 “合m为一,一分为m”
2
3 4 4
1
三、香农-费诺-埃利斯码
香农-费诺-埃利斯码
不是分组码,也不是最佳码,但效率高
信息论霍夫曼编码译码实验报告

实验一一、实验背景*哈夫曼编码(Huffman Coding)是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。
Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般叫作Huffman编码。
二、实验要求*利用程序实现哈夫曼编码,以加深对哈夫曼编码的理解,并锻炼编程能力。
三、代码分析#include<stdio.h>#define n 3 //叶子数目#define m (2*n-1) //结点总数#define maxval 10000.0 //maxval是float类型的最大值#define maxsize 100 //哈夫曼编码的最大位数typedef struct //定义霍夫曼树结构体{char ch; //消息float weight; //所占权重int lchild,rchild,parent; //定义左孩子、右孩子}hufmtree;typedef struct //定义霍夫曼编码结构体{char bits[n]; //位串int start; //编码在位串中的起始位置char ch; //字符}codetype;void huffman(hufmtree tree[]); //建立哈夫曼树void huffmancode(codetype code[],hufmtree tree[]); //根据哈夫曼树求出哈夫曼编码void decode(hufmtree tree[]); //依次读入电文,根据哈夫曼树译码void main(){printf(" ——哈夫曼编码——\n");printf("信源共有%d个符号\n",n);hufmtree tree[m]; //m个结点,即有m个树形结构codetype code[n]; //信源有n个消息,则需要n个编码int i,j; //循环变量huffman(tree); //建立哈夫曼树huffmancode(code,tree); //根据哈夫曼树求出哈夫曼编码printf("【输出每个字符的哈夫曼编码】\n");for(i=0;i<n;i++){printf("%c: ",code[i].ch);for(j=code[i].start;j<n;j++)printf("%c ",code[i].bits[j]);//“消息:该消息的编码”printf("\n");}printf("【读入电文,并进行译码】\n");decode(tree); //依次读入电文,根据哈夫曼树译码}void huffman(hufmtree tree[]) //建立哈夫曼树{int i,j,p1,p2; //p1,p2分别记住每次合并时权值最小和次小的两个根结点的下标float small1,small2,f;char c;for(i=0;i<m;i++) //初始化{tree[i].parent=0;tree[i].lchild=-1;tree[i].rchild=-1;tree[i].weight=0.0;}printf("【依次读入前%d个结点的字符及权值(中间用空格隔开)】\n",n);for(i=0;i<n;i++) //读入前n个结点的字符及权值{printf("输入第%d个字符为和权值",i+1);scanf("%c %f",&c,&f);getchar(); //吸收回车符tree[i].ch=c;tree[i].weight=f; //将接收到的结点的字符及权值存入它对应的结构体数据中}for(i=n;i<m;i++) //进行n-1次合并,产生n-1个新结点{p1=0;p2=0;small1=maxval;small2=maxval; //maxval是float类型的最大值for(j=0;j<i;j++) //选出两个权值最小的根结点{if(tree[j].parent==0) //还未找到父结点的if(tree[j].weight<small1) //如果有比最小的还小的{small2=small1; //改变最小权、次小权及对应的位置small1=tree[j].weight;p2=p1;p1=j;}else if(tree[j].weight<small2) //如果有比最小的大,但比第二小的小的{small2=tree[j].weight; //改变次小权及位置p2=j;}}//找出的两个结点是新节点i的两个孩子tree[p1].parent=i;tree[p2].parent=i;tree[i].lchild=p1; //最小权根结点是新结点的左孩子tree[i].rchild=p2; //次小权根结点是新结点的右孩子tree[i].weight=tree[p1].weight+tree[p2].weight;}} //huffman//codetype code[]为求出的哈夫曼编码//hufmtree tree[]为已知的哈夫曼树void huffmancode(codetype code[],hufmtree tree[]) //根据哈夫曼树求出哈夫曼编码{int i,c,p;codetype cd; //缓冲变量for(i=0;i<n;i++){cd.start=n; //编码在位串中的起始位置cd.ch=tree[i].ch;c=i; //从叶结点出发向上回溯,第i个叶结点p=tree[i].parent; //tree[p]是tree[i]的父结点while(p!=0){cd.start--;if(tree[p].lchild==c)cd.bits[cd.start]='0'; //tree[i]是左子树,生成代码'0' elsecd.bits[cd.start]='1'; //tree[i]是右子树,生成代码'1' c=p; //c记录此时的父结点p=tree[p].parent; //p记录新的父结点,即原来的父结点的父结点,向上溯回}code[i]=cd; //第i+1个字符的编码存入code[i] }} //huffmancodevoid decode(hufmtree tree[])//依次读入电文,根据哈夫曼树译码{int i,j=0;char b[maxsize];i=m-1; //从根结点开始往下搜索printf("输入发送的编码:");gets(b);printf("译码后的字符为");while(b[j]!='\0'){if(b[j]=='0')i=tree[i].lchild; //走向左子树elsei=tree[i].rchild; //走向右子树if(tree[i].lchild==-1) //如果回到叶结点,则把该结点的消息符号输出{printf("%c",tree[i].ch);i=m-1; //回到根结点}j++;}printf("\n");if(tree[i].lchild!=-1&&b[j]=='\0') //电文读完,但尚未到叶子结点printf("\nERROR\n"); //输入电文有错}//decode四、实验补充说明解码时,以回车键结束输入电文。
Huffman编码原理简介

以下是Huffman编码原理简介:霍夫曼(Huffman)编码是1952年为文本文件而建立,是一种统计编码。
属于无损压缩编码。
霍夫曼编码的码长是变化的,对于出现频率高的信息,编码的长度较短;而对于出现频率低的信息,编码长度较长。
这样,处理全部信息的总码长一定小于实际信息的符号长度。
对于学多媒体的同学来说,需要知道Huffman编码过程的几个步骤:l)将信号源的符号按照出现概率递减的顺序排列。
(注意,一定要递减)2)将最下面的两个最小出现概率进行合并相加,得到的结果作为新符号的出现概率。
3)重复进行步骤1和2直到概率相加的结果等于1为止。
4)在合并运算时,概率大的符号用编码0表示,概率小的符号用编码1表示。
5)记录下概率为1处到当前信号源符号之间的0,l序列,从而得到每个符号的编码。
下面我举个简单例子:一串信号源S={s1,s2,s3,s4,s5}对应概率为p={40,30,15,10,5},(百分率)按照递减的格式排列概率后,根据第二步,会得到一个新的概率列表,依然按照递减排列,注意:如果遇到相同概率,合并后的概率放在下面!最后概率最大的编码为0,最小的编码为1。
如图所示:所以,编码结果为s1=1s2=00s3=010s4=0110s5=0111霍夫曼编码具有如下特点:1) 编出来的码都是异字头码,保证了码的唯一可译性。
2) 由于编码长度可变。
因此译码时间较长,使得霍夫曼编码的压缩与还原相当费时。
3) 编码长度不统一,硬件实现有难度。
4) 对不同信号源的编码效率不同,当信号源的符号概率为2的负幂次方时,达到100%的编码效率;若信号源符号的概率相等,则编码效率最低。
5) 由于0与1的指定是任意的,故由上述过程编出的最佳码不是唯一的,但其平均码长是一样的,故不影响编码效率与数据压缩性能。
霍夫曼编码的C语言实现#include <stdio.h>#include <malloc.h>#include <conio.h>#include <string.h>#include <stdlib.h>#define HuffmanTree HF#define HuffmanCode HMCtypedef struct{unsigned int weight;unsigned int parent,lchild,rchild;} HTNode,*HF;typedef char **HMC;typedef struct {unsigned int s1;unsigned int s2;} MinCode;void Error(char *message);HMC HuffmanCoding(HF HT,HMC HC,unsigned int *w,unsigned int n); MinCode Select(HF HT,unsigned int n);void Error(char *message){fprintf(stderr,"Error:%s\n",message);exit(1);}HMC HuffmanCoding(HF HT,HMC HC,unsigned int *w,unsigned int n) {unsigned int i,s1=0,s2=0;HF p;char *cd;unsigned int f,c,start,m;MinCode min;if(n<=1) Error("Code too small!");m=2*n-1;HT=(HF)malloc((m+1)*sizeof(HTNode));for(p=HT,i=0;i<=n;i++,p++,w++){p->weight=*w;p->parent=0;p->lchild=0;p->rchild=0;}for(;i<=m;i++,p++){p->weight=0;p->parent=0;p->lchild=0;p->rchild=0;}for(i=n+1;i<=m;i++){min=Select(HT,i-1);s1=min.s1;s2=min.s2;HT[s1].parent=i;HT[s2].parent=i;HT[i].rchild=s2;HT[i].weight=HT[s1].weight+HT[s2].weight;}printf("HT List:\n");printf("Number\t\tweight\t\tparent\t\tlchild\t\trchild\n"); for(i=1;i<=m;i++)printf("%d\t\t%d\t\t%d\t\t%d\t\t%d\n",i,HT[i].weight,HT[i].parent,HT[i].lchild,HT[i].rchild); HC=(HMC)malloc((n+1)*sizeof(char *));cd=(char *)malloc(n*sizeof(char *));cd[n-1]='\0';for(i=1;i<=n;i++){start=n-1;for(c=i,f=HT[i].parent;f!=0;c=f,f=HT[f].parent)if(HT[f].lchild==c) cd[--start]='0';else cd[--start]='1';HC[i]=(char *)malloc((n-start)*sizeof(char *));strcpy(HC[i],&cd[start]);}free(cd);return HC;}void main(){MinCode Select(HF HT,unsigned int n);HF HT=NULL;HuffmanCode HC=NULL;unsigned int *w=NULL;printf("请输入节点数n:");scanf("%d",&n);w=(unsigned int *)malloc((n+1)*sizeof(unsigned int *)); w[0]=0;printf("请输入权重:\n");for(i=1;i<=n;i++){printf("w[%d]=",i);scanf("%d",&w[i]);}HC=HuffmanCoding(HT,HC,w,n);printf("HMC:\n");printf("Number\t\tWeight\t\tCode\n");for(i=1;i<=n;i++)printf("%d\t\t%d\t\t%s\n",i,w[i],HC[i]);}MinCode Select(HF HT,unsigned int n){unsigned int min,secmin;unsigned int temp;unsigned int i,s1,s2,tempi;MinCode code;s1=1;s2=1;for(i=1;i<=n;i++)if(HT[i].parent==0){min=HT[i].weight;s1=i;break;}tempi=i++;for(;i<=n;i++)if(HT[i].weight<min&&HT[i].parent==0){min=HT[i].weight;s1=i;}for(i=tempi;i<=n;i++)if(HT[i].parent==0&&i!=s1){secmin=HT[i].weight;s2=i;break;}for(i=1;i<=n;i++)if(HT[i].weight<secmin&&i!=s1&&HT[i].parent==0) {secmin=HT[i].weight;s2=i;}if(s1>s2){temp=s1;s1=s2;s2=temp;}code.s1=s1;code.s2=s2;return code;}。
信息论 实验六 Huffman编码

实验六 Huffman 编码一、实验目的:掌握Huffman 编码的方法二、实验内容:对信源123456,,,,,()0.250.250.020.150.10.05a a a a a a X P X ⎧⎫⎛⎫=⎨⎬ ⎪⎝⎭⎩⎭进行二进制Huffman 编码。
并计算其平均码长,编码效率。
三、实验步骤(1)将概率按从小到大的顺序排列(2)给两个概率最小的信源符号1()P a 和2()P a 各分配一个码位“0”和“1”,将这两个信源符号合并成一个新符号,并用这两个最小的概率之和最为新符号的概率,结果得到一个只包含(n-1)个信源符号的新信源,称为信源的第一次缩减信源,用S1表示。
(3)将缩减信源S1的符号仍按概率从大到小的顺序排列,重复步骤2,得到只含(n-2)个符号的缩减信源S2。
(4)重复上述步骤,直至缩减信源只剩两个符号为止,此时所剩的两个符号的概率之和为1。
然后从最后一级缩减信源开始,依编码路径向前返回,就得到各信源符号所对应的码字。
四、实验数据及结果分析(1)将信源符号按概率从小到大的顺序排列。
P=(0.25 0.25 0.2 0.15 0.1 0.05);(2)输出每个灰度级的编码00010000001111001(3)计算其平均码长和编码效率平均码长L=2.4500编码效率xiaolv=0.9891(4)运行截图如下所示:图一运行及结果五、代码附录n=input('N=');%输入信源符号的个数L=0; H=0;for i=1:nP(i)=input('P=');%输入信源符号概率分布s=s+P(i);endif s~=1error('不符合概率分布');endP=sort(P);p=P;mark=zeros(n-1,n); %mark为n-1行,n列矩阵,用来记录每行概率排列次序for i=1:n-1[P,num]=sort(P); %对输入元素排序并记录mark(i,:)=[num(1:n-i+1),zeros(1,i-1)];P=[P(1)+P(2),P(3:n),1];endfor i=1:n-1table(i,:)=blanks(n*n); %blanks 创建空格串endtable(n-1,n)='1';table(n-1,2*n)='0'for i=2:n-1table(n-i,1:n-1)=table(n-i+1,n*(find(mark(n-i+1,:)==1))-(n-2):n*(find(mark(n-i+1,:)==1))); %按mark的记录依次赋值table(n-i,n)='1';table(n-i,n+1:2*n-1)=table(n-i,1:n-1);table(n-i,2*n)='0';for j=1:i-1table(n-i,(j+1)*n+1:(j+2)*n)=table(n-i+1,n*(find(mark(n-i+1,:)==j+1)-1)+1:n*find(mark(n-i+1,:)==j+1));%mark的记录依次赋值endend%得到编码后的码字for i=1:nW(i,1:n)=table(1,n*(find(mark(1,:)==i)-1)+1:find(mark(1,:)==i)*n);l(i)=length(find(abs(W(i,:))~=32));%32表示空字符,要找不是空字符的个数,即为每个数编码的个数L=L+p(i)*l(i); %计算平均码长H=H-p(i)*log2(p(i));%计算信源熵endxiaolv=H/L; %计算编码效率disp('输出每个概率的编码');disp(W);disp('输出平均码长L:');disp(L);disp('输出编码效率xiaolv:');disp(xiaolv);六,实验总结:通过该实验,掌握了Huffman编码。
信息论综合性实验报告 Huffman编码及译码 代码

Xx大学yy学院综合性设计性实验报告专业班级:学号:姓名:实验所属课程:信息论与编码技术实验室(中心):信息科学与工程学院软件中心指导教师:实验完成时间: 2012 年 12 月 9 日一、设计题目:Huffman编码及译码二、实验内容及要求:<一>实验内容:对所给的字符串进行huffman的编译码;译码对应原始序列,在将编码进行移位操作时,再进行译码输出,得出误码率。
<二>实验要求:自己设计一段信源序列,利用Huffman编码对其进行编码,然后利用相应的译方法进行译码,同时考察译码错误对后续序列带来的影响。
三、实验过程(详细设计):<一> huffman编码原理:Huffman编码是一种紧致编码,但编码序列的码并非是唯一的。
它是根据源数据各信号发生的概率进行编码,在源数据中出现的概率越大的信号,分配的码字越短;出现概率越小的信号,其码字越长,从而达到用尽可能少的码字表示源数据的目的。
Huffman编码的步骤如下:设信源X有m个符号(消息),信源概率分布如下:X = ⎧ x1, x2 ,..., x m ⎫⎩ p1 2 ,..., p m ⎭(1)把信源X 中的消息按概率从大到小的顺序排列;(2)把最后两个出现概率最小的消息合并成一个消息,从而使信源的消息数减少,并同时再按信源符号(消息)出现的概率从大到小排列;(3)重复上述2 个步骤,直到信源最后为一个序列只有一个1;(4)将被整合的消息分别赋予1 和0,并对最后的两个消息也相应地赋予1 和0.(5)通过以上步骤即可完成编码操作。
<二> huffman译码原理:通过在刚开始生成的随机编码序列,得到列出的0 1 序列与源字符串一一对应,就完成了译码。
而对错位后的编码序列,我只是只错位了前两个进行译码,效果不是很明显。
<三>算法设计:1、编码部分:(1)主函数主要用于调用前面所编写的各个函数模块,按照主函数(主函数代码如下)所列出来的调用顺序,进行一一叙述。
信息论编码哈夫曼编码的实现

信息论编码哈夫曼编码的实现院系:信息工程院系专业:通信工程专业学号:信息论发展简史与信息科学信息论从诞生到今天,已有五十多年历史,现已成为一门独立的理论科学,回顾它的发展历史,我们可以知道理论是如何从实践中经过抽象、概括、提高而逐步形成的。
1.信息论形成的背景与基础信息论是在人们长期的通信工程实践中,由通信技术和概率论、随机过程和数理统计相结合而逐步发展起来的一门学科。
人们公认的信息论的奠基人是当代伟大的数学家、美国贝尔实验室杰出的科学家香农,他在1948年发表了著名的论文《通信的数学理论》,为信息论奠定了理论基础。
近半个世纪以来,以通信理论为核心的经典信息论,正以信息技术为物化手段,向高精尖方向迅猛发展,并以神奇般的力量把人类社会推入了信息时代。
随着信息理论的迅猛发展和信息概念的不断深化,信息论所涉及的内容早已超越了狭义的通信工程范畴,进入了信息科学领域。
通信系统是人类社会的神经系统,即使在原始社会也存在着最简单的通信工具和通信系统,这方面的社会实践是悠久漫长的。
电的通信系统(电信系统)已有100多年的历史了。
在一百余年的发展过程中,一个很有意义的历史事实是:当物理学中的电磁理论以及后来的电子学理论一旦有某些进展,很快就会促进电信系统的创造发明或改进。
这是因为通信系统对人类社会的发展,其关系实在是太密切了。
日常生活、工农业生产、科学研究以及战争等等,一切都离不开消息传递和信息流动。
例如,当法拉第(M.Faraday)于1820年--1830年期间发现电磁感应的基本规律后,不久莫尔斯(F.B.Morse)就建立起电报系统(1832—1835)。
1876年,贝尔(A.G.BELL)又发明了电话系统。
1864年麦克斯韦(Maxell)预言了电磁波的存在,1888年赫兹(H.Hertz)用实验证明了这一预言。
接着1895年英国的马可尼(G.Marconi)和俄国的波波夫(A.C.ΠoΠoB)就发明了无线电通信。
二元霍夫曼编码-信息论与编码实验报告参考模板

计算机与信息工程学院综合性实验报告一、实验目的根据霍夫曼编码的原理,用MATLAB设计进行霍夫曼编码的程序,并得出正确的结果。
二、实验仪器或设备1、一台计算机。
2、MATLAB r2013a。
三、二元霍夫曼编码原理1、将信源消息符号按其出现的概率大小依次排列,p1>p2>…>p q2、取两个概率最小的字母分别配以0和1两个码元,并将这两个概率相加作为一个新字母的概率,从而得到只包含q-1个符号的新信源S1。
3、对重排后的缩减信源S1重新以递减次序排序,两个概率最小符号重复步骤(2)的过程。
4、不断继续上述过程,直到最后两个符号配以0和1为止。
5、从最后一级开始,向前返回得到各个信源符号所对应的码元序列,即相应的码字。
四、霍夫曼编码实现程序function [outnum]=lml_huffman(a)%主程序,输入一组概率,输出此组概率的霍夫曼编码%a:一组概率值,如a=[0.2 0.3 0.1 0.4]等%outnum:输出的霍夫曼码,以cell中的字符数组表示if sum(a)~=1warning('输入概率之和不为“1”,但程序仍将继续运行')end[cho,sequ,i,l]=probality(a);global lmlcode %用于输出霍夫曼码,定义为cell型global cellnum %用于编码的累加计算cellnum=1;lmlcode=cell(l,1);j=1; %第一部分add_num=char;[l_add]=addnum(add_num,i,j,l);[output,m]=disgress(sequ,i,j,l,l_add);dealnum(output,m); %在全局变量中输出霍夫曼码j=2; %第二部分[l_add]=addnum(add_num,i,j,l);[output,n]=disgress(sequ,i,j,l,l_add);dealnum(output,n);[outnum]=comset(lmlcode,cho(1,:));%将概率和编码进行关联function [output]=addnum(input,i,j,l)%对概率矩阵中每一行最后两个不为0的数进行编码,即在某个编码后添加0,1或空%输出:% input:输入的某个未完成的编码% (i,j):当前检索目标在sequ矩阵中的位置% l:sequ矩阵的列数%PS: sequ矩阵在此函数中未用到%PS:此函数为编码第一步if j==(l-i)output=[input '0'];else if j==(l-i+1)output=[input '1'];elseoutput=input;endendfunction [ecode]=comset(code,pro)%将概率和编码进行关联%code:已编成的霍夫曼码%pro:输入的一组概率%ecode:最终完成的码l=length(code);ecode=cell(l,2);for i=1:llang(i)=length(code{i});end[a,b]=sort(lang);for i=1:lecode{i,1}=code{b(i)};ecode{i,2}=pro(i);endfunction [final,a]=dealnum(imput,m)%整理并在全局变量中输出已完成的霍夫曼码%输入: imput:程序运算后的生成cell型矩阵% m:标识数%输出: final:整理后的霍夫曼码% a:标识数global lmlcodeglobal cellnumif m==1lmlcode{cellnum}=imput;cellnum=cellnum+1;final='';a='';else if m==2[final1,a1]=dealnum(imput{1,1},imput{1,2});[final2,a2]=dealnum(imput{2,1},imput{2,2});[final3,a3]=dealnum(final1,a1);[final4,a4]=dealnum(final2,a2);final=[final3 final4];a=[a3 a4];elsefinal=imput;a=m;endendfunction [outnum,p]=findsumother(sequ,i,j,l,add_num)%当前检索目标在sequ(i,j)处为非1时的处理程序,即跳转到下一级进行整理%输入: sequ:概率转移矩阵% (i,j):当前检索目标在sequ矩阵中的位置% l:sequ矩阵的列数% add_num:当前进行的编码%输出:(与disgress类同)% outnum:进行霍夫曼编码,用cell型表示% p:标识数j=l-i+2-sequ(i,j);i=i-1;[add_num1]=addnum(add_num,i,j,l);[outnum,p]=disgress(sequ,i,j,l,add_num1);function [outnum1,outnum2,p,q]=findsumis1(sequ,i,j,l,add_num)%当前检索目标在sequ(i,j)处为1时的处理程序,%即对下一级的最小两概率进行求和移位编码整理%输入: sequ:概率转移% (i,j):当前检索目标在sequ矩阵中的位置% l:sequ矩阵的列数% add_num:当前进行的编码%输出:(与disgress类同)% outnum1&[outnum2:进行霍夫曼编码,用cell型表示% p&q:标识数i=i-1;j1=l-i;j2=l-i+1;[add_num1]=addnum(add_num,i,j1,l);[outnum1,p]=disgress(sequ,i,j1,l,add_num1);[add_num2]=addnum(add_num,i,j2,l);[outnum2,q]=disgress(sequ,i,j2,l,add_num2);function [output,m]=disgress(sequ,i,j,l,add_num)%当前检索目标,累加数,输出下一级霍夫曼码及其个数,此函数被调用次数最多%输入:sequ:概率转移矩阵% (i,j):当前检索目标在sequ矩阵中的位置% l:sequ矩阵的列数% add_num:当前进行的编码%输出:output:进行霍夫曼编码,用cell型表示% m:标识数%PS:此函数为编码第二步if i~=1if sequ(i,j)==1[output1,output2,p,q]=findsumis1(sequ,i,j,l,add_num);output=cell(2);output{1,1}=output1;output{1,2}=p;output{2,1}=output2;output{2,2}=q;m=2;else if sequ(i,j)~=1[output1,p]=findsumother(sequ,i,j,l,add_num);output=output1;m=p;endendelseoutput=add_num;m=1;end五、实验程序实现方法演示若在command window中输入的概率数组为p=[0.1 0.15 0.20 0.25 0.30]使用子函数[output,sequ,i,j]=probality(p)对此组概率进行预处理,处理结果如下图所示:图5.1 概率数据处理过程简图图5.2 对图1中数据的转移方式标示图图2标明了对图1中各数据的位置转移过程。
信息论与编码第八章课后习题答案

扩展信源的平均码长为:
L3 = 0.729 + 0.081*9 + 0.009*15 + 0.005 = 1.598
L3 = 0.532667 码符号/信源符号 N 四次扩展信源略; 当 N → ∞ 时,根据香农第一定理,平均码长为:
LN = H (S ) = 0.469 码符号/信源符号 N log r
第八章课后习题
【8.1】求概率分布为(1/3,1/5,1/5,2/15,2/15)信源的二元霍夫曼码。讨论此码对于 概率分布为(1/5,1/5,1/5,1/5,1/5)的信源也是最佳二元码。 解:
概率分布为(1/3,1/5,1/5,2/15,2/15)信源二元霍夫曼编码过程如下:
同样,对于概率分布为(1/5,1/5,1/5,1/5,1/5)的信源,编码过程如下:
488 2 少?如何编码? 解:
平均每个消息携带的信息量为 2 比特,因此发送每个消息最少需要的二元脉 冲数为 2。如果四个消息非等概率分布,采用紧致码编码,可使得所需要的二元 脉冲数最少,编码过程如下:
平均码长为:
∑ L = P(si )li = 1.75 二元码符号/信源符号
即在此情况下消息所需的二元脉冲数为 1.75 个。 【8.6】若某一信源有 N 个符号,并且每个符号等概率出现,对这信源用最佳霍 夫曼码进行二元编码,问当 N = 2i 和 N = 2i +1( i 是正整数)时,每个码字的长 度等于多少?平均码长是多少? 解:
码长的方差,并计算平均码长和方差,说明哪一种码更实用些。 解:
进行三元编码,需增补一个概率为 0 的信源符号,两种编码方法如下所示。
图1
图2
ห้องสมุดไป่ตู้
信息论实验信源的二元Huffman编码

概率:0.17编码:110
概率:0.01编码:1000
概率:0.15编码:101
概率:0.2编码:01
概率:0.19编码:00
概率:0.1编码:1001
平均码长为:2.72
编码效率为:0.959075
六.实验总结及心得体会
Huffman编码方法是《数据结构》课程中的一个重要内容,当时是用二叉树来实现的。在《信息论与编码》中,Huffman树的概念虽然提的很少,但整体思想仍然是相同的,因此编程过程还比较顺利。
for i=2:n-1
c(n-i,1:n-1)=c(n-i+1,n*(find(m(n-i+1,:)==1))-(n-2):n*(find(m(n-i+1,:)==1)));
c(n-i,n)='0';
c(n-i,n+1:2*n-1)=c(n-i,1:n-1);
c(n-i,2*n)='1';
for j=1:i-1
q=p;%信源的概率赋给q,以便后面排序、合并用
m=zeros(n-1,n);%定义m为零数组,记录排列顺序(小概率求和后再重新排列,这就存在排序的问题)
for i=1:n-1
[q,k]=sort(q);%k是排列后的顺序,sort(q)是对q进行升序
m(i,:)=[k(1:n-i+1),zeros(1,i-1)];%概率小的相加之后重新排序,排列顺序记录在m矩阵中
if (length(find(p<0))~=0)
error('数组中概率有负的');%p概率为负拒绝编码
end
if (abs(sum(p)-1)>10e-10)
信息论 第4章(哈夫曼编码和游程编码)

游程编码的基本原理
很多信源产生的消息有一定相关性,往往 连续多次输出同样的消息,同一个消息连续输 出的个数称为游程(Run-Length).我们只需要 输出一个消息的样本和对应重复次数,就完全 可以恢复原来的消息系列.原始消息系列经过 这种方式编码后,就成为一个个编码单元(如下 图),其中标识码是一个能够和消息码区分的特 殊符号.
文件传真压缩方法具体流程
主要利用终止码和形成码(见书本P43-44), 一般A4的纸每行的像素为1728,具体编码规则 如下: (1)当游程长度小于64时,直接用一个对应 的终止码表示。 (2)当游程长度在64到1728之间时,用一个 形成码加一个终止码表示。 例如:白游程为662时用640形成码(白)加22终 止码(白)表示,即:01100111 0000011. 黑游程为256时用256形成码(黑)加0终止码(黑) 表示,即:000001011011 0000110111.
哈夫曼(Huffman) (3)哈夫曼(Huffman)编码
哈夫曼编码:将信源中的各个消息按概率排序, 不断将概率最小的两个消息进行合并,直到合 并为一个整体,然后根据合并的过程分配码字, 得到各个消息的编码。 该方法简单明了,并且可以保证最终的编 码方案一定是最优编码方案。
哈夫曼(Huffman) 哈夫曼(Huffman)编码的例子
香农编码的例子
信息论第八章课后习题

(1)现将图像通过给定的信道传输,不考虑图像的任何统计特性,并采用二元
等长码,问需要多长时间才能传完这幅图像?
(2)若考虑图像的统计特性(不考虑图像的像素之间的依赖性),求此图像的
信源熵
H (S),并对灰度级进行霍夫曼最佳二元编码,问平均每个像素需
用多少二元码符号来表示?这时需多少时间才能传送完这幅图像?
1 1 1 1 1 1 1 1 1 1
2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 3 3 3
3 3 3 3 3 3 3 4 4 4
4 4 4 4 4 4 4 5 5 5
5 5 5 5 6 6 6 6 6 6
7 7 7 7 7 8 8 8 8 8
另有一无损无噪二元信道,单位时间(秒)内传输
可见,二者的码字完全相同。
【8.2】设二元霍夫曼码为
(00,01,10,11)和(0,10,110,111),求出可以编得这样霍夫
曼码的信源的所有概率分布。
解:
二元霍夫曼编码的过程必定是信源缩减的过程,编码为
(00,01,10,11)的信
源,其码树如下图所示。
假设四个信源符号的概率分别是
i(2i -1) + 2(i +1) i2i + i + 22
L= == i +
i ii
2 + 12 + 12 + 1
【8.7】设信源
ss Lss
12 M -1 M ù
S :
pp L pp
12 M -1 M
M
i=1
é
信息论-信源哈夫曼编码
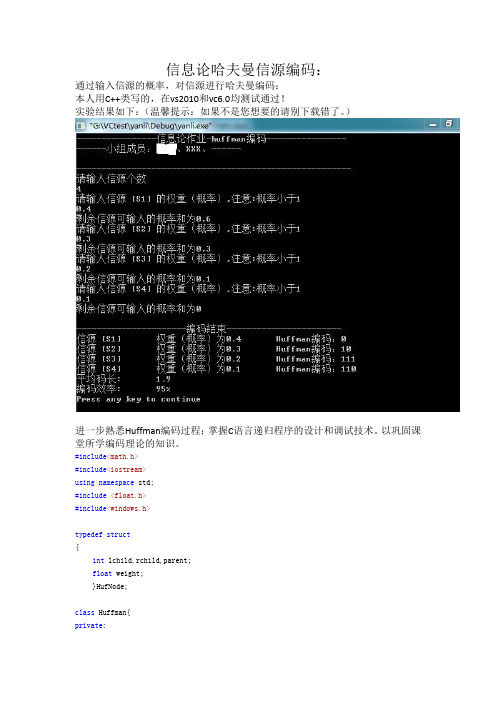
信息论哈夫曼信源编码:通过输入信源的概率,对信源进行哈夫曼编码:本人用C++类写的,在vs2010和vc6.0均测试通过!实验结果如下:(温馨提示:如果不是您想要的请别下载错了。
)进一步熟悉Huffman编码过程;掌握C语言递归程序的设计和调试技术。
以巩固课堂所学编码理论的知识。
#include<math.h>#include<iostream>using namespace std;#include<float.h>#include<windows.h>typedef struct{int lchild,rchild,parent;float weight;}HufNode;class Huffman{private:int Num;//节点个数public://构造函数Huffman(int n){Num=n;}~Huffman(){}//析构函数int getNum();//声明获取节点个数HufNode *setHuffmanArray(int);//声明生成存储哈夫曼树数组函数void InitHuffmanTree(HufNode *T);//声明初始化哈夫曼树函数void InputWeight(HufNode *T);//声明输入权重(概率)函数void SelectMin(HufNode *T,int ,int *,int *);//声明选择最小权重函数void CreateHuffmanTree(HufNode *T);//声明建立哈夫曼树函数int HuffmanCode(HufNode *T,int);//声明编码函数};//生成存储哈夫曼树数组函数HufNode *Huffman::setHuffmanArray(int n){HufNode *huffmantree;huffmantree=(HufNode*)malloc(n*sizeof(HufNode));return huffmantree;}//获取节点个数函数int Huffman::getNum(){return this->Num;}//初始化哈夫曼树函数void Huffman::InitHuffmanTree(HufNode *T){//若一棵哈夫曼树有n个叶子,则这个哈夫曼树就有2*n-1个,所以循环生成2n-1个节点,其中this->getNum()就得到了nfor(int i = 0;i < 2*(this->getNum())-1;i++){//为树中每个节点赋初值T[i].lchild =-1;T[i].rchild =-1;T[i].parent =-1;T[i].weight =0.0;}}//输入权重(概率)函数void Huffman::InputWeight(HufNode *T){float temp=0;float temp_sum=0;for(int k=0;k<(this->getNum());k++){cout<<"请输入信源 [S"<<k+1<<"] 的权重(概率),注意:概率小于1"<<endl;cin>>temp;if(temp>=1){cout<<"输入错误程序退出"<<endl;exit(0); //程序终止退出}T[k].weight=temp;temp_sum+=temp;cout<<"剩余信源可输入的概率和为"<<1.0-temp_sum<<endl;if(temp_sum>1){cout<<"信源概率和大于1,程序退出"<<endl;exit(0);}}}//选择最小权重节点函数,将最小的为T[*p1],次小的给T[*p2]void Huffman::SelectMin(HufNode *T,int i,int *p1,int *p2){int m;m=2*(this->getNum())-1;*p1=*p2=m-1; //给*p1和*p2赋初值为(2n-1)-1,即p1,p2均为倒数第二个节点T[m-1].weight = FLT_MAX; //FLT_MAX为c语言的明显常量,表示float的最大值for(int j = 0;j <= i;j++){if(T[j].parent !=-1)continue;if(T[j].weight < T[*p1].weight){//cout<<T[j].weight<<"<"<<T[*p1].weight<<endl;*p2 = *p1;*p1 = j;}else if(T[j].weight < T[*p2].weight)*p2 = j;//cout<<T[j].weight<<endl;}}void Huffman::CreateHuffmanTree(HufNode *T){int n,m,p1,p2;n=this->getNum();//n为叶子节点个数m=(2*(this->getNum())-1);//m为2n-1this->InitHuffmanTree(T);this->InputWeight(T);for(int i = n;i < m;i++){SelectMin(T,i-1,&p1,&p2);T[p1].parent = T[p2].parent = i;//将最小的两个节点T[p1],T[p2]的父亲赋值nT[i].lchild = p1;//左孩子为最小节点T[i].rchild = p2;//右孩子为次小节点T[i].weight = T[p1].weight+T[p2].weight;}}int Huffman::HuffmanCode(HufNode *T,int i){cout<<"信源 [S"<<i+1<<"]\t权重(概率)为"<<T[i].weight<<"\t";int *arr,count = 0,j;arr=(int*)malloc((this->getNum())*sizeof(int));while(T[i].parent != -1){arr[count++] = T[T[i].parent].lchild == i?0:1;//判断当前节点是否为左孩子,若是则赋0,不是则赋1(左0右1原则)i = T[i].parent;}cout<<"Huffman编码:";for(j = count-1;j >= 0;j--)cout<<arr[j];cout<<endl;return count;free(arr);}void main(){int n=0;float ave = 0;cout<<"----------------信息论作业-huffman编码----------------"<<endl;cout<<"------小组成员:XXX、XXX、------\t"<<endl;cout<<endl;cout<<"-------------------------------------------------------"<<endl;cout<<"请输入信源个数"<<endl;cin>>n;Huffman huff(n);HufNode *T;T=(HufNode*)malloc((2*n-1)*sizeof(HufNode));T=huff.setHuffmanArray((2*n-1));huff.CreateHuffmanTree(T);cout<<endl;cout<<"----------------------编码结束-----------------------"<<endl;for(int i = 0;i < huff.getNum();i++)ave += T[i].weight*huff.HuffmanCode(T,i);free(T);cout<<"平均码长:\t"<<ave<<endl;cout<<"编码效率:\t"<<ave/ceil(log((double)huff.getNum())/log((double)2))*100<<"%"<<endl; }实验结果如下:上程序即为此哈夫曼树:10 10.60.4S4 0 10.3 0.3S3 0 10.1 0.2S4 S3。
第二章 无失真信源编码3Huffman编码

U
P
u1 0.5
u2 0.25
u3 0.125
u4 0.125
码长
1 2 3 3
消息 符号 码字 符号 概率
ui P(ui)
0
u1 0.5
10 u2 0.25
110 u3 0.125
111 u4 0.125
信息熵:
H(U) p(ui )lbp(ui ) 1. 75bit i
0
平均码长:
2.3 霍夫曼码及其他编码方法
一、霍夫曼码 二、费诺编码 三、香农-费诺-埃利斯码
一、Huffman编码
1.二元Huffman编码
步骤:
① 递减排序;S=[s1,s2,…,sq] ② 合并概率最小的两个符号; ③ 重复①②,直至缩减信源中只有两个符号为止; ④ 分配码元。
例1:
已知离散无记忆信源如下所示,对应的霍夫曼编码为:
消息 概率
第一次 分组
第二次 分组
第三次 分组
第四次 分组
码字
码长
si
P(si)
s1
0.20
0
00 2
s2
0L.19
0P(si
)li
1
2.740code
/
sig
010
3
s3
0.18
1
011 3
s4
0.17
0
10 2
H (S )
s5 R0.15 L1 0.953 b0it / code 110
3
55
LL PP((ssii))llii 00..4421 0.2 2 0.2 23 0.1 43 0.1 43 2.2 code / sig
ii11
实验1 Huffman编码生成器-matlab

1.计算机
2.Windows 2000或以上
3.MatLab
四、实验原理
Huffman编码算法
为使平均码长最短,必须使最后一步缩减信源有m个信源符号。如果第一步给概率最小的符号分配码元时,所取的符号数就不一定是m个。
对于m进制编码,若所有码字构成全树,可分离的码字数必为m+k(m-1),式中k为非负整数,即缩减次数。
% L为编码返回的平均码字长度,q为编码效率%
%*****************************************%
function [W,L,q]=huffman(P)
if (length(find(P<=0))~=0)
error('Not a prob.vector,negative component'); %判断是否符合概率分布条件
% H为信息熵%
%******************************%
function H=entropy(P,r)
if (length(find(P<=0))~=0)
error('Not a prob.vector,negative component'); %判断是否符合概率分布条件
end
s2='Huffman编码平均码字长度L:';
s3='Huffman编码的编码效率q:';
disp(s0);
disp(s1),disp(B),disp(W);
disp(s2),disp(L);
disp(s3),disp(q);
%函数说明:%
% H=entropy(P,r)为信息熵函数%
实验二、Huffman编码

信息论与编码实验报告完成时间:2012 年 12 月 22 日1、简要总结Huffman编码的基本原理及特点;哈夫曼码是用概率匹配方法进行信源编码。
它有两个明显的特点:一是哈夫曼的编码方法保证了概率大的符号对应于短码,概率小的符号对应于长码,充分利用了短码;二是缩减信源的最后两个码字总是最后一位不同,从而保证了哈夫曼码是即时码特点:(1)它是一种分组码;(2)它是一种唯一可译码;(3)它是一种即时码。
2、写出Huffman编码基本步骤,画出实现Huffman编码的程序流程图;步骤进行:1)将信号源的符号按照出现概率递减的顺序排列。
2)将两个最小出现概率进行合并相加,得到的结果作为新符号的出现概率。
3)重复进行步骤1和2直到概率相加的结果等于1为止。
4)在合并运算时,概率大的符号用编码0表示,概率小的符号用编码1表示。
5)记录下概率为1处到当前信号源符号之间的0,1序列,从而得到每个符号的编码。
3、实现二元Huffman码编码的Matlab源程序;probabilities = [0.0856 0.0139 0.0279 0.0378 0.1304 0.0289 0.0199 0.0528 0.0627 0.0013 0.0042 0.0339 0.0249 0.0707 0.0797 0.0199 0.0012 0.0677 0.0607 0.1045 0.02490.0092 0.0149 0.0017 0.0199 0.0008];probabilities = probabilities/sum(probabilities);for index = 1:length(probabilities)codewords{index} = [];set_contents{index} = index;set_probabilities(index) = probabilities(index);enddisp('-------------------------------------------------------------------------');disp('The sets of symbols and their probabilities are:')for set_index = 1:length(set_probabilities)disp([num2str(set_probabilities(set_index)),' ', num2str(set_contents{set_index})]);endwhile length(set_contents) > 1[temp, sorted_indices] = sort(set_probabilities);zero_set = set_contents{sorted_indices(1)};zero_probability = set_probabilities(sorted_indices(1));for codeword_index = 1:length(zero_set)codewords{zero_set(codeword_index)} = [codewords{zero_set(codeword_index)}, 0];endone_set = set_contents{sorted_indices(2)};one_probability = set_probabilities(sorted_indices(2));for codeword_index = 1:length(one_set)codewords{one_set(codeword_index)} = [codewords{one_set(codeword_index)}, 1];enddisp('The symbols, their probabilities and the allocated bits are:');for index = 1:length(codewords)disp([num2str(index),' ',num2str(probabilities(index)),' ',num2str(codewords{index})]);endset_contents(sorted_indices(1:2)) = [];set_contents{length(set_contents)+1} = [zero_set, one_set];set_probabilities(sorted_indices(1:2)) = [];set_probabilities(length(set_probabilities)+1) = zero_probability + one_probability;disp('The sets and their probabilities are:')for set_index = 1:length(set_probabilities)disp([num2str(set_probabilities(set_index)),' ', num2str(set_contents{set_index})]);endenddisp('-------------------------------------------------------------------------');disp('The symbols, their probabilities and the allocated Huffman codewords are:');for index = 1:length(codewords)disp([num2str(index), ' ', num2str(probabilities(index)),' ',num2str(codewords{index}(length(codewords{index}):-1:1))]);endentropy = sum(probabilities.*log2(1./probabilities));av_length = 0;for index = 1:length(codewords)av_length = av_length + probabilities(index)*length(codewords{index});enddisp(['The symbol entropy is: ',num2str(entropy)]);disp(['The average Huffman codeword length is: ',num2str(av_length)]);disp(['The Huffman coding rate is: ',num2str(entropy/av_length)]);4、讨论不同的Huffman编码的平均码长如何变化,码字长度偏离平均码长对编码性能的影响。
《信息论与信源编码》实验报告

《信息论与信源编码》实验报告1、实验目的(1) 理解信源编码的基本原理;(2) 熟练掌握Huffman编码的方法;(3) 理解无失真信源编码和限失真编码方法在实际图像信源编码应用中的差异。
2、实验设备与软件(1) PC计算机系统(2) VC++6.0语言编程环境(3) 基于VC++6.0的图像处理实验基本程序框架imageprocessing_S(4) 常用图像浏览编辑软件Acdsee和数据压缩软件winrar。
(5) 实验所需要的bmp格式图像(灰度图象若干幅)3、实验内容与步骤(1) 针对“图像1.bmp”、“图像2.bmp”和“图像3.bmp”进行灰度频率统计(即计算图像灰度直方图),在此基础上添加函数代码构造Huffman码表,针对图像数据进行Huffman编码,观察和分析不同图像信源的编码效率和压缩比。
(2) 利用图像处理软件Acdsee将“图像1.bmp”、“图像2.bmp”和“图像3.bmp”转换为质量因子为10、50、90的JPG格式图像(共生成9幅JPG图像),比较图像格式转换前后数据量的差异,比较不同品质因素对图像质量的影响;(3) 数据压缩软件winrar将“图像1.bmp”、“图像2.bmp”和“图像3.bmp”分别生成压缩包文件,观察和分析压缩前后数据量的差异;(4) 针对任意一幅图像,比较原始BMP图像数据量、Huffman编码后的数据量(不含码表)、品质因素分别为10、50、90时的JPG文件数据量和rar压缩包的数据量,分析不同编码方案下图像数据量变化的原因。
4、实验结果及分析(1)在VC环境下,添加代码构造Huffman编码表,对比试验结果如下:a.图像1.bmp:图1 图像1.bmp图像的像素点个数共640×480个,原图像大小为301KB,图像信息熵为5.92bit/符号,通过Huffman编码后,其编码后的平均码长为5.960码元/信源符号,编码效率为99.468%,编码后的图像大小为228.871KB,压缩比为1.342。
matlab信源二进制赫夫曼编码

信源二进制赫夫曼编码是一种常见的数据压缩算法,它可以有效地降低数据传输和存储的成本。
在本文中,我将深入探讨matlab中的信源二进制赫夫曼编码的原理、实现和应用,并共享我的个人观点和理解。
让我们来了解一下信源编码的基本概念。
信源编码是一种将离散或连续信号转换为离散符号的过程,其目的是尽量减少信号的冗余度,以便更高效地传输和存储。
在数字通信和数据存储领域,信源编码起着至关重要的作用。
而二进制赫夫曼编码是一种常见的无损数据压缩算法,其核心思想是通过对出现频率较高的符号赋予较短的编码,而对出现频率较低的符号赋予较长的编码,从而实现数据的压缩。
在matlab中,我们可以利用赫夫曼树和编码表来实现信源二进制赫夫曼编码。
接下来,我将详细介绍matlab中的信源二进制赫夫曼编码的实现过程。
在matlab中,我们可以使用`huffmandict`函数来创建赫夫曼编码字典,该函数需要输入符号和它们对应的概率作为参数。
我们可以使用`huffmanenco`函数来对输入的符号序列进行赫夫曼编码,得到压缩后的二进制码字。
我们可以使用`huffmandeco`函数来对压缩后的二进制码字进行解码,得到原始的符号序列。
通过这些函数的组合,我们可以在matlab中轻松实现信源二进制赫夫曼编码。
具体的实现细节和示例代码我将在下文中进行详细讲解。
信源二进制赫夫曼编码的应用非常广泛,特别是在无线通信、图像压缩和音频处理等领域。
通过使用赫夫曼编码,我们可以大大减小数据传输和存储的成本,提高系统的效率和可靠性。
赫夫曼编码也是信息论中的重要概念,它为我们理解信息压缩和编码提供了重要的思路和方法。
从个人观点来看,信源二进制赫夫曼编码作为一种经典的数据压缩算法,具有重要的理论意义和实际应用价值。
在matlab中,我们可以利用现成的函数库来实现赫夫曼编码,同时也可以根据具体的应用场景进行定制化的优化。
通过不断深入研究和实践,我们可以进一步发掘赫夫曼编码的潜力,为数据压缩和信息传输领域带来更多的创新和突破。
实验二: Huffman 编码

实验二: Huffman 编码一、实验目的(1) 进一步熟悉Huffman 编码过程。
(2) 掌握C 语言递归程序的设计和调试技术。
二、实验要求(1) 输入:信源符号个数r 、信源的概率分布P(2) 输出:每个信源符号对应的Huffman 编码的码字。
三、算法1: procedure Huffman({i s }; {i p })2: if q = = 2 then3: return 00s →,11s →4: else5: 降序排序{i p }6: 缩减信源:创建一个符号's 以取代2q s -,1q s -,其概率为'21q q p p p --=+ 7: 递归调用Huffman 算法以得到'03,...,,q s s s - 的编码:'03,...,,q w w w -,相应的概率分布为'03,...,,q p p p -8: return ''003321,...,,0,1q q q q s w s w s w s w ----→→→→9: end if10: end procedure四、实验报告要求(1) 简述实验目的及实验原理(实验原理用流程图表示)。
(2) 按实验要求编写程序,并附上程序代码和结果图。
(3) 总结在编程过程中遇到的问题、解决办法和收获。
五、参考程序1 /* *******************************************************************2 * Huffman 编码3 * Purpose : Huffman recursive coding algorithm4 *5 *6 ****************************************************************** */7 # include < stdio .h>8 # include < stdlib .h>9 # include < string .h>10 # include < math .h>1112 # define DELTA 1.0e -61314 void sort ( double *, char ** , int *, int );15 void code ( double *, char ** , int *, int );1617 int18 main ( void )19 {20 float *p_i , * p;21 float sum ;22 float temp ;23 char **c;24 int *idx ;25 int q;26 int i;2728 /* Read the number of source symbol in */29 fscanf (stdin , "%d" , &q);3031 /* Allocation memory */32 idx = ( int *) calloc (q , sizeof (int ));33 p_i = ( float *) calloc (q , sizeof ( float ));34 p = ( float *) calloc (q , sizeof ( float ));35 c = ( char **) calloc (q , sizeof ( char *));3637 for (i = 0; i < q; i++)38 {39 c[i ] = ( char *) calloc (1 , sizeof ( char ));40 c[i ][0] = '\0 ';41 }4243 /* Read the probability of each symbol in and validate them */44 sum = 0.0;45 for (i = 0; i < q; i++)46 {47 fscanf (stdin , "%f" , &p[i ]);48 p_i[i ] = p[i];49 idx[i ] = i;50 sum += p_i[i];51 }5253 if ( fabs ( sum - 1.0) > DELTA )54 {55 fprintf ( stderr , " p_i error \n");56 exit ( -1);57 }5859 /* Coding */60 code (p_i , c , idx , q);6162 /* Output result */63 for (i = 0; i < q; i++)64 {65 fprintf ( stdout , "%d %.6 f %s\n" , idx[i], p[ idx[i]] , c[ idx[i ]]);66 }6768 /* Free the memory */69 for (i = q; i > 0; - -i)70 {71 free (c[i ]);72 }73 free (c);74 free (p);75 free (p_i );76 free (idx );7778 exit (0);79 }8081 /*82 * Sorting algorithm83 */84 void85 sort ( float *p , char ** c , int * idx , int q)86 {87 int finish = 0;88 int i , j;89 int l1 , l2;90 char *s;91 float t;9293 while (i < q && ! finish )94 {95 finish = 1;96 for (j = 0; j < q - i; j ++)97 {98 if(p[j] < p[j + 1])99 {100 t = p[j];101 p[j ] = p[j + 1];102 p[j + 1] = t;103104 l1 = idx[j];105 idx[j ] = idx[j + 1];106 idx[j + 1] = l1;107108 l1 = strlen (c[j]);109 l2 = strlen (c[j + 1]);110 s = ( char *) calloc (l1 + 1 , sizeof ( char )); 111112 strcpy (s , c[j]);113114 realloc (c[j], l2 + 1);115 strcpy (c[j], c[j + 1]);116117 realloc (c[j + 1] , l1 + 1);118 strcpy (c[j + 1] , s);119120 free (s);121 }122 }123 i++;124 }125 }126127 /*128 * Huffman recursive coding algorithm129 */130 void code ( float *p , char **c , int * idx , int q) 131 {132 int l1 , l2;133 char *s;134135 /* If q=2 , return the code words */136 if(q == 2)137 {138 realloc (c [0] , 3);139 realloc (c [1] , 3);140141 strcat (c[0] , "0");142 strcat (c[1] , "1");143 }144 else145 {146 /* If q >2 , reduce the source . */147 p[q - 2] = p[q - 1] + p[q - 2];148 /* Call the coding algorithm recursively */149 sort (p , c , idx , q - 1);150 code (p , c , idx , q - 1);151152 /* Resume the source and return the code words */ 153 l1 = strlen (c[q - 2]);154 l2 = strlen (c[q - 1]);155156 s = ( char *) calloc (l1 + 2 , sizeof ( char *)); 157 strcpy (s , c[q - 2]);158159 realloc (c[q - 2] , l1 + 2);160 strcat (c[q - 2] , "0");161162 realloc (c[q - 1] , l2 + 2);163 strcat (s , "1");164 strcpy (c[q - 1] , s);165166 free (s);167 }168 }。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
c(n-i,1:n-1)=c(n-i+1,n*(find(m(n-i+1,:)==1))-(n-2):n*(find(m(n-i+1,:)==1)));
c(n-i,n)='0';
c(n-i,n+1:2*n-1)=c(n-i,1:n-1);
c(n-i,2*n)='1';
for j=1:i-1
概率:0.18编码:111
概率:0.17编码:110
概率:0.01编码:1000
概率:0.15编码:101
概率:0.2编码:01
概率:0.19编码:00
概率:0.1编码:1001
平均码长为:2.72
编码效率为:0.959075
六.实验总结及心得体会
Huffman编码方法是《数据结构》课程中的一个重要内容,当时是用二叉树来实现的。在《信息论与编码》中,Huffman树的概念虽然提的很少,但整体思想仍然是相同的,因此编程过程还比较顺利。
实验中涉及到大量向量、排序、比较运算,让我体验到了采用MATLAB处理这一类编程问题的方便性。
七.教师评语
教师签名:
年月日
输入:信源 的分布 , ;
输出:二元变长码 ,平均码长 ,编码效率 。
三.实验方案或步骤(程序设计说明)
(1)把信源符号 (i=1,2,…,m)出现的概率 按由大到小的顺序排列;
(2)对两个概率最小的符号分别标“0”和“1”,然后把这两个概率相加作为一个新的辅助符号的概率;
(3)将这个新的辅助符号与其他符号一起重新按概率大小顺序排列;
输入信源X的分布,格式[p1 p2…pm]:
[0.2,0.3,0.4,0.06,0.04]
概率:0.2编码:111
概率:0.3编码:10
概率:0.4编码:0
概率:0.06编码:1101
概率:0.04编码:1100
平均码长为:2
编码效率为:0.971767
输入信源X的分布,格式[p1 p2…pm]:
[0.18,0.17,0.01,0.15,0.2,0.19,0.1]
(4)跳到第2步,直到出现概率相加为1为止;
(5)用线将符号连接起来,得到一个码树,树的m个端点对应m个信源符号;
(6)从最后一个概率为1的节点开始,沿着码树分别到达每个信源符号,将一路遇到的“0”和“1”顺序排列起来,就是对应端点的信源符号的码字。
四.实验程序(经调试后正确的源程序)
p=input('\n输入信源X的分布,格式[p1 p2…pm]:\n');
if (length(find(p<0))~=0)
error('数组中概率有负的');%p概率为负拒绝编码
end
if (abs(sum(p)-1)>10e-10)
error('概率之和不为1');%概率之和与1差的绝对值大于10的负10次方
end
n=length(p);%数组中元素的个数,循环操作用
q=[q(1)+q(2),q(3:n),1];%最后两个概率小的合并成一个
end
for i=1:n-1
c(i,:)=blanks(n*n);%blanks(n*n)是一个1行n*n列的数组,里面是空的
end
c(n-1,n)='0';%把c这个空数组的(n-1,n)这个位置赋值0
c(n-1,2*n)='1';%把c这个空数组的(n-1,2*n)这个位置赋值1
ll(i)=length(find(abs(h(i,:))~=32));%ll为各码的码长
end
la=sum(p.*ll);%la是平均码长
H=sum(-p.*log2(p));%H是信息熵
RW=H/la;%RW是编码效率
for i=1:n%显示概率及Huffman编码
fprintf('概率:%g编码:%s\n',p(i),h(i,:))
c(n-i,(j+1)*n+1:(j+2)*n)=c(n-i+1,n*(find(m(n-i+1,:)==j+1)-1)+1:n*find(m(n-i+1,:)==j+1));
end
end
for i=1:n
h(i,1:n)=c(1,n*(find(m(1,:)==i)-1)+1:find(m(1,:)==i)*n);%h是Huffman编码
信源的二元Huffman编码
一.实验目的
任选C语言,C++,或MATLAB等一种方法编写程序,对离散信源进行二元Huffman编码,计算平均码长及编码效率,并通过1~2个运行的结果,验证程序的正确性。
通过实验,掌握r元Huffman编码的方法,学会平均码长与编码效率等常见计算。
二.实验内容
编写程序实现:
end
fprintf('平均码长为:%g\n',la)%显示平均码长
fprintf('编码效率为:%g\n',RW)%显示编码效率
%例1:p=[0.2,0.3,0.4,0.06,0.04];
%例2:p=[0.18,0.17,0.01,0.15,0.2,0.19,0.1];
五.程序运行结果(列举2-3个)
q=p;%信源的概率赋给q,以便后面排序、合并用
m=zeros(n-1,n);%定义m为零数组,记录排列顺序(小概率求和后再重新排列,这就存在排序的问题)
for i=1:n-1
[q,k]=sΒιβλιοθήκη rt(q);%k是排列后的顺序,sort(q)是对q进行升序
m(i,:)=[k(1:n-i+1),zeros(1,i-1)];%概率小的相加之后重新排序,排列顺序记录在m矩阵中