joinmap使用图文教程
joinmap使用图文教程

joinmap使用图文教程
文档来源为:从网络收集整理.word 版本可编辑.欢迎下载支持.
1 新建 new project
点击 dataset 新建 new
dataset 设置数据格式和大小
选择数据复制粘贴到矩
阵检测数据是否有错误
第一个错误蓝色选中之
后错误显示红色
点击错误处按下F2 修改
再次检测数据是否错误
创建群体节点计算位点基因型频率情况:
计算连锁群
设置参数,然后计算
确定那个群需要作出连锁图右键点击使之成为红色点击create group using the grouping tree
点击计算
点击calculate map 生产连锁遗传图
用另一种直观的方式查看基因型
点击(De-)Colorize
用最大似然法再次利用group1作图
选择group 并选择ML 点击OK
点击calculate map 再次作图
最后将两张图放在一起比较
右键点击选择两个连锁MAP
点击join 里的 combine maps
OK 完成更多调试请自我感觉!这只是一个example !Its finished by Dragon, please call me Dragon! [使用文档中的独特引言吸引读者的注意力,或者使用此空间强调要点。
要在此页面上的任
何位置放置此文本框,只需拖动它即可。
] Info 数
据概要不可更改的数
据显示
Loci 和 individual 显示的是loci 和 individual 的名称和序号,在这里可以删除一些loci 和 individual。
map join 写法

map join 写法Map Join是一种常见的Join操作,它将两个数据集按照某个键进行匹配,并将匹配的结果合并成一个新的数据集。
在Map Join中,一个数据集作为驱动表,另一个数据集作为被驱动表。
驱动表会被加载到内存中,而每个驱动表的键值都会被传递给被驱动表,以查找匹配的行。
以下是一个使用Python语言实现Map Join的示例代码:```python# 假设我们有两个数据集data1和data2,它们都有一个键列key data1 = [('a', 1), ('b', 2), ('c', 3)]data2 = [('a', 'x'), ('b', 'y'), ('d', 'z')]# 将数据集转换为Pandas的DataFrame对象df1 = pd.DataFrame(data1, columns=['key', 'value1'])df2 = pd.DataFrame(data2, columns=['key', 'value2'])# 使用merge函数进行Map Join操作result = df1.merge(df2, on='key', how='inner')# 输出结果print(result)```在这个示例中,我们首先将两个数据集转换为Pandas的DataFrame对象。
然后,我们使用merge函数进行Map Join操作,其中on参数指定了键列的名称,how参数指定了Join的方式(这里是内连接)。
最后,我们输出结果。
需要注意的是,在实际使用中,我们需要根据实际情况选择合适的Join方式,并考虑数据的加载方式、内存使用等因素,以避免出现性能问题。
巧用Mapinfo软件SQL查询功能肖

巧用M a p i n f o软件S Q L查询功能肖Final approval draft on November 22, 2020巧用Mapinfo软件SQL查询功能提高工作效率1.新建图层操作顶端菜单:“文件->新建表”:出现“新建表窗口”如下:在“新建表窗口”中选择Open New Mapper,如果已经打开了一个地图窗口,也可以选择Add to Current Mapper。
选择Create New 创建一个新的表结构。
点击“Create…”按钮,出现“新建表结构”的窗口如下:在“新建表结构窗口”的下部输入Name、Type、Width用于定义字段的名字、类型和长度。
每输入完一个字段Name、Type和Width,点击窗口右上部的Add Field 按钮进入下一个字段的定义。
所有字段定义完成后,点击“新建表结构窗口”下部的Create…按钮,出现如下保存窗口,选择合适的路径,输入文件名后保存tab文件,保存类型选择默认的tab文件。
经过以上操作,空白的网格图层就新建并定义好了。
2.网格划分及去除重叠区域方法3.网格划分方法步骤一、使用顶端菜单:“文件->打开”或工具栏上的“打开”按钮,打开各参考图层步骤二、与步骤一同样的方法打开前一节建立的空白网格图层,并设置网格图层可编辑,如下图:步骤三、网格图层设置为可编辑后,使用“多边形”绘图工具开始绘制物理网格,如下图:如果与之前画的网格有共同的边界,建议尽量有交叠区域,便于去除重叠区域后形成无缝的边界。
4.去除重叠区域的方法5.步骤一、确认网格图层处于可编辑状态6.步骤二、选择两个网格中的一个网格,右键->编辑对象->设置目标,如下图:7.8.步骤三、选择另一个网格,右键->编辑对象->擦除,如下图:9.10.在弹出的窗口点击“OK”,如下图:11.计算网格面积使用顶端菜单:表->更新列:弹出更新列窗口如下,选择需要更新的表(Table to Update)为物理网格图层,需要更新的列(Column to Update)为网格面积,值来源(Get Value From Table)同样为物理网格图层,选择后点击“Assist…”按钮:弹出表达式窗口如下,选择functions框里的Area函数,然后点击“OK”按钮,网格的面积就计算并填入图层了,保存图层。
(完整版)jionmap使用说明

在Excel中输入,横向是用到的株系,纵向是marker,主题内容填A或B,保存为.csv(逗号分隔)格式。
然后打开写字板,在写字板中打开这个.csv格式文件,另存为.loc格式即可。
在我给你的例子中,name = demoF2popt = F2nloc =65nind = 104name表示名字(自己取),popt表示群体,如F2;nloc表示标记的数目,nind表示单株的数目。
下面是标记名称和单株的基因型,在F2中,对于共显性标记,采用ABH记录法。
即:亲本1的纯合带型记为“A”,亲本2的纯合带型记为“B”,杂合带型记为“H”,缺失数据记为“-”。
对于显性标记,若亲本1无带时,只有A和C,有带记为“C”,无带记为“A”。
若亲本2无带时,只有B和D,有带记为“D”,无带记为“B”。
在EXCEL中按以上格式整理后,考入文本文档,例如取名jiansheng安装好joinmap后,打开joinmap,点击file,再点击new project,然后取一个文件名,点击保存,这时进入一个新的joinmap界面,再点击file,点击load data,选择上面我们的文本文档jiansheng,点击打开,又进入一个新的界面,会出现name = demoF2popt = F2nloc =65nind = 104finial number indivals=104这时点击options,再点calution options,可以修改LOD lower 值,假定改为5.选择后,点击OK,又回到刚才的界面。
然后点击LOD grouping tree,然后点击calcuate,(或者计算器的那个图形)。
然后,会出现树状的图形。
如果你上面选的LOD值为5.0,则你用右键点击用5.0/1(56)、5.0/2(5),5.0/3(2)这里5.0表示LOD,1表示连锁群,56表示标记数。
这里共有3个连锁群。
如果你以前选择LOD=3,这里会出现1个连锁群,所以你自己可以选择LOD值,这样连锁上的标记数也不同。
数据库join语句用法

在数据库中,JOIN语句用于将两个或多个表中的数据连接在一起,基于它们之间的关联条件。
使用JOIN语句可以方便地获取相关表中的数据,并在查询结果中返回匹配的行。
下面是一些常见的JOIN语句的用法:
1. 内连接(INNER JOIN):返回两个表中匹配的行。
语法如下:
SELECT 列名
FROM 表名1
INNER JOIN 表名2
ON 表名1.列名 = 表名2.列名;
2. 左连接(LEFT JOIN):返回左表中所有的行,以及右表中与左表匹配的行。
如果右表中没有匹配的行,则返回NULL 值。
语法如下:
SELECT 列名
FROM 表名1
LEFT JOIN 表名2
ON 表名1.列名 = 表名2.列名;
3. 右连接(RIGHT JOIN):返回右表中所有的行,以及左表
中与右表匹配的行。
如果左表中没有匹配的行,则返回NULL值。
语法如下:
SELECT 列名
FROM 表名1
RIGHT JOIN 表名2
ON 表名1.列名 = 表名2.列名;
4. 全连接(FULL JOIN):返回两个表中所有的行,如果某个表中没有匹配的行,则返回NULL值。
语法如下:SELECT 列名
FROM 表名1
FULL JOIN 表名2
ON 表名1.列名 = 表名2.列名;
除了以上常见的JOIN类型,还有其他一些JOIN语句,如交叉连接(CROSS JOIN)、自然连接(NATURAL JOIN)等。
根据具体的需求和数据库系统的支持,可以选择适合的JOIN 类型来执行查询操作。
(仅供参考)Icimapping 连锁图中文操作说明
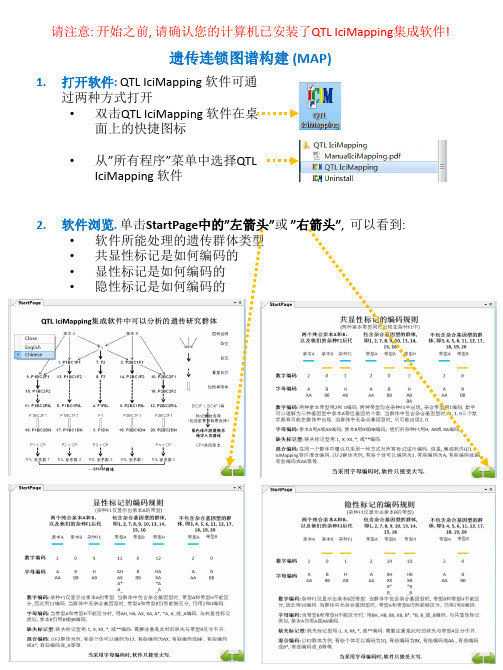
• 对连锁群重命名: 鼠标指向连锁群”Chromsome4”, 然后右击, 从弹出的快捷菜 单中选择”Rename”实现对”Chromosome4”的重命名, 或者…
• 将连锁群上移或下移
• 删除连锁群内的所有标记
• 改变连锁群首尾标记的循序
12
遗传连锁图谱构建
15. 高级用户 – 在EXCEL中管理遗传群体的信息 • 工作表”GeneralInfo”定义遗传群体的一些基本信息, 每项信息占1行.
记移动到”Chromosome4”): 鼠标指向所要移动的标记”F6L9.78”, 然后右击, 从 弹出的快捷菜单中选择”Move to -> Chromosome4”将 ”F6L9.78”移动 到”Chromosome4”; 对”SNP53”, “FRI”和”CNP254”重复上述过程.
• 对连锁群”Chromsome4”再排序: 鼠标指向连锁群”Chromsome4”, 然后右击, 从弹出的快捷菜单中选择”Ordering”实现对”Chromosome4”的重排序
13
如何构建整合图谱?
• 选择软件的IMP功能 • 向工程中导入待整合的
图谱. 例如, 把软件中附 带的”Arab_1.imp”打开. • 依次执行”Grouping”, “Ordering”, “Rippling (可 选项)”, 和”Outputting”建 立整合图谱.
14
如果想要计算F2群体中, 2个显性标记间的重组率, 怎么办?
• 从标记群中删除标记 (例如”Group4”中的”FRI”和”SNP254”): 鼠标指向待删除 标记” FRI”, 然后右击, 从弹出的快捷菜单中, 选择”Delete” 将”FRI” 从”Group4[*]”中删除; 对”SNP254”重复上述过程.
join数据库用法

join数据库用法【最新版】目录1.JOIN 的定义与作用2.JOIN 的基本语法3.JOIN 的类型4.JOIN 的实际应用举例5.JOIN 的注意事项正文一、JOIN 的定义与作用JOIN(连接)是数据库中用于将两个或多个表进行数据合并操作的一种技术。
它的主要作用是将不同表中的数据按照一定的条件进行组合,以便于用户在一次查询中获取多方面的信息。
二、JOIN 的基本语法JOIN 语句通常出现在 SELECT 语句中,其基本语法如下:```SELECT column1, column2,...FROM table1JOIN table2ON table1.column = table2.column```三、JOIN 的类型根据连接条件(ON 子句)的不同,JOIN 可以分为以下几种类型:1.内连接(Inner Join):根据指定的连接条件,返回两个表中匹配的记录。
```SELECT column1, column2,...FROM table1INNER JOIN table2ON table1.column = table2.column```2.左外连接(Left Outer Join):返回左表中的所有记录,以及右表中与左表匹配的记录。
```SELECT column1, column2,...FROM table1LEFT OUTER JOIN table2ON table1.column = table2.column```3.右外连接(Right Outer Join):返回右表中的所有记录,以及左表中与右表匹配的记录。
```SELECT column1, column2,...FROM table1RIGHT OUTER JOIN table2ON table1.column = table2.column4.全外连接(Full Outer Join):返回两个表中的所有记录。
selectjoinmaps用法

selectjoinmaps用法selectjoinmaps是一个SQL语句中的操作符,用于将两个或多个表中的数据进行连接。
它通常用于从多个表中检索数据,并将它们以某种方式进行关联。
在使用selectjoinmaps时,需要指定连接条件,以便确定如何将表中的行进行匹配。
selectjoinmaps的用法可以分为以下几种情况:1. 内连接(inner join),内连接是selectjoinmaps的默认操作,它返回两个表中满足连接条件的行。
语法为SELECT FROM table1 INNER JOIN table2 ON table1.column = table2.column;2. 左连接(left join),左连接返回左表中的所有行,以及右表中满足连接条件的行。
如果右表中没有匹配的行,则返回NULL 值。
语法为SELECT FROM table1 LEFT JOIN table2 ONtable1.column = table2.column;3. 右连接(right join),右连接返回右表中的所有行,以及左表中满足连接条件的行。
如果左表中没有匹配的行,则返回NULL 值。
语法为SELECT FROM table1 RIGHT JOIN table2 ONtable1.column = table2.column;4. 全外连接(full outer join),全外连接返回两个表中的所有行,如果某个表中没有匹配的行,则返回NULL值。
语法为SELECT FROM table1 FULL OUTER JOIN table2 ON table1.column = table2.column;5. 交叉连接(cross join),交叉连接返回两个表中的所有可能的组合,它不需要任何连接条件。
语法为SELECT FROM table1 CROSS JOIN table2;除了上述基本的用法外,selectjoinmaps还可以与其他操作符结合使用,如使用WHERE子句对连接后的结果进行筛选,或者使用GROUP BY子句对连接后的数据进行分组聚合操作。
mysql中的join用法

mysql中的join用法一、简介在MySQL中,JOIN是一种用于联接(join)多个表的SQL查询语句。
通过JOIN,我们可以将多个表中的数据组合在一起,以便进行数据分析和查询。
常见的JOIN类型包括内连接(INNERJOIN)、左连接(LEFTJOIN)、右连接(RIGHTJOIN)和全连接(FULLJOIN)。
二、JOIN类型1.内连接(INNERJOIN):返回两个表中匹配的数据。
只有当两个表中对应行的列匹配时,才会返回该行数据。
```sqlSELECT列名FROM表1INNERJOIN表2ON表1.列=表2.列;```2.左连接(LEFTJOIN):返回左表中的所有数据,以及右表中与左表匹配的数据。
如果右表中没有匹配的数据,则返回NULL值。
```sqlSELECT列名FROM表1LEFTJOIN表2ON表1.列=表2.列;```3.右连接(RIGHTJOIN):返回右表中的所有数据,以及左表中与右表匹配的数据。
如果左表中没有匹配的数据,则不返回任何数据。
```sqlSELECT列名FROM表1RIGHTJOIN表2ON表1.列=表2.列;```4.全连接(FULLJOIN):返回左表和右表中的所有数据,如果某个表中没有匹配的数据,则返回NULL值。
注意:MySQL中不支持FULLOUTERJOIN,需要使用其他方法来实现类似的效果,例如使用UNIONALL结合多个SELECT语句。
三、JOIN条件在JOIN语句中,我们使用ON子句来指定连接条件。
这个条件通常是一个等式,用于比较两个表中的列。
但是,也可以使用其他类型的比较操作符,如大于(>)、小于(<)和小于等于(<=)等。
四、其他用法1.自连接(SelfJoin):当一个表引用自身作为另一个表时,可以使用自连接。
这通常用于分析或聚合同一个表中的数据。
2.复合连接条件:可以同时使用多个连接条件来联接多个表。
这可以通过在ON子句中使用AND或OR操作符来实现。
join在python中的用法

join在python中的用法Python中的join方法是一种用于字符串操作的有用方法,它可以将给定序列中的元素以指定的分隔符链接起来。
它接受一个字符串参数作为分隔符,并返回一个字符串,它是由在序列中指定的元素链接起来的。
join方法在Python中是一种常用的字符串处理方法,它用于将序列中的元素放在一起,生成一个新的字符串。
它可以非常有效地将可迭代序列的元素转换为字符串,而且比其他字符串操作方法更加高效。
使用join方法可以创建字符串的多种形式,其中包括由逗号分隔的字符串,以及由更复杂的分隔符分隔的字符串。
它还可以被用来在字符串中添加换行符,以及通过去除序列中的空格创建一个紧凑的字符串。
使用join方法有几种不同的方式:1.使用默认的分隔符:使用join方法时,如果没有指定任何分隔符,默认情况下将使用空格作为分隔符。
因此,可以直接传递序列元素到join方法,它将使用默认的分隔符将所有元素链接在一起。
例如,考虑到以下代码:list1 = [Python is a great languagestr1 = join(list1)这里,我们没有指定任何分隔符,因此它将使用空格作为分隔符,并将list1中的元素链接在一起,生成一个字符串,如下所示:str1: Python is a great language2.使用指定的分隔符:另一方面,可以使用join方法指定自定义的分隔符,这种方法可以创建任意形式的分隔符字符串。
要使用自定义的分隔符,首先需要将用作分隔符的字符串作为参数传递给join方法,然后将序列中的元素传递给此方法。
例如,考虑到以下代码:list1 = [Python is a great languagestr1 = join(list1)这里,我们传递一个斜杠作为参数到join方法,它将使用斜杠作为分隔符将list1中的元素链接在一起,生成一个字符串,如下所示:str1: Python/is/a/great/language并且,在使用自定义分隔符时,还可以使用前缀和后缀字符串,有助于在字符串中添加更多格式,如换行符和空白字符。
mysql中join 用法

mysql中join 用法MySQL中的JOIN语法是用于将两个或多个相关的表连接起来,以便在一个查询中检索相关联的数据。
JOIN操作可用于联接表,将其组合,并组合它们的行来创建一个完整的结果集,也就是展示出查询结果的所有列,而不是单独查询各自的表。
本文将以中括号为主题,解释MySQL中使用JOIN的语法、类型以及实例,帮助读者更好地理解JOIN操作。
一、JOIN操作的语法MySQL中JOIN操作的语法如下所示:SELECT [column_list] FROM table1 JOIN table2 ON [join_condition];其中,column_list表示要选择的列,table1和table2表示要连接的两个表,join_condition表示连接的条件,可以是单个或多个表中的列等值条件。
二、JOIN类型MySQL中JOIN操作有多种类型,可以根据需求选择不同类型的JOIN来实现。
下面列出了MySQL中的常见JOIN类型:1. INNER JOININNER JOIN操作基于某种关联条件将两个表中的行匹配,并且仅返回两个表中都存在的行。
另外,此操作也称为等值连接或自然连接,并且是MySQL中默认的连接类型。
INNER JOIN语句的示例:SELECT a.id, , b.salary FROM employees a INNER JOIN salaries b ON a.emp_no = b.emp_no;这个查询语句将从两个表中选择id、name和salary列,并通过连接条件'emp_no'将两个表合并起来进行匹配。
2. LEFT JOINLEFT JOIN操作基于某种关联条件将两个表中的行匹配,并且返回左表中的所有行,而只返回右表中与左表中的行匹配的行。
LEFT JOIN语句的示例:SELECT a.id, , b.salary FROM employees a LEFT JOIN salaries b ON a.emp_no = b.emp_no;这条查询语句将从employees和salaries表中选择各自的id、name、salary 列,并基于连接条件'emp_no'连接这些列。
join函数用法

join函数用法`join(` 是一个字符串方法,用于将序列中的字符串连接在一起。
它的用法是 `str.join(sequence)`,其中 `str` 是连接字符串,`sequence` 是要连接的字符串序列。
以下是 `join(` 的详细用法:1.将字符串列表连接成一个字符串:```pythonfruits = ['apple', 'banana', 'kiwi']result = '-'.join(fruits)print(result)# 输出: apple-banana-kiwi```在这个例子中,`join(` 方法将字符串列表 `fruits` 中的所有字符串连接在一起,用 `-` 分隔。
最终输出结果是 `apple-banana-kiwi`。
2.用空字符串连接字符串列表:```pythonfruits = ['apple', 'banana', 'kiwi']result = ''.join(fruits)print(result)# 输出: applebananakiwi```在这个例子中,`join(` 方法将字符串列表 `fruits` 中的所有字符串连接在一起,没有使用分隔符。
最终输出结果是 `applebananakiwi`。
3.连接元组中的字符串:```pythonfruits = ('apple', 'banana', 'kiwi')result = '-'.join(fruits)print(result)# 输出: apple-banana-kiwi```在这个例子中,`join(` 方法将元组 `fruits` 中的所有字符串连接在一起,用 `-` 分隔。
最终输出结果是 `apple-banana-kiwi`。
mapjion 用法

mapjion 用法"map" 和 "join" 是两个在编程中常用的函数,它们通常用于处理数据和字符串。
我会分别从这两个函数的用法来进行解释。
首先,让我们来讨论一下 "map" 函数。
在编程中,"map" 函数通常用于对可迭代对象(如列表、元组等)中的每个元素应用同一个函数。
这意味着你可以使用 "map" 函数将一个函数应用到一个序列中的所有项,然后返回一个包含结果的新序列。
例如,如果你有一个列表,你可以使用 "map" 函数对列表中的每个元素进行平方操作。
语法上,它通常是这样的,map(function, iterable),其中function 是要应用的函数,iterable 是要处理的可迭代对象。
接下来是 "join" 函数。
在编程中,"join" 函数通常用于将序列中的元素连接成一个字符串。
这个函数通常与字符串对象一起使用,语法上是这样的,separator.join(iterable),其中separator 是分隔符(即用来连接元素的字符串),iterable 是要连接的可迭代对象。
如果你要将这两个函数结合起来使用,你可以先使用 "map" 函数对序列中的元素进行处理,然后再使用 "join" 函数将处理后的元素连接成一个字符串。
总的来说,"map" 函数用于对序列中的每个元素应用同一个函数,而 "join" 函数用于将序列中的元素连接成一个字符串。
当它们结合在一起使用时,可以对序列中的元素进行处理,并将处理后的结果连接成一个字符串。
希望这个解释能够帮助你理解 "map" 和 "join" 函数的用法。
如果你有任何进一步的问题,欢迎随时问我。
flink的几种join总结 cogroup -回复

flink的几种join总结cogroup -回复标题:Flink中的几种Join与Cogroup操作详解在大数据处理中,Apache Flink是一个强大的开源流处理和批处理框架。
其核心特性之一就是对数据的高效JOIN和COGROUP操作。
本文将详细介绍Flink中的几种JOIN和COGROUP操作,包括他们的工作原理、使用场景以及优缺点。
一、JOIN操作JOIN是数据库操作中最常见的操作之一,它用于合并两个或多个数据集中的记录。
在Flink中,主要有以下几种JOIN操作:1. Inner Join:返回两个数据集的交集。
只有当两个数据集中的键相等时,才会生成结果。
2. Left/Right/Full Outer Join:这些JOIN操作会返回所有输入数据集的记录。
对于不匹配的记录,LEFT OUTER JOIN会在右侧数据集中填充NULL值,RIGHT OUTER JOIN则在左侧数据集中填充NULL值,FULL OUTER JOIN则在两侧都填充NULL值。
3. Interval Join:这是一种特殊的JOIN操作,用于处理时间序列数据。
它只连接在时间窗口内发生的数据。
4. Broadcast Join:在这种JOIN操作中,较小的数据集会被广播到所有的并行任务中,然后每个任务都会与这个广播的数据集进行JOIN操作。
这种JOIN操作适用于数据分布极度不均匀的情况。
二、COGROUP操作COGROUP是Flink中的一种特殊操作,它可以将两个或多个数据集按照相同的键进行分组,并将相同键的所有元素放在一个列表中。
COGROUP 的结果是一个新的数据集,其中每个元素都是一个元组,元组的第一个元素是键,其余元素是对应键的各个数据集的元素列表。
三、JOIN与COGROUP的选择在实际应用中,选择使用JOIN还是COGROUP主要取决于具体的业务需求和数据特性。
- 当需要基于键关联两个或多个数据集时,JOIN操作通常是最佳选择。
mysql join查询索引原理

mysql join查询索引原理MySQL的JOIN查询是一个非常常见的SQL操作,它可以用于同时从多个表中检索数据。
在执行JOIN操作时,MySQL使用索引来加速查询。
索引是一种数据结构,它允许数据库系统快速定位和访问表中的数据。
在本文中,我们将详细介绍MySQL JOIN操作中索引的工作原理,包括不同类型的JOIN和如何使用索引来提高查询性能。
一、MySQL JOIN查询的基本概念MySQL的JOIN查询是通过将具有共同字段的表连接起来来检索数据的操作。
在JOIN查询中,可以使用多种JOIN类型,包括INNER JOIN、LEFT JOIN、RIGHT JOIN和FULL OUTER JOIN。
JOIN操作的基本语法如下:SELECT 列 FROM 表1 JOIN 表2 ON 表1.共同字段 = 表2.共同字段;在执行JOIN查询时,MySQL需要将两个表的数据进行匹配,以确定需要返回的结果。
这就需要根据共同字段在表中建立索引来加速查询。
二、MySQL索引的基本概念MySQL索引是一种数据结构,它允许数据库系统快速定位和访问表中的数据。
索引基于某种排序方式,它将表中的某个字段的值映射到对应的记录。
索引能够提高查询的速度,减少数据库系统需要扫描的数据量。
MySQL中有多种类型的索引,包括主键索引、唯一索引、普通索引和全文索引。
主键索引是用于唯一标识每一行的索引,它只能有一个。
唯一索引也是用于唯一标识每一行的索引,但可以有多个。
普通索引是对表中的字段进行索引,它可以用于加速查询。
全文索引是对文本类型的字段进行索引,它可以用于进行全文搜索。
三、JOIN操作和索引的关系在执行JOIN查询时,MySQL需要根据共同字段的值将两个表中的数据进行匹配。
为了提高查询性能,可以在这些共同字段上创建索引。
只有当共同字段上存在索引时,MySQL才能够利用索引加速JOIN操作。
1. INNER JOIN和索引INNER JOIN是最常见也是最基本的JOIN操作,在查询中返回两个表中匹配的行数据。
数据库 join用法

数据库 join用法在数据库中,`JOIN` 用于将两个或多个表中的数据组合在一起,基于它们之间的关联条件。
下面是一些常见的 `JOIN` 用法:1. `INNER JOIN`(内连接):返回两个表中满足关联条件的匹配行。
```sqlSELECT *FROM table1INNER JOIN table2 ON table1.column_name = table2.column_name;```2. `LEFT JOIN`(左连接):返回左表中的所有行,以及右表中满足关联条件的匹配行。
如果右表没有匹配行,则结果为 NULL 。
```sqlSELECT *FROM table1LEFT JOIN table2 ON table1.column_name = table2.column_name;```3. `RIGHT JOIN`(右连接):返回右表中的所有行,以及左表中满足关联条件的匹配行。
如果左表没有匹配行,则结果为 NULL 。
```sqlSELECT *FROM table1RIGHT JOIN table2 ON table1.column_name = table2.column_name;```4. `FULL JOIN`(全连接):返回两个表中满足关联条件的匹配行,以及任何一方没有匹配行的结果为 NULL 。
```sqlSELECT *FROM table1FULL JOIN table2 ON table1.column_name = table2.column_name;```除了以上常见的连接类型,还有其他一些连接方式,如 `CROSS JOIN`(交叉连接)、`SELF JOIN`(自连接)等。
在使用 `JOIN` 时,需要注意关联条件的正确性,并根据实际需求选择合适的连接类型。
这只是 `JOIN` 的一些基本用法,具体的语法和功能可能因数据库管理系统而有所不同。
在实际应用中,根据具体的数据库系统和需求进行相应的调整。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
新建new project
点击dataset 新建new dataset
设置数据格式和大小
选择数据复制粘贴到矩阵
检测数据是否有错误
第一个错误蓝色选中 之后错误显示红色 点击错误处 按下F2 修改 再次检测数据是否错误 创建群体节点
计算连锁群
设置参数,然后计算
确定那个群需要作出连锁图右键点击使之成为红色
点击create group using the grouping tree
点击计算
点击calculate map 生产连锁遗传图
用另一种直观的方式查看基因型
点击(De-)Colorize
用最大似然法再次利用group1作图
选择group 并选择ML 点击OK
点击calculate map 再次作图
最后将两张图放在一起比较
右键点击选择两个连锁MAP
点击join里的combine maps
OK 完成更多调试请自我感觉!这只是一个example!Its finished by Dragon, please call me Dragon!。