第七章 查找
信息检索与信息素养概论(第二版)第7章 中文报刊与图书数据库检索方法

检索字段选择更加明确
以上图片截图来源于/ZK/index.aspx
《信息检索与信息素养概论》
二、维普资讯网 3 高级检索
维普的高级检索可用选择式,更有为专业人士提供的直接输入检索式的检索方式
以上图片截图来源于/ZK/index.aspx
《信息检索与信息素养概论》
二、维普资讯网 4 期刊导航
期刊导航共四种查询方式, 点击之后逐步检索,步骤和 前几种方法一样。
以上图片截图来源于/journal/index.aspx
《信息检索与信息素养概论》
二、维普资讯网 (三)检索结果
维普资讯网检索结果界面多数可显示检索条件、检索命中文献总篇数,并将检索 中结果以“序号、全文下载、标题、作者、出处”的等等题录形式加以显示。如
《信息检索与信息素养概论》
二、维普资讯网 3 检索范围、年限时间选择 2 传统检索
2 检索式的输入
或5 进行二次检索
1 检索入口选择
4检索入口选择
以上图片截图来源于/zk/custom.aspx
《信息检索与信息素养概论》
二、维普资讯网 3 高级检索
与快速基本检索和传统检 索相比多了相对应的比较
详细结果显示
两种也读方式: 在线阅读 下载全文
注意:维普资讯网的全文显示格式有维普浏览器和PDF全文浏览器两种,第一次阅读全文必须下载安装其中一 个,否则无法阅读全文。
《信息检索与信息素养概论》
三、万方数据知识服务平台
(一)数据库概况
国内最大的数字资源库系统,由中国科技信息研究所直属的万 方数据公司开发。包含科技信息系统(学位论文数据库、数字化期 刊、学术会议数据库、商务信息系统)。其中,数字化期刊数据库 子系统是以中国科技论文与引文数据库及其他相关数据库中的期刊 条目部分内容,基本包括我国文献计量单位中自然科学类统计源期 刊和社会科学类核心源期刊,集纳理、工、农、医、人文五大类70 多个类目共2500多种科技类核心期刊全文。不仅是我国首家网上期 刊的出版联盟,而且是核心期刊测评和论文统计分析的数据源基础。
第七章 文书工作与档案管理-档案的检索、利用与编研

7.文号索引
文号索引是将档案的文号与档号相对 应,提供按文号检索档案途径的检索工具。 文号索引一般采用表格形式,所以通常称 之为文号档号对照表。
8.人名索引
人名索引是揭示档案中所涉及的人物 并指明其出处的检索工具。档案人名索引 的编制方法,是将档案内容中涉及的人名 摘录出来加以排列,所以索引的格式主要 包括人名和档号两种。档案馆(室)日常使 用的人名索引,通常采用卡片形式。
分类标引概念转换的基本做法是根据 主题分析的结果,查找档案分类表,将其 相应类目的分类号作为检索标识赋予被标 引文件。
7.1.3 常用档案检索工具及其编制方法
1. 案卷目录
案卷目录是以案卷为单位,依据档案 整理顺序组织起来的,固定案卷位置,统 计案卷数量,监督、保护档案材料的一种 管理工具;也是档案馆(室)最基本的、使 用较为频繁的一种检索工具。它既是查找 档案最基本的工具,又是编制其他检索工 具所必须使用的工具。
(1)主题分析
主题分析是确定被标引档案主题概念 的过程。主题分析的主要内容有两方面: 一是分析主题的类型;二是分析主题的构 成要素(亦称主题因素)。主题的类型依据 档案内容可分为单主题和多主题。单主题 是指一件(卷)档案只表达一个问题,多主 题是指一件档案表达两个以上的问题。
(2)概念转换
在确定了文件的主题概念之后,应将 其转换为检索语言标出,这个过程即为概 念转换的过程,也就是给出检索标识的过 程。
(1)档案开放的本质
档案开放的本质就是让更多的人利用更 多的档案,充分发挥档案的价值。
档案的开放和档案的利用也是一对具有 从属关系的概念。档案的开放从属于档案的 利用,档案的开放也是档案利用的一种特殊 形式。
(2)档案开放的办法
各级国家档案馆开放档案的利用手续: 大陆公民持有效身份证或工作证、介绍信, 可直接到档案馆利用。
《数据库》第七章 基本SQL查询

8
Inspur Education
从表中选择多个列
要查看数据库中所有图书的名称和出版日期
SELECT bookname,pubdate
5
Inspur Education
选择表中的所有数据
显示客户customers表中所有的数据
SELECT * FROM books;
在SELECT后面键入*号
6
Inspur Education
从表中选择一列 2-1
在Oracle中,可以只在结果中返回特定的列。SELECT语 句中选择特定列被称为“投影(projection)”。可以 选择表中的一列,也可以选择多个列或者是所有的列。
示例:查询所有BOOKNAME列以“j”开头的书本。
SELECT * FROM books WHERE bookname LIKE 'j%';
17
Inspur Education
WHERE子句——连接运算符
在WHERE子句中可以使用连接运算符将各个表达式关联起 来,组成复合判断条件。常用的连接运算符有AND和OR。
INSERT INTO books (isbn, bookname, pubdate, quantity, bcost, bretail, bcategory)
VALUES (2, 'a语言', to_date('2017-10-8', 'yyyy-mm-dd'), null, '40', '68', 'computer');
第七章文献调查法

第四节 对文献调查法的评价
• 文献调查法是对人类以往知识的调查,是一种间接的、非介入的调 查。文献调查法的基本特点决定着它有许多优点,也有许多缺点。
一、文献调查法的优点
(1)文献调查可以超越时间、空间的限制,通过对古今中外文献的调查可以研 究极其广泛的社会情况。 (2)文献调查主要是书面调查,如果搜集的文献是真实的,那么它就能够获得 比口头调查更准确、更可靠的信息 (3)文献调查是一种间接的、非介入性的调查,这就避免了直接调查中调查者 与受调查者互动过程中可能产生的种种反应性误差。 (4)文献调查是一种非常方便、自由、安全的调查方法 (5)文献调查省时、省钱,效率高。文献调查是在前人和他人劳动成果基础上 进行的调查,是获取知识的捷径。
第一节 文献和文献调查法
一、文献的概念、种类和发展趋势 1、文献 从现代的观点看,一切记录人类知识的文字、图像、数字、符号、音频、 视频等物体统称为文献。任何文献都必须具备三个基本要素: ①一定的知识内容—一张白纸 ②一定的物质载体—传说 ③一定的记录方式—文物、古董
• 从知识的角度看,文献就是通过一定记录方式记录在一定物质载体 上的知识;从物质载体的角度看,文献就是用一定记录方式记录下 一定知识内容的一切载体。
三、获取文献的主要途径
• 查找文献是为了获取文献。获取文献的方法多种多样,对于纸质文献和 网络文献应分别采用不同的获取方法。
• 对于纸质文献,主要采用索取、交换、购买、拍照、录制、借阅、复制 等方法获取。
• 对于网络文献,可先通过浏览和搜索网站检索,然后将有用文献复制或 下载,依据一定的标准进行分类保存到相应文档里。搜索引擎和虚拟图 书馆是两种获取网络文献的重要途径,前者有利于提高检全率,后者有 利于提高检准率
7第七章 专利信息检索

617 7000 47000 54000 1980. 1. 1~1984. 12. 31
第四版 8 20 118 618
第五版 8 20 第六版 8 20 第七版 8 20 118 118 120 620 624 628
58545 1985. 1. 1~1989. 12. 31
64684 1990. 1. 1~1994. 12. 31 66691 1995.1. 1~1999. 12. 31 69000 2000.1. 1~2004. 12. 31
国际专利分类号由五级号组成,五级以下的各级分组, 类号顺序制编号,其类目的级别用类名前的圆点“·” 表示。下面,是一个完整的IPC分类号: F 04 D 29/00 ↑ ↑ ↑ ↑ 部 类 小类 主组 (至主组级)
F 04 D 29 / 30(至分组级) ↑ ↑ ↑ ↑ ↑ 部 类 小类 主组 分组
五、中国专利文献编号体系及其变化
中国专利文献的编号体系变化与专利法修改和管理方 面的需求,以及程序上的需要有关。
我国专利文献的编号体系由于1989年和1993年分别作 过修改,因而分成以下三个阶段: 第一阶段:1985-1988 第二阶段:1989-1992 第三阶段:1993-
(1)1985-1988年的编号体系 这一阶段的编号体系有以下特点: a. 申请号、专利号、公开(公告)号、审定号共用 一套号码。 b. 三种专利(发明专利、实用新型、外观设计)分 别编号,其申请号都由八位数字组成,前两位表示 申请年份;第三位数字表示专利种类,其中“1”代 表发明,“2”代表实用新型,“3”代表外观设计; 后五位数字是序号。 c. 编号每年自1号开始,专利号与申请号相同。 d. 公开号、审定号、公告号是在申请号前冠以字母 CN,后面标注文献种类代码,如CN88100001B。
第七章 Internet 信息检索工具—搜索引擎

(4)用户接口
供用户输入查询,显示匹配结果。 用户接口的设计和实现使用人机交互的 理论和方法,以充分适应人类的思维习 惯。
4、搜索引擎的主要任务
(1) 信息搜集 各个搜索引擎都派出绰号为蜘蛛(Spider)或机 器人(Robots)的“网页搜索软件”,在各网 页中爬行,访问网络中公开区域的每一个站点 并记录其网址,将它们带回搜索引擎,从而创 建出一个详尽的网络目录。由于网络文档的不 断变化,机器人也不断地把以前已经分类组织 的目录更新。
第七章 Internet 信息检索工 具—搜索引擎
7.1搜索引擎基本理论
1、什么是搜索引擎?
简单地说,所谓搜索引擎,就是采用信息自 动跟踪标引等技术、建立在因特网上专门提 供网络信息资源导航服务检索工具。 它能够通过Internet 接受用户的查询指令 ,并向用户提供符合其查询要求的信息资源 网址。
5、搜索引擎的种类
检索型搜索引擎:它使用自动索引软件来发现、收集并标引网 页,建立数据库,并以Web形式让用户找到所需信息资源。比 较著名的有:息系统地分门归类,经过人工 整理后形成庞大而有序的分类目录体系,用户可以在目录体系 的导引下通过逐级浏览,发现、检索到有关的信息。雅虎就是 以卓越的分类目录型导航服务而称誉全球,典型的分类目录搜 索引擎如Yahoo ( /) 混合型搜索引擎:它兼有检索型和目录型两种方式。如:新浪、 搜狐、网易、中华等门户网站。 多元搜索引擎:也称为集合型搜索引擎。它是将多个搜索引擎 集成在一起,通过统一的检索界面进行网络信息多元搜索 的 检索工具。按照工作方式的不同可分为并行处理式和串行处理 式两大类。著名的有: Meta crawler、Dogpile、Mamma和万 维搜索(Http:///)等。
引号 引号( “ ” )的作用是,括在其中的多个词 被当作一个短语来检索。绝大部分主要搜索引 擎都支持短语检索,找到含有与短语词序和意 义完全相同的页面。例如,检索式 “ electronic magazine ” ,表示把 electronic magazine 当作一个短语来搜索。 如果不加引号,搜索引擎就会把两词之间的空 格按“与”处理,查出包含 electronic 和 magazine 的页面,结果应与用户要求的主题 内容相去甚远。
《数据结构(C语言版 第2版)》(严蔚敏 著)第七章练习题答案

《数据结构(C语言版第2版)》(严蔚敏著)第七章练习题答案第7章查找1.选择题(1)对n个元素的表做顺序查找时,若查找每个元素的概率相同,则平均查找长度为()。
A.(n-1)/2B.n/2C.(n+1)/2D.n答案:C解释:总查找次数N=1+2+3+…+n=n(n+1)/2,则平均查找长度为N/n=(n+1)/2。
(2)适用于折半查找的表的存储方式及元素排列要求为()。
A.链接方式存储,元素无序B.链接方式存储,元素有序C.顺序方式存储,元素无序D.顺序方式存储,元素有序答案:D解释:折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
(3)如果要求一个线性表既能较快的查找,又能适应动态变化的要求,最好采用()查找法。
A.顺序查找B.折半查找C.分块查找D.哈希查找答案:C解释:分块查找的优点是:在表中插入和删除数据元素时,只要找到该元素对应的块,就可以在该块内进行插入和删除运算。
由于块内是无序的,故插入和删除比较容易,无需进行大量移动。
如果线性表既要快速查找又经常动态变化,则可采用分块查找。
(4)折半查找有序表(4,6,10,12,20,30,50,70,88,100)。
若查找表中元素58,则它将依次与表中()比较大小,查找结果是失败。
A.20,70,30,50B.30,88,70,50C.20,50D.30,88,50答案:A解释:表中共10个元素,第一次取⎣(1+10)/2⎦=5,与第五个元素20比较,58大于20,再取⎣(6+10)/2⎦=8,与第八个元素70比较,依次类推再与30、50比较,最终查找失败。
(5)对22个记录的有序表作折半查找,当查找失败时,至少需要比较()次关键字。
A.3B.4C.5D.6答案:B解释:22个记录的有序表,其折半查找的判定树深度为⎣log222⎦+1=5,且该判定树不是满二叉树,即查找失败时至多比较5次,至少比较4次。
(6)折半搜索与二叉排序树的时间性能()。
王道数据结构 第七章 查找思维导图-高清脑图模板
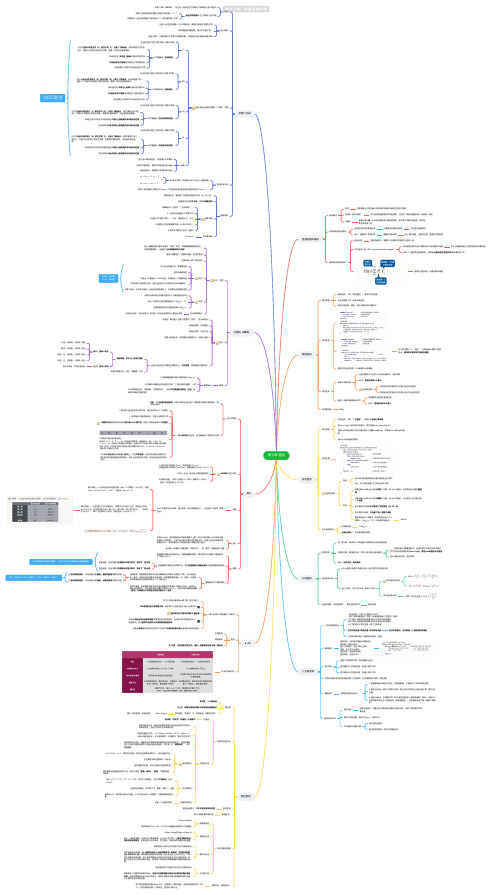
每次调整的对象都是“最小不平衡子树”
插入操作
在插入操作,只要将最小不平衡子树调整平衡,则其他祖先结点都会恢复平衡
在A的左孩子的左子树中插入导致不平衡
由于在结点A的左孩子(L)的左子树(L)上插入了新结点,A的平衡因子由1增
至2,导致以A为根的子树失去平衡,需要一次向右的旋转操作。
LL
将A的左孩子B向右上旋转代替A成为根节点 将A结点向右下旋转成为B的右子树的根结点
RR平衡旋转(左单旋转)
而B的原左子树则作为A结点的右子树
在A的左孩子的右子树中插入导致不平衡
由于在结点A的左孩子(L)的右子树(R)上插入了新结点,A的平衡因子由1增
LR
至2,导致以A为根的子树失去平衡,需要两次旋转操作,先左旋转再右旋转。
将A的左孩子B的右子树的根结点C向左上旋转提升至B结点的位置
本质:永远保证 子树0<关键字1<子树1<关键字2<子树2<...
当左兄弟很宽裕时,用当前结点的前驱、前驱的前驱来填补空缺 当右兄弟很宽裕时,用当前结点的后继、后继的后继来填补空缺
兄弟够借。若被删除关键字所在结点删除前的关键字个数低于下限,且与此结点 右(或左)兄弟结点的关键字还很宽裕,则需要调整该结点、右(或左)兄弟结 点及其双亲结点及其双亲结点(父子换位法)
LL平衡旋转(右单旋转)
而B的原右子树则作为A结点的左子树
在A的右孩子的右子树中插入导致不平衡
由于在结点A的右孩子(R)的右子树(R)上插入了新结点,A的平衡因子由-1
减至-2,导致以A为根的子树失去平衡,需要一次向左的旋转操作。
RR
将A的右孩子B向左上旋转代替A成为根节点 将A结点向左下旋转成为B的左子树的根结点
数据结构课程学习报告

一、课程简介算法与数据结构是计算机等相关专业的一门十分重要的专业基础课,在计算机学科中起到承前启后的作用。
它主要研究计算机加工对象的逻辑结构、在计算机中的表示形式以及实现各种基本操作的算法。
要求学生学会分析研究计算机加工的数据结构的特性,以便为应用涉及的数据选择适当的逻辑结构、存储结构及其相应的算法,并初步掌握算法的时间分析和空间分析技术,培养学生数据抽象的能力。
本课程主要是让我们掌握数据结构的基本概念、线性表、栈和队列、串和数组、树形结构、图结构、查找、排序等内容。
二、各章知识点概述第一章---绪论学习内容:数据结构相关的基本概念,包括数据、数据元素、数据项、数据对象、数据结构、逻辑结构、存储结构等;算法时间复杂度的分析。
重难点:数据结构相关的基本概念,数据结构所含两个层次的具体含义及其相互关系以及算法时间复杂度的分析方法(多重循序)。
第二章---线性表学习内容:第二章线性表主要内容是顺序表和链表的相关概念,顺序表和链表的查找、插入和删除等相关操作及其算法实现,链表的创建算法,并能够设计出线性表应用的常用算法,比如线性表的合并等;能够从时间和空间复杂度的角度比较两种存储结构的不同特点及其适用场合,明确它们各自的优缺点。
重难点:理清顺序表和链表的特点,学会用C写相关操作的代码。
第三章---栈和队列学习内容:栈和队列的特点。
顺序栈和链栈的进栈和出栈算法,以及循环队列和链队列的进队和出队算法。
重难点:学会灵活运用栈和队列解决实际应用问题,用C及栈和队列的特点写相关操作的代码。
比如表达式求值算法,理解递归算法执行过程中栈的状态变化过程,以更好地使用递归算法等。
第四章---串、数组和广义表学习内容:串的存储方法,理解串的两种模式匹配算法—BF算法和KMP算法。
明确数组和广义表这两种数据结构的特点,数组地址计算方法,几种特殊矩阵的压缩存储方法。
广义表的定义、性质及GetHead和GetTail的操作。
重难点:KMP算法;数组存储时地址的计算方法等。
查找

2020/7/2
第37页
【分块查找算法】
查找步骤: • 首先用给定值在索引表中查找,确定满足条
件的数据元素应存放在哪一块中, • 对索引表查找的方法既可以采用二分法查找,
也可以采用顺序查找, • 然后再到相应的块中进行顺序查找,便可以
得到查找的结果。
2020/7/2
第38页
例如,给定关键字序列如下:
2020/7/2
第10页
7.1 静态查找表
7.2 动态查找树表 7.3 哈希表
2020/7/2
第11页
7.1 静态查找表
2020/7/2
第12页
一、顺序查找表
以顺序表或线性链表表示静 态查找表
2020/7/2
第13页
数据元素类型的定义为:
typedef struct { keytype key; // 关键字域
2020/7/2
第33页
例对于给定11个数据元素的有序表 {2,3,10,15,20,25,28,29,30,35,40},采用二分查找,试问:
(1)若查找给定值为20的元素,将依次与表中哪些 元素比较?
(2)若查找给定值为26的元素,将依次与哪些元素 比较?
(3)假设查找表中每个元素的概率相同,求查找成 功时的平均查找长度和查找不成功时的平均查找长度。
lowmid high
2020/7/2
第28页
1 2 3 4 5 6 7 8 9 10 11 5 13 19 21 37 56 64 75 80 88 92
lowmid high
1 2 3 4 5 6 7 8 9 10 11 5 13 19 21 37 56 64 75 80 88 92
low high mid
数据结构与算法》(张晓莉)习题:选择题、判断题76542

第一章绪论1. 从逻辑上可以把数据结构分为( C )两大类。
A.动态结构、静态结构B.顺序结构、链式结构C.线性结构、非线性结构D.初等结构、构造型结构2. 在下面的程序段中,对x的赋值语句的频度为( C )。
For(k=1;k<=n;k++)For(j=1;j<=n;j++)x=x+1;A.O(2n) B.O(n) C.O(n2) D.O(log2n)3. 采用顺序存储结构表示数据时,相邻的数据元素的存储地址( A )。
A.一定连续B.一定不连续C.不一定连续D.部分连续、部分不连续4. 下面关于算法的说法,正确的是( D )。
A.算法的时间复杂度一般与算法的空间复杂度成正比B.解决某问题的算法可能有多种,但肯定采用相同的数据结构C.算法的可行性是指算法的指令不能有二义性D.同一个算法,实现语言的级别越高,执行效率就越低5. 在发生非法操作时,算法能够作出适当处理的特性称为( B )。
A.正确性B.健壮性C.可读性D.可移植性第二章线性表1. 线性表是( A )。
A.一个有限序列,可以为空B.一个有限序列,不能为空C.一个无限序列,可以为空D.一个无限序列,不能为空2.对顺序存储的线性表,设其长度为n,在任何位置上插入或删除操作都是等概率的。
插入一个元素时平均要移动表中的( A )个元素。
A.n/2 B.(n+1)/2 C.(n-1)/2 D.n3.线性表采用链式存储时,其地址( D )。
A.必须是连续的B.部分地址必须是连续的C.一定是不连续的D.连续与否均可以4.用链表表示线性表的优点是( C )。
A.便于随机存取B.花费的存储空间较顺序存储少C.便于插入和删除D.数据元素的物理顺序与逻辑顺序相同5.链表中最常用的操作是在最后一个元素之后插入一个元素和删除最后一个元素,则采用( C )存储方式最节省运算时间。
A.单链表B.双链表C.单循环链表D.带头结点的双向循环链表6.下面关于线性表的叙述,错误的是( B )。
第7章 SELECT高级查询

1-5
《Oracle数据库应用与实践》.
(1).两表的笛卡儿积运算
条件:当两表仅通过SELECT子句和FROM子句建立连接,而不加 连接条件时,那么查询结果为两张表的笛卡儿积。 【例7-1】使用SELECT子句和FORM子句,从scott用户的emp表和dept
三种方法:
1.内连接查询 2.外连接查询 3.交叉连接
1-11
《Oracle数据库应用与实践》.
1.内连接查询
内连接:一般使用INNER JOIN关键字,INNER可以省略,默认表示内 连接。
内连接查询分为:
(1)等值连接 (2)不等连接 (3)自然连接
1-12
《Oracle数据库应用与实践》.
(1)等值连接
1-16
《Oracle数据库应用与实践》.
2.外连接查询
内连接查询:保证查询结果集中所有行都要满足连接条件
外连接查询 :返回的查询结果集中不仅包含符合连接条件行,还包含连 接运算符的左表或右表,或两个连接表中不符合连接条件的行。 对于外连接,Oracle可以使用加号(+)来表示,也可以使用 LEFT、RIGHT和FULL OUNTER JOIN关键字.。
1-19
《Oracle数据库应用与实践》.
SQL> SELECT dname,ename FROM scott.dept LEFT JOIN scott.emp ON dept.deptno= emp.deptno ; DNAME ENAME ---------------------SALES CLARK SALES ALLEN SALES WARD RESEARCH JONES 如果。。。
第七章 人物与历史、地理、事件检索

(四)、查找人物年号、庙号、 谥号和避讳的工具书
年号:是封建皇帝纪年的名号,新君即位必须更改 年号。 庙号:是指皇帝死后,在太庙立室奉祀,并特立名 号,称某祖、某宗。 谥号:是指古代帝王、诸侯、卿大夫、高官大臣死 后,朝廷根据他们的生平行为给予的一种称号。 避讳:简单地说,就是文字上不得触犯当代帝皇和 所尊者之名,必须用其他方法回避。避讳方法︰一 是改字;二是空字;三是缺笔; 四是同音替代。
唐代李贺曾因打算参加进士考试而引起轩然 大波。攻击者认为李贺父名李晋肃。晋、进 同音,李贺参加进士考试不合避讳的要求,是 不孝的表现,李贺不能考进士。为此,韩愈专 门写了《讳辩》为李贺辩解。韩愈认为:避讳 的传统做法是避同字而不避同音,要求避同音 不合先人避讳的成例。他反驳攻击者说:假 如要求避同音,先人有名仁的,他的子孙后代 如何为人?岂非断子绝孙不成?既然后人之 名不允许与先人同音,又怎么可以与先人的姓 同音呢?韩愈的辩解得到时人的赞许。
(六)、查找同姓名和集体名称 的工具书
我国古今同姓名的人较多,在查找历史人物时特 别要注意,判断某一姓名是不是你所要查找的人 物,不仅要姓名相同,而且要时代籍贯、生卒年 月和经历都要相吻合,也就是实为其人,才不会 张冠李戴。解决这一问题的工具书是《古今同姓 名大辞典》。如要查找《论衡》的作者王充,古 代就有多人叫这个名字,我们可以通过《古今同 姓名大辞典》中所引条文内容,从诸多王充姓名 的生平事迹来判断谁是《论衡》的作者王充。
第一节 人物资料检索
历史,是人类社会的发展过程。了解历史、 查找历史文献往往是从人物资料开始检索 的,而人物资料的查找又往往是从人名开 始的。
数据结构(Java语言描述)第七章 查找

第七章 查找
目录
1 查找
2 静态查找表
第七章 查找
动态查找表 哈希表 小结
总体要求
•掌握顺序查找、折半查找的实现方法; •掌握动态查找表(包括:二叉排序树、二叉平衡树 、B-树)的构造和查找方法; •掌握哈希表、哈希函数冲突的基本概念和解决冲突 的方法。
7.1基本概念
1、数据项 数据项是具有独立含义的标识单位,是数据不可分 割的最小单位。 2、数据元素 数据元素数是据由项若(名干) 数据项构成的数据单位,是在某
}
性能分析:i 0 1 2 3 4
5 13 19 21 37
Ci 3 4 2 3 4
查找成功:
比较次数 = 路径上的结点数
比较次数 = 结点 4 的层数
比较次数
2
56 7 56 64 75 1 34
判定树
5
8 9 10 80 88 92 2 34
查找37 8
树的深度
0
3
6
9
≤=
log2n +1
1
4
}
【算法7-1】初始化顺序表 public SeqTable(T[] data,int n){
elem=new ArrayList<ElemType<T>>(); ElemType<T> e; for(int i=0;i<n;i++){
e=new ElemType<T>(data[i]); elem.add(i, e); } length=n; }
前者叫作最大查找长度(Maximun Search Length),即 MSL。后者叫作平均查找长度(Average Search Length) ,即ASL。
会计基础第七章 第五节错账查找与改正的方法第六节会计账簿的更换与保管

第七章第五节错账查找与更正的方法第六节会计账簿的更换与保管1、在记账后,如果发现记账凭证中科目正确,但所记金额大于应记金额,应采用( )方法更正。
A、划线更正法B、红字更正法C、以上三种中的任意一种D、补充登记法正确答案:B解析:本题考核的是错账更正方法,红字更正法适用于①记账后在当年内发现记账凭证所记的会计科目错误,从而引起记账错误,采用红字更正法。
②记账凭证会计科目无误而所记金额大于应记金额时,按多记的金额用红字编制一张与原记账凭证应借、应贷科目完全相同的记账凭证,以冲销多记的金额,并据以记账。
2、企业开出转账支票1970元购买办公用品,根据记账凭证登记银行存款日记账时,记账方向无误但金额误记为1790元,应采用的更正方法是()。
A、在银行存款日记账中划线更正B、把错误凭证撕掉重编C、补充登记180元D、红字冲销180元正确答案:A解析:本题考的是错帐的更正方法。
在结账前发现账簿记录有文字或数字错误,而记账凭证没有错误,采用划线更正法。
3、某企业购买办公用品支付库存现金1 500元,会计人员在作账务处理时借贷方分别多记了50元,则应做的更正分录是()。
A、借:库存现金 -50 贷:管理费用 -50B、借:管理费用 -50 贷:银行存款 -50C、借:管理费用 -50 贷:库存现金 -50D、借:管理费用 50 贷:库存现金 50正确答案:C解析:本题的考点为红字更正法的应用。
本题应该采用红字更正法进行更正,用红字金额冲销多记的50元。
4、记账人员在登记账簿后,发现所依据的记账凭证中使用的会计科目有误,则更正时应采用的更正方法是()。
A、红字更正法B、划线更正法C、补充登记法D、涂改更正法正确答案:A解析:记帐后在当年内发现记账凭证所记的会计科目错误,应采用红字更正法。
5、不属于错账更正的方法有()。
A、红字更正法B、平行登记法C、补充登记法D、划线更正法正确答案:B 解析:本题考核错帐更正的方法,错帐更正的方法有划线更正法、红字更正法、补充登记法6、下列说法正确的是()。
第七章 图,查找,排序

最短路径问题:如果从图中某一顶点(称为 源点)到达另一顶点(称为终点)的路径可能 不止一条,如何找到一条路径使得沿此路 径上各边上的权值总和达到最小。 问题解法 边上权值非负情形的单源最短路径问题 — Dijkstra算法 边上权值为任意值的单源最短路径问题 — Bellman和Ford算法 所有顶点之间的最短路径 — Floyd算法 19
在构造过程中,还设置了两个辅助数组: lowcost[ ] 存放生成树顶点集合内顶点到 生成树外各顶点的各边上的当前最小权值; nearvex[ ] 记录生成树顶点集合外各顶点 距离集合内哪个顶点最近(即权值最小)。 例子
0
24 28 14
10
1
16 18 12
5
25
6
2
4 22 3
0 28 10
23
计算从单个顶点到其它各顶点最短路径
void ShortestPath (MTGraph G, int v ){
//MTGraph是一个有 n 个顶点的带权有向图,各边上的 权值由Edge[i][j]给出。 //dist[j], 0 j<n, 是当前求到的从顶点v 到顶点 j 的最短 路径长度, 用数组path[j], 0 j<n, 存放求到的最短路径。
//求生成树外顶点到生成树内顶点具有最 //小权值的边, v是当前具最小权值的边
16
if ( v ) { //v=0表示再也找不到要求顶点 T[k].tail = nearvex[v]; //选边加入生成树 T[k].head = v; T[k++].cost = lowcost[v]; nearvex[v] = -1; //该边加入生成树标记 for ( j = 0; j < G.n; j++ ) if ( nearvex[j] != -1 && G.Edge[v][j] < lowcost[j] ) { lowcost[j] = G.Edge[v][j]; //修改 nearvex[j] = v; } }
数据结构题库

第一章绪论1.一个算法应该是(B)。
A.程序B.问题求解步骤的描述C.要满足五个基本特性D.A和C C是特性不是定义2.某算法的时间复杂度为O(n2),表明该算法(C)。
A.问题规模是n2B.执行时间等于n2C.执行时间与n2成正比D.问题规模与n2成正比3.设n表示问题规模,下面程序片段的时间复杂度是()。
x=2;w h i l e(x<n/2)x=2*x;设x=2×2语句的执行次数为t2^(t+1)=n/2f(n)=l o g2(n/2)-2O(l o g2(n/2))时间复杂度不要常数4.下面程序段的时间复杂度是().c o u n t=0;f o r(k=1;k<=n;k*=2)f o r(j=1;j<=n;j++)c o u n t++;T1(n)=O(l o g2(n))T2(n)=O(n)T=T1×T2=O(n l o g2(n))第二章线性表1.设线性表有n个元素,严格来说,以下操作中,哪些操作在顺序表上实现要比在链表上实现的效率高。
A BA.输出第i个数据元素的值B.交换第两个指定位置的数据元素C.输出这n个数据元素2.在一个长度为n的顺序表中删除第i(1<=i<=n)个元素时,需要向前移动n-i个元素。
3.设计算法从顺序表中删除具有最小值的元素(假设最小值唯一)并由函数返回被删除的元素值,空出的位置由最后一个元素填补,若顺序表为空则显示错误信息并退出运行。
要求:(1)给出算法的设计思想;(2)根据设计思想,采用C语言描述算法,关键之处给出注释;(3)说明你设计的算法时间复杂度。
4.给定一个带头结点的单链表L,设h e a d为头指针,结点的结构为(d a t a,n e x t),d a t a为整型元素,n e x t为指针。
设计算法,将L逆置,要求算法的空间复杂度为O(1)。
要求:(1)给出算法的设计思想;(2)根据设计思想,采用C语言描述算法,关键之处给出注释;(3)说明你设计的算法时间复杂度。
第七章-搜索引擎PPT课件

.
28
分 类:
垂直主题搜索引擎(专业搜索引擎) 以其高度的目标化和专业化在各类搜索引擎中占据了
一系席之地。比如象股票、天气、新闻等类的搜索引擎, 具有很高的针对性,用户对查询结果的满意度较高。服务 垂直(专业)化是互联网发展的大势所趋,区别于大而全 的水平网站,垂直网站更注重在单一领域提供更专业、更 精深的服务 。比如IT罗盘就是以精选式IT讯息垂直搜索 为特征的搜索引擎。图形天下Go2map就是专门提供地图搜 索服务的地图搜索引擎。
AltaVista是第一个支持自然语言搜索的搜索引擎,第一 个实现高级搜索语法的搜索引擎(如AND, OR, NOT等)。
.
13
发 展:
1998年10月之前,Google只是斯坦福大学的一个小项目。95年博士生 Larry Page开始学习搜索引擎设计,于1997年9月15日注册了 的域名,1999年2月,Google完成了从Alpha版到Beta版的 蜕变。Google公司则把1998年9月27日认作自己的生日。 Google在Pagerank、动态摘要、网页快照、DailyRefresh、多文 档格式支持、地图股票词典寻人等集成搜索、多语言支持、用户界面 等功能上的革新,象Altavista一样,再一次永远改变了搜索引擎的定 义。在2000年中以前,Google虽然以搜索准确性备受赞誉,但因为数 据库不如其它搜索引擎大,缺乏高级搜索语法,所以使用价值不是很 高,推广并不快。直到2000年中数据库升级后,又借被Yahoo选作搜索 引擎的东风,才一飞冲天。
.
22
原 理:
搜索引擎的Spider一般要定期重新访问所有网页(各搜索 引擎的周期不同,可能是几天、几周或几月,也可能对不 同重要性的网页有不同的更新频率),更新网页索引数据 库,以反映出网页内容的更新情况,增加新的网页信息, 去除死链接,并根据网页内容和链接关系的变化重新排序。 这样,网页的具体内容和变化情况就会反映到用户查询的 结果中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
查找失败的平均查找长度: 1 n ’ ASLu= n+1 ∑l j-1 j=0 l’j为第j个失败结点所在的层次编号,到达该失败结 点的关键字比较次数为l’j-1。
6、习题
(1)有序顺序表,对于相同的给定元素分别进行顺序 查找和折半查找,比较次数分别是s,b,在查找成功 的情况下,s,b的关系( ),在查找失败的情况下, s,b的关系( )。
3、算法实现: int Bin_Search(int r[] , int n,int key) { int Low=1,High=n, Mid ; while (Low<High) { Mid=(Low+High)/2 ; if (r[MID]==key) return(Mid) ; else if (r[MID]<Key) Low=Mid+1 ; else High=Mid-1 ; } return(0) ; /* 查找失败 */ }
2、查找算法的时间性能: 对于查找成功的情况,将关键字比较次数的数学期望 值称为平均查找长度: ASL=∑ PiCi n为查找表中记录个数
i=1
n
∑ Pi=1
i=1
n
其中: Pi :查找第i个记录的概率,不失一般性,认 为查找每个记录的概率相等,即 P1=P2=…=Pn=1/n ; Ci:查找第i个记录需要进行比较的次数。 对于查找失败的情况,平均查找长度为查找失败对应 的比较次数。
(3)具有n个关键码的B-树有多少个叶子(
)。
(4)向m阶B-树插入元素,什吗情况· 会产生分裂?
(5)删除 m阶B-树中元素,什吗情况会产生分裂?
(6)给定一组记录,其关键字为整数,插入关键字的 顺序是{68,54,82,35,75,90,103,22} a.给出从空树开始顺序插入这些记录后的3阶B树; b.分别给出在这棵B树上删除22,75后的3阶B树。
删除g
h
f bd
f
m e l
p
bd
(2)若结点N中的关键字个数=m/2-1:若结点N的 左(右)兄弟结点中的关键字个数>m/2-1,则将 结点N的左(或右)兄弟结点中的最大(或最小)关 键字上移到其父结点中,而父结点中大于(或小 于)且紧靠上移关键字的关键字下移到结点N。 h
删除q
h
f m eg
4、折半查找判定树:查找时每经过一次比较,查找范 围就缩小一半,该过程可用一棵二叉树表示: ◆根结点就是第一次进行比较的中间位置的记录; ◆排在中间位置前面的作为左子树的结点 ◆排在中间位置后面的作为右子树的结点; 对各子树来说都是相同的。这样所得到的二叉树称为 折半查找判定树(Decision Tree)。将二叉判定树的第 ㏒2n+1层上的结点补齐就成为一棵满二叉树,深度不 变,h= ㏒2(n+1) 。 5、算法分析:在等概率的情况下查找成功的平均查找 长度: 1 n ASLs= n ∑li i=1 li为第i个元素所在的层次编号
顺序查找
1、查找思想:从表的一端开始逐个将记录的关键字 和给定K值进行比较,若某个记录的关键字和给定K值 相等,查找成功;否则,若扫描完整个表,仍然没有 找到相应的记录,则查找失败。 2、算法分析:在等概率的情况下查找成功的平均查 找长度为(n+1)/2;查找不成功的关键字比较次数为 n+1。
3、习题 (1)静态查找与动态查找的根本其区别?
②二次探测法 Hi=(H(key)+di)%m,m为表长,di=12 , -12 , 22 , 22 , …, k2 , -k2 , k≤(m-1)/2,H0是一个非负整数, m应是值为4k+3的一个整数。如3,7,11,19, …。当表 的长度m为质数且装填因子不超过0.5时,新的表项一 定能够插入,且任何一个位置不会被探测两次。 例:设散列函数为H(key)=key%7,取m=11,用二次探测 法处理冲突,请画出依次输入关键字序列 {46,21,80,62,18,34,12,40}的散列表。
gm bf
p
l
p
7、B-树的查找效率:B-树的差查找效率主要取决于 结点所在的层数,含有n个关键字的m阶B-树的最大深 度不超过log m/2 ((N+1)/2)+1。
、习题
(1)下列关于m阶B-树说法错误的是(
A.根结点至多有m锞子树
)。
B.所有叶子在同一层次
C.非叶子结点至少有[m/2]锞子树 D.根结点的数据是有序的 (2)下列关于m阶B-树说法正确的是( )。 A.每个结点至少有两个非空子树 B.树中的每个结点至多有m-1个关键码 C.所有叶子在同一层 D.当插入一个结点引起分裂时树长高一层
key
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
8 14 11 18 20 35 40 32 44 38 56 62 68 67 65
link 索引表 key 20 44 68
数据区 2、多级索引结构和m叉树: 当数据元素个数很多,索 引表很大,可以建立多级 索引,这种多级索引结构 一级索引 形成一种m叉查找树。 70 二级索引
(5)对有2k-1元素的有序表进行折半查找,查找成功 的情况下最多要比较多少次?查找失败的情况下最 多要比较多少次?
B-树
1、线性索引:先把n个元素分成b个子表(块),块内 关键字无序(或有序),块间关键字有序,另需建立一 个索引表,索引项的关键字域存放相应块的最高关键 字,链域存放对应块第一个元素在数据区中的起始位 置。
a 1 b 1 15 d 2 ∧ 10 ∧ 20 ∧ 24 3 c 33 48 53
e 1 ∧ 20 ∧
f 2 ∧ 28 ∧ 31 ∧
g h 1 ∧ 37 ∧ 1 ∧ 50 ∧
i 1 ∧ 56 ∧
一棵包含13个关键字的4阶B_树
m阶B树最大结点个数
若m阶B树的高度为h,最大结点个数为n,根 h 据m叉树的性质有: 1 (mh-1) i-1 N=≤ ∑m = m-1 i=1
4、B-树的查找:
BT
50 30 60 70
10
40
56 59
65
75 80
B树的查找过程是一个在结点内查找和循某一条路径向 下一层查找交替进行的过程。
5、B-树的插入:
插入89后结点溢出
插入到某个叶子结点,若插入后结 点p关键字个数超出m-1个,结点p 需要分裂成两个结点p和q。 p:(m/2-1,p0,k1,…,k m/2-1,p m/2-1) q:(m-m/2, pm/2,km/2+1,…,km,pm) 位于中间结点的关键字km/2提升为 p和q这两个结点的双亲。
f
bd eg
p lm q bd
l
p
(3)若结点N和其兄弟结点中的关键字数=m/2-1: 删除结点N中的关键字,再将结点N中的关键字、 指针与其兄弟结点以及分割二者的父结点中的 某个关键字Ki,合并为一个结点,若因此使父结 点中的关键字个数<m/2-1 ,则依此类推。
g
f b e l m
删除e
A.s=b B. s>b C.s<b D. 不能确定 (2)对有10个元素的有序顺序表进行折半查找,求等 概率情况下查找成功和查找失败的平均查找长度?
(3)折半查找判定树不属于( C.完全二叉树 D.二叉树
)。
A.平衡二叉树 B. 二叉排序树 (4)当n足够大时,对有序顺序表进行折半查找,在 等概率情况下,查找成功的平均查找长度是?
3、处理冲突的方法 (1)开放定址法: 当发生冲突时,生成一个探测序列,沿此序列逐个地址 探测,直到找出一个空位置。 Hi=(H(key)+di)%m,m为表长 ①线性探测法 di =1,…,m-1。 例:设散列函数为H(key)=key%7,取m=8,用线性探测 法处理冲突,请画出依次输入关键字{46,21,62,34,10} 后的散列表。 该方法容易出现堆积
(2)下面那种数据结构查找效率最低?
A.有序顺序表 C.堆 B.二叉排序树 D.散列表
折半查找
1、前提条件:表中的所有记录是按关键字有序(升序 或降序) 。 2、查找思想:用Low、High和Mid表示待查找区间的下 界、上界和中间位置指针,初值为Low=1,High=n。 ⑴取中间位置Mid:Mid=(Low+High)/2 ; ⑵比较中间位置记录的关键字与给定的K值: ①相等:查找成功; ②大于:待查记录在区间的前半段,修改上 界指 针: High=Mid-1,转⑴ ; ③小于:待查记录在区间的后半段,修改下 界指针:Low=Mid+1,转⑴ ; (3)直到越界(Low>High),查找失败。
m阶B树最小高度
因为m阶B树中每个结点中最多有m-1个关键字, 所以一棵高度为h的m阶B树中关键字的个数为: N≤mh-1,因此有h≥logm(N+1)
m阶B树最大高度
若让m阶B树中每个结点关键字个数达到最少,则容 纳同样多关键字的情况下B树的高度可达到最大, 经过分析和推导,可得h≤log m/2 ((N+1)/2)+1
2、常见的散列函数 除留余数法: H(key)=key%p p≤m,p为不大于表长m 的最大质数。 平方取中法: 把关键字自乘,取其中间几位作为存 储地址。例:K=42016,K2=17653344256 取中间三位 344作为存储地址。 折叠法:将关键字分成若干段,其中每段长度小于或 等于地址空间位数。例 K=5824422415,地址空间是4 位。分段:5824|4224|15 在散列函数中,除留余数法优于其他类型的散列函数, 最差的是折叠法。
6、B-树的删除: 若N不是叶子结点,设K是N中的第i个关键字,则将指 针Pi所指子树中的最小关键字,K’放在(K)的位置,然 后删除K’,而K’一定在叶子结点上。 h g m e gl p